Asymptotics of Network Embeddings Learned via Subsampling
Abstract
Network data are ubiquitous in modern machine learning, with tasks of interest including node classification, node clustering and link prediction. A frequent approach begins by learning an Euclidean embedding of the network, to which algorithms developed for vector-valued data are applied. For large networks, embeddings are learned using stochastic gradient methods where the sub-sampling scheme can be freely chosen. Despite the strong empirical performance of such methods, they are not well understood theoretically. Our work encapsulates representation methods using a subsampling approach, such as node2vec, into a single unifying framework. We prove, under the assumption that the graph is exchangeable, that the distribution of the learned embedding vectors asymptotically decouples. Moreover, we characterize the asymptotic distribution and provided rates of convergence, in terms of the latent parameters, which includes the choice of loss function and the embedding dimension. This provides a theoretical foundation to understand what the embedding vectors represent and how well these methods perform on downstream tasks. Notably, we observe that typically used loss functions may lead to shortcomings, such as a lack of Fisher consistency.
Keywords: networks, embeddings, representation learning, graphons, subsampling
1 Introduction
Network data are commonplace in modern-day data analysis tasks. Some examples of network data include social networks detailing interactions between users, citation and knowledge networks between academic papers, and protein-protein interaction networks, where the presence of an edge indicates that two proteins in a common cell interact with each other. With such data, there are several types of tasks we may be interested in. Within a citation network, we can classify different papers as belonging to particular subfields (a community detection task; e.g Fortunato, 2010; Fortunato and Hric, 2016). In protein-protein interaction networks, it is too costly to examine whether every protein pair will interact together (Qi et al., 2006), and so given a partially observed network we are interested in predicting the values of the unobserved edges. As users join a social network, they are recommended individuals who they could interact with (Hasan and Zaki, 2011).
A highly successful approach to solve network prediction tasks is to first learn an embedding or latent representation of the network into some manifold, usually a Euclidean space. A classical way of doing so is to perform principal component analysis or dimension reduction on the Laplacian of the adjacency matrix of the network (Belkin and Niyogi, 2003). This originates from spectral clustering methods (Pothen et al., 1990; Shi and Malik, 2000; Ng et al., 2001), where a clustering algorithm is applied to the matrix formed with the eigenvectors corresponding to the top -eigenvalues of a Laplacian matrix. One shortcoming is that for large data sets, computing the SVD of a large matrix to obtain the eigenvectors becomes increasingly computationally restrictive. Approaches which scale better for larger data sets originate from natural language processing (NLP). DeepWalk (Perozzi et al., 2014) and node2vec (Grover and Leskovec, 2016) are both network embedding methods which apply embedding methods designed for NLP, by treating various types of random walks on a graph as “sentences”, with nodes as “words” within a vocabulary. We refer to Hamilton et al. (2017b) and Cai et al. (2018) for comprehensive overviews of algorithms for creating network embeddings. See Agrawal et al. (2021) for a discussion on how such embedding methods are related to other classical methods such as multidimensional scaling, and embedding methods for other data types.
To obtain an embedding of the network, each node or vertex of the network (say ) is represented by a single -dimensional vector , which are learned by minimizing a loss function between features of the network and the collection of embedding vectors. There are several benefits to this approach. As the learned embeddings capture latent information of each node through a Euclidean vector, we can use traditional machine learning methods (such as logistic regression) to perform a downstream task. The fact that the embeddings lie within a Euclidean space also means that they are amenable to (stochastic) gradient based optimization. One important point is that, unlike in an i.i.d setting where subsamples are essentially always obtained via sampling uniformly at random, here there is substantial freedom in the way in which subsampling is performed. Veitch et al. (2018) shows that this choice has a significant influence in downstream task performance.
Despite their applied success, our current theoretical understanding of methods such as node2vec are lacking. We currently lack quantitative descriptions of what the embedding vectors represent and the information they contain, which has implications for whether the learned embeddings can be useful for downstream tasks. We also do not have quantitative descriptions for how the choice of subsampling scheme affects learned representations. The contributions of our paper in addressing this are threefold:
-
a)
Under the assumption that the observed network arises from an exchangeable graph, we describe the limiting distribution of the embeddings learned via procedures which depend on minimizing losses formed over random subsamples of a network, such as node2vec (Grover and Leskovec, 2016). The limiting distribution depends both on the underlying model of the graph and the choice of subsampling scheme, and we describe it explicitly for common choices of subsampling schemes, such as uniform edge sampling (Tang et al., 2015) or random-walk samplers (Perozzi et al., 2014; Grover and Leskovec, 2016).
-
b)
Embedding methods are frequently learned via minimizing losses which depend on the embedding vectors only through their pairwise inner products. We show that this restricts the class of networks for which an informative embedding can be learned, and that networks generated from distinct probabilistic models can have embeddings which are asymptotically indistinguishable. We also show that this can be fixed by changing the loss to use an indefinite or Krein inner product between the embedding vectors. We illustrate on real data that doing so can lead to improved performance in downstream tasks.
-
c)
We show that for sampling schemes based upon performing random walks on the graph, the learned embeddings are scale-invariant in the following sense. Suppose that we have two identical copies of a network generated from a sparsified exchangeable graph, and on one we delete each edge with probability . Then in the limit as the number of vertices increases to infinity, the asymptotic distributions of the embedding vectors trained on the two networks will be asymptotically distinguishable. We highlight that this may provide some explanation as to the desirability of using random walk based methods for learning embeddings of sparse networks.
1.1 Motivation
We note that several approaches to learn network embeddings (Perozzi et al., 2014; Tang et al., 2015; Grover and Leskovec, 2016) do so by performing stochastic gradient updates of the embedding vectors by updates
| (1) |
Here is the sigmoid function, the sets and are pairs of nodes which are chosen randomly at each iteration (referred to as positive and negative samples respectively) and is a step size. The goal of the objective is to force pairs of vertices within to be close in the embedding space, and those within to be far apart. At the most basic level, we could just have that consists of edges within the graph and non-edges, so that vertices which are disconnected from each other are further apart in the embedding space than those which are connected. In a scheme such as node2vec, arises through a random walk on the network, and arises by choosing vertices according to a unigram negative sampling distribution for each vertex in the random walk .
For simplicity, assume that the only information available for training is a fully observed adjacency matrix of a network of size . Moreover, we let and be random sets which consist only of pairs of vertices which are connected () and not connected () respectively. In this case, if we write , then the algorithm scheme described in (1) arises from trying to minimize the empirical risk function (which depends on the underlying graph )
| (2) |
with a stochastic optimization scheme (Robbins and Monro, 1951), where we write for the cross entropy loss.
This means that the optimization scheme in (1) attempts to find a minimizer of the function defined in (2). We ask several questions about these minimizers where there is currently little understanding:
-
Q1:
To what extent is there a unique minimizer to the empirical risk (2)?
-
Q2:
Does the distribution of the learnt embedding vectors change as a result of changing the underlying sampling scheme? If so, can we describe quantitatively how?
-
Q3:
During learning of the embedding vectors, are we using a loss which limits the information we can capture in a learned representation? If so, can we fix this in some way?
Answering these questions allow us to evaluate the impact of various heuristic choices made in the design of algorithms such as node2vec, where our results will allow us to describe the impact with respect to downstream tasks such as edge prediction. We go into more depth into these questions below, and discuss in Section 1.5 how our main results help address these questions.
1.1.1 Uniqueness of minimizers of the empirical risk
We highlight that the loss and risk functions in (1) and (2) are invariant under any joint transformation of the embedding vectors by an orthogonal matrix . As a result, we can at most ask whether the gram matrix induced by the embedding vectors is uniquely characterized. This is challenging as the embedding dimension is significantly less than the number of vertices - even for networks involving millions of nodes, the embedding dimensions used by practitioners are of the order of magnitude of hundreds. As a result the gram matrix is rank constrained. Consequently, when reformulating (2) to optimize over the matrix , the optimization domain is non-convex, meaning answering this question is non-trivial. Answering this allows us to understand whether the embedding dimension fundamentally influences the representation we are learning, or instead only influences how accurately we can learn such a representation.
1.1.2 Dependence of embeddings on the sampling scheme choice in learning
While we know that random-walk schemes such as node2vec are empirically successful, there has been little discussion as to how the representation learnt by such schemes compares to (for example) schemes where we sample vertices randomly and look at the induced subgraph. This is useful for understanding their performance on downstream tasks such as community detection or link prediction. Another useful example is for when embeddings are used for causal inference (Veitch et al., 2019), where there is the needed to validate assumptions that the embeddings containing information relevant to the prediction of propensity scores and expected outcomes. A final example arises in methods which try and attempt to “de-bias” embeddings through the use of adaptive sampling schemes (Rahman et al., 2019), to understand what extent they satisfy different fairness criteria.
We are also interested in understanding how the hyperparameters of a sampling scheme affect the expected value and variance of gradient estimates when performing stochastic gradient descent. The distinction is important, as the expected value influences the empirical risk being minimized - therefore the underlying representation - and the variance the speed at which an optimization algorithm converges (Dekel et al., 2012). When using stochastic gradient descent in an i.i.d data setting, the mini-batch size does not effect the expected value of the gradient estimate given the observed data, but only its variance, which decreases as the mini-batch size increases. However, for a scheme like node2vec, it is not clear whether hyperparameters such as the random walk length, or the unigram parameter affect the expectation or variance of the gradient estimates (conditional on the graph ).
1.1.3 Information-limiting loss functions
One important property of representations which make them useful for downstream tasks are their ability to differentiate between different graph structures. One way to examine this is to consider different probabilistic models for a network, and to then examine whether the resulting embeddings are distinguishable from each other. If they are not, then this suggests some information about the network has been lost in learning the representation. By examining the range of distributions which have the same learned representation, we can understand this information loss and the effect on downstream task performance.
1.2 Overview of results
1.2.1 Embedding methods implicitly fit graphon models
We highlight that the loss in (2) is the same as the loss obtained by maximizing the log-likelihood formed by a probabilistic model for the network of the form
| (3) |
using stochastic gradient ascent. Here is a closed set corresponding to a constrained set for the embedding vectors. In the limit as the number of vertices increases to infinity, such a model corresponds to an exchangeable graph (Lovász, 2012), as the infinite adjacency matrices are invariant to a permutation of the labels of the vertices.
In an exchangeable graph, each vertex has a latent feature , with edges arising independently with for a function called a graphon; see Lovász (2012) for an overview. Such models can be thought of as generalizations of a stochastic block model (Holland et al., 1983), which have a correspondence to when the function is a piecewise constant function on sets for some partition of , with the partitions acting as the different communities within the SBM. If is the size of , and we write for the value of on , this is equivalent to the usual presentation of a stochastic block model
| (4) |
where is the community label of vertex . One can also consider sparsified exchangeable graphs, where for a graph on vertices, edges are generated with probability for a graphon and a sparsity factor as . This accounts for the fact that most real world graphs are not “dense” and do not have the number of edges scaling as ; in a sparsified graphon, the number of edges now scales as .
For the purposes of theoretical analysis, we look at the minimizers of (2) when the network arises as a finite sample observation from a sparsified exchangeable graph whose graphon is sufficiently regular. We then examine statistically the behavior of the minimizers as the number of vertices grows towards infinity. As embedding methods are frequently used on very large networks, a large sample statistical analysis is well suited for this task. One important observation is that even when the observed data is from a sparse graph, embedding methods which fall under (3) are implicitly fitting a dense model to the data. As we know empirically that embedding methods such as node2vec produce useful representations in sparse settings, we introduce the sparsity to allow some insight as to how this can occur.
1.2.2 Types of results obtained
We now discuss our main results, with a general overview followed by explicit examples. In Theorems 10 and 19, we show that under regularity assumptions on the graphon, in the limit as the number of vertices increases to infinity, we have for any sequence of minimizers to that
| (5) |
for a function we determine, and rate . Both and depend on the graphon and the choice of sampling scheme. The rate also depends on the embedding dimension ; we note that our results may sometimes require as in order for , but will always do so sub-linearly with . As a result (5) allows us to guarantee that on average, the inner products between embedding vectors contain some information about the underlying structure of the graph, as parameterized through the graphon function . One notable application of this type of result is that it allows us to give guarantees for the asymptotic risk on edge prediction tasks, when using the values as scores to threshold for whether there is the presence of an edge in the graph. Our results apply to sparsified exchangeable graphs whose graphons are either piecewise constant (corresponding to a stochastic block model), or piecewise Hölder continuous.
To show how our results address the questions introduced in Section 1.1, and to highlight the connection with using the embedding vectors for edge prediction tasks, we give explicit examples (with minimal additiional notation) of results which can be obtained from the main theorems of the paper. For the remainder of the section, suppose that
denotes the cross-entropy loss function (where and ). We consider graphs which arise from a sub-family of stochastic block models - frequently called SBM models - where a graph of size is generated via the probabilistic model
| (6) |
Here is a sparsifying sequence. For our results below, we will consider the cases when or (so in the second case). With regards to the choice of sampling schemes, we consider two choices:
-
i)
Uniform vertex sampling: A sampling scheme where we select vertices uniformly at random, and then form a loss over the induced sub-graph formed by these vertices.
- ii)
Recall that defining a sampling scheme and a loss function induces a empirical risk as given in (2), with the sampling scheme defining sampling probabilities . Below we will give theorem statements for two types of empirical risks, depending on how we combine two embedding vectors and to give a scalar. The first uses a regular positive definite inner product , and the second uses a Krein inner product, which takes the form where is a diagonal matrix with entries .
Supposing we have embedding vectors , we consider the risks
| (7) | ||||
| (8) |
where and is the -dimensional identity matrix. With this, we are now in a position to state results of the form given in (5). As it is easier to state results when using the second risk , we will begin with this, and state two results corresponding to either the uniform vertex sampling scheme, or the node2vec sampling scheme. We then discuss implications of the results afterwards.
Theorem 1
Suppose that we use the uniform vertex sampling scheme described above, we choose the embedding dimension , and for all . Then for any sequence of minimizers to , we have that
in probability as , where is the matrix
Theorem 2
Suppose in Theorem 1 we instead use the node2vec sampling scheme described earlier, and now either or . Then the same convergence guarantee holds, except now the matrix takes the form
With these two results, we make a few observations:
-
i)
In our convergence theorems, we say that for any sequence of minimizers, the matrix will have the same limiting distribution. Although here we explicitly choose , can be any sequence which which diverges to infinity (provided it does so sufficiently slowly) and have the same result hold. Consequently, this suggests that up to symmetry and statistical error, the minimizers of the empirical risk will be essentially unique, giving an answer to Q1.
-
ii)
For different sampling schemes, we are able to give a closed form description of the limiting distribution of the matrices , and we can see that they are different for different sampling schemes. This affirms Q2 as posed above in the positive. One interesting observation from the Theorems 1 and 2 is the dependence on the sparsity factor. While a uniform vertex sampling scheme does not work well in the sparsified setting (and so we give convergence results only when ) in node2vec the representation remains stable in the limit when .
-
iii)
Theorem 1 tells us that if we use a uniform sampling scheme, then using the Krein inner product during learning and the as scores, we are able to perform edge prediction up to the information theoretic threshold.
-
iv)
If in Theorem 2 we instead let the walk length in node2vec to be of length , the term in the limiting distribution for node2vec would be replaced by . This means that in the limit , the limiting distribution is independent of the walk length. We discuss later in Section 4.1 the roles of the hyperparameters in node2vec, and argue that the walk length places a role in only reducing the variance of gradient estimates.
So far we have only given results for minimizers of the loss . We now give an example of a convergence result for , and afterwards discuss how this result addresses Q3 as posed above.
Theorem 3
Suppose the graph arises from a SBM() model. Let denote the inverse sigmoid function. Suppose that we use the uniform vertex sampling scheme described above, the embedding dimension satisfies and . Then for any sequence of minimizers to , we have that
and the values of and depend on and as follows:
-
a)
If and , then and ;
-
b)
If and , then ;
-
c)
If and , then ;
-
d)
Otherwise, .
From the above theorem we can see that the representation produced is not an invertible function of the model from which the data arose. For example in the regime where and , the representation depends only on the size of the gap , and so one can choose different values of for which the limiting distribution is the same. This answers the first part of Q3. (We discuss this further in Section 3.4; see the discussion after Proposition 20.) In contrast, this does not occur in Theorem 1 - the representation learned is an invertible function of the underlying model. Theorem 3 also highlights that, when using only the regular inner product during training and scores , there are regimes (such as when ) where the scores produced will be unsuitable for purposes of edge prediction.
The fundamental difference between Theorems 1 and 3 is that the risk we consider in Theorem 1 arises by making the implicit assumption that the network arises from a probabilistic model . This means the inverse-logit matrix of edge probabilities are not constrained to be positive-definite, whereas using as in (3) to give places a positive-definite constraint on this matrix. This can be interpreted as a form of model misspecification of the data generating process. To address the information loss which occurs when parameterizing the loss through inner products , we can fix this by replacing it with a Krein inner product. This gives an answer to the second part of Q3. We later demonstrate that making this change can lead to improved performance when using the learned embeddings for downstream tasks on real data (Section 5.2), suggesting these findings are not just an artefact of just the type of models we consider.
1.3 Related works
There is a large literature looking at embeddings formed via spectral clustering methods under various network models from a statistical perspective; see e.g Ma et al. (2021); Deng et al. (2021) for some recent examples. For models supporting a natural community structure, these frequently take the form of giving guarantees on the behavior of the embeddings, and then argue that using a clustering method with the embedding vectors allows for weak/strong consistency of community detection. See Abbe (2017) for an overview of the information theoretic thresholds for the different type of recovery guarantees.
Lei and Rinaldo (2015) consider spectral clustering using the eigenvectors of the adjacency matrix for a stochastic block model. Rubin-Delanchy et al. (2017) consider spectral embeddings using both the adjacency matrix and Laplacian matrices from models arising from generative models of the form where ) and the are i.i.d random variables with known and fixed - such graphs are referred to frequently as dot product graphs. These allow for a broader class of models than stochastic block models, such as mixed-membership models. The case was considered by Tang and Priebe (2018), with central limit theorem results given in Levin et al. (2021); see Athreya et al. (2018) for a broader review of statistical analyses of various methods on these graphs. In Lei (2021), they consider similar models where where is a Krein space (formally, this is a direct sum of Hilbert spaces equipped with an indefinite inner product, formed by taking the difference of the inner products on the summand Hilbert spaces), with their results applying to non-negative definite graphons and graphons which are Hölder continuous for exponents . They then discuss the estimation of the using the eigendecomposition of the adjacency matrix (which we have noted can be viewed as a type of embedding) from a functional data analysis perspective. We note that in our work we do not directly assume a model of such a form, but some of our proofs use some similar ideas.
With regards to embeddings learned via random walk approaches such as node2vec (Grover and Leskovec, 2016), there are a few works which study modified loss functions. To be precise, these suppose that each vertex has two embedding vectors and , with terms of the form replaced in the loss with , and , are allowed to vary independently with each other. Qiu et al. (2018) study several different embedding methods within this context (including those involving random walks) where they explicitly write down the closed form of the minimizing matrix for the loss having averaged over the random walk process when and is fixed. In order to be always able to write down explicitly the minimizing matrix, they rely on the assumption that and that and are unconstrained of each other, so that the matrix is unconstrained. This avoids the issues of non-convexity in the problem. We note that in our work we are able to handle the case where we enforce the constraints (as in the original node2vec paper) and , so we address the non-convexity.
Zhang and Tang (2021) then considers the same minimizing matrix as in Qiu et al. (2018) for stochastic block models, and examines the best rank approximation (with respect to the Frobenius norm) to this matrix, in the regime where and is less than or equal to the number of communities. We comment that our work gives convergence guarantees under broad families of sampling schemes, including - but not limited to - those involving random walks, and for general smooth graphons rather than only stochastic block models. Veitch et al. (2018) discusses the role of subsampling as a model choice, within the context of specifying stochastic gradient schemes for empirical risk minimization for learning network representations, and highlights the role they play in empirical performance.
1.4 Notation and nomenclature
For this section, we write for the Lebesgue measure, the interior of a set and as the closure of . We say that a partition of , written , is a finite collection of pairwise disjoint, connected sets whose union is , and and for all . For a partition of , we define
which gives a partition of . A refinement of is a partition where for every , there exists a (necessarily unique) such that .
We say a function is Hölder, where is closed and , are constants, if
We say a function is piecewise Hölder if the following holds: for any , the restriction admits a continuous extension to , with this extension being Hölder. Similarly, we say that a function is piecewise continuous on if for every , admits a continuous extension to .
For a graph with vertex set and edge set , we let denote the adjacency matrix of , so iff . Here we consider undirected graphs with no self-loops, so ; we count and together as one edge. For such a graph, we let
-
•
denote the number of edges of ;
-
•
denotes the degree of the vertex , so .
A subsample of a graph is a collection of vertices , along with a symmetric subset of the adjacency matrix of restricted to ; that is, a subset of . The notation therefore refers to whether is an element of the aforementioned subset of .
In the paper, we consider sequences of random graphs generated by a sequence of graphons . A graphon is a symmetric measurable function . To generate these graphs, we draw latent variables independently for , and then for set
independently, and for . We then let be the graph formed with adjacency matrix restricted to the first vertices. Unless mentioned otherwise, we understand that references to and - now dropping the superscript - refer to the above generative process. For a graphon , we will denote
-
•
for the edge density of ;
-
•
for the degree function of ;
-
•
, so .
Given a sequence of random graphs generated in the above fashion, we define the random variables and for the number of edges, and degrees of a vertex in , respectively.
For triangular arrays of random variables and , we say that if for all , , there exists such that for all we have that . If can be chosen uniformly in , then we simply write . We use similar notation for , (where iff ), (where iff ) and (where iff and ). For non-stochastic quantities, we use similar notation, except that we drop the subscript . Throughout, we use the notation to denote the measure of sets; specifically, if then is the number of elements of the set , and if then or is the Lebesgue measure of the set . Similarly, for sequences and functions, we use to denote the or norms respectively. The notation indicates the set of integers .
1.5 Outline of paper
In Section 2, we discuss the main object of study in the paper, and the assumptions we require throughout. The assumptions concern the data generating process of the observed network, the behavior of the subsampling scheme used, and the properties of the loss function used to learn embedding vectors. Section 3 consist of the main theoretical results of the paper, giving a consistency result for the learned embedding vectors under different subsampling schemes. Section 4 gives examples of subsampling schemes which our approach allows us to analyze, and highlights a scale invariance property of subsampling schemes which perform random walks on a graph. In Section 5, we demonstrate on real data the benefit in using an indefinite or Krein inner product between embedding vectors, and demonstrate the validity of our theoretical results on simulated data. Proofs are deferred to the appendix, with a brief outline of the ideas used for the main results given in Appendix B.
2 Framework of analysis
We consider the problem of minimizing the empirical risk function
| (9) |
where we have that
-
i)
the embedding vectors are -dimensional (where is allowed to grow with ), with corresponding to the embedding of vertex of the graph;
-
ii)
is a non-negative loss function;
-
iii)
is a (bilinear) similarity measure between embedding vectors; and
-
iv)
refers to a stochastic subsampling scheme of the graph , with representing a graph on vertices.
We now discuss our assumptions for the analysis of this object, which relate to a generative model of the graph , the loss function used, and the properties of the subsampling scheme. For purposes of readability, we first provide a simplified set of assumptions, and give a general set of assumptions for which our theoretical results hold in Appendix A.
2.1 Data generating process of the network
We begin by imposing some regularity conditions on the data generating process of the network. Recall that we assume the graphs are generated from a graphon process with latent variables and generating graphon , where is a graphon and is a sparsity factor which may shrink to zero as .
Remark 4
The above assumption corresponds to the graph being an exchangeable graph. Parameterizing such graphs through a graphon and one dimensional latent variables is a canonical choice as a result of the Aldous-Hoover theorem (e.g Aldous, 1981), and is extensive in the network analysis literature. However, this is not the only possible choice for the latent space. More generally we could consider some probability measure on , and a symmetric measurable function , where the graph is generated by assigning a latent variable independently for each vertex, and then joining vertices with an edge independently of each other with probability .
From a modelling perspective a higher dimensional latent space is desirable; an interesting fact is that any such graph is equivalent in law to one drawn from a graphon with latent variables (Janson, 2009, Theorem 7.1). As a simple illustration of this fact, suppose that users in a social network graph have characteristics for some , and that two individuals and are connected in the network (independently of any other pair of users) with probability , which depends only on their characteristics. Assuming that the are drawn i.i.d from a distribution on , we can always simulate such a distribution by partitioning according to the probability mass function , drawing a latent variable , and then assigning to the value corresponding to the part of the partition of for which landed in. Letting denote this mapping, the model is then equivalent to a one with a graphon . Consequently, our results will be presented mostly in terms of graphons . However, they can be extended with relative ease to graphons with higher dimensional latent spaces, which we discuss further in Section 3.3.
Assumption 1 (Regularity + smoothness of the graphon)
We suppose that the sequence of graphons generating are, up to weak equivalence of graphons (Lovász, 2012), such that i) the graphon is piecewise Hölder, , , for some partition of and constants , ; ii) there exist constants such that and a.e; and iii) the sparsifying sequence is such that .
Remark 5
We will briefly discuss the implications of the above assumptions. The smoothness assumptions in a) are standard when assuming networks are generated from graphon models (e.g Wolfe and Olhede, 2013; Gao et al., 2015; Klopp et al., 2017; Xu, 2018). The assumption in b) that is bounded from below is strong, and is weakened in the most general assumptions listed in Appendix A. This, along with the assumption that , implies that the degree structure of is regular, in that the degrees of every vertex are roughly of the same order, and will grow to infinity as does; this is a limitation in that real world networks do not always exhibit this type of behavior, and have either scale-free or heavy-tailed degree distributions (e.g Albert et al., 1999; Broido and Clauset, 2019; Zhou et al., 2020). Regardless of the sparsity factor, graphon models will tend to have structural deficits; for example, they tend to not give rise to partially isolated substructures (Orbanz, 2017). We note that assumptions on the sparsity factor where grows like for some , remain standard when using graphons as a tool for theoretical analyses (e.g Wolfe and Olhede, 2013; Borgs et al., 2015; Klopp et al., 2017; Xu, 2018; Oono and Suzuki, 2021). Future work could extend our results to generalizations of graphon models, such as graphex models (Veitch and Roy, 2015; Borgs et al., 2019), which better account for issues of sparsity and regularity of graphs.
2.2 Assumptions on the loss function and
We now discuss our assumptions on the loss function , which we follow with a discussion as to the form of the functions .
Assumption 2 (Form of the loss function)
We assume that the loss function is equal to the cross-entropy loss
| (10) |
where is the sigmoid function.
We note that our analysis can be extended to loss functions of the form
where corresponds to a distribution which is continuous, symmetric about and strictly log-concave. This includes the probit loss (Assumption BI), or more general classes of strictly convex functions which include the squared loss (Assumption B). We now discuss the form of .
Assumption 3 (Properties of the similarity measure )
Supposing we have embedding vectors , we assume that the similarity measure is equal to one of the following bilinear forms:
-
i)
(i.e a regular or definite inner product) or
-
ii)
for some (i.e an indefinite or Krein inner product);
where , for , and .
2.3 Assumptions on the sampling scheme
We now introduce our assumptions on the sampling scheme. For most subsampling schemes, the probability that the pair is part of the subsample depends only on local features of the underlying graph . We formalize this notion as follows:
Assumption 4 (Strong local convergence)
There exists a sequence of -measurable functions, with for each , such that
for some non-negative sequence .
We refer to the as sampling weights. This condition implies that the probability that is sampled depends approximately on only local information, namely the latent variables , and the value of , i.e that
| (11) |
As a result of the concentration of measure phenomenon, many sampling frameworks satisfy this condition (see Section 4). This includes those used in practice, such as uniform vertex sampling, uniform edge sampling (Tang et al., 2015), along with “random walk with unigram negative sampling” schemes like those of Deepwalk (Perozzi et al., 2014) and node2vec (Grover and Leskovec, 2016). In particular, we are able to give explicit formulae for the sampling weights in these scenarios. We also impose some regularity conditions on the conditional averages of the sampling weights.
Assumption 5 (Regularity of the sampling weighs)
Remark 6
For all the sampling schemes we consider, the conditions on and will follow from Assumption 1 and the formulae for the sampling weights we derive in Section 4; in particular, the exponent will be a function of and the particular choice of sampling scheme. To illustrate this, if we suppose that we use a random walk scheme with unigram negative sampling (Perozzi et al., 2014) as later described in Algorithm 4, we show later (Proposition 26) that
| (12) | ||||
| (13) |
where , and are hyperparameters of the sampling scheme. In particular, if is piecewise Hölder with exponent , then we show (Lemma 82) that and will be piecewise Hölder with exponent .
3 Asymptotics of the learned embedding vectors
In this section, we discuss the population risk corresponding to the empirical risk (9), show that any minimizer of (9) converges to a minimizer of this population risk, and then discuss some implications and uses of this result.
3.1 Convergence of empirical risk to population risk
Given the empirical risk (9), and assuming that the embedding vectors are constrained to lie within a compact set for some , our first result shows that the population limit analogue of (9) has the form
| (14) |
where the domain consists of functions for functions . We can interpret as giving embedding vectors for vertices with latent feature , with then measuring the similarity between two vertices with latent features and . We write
| (15) |
for all such functions which are represented in this fashion. We then have that the minimized empirical risk converges to the minimized population risk :
Theorem 7
The proof can be found in Appendix C (with Theorem 30 stating a more general result under the assumptions listed in Appendix A), with a proof sketch in Appendix B.
Remark 8
The error term above consists of three parts. The term relates to the fluctuations of the empirical sampling probabilities to the sampling weights and . The second term arises as the penalty for getting uniform convergence of the loss functions when averaged over the adjacency assignments. The final term arises from using a stochastic block approximation for the functions and , and optimizing the tradeoff between the number of blocks for approximating these functions, and the relative error in the proportion of the in a block versus the size of the block.
Remark 9
Typically for random walk schemes we have that and under Assumption 1, and so the error term is of the form
One affect of this is that as decreases in magnitude, the permissable embedding dimensions decrease also; we also always require that in order for the rate .
3.2 Convergence of the learned embedding vectors
We now argue that the minimizers of (9) converge in an appropriate sense to a minimizer of over a constraint set which depends on the choice of similarity measure . Before considering any constrained estimation of , we highlight that depending on the form of , we can write down a closed form to the unconstrained minimizer of over all (symmetric) functions . When is the cross-entropy loss, by minimizing the integrand of point-wise, the unconstrained minimizer of will equal
| (16) |
As and are proportional to and respectively, we are learning a re-weighting of the original graphon. As a special case, if the sampling formulae are such that (so the probability that a pair of vertices is sampled is asymptotically independent of whether they are connected in the underlying graph) then (16) simplifies to the equation . This is the case for a sampling scheme which samples vertices uniformly at random and then returns the induced subgraph (Algorithm 1). Otherwise, will still depend on , but may not be an invertible transformation of ; for example, for a random walk sampler with walk length , one negative sample per positively sampled vertex, and a unigram negative sampler with (Algorithm 4), we get that
| (17) |
As a result of Theorem 7, we posit that when taking as , the embedding vectors learned via minimizing (9) will converge to a minimizer of when is constrained to the “limit” of the sets in (15) as . As this set depends on , whether is a positive-definite inner product (or not) corresponds to whether is constrained to being non-negative definite (or not) in the following sense: suppose allows an expansion of the form
| (18) |
for some numbers and orthonormal functions . Then, are the all non-negative - in which case is non-negative definite - or not? We prove in Appendix H that as a consequence of our assumptions, we can write
| (19) |
where for each the collection of functions are orthonormal. With this, we begin with giving a convergence guarantee when for all . In this case, is the limiting distribution of the inner products of the embedding vectors learned via minimizing (9).
Theorem 10
Suppose that Assumptions 1, 2, 4 and 5 hold. Also suppose that Assumption 3 holds with with . Finally, suppose that in (19) the are non-negative for all . Then there exists sufficiently large such that whenever , for any sequence of minimizers , we have that
In the case where the and are piecewise constant on a fixed partition for all , where is a partition of into parts, then is piecewise constant on also, there exists such that, then provided , the above convergence result holds with
See Theorem 66 in Appendix D for the proof, with the latter theorem holding under more general regularity conditions. We highlight that in the above theorem, one can also take with and and have the convergence theorem also hold, with the term being replaced by a term.
Remark 11
In the above bound for , the first three terms correspond to the terms in the convergence of the loss function as in Theorem 7. The fourth term arises from relating the matrix back to the function . The fifth term arises from the error in considering the difference between and the best rank approximation to ; in particular, if is actually finite rank in that for all , for some free of , then provided we can discard the term, and so under the conditions in which the rate in Theorem 7 converges to zero, the rate in Theorem 10 also goes to zero as .
In general, from the above result we can argue that there exists a sequence of embedding dimensions such that as , albeit possibly at a slow rate (by choosing e.g for very small). If the and are piecewise constant on a partition of size , then it is in fact possible to obtain consistency as soon as and . Here, there is a tradeoff between choosing large enough so that we get a good rank approximation to , and keeping the capacity of the optimization domain sufficiently small that the convergence of the minimal loss values is quick (see Remark 13 for a discussion of choosing optimally).
We finally note that in the statement of Theorem 10 the constant is held fixed; it is however possible to take and have the bound increase only by a multiplicative factor of for some constant .
In the case where some of the are negative, we can obtain a similar result which gives convergence to , although now choosing is necessary. We show later in Proposition 20 an example of a two community SBM which highlights the necessity of using a Krein inner product.
Theorem 12
Suppose that Assumptions 1, 2, 3, 4 and 5 hold. Given an embedding dimension , pick and in where , such that is equal to the number of non-negative values out of the absolutely largest values of in (19). Then there exists sufficiently large such that whenever , for any sequence of minimizers , we have that
In the case where the and are piecewise constant on a fixed partition for all , where is a partition of into parts, then there exists for which, as soon as , we have that the above convergence result holds with
Remark 13
The term above is the analogue of the term in Theorem 10, which arises from the fact that the decay of the as a function of is quicker when we can guarantee that they are all positive. Consequently, we have analogous remarks for that if the are all zero for , then as soon as , this term will disappear. Similarly, the term arises from looking at the best rank approximation to . As the eigenvalues can be positive and negative, the choice of and means we choose the top eigenvalues (by absolute value) for any given , and so we can obtain the rate. To see how the rates of convergence are affected by the optimal choice of embedding dimension , when and , optimizing over gives
and so the last term will tend to dominate in the sparse regime.
To summarize, Theorems 10 and 12 characterize the distribution of pairs of embedding vectors, through the similarity measure used for training. They show that the distribution of embedding vectors asymptotically decouple in that, in an average sense, the distribution of depends only on the latent features for the respective vertices. Moreover, when we have a cross-entropy loss and the similarity measure is correctly specified, we can explicitly write down the limiting distribution in terms of the sampling formulae corresponding to the choice of sampling scheme, and the original generating graphon.
3.3 Extension to graphons on higher dimensional latent spaces
As discussed earlier in Remark 4, it is possible to consider graphons more generally as functions with latent variables drawn from some probability distribution on . As these can always be made equivalent to graphons , there is a natural question as to whether our results can be applied to higher dimensional graphons. To illustrate that we can do so, here we illustrate what occurs when we have a graphon with latent variables independently for some , with a graphon function :
Assumption 6 (Graphon with high dimensional latent factors)
Suppose that the are generated by a sequence of graphons where; the latent parameters for some ; the graphon is symmetric and piecewise Hölder for some partition of ; there exist constants such that a.e; and . Moreover, we suppose that the functions
defined for , are piecewise Hölder for some exponent ; are uniformly bounded above; and uniformly bounded below and away from zero.
To apply our existing results, we will make use of the following theorem.
Theorem 14
Let be a graphon on which is Hölder. Then there exists an equivalent graphon on which is Hölder where depends only on and . Moreover, for any and function we have that .
Proof [Proof of Theorem 14]
The first part is simply Theorem 2.1 of Janson and Olhede (2021), which uses the fact that there exists a measure preserving map which is Hölder(, ) for some constant , in which case is equivalent to and is Hölder. The second part then follows by the change of variables formulae and the fact that is measure preserving.
In this setting, the population risk (14) is now of the form
| (20) |
We can now obtain analogous versions of Theorems 7 and 12 as follows:
Theorem 16
Suppose that Assumptions 2, 3 and 6 hold, and that we use Algorithm 4 (random walk + unigram negative sampling) for the sampling scheme with , so that in Assumption 6. Under the same assumptions on the choice of the embedding dimension as given in Theorem 12, it follows that there exists sufficiently large such that whenever , for any sequence of minimizers , we have that
where
Remark 17
We note that the rates of convergence in Theorems 15 and 16 depend on the dimension of the latent parameters. This cannot be avoided by our proof strategy - if we manually modified the proof, rather than simply applying Theorem 14, we would still end up with the same rates of convergence. For example, part of our bounds depend on the decay of the eigenvalues of the operator , which under our smoothness assumptions will have eigenvalues decay as (Birman and Solomyak, 1977). We highlight that such dependence on the latent dimension is common for other tasks involving networks, such as graphon estimation (Xu, 2018), and such dependence commonly arises in non-parametric estimation tasks (Tsybakov, 2008).
Remark 18
We highlight that there is some debate as to the types of graphs which can arise from latent variable models when the latent dimension is high (Seshadhri et al., 2020; Chanpuriya et al., 2020). We highlight that this is distinct from matters of what embedding dimensions should be chosen when fitting an embedding model, as methods such as node2vec are not necessarily trying to recover exactly the latent variables used as part of a generative model. For example, from Theorem 16 above, if we suppose that and substitute this into the given formula for , we can see that is not a function of due to the terms in the denominator.
3.4 Importance of the choice of similarity measure
Theorem 10 only applies when the in (19) are all non-negative, and Theorem 12 only applies to the case where we have some negative and we make the choice of . We now study the case where there are some negative and we choose .
Theorem 19
Suppose that Assumptions 1, 2, 4 and 5 hold, and suppose that Assumption 3 holds with denoting the inner product on . Define
where the closure is taken in a suitable topology (see Appendix D.2). Note that the set does not depend on (see Lemma 55). Then there exists a unique minimizer to over . Under some further regularity conditions (see Theorem 66), there exists and a sequence of embedding dimensions , such that whenever , for any sequence of minimizers , we have that
If moreover we know that and are piecewise constant on a fixed partition for all , where is a partition of into parts, then is also piecewise constant on the partition , and can be calculated exactly via a finite dimensional convex program.
In the case where we select , we now argue that this leads to a lack of injectivity - it will not be possible to distinguish two different graph distributions from the learned embeddings alone. As a consequence, there is necessarily some information about the network lost, the importance of which depends on the downstream task at hand. For example, suppose the graph is generated by a two-community stochastic block model with even sized communities, with within-community edge probability and between-community edge probability . We then have the following:
Proposition 20
Suppose that the graphon corresponds to a SBM with two communities of equal size, such that the within-community edge probability is and the between-community edge probability is ; i.e that
and that we learn embeddings using a cross entropy loss and a uniform vertex subsampling scheme (Algorithm 1 in Section 4). Then the global minima of over is given by
where
-
a)
if and , then , ;
-
b)
if and , then ;
-
c)
if and , then ;
-
d)
otherwise, , .
Lack of injectivity: As mentioned earlier, we can have multiple graphons for which the minima of over non-negative definite are identical; for instance, note that in the above example when and , then the minima of over non-negative definite depends only on the gap .
Loss of information: In the case where and , Theorem 19 and Proposition 20 tell us that the embedding vectors learned via minimizing (9) will satisfy
In particular, the generating graphon cannot be directly recovered from as it only identified up to the value of . Despite this, we note that still preserves the community structure of the network, in that if and only if and belong to the same community. It therefore follows that asymptotically, on average the learned embedding vectors corresponding to vertices in the same community are positively correlated, whereas those in opposing communities are negatively correlated.
When the minima is a constant function (such as when above), the limiting distribution contains no usable information about the underlying graphon, and therefore neither do the inner products of the learned embedding vectors. We discuss when this occurs for general graphon models in Proposition 71. In all, this highlights the advantage in using a Krein inner product between embedding vectors, as these issues are avoided. Later in Section 5.2 we observe empirically the benefits of making such a choice.
3.5 Application of embedding convergence: performance of link prediction
We discuss the asymptotic performance of embedding methods when used for a link prediction downstream task. Consider the scenario where we make a partial observation of an underlying network , with the property that if then , but if , we do not know whether or . For example, this model is appropriate for when we are wanting to predict the future evolution of a network. The task is then to make predictions about using the observed data .
In the context above, link prediction algorithms frequently use the network to produce a score corresponding to the likelihood of whether the pair is an edge in the network . The scores are usually interpreted so that the larger is, the more likely it will occur that . We consider metrics to evaluate performance of the form
| (21) |
when using the scores to predict the presence of edges in a network . We write for a discrepancy measure between the predicted score and an observed edge or non-edge in the test set. For example, in the case where
| (22) |
is a zero-one loss (having thresholded the scores by to obtain a -valued prediction), (21) becomes the misclassification error. Smoother losses can be obtained by using
| (23) | ||||
| (24) |
i.e the softmax cross-entropy or hinge losses respectively. Given a network embedding with embedding vectors for each vertex , one frequent way of producing scores is to let where is a similarity measure as in Assumption 3. By applying Theorems 10, 12 or 19, we can begin to analyze the performance of a link prediction method using scores produced by embeddings learned via minimizing (9).
Proposition 21
Let be the set of symmetric adjacency matrices on vertices with no self-loops. Suppose that is a sequence of adjacency matrices drawn from a graphon process satisfying the conditions in one of Theorems 10, 12 or 19, with denoting the embedding vectors learned via minimizing (9) using . Let be the minimal value of which appears in the aforementioned convergence theorems, and the corresponding convergence rate. Recall that denotes the similarity measure in Assumption 3. Write and for the scoring matrices formed by using the learned embeddings from minimizing (9) and respectively. Then we have that for any loss function which is Lipschitz in for that
When denotes (21) using the zero-one loss with threshold , further assume that there exists a finite set for which
| (25) |
Then for any sequence with as , we have that
Remark 22
We note that examples of loss functions which are Lipschitz include the hinge loss (24), along with any ‘clipped’ version of the softmax cross entropy loss (23), where the scores are truncated so that the loss does not become unbounded as . A sufficient condition for the regularity condition (25) to hold is that the total number of jumps in the distribution functions associated to the for all is finite; for example, this occurs if is a piecewise constant function.
We now illustrate a use of the theorem above, in the context of the censoring example introduced at the beginning of the section. Suppose that the network is generated via a graphon . We then calculate that
independently across all pairs (as the probability that given is zero). If we further have that for some symmetric, measurable function , then also has the law of an exchangeable graph. As a simple example, we could consider , corresponding to edges being randomly deleted from .
If we instead assume that has the law of an exchangeable graph with graphon , then we can calculate that
independently across all pairs . Again, if , then will have the law of an exchangeable graph too. For example, in the context of the social network example, one may suppose that the likelihood of an edge forming between two vertices is linked to the proportion of users who they are both connected with, or that it is linked to their respective degrees. We could then hypothesize that e.g
If either of the conditions hold, we can switch between using or by using and respectively.
Now suppose that we learn an embedding using the network to produce a scoring matrix (as described above) to make predictions about . Moreover assume that in (9) we use the cross-entropy loss, a Krein inner product for the bilinear from , and that satisfies the conditions in Theorem 12. This implies that the optimal value of (where and are functions of , and so we make the dependence on explicit) is given by as in (16). Provided the number of vertices in is large, Proposition 21 tells us that will be approximately equal to . When is the softmax cross-entropy loss, we then get that
| (26) | ||||
With the expression on the right hand side, it is then possible to numerically investigate for which network models (given a fixed entropy) will a particular choice of sampling scheme be effective in combating particular types of censoring. This is because once the entropy of has been fixed, minimizing the RHS in (26) corresponds to minimizing the KL divergence between the measures with densities
defined for and .
4 Asymptotic local formulae for various sampling schemes
In this section we show that frequently used sampling schemes satisfy the strong local convergence assumption (Assumption 4) and give the corresponding sampling formulae and rates of convergence. We leave the corresponding proofs to Appendix F. We begin with a scheme which simply selects vertices of the graph at random.
Algorithm 1 (Uniform vertex sampling)
Given a graph and number of samples , we select vertices from uniformly and without replacement, and then return as the induced subgraph using these sampled vertices.
Proposition 23
We now consider uniform edge sampling (e.g Tang et al., 2015), complemented with a unigram negative sampling regime (e.g Mikolov et al., 2013). We recall from the discussion in Section 1.1 that a negative sampling scheme is intended to force pairs of vertices which are negatively sampled to be far apart from each other in an embedding space, in contrast to those which are positively sampled.
Algorithm 2 (Uniform edge sampling with unigram negative sampling)
Given a graph , number of edges to sample and number of negative samples per ‘positively’ sampled vertex, we perform the following steps:
-
i)
Form by sampling edges from uniformly and without replacement;
-
ii)
We form a sample set of negative samples by drawing, for each , vertices i.i.d according to the unigram distribution
and then adjoining if .
We then return .
Proposition 24
Alternatively to using a unigram distribution for negative sampling, one other approach is to select edges (such as via uniform sampling as above), and then return the induced subgraph as the entire sample.
Algorithm 3 (Uniform edge sampling and induced subgraph negative sampling)
Given a graph and number of edges to sample, we perform the following steps:
-
i)
Form by sampling edges from uniformly and without replacement;
-
ii)
Return as the induced subgraph formed from all of the vertices .
Proposition 25
We can also consider random walk based sampling schemes (see e.g. Perozzi et al., 2014).
Algorithm 4 (Random walk sampling with unigram negative sampling)
Given a graph , a walk length , number of negative samples per positively sampled vertex, unigram parameter and an initial distribution , we
-
i)
Select an initial vertex according to ;
-
ii)
Perform a simple random walk on of length to form a path , and report for as part of ;
-
iii)
For each vertex , we select vertices independently and identically according to the unigram distribution
and then form as the collection of which are non-edges in ;
and then return .
In the above scheme, there is freedom in how we can specify the initial vertex of the random walk. Here we will do so using the stationary distribution of a simple random walk on , namely , as this simplifies the analysis of the scheme.
Proposition 26
One important property of the samplers discussed in Algorithms 2, 3 and 4 is that they are essentially invariant to the scale of the underlying graph, in that the dominating parts of the expressions for the are free of the sparsity factor . We write this down for the random walk sampler.
Lemma 27
Remark 28
We note that in algorithmic implementations of negative sampling schemes in practice, there is usually not an explicit check for whether the negatively sampled edges are non-edges in the original graph. This is done for the reason that graphs encountered in the real world are frequently sparse, and so the check would take up computational time while only having a small effect on the learnt embeddings. This would correspond to removing the factor in the above formula for , and so Lemma 27 reaffirms the above reasoning.
4.1 Expectations and variances of random-walk based gradient estimates
Throughout we have studied the empirical risk induced through using a stochastic gradient scheme to learn a network embedding, given a subsampling scheme . Subsampling schemes used by practitioners (such as in node2vec) depend on some choice of hyperparameters. These are selected either via a grid-search, or by using default suggestions - for example, the unigram sampler in Algorithm 4 is commonly used with , as recommended in Mikolov et al. (2013). A priori, the role of such parameters is not obvious, and so we give some insights into the role of particular hyperparameters within the random walk scheme described in Algorithm 4. We focus on the expected value and variance of the gradient estimates used during training.
To illustrate the importance of these two values, we discuss first what happens in a traditional empirical risk minimization setting, where given data where is large and a loss function , we try to optimize over the empirical loss function by using a stochastic gradient scheme. More specifically, we obtain a sequence via
given an initial point , step sizes and a random gradient estimate . We then run this for a sufficiently large number of iterations such that ; see e.g Robbins and Monro (1951). For the empirical risk minimization setting detailed above, one common approach has take the form
where are sampled i.i.d uniformly from for each . We then get for any choice of , and when assuming that the gradient of is bounded. In general, the variance of the gradient estimates determines the speed of convergence of a stochastic gradient scheme - the smaller the variance, the quicker the convergence (Dekel et al., 2012) - and so choosing a larger batch size should leave to better convergence. Importantly, when comparing two gradient estimates, we cannot make a bona-fide comparison of their variances without ensuring that they have similar expectations, as otherwise the two schemes are optimizing different empirical risks.
In the network embedding setting, to form a gradient estimate we could take independent subsamples and average over these, to get an estimator which (when averaging over the subsampling process) gives an unbiased estimator of the gradient of the empirical risk . This also has the variance of the gradient estimates decaying as . A more interesting question is to study what occurs when we only use one subsampling scheme per gradient estimate - as in practice - and vary the hyperparameters. For example, in the random walk scheme Algorithm 4, as a consequence of Proposition 26, under the assumptions of Theorem 12, the matrix is approximately equal to
which is essentially free of the random walk length once is sufficiently large. A natural question is to therefore ask what the role of is in such a setting. In the result below, we highlight that the role of leads to producing gradient estimates with reduced variance. The proof is given on page F.2.
Proposition 29
Let be a single instance of the subsampling scheme described in Algorithm 4 given a graph . Define the random vector
so . Supposing that Assumptions 1, 2 and 3 hold, then we have that, writing ,
for some function free of , and letting be the -th component of , we have that
uniformly over all and . In particular, the representation learned by Algorithm 4 is approximately invariant to the walk length for large , as guaranteed by Theorem 12; the gradients are asymptotically free of the walk length when and are large; and the norm of the variance of the gradients decays as .
5 Experiments
We perform experiments111Code is available at https://github.com/aday651/embed-asym-experiments. on both simulated and real data, illustrating the validity of our theoretical results. We also highlight that the use of a Krein inner product between embedding vectors can lead to improved performance when using the learned embeddings for downstream tasks.
5.1 Simulated data experiments
To illustrate our theoretical results, we perform two different sets of experiments on simulated data. The first demonstrates some potential limitations of using the regular inner product between embedding vectors in the empirical risk being optimized. The second demonstrates the validity of the sampling formulae for different sampling schemes.
For the first experiment, we consider generating networks with vertices, where each vertex is given a latent vector drawn independently (where ), with edges formed between vertices independently with probability
Here is the sigmoid function, and for any . We simulate twenty networks for each possible combination of: , , , , , , , or ; and equal to , , , or . We then train each network using a constant step-size SGD method with a uniform vertex sampler for 40 epochs222By epochs, we are referring to the cumulative number of pairs of vertices which are used to form a gradient at each iteration, relative to the total number of edges in the graph., using a similarity measure between embedding vectors for various values of . Some are equal to , so that the similarity measure used for the data generating process and training are identical. Some are greater than , so the data generating process still falls within the constraints of the model. Finally, we also let some be less than , in which case the data generating process falls outside the specified model class for learning. With the learned embeddings we then calculate the value of
| (27) |
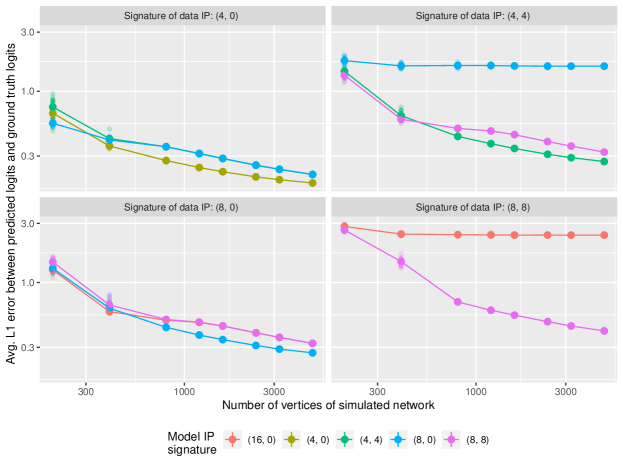
In words, we are computing the average error between the estimated edge logits using the learned embeddings (with a bilinear form between embedding vectors in the loss function), and the actual edge logits used to generate the network. The results are displayed in Figure 1. By the convergence theorems discussed in Sections 3.2 and 3.4, we expect that (27) will be if and only if and , and indeed this is the trend displayed in Figure 1.
For the second result, we illustrate the validity of the sampling formulae calculated in Section 4. To do so, we begin by generating a network of vertices from one of the following stochastic block models, where denotes the community sizes and the community linkage matrices:
| SBM1: | ||||
| SBM2: |
Here each vertex is assigned a latent variable which is used to determine the corresponding community (depending on where lies within the partition of induced by ). As illustrated in Sections 3 and 4, depending on the sampling scheme (samp), and whether we use a regular or Krein inner product (IP) as the similarity measure between embedding vectors (recall Assumption C), there is a function for which the minimizers of (9) satisfy
| (28) |
We note that for stochastic block models, when we choose - corresponding to minimizing over - we can numerically compute the formula for via a convex program as a result of Proposition 59. In the case where we choose to be a Krein inner product, the discussion in Section 3.2 tells us that we can write down the minima of over exactly.
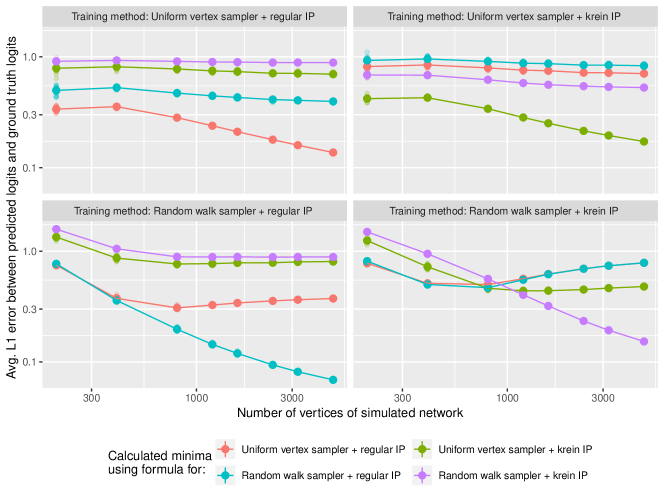
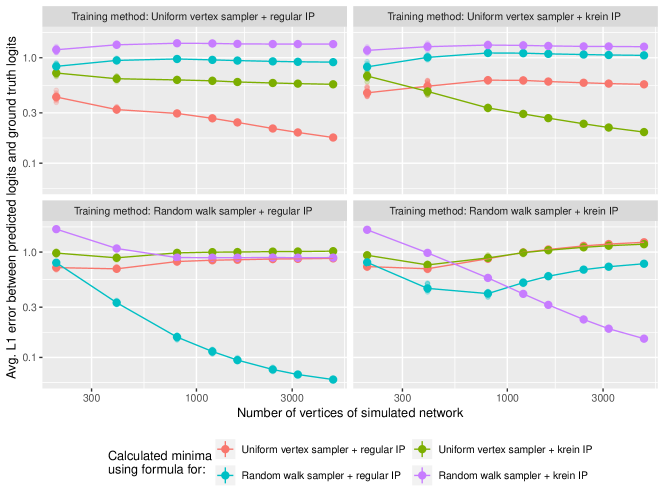
For each generated network, we train using either a) a random vertex sampler or a random walk + unigram sampler, and b) either the regular or Krein inner product for . We then calculate the value of (28) for each possible form of for the sampling schemes and inner products we consider. The experiments are then repeated for the same values of , and number of networks per choice of , as in the first experiment; the results are displayed in Figure 2. From the figure, we observe that the LHS of (28) decays to zero only when the choice of corresponds to the sampling scheme and inner product actually used, as expected.
5.2 Real data experiments
We now demonstrate on real data sets that the use of the Krein inner product leads to improved prediction of whether vertices are connected in a network, and as a consequence can lead to improvements in downstream tasks performance. To do so, we will consider a semi-supervised multi-label node classification task on two different data sets: a protein-protein interaction network (Grover and Leskovec, 2016; Breitkreutz et al., 2008) with 3,890 vertices, 76,583 edges and 50 classes; and the Blog Catalog data set (Tang and Liu, 2009) with 10,312 vertices, 333,983 edges and 39 classes.
For each data set, we perform the same type of semi-supervised experiments as in Veitch et al. (2018). We learn 128 dimensional embeddings of the networks using two sampling schemes - random walk/skipgram sampling and p-sampling, both augmented with unigram negative samplers - and either a regular inner product (with signature ) or a Krein inner product (with signature ). We simultaneously train a multinomial logistic regression classifier from the embedding vectors to the vertex classes, with half of the labels censored during training (to be predicted afterwards), and the normalized label loss kept at a ratio of 0.01 to that of the normalized edge logit loss.
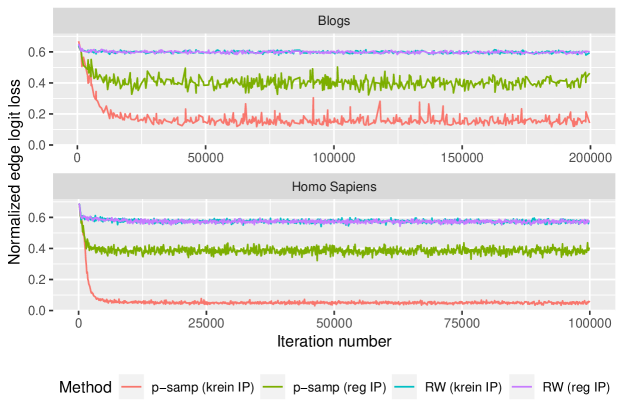
After training, we draw test sets according to three different methods (uniform vertex sampling, a random walk sampler and a p-sampler), and calculate the associated macro F1 scores333For a multi-class classification problem, the F1 score for a class is the harmonic average of the precision and recall; the macro F1 score is then the arithmetic average of these quantities over all the classes.. The results of this are displayed in Table 1, and the plots of the normalized edge loss during training for each of the data sets can be found in Figure 3. From these, we observe that for each of the data sets when using p-sampling with a unigram negative sampler, there is a large decrease in the normalized edge loss during training when using the Krein inner product compared to the regular inner product. We also see a sizeable increase in the average macro F1 scores. For the skipgram/random walk sampler, we do not observe an improvement in the edge logit loss, but observe a minor increase in macro F1 scores.
| Dataset | Sampling scheme | Inner product | Average macro F1 scores | ||
|---|---|---|---|---|---|
| Uniform | Random walk | p-sampling | |||
| PPI | Skipgram/RW + NS | Regular | 0.203 | 0.250 | 0.246 |
| Skipgram/RW + NS | Krein | 0.245 | 0.298 | 0.290 | |
| p-sampling + NS | Regular | 0.408 | 0.423 | 0.417 | |
| p-sampling + NS | Krein | 0.486 | 0.468 | 0.461 | |
| Blogs | Skipgram/RW + NS | Regular | 0.154 | 0.192 | 0.194 |
| Skipgram/RW + NS | Krein | 0.250 | 0.279 | 0.285 | |
| p-sampling + NS | Regular | 0.132 | 0.155 | 0.166 | |
| p-sampling + NS | Krein | 0.349 | 0.291 | 0.290 | |
6 Discussion
In our paper, we have obtained convergence guarantees for embeddings learnt via minimizing empirical risks formed through subsampling schemes on a network, in generality for subsampling schemes which depend only on local properties of the network. As a consequence of our theory, we also have argued that using an inner product between embedding vectors in losses of the form (9) can limit the information contained within the learned embedding vectors. Mitigating this through the use of a Krein inner product instead can lead to improved performance in downstream tasks.
We note that our results apply within the framework of (sparsified) exchangeable graphs. While such graphs are convenient for theoretical purposes, and can reflect how real world networks are sparse, they are generally not capable of capturing the power-law type degree distributions of observed networks. There are alternative families of models for network data which are not vertex exchangeable and alleviate some of these problems, such as graphs generated by a graphex process (Veitch and Roy, 2015; Borgs et al., 2017, 2018), along with other models such as those proposed by Caron and Fox (2017) and Crane and Dempsey (2018). As these models all contain enough structure similar to that of exchangeability (such as through an underlying point process to generate the network - see Orbanz (2017) for a general discussion on these points), we anticipate that our overall approach can be used to analyze the performance of embedding methods on broader classes of models for networks.
Our theory only considers embeddings learnt in an unsupervised, transductive fashion, whereas inductive methods for learning network embeddings are increasing popular. We highlight that inductive methods such as GraphSAGE (Hamilton et al., 2017a) work by parameterizing node embeddings through an encoder (possibly with the inclusion of nodal covariates), with the output embeddings then trained through a DeepWalk procedure. Provided that the encoder used is sufficiently flexible so that the range of embedding vectors is unconstrained (which is likely the case for the neural network architectures frequently employed), our results still apply in that we can give convergence guarantees for the output of the encoder analogously to Theorems 10, 12 and 19.
Acknowledgements
We acknowledge computing resources from Columbia University’s Shared Research Computing Facility project, which is supported by NIH Research Facility Improvement Grant 1G20RR030893-01, and associated funds from the New York State Empire State Development, Division of Science Technology and Innovation (NYSTAR) Contract C090171, both awarded April 15, 2010. Part of this work was completed while M. Austern was at Microsoft Research, New England. We thank the two anonymous reviewers and the editor for their feedback, which significantly improved the readability and contributions of the paper.
Appendix A Technical Assumptions
Here we introduce a more general set of technical assumptions than those introduced in Section 2 for which our technical results hold. For convenience, at points we will duplicate our assumptions to keep the labelling consistent, and so Assumptions A,B and E are generalizations of Assumptions 1, 2 and 5 respectively, and Assumptions C and D are the same as Assumptions 3 and 4 respectively.
Assumption A (Regularity and smoothness of the graphon)
We suppose that the underlying sequence of graphons generating are, up to weak equivalence of graphons (Lovász, 2012), such that:
-
a)
The graphon is piecewise Hölder, , , for some partition of and constants , ;
-
b)
The degree function is such that for some exponent ;
-
c)
The graphon is such that for some exponent ;
-
d)
There exists a constant such that a.e;
-
e)
The sparsifying sequence is such that if , and if .
Assumption B (Properties of the loss function)
Assume that the loss function is non-negative, twice differentiable and strictly convex in for , and is injective in the sense that if for and , then . Moreover, we suppose that there exists (where we call the growth rate of the loss function ) such that
-
i)
For , the loss function is locally Lipschitz in that there exists a constant such that
-
ii)
Moreover, there exists constants and such that, for all and , we have
These conditions ensure that and grows like as and respectively.
Note that the cross-entropy loss satisifies the above conditions with , and also satisifies the conditions below:
Assumption BI (Loss functions arising from probabilistic models)
In addition to requiring all of Assumption B to hold, we additionally suppose that there exists a c.d.f for which
where corresponds to a distribution which is continuous, symmetric about , strictly log-concave, and has an inverse which is Lipschitz on compact sets.
In addition to the cross-entropy loss, the above assumptions allows for probit losses (taking to be the c.d.f of a Gaussian distribution). Note that for such loss functions, the value of is linked to the tail behavior of the distribution in that it behaves as - for instance, the logistic distribution is sub-exponential and the cross entropy loss satisifies Assumption BI with , whereas a Gaussian is sub-Gaussian and thus Assumption BI will hold with .
Assumption C (Properties of the similarity measure )
Supposing we have embedding vectors , we assume that the similarity measure is equal to one of the following bilinear forms:
-
i)
(i.e a regular or definite inner product) or
-
ii)
for some (i.e an indefinite or Krein inner product);
where , for , and .
Assumption D (Strong local convergence)
There exists a sequence of -measurable functions, with for each , such that
for some non-negative sequence .
Assumption E (Regularity of the sampling weighs)
We assume that, for each , the functions
are piecewise Hölder, where is the same partition as in Assumption Aa), but the exponents and may differ from that of and in Assumption Aa). We moreover suppose that and are uniformly bounded in , are positive a.e, and that and are uniformly bounded in for some constant .
Appendix B Proof outline for Theorems 7, 10, 12 and 19
We begin with outlining the approach of the proof of Theorem 7; that is, the convergence of the empirical risk to the population risk. Note that in the expression of the empirical risk , as a consequence of Assumption 4, we are able to replace the sampling probabilities in with the . After also including the terms with , as part of the summation (which is possible as we are adding terms to an average of quantities), we can asymptotically consider minimizing the expression
To proceed further, we now suppose that corresponds to a stochastic block model; more specifically, we suppose there exists a partition of into intervals for which is constant on the for . Note that is implicitly a function of for , and therefore it also piecewise constant on . As an abuse of notation, we write for the value of when . If we write
we can then perform a decomposition of into a sum
For now working conditionally on the , we note that for each of the , the gap between the averages
| (29) |
and
| (30) |
where we recall that , will be small asymptotically. In particular, the difference of the two has expectation zero as the expected value of (29) conditional on the is (30), and will have variance as (29) is an average of independently distributed bounded random variables. As the variance bound is independent of outside of the size of the set , which will be , it therefore follows that the difference between (29) and (30) will therefore also be small asymptotically unconditionally on the too. We can therefore consider minimizing
| (31) |
We now use Jensen’s inequality (which is permissible as the loss is strictly convex) and the bilinearity of , which gives us that
where we have defined if , and the inequality is strict unless the are constant across . This means that for the purposes of minimizing (31), we know that we can restrict ourselves to only taking an embedding vector per latent feature. Making use of the fact that , we are left with
Making the identification for , we then end up exactly with where as desired. The details in the appendix discuss how to apply the argument when is a general (sufficiently smooth) graphon and not just a stochastic block model, along with arguing that the above functions converge uniformly over the embedding vectors, and not just pointwise.
Once we have the population risk , the proof technique for the convergence of the minimizers to (9) in Theorems 10, 12 and 19 follow the usual strategy for obtaining consistency results - given uniform convergence of an empirical risk to a population risk, we want to show that the latter has a unique minima which is well-separated, in that points which are outside of a neighbourhood of the minima will have function values which are bounded away from the minimal value also. There are a several technical aspects which are handled in the appendix, relating to the infinite dimensional nature of our optimization problem, the non-convexity of the constraint sets and the change in domain from embedding vectors to kernels .
Appendix C Proof of Theorem 7
For notational convenience, we will write for the collection of embedding vectors for vertices , and write
We will also write and for the collection of latent features and adjacency assignments for . We aim to prove the following result:
Theorem 30
Remark 31 (Issues of measurability)
We make one technical point at the beginning of the proof to prevent repetition - throughout we will be taking infima and suprema of uncountably many random variables over sets which depend on the and . Moreover, we will want to reason about either these minimal/maximal values, or the corresponding argmin sets. We need to ensure the measurability of these types of quantities.
We note two important facts which will allow us to do so: the fact that the are measurable functions, and that the loss functions are continuous for . Consequently, all of the functions we take suprema or minima over are Carathédory; that is of the form , where is continuous for all , and is measurable for all . Here plays the role of some Euclidean space, and a probability space supporting the and . Moreover, all of our suprema and minima will be taken either over a) a non-random compact subset of for some , or b) a set of the form
where i) for some measurable function and norm on , ii) is Carathédory, and iii) the constant satisfies (so is non-empty). With this, we can guarantee the measurability of any quantities we will consider; an application of Aubin and Frankowska (2009, Theorem 8.2.9) implies that , and therefore also , are measurable correspondences with non-empty compact values, and therefore the measurable maximum theorem (e.g Aliprantis and Border, 2006, Theorem 18.19) will guarantee the measurability of all the quantities we want to consider.
C.1 Replacing sampling probabilities with
To begin, we justify why minimizing
is asymptotically equivalent to that of minimizing .
Lemma 32
Proof [Proof of Lemma 32] We will argue that the loss functions will converge uniformly over sets of the form , where can be any constant strictly greater than one. Such sets contain the minima of e.g , and as we are working on (stochastically) bounded level sets of , this will be enough to allow us to use Assumption D in order to obtain the desired conclusion. With this in mind, we denote and then define the sets
Our aim is to show that with asymptotic probability . Note that
so and (meaning the sets are non-empty). Moreover, these sets will always contain the argmin sets of and respectively (as any minimizer will satisfy e.g ). In particular, once we show that as , we will have shown the first part of the lemma, and we can then reduce to showing uniform convergence of over . Pick an arbitrary . Then by Assumption D, we get that
By Lemma 48 - noting that with asymptotic probability all the quantities involved are positive - we have that
| (32) |
and so
for sufficiently large. This holds freely of the choice of , and so with asymptotic probability . To conclude, we then note that over the set , we have
as desired. Here we use the fact that is , which follows as a result of the fact that is by Lemma 49 and (by Assumption D), and then noting that
analogously to (32).
C.2 Averaging the empirical loss over possible edge assignments
Now that we can work with , we want to examine what occurs as we take . Intuitively, what we will attain should correspond to what occurs when we average this risk over the sampling distribution of the graph; to do so, we begin by averaging over the (while working conditionally on the ). As a result, we want to argue that is asymptotically close to
| (33) |
where we recall
As the above functions depend only on the values of the , we will freely interchange between the functions having argument or (whichever is most convenient, mostly for the sake of saving space), with the dependence of on implicit. We write
| (34) |
for the corresponding set of which are induced via , and define the metric
| (35) |
which is induced by the choice of loss function in Assumption B. (The injectivity constraints on the loss function specified in Assumption B ensure that ; the remaining metric properties follow immediately.) We now work towards proving the following result:
Theorem 33
Here the Talagrand -functional is defined as
where the infimum is taken over all refining sequences of partitions of , where for and , denotes the unique partition of for which lies within the partition, and denotes the diameter of . See Talagrand (2014, Chapter 2) for various definitions which are equivalent up to universal constants.
Remark 34
We briefly note that rather than calculating the above quantity explicitly, all we require444We note that when , can only be smaller than the metric entropy by a factor of (Talagrand, 2014, Exercise 2.3.4), and so this bound will be tight enough for our purposes. are the bounds
where is some universal constant, and is the minimal size of an -covering of with respect to the metric (so the RHS is simply the metric entropy of ). We state the bound in terms of simply as it allows for the easier use of the chaining bound (Theorem 35) stated and used later.
The proof technique consists of a combination of a truncation argument, a chaining argument, and the method of exchangeable pairs. To recap from Chatterjee (2005) the method of exchangeable pairs, suppose that is a random variable on a Banach space and is a measurable function such that . Given an exchangeable pair (so that in distribution) and an anti-symmetric function such that
then provided one has and the “variance bound”
| (36) |
almost surely for some constant , then we have a concentration inequality for the tails of of the form
In particular, we can interpret this as saying that is sub-Gaussian. If we now had a mean zero stochastic process where we equip with a metric , and we could also construct an exchangeable pair and functions for such that i) and ii) the corresponding variance term (36) is bounded by , we have the tail bound
We could then apply standard chaining results for the supremum of sub-Gaussian processes, such as those in Talagrand (2014):
Proposition 35 (Talagrand, 2014, Theorem 2.2.27)
Let be a metric space and suppose is a mean-zero stochastic process on . Suppose that there exists a constant such that for all ,
Then there exist universal constants and such that
for all , where is the Talagrand -functional of and denotes the diameter of the set with respect to .
In particular, this result allows one to easily control the supremum of a stochastic process with an uncountable index, by exploiting the continuity of the underlying process. With the above result, we can rephrase Theorem 33 in terms of controlling the supremum of the absolute value of the stochastic process
| (37) | ||||
over , where we keep track of where necessary (and will suppress the dependence on this when not). To control the above stochastic process, we will use the method of exchangeable pairs, while working conditional on the , to give us control of (37) for fixed ; we can then use Proposition 35 to give us control over all the . We note that as our argument will partly employ a truncation argument, we require the following minor modification of the method of exchangeable pairs:
Lemma 36
Suppose that is an exchangeable pair with functions and satisfying the conditions stated above, and moreover that is an event such that and for all . Then
Proof [Proof of Lemma 36] The method of proof is identical to that of (Chatterjee, 2005), except one replaces the moment generating function of with . Following the proof through gives , and so , and so the result follows from optimizing the Chernoff bound
with as usual (and similarly so for the reverse tail).
Proof [Proof of Theorem 33] (Step 1: Breaking up the tail bound into controllable terms.) To begin, we define
| (38) | ||||
| (39) |
and note that . We now fix . By Lemma 49 we know that (where we understand that ), and therefore there exists for which, once , we have that
As by Markov’s inequality we have that
for any , if we define we therefore have that for that
and therefore there exists such that, once , we have that
Writing , we now write
and control each of the four terms. For the latter two terms and , we know that once , their sum is less than or equal to , and so we focus on the details for the first two terms. For the first term, we will show that for any that
| (40) |
which allows us to apply Proposition 35, and for the second term we will get that
| (41) |
where . As the details are essentially identical for both, we will through the proof of (40) only. Before doing so though, we show how these results will allow us to obtain the theorem statement. Note that as a consequence of Proposition 35 (recall that are universal constants introduced in the chaining bound) we have, writing (where is a constant we choose later) and , that
| (42) | ||||
Here we have temporarily suppressed the dependence of the metric on and for reasons of space, and note that the above inequality holds provided . Taking expectations then allows us to show that by taking any
(where we have inverted the bound in (42) and substituted in the value of ). By using such a choice of , we then note that in (41) we get that
Noting that (recall Remark 34), it therefore follows that by choosing
in the expression for , we get that also.
Putting this altogether, as we have that , it therefore follows from the above discussion that given any , we will be able to find constants and (the value of given at the beginning of the proof; for , the value of from the discussion above), such that once , we have that
and so we get the claimed result.
(Step 2: Deriving concentration using the method of exchangeable pairs.) We now focus on deriving the inequality (40). For the current discussion, we now make explicit the dependence of e.g on the draws of the adjacency matrix . Note that throughout we will be working conditionally on , with the intention of then later restricting ourselves to only handling the which lie within the event . (Note this set has no dependence on the adjacency matrix , and so we are only restricting the possible values of which we are conditioning on when using the method of exchangeable pairs.) We now define an exchangeable pair as follows:
-
a)
Out of the set , pick a pair uniformly at random.
-
b)
With this, we then make an independent draw , set for the remaining , and set for .
We then define the random variables
Note that as we have that , and similarly we have that
In order to obtain a concentration inequality via the method of exchangeable pairs, we first need to verify that on for all . To do so, we note that and are in fact bounded on the event . We argue for the former (as the arguments for both are similar). Letting denote the maximum of the and across , we can write that
(where the used Jensen’s inequality to obtain the bounds in terms of and ). We now work on bounding the variance term. We have that
(recall the definitions of and in (38) and (39) respectively). Here follows via noting that when conditioning on , only the and contributions to the summation are non-zero, follows by using the inequality , and follows via taking the maximum of the loss function differences out of the summation and using the definition of . Now, note that on the event , we have that
and so by Lemma 36 we get the desired bound.
C.3 Approximation via a SBM
Now that we know it suffices to examine , we recall the proof sketch in Section B. If the are piecewise constant functions, then this argument shows that we can reason about the distribution of the embedding vectors which lie in some particular regions (namely the sets on which the are constant). In general, we need to first approximate the by a piecewise constant function, which is possible due to the smoothness assumptions placed on them in Assumption E. Note that if the are already piecewise constant, then this section can be skipped.
To formalize this further, we introduce some more notation. Let be a partition of the unit interval into disjoint intervals, which is a refinement of the partition of specified in Assumption E. For now we keep arbitrary; we will later specify the choice of the partition at the end of the proof to optimize the bound we eventually derive. We denote for ,
We now consider the intermediate loss functions
where for any symmetric integrable function we denote
To bound the approximation error, we use the following result:
Lemma 37 (Wolfe and Olhede, 2013, Lemma C.6, restated)
Suppose that is a symmetric piecewise Hölder function, and that is a partition of which is also a refinement of . Then we have, for any ,
Lemma 38
Remark 39 (Minimizers of infinite dimensional functions)
Note that we have referred to the argmin of and . For , the arguments in the next section will reduce this down to a finite dimensional problem, for which showing the existence of a minimizer is straightforward. For , the issue is more technically involved; we show later in Corollary 60 that a minimizer does exist.
Proof [Proof of Lemma 38] For convenience, write and . We detail the proof for the bound on , as the argument for works the same way. We now begin by bounding
where in the last inequality we have used Lemma 37. We can then write
| (43) | ||||
where we used Hölder’s inequality. We now control the terms in the product. For the first, we note that as we assume that , by Markov’s inequality we get that
For the second term, we will use a special case of Littlewood’s inequality, which tells us that for we have that for any ; we will apply this to the sequences and use the and norms on this sequence. If we assume the are such that we have the bound
| (44) |
for some constant , then as we also have the bound (where we write )
it follows by Littlewood’s inequality with that
where is some constant free of . As , by Markov’s inequality we have that ; it therefore follows that for any for which (44) is satisfied, we have that
| (45) |
with the bound holding uniformly over such . To conclude, note that when dividing and multiplying by in the argument in (43), we could have also done so with and have the same argument apply, due to the fact that
(The first inequality is by Lemma 50.) Consequently, it therefore follows that if we define
for any fixed constant , we get that the bound derived in (45) holds uniformly across all such , and so the stated result holds.
C.4 Adding in the diagonal term
Here we show that the effect of changing the sum in from one over all with , to one over all pairs , is asymptotically negligible.
Lemma 40
Proof [Proof of Lemma 40] Note that for all , so we work on showing an upper bound on this quantity. Writing , note that as , we also have that , and therefore
Here we have used that , which holds regardless of whether in Assumption C is a regular inner product, or a Krein inner product. As the RHS above is free of , we get the claimed result.
As this is a minor change to the loss function, from now on we will just rewrite
| (46) |
rather than explicitly writing a superscript each time.
C.5 Linking minimizing embedding vectors to minimizing kernels
With this, we now note that we can write
| (47) |
where
and we recall that . In order to minimize , we can exploit the strict convexity of the and the bilinearity of the in order to simplify the optimization problem.
Lemma 41
Suppose that Assumption B, C and E hold. Moreover suppose that the partition used to define the above loss functions satisfies . Then minimizing over for a closed, convex and non-empty subset is equivalent to minimizing
| (48) |
where with the for , i.e , whose notation we recall from (34)). Moreover, if is a minimizer of , then there must exist vectors for such that
Proof [Proof of Lemma 41] To ease on notation, write for . Note that by Jensen’s inequality and the bilinearity of , we have that for all , , that
Moreover, as is strictly convex, note that the above inequality is an equality (for a fixed ), if and only if is constant for all . As by Assumption E we may deduce that for all (as and are positive a.e) and , it follows that if we define
(note that as is convex, the averages also lie within ), then we have that
with equality iff is equal across , for all pairs of . (Note that the above average is well defined as as by Lemma 46, due to the condition on the sizes of the partitioning sets of .)
We can then observe that is equivalent to (where ) via the correspondence
Moreover, we know that if and only if is constant on each block . It therefore follows that if is a minimizer of , then this must be the case. As is bilinear, this implies that
so if we write as according to the above correspondence, we get the last part of the lemma statement.
As we can similarly write
| (49) |
via essentially the same argument, we get the following:
Lemma 42
Suppose that Assumption B, C and E hold. Then minimizing
over - where is closed, convex and non-empty, and we recall the definition of from Equation (15) - is equivalent to minimizing
| (50) |
over . Moreover, if is a minimizer of , then must be of the form (up to a.e equivalence) for which is piecewise constant on the .
Proof [Proof of Lemma 42] Note that similar to before, as we can write for some functions , we have that
where there is equality if and only is constant on for every . With this, the proof follows essentially identically to that of Lemma 41.
Note that by having done this, we have managed to place the problems of minimizing the functions (Equation 47) and (Equation 49) - the latter an infinite dimensional problem, the former dimensional - into a common domain of optimization, from which we can compare the two. Looking at and for , it follows that the only remaining step is to replace the instances of with in order for us to be done:
Lemma 43
C.6 Obtaining rates of convergence
To get the bounds stated in Theorem 30, we collect and chain up the previously obtained bounds from the earlier parts. Noting that the bounds are stated in terms of suprema over sets containing all the minimizers (or do so with asymptotic probability ), we can bound the difference in the minimal values by the supremum of the difference of the functions over . Indeed, suppose we have two functions and such that all the minima of and lie within a set with asymptotic probability ; letting and be some minima of these sets, we therefore get that on an event of asymptotic probability that
and via a similar argument for we get that
With this in mind, we now seek to apply the results developed earlier. To do so, we need to make a choice of a sequence of partitions . To do so, we make a choice so that the uniformly over , and that they each are a refining partition of the partition from Assumption A. (This is possible simply by dividing each into intervals of the same size, each of order .) Recall the notation ; from Equation 15; and from Equation 34. It therefore follows by collating the terms from, respectively, Lemma 32; Theorem 33 + Lemma 44; Lemma 38; Lemma 40; Lemma 41; Lemma 43; Lemma 42; and Lemma 38 (again), we end up with a bound of the form
| (51) | ||||
| (52) | ||||
| (53) |
The remaining task is to balance the embedding dimension and the size of in order to optimize the bound; to begin, the term is always negligible (as it is dominated by the term). We note that when (so the term disappears), we want to balance the and bounds to be equal, leading to a choice of to give an optimal bound. When , we choose the same value of ; we note that we can still have a bound which is for for some sufficiently small . In the case where the are piecewise constant on a partition where is of size , the term disappears (as we no longer need to perform the piecewise approximation step given by Lemma 40 and can just have that for all ). Consequently, the bound from Lemma 38 becomes , from which the claimed result follows.
C.7 Proof for higher dimensional graphons
Proof [Proof of Theorem 15]
Note that in following the proof argument above, the details depend only on that the are drawn i.i.d, and does not require a particular form of the distribution, and so the result follows immediately.
C.8 Additional lemmata
Lemma 44
Proof [Proof of Lemma 44] We begin by upper bounding by a metric which is easier to work with. Using the fact that is locally Lipschitz, we have that
To handle the term, recall that as and for , we have that when we can bound
where we used the triangle inequality followed by Hölder’s inequality. We can achieve the same bound when , by using the triangle inequality to bound
and then by applying the above argument twice. It therefore follows that in either case, letting denote the set such that , we have the bound
This is because when we have two metrics and such that , the corresponding -functionals satisfy (Talagrand, 2014, Exercise 2.2.20). The RHS is then straightforward to bound by Remark 34; note that
and therefore
Combining everything gives the desired result.
Lemma 45
Let where the , , and , where is the minimum of the over . Then we have that
Proof [Proof of Lemma 45] We suppress the subscript in the and for the proof. Recall that . By e.g Vershynin (2018, Exercise 2.3.5), for all we have that
for some absolute constant . Therefore, by taking a union bound we get that
In particular, given any , if we take (which will lie in for any fixed once is large enough), then
if e.g and . The stated conclusion therefore follows.
Lemma 46
Let with the same conditions on the as in Lemma 45, and write for the maximum of the over . Then we have that
In particular, if the for some so , then , so as .
Proof [Proof of Lemma 46] Again, we suppress the subscript in the and for the proof. Begin by noting that if is a sequence of real numbers, then for all we have that
As a consequence we therefore have that (writing )
and so we can just apply the bound derived in Lemma 45.
Proposition 47
Let , where , is the minimum of the and . Then we have that
In particular, if then
In the regime where and are fixed, we recover the standard rate.
Proof [Proof of Proposition 45] Again, we suppress the subscript in the and for the proof. By the triangle inequality we have that
As we can bound
by Lemma 45, using this again and the above inequality gives the desired result.
Lemma 48 (Cauchy’s third inequality)
Let , and be sequences of positive numbers. Then
Proof [Proof of Lemma 48] This follows by writing
and then applying the inequalities
and rearranging.
Lemma 49
Suppose is a sequence of integrable non-negative functions, where and . Then
Proof [Proof of Lemma 49] Note that as the quantities are identically distributed sums over quantities, we have
so the desired conclusions follow via an application of Markov’s inequality (as the are non-negative, so are and ).
Lemma 50
Suppose that is a partition of , and is a function such that a.e and . Then , and in fact .
Proof [Proof of Lemma 50] We write
where the second line follows by using Jensen’s inequality applied to the function .
Appendix D Proof of Theorems 10 - 19
We break this section up into four parts. The first discusses properties of the we will need (such as convexity and continuity), the second considers minimizers of over particular subsets of functions, and the third examines lower and upper bounds to the difference in values of when minimized over different sets. These are then combined together to talk about the embedding vectors learned by , and comparing this to a suitable minimizer of .
D.1 Properties of
We begin with proving various properties of which will be necessary in order to talk about constrained optimization of this function.
Proof [Proof of Lemma 51] Without loss of generality we may just consider the case where , are not equal almost everywhere, so the set
has positive Lebesgue measure. Now, letting be fixed, via strictly convexity of the loss function, we have that
on the set for , and that it equals zero on the set . As the are positive a.e, it therefore follows that is strictly positive on and zero on , and consequently
giving the desired conclusion.
Lemma 52
Proof [Proof of Lemma 52] Note that the are assumed to be bounded away from zero as , uniformly so by , and also are assumed to be bounded above, say by . To obtain the upper bound, we use the growth assumptions on the loss function to give
and similarly for the lower bound we find that
giving the first part of the theorem statement. The second part then follows by using the second inequality and rearranging.
Lemma 53
Suppose that Assumption B holds, where denotes the growth rate of the loss function. Then is locally Lipschitz on for any in the following sense: if , , then
where . In particular, is uniformly continuous on bounded sets in .
Proof [Proof of Lemma 53] Note that by the (local) Lipschitz property of the loss function , we have that
for , and therefore via the triangle inequality we obtain the bound
Applying the generalized Hölder’s inequality with exponents , and to each of the three products in the above integral respectively then gives that
as claimed.
Proposition 54
Suppose that Assumption B holds, where denotes the growth rate of the loss function. Then is Gateaux differentiable on with derivative
where . In particular, is subdifferentiable with sub-derivative
Proof [Proof of Proposition 54] For the Gateaux differentiability, we begin by noting that if , then , and therefore by the assumed growth condition on the first derivatives of , it follows that is well-defined by Hölder’s inequality. Writing
we note that the integrand converges to zero pointwise when as is differentiable. Moreover, as
by the mean value inequality the integrand is dominated by
which is integrable. The dominated convergence theorem therefore gives the first part of the proposition statement. The second part therefore follows by using the fact that is convex and Gateaux differentiable, hence the sub-gradient is simply the Gateaux derivative (e.g Barbu and Precupanu, 2012, Proposition 2.40).
D.2 Minimizers of over and related sets
Recall that we earlier denoted
with an implicit choice of the similarity measure , and for some and . To distinguish between using the regular and indefinite/Krein inner product, we define the following sets, for and :
Here the closures are taken with respect to the weak topology on (see Appendix G), for the value of corresponding to that of the loss function in Assumption B. We note that the sets , , and are all independent of as a result of the lemma below, whence why e.g the equalities and are written above.
Lemma 55
For all and we have that . Consequently, the sets and are independent of the choice of . Similarly, the sets and are independent of the choice of .
Proof [Proof of Lemma 55] We give the argument for the non-negative definite case as the other case follows with the same style of argument. The first inclusion is immediate. For the second, suppose , so we have a representation
Then as we can equivalently write this as
with , we have that , and so get the second inclusion. We therefore have that ; as one naturally has the inclusion that for all , it follows that the sets are equal for all , and so the same holds for the closures of these sets.
From now onwards, we will always drop the dependence of from the sets , , and , and only refer to , , and onwards respectively.
Lemma 56
The sets and are convex, and therefore their weak and norm closures in coincide. Moreover, the sets and are convex.
Proof [Proof of Lemma 56] The style of argument is essentially the same for both cases, so we focus on and . Note that for any we have that
It therefore follows that is a convex set. A standard fact from functional analysis (see Appendix G) then says that convex sets are norm closed iff they are weakly closed. Moreover, as the norm closure of a convex set is convex, we also get that is a convex set too.
Remark 57
We note that while is a convex set, the sets for are not convex. This is analogous to how the set of matrices of rank is not convex.
Proposition 58
The sets and are weakly compact in for and any , .
Proof [Proof of Proposition 58] We work with , knowing that the other case follows similarly. We want to argue that the set is weakly closed, and then that it is relatively weakly compact.
We begin by noting that the set of functions is weakly compact. As this set is convex and norm closed (if in , we can extract a subsequence which converges a.e to and whose image will therefore lie within a.e), and therefore will also be weakly closed. The compactness then follows by noting that as is bounded, the set of functions is also relatively weakly compact (by Banach-Alogolu in the case, and Dunford-Pettis in the case - see Appendix G).
Now suppose we have a sequence , say for some functions (so are the coordinate functions of ), such that converges weakly to some . By weak compactness, we can extract a subsequence of the , say , which converges weakly in to some function . Writing for the Hölder conjugate to , we then know that for any functions we have that
by using the weak convergence of the . By taking and for arbitrary closed sets and , it follows that and agree on products of closed sets, and therefore must be equal almost everywhere (as the latter is a -system generating the Borel sets on ). In particular, this implies that . The weak compactness follows by noting that as is bounded, and therefore the functions belonging to are bounded in , whence is relatively weakly compact. As we also know that is also weakly closed, we can conclude.
We now discuss minimizing over the sets introduced at the beginning of this section. It will be convenient to begin with the case where the and are stepfunctions.
Proposition 59
Suppose that Assumption B holds, and further suppose that and as introduced in Assumption E are piecewise constant on (thus also bounded below), where is a partition of into finitely many intervals, say in total. Then there exists unique minimizers to the optimization problem
Moreover, there exists and such that the minimum of over are identical across all and , and therefore also equal to the minimizer over . The same statement holds when replacing , and .
Proof [Proof of Proposition 59] We give the argument for when the constraint sets are non-negative definite, as the argument for the other case is very similar. Suppose that is of size and is composed of intervals . Note that when and are piecewise constant as assumed, we can argue analogously to Lemma 42 (via the strict convexity of the loss function) that any minimal value of over must be piecewise constant on , i.e we can write for some vectors , . Moreover, by Lemma 52 we know any minima must satisfy for some . We want to argue that the set of functions belonging to
is weakly compact, so by Corollary 84 we know that there is a unique minima to over . To do so, we first note that the set is weakly closed, as is convex and norm closed. In the case where , the set is therefore weakly compact by Banach-Alagolu (see Appendix G) as is a weakly closed subset of the weakly compact set . In the case where , to apply the Dunford-Pettis criterion we need to argue that the set of functions is uniformly integrable. Indeed, if we let denote the value of on , then we can write that
so , whence is uniformly integrable. In both cases ( and ), we therefore have that there exists a (unique) minima to over .
We note that in the discussion above, we have reduced the minimization problem to one over the cone of non-negative definite symmetric matrices. If we consider optimizing the function
and , over all non-negative definite symmetric matrices , then we know that it has a unique minimizer with eigendecomposition . Let equal the rank of , i.e the number of for which . If we then define , it therefore follows that is the unique minima to over . Moreover, the above representation tells us that as soon as and , and therefore is the unique minima of over all such too.
Corollary 60
Suppose that Assumptions B holds with as the growth rate of the loss, and Assumption E holds with , so iff by Lemma 52. Then there exists solutions to
for any , , , and . Moreover, there exists unique solutions to
Additionally, the minimizers of over and are continuous in the functions in the following sense: if we have functions , with minimizers
over or , then if as , we have that converges weakly in to .
Proof [Proof of Corollary 60] The first statement follows by combining Lemmas 51, 53 and Proposition 58 and applying Corollary 84. For the second, we note that the optimization domains are convex by Lemma 56. In the case where , Lemma 52 and Banach-Alagolu allows us to argue that the minima over and lies within a weakly compact set, and so such a minima exists and is unique.
In the case, we already know that a minima to exists when the and are piecewise constant on some partition , where is a partition of . Consider the function
defined on , where for some , so . We then know by Proposition 59 that a unique minimizer to exists on a set of which is dense in (namely, symmetric stepfunctions). We now verify that satisfies the conditions in Theorem 85. The strict convexity condition in a) follows by Lemma 51. We now note that via the same type of argument as in Lemma 53, we have that
| (54) |
from which the continuity condition b) holds. Moreover, by the same type of argument in Lemma 52, if we have that then , and so this plus (54) verifies condition c). With this, we can apply Theorem 85, from which we get the claimed existence result when , along with continuity of the minimizers for .
D.3 Upper and lower bounds
In order to get a convergence result for the learned embeddings, we need some upper and lower bounds on quantities of the form , where is the unique minima of over either or . We begin with lower bounds in terms of quantities involving .
Lemma 61
Proof
By the strict convexity of and the KKT conditions.
Proposition 62
Suppose that Assumptions B and E hold with as the growth rate of the loss function and . Suppose is a weakly closed convex set of , and that there exists a minima (whence unique) to over . Write . Then for any , we have the following:
-
i)
If for some constant for all and (for example the probit loss - see Lemma 68), then
-
ii)
Suppose that is the cross entropy loss. Then
where .
Proof [Proof of Proposition 62] Let ; therefore and . Now, as is twice differentiable in for , by the integral version of Taylor’s theorem we have that
for . Therefore, if we multiply by , sum over and integrate over the unit square, it follows that
where we have used the expression for as derived in Proposition 54. By the KKT conditions stated in Corollary 61, as is the unique minima to the constrained optimization problem, we get that
In order to lower bound the RHS further, we then work with the two specified cases in order. In the case where for some constant for all and , then we get the bound
after integrating over , from which we get the stated bound by using the fact that and are bounded away from zero. In the cross entropy case, this follows by using the expression given in Lemma 68 and then using Fubini.
We now want to work on obtaining upper bounds for , in the case where is a minimizer to over one of the sets or .
Lemma 63
Suppose that Assumption B holds with and Assumption E holds with , and let be the unique minima of over . Moreover suppose that for all , so we can therefore write
| (55) |
where we understand the equality sign above to be understood as a limit in . Here the for each are sorted in monotone decreasing order in , and for each . Additionally assume that for all . Then for any , we get that
In the case when is the unique minima to over , we again assume that for all , so the expansion (55) still holds. Here the may not be non-negative, and are sorted so that for all . Additionally assume that for all . For each , define , and given a sequence , define
We then have for any that
Proof [Proof of Lemma 63] Note that
is a best rank- approximation to , with the assumption that implying for each . Consequently we have that and therefore
We then apply Proposition 53 with , noting that
to get the first stated result. The argument in the case where is replaced with is the same, after noting that our choice of and forces the best rank- approximation to be within .
Remark 64
Note that the eigenvalue bound obtained via the Parseval identity is that , which is unable to give rates of convergence of the best rank- approximation of to , as the series is not summable. Under some additional smoothness conditions on , we can obtain summable eigenvalue bounds (see Section H).
Corollary 65
Suppose that Assumption B holds with and Assumption E holds with , and let be the unique minima of over . Suppose that one of the following sets of regularity conditions hold:
-
(A)
The satisfy and are -piecewise equicontinuous (that is, for all there exists such that whenever lie within the same partition of and , we have that for all ).
-
(B)
The are each piecewise Hölder(, , , ) and .
Then there exists such that whenever , we have that
In the case where is the unique minima of over and either (A) or (B) as above hold, define as according to Lemma 63. Then there exists such that whenever , the above bound becomes
D.4 Convergence of the learned embeddings
Theorem 66
Suppose that Assumptions B holds with either the cross-entropy loss (so ) or a loss function satisfying for all , with ; Assumptions A C and D hold; and that Assumption E holds with . Suppose that is any minimizer of over the set , where we require that for a constant specified as part of one of the three regularity conditions listed below. Write for the relevant rate from Theorem 30, and define the function if the regular inner product, or if is a Krein or indefinite inner product in Assumption C. Let be the unique minima of over or , depending on whether or respectively. We now assume one of the following sets of regularity conditions:
- (A)
-
(B)
In addition to (A), we assume that the are piecewise Hölder(, , , ) continuous for some constants , free of .
-
(C)
The functions and are piecewise constant on . Moreover, the values of , , and are chosen to satisfy the conditions in the last two sentences of Theorem 59.
We then have that
where .
Proof [Proof of Theorem 66] Let be a minimizer of over . We begin with associating a kernel to a collection of embedding vectors . To do so, given , let be the associated order statistics for , and be the mapping which sends to the rank of . We then define the sets
and the function
The purpose of defining to have a “border” around the edges of is so that we can allow the sets to be the same size, to simplify the bookkeeping below.
We will now work on upper bounding to give us a rate at which this quantity converges. We will then lower bound this by some norm of , which will be comparable to the quantity for which we give a rate of convergence for.
Step 1: Bounding from above. By the triangle inequality, we have that
We note that is by Theorem 30. The other two parts require more discussion depending on which of (A), (B) or (C) hold; we begin by bounding first.
Step 1A: Bounding (I). Here we apply Corollary 65 for when either (A) or (B) hold, and Theorem 59 for when (C) holds. In the latter case, we note that the conditions on and (respectively , and ) imply that the minimizer to over (respectively ) is equal to the minimizer over (respectively ) whenever . It therefore follows that in either of the three cases, when we know that whenever we have that
In the case where , we similarly have that
Step 1B: Bounding (III). We will detail the argument and bounds under condition (B) first, and then describe what changes under conditions (A) and (C) afterwards. We begin by defining the quantity
so we can therefore write (as is piecewise constant)
Note that the term holds uniformly across any choice of embedding vectors . Recalling the function
from (33), we introduce the function
where we have added the diagonal term , and note that analogously to Lemma 40 (and with the exact same proof) we have that
| (56) |
We can therefore write
| (57) |
We begin by bounding the second and third terms above. We note that the third term can be bounded above by by combining Lemma 32, Theorem 33 and the bound (56). This also tells us that , so the second term will be .
For the first term, we exploit the smoothness of the , noting that we need to take some care in handling that it is only piecewise smooth. To handle the piecewise aspect, write , where the are ordered so that if and , then iff . We then define the sets , ,
We want to determine the size of the set . To do so, we note that as is a partition of , we have that the are pairwise disjoint (and similarly so for the ), and therefore so are the . To determine the size of the , we note that as is a bijection (sending the index to the order rank of out of the ), the size of is equal to the size of . We then note that the sets are sets of contiguous integers, which begin and end at points
respectively. Note that as is distributed, we have that (for example by Proposition 45) and therefore the beginning and endpoints are equal to
Similarly, the sets are sets of contiguous integers beginning and ending at the points
respectively. It therefore follows that the size of the intersection, and therefore , must be at least where , . Consequently, as the are disjoint we have that , and so .
With this, we now begin bounding
considering separately the cases where , and when either or . In the case where , we get that
| (58) |
where the last equality follows by Lemma 69, and we note that the stated bound holds uniformly over all and pairs of indices . In the case where either or , then all we can say is that the difference of the two quantities is uniformly bounded above by . To summarize, we have that
| (59) |
holding uniformly across the vertices. We therefore have that
| (60) |
To finalize the above bound, we want to argue that
| (61) |
To do so, we note that as , by combining Lemma 32, Theorem 33 and the bound (56), we know that
with asymptotic probability one. One of the intermediate steps in the proof of Lemma 38 then shows that this implies (61) as desired.
Consequently, it therefore follows by combining (60) and (61) with (57) that we get
Here the term is negligible compared to . We now discuss how this bound changes when (A) and (C) hold. In the case of (A), the equicontinuity condition implies that we can guarantee that the bound (58) is , and so we obtain the bound after piecing together the other parts. In the case of (C), we note that the bound (58) is equal to zero, and consequently the bound in (60) is , so we have the bound .
Step 2: Lower bounding and concluding. To summarize what we have shown so far in Step 1, we have obtained the bounds
where or , depending on whether is an indefinite or the regular inner product on respectively. To proceed, we work first in the case when (B) holds, and the loss function is the cross-entropy loss. We then discuss afterwards what occurs when either (A) or (C) hold, along with when the loss function instead satisfies .
We now note that as is the unique minima of under either the constraint set or , Proposition 62 tells us that we can obtain a lower bound on of the form
| (62) |
where . As is assumed to be uniformly bounded in , and is assumed to be uniformly bounded too, this implies that
and therefore by Lemma 70 we get that
| (63) |
We now introduce the function
and note that by the same arguments as in (60) above, it follows that
| (64) |
Note that the term above decays faster than , and as we are interested in the regime where , it will be dominated by an term also. It therefore follows by the triangle inequality that
| (65) |
as desired. In the case where (A) holds, we know that the bound (63) is now , and (64) will also be by the asymptotic equicontinuity condition, and so (65) will be too. In the case where (C) holds, we firstly note that Theorem 59 implies that , and so the parts of the argument relying on this assumption still go through. We then have that (63) will be , and (64) will be , and so (65) will be . In the case where the loss function is such that for all and - we state the bounds for when (B) holds, as the argument does not change between the cases - we note that in (62), Proposition 62 instead tells us that
Consequently, (63) becomes
from which we can obtain the bound in (63) by Jensen’s inequality to therefore obtain the same bound as in (65).
D.5 Graphon with high dimensional latent features
Proof [Proof of Theorem 16] Recall that for Algorithm 4, we have that
In particular, as the graphon on is equivalent to a graphon on which is Hölder with exponent by Theorem 14, it follows that
will be Hölder with exponent by Lemma 82. Similarly by Theorem 14 and Lemma 81, we also know that and are bounded above uniformly in , and are bounded below and away from zero uniformly in . Consequently, we can then apply Theorem 12 to get the stated result.
D.6 Additional lemmata
Lemma 68
Suppose that Assumption BI holds, so
for some c.d.f function . If is the c.d.f of a standard Normal distribution, then for all , . If is the c.d.f of the logistic distribution (so is the cross entropy loss), then we have that
Proof [Proof of Lemma 68] Note that if the loss function is of the stated form with a symmetric, twice differentiable c.d.f , we get that
for . Due to the relation , it follows that is even and is odd, meaning that the two derivatives for will be equal, and the second derivative is an even function in . Consequently, we only need to work with .
With this, we begin with working with the probit loss. Note that by Abramowitz and Stegun (1964, Formula 7.1.13) we have the tail bound
where is the corresponding p.d.f. It follows that the second derivative of is therefore bounded below by (for )
This function is monotonically decreasing, and by the use of L’Hopitals rule we have that
it follows that will be bounded below by .
If , then we claim that
for . To see that this inequality is true, note that we can rearrange it to say that
In the case when , the inequality follows by noting that the polynomial is non-negative for and substituting in , and in the case when follows by noting that the two functions which we are comparing are even. With this inequality we therefore have that
where in the second line we used the triangle inequality, and in the last line we used the inequality . (This last inequality can be derived by noting that the inequality holds at , and that the derivatives of the functions also satisfy the inequality.)
Lemma 69
Let for , and let be the associated order statistics. Then
Proof [Proof of Lemma 69] As the , we have by Marchal and Arbel (2017, Theorem 2.1) that
i.e the are sub-Gaussian random variables. The desired result therefore follows by using standard maximal inequalities for sub-Gaussian random variables.
Lemma 70
Suppose that is a sequence of measurable functions on such that
where is a sequence converging to zero. Then .
Proof [Proof of Lemma 70] Recall that for , if and only if , and therefore by Jensen’s inequality we have that
Therefore by decomposing into parts where and , we get contributions and respectively, and so the desired result follows.
Appendix E Additional results from Section 3
Proof [Proof of Proposition 21] Throughout, we denote and . In the case where is Lipschitz for , if we let be the maximum of the Lipschitz constants for and , and write , we get that for any that
and therefore we can apply Theorem 66 (which encapsulates Theorems 10, 12 and 19) to give the first claimed result. When is the zero-one loss, we can write
where we note that the RHS is free of . We now note that the term equals iff either a) and , or b) and ; otherwise it equals . If for , then a) implies that . If b) holds, then either
-
i)
, , and therefore ; or
-
ii)
one of the above conditions does not hold, in which case .
If we instead take , then the above statements still hold provided we write ; without loss of generality, we work with onwards. Consequently, we get
The first term will converge to zero in probability by Theorem 66 provided as with , where is the convergence rate from Theorem 66. For the second term, we want to control this term uniformly over all , where we recall that is the finite set of exceptions for the regularity condition stated in Equation (25). Begin by noting that as the are uniformly bounded (as a result of the assumptions within Theorem 66), we can reduce the above supremum to being over for some free of . With this, if we write
then if we let be a minimal -covering of (which has cardinality ), we know that
Here, the first inequality follows by noting that for any , there exist two points (pick the closest points to the left and right of within ) such that
and the second inequality follows by adding and subtracting
With the regularity assumption, we know that
as uniformly in . As for the term, by a union bound and the bounded differences concentration inequality (Boucheron et al., 2016, Theorem 6.2), we have that
which converges to zero for any fixed provided for any constant . In particular, this tells us that provided with as , and so the desired conclusion follows.
Proof [Proof of Proposition 20] By the argument in the proof of Proposition 59, we know that we can reduce the problem of optimizing over to minimizing the function
over all positive definite matrices
and that a unique solution to this optimization problem exists. Note that the positive definite constraint forces that and . Now, as the above function is symmetric in and and the function is strictly convex for all , it follows by convexity that a minima of must have . This therefore simplifies the above problem to solving the convex optimization problem
| minimize: | |||
| subject to: |
Letting be dual variables for , the KKT conditions for this problem state that any minima must satisfy
We now work case by case, considering what occurs on the interior of the constraint region; then the edges with ; and then we finish with :
-
•
In the case where and , the solution is given by and , which is feasible provided , (if ) and (if ).
-
•
In the case where and , then , and so the optimal solution has with , which is feasible provided but .
-
•
In the case where and , then , so , and so is feasible if and .
-
•
The only remaining case is when , and occurs in the complement of the union of the above cases, i.e when and .
As the optimization problem is feasible (in that we can guarantee that a minima exists) for all values of , and each of the above cases correspond to a partition of the space with a unique minima in each case, these do indeed correspond to the minima of in each of the designated regimes, as stated.
Proposition 71
Suppose that the loss function in Assumption BI is the cross-entropy loss. Then the minima of over is equal to a constant if and only if
where denotes the positive definite ordering (see Section H) on symmetric kernels . In the case where we have that and for some (such as when the sampling scheme is uniform vertex sampling as in Algorithm 1), this condition is equivalent to .
Proof [Proof of Proposition 71] We begin by noting that if is the minima of over , then the KKT conditions guarantee that
| (66) |
for all . In the case where , by choosing and varying either side of , it follows that we in fact must have that
It therefore follows that if is the minima, then we necessarily have that , which is greater than if and only if . Substituting this value of back into (66) and rearranging then tells us that for all we have that
| (67) |
In the case where , we instead immediately obtain
| (68) |
from (66). As the and are non-negative, by a density argument we can extend (E) and (68) to hold for all non-negative definite kernels . Consequently, if we write for the positive definite ordering of symmetric kernels, this is equivalent to saying that
Specializing further to the case where and , this simplifies to saying that (recalling the notation )
and so we are done.
Appendix F Proof of results in Section 4
We begin with several results which give concentration and quantative results for various summary statistics of the network (e.g the number of edges and the degree), before giving the sampling formula (and rates of convergence) for each of the algorithms we discuss in Section 4.
F.1 Large sample behavior of graph summary statistics
Proposition 72
Let be a graph drawn from a graphon process with generating graphon for some sequence with . Recall that part of Assumption A requires that for some . Then we have the following:
-
a)
Letting denote the degree of a vertex with latent feature , we have for all that
-
b)
Under the additional requirement that Assumption A holds with , we have that
- c)
-
d)
We have that
where we write , and consequently
-
e)
Writing for the number of edges of , we have for all that
and consequently .
-
f)
Under the additional requirement that Assumption A holds with , we have that
Proof [Proof of Proposition 72] For a), begin by noting that for the degree we can write
where . We then form an exchangeable pair (where we work conditional on and write ) by selecting a vertex and then redrawing and otherwise setting for . Writing and for independent copies of and , and also writing to make the dependence on explicit, we have that
We then have that
where we used the inequality to obtain the penultimate line, and the inequality in the last. With this, we apply a self-bounding exchangeable pair concentration inequality (Chatterjee, 2005, Theorem 3.9) which states that for an exchangeable pair and mean-zero function , if we have that the associated variance function (see Equation 36 in Section C.2 for a recap) satisfies , then we have that
| (69) |
For b), by part a) and taking a union bound, we get that
where the expectation is over . If there exists a constant such that a.e, then we can upper bound this expectation by . Consequently, if one takes for some sufficiently large, this quantity will decay towards zero as , giving us the first part of the result. For the second part of b), note that for a positive random variable we have
by Fubini’s theorem, and therefore we get that
where we write . When for some , as a consequence of Markov’s inequality we get that for some constant , and consequently that
In particular, if one takes , then for any one can choose sufficiently large such that the RHS is less than for sufficiently large, and so we get the stated result.
For c), we note that by the prior result that
holds uniformly across all the vertices, and if or if . As a result of the delta method (by considering the function about ), it therefore follows that
holds uniformly across all vertices too. With these two results, it follows that to study the minimum degree (or maximum reciprocal degree) we can instead focus on the i.i.d sequence . In the case where is bounded away from zero (i.e when ), is bounded above and consequently
In the case where , the fact that implies that has tails dominated by a Pareto distribution with shape parameter and scale parameter . It is known from extreme value theory that the maximum of i.i.d such random variables, say , is such that (Vaart, 1998, Example 21.15), and consequently we have that is . Combining this all together gives that . As the minimum degree is the reciprocal of the maximum of the , the other part follows immediately.
For d), we choose a similar exchangeable pair as above, except we now no longer work conditional on some (and choose ), in which case we see that
and we get an associated stochastic variance term
where in the last line we used the inequalities , and (the last two hold as ). We get the stated concentration inequality by applying (69).
For the concentration of the edge set in e), we will form an exchangeable pair by drawing a vertex uniformly at random from , then letting (for ) if and otherwise redrawing if either or . We then set for . If we define
then we can calculate that
The associated stochastic variance term is then of the form, letting be an independent copy of ,
where the first inequality follows by Cauchy-Schwarz, the second by using the inequality when , and the third by using the inequality . The stated concentration inequality then holds by applying (69).
For part f), we simply combine some of the earlier parts, and write
where is the rate obtained from part b).
Proposition 73
Write , and let be the stationary distribution of a simple random walk on , so for all , and let be a simple random walk on where . Write
be the corresponding unigram distribution for any . Suppose that Assumption A also holds with . Then for , we have that
where if and .
Proof [Proof of Proposition 73] We begin by handling the probability that a vertex is sampled in a simple random walk of length ; the idea is to show that the self-intersection probability of the walk is negligible. Note that by stationarity of the simple random walk we have for all that
Also note that for any sequence of events , we have that
(simply consider the LHS and RHS when exactly when ). Therefore if we let and take expectations, we get the inequality
To proceed with bounding the self-intersection probability, write for the set of neighbours of a vertex in , so by the Markov property we can write
where in the last line we pulled the max term out of the summation, used stationarity of the simple random walk, and that for all . By part c) of Proposition 72, it therefore follows that
By part f) of Proposition 72, we can then control the denominator to find that
For the large sample behaviour of the unigram distribution, we may then deduce that
for any (where we used Lemma 48 followed by the delta method applied to ). Combining this with part d) of Proposition 72 then allows us to get the desired conclusion.
F.2 Sampling formula for different sampling schemes
Here it will be convenient to define the rate function
which depends on the choice of the sparsifying sequence used to generate the model; we note that under our assumptions. Propositions 74 to 77 correspond to Propositions 23 to 26 in Section 4.
Proposition 74
Proof [Proof of Proposition 74]
Here a vertex is sampled with probability , and any two distinct vertices are sampled with probability ; the stated formulae therefore follow immediately. We then calculate that and . Under the stated assumptions, the integrability conditions on and then follow directly.
Proposition 75
Proof [Proof of Proposition 75] Let denote the edges which are sampled without replacement from the edge set of , and recall that denotes the number of edges of . We then have that
where we note that the term has no dependence on or . Note by Lemma 79 we have that
uniformly across all vertices , and consequently
where the last equality follows by Proposition 72. The same arguments as in Proposition 73 tell us that
| (70) |
With this, we are now in a position to derive the sampling formula for the specified sampling scheme. As can only be part of or (not both), we can write that
| (I) | ||||
| (II) | ||||
| (III) | ||||
We begin with (I) and (II); as they are symmetric in we can just consider (I). Writing on occasion for reasons of space, we have
By Lemma 79 and (70), we know that
As for the term, we note that it equals (as without loss of generality we can assume )
by Lemma 79, and whence
For (III), we begin by noting that as
for any events and , we have by Lemma 80 that
As by a similar argument to above we know that
it therefore follows that the (III) term will be asymptotically negligible, leaving us with the sampling formula
from which we get the stated result for the sampling formula and convergence rate. The remaining properties to check can then be done so via routine calculation and the use of Lemmas 81 and 82.
Proposition 76
Proof [Proof of Propsition 76] We note that most of the calculations can be taken from Proposition 24. Begin by noting that is selected either as part of , or but is not selected as part of (and that these occurrences are mutually exclusive). The probability of the first we know from earlier, and the probability of the second is given by
The second term in the product equals , and the first equals
where we have used Lemma 80 followed by Proposition 72. It therefore follows that
The remaining properties to check can then be done so via routine calculation and the use of Lemmas 81 and 82.
Proposition 77
Proof [Proof of Proposition 77] We begin by handling the probability that appears within . Letting be a SRW on , we first note that for any and , we have that
Writing for and , we then have
By bounding the probability of the walk intersecting through either or twice in a way analogous to that in Proposition 73, and then using Proposition 72, we get that
As for the negative samples, if we write for and , and , we can write
Note that for , and moreover that
Now, via the same arguments as in Proposition 73 with regards to the self intersection probability of the random walk, we have that
Combining Proposition 73 and Lemma 78 therefore gives
The remaining properties to check can then be done so via routine calculation and the use of Lemmas 81 and 82.
Proof [Proof of Proposition 29] We begin with the expectation; note that by the strong local convergence property of the sampling scheme we have that
where is free of , and so the first part of the theorem statement holds.
For the variance of the estimate, we look at , the -th entry of , and note that as for the events and are not necessarily independent, we have that
where we write to reduce notation. To study these terms, we make use of the fact that
In particular, we have that
by the strong local convergence assumption holding. Studying the covariance term requires more care; in particular, we note the covariance will depend on both of the values of and . The case where and will be most involved, and so we focus on this case first. Recall that in this case, and can only be sampled as part of a random walk; letting denote the vertices obtained on a random walk, we define the events
and so we want to study the covariance of the events and . For now, we will also write to refer to probabilities computed conditional on the realization of the graph . Recalling the identity
for any sequence of events , by applying this identity twice we can derive that
For the terms in the first sum, we can expand this as
We note that when , all the probabilities equal , and when there are two contributions of the form e.g
(where we have used the Markov property and the stationarity of the random walk), with the remaining terms equaling zero. The contributions of the terms where are all of the order e.g
(where the bounds hold uniformly over any ). For terms where , we get terms of the order e.g
where the term follows by using the fact that uniformly across , and that the number of paths of length between and is uniformly across and . By similar arguments, the terms in the other sums will be an order of magnitude less than that of the terms from the first sum (they will be multiplied by factors no greater in magnitude than ), and consequently it follows that when , we have that
where we already have calculated the asymptotics for and in Proposition 73, and we applied Proposition 72 to handle the degree term.
When and , the covariance is equal to zero, as once has been sampled as part of the random walk, the pair can only be subsampled from the negative sampling distribution, which does so independently of the process from the random walk; the same argument applies for when and .
The final case to consider is when and ; to handle this term, we note that if is not sampled as part of the random walk, then the events that and are sampled as part of the negative sampling distribution are independent. As a result, we only need to focus on conditioning on the events where does appear in the random walk; note that if appears multiple times, then the pairs and could be sampled during any of the corresponding negative sampling steps. if we let be drawn independently for (which corresponds to the vertices negative sampled) with probability according to the unigram distribution (by Proposition 73), and let be the number of times the vertex appears in the random walk, then we have that
where in the fourth line, we used the fact that the sum of independent multinomial distributions is multinomial; in the fifth line we used Lemma 83; and in the last line, we used the fact that as , by linearity of expectations we have
where again we have used Proposition 72.
Pulling this altogether, it follows that
where we write
To bound the variance, we note that uniformly across all we have that
To conclude, we note that under the assumption that the embedding vectors for all , and as the gradient of the cross entropy is absolutely bounded by (and consequently so are the and ), by applying Hölder’s inequality we find that
uniformly across all and , and so the stated conclusion follows.
F.3 Additional quantative bounds
Lemma 78
Suppose that for , with as . Then
Lemma 79
Suppose that with and . Then we have that
Proof [Proof of Lemma 79] We begin by recalling Stirling’s approximation, which tells us that
We can then write
Letting denote the term, and using that and as , we have that
Combining this all together gives the stated result.
Lemma 80
Suppose that with , and of the same order, and with . Then we have that
Proof [Proof of Lemma 80] The argument is the same as in Lemma 79, except we need to use the higher ordered termed expansion
in order to get the stated result. With this, the result follows by routine calculations which we therefore omit.
Lemma 81
Suppose that is such that for some . Then the function belongs to where .
Proof [Proof of Lemma 81]
Note that we have that . As we have that , it follows that , and consequently , so the conclusion follows.
Lemma 82
Suppose that is piecewise Hölder for some partition of . Then
-
a)
The degree function is piecewise Hölder;
-
b)
The function is piecewise Hölder(, , , ) where and .
Proof [Proof of Lemma 82] The first part follows immediately by noting that, whenever ,
by using the Hölder properties of . For the second part, note that the function is Hölder where , and so is piecewise Hölder(, , , ). To conclude, by the triangle inequality we then get that whenever , , we have
giving the stated result.
Lemma 83
Let be such that we have that uniformly across all . Then
Appendix G Optimization of convex functions on spaces
In this section we summarize the necessary functional analysis needed in order to study the minimizers of convex functionals on spaces.
G.1 Weak topologies on
The material stated in this section is textbook, with Aliprantis and Border (2006); Barbu and Precupanu (2012); Brézis (2011) and Riesz and Szőkefalvi-Nagy (1990) all useful references. We begin with a Banach space , whose continuous dual space consists of all continuous linear functionals . The weak topology on is the coarsest topology on for which these functionals remain continuous. (The norm topology on is also referred to as the strong topology.) We can describe this topology via a base of neighbourhoods
for , and . For sequences, we say that a sequence converges weakly to some element provided as for all . We now state some useful facts about weak topologies on Banach spaces:
-
a)
A non-empty convex set is closed in the weak topology iff it is closed in the strong topology. (The corresponding statement for open sets is not true.)
-
b)
A convex, norm-continuous function is lower semi-continuous (l.s.c) in the weak topology; that is, the level sets are weakly closed for all .
-
c)
The weak topology on is Hausdorff.
Corollary 84
Let be a Banach space and be a convex, norm continuous function, and let be a weakly compact set. Then there exists a minimizer of over . If the set is convex and is strictly convex, then the minima is unique.
Proof [Proof of Corollary 84]
By applying a) and b) above and using Weierstrass’ theorem in the weak topology, we get the first part; the second part is standard.
Specializing now to the case where where is a -finite measure space, the Riesz representation theorem guarantees that for , if is the Hölder conjugate of so , then the mapping
gives an isometric isomorphism between and . The relatively weakly compact sets (that is, the sets whose weak closures are compact) in can be characterized as follows:
-
a)
(Banach–Alaoglu) For , the closed unit ball is weakly compact, and the relatively weakly compact sets are exactly those which are norm bounded.
-
b)
(Dunford-Pettis) A set is relatively weakly compact if and only if the set is uniformly integrable. (This is a stricter condition than in the case.)
G.2 Minimizing functionals over
Note that to apply Corollary 84, we require the optimization domain to be weakly compact. In the case where we are optimizing over for , we note that the uniform integrability property is stricter than that of norm-boundedness. We are mainly motivated by wanting to optimize the functional over a weakly closed set which is only norm-bounded, which therefore will cause us trouble in the regime where . However, if the function we are seeking to optimize is more structured, we can still guarantee the existence of a minimizer; this is the purpose of the next result.
Theorem 85
Let be a norm closed subset of a Banach space equipped with a norm , and let denote the corresponding subspace topology on . Let be a Banach space equipped with strong and weak topologies and , and whose norm is denoted . Let be a function which is bounded below, and has the following additional properties:
-
a)
is strictly convex for all ;
-
b)
is -continuous;
-
c)
For any such that the level set is non-empty, there exists a constant for which
(71) for any and .
Let be a weakly closed convex set in , and let . By the strict convexity, there exists a set for which if and for . If there exists a dense set for which , then , and the function is -to- continuous.
The purpose of the above theorem is that provided we can argue the existence of a minimizer on a dense set of values of , then we can exploit the continuity and convexity of in order to upgrade our existence guarantee to hold for all functions . In order to prove the above result, we require two intermediate results: one is a simple topological result, and the other a refinement of a version of Berge’s maximum principle introduced in Horsley et al. (1998). Before doing so, we introduce some terminology:
-
a)
A correspondence is a set-valued mapping for which every is assigned a subset . (A function is therefore a singleton valued correspondence.)
-
b)
The graph of a correspondence is the subset of given by .
-
c)
Let be a topology on , and a topology on . Then we say that is -to- lower hemicontinuous if the set is open in for every open set in .
-
d)
We say a correspondence is -to- upper hemicontinuous if the set is open in for all open sets .
-
e)
When is a bond-fide function, the above notions in c) and d) are the same as lower semi-continuity (l.s.c) and upper semi-continuity (u.s.c) for functions respectively.
Lemma 86
Let and be topological spaces. Suppose that is at most singleton valued, with denoting the set of for which , so for and if . If is an upper hemicontinuous correspondence, then is closed in , and is a continuous function with respect to the subspace topology on induced by . In particular, if is also dense, then .
Proof [Proof of Lemma 86]
Note that by the upper hemicontinuity property, is open and whence is closed. As for the continuity, we want to show that is open in the subspace topology on given any open set in . As , this is indeed the case. For the final statement, we simply note that , where the first equality is because is closed, and the second as is dense.
Theorem 87 (Summary and extension of Horsley et al., 1998)
Let be a Hausdorff topological space, and let be a Banach space equipped with topologies (informally, a “strong” topology) and (informally, a “weak” topology). Let be a correspondence, and suppose that is a function. Define the sets
| (72) | ||||
| (73) |
Then we have the following:
-
a)
Suppose that is -to- lower hemicontinuous, the graph of is -closed in , and that the set is -closed in . Then the graph of is also -closed in .
-
b)
If in addition to a) we have that is -to- upper hemicontinuous and has -compact values, then is also -to- upper hemicontinuous and has -compact values.
-
c)
If in addition to a) we have that is -to- upper hemicontinuous and is -compact valued, then is -to- upper hemicontinuous.
Proof [Proof of Theorem 87]
The first two parts are simply Theorem 2.2 and Corollaries 2.3 and 2.4 of Horsley et al. (1998) applied to the relation defined by the set above. The third is a modification of the argument in Corollary 2.4. Begin by writing . It is known that the intersection of a closed correspondence and a upper hemicontinuous, compact-valued correspondence is upper hemicontinuous and compact-valued (Aliprantis and Border, 2006, Theorem 17.25, p567); one can show with the same proof that if is only upper hemicontinuous and closed-valued, and is compact valued, then is upper hemicontinuous also. From this, part c) follows.
Proof [Proof of Theorem 85] Our aim is to apply Theorem 87, using the correspondence for all , and (now writing and ). As this correspondence is constant, the graph of is closed in , as it simply equals and is weakly closed. As is convex and weakly closed, it is also strongly closed, and therefore the correspondence is both -to- lower hemicontinuous and -to- upper hemicontinuous. Note that as defined in (73) is the correspondence which defines the minima set of for each and so equals ; via the strict convexity of for each , we know that is at most a singleton, and therefore is -compact valued (as the empty set and singletons are compact).
Consequently, in order to apply part c) of Theorem 87, the remaining part is to show that the set as defined in (72) is -closed. To do so, we will argue that the complement is open. Fix a point . As , there exists such that . Note that if we can find
-
a)
a -nbhd (neighbourhood) of and a -nbhd of such that for all ; and
-
b)
a -nbhd of and a -nbhd of such that for all ;
then would be a -nbhd of contained in , whence would be open. To do so, we want to show that a) is -u.s.c and b) is -l.s.c.
Part a) follows immediately by the assumption that is -continuous. For b), it suffices to show that the level sets are -closed. To do so, let be a net which converges to ; note that as the weak and norm topologies on a Banach space are Hausdorff and the product topology on Hausdorff topologies is Hausdorff, the limit is unique. We aim to show that for any , we have that , so the conclusion follows by taking .
To do so, we begin by noting that as is a net converging to in a metrizable space (the topology is induced by the metric ), we can find a cofinal subsequence (that is, a subnet which is a sequence) along which as . (Indeed, we simply note that for each , we can find for which for all .) With this, we now note that for each , must be in the weak closure of (i.e, the convex hull of the for , which therefore contains each for ). As this is a convex set, the weak and strong closures of this set are equal, and consequently must be in the strong closure of each of the too. Consequently, we can therefore always find some element for which . In particular, we therefore have that the sequence -converges to .
To proceed further, we note that for each , there exists such that all but finitely many of the are zero, with the non-zero elements positive and , with . The convexity of plus the continuity condition (71) then implies that
In particular, given any , we can choose such that for all , and whence for we have that
Consequently passing to the strong limit using the -continuity of gives us that , as desired.
Appendix H Properties of piecewise Hölder functions and kernels
In this section we discuss some useful properties of symmetric, piecewise Hölder continuous functions, relating to the decay of their eigenvalues when viewed as operators between spaces. Letting be the Hölder conjugate of (so ), for a symmetric function we can consider the operator defined by
| (74) |
We usually refer to as the kernel of such an operator. is then self-adjoint, in that for any functions we have that , where .
We introduce some terminology and theoretical results concerning such operators. We say that an operator is compact if the image of the ball under is relatively compact in . If , then is a compact operator. An operator is of finite rank if the range of is of dimension . We say that an operator is positive if for all . This induces a partial ordering on the operators, where iff is positive. In the case when , if is positive, then there exists a unique positive square root of (say ) such that , i.e that for all . Again in the case where , as is a self-adjoint compact operator, by the spectral theorem (e.g Fabian et al., 2001, Theorem 7.46) there exists a sequence of eigenvalues and eigenvectors (which form an orthonormal basis of ) such that
where the latter sum is understood to converge in , and . Supposing that is also positive, then one can prove (e.g König, 1986, Theorem 3.A.1) that is trace class, in that , and we refer to this as the trace, or trace norm, of .
We now give some useful properties of the algebraic properties of piecewise Hölder continuous functions, before proving a result concerning the eigenvalues of when is piecewise Hölder.
Lemma 88
Let be two piecewise Hölder continuous functions, which are both bounded below by and bounded above by , so . Then:
-
i)
For any scalar , is piecewise Hölder(, , , ), and is piecewise Hölder(, , , .
-
ii)
is bounded below by and bounded above by ;
-
iii)
and are Hölder continuous.
-
iv)
If is a continuous distribution function satisfying the conditions in Assumption BI, then , and is Hölder( where .
Proof [Proof of Lemma 88] Part i) is immediate. Part ii) follows by noting that as and are bounded below by and above by , we have that
As is a monotone bijection , we therefore get the first part of iv) also. For iii), for any and we have that
giving the first part of iii). For the second, note that we can write where is -Lipschitz; consequently has the same Hölder properties as . As is Lipschitz on compact sets and we know that is contained within a compact interval (say ), the same reasoning gives that is also Hölder with the same exponent and partition, and a constant depending only on the Hölder constant of , the upper/lower bounds on and the Lipschitz constant of on . This then gives the second part of iv).
To have the next theorem hold in slightly more generality, we introduce the notion of -piecewise equicontinuity of a family of functions , which holds if for all , there exists such that whenever lie within the same partition of and , we have that for all .
Theorem 89
Suppose that is Hölder(, , , ) continuous and symmetric. For such a , define as in (74), so is a self-adjoint, compact operator. Writing for the eigenvalues of sorted in decreasing order of magnitude, we have that
or that (also uniformly over such ). If is also positive, then this bound can be improved to uniformly, or
For any given and , the second bound stated also holds uniformly across for which and having at most negative eigenvalues. More generally, suppose that is a family of -piecewise equicontinuous functions, in which case we have that
Proof [Proof of Theorem 89] We adapt the proofs of Reade (1983a, Lemma 1) and the main result of Reade (1983b) so that they apply when is piecewise Hölder, and to track the constants from the aforementioned proofs so we can argue that the bounds we adapt hold uniformly across all which are Hölder(, , , ). The idea of these proofs is to exploit the smoothness of to build finite rank approximations whose error in particular norms is easy to calculate, giving eigenvalue bounds. We then discuss how the proofs can be modified for the equicontinuous case.
Starting when a-priori is not known to be positive, for any kernel corresponding to an operator of rank , we know that . As is piecewise Hölder continuous with respect to a partition , one strategy is to choose to be piecewise constant on a partition which is a refinement of .
To do so, begin by writing for some . For , note that we can find for such that . By summing over the index, this implies that , and so we can choose such that by the pigeonhole principle, as there are possible values of the sum, yet possible choices of . With this, we can define a partition of where the are intervals of length stacked alongside each other in consecutive order, where such that . This is a refining partition of , and moreover
With this, if we define as being a piecewise constant on , equal to the value of on the midpoint of the , then is the kernel of an operator of rank by Lemma 92. We then note that by the piecewise Hölder properties of , and as is piecewise constant on a refinement of , if then
Consequently (where the implied constant attached to the term depends only on , and the partition ), and so we get the first part of the result.
Note that if we only know that the belong to a equicontinuous family , then we can still apply the same construction and find that as . Indeed, given , let be such that once we have that for all . Then provided we choose to be so that the , the above construction guarantees us that a.e uniformly over all .
For the case where is non-negative definite, we will use a version of the Courant-Fischer min-max principle (Reade, 1983b, Lemma 1), which states that if is a kernel of a rank symmetric operator, then . Define
Note that is non-negative definite, of rank , and as, by Jensen’s inequality,
for any function . Therefore if we define (where is the square root of ), then by Lemma 94 we know that is of rank and . By following through the arguments in Reade (1983b, p.155) (noting that in Lemma 94 we verify that the trace of a piecewise continuous kernel is given by its integral over the diagonal), we may then argue that
and so as desired, with the implied constant depending only on and ; this then gives the stated bound on . In the case where has negative eigenvalues, note that the eigenvectors are piecewise Hölder by Lemma 93, and the eigenvalues are bounded above by . In particular, for each , if we subtract the negative part of from itself then we still have a class of piecewise Hölder continuous functions with partition , exponent and constant depending on , and . We can then apply the above result (as we are only interested in tail bounds for the eigenvalues), and get tail bounds which depend only on these quantities again.
We want to apply these results to of the form
| (75) |
where is a c.d.f as in Assumption BI, and the and come from Assumption E. By the above results, we can obtain the following:
Corollary 90
Suppose that Assumptions A and E hold with , and that is a c.d.f satisfying the properties stated in Assumption BI. Denote . Then there exists , free of and depending only on , and , such that where is as in (75). Moreover, there exists depending only on , , and - so again free of - such that is piecewise Hölder(, , , ) for all .
Proposition 91
Suppose that Assumption B holds with , where is the growth rate of the loss function , that Assumption A holds, and Assumption E holds with . Then we have that ; if is positive for all , then we moreover have that . Moreover, there exists free of such that whenever , denoting for the best rank approximation in to (that is, the operator for which is minimized over all positive rank operators for ), then for all , and .
In the case when is positive, then is also positive for all and , and consequently for all , and . In fact, the same conclusions above hold provided where is a family of -piecewise equicontinuous functions with , with the choice of holding uniformly over all .
Proof [Proof of Proposition 91] Let and denote, respectively, the eigenvalues and eigenvectors of . Working with the eigenvalues, note that , which is bounded uniformly in by Corollary 90. As for the eigenvectors, we note that by Lemma 93 they are all piecewise Hölder(, , , ) (where is as in Corollary 90); as they all have norm equal to one, it therefore follows by Lemma 95 that the eigenvectors are also uniformly bounded in . As we now can write
where the sum is understood to converge in (and therefore also in for any ), the desired conclusion follows with . In the case where the lie within a piecewise equicontinuous class where , the same arguments hold and therefore the stated conclusion does too.
H.1 Additional lemmata
Lemma 92
Let be symmetric and piecewise constant on a partition , where is a partition of . Then if is of size , is of rank .
Proof [Proof of Lemma 92]
Suppose for some intervals , and define the matrix where we can choose any and have be well defined as is piecewise constant. Then as is a -by- symmetric matrix, by the spectral theorem, there exists (possibly allowing for zero eigenvalues) and eigenvectors such that . Then if we define functions by for , , we have that and therefore is of rank .
Lemma 93
Suppose that is Hölder(, , , ) continuous and symmetric. Then for any we have that is Hölder(, , , ). In particular, is a self adjoint, compact operator. Moreover, the eigenvectors of , normalized to have norm , can be taken to each be piecewise Hölder(, , , ), and are uniformly bounded in .
Similarly, if is a -piecewise equicontinuous family of symmetric functions , then the collection of all the eigenvectors of for are -piecewise equicontinuous and uniformly bounded in .
Proof [Proof of Lemma 93] Let . Beginning with the Hölder case, for any pair we have
so the image of the ball is contained within the class of Hölder(, , , ) functions. This implies the claimed results, where the compactness of the operator follows by using the Arzela-Ascoli theorem with this fact, and the statement on eigenvectors of is immediate by the above derivation and an application of Lemma 95. For the case where we have some equicontinuous family , let , so there exists some such that whenever and lie within the same partition of , we have that for all . Therefore, if , for all and so we get that
giving the desired conclusion.
Lemma 94 (Mercer’s theorem + more for piecewise continuous kernels)
Let be a symmetric piecewise continuous function on , according to some partition of , for which the associated operator is positive. Then . Moreover, if is the unique positive square root of and is an operator of rank such that , then is of rank , the corresponding kernel is piecewise continuous, and .
Proof [Proof of Lemma 94] Note that in the case where is positive and continuous, it is well known as a consequence of Mercer’s theorem that we can write the trace norm of as the integral over the diagonal of . In the case where is piecewise continuous, if we write and for the eigenvalues and (normalized) eigenfunctions of , then we know that the eigenfunctions are piecewise continuous (by the argument in Lemma 93). By following the arguments in the proof of Mercer’s theorem for the continuous case (e.g Riesz and Szőkefalvi-Nagy, 1990, p245-246), one can argue that
| (76) |
convergences pointwise for all except at (potentially) the discontinuity points of , of which there are only finitely many. Therefore by the monotone convergence theorem, we then get that
Moreover, as a consequence of Dini’s theorem, we know that for any for some , there exists a compact set such that and the convergence in (76) is uniform on . This last part then allows us to follow through the proof of Reade (1983b, Lemma 2) to note that if is the unique non-negative definite square root of , then is piecewise continuous for any . It then follows by the same argument as in Reade (1983b, Lemma 3) that if is an operator of rank such that and is a non-negative definite operator which is piecewise continuous with square root , then is of rank , is piecewise continuous and satisfies .
Lemma 95
Let be compact, and let be a sequence of piecewise Hölder(, , , ) functions. If we also suppose that for any , then . The same conclusion follows if we have a sequence of piecewise equicontinuous functions.
Proof [Proof of Lemma 95] Without loss of generality we may suppose that (as uniform boundedness in any norm with implies uniform boundedness in when is compact). If we pick and (so that is well defined as is piecewise continuous on ), by the triangle inequality and integrating we then have that
where denotes the Lebesgue measure of . As the RHS is finite and bounded uniformly in , we get the desired result. The same argument works in the piecewise equicontinuous case.
References
- Abbe (2017) Emmanuel Abbe. Community detection and stochastic block models: recent developments. The Journal of Machine Learning Research, 18(1):6446–6531, January 2017. ISSN 1532-4435.
- Abramowitz and Stegun (1964) Milton Abramowitz and Irene A. Stegun. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Dover, New York, ninth edition edition, 1964.
- Agrawal et al. (2021) Akshay Agrawal, Alnur Ali, and Stephen Boyd. Minimum-Distortion Embedding. arXiv:2103.02559 [cs, math, stat], August 2021. URL http://arxiv.org/abs/2103.02559. arXiv: 2103.02559.
- Albert et al. (1999) Réka Albert, Hawoong Jeong, and Albert-László Barabási. Diameter of the World-Wide Web. Nature, 401(6749):130–131, September 1999. ISSN 1476-4687. doi: 10.1038/43601. URL https://www.nature.com/articles/43601.
- Aldous (1981) David J. Aldous. Representations for partially exchangeable arrays of random variables. Journal of Multivariate Analysis, 11(4):581–598, December 1981. ISSN 0047-259X. doi: 10.1016/0047-259X(81)90099-3. URL https://www.sciencedirect.com/science/article/pii/0047259X81900993.
- Aliprantis and Border (2006) Charalambos D. Aliprantis and Kim Border. Infinite Dimensional Analysis: A Hitchhiker’s Guide. Springer-Verlag, Berlin Heidelberg, 3 edition, 2006. ISBN 978-3-540-29586-0. doi: 10.1007/3-540-29587-9. URL https://www.springer.com/gp/book/9783540295860.
- Athreya et al. (2018) Avanti Athreya, Donniell E. Fishkind, Minh Tang, Carey E. Priebe, Youngser Park, Joshua T. Vogelstein, Keith Levin, Vince Lyzinski, Yichen Qin, and Daniel L. Sussman. Statistical Inference on Random Dot Product Graphs: a Survey. Journal of Machine Learning Research, 18(226):1–92, 2018. ISSN 1533-7928. URL http://jmlr.org/papers/v18/17-448.html.
- Aubin and Frankowska (2009) Jean-Pierre Aubin and Hélène Frankowska. Set-Valued Analysis. Modern Birkhäuser Classics. Birkhäuser Basel, 2009. ISBN 978-0-8176-4847-3. doi: 10.1007/978-0-8176-4848-0. URL https://www.springer.com/us/book/9780817648473.
- Barbu and Precupanu (2012) Viorel Barbu and Teodor Precupanu. Convexity and Optimization in Banach Spaces. Springer Monographs in Mathematics. Springer Netherlands, 4 edition, 2012. ISBN 978-94-007-2246-0. URL https://www.springer.com/gp/book/9789400722460.
- Belkin and Niyogi (2003) Mikhail Belkin and Partha Niyogi. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Computation, 15(6):1373–1396, June 2003. ISSN 0899-7667. doi: 10.1162/089976603321780317. URL https://doi.org/10.1162/089976603321780317.
- Birman and Solomyak (1977) M. Sh Birman and M. Z. Solomyak. Estimates of Singular Numbers of Integral Operators. Russian Mathematical Surveys, 32(1):15–89, February 1977. doi: 10.1070/rm1977v032n01abeh001592. URL https://doi.org/10.1070/rm1977v032n01abeh001592.
- Borgs et al. (2015) Christian Borgs, Jennifer T. Chayes, and Adam Smith. Private Graphon Estimation for Sparse Graphs. arXiv:1506.06162 [cs, math, stat], June 2015. URL http://arxiv.org/abs/1506.06162. arXiv: 1506.06162.
- Borgs et al. (2017) Christian Borgs, Jennifer T. Chayes, Henry Cohn, and Victor Veitch. Sampling perspectives on sparse exchangeable graphs. arXiv:1708.03237 [math], August 2017. URL http://arxiv.org/abs/1708.03237. arXiv: 1708.03237.
- Borgs et al. (2018) Christian Borgs, Jennifer T. Chayes, Henry Cohn, and Nina Holden. Sparse exchangeable graphs and their limits via graphon processes. arXiv:1601.07134 [math], June 2018. URL http://arxiv.org/abs/1601.07134. arXiv: 1601.07134.
- Borgs et al. (2019) Christian Borgs, Jennifer T. Chayes, Henry Cohn, and Victor Veitch. Sampling perspectives on sparse exchangeable graphs. The Annals of Probability, 47(5):2754–2800, September 2019. ISSN 0091-1798, 2168-894X. doi: 10.1214/18-AOP1320. URL https://projecteuclid.org/journals/annals-of-probability/volume-47/issue-5/Sampling-perspectives-on-sparse-exchangeable-graphs/10.1214/18-AOP1320.full. Publisher: Institute of Mathematical Statistics.
- Boucheron et al. (2016) Stephane Boucheron, Gabor Lugosi, and Pascal Massart. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2016. ISBN 0-19-876765-X.
- Breitkreutz et al. (2008) Bobby-Joe Breitkreutz, Chris Stark, Teresa Reguly, Lorrie Boucher, Ashton Breitkreutz, Michael Livstone, Rose Oughtred, Daniel H. Lackner, Jürg Bähler, Valerie Wood, Kara Dolinski, and Mike Tyers. The BioGRID Interaction Database: 2008 update. Nucleic Acids Research, 36(Database issue):D637–640, January 2008. ISSN 1362-4962. doi: 10.1093/nar/gkm1001.
- Broido and Clauset (2019) Anna D. Broido and Aaron Clauset. Scale-free networks are rare. Nature Communications, 10(1):1017, December 2019. ISSN 2041-1723. doi: 10.1038/s41467-019-08746-5. URL http://arxiv.org/abs/1801.03400. arXiv: 1801.03400.
- Brézis (2011) H Brézis. Functional analysis, Sobolev spaces and partial differential equations. Springer, New York London, 2011. ISBN 978-0-387-70914-7.
- Cai et al. (2018) H. Cai, V. W. Zheng, and K. C. Chang. A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications. IEEE Transactions on Knowledge and Data Engineering, 30(9):1616–1637, September 2018. ISSN 1041-4347. doi: 10.1109/TKDE.2018.2807452.
- Caron and Fox (2017) François Caron and Emily B. Fox. Sparse graphs using exchangeable random measures. Journal of the Royal Statistical Society. Series B, Statistical Methodology, 79(5):1295–1366, November 2017. ISSN 1369-7412. doi: 10.1111/rssb.12233. Number: 5.
- Chanpuriya et al. (2020) Sudhanshu Chanpuriya, Cameron Musco, Konstantinos Sotiropoulos, and Charalampos E. Tsourakakis. Node Embeddings and Exact Low-Rank Representations of Complex Networks. arXiv:2006.05592 [cs, stat], October 2020. URL http://arxiv.org/abs/2006.05592. arXiv: 2006.05592.
- Chatterjee (2005) Sourav Chatterjee. Concentration inequalities with exchangeable pairs (Ph.D. thesis). arXiv:math/0507526, July 2005. URL http://arxiv.org/abs/math/0507526. arXiv: math/0507526.
- Crane and Dempsey (2018) Harry Crane and Walter Dempsey. Edge Exchangeable Models for Interaction Networks. Journal of the American Statistical Association, 113(523):1311–1326, July 2018. ISSN 0162-1459. doi: 10.1080/01621459.2017.1341413. URL https://doi.org/10.1080/01621459.2017.1341413. Publisher: Taylor & Francis _eprint: https://doi.org/10.1080/01621459.2017.1341413.
- Dekel et al. (2012) Ofer Dekel, Ran Gilad-Bachrach, Ohad Shamir, and Lin Xiao. Optimal distributed online prediction using mini-batches. The Journal of Machine Learning Research, 13:165–202, January 2012. ISSN 1532-4435.
- Deng et al. (2021) Shaofeng Deng, Shuyang Ling, and Thomas Strohmer. Strong Consistency, Graph Laplacians, and the Stochastic Block Model. Journal of Machine Learning Research, 22(117):1–44, 2021. ISSN 1533-7928. URL http://jmlr.org/papers/v22/20-391.html.
- Fabian et al. (2001) Marian Fabian, Petr Habala, Petr Hajek, Vicente Montesinos Santalucia, Jan Pelant, and Vaclav Zizler. Functional Analysis and Infinite-Dimensional Geometry. CMS Books in Mathematics. Springer-Verlag, New York, 2001. ISBN 978-0-387-95219-2. doi: 10.1007/978-1-4757-3480-5. URL https://www.springer.com/us/book/9780387952192.
- Fortunato (2010) Santo Fortunato. Community detection in graphs. Physics Reports, 486(3):75–174, February 2010. ISSN 0370-1573. doi: 10.1016/j.physrep.2009.11.002. URL https://www.sciencedirect.com/science/article/pii/S0370157309002841.
- Fortunato and Hric (2016) Santo Fortunato and Darko Hric. Community detection in networks: A user guide. Physics Reports, 659:1–44, November 2016. ISSN 0370-1573. doi: 10.1016/j.physrep.2016.09.002. URL https://www.sciencedirect.com/science/article/pii/S0370157316302964.
- Gao et al. (2015) Chao Gao, Yu Lu, and Harrison H. Zhou. Rate-optimal graphon estimation. The Annals of Statistics, 43(6):2624–2652, December 2015. ISSN 0090-5364, 2168-8966. doi: 10.1214/15-AOS1354. URL https://projecteuclid.org/journals/annals-of-statistics/volume-43/issue-6/Rate-optimal-graphon-estimation/10.1214/15-AOS1354.full. Publisher: Institute of Mathematical Statistics.
- Grover and Leskovec (2016) Aditya Grover and Jure Leskovec. node2vec: Scalable Feature Learning for Networks. pages 855–864. ACM, August 2016. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672.2939754. URL http://dl.acm.org/citation.cfm?id=2939672.2939754.
- Hamilton et al. (2017a) Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive Representation Learning on Large Graphs. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017a. URL https://proceedings.neurips.cc/paper/2017/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf.
- Hamilton et al. (2017b) William L. Hamilton, Rex Ying, and Jure Leskovec. Representation Learning on Graphs: Methods and Applications. IEEE Data Eng. Bull., 40(3):52–74, 2017b. URL http://sites.computer.org/debull/A17sept/p52.pdf. Number: 3.
- Hasan and Zaki (2011) Mohammad Al Hasan and Mohammed J. Zaki. A Survey of Link Prediction in Social Networks. In Charu C. Aggarwal, editor, Social Network Data Analytics, pages 243–275. Springer US, Boston, MA, 2011. ISBN 978-1-4419-8462-3. doi: 10.1007/978-1-4419-8462-3˙9. URL https://doi.org/10.1007/978-1-4419-8462-3_9.
- Holland et al. (1983) Paul W. Holland, Kathryn Blackmond Laskey, and Samuel Leinhardt. Stochastic blockmodels: First steps. Social Networks, 5(2):109–137, June 1983. ISSN 0378-8733. doi: 10.1016/0378-8733(83)90021-7. URL http://www.sciencedirect.com/science/article/pii/0378873383900217. Number: 2.
- Horsley et al. (1998) Anthony Horsley, Timothy Zandt, and Andrew Wrobel. Berge’s maximum theorem with two topologies on the action set. Economics Letters, 61:285–291, February 1998. doi: 10.1016/S0165-1765(98)00177-3.
- Janson (2009) Svante Janson. Standard representation of multivariate functions on a general probability space. Electronic Communications in Probability, 14(none):343–346, January 2009. ISSN 1083-589X, 1083-589X. doi: 10.1214/ECP.v14-1477. URL https://projecteuclid.org/journals/electronic-communications-in-probability/volume-14/issue-none/Standard-representation-of-multivariate-functions-on-a-general-probability-space/10.1214/ECP.v14-1477.full. Publisher: Institute of Mathematical Statistics and Bernoulli Society.
- Janson and Olhede (2021) Svante Janson and Sofia Olhede. Can smooth graphons in several dimensions be represented by smooth graphons on [0,1]? arXiv:2101.07587 [math, stat], January 2021. URL http://arxiv.org/abs/2101.07587. arXiv: 2101.07587.
- Klopp et al. (2017) Olga Klopp, Alexandre B. Tsybakov, and Nicolas Verzelen. Oracle Inequalities For Network Models and Sparse Graphon Estimation. The Annals of Statistics, 45(1):316–354, 2017. ISSN 0090-5364. URL https://www.jstor.org/stable/44245780. Publisher: Institute of Mathematical Statistics.
- König (1986) Hermann König. Eigenvalue Distribution of Compact Operators. Birkhäuser Basel, 1986. doi: 10.1007/978-3-0348-6278-3. URL https://doi.org/10.1007/978-3-0348-6278-3.
- Lei (2021) Jing Lei. Network representation using graph root distributions. The Annals of Statistics, 49(2):745–768, April 2021. ISSN 0090-5364, 2168-8966. doi: 10.1214/20-AOS1976. URL https://projecteuclid.org/journals/annals-of-statistics/volume-49/issue-2/Network-representation-using-graph-root-distributions/10.1214/20-AOS1976.full. Publisher: Institute of Mathematical Statistics.
- Lei and Rinaldo (2015) Jing Lei and Alessandro Rinaldo. Consistency of spectral clustering in stochastic block models. The Annals of Statistics, 43(1), February 2015. ISSN 0090-5364. doi: 10.1214/14-AOS1274. URL http://arxiv.org/abs/1312.2050. arXiv: 1312.2050.
- Levin et al. (2021) Keith D. Levin, Fred Roosta, Minh Tang, Michael W. Mahoney, and Carey E. Priebe. Limit theorems for out-of-sample extensions of the adjacency and Laplacian spectral embeddings. Journal of Machine Learning Research, 22(194):1–59, 2021. ISSN 1533-7928. URL http://jmlr.org/papers/v22/19-852.html.
- Lovász (2012) László Lovász. Large Networks and Graph Limits., volume 60 of Colloquium Publications. American Mathematical Society, 2012. ISBN 978-0-8218-9085-1.
- Ma et al. (2021) Shujie Ma, Liangjun Su, and Yichong Zhang. Determining the Number of Communities in Degree-corrected Stochastic Block Models. Journal of Machine Learning Research, 22(69):1–63, 2021. ISSN 1533-7928. URL http://jmlr.org/papers/v22/20-037.html.
- Marchal and Arbel (2017) Olivier Marchal and Julyan Arbel. On the sub-Gaussianity of the Beta and Dirichlet distributions. Electronic Communications in Probability, 22, 2017. ISSN 1083-589X. doi: 10.1214/17-ECP92. URL https://projecteuclid.org/euclid.ecp/1507860211. Publisher: The Institute of Mathematical Statistics and the Bernoulli Society.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean. Distributed Representations of Words and Phrases and their Compositionality. Advances in Neural Information Processing Systems, 26:3111–3119, 2013. URL https://papers.nips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html.
- Ng et al. (2001) Andrew Y. Ng, Michael I. Jordan, and Yair Weiss. On spectral clustering: analysis and an algorithm. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, NIPS’01, pages 849–856, Cambridge, MA, USA, January 2001. MIT Press.
- Oono and Suzuki (2021) Kenta Oono and Taiji Suzuki. Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. arXiv:1905.10947 [cs, stat], January 2021. URL http://arxiv.org/abs/1905.10947. arXiv: 1905.10947.
- Orbanz (2017) Peter Orbanz. Subsampling large graphs and invariance in networks. arXiv:1710.04217 [math, stat], October 2017. URL http://arxiv.org/abs/1710.04217. arXiv: 1710.04217.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. DeepWalk: Online Learning of Social Representations. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining - KDD ’14, pages 701–710, 2014. doi: 10.1145/2623330.2623732. URL http://arxiv.org/abs/1403.6652. arXiv: 1403.6652.
- Pothen et al. (1990) Alex Pothen, Horst D. Simon, and Kan-Pu Liou. Partitioning sparse matrices with eigenvectors of graphs. SIAM Journal on Matrix Analysis and Applications, 11(3):430–452, May 1990. ISSN 0895-4798. doi: 10.1137/0611030. URL https://doi.org/10.1137/0611030.
- Qi et al. (2006) Yanjun Qi, Ziv Bar-Joseph, and Judith Klein-Seetharaman. Evaluation of Different Biological Data and Computational Classification Methods for Use in Protein Interaction Prediction. Proteins, 63(3):490–500, May 2006. ISSN 0887-3585. doi: 10.1002/prot.20865. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250929/.
- Qiu et al. (2018) Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Kuansan Wang, and Jie Tang. Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec. Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining - WSDM ’18, pages 459–467, 2018. doi: 10.1145/3159652.3159706. URL http://arxiv.org/abs/1710.02971. arXiv: 1710.02971.
- Rahman et al. (2019) Tahleen Rahman, Bartlomiej Surma, Michael Backes, and Yang Zhang. Fairwalk: Towards Fair Graph Embedding. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, pages 3289–3295, 2019. URL https://www.ijcai.org/proceedings/2019/456.
- Reade (1983a) J. B. Reade. Eigen-values of Lipschitz kernels. Mathematical Proceedings of the Cambridge Philosophical Society, 93(1):135–140, January 1983a. ISSN 1469-8064, 0305-0041. doi: 10.1017/S0305004100060412. URL http://www.cambridge.org/core/journals/mathematical-proceedings-of-the-cambridge-philosophical-society/article/eigenvalues-of-lipschitz-kernels/56110F30494C86F8D7A18D2DB9630677. Number: 1 Publisher: Cambridge University Press.
- Reade (1983b) J. B. Reade. Eigenvalues of Positive Definite Kernels. SIAM Journal on Mathematical Analysis, 14(1):152–157, January 1983b. ISSN 0036-1410. doi: 10.1137/0514012. URL http://epubs.siam.org/doi/abs/10.1137/0514012. Number: 1 Publisher: Society for Industrial and Applied Mathematics.
- Riesz and Szőkefalvi-Nagy (1990) Frigyes Riesz and Béla Szőkefalvi-Nagy. Functional analysis. Dover Publications, New York, dover ed edition, 1990. ISBN 978-0-486-66289-3.
- Robbins and Monro (1951) Herbert Robbins and Sutton Monro. A Stochastic Approximation Method. The Annals of Mathematical Statistics, 22(3):400–407, September 1951. ISSN 0003-4851, 2168-8990. doi: 10.1214/aoms/1177729586. URL https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-22/issue-3/A-Stochastic-Approximation-Method/10.1214/aoms/1177729586.full. Publisher: Institute of Mathematical Statistics.
- Rubin-Delanchy et al. (2017) Patrick Rubin-Delanchy, Carey E. Priebe, Minh Tang, and Joshua Cape. A statistical interpretation of spectral embedding: the generalised random dot product graph. arXiv:1709.05506 [cs, stat], September 2017. URL http://arxiv.org/abs/1709.05506. arXiv: 1709.05506.
- Seshadhri et al. (2020) C. Seshadhri, Aneesh Sharma, Andrew Stolman, and Ashish Goel. The impossibility of low-rank representations for triangle-rich complex networks. Proceedings of the National Academy of Sciences, 117(11):5631–5637, March 2020. doi: 10.1073/pnas.1911030117. URL https://www.pnas.org/doi/10.1073/pnas.1911030117. Publisher: Proceedings of the National Academy of Sciences.
- Shi and Malik (2000) Jianbo Shi and J. Malik. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):888–905, August 2000. ISSN 1939-3539. doi: 10.1109/34.868688. Conference Name: IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Talagrand (2014) Michel Talagrand. Upper and Lower Bounds for Stochastic Processes: Modern Methods and Classical Problems. Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge / A Series of Modern Surveys in Mathematics. Springer-Verlag, Berlin Heidelberg, 2014. ISBN 978-3-642-54074-5. doi: 10.1007/978-3-642-54075-2. URL https://www.springer.com/gp/book/9783642540745.
- Tang et al. (2015) Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. LINE: Large-scale Information Network Embedding. Proceedings of the 24th International Conference on World Wide Web, pages 1067–1077, May 2015. doi: 10.1145/2736277.2741093. URL http://arxiv.org/abs/1503.03578. arXiv: 1503.03578.
- Tang and Liu (2009) Lei Tang and Huan Liu. Relational learning via latent social dimensions. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’09, pages 817–826, New York, NY, USA, June 2009. Association for Computing Machinery. ISBN 978-1-60558-495-9. doi: 10.1145/1557019.1557109. URL https://doi.org/10.1145/1557019.1557109.
- Tang and Priebe (2018) Minh Tang and Carey E. Priebe. Limit theorems for eigenvectors of the normalized Laplacian for random graphs. The Annals of Statistics, 46(5):2360–2415, October 2018. ISSN 0090-5364, 2168-8966. doi: 10.1214/17-AOS1623. URL https://projecteuclid.org/journals/annals-of-statistics/volume-46/issue-5/Limit-theorems-for-eigenvectors-of-the-normalized-Laplacian-for-random/10.1214/17-AOS1623.full. Publisher: Institute of Mathematical Statistics.
- Tsybakov (2008) Alexandre B Tsybakov. Introduction to Nonparametric Estimation. Springer Series in Statistics. Springer, New York, NY, 1 edition, November 2008.
- Vaart (1998) A. W. van der Vaart. Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 1998. doi: 10.1017/CBO9780511802256.
- Veitch and Roy (2015) Victor Veitch and Daniel M. Roy. The Class of Random Graphs Arising from Exchangeable Random Measures. arXiv:1512.03099 [cs, math, stat], December 2015. URL http://arxiv.org/abs/1512.03099. arXiv: 1512.03099.
- Veitch et al. (2018) Victor Veitch, Morgane Austern, Wenda Zhou, David M. Blei, and Peter Orbanz. Empirical Risk Minimization and Stochastic Gradient Descent for Relational Data. arXiv:1806.10701 [cs, stat], June 2018. URL http://arxiv.org/abs/1806.10701. arXiv: 1806.10701.
- Veitch et al. (2019) Victor Veitch, Yixin Wang, and David M. Blei. Using Embeddings to Correct for Unobserved Confounding in Networks. arXiv:1902.04114 [cs, stat], May 2019. URL http://arxiv.org/abs/1902.04114. arXiv: 1902.04114.
- Vershynin (2018) Roman Vershynin. High-Dimensional Probability: An Introduction with Applications in Data Science. 2018. doi: 10.1017/9781108231596.
- Wolfe and Olhede (2013) Patrick J. Wolfe and Sofia C. Olhede. Nonparametric graphon estimation. arXiv:1309.5936 [math, stat], September 2013. URL http://arxiv.org/abs/1309.5936. arXiv: 1309.5936.
- Xu (2018) Jiaming Xu. Rates of Convergence of Spectral Methods for Graphon Estimation. In Proceedings of the 35th International Conference on Machine Learning, pages 5433–5442. PMLR, July 2018. URL https://proceedings.mlr.press/v80/xu18a.html. ISSN: 2640-3498.
- Zhang and Tang (2021) Yichi Zhang and Minh Tang. Consistency of random-walk based network embedding algorithms. arXiv:2101.07354 [cs, stat], January 2021. URL http://arxiv.org/abs/2101.07354. arXiv: 2101.07354.
- Zhou et al. (2020) Bin Zhou, Xiangyi Meng, and H. Eugene Stanley. Power-law distribution of degree–degree distance: A better representation of the scale-free property of complex networks. Proceedings of the National Academy of Sciences, 117(26):14812–14818, June 2020. doi: 10.1073/pnas.1918901117. URL https://www.pnas.org/doi/10.1073/pnas.1918901117. Publisher: Proceedings of the National Academy of Sciences.