Asymptotic Distribution of the Markowitz Portfolio
Abstract
The asymptotic distribution of the Markowitz portfolio, , is derived, for the general case (assuming fourth moments of returns exist), and for the case of multivariate normal returns. The derivation allows for inference which is robust to heteroskedasticity and autocorrelation of moments up to order four. As a side effect, one can estimate the proportion of error in the Markowitz portfolio due to mis-estimation of the covariance matrix. A likelihood ratio test is given which generalizes Dempster’s Covariance Selection test to allow inference on linear combinations of the precision matrix and the Markowitz portfolio. [15] Extensions of the main method to deal with hedged portfolios, conditional heteroskedasticity, conditional expectation, and constrained estimation are given. It is shown that the Hotelling-Lawley statistic generalizes the (squared) Sharpe ratio under the conditional expectation model. Asymptotic distributions of all four of the common ‘MGLH’ statistics are found, assuming random covariates. [60] Examples are given demonstrating the possible uses of these results.
1 Introduction
Given assets with expected return and covariance of return , the portfolio defined as
| (1) |
plays a special role in modern portfolio theory. [38, 5, 9] It is known as the ‘efficient portfolio’, the ‘tangency portfolio’, and, somewhat informally, the ‘Markowitz portfolio’. It appears, for various , in the solution to numerous portfolio optimization problems. Besides the classic mean-variance formulation, it solves the (population) Sharpe ratio maximization problem:
| (2) |
where is the risk-free, or ‘disastrous’, rate of return, and is some given ‘risk budget’. The solution to this optimization problem is , where
In practice, the Markowitz portfolio has a somewhat checkered history. The population parameters and are not known and must be estimated from samples. Estimation error results in a feasible portfolio, , of dubious value. Michaud went so far as to call mean-variance optimization, “error maximization.” [44] It has been suggested that simple portfolio heuristics outperform the Markowitz portfolio in practice. [13]
This paper focuses on the asymptotic distribution of the sample Markowitz portfolio. By formulating the problem as a linear regression, Britten-Jones very cleverly devised hypothesis tests on elements of , assuming multivariate Gaussian returns. [7] In a remarkable series of papers, Okhrin and Schmid, and Bodnar and Okhrin give the (univariate) density of the dot product of and a deterministic vector, again for the case of Gaussian returns. [50, 3] Okhrin and Schmid also show that all moments of of order greater than or equal to one do not exist. [50]
Here I derive asymptotic normality of , the sample analogue of , assuming only that the first four moments exist. Feasible estimation of the variance of is amenable to heteroskedasticity and autocorrelation robust inference. [68] The asymptotic distribution under Gaussian returns is also derived.
After estimating the covariance of , one can compute Wald test statistics for the elements of , possibly leading one to drop some assets from consideration (‘sparsification’). Having an estimate of the covariance can also allow portfolio shrinkage. [14, 31]
The derivations in this paper actually solve a more general problem than the distribution of the sample Markowitz portfolio. The covariance of and the ‘precision matrix,’ are derived. This allows one, for example, to estimate the proportion of error in the Markowitz portfolio attributable to mis-estimation of the covariance matrix. According to lore, the error in portfolio weights is mostly attributable to mis-estimation of , not of . [8, 43]
Finally, assuming Gaussian returns, a likelihood ratio test for performing inference on linear combinations of elements of the Markowitz portfolio and the precision matrix is derived. This test generalizes a procedure by Dempster for inference on the precision matrix alone. [15]
2 The augmented second moment
Let be an array of returns of assets, with mean , and covariance . Let be prepended with a 1: . Consider the second moment of :
| (3) |
By inspection one can confirm that the inverse of is
| (4) |
where is the Markowitz portfolio, and is the Sharpe ratio of that portfolio. The matrix contains the first and second moment of , but is also the uncentered second moment of , a fact which makes it amenable to analysis via the central limit theorem.
The relationships above are merely facts of linear algebra, and so hold for sample estimates as well:
where , are some sample estimates of and , and .
Given i.i.d. observations , let be the matrix whose rows are the vectors . The naïve sample estimator
| (5) |
is an unbiased estimator since .
2.1 Matrix Derivatives
Some notation and technical results concerning matrices are required.
Definition 2.1 (Matrix operations).
For matrix , let , and be the vector and half-space vector operators. The former turns an matrix into an vector of its columns stacked on top of each other; the latter vectorizes a symmetric (or lower triangular) matrix into a vector of the non-redundant elements. Let be the ‘Elimination Matrix,’ a matrix of zeros and ones with the property that The ‘Duplication Matrix,’ , is the matrix of zeros and ones that reverses this operation: [36] Note that this implies that
We will let be the ’commutation matrix’, i.e., the matrix whose rows are a permutation of the rows of the identity matrix such that for square matrix .
Definition 2.2 (Derivatives).
For -vector , and -vector , let the derivative be the matrix whose first column is the partial derivative of with respect to . This follows the so-called ‘numerator layout’ convention. For matrices and , define
Lemma 2.3 (Miscellaneous Derivatives).
For symmetric matrices and ,
| (6) |
Proof.
For the first equation, note that , thus by the chain rule:
by linearity of the derivative. The other identities follow similarly. ∎
Lemma 2.4 (Derivative of matrix inverse).
For invertible matrix ,
| (7) |
For symmetric , the derivative with respect to the non-redundant part is
| (8) |
Note how this result generalizes the scalar derivative:
2.2 Asymptotic distribution of the Markowitz portfolio
Collecting the mean and covariance into the second moment matrix gives the asymptotic distribution of the sample Markowitz portfolio without much work. In some sense, this computation generalizes the ‘standard’ asymptotic analysis of Sharpe ratio of multiple assets. [27, 34, 32, 33]
Theorem 2.5.
Let be the unbiased sample estimate of , based on i.i.d. samples of . Let be the variance of . Then, asymptotically in ,
| (9) |
where
| (10) |
Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
Proof.
To estimate the covariance of , plug in for in the covariance computation, and use some consistent estimator for , call it . One way to compute is to via the sample covariance of the vectors . More elaborate covariance estimators can be used, for example, to deal with violations of the i.i.d. assumptions. [68] Note that because the first element of is a deterministic , the first row and column of is all zeros, and we need not estimate it.
2.3 The Sharpe ratio optimal portfolio
Lemma 2.6 (Sharpe ratio optimal portfolio).
Assuming , and is invertible, the portfolio optimization problem
| (12) |
for is solved by
| (13) |
Moreover, this is the unique solution whenever . The maximal objective achieved by this portfolio is .
Proof.
By the Lagrange multiplier technique, the optimal portfolio solves the following equations:
where is the Lagrange multiplier, and are scalar constants. Solving the first equation gives us
This reduces the problem to the univariate optimization
| (14) |
where The optimum occurs for , moreover the optimum is unique when . ∎
Note that the first element of is , and elements 2 through are . Thus, , the portfolio that maximizes the Sharpe ratio, is some transformation of , and another application of the delta method gives its asymptotic distribution, as in the following corollary to Theorem 2.5.
Corollary 2.7.
Let
| (15) |
and similarly, let be the sample analogue, where is some risk budget. Then
| (16) |
where
| (17) |
Moreover, we may express as
| (18) |
Proof.
By the delta method, and Theorem 2.5, it suffices to show that
To show this, note that is times elements 2 through of divided by , where is the column of the identity matrix. The result follows from basic calculus.
To establish Equation 18, note that only the first columns of have non-zero entries, thus the elimination matrix, , can be ignored in the term on the right, and we could write the derivative as
And we can write the product as
Perform the matrix multiplication to find
which then further simplifies to the form given.
∎
The sample statistic is, up to scaling involving , just Hotelling’s statistic. [1] One can perform inference on via this statistic, at least under Gaussian returns, where the distribution of takes a (noncentral) -distribution. Note, however, that is the maximal population Sharpe ratio of any portfolio, so it is an upper bound of the Sharpe ratio of the sample portfolio . It is of little comfort to have an estimate of when the sample portfolio may have a small, or even negative, Sharpe ratio.
Because is an upper bound on the Sharpe ratio of a portfolio, it seems odd to claim that the Sharpe ratio of the sample portfolio might be asymptotically normal with mean . In fact, the delta method will fail because the gradient of with respect to the portfolio is zero at . One solution to this puzzle is to estimate the ‘signal-noise ratio,’ incorporating a strictly positive . In this case a portfolio may achieve a higher value than , which is achieved by , by violating the risk budget. To push this argument forward, we construct a quadratic approximation to the signal-noise ratio function.
Suppose , and assume the population parameters, are fixed. Define the signal-noise ratio as
| (19) |
We will usually drop the dependence on and and simply write . Defining as in Equation 13, note that
Lemma 2.8 (Quadratic Taylor expansion of signal-noise ratio).
Proof.
By Taylor’s theorem,
By simple calculus,
| (20) |
To compute the Hessian, take the derivative of this gradient:
| (21) |
At the derivative takes value
and the Hessian takes value
completing the proof. ∎
Corollary 2.9.
Then, asymptotically in ,
| (22) |
where
| (23) |
Moreover, we may express as
| (24) |
Proof.
Caution.
Since and are population parameters, is an unobserved quantity. Nevertheless, we can estimate the variance of , and possibly construct confidence intervals on it using sample statistics.
This corollary is useless in the case where , and gives somewhat puzzling results when one considers , since it suggest that the variance of goes to zero. This is not the case, because the rate of convergence in the corollary is a function of . To consider the case, one must take the quadratic Taylor expansion of the signal-noise ratio function.
Corollary 2.10.
We now seek to link the sample estimate of the optimal achievable Sharpe ratio with the achieved signal-noise ratio of the sample Markowitz portfolio. The magnitude of (along with ) is the only information on which we might estimate whether the sample Markowitz portfolio is any good. If we view them both as functions of , we can find their expected values and any covariance between them. Somewhat surprisingly, the two quantities are asymptotically almost uncorrelated.
Thus for the following theorem, let us abuse notation to express the signal-noise ratio function, defined in Equation 26 as a function of some vector:
| (28) |
Then corresponds to the definition in Equation 26. Moreover, define the “optimal signal-noise ratio” function also as a function of a vector as
| (29) |
We have , as desired. In an abuse of notation we will simply write and instead of writing out the vector function.
Theorem 2.11.
Proof.
The distribution of is a restatement of Corollary 2.10. To prove the distribution of , perform a Taylor’s series expansion of the function :
By similar reasoning,
Now by Theorem 2.5, we know the asymptotic distribution of , and thus we get the claimed distributional form for some , with
We can eliminate the and write the as a length vector, or rather as , where this is a length vector. The product of Kronecker products is the Kronecker product of matrix products so
establishing the identity of . ∎
This theorem suggests the use of the observable quantity to perform inference on the unknown quantity, . Asymptotically they have low correlation, and small error between them, which we quantify in the following corollaries.
Corollary 2.12.
The covariance of these two quantities is asymptotically :
| (31) |
and their correlation is asymptotically .
Proof.
To find the moments of and , we take to be multivariate standard normal, and thus odd powered products have zero expectation. Their covariance comes entirely from the product of the quadratic (in ) terms. By the same logic, the asymptotic standard error of is , while that of is . ∎
Corollary 2.13.
The difference has the following asymptotic mean and variance:
| (32) | ||||
| (33) |
where , , and are given in the theorem. Their ratio has the following asymptotic mean and variance:
| (34) | ||||
| (35) |
This corollary gives a recipe for building confidence intervals on via the observed , namely by plugging in sample estimates for and , and . This result is comparable to the “Sharpe Ratio Information Criterion” estimator for . [51]
To use this corollary, one may need a compact expression for . We start with Equation 18, and write
But note that (and so ) so we may write
| (38) |
Similarly, a compact form for :
| (39) |
3 Distribution under Gaussian returns
The goal of this section is to derive a variant of Theorem 2.5 for the case where follow a multivariate Gaussian distribution. First, assuming , we can express the density of , and of , in terms of , , and .
Lemma 3.1 (Gaussian sample density).
Suppose . Letting , and , then the negative log likelihood of is
| (40) |
for the constant
Proof.
By the block determinant formula,
Note also that
These relationships hold without assuming a particular distribution for .
The density of is then
and the result follows. ∎
Lemma 3.2 (Gaussian second moment matrix density).
Let , , and . Given i.i.d. samples , let Let . Then the density of is
| (41) |
for some
Proof.
Let be the matrix whose rows are the vectors . From Lemma 3.1, and using linearity of the trace, the negative log density of is
By Lemma (5.1.1) of Press [55], this can be expressed as a density on :
where is the term in brackets on the third line. Factoring out and taking an exponent gives the result. ∎
Corollary 3.3.
Corollary 3.4.
The derivatives of log likelihood are given by
| (42) |
Proof.
This immediately gives us the Maximum Likelihood Estimator.
Corollary 3.5 (MLE).
is the maximum likelihood estimator of .
To compute the covariance of , , in the Gaussian case, one can compute the Fisher Information, then appeal to the fact that is the MLE. However, because the first element of is a deterministic , the first row and column of are all zeros. This is an unfortunate wrinkle. One solution would be to to compute the Fisher Information with respect to the nonredundant variables; however, a direct brute-force approach is also possible, and gives a slightly more general result, as in the following section.
3.1 Distribution under elliptical returns
We pursue a slightly more general result on the distribution of , assuming that are drawn independently from an elliptical distribution, with mean , covariance , and ‘kurtosis factor’ , by which we mean the excess kurtosis of each is . In the Gaussian case, .
To be concrete, we suppose , where , and where is a scalar random variable independent of . The covariance is related to the matrix via
The kurtosis parameter is then defined as
An extension of Isserlis’ Theorem to the elliptical distribution gives moments of products of elements of . [64, 29] This result is comparable to the covariance of the centered second moments given as Equation (2.1) of Iwashita and Siotani, but is applicable to the uncentered second moment. [25]
Theorem 3.6.
Let be the unbiased sample estimate of , based on i.i.d. samples of , assumed to take an elliptical distribution with kurtosis parameter . In analogue to how are built from , define
| (43) |
Note that Then
| (44) | ||||
As it is cumbersome and unenlightening, we relegate the proof to the appendix. The central limit theorem then gives us the following corollary.
Corollary 3.7.
Under the conditions of the previous theorem, asymptotically in ,
| (45) |
where is defined in Equation 44.
Using Theorem 2.5 we also immediately get the following
Corollary 3.8.
Under the conditions of the previous theorem, asymptotically in ,
| (46) |
where is defined in Equation 44, and
| (47) |
An uglier form of the same corollary gives the covariance explicitly. See the appendix for the proof.
Corollary 3.9.
Under the conditions of the previous theorem, asymptotically in ,
| (48) |
where
We are often concerned with the signal-noise ratio and sample Markowitz portfolio, whose joint asymptotic distribution we can pick out from the previous corollary:
Corollary 3.10.
Under the conditions of the previous theorem, asymptotically in ,
| (49) |
where
Furthermore, if is an orthogonal matrix () such that
where is the lower triangular Cholesky factor of , then asymptotically in ,
| (50) |
where
We note that the asymptotic variance of we find here for the case of Gaussian returns () is consistent with the exact variance one computes from the non-central distribution, via the connection to Hotelling’s . That variance (assuming, as we do here, that is estimated with in the numerator, not ) is
Our asymptotic variance captures only the leading term, as one would expect.
The choice to rescale by and in Equation 50 is worthy of explanation. First note that the true expected return of is equal to
That is the expected return is determined entirely by the first element of . Now note that the volatility of is equal to the Euclidian norm of that vector:
The rotation also gives a diagonal asymptotic covariance. That is, the matrix is diagonal, so we treat the errors in the vector as asymptotically uncorrelated.
We can use these facts to arrive at an approximate asymptotic distribution of the signal-noise ratio of the Markowitz portfolio, defined via the function
So, by the above
Asymptotically we can think of this as
where
and where the are independent standard normals.
Now consider the Tangent of Arcsine, or “tas,” transform defined as . [52] Applying this transformation to the rescaled signal-noise ratio, one arrives at
which looks a lot like a non-central random variable, up to scaling. So write
| (51) |
where is a non-central random variable with degrees of freedom and non-centrality parameter . See Section 7.1.2, however, for simulations which indicate that an unreasonably large sample size is required for this approximation to be of any use.
We can perform one more transformation and use the delta method once again on the map to convert Equation 50 into
| (52) |
where
Note that the variance for given here is just Mertens’ form of the standard error of the Sharpe ratio, given that elliptical distributions have zero skew and excess kurtosis of . [42]
We can take this a step further by swapping in for to arrive at
| (53) |
where
Now perform the same transformation to a random variable to claim that
| (54) |
where is a non-central random variable with degrees of freedom and non-centrality parameter , and
This suggests another confidence limit, namely take to be the quantile of the non-central distribution with degrees of freedom and non-centrality parameter , where and plug in for wherever needed, then invert Equation 54 to get a confidence limit on . This confidence limit is also of dubious value, however, see Section 7.1.1.
Note that the relation in Equation 51 requires one to know . To perform inference on given the observed data, we adapt Corollary 2.13 to the case of elliptical returns.
Theorem 3.11.
Let be the unbiased sample estimate of , based on i.i.d. samples of , assumed to take an elliptical distribution with kurtosis parameter . Let be the sample Markowitz portfolio, and be the sample Sharpe ratio of that portfolio. Define the signal-noise ratio of as
Then, asymptotically in , the difference has the following mean and variance:
| (55) | ||||
| (56) |
And the ratio has the asymptotic mean and variance
| (57) | ||||
| (58) |
We relegate the long proof to the Appendix. Note that a similar line of reasoning should produce the asymptotic distribution of Hotelling’s under elliptical returns, which could be compared to form given by Iwashita. [24] Also of note is the result of Paulsen and Söhl [51], who show that for Gaussian returns,
The theorem suggests the following confidence intervals for , by plugging in for the unknown quantity :
| (59) |
where one can take for the difference formula, and for the ratio formula. However, these confidence intervals are not well supported by simulations, in the sense that they require very large to give near nominal coverage, cf. Section 7.1.1.
3.2 Distribution under matrix normal returns
Now we consider the case where the (augmented) returns follow a matrix normal distribution. That is, we suppose that there is a matrix and symmetric positive semi-definite matrices and , respectively of size and such that
This form allows us to consider deviations from the i.i.d. assumption by allowing e.g., the to change over time, autocorrelation in returns and so on111We do not consider the elliptical distribution in this case, as it can impose long term dependence among returns even when they are uncorrelated..
We now seek the moments of
Lemma 3.12.
For matrix normal returns , the mean and covariance of the gram are
| (60) |
and
| (61) |
As a check we note this result is consistent with Theorem 3.6 in the i.i.d. case, which corresponds to , , .
Lemma 3.13.
Let , where and are rescaled such that . Let
Define
Then asymptotically in ,
| (62) |
with
In particular, letting , and , then
| (63) |
for
The proof follows along the lines of Corollary 3.10 and is omitted. This corollary could be useful in finding the asymptotic distribution of (and Hotellings ) under certain divergences from i.i.d. normality. For example, one could impose a general autocorrelation by making for some . One could impose heteroskedasticity structure where and for some scalar lambda. It has been shown that the Sharpe ratio is relatively robust to deviations from assumptions under similar configurations. [53]
3.3 Likelihood ratio test on Markowitz portfolio
Let us again consider to take a Gaussian distribution, rather than a general elliptical distribution. Consider the null hypothesis
| (64) |
The constraints have to be sensible. For example, they cannot violate the positive definiteness of , symmetry, etc. Without loss of generality, we can assume that the are symmetric, since is symmetric, and for symmetric and square , , and so we could replace any non-symmetric with .
Employing the Lagrange multiplier technique, the maximum likelihood estimator under the null hypothesis, call it , solves the following equation
Thus the MLE under the null is
| (65) |
The maximum likelihood estimator under the constraints has to be found numerically by solving for the , subject to the constraints in Equation 64.
This framework slightly generalizes Dempster’s “Covariance Selection,” [15] which reduces to the case where each is zero, and each is a matrix of all zeros except two (symmetric) ones somewhere in the lower right sub-matrix. In all other respects, however, the solution here follows Dempster.
An iterative technique for finding the MLE based on a Newton step would proceed as follow. [48] Let be some initial estimate of the vector of . (A good initial estimate can likely be had by abusing the asymptotic normality result from Section 2.2.) The residual of the estimate, is
| (66) |
The Jacobian of this residual with respect to the element of s
| (67) |
Newton’s method is then the iterative scheme
| (68) |
When (if?) the iterative scheme converges on the optimum, plugging in into Equation 65 gives the MLE under the null. The likelihood ratio test statistic is
| (69) |
using the fact that is the unrestricted MLE, per Corollary 3.5. By Wilks’ Theorem, under the null hypothesis, is, asymptotically in , distributed as a chi-square with degrees of freedom. [66] However, most ‘interesting’ null tests posit to be somewhere on the boundary of acceptable values; for such tests, asymptotic convergence is to some other distribution. [2]
4 Extensions
For large samples, Wald statistics of the elements of the Markowitz portfolio computed using the procedure outlined above tend to be very similar to the t-statistics produced by the procedure of Britten-Jones. [7] However, the technique proposed here admits a number of interesting extensions.
The script for each of these extensions is the same: define, then solve, some portfolio optimization problem; show that the solution can be defined in terms of some transformation of , giving an implicit recipe for constructing the sample portfolio based on the same transformation of ; find the asymptotic distribution of the sample portfolio in terms of .
4.1 Subspace Constraint
Consider the constrained portfolio optimization problem
| (70) |
where is a matrix of rank , is the disastrous rate, and is the risk budget. Let the rows of span the null space of the rows of ; that is, , and . We can interpret the orthogonality constraint as stating that must be a linear combination of the columns of , thus . The columns of may be considered ‘baskets’ of assets to which our investments are restricted.
We can rewrite the portfolio optimization problem in terms of solving for , but then find the asymptotic distribution of the resultant . Note that the expected return and covariance of the portfolio are, respectively, and . Thus we can plug in and into Lemma 2.6 to get the following analogue.
Lemma 4.1 (subspace constrained Sharpe ratio optimal portfolio).
Assuming the rows of span the null space of the rows of , , and is invertible, the portfolio optimization problem
| (71) |
for is solved by
When the solution is unique.
We can easily find the asymptotic distribution of , the sample analogue of the optimal portfolio in Lemma 4.1. First define the subspace second moment.
Definition 4.2.
Let be the matrix,
Simple algebra proves the following lemma.
Lemma 4.3.
The elements of are
In particular, elements through of are the portfolio defined in Lemma 4.1, up to the scaling constant which is the ratio of to the square root of the first element of minus one.
The asymptotic distribution of is given by the following theorem, which is the analogue of Theorem 2.5.
Theorem 4.4.
Let be the unbiased sample estimate of , based on i.i.d. samples of . Let be defined as in Definition 4.2. Let be the variance of . Then, asymptotically in ,
| (72) |
where
Proof.
By the multivariate delta method, it suffices to prove that
Via Lemma 2.3, it suffices to prove that
4.2 Hedging Constraint
Consider, now, the constrained portfolio optimization problem,
| (73) |
where is now a matrix of rank . We can interpret the constraint as stating that the covariance of the returns of a feasible portfolio with the returns of a portfolio whose weights are in a given row of shall equal zero. In the garden variety application of this problem, consists of rows of the identity matrix; in this case, feasible portfolios are ‘hedged’ with respect to the assets selected by (although they may hold some position in the hedged assets).
Lemma 4.5 (constrained Sharpe ratio optimal portfolio).
Assuming , and is invertible, the portfolio optimization problem
| (74) |
for is solved by
When the solution is unique.
Proof.
By the Lagrange multiplier technique, the optimal portfolio solves the following equations:
where are Lagrange multipliers, and are scalar constants.
Solving the first equation gives
Reconciling this with the hedging equation we have
and therefore Thus
Plugging this into the objective reduces the problem to the univariate optimization
where The optimum occurs for , moreover the optimum is unique when . ∎
The optimal hedged portfolio in Lemma 4.5 is, up to scaling, the difference of the unconstrained optimal portfolio from Lemma 2.6 and the subspace constrained portfolio in Lemma 4.1. This ‘delta’ analogy continues for the rest of this section.
Definition 4.6 (Delta Inverse Second Moment).
Let be the matrix,
Define the ‘delta inverse second moment’ as
Simple algebra proves the following lemma.
Lemma 4.7.
The elements of are
In particular, elements through of are the portfolio defined in Lemma 4.5, up to the scaling constant which is the ratio of to the square root of the first element of .
The statistic , for the case where is some rows of the identity matrix, was first proposed by Rao, and its distribution under Gaussian returns was later found by Giri. [57, 20] This test statistic may be used for tests of portfolio spanning for the case where a risk-free instrument is traded. [23, 30]
The asymptotic distribution of is given by the following theorem, which is the analogue of Theorem 2.5.
Theorem 4.8.
Let be the unbiased sample estimate of , based on i.i.d. samples of . Let be defined as in Definition 4.6, and similarly define . Let be the variance of . Then, asymptotically in ,
| (75) |
where
Proof.
Minor modification of proof of Theorem 4.4. ∎
Caution.
In the hedged portfolio optimization problem considered here, the optimal portfolio will, in general, hold money in the row space of . For example, in the garden variety application, where one is hedging out exposure to ‘the market’ by including a broad market ETF, and taking to be the corresponding row of the identity matrix, the final portfolio may hold some position in that broad market ETF. This is fine for an ETF, but one may wish to hedge out exposure to an untradeable returns stream–the returns of an index, say. Combining the hedging constraint of this section with the subspace constraint of Section 4.1 is simple in the case where the rows of are spanned by the rows of . The more general case, however, is rather more complicated.
4.3 Conditional Heteroskedasticity
The methods described above ignore ‘volatility clustering’, and assume homoskedasticity. [11, 47, 4] To deal with this, consider a strictly positive scalar random variable, , observable at the time the investment decision is required to capture . For reasons to be obvious later, it is more convenient to think of as a ‘quietude’ indicator, or a ‘weight’ for a weighted regression.
Two simple competing models for conditional heteroskedasticity are
| (76) | ||||||
| (77) |
Under the model in Equation 76, the maximal Sharpe ratio is , independent of ; under Equation 77, it is is . The model names reflect whether or not the maximal Sharpe ratio varies conditional on .
The optimal portfolio under both models is the same, as stated in the following lemma, the proof of which follows by simply using Lemma 2.6.
Lemma 4.9 (Conditional Sharpe ratio optimal portfolio).
To perform inference on the portfolio from Lemma 4.9, under the ‘constant’ model of Equation 76, apply the unconditional techniques to the sample second moment of .
For the ‘floating’ model of Equation 77, however, some adjustment to the technique is required. Define ; that is, . Consider the second moment of :
| (80) |
The inverse of is
| (81) |
Once again, the optimal portfolio (up to scaling and sign), appears in . Similarly, define the sample analogue:
| (82) |
We can find the asymptotic distribution of using the same techniques as in the unconditional case, as in the following analogue of Theorem 2.5:
Theorem 4.10.
Let , based on i.i.d. samples of . Let be the variance of . Then, asymptotically in ,
| (83) |
where
| (84) |
Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
The only real difference from the unconditional case is that we cannot automatically assume that the first row and column of is zero (unless is actually constant, which misses the point). Moreover, the shortcut for estimating under Gaussian returns is not valid without some patching, an exercise left for the reader.
Dependence or independence of maximal Sharpe ratio from volatility is an assumption which, ideally, one could test with data. A mixed model containing both characteristics can be written as follows:
| (85) |
One could then test whether elements of or of are zero. Analyzing this model is somewhat complicated without moving to a more general framework, as in the sequel.
4.4 Conditional Expectation and Heteroskedasticity
Suppose you observe random variables , and -vector at some time prior to when the investment decision is required to capture . It need not be the case that and are independent. The general model is now
| (86) |
where is some matrix. Without the term, these are the ‘predictive regression’ equations commonly used in Tactical Asset Allocation. [10, 22, 5]
By letting we recover the mixed model in Equation 85; the bi-conditional model is considerably more general, however. The conditionally-optimal portfolio is given by the following lemma. Once again, the proof proceeds simply by plugging in the conditional expected return and volatility into Lemma 2.6.
Lemma 4.11 (Conditional Sharpe ratio optimal portfolio).
Under the model in Equation 86, conditional on observing and , the portfolio optimization problem
| (87) |
for is solved by
| (88) |
Moreover, this is the unique solution whenever .
Caution.
It is emphatically not the case that investing in the portfolio from Lemma 4.11 at every time step is long-term Sharpe ratio optimal. One may possibly achieve a higher long-term Sharpe ratio by down-levering at times when the conditional Sharpe ratio is low. The optimal long term investment strategy falls under the rubric of ‘multiperiod portfolio choice’, and is an area of active research. [46, 17, 5]
The matrix is the generalization of the Markowitz portfolio: it is the multiplier for a model under which the optimal portfolio is linear in the features (up to scaling to satisfy the risk budget). We can think of this matrix as the ‘Markowitz coefficient’. If an entire column of is zero, it suggests that the corresponding element of can be ignored in investment decisions; if an entire row of is zero, it suggests the corresponding instrument delivers no return or hedging benefit.
Conditional on observing and , the maximal achievable squared signal-noise ratio is
This is independent of , but depends on . The unconditional expected value of the maximal squared signal-noise ratio is thus
This quantity is the Hotelling-Lawley trace, typically used to test the so-called Multivariate General Linear Hypothesis. [58, 45] See Section 6.
To perform inference on the Markowitz coefficient, we can proceed exactly as above. Let
| (89) |
Consider the second moment of :
| (90) |
The inverse of is
| (91) |
Once again, the Markowitz coefficient (up to scaling and sign), appears in .
The following theorem is an analogue of, and shares a proof with, Theorem 2.5.
Theorem 4.12.
Let , based on i.i.d. samples of , where
Let be the variance of . Then, asymptotically in ,
| (92) |
where
| (93) |
Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
4.5 Conditional Expectation and Heteroskedasticity with Hedging Constraint
A little work allows us to combine the conditional model of Section 4.4 with the hedging constraint of Section 4.2. Suppose returns follow the model of Equation 86. To prove the following lemma, simply plug in for , and for into Lemma 4.5.
Lemma 4.13 (Hedged Conditional Sharpe ratio optimal portfolio).
Let be a given matrix of rank . Under the model in Equation 86, conditional on observing and , the portfolio optimization problem
| (94) |
for is solved by
Moreover, this is the unique solution whenever .
The same cautions regarding multiperiod portfolio choice apply to the above lemma. Results analogous to those of Section 4.2 follow, but with one minor modification to the analogue of Definition 4.6.
Lemma 4.14.
Let now be the matrix,
where the upper right corner is the identity matrix. Define the ‘delta inverse second moment’ as
| (95) |
where is defined as in Equation 90. The elements of are
In particular, the Markowitz coefficient from Lemma 4.13 appears in the lower left corner of , and the denominator of the constant from Lemma 4.13 depends on a quadratic form of with the upper right left corner of .
Theorem 4.15.
Let , based on i.i.d. samples of , where
Let be the variance of . Define as in Equation 95 for given matrix .
Then, asymptotically in ,
| (96) |
where
Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
4.6 Conditional Expectation and Multivariate Heteroskedasticity
Here we extend the model from Section 4.4 to accept multiple heteroskedasticity ‘features’. First note that if we redefined to be , we could rewrite the model in Equation 86 as
This can be generalized to vector-valued by means of the flattening trick. [6]
Suppose you observe the state variables -vector , and -vector at some time prior to when the investment decision is required to capture . It need not be the case that and are independent. For sane interpretation of the model, it makes sense that all elements of are positive. The general model is now
| (97) |
where is some matrix, and is now a matrix.
Conditional on observing , a portfolio on the assets, , can be expressed as the portfolio on the assets whose returns are the vector ; here refers to the element-wise, or Hadamard, inverse of . Thus we may perform portfolio conditional optimization on the enlarged space of assets, and then, conditional on , impose a subspace constraint requiring the portfolio to be spanned by the column space of , where is used to mean the Kronecker product with , the Hadamard inverse of .
We can then combine the results of Section 4.1 and Section 4.4 to solve the portfolio optimization problem, and perform inference on that portfolio. The following is the analogue of Lemma 4.11 combined with Lemma 4.1.
Lemma 4.16 (Conditional Sharpe ratio optimal portfolio).
Suppose returns follow the model in Equation 97, and suppose and have been observed. Let and suppose is not all zeros. Then the portfolio optimization problem
| (98) |
for is solved by
Moreover, the solution is unique whenever . This portfolio achieves the maximal objective of
5 Constrained Estimation
Now consider the case where the population parameter is known or suspected, a priori, to satisfy some constraints. One then wishes to impose the same constraints on the sample estimate prior to constructing the Markowitz portfolio, imposing a hedge, etc.
To avoid the possibility that the constrained estimate is not positive definite or the need for cone programming to find the estimate, here we assume the constraint can be expressed in terms of the (lower) Cholesky factor of . Note that this takes the form
| (99) |
as can be confirmed by multiplying the above by its transpose.
5.1 Linear constraints
Now consider equality constraints of the form for conformable matrices , a less general form of the Multivariate General Linear Hypothesis, of which more in the sequel. Via equalities of this form, one can constrain the mean of certain assets to be zero (for example, assets to be hedged out), or force certain elements of to have no marginal predictive ability on certain elements of . When this constraint is satisfied, note that
which can be rewritten as
This motivates the imposition of equality constraints of the form
| (100) |
where is some matrix and is a -vector, where is the number of elements in .
Now consider the optimization problem
| (101) |
where is some symmetric positive definite ‘weighting’ matrix, the identity in the garden variety application. The solution to this problem can easily be identified via the Lagrange multiplier technique to be
Define to be the matrix whose Cholesky factor solves minimization problem 101:
When the population parameter satisfies the constraints, this sample estimate is asymptotically unbiased.
Theorem 5.1.
Suppose for given matrix and -vector . Let be a symmetric, positive definite matrix. Let , based on i.i.d. samples of , where
Let be the variance of . Define such that
Then, asymptotically in ,
| (102) |
where defined as
where is the Commutation matrix.
Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
Proof.
Define the functions , , as follows:
where is the function that takes a conformable vector to a lower triangular matrix. We have then defined as . By the central limit theorem, and the matrix chain rule, it suffices to show that is the derivative of evaluated at , that is the derivative of evaluated at , and is the derivative of evaluated at .
These are established by Equation 123 of Lemma A.1, and Lemma A.2, and by the assumption that , which implies that .
∎
5.2 Rank constraints
Another plausible type of constraint is a rank constraint. Here it is suspected a priori that the matrix has rank . One sane response of a portfolio manager with this belief is to project to a rank matrix, take the pseudoinverse, and use the (negative) corner sub-matrix as the Markowitz coefficient. (cf. Lemma 4.13) Here we consider the asymptotic distribution of this reduced rank Markowitz coefficient.
To find the asymptotic distribution of sample estimates of with a rank constraint, the derivative of the reduced rank decomposition is needed. [54, 26]
Lemma 5.2.
Let be a real symmetric matrix with rank . Let be the function that returns the eigenvalue of , and similarly let compute the corresponding eigenvector. Then
| (104) | ||||
| (105) |
Proof.
From these, the derivative of the diagonal matrix with diagonal
can be computed with respect to for arbitrary non-zero . Similarly the derivative of the matrix whose columns are can be computed with respect to . From these the derivative of the pseudo-inverse of the rank approximation to can be computed with respect to . By the delta method, then, an asymptotic normal distribution of the pseudo-inverse of the rank approximation to can be established. The formula for the variance is best left unwritten, since it would be too complex to be enlightening, and is best constructed by automatic differentiation anyway.
6 The multivariate general linear hypothesis
Dropping the conditional heteroskedasticity term from Equation 86, we have the model
The unknowns and can be estimated by multivariate multiple linear regression. Testing for significance of the elements of is via the Multivariate General Linear Hypothesis (MGLH). [45, 59, 60, 49, 63, 67] The MGLH can be posed as
| (106) |
for matrix , matrix , and matrix . We require and to have full rank, and and In the garden-variety application one tests whether is all zero by letting and be identity matrices, and a matrix of all zeros.
Testing the MGLH proceeds by one of four test statistics, each defined in terms of two matrices, the model variance matrix, , and the error variance matrix, , defined as
| (107) |
where . Note that typically in non-finance applications, the regressors are deterministic and controlled by the experimenter (giving rise to the term ‘design matrix’). In this case, it is assumed that estimates the population analogue, , without error, though some work has been done for the case of ‘random explanatory variables.’ [60]
The four test statistics for the MGLH are:
| (108) | ||||
| (109) | ||||
| (110) | ||||
| (111) | ||||
Of these four, Roy’s largest root has historically been the least well understood. [28] Each of these can be described as some function of the eigenvalues of the matrix . Under the null hypothesis, , the matrix ‘should’ be all zeros, in a sense that will be made precise later, and thus the Hotelling Lawley trace and Roy’s largest root ‘should’ equal zero, the Pillai Bartlett trace ‘should’ equal , and Wilk’s LRT ‘should’ equal .
One can describe the MGLH tests statistics in terms of the asymptotic expansions of the matrix given in the previous sections. As in Section 4.4, let
| (112) |
The second moment of is
| (113) |
We can express the MGLH statistics in terms of the product of two matrices defined in terms of . Let be the matrix
Linear algebra confirms that
| (114) |
Thus
| (115) |
Now define
| (116) |
Thus
| (117) |
This matrix is ‘morally equivalent’222To quote my advisor, Noel Walkington. to the matrix , in that they have the same eigenvalues. This holds because . [54, equation (280)] Taking into account that they have diferent sizes (one is , the other ), the MGLH statistics can be expressed as:
To find the asymptotic distribution of , and of the MGLH test statistics, the derivatives of the matrices above with respect to need to be found. In practice this would certainly be better achieved through automatic differentation. [56] For concreteness, however, the derivatives are given here.
It must also be noted that the straightforward application of the delta method results in asymptotic normal approximations for the MGLH statistics. By their very nature, however, these statistics look much more like (non-central) Chi-square or F statistics. [49] Further study is warranted on this matter, perhaps using Hall’s approach. [21]
Lemma 6.1 (Some derivatives).
Define
| (118) |
Then
where we define
Proof.
These follow from Lemma A.1 and the chain rule. ∎
Lemma 6.2 (MGLH derivatives).
Define the population analogues of the MGLH statistics as
| (119) | ||||||
| (120) |
where
Proof.
Theorem 6.3.
Let , based on i.i.d. samples of , where
Let be the variance of . Define and as in Equation 107, for given matrix , matrix , and matrix .
Define the MGLH test statistics, , , , and as in Equations 108 through 111, and let , , and be their population analogues.
Then, asymptotically in ,
where , , , are given in Lemma 6.2. Furthermore, we may replace in this equation with an asymptotically consistent estimator, .
Proof.
This follows from the delta method and Lemma 6.2. ∎
7 Examples
7.1 Random Data
Empirically, the marginal Wald test for zero weighting in the Markowitz portfolio based on the approximation of Theorem 2.5 are nearly identical to the -statistics produced by the procedure of Britten-Jones. [7] Here days of Gaussian returns for assets with mean zero and some randomly generated covariance are randomly generated. The procedure of Britten-Jones is applied marginally on each asset. The Wald statistic is also computed via Theorem 2.5 by ‘plugging in’ the sample estimate, , to estimate the standard error. The two test values for the assets are presented in Table 1, and match very well.
The value of the asymptotic approach is that it admits the generalizations of Section 4, and allows robust estimation of . [68]
| rets1 | rets2 | rets3 | rets4 | rets5 | |
|---|---|---|---|---|---|
| Britten.Jones | 0.4950 | 0.0479 | 1.2077 | -0.4544 | -1.4636 |
| Wald | 0.4965 | 0.0479 | 1.2107 | -0.4573 | -1.4635 |
7.1.1 Normal Returns
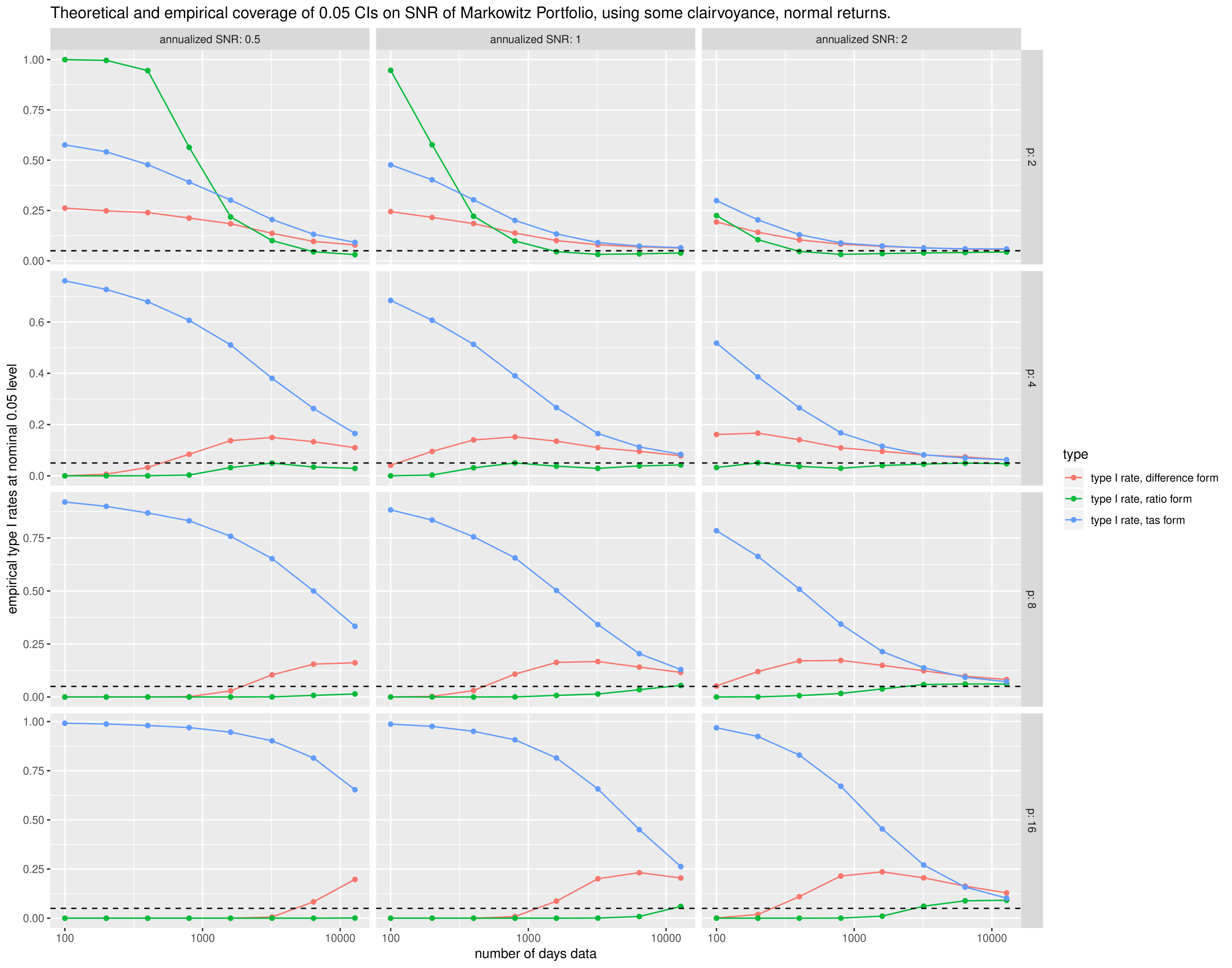
We test the confidence intervals of Theorem 3.11 and Equation 54 for random data. We draw returns from the multivariate normal distribution, for which . We fix the number of days of data, , the number of assets, , and the optimal signal-noise ratio, , and perform simulations. We then let vary from 100 to days; we let vary from 2 to 16; we let vary from 0.5 to 2 in ‘annualized’ units (per square root year), where we assume 252 days per year. We compute the lower confidence limits on , the signal-noise ratio of the sample Markowitz portfolio based on the difference and ratio forms from the theorem. The confidence limtis are computed very optimistically, by using the actual in the expressions for the mean and variance of and . For the ‘TAS’ form of confidence limit, we use once in the non-centrality parameter, but otherwise use the actual when computing parameters. Thus while this does not test the confidence limits in the way they would be practically used (e.g., Equation 59), the results are sufficiently discouraging even with this bit of clairvoyance to recommend against their general use.
We compute the lower 0.05 confidence limit based on the difference and ratio forms and the ‘TAS’ transform. We then compute the empirical type I rate. These are plotted against in Figure 1. We show facet columns for , and facet rows for . The confidence intervals fail to achieve nominal coverage except perhaps for the largest values of , though these are much larger than would be used in practice.
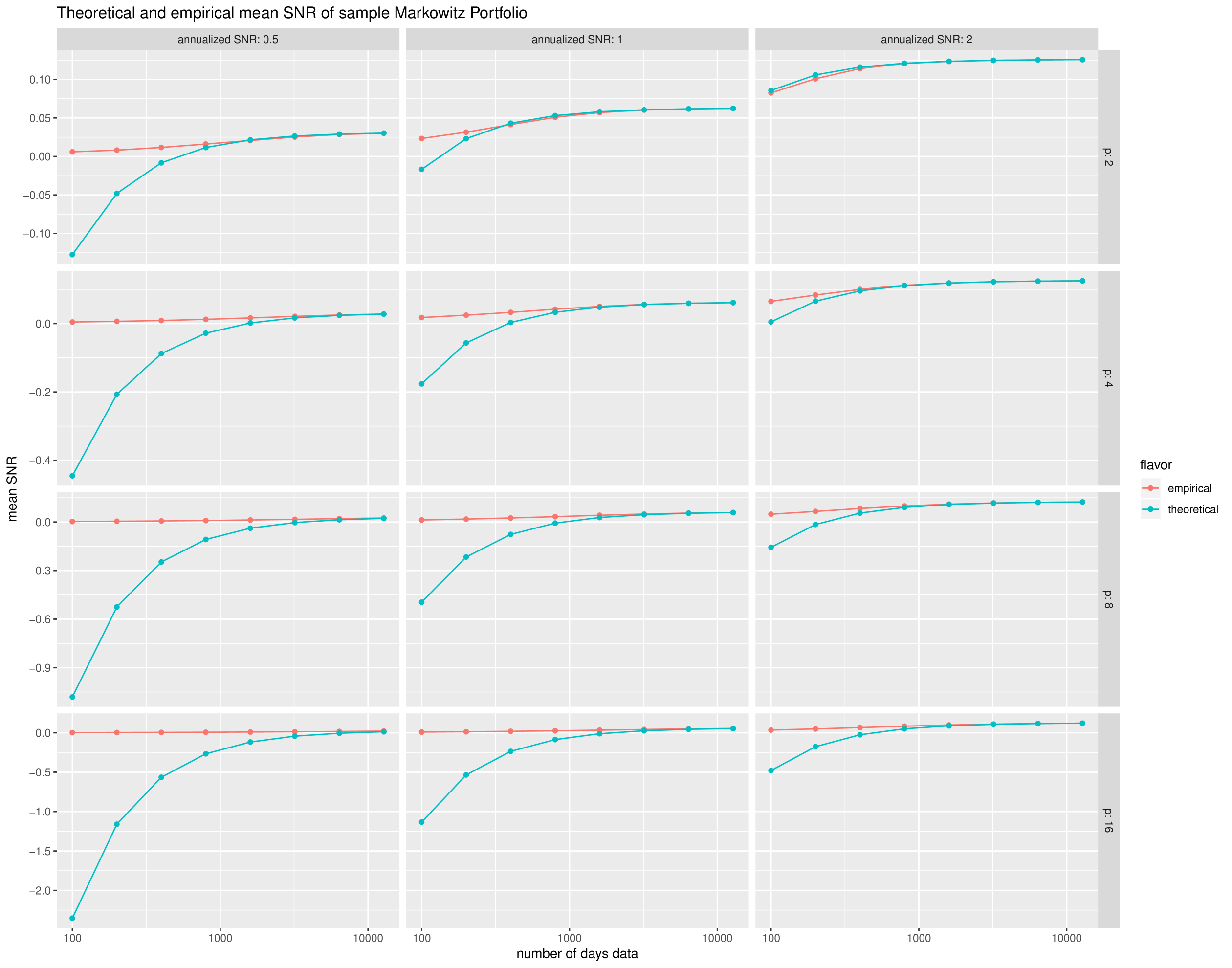
As a check, we also compare the empirical mean of the signal-noise ratio of the Markowitz portfolio from our experiments with the theoretical asymptotic value from Theorem 3.11, namely
We plot the empirical and theoretical means in Figure 2, again versus with facet columns for , and facet rows for . The theoretical asymptotic value gives a good approximation for larger sample sizes, but ‘only’ around 6 years of daily data are required. Note that the theoretical value gets worse as , as one would expect: the signal-noise ratio of any portfolio must be no greater than in absolute value, but the theoretical value goes to .
7.1.2 Elliptical Returns
We now test Equation 50 via simulation. We fix the number of days of data, , the number of assets, , and the optimal signal-noise ratio, , and the kurtosis factor, , and perform simulations. We let vary from 100 to days; we let vary from 4 to 16; we let vary from 1 to 16; we let vary from 0.5 to 2 in ‘annualized’ units (per square root year), where we assume 252 days per year. When we draw from a multivariate normal distribution; when , we draw from a multivariate shifted distribution.
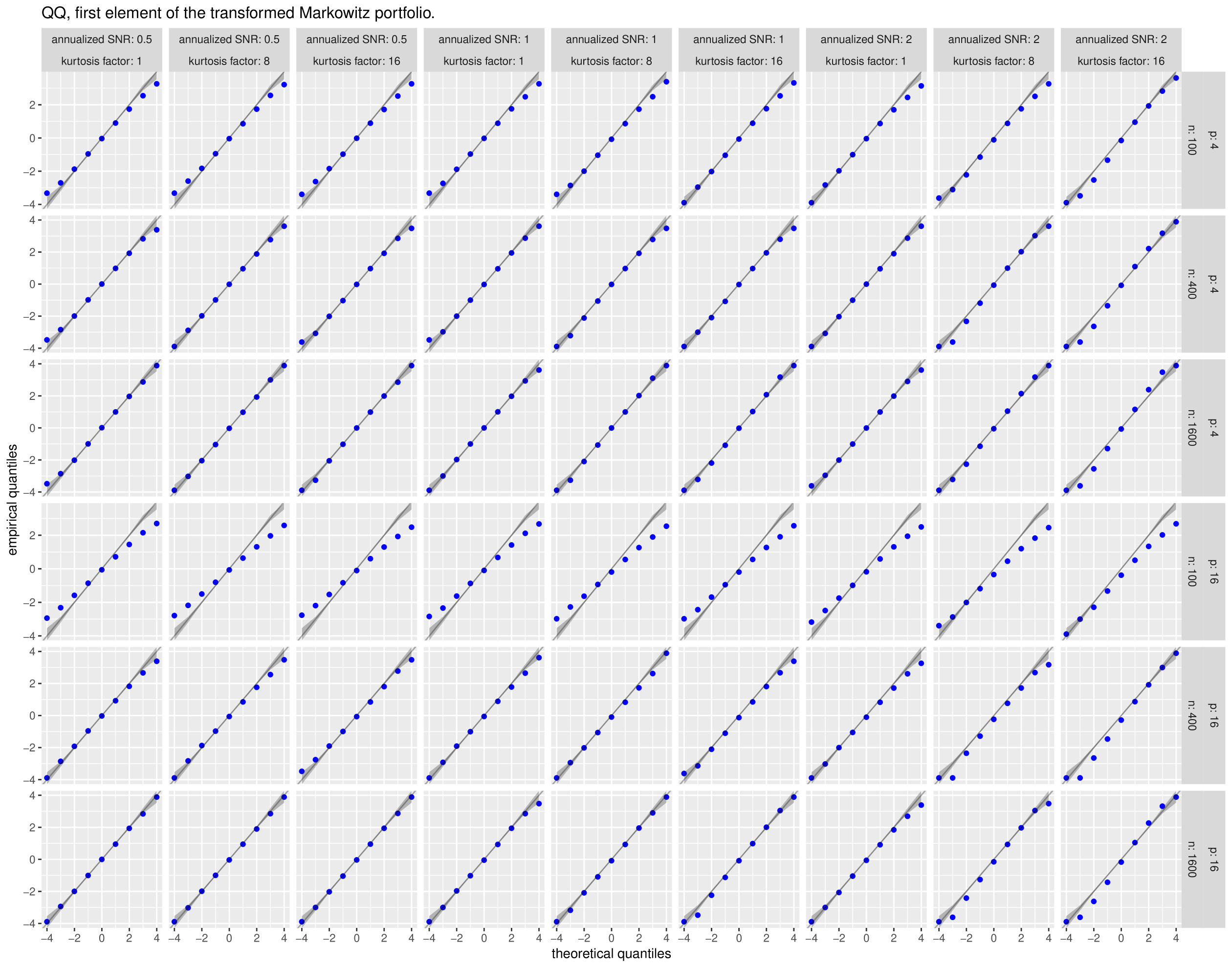
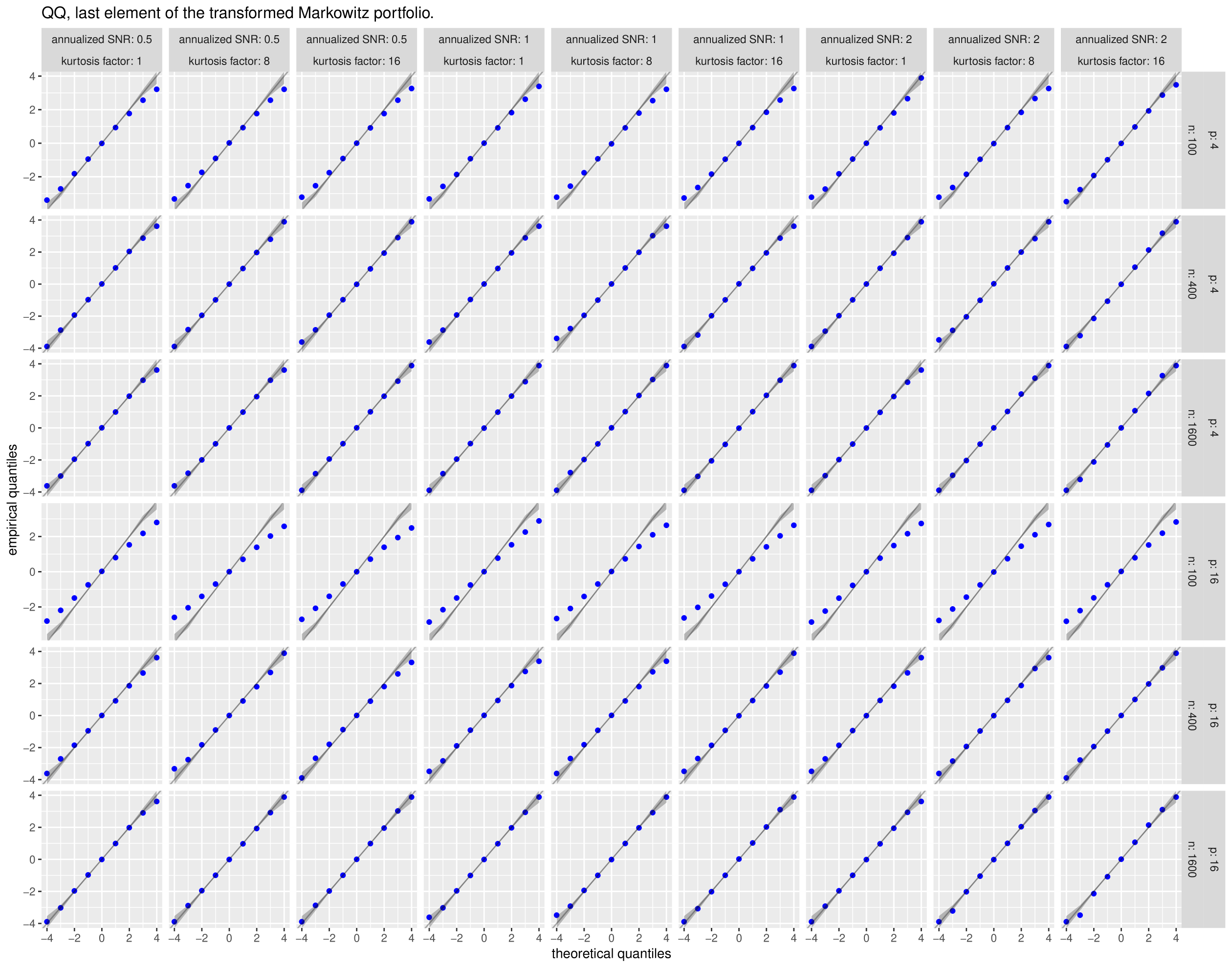
For each simulation, we collect the first and last elements of the vector
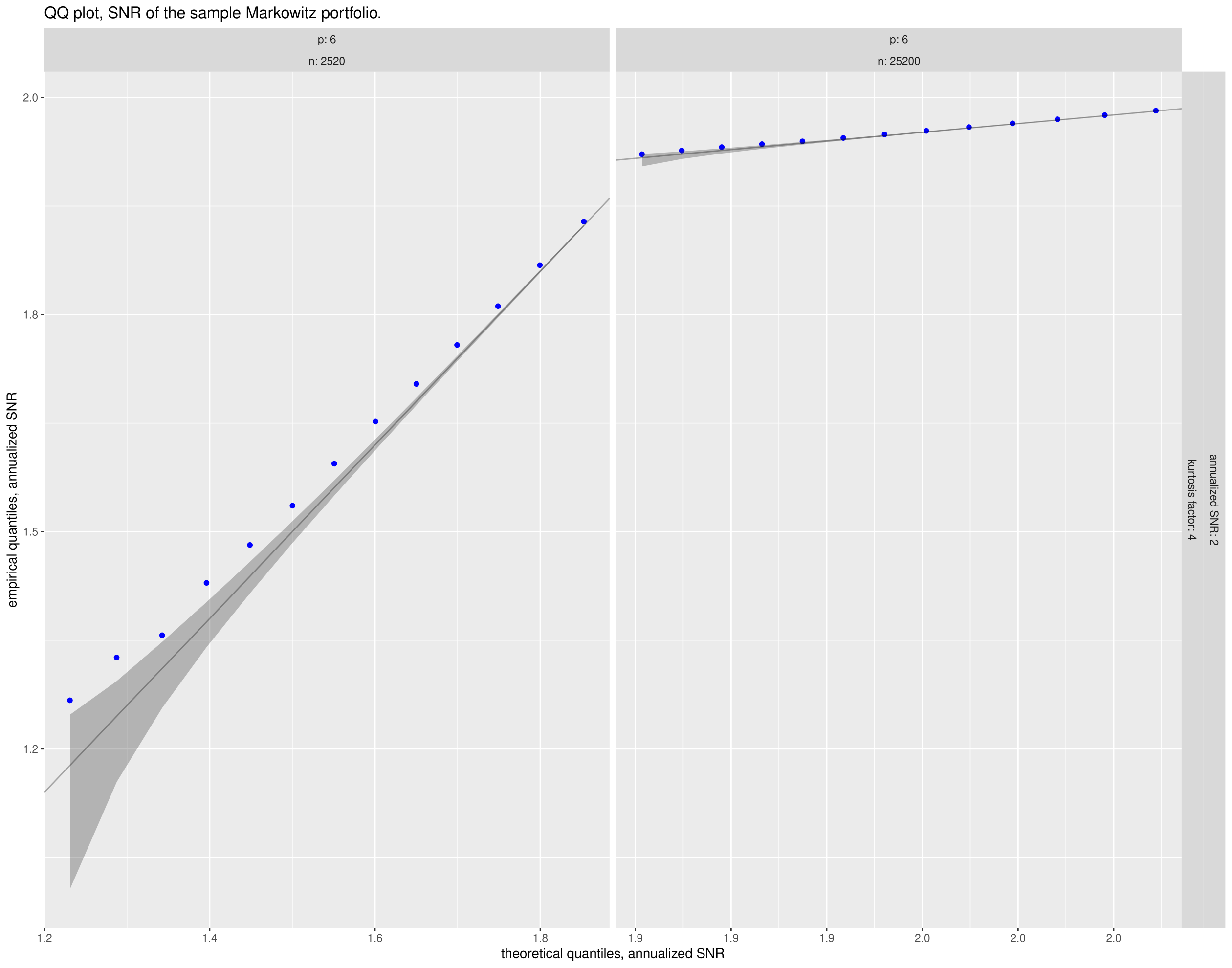
By Equation 50 these should be asymptotically distributed as a standard normal. In Figure 3 we give Q-Q plots of the first element of this vector versus quantiles of the standard normal for each setting of the simulation parameters. Rather than present the full Q-Q plot (each facet would contain 10,000 points), we take evenly spaced points between and , then convert them into percentage points of the standard normal. We then find the empirical quantiles at those levels and plot the empirical quantiles against the selected theoretical. This allows us to also plot the pointwise confidence bands, which should be very small for the sample size, except at the periphery. Similarly, in Figure 4 we give the same kind of subsampled Q-Q plots of the last element of this vector.
With some exception, the Q-Q plots show a fair degree of support for normality when is reasonably large. For example, for , a sample of is apparently sufficient to get near normality for the last element of the vector. The first element of the vector, which one suspects is dependent on , appears to suffer when is larger.
We also check Equation 51 via a smaller set of simulations. We fix in annualized units, , and . We then test two different sample sizes: and , corresponding to 10 and 100 years of daily data, at a rate of days per year. For a given simulation we draw the appropriate number of days of independent returns from a shifted multivariate distribution. We compute the sample Markowitz portfolio and compute its signal-noise ratio, . We perform this simulation 50,000 times for each setting of . We construct theoretical approximate quantiles of using Equation 51, then plot the empirical quantiles versus the theoretical quantiles in Figure 5. It appears that more than 10 years of daily data (but fewer than 100 years worth) are required for this approximation to be any good. When the approximation breaks down, it tends to underestimate the true signal-noise ratio.
7.2 Fama French Three Factor Portfolios
The monthly returns of the Fama French 3 factor portfolios from Jul 1926 to Jul 2013 were downloaded from Quandl. [19, 41] The returns excess the risk-free rate (which is also given in the same data) are computed. The procedure of Britten-Jones is applied to get marginal statistics for each of the three assets. The marginal Wald statistics are also computed, first using the vanilla estimator of , then using a robust (HAC) estimator via the errors via the sandwich package. [68] These are presented in Table 2. The Wald statistics are slightly less optimistic than the Britten-Jones -statistics for the long MKT and short SMB positions. This is amplified when the HAC estimator is used.
| MKT | HML | SMB | |
|---|---|---|---|
| Britten.Jones | 4.10 | 0.30 | -1.97 |
| Wald | 3.86 | 0.31 | -1.92 |
| Wald.HAC | 3.51 | 0.27 | -1.78 |
7.2.1 Incorporating conditional heteroskedasticity
A rolling estimate of general market volatility is computed by taking the 11 month FIR mean of the median absolute return of the three portfolios, delayed by one month. The model of ‘constant maximal Sharpe ratio’ (i.e., Equation 76) is assumed, where is the inverse of this estimated volatility. This is equivalent to dividing the returns by the estimated volatility, then applying the unconditional estimator.
The marginal Wald statistics are presented in Table 3, and are more ‘confident’ in the long MKT position, and short SMB position, with little evidence to support a long or short position in HML.
| MKT | HML | SMB | |
| HAC.wald.wt | 4.51 | 0.62 | -2.93 |
7.2.2 Conditional expectation
The Shiller cyclically adjusted price/earnings data (CAPE) are downloaded from Quandl. [41] The CAPE data are delayed by a month so that they qualify as features which could be used in the investment decision. That is, we are testing a model where CAPE are used to predict returns, not ‘explain’ them, contemporaneously. The CAPE data are centered by subtracting the mean. The marginal Wald statistics, computed using a HAC estimator for , for the 6 elements of the Markowitz coefficient matrix are presented in Table 4, and indicate a significant unconditional long MKT position; when CAPE is above the long term average value of 17.54, decreasing the position in MKT is warranted.
| MKT | HML | SMB | |
|---|---|---|---|
| Intercept | 2.22 | 0.59 | -1.33 |
| CAPE | -2.46 | -1.13 | -0.70 |
| MKT | HML | SMB | |
|---|---|---|---|
| Intercept | 3.49 | 0.27 | -1.77 |
| del.CAPE | 1.19 | 0.03 | 2.52 |
The CAPE data change at a very low frequency. It is possible that the changes in the CAPE data are predictive of future returns. The Wald statistics of the Markowitz coefficient using the first difference in monthly CAPE dataa, delayed by a month, are presented in Table 5. These suggest a long unconditional position in MKT, with the differences in CAPE providing a ‘timing’ signal for an unconditional short SMB position.
7.2.3 Attribution of error
Theorem 2.5 gives the asymptotic distribution of , which contains the (negative) Markowitz portfolio and the precision matrix. This allows one to estimate the amount of error in the Markowitz portfolio which is attributable to mis-estimation of the covariance. The remainder one can attribute to mis-estimation of the mean vector, which, is typically implicated as the leading effect. [8]
The computation is performed as follows: the estimated covariance of is turned into a correlation matrix in the usual way333That is, by a Hadamard divide of the rank one matrix of the outer product of the diagonal. Or, more practically, by the R function cov2cor.. This gives a correlation matrix, call it , some of the elements of which correspond to the negative Markowitz portfolio, and some to the precision matrix. For a single element of the Markowitz portfolio, let be a sub-column of consisting of the column corresponding to that element of the Markowitz portfolio and the rows of the precision matrix. And let be the sub-matrix of corresponding to the precision matrix. The multiple correlation coefficient is then . This is an ‘R-squared’ number between zero and one, estimating the proportion of variance in that element of the Markowitz portfolio ‘explained’ by error in the precision matrix.
| vanilla | weighted | |
|---|---|---|
| MKT | 41 % | 32 % |
| HML | 11 % | 6.8 % |
| SMB | 29 % | 13 % |
Here, for each of the members of the vanilla Markowitz portfolio on the 3 assets, this squared coefficient of multiple correlation, is expressed as percents in Table 6. A HAC estimator for is used. In the ‘weighted’ column, the returns are divided by the rolling estimate of volatility described above, assuming a model of ‘constant maximal Sharpe ratio’. We can claim, then, that approximately 41 percent of the error in the MKT position is due to mis-estimation of the precision matrix.
References
- Anderson [2003] T. W. Anderson. An Introduction to Multivariate Statistical Analysis. Wiley Series in Probability and Statistics. Wiley, 2003. ISBN 9780471360919. URL http://books.google.com/books?id=Cmm9QgAACAAJ.
- Andrews [2001] Donald WK Andrews. Testing when a parameter is on the boundary of the maintained hypothesis. Econometrica, 69(3):683–734, 2001. URL http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.2587&rep=rep1&type=pdf.
- Bodnar and Okhrin [2011] Taras Bodnar and Yarema Okhrin. On the product of inverse Wishart and normal distributions with applications to discriminant analysis and portfolio theory. Scandinavian Journal of Statistics, 38(2):311–331, 2011. ISSN 1467-9469. doi: 10.1111/j.1467-9469.2011.00729.x. URL http://dx.doi.org/10.1111/j.1467-9469.2011.00729.x.
- Bollerslev [1987] Tim Bollerslev. A conditionally heteroskedastic time series model for speculative prices and rates of return. The Review of Economics and Statistics, 69(3):pp. 542–547, 1987. ISSN 00346535. URL http://www.jstor.org/stable/1925546.
- Brandt [2009] Michael W Brandt. Portfolio choice problems. Handbook of financial econometrics, 1:269–336, 2009. URL https://faculty.fuqua.duke.edu/~mbrandt/papers/published/portreview.pdf.
- Brandt and Santa-Clara [2006] Michael W. Brandt and Pedro Santa-Clara. Dynamic portfolio selection by augmenting the asset space. The Journal of Finance, 61(5):2187–2217, 2006. ISSN 1540-6261. doi: 10.1111/j.1540-6261.2006.01055.x. URL http://faculty.fuqua.duke.edu/~mbrandt/papers/published/condport.pdf.
- Britten-Jones [1999] Mark Britten-Jones. The sampling error in estimates of mean-variance efficient portfolio weights. The Journal of Finance, 54(2):655–671, 1999. URL http://www.jstor.org/stable/2697722.
- Chopra and Ziemba [1993] Vijay Kumar Chopra and William T. Ziemba. The effect of errors in means, variances, and covariances on optimal portfolio choice. The Journal of Portfolio Management, 19(2):6–11, 1993. URL http://faculty.fuqua.duke.edu/~charvey/Teaching/BA453_2006/Chopra_The_effect_of_1993.pdf.
- Cochrane [2001] John Howland Cochrane. Asset pricing. Princeton Univ. Press, Princeton [u.a.], 2001. ISBN 0691074984. URL http://press.princeton.edu/titles/7836.html.
- Connor [1997] Gregory Connor. Sensible return forecasting for portfolio management. Financial Analysts Journal, 53(5):pp. 44–51, 1997. ISSN 0015198X. URL https://faculty.fuqua.duke.edu/~charvey/Teaching/BA453_2006/Connor_Sensible_Return_Forecasting_1997.pdf.
- Cont [2001] Rama Cont. Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance, 1(2):223–236, 2001. doi: 10.1080/713665670. URL http://personal.fmipa.itb.ac.id/khreshna/files/2011/02/cont2001.pdf.
- Cragg [1983] J. G. Cragg. More efficient estimation in the presence of heteroscedasticity of unknown form. Econometrica, 51(3):pp. 751–763, 1983. ISSN 00129682. URL http://www.jstor.org/stable/1912156.
- DeMiguel et al. [2009] Victor DeMiguel, Lorenzo Garlappi, and Raman Uppal. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Review of Financial Studies, 22(5):1915–1953, 2009. URL http://faculty.london.edu/avmiguel/DeMiguel-Garlappi-Uppal-RFS.pdf.
- DeMiguel et al. [2013] Victor DeMiguel, Alberto Martin-Utrera, and Francisco J Nogales. Size matters: Optimal calibration of shrinkage estimators for portfolio selection. Journal of Banking & Finance, 2013. URL http://faculty.london.edu/avmiguel/DMN-2011-07-21.pdf.
- Dempster [1972] A. P. Dempster. Covariance selection. Biometrics, 28(1):pp. 157–175, 1972. ISSN 0006341X. URL http://www.jstor.org/stable/2528966.
- Duncan [1983] Gregory M. Duncan. Estimation and inference for heteroscedastic systems of equations. International Economic Review, 24(3):pp. 559–566, 1983. ISSN 00206598. URL http://www.jstor.org/stable/2648786.
- Fabozzi et al. [2007] F. J. Fabozzi, P. N. Kolm, D. Pachamanova, and S. M. Focardi. Robust Portfolio Optimization and Management. Frank J. Fabozzi series. Wiley, 2007. ISBN 9780470164891. URL http://books.google.com/books?id=PUnRxEBIFb4C.
- Fackler [2005] Paul L. Fackler. Notes on matrix calculus. Privately Published, 2005. URL http://www4.ncsu.edu/~pfackler/MatCalc.pdf.
- Fama and French [1992] Eugene F. Fama and Kenneth R. French. The cross-section of expected stock returns. Journal of Finance, 47(2):427, 1992. URL http://www.jstor.org/stable/2329112.
- Giri [1964] Narayan C. Giri. On the likelihood ratio test of a normal multivariate testing problem. The Annals of Mathematical Statistics, 35(1):181–189, 1964. doi: 10.1214/aoms/1177703740. URL http://projecteuclid.org/euclid.aoms/1177703740.
- Hall [1983] Peter Hall. Chi squared approximations to the distribution of a sum of independent random variables. The Annals of Probability, 11(4):pp. 1028–1036, 1983. ISSN 00911798. URL http://www.jstor.org/stable/2243514.
- Herold and Maurer [2004] Ulf Herold and Raimond Maurer. Tactical asset allocation and estimation risk. Financial Markets and Portfolio Management, 18(1):39–57, 2004. ISSN 1555-4961. doi: 10.1007/s11408-004-0104-2. URL http://dx.doi.org/10.1007/s11408-004-0104-2.
- Huberman and Kandel [1987] Gur Huberman and Shmuel Kandel. Mean-variance spanning. The Journal of Finance, 42(4):pp. 873–888, 1987. ISSN 00221082. URL http://www.jstor.org/stable/2328296.
- Iwashita [1997] Toshiya Iwashita. Asymptotic null and nonnull distribution of Hotelling’s -statistic under the elliptical distribution. Journal of Statistical Planning and Inference, 61(1):85 – 104, 1997. ISSN 0378-3758. doi: https://doi.org/10.1016/S0378-3758(96)00153-X. URL http://www.sciencedirect.com/science/article/pii/S037837589600153X.
- Iwashita and Siotani [1994] Toshiya Iwashita and Minoru Siotani. Asymptotic distributions of functions of a sample covariance matrix under the elliptical distribution. Canadian Journal of Statistics, 22(2):273–283, 1994. ISSN 1708-945X. doi: 10.2307/3315589. URL http://dx.doi.org/10.2307/3315589.
- Izenman [1975] Alan Julian Izenman. Reduced-rank regression for the multivariate linear model. Journal of Multivariate Analysis, 5(2):248 – 264, 1975. ISSN 0047-259X. doi: http://dx.doi.org/10.1016/0047-259X(75)90042-1. URL http://www.sciencedirect.com/science/article/pii/0047259X75900421.
- Jobson and Korkie [1981] J. D. Jobson and Bob M. Korkie. Performance hypothesis testing with the Sharpe and Treynor measures. The Journal of Finance, 36(4):pp. 889–908, 1981. ISSN 00221082. URL http://www.jstor.org/stable/2327554.
- Johnstone [2009] Iain M. Johnstone. Approximate null distribution of the largest root in multivariate analysis. Annals of Applied Statistics, 3(4):1616–1633, 2009. URL http://projecteuclid.org/euclid.aoas/1267453956.
- Kan [2008] Raymond Kan. From moments of sum to moments of product. Journal of Multivariate Analysis, 99(3):542 – 554, 2008. ISSN 0047-259X. doi: https://doi.org/10.1016/j.jmva.2007.01.013. URL http://www.sciencedirect.com/science/article/pii/S0047259X07000139.
- Kan and Zhou [2012] Raymond Kan and GuoFu Zhou. Tests of mean-variance spanning. Annals of Economics and Finance, 13(1), 2012. URL http://www.aeconf.net/Articles/May2012/aef130105.pdf.
- Kinkawa [2010] Takuya Kinkawa. Estimation of optimal portfolio weights using shrinkage technique. 2010. URL http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1576052.
- Ledoit and Wolf [2008] Olivier Ledoit and Michael Wolf. Robust performance hypothesis testing with the Sharpe ratio. Journal of Empirical Finance, 15(5):850–859, Dec 2008. ISSN 0927-5398. doi: http://dx.doi.org/10.1016/j.jempfin.2008.03.002. URL http://www.ledoit.net/jef2008_abstract.htm.
- Leung and Wong [2008] Pui-Lam Leung and Wing-Keung Wong. On testing the equality of multiple Sharpe ratios, with application on the evaluation of iShares. Journal of Risk, 10(3):15–30, 2008. URL http://www.risk.net/digital_assets/4760/v10n3a2.pdf.
- Lo [2002] Andrew W. Lo. The statistics of Sharpe ratios. Financial Analysts Journal, 58(4), July/August 2002. URL http://ssrn.com/paper=377260.
- Magnus and Neudecker [1979] Jan R. Magnus and H. Neudecker. The commutation matrix: Some properties and applications. Ann. Statist., 7(2):381–394, 03 1979. doi: 10.1214/aos/1176344621. URL https://doi.org/10.1214/aos/1176344621.
- Magnus and Neudecker [1980] Jan R. Magnus and H. Neudecker. The elimination matrix: Some lemmas and applications. SIAM Journal on Algebraic Discrete Methods, 1(4):422–449, dec 1980. doi: 10.1137/0601049. URL http://www.janmagnus.nl/papers/JRM008.pdf.
- Magnus and Neudecker [2007] Jan R. Magnus and H. Neudecker. Matrix Differential Calculus with Applications in Statistics and Econometrics. Wiley Series in Probability and Statistics: Texts and References Section. Wiley, 3rd edition, 2007. ISBN 9780471986331. URL http://www.janmagnus.nl/misc/mdc2007-3rdedition.
- Markowitz [1952] Harry Markowitz. Portfolio selection. The Journal of Finance, 7(1):pp. 77–91, 1952. ISSN 00221082. URL http://www.jstor.org/stable/2975974.
- Markowitz [1999] Harry Markowitz. The early history of portfolio theory: 1600-1960. Financial Analysts Journal, pages 5–16, 1999. URL http://www.jstor.org/stable/10.2307/4480178.
- Markowitz [2012] Harry Markowitz. Foundations of portfolio theory. The Journal of Finance, 46(2):469–477, 2012. URL http://onlinelibrary.wiley.com/doi/10.1111/j.1540-6261.1991.tb02669.x/abstract.
- McTaggart and Daroczi [2014] Raymond McTaggart and Gergely Daroczi. Quandl: Quandl Data Connection, 2014. URL http://CRAN.R-project.org/package=Quandl. R package version 2.4.0.
- Mertens [2002] Elmar Mertens. Comments on variance of the IID estimator in Lo (2002). Technical report, Working Paper University of Basel, Wirtschaftswissenschaftliches Zentrum, Department of Finance, 2002. URL http://www.elmarmertens.com/research/discussion/soprano01.pdf.
- Merton [1980] Robert C. Merton. On estimating the expected return on the market: An exploratory investigation. Working Paper 444, National Bureau of Economic Research, February 1980. URL http://www.nber.org/papers/w0444.
- Michaud [1989] Richard O. Michaud. The Markowitz optimization enigma: is ‘optimized’ optimal? Financial Analysts Journal, pages 31–42, 1989. URL http://newfrontieradvisors.com/Research/Articles/documents/markowitz-optimization-enigma-010189.pdf.
- Muller and Peterson [1984] Keith E. Muller and Bercedis L. Peterson. Practical methods for computing power in testing the multivariate general linear hypothesis. Computational Statistics & Data Analysis, 2(2):143–158, 1984. ISSN 0167-9473. doi: 10.1016/0167-9473(84)90002-1. URL http://www.sciencedirect.com/science/article/pii/0167947384900021.
- Mulvey et al. [2003] John M Mulvey, William R Pauling, and Ronald E Madey. Advantages of multiperiod portfolio models. The Journal of Portfolio Management, 29(2):35–45, 2003. doi: 10.3905/jpm.2003.319871. URL http://dx.doi.org/10.3905/jpm.2003.319871#sthash.oKQ9cHFy.jsYuZ7C2.dpuf.
- Nelson [1991] Daniel B. Nelson. Conditional heteroskedasticity in asset returns: A new approach. Econometrica, 59(2):pp. 347–370, 1991. ISSN 00129682. URL http://finance.martinsewell.com/stylized-facts/distribution/Nelson1991.pdf.
- Nocedal and Wright [2006] J. Nocedal and S. J. Wright. Numerical Optimization. Springer series in operations research and financial engineering. Springer, 2006. ISBN 9780387400655. URL http://books.google.com/books?id=VbHYoSyelFcC.
- O’Brien and Shieh [1999] Ralph G. O’Brien and Gwowen Shieh. Pragmatic, unifying algorithm gives power probabilities for common F tests of the multivariate general linear hypothesis, 1999. URL http://www.bio.ri.ccf.org/Power/.
- Okhrin and Schmid [2006] Yarema Okhrin and Wolfgang Schmid. Distributional properties of portfolio weights. Journal of Econometrics, 134(1):235–256, 2006. URL http://www.sciencedirect.com/science/article/pii/S0304407605001442.
- Paulsen and Söhl [2016] Dirk Paulsen and Jakob Söhl. Noise fit, estimation error and a Sharpe information criterion, 2016. URL http://arxiv.org/abs/1602.06186.
- Pav [2014] Steven E. Pav. Bounds on portfolio quality. Privately Published, 2014. URL http://arxiv.org/abs/1409.5936.
- Pav [2017] Steven E. Pav. A short Sharpe course. Privately Published, 2017. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3036276.
- Petersen and Pedersen [2012] Kaare Brandt Petersen and Michael Syskind Pedersen. The matrix cookbook, nov 2012. URL http://www2.imm.dtu.dk/pubdb/p.php?3274. Version 20121115.
- Press [2012] S. J. Press. Applied Multivariate Analysis: Using Bayesian and Frequentist Methods of Inference. Dover Publications, Incorporated, 2012. ISBN 9780486139388. URL http://books.google.com/books?id=WneJJEHYHLYC.
- Rall [1981] L. B. Rall. Automatic Differentiation: Techniques and Applications. Lecture Notes in Computer Science. Springer, 1981. ISBN 9783540108610. URL http://books.google.com/books?id=5QxRAAAAMAAJ.
- Rao [1952] C. Radhakrishna Rao. Advanced Statistical Methods in Biometric Research. John Wiley and Sons, 1952. URL http://books.google.com/books?id=HvFLAAAAMAAJ.
- Rencher [2002] Alvin C. Rencher. Methods of Multivariate Analysis. Wiley series in probability and mathematical statistics. Probability and mathematical statistics. J. Wiley, 2002. ISBN 9780471418894. URL http://books.google.com/books?id=SpvBd7IUCxkC.
- Shieh [2003] Gwowen Shieh. A comparative study of power and sample size calculations for multivariate general linear models. Multivariate Behavioral Research, 38(3):285–307, 2003. doi: 10.1207/S15327906MBR3803˙01. URL http://www.tandfonline.com/doi/abs/10.1207/S15327906MBR3803_01.
- Shieh [2005] Gwowen Shieh. Power and sample size calculations for multivariate linear models with random explanatory variables. Psychometrika, 70(2):347–358, 2005. doi: 10.1007/s11336-003-1094-0. URL https://ir.nctu.edu.tw/bitstream/11536/13599/1/000235235100007.pdf.
- Silvapulle and Sen [2005] Mervyn J. Silvapulle and Pranab Kumar Sen. Constrained statistical inference : inequality, order, and shape restrictions. Wiley-Interscience, Hoboken, N.J., 2005. ISBN 0471208272. URL http://books.google.com/books?isbn=0471208272.
- Tang [1994] Dei-In Tang. Uniformly more powerful tests in a one-sided multivariate problem. Journal of the American Statistical Association, 89(427):pp. 1006–1011, 1994. ISSN 01621459. URL http://www.jstor.org/stable/2290927.
- Timm [2002] N. H. Timm. Applied multivariate analysis: methods and case studies. Springer Texts in Statistics. Physica-Verlag, 2002. ISBN 9780387227719. URL http://amzn.to/TMdgaE.
- Vignat and Bhatnagar [2007] C. Vignat and S. Bhatnagar. An extension of Wick’s theorem, 2007. URL http://arxiv.org/abs/0709.1999.
- Wasserman [2004] Larry Wasserman. All of Statistics: A Concise Course in Statistical Inference. Springer Texts in Statistics. Springer, 2004. ISBN 9780387402727. URL http://books.google.com/books?id=th3fbFI1DaMC.
- Wilks [1938] S. S. Wilks. The large-sample distribution of the likelihood ratio for testing composite hypotheses. The Annals of Mathematical Statistics, 9(1):pp. 60–62, 1938. ISSN 00034851. URL http://www.jstor.org/stable/2957648.
- Yanagihara [2001] Hirokazu Yanagihara. Asymptotic expansions of the null distributions of three test statistics in a nonnormal GMANOVA model. Hiroshima Mathematical Journal, 31(2):213–262, 07 2001. URL http://projecteuclid.org/euclid.hmj/1151105700.
- Zeileis [2004] Achim Zeileis. Econometric computing with HC and HAC covariance matrix estimators. Journal of Statistical Software, 11(10):1–17, 11 2004. ISSN 1548-7660. URL http://www.jstatsoft.org/v11/i10.
Appendix A Matrix Derivatives
Lemma A.1 (Derivatives).
Given conformable, symmetric, matrices , , , and constant matrix , define
Then
| (121) | ||||
| (122) | ||||
| (123) | ||||
| (124) | ||||
| (125) | ||||
| (126) | ||||
| (127) |
Here is the ’commutation matrix.’
Let be the eigenvalue of , with corresponding eigenvector , normalized so that . Then
| (128) |
Proof.
For Equation 121, write
Lemma 2.4 gives the derivative on the left; to get the derivative on the right, note that , then use linearity of the derivative.
For Equation 122, write . Then consider the derivative of with respect to any scalar :
where is the inverse of . That is, is the identity over square matrices. (This wrinkle is needed because we have defined derivatives of matrices to be the derivative of their vectorization.)
For Equation 123, by Equation 122,
Now let be any conformable square matrix. We have:
Because was arbitrary, we have and the result follows.
Using the product rule for Kronecker products [54], then using the vector identity again we have
Then apply this result to every element of to get the result.
For Equation 125, first consider the derivative of with respect to a scalar . This is known to take form: [54]
where the is here because of how we have defined derivatives of matrices. Rewrite the trace as the dot product of two vectors:
Using this to compute the derivative with respect to each element of gives the result. Equation 126 follows from the scalar product rule since . Equation 127 then follows, using the scalar chain rule.
For Equation 128, the derivative of the eigenvalue of matrix with respect to a scalar is known to be: [54, equation (67)]
Take the vectorization of this scalar, and rewrite it in Kronecker form:
Use this to compute the derivative of with respect to each element of .
∎
Lemma A.2 (Cholesky Derivatives).
Let be a symmetric positive definite matrix. Let be its lower triangular Cholesky factor. That is, is the lower triangular matrix such that . Then
| (129) |
where is the ’commutation matrix’. [37]
Appendix B Proofs
Proof of Theorem 3.6.
We note that in the Gaussian case () this result is proved by Magnus and Neudecker, up to a rearrangement in the terms [35, Theorem 4.4 (ii)].
First we suppose that the first element of , rather than being a deterministic 1, is a random variable with mean , no covariance with the elements of , and a variance of . We assume the random first element is such that is elliptically distributed with mean and covariance . After finding the variance of , we will take Below we will use to mean , which converges to our usual definition as .
An extension of Isserlis’ theorem gives the moments of centered elements of . [64, 29] In particular, the first four centered moments are
It is a tedious exercise to compute the raw uncentered moments:
We now want to compute the covariance of with . We have
Now we need only translate this scalar result into the vector result in the theorem. If is -dimensional, then the variance-covariance matrix of is whose element is given above. The term is the element of . The term is the element of . The term is the element of , and thus is the element of . We can similarly identify the terms , , and , and thus
∎
Proof of Corollary 3.9.
From the previous corollary, it suffices to prove the identity of . Define . Then note that Equation 44 becomes
By Lemma 3.5 of Magnus and Neudecker, note that . [36] So consider
Now by Lemma 2.1 of Magnus and Neudecker, , so we can slide the matrix around. Also note that because is symmetric, . Then
where we have slided the matrix to the left, and multiplied by . Now work on the right sides, shifting , collapsing to , and multiplying by from the right:
Now note that . Then
∎
Proof of Theorem 3.11.
Starting from Corollary 2.13, take , with defined in Theorem 3.6. In Equation 38 we give the abbreviated form for .
Because of the symmetry of , we can drop the and terms (but not the matrix). We decompose into four terms based on the terms of .
Now we need some technical results. The first is that for conformable matrices
The other concerns traces with , where , and where is the commutation matrix. Let and be square matrices of the same size, then
| (130) |
The proof is simple: since is a known result, we need only focus on the term. Note then that
This is Magnus and Neudecker Theorem 3.1 (xiii). [35] We will also implicitly use the fact that one can rotate terms in a trace operator. We then tackle the trace terms one at a time.
But note that
thus .
Now consider
Note that
So
Now consider
Proceeding as before we have
Then
Finally
We have
because . Thus .
Putting them together we have
Now consider the term with in Corollary 2.13. Define the four terms as
Again, we will casually drop the and as needed.
Collecting terms,
∎
Appendix C Confirming Theorem 3.11
Here we ‘confirm’ Theorem 3.11, by which we mean we generate random population values of and , then compute from Theorem 3.6, and use it with to generate the estimate values of and from Corollary 2.13. We then compare these to the forms given in Theorem 3.11, finding that they are equal to machine precision. Note that this does nothing to confirm Theorem 3.6 nor Corollary 2.13, rather it gives some assurance that Theorem 3.11 is consistent with those two results.
library(matrixcalc) # linear algebra utilities # quadratic form x’ A x qform <- function(A,x) { t(x) %*% (A %*% x) } # quadratic form x A x’ qoform <- function(A,x) { qform(A,t(x)) } # outer gram: x x’ ogram <- function(x) { x %*% t(x) } # A kron A AkronA <- function(A) { kronecker(A,A,FUN=’*’) } # matrix trace matrace <- function(A) { matrixcalc::matrix.trace(A) } # duplication, elimination, commutation, symmetrizer # commutation matrix; # is pˆ2 x pˆ2 Comm <- function(p) { Ko <- diag(p^2) dummy <- diag(p) newidx <- (row(dummy) - 1) * ncol(dummy) + col(dummy) Ko[newidx,,drop=FALSE] } # Symmetrizing matrix, N # is pˆ2 x pˆ2 Symm <- function(p) { 0.5 * (Comm(p) + diag(p^2)) } # Duplication & Elimination matrices Dupp <- function(p) { matrixcalc::duplication.matrix(n=p) } Elim <- function(p) { matrixcalc::elimination.matrix(n=p) } # vector function fvec <- function(x) { dim(x) <- c(length(x),1) x } # compute Theta from mu, Sigma make_Theta <- function(mu,Sigma) { stopifnot(nrow(Sigma) == ncol(Sigma), nrow(Sigma) == length(mu)) mu_twid <- c(1,mu) Sg_twid <- cbind(0,rbind(0,Sigma)) Theta <- Sg_twid + ogram(mu_twid) Theta_i <- solve(Theta) zeta_sq <- Theta_i[1,1] - 1 list(pp1=nrow(Theta), p=nrow(Theta)-1, mu_twid=mu_twid, Sg_twid=Sg_twid, Theta=Theta, Theta_i=Theta_i, zeta_sq=zeta_sq, zeta=sqrt(zeta_sq)) } # construct four parts of Omega˙0 from the Theorem; Omega_bits <- function(mu,Sigma,kurtf=1) { tvals <- make˙Theta(mu,Sigma) Nmat <- Symm(tvals$pp1) P1 <- (kurtf-1) * ogram(fvec(tvals$Sg_twid)) P2 <- (kurtf-1) * 2 * Nmat %*% AkronA(tvals$Sg_twid) P3 <- 2 * Nmat %*% AkronA(tvals$Theta) P4 <- 2 * Nmat %*% AkronA(ogram(tvals$mu_twid)) list(P1=P1,P2=P2,P3=P3,P4=P4) } Omega_0 <- function(mu,Sigma,kurtf=1) { obits <- Omega˙bits(mu=mu,Sigma=Sigma,kurtf=kurtf) obits$P1 + obits$P2 + obits$P3 - obits$P4 } # construct matrices F and H and vector h FHh_values <- function(mu,Sigma,R=1) { tvals <- make˙Theta(mu,Sigma) zeta_sq <- tvals$zeta_sq zeta <- sqrt(zeta_sq) mp <- t(t(-tvals$Theta_i[2:tvals$pp1,1])) Fmat <- (1 / R^2) * ((ogram(mu) / zeta) - (zeta * Sigma)) H1 <- - cbind(cbind((1 / (2 *zeta_sq)) * mp, (R / zeta) * diag(tvals$p)), matrix(0,nrow=tvals$p,ncol=tvals$p * tvals$pp1)) H2 <- - AkronA(tvals$Theta_i) Hmat <- H1 %*% H2 %*% Dupp(tvals$pp1) hvec <- - AkronA(tvals$Theta_i[1,,drop=FALSE]) %*% Dupp(tvals$pp1) list(Fmat=Fmat, Hmat=Hmat, hvec=hvec) } # compute the expected bias and variance # in two ways, one directly from the identity of # H, F, h and Omega˙0 # the other from the theorem # # then compute relative errors of the theorem’s approximation. testit <- function(mu,Sigma,kurtf=1,R=1) { p <- length(mu) tvals <- make˙Theta(mu,Sigma) OmegMat <- Omega˙0(mu,Sigma,kurtf=kurtf) Omega <- qoform(A=OmegMat,Elim(p+1)) FHh <- FHh˙values(mu,Sigma,R=R) # now test corollary ’true’ values HtFH <- qform(A=FHh$Fmat,x=FHh