Approximating The -Mean Curve of Large Data-Sets
Abstract
A set of piecewise linear functions, called polylines, each with at most vertices can be simplified into a polyline with vertices, such that the Fréchet distances to each of these polylines are minimized under the distance. We call for with a -mean curve (-MC).
We discuss , for which distance satisfies the triangle inequality and -mean has not been discussed before for most values . Computing the -mean polyline is NP-hard for and some values of , so we discuss approximation algorithms.
We give a time exact algorithm for and . Also, we reduce the Fréchet distance to the discrete Fréchet distance which adds a factor to both and . Then we use our exact algorithm to find a -approximation for in time. Our method is based on a generalization of the free-space diagram (FSD) for Fréchet distance and composable core-sets for approximate summaries.
1 Introduction
A polygonal curve is a sequence of points, e.g. GPS data such as vehicle tracks on a map, time series, movement patterns, or discretized borders of countries on a map. Trajectories appear in spatial databases and networks, geographic information systems (GIS), and any dataset with temporal labels for coordinates. Simplification is a method of reducing the size of the input trajectory, mostly to achieve reduced noise, optimize the storage space, or as a preprocessing step to improve the running time of later processing algorithms.
For large datasets and models for them, such as streaming, divide and conquer including massively parallel computations (MPC) [9], MapReduce class (MRC) [28], and composable core-sets [27], there are few algorithms with good theoretical guarantees. Even on medium-sized datasets, existing algorithms take at least quadratic time for some similarity measures, and are therefore too slow to be useful in practice. Methods for partitioning data while keeping the theoretical guarantees and relaxing the condition of the simplified curve be built from the points of the original curve are our main tools in achieving these goals.
The min-k curve simplification problem finds a subcurve with the same start and end vertices and the minimum number of vertices with distance at most from the original curve. However, for a set of curves, the simplification errors are aggregated, if they are computed independently. We focus on the simplification of a set of curves by finding a representative curve that is a good cluster representative for -based clusterings and has almost k vertices, assuming that the input curves have Fréchet distances at most from each other.
In a simplification algorithm, a shortcut is a segment that replaces a part of the curve starting and ending at vertices of that curve.
The Fréchet distance is the minimum length of the leash between a man walking on one curve from the start to the end, and his dog walking on the other curve from the start to the end, given that none of them ever goes back. Deciding the Fréchet distance between two curves takes time for curves with vertices using the free space diagram (FSD) [7]. The Fréchet distance cannot be decided in time [10] or even approximated by a factor better than [17], for any , unless SETH fails. For input curves with vertices, assuming SETH is true, it is not possible to decide the Fréchet distance of the curves in time, for all [12].
1.1 Previous results.
Computing a representative curve is a well studied problem [13, 36, 25, 19, 35, 6, 14, 15]. For similar (close) monotone trajectories with the same start and end vertices, Buchin, et al [13] presented algorithms for computing the median trajectory and the homotopic median trajectory.
A curve simplification where the points of the simplified curve should be a subset of the vertices of the input curve is called a discrete curve simplification. Discrete curve simplification under Fréchet distance is solvable in time [26], and no algorithm with running time exists for all , if SETH holds [12].
In the global min- simplification, is a subsequence of with at most vertices that minimizes . The current best exact min- simplification algorithms for global Fréchet distance have cubic complexity [11].
A similar problem is -segment mean curve [32], where a monotone path is simplified into a possibly discontinuous -piecewise linear function. Also, the problem of min- simplification with arbitrary points of the plane, where the distance is given and the goal is to minimize the number of vertices has been discussed in [34].
Approximation algorithms with near linear time exist for local simplification under Fréchet distance [3, 2], where only the error of each shortcut is taken into account. Global discrete curve simplification using Fréchet distance can be solved in time [11]. If conjecture holds, there is no algorithm for global simplification using Fréchet distance with running time , for any [11].
The combination of the representative curve and curve simplification problems is the -clustering problem, where the cost of clustering a set of curves into clusters with centers , such that
is minimized using curves with complexity as cluster representatives (centers).
Driemel et al. [21] proposed -approximation algorithms for -center and -median clustering of curves in 1D and a -approximation for any dimensions, assuming the complexity of a center and is constant. Buchin et al. [14] presented an algorithm for computing the -center of a set of curves under Fréchet distance, such that the complexity of the representative curves (centers) is fixed, and prove that it is NP-hard to find a polynomial approximation scheme (PTAS) for this problem. They also presented a -approximation algorithm for this problem in the plane and a -approximation for , and proved the lower bound for the discrete Fréchet distance in 2D if .
-mean trajectories for using -center [14, 21], and using -median [21] exist. The computation of -MC based on the Fréchet reparameterization has already been discussed and implemented for [16], however, such a computation can have complexity , which is infeasible for large datasets. For , the problem is W[1]-hard using as the parameter [18].
1.2 Our results.
We call the objective function of -MC the -norm of the Fréchet distance. Since the root function is monotone for , which are the values that appear in the cost of -based clustering problems, it is sufficient to minimize the -th power of Fréchet distance or . Note that while both -norms and the Fréchet distance satisfy the triangle inequality, their combination does not. For example, for , the inequality becomes
which does not always hold.
Given the re-parameterizations of the input curves that gives the optimal -MC, the problem of finding the -MC curve can be solved by reducing it to the point version of the problem, where a set of points is given and the goal is to find a point that minimizes the -norm of distances from itself to the rest of the points. However, since the Fréchet distance only cares about the maximum distance between the points, only the points whose matching gives the maximum distance need to be considered. These are the Fréchet events.
Based on this observation, we give the following new results, and define new concepts that explain some of the reasons behind the good performances of existing algorithms and heuristics:
-
•
We consider the -MC for most values of and give approximation algorithms for them. Table 1 summarizes the results on -mean curves of curves.
-
•
We give a divide and conquer algorithm for computing the representative curve. The parallel implementation of our algorithm has time complexity independent from .
-
•
We give a new simplification algorithm which can simplify an input curve with error and vertices, where is the length of the optimal simplification. It is based on a reduction to the discrete case.
| -Mean | Time | Reference | ||
| Continuous -Mean: | ||||
| Lower bound [14] | ||||
| Lower bound [15] | ||||
| Algorithm 1 | ||||
| Algorithm 2 | ||||
| Algorithm 4 | ||||
| Discrete -Mean: | ||||
| [14] | ||||
| Algorithm 3 |
The results marked with † is for one recursion, they can be run on larger inputs by recursively calling themselves at the cost of increasing the approximation factor.
2 Preliminaries
A polygonal curve is a sequence of points and the segments connecting each point to its next point in the sequence, , for .
The Fréchet distance of two curves is defined as
where and are reparameterizations, i.e., continuous, non-decreasing, bijections from [0,1] to [0,1], and is a point metric.
In the Fréchet distance of a set of curves, is the diameter of the mapped points from the input curves and can be computed in time [23]. The Fréchet distance of curves is the diameter of their minimum enclosing ball or the -center of the curves using Fréchet distance. Using triangle inequality, the Fréchet distance of the curves is at most twice the distance from -center to the farthest curve.
The free-space diagram (FSD) [7] between two polygonal curves for a constant error , is a 2D region in the joint parameter space of those curves where each dimension is an arc-length parameterization of one of the curves, and the free space (FS) is the set of all points that are within distance of each other: and the rest of the points are non-free. Therefore, each point of FSD defines a mapping/correspondence between a point on and a point on . The Fréchet distance between two curves is at most iff there is an -monotone path in the free space diagram from to . In figures, the free space is usually shown in white, and the non-free regions are shown in gray. The orthogonal lines drawn from the vertices of the input curves build a grid (FSD grid), whose cells are called the FSD cells.
A special transformed FSD called the deformed FSD was already defined for a variation of the Fréchet distance called the backward Fréchet distance, assuming the edges of input curves have weights [24].
A curve is -packed [20] if the total arc length of inside any ball of radius is at most . The time complexity of computing a -approximation of the Fréchet distance between -packed curves is [20]. -Packed curves also have the property that for a given , the complexity of the RS is within a constant factor of the complexity of the RS for , for any . The value of a -packed curve can be approximated within factor , for any in time, where is the length of the curve and is the distance between the closest points on the curve [4].
-based clustering problems are clusterings with cost equal to the -norm of the distances between the points and their corresponding centers. For a real number , the cost of a set of points , is defined as
is also the cluster center of in an -based clustering. There is a -approximation algorithm using linear programming for computing the cost for fixed [30]. For special cases such as and explicit mathematical formulas for exist which can be used to compute in linear time. Constant factor approximations for -based clustering also exist [8].
Given a curve and a set of curves , the -norm of the Fréchet distances is defined as
The -norm of the Fréchet distances may not satisfy the triangle inequality for different curves .
Based on this definition, given the optimal mapping between the points of the curves, it is possible to compute the corresponding curve by finding the center of the mapped points for every pair of points from the curves by solving the cost optimization.
Finding the minimum-link (min-link) path in a polygonal domain asks for finding a minimum-link s-t path (a path from to ) such that the number of bends is minimized and the path lies inside the polygon and those not go through a set of polygonal holes. This problem can be solved in time, where is the number of edges in the visibility graph of the polygon [31, 33].
3 -MC of two polylines
3.1 A certificate for -simplification in FSD
Certificate for Fréchet distance
Given two curves and a constant , consider a set of certificates that indicate whether there is a -monotone -monotone mapping of cost at most between the points of the -th edge of the first curve with the -th edge of the second curve , where is mapped to at the beginning of the mapping and is mapped to at the end of this mapping. Then, the Fréchet distance of and is at most if a sequence of certificates exists where the first points of the first certificate are the start vertices of the curves, namely , and the end vertices of the last certificate are the last vertices of the curves, namely . Formally,
where denotes the set , denotes the member of the tuple , and is the indicator variable for the Fréchet distance of two line segments.
Certificate for path of length
We define a certificate for a path between two points and of length with restriction on the feasibility of edges can be defined by the recurrence relation
An example of this problem is the shortest path in a polygon with holes, where the feasibility constraint for the validity of a segment is that it does not intersect a hole.
Certificate for -simplification under Fréchet distance
Similarly, a certificate can be defined for the existence of a path of length and Fréchet distance at most . Let be the certificate of existence of a path of length . Then, the certificate for a simplification of length is given by . In Section 3.2, we discuss how to build a diagram and define the certificate for -simplification using the Fréchet distance on it.
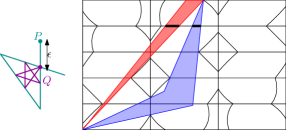
Some previous work [11, 34] assume there is one interval on each edge and consider the first point of the interval [11], or the whole interval [34]. As shown in Figure 1, this is not always the case.
3.2 Normalized free-space diagram
Scaling the axes of the free-space diagram by a constant has already been discussed [24]. In Lemma 1 we show a more general transformation works.
Lemma 1.
For a set of transformations , the free-space diagram with the free-space has the same set of feasible reparameterizations, if is a one-to-one non-decreasing function.
Proof.
Substituting gives:
The function is one-to-one, so . Since and its non-decreasing, it is still a reparameterization of , and the set of reparameterizations remains the same. ∎
We introduce a scaled FSD called normalized FSD which changes the representation of the curves in FSD such that a path in FSD corresponds to a segment in the original space if the derivatives of any point on the curve with respect to each of the FSD axes (input curves) is the same. We formalize this in Lemma 2, where the length of each segment from the input curves is divided by , and is the slope of the segment. To handle negative slopes as well, we add at most points on each of the edges of FSD cells that correspond to the intersection of the extensions of the shortcuts through previous vertices with the corresponding segment of that FSD edge in the Euclidean plane. This is formally explained in Lemma 3. In the rest of the paper, when we use FSD, we mean the normalized free-space diagram.
Lemma 2.
A segment in the normalized FSD corresponds to a segment in the original space (Euclidean plane), if the slopes of the edges of each input curve have the same sign, i.e. all positive slopes or all negative.
Proof.
Assume and are two input curves, and we want to find a condition on a curve in the parameter space of that guarantees it will correspond to a polygonal curve in the Euclidean plane.
Choose an arbitrary segment from each of these curves. We want to change the mapping of the points of and to the axes of the FSD to keep the slope of constant along different segments. Let be the length of the curve from its start vertex to the point where the length of the curve reaches . So, the domain of is , where is the length of curve . Similarly, define and . Figure 2 shows unit vectors in the direction of for a segment of , respectively.

For each segment of the curves, we define a reparameterization.
Let where , be a segment of curve with slope and -intercept .
The reformulation of in terms of is given in the following formula:
since using the derivatives of length variables:
Similarly, we reparameterize a segment of curve in terms of its length variable .
The axes of the normalized FSD are and . So we need to compute the slope of the line segment from curve in terms of and :
and the equation for is similar.
This means that scaling each segment of the curve by a factor preserves the slope of in terms of in the Euclidean plane.
Based on Lemma 1, if a transformation converts the ellipse that is the free-space inside a cell into a degenerate ellipse, it does not work anymore. We show how to handle these cases that they still preserves the properties. If the original free-space is a degenerate case, the transformation only changes the slope of the lines.
After scaling parts of the axes of the FSD, the slope of segment will not change if the slopes of the segments of the input curves have the same sign. If this is not the case, use another segment from one of the curves to compute the reparameterization, and then map the points accordingly. This is possible if at least one of the edges of one of the curves has a different slope; otherwise all the points on the each of the curves are collinear. In that case, the original free-space is a degenerate ellipse, i.e. linear functions, for which the scaling by a constant factor as described in this lemma works.
∎
Without the transformation described in Lemma 2, a polyline in the FSD still represents a polyline in the Euclidean space, however, the number of vertices can be different.
To add the signs of the slopes of the shortcut segments, it is enough to add them to the boundaries of the cells, and instead of computing the minimum-link path, compute the unweighted shortest path with these vertices in addition to the intersections of the free-space with the FSD grid (cell boundaries). The edges have weight when the slope of the last segment is equal to the slope of the next segment, otherwise the edges have weight . Because only non-decreasing paths from the start to the end vertex correspond to valid reparameterizations, direct the edges in the order of increasing index. By computing the shortest path in the resulting DAG, the minimum complexity polyline in NFSD is computed.
Let be the set of intersection points between the shortcuts for and the segment , for two polylines and . Build the graph with vertices , where is the set of vertices in FSD, i.e. the intersection points of the free-space with the grid lines of FSD, which are the points that map a vertex of one curve to each point on the other curve. The edges connect the vertices with a segment with non-negative slope between them that lies completely in the free-space, with an edge of weight in the graph.
Based on the definition, three cases for the simplification can be solved using , depending on the subset we choose the vertices of the simplification from:
-
•
Vertices of the input curves: use the vertex for the grid line containing the edge of the cell containing that point. Remember that each grid line is a vertex of an input polyline in all FSDs.
-
•
Vertices of one input curve (curve ): The shortest path must be computed using only the vertices of and the edges between the vertices of or with a subset of only if the incoming and outgoing edges have the same slope after mapping to the Euclidean plane.
-
•
Any point of the Euclidean plane: It is enough to map the vertices of to the Euclidean plane.
Lemma 3 shows the simplification can be computed using the shortest path on , or a subgraph of it.
Lemma 3.
The shortest path in from the start vertex to the end vertex gives the minimum complexity path in the Euclidean plane.
Proof.
Based on Lemma 2, the edges of that connect two points where the slope of segments between them does not change, i.e. the part of the curve between them is monotone, map to a single segment in the Euclidean plane.
Consider a reparameterization that gives the optimal simplification. For each vertex that is shortcutted in this simplification, there is a point on the boundary of the cell intersecting that path in NFSD. Since contains all such intersections, its vertices are a subset of . So, for every optimal simplification there is a path in NFSD.
To show every shortest path in NFSD gives an optimal simplification, for each vertex of the shortest path between two edges with different slopes in the Euclidean plane, choose a vertex from or depending on the boundary edge that contained that point.
If we only want the vertices of to exist in the output solution, the shortest path must be computed using only the vertices of and the edges between the vertices of or with a subset of only if the incoming and outgoing edges have the same slope after mapping to the Euclidean plane.
Based on the definition of the edges, the slope is preserved in each edge. So, each edge in NFSD is equivalent to a segment in the Euclidean plane. This means the weight of the curve in the NFSD is equal to the complexity of the polyline in the Euclidean plane.
∎
Adding points on each boundary edge increases the complexity of NFSD to . So, the simplification that minimizes the Fréchet distance between the simplified and original curves can be computed in time and in time for monotone curves. For monotone curves, all the slopes have the same sign, so we do not need to add points on the boundaries of the cells.
Note that knowing only the slopes of the lines is not enough and the mapped length of the curve is also needed to define a -simplification. More specifically, there can be partial -simplifications of a single polyline that end at the same edge, which can result in distinct optimal matchings. In NFSD, this is equivalent to having multiple monotone shortest paths between and . In a diagram with holes, the intervals on the edges that represent these partial solutions might not be continuous. In NFSDs/FSDs, the free-space acts as a certificate for valid partial matchings for Fréchet distance, however, the certificates for -simplifications are only covered by NFSDs.
3.3 Exact -mean curve
In Lemma 4, we show the reparameterization that gives the -mean curve of two curves is the one that gives the Fréchet distance between them.
Lemma 4.
The Fréchet reparameterization of curves and , minimizes the distances to the -MC of and .
Proof.
Let and be a pair of points mapped to each other in the Fréchet mapping between and . Let be the point on which lies on the -MC of . The goal is to minimize the cost of -MC for these points:
Then, we take the derivative of the above cost expression in terms of :
This is a minimum of the function, since for the derivative is positive and for smaller values it is negative.
Substituting this value in the cost expression gives .
This means that the minimum of also minimizes the cost expression.
The maximum of for all pairs is the maximum distance in the reparameterizations of that realizes the Fréchet distance.
∎
Based on [23], the higher dimensional FSDs (for more than two curves) can be constructed by building the FSDs of pairs of curves, extending them in the direction of the axes corresponding to the rest of the curves, and taking their intersection. Based on Lemma 1, NFSD represents the same set of reparameterizations as FSD. A -NFSD is the -dimensional NFSD in which the NFSD for each pair of the input curves uses distance from and distance from as the distance (to define the free-space).
Lemma 5.
Given a set of non-negative constants and a set of curves , the shortest path in the -NFSD of gives the minimum-link path in the Euclidean plane with distance at most from , for each . Assume and .
Proof.
A point in the free-space inside each cell of an -NFSD for curves satisfies:
So,
These are a set of ellipses, which are monotone except at their extreme points and the boundaries of the domain of their definition. Candidates for the optimal matchings of each point are the intersections between the grid lines, the extentions of the shortcut lines, and the ellipses.
The free-space inside each cell of NFSD for two curves is an scaled ellipse, as proved in Lemma 2; the higher dimensional NFSD is similarly proved to have an ellipsoid inside each cell as the free-space.
Using Lemma 3, the complexity (the number of vertices) of the shortest path in NFSD is equal to the complexity of the simplification in the original space. Since the scaling constants in each dimension are independent from each other, Lemma 2 generalizes to any dimension, i.e. any number of curves.
Let be the minimum-link path from to in this -NFSD. We showed that satisfies the Fréchet distance , i.e. for each point , the distances to each of the curves satisfy . Any optimal simplification maps to a path in -NFSD, based on Lemma 1. is a polyline for because -NFSD preserves the slope of the lines with respect to the input curves and changing only effects the shape of the free-space.
∎
The changes to the graph built from an -NFSD after changing form a discrete set of events, i.e. values at which changes. In Lemma 6, we discuss the events at which the complexity of the shortest path in -NFSD change, i.e. the certificates for -MC.
Lemma 6.
The number of events for the min- -MC simplification of a curve with respect to curves is , and each event can be computed in time.
Proof.
Changes to the graph built from an -NFSD when changing happen at the intersections of the free-space inside the cell with the cell boundary, or when the monotonicity of the path between the cells changes which happen when the intersections of intervals on the boundaries of the cells. In Lemma 5, we showed the shape of the free-space inside a cell is a transformed unit ball of norm, i.e. . For each edge of one curve and a vertex from the rest of the polylines, the intersection of this transformed ball and the boundary gives intervals. These events are the intersections of the transformed ball with the boundary, and the intersections of the projections of the intervals on their shared edge. Changing scale and translates the transformed unit ball of the norm that represents the free-space inside each cell. So, the intersections of it with each cell boundary is still one continuous interval for each (vertex,edge) pair. Each NFSD has cells, each with intersections, so the number of these events is .
For different slope signs, instead of a straight line segment, we look for segments that share an endpoint on the edge between the cell with different slopes and its neighboring cells, such that and are the reflections of each other with respect to . As discussed in the definition of for NFSD, these are the set of shortcuts and their extensions or reflections in case of slope changes. Based on the type of simplification, the size of is different:
-
•
Any point on one of the input curves can be used in -MC:
There are shortcuts, each intersecting with each of the edges of the NFSD grid, resulting in event points. -
•
The vertices of one of the input curves, :
Only the edges of that change slope at a point on the edges that are on the grid line for a vertex of are allowed. Since edges remain, each containing points on them (), the number of events is .
∎
Theorem 1.
The -MC of a curves can be computed in time.
Proof.
As long as the graph built on -NFSD is not changed, changing will not change the solution. So, it is enough to check the values from Lemma 6. For each of these values, we build a -NFSD and compute the shortest path in , one of which is the -MC of the curves (Lemma 3). There are values , and computing the shortest path in an -NFSD takes time, resulting in a time algorithm.
∎
Algorithm 1 implements Theorem 1. Also, the algorithm can be used to compute a min- simplification.
Since the time complexity of the exact -MC algorithm is exponential in the number of curves , we discuss approximation algorithms for such cases.
3.4 Reducing the Continuous Version to the Discrete Version: A Simplified Version of Algorithm 1
Here, we discuss a simplified version of Algorithm 1 for and , where instead of computing the path in the parameter space (FSD), we simulate the algorithm in the original space while computing the dynamic program for FSD. So, the complexity does not depend on the ply.
Let be the polygon built on the intersections of the ellipses (the free spaces) in each cell and the boundary of the cell. For each pair of vertices in , compute the intersection of with the boundary of , including the boundary of the holes. Also, consider the extension of the shortcuts and the intersections between them. Add the points on the original curves corresponding to these points in FSD. Note that constructing the free-space diagram is not necessary to compute these events.
In Algorithm 2, we used unit direction vectors to indicate the slopes of the segments. The output of the algorithm is also curve-restricted, i.e. the vertices of the simplification lie on the edges of the input curve. Lemma 7 formulates the effects of the modifications.
An intersection between two shortcuts is a point in FSD that does not fall on an edge of FSD grid, i.e. it does not map a vertex of one of the input curves, therefore, it cannot be chosen as a vertex of the simplification. Lemma 7 proves there is a path of twice the length that goes uses only the vertices of one of the curves.
Lemma 7.
Each monotone path of length in the parameter space can be mapped to a monotone path of length at most in , if the events of the intersections between the shortcuts are not used as the vertices of the simplification.
Proof.
Consider a monotone path in the FSD with a point on the monotone path inside the free space. Let be the cell containing . Compute the intersection of the neighboring edges and with and call them and (See Section 3.4).
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/55657705-d5a2-4d0f-8b6e-7466d914887f/x3.png)
Since the free space in each cell is an ellipse, and therefore convex, replacing with and then does not change the monotonicity of the curve, and only increases the length of the curve by . Using the same convexity argument in neighboring cells, and fall inside the free space. This can happen once for each vertex, since will be on an edge of the grid (equivalently a vertex of the curve) after that. By induction on the length of the curve, repeating this for all vertices gives a path of length at most .
∎
Algorithm 2 adds a vertex for the intersections of disks of radius with every edge and shortcut, and then computes the simplification. In Theorem 2, we show there is a -simplification of error at most , if a -simplification with error at most exists.
Theorem 2.
Algorithm 2 finds a simplification of the input curve with at most vertices and error at most , where is the size of the optimal simplification using any subset of points in the plane as vertices.
Proof.
The vertices of the input curve that replace the vertices of the optimal simplification with any subset of the points in the plane as vertices, as described in Lemma 7, can be replaced by two points on the curve and with distance at most from the simplification (points and from Lemma 7). This is because the free space interval on each edge has distance at most from one of the curves. If a curve simplification using points of the plane with Fréchet distance (or equivalently, a re-parameterization of the curves with distance ) exists, each part of the curve that lies inside a disk of radius can be covered by the center of that disk (a vertex of the input curve), so it does not increase the Fréchet distance. Since the algorithm restricts the points to be on the curves, any point inside the disk can be chosen as part of the output instead of its center, resulting in estimation error which is the sum of the errors at each endpoint of an edge of the optimal simplification. So, the previous Fréchet mapping (between the optimal simplification and the input) can be used with Fréchet distance for the -simplification, because the points of the -simplification have distance at most to the points of the optimal -simplification, and the optimal -simplification has distance at most to the input curve.
The complexity of the curve follows from Lemma 7. This argument in the Euclidean plane is equivalent to that a point on the part of an edge that lies inside a disk might be replaced by the intersection points with that disk, and therefore double the complexity of the computed path.
∎
4 -Mean Curve of A Set of Curves
By substituting the Fréchet events of two curves with the Fréchet events of curves, the results of the previous section extend to curves, for , since the maximum of the distances is considered. For other -mean curves, their distances to the -MC can be different, so the previous methods do not apply.
In this section, we discuss two algorithms for -MC of curves and analyze their approximation factors.
4.1 The Pairwise Algorithm for Discrete -Mean Curve
The -MCs of a set of curves, like simplification using the Fréchet distance, is not unique. So, dividing the computation of the -MC with at most vertices into first computing the Fréchet distance of a set of curves, and then simplifying the resulting curve does not yield the optimal solution.
Algorithm 3 computes an approximate -MC. In this algorithm, all the Fréchet distances between the curves are computed, then, the simplification of the one with the minimum distance to the rest of the curves is reported as an approximate solution.
Lemma 8.
Algorithm 3 is a -approximation for discrete -MC.
Proof.
Assume is the curve that has the optimal solution as its simplification and let be an optimal min- simplification of . Since is an optimal simplification, then Since -MC is also a simplification for , its distance to is at least as much as the optimal simplification. Using triangle inequality of norms, the approximation factor is proved:
∎
Lemma 9.
Proof.
Computing the Fréchet distance of two curves takes time. Testing each curve as the center and computing the norm of the Fréchet distance of all curves requires distance computations between each pair of curves. This takes time. Finding the minimum takes time. Computing the -MC with vertices takes time.
∎
Note that in Algorithm 3, while distances in matrix satisfy the triangle inequality, their -th power does not. So, approximation algorithms based on triangle inequality cannot be used to prune away large distances in .
4.2 An Algorithm for -Mean of Curves
Algorithm 4 simplifies the input curves with error less than their distances to the optimal -MC, then it computes an approximate -MC.
Theorem 3.
The approximation factor of Algorithm 4 is , if an -approximation simplification algorithm is used.
Proof.
denotes the -mean of curves computed by the algorithm, and denotes the optimal solution. is a simplification with error equal to the minimum error of simplifications of with at most vertices, so it has a distance less than any other curve, including : Since is the -MC with minimum cost for curves , it has a lower cost than . Using triangle inequality of Fréchet distance:
Substituting the approximation factors for computing from gives the approximation factor:
∎
Theorem 4.
Algorithm 4 takes time for continuous -MC, if a time -MC algorithm on curves, each with complexity at most , is used.
Proof.
Computing the simplification of a set of curves takes time. The simplification algorithm is used times in the first step of the algorithm, so the total time complexity of that step is . Computing the -mean of curves takes time. So, the running time of the algorithm is .
∎
5 Experiments
In this section, we use two types of trajectory data to evaluate our algorithm. The first one is a set of GPS tracks in different cities, and the second one is a set of pen trajectories while writing characters on a tablet. Our divide and conquer method when used in combination with our simplification algorithm produces results with good approximation factor, faster than existing algorithms that have at least quadratic time complexity due to computing the Fréchet distance on the whole input.
5.1 GPS Trajectory Datasets
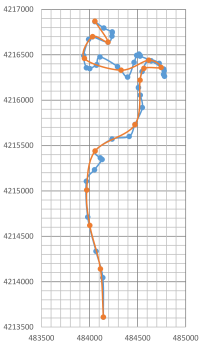
We used two tracks from the datasets of [5] of map construction repository [1], which are GPS coordinates of trajectories in several cities. One of them is track 29 of Athens Small dataset with 47 points. The other one is track 82 from Chicago dataset with 363 points. In this experiment, we only consider the first two coordinates of the tracks and use as the simplification error and as the rounding error, and for the simplification algorithm we use Algorithm 2.
In Figure 3, the original curve and its simplification with are given. The number of events used is and the output size is .
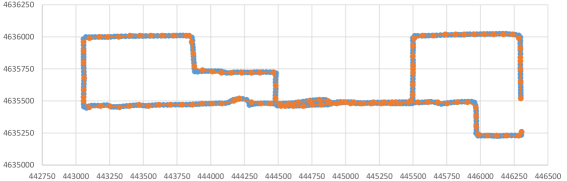
Since track 82 of Chicago dataset is too large for the algorithm to compute fast, we break it into chunks of points, which gives chunks. Also, we first compute a simplification and then a simplification using the points of the plane on each part of the curve, and concatenate the results. The output size is points. The parameters are and .
5.2 Character Trajectories Dataset
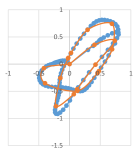
We ran the algorithm on the first trajectory of the dataset “Character Trajectories Data Set” [38, 39, 37] from UCI Machine Learning Repository [22]. Data is the pen tip trajectories of characters with a single pen-down which was captured using a WACOM tablet with sampling frequency 200Hz, and the data was normalized and smoothed. The dataset contains 2858 character samples.
We only considered the first two dimensions x and y, and ignored the last dimension which was the pen-tip force. Since the points are close to each other, the number of events can be high, so, we partition each trajectory into subsets of smaller size, compute their simplification (using the points of the plane), and then attach them and compute their overall estimation.
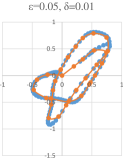
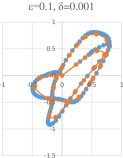
The first trajectory has 178 points, and the input was partitioned into chunks of points. In Figure 5(a), its simplification (using the points of the plane) with error and the rounding error is shown, where the size of the output is . In Figure 5(b), the output for and is shown, and the output size is . Running the algorithm on the concatenation of the estimations of the parts with the same error is shown in Figure 5(c) and it gives an output of size , and the overall error is the sum of the errors, which is .
6 Discussions and Open Problems
Using the free-space diagram to map two dimensional points into curve-length variables removes useful information such as the slope (line inclination). In this paper, we added this information by adding some vertices to the original definition of FSD and used it to give a simplification algorithm. Our algorithm generalizes to norm of the Fréchet distances, not to be confused with using norms as the metric space instead of the Euclidean plane.
We also show that the -mean curve satisfies the composable property for core-sets, and results in a constant factor approximation summary.
7 Theoretical Insights to Existing Heuristics
Greedy simplification by moving a disk along the curve.
The heuristic simplification algorithm that sweep the curve and simplifies the part of the curve that is inside the disk of radius is a commonly used algorithm in practice, which does not have any theoretical guarantees except for the error . When discussing this simplification algorithms in the parameter space (FSD) of the curve with itself with as input, we see it is in fact the lowermost feasible path. Replacing this path with the shortest path gives an algorithm for min- simplification with complexity dependent on the size of the FSD for . For monotone curves, this is an output-sensitive exact algorithm that takes time.
Local polyline simplification using Fréchet distance
References
- [1] Map construction algorithms.
- [2] M. A. Abam, M. De Berg, P. Hachenberger, and A. Zarei. Streaming algorithms for line simplification. Discrete Comput. Geom., 43(3):497–515, 2010.
- [3] P. K. Agarwal, S. Har-Peled, N. H. Mustafa, and Y. Wang. Near-linear time approximation algorithms for curve simplification. Algorithmica, 42(3-4):203–219, 2005.
- [4] S. Aghamolaei, V. Keikha, M. Ghodsi, and A. Mohades. Windowing queries using Minkowski sum and their extension to MapReduce. Journal of Supercomputing, 2020.
- [5] M. Ahmed, S. Karagiorgou, D. Pfoser, and C. Wenk. A comparison and evaluation of map construction algorithms using vehicle tracking data. GeoInformatica, 19(3):601–632, 2015.
- [6] H.-K. Ahn, H. Alt, M. Buchin, E. Oh, L. Scharf, and C. Wenk. A middle curve based on discrete Fréchet distance. In Latin American Symp. Theoret. Informatics, pages 14–26. Springer, 2016.
- [7] H. Alt and M. Godau. Computing the Fréchet distance between two polygonal curves. Int. J. of Comput. Geom. Appl., 5(01n02):75–91, 1995.
- [8] M. Bateni, A. Bhaskara, S. Lattanzi, and V. Mirrokni. Distributed balanced clustering via mapping coresets. In Adv. in Neural Info. Process. Syst., pages 2591–2599, 2014.
- [9] P. Beame, P. Koutris, and D. Suciu. Communication steps for parallel query processing. In Proceedings of the 32nd ACM SIGMOD-SIGACT-SIGAI Sympos. Princ. Database Syst., pages 273–284. ACM, 2013.
- [10] K. Bringmann. Why walking the dog takes time: Fréchet distance has no strongly subquadratic algorithms unless seth fails. In Annu. IEEE Sympos. Found. Comput. Sci., pages 661–670. IEEE, 2014.
- [11] K. Bringmann and B. R. Chaudhury. Polyline simplification has cubic complexity. arXiv preprint arXiv:1810.00621, 2018.
- [12] K. Buchin, M. Buchin, M. Konzack, W. Mulzer, and A. Schulz. Fine-grained analysis of problems on curves. EuroCG, Lugano, Switzerland, 2016.
- [13] K. Buchin, M. Buchin, M. van Kreveld, M. Löffler, R. I. Silveira, C. Wenk, and L. Wiratma. Median trajectories. Algorithmica, 66(3):595–614, Jul 2013.
- [14] K. Buchin, A. Driemel, J. Gudmundsson, M. Horton, I. Kostitsyna, M. Löffler, and M. Struijs. Approximating (k,)-center clustering for curves. In Proceedings of the 30th ACM-SIAM Sympos. Discrete Algorithms, pages 2922–2938. SIAM, 2019.
- [15] K. Buchin, A. Driemel, and M. Struijs. On the hardness of computing an average curve. arXiv preprint arXiv:1902.08053, 2019.
- [16] K. Buchin, A. Driemel, N. van de L’Isle, and A. Nusser. klcluster: Center-based clustering of trajectories. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, pages 496–499, 2019.
- [17] K. Buchin, T. Ophelders, and B. Speckmann. Seth says: Weak Fréchet distance is faster, but only if it is continuous and in one dimension. In Proceedings of the 30th Annu. ACM Sympos. Comput. Geom., pages 2887–2901. SIAM, 2019.
- [18] M. Buchin, N. Funk, and A. Krivošija. On the complexity of the middle curve problem. arXiv preprint arXiv:2001.10298, 2020.
- [19] E. Chambers, I. Kostitsyna, M. Löffler, and F. Staals. Homotopy measures for representative trajectories. In Inform. Process. Lett., volume 57. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2016.
- [20] A. Driemel, S. Har-Peled, and C. Wenk. Approximating the Fréchet distance for realistic curves in near linear time. Discrete Comput. Geom., 48(1):94–127, 2012.
- [21] A. Driemel, A. Krivošija, and C. Sohler. Clustering time series under the Fréchet distance. In Proceedings of the 27th ACM-SIAM Sympos. Discrete Algorithms, pages 766–785. Society for Industrial and Applied Mathematics, 2016.
- [22] D. Dua and C. Graff. UCI machine learning repository, 2017.
- [23] A. Dumitrescu and G. Rote. On the Fréchet distance of a set of curves. In Canad. Conf. Computat. Geom., pages 162–165, 2004.
- [24] A. Gheibi, A. Maheshwari, and J.-R. Sack. Weighted minimum backward Fréchet distance. Theoret. Comput. Sci., 783:9–21, 2019.
- [25] S. Har-Peled and B. Raichel. The Fréchet distance revisited and extended. ACM Trans. Algorithms, 10(1):3, 2014.
- [26] H. Imai and M. Iri. Polygonal approximations of a curve—formulations and algorithms. In Machine Intelligence and Pattern Recognition, volume 6, pages 71–86. Elsevier, 1988.
- [27] P. Indyk, S. Mahabadi, M. Mahdian, and V. S. Mirrokni. Composable core-sets for diversity and coverage maximization. In Proceedings of the 33rd ACM SIGMOD-SIGACT-SIGAI Sympos. Princ. Database Syst., pages 100–108. ACM, 2014.
- [28] H. Karloff, S. Suri, and S. Vassilvitskii. A model of computation for mapreduce. In Proceedings of the 21st ACM-SIAM Sympos. Discrete Algorithms, pages 938–948. Society for Industrial and Applied Mathematics, 2010.
- [29] M. v. Kreveld, M. Löffler, and L. Wiratma. On optimal polyline simplification using the Hausdorff and Fréchet distance. In Proceedings of the 34th Annu. ACM Sympos. Comput. Geom., volume 99, pages 56–1. Leibniz International Proceedings in Informatics (LIPIcs), 2018.
- [30] J.-H. Lin and J. S. Vitter. Approximation algorithms for geometric median problems. 1992.
- [31] J. S. Mitchell, G. Rote, and G. Woeginger. Minimum-link paths among obstacles in the plane. Algorithmica, 8(1-6):431–459, 1992.
- [32] G. Rosman, M. Volkov, D. Feldman, J. W. Fisher III, and D. Rus. Coresets for k-segmentation of streaming data. In Adv. in Neural Info. Process. Syst., pages 559–567. Curran Associates, Inc., 2014.
- [33] C. D. Toth, J. O’Rourke, and J. E. Goodman. Handbook of discrete and computational geometry. Chapman and Hall/CRC, 2017.
- [34] M. van de Kerkhof, I. Kostitsyna, M. Löffler, M. Mirzanezhad, and C. Wenk. Global curve simplification. In Proceedings of the 27th Annu. European Sympos. Algorithms. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2019.
- [35] M. van Kreveld, M. Loffler, and F. Staals. Central trajectories. arXiv preprint arXiv:1501.01822, 2015.
- [36] M. van Kreveld and L. Wiratma. Median trajectories using well-visited regions and shortest paths. In Proceedings of the 19th ACM SIGSPATIAL Internat. Conf. Advances Geogr. Inform. Syst., pages 241–250. ACM, 2011.
- [37] B. Williams, M. Toussaint, and A. J. Storkey. Modelling motion primitives and their timing in biologically executed movements. Advances in neural information processing systems, 20:1609–1616, 2007.
- [38] B. H. Williams, M. Toussaint, and A. J. Storkey. Extracting motion primitives from natural handwriting data. In International Conference on Artificial Neural Networks, pages 634–643. Springer, 2006.
- [39] B. H. Williams, M. Toussaint, and A. J. Storkey. A primitive based generative model to infer timing information in unpartitioned handwriting data. In IJCAI, pages 1119–1124, 2007.