Assign and Appraise: Achieving Optimal Performance in Collaborative Teams
Abstract
Tackling complex team problems requires understanding each team member’s skills in order to devise a task assignment maximizing the team performance. This paper proposes a novel quantitative model describing the decentralized process by which individuals in a team learn who has what abilities, while concurrently assigning tasks to each of the team members. In the model, the appraisal network represents team member’s evaluations of one another and each team member chooses their own workload. The appraisals and workload assignment change simultaneously: each member builds their own local appraisal of neighboring members based on the performance exhibited on previous tasks, while the workload is redistributed based on the current appraisal estimates. We show that the appraisal states can be reduced to a lower dimension due to the presence of conserved quantities associated to the cycles of the appraisal network. Building on this, we provide rigorous results characterizing the ability, or inability, of the team to learn each other’s skill and thus converge to an allocation maximizing the team performance. We complement our analysis with extensive numerical experiments.
Index Terms:
Appraisal networks, transactive memory systems, coevolutionary networks, evolutionary games.I Introduction
Research, technology, and innovation is increasingly reliant on teams of individuals with various specializations and interdisciplinary skill sets. In its simplest form, a group of individuals completing routine tasks is a resource allocation problem. However, tackling complex problems such as scientific research [15], software development [20], or problem solving [13] requires consideration of the team structure, cognitive affects, and interdependencies between team members [9]. In these complex scenarios, it is fundamental to discover what skills each member is endowed with, so as to devise a task assignment that maximizes the resulting collective team performance.
I-A Problem description
In this paper, we focus on a quantitative model describing the process by which individuals in a team evaluate one another while concurrently assigning work to each of the team members, in order to maximize the collective team performance (see Figure 1). More specifically, we assume each team member is endowed with a skill level (a-priori unknown), and that the team needs to divide a complex task among its members. We let each team member build their own local appraisal of neighboring team members’ based on the performance exhibited on previous tasks. Upcoming tasks are then distributed according to the current appraisal estimates. Finally, the performance of each member is newly observed by neighboring members, who, in turn, update their appraisal. Any model satisfying these assumptions is composed of two building blocks: i) an appraisal component modeling how team members update their appraisals (left block in Figure 1), and ii) a work assignment component describing how the task is divided within the team (right block in Figure 1).
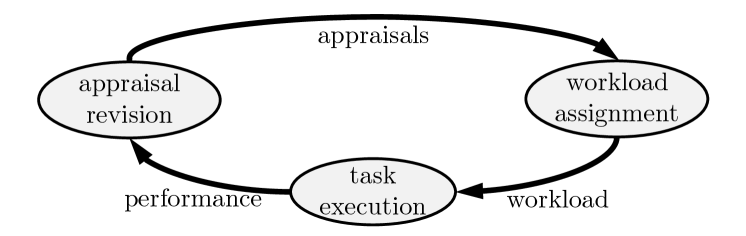
We model the appraisal process i) through the lens of transactive memory systems, a conceptual model introduced by Wegner [23], which assumes that a team is capable of developing collective knowledge regarding who has what information and capabilities. Our choice of dynamics describing the evolution of the interpersonal appraisals is inspired from replicator dynamics, whereby each team member updates their appraisal of a neighboring member proportionally to the difference between member performance and the (appraisal-weighted) average performance of the team.
We model the work assignment process ii) as a compartmental system [14], and utilize two natural dynamics to describe how the task is divided based on the current appraisals. These dynamics correspond to utilizing different centrality measures to subdivide a complex task. It is crucial to observe that the coupling between the appraisal revision and the work assignment process results in a coevolutionary network problem.
This paper follows a trend initiated recently, whereby many traditionally qualitative fields such as social psychology and organizational sciences are developing quantitative models. In this regard, our aim is to quantify the development of transactive memory within a team and study what conditions cause a team to fail or succeed at allocating a task optimally among members. To do so, we leverage control theoretical tools as well as ideas from evolutionary game theory, and notions from graph theory.
I-B Contributions
Our main contributions are as follows.
-
(i)
We formulate a quantitative model to capture the coevolution of the workload division and appraisal network, where the optimal workload assignment maximizing the collective team performance is an equilibrium of the model. While we let the appraisal network evolve according to a replicator-like dynamics, we consider two different mechanisms for workload division and show well-posedness of the model.
-
(ii)
Regardless of the mechanism used for workload division, we derive conserved quantities associated to the cycles of the appraisal network. Leveraging this result, for a team of individuals, we significantly reduce the dimension of the system from to a dimensional submanifold.
-
(iii)
We provide rigorous positive and negative results that characterize the asymptotic behavior for either of the workload division mechanisms. When adopting the first workload division mechanism, we show that under a mild assumption, strongly connected teams are always able to learn each member’s correct skill level, and thus determine the optimal workload division. In the second model variation, strong connectivity is insufficient to guarantee that the team learns the optimal workload, but more specific assumptions allow the team to converge to the optimal workload.
-
(iv)
Finally, we enrich our analysis by means of numerical experiments that provide further insight into the limiting behavior.
I-C Related works
Quantitative models of transactive memory systems
Wegner’s transactive memory systems (TMS) model [23] describes how cognitive states affect the collective performance of a team performing complex tasks. This widely established model captures both learning on the individual and collective level, as well as the evolution of the interaction between individuals within a team.
There are very few quantitative models attempting to describe TMS and most of these models rely on numerical analysis to study the evolution of team knowledge [10], or what events are disruptive to learning and productivity in groups [1]. However, numerical analysis alone has natural limitations, whereas a mathematical perspective to TMS can establish the emergence of learning behaviors for entire classes of models. Moreover, while our proposed model is agent-based with collective knowledge represented as a weighted digraph, [10, 1] are not agent-based models and use a scalar value to encode the team’s collective knowledge.
The collective learning model introduced by Mei et al. [16] was the first to quantify TMS with appraisal networks and provide convergence analysis. In particular, for the assign/appraise model in [16], the appraisal update protocol is akin to one originally introduced in [7] and assumes each team member only updates their own appraisal based on performance comparisons. Additionally, the workload assignment is a centralized process determined by the eigenvector centrality of the network [3]. Our model significantly differs from [16] in that team members update their own and neighboring team members’ appraisals. Additionally, the workload assignment is a distributed and dynamic process.
Distributed optimization
Our model has direct ties with the field of distributed optimization. Under suitable conditions discussed later, in fact, the team will be able to learn each other’s skill levels, and thus agree on a work assignment maximizing the collective performance in a distributed fashion. Additionally, any change in the problem dimension, due to the addition or subtraction of agents, only requires local adaptions. In light of this observation, one could reinterpret the assign and appraisal model studied here as a distributed optimization algorithm, where the objective is that of maximizing the team performance through local communication. In comparison to our work, existing distributed optimization algorithms often require more complex dynamics. For example, [17] requires that the optimal solution estimates are projected back into the constrained set, while Newton-like methods [24] require higher order information.
Perhaps closest to this perspective on our problem is the work of Barreiro-Gomez et al. [2], where evolutionary game theory is used to design distributed optimization algorithms. Nevertheless, we observe that the objective we pursue here is that of quantifying if and to what extent team members learn how to share a task optimally. In this respect, the dynamics we consider do not arise as the result of a design choice (as it is in [2]), but they are rather defining the problem itself.
Adaptive coevolutionary networks
Our model is an example of appraisal network coevolving with a resource allocation process. Research regarding adaptive networks has gained traction in recent decades, appearing in biological systems and game theoretical applications [11]. Wang et al. [22], for example, review coupled disease-behavior dynamics, while Ogura et al. [19] propose an epidemic model where awareness causes individuals to distance themselves from infected neighbors. Finally, we note that coevolutionary game theory considers dynamics on the population strategies and dynamics of the environment, where the payoff matrix evolves with the environment state [26, 8].
I-D Paper organization
Section II contains the problem framework, model definition, the model’s well-posedness, and equilibrium corresponding to the optimal workload. Section III contains the properties of the appraisal dynamics and reduced order dynamics. Section IV and V present the convergence results for the model with both workload division mechanisms. Section VI contains numerical studies illustrating the various cases of asymptotic behavior.
I-E Notation
Let ( resp.) denote the -dimensional column vector with all ones (zero resp.). Let represent the identity matrix. For a matrix or vector , let and denote component-wise inequalities. Given , let denote the diagonal matrix such that the th entry on the diagonal equals . Let ( resp.) denote Hadamard entrywise multiplication (division resp.) between two matrices of the same dimensions. For and , we shall use the property
| (1) |
Define the -dimensional simplex as and the relative interior of the simplex as .
A nonnegative matrix is row-stochastic if . For a nonnegative matrix , is the weighted digraph associated to , with node set and directed edge from node to if and only if . A nonnegative matrix is irreducible if its associated digraph is strongly connected. The Laplacian matrix of a nonnegative matrix is defined as . For irreducible and row-stochastic, denotes the left dominant eigenvector of , i.e., the entry-wise positive left eigenvector normalized to have unit sum and associated with the dominant eigenvalue of [6, Perron Frobenius theorem].
II Problem Framework and ASAP Model
In this section, we first propose the Assignment and Appraisal (ASAP) model and establish that it is well-posed for finite time. The proposed ASAP model can be considered a socio-inspired, distributed, and online algorithm for optimal resource allocation problems. Our model captures two fundamental processes within teams: workload distribution and transactive memory. We consider two distributed, dynamic models for the workload division: a compartmental system model and a linear model that uses average-appraisal as the input for adjusting workload. The transactive memory is quantified by the appraisal network and reflects individualized peer evaluation in the team. The development of the transactive memory system allows the team to estimate the work assignment that maximizes the collective team performance.
II-A Workload assignment, performance observation, and appraisal network
Workload assignment
We consider a team of individuals performing a sequence of tasks. Let denote the vector of workload assignments for a given task, where is the work assignment of individual .
Individual performance
Let represent the vector of individual performances that change as a function of the work assignment, where and is the performance of individual . In general, individuals will perform better if they have less workload; we formalize this notion with the following two assumptions.
Assumption 1.
(Smooth and strictly decreasing performance functions) Assume function is , strictly decreasing, convex, integrable, and .
Assumption 2.
(Power law performance functions) Assume function is of the form where and .
Appraisal network
Let denote the nonnegative, row-stochastic appraisal matrix, where is individual ’s appraisal of individual . The appraisal matrix represents the team’s network structure and transactive memory system.
II-B Model description and problem statement
In this work, we design a model where the workload assignment coevolves with the appraisals: the workload assignment changes as a function of the appraisals and the appraisals update based on perceived performance disparities for the assigned workload. Suppose at each time , the team has a workload assignment , individual performances , and appraisal matrix . Since we are studying teams, it is reasonable to assume the appraisal network is strongly connected and each individual appraises themself. This translates to an irreducible initial appraisal matrix with strictly positive self-appraisals for all . All members also start with strictly positive workload . For shorthand throughout the rest of the paper, we use and .
Before introducing the model, first we define the work flow function , where describes how individual adjusts their own work assignment. Then our coevolving assignment and appraisal process is quantified by the following dynamical system.
Definition 3 (ASAP (assignment and appraisal) model).
Consider performance functions satisfying Assumption 1 or 2. The coevolution of the appraisal network and workload assignment obey the following coupled dynamics,
| (2) |
which reads in matrix form
| (3) |
The work flow function obeys one of the following work flow models:
| Donor-controlled: | (4) | |||
| Average-appraisal: | (5) |
The appraisal weights of the ASAP model (2) update based on performance feedback between neighboring individuals. For neighboring team members and , will increase their appraisal of if ’s performance is larger than the weighted average performance observed by , i.e. . Individual also updates their self-appraisal with the same mechanism. The irreducibility and strictly positive self-appraisal assumptions on the appraisal network means that every individual’s performance is evaluated by themself and at least one other individual within the team.
The donor-controlled work flow (4) models a team where individuals exchange portions of their workload assignment with their neighbors, and the amount of work exchanged depends on their current work assignments and the appraisal values. The work individual gives to individual has flow rate and is proportional to . The average-appraisal work flow (5) assumes that each individual collects feedback from neighboring team members through appraisal evaluations. Each individual uses this feedback to calculate their average-appraisal , which is then used to adjust their own workload assignment. The average-appraisal is equivalent to the degree centrality of the appraisal network. Note that while the donor-controlled work flow is decentralized and distributed, the average-appraisal work flow is only distributed since it requires individuals to know the total number of team members.
In the following lemma, we show that the ASAP model is well-posed and the appraisal network maintains the same network topology for finite time.
Lemma 4 (Finite-time properties for the ASAP model).
Proof.
Before proving statement (i), we give some properties of the appraisal dynamics. If , then , which implies . By using the Hadamard product property (1), the matrix form of the appraisal dynamics can also be written as . Then for , , so remains row-stochastic for .
Next, we use row-stochastic to prove for donor-controlled work flow and . Left multiplying the dynamics by , we have . Next, let . For , , and , then . Therefore . Lastly, we apply the Grönwall-Bellman Comparison Lemma to also show that lives in the relative interior of the simplex. For and , then for . Therefore, if , then for .
The proof for statement (i) can be extended to the average-appraisal work flow (5) following the same process, since .
For statement (ii), to prove that maintains the same zero/positive pattern for , consider any such that . Since , then by the performance function assumptions and is finite for any and . Let . Then the convex combination of individual performances is upper bounded by . Now we can write the following lower bound for the time derivative of ,
Using the Grönwall-Bellman Comparison Lemma again, for , then
Therefore, remains row-stochastic and maintains the same zero/positive pattern as for finite time. ∎
II-C Team performance and optimal workload as model equilibria
We are interested in the collective team performance and while no single collective team performance function is widely accepted in the social sciences, we consider three such functions. Under minor technical assumptions, the optimal workload for all three is characterized by equal performance levels by the individuals and is an equilibrium point of the ASAP model. If represents the marginal utility of individual , then the collective team performance can be measured by the total utility,
The team performance can alternatively be measured by the “weakest link” or minimum performer,
Another metric often used is the weighted average individual performance:
The next theorem clarifies when the workload maximizing either , , or is an equilibrium of the ASAP model.
Theorem 5 (Optimal performance as equilibria of dynamics).
Consider performance functions satisfying Assumption 1 for all . Then
-
(i)
there exists a unique pair such that , , and .
Additionally, let denote , , or . Let Assumption 2 hold when . Then
-
(ii)
is the unique solution to
Finally, consider the ASAP model (2) with donor-controlled work flow (4) and let be row-stochastic, irreducible, with strictly positive diagonal and . Then
-
(iii)
there exists at least one matrix with the same zero/positive pattern as that satisfies ; and
-
(iv)
every pair , such that has the same zero/positive pattern as and , is an equilibrium.
For average-appraisal work flow (5), statements (iii)-(iv) may not hold for , since there may not exist an with the same zero/positive pattern as . Section V elaborates on these results.
Proof.
Regarding statement (i), recall that is and strictly decreasing by Assumption 1 or 2. Now we show that given our assumptions, there exists such that holds. Let denote the inverse of and let denote the composition of functions where . Given , then for all . Then taking into account ,
strictly decreasing implies ( resp.) is strictly decreasing (strictly increasing resp.). Therefore the left hand side of the above equation is strictly increasing, so there is a unique solving the equation. Therefore there is a unique that satisfies , where .
Regarding statement (ii), is strictly decreasing, , and convex by Assumption 1-2. Then , , and are all strictly concave. Since we are maximizing over a compact set, and is finite for , there exists a unique optimal solution . Next we show that must satisfy where for each collective team performance measure and .
First, consider . Let and . Then the KKT conditions are given by: , , and . If , then for the first KKT condition to hold, but we require . Similarly, for any would satisfy the second KKT condition, but violate the first KKT condition. As a result, and . This implies that for all . Therefore and there exists such that .
Second, consider . Define the set and let denote the number of elements in . We prove the claim by contradiction. Assume is the optimal solution such that there exists at least one such that for . Then there exists a sufficiently small and such that , where and . This contradicts the fact that is the optimal solution. Additionally, we can prove that by assuming there exists at least one such that and following the same proof by contradiction process. Therefore and .
Third, consider . Let and . Then the KKT conditions are given by: , , and . The rest of the proof follows from the same argument as used for .
Regarding statements (iii) and (iv), let and . We prove that there exists some such that . From the assumptions on , then there exists such that for . Then solving for , we have . Next, we choose for , which gives the following bounds on for all ,
With , then has the same zero/positive pattern as . This shows that, given , there always exists a matrix with left dominant eigenvector and with the same pattern as .
Next, we prove that any such pair is an equilibrium. Our assumptions on and the Perron-Frobenius theorem together imply that the . For the ASAP model (2) with donor-controlled work flow (4), the equilibrium conditions on the self-appraisal states and work assignment read:
| (6) | ||||
| (7) |
Equation (6) is satisfied because we know from statement (ii) that . Equation (7) is satisfied because we know . This concludes the proof of statements (iii) and (iv). ∎
The equilibria described in the above lemma also resemble an evolutionarily stable set [12], which is defined as the set of strategies with the same payoff. Our proof illustrates that at least one always exists, but in general, there are multiple matrices that satisfy a particular zero/positive irreducible matrix pattern with with the same collective team performance. We will later show that, under mild conditions, this optimal solution is an equilibrium of our dynamics with various attractivity properties (see Section IV and V).
III Properties of Appraisal Dynamics: Conserved Quantities and Reduced Order Dynamics
In this section, we show that every cycle in the appraisal network is associated to a conserved quantity. Leveraging these conserved quantities, we reduce the appraisal dynamics to an dimensional submanifold. Before doing so, we introduce the notion of cycles, cycle path vectors, the cycle set, and the cycle space. For a given initial appraisal matrix with strictly positive diagonal, let denote the total number of strictly positive interpersonal appraisals in the edge set . Recall that if for any , then , which implies for all . Therefore we can consider the total number of appraisal states to be the number of edges in , which gives a total of appraisal states.
Definition 6 (Cycles, cycle path vectors, and cycle set).
Consider the digraph associated to matrix .
A cycle is an ordered sequence of nodes with no node appearing more than once, that starts and ends at the same node, has at least two distinct nodes, and each sequential pair of nodes in the cycle denotes an edge . We do not consider self-loops, i.e. self-appraisal edges, to be part of any cycles.
Let denote the cycle path vector associated to cycle . Let each off-diagonal edge of the appraisal matrix be assigned to a number in the ordered set . For every edge , the th component of is defined as
Let denote the cycle set, i.e. the set of all cycles, in digraph .
To refer to a particular cycle, we will use the cycle’s associated cycle path vector, which then allows us to define the cycle space.
Definition 7 (Cycle space).
A cycle space is a subspace of m spanned by cycle path vectors. By [4, pg. 29, Theorem 9], the cycle space of a strongly connected digraph is spanned by a basis of cycle path vectors.
Let denote a matrix where the columns are a basis of the cycle space.
The following theorem (i) rigorously defines the conserved quantities associated to cycles in the appraisal network; (ii) shows that the appraisal states can be reduced from dimension to using the conserved quantities; and (iii) uses both the previous properties to introduce reduced order dynamics that have a one-to-one correspondence with the appraisal trajectories.
Theorem 8 (Conserved cycle constants give reduced order dynamics).
Consider the ASAP model (3) with donor-controlled (4) or average-appraisal (5) work flow. Given initial conditions row-stochastic, irreducible, with strictly positive diagonal and , let be the resulting trajectory. Then
-
(i)
for any cycle , the quantity
(8) is constant; we refer to as the cycle constant associated to cycle ;
-
(ii)
the appraisal matrix takes value in a submanifold of dimension ;
-
(iii)
given a solution with initial condition of the dynamics
(9) where is defined by
(10) then and ;
- (iv)
-
(v)
if additionally , then the positive matrix is rank 1 for all time .
Proof.
Regarding statement (i), we show that is constant for any by taking the natural logarithm of both sides of (8) and showing that the derivative vanishes. By Lemma 4, is well-defined since for any and finite time .
Therefore, is constant for all .
Regarding statement (ii), first, we will introduce a change of variables from to , that comes from the appraisal dynamics property that allows for row-stochasticity to be preserved. This allows the states of to be reduced to states of . Second, we show that there exists independent cycle constants, define constraint equations associated to the cycle constants, and apply the implicit function theorem to show that the states of further reduce to states.
Let for all . This is well-defined in finite-time by Theorem 4 and the assumption that has strictly positive diagonal. Since the diagonal entries of remain constant and zero-valued edges remain zero, then we can consider the total states of to be the off-diagonal edges of . Next, we introduce the cycle constant constraint functions and use the implicit function theorem to show that the states can be further reduced to using the cycle constants. For edge , let . Let where and . Consider the cycle constant constraint function , where is associated to cycle path vector for all and the selected cycles form a basis for the cycle subspace such that . In matrix form, reads as
We partition into block matrices, where and . Then taking the partial derivative of with respect to ,
The ordering of the rows of is determined by the ordering of the edges . Since is full column rank by definition, then there exists an edge ordering such that . For this ordering with , then . By the implicit function theorem, is a continuous function of . Equivalently, can then be reduced from states to . Therefore if is irreducible with strictly positive diagonal, then can be reduced to an dimensional submanifold.
Regarding statement (iii), we show that, if satisfies the dynamics of (9), then defined by equation (10) satisfies the original ASAP dynamics (3). For shorthand, let . We compute:
We also note that
Our claim follows from the uniqueness of solutions to ordinary differential equations.
Statement (iv) follows trivially from verifying that and are equilibrium points of the corresponding dynamics with .
Regarding statement (v), we first show that the positive matrix is rank for all time . First we multiply by the diagonal matrix . Then we show that is rank , which implies that is also rank .
By assumption , is a complete graph for finite . Then the cycle constants (8), and any nodes , we have and . Rearranging these two equations gives . This shows that every row of is equivalent and . ∎
Case study for team of two
In order to illustrate the role of the cycle constants (8), we consider an example of a two-person team with performance functions and . Figure 2 shows the evolution of the trajectories for various initial conditions of the ASAP model with donor-controlled work flow. The trajectories illustrate the conserved quantities associated to the cycles in the appraisal network, which is
| (11) |
for the two-node case. Then the cycle constant with Theorem 8(ii) allows us to write the dynamics for as
| (12) |
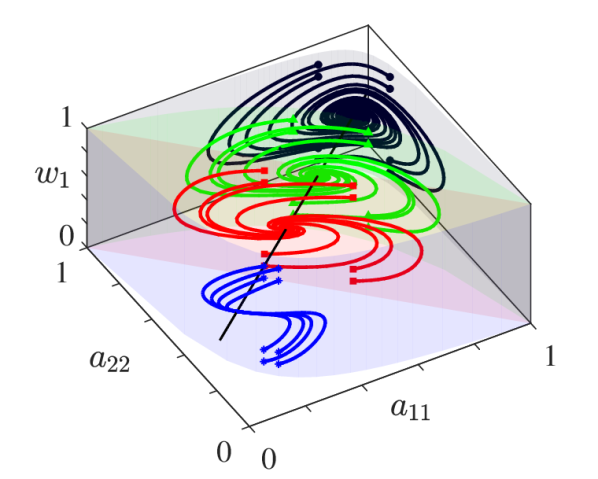
The cycle constants can be thought of as a parameter that measures the level of deviation between individual’s initial perception of each other’s skills. When for some , then all individuals along cycle are in agreement over the appraisals for every other individual.
IV Stability Analysis for the ASAP Model with Donor-Controlled Work Flow
In this section, we study the asymptotic behavior of the ASAP model with donor-controlled work flow. Our analysis is based on a Lyapunov argument. Utilizing this approach, we identify initial appraisal network conditions for teams with complete graphs where the optimal workload is learned without any other additional assumptions. Under a technical assumption, we also rigorously prove that for any strongly connected team, the dynamics will converge to the optimal workload.
The next lemma defines the performance-entropy function, which we show to be a Lyapunov function for the ASAP model under certain structural assumptions on the appraisal network.
Lemma 9 (Performance-entropy function).
The first term of the function is the rescaled total utility, . The second term, , is the Kullback-Liebler relative entropy measure [25].
Proof.
By Assumption 1, is convex with minimum value if and only if . Therefore this term is positive definite for . Since the function is strictly convex and , Jensen’s inequality can be used to give the following lower bound,
where the inequality holds strictly if and only if .
For the last statement of the lemma and with the assumption , the Lie derivative of is
Then using Hadamard product property (1) and , further simplifies to
The next theorem states the convergence results to the optimal workload for various cases on the connectivity of the initial appraisal matrix. For donor-controlled work flow, the optimal workload is equal to the eigenvector centrality of the network [5], which is a measure of the individual’s importance as a function of the network structure and appraisal values. Therefore the equilibrium workload value quantifies each team member’s contribution to the team and learning the optimal workload reflects the development of TMS within the team. Note that statement (iii) relies on the assumption that conjecture given in the statement holds. This conjecture is discussed further at the end of the section, where we provide extensive simulations to illustrate its high likelihood.
Theorem 10 (Convergence to optimal workload for strongly connected teams).
Consider the ASAP model (2) with donor-controlled work flow (4). Given initial conditions row-stochastic, irreducible, with strictly positive diagonal and . The following statements hold:
-
(i)
if and , then such that is row-stochastic and ;
-
(ii)
if there exists such that is also rank , then .
Moreover, define as in Theorem 8(iii).
-
(iii)
If is uniformly bounded for all and , then such that is row-stochastic, has the same zero/positive pattern as , and .
Proof.
Statement (i) follows directly from the fact that the function defined by (13) is a Lyapunov function for the system. For brevity, we omit the proof of Statement (i), since it follows a similar proof to statement (ii).
Regarding statement (ii), if is the rank form given by the theorem assumptions, then for all cycles by Theorem 8(i). This implies that for any , all , and . For the storage function as defined by (13), the Lie derivative (14) simplifies to,
From , then . Since strictly decreasing by Assumption 1 or 2, then for . Then is a Lyapunov function for the rank initial appraisal case and .
Regarding statement (iii), we start by considering the equivalent reduced order appraisal dynamics (9) and by proving asymptotic convergence using LaSalle’s Invariance Principle. Define the function , which is a modification of the storage function (13) by replacing the term with for all ,
| (15) |
The Lie derivative of is
We can now define the sublevel set , which is closed and positively invariant. Note that if there exists any such that , then . However, and is finite, so must be bounded away from zero by a positive value for . By our assumption, is also upper bounded. Then there exists constants such that . Then by LaSalle’s Invariance Principle, the trajectories must converge to the largest invariant set contained in the intersection of
By Theorem 5, if , then and . This implies , so . By Theorem 8(iv), corresponds to equilibrium . Therefore is equivalent to such that and , where and have the same zero/positive pattern. ∎
Theorem 10(iii) establishes asymptotic convergence from all initial conditions of interest under the assumption that the trajectory is uniformly bounded. Throughout our numerical simulation studies, we have empirically observed that this assumption has always been satisfied. We now present a Monte Carlo analysis [21] to estimate the probability that this uniform boundedness assumption holds.
For any randomly generated pair , which corresponds to , define the indicator function as
-
(i)
if there exists such that for all ;
-
(ii)
, otherwise.
Let . We estimate as follows. We generate independent identically distributed random sample pairs, for , where is row-stochastic, irreducible, with strictly positive diagonal and .
Finally, we define the empirical probability as
For any accuracy and confidence level , then by the Chernoff Bound [21, Equation 9.14], with probability greater than confidence level if
| (16) |
For , the Chernoff bound (16) is satisfied by .
Our simulation setup is as follows. We run independent MATLAB
simulations for the ASAP model (2) with donor-controlled
work flow (5). We consider , irreducible with
strictly positive diagonal generated using the Erdös-Renyi random
graph model with edge connectivity probability , and performance
functions of the form for
and . We find
that . Therefore, we can make the following statement.
Consider
(i) ;
(ii) irreducible with strictly positive diagonal generated by the Erdös-Renyi random graph model with edge connectivity probability , and randomly generated edge weights normalized to be row-stochastic; and
(iii) .
Then with confidence level, there is at least
probability that is uniformly upper bounded
for .
V Stability Analysis for the ASAP Model with Average-Appraisal Work Flow
This section investigates the asymptotic behavior of the ASAP model (2) with average-appraisal work flow (5). In contrast with the eigenvector centrality model, we observe that strongly connected teams obeying this work flow model are not always able to learn their optimal work assignment. First we give a necessary condition on the initial appraisal matrix and optimal work assignment for convergence to the optimal team performance. Second, we prove that learning the optimal work assignment can be guaranteed if the team has a complete network topology or if the collective team performance is optimized by an equally distributed workload. Note that the results in Sections II-III also hold for average-appraisal work flow, only if the equilibrium satisfies .
Let denote the ceiling function which rounds up all elements of to the nearest integer. The following lemma gives a condition that guarantees when the team is unable to learn the optimal workload assignment.
Lemma 11 (Condition for failure to learn optimal work assignment for the degree centrality model).
Proof.
By the Grönwall-Bellman Comparison Lemma, implies that
Therefore if there exists at least one such that , then . ∎
This sufficient condition for failure to learn the optimal workload can also be stated as a necessary condition for learning the optimal workload. In other words, if , then for all .
While the average-appraisal work flow does not converge to the optimal equilibrium for strongly connected teams and general initial conditions, the following lemma describes two cases that do guarantee learning of the optimal workload.
Lemma 12 (Convergence to optimal workload for average-appraisal work flow).
Consider the ASAP model (2) with average-appraisal work flow (5). The following statements hold.
-
(i)
If is row-stochastic, irreducible, with strictly positive diagonal, , and , then where has the same zero/positive pattern as and is doubly-stochastic with ;
-
(ii)
if is row-stochastic and , then where and .
Proof.
Regarding statement (i), the storage function from (13) is a Lyapunov function for the given dynamics with assumption . The Lie derivative is
By Lemma 9, if and only if and such that . Therefore where and have the same zero/positive pattern.
Regarding statement (ii), consider the reduced order dynamics (9), with for shorthand. Define the function as where
First, we show that is lower bounded. Second, we illustrate that is monotonically decreasing for . Then this allows us to show convergence to an optimal equilibrium.
Let . From the proof of Lemma 9, for all . Then is lower bounded by
Now we show that . Define the function , where , which reads element-wise as . Using as in (10), then the rate of change of is given by
Plugging into , the Lie derivative of is
Since , implies that , we can conclude that there exists some strictly positive constant such that .
Note that if and only if by Lemma 9. Because has a finite lower bound and is monotonically decreasing for , then as , will decrease to the level set where . Then implies and . Therefore such that . ∎
VI Numerical Simulations
In this section, we utilize numerical simulations to investigate various cases of the ASAP model to illustrate when teams succeed and fail at optimizing their collective performance.
For all the simulations in this section, we consider performance functions of the form for and all , which satisfy Assumptions 1-2. Then the same optimal workload maximizes any choice of collective team performance we have introduced.
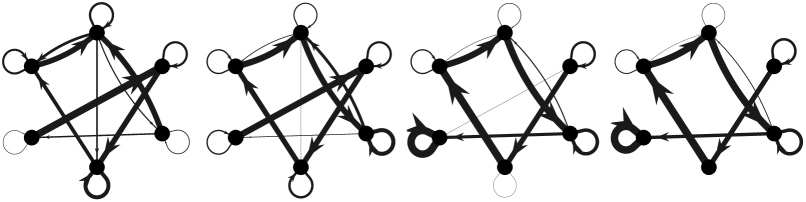
First, we provide an example of a team with a strongly connected appraisal network and strictly positive self-appraisal weights, i.e. satisfying the assumptions of Theorem 10(iii), to illustrate a case where the team learns the optimal work assignment. Figure 3 illustrates the evolution of the appraisal network and work assignment of the ASAP model (2) with donor-controlled work flow (4).
|
|
|
|
|
|
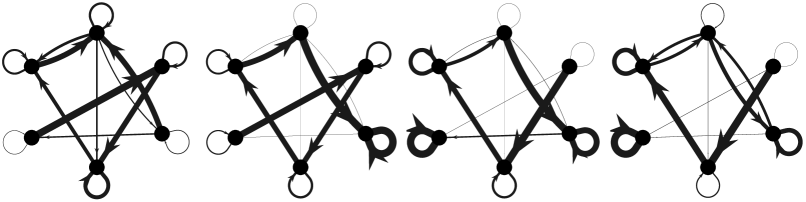
|
VI-A Distributed optimization illustrated with switching team members
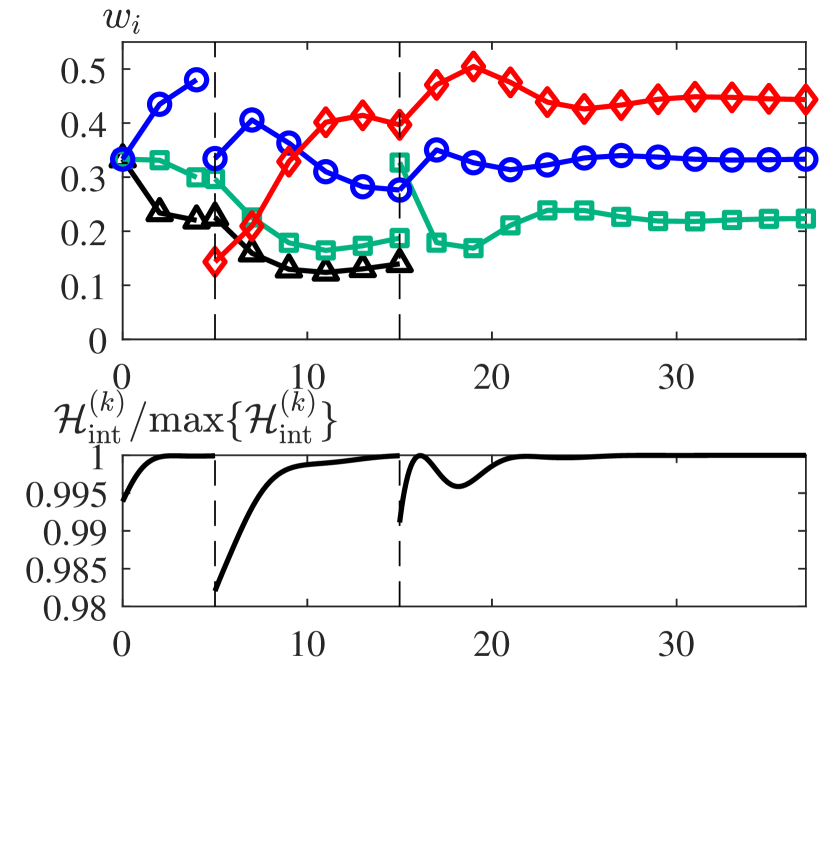
Next we consider another example of the ASAP model (2) with donor-controlled work flow (4), where individuals are switching in and out of the team. Under the behavior governed by the ASAP model, only affected neighboring individuals need to be aware of an addition or subtraction of a team member, since the model is both distributed and decentralized. In this example, when individual is added to the team as a neighbor of individual , allocates a portion of their work assignment to the new individual . Similarly, if individual is removed, then ’s neighbors will absorb ’s workload. Let , , and denote the subteams from time intervals , , and , respectively. Then let denote the collective performance for the th subteam. Figure 4 illustrates the appraisal network topologies of each subteam and the evolution of the workload and normalized collective team performance .



VI-B Failure to learn
Partial observation of performance feedback does not guarantee learning optimal work assignment
Partial observation occurs when the appraisal network does not have the desired strongly connected property, resulting in team members having insufficient feedback to determine their optimal work assignment. We consider an example of the ASAP model (2) with donor-controlled work flow (4) and reducible initial appraisal network . Figure 5(a) illustrates how some appraisal weights between neighboring individuals approach zero asymptotically, resulting in the team not being capable of learning the work distribution that maximizes the collective team performance.
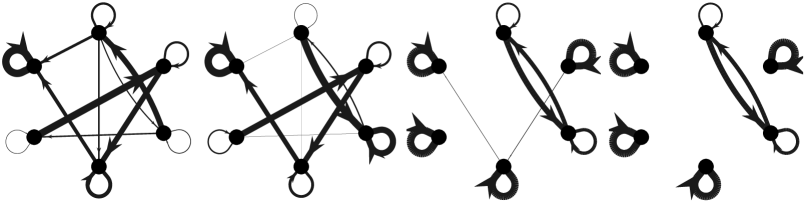
Average-appraisal feedback limits direct cooperation
Figure 5(b) is an example of a team obeying the ASAP model (2) with average-appraisal work flow (5). Even if the team does not satisfy the sufficient conditions for failure from Lemma 11, when individuals adjust their work assignment with only their average-appraisal as the input, the team may still not succeed in learning the correct workload to maximize the team performance.
VII Conclusion
This paper proposes novel models for the evolution of interpersonal appraisals and the assignment of workload in a team of individuals engaged in a sequence of tasks. We propose appraisal networks as a mathematical multi-agent model for the applied psychological concept of TMS. For two natural models of workload assignment, we establish conditions under which a correct TMS develops and allows the team to achieve optimal workload assignment and optimal performance. Our two proposed workload assignment mechanisms feature different degrees of coordination among team members. The donor-controlled work flow model requires a higher level of coordination compared to the average-appraisal work flow and, as a result, achieves optimal behavior under weaker requirements on the initial appraisal matrix.
Possible future research directions include studying team’s behavior when individuals in the team update their appraisals and work assignments asynchronously. The updates could be modeled using an additional contact network with switching topology. More investigation can also be done to determine if it is possible to predict which appraisal weights in a weakly connected network approach zero asymptotically, using only information on the initial work distribution and appraisal values.
VIII Code Availability
The source code is publicly available under https://github.com/eyhuang66/assign-appraise-dynamics-of-teams.
References
- [1] E. G. Anderson Jr and K. Lewis. A dynamic model of individual and collective learning amid disruption. Organization Science, 25(2):356–376, 2014. doi:10.1287/orsc.2013.0854.
- [2] J. Barreiro-Gomez, G. Obando, and N. Quijano. Distributed population dynamics: Optimization and control applications. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(2):304–314, 2016. doi:10.1109/TSMC.2016.2523934.
- [3] P. Bauer. A sequential elimination procedure for choosing the best population(s) based on multiple testing. Journal of Statistical Planning and Inference, 21(2):245–252, 1989. doi:10.1016/0378-3758(89)90008-6.
- [4] C. Berge. Graphs and Hypergraphs. North-Holland, 1973, ISBN 072042450X.
- [5] P. Bonacich. Power and centrality: A family of measures. American Journal of Sociology, 92(5):1170–1182, 1987. doi:10.1086/228631.
- [6] F. Bullo. Lectures on Network Systems. Kindle Direct Publishing, 1.4 edition, July 2020, ISBN 978-1986425643. With contributions by J. Cortés, F. Dörfler, and S. Martínez. URL: http://motion.me.ucsb.edu/book-lns.
- [7] N. E. Friedkin. A formal theory of reflected appraisals in the evolution of power. Administrative Science Quarterly, 56(4):501–529, 2011. doi:10.1177/0001839212441349.
- [8] L. Gong, J. Gao, and M. Cao. Evolutionary game dynamics for two interacting populations in a co-evolving environment. In IEEE Conf. on Decision and Control, pages 3535–3540, 2018. doi:10.1109/CDC.2018.8619801.
- [9] A. C. Graesser, S. M. Fiore, S. Greiff, J. Andrews-Todd, P. W. Foltz, and F. W. Hesse. Advancing the science of collaborative problem solving. Psychological Science in the Public Interest, 19(2):59–92, 2018. doi:10.1177/1529100618808244.
- [10] J. A. Grand, M. T. Braun, G. Kuljanin, S. W. J. Kozlowski, and G. T. Chao. The dynamics of team cognition: A process-oriented theory of knowledge emergence in teams. Journal of Applied Psychology, 101(10):1353–1385, 2016. doi:10.1037/apl0000136.
- [11] T. Gross and B. Blasius. Adaptive coevolutionary networks: A review. Journal of The Royal Society Interface, 5(20):259–271, 2008. doi:10.1098/rsif.2007.1229.
- [12] J. Hofbauer and K. Sigmund. Evolutionary Games and Population Dynamics. Cambridge University Press, 1998, ISBN 052162570X.
- [13] C. Hsiung. The effectiveness of cooperative learning. Journal of Engineering Education, 101(1):119–137, 2012. doi:10.1002/j.2168-9830.2012.tb00044.x.
- [14] J. A. Jacquez and C. P. Simon. Qualitative theory of compartmental systems. SIAM Review, 35(1):43–79, 1993. doi:10.1137/1035003.
- [15] S. W. J. Kozlowski, W. J. Steve, and B. S. Bell. Evidence-based principles and strategies for optimizing team functioning and performance in science teams. In Strategies for Team Science Success, pages 269–293. Springer, 2019. doi:10.1007/978-3-030-20992-6_21.
- [16] W. Mei, N. E. Friedkin, K. Lewis, and F. Bullo. Dynamic models of appraisal networks explaining collective learning. IEEE Transactions on Automatic Control, 63(9):2898–2912, 2018. doi:10.1109/TAC.2017.2775963.
- [17] A. Nedić, A. Ozdaglar, and P. A. Parrilo. Constrained consensus and optimization in multi-agent networks. IEEE Transactions on Automatic Control, 55(4):922–938, 2010. doi:10.1109/TAC.2010.2041686.
- [18] A. Newell and P. S. Rosenbloom. Mechanisms of skill acquisition and the law of practice. In J. R. Anderson, editor, Cognitive Skills and Their Acquisition, volume 1, pages 1–55. Taylor & Francis, 1981.
- [19] M. Ogura and V. M. Preciado. Stability of spreading processes over time-varying large-scale networks. IEEE Transactions on Network Science and Engineering, 3:44–57, 2016. doi:10.1109/TNSE.2016.2516346.
- [20] S. Ryan and R. V. O’Connor. Acquiring and sharing tacit knowledge in software development teams: An empirical study. Information and Software Technology, 55(9):1614–1624, 2013. doi:10.1016/j.infsof.2013.02.013.
- [21] R. Tempo, G. Calafiore, and F. Dabbene. Randomized Algorithms for Analysis and Control of Uncertain Systems. Springer, 2005, ISBN 1-85233-524-6.
- [22] Z. Wang, M. A. Andrews, Z. X. Wu, L. Wang, and C. T. Bauch. Coupled disease-behavior dynamics on complex networks: A review. Physics of Life Reviews, 15:1–29, 2015. doi:10.1016/j.plrev.2015.07.006.
- [23] D. M. Wegner. Transactive memory: A contemporary analysis of the group mind. In B. Mullen and G. R. Goethals, editors, Theories of Group Behavior, pages 185–208. Springer, 1987. doi:10.1007/978-1-4612-4634-3_9.
- [24] E. Wei, A. Ozdaglar, and A. Jadbabaie. A distributed Newton method for network utility maximization, I: Algorithm. IEEE Transactions on Automatic Control, 58(9):2162–2175, 2013. doi:10.1109/TAC.2013.2253218.
- [25] J. W. Weibull. Evolutionary Game Theory. MIT Press, 1997, ISBN 9780262731218.
- [26] J. S. Weitz, C. Eksin, S. P. Brown K. Paarporn, and W. C. Ratcliff. An oscillating tragedy of the commons in replicator dynamics with game-environment feedback. Proceedings of the National Academy of Sciences, 113(47):E7518–E7525, 2016. doi:10.1073/pnas.1604096113.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5c9b0baa-71d2-4433-8597-dd4286049aa5/Author_eyhuang.jpg) |
Elizabeth Y. Huang received the B.S. degree in mechanical engineering from the University of California, San Diego, USA in 2016. She is currently working toward her Ph.D. in mechanical engineering from the University of California, Santa Barbara, USA. Her research interests include the application of control and algebraic graph theoretical tools for the study of networks of multi-agent systems, such as social networks, evolutionary dynamics, and power systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5c9b0baa-71d2-4433-8597-dd4286049aa5/DP_color.jpg) |
Dario Paccagnan is a Postdoctoral Fellow with the Mechanical Engineering Department and the Center for Control, Dynamical Systems and Computation, University of California, Santa Barbara. In 2018, Dario obtained a Ph.D. degree from the Information Technology and Electrical Engineering Department, ETH Zürich, Switzerland. He received a B.Sc. and M.Sc. in Aerospace Engineering in 2011 and 2014 from the University of Padova, Italy, and a M.Sc. in Mathematical Modelling and Computation from the Technical University of Denmark in 2014; all with Honors. Dario was a visiting scholar at the University of California, Santa Barbara in 2017, and at Imperial College of London, in 2014. His interests are at the interface between control theory and game theory, with a focus on the design of behavior-influencing mechanisms for socio-technical systems. Applications include multiagent systems and smart cities. Dr. Paccagnan was awarded the ETH medal, and is recipient of the SNSF fellowship for his work in Distributed Optimization and Game Design. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5c9b0baa-71d2-4433-8597-dd4286049aa5/Author_WenjunMei.png) |
Wenjun Mei is a postdoctoral researcher in the Automatic Control Laboratory at ETH, Zurich. He received the Bachelor of Science degree in Theoretical and Applied Mechanics from Peking University in 2011 and the Ph.D degree in Mechanical Engineering from University of California, Santa Barbara, in 2017. He is on the editorial board of the Journal of Mathematical Sociology. His current research interests focus on network multi-agent systems, including social, economic and engineering networks, population games and evolutionary dynamics, network games and optimization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/5c9b0baa-71d2-4433-8597-dd4286049aa5/x16.png) |
Francesco Bullo (S’95-M’99-SM’03-F’10) is a Professor with the Mechanical Engineering Department and the Center for Control, Dynamical Systems and Computation at the University of California, Santa Barbara. He was previously associated with the University of Padova (Laurea degree in Electrical Engineering, 1994), the California Institute of Technology (Ph.D. degree in Control and Dynamical Systems, 1999), and the University of Illinois. He served on the editorial boards of IEEE, SIAM, and ESAIM journals and as IEEE CSS President. His research interests focus on network systems and distributed control with application to robotic coordination, power grids and social networks. He is the coauthor of “Geometric Control of Mechanical Systems” (Springer, 2004), “Distributed Control of Robotic Networks” (Princeton, 2009), and “Lectures on Network Systems” (Kindle Direct Publishing, 2019, v1.3). He received best paper awards for his work in IEEE Control Systems, Automatica, SIAM Journal on Control and Optimization, IEEE Transactions on Circuits and Systems, and IEEE Transactions on Control of Network Systems. He is a Fellow of IEEE, IFAC, and SIAM. |