Approximate Inference for Stochastic Planning in Factored Spaces
Abstract
Stochastic planning can be reduced to probabilistic inference in large discrete graphical models, but hardness of inference requires approximation schemes to be used. In this paper we argue that such applications can be disentangled along two dimensions. The first is the direction of information flow in the idealized exact optimization objective, i.e., forward vs. backward inference. The second is the type of approximation used to compute this objective, e.g., Belief Propagation (BP) vs. mean field variational inference (MFVI). This new categorization allows us to unify a large amount of isolated efforts in prior work explaining their connections and differences as well as potential improvements. An extensive experimental evaluation over large stochastic planning problems shows the advantage of forward BP over several algorithms based on MFVI. An analysis of practical limitations of MFVI motivates a novel algorithm, collapsed state variational inference (CSVI), which provides a tighter approximation and achieves comparable planning performance with forward BP.
1 Introduction
The connection between planning and probabilistic inference is well known and multiple reductions exist showing how inference algorithms can be used to solve stochastic planning problems. Such reductions are equivalent when one can perform exact inference but this is not typically the case for challenging planning problems that have many state variables, a.k.a. factored spaces, where approximate inference schemes are introduced. The planning and reinforcement learning literatures include multiple such efforts where different algorithmic frameworks are combined with different approximation schemes. For example, constructions exist through weighted model counting Domshlak and Hoffmann [2006], several forms of variational inference (e.g., [Toussaint and Storkey, 2006, Levine, 2018]), and several forms belief propagation (e.g., [Liu and Ihler, 2012, Cui et al., 2019]). However, it is not clear how different algorithmic approaches are related to one another and how the choice of approach interacts with the choice of approximation scheme.
The paper makes three contributions. First we provide a unified scheme that connects previous approaches along two dimensions, using either forward or backward reasoning, and choosing what approximation to use, where we address Belief Propagation (BP) and mean field variational inference (MFVI). This allows us to put prior work in a unified framework that explains choices made by corresponding algorithms. In particular, our analysis shows that Forward MFVI which is used in some papers can be understood to run multiple iterations of Backward MFVI and thus provides tighter approximations. Second, through extensive experiments over large planning problems, we show that forward reasoning with Belief Propagation provides the best performance among these algorithms, that MFVI provides poor performance in some domains, and that modifying MFVI using exponentiated rewards helps in some cases but not sufficiently. We also analyze the failures of MFVI experimentally pointing to sensitivity in updates. Third, based on the analysis, we propose a novel algorithm, Collapsed State Variational Inference (CSVI), that uses mean field with collapsed variational inference where state variables are integrated out. CSVI is motivated theoretically due to its tighter variational approximation and we show empirically that it matches the performance of Forward Belief Propagation. This shows that while naive application of mean field for planning fails, other variational approximations like CSVI can yield strong planning performance. Due to space constraints some technical details and experiment results are omitted from the main paper and are provided in [Wu and Khardon, 2022], which we refer to below as the the appendix.
2 Problem Formulation
We consider finite horizon MDPs as specifications of planning problems. Such specifications are often compiled from a high level description language but this is orthogonal to the discussion in the paper. Specifically, consider Markov Decision Processes , where denotes the state space, is a distribution over start states, denotes the action space, denotes the transition probability , denotes the reward function , denotes the horizon and is the discount factor. In this paper we set , but this does not significantly affect any of the formulations. A solution is given by a policy, , that specifies with policy parameters allowing for non-stationary policies. The task in planning is to find a policy that maximizes the expected cumulative reward where the expectation is taken w.r.t. trajectories generated from the MDP with policy , that is, , , and .
In this paper we follow recent practice in stochastic planning and use the online planning framework, where in a state , the algorithm computes for a limited time to pick an action , uses to control the MDP to get to the next state, and repeats this process. Online planning is often used with receding horizon control, where the planner uses a step lookahead in its search and then extracts the first action to be applied in .
Solving a finite horizon MDP is equivalent to solving an inference problem in the corresponding Dynamic Bayesian Network (DBN), or more precisely in the dynamic decision network. We assume a factored form of states consisting of binary state variables, i.e. . We also assume a factored action representation .
The MDP formulation above requires real-value reward nodes in the DBN. To facilitate inference one can replace these nodes with constructions that use only binary variables, and various such constructions appear in the literature. In the following we develop one such construction and use that in our experiments. We introduce binary reward random variables to capture the reward after taking action in the previous time step , the distribution of which is defined as
| (1) |
We can then define where to capture the cumulative reward. We call the resulting DBN the intermediate representation. However, has parents which hinders efficient inference. To avoid the use of , we introduce cumulative reward binary random variables . To keep the consistency of the graphical structure, we create an auxiliary node , and for the distribution of is defined recursively depending on the previous cumulative reward and current reward :
| (2) |
In many planning problems the reward is given as an additive function over a set of small factors. For such problems we introduce another chain of binary reward variables within a time step using a similar construction. This yields a DBN that only includes binary variables with a small number of parents. As the following proposition shows the three constructions, using cumulative reward, using and using are equivalent. Further details and proofs are given in the the appendix.
Proposition 1
The construction satisfies where expectations are w.r.t. trajectories as above.
3 Planning Through Inference
In the following we restrict our discussion to open loop policies, that is, where the policy is time dependent but does not depend on the state (other than if it is fixed). Thus for an action sequence , we have . This covers most of previous work on planning as inference in the literature. The extension to standard policies is straightforward but requires more complex algorithms for optimization.
3.1 Forward Backward Framework
We now present a simple framework that captures many algorithms in the literature. For the discussion below note that some algorithms optimize policy parameters and then choose the actions, whereas others optimize the action sequence directly.
The Backward Framework: Observe that if is the uniform distribution, , then
| (3) |
where the second equality is true because is a fixed constant for all and does not depend on . This suggests that we can optimize by optimizing . Since calculating is hard, the backward framework optimizes an approximation of . The choice of different approximations will give us different concrete algorithms. This is captured in Algorithm 1
The Forward Framework: in contrast, the forward approach aims to directly optimize w.r.t the policy parameters (or alternatively, but we focus on the more general case). Approximating with a score function defined on policy parameters yields the forward framework. In the ideal case, maximizing will give us a delta function, directly selecting a concrete sequence. If not, we can use or sample from the corresponding distribution. This is captured in Algorithm 2
3.2 Forward and Backward Loopy Belief Propagation
The forward and backward algorithms can be combined with any approximation scheme. We start by considering loopy BP (LBP) algorithms [Pearl, 1988, Kschischang et al., 2001]. For this construction we translate the DBN into a factor graph using standard constructions. For backward LBP, we instantiate as evidence, fix the factors corresponding to to be the uniform distribution, and run LBP to calculate the marginal probabilities on action variables. That is, is given by the output of LBP. Note that this is algorithmically simple because we do not need a separate optimization step aside from Belief Propagation. However, LBP may need many iterations to converge or may not converge at all.
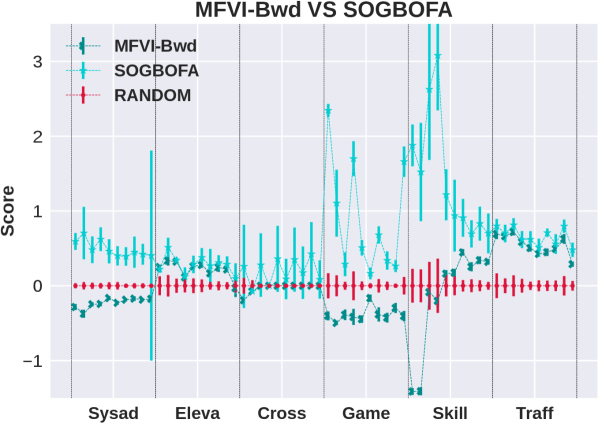
For the forward algorithm, we define to be the approximate marginal of computed by LBP. However, LBP does not optimize . As discussed below, multiple techniques for optimizing for LBP exist in the literature. In the experiments we use the SOGBOFA system [Cui et al., 2019] that combines LBP with gradient based search.
3.3 Forward and Backward Mean Field Variational Inference
The idea in variational inference is to minimize the KL divergence between the approximate posterior and the true posterior over latent variables, i.e., in our case
where the latent variables are , , , , that is, the sequences of state, action, reward, and cumulative reward variables, where excludes . This is equivalent to maximizing the evidence lower bound (ELBO). In our case the ELBO is given in the next equation, where in the mean field approximation is a product of independent factors
| (4) |
For backward MFVI, note that is the marginal distribution of the true posterior . Therefore we first maximize to obtain and then set to be the corresponding marginal. Detailed update equations for MFVI are given in the the appendix.
For forward MFVI, we can pick where we need to optimize both and . For this, the standard approach is the Variational Expectation Maximization algorithm which optimizes in the step and in the step. To elaborate the algorithm, note that the ELBO can be reformulated as follows:
| (5) |
where the first term does not depend on . Therefore:
-
•
In the E step, we maximize w.r.t. . Note that this is exactly as in the Backward Algorithm but under a general .
-
•
In the M-step, we keep fixed and optimize the w.r.t. . From Eq (5) we see that this is equivalent to minimizing . If and are from the same class of distributions, this step assigns .
From the procedure, we have the following observation.
Remark 2
For the mean field approximation, the forward algorithm is an iterative process that alternates the backward algorithm with policy updates.
This connection was not observed in prior work where the forward and backward algorithms are not clearly distinguished. Finally, as pointed by Toussaint and Storkey [2006] the E step is analogous to policy evaluation (except that we calculate marginals for many variables besides the reward) and the M step is analogous to policy improvement, so forward MFVI can be seen as an approximate version of Policy Iteration.
4 Related Work
The idea of using inference for stochastic planning has a long history and has attracted many different approaches. For example, Cooper [1988] showed how inference can be used for decision making in influence diagrams, Domshlak and Hoffmann [2006] use an approach based on weighted model counting, Nitti et al. [2015] use a probabilistic programming formulation, and Lee et al. [2021] use anytime marginal MAP solvers for planning problems.
Several groups have developed approaches that follow the forward variational framework, going back to Dayan and Hinton [1997]. This idea is often developed by defining a reward weighted path distribution which is similar to conditioning on in our framework, and developing algorithms from this formulation [Furmston and Barber, 2010, 2011, Toussaint and Storkey, 2006, Kumar et al., 2015]. We note, however, that these works did not explicitly address factoring over state and action variables.
On the other hand, some papers in robotics and reinforcement learning (RL) [Toussaint, 2009, Kappen et al., 2012, Levine, 2018] follow the backward variational framework. In contrast with the discussion above they use a formulation where the reward over trajectories is exponentiated. As shown by Levine [2018] this modifies the original optimization objective by adding a term with the expected entropy of the policy, and hence solves a slightly different problem, but the entropy term may be beneficial for exploration in RL. In addition, the work of Neumann [2011] uses the forward variational algorithm, but with an exponentiated reward, and additional sampling-based approximations. We can see that the forward and backward variational approaches have been widely used but have not been differentiated before. Our analysis above clarifies the relationship between these approaches.
For the case of BP approximation, Murphy and Weiss [2001] proposed the Factored Frontier Algorithm which is a forward BP method for marginal inference, and Boyen and Koller [1998] developed approximation bounds for forward inference. The work of Liu and Ihler [2012], Kiselev and Poupart [2014] follows the forward BP framework, but develops a generalized belief propagation algorithm that solves both optimization and expectation steps using message passing. The work of Cui et al. [2019] also follows the forward BP framework but decouples the expectation which is done through BP from the optimization that uses an approximation based on gradient search.
Several works have made additional assumptions on the structure of the DBN in their discussion of graph-based MDPs. Cheng et al. [2013] extend the algorithm of Liu and Ihler [2012] to this case. Peyrard and Sabbadin [2006] and Sabbadin et al. [2012] use the Mean Field approximation method but only use it to approximate the distribution over state variables. They then use the approximate distribution to approximate steps of the Policy Iteration algorithm. Hence their algorithm is different from MFVI in that reward variables are not included in the variational approximation. Finally, our work can be seen to extend the comparison of Mean Field and Loopy BP for general inference tasks [Weiss, 2001]. As in this early work, our experiments show that optimization of variational objectives can lead to local optima and that BP can provide some advantage.
5 Experiments and Analysis of MFVI & Belief Propagation Algorithms
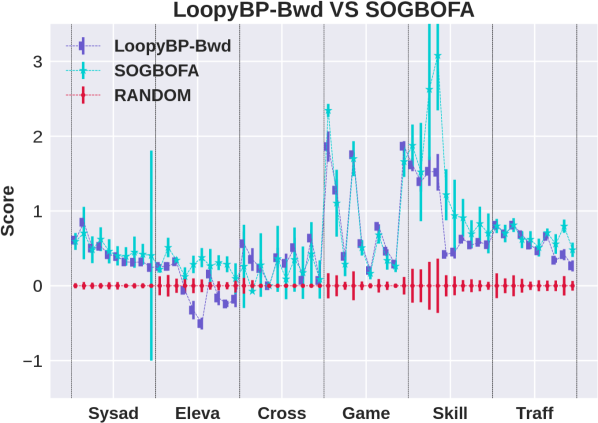
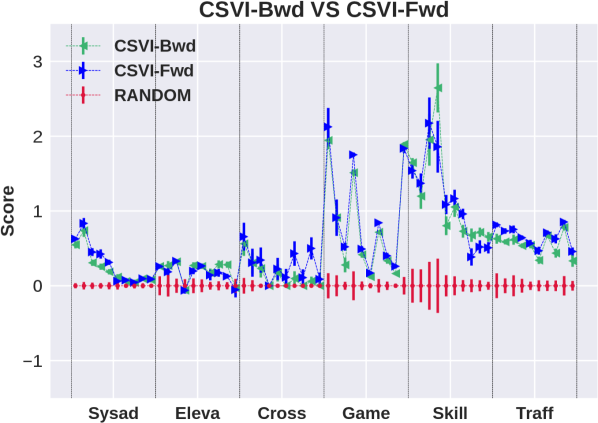
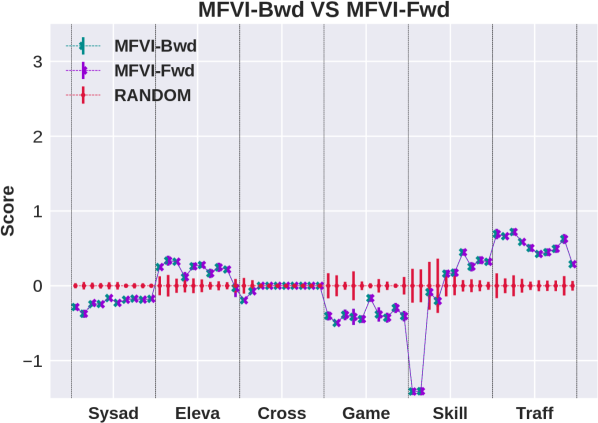
This section presents an experimental evaluation of the algorithms. The code for regenerating all the results is available on Github111https://github.com/Zhennan-Wu/AISPFS. Our goal in this paper is to understand the quality of decisions provided by different approximate inference schemes, ignoring implementation details. Therefore, during the experiments we do not limit run time but instead allow the algorithms to converge, within bounds given below, before proposing a decision. We chose 6 problem domains from the ICAPS 2011 International Probabilistic Planning Competition to conduct our experiments. Each domain has 10 instances with factorized structure, horizon of 40 and discount factor of 1, and instances differ by the number of state and action variables. For our experiments we use the SPUDD [Hoey et al., 1999] translation of the original RDDL [Sanner et al., 2010] specification, which compiles away action factoring. This simplifies the implementation because it removes the need to reconcile action constraints with factoring. To control our overall experimental time we use online planning with receding horizon control, where we set the search horizon to be the minimum value between 9 and the remaining time steps.
Algorithmic parameters for MFVI: we perform at most 100 Variational updates and stop early if the infinity norm of the difference between consecutive approximation distributions is less than 0.1. We perform 3 outer iterations, i.e., policy updates for the forward version.
Algorithmic parameters for BP variants: We use SOGBOFA [Cui et al., 2019]222https://github.com/hcui01/SOGBOFA as forward Loopy BP, fixing search depth to 9, and limiting the number of gradient updates to 500. We note that SOGBOFA has outperformed other planners, including search based planners, in IPPC 2018 problems and is a state of the art baseline for the evaluation. For the backward algorithm, our implementation is based on Zhou et al. [2022] with parallel message update and a bound of 100 iterations with no damping ().
Normalized mean one standard deviation of the cumulative reward over 12 simulations are shown in all the plots. Denote the mean value and standard deviation of the cumulative reward of algorithm on instance to be , , respectively. To facilitate comparisons across domains we report scores normalized relative to the random policy. Specifically, for algorithm on instance , and where the random algorithm has score 0 and higher scores indicates better performance. For reference, the raw results are given in the the appendix.
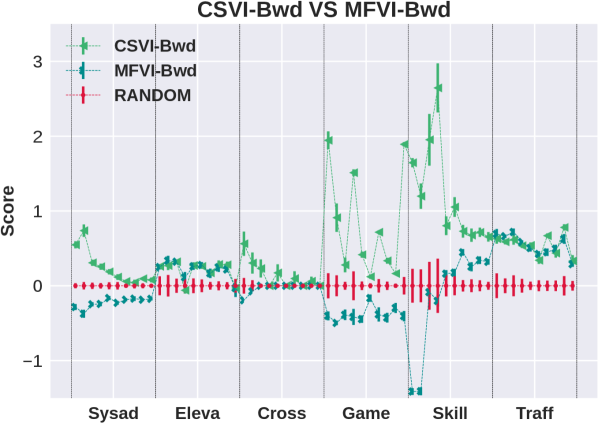
Comparison of Algorithms
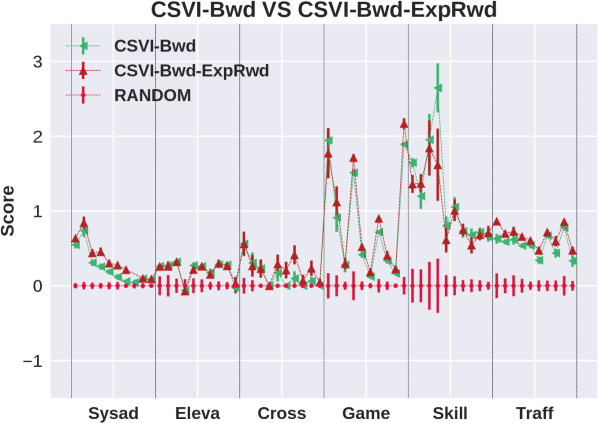
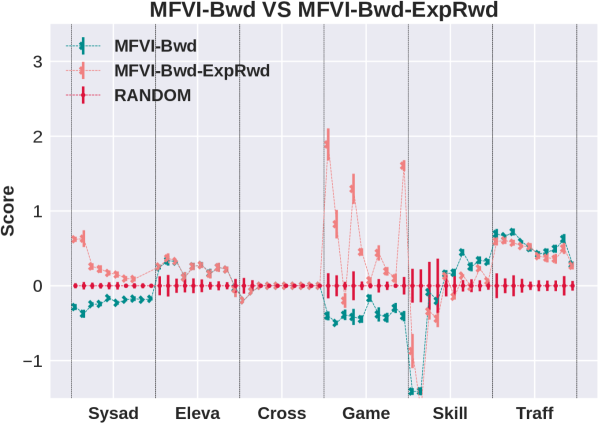
Results are shown in the left column of Figure 1. The top plot shows that search direction is important for BP: the forward algorithm (SOGBOFA) outperforms the backward algorithm.333 While our focus is on the quality of approximation it is worth noting that Cui et al. [2018] have shown that with a directed model (equivalent to the Forward Framework with no downstream evidence as in our case), LBP converges in one iteration. Thus the forward algorithm is also faster. In contrast, the second plot shows that for MFVI, there is no significant difference between the forward and backward variants. This is an interesting result because, as shown above, the forward algorithms mimic Policy Iteration and they provide a tighter approximation. The third plot compares MFVI to BP showing that MFVI has poor performance in some problems and forward BP dominates in all problems. Finally, we can show (see the appendix) that the exponentiated variant of MFVI can be captured in our framework by conditioning on all reward and cumulative reward variables. The bottom plot compares this variant to standard MFVI. We see that the performance improves in two domains but the exponentiated variant is still dominated by forward BP.
Exploring the performance of MFVI
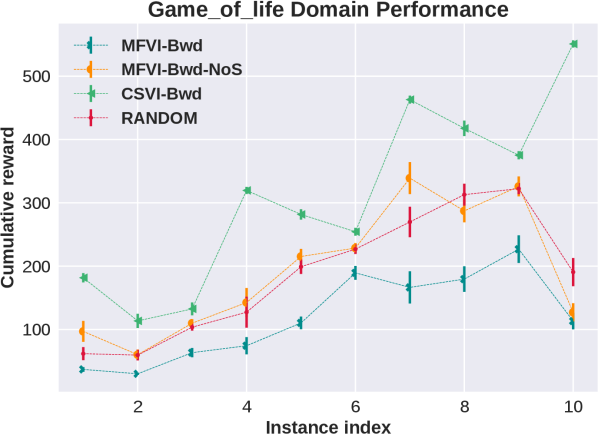
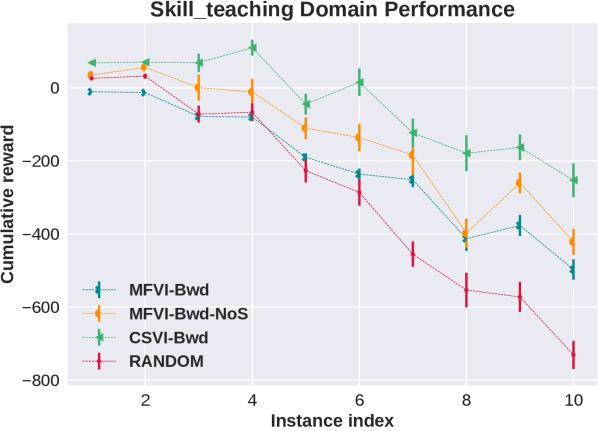
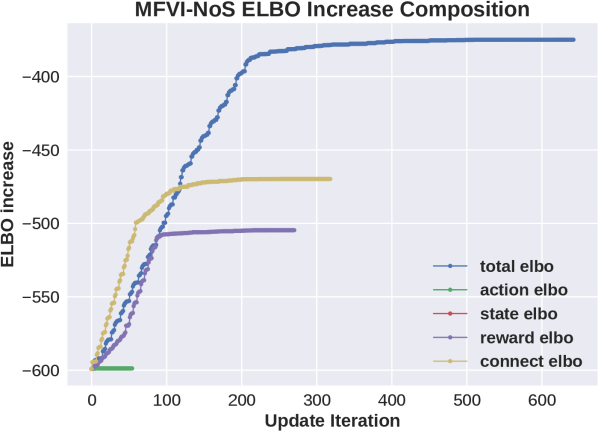
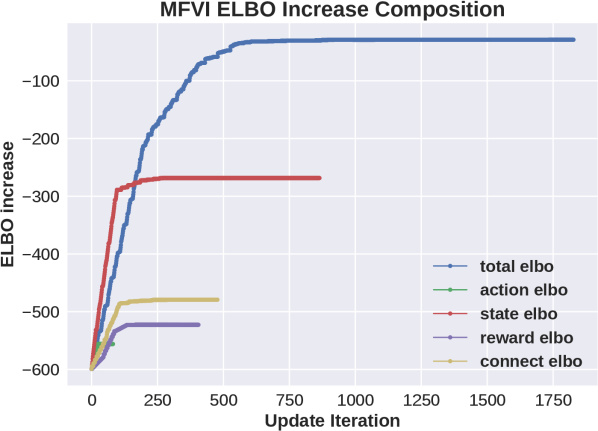
We believe that the main reason for the failure of MFVI is due to interaction between the flexibility that the mean field approximation allows with many state variables, and the sensitivity to ordering of updates due to local optima. To explore this we performed several additional experiments. In the first we introduce a new variant algorithm, MFVI-NoS, which does not update the marginal distribution over state variables, i.e. keeps them at the initialized value of . Results for two domains are shown in the top half of the third column of Figure 1. We see that while the NoS variant restricts the algorithm it improves the performance in these domains (this does not happen in all domains). Another view of this phenomenon is given by the relative contribution of each group of variables to the increase in the ELBO during updates of variational parameters. The bottom half of the third column of Figure 1 visualizes this for the MFVI and MFVI-NoS variants in one problem. We see that for MFVI the largest increase in ELBO is contributed by adjusting state variables and the NoS variant increases the share of other variables. We further explore this in the full paper using an artificial problem, showing that in this case limiting the flexibility of MFVI can lead to better posterior, that MFVI is sensitive to a choice of which subset of state variables is updated, and in addition to the order of updates.
6 CSVI
Motivated by the analysis above, we propose a new algorithm for variational inference in planning. Instead of treating all the latent nodes in the DBN in the same manner and computing approximate distributions over all these variables, the algorithm focuses on the action variables and effectively marginalize out other terms to achieve a tighter ELBO. This type of approach is known as collapsed variational inference, which has been shown to be effective in models where the marginalization can be done analytically (e.g., Teh et al. [2006]) but for planning one has to resolve additional computational challenges as we show below. Specifically we propose to use the following provably tighter ELBO
| (6) |
Here we have the same factorized transitions and policy distribution. However, we do not compute approximation distributions over state, reward, and cumulative reward variables. With mean field, the standard solution [Bishop, 2006] yields the update equation
| (7) |
| where | |||
| (9) | |||
The tighter approximation appears to yield an infeasible update, because is entangled in and we must perform an explicit marginalization in for each update.
We next show how the update equation can be approximated via sampling. The key is to first extract from the expectation. We therefore have:
| (10) |
Recall that is a product of independent terms. This implies that the first part can be substituted with since all other terms are constants w.r.t the variable of interest in (7) and they will vanish in the normalized update of . The second part is conditioned on and does not include terms. Its expectation can be estimated through sampling. In particular, sampling can be intuitively done as follows: keeping fixed, sample the action sequence from approximate distribution . Then complement this by sampling values for , , nodes, including . The resulting values for are generated from the correct distribution and the average over gives an estimate of the expectation. Since we are using sampling and averaging inside the logarithm this yields biased estimates for updates, but this type of biased estimates has been shown to work in other cases in machine learning (e.g., [Wei et al., 2021]) and it can be mitigated by taking sufficient samples. It is interesting to note from the above update that the policy distribution serves as a weight bias in the action update procedure. Algorithm 3 summarizes the update procedure.
Performance of CSVI
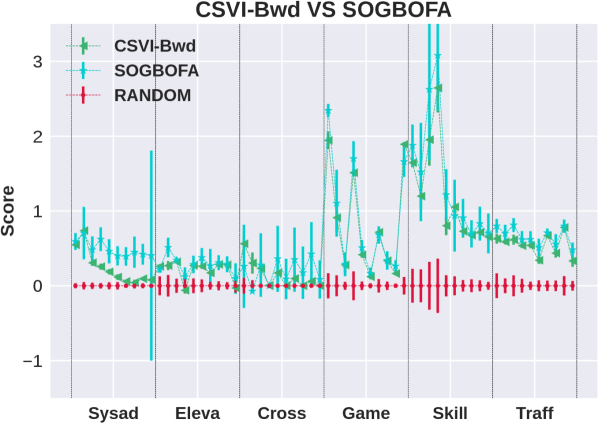
For CSVI our implementation uses the same parameters as in MFVI except that we make at most 10 variational updates. The sample sizes are set to and . Results are shown in the middle column of Figure 1. Considering the plots from top to bottom we observe that there is no significant difference between forward and backward variants of CSVI and that CSVI is significantly better than MFVI. The third plot shows that the exponentiated reward variant does not improve the performance of CSVI. This suggests that the improvement over exponential variant for MFVI is due to stabilizing the optimization rather than presenting a better objective. The fourth plots shows that the performance of CSVI is competitive with forward BP and therefore CSVI provides state of the art performance in stochastic planning.
7 Conclusion
In this paper we provide a unified scheme that categorizes many previous approaches along two dimensions, using either forward or backward reasoning and choosing an approximation scheme. Specifically, we focus on belief propagation and mean field variational inference as the approximation choices. In this context, we illustrate the advantage of Forward Loopy BP as providing the best performance. Algorithms based on MFVI perform poorly in some domains. They are improved by exponential reward weighting but not sufficiently so. An experimental analysis points to sensitivity of the optimization as a source for this failure. Motivated by this analysis we propose a novel algorithm, Collapsed State Variational Inference, which provides a tighter variational approximation, and while being computationally demanding it performs competitively with Forward Loopy BP. The results highlight that while BP has been less in focus in recent years, it provides a strong baseline for stochastic planning. It also shows the importance of focusing variational approximations on variables of interest as done in CSVI and the potential for developing strong variational algorithms for planning. These observations suggest interesting directions for future work including developing efficient variants of CSVI, using amortized variational inference in planning to improve CSVI, alternative schemes to capture the posterior distributions in VI, and developing tighter approximations and optimization algorithms through BP methods.
Acknowledgements
This work was supported by NSF under grant IIS-1906694 and grant IIS-2002393. Some of the experiments in this paper were run on the Big Red 3 computing system at Indiana University, supported in part by Lilly Endowment,Inc., through its support for the Indiana University Pervasive Technology Institute.
References
- Bishop [2006] Christopher M. Bishop. Pattern recognition and machine learning. Springer, 2006.
- Boyen and Koller [1998] X. Boyen and D. Koller. Tractable inference for complex stochastic processes. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, pages 33–42, 1998.
- Cheng et al. [2013] Qiang Cheng, Qiang Liu, Feng Chen, and Alexander T Ihler. Variational planning for graph-based MDPs. Advances in Neural Information Processing Systems, 26, 2013.
- Cooper [1988] Gregory F. Cooper. A method for using belief networks as influence diagrams. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, 1988.
- Cui et al. [2015] Hao Cui, Roni Khardon, Alan Fern, and Prasad Tadepalli. Factored MCTS for large scale stochastic planning. In Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
- Cui et al. [2018] Hao Cui, Radu Marinescu, and Roni Khardon. From stochastic planning to marginal MAP. Advances in Neural Information Processing Systems, 31, 2018.
- Cui et al. [2019] Hao Cui, Thomas Keller, and Roni Khardon. Stochastic planning with lifted symbolic trajectory optimization. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 29, pages 119–127, 2019.
- Dayan and Hinton [1997] Peter Dayan and Geoffrey E Hinton. Using expectation-maximization for reinforcement learning. Neural Computation, 9(2):271–278, 1997.
- Domshlak and Hoffmann [2006] Carmel Domshlak and Jörg Hoffmann. Fast probabilistic planning through weighted model counting. In International Conference on Automated Planning and Scheduling, pages 243–252, 2006.
- Furmston and Barber [2010] Thomas Furmston and David Barber. Variational methods for reinforcement learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, pages 241–248, 2010.
- Furmston and Barber [2011] Thomas Furmston and David Barber. Efficient inference in markov control problems. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, pages 221–229, 2011.
- Hoey et al. [1999] Jesse Hoey, Robert St-Aubin, Alan Hu, and Craig Boutilier. SPUDD: stochastic planning using decision diagrams. In Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence, pages 279–288, 1999.
- Kappen et al. [2012] Hilbert J Kappen, Vicenç Gómez, and Manfred Opper. Optimal control as a graphical model inference problem. Machine learning, 87(2):159–182, 2012.
- Kiselev and Poupart [2014] Igor Kiselev and Pascal Poupart. POMDP planning by marginal-MAP probabilistic inference in generative models. In Proceedings of the 2014 AAMAS Workshop on Adaptive Learning Agents, 2014.
- Kschischang et al. [2001] F.R. Kschischang, B.J. Frey, and H.-A. Loeliger. Factor graphs and the sum-product algorithm. IEEE Transactions on Information Theory, 47(2):498–519, 2001.
- Kumar et al. [2015] Akshat Kumar, Shlomo Zilberstein, and Marc Toussaint. Probabilistic inference techniques for scalable multiagent decision making. Journal of Artificial Intelligence Research, 53:223–270, 2015.
- Lee et al. [2021] Junkyu Lee, Radu Marinescu, and Rina Dechter. Submodel decomposition bounds for influence diagrams. In Proceedings of the AAAI Conference on Artificial Intelligence, 2021.
- Levine [2018] Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018.
- Liu and Ihler [2012] Qiang Liu and Alexander Ihler. Belief propagation for structured decision making. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, pages 523–532, 2012.
- Murphy and Weiss [2001] Kevin Murphy and Yair Weiss. The factored frontier algorithm for approximate inference in DBNs. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, pages 378–385, 2001.
- Neumann [2011] Gerhard Neumann. Variational inference for policy search in changing situations. In Proceedings of the 28th International Conference on International Conference on Machine Learning, pages 817–824, 2011.
- Nitti et al. [2015] Davide Nitti, Vaishak Belle, and Luc De Raedt. Planning in discrete and continuous markov decision processes by probabilistic programming. In Joint European conference on machine learning and knowledge discovery in databases, pages 327–342. Springer, 2015.
- Pearl [1988] Judea Pearl. Probabilistic reasoning in intelligent systems: networks of plausible inference. Morgan Kaufmann, 1988.
- Peyrard and Sabbadin [2006] Nathalie Peyrard and Régis Sabbadin. Mean field approximation of the policy iteration algorithm for graph-based markov decision processes. In 17th European Conference on Artificial Intelligence August 29–September 1, 2006, Riva del Garda, Italy, pages 595–599, 2006.
- Sabbadin et al. [2012] Régis Sabbadin, Nathalie Peyrard, and Nicklas Forsell. A framework and a mean-field algorithm for the local control of spatial processes. International Journal of Approximate Reasoning, 53(1):66–86, 2012.
- Sanner et al. [2010] Scott Sanner et al. Relational dynamic influence diagram language (rddl): Language description. Unpublished ms. Australian National University, 32:27, 2010.
- Teh et al. [2006] Yee Teh, David Newman, and Max Welling. A collapsed variational Bayesian inference algorithm for latent Dirichlet allocation. Advances in neural information processing systems, 19, 2006.
- Toussaint [2009] Marc Toussaint. Robot trajectory optimization using approximate inference. In Proceedings of the 26th annual international conference on machine learning, pages 1049–1056, 2009.
- Toussaint and Storkey [2006] Marc Toussaint and Amos J. Storkey. Probabilistic inference for solving discrete and continuous state markov decision processes. In Machine Learning, Proceedings of the Twenty-Third International Conference, volume 148, pages 945–952, 2006.
- Wei et al. [2021] Yadi Wei, Rishit Sheth, and Roni Khardon. Direct loss minimization for bayesian predictors. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, AISTATS, 2021.
- Weiss [2001] Yair Weiss. Comparing the mean field method and belief propagation for approximate inference in MRFs. In Advanced Mean Field Methods: Theory and Practice, pages 229–239. MIT Press, 2001.
- Wu and Khardon [2022] Zhennan Wu and Roni Khardon. Approximate inference for stochastic planning in factored spaces. arXiv, 2203.12139, 2022.
- Zhou et al. [2022] Guangyao Zhou, Nishanth Kumar, Antoine Dedieu, Miguel Lázaro-Gredilla, Shrinu Kushagra, and Dileep George. PGMax: Factor Graphs for Discrete Probabilistic Graphical Models and Loopy Belief Propagation in JAX. arXiv preprint arXiv:2202.04110, 2022.
Appendix A Equivalence of Different Reward Formulations
In the MDP framework, we are trying to maximize the cumulative reward. We first show that this is captured by the sum of binary reward variables.
| (11) | ||||
| (12) |
A.1 Cumulative Binary Reward Over time
Under the intermediate DBN setting, we need to calculate the expectation of the total reward . We have:
| (13) | |||
| Marginalize out all terms with index | |||
| (14) | |||
| Marginalize out all the reward terms with index | |||
| (15) | |||
| (16) |
Therefore the intermediate DBN with is also captured by the sum of binary reward variables.
For our final proposed DBN, we have the expectation:
| (17) | |||
| Marginalizing out , and in the first part of the equation | |||
| (18) |
where
| (19) | ||||
| (20) |
Notice that
| (21) |
For part , since is binary
| (22) | |||
| Marginalize out , for | |||
| (23) |
Given these observations we have the recursive equation
| (24) |
i.e., the expectation of and are equivalent in two DBNs and they are both proportional to the expected cumulative reward of the original MDP problem.
Appendix B Accumulating reward from multiple nodes in the same time step
In large factored state and action spaces, the rewards are typically specified as an addition function over small factors that only depend on a small number of state and action variables given by some decision rules. The sum variable might have many parents and therefore we require an addition construction for the DBN. Since this construction is done for each time step separately, in this section we simplify the notation and omit the subscript of time step .
The construction is similar to the accumulation of reward over time. Assume there are decision rules to determine the reward at a particular time step with some state and action. Given some order over the decision rules, we expand the DBN so that each decision rule corresponds to a binary partial reward node , (), with edge between the partial reward node and the dependent state and action nodes according to the decision rule. Then for each partial reward node , we create a binary collecting reward node that connects to the partial reward node and the collecting reward node of the previous partial reward node. We also create an additional collecting reward node which is set to .
We then define the conditional distribution of given , to be
| (25) |
and the partial reward distribution to be
| (26) |
We want to show that for every time step.
| Separate the formula above w.r.t. and | ||||
| (27) |
where
| part1 | (28) |
because the whole equation vanishes when , and got marginalized out. In addition,
| part2 | (29) |
because all other variables are marginalized out.
Thus we have
| (30) |
Appendix C Exponentially Weighted Reward
As discussed in the main paper, some prior work uses backward variational inference but does so with an exponential reward weighting. Here we show how this setting can be captured within our framework. Recall that Levine [2018] formulates the objective function as
| (31) |
where
| (32) | ||||
| (33) |
Here are indicator random variables denoting “optimality” in time and the trajectory distribution is with an implicit uninformative policy.
In our formulation, represents the cumulative reward up to time , and we have established that . Recall in our graphical model, a complete trajectory distribution is
| (34) |
To recover the joint probability of the formulation from Levine [2018], we need the following steps:
-
1.
Change reward distribution to .
-
2.
The trajectory distribution need to conditioned on .
Then in our formulation we have
| (35) |
which is the same as the optimal trajectory distribution above. Then the objective of Levine [2018] can be seen to minimize
| (36) |
which is captured in our framework with the backward VI by using additional observation variables. Using the same methodology as above, in our framework both forward and backward variants of this MFVI variant can be implemented.
Appendix D Full closed form update formula for MFVI
For completeness we list the full update formulas of MFVI:
| (37) | ||||
| (38) | ||||
| (39) | ||||
| (40) |
Appendix E Analysis of MFVI on a Demo Problem
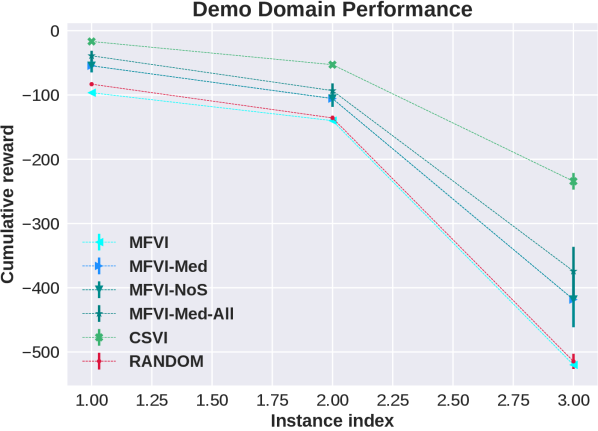
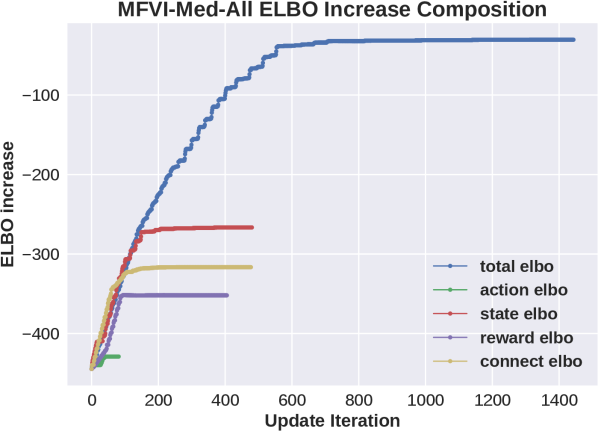
In this section we further investigate the sensitivity of MFVI to updates of state variables. To achieve this, we design a new “cooking” domain, partly inspired by the structure of the Skill Teaching Domain, in the spirit of making inference intuitively clear. We have 2 dishes and three actions, “cook dish1”, “cook dish2”, “do nothing”. By applying the “cook” action repeatedly each dish goes (with some probability) through 5 potential stages stating at “not cooked”, and moving to “not cooked and cooking”, “cookMed”, “cookMed and cooking”, “cookWell”, “Burned”. These stages are encoded by binary variables “cookMed”, “cookWell”, “cooking”. An additional state variable “watching” per dish, which is equal to “cooking” adds flexibility while not affecting the dynamics. The reward is given when “cookMed” and “cookWell” are true but not when “burned”. Hence when conditioned on high cumulative reward we should expect to see ”cookMed” initially set to true.
We next explore algorithmic variants. The NoS variant does not update state variables at all, as in the main paper. Since “cookMed” is important we create additional update schemes around it. “MFVI-Med” fixes the distribution of other state variables to be uniformly random and only updates “cookMed” state variables together with action, reward, cumulative reward variables. “MFVI-Med-All” performs an asynchronous update stating by running ‘MFVI-Med” to convergence and then following by running MFVI until it converges again.
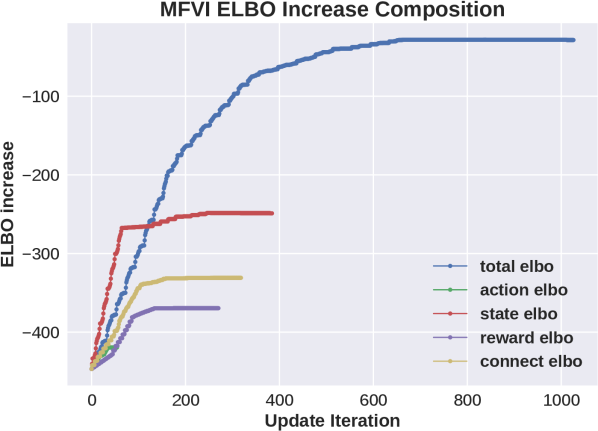
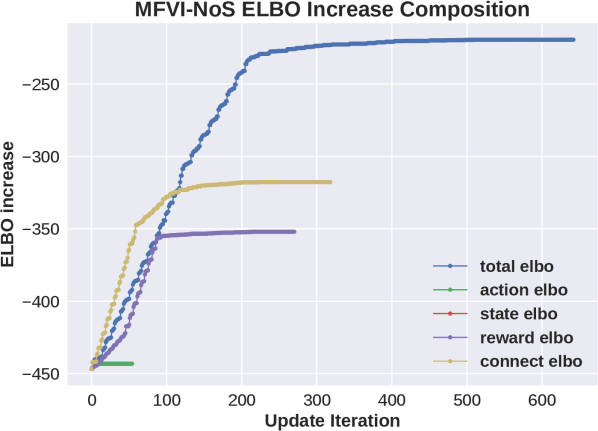
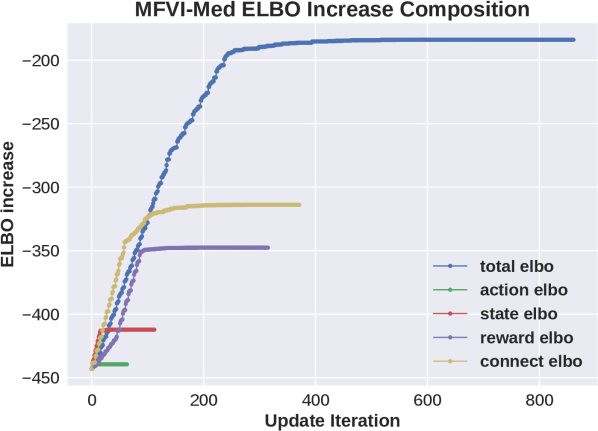
Results are shown in Fig 2. Consider first the plots that show increase in ELBO as a function of updates. We see that for MFVI the relative effect of state variables on the increase in ELBO is larger than all other variables. Comparing this to the NoS variant we see that in that case reward and cumulative variables are more important and the improvement it provides is potentially due to removing the large changes in ELBO due to state variables. On the other hand, as shown in the performance plot on the left, the two new variants based on the “cookMed” variable, still improve the performance but also have a large gap in the effect on ELBO, so this does not provide a full explanation. The success of “MFVI-Med-All” shows that the flexibility is not the whole story, but that the algorithm is sensitive to the order of updates.
As a final diagnostic, we print out the approximate posterior distribution of “cookMed”, and “cooking” variables of different schemes starting from the state where all the variables are set to be 0. Ideally, these four variables should be all biased towards 1. We see that for VI-Med and VI-Med-All, their approximate posterior, though not fully accurate, provides useful information for action distribution update while MFVI provides approximate state posterior in the wrong direction. This shows that MFVI can converge to uninformative local optima, which causes its poor performance. Overall we believe that the large number of state variables, their relative effect on the ELBO, and the sensitivity of the variational algorithm to order of updates are the cause of failure in some domains.
| Variables | VI-noS | VI-Med | VI-Med-All | MFVI |
|---|---|---|---|---|
| t1-CookMed [d1, d2] | [0.5, 0.5] | [1.48e-3, 4.09e-6] | [3.37e-7, 5.47e-5] | [3.59e-5, 5.38e-5] |
| t1-Cooking [d1, d2] | [4.95e-1, 4.95e-1] | [4.95e-1, 4.95e-1] | [0.99, 1.00e-12] | [5.00e-5, 5.00e-5] |
| t2-CookMed [d1, d2] | [0.5, 0.5] | [0.99, 8.49e-4] | [0.94, 5.86e-5] | [7.57e-5, 5.90e-5] |
| t2-Cooking [d1, d2] | [4.85e-1, 4.85e-1] | [4.67e-1, 4.67e-1] | [2.49e-1, 2.51e-1] | [5.00e-5, 5.00e-5] |
Appendix F Details Experimental Results in All Domains
In this section we show the raw, un-normalized results separately for all domains (represented by the first five letters of the domain names in the main paper). We include results for a second implementation of forward Loopy BP which is discussed in the following subsection.
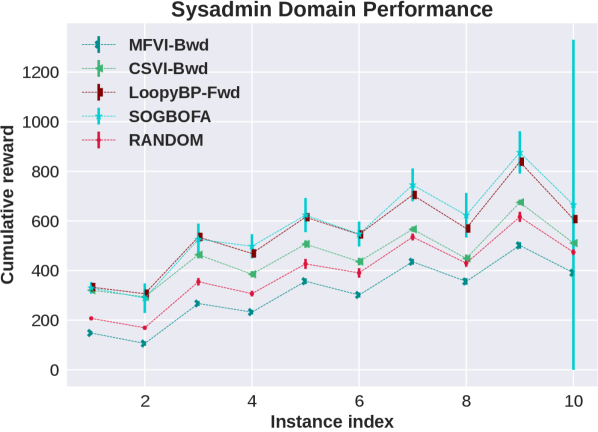
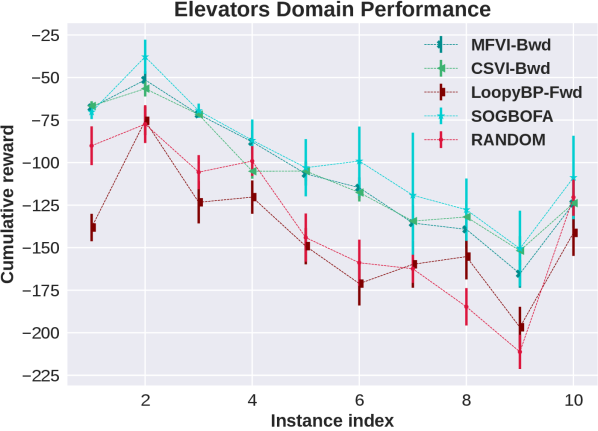
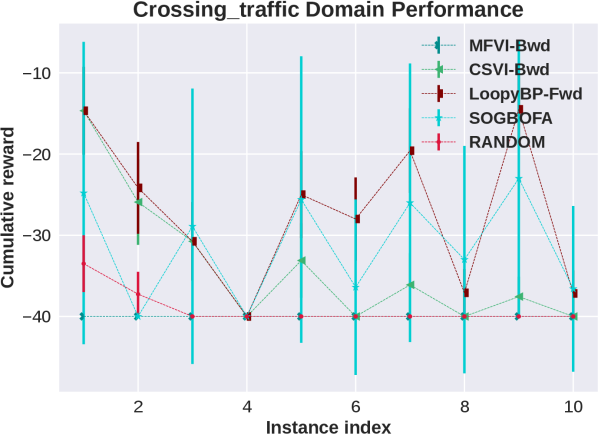
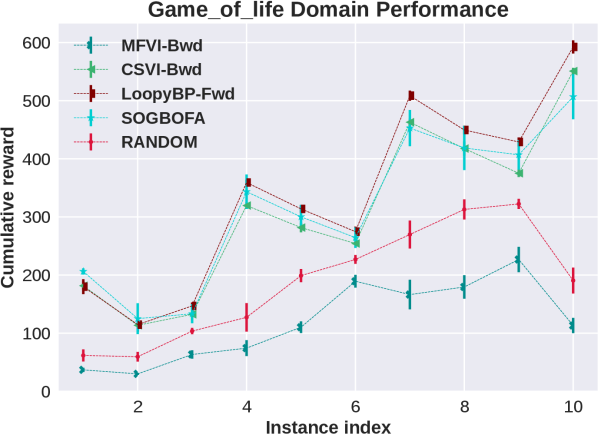
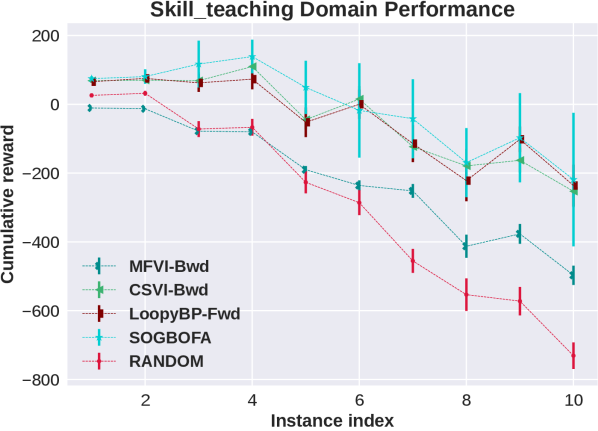
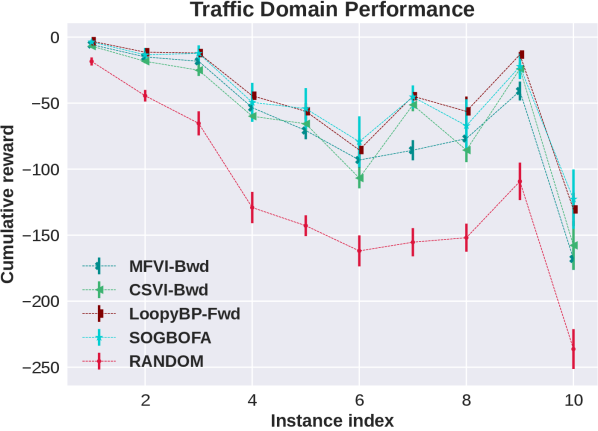
F.1 Different Optimization Strategies for Forward Loopy BP
Recall that in the forward Loopy BP algorithm, we define to be the approximate marginal distribution of computed by LBP. For the same construction, but using BP with a directed model, Cui et al. [2018] showed that LBP does converge and that it does so in one iteration. This holds because factors are conditional probability tables and we do not have downstream evidence. The same holds in our case, for the corresponding message order. However, this does not solve the optimization problem, i.e. selecting or .
In this context we experimented with two methods. The first one is discussed in the main paper. Namely, the SOGBOFA algorithm [Cui et al., 2019] that fully optimizes by combining the one pass inference of the marginal problem, which is done symbolically, with a gradient search. The second one (labeled ”LoopyBP-Fwd” in the plot) is a computationally cheap compromise, introduced by Cui et al. [2015], which uses a uniform distribution for , and performs the optimization by enumerating values for . That is, the second variant only optimizes the current action and uses a random rollout for subsequent actions. To make this as close as possible to SOGBOFA we used an implementation of BP with sequential updates where we can perform just one pass of forward messages (due to convergence).444 We have also experimented with the fast implementation using parallel updates as used by the backward algorithm which gives comparable results with 100 iterations of message propagation.
From the domain-by-domain experimental results we see that in all domains except Elevators the two algorithms have comparable and consistent performance. The need for optimizing the rollout policy for Elevators was discussed in Cui et al. [2015] Cui et al. [2019]. Briefly, a combination of positive and negative rewards in this domain means that random rollouts are not informative and, due to the large penalty, all actions look risky and the simpler planning algorithm chooses to do nothing. More importantly, for our experiments, the consistency in performance shows that the experimental advantage of SOGBOFA across all domains is not due to differences in implementation details but rather due to the inference strategy.