12016
Action editor: {action editor name}. Submission received: DD Month YYYY; revised version received: DD Month YYYY; accepted for publication: DD Month YYYY.
ArguGPT: evaluating, understanding and identifying argumentative essays generated by GPT models
Abstract
Content generated by artificial intelligence models have presented considerable challenge to educators around the world. When students submit AI generated content (AIGC) as their own work, instructors will need to be able to detect such text, either with the naked eye or with the help of computational tools. There is also growing need and interest to understand the lexical, syntactic and stylistic features of AIGC among computational linguists.
To address these challenges in the context of argumentative essay writing, we present ArguGPT, a carefully balanced corpus of 4,038 argumentative essays generated by 7 GPT models in response to essay prompts from three sources: (1) in-class or homework exercises, (2) TOEFL writing tasks and (3) GRE writing tasks. These machine-generated texts are paired with roughly equal number of human-written essays with low, medium and high scores matched in essay prompts. We also include an out-of-distribution test set where the machine essays are generated by models other than the GPT family—claude-instant, bloomz and flan-t5—to examine AIGC detectors’ generalization ability.
We then hire English instructors to distinguish machine essays from human ones. Results show that when first exposed to machine-generated essays, the instructors only have an accuracy of 61 percent in detecting them. But the number rises to 67 percent after one round of minimal self-training. Next, we perform linguistic analyses of the machine and human essays, which show that machines produce sentences with more complex syntactic structures while human essays tend to be lexically more complex. Finally, we test existing AIGC detectors and build our own detectors using SVMs as well as the RoBERTa model. Our results suggest that a RoBERTa fine-tuned with the training set of ArguGPT can achieve above 90% accuracy in document, paragraph and sentence-level classification. The document-level RoBERTa can generalize to other models as well (such as claude-instant), while off-the-shelf detectors such as GPTZero fail to generalize to our out-of-distribution data.
To the best of our knowledge, this is the first comprehensive analysis of argumentative essays produced by generative large language models. Our work demonstrates the need for educators to acquaint themselves with AIGC, presents the characteristics of AI generated argumentative essays and shows that detecting AIGC from the same domain seems to be an easy task for machine-learning based classifiers while transferring to essays generated by other models is challenging. Machine-authored essays in ArguGPT and our models are publicly available at https://github.com/huhailinguist/ArguGPT.
1 Introduction
Recent large language models (LLM) such as ChatGPT have shown incredible generative abilities. They have created many opportunities, as well as challenges for students and educators around the world.111This paper is written and polished by humans, with the exception of Appendix D. While students can use them to obtain information and increase efficiency in learning, many educators are concerned that ChatGPT will make it easier for students to cheat in their homework assignments, for example, by asking ChatGPT to summarize their readings, solve math problems, and even write responses and essays: tasks that are supposed to be completed by students themselves. Educators have started to find that well-written essays submitted by students, some even deemed “the best in class”, were actually written by ChatGPT, making it increasingly difficult to evaluate students’ performance in class. For instance, a philosophy professor from North Michigan University has discovered that the best essay in his class was in fact written by ChatGPT.222See https://www.nytimes.com/2023/01/16/technology/chatgpt-artificial-intelligence-universities.html Thus it is critical for educators to identify AI generated content (AIGC), either with the naked eye, or the help of some tools.
There is also growing interest and need among computational linguists to study texts generated by language models. Several studies have examined whether humans can identify AI-generated text (Brown et al., 2020; Clark et al., 2021; Dou et al., 2022). Others have built text classifiers to distinguish AI-written from human-written text (Gehrmann, Strobelt, and Rush, 2019; Mitchell et al., 2023; Guo et al., 2023).
The focus of this paper is on argumentative essays in the context of English as Other or Second Language (EOSL). There are an estimated 2 billion people learning/speaking English, and at least 12 million instructors worldwide333Data released by British Council in 2013 (See https://www.britishcouncil.org/research-policy-insight/policy-reports/the-english-effect). It is thus of practical significance for EOSL instructors to be able to identify AIGC; computational linguists also need to build efficient educational applications that accurately detect AI-generated essays.
Therefore, our first goal is to establish a baseline of the performance of the EOSL instructors in distinguishing AIGC from texts written by non-native speakers. We also want to examine whether their accuracy could be improved with minimal training. Next, we analyze the linguistic features of AIGC which contributes to a growing body of literature on AI-generated text (Dou et al., 2022; Guo et al., 2023). Last but not least, we aim to build and evaluate the performance of machine-learning classifiers on detecting AIGC.
Concretely, we ask the following questions:
-
•
Can human evaluators (language teachers) distinguish argumentative essays in English generated by GPT models from those written by human language learners?
-
•
What are the linguistic features of machine-generated essays, compared with essays written by language learners?
-
•
Can machine learning classifiers distinguish machine-generated essays from human-written ones?
To answer these questions, we first collect 4,038 machine-generated essays using seven models of the GPT family (GPT2-XL, variants of GPT3, and ChatGPT), in response to 632 prompts from multiple levels of English proficiency and writing tasks (in-class writing exercises, TOEFL and GRE). We then pair these essays with 4,115 human-written ones at low, medium and high level to form the ArguGPT corpus. Also, an out-of-distribution test set is collected to evaluate the generalization ablity of our detectors, containing 500 machine essays and 500 human essays. We conduct human evaluation tests by asking 43 novice and experienced English instructors in China to identify whether a text is written by machine or human. Next, we compare the 31 syntactic and lexical linguistic measures of human-authored and machine-generated essays, using the tools and methods from Lu (2010, 2012), aiming to uncover the textual characteristics of GPT-generated essays. Finally, we benchmark existing AIGC detectors such as GPTZero444https://gptzero.me/ and our own detectors based on SVM and RoBERTa on the development and test sets of the ArguGPT corpus.
Our major findings and contributions are: (1) We provide the first large-scale, balanced corpus of AI-generated argumentative essays for NLP and ESOL researchers. (2) We show that it is difficult for English instructors to identify GPT-generated texts. English instructors distinguish human- and GPT-authored essays with an accuracy of 61.6% in the first round, and after some minimal training, the accuracy rises to 67.7%, roughly 10 points higher than previously reported in Clark et al. (2021), probably due to the instructors’ familiarity with student-written texts. Interestingly, they are better at detecting low-level human essays but high-level machine essays. (3) In terms of syntactic and lexical complexity, we find that the best GPT models produce syntactically more complex sentences than humans (English language learners), but GPT-authored essays are often lexically less complex. (4) We discover that machine-learning classifiers can easily distinguish between machine-generated and human-authored essays, usually with very high accuracy, similar to results from Guo et al. (2023). GPTZero has 90+% accuracy both at the essay level and sentence level. Our best performing RoBERTa-large model finetuned on ArguGPT achieves 99% accuracy on the test set at the essay level and 93% at the sentence level. (5) However, on the out-of-distribution test set, only the RoBERTa model finetuned on ArguGPT corpus shows consistent transfer learning ability. Performance of the two off-the-shelf detectors dropped dramatically, especially on detecting essays written by models not included in ArguGPT, e.g., gpt-4 and claude-instant. (6) The machine-authored essays555As we do not have copyright to the human-authored essays, we will only release the index of the human essays use in our study. Interested readers can purchase relevant corpora from their owners to reproduce our results. will be released at https://github.com/huhailinguist/ArguGPT. Demo of our ArguGPT detector and related models are/will be available at https://huggingface.co/spaces/SJTU-CL/argugpt-detector.
This paper is structured in the following manner. Section 2 introduces the compilation process of the ArguGPT corpus. Section 3 describes the method used for conducting human evaluation. Section 4 presents the linguistic analysis we conduct from syntactic and lexical perspectives. Section 5 discusses the performance of existing AIGC detectors and our own detectors on the test set of ArguGPT. Section 6 introduces related works on Large Language Models (LLMs), human evaluation of AIGC, AIGC detectors, and AIGC’s impact on education. Section 7 concludes the paper.
2 The ArguGPT corpus
In this section, we describe how we compile the ArguGPT corpus and an out-of-distribution (OOD) dataset for the evaluation of generalization ability.
2.1 Description of the ArguGPT corpus
The ArguGPT corpus contains 4,115 human-written essays and 4,038 machine-generated essays produced by 7 GPT models. These essays are responses to prompts from three sources: (1) in-class writing exercises (WECCL, Written English Corpus of Chinese Learners), (2) independent writing tasks in TOEFL exams (TOEFL11), and (3) the issue writing task in GRE (GRE) (see Table 1). We first collect human essays from two existing corpora—WECCL (Wen, Wang, and Liang, 2005) and TOEFL11 (Blanchard et al., 2013), and compile a corpus for human-written GRE essays from GRE-prep materials ourselves. Next, we use the essay prompts from the three corpora of human essays to generate essays from seven GPT models listed in Table 5. Example essay prompts can be found in Table 2.
Here we list the characteristics of the ArguGPT corpus:
-
•
The human-written and machine-generated portions are comparable and matched in several respects: the number of the essays, the corpus size in tokens, the mean length of the essays, and the levels of the essays.
-
•
Each machine-generated essay comes with a score given by an automated scoring system. (see Section 2.3 for details).
-
•
The essays cover different levels of English proficiency. WECCL essays are written by low and intermediate English learners; TOEFL contains essays from all levels of writing ability; GRE essays are model essays written by highly proficient language users.
-
•
The human-written GRE essays are, to the best of our knowledge, the first corpus of GRE essays.
| Sub-corpus | # essays | # tokens | mean len | # prompts | # low level | # mid level | # high level |
| WECCL-human | 1,845 | 450,657 | 244 | 25 | 369 | 1,107 | 369 |
| WECCL-machine | 1,813 | 442,531 | 244 | 25 | 281 | 785 | 747 |
| TOEFL11-human | 1,680 | 503,504 | 299 | 8 | 336 | 1,008 | 336 |
| TOEFL11-machine | 1,635 | 442,963 | 270 | 8 | 346 | 953 | 336 |
| GRE-human | 590 | 341,495 | 578 | 590 | 6 | 152 | 432 |
| GRE-machine | 590 | 268,640 | 455 | 590 | 2 | 145 | 443 |
| OOD-human | 500 | 132,902 | 266 | - | - | - | - |
| OOD-machine | 500 | 180,120 | 360 | - | - | - | - |
| Total (w/o OOD) | 8,153 | 2,449,790 | 300 | 623 | 1,340 | 4,150 | 2,663 |
| Sub-corpus | Example Essay Prompt |
| WECCL | Education is expensive, but the consequences of a failure to educate, especially in an increasingly globalized world, are even more expensive. |
| Some people think that education is a life-long process, while others don’t agree. | |
| TOEFL11 | It is better to have broad knowledge of many academic subjects than to specialize in one specific subject. |
| Young people enjoy life more than older people do. | |
| GRE | Major policy decisions should always be left to politicians and other government experts. |
| The surest indicator of a great nation is not the achievements of its rulers, artists, or scientists, but the general well-being of all its people. |
To the best of our knowledge, this is the first large-scale, prompt-balanced corpus of human and machine written English argumentative essays, with automated scores. We believe it can be beneficial to ESOL instructors, corpus linguists, and AIGC researchers.
2.2 Collecting human-written essays
Our goal is to collect human essays representing different levels of English proficiency. To this end, we decided to include essays from three sources: (1) WECCL, which we believe is representative of the writings from low to intermediate EOSL learners, (2) TOEFL11, representative of intermediate to advanced learners, and (3) GRE, which represents more advanced learners as well as native speakers. We elaborate on how the essays are collected and sampled below.
2.2.1 WECCL
WECCL (Written English Corpus of Chinese Learners) corpus is the sub-corpus of SWECCL (Spoken and Written English Corpus of Chinese Learners) (Wen, Wang, and Liang, 2005). Texts in WECCL are essays written by English learners from Chinese universities, collected in the form of in-class writing tasks or after-class writing assignments. WECCL contains exposition essays and argumentative essays, but only argumentative essays are used in our corpus. The original WECCL corpus has 4,678 essays in response to 26 prompts. We score these essays with aforementioned automated scoring system, and then categorize them into three levels: low (score 13), medium (14 score 17), and high (score 18). To keep it balanced with the TOEFL subcorpus, we down-sample WECCL into 1,845 essays, ensuring the ratio of low:medium:high is 1:3:1. From Table 1, we can see that WECCL essays are shorted in length among the three human sub-corpora, with mean length 244 words per essay.
2.2.2 TOEFL11
We use the TOEFL11 corpus released by ETS (Blanchard et al., 2013), which includes 12,100 essays written for the independent writing task in the Test of English as Foreign Language (TOEFL) by English learners with 11 native languages in response to 8 prompts. Since the essays come with three score levels (i.e., low, medium, high), we do not score them using the YouDao system. We down-sample TOEFL11 to 1,680 essays, making sure that we have the same number of essays per prompt. The ratio of low, medium, high is set to 1:3:1 as well.
2.2.3 GRE
We also collect essays in response to the GRE issue task. The Graduate Record Exam (GRE) has two writing tasks. The issue task asks the test taker to write an essay on a specific issue whereas the argument task requires the test take to read a text first and analyze the argument presented in the text mainly from logical aspect666More information about GRE writing could be found: https://www.ets.org/gre/test-takers/general-test/prepare/content/analytical-writing.html. In keeping with the prompts of WECCL and TOEFL11, we only consider the issue task in GRE.
As there are no publicly available corpus of GRE essays, we first collected 981 human written essays from 14 GRE-prep materials. An initial inspection shows that the collected essays have following two problems: 1) some prompts do not conform to the usual GRE writing prompts (e.g., some prompts have only one phrase: “Imaginative works vs. factual accounts”), 2) some essays show up in different GRE-prep materials. After removing the problematic prompts and keeping only one of the reduplicated essays, a total of 590 essays remained. We then score these essays using the YouDao automatic scoring system, and assign essays to three levels: low (score 3), medium (3 score 5) and high (score 5).
Note that as these essays are sample essays from humans, only 6 out of the 590 essays are grouped into low level (see Table 1).
2.3 Automatic scoring of essays
We use automated scoring systems to score the essays in ArguGPT for two reasons: (1) to allow balanced sampling from different levels of human essays, and (2) to estimate the quality of machine essays generated by different models.777We did not score human TOEFL essays as they come with a three-level (low, medium and high) score from the TOEFL11 corpus (Blanchard et al., 2013).
In the pilot study, we use two automated scoring systems (YouDao and Pigai888YouDao: https://ai.youdao.com; Pigai: http://www.pigai.org/) to score a total of 480 machine essays on 10 prompts with 6 GPT models. Analyses show that the scores given by the two systems are highly correlated: we see a Pearson correlation of 0.7570 for all 480 essays, 0.8730 when scores are grouped by prompts, and 0.9510 when grouped by models. Thus we decide to use only one system—YouDao, which provides an API for easy scoring. We further experiment with different settings of the YouDao system and decide to use their 30-point scale for TOEFL, 6-point scale for GRE, as they are optimized for TOEFL and GRE writing tasks, and a 20-point scale for WECCL, as our experiments show that this scale is most discriminating for essays generated by different models responding to WECCL prompts (see Appendix B.1 for details).
2.4 Collecting machine-generated essays
In this section, we introduce how we collect machine-generated essays. We conduct minimal prompt-tuning to select a proper format of prompt according to scores given by the automated scoring system. Finally, we use those prompts to generate essays.
2.4.1 Prompt selection
GPT models are prompt-sensitive (Chen et al., 2023). Thus for this study, we perform prompt tuning in our pilot.
We distinguish essay prompt from added prompt. An essay prompt is the sentence(s) that the test taker should respond to, e.g., “Young people enjoy life more than older people do.” An added prompt is the prompt or instruction added by us to prompt the model, e.g., “Please write an essay of 400 words.” One example is shown in Table 3.
| Prompt Type | Example |
| added prompt (prefix) | Do you agree or disagree with the following statement? |
| essay prompt | Young people enjoy life more than older people do. |
| added prompt (suffix) | Use specific reasons and examples to support your answer. |
An added prompt consists of two parts as the prefix and suffix to the essay prompt. Yet the prefix part is optional in our experimental settings. Therefore, the full prompt given to the machines is in the following format, where sometimes only the suffix part of the added prompt is used:
Our goal is to find the best-added prompt that maximizes the scores given by the YouDao automated system. To this end, we first devise 20 added prompts and manually inspect the generated essays, which are then narrowed down to 5 added prompts that produce good essays. Next, we generate essays using each of the 5 added prompts and 2 essay prompts from each of the WECCL, TOEFL11 and GRE sub-corpus. The mean score of the essays generated by these prompts are shown in Table 4.
| No. | Content of the Added Prompt | TOEFL11 | WECCL | GRE |
| 1 | Do you agree or disagree? Use specific reasons and examples to support your answer. Write an essay of roughly 300/400/500 words. | 20.53 | 20.56 | 20.97 |
| 2 | Do you agree or disagree? It is a test for English writing. Please write an essay of roughly 300/400/500 words. | 19.68 | 20.09 | 20.21 |
| 3 | Do you agree or disagree? Pretend you are the best student in a writing class. Write an essay of roughly 300/400/500 words, with a large vocabulary and a wide range of sentence structures to impress your professor. | 20.41 | 19.71 | 19.65 |
| 4 | Do you agree or disagree? Pretend you are a professional American writer. Write an essay of roughly 300/400/500 words, with the potential of winning a Nobel prize in literature. | 20.09 | 20.52 | 19.79 |
| 5 | Do you agree or disagree? From an undergraduate student’s perspective, write an essay of roughly 300/400/500 words to illustrate your idea. | 20.65 | 20.32 | 19.99 |
From Table 4, we see that essays from different prompts seem to be very close on their scores. Thus we choose prompt 01 because it has the highest average score for the three subcorpora (for more detail, see Appendix C):
<Essay prompt> + Do you agree or disagree? Use specific reasons and examples to support your answer. Write an essay of roughly 300/400/500 words.
To balance the length of machine essays with human essays, the prompts for WECCL, TOEFL11 and GRE differ in their requirement of essay length (300, 400 and 500 words respectively).
2.4.2 Generation configuration
We experiment with essay generation using 7 GPT models (see Table 5). We use all 7 models to generate essays in response to prompts in TOEFL11 and WECCL 999We give gpt2-xl beginning sentences randomly chosen from human essays for continuous writing, and remove those beginning sentences after generation.. However, as our GRE essays are mostly sample essays with high scores, we generate all 590 GRE machine essays using the two more powerful models: text-davinci-003 and gpt-3.5-turbo.
For the balance of the ArguGPT corpus, we generate 210 essays for each TOEFL11 prompt (30 essays per model with 6 essays per temperature for temp ), 35-210 essays for each WECCL prompt (the number of human essays for each WECCL prompt is different), and only 1 essay for each GRE prompt.
In our pilot study, we find that GPT-generated essays may have the following three problems: 1) Short: Essays contain only one or two sentences. 2) Repetitive: One essay contains repetitive sentences or paragraphs. 3) Overlapped: Essays generated by the same model may overlap with each other.
Thus we filter out essays with any of the three problems. First, we remove essays shorter than 100 words101010The minimal length of gpt2-xl is set to 50, for it is more difficult for gpt2-xl to generate longer texts.. Then we compute the similarity of each sentence pair in an essay by comparing how many words co-occur in both sentences. If 80% of words co-occur, then the sentence pair is considered to be two similar sentences. If 40% of sentences in one essay are similar sentences, then the essay is considered to be repetitive and will be removed. In like manner, we pair sentences in Essay A with sentences in Essay B. If 40% of sentences in Essay A and Essay B altogether are similar, then Essay A is considered to be overlapped with Essay B, which will result in the removal of Essay B.
The proportion of essays generated is given in Table 5. We have generated 9,647 essays in total, with 4,708 valid. Then we sample essays from machine-written WECCL/GRE essays to match the number of essays in human-written WECCL/GRE essays. We also manually remove some gpt2-generated essays that are apparently not in the style of argumentative writing (See Appendix A), resulting in 4,038 machine-generated essays in total.
| Model | Time stamp | # total | # valid | # short | # repetitive | # overlapped |
| gpt2-xl | Nov, 2019 | 4,573 | 563 | 1,637 | 0 | 2,373 |
| text-babbage-001 | April, 2022 | 917 | 479 | 181 | 240 | 17 |
| text-curie-001 | April, 2022 | 654 | 498 | 15 | 110 | 31 |
| text-davinci-001 | April, 2022 | 632 | 493 | 1 | 41 | 97 |
| text-davinci-002 | April, 2022 | 621 | 495 | 1 | 56 | 69 |
| text-davinci-003 | Nov, 2022 | 1,130 | 1,090 | 0 | 30 | 10 |
| gpt-3.5-turbo | Mar, 2023 | 1,122 | 1,090 | 0 | 4 | 28 |
| # total | - | 9,647 | 4,708 | 1,835 | 481 | 2,625 |
2.5 Preprocessing
We preprocess all human and machine texts in the same manner, so that the GPT/human-authored texts would not be recognized based on superficial features such as spaces after punctuation and inconsistent paragraph breaks.
Specifically, we perform the following preprocessing steps.
-
•
Essays generated by gpt-3.5-turbo often begin with “As an AI model…”, which gives away its author. Therefore, we remove sentences beginning with “As an AI model …”.
-
•
There are incorrect uses of capitalization. We capitalize the first letter of every sentence and the pronoun “I”.
-
•
There are incorrect uses of spaces and line breaks. We normalize the use of spaces and line breaks. One space is inserted after every punctuation; one space is inserted between two words; all spaces at the beginning of each paragraph are deleted; two line breaks are inserted at the end of each paragraph.
-
•
We normalize the use of apostrophes (e.g., don-t -> don’t).
2.6 Collecting out-of-distribution data
An out-of-distribution (OOD) test set is collected to evaluate the generalization ability of the detectors trained on the in-distribution dataset. Ideally, we should pair human and machine essays with the same writing prompts to compose the OOD test set, with which we can see the performance of detectors on both positive and negative samples at the same time. However, after compiling the ArguGPT dataset, we find no more human-written argumentative essays with accessible writing prompts. Therefore, we simply collect 500 human essays and 500 machine essays respectively without pairing them together.
The OOD test set is divided into two parts, as Machine OOD and Human OOD. Machine essays are generated by LLMs and human essays are written by Chinese English learners (see Table 6). Human essays and machine ones in OOD dataset share different writing prompts. In the two independent sub-sets, we can evaluate the performance on negative and positive samples respectively.
| OOD_machine | OOD_human | ||||
| sub-corpus | # essays | # tokens | sub-corpus | # essays | # tokens |
| gpt-3.5-turbo | 100 | 44,028 | st2: high school students | 100 | 19,975 |
| gpt-4 | 100 | 43,986 | st3: junior college students | 100 | 16,318 |
| claude-instant | 100 | 31,815 | st4: senior college students | 100 | 17,165 |
| bloomz-7b | 100 | 29,659 | st5: junior English majors | 100 | 24,978 |
| flan-t5-11b | 100 | 30,632 | st6: senior English majors | 100 | 54,466 |
Human OOD essays
The human OOD dataset is collected to test how the detectors trained with limited writing prompts perform on human essays in response to unseen ones. Human essays are sampled from CLEC (Chinese Learner English Corpus) Gui and Yang (2003), containing argumentative essays written by Chinese English learners of five different levels111111Writing prompts of these essays are not published by authors of CLEC. (see Table 6 for details).
Being written by Chinese English learners, essays in CLEC share similar linguistic properties as WECCL. However, the writing prompts in CLEC are speculated to be different from WECCL for the topics of these essays never occur in the ArguGPT dataset. Therefore, this dataset can be used to evaluate the performance of detectors on the out-of-distribution writing prompts while the linguistic features are probably in-distribution.
Machine OOD essays
The machine OOD test set is collected to evaluate the performance of the detectors in two cases: (1) new writing prompts, and (2) LLMs that are not used to generate the essays in the training set.
As the writing prompts in ArguGPT have two parts (i.e., essay prompt and essay prompt), we use the following steps to generate the prompts (see Table 7): half of the writing prompts are composed of 25 unseen essay prompts generated by ChatGPT, with the same added prompt used in the training portion of the ArguGPT dataset as the suffix; another half are 25 prompts resulted from combinations of 5 essay prompts sampled from the training set, with 5 unseen added prompts that are again generated by ChatGPT.
| type | # | source | example | |
| w/ unseen added prompts | essay | 5 | sampled from ArguGPT | Young people enjoy life more than older people do. |
| added | 5 | generated by ChatGPT | Analyze the statement <essay prompt> , by examining its causes, effects, and potential solutions. Write an essay of roughly 400 words. | |
| w/ unseen essay prompts | essay | 25 | generated by ChatGPT | Social media has more harmful effects than beneficial effects on society. |
| added | 1 | the one used in ArguGPT | <essay prompt> Do you agree or disagree? Use specific reasons and examples to support your answer. Write an essay of roughly 400 words. |
We use five models to generate machine-written argumentative essays in response to above 50 prompts, four of which are not used in the generation of the training data, thus serving our purpose to examine the generalization ability of our detectors:
-
•
gpt-3.5-turbo: gpt-3.5-turbo is an in-distribution (ID) model used in the ArguGPT dataset. We want to test the generalization ability on the ID model in response to OOD prompts. The essays of gpt-3.5-turbo are collected via OpenAI’s API.
-
•
gpt-4: gpt-4 is an OOD model from the GPT family. Therefore, we can see how the detectors trained on data generated by previous models predict ones written by the latest one. The essays of gpt-4 are accessed via the web-interface.
-
•
claude-instant: claude-instant121212https://claude-ai.ai/ is a large language model developed by Anthropic. With essays generated by claude-instant, we can test how the detectors transfer the ability to the model from non-GPT family. The essays of claude-instant are collected in the web-interface as gpt-4.
-
•
bloomz-7b (Workshop et al., 2023) and flan-t5-11b (Chung et al., 2022): We also use two language models in a much smaller scale, to investigate how well these detectors can detect essays generated by smaller language models. For these two models we run them locally on two 24GB RAM GPUs to generate essays.
Each model is asked to generate 2 essays for each prompt, amounting to 500 argumentative essays in total, serving as the machine OOD test set for positive samples.
3 Human evaluation
Our first research question is whether ESL instructors can identify the texts generated by GPT models. To answer this question, we recruit a total of 43 ESL instructors for two rounds of Turing tests. In each round, they are asked to identify which 5 essays are machine-written from 10 randomly sampled TOEFL essays. They are also asked to share their observations on the linguistic and stylistic characteristics of GPT-generated essays. In Section 3.1, we describe details of this experiment. In Section 3.2 we present and analyze the results.
3.1 Methods
Task
We ask human participants to determine whether an essay is written by a human or a machine. Previous research show that it is difficult for a layperson to spot a machine generated text (Brown et al., 2020; Dou et al., 2022; Guo et al., 2023). In light of such discoveries, we present 5 machine generated essays and 5 human essays each round to the participant, and ask them to rate the probability of each text being written by a human/machine on a 6-point Likert Scale, where 1 corresponds to “definitely human” and 6 corresponds to “definitely machine”. For the 5 machine essays, we sample 1 from each of the following 5 models: gpt2-xl, text-babbage-001, text-curie-001, text-davinci-003, gpt-3.5-turbo. For the 5 human essays, we sample 1 low, 3 medium and 1 high level essays, disregarding the native language of the human author.
Each participant will perform such a rating task for two rounds, on two different sets of essays. Answers given by participants are correct when they rating 1-3 point for human essays and 4-6 point for machine essays. After each round, they will be presented with the correct answers, giving them a chance to observe the features of the GPT-generated essays, which they are asked to write down and submit in a text box. Then they will be presented with the next set of essays. See Figure 1 for the pipeline of the experiment. We expect the accuracy to be higher in the second set of essays as the participants have seen machine essays and the correct answers in the first round. Instructions for the experiment can be found in Appendix D.
Participants
We recruit a total of 43 ESL instructors/teaching assistants from over 5 universities across China. The instructors from the English Department and/or College English Department131313The former is responsible for teaching English majors, while the latter is responsible for teaching general English courses to non-English majors in the university. include assistant professors/lecturers, associate professors, professors, and Ph.D. and MA students who have experiences as teaching assistants. Details are presented in Table 8. Each participant are compensated RMB (40 + 2correct answers), as an incentive for them to try their best in the task. The mean time of completion for round 1 and 2 is 15 minutes and 10 minutes respectively141414We did not see a strong correlation between completion time and the participants’ accuracy in the rating task(Pearson around 0.1).
| Identity | # Participants | Accuracy |
| MA student | 4 | 0.5875 |
| Ph.D. Student | 16 | 0.6656 |
| Assi. Professor/Lecturer | 11 | 0.6364 |
| Asso. Professor | 7 | 0.6929 |
| Professor | 3 | 0.6500 |
| Other | 2 | 0.5000 |
| total | 43 | - |
3.2 Results
The 43 participants make 860 ratings in response to 280 essays, which are taken from the 300 TOEFL essays in the test split of the corpus (see Section 5). We count the number of correct answers among the 860 choices in order to obtain the accuracy.
3.2.1 Quantitative analysis
The accuracy of our human participants in identifying machine essays is presented in Table 9. From the left side of Table 9, we see that the mean accuracy from all subjects in both rounds is 0.6465, roughly 15 percent more than the baseline, which is 0.5, since we have an equal number of human and machine texts in the test set.
One interesting discovery is that it is much easier for our participants to identify human essays. The accuracy of identifying human essays reaches 0.7744, while the accuracy of machine is only at chance level: 0.5186. We believe this is because all of our participants have a lot of experience reading ESOL learners’ writings and are thus quite familiar with the style and errors one can find in an essay written by a human language learner.
However, only 11 out of the 43 participants indicated that they are familiar with the (Chat)GPT models; that is, most of them are unfamiliar with the type of text generated by these models, which could explain why they have lower accuracy when identifying GPT-authored texts.
Going down the left side of Table 9, participants who self-report that they have some familiarity with LLMs have better performance on our task than those who are not familiar with LLMs (0.69 vs 0.64).
We also observe some interesting trends, as shown on the right side of Table 9. Participants are better at identifying low level human essays (acc: 0.8372), and essays generated by more advanced models such as text-davinci-003 and gpt-3.5-turbo (acc: 0.6279). Participants are particularly bad at identifying essays generated by gpt2-xl (acc: 0.3721). This is different from Clark et al. (2021, section 1) who suggested that the evaluators “underestimated the quality of text current models are capable of generating”. When our experiments were conducted, ChatGPT has become the latest model and participants seem to overestimate the non-ChatGPT models, by assigning gpt2-xl essays to human essays, as they have commonly seen student essays with low quality.
| Group by | Group | Accuracy | Author | Accuracy | |
| Essay type | Overall | 0.6465 | M | gpt2-xl | 0.3721 |
| Human essays | 0.7744 | text-babbage-001 | 0.4651 | ||
| Machine essays | 0.5186 | text-curie-001 | 0.4651 | ||
| Same essay prompt | Yes | 0.6472 | text-davinci-003 | 0.6628 | |
| for 10 essays | No | 0.6460 | gpt-3.5-turbo | 0.6279 | |
| Familiarity | Not familiar (600 ratings) | 0.6400 | H | human-low | 0.8372 |
| w/ GPT | Familiar (220 ratings) | 0.6909 | human-medium | 0.7752 | |
| Other (40 ratings) | 0.5000 | human-high | 0.7093 |
| Round 1 | Round 2 | |||||
| Overall | Human | Machine | Overall | Human | Machine | |
| Accuracy | 0.6163 | 0.7535 | 0.4791 | 0.6767 | 0.7954 | 0.5581 |
Subjects’ overall accuracy in the first round is 0.6163, while performance in the second round rises to 0.6767 (see Table 10). This suggests that after some exposure to machine texts (i.e., 5 machine texts and 5 human texts side by side) and reflection on the linguistic features of machine texts, our subjects become better at identifying machine texts, with the accuracy rising from 0.4791 to 0.5581. This result is in line with Clark et al. (2021) who employed 3 methods that ultimately improved human evaluators’ judgment accuracy from chance level to 55%. We also see a 4% improvement in the accuracy of identifying our human-written essays.
3.2.2 Qualitative analysis
In this section, we summarize the features of machine-essays provided by our participants in the experiment.
First, participants associate two distinctive features with human essays: (1) human essays have more spelling and grammatical errors, which is also mentioned in Dou et al. (2022), and (2) human essays may contain more personal experience. Seeing typos/grammatical mistakes and personal experience in one essay, participants are very likely to categorize it as human-authored.
As for machine essays, participants generally think (1) machine essays provide many similar examples, and (2) machine essays have repetitive expressions. These two features corroborate the findings of Dou et al. (2022). Reasons when participants make the right choices are presented in Table 11.
| Text Excerpt | Author | Choice | Reason |
| So to the oppsite of the point that mentioned in the theme, I think there will more people choose cars as their first transpotation when they are out and certainly there will be more cars in twenty years. | human- medium | Human | There are too many typos and grammatical errors. |
| Apart from that the civil service is the Germnan alternative to the militarz service. For the period of one year young people can help in there communities. | human- high | Human | The essay might be written by a German speaker. |
| Firstly… when I traveled to Japan… Secondly… when I went on a group tour to Europe… Thirdly… when I went on a safari in Africa… | gpt- 3.5- turbo | Machine | Examples provided are redundant. |
| I wholeheartedly… getting a more personalized experience… Some of the benefits… getting a more personalized experience… So, overall… get a more personalized experience… | text- curie- 001 | Machine | There are too many repetitive expressions. |
However, even with the knowledge of the two features of machine essays discussed above, participants are not very confident when identifying machine essays. There are redundant and repetitive expressions in human writings as well, which might confuse participants in this regard. Another important feature frequently mentioned by participants is off-prompt, meaning the writing digresses from the topic given by the prompt. Some tend to think it is a feature of machine essays, while others think it features human essays.
After being presented with correct answers in the human evaluation experiment, participants summarize their impression on AI-generated argumentative essays. We list some of the commonly mentioned ones below.
-
•
Language of machines is more fluent and precise. (1) There are no grammatical mistakes or typos in machine-generated essays. (2) Sentences produced by machines have more complex syntactic structures. (3) The structure of argumentation in machine essays is complete.
-
•
Machine-generated argumentative essays avoid subjectivity. (1) Machines never provide personal experience as examples. (2) Machines seldom use “I” or “I think”. (3) It is impossible to speculate the background information of the author in machine essays.
-
•
Machines hardly provide really insightful opinions. (1) Opinions or statements provided by machines are very general, which seldom go into details. (2) Examples in machine-generated essays are comprehensive, but they are plainly listed rather than coherently organized.
After browsing the reasons given by our participants, we find that grammatical mistakes (including typos) and use of personal experience are usually distinctive and effective features to identify human essays (English learners in our case), according to which participants can have a higher accuracy. However, a fixed writing format and off-prompt are not so reliable. If participants identify machine essays by these two features, the accuracy will drop. For a fixed writing format and off-prompt often feature human-authored essays as well.
3.3 Summary
Our results indicate that knowing the answers of the first round test is helpful for identifying texts in the second round, which is consistent with Clark et al. (2021). Contra Brown et al. (2020), our results show that essays generated by more advanced models are more distinguishable. Moreover, the accuracy on identifying texts generated by models from GPT2 and GPT3 series are lower than what is reported in previous literature (Uchendu et al., 2021; Clark et al., 2021; Brown et al., 2020). It indicates that human participants anticipate that machines are better than human at writing argumentative essays. When the models (e.g., gpt2-xl) generate an essay of lower quality, our human participants might feel more confused because they expect the machines should have better performance.
Looking into the summaries of AIGC features provided by participants, we can see that participants have a more detailed picture of how human essays look like (e.g., the mistakes that human English learners are likely to make). On the other hand, they can also capture some features of machine essays after reading several of them, though these features were not strong enough to help participants determine whether essays are human- or machine-authored.
Therefore, we think that if English teachers become more familiar with AIGC, they will be more capable to identify the features between human and machine.
4 Linguistic analysis
In this section, we compare the linguistic features of machine and human essays. We group the essays by author: (1) low-level human, (2) medium-level human, (3) high-level human, (4) gpt2-xl, (5) text-babbage-001, (6) text-curie-001, (7) text-davinci-001, (8) text-davinci-002, (9) text-davinci-003, and (10) gpt-3.5-turbo.
We first present some descriptive statistics of human and machine essays. We then use established measures and tools in second-language (L2) writing research to analyze the syntactic complexity and lexical richness of both human and machine written texts (Lu, 2012, 2010).
4.1 Methods
Descriptive statistics
We use in-house Python scripts and NLTK (Bird, 2002) to obtain descriptive statistics of the essays in the following 5 measures: (1) mean essay length, (2) mean number of paragraphs per essay, (3) mean paragraph length, (4) mean number of sentences per essay, and (5) mean sentence length.
Syntactic complexity
To analyze the syntactic complexity of the essays, we apply the L2 Syntactic Complexity Analyzer to calculate 14 syntactic complexity indices for each text (Lu, 2010). These measures have been widely used in L2 writing research. Table 12 presents details of the indices. However, only six out of these 14 measures are reported by Lu (2010) to be linearly correlated with language proficiency levels. Therefore, we only present the results for these six measures.
| Measure | Code | Definition | ||
| Length of production unit | ||||
| Mean length of clause | MLC | # of words / # of clauses | ||
| Mean length of T-unit | MLT | # of words / # of T-units | ||
| Coordination | ||||
| Coordinate phrases per clause | CP/C | # of coordinate phrases / # of clauses | ||
| Coordinate phrases per T-unit | CP/T | # of coordinate phrases / # of T-units | ||
| Particular structures | ||||
| Complex nominals per clause | CN/C | # of complex nominals / # of clauses | ||
| Complex nominals per T-unit | CN/T | # of complex nominals / # of T-units | ||
Lexical complexity
Lexical complexity or richness is a good indicator of essay quality and has been considered a useful and reliable measure to examine the proficiency of L2 learners (Laufer and Nation, 1995). Many L2 studies have discussed the criteria for evaluating lexical complexity. In this study, we follow Lu (2012) who compared 26 measures in language acquisition literature and developed a computational system to calculate lexical richness from three dimensions: lexical density, lexical sophistication, and lexical variation.
Lexical density means the ratio of the number of lexical words to the total words in a text. We follow Lu (2012) to define lexical words as nouns, adjectives, verbs, as well as adverbs with an adjectival base, such as “well" and the words formed by “-ly" suffix. Modal verbs and auxiliary verbs are not included. Lexical sophistication calculates the advanced or unusual words in a text (Read, 2000). We further operationalize sophisticated words as the lexical words, and verbs which are not on the list of the 2,000 most frequent words generated from the American National Corpus. As for lexical variation, it refers to the use of different words and reflects the learner’s vocabulary size.
N-gram analysis
We use the NLTK package to extract trigrams, 4-grams and 5-grams from both human and machine essays and calculate their frequencies in order to find out the usage preferences in human and machine essays. We then compute log-likelihood (Rayson and Garside, 2000) for each N-gram in order to uncover phrases that are overused in either machine or human essays.
4.2 Results
4.2.1 Descriptive statistics
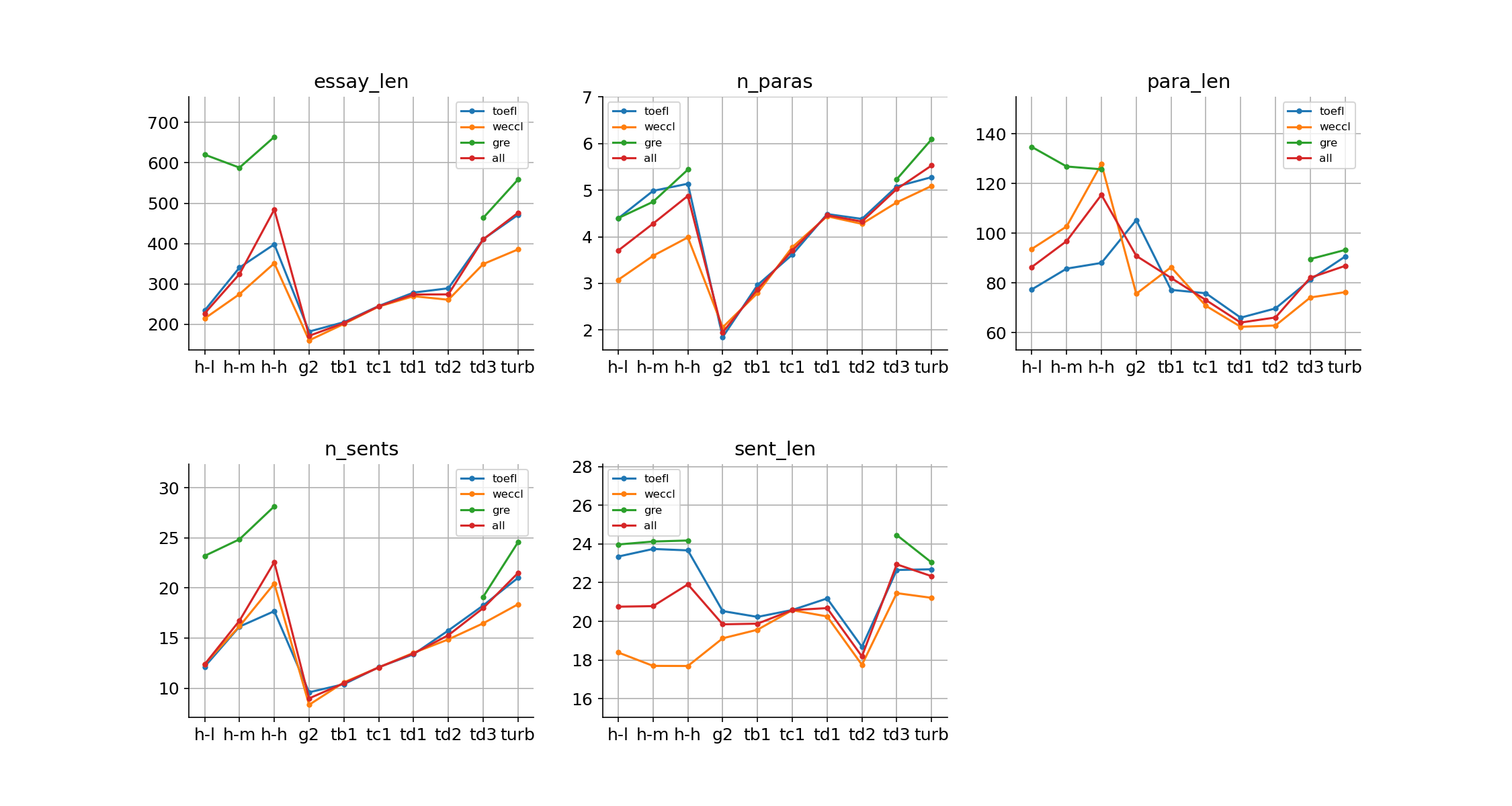
The descriptive statistics of sub-corpora in the ArguGPT corpus are presented in Figure 2. As for humans, essays with higher scores are likely to have a longer length from both essay-level and paragraph-level and more paragraphs and sentences in one essay. However, humans of all three levels write sentences of similar length.
In like manner, more advanced AI models are likely to have longer essay length, more paragraphs and sentences. However, the mean length of paragraphs goes down from gpt2-xl to text-davinci-001, and goes up slightly from text-davinci-002 to gpt-3.5-turbo. As for the mean length of sentences, text-davinci-002 writes the shortest sentences among machines.
Different machines match humans of different performance levels of mean essay-, paragraph-, and sentence-level length. However, regarding the length of paragraphs, human writers outperform machine writers.
4.2.2 Syntactic complexity
Figure 3 gives the means of the six syntactic complexity values of the essays which are grouped by sub-corpora in the ArguGPT corpus.
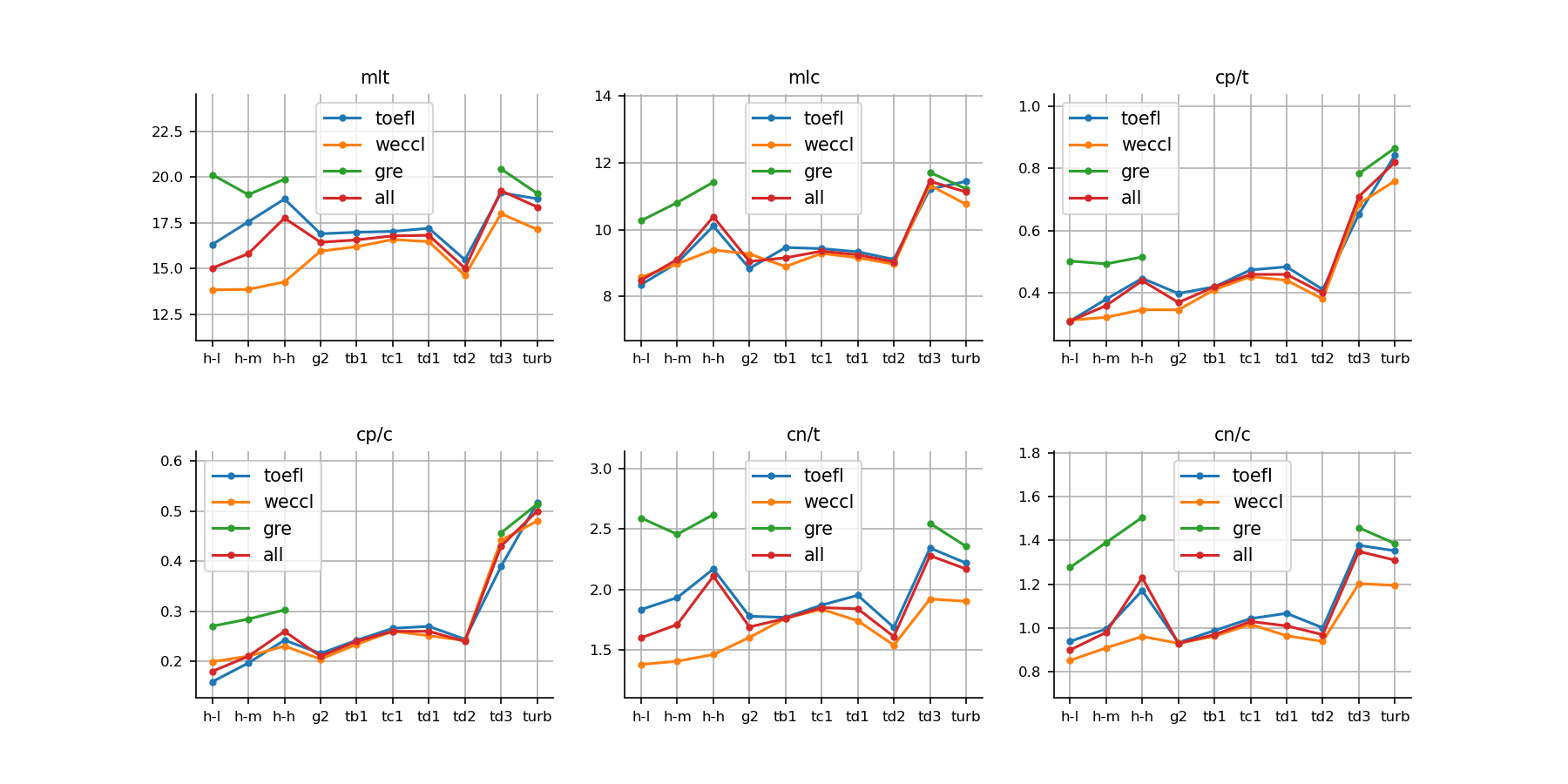
As shown in Figure 3, all 6 chosen syntactic complexity values progress linearly across 3 score levels for human essays. They also indicate a general growing trend across the language models following the order of development. It is noticeable that text-davinci-002 is worse w.r.t. these measures than previous and later models. According to MLT (Mean length of T-unit) and CN/T (complex nominals per T-unit), it is even outperformed by gpt2-xl.
When we compare human essays with machine essays, even high-level human English learners are outperformed by gpt-3.5-turbo and text-davinci-003 in all 6 measures. This is particularly true for CP/T and CP/C, which indicates that coordinate phrases are much more common in the essays from the last two models than from human learners. On the other hand, gpt2, text-babbage-001, text-curie-001, and text-davinci-001/002 seem to be on par with human learners on these measures.
We take the above results to suggest that in general, more powerful models such as davince-003 and ChatGPT produce syntactically more complex essays than even high-level English learners.
4.2.3 Lexical complexity
The lexical complexity of ArguGPT corpus is presented in Figures 4 to 7 (for actual numbers, see Table 27 and Table 28 in the Appendix).
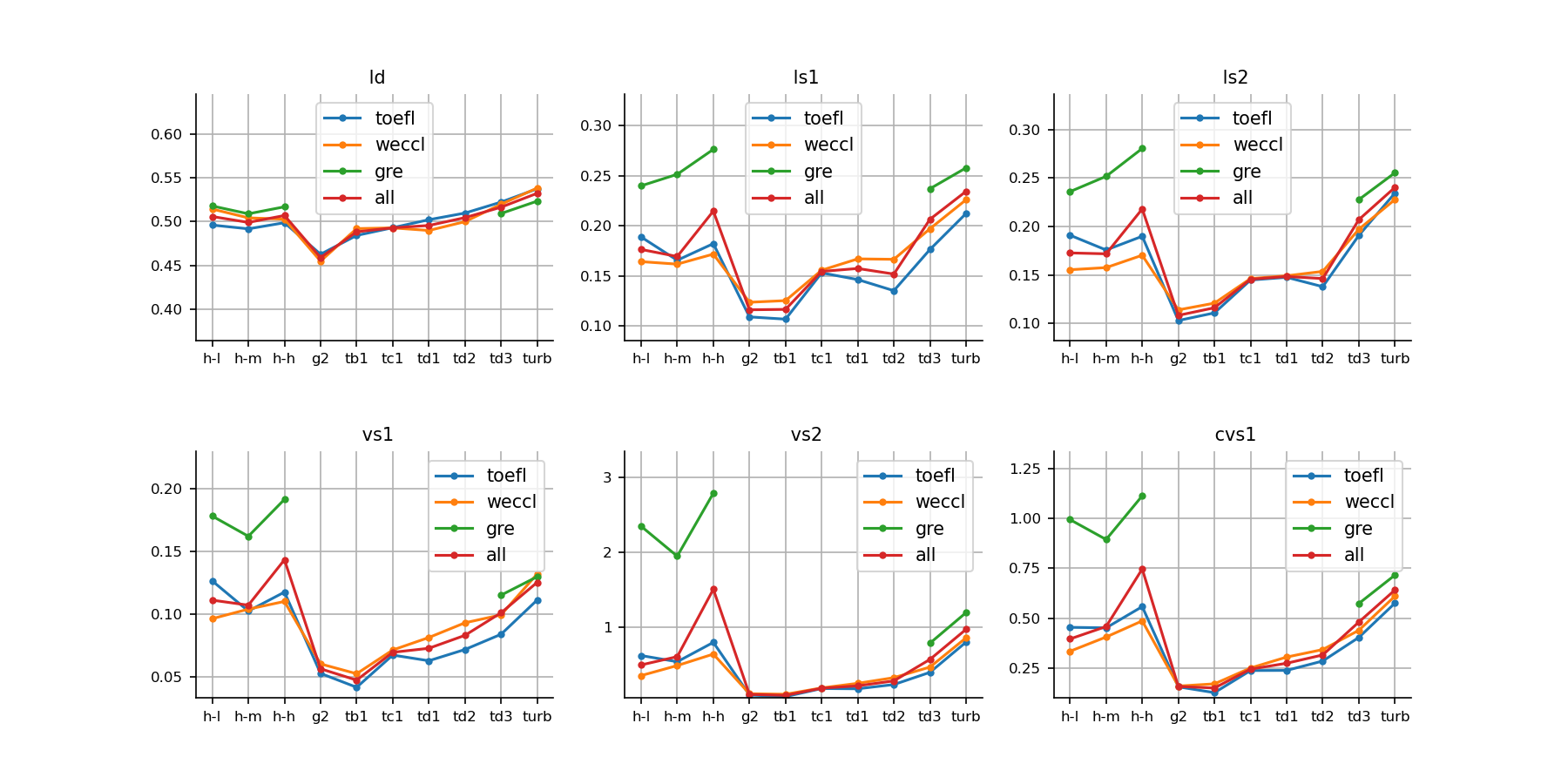
Lexical density
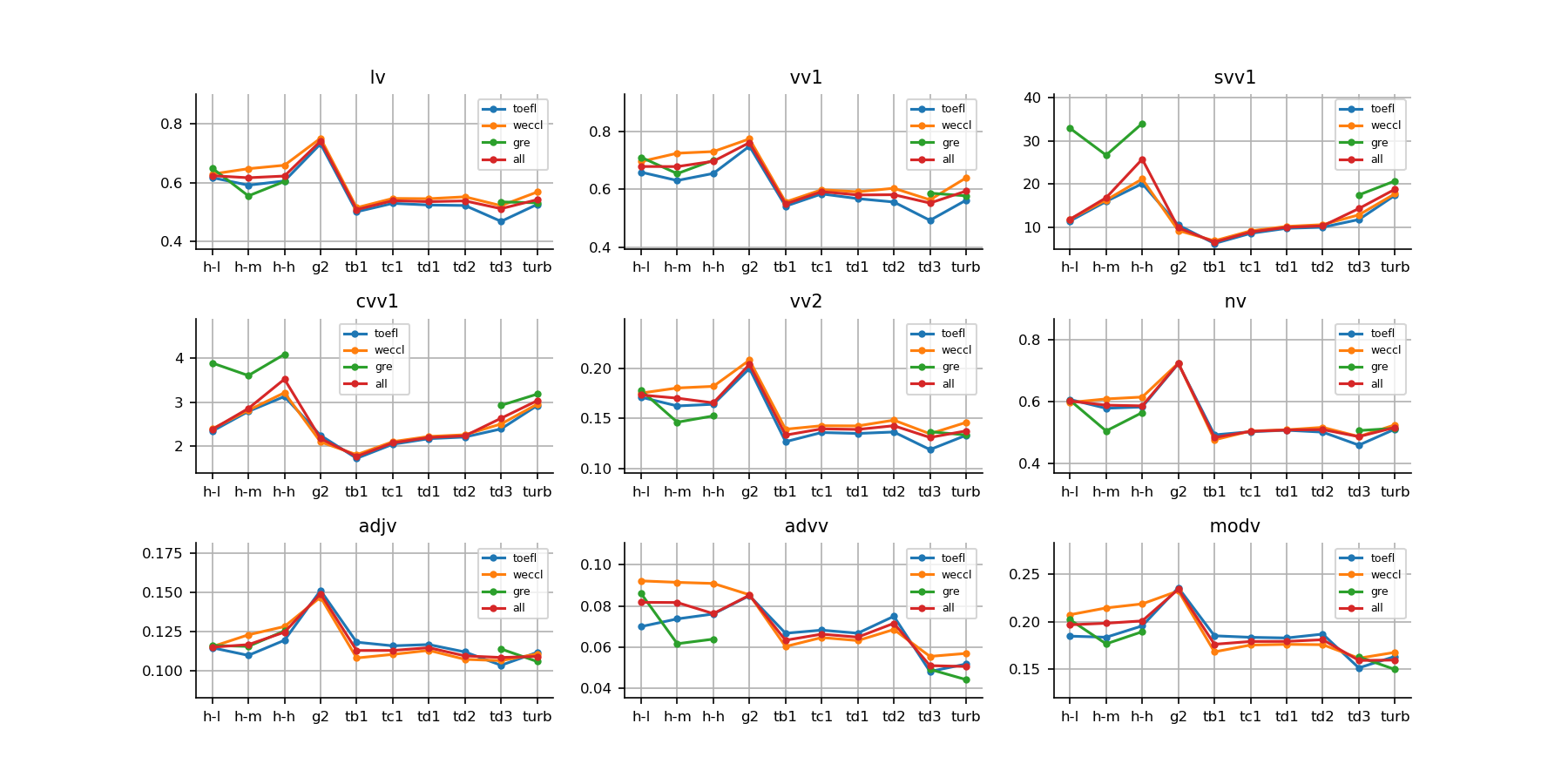
Lexical density in Figure 4 shows that human essays tend to use more function words compared to text-davinci-003 and gpt-3.5-turbo, as these two models prefer more lexical words.
Lexical sophistication
As for lexical sophistication (also shown in Figure 4), advanced L2 learners outperform or are on par with gpt-3.5-turbo in all five indicators (lexical sophistication 1/2, and three measures of verb sophistication).
In terms of verb sophistication (bottom row of Figure 4), the differences are pronounced between low/medium level and high level of human writing. Advanced learners surpass gpt-3.5-turbo while the intermediate level is on par with text-davinci-003. However, high-level human essays in WECCL perform worse than gpt-3.5-turbo. Moreover, GRE essays have much higher values than WECCL and TOEFL in these three measures, especially for the advanced level. We attribute this to the nature of our GRE corpus, where essays are all example essays for those preparing for the GRE test to emulate rather than representative of all levels of test takers.
Lexical variation
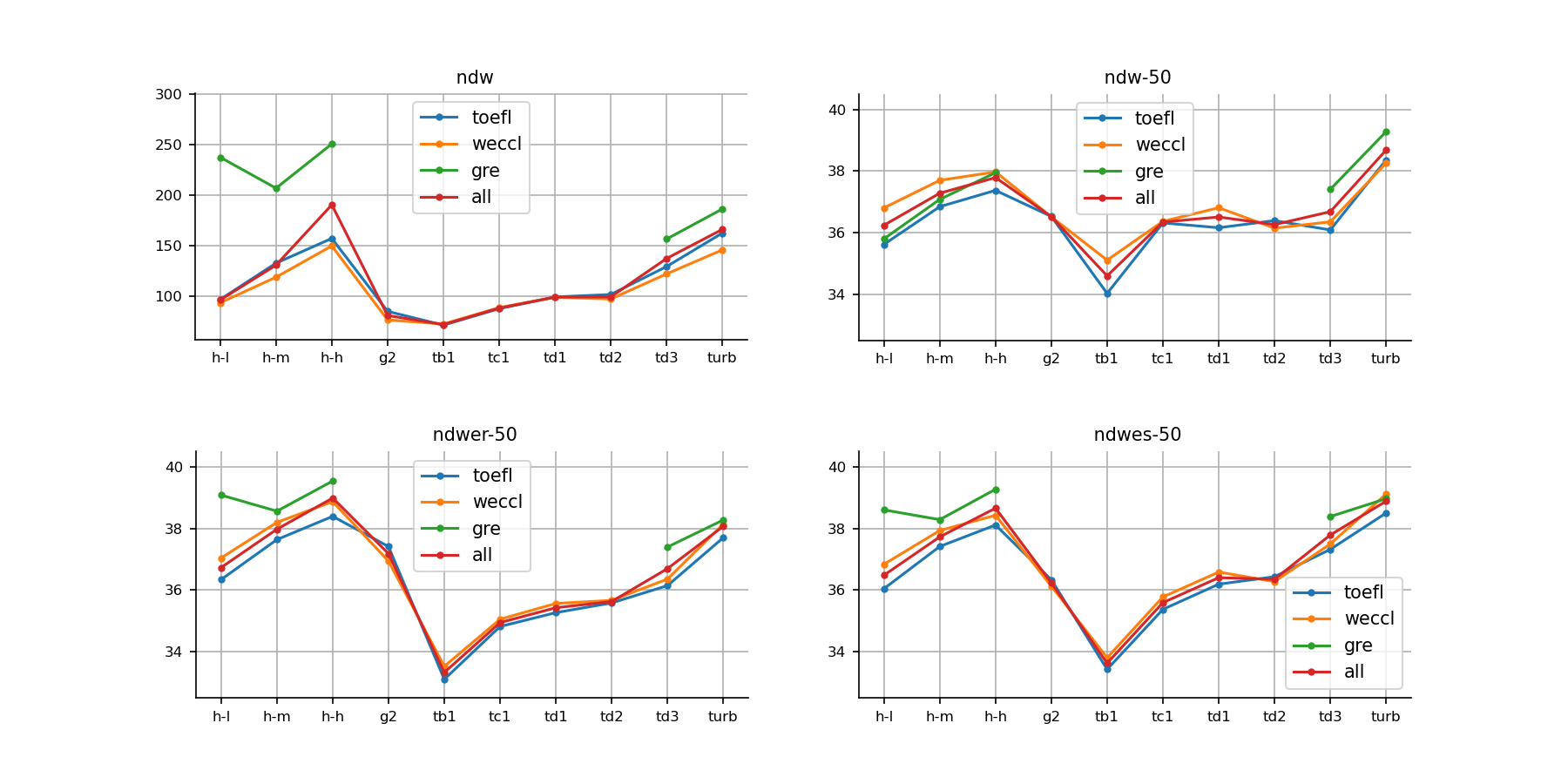
Measures for lexical variation are shown in Figure 5 (number of different words), Figure 6 (type-token ratio) and Figure 7 (type-token ratio of word class). They indicate the range and diversity of a learner’s vocabulary.
Among the four measures of the number of different words in Figure 5, advanced learners exceed gpt-3.5-turbo in two metrics. Text-davinci-003 and gpt-3.5-turbo are comparable to medium and high levels of L2 speakers’ writing, respectively. The trend is similar in WECCL and TOEFL corpora, except for the GRE corpus. Our GRE essays have the largest vocabulary and surpass gpt-3.5-turbo in three metrics.
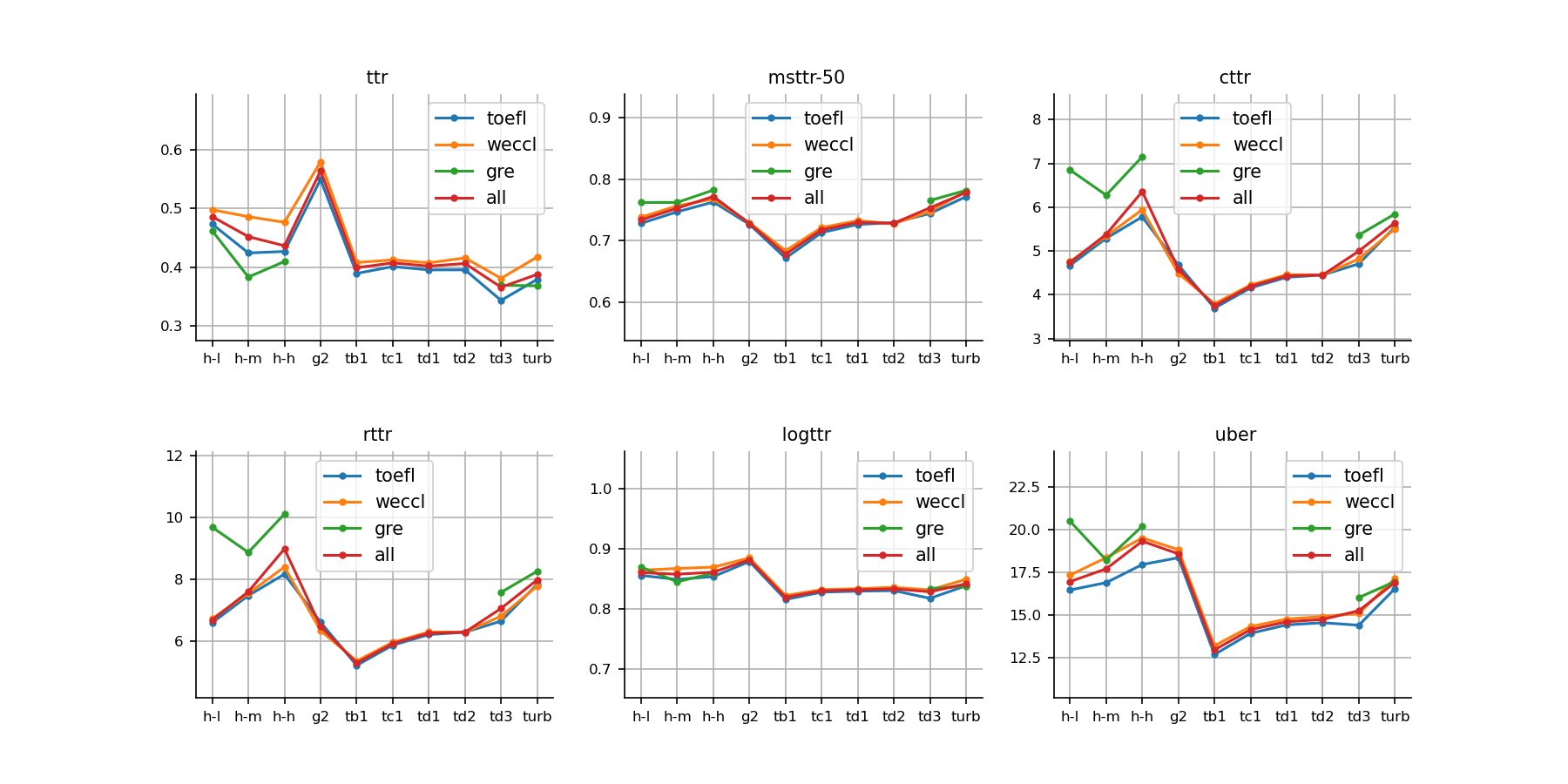
Type-token ratio (TTR) is an important measure of lexical richness. Six indices of TTR in Figure 6 all suggest that, while gpt-3.5-turbo excels the medium-skilled test takers in WECCL and TOEFL, there is still a discernible gap between the performance of machines and that of skillful non-native speakers. GRE test takers at all levels outstrip the machines. It should be emphasized that TTR is not standardized compared to CTTR (corrected TTR) and its other variants, and shorter essays tend to have a higher TTR. Therefore, essays generated by gpt2-xl have a higher TTR. Other standardized variants better represent the lexical richness of the essays.
Type-token ratio can be further explored with respect to each word class. Figure 7 shows the variation of lexical words and other five ratios, including verbs, nouns, adjectives, adverbs and modifiers. We observe that advanced learners outperform gpt-3.5-turbo in all metrics among the three corpora. The margins are obvious in lexical words, verbs, nouns and adverbs. Note that SVV1 and CVV1 are standardized compared with other metrics, and may be more suitable for analysis of the discrepancies. The verb system is recognized as the focus in second language acquisition, for it is essential to construct any language (Housen, 2002), and humans showcase a stronger ability in applying abundant verbs than machines.
We take these results to suggest that unlike syntactic complexity, high-level English learners and native speakers of English are on par or even exceed gpt-3.5-turbo in terms of lexical complexity.
4.2.4 N-gram analysis
Table 13 lists 20 trigrams that are used significantly more frequently by language models than human. It is worth noting that “i believe that” appears 2,056 times in 3,338 machine-generated essays, but only 207 times in 3,415 human essays. This seems to be a pet phrase for text-davinci-001, as the phrase occurs 503 times in 509 texts generated by text-davinci-001, while the number of occurrences in 284 essays produced by gpt2-xl is only 31.
| Overused by machines | Overused by humans | ||||||
| Trigram | log-lklhd | M | H | Trigram | log-lklhd | M | H |
| i believe that | 1987.2 | 2056 | 207 | more and more | 313.4 | 179 | 753 |
| can lead to | 1488.6 | 1152 | 32 | what’s more | 230.4 | 2 | 197 |
| more likely to | 1257.1 | 1034 | 43 | the young people | 205.6 | 5 | 193 |
| it is important | 1063.8 | 1130 | 122 | we have to | 194.7 | 29 | 269 |
| are more likely | 831.9 | 679 | 27 | in a word | 184.7 | 1 | 154 |
| be able to | 775.3 | 1296 | 311 | to sum up | 178.7 | 3 | 161 |
| is important to | 646.7 | 707 | 82 | most of the | 177.6 | 27 | 247 |
| lead to a | 644.0 | 554 | 29 | in the society | 175.9 | 1 | 147 |
| a sense of | 531.4 | 562 | 60 | and so on | 171.1 | 24 | 232 |
| this can lead | 528.2 | 364 | 2 | we all know | 157.9 | 4 | 149 |
| can help to | 496.6 | 373 | 8 | the famous people | 156.7 | 4 | 148 |
| understanding of the | 493.7 | 507 | 50 | the same time | 156.4 | 48 | 282 |
| believe that it | 470.6 | 439 | 32 | of the society | 147.3 | 15 | 182 |
| this is because | 468.2 | 564 | 81 | we can not | 147.1 | 43 | 260 |
| likely to be | 459.7 | 422 | 29 | i think the | 144.6 | 17 | 186 |
| this can be | 455.0 | 445 | 38 | as far as | 144.3 | 3 | 133 |
| believe that the | 427.9 | 499 | 67 | so i think | 142.1 | 2 | 126 |
| the world around | 421.2 | 345 | 14 | at the same | 138.4 | 57 | 284 |
| may not be | 410.9 | 504 | 75 | his or her | 133.7 | 19 | 182 |
| skills and knowledge | 404.3 | 292 | 4 | i want to | 133.5 | 13 | 163 |
The right side of Table 13 lists 20 trigrams which are used significantly more frequently by humans. We can see from the log-likelihood value that the difference in usage of these phrases between humans and machines is not as prominent as those overused by machines. Nevertheless, it is still noticeable that “more and more” appears more often in human writing. When looking into the usage of this phrase in the TOEFL corpus, which contains essays written by English learners with 11 different native languages, we found that it is preferred by students whose first language is Chinese or French.
4.3 Summary
To sum up, the results of the linguistic analysis suggest that for syntactic complexity, text-davinci-003 and gpt-3.5-turbo produce syntactically more complex essays than most ESOL learners, especially on measures related to coordinating phrases, while other models are on par with the human essays in our corpus.
For lexical complexity, models like gpt2-xl, text-babbage/curie-001, and text-davinci-001/002, for the most part, are on par with elementary/intermediate English learners on several measures, while text-davinci-003 and gpt-3.5-turbo are approximately on the level of advanced English learners. For some lexical richness measures (verb sophistication, for instance) and GRE essays, our human data show even greater complexity than the best AI models.
In other words, sentences produced by machines are of greater length and syntactic complexity, but words used by machines are likely of less richness and diversity when compared to human writers (mostly English learners in our case).
Moreover, from the N-gram analysis, machines prefer expressions such as “I believe that”, “can lead to”, and “more likely to”, while these phrases are seldom used in our human-authored essays.
Additionally, we find that there is a general trend of increasing lexical/syntactic complexity as the models progress, but for certain measures, gpt2-xl and text-davinci-002 seem to be the exceptions.
5 Building and testing AIGC detectors
In this section, we examine whether machine-learning classifiers can distinguish machine-authored essays from human-written ones.
Specifically, we test two existing AIGC detectors—GPTZero and RoBERTa of Guo et al., and build and test our own detectors—SVM models with different linguistic features and a deep learning classifier based on RoBERTa. We also experiment zero/few-shot learning with gpt-3.5-turbo.
5.1 Experimental settings
We split the ArguGPT corpus into train, dev, and test sets (see Table 14), where the dev and test sets contain 700 essays respectively. In the dev and test sets, the proportion of low : medium : high level human essays is kept to 1:3:1 for WECCL and TOEFL11. As for WECCL and TOEFL11 machine essays, we sample 150 essays for each exam that are generated by 5 models (excluding text-davinci-001 and text-davinci-002). For GRE essays in the dev and test sets, we randomly sample 50 human essays, and 50 machine essays generated by text-davinci-003 and gpt-3.5-turbo.
For the two existing detectors—GPTZero and the RoBERTa model from (Guo et al., 2023), we use them as off-the-shelf tools without further fine-tuning or modification.
We train SVMs and finetune a RoBERTa-large model using the training set of ArguGPT. We perform zero/few-shot learning with gpt-3.5-turbo via OpenAI’s API.
For all experiments, we train and evaluate on document-, paragraph-, and sentence-level.
| Split | # WECCL | # TOEFL11 | # GRE | # Doc | # Para | # Sent |
| train | 3,058 | 2,715 | 980 | 6,753 | 29,124 | 111,283 |
| dev | 300 | 300 | 100 | 700 | 2,947 | 11,302 |
| test | 300 | 300 | 100 | 700 | 2,953 | 11,704 |
5.2 Results
The results for all detectors are summarized in Table 15.
| Test set | Our detectors | Existing detectors | |||||
| Test data | maj. bsln | Train data | RoBERTa | Best SVM | GPTZero | Guo et al. (2023) | |
| Doc | 50 | Doc | all | 99.38 | 95.14 | 96.86 | 89.86 |
| 50% | 99.76 | 94.14 | |||||
| 25% | 99.14 | 93.86 | |||||
| 10% | 97.67 | 92.29 | |||||
| Para | 52.62 | Doc | all | 74.58 | 83.61 | 92.11 | 79.95 |
| Para | 97.88 | 90.55 | |||||
| Sent | 54.18 | Doc | all | 49.73 | 72.15 | 90.10 | 71.44 |
| Sent | 93.84 | 81 | |||||
5.2.1 Existing detectors for AIGC: GPTZero and RoBERTa from (Guo et al., 2023)
We test two existing detectors for AIGC: GPTZero and finetuned RoBERTa of Guo et al. 151515https://huggingface.co/Hello-SimpleAI/chatgpt-detector-roberta.
We evaluate each detector’s performance on the ArguGPT test set. The RoBERTa model from Guo et al. (2023), which was finetuned on text in other genres such as finance and medicine, achieves an accuracy of around 90% for document-level classification, lower than the other classifiers, possibly due to the nature of their training data. The same model achieves 79.95% and 71.44% respectively on paragraph and sentence level classification.
As for GPTZero, we use their API, which returns the probability of being written by an AI model; the returned result includes probabilities for the entire essay, each paragraph and each sentence. We consider any text with a probability higher than 0.65 to be AI-written, following the documentation of GPTZero. Its performance is shown in Table 15. We can see that GPTZero reaches very high accuracy on document, paragraph and sentence levels (all above 90%).
5.2.2 SVM detector
In this section, we aim to find out if AIGC and human-written essays are distinguishable using hand-crafted linguistic features and a SVM classifier. By training SVMs on document-level with syntactic and stylistic features (i.e., no content information) as well as word unigrams (which include content words) and comparing their performance, we select the best set of features for classification and apply these features on paragraph and sentence levels.
Linguistic Features
We select some commonly used linguistic features and extract them with translationese101010https://github.com/huhailinguist/translationese which is extended from https://github.com/lutzky/translationese. package, which has been used in linguistically informed text classification tasks for translated and non-translated texts (Volansky, Ordan, and Wintner, 2015; Hu and Kübler, 2021). The implementation uses Stanford CoreNLP (Manning et al., 2014) for POS-tagging and constituency parsing. Specifically, we experimented with the following features:
-
•
CFGRs: The ratio of each context-free grammar (CFG) rule in the given text to the total number of CFGRs.
-
•
function words: The normalized frequency of each function word’s occurrence in the chunk. Our list of function words comes from (Koppel and Ordan, 2011). It consists of function words and some content words that are crucial in organizing the text, which constitutes 467 words in total.
-
•
most frequent words: The normalized frequencies (ratio to the token number) of the most frequent words () in a large reference corpus TOP_WORDS111111https://github.com/huhailinguist/translationese/blob/master/translationese/word_ranks.py. The top words are mainly function words.
-
•
POS unigrams: The frequency of each unigram of POS.
-
•
punctuation: The frequency (ratio to the token number) of punctuation in a given chunk.
-
•
word unigrams: The frequency of the unigram of words. We only include unigrams with more than three occurrences in the given text.
Among the features, CFGRs and POS unigrams separately represent the sentence structures and part of speech preference. They are the stylistic features reflecting the patterns underlying the superficial language expressions. function words, word unigrams and most frequent words reveal the concrete choices in lexical items. punctuation represents the habit of punctuation use.
We use the general SVM model from scikit-learn package (Pedregosa et al., 2011). We optimize its parameters including the and and the kernel functions by training with different combinations of them and selecting the one with the best performance on the development set. We also normalize our feature matrices before passing it to the model.
| Linguistic Features | Training Set | Feature Number | |||
| All | 50% | 25% | 10% | ||
| CFGRs (frequency 10) | 91.71 | 90.29 | 90.14 | 87 | 939 |
| CFGRs (frequency 20) | 78.71 | 78 | 78.14 | 76.71 | 131 |
| Function Words | 95.14 | 94.14 | 93.86 | 92.29 | 467 |
| Top 10 Frequent Words | 75.14 | 76.29 | 75.71 | 75.43 | 10 |
| Top 50 Frequent Words | 89.00 | 87.14 | 87.00 | 86.00 | 50 |
| POS Unigrams | 90.71 | 88.86 | 88.71 | 87.71 | 45 |
| Punctuation | 80 | 80.14 | 78.86 | 79.14 | 14 |
| Word Unigrams | 90.71 | 87.86 | 87.57 | 86.14 | 2,409 |
Results
As shown in Table 16, the classifier trained with function words attains an accuracy of 94.33% with the full training set. The detector trained with POS unigrams also perform well in this task, reaching an accuracy of 87%. The detectors using context free grammar rules and word unigrams as training feature also report an over 85% accuracy but with more features than POS unigrams. Increasing the number of frequent words from 10 to 50 enhances the accuracy by nearly 10%. It is interesting to note that using only 14 punctuations as features can give us an accuracy of 80%.
Analysis
We observe that training with syntactic and stylistic features results in high performance in our detector, which is shown in the accuracy in detector trained with POS unigrams and context free grammar rules. In particular, the detectors trained with CFGRs and POS unigrams outperform that trained with word unigrams. This indicates that relying on syntactic information alone, the detector can tell the differences between AIGC and human-written essays.
The detector trained with function words achieve the highest accuracy (95.14%, suggesting that humans and machines have different usage patterns for these words.
The performance of the model trained with the distribution of punctuation is around 80% with only 14 features, which suggests that humans and machines use punctuations very differently.
Overall, our results show that the SVM detector can distinguish the AIGC from human-written essays with high accuracy based on syntactic features alone. When trained with functions words as features, the SVM can achieve 95% accuracy at the document level.
5.2.3 Fine-tuning RoBERTa-large for classification
Methods
To further investigate whether AI generated essays are statistically distinguishable from human essays, we fine-tune a RoBERTa-large161616We use the huggingface implementation (Wolf et al., 2019) from https://huggingface.co/roberta-large. (Liu et al., 2019). Similar to how we train SVM detectors, we also train RoBERTa detectors on training sets of different granularities or different sizes to analyze the difficulties of AIGC detection. We train the model for 2 epochs using the largest batch size that can fit into a single GPU with 24 GB RAM. The full set of training hyperparameters are presented in Table 24. We evaluate the detector on the test set, but also report its performance on the portions of essays generated by different models, as presented in Table 17.
| Train data | gpt2-xl | babbage | curie | davinci-003 | turbo | all |
| gpt2-xl | 97.46 | 100.00 | 98.33 | 98.82 | 97.67 | 98.05 |
| babbage-001 | 98.31 | 100.00 | 98.33 | 98.82 | 98.84 | 99.19 |
| curie-001 | 97.74 | 100.00 | 99.44 | 99.41 | 99.81 | 99.33 |
| davinci-001 | 98.02 | 100.00 | 100.00 | 99.41 | 99.23 | 99.24 |
| davinci-002 | 98.31 | 99.72 | 99.45 | 99.80 | 99.42 | 99.33 |
| davinci-003 | 86.44 | 99.45 | 99.17 | 99.61 | 99.61 | 97.19 |
| turbo | 81.36 | 97.50 | 99.44 | 99.22 | 99.23 | 96.00 |
| 10% | - | - | - | - | - | 99.67 |
| 25% | - | - | - | - | - | 99.14 |
| 50% | - | - | - | - | - | 99.76 |
| all | 99.15 | 99.72 | 99.45 | 99.41 | 100.00 | 99.38 |
Results
From Table 17, we observe that RoBERTa easily achieves 99 accuracy in detecting AI generated essays, even when trained only on less then 10% of the data. When directly transferred to detecting paragraph-level and sentence-level data (see Table 15), the model’s performance drops by 23 points and 44 points respectively, but this is due to the distinct length gaps between training data and test data rather then the inherent difficulty in discriminated machine-generated sentences from human-written ones, as models trained on paragraph-level and sentence-level data scores 97.88 and 99.38 accuracy respectively on each one’s i.i.d test data.
Table 17 also confirms that the essays generated by models from GPT-3.5 family share a similar distribution, while the essays generated by GPT-2 are likely from a different distribution. But we hypothesize that this is not because essays generated by GPT-2 are harder to distinguish from human essays, but rather because its essays are not as well-posed as those generated by other models, and thus introduces larger noise into the detector’s training process.
5.2.4 Zero/few-shot learning experiment of gpt-3.5-turbo as AIGC detector
Methods
We test the capability of gpt-3.5-turbo (ChatGPT) on the AIGC detection task. We experiment with zero/one/two-shot learning by putting zero/one/two pairs of positive and negative examples in the prompt (for details see Appendix F).
All evaluation is done on our validation set. Since the performance is very poor, we do not further evaluate it on the test set.
Results
The accuracy for gpt-3.5-turbo on the AIGC detection task is presented in Table 18. The results show that gpt-3.5-turbo performs poorly on the AIGC detection task. Under the zero-shot scenario, the model classifies almost all essays as AI-generated. Therefore, the accuracy of zero-shot is close to 50%. Under the one-shot/two-shot scenarios, the average accuracy for the six pairs of prompts is also roughly 50%, suggesting that perhaps this task is still too difficult for the model in a few-shot setting. The model also has poor performance at paragraph-level classification, and we do not further experiment on sentence-level evaluation.
| Doc | Para | |
| Zero-shot | 50.33 | 43.28 |
| One-shot | 44.56 | 36.47 |
| Two-shot | 51.66 | 37.81 |
5.2.5 Out-of-distribution performance
To investigate the generalization ability of AIGC detectors, four aforementioned detectors are evaluated on the OOD dataset on the doc-, para-171717We don’t paragraph human essays for CLEC does not provide explicit notations for paragraphs., and sent-level, including (1) our RoBERTa trained on the training set of ArguGPT dataset, (2) the SVM model trained on the features of function words, (3) GPTZero (version 2023-06-12), and (4) RoBERTa released by Guo et al.. The results are presented in Table 19.
We first make three general observations:
-
•
It is much easier for detectors to detect OOD human essays—all detectors have 90+% accuracy—than machine essays—some detectors have poor performance, at around 50%.
-
•
GPTZero has the best performance on the human OOD test set with document-level accuracy at 100.00% and sentence level at 96.92%.
-
•
Our RoBERTa trained on the ArguGPT dataset has the best performance on the machine OOD test set (doc: 97.00%; para: 93.13%; sent: 83.57%).
Results on the human OOD test set
We observe that the performance on the human OOD test set is much better than the performance on the machine OOD test set. Apart from the RoBERTa fine-tuned on other text genres (Guo et al., 2023) which has a sent-level accuracy of 60.60%, all other four detectors have the accuracy of 94%+ for human OOD test set at both sent- and doc-level, among which GPTZero is the best detector for human OOD essays (doc: 100.00%; sent: 96.92%).
| Machine | ||||||||
| Model | Level | Sub-corpus | Overall | ID acc./ | ||||
| turbo | gpt-4 | claude | bloomz | flan-t5 | OOD acc. | |||
| RoBERTa | doc | 99.67 | 100.00 | 97.00 | 95.67 | 92.67 | 97.00 | 99.71/2.71 |
| para | 98.85 | 95.82 | 90.33 | 79.27 | 75.67 | 93.13 | 98.71/5.58 | |
| sent | 97.01 | 92.83 | 83.81 | 63.85 | 77.80 | 83.57 | 97.26/13.69 | |
| Best SVM | doc | 85.00 | 88.00 | 75.00 | 60.00 | 53.00 | 72.20 | 94.00/21.80 |
| para | 83.80 | 60.69 | 59.61 | 39.00 | 46.00 | 64.43 | 89.42/24.99 | |
| sent | 72.65 | 57.83 | 56.14 | 16.00 | 28.00 | 53.13 | 78.33/25.20 | |
| GPTZero | doc | 94.00 | 32.00 | 11.00 | 54.00 | 76.00 | 53.40 | 95.42/42.02 |
| para | 94.27 | 50.00 | 21.16 | 56.09 | 84.00 | 57.72 | 94.06/36.34 | |
| sent | 96.77 | 56.25 | 22.52 | 62.13 | 87.50 | 65.37 | 96.57/31.20 | |
| Guo et al. (2023) | doc | 80.00 | 15.00 | 30.00 | 84.00 | 87.00 | 59.20 | 94.00/34.80 |
| para | 90.83 | 49.86 | 47.25 | 76.21 | 87.00 | 64.67 | 92.42/27.75 | |
| sent | 88.08 | 59.86 | 59.92 | 61.87 | 79.88 | 69.87 | 87.19/17.32 | |
| Human | ||||||||
| Model | Level | Sub-corpus | Overall | ID acc./ | ||||
| st2 | st3 | st4 | st5 | st6 | OOD acc. | |||
| RoBERTa | doc | 95.33 | 99.67 | 100.00 | 97.33 | 100.00 | 98.47 | 99.05/0.58 |
| para | - | - | - | - | - | - | - | |
| sent | 94.64 | 95.65 | 96.64 | 94.75 | 89.22 | 93.20 | 90.93/-2.27 | |
| Best SVM | doc | 92.00 | 91.00 | 95.00 | 97.00 | 99.00 | 94.80 | 96.29/1.49 |
| para | - | - | - | - | - | - | - | |
| sent | 92.89 | 90.01 | 92.00 | 89.75 | 81.61 | 87.91 | 83.25/-4.66 | |
| GPTZero | doc | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 98.28/-1.72 |
| para | - | - | - | - | - | - | - | |
| sent | 98.09 | 94.17 | 99.75 | 96.00 | 95.61 | 96.92 | 96.57/-0.35 | |
| Guo et al. (2023) | doc | 96.00 | 100.00 | 99.00 | 100.00 | 100.00 | 99.00 | 85.71/-13.29 |
| para | - | - | - | - | - | - | - | |
| sent | 71.11 | 62.64 | 71.46 | 64.82 | 46.98 | 60.60 | 58.23/-2.37 | |
Results on machine OOD test set
When we turn to results on OOD essays written by generative models, we see that the RoBERTa finetuned on ArguGPT training data achieves exceptionally high accuracy at all three levels (doc: 97%, para: 93%, sent: 83%). At the document level, the performance is only 2 percentage points below the in-distribution performance, while at the sentence level, we see a drop of roughly 13% from in-distribution performance (see last column of Table 19).
Our best model of SVMs performs second best at the document-level. Nevertheless, the SVM model has the lowest accuracy in prediction at the sentence level.
On the other hand, the two detectors that are not specifically trained for argumentative essay detection—GPTZero and RoBERTa of Guo et al.—exhibit surprisingly poor performance, with an accuracy of 53.40% and 59.20% respectively. For the RoBERTa from Guo et al. (2023), this could be attributed to the fact that their training data do not contain argumentative essays, and that all the texts in their training data are generated by one model—gpt-3.5-turbo.
The performance of GPTZero is particularly unsatisfactory for essays generated by gpt-4 (32% at doc-level) and claude-instant (11%). Thus one should be cautious when using GPTZero for detection essays written by AI models other than gpt-3.5-turbo. We also note that GPTZero has better performance on finer-grained prediction (i.e. sent-level para-level doc-level). However, there is a reverse trend for the ArguGPT-finetuned RoBERTa, namely it performs best at the document-level, but worst at sent-level.
For essays generated by different models, detectors have drastically different performance. For essays generated by gpt-3.5-turbo, all detectors have a similar performance compared to the in-distribution (ID) evaluation on the ArguGPT test set, except for the SVM and RoBERTa from Guo et al. (2023) which has a roughly 10% gap between the OOD and ID performance. However, for essays generated by gpt-4 and claude-instant, it becomes extremely difficult for two off-the-shelf detectors, GPTZero and Guo et al. (2023), with their accuracy between 11% and 32%. On the other hand, our RoBERTa finetuned on the ArguGPT training data shows almost no performance drop from ID to OOD evaluation at the document level (acc: 95+%). For essays generated by the two smaller language models bloomz-7b and flan-t5-11b, we observe that the two off-the-shelf detectors have a better performance, with accuracy between 54% and 87% at the doc-level.
Discussion and implications
Our experiments on the OOD test set have several implications.
First, when evaluating AIGC detectors, it is necessary to construct a more comprehensive evaluation set that covers text generated by multiple models, as detection accuracy varies dramatically for text generated by different models. In our experiments, detectors have much better performance of predicting gpt-3.5-turbo than other models. However, as these generative models quickly update and new models emerge, an evaluation set should ideally cover as many models as possible so as to reflect the actual detection performance.
Second, transferring to detect AIGC generated by a different model might be more difficult than transferring to a different text genre. This is manifest in the ID and OOD performance of the RoBERTa by Guo et al. (2023), which is fine-tuned on text of 5 genres generated solely by gpt-3.5-turbo: while it has 80+% accuracy on detecting argumentative essays written by gpt-3.5-turbo, the performance drops to 15% and 30% respectively for essays generated by gpt-4 and claude-instant. Our results suggest that text produced by different models may have distinctive textual features that can be challenging for transfer learning. This resonates with our first point where a more comprehensive evaluation set is necessary.
Third, it is easier for the detectors to identify human essays than machine essays. Our OOD results show that the detectors have higher performance on human essays, suggesting that the human essays in our OOD set are more or less homogeneous to the ID data, whereas the machine essays are likely from a genuine different distribution.
6 Related work
6.1 The evolution of large language models
Since Vaswani et al. (2017) proposed Transformer, a machine translation model that relies on self-attention, language models have kept advancing at an unprecedented pace in recent years. The field has seen innovative ideas ranging from the pretraining-finetuning paradigm (Radford et al., 2018; Devlin et al., 2018) and larger-scale mixed-task training (Raffel et al., 2019) to implicit (Radford et al., 2019) and explicit (Wei et al., 2021; Sanh et al., 2021) multitask learning and in-context learning (Brown et al., 2020). Some works scaled language models to hundreds of billions of parameters (Rae et al., 2021; Smith et al., 2022; Chowdhery et al., 2022), while others reevaluated scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022) and trained smaller models on larger amount of higher-quality data (Anil et al., 2023; Li et al., 2023). Some trained them to follow natural (Mishra et al., 2022), supernatural (Wang et al., 2022b), and unnatural (Honovich et al., 2022) instructions. Others investigated their abilities in reasoning with chain-of-thought (Wei et al., 2022; Wang et al., 2022a; Kojima et al., 2022).
More recently, OpenAI’s GPT models have become front-runners in language models that displayed exceeding performances in various tasks. GPT-2 is a decoder-only auto-regressive language model with 1.5B parameters presented by Radford et al., who pretrained the model on 40GB of Web-based text and found it to demonstrate preliminary zero-shot generation abilities on downstream tasks such as task-specific language modeling, commonsense reasoning, summarization, and translation. GPT-3 (i.e. davinci, Brown et al., 2020) is an enlarged version of GPT-2 with 175B parameters and pre-trained on a larger corpus that mainly consists of CommonCrawl. InstructGPT (Ouyang et al., 2022), also known as text-davinci-001, is a more advanced version of GPT-3 finetuned by both instructions and reinforcement learning with human feedback (RLHF). Text-davinci-002 applied the same procedures to Codex (i.e. code-davinci-002, Chen et al., 2021), a variant of GPT-3 that is further pretrained on code using the same negative log-likelihood objective as language modeling. Text-davinci-003 improved text-davinci-002 further by introducing Proximal Policy Optimization (PPO). GPT-3.5-turbo, more commonly known as ChatGPT, is a variant of text-davinci-003 optimized for dialogues. Besides all these large language models, OpenAI has also released a series of smaller models, including curie, babbage, and ada, each one smaller in size and faster at inference.
6.2 Human evaluation of AIGC
In Natural Langauge Generation (NLG) tasks, human evaluation is often considered to be the gold standard, for the goal of NLG is to generate readable texts for human (Celikyilmaz, Clark, and Gao, 2020). Human subjects are often asked to perform a Turing test (Turing, 1950) in order to evaluate the human-likeness of machine-generated texts.
Brown et al. (2020) asked 80 participants to identify news articles generated by language models with different parameter sizes from human-written articles. The results show that the accuracy of human identifying model generated articles dropped to a chance level with large language models like GPT-3. Clark et al. (2021) recruited 780 participants to identify texts generated by the GPT-2 and the davinci models. The results indicate that the accuracy of human participants is around 50%, though the accuracy becomes higher after training. They suggested that human could misunderstand and underestimate the ability of machine. Uchendu et al. (2021) also reported that human subjects were able to identify machine-generated texts only at a chance level.
Dou et al. (2022) proposed a framework that used crowd annotation to scrutinize model-generated texts. The results show that there are some gaps between human-authored and machine-generated texts; for instance, human-authored texts contain more grammatical errors while machine-generated texts are more redundant. Guo et al. (2023) asked participants to compare the responses from both human experts and ChatGPT in various domains; their results suggest that people find answers generated by ChatGPT generally more helpful than those generated by human experts in certain areas. They also identified some distinctive features of ChatGPT that are different from human experts, including that ChatGPT is more likely to focus on the topic, display objective and formal expression with less emotion.
In summary, it is difficult for human subjects to distinguish texts generated by advanced large language models from human-written texts.
6.3 AIGC detector
AIGC detection is a text classification task that aims to distinguish machine-generated texts from human-written texts. Even before the release of ChatGPT, researchers had presented many works on machine-generated text detection. Gehrmann, Strobelt, and Rush (2019) developed GLTR, a tool that applies statistical methods to detect machine-generated texts and improve human readers’ accuracy in identifying machine-generated text detection. Zellers et al. (2019) developed Grover, a large language model that was trained to detect machine-generated news articles. Uchendu et al. (2020) trained several simple neural models that aim to not only distinguish machine-generated texts from human-written texts, i.e. the Turning Test (TT), but furthermore, identify which NLG method generated the texts in question, i.e. the Authorship Attribution (AA) tasks. They found that those neural models (especially fine-tuned RoBERTa) performed reasonably well on the classification tasks, though texts generated by GPT2, FAIR, and GROVER were more difficult than other models. Uchendu et al. (2021) introduced a TuringBench dataset for TT and AA tasks. Results from their preliminary experiments indicate that better solutions, including more complex models, are needed in order to meet the challenges in text classification.
The recent surge of AIGC, as a result of advances in large language models, further motivates researchers to explore AIGC detectors. GPTZero is one of the earliest published ChatGPT-generated content detectors. OpenAI also published its own detector181818https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text after the prevalence of ChatGPT. Guo et al. (2023) trained detectors basing on deep learning and linguistic features to detect ChatGPT-generated texts in Q&A domain. Mitrović, Andreoletti, and Ayoub (2023) trained perplexity-based and DistilBert fine-tuned detectors. Mitchell et al. (2023) developed a zero-shot detector.
6.4 AIGC in the education domain
Large language models, especially OpenAI’s GPT-3 and ChatGPT, have displayed impressive performance in academic and professional exams. Choi et al. (2023) used ChatGPT to produce answers on Law School’s exams consisting of 95 multiple choice questions and 12 essay questions. The results show that ChatGPT achieved a low but passing grade in all those exams. Zhang et al. (2022) evaluated the answers generated by large language models, including Meta’s OPT, OpenAI’s GPT-3, ChatGPT, and Codex, on questions from final exams of undergraduate-level Machine Learning courses. The results show that large language models achieved passing grades on all selected final exams except one and scored as high as a B+ grade. They also used those models to generate new questions for Machine Learning courses and compared the quality, appropriateness, and difficulty of those questions with human-written questions via an online survey. The results suggest that AI-generated questions, though slightly easier than human-written questions, were comparable to human-written questions regarding quality and appropriateness. Kung et al. (2023) analyzed ChatGPT’s performance on the United States Medical Licensing Exam (USMLE), a set of three standardized tests that assess expert-level knowledge and are required for medical licensure in the US. The findings indicate that ChatGPT performed at or near the passing threshold of 60% and was able to provide comprehensible reasoning and valid clinical insights.
Additionally, the latest GPT-4 model has shown remarkable progress, further surpassing the previous GPT models. Its performance is comparable to that of humans on most professional and academic tests, and it even achieved a top 10% score on a simulated bar exam (OpenAI, 2023). One exception to GPT models’ stellar performances across various subjects in exams is their ability to solve mathematical problems. Frieder et al. (2023) evaluated ChatGPT’s performance on a data set consisting of mathematical exercises, problems, and proofs. The results show that ChatGPT failed to deliver high-quality proofs or calculations consistently, especially for those in advanced mathematics.
Furthermore, the remarkable performances of large language models suggest that they have the potential to influence various aspects of the education domain. Kung et al. (2023) pointed out that large language models such as ChatGPT could facilitate human learners in a medical education setting. Zhai (2022) examined ChatGPT’s ability in academic writing and concluded that ChatGPT could deliver a high-quality academic paper quickly with minimal input. Dis et al. (2023) presented the potential benefits of ChatGPT for research, including increased efficiency for researchers and the possibility of reviewing articles. Thorp (2023) argued that ChatGPT could provide high-accuracy English translation and proofreading to non-native English speakers, narrowing the disadvantages they face in the field of science.
However, the increasing use and broad implications of large language models have raised ethical concerns regarding the accuracy and authenticity of generated content, academic integrity, and plagiarism. Science has updated its policies to prohibit ChatGPT from being listed as an author, and AI-generated texts should not be included in published work (Thorp, 2023). Gao et al. (2022) used ChatGPT to generate research abstracts based on existing abstracts from medical journals. They found that plagiarism detectors failed to identify AI-generated abstracts. Though the AIGC detector can distinguish generated and human-written, original abstracts, human reviewers found it challenging to identify generated abstracts. Alkaissi and McFarlane (2023) used ChatGPT to write about the pathogenesis of medical conditions. The results show that while ChatGPT could search for related information and produce credible and coherent scientific writings, the references it provided contained unrelated or even fabricated publications. Both teams of authors recommend that editorial processes for journals and conferences should integrate AIGC detectors and clearly disclose the use of these technologies.
7 Conclusion
To sum up, in this paper we have (1) compiled a human-machine balanced corpus of argumentative essays, (2) hired 43 English instructors and conducted human evaluation and identification of machine-authored essays, (3) analyzed and compared human and machine essays from the perspectives of syntactical and lexical complexity, and (4) built and evaluated classifiers for detection of GPT-generated essays.
Results of human evaluation suggest that English instructors have difficulty in distinguishing machine-generated essays from human-written ones, with an accuracy of 0.6163 in round 1, which can be improved to 0.6767 when they are shown the correct answers for round 1 and asked to reflect on the characteristics of machine-written essays. They have a higher accuracy of identifying low-level human essays and high-level machine essays, suggesting that participants anticipate that GPT-generated essays should have higher quality than human-written ones.
In our linguistic analyses, we find that GPT models produce sentences with more complex syntax than human, but the diction and vocabulary of human essays tend to be more diverse. What should be noted is that more advanced language models generally rank higher on synatctic and lexical complexity.
Finally, it is easy for machine-learning classifiers to capture the differences between human-authored and machine-generated essays, as an in-domain RoBERTa-large model achieves 99+% accuracy on the document-level and 93+% on sentence-level classification. Results of SVM classifiers show that using surface (POS unigram) and deep (context-free grammar) syntactic features alone yields high performance, suggesting that human and machine essays can be distinguished by these structural characteristics. However, it is difficult for most detectors (except our document-level RoBERTa) to transfer to out-of-distribution generative models.
We hope our study can be helpful to ESOL instructors in identifying AIGC, and also useful for NLP practitioners interested in human evaluation and textual analysis of AIGC.
Acknowledgments
We thank Rui Wang, Yifan Zhu, and Huilin Chen for discussions on early drafts of the paper and their help in the human evaluation. We are also grateful to all participants in our human evaluation experiment. This project is supported by the Humanities and Social Sciences Grant from the Chinese Ministry of Education (No. 22YJC740020) awarded to Hai Hu.
References
- Alkaissi and McFarlane (2023) Alkaissi, Hussam and Samy I McFarlane. 2023. Artificial hallucinations in ChatGPT: Implications in scientific writing. Cureus.
- Anil et al. (2023) Anil, Rohan, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernández Ábrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan A. Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vladimir Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, and et al. 2023. Palm 2 technical report. CoRR, abs/2305.10403.
- Bird (2002) Bird, Steven. 2002. Nltk: The natural language toolkit. ArXiv, cs.CL/0205028.
- Blanchard et al. (2013) Blanchard, Daniel, Joel Tetreault, Derrick Higgins, Aoife Cahill, and Martin Chodorow. 2013. Toefl11: A corpus of non-native english. ETS Research Report Series, 2013(2):i–15.
- Brown et al. (2020) Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Celikyilmaz, Clark, and Gao (2020) Celikyilmaz, Asli, Elizabeth Clark, and Jianfeng Gao. 2020. Evaluation of text generation: A survey. arXiv preprint arXiv:2006.14799.
- Chen et al. (2021) Chen, Mark, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. CoRR, abs/2107.03374.
- Chen et al. (2023) Chen, Xuanting, Junjie Ye, Can Zu, Nuo Xu, Rui Zheng, Minlong Peng, Jie Zhou, Tao Gui, Qi Zhang, and Xuanjing Huang. 2023. How robust is gpt-3.5 to predecessors? a comprehensive study on language understanding tasks. arXiv preprint arXiv:2303.00293.
- Choi et al. (2023) Choi, Jonathan H, Kristin E Hickman, Amy Monahan, and Daniel B Schwarcz. 2023. ChatGPT goes to law school. SSRN Electron. J.
- Chowdhery et al. (2022) Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways. CoRR, abs/2204.02311.
- Chung et al. (2022) Chung, Hyung Won, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. CoRR, abs/2210.11416.
- Clark et al. (2021) Clark, Elizabeth, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. 2021. All That’s ‘Human’ Is Not Gold: Evaluating Human Evaluation of Generated Text. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7282–7296, Association for Computational Linguistics, Online.
- Devlin et al. (2018) Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805.
- Dis et al. (2023) Dis, Eva, Johan Bollen, Willem Zuidema, Robert Rooij, and Claudi Bockting. 2023. Chatgpt: five priorities for research. Nature, 614:224–226.
- Dou et al. (2022) Dou, Yao, Maxwell Forbes, Rik Koncel-Kedziorski, Noah A. Smith, and Yejin Choi. 2022. Is GPT-3 Text Indistinguishable from Human Text? Scarecrow: A Framework for Scrutinizing Machine Text. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7250–7274, Association for Computational Linguistics, Dublin, Ireland.
- Frieder et al. (2023) Frieder, Simon, Luca Pinchetti, Ryan-Rhys Griffiths, Tommaso Salvatori, Thomas Lukasiewicz, Philipp Christian Petersen, Alexis Chevalier, and Julius Berner. 2023. Mathematical capabilities of chatgpt.
- Gao et al. (2022) Gao, Catherine A., Frederick M. Howard, Nikolay S. Markov, Emma C. Dyer, Siddhi Ramesh, Yuan Luo, and Alexander T. Pearson. 2022. Comparing scientific abstracts generated by chatgpt to original abstracts using an artificial intelligence output detector, plagiarism detector, and blinded human reviewers. bioRxiv.
- Gehrmann, Strobelt, and Rush (2019) Gehrmann, Sebastian, Hendrik Strobelt, and Alexander M Rush. 2019. Gltr: Statistical detection and visualization of generated text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111–116.
- Gui and Yang (2003) Gui, Shichun and Huizhong Yang. 2003. Chinese Learner English Corpus. Shanghai Foreign Language Education Press.
- Guo et al. (2023) Guo, Biyang, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. 2023. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv preprint arXiv:2301.07597.
- Hoffmann et al. (2022) Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. 2022. Training compute-optimal large language models. CoRR, abs/2203.15556.
- Honnibal and Johnson (2015) Honnibal, Matthew and Mark Johnson. 2015. An improved non-monotonic transition system for dependency parsing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1373–1378, Association for Computational Linguistics, Lisbon, Portugal.
- Honovich et al. (2022) Honovich, Or, Thomas Scialom, Omer Levy, and Timo Schick. 2022. Unnatural instructions: Tuning language models with (almost) no human labor. CoRR, abs/2212.09689.
- Housen (2002) Housen, Alex. 2002. A corpus-based study of the l2-acquisition of the english verb system. Computer learner corpora, second language acquisition and foreign language teaching, 6:2002–77.
- Hu and Kübler (2021) Hu, Hai and Sandra Kübler. 2021. Investigating translated chinese and its variants using machine learning. Natural Language Engineering, 27(3):339–372.
- Hunt (1965) Hunt, Kellogg W. 1965. Grammatical structures written at three grade levels. 8. National Council of Teachers of English.
- Hunt (1970) Hunt, Kellogg W. 1970. Do sentences in the second language grow like those in the first? Tesol Quarterly, pages 195–202.
- Kaplan et al. (2020) Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. CoRR, abs/2001.08361.
- Kojima et al. (2022) Kojima, Takeshi, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. CoRR, abs/2205.11916.
- Koppel and Ordan (2011) Koppel, Moshe and Noam Ordan. 2011. Translationese and its dialects. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pages 1318–1326.
- Kung et al. (2023) Kung, Tiffany H, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, and Victor Tseng. 2023. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health, 2(2):e0000198.
- Laufer and Nation (1995) Laufer, Batia and Paul Nation. 1995. Vocabulary size and use: Lexical richness in l2 written production. Applied linguistics, 16(3):307–322.
- Li et al. (2023) Li, Yuanzhi, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. 2023. Textbooks are all you need II: phi-1.5 technical report. CoRR, abs/2309.05463.
- Liu et al. (2019) Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
- Lu (2010) Lu, Xiaofei. 2010. Automatic analysis of syntactic complexity in second language writing. International Journal of Corpus Linguistics, 15:474–496.
- Lu (2012) Lu, Xiaofei. 2012. The relationship of lexical richness to the quality of esl learners’ oral narratives. The Modern Language Journal, 96:190–208.
- Manning et al. (2014) Manning, Christopher D., Mihai Surdeanu, John Bauer, Jenny Rose Finkel, Steven Bethard, and David McClosky. 2014. The stanford corenlp natural language processing toolkit. In Annual Meeting of the Association for Computational Linguistics.
- Mishra et al. (2022) Mishra, Swaroop, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. 2022. Cross-task generalization via natural language crowdsourcing instructions. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 3470–3487, Association for Computational Linguistics.
- Mitchell et al. (2023) Mitchell, Eric, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine-generated text detection using probability curvature. arXiv preprint arXiv:2301.11305.
- Mitrović, Andreoletti, and Ayoub (2023) Mitrović, Sandra, Davide Andreoletti, and Omran Ayoub. 2023. Chatgpt or human? detect and explain. explaining decisions of machine learning model for detecting short chatgpt-generated text. arXiv preprint arXiv:2301.13852.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Ouyang, Long, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems.
- Pedregosa et al. (2011) Pedregosa, F., G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830.
- Radford et al. (2018) Radford, Alec, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
- Radford et al. (2019) Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rae et al. (2021) Rae, Jack W., Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, H. Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John Mellor, Irina Higgins, Antonia Creswell, Nat McAleese, Amy Wu, Erich Elsen, Siddhant M. Jayakumar, Elena Buchatskaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, Laurent Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gribovskaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsimpoukelli, Nikolai Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Toby Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d’Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew J. Johnson, Blake A. Hechtman, Laura Weidinger, Iason Gabriel, William S. Isaac, Edward Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem Ayoub, Jeff Stanway, Lorrayne Bennett, Demis Hassabis, Koray Kavukcuoglu, and Geoffrey Irving. 2021. Scaling language models: Methods, analysis & insights from training gopher. CoRR, abs/2112.11446.
- Raffel et al. (2019) Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR, abs/1910.10683.
- Rayson and Garside (2000) Rayson, Paul and Roger Garside. 2000. Comparing corpora using frequency profiling. In The workshop on comparing corpora, pages 1–6.
- Read (2000) Read, John. 2000. Assessing vocabulary. Cambridge university press.
- Sanh et al. (2021) Sanh, Victor, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M. Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal V. Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Févry, Jason Alan Fries, Ryan Teehan, Stella Biderman, Leo Gao, Tali Bers, Thomas Wolf, and Alexander M. Rush. 2021. Multitask prompted training enables zero-shot task generalization. CoRR, abs/2110.08207.
- Smith et al. (2022) Smith, Shaden, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, Elton Zheng, Rewon Child, Reza Yazdani Aminabadi, Julie Bernauer, Xia Song, Mohammad Shoeybi, Yuxiong He, Michael Houston, Saurabh Tiwary, and Bryan Catanzaro. 2022. Using deepspeed and megatron to train megatron-turing NLG 530b, A large-scale generative language model. CoRR, abs/2201.11990.
- Thorp (2023) Thorp, H. Holden. 2023. Chatgpt is fun, but not an author. Science, 379(6630):313–313.
- Turing (1950) Turing, Alan. 1950. Computing machinery and intelligence. Mind, 59(236):433.
- Uchendu et al. (2020) Uchendu, Adaku, Thai Le, Kai Shu, and Dongwon Lee. 2020. Authorship attribution for neural text generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8384–8395, Association for Computational Linguistics, Online.
- Uchendu et al. (2021) Uchendu, Adaku, Zeyu Ma, Thai Le, Rui Zhang, and Dongwon Lee. 2021. Turingbench: A benchmark environment for turing test in the age of neural text generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2001–2016.
- Vaswani et al. (2017) Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. CoRR, abs/1706.03762.
- Volansky, Ordan, and Wintner (2015) Volansky, Vered, Noam Ordan, and Shuly Wintner. 2015. On the features of translationese. Digital Scholarship in the Humanities, 30(1):98–118.
- Wang et al. (2022a) Wang, Xuezhi, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, and Denny Zhou. 2022a. Self-consistency improves chain of thought reasoning in language models. CoRR, abs/2203.11171.
- Wang et al. (2022b) Wang, Yizhong, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Gary Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit, Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Savan Doshi, Shailaja Keyur Sampat, Siddhartha Mishra, Sujan Reddy A, Sumanta Patro, Tanay Dixit, and Xudong Shen. 2022b. Super-naturalinstructions: Generalization via declarative instructions on 1600+ NLP tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 5085–5109, Association for Computational Linguistics.
- Wei et al. (2021) Wei, Jason, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2021. Finetuned language models are zero-shot learners. CoRR, abs/2109.01652.
- Wei et al. (2022) Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903.
- Wen, Wang, and Liang (2005) Wen, Qiufang, Lifei Wang, and Maocheng Liang. 2005. Spoken and written english corpus of chinese learners. Foreign Language Teaching and Research Press.
- Wolf et al. (2019) Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Transformers: State-of-the-art natural language processing. In Conference on Empirical Methods in Natural Language Processing.
- Workshop et al. (2023) Workshop, BigScience, :, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, Stella Biderman, Albert Webson, Pawan Sasanka Ammanamanchi, Thomas Wang, Benoît Sagot, Niklas Muennighoff, Albert Villanova del Moral, Olatunji Ruwase, Rachel Bawden, Stas Bekman, Angelina McMillan-Major, Iz Beltagy, Huu Nguyen, Lucile Saulnier, Samson Tan, Pedro Ortiz Suarez, Victor Sanh, Hugo Laurençon, Yacine Jernite, Julien Launay, Margaret Mitchell, Colin Raffel, Aaron Gokaslan, Adi Simhi, Aitor Soroa, Alham Fikri Aji, Amit Alfassy, Anna Rogers, Ariel Kreisberg Nitzav, Canwen Xu, Chenghao Mou, Chris Emezue, Christopher Klamm, Colin Leong, Daniel van Strien, David Ifeoluwa Adelani, Dragomir Radev, Eduardo González Ponferrada, Efrat Levkovizh, Ethan Kim, Eyal Bar Natan, Francesco De Toni, Gérard Dupont, Germán Kruszewski, Giada Pistilli, Hady Elsahar, Hamza Benyamina, Hieu Tran, Ian Yu, Idris Abdulmumin, Isaac Johnson, Itziar Gonzalez-Dios, Javier de la Rosa, Jenny Chim, Jesse Dodge, Jian Zhu, Jonathan Chang, Jörg Frohberg, Joseph Tobing, Joydeep Bhattacharjee, Khalid Almubarak, Kimbo Chen, Kyle Lo, Leandro Von Werra, Leon Weber, Long Phan, Loubna Ben allal, Ludovic Tanguy, Manan Dey, Manuel Romero Muñoz, Maraim Masoud, María Grandury, Mario Šaško, Max Huang, Maximin Coavoux, Mayank Singh, Mike Tian-Jian Jiang, Minh Chien Vu, Mohammad A. Jauhar, Mustafa Ghaleb, Nishant Subramani, Nora Kassner, Nurulaqilla Khamis, Olivier Nguyen, Omar Espejel, Ona de Gibert, Paulo Villegas, Peter Henderson, Pierre Colombo, Priscilla Amuok, Quentin Lhoest, Rheza Harliman, Rishi Bommasani, Roberto Luis López, Rui Ribeiro, Salomey Osei, Sampo Pyysalo, Sebastian Nagel, Shamik Bose, Shamsuddeen Hassan Muhammad, Shanya Sharma, Shayne Longpre, Somaieh Nikpoor, Stanislav Silberberg, Suhas Pai, Sydney Zink, Tiago Timponi Torrent, Timo Schick, Tristan Thrush, Valentin Danchev, Vassilina Nikoulina, Veronika Laippala, Violette Lepercq, Vrinda Prabhu, Zaid Alyafeai, Zeerak Talat, Arun Raja, Benjamin Heinzerling, Chenglei Si, Davut Emre Taşar, Elizabeth Salesky, Sabrina J. Mielke, Wilson Y. Lee, Abheesht Sharma, Andrea Santilli, Antoine Chaffin, Arnaud Stiegler, Debajyoti Datta, Eliza Szczechla, Gunjan Chhablani, Han Wang, Harshit Pandey, Hendrik Strobelt, Jason Alan Fries, Jos Rozen, Leo Gao, Lintang Sutawika, M Saiful Bari, Maged S. Al-shaibani, Matteo Manica, Nihal Nayak, Ryan Teehan, Samuel Albanie, Sheng Shen, Srulik Ben-David, Stephen H. Bach, Taewoon Kim, Tali Bers, Thibault Fevry, Trishala Neeraj, Urmish Thakker, Vikas Raunak, Xiangru Tang, Zheng-Xin Yong, Zhiqing Sun, Shaked Brody, Yallow Uri, Hadar Tojarieh, Adam Roberts, Hyung Won Chung, Jaesung Tae, Jason Phang, Ofir Press, Conglong Li, Deepak Narayanan, Hatim Bourfoune, Jared Casper, Jeff Rasley, Max Ryabinin, Mayank Mishra, Minjia Zhang, Mohammad Shoeybi, Myriam Peyrounette, Nicolas Patry, Nouamane Tazi, Omar Sanseviero, Patrick von Platen, Pierre Cornette, Pierre François Lavallée, Rémi Lacroix, Samyam Rajbhandari, Sanchit Gandhi, Shaden Smith, Stéphane Requena, Suraj Patil, Tim Dettmers, Ahmed Baruwa, Amanpreet Singh, Anastasia Cheveleva, Anne-Laure Ligozat, Arjun Subramonian, Aurélie Névéol, Charles Lovering, Dan Garrette, Deepak Tunuguntla, Ehud Reiter, Ekaterina Taktasheva, Ekaterina Voloshina, Eli Bogdanov, Genta Indra Winata, Hailey Schoelkopf, Jan-Christoph Kalo, Jekaterina Novikova, Jessica Zosa Forde, Jordan Clive, Jungo Kasai, Ken Kawamura, Liam Hazan, Marine Carpuat, Miruna Clinciu, Najoung Kim, Newton Cheng, Oleg Serikov, Omer Antverg, Oskar van der Wal, Rui Zhang, Ruochen Zhang, Sebastian Gehrmann, Shachar Mirkin, Shani Pais, Tatiana Shavrina, Thomas Scialom, Tian Yun, Tomasz Limisiewicz, Verena Rieser, Vitaly Protasov, Vladislav Mikhailov, Yada Pruksachatkun, Yonatan Belinkov, Zachary Bamberger, Zdeněk Kasner, Alice Rueda, Amanda Pestana, Amir Feizpour, Ammar Khan, Amy Faranak, Ana Santos, Anthony Hevia, Antigona Unldreaj, Arash Aghagol, Arezoo Abdollahi, Aycha Tammour, Azadeh HajiHosseini, Bahareh Behroozi, Benjamin Ajibade, Bharat Saxena, Carlos Muñoz Ferrandis, Daniel McDuff, Danish Contractor, David Lansky, Davis David, Douwe Kiela, Duong A. Nguyen, Edward Tan, Emi Baylor, Ezinwanne Ozoani, Fatima Mirza, Frankline Ononiwu, Habib Rezanejad, Hessie Jones, Indrani Bhattacharya, Irene Solaiman, Irina Sedenko, Isar Nejadgholi, Jesse Passmore, Josh Seltzer, Julio Bonis Sanz, Livia Dutra, Mairon Samagaio, Maraim Elbadri, Margot Mieskes, Marissa Gerchick, Martha Akinlolu, Michael McKenna, Mike Qiu, Muhammed Ghauri, Mykola Burynok, Nafis Abrar, Nazneen Rajani, Nour Elkott, Nour Fahmy, Olanrewaju Samuel, Ran An, Rasmus Kromann, Ryan Hao, Samira Alizadeh, Sarmad Shubber, Silas Wang, Sourav Roy, Sylvain Viguier, Thanh Le, Tobi Oyebade, Trieu Le, Yoyo Yang, Zach Nguyen, Abhinav Ramesh Kashyap, Alfredo Palasciano, Alison Callahan, Anima Shukla, Antonio Miranda-Escalada, Ayush Singh, Benjamin Beilharz, Bo Wang, Caio Brito, Chenxi Zhou, Chirag Jain, Chuxin Xu, Clémentine Fourrier, Daniel León Periñán, Daniel Molano, Dian Yu, Enrique Manjavacas, Fabio Barth, Florian Fuhrimann, Gabriel Altay, Giyaseddin Bayrak, Gully Burns, Helena U. Vrabec, Imane Bello, Ishani Dash, Jihyun Kang, John Giorgi, Jonas Golde, Jose David Posada, Karthik Rangasai Sivaraman, Lokesh Bulchandani, Lu Liu, Luisa Shinzato, Madeleine Hahn de Bykhovetz, Maiko Takeuchi, Marc Pàmies, Maria A Castillo, Marianna Nezhurina, Mario Sänger, Matthias Samwald, Michael Cullan, Michael Weinberg, Michiel De Wolf, Mina Mihaljcic, Minna Liu, Moritz Freidank, Myungsun Kang, Natasha Seelam, Nathan Dahlberg, Nicholas Michio Broad, Nikolaus Muellner, Pascale Fung, Patrick Haller, Ramya Chandrasekhar, Renata Eisenberg, Robert Martin, Rodrigo Canalli, Rosaline Su, Ruisi Su, Samuel Cahyawijaya, Samuele Garda, Shlok S Deshmukh, Shubhanshu Mishra, Sid Kiblawi, Simon Ott, Sinee Sang-aroonsiri, Srishti Kumar, Stefan Schweter, Sushil Bharati, Tanmay Laud, Théo Gigant, Tomoya Kainuma, Wojciech Kusa, Yanis Labrak, Yash Shailesh Bajaj, Yash Venkatraman, Yifan Xu, Yingxin Xu, Yu Xu, Zhe Tan, Zhongli Xie, Zifan Ye, Mathilde Bras, Younes Belkada, and Thomas Wolf. 2023. Bloom: A 176b-parameter open-access multilingual language model.
- Zellers et al. (2019) Zellers, Rowan, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. Advances in neural information processing systems, 32.
- Zhai (2022) Zhai, Xiaoming. 2022. ChatGPT user experience: Implications for education. SSRN Electron. J.
- Zhang et al. (2022) Zhang, Sarah, Reece Shuttleworth, Zad Chin, Pedro Lantigua, Saisamrit Surbehera, Gregory Hunter, Derek Austin, Yann Hicke, Leonard Tang, Sathwik Karnik, Darnell Granberry, and Iddo Drori. 2022. Automatically answering and generating machine learning final exams.
Appendix
Appendix A Examples of deleted gpt2-generated texts
Here we present some essays generated by gpt-2 that were manually removed.
Q&A
Q: What is the most important thing you have learned in your life so far that you would like to pass on to the next generation? // A: I have learnt that there is no such thing as a free lunch…
Providing URL
If you’re not sure what to write about, you can always ask a friend or family member to help you out. You can also use a free online writing service like WriterDuet.com to get started.
Nonsense
Refuse to answer % % ALL 18-34 35-44 45-54 55-64 65-74 75-84 85-94 95-100 % of all voters Clinton (D) Trump (R) Johnson (L) Stein (G) Undecided (V) Refused (N) Total All voters 45.4% 35.0% 27.3% 25.6% 21.5% 17.1% 13.9% 10.8% 8.2%…
Speaking Chinese
What do you think is the most important thing you can do to improve the quality of life for yourself and your loved ones? 龚属思想让我们没有办法自己的情况下,但这个世界的经验也不会觉得到过去的…
Appendix B Automatic scoring details
B.1 Scores given by YouDao automated scoring systems under different criteria
| Essay label | babbage-001 | curie-001 | text-davinci-001 | text-davinci-002 | text-davinci-003 | gpt-3.5-turbo |
| 01 | 96.8 | 106.5 | 89.4 | 93.1 | 105.6 | 100.1 |
| 02 | 89.1 | 83.1 | 87.4 | 92.0 | 106.5 | 106.5 |
| 03 | 106.5 | 106.2 | 83.4 | 106.5 | 102.0 | 106.5 |
| 04 | 78.5 | 98.8 | 81.2 | 85.2 | 103.9 | 106.4 |
| 05 | 78.7 | 93.5 | 104.9 | 101.1 | 106.5 | 105.6 |
| 06 | 100.3 | 101.2 | 89.8 | 105.2 | 106.5 | 103.3 |
| No. | babbage-001 | curie-001 | text-davinci-001 | text-davinci-002 | text-davinci-003 | gpt-3.5-turbo |
| 01 | 15 | 16 | 15 | 16 | 20 | 19 |
| 02 | 15 | 14 | 15 | 16 | 16 | 20 |
| 03 | 19 | 19 | 13 | 19 | 16 | 20 |
| 04 | 12 | 17 | 11 | 15 | 19 | 20 |
| 05 | 14 | 16 | 19 | 18 | 19 | 19 |
| 06 | 18 | 16 | 15 | 18 | 19 | 20 |
| No. | babbage-001 | curie-001 | text-davinci-001 | text-davinci-002 | text-davinci-003 | gpt-3.5-turbo |
| 01 | 99 | 96 | 86 | 97 | 98 | 99 |
| 02 | 89 | 85 | 85 | 97 | 99 | 94 |
| 03 | 98 | 97 | 90 | 97 | 99 | 99 |
| 04 | 90 | 98 | 88 | 95 | 91 | 98 |
| 05 | 89 | 99 | 97 | 96 | 98 | 97 |
| 06 | 94 | 93 | 88 | 98 | 91 | 98 |
Appendix C Details for added prompts
| Prompt label | Detail |
| 01 | Do you agree or disagree? Use specific reasons and examples to support your answer. Write an essay of roughly 300/400/500 words. |
| 02 | Do you agree or disagree? It is a test for English writing. Please write an essay of roughly 300/400/500 words. |
| 03 | Do you agree or disagree? Pretend you are the best student in a writing class. Write an essay of roughly 300/400/500 words, with a large vocabulary and a wide range of sentence structures to impress your professor. |
| 04 | Do you agree or disagree? Pretend you are a professional American writer. Write an essay of roughly 300/400/500 words, with the potential of winning a Nobel prize in literature. |
| 05 | Do you agree or disagree? From an undergraduate student’s perspective, write an essay of roughly 300/400/500 words to illustrate your idea. |
Appendix D Instructions for human experiment
English Essays Judgment Experiment
Welcome to the English Judgment Experiment by Shanghai Jiao Tong University!191919The instruction is translated by DeepL and proofread by one of the authors. The task of this experiment is to determine whether an essay is written by a human or a machine (AI model). You will complete the experiment in two rounds with the same experimental setup. In each round, 10 English essays will be judged, with some written by humans and others by machines. You will see the essay question and the writing from TOEFL (Test of English as a Foreign Language). The essay questions are randomly the same or different.
A variety of AI models, regardless of their performances, were used in this experiment, including ChatGPT(i.e., get-3.5-turbo). The human essays are written by TOEFL test takers from around the world. They have different native languages and varying levels of English language proficiency. The purpose of this experiment is to understand the sensitivity of English teachers to machine-generated essays and to improve their ability to recognize the machine-generated essays in the second experiment through the first round of tests.
To determine the authorship of an essay, you should choose one of the following six options:
1 = Definitely written by humans,
2 = Probably written by humans,
3 = Likely written by humans,
4 = Likely written by machines,
5 = Probably written by machines,
6 = Definitely written by machines.
You can give reasons for your judgment (optional).
When you have finished your answer, click “submit." You will see the correct answers on a new page, and you should summarize the characteristics of machine-generated essays (required). After completing the first round, you will move on to the second round, which will follow the same procedure as the first round. We would like you to apply the experience gained from the first round to improve your accuracy in the second round.
Your goal is to make as many correct judgments as possible, and each correct answer will increase the payout by 1 RMB. Please do not take screenshots during the experiment! All results will be disclosed after they are compiled. Please use a computer for the experiment.
Estimated time: 20-30 minutes.
Experimental reward: 40 RMB (basic reward) with bonus (number of correct answers*2 RMB). As there are 20 questions in total, the maximum reward is 80 RMB. Please fill in your Alipay account and the actual name of the account holder on the last page (required for funding reimbursement). You can also choose not to be paid if you want to keep your Alipay information private. The payment will be made within one month after the completion of the experiment.
Notice:
-
•
To ensure that the experiment runs properly, please do not share your username or password with others, and do not use multiple devices to log into your account at the same time during the experiment. All non-up-to-date sessions will be forced to log out.
-
•
The purpose of the user name is to number the experiment data. The password is to prevent others from attacking this site and has no effect on the experiment. You can set your password at will.
-
•
At the end of the experiment, please fill in the information related to your teaching experience. Your information and answers will be kept confidential and used only for the analysis of experimental results.
-
•
If you have any questions or suggestions, please contact argugpt@163.com (preferred) or hu.hai@sjtu.edu.cn.
Questionnaire for Human Experiment
Thank you for taking the English Essays Judgment Experiment by Shanghai Jiao Tong University!
Please fill out the following personal information. Your information will be kept confidential and used only for the analysis of experimental results.
You are currently:
-
•
Undergraduate student majoring in English (including translation and linguistics)
-
•
Master’s student in English
-
•
PhD student in English
-
•
Assistant professor or lecturer in English (including public and foreign affairs, translation, English specialization, etc.)
-
•
Professor of English
-
•
High school English teacher
-
•
Middle school English teacher
-
•
English teacher of training institution
-
•
Other: (Please fill in the blank)
Which of the following statement best describes your situation:
-
•
I am an English major, but have basically never corrected student essays
-
•
I am an English major and have corrected student essays (as a teaching assistant or by marking essays for CET-4 or CET-6)
-
•
I am a teacher and have been teaching English courses for 1-5 years
-
•
I am a teacher and have been teaching English courses for 5-10 years
-
•
I am a teacher and have been teaching English courses for 10-20 years
-
•
I am a teacher and have been teaching English courses for 20-30 years
-
•
I am a teacher and have been teaching English courses for 30 years or more
-
•
Other: (Please fill in the blank)
Do you know about AI writing tools such as ChatGPT or XieZuoCat?
-
•
No, I haven’t heard any of them.
-
•
Yes, but I don’t know how AI writing tools work.
-
•
Yes, and I know how they work.
Have you ever used AI writing tools such as ChatGPT or XieZuoCat before?
-
•
No, never.
-
•
Yes, occasionally.
-
•
Yes, usually.
-
•
If you have used AI tools, please describe the scenarios and purposes of your use.
How do you usually mark your compositions? (multiple choice)
-
•
Corrected by myself
-
•
Corrected by an teaching assistant
-
•
PiGaiWang
-
•
Youdao
-
•
Grammarly
-
•
iwrite
Would you consider using AI tools in your teaching?
-
•
Very reluctant
-
•
Reluctant
-
•
Not necessarily
-
•
Willing
-
•
Very willing
Do you think your ability to identify machine-generated essays is improved through this experiment?
-
•
Yes
-
•
No idea
-
•
No
Do you think AI writing poses a challenge to foreign language teaching?
-
•
Please fill in the blank
Appendix E Training details of RoBERTa
The same set of hyperparameters presented in Table 24 are used to train document, paragraph, and sentence level classifiers. These hyperparameters are empirically selected, without any tuning on the validation set.
| Hyperparam | |
| Learning Rate | 7.5e-6 |
| Batch Size | 5 |
| Weight Decay | 0.01 |
| Epochs | 2 |
| LR Decay | linear |
| Warmup Ratio | 0.05 |
Appendix F Zero/few-shot prompts for gpt-turbo-3.5 in AIGC detection experiment
In order to reduce the impact of different prompt essays on the performance of the model, we select a total of six pairs of essays as our example essays in one/two-shot scenarios. In each pair, two essays are generated/written under the same prompt. For human essays, we select two essays from each level (low, medium, and high). As their counterpart in machine essays, we select six essays generated by different GPT models and divided them into three groups corresponding to the three different levels. With the six pairs of example essays, we have six sets of results for one-shot and three for two-shot. Details of the prompts are show in Table 25.
| # Shot | Prompts |
| zero-shot | Question: Is the following content written by human or machine? Please reply human or machine. Essay: <test_essay> Answer: |
| one-shot | Question: Is the following content written by human or machine? Please reply human or machine. Essay: <human_essay> Answer: Human Question: Is the following content written by human or machine? Please reply human or machine. Essay: <machine_essay> Answer: Machine Question: Is the following content written by human or machine? Please reply human or machine. Essay: <test_essay> Answer: |
| two-shot | Question: Is the following content written by human or machine? Please reply human or machine. Essay: <human_essay_1> Answer: Human Question: Is the following content written by human or machine? Please reply human or machine. Essay: <machine_essay_1> Answer: Machine Question: Is the following content written by human or machine? Please reply human or machine. Essay: <human_essay_2> Answer: Human Question: Is the following content written by human or machine? Please reply human or machine. Essay: <machine_essay_2> Answer: Machine Question: Is the following content written by human or machine? Please reply human or machine. Essay: <test_essay> Answer: |
Appendix G Linguistic analysis
G.1 Lexical richness metrics
| Dimension | Measure | Code | Formula |
| Lexical Density | Lexical Density | LD | |
| Lexical Sophistication | Lexical Sophistication-I | LS1 | |
| Lexical Sophistication-II | LS2 | ||
| Verb Sophistication-I | VS1 | ||
| Verb Sophistication-II | VS2 | ||
| Corrected VS1 | CVS1 | ||
| Lexical Variation | Number of Different Words | NDW | |
| Ndw (First 50 Words) | NDW-50 | in the first 50 words of sample | |
| Ndw (Expected Random 50) | NDW-ER50 | Mean of 10 random 50-word samples | |
| Ndw (Expected Sequence 50) | NDW-ES50 | Mean of 10 random 50-word sequences | |
| Type-Token Ratio | TTR | ||
| Mean Segmental TTR (50) | MSTTR-50 | Mean TTR of all 50-word segments | |
| Corrected TTR | CTTR | ||
| Root TTR | RTTR | ||
| Bilogarithmic TTR | LogTTR | ||
| Uber Index | Uber | ||
| Lexical Word Variation | LV | ||
| Verb Variation-I | VV1 | ||
| Squared VV1 | SVV1 | ||
| Corrected VV1 | CVV1 | ||
| Verb Variation-Ii | VV2 | ||
| Noun Variation | NV | ||
| Adjective Variation | AdjV | ||
| Adverb Variation | AdvV | ||
| Modifier Variation | ModV |
G.2 Lexical richness of ArguGPT Corpus
| Lexical Density | Lexical Sophistication | |||||
| Lexical Density | Lexical Sophistication | Verb Sophistication | ||||
| ld | ls1 | ls2 | vs1 | vs2 | cvs1 | |
| human-low | 0.51 | 0.18 | 0.17 | 0.11 | 0.50 | 0.40 |
| human-medium | 0.50 | 0.17 | 0.17 | 0.11 | 0.61 | 0.46 |
| human-high | 0.51 | 0.21 | 0.22 | 0.14 | 1.51 | 0.75 |
| human-average | 0.50 | 0.19 | 0.19 | 0.12 | 0.87 | 0.53 |
| gpt2-xl | 0.46 | 0.12 | 0.11 | 0.06 | 0.11 | 0.16 |
| text-babbage-001 | 0.49 | 0.12 | 0.12 | 0.05 | 0.09 | 0.15 |
| text-curie-001 | 0.49 | 0.15 | 0.15 | 0.07 | 0.19 | 0.25 |
| text-davinci-001 | 0.50 | 0.16 | 0.15 | 0.07 | 0.22 | 0.27 |
| text-davinci-002 | 0.50 | 0.15 | 0.15 | 0.08 | 0.29 | 0.32 |
| text-davinci-003 | 0.52 | 0.21 | 0.21 | 0.10 | 0.57 | 0.48 |
| gpt-3.5-turbo | 0.53 | 0.23 | 0.24 | 0.13 | 0.97 | 0.64 |
| Lexical Variation | |||||||||||||||||||
| Number of Different Words | Type-Token Ratio | Type-Token Ratio of Word Class | |||||||||||||||||
| ndw | ndwz | ndwerz | ndwesz | ttr | msttr | cttr | rttr | logttr | uber | lv | vv1 | svv1 | cvv1 | vv2 | nv | adjv | advv | modv | |
| human-low | 96.53 | 36.24 | 36.73 | 36.48 | 0.49 | 0.73 | 4.74 | 6.70 | 0.86 | 16.94 | 0.62 | 0.68 | 11.86 | 2.37 | 0.17 | 0.60 | 0.11 | 0.08 | 0.20 |
| human-medium | 131.03 | 37.28 | 37.97 | 37.72 | 0.45 | 0.75 | 5.38 | 7.61 | 0.86 | 17.69 | 0.62 | 0.68 | 16.85 | 2.85 | 0.17 | 0.59 | 0.12 | 0.08 | 0.20 |
| human-high | 190.76 | 37.79 | 38.98 | 38.65 | 0.44 | 0.77 | 6.36 | 8.99 | 0.86 | 19.31 | 0.62 | 0.70 | 25.79 | 3.52 | 0.17 | 0.59 | 0.12 | 0.08 | 0.20 |
| human-average | 139.44 | 37.10 | 37.89 | 37.62 | 0.46 | 0.75 | 5.49 | 7.77 | 0.86 | 17.98 | 0.62 | 0.68 | 18.17 | 2.92 | 0.17 | 0.59 | 0.12 | 0.08 | 0.20 |
| gpt2-xl | 81.14 | 36.52 | 37.18 | 36.23 | 0.56 | 0.73 | 4.59 | 6.49 | 0.88 | 18.57 | 0.74 | 0.76 | 9.87 | 2.16 | 0.20 | 0.72 | 0.15 | 0.09 | 0.23 |
| text-babbage-001 | 72.20 | 34.60 | 33.32 | 33.62 | 0.40 | 0.68 | 3.75 | 5.30 | 0.82 | 12.94 | 0.51 | 0.55 | 6.56 | 1.76 | 0.13 | 0.48 | 0.11 | 0.06 | 0.18 |
| text-curie-001 | 88.49 | 36.34 | 34.94 | 35.59 | 0.41 | 0.72 | 4.19 | 5.93 | 0.83 | 14.12 | 0.54 | 0.59 | 8.89 | 2.07 | 0.14 | 0.50 | 0.11 | 0.07 | 0.18 |
| text-davinci-001 | 99.36 | 36.51 | 35.42 | 36.40 | 0.40 | 0.73 | 4.43 | 6.27 | 0.83 | 14.58 | 0.54 | 0.58 | 9.99 | 2.19 | 0.14 | 0.51 | 0.11 | 0.06 | 0.18 |
| text-davinci-002 | 99.59 | 36.26 | 35.62 | 36.35 | 0.41 | 0.73 | 4.45 | 6.30 | 0.83 | 14.72 | 0.54 | 0.58 | 10.32 | 2.23 | 0.14 | 0.51 | 0.11 | 0.07 | 0.18 |
| text-davinci-003 | 137.61 | 36.68 | 36.69 | 37.78 | 0.37 | 0.75 | 5.00 | 7.07 | 0.83 | 15.24 | 0.51 | 0.55 | 14.34 | 2.63 | 0.13 | 0.49 | 0.11 | 0.05 | 0.16 |
| gpt-3.5-turbo | 166.42 | 38.68 | 38.07 | 38.88 | 0.39 | 0.78 | 5.65 | 7.99 | 0.84 | 16.89 | 0.54 | 0.59 | 18.81 | 3.03 | 0.14 | 0.52 | 0.11 | 0.05 | 0.16 |