Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level
Abstract.
In-memory key-value stores (IMKVSes) serve many online applications because of their efficiency. To support data backup, popular industrial IMKVSes periodically take a point-in-time snapshot of the in-memory data with the system call fork. However, this mechanism can result in latency spikes for queries arriving during the snapshot period because fork leads the engine into the kernel mode in which the engine is out-of-service for queries. In contrast to existing research focusing on optimizing snapshot algorithms, we optimize the fork operation to address the latency spikes problem from the operating system (OS) level, while keeping the data persistent mechanism in IMKVSes unchanged. Specifically, we first conduct an in-depth study to reveal the impact of the fork operation as well as the optimization techniques on query latency. Based on findings in the study, we propose Async-fork to offload the work of copying the page table from the engine (the parent process) to the child process as copying the page table dominates the execution time of fork. To keep data consistent between the parent and the child, we design the proactive synchronization strategy. Async-fork is implemented in the Linux kernel and deployed into the online Redis database in public clouds. Our experiment results show that compared with the default fork method in OS, Async-fork reduces the tail latency of queries arriving during the snapshot period by 81.76% on an 8GB instance and 99.84% on a 64GB instance.
PVLDB Reference Format:
PVLDB, 16(5): XXX-XXX, 2023.
doi:XX.XX/XXX.XX
††∗These authors contributed equally to this work.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 16, No. 5 ISSN 2150-8097.
doi:XX.XX/XXX.XX
1. Introduction
In-memory key-value stores (IMKVSes) are widely used in real-world applications, especially online services (e.g., e-commerce and social network), because of their ultra-fast query processing speed. For example, Memcached (Shafer, 2012), Redis (RedisLab, 2021b), KeyDB (Inc., 2022a) and their variants (Chandramouli et al., 2018; Fan et al., 2013; Harris, 2010; Bailey et al., 2013) have been deployed in production environments of big internet companies such as Facebook, Amazon and Twitter. As all data resides in memory, the data persistent function is a key feature of IMKVSes for data backup.
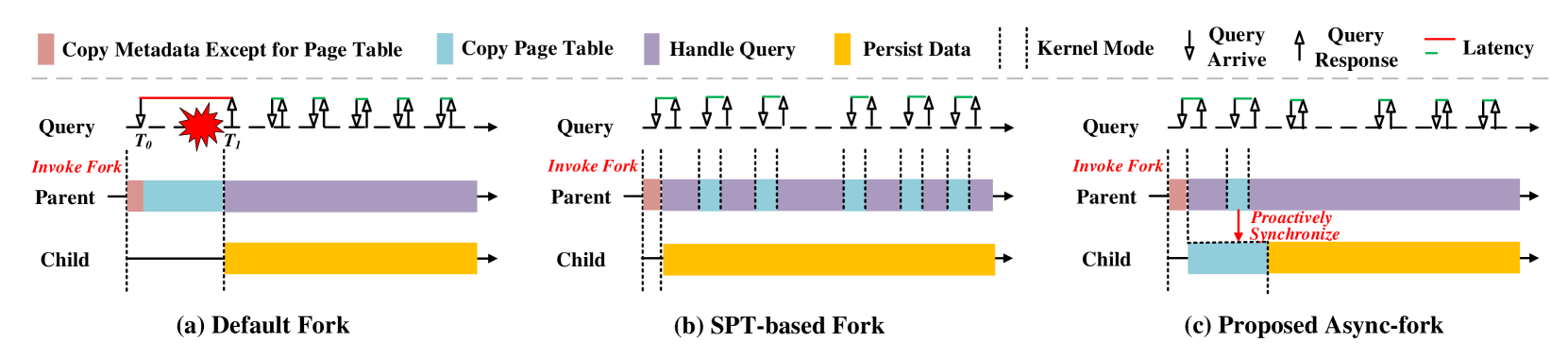
A common data persistent approach is to take a point-in-time snapshot of the in-memory data with the system call fork and dump the snapshot into the file system. Figure 1(a) gives an example of the fork-based snapshot method. In the beginning, the storage engine (the parent process) invokes fork to create a child process. As fork creates a new process by duplicating the parent process, the child process will hold the same data as the parent. Thus, we can ask the child process to write the data into a file in the background but keep the parent process continuous processing queries. Although the storage engine delegates the heavy IO task to the child process, the fork-based snapshot method can incur latency spikes (Technology, 2017; Li et al., 2018). Specifically, queries arriving during the period of taking a snapshot (from the start of fork to the end of persisting data) can have a long latency because the storage engine runs into the kernel mode and is out-of-service for queries. For example, the query arrives in time in Figure 1(a). For brevity, queries arriving during the period of taking a snapshot are called snapshot queries, while the others are called normal queries. In general, IMKVSes take a snapshot periodically (e.g., Redis by default takes a snapshot every 60 seconds if at least 10000 records are modified (RedisLab, 2022b; Zhao et al., 2021)). Consequently, latency spikes for snapshot queries are not rare.
To solve the problem, researchers proposed a variety of snapshot algorithms such as Copy-on-Update (Liedes and Wolski, 2006; Cao, 2013), Zigzag (Cao et al., 2011) and Ping-Pong (Cao et al., 2011). These algorithms focus on lowering the cost of taking a snapshot by optimizing the occasion of copying data and reducing the amount of data copied. However, a recent study (Li et al., 2018) finds that the performance of the fork-based method is generally competitive with these advanced methods, and even outperforms them for write-intensive workloads. Additionally, the implementation of the fork-based method is very simple and requires a small engineering effort. As such, industrial IMKVSes do not adopt these snapshot algorithms from academia and keep the fork-based as the built-in data persistent approach. As a result, IMKVSes still have latency spikes caused by the fork operation, which can harm the service quality of online applications.
In contrast to existing research focusing on optimizing snapshot algorithms, we propose a straightforward approach to address the problem. Specifically, we optimize the fork operation to reduce the long latency incurred by the fork-based snapshot from the operating system (OS) level, while keeping the data persistent mechanism in IMKVSes unchanged.
We first conduct an in-depth study to reveal the impact of the fork operation on query latency. Our profiling results on the default fork operation show that the overhead of fork results in a long tail latency (up to hundreds of milliseconds) for snapshot queries, and copying the page table dominates the execution time of fork. This motivates us to further investigate the impact of advanced techniques (Community, 2021a, b; McCracken, 2003; Dong et al., 2016; Zhao et al., 2021) that can accelerate the fork operation. We consider two optimization strategies, the huge page (Community, 2021a, b) and the shared page table (McCracken, 2003; Dong et al., 2016; Zhao et al., 2021). As the huge page can degrade the performance of IMKVSes (RedisLab, 2021d; Inc., 2022d), our profiling only involves the shared page table-based fork (SPT-based fork) (Zhao et al., 2021), which is the latest method. The SPT-based fork proposed to share the page table between the parent process and the child process in a copy-on-write (CoW) manner to reduce the cost of the fork operation. However, the CoW can frequently interrupt the parent process as shown in Figure 1(b). Our profiling results show that frequent interruption can incur non-negligible overhead for snapshot queries although the SPT-based fork significantly reduces the tail latency compared with the default fork operation. Moreover, our analysis finds that the shared page table introduces the data leakage vulnerability, which potentially leads to an inconsistent snapshot. Thus, both the huge table and shared page table techniques cannot be applied in this scenario.
Motivated by these findings, we propose Async-fork to mitigate the latency spikes for snapshot queries by optimizing the fork operation. Figure 1(c) demonstrates the general idea. As copying the page table dominates the cost of the fork operation, Async-fork offloads this workload from the parent process to the child process to reduce the duration that the parent process runs into the kernel mode. This design also ensures that both the parent and child processes have an exclusive page table to avoid the data leakage vulnerability caused by the shared page table.
However, it is far from trivial to achieve in design since the asynchronization operations of the two processes on the page table can result in an inconsistent snapshot, i.e., the parent process may modify the page table, while the copy operation of the child process is in process. To address the problem, we design the proactive synchronization technique. This technique enables the parent process to detect all modifications (including that triggered by either users or OS) to the page table. If the parent process detects that some page table entries will be modified and these entries are not copied, then it will proactively copy them to the child process. Otherwise, these entries must have been copied to the child process and the parent process will directly modify them. In this way, the proactive synchronization technique keeps the snapshot consistent and reduces the number of interruptions to the parent process compared with SPT-based fork. Additionally, we parallelize the copy operation of the child process to further accelerate Async-fork.
We implement Async-fork in the Linux kernel (both x86 and ARM64). Async-fork is integrated into the OS and transparent to IMKVSes. The technique is also deployed in the online Redis databases in public Clouds111https://www.alibabacloud.com/product/apsaradb-for-redis. Last accessed on 2022/11/13.. Despite that, we conduct experiments on our local machine for the purpose of test flexibility. In the experiments, we select two popular IMKVSes, Redis and KeyDB, and use the Redis benchmark (RedisLab, 2021a) and Memtier benchmark (RedisLab, 2022a). The database instance size is varied from 1GB, 2GB, and 4GB … to 64GB. Although the SPT-based fork (Zhao et al., 2021) may lead to data leakage, our experiment involves this method for comparison purposes because of its efficiency. For Redis, our experiment results show that 1) compared with the default fork, Async-fork reduces the 99%-ile latency of snapshot queries by 17.57% (from 0.074ms to 0.061ms) on 1GB instance, 81.76% (from 0.435ms to 0.079ms) on 8GB instance and 99.84% (from 991.9ms to 1.5ms) on 64GB instance; and 2) compared with the latest SPT-based fork, Async-fork reduces the 99%-ile latency of snapshot queries by 2.87% on 1GB instance, 39.73% on 8GB instance and 61.97% on 64GB instance. We obtain similar results on KeyDB. These results demonstrate the efficacy of the technique proposed in this paper, especially for the large instances that can lead to long latency.
In summary, we make the following contributions in this paper.
-
•
We conduct an in-depth study of the impact of the fork operations on the latency of snapshot queries in IMKVSes.
-
•
We propose Async-fork that can mitigate the long latency of snapshot queries from the OS level, which is orthogonal to existing research on the problem.
-
•
The technique is implemented in the Linux kernel (both x86 and ARM64) and deployed in the online Redis database in public clouds.
-
•
We conduct extensive experiments with Redis and KeyDB to evaluate the efficacy of the proposed techniques.
2. Background
In this section, we first introduce the preliminaries and then discuss the related work.
2.1. Preliminary
We first briefly review two operating system concepts, virtual memory and fork that are closely related to this work. As our technique is implemented and deployed in Linux, we introduce these concepts in the context of Linux. Then, we discuss the use cases of fork in databases.
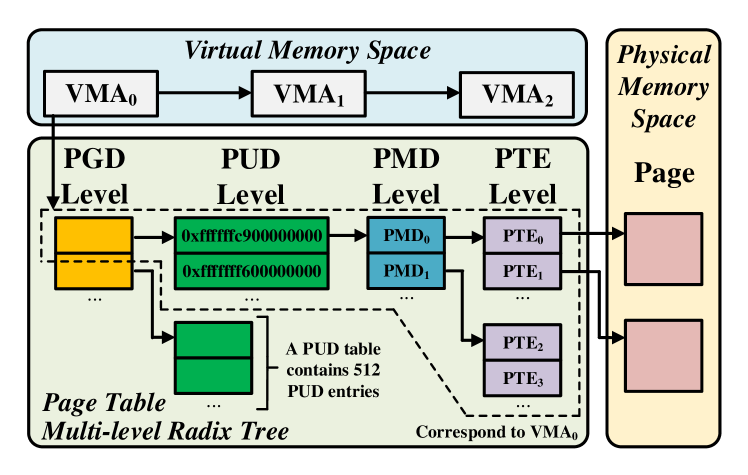
Virtual Memory. As an effective approach to managing hardware memory resources, virtual memory is widely used in modern operating systems. A process has its own virtual memory space, which is organized into a set of virtual memory areas (VMA). Each VMA describes a continuous area in the virtual memory space. The page table is the data structure used to map the virtual memory space to the physical memory. It consists of a collection of page table entries (PTE), each of which maintains the virtual-to-physical address translation information and access permissions. A VMA corresponds to multiple PTEs.
Figure 2 shows an example of the page table. To reduce the memory cost, the page table is stored as a multi-level radix tree in which PTEs locate in leaf nodes (i.e., PTE Level in Figure 2). The part in the area marked with the dashed line corresponds to VMA0. The tree at most has five levels. From top to bottom, they are the page global directory (PGD) level, the P4D level, the page upper directory (PUD) level, the page middle directory (PMD) level and the PTE level. As P4D is generally disabled, we focus on the other four levels in this paper. Except for the PTE level, an entry stores the physical address of a page while this page is used as the next-level node (table). With the page size setting to 4KB, a table in each level contains 512 entries. Given a VMA, “VMA’s PTEs” refers to the PTEs corresponding to the VMA and “VMA’s PMDs” is the set of PMD entries that are parents of these PTEs in the tree. For example, PMD0 and PMD1 belong to VMA0’s PMDs in Figure 2.
Fork Operation. Fork is a system call that creates a new process by duplicating the calling process (for, [n.d.]). Both processes have separate memory spaces. The new (resp. calling) process is called the child (resp. parent) process. To accelerate the operation, Linux implements fork with the copy-on-write (CoW) strategy. Specifically, while invoking fork, the parent process runs in the kernel mode and copies the metadata (e.g, VMAs, the page table, file descriptors, and signals) to the child process. The PTEs of both parent and child are set to write-protected. After that, the process that first modifies a write-protected page triggers a page fault, which leads to the copy of the page. In a word, benefiting from CoW, fork copies the metadata only.
Use Cases of fork in Database. Fork has a number of database use cases because it can easily and efficiently create a snapshot of in-memory data, the consistency of which is guaranteed by the OS. In general, these cases can be categorized into two classes based on the usage of the snapshot. First, use fork to delegate dedicated tasks, which have expensive IO or computation costs, to a child process without blocking the service of the parent process. MDC (Park et al., 2020) uses fork to record checkpoints for in-memory databases. Redis uses fork to conduct log rewriting (RedisLab, 2021e) that optimizes the Append Only File (AOF). FlurryDB (Mior and de Lara, 2011) proposes to create replica based on fork in distributed environments. Second, use fork to create snapshots to support concurrent transaction processing because fork provides the snapshot isolation between processes. HyPer (Kemper and Neumann, 2011) proposes to evaluate hybrid OLTP and OLAP queries based on snapshots created by fork. AnKer (Sharma et al., 2018) designs a fine-grained snapshot mechanism to support MVCC. In particular, AnKer takes a partial snapshot of in-memory data by co-designing the database engine and the system call fork. Different from our research on accelerating the fork operation from the OS level, AnKer focuses on optimizing which in-memory data should be captured by the snapshot.
All these use cases can potentially benefit from Async-fork because 1) they can encounter the query latency spike problem incurred by the fork operation; and 2) Async-fork can accelerate the snapshot creation. This paper focuses on the scenario that uses fork to take a point-in-time snapshot of in-memory data to persist the data (RedisLab, 2021e; Inc., 2022c). In particular, the storage engine calls fork to create a child process that holds the same data as it. Then, the child process writes the data to the hard drive, while the storage engine can continue to serve users’ queries. Although the storage engine delegates the data dump task to the child process, it will be out-of-service for queries during the invocation of fork because it runs into the kernel mode. We are particularly interested in this scenario because the IMKVS is one of the most important services in public cloud and popular IMKVSes (e.g., Redis and KeyDB) (solid IT, 2022) use this mechanism to persist data. Consequently, these stores encounter serious a query latency spike problem (see Section 3), while they are generally used in mission-critical applications that have a rigid latency constraint. We also evaluate the effectiveness of Async-fork on log rewriting in Redis (RedisLab, 2021e). The experiment results are presented in the technical report (tec, 2022).
Remarks. Instead of developing a general-purpose solution to replace the default fork in the OS, the goal of Async-fork is to provide an efficient fork operation for the scenarios (especially for IMKVSes) where 1) the applications are memory-intensive, and 2) the parent process is latency-sensitive. Our design allows Async-fork and the default fork to run in parallel in the OS. Users can easily choose the fork method used in applications (see Section 5.2).
2.2. Related Work
Consistent snapshot is essential for in-memory databases to support backup and disaster recovery (Zhang et al., 2015; Li et al., 2018; Diaconu et al., 2013; Antirez, [n.d.]). Some consistent snapshot mechanisms have been proposed to trade off throughput, latency, and memory footprint (Bronevetsky et al., 2006; Cao, 2013; Cao et al., 2011; Liedes and Wolski, 2006; Li et al., 2018). Naive snapshot (Bronevetsky et al., 2006) blocked the storage engine until a deep copy of all the in-memory data is created, which is not suitable for IMKVSes in which the latency is critical. There are also some non-blocking snapshot mechanisms. Copy-on-Update (Liedes and Wolski, 2006; Cao, 2013) proposed to create a shadow copy of the in-memory data; the storage engine is free to access any data but create a deep copy when updates it for the first time. Note that, the fork-based snapshot is a Copy-on-Update variant that leverages the operating system. Some other mechanisms used multi-version concurrency control (MVCC) (Bernstein et al., 1987) to keep multiple versions of in-memory data. Zigzag (Cao et al., 2011) maintained another untouched copy of the in-memory data and introduced metadata bits to indicate which copy the store engine should read from or write to. Based on Zigzag, Ping-Pong (Cao et al., 2011) maintained three versions of the data to lower the cost of managing metadata bits. Hourglass and Piggyback (Li et al., 2018) were developed by combining Zigzag and Ping-Pong.
Although fork-based snapshot results in long latency during snapshot process, popular industrial IMKVSes (Redis and KeyDB) still adopts fork-based snapshot for two reasons: 1) fork provides a simple engineering implementation for consistent snapshot, while it requires great efforts to integrate the above approaches into the IMKVS. 2) None of the above approaches completely outperform the fork-based snapshot in write-intensive workloads (Li et al., 2018). For example, Ping-Pong and Hourglass can mitigate the latency spikes, while Ping-Pong incurs 3x memory footprint and Hourglass results in higher latency during normal operation. This work resolves the latency spikes of the fork-based snapshot, while keeping its original superiorities.
Previous work (Liedes and Wolski, 2006; Park et al., 2020) noted that the memory footprint increases during snapshot process due to the CoW strategy. MDC (Park et al., 2020) proposed to release the pages that have been persisted as soon as possible. AnKer (Sharma et al., 2018) introduced a fine-grained version of fork to take partial snapshot when databases do not need to persist all the data. CCoW (Ha and Kim, 2022) optimized the CoW mechanism based on the spatial locality of memory access. It prioritizes the copy for high-locality memory regions to improve the performance on write-intensive workloads. Async-fork is orthogonal and complementary to them.
There is also other approach to persist data in IMKVSes. Redis and KeyDB use Append Only File (AOF) (RedisLab, 2021e; Inc., 2022c) to log every write operation received by the storage engine, that will be played again after the database reboots to reconstruct the original dataset. The snapshot and AOF are complementary, and it is recommended to enable both of them simultaneously in IMKVSes.
3. Motivation
In this section, we present our profiling results to demonstrate the impact of the fork operation on the query latency. We first evaluate the performance of fork for taking the snapshot to pinpoint the key performance factors. We then reveal the impact of the fork operation on query latency. In addition to the default fork in Linux, our profiling involves the state-of-the-art approach (Zhao et al., 2021) of optimizing the fork operation. Lastly, we summarize our findings according to the profiling results.
Profiling Setting. We use Redis benchmark (RedisLab, 2021a) to study the performance in the experiments. The detailed configuration of the test machine is introduced in Section 6.1. The experiment reports the latency of a query, that is the elapsed time between the time point that the client issues the query and that the client receives the response. In the experiment, we enhance the benchmark by generating queries in the open-loop mode (Schroeder et al., 2006; Zhang et al., 2016). This enhancement sends commands to the server without waiting for replies to previous queries to simulate real-world environments. The database instance size is varied from 1GB to 64GB. By default, Redis takes one snapshot per 60 seconds if at least 10000 keys changed. In order to measure the impact of the fork operation accurately, we execute the BGSAVE command to trigger the operation of taking a snapshot. We classify queries into two groups, normal and snapshot, based on their arrival time. The snapshot queries are the queries arriving during the period of taking the snapshot (i.e., from the invocation of fork until the end of persisting the in-memory data), while the others are normal queries. We measure the 99%-ile (p99) latency and the maximum latency of normal and snapshot queries, respectively. The two latencies greatly impact user experiences and are often used to measure the performance of user-facing databases (Kasture and Sanchez, 2016; Li et al., 2018). We repeat each experiment five times and report the average value.
3.1. Performance of fork for Taking a Snapshot
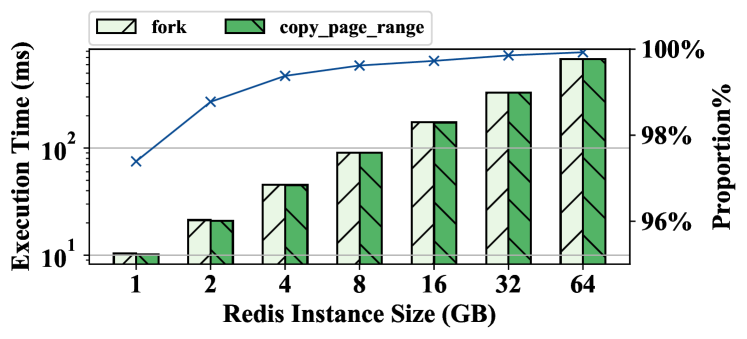
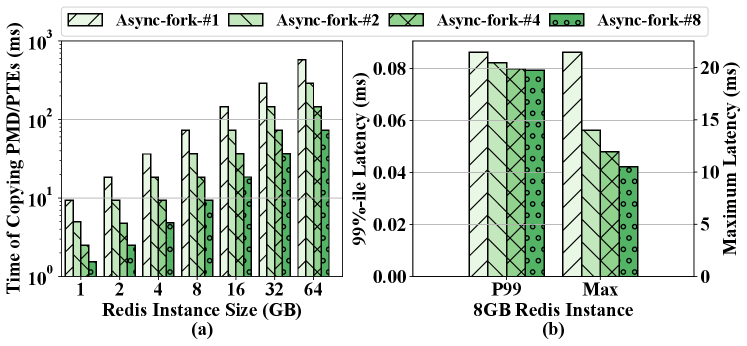
Figure 3 presents the execution time of fork and the time of copying the page table in the fork operation. We can see that the execution time grows roughly linearly with the instance size increasing from 1GB to 64GB. The 1GB instance takes less than 10 ms, while the 64GB instance takes more than 600 ms. We can also see that the time of the page table copy dominates the execution time. Particularly, the copy operation takes over 97% percentage of the execution time on all test cases and up to 99.93% percentage on the 64 GB instance. Without loss of generality, we measure the detailed metrics of copying the page table on the 8 GB instance to further study the copy operation.
In the experiment, the page table of the 8GB instance has one PGD entry, eight PUDs, PMDs and PTEs. Overall, fork copies the table level-by-level from top to bottom along the radix tree. The copy of one PGD/PUD/PMD entry requires to apply for a page to store its children and initialize the page. The operation takes around 500 ns. Thus, the copy of the PMDs takes around 2 ms, while the overhead of copying PGDs and PUDs is trivial because there are only a few entries. The rest time (around 70 ms) is spent on copying PTEs. Based on the results, we have the following observation.
Observation 1. For the fork operation, the execution time dramatically grows with the instance size increasing, and the page table copy dominates the cost. For the page table copy, the overhead of copying PGDs and PUDs is trivial, while that of copying PMDs and PTEs is non-negligible.
3.2. Impact of Fork Operations on Latency
We reveal the impact of the fork operation on the query latency in this subsection. Before presenting the results, we first introduce existing optimization approaches to the fork operation.
Huge Page (Community, 2021a, b). In the operating system (OS), we can increase the page size to reduce the number of pages used by a process, for example, setting the page size to 2MB instead of 4KB. The large page size can reduce the number of PTEs and accelerate the fork operation. However, previous study found that the page fault latency can increase from 3.6 to 378 after enabling huge page because compacting and zeroing memory in the page fault incurs higher overhead on huge page than that on regular page (Kwon et al., 2016). Moreover, Redis consumes much more memory space after enabling the huge page because applications do not always fully utilize the big page (e.g., in the experiment of (Kwon et al., 2016), the memory consumption of Redis increased from 12.2GB to 20.7GB). Additionally, allocating huge page can lead to many fragments in the physical memory because it requires consecutive physical memory areas to build a huge page. Consequently, the kernel needs to perform a heavy defragment operation which leads to high CPU utilization (Panwar et al., 2018). The experiment of (Panwar et al., 2018) shows that the benchmark milc in SPEC CPU 2006 spends 343 seconds (37% of its overall execution time) in kernel mode to perform the defragment operation when the memory is highly fragmented.
| Step | Operation | Parent(P) | Child(C) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | Initial state |
|
|
||||||
| 2 |
|
|
|
||||||
| 3 | P: Flush TLB |
|
|
||||||
| 4 |
|
|
|
||||||
| 5 | P: Update PTE |
|
|
||||||
| 6 | P&C: Access V |
|
|
Consequently, huge page is recommended to be disabled in many databases (e.g., Couchbase, MongoDB, KeyDB and Redis (Couchbase, 2021; Mongodb, 2021; Inc., 2022d; RedisLab, 2021d)). In particular, two No-SQL databases, Couchbase and MongoDB, recommend users to disable the technique because huge page performs poorly with random memory accesses in workloads (Couchbase, 2021; Mongodb, 2021). KeyDB and Redis, which are two IMKVSes, recommend users to disable huge page because the technique can incur a big latency penalty and big memory usage (Inc., 2022d; RedisLab, 2021d). Specifically, if we enable the huge page, the parent and child processes share huge pages after calling fork to persist on disk. In a busy instance, a few event loops in either of the two processes will cause to target thousands of pages and trigger the copy operation of a large amount of process memory because of the copy-on-write mechanism in OS. Consequently, this leads to a big latency and a big memory usage. As such, our profiling does not involve this technique.
Shared Page Table (McCracken, 2003; Dong et al., 2016; Zhao et al., 2021). This technique proposed to share the page table between parent and child in a copy-on-write (CoW) manner. Specifically, the fork operation returns immediately after copying the metadata except for the page table. The page table will be copied in a CoW manner. However, we find that the shared page table design introduces the data leakage problem, the working set size estimation problem and the NUMA problem. First, the inconsistency between the shared page table and the translation lookaside buffer (TLB) of the child process can lead to the data leakage problem. Second, we cannot accurately estimate the working set size, which indicates the memory usage of each process and is important for cloud resource management (Zhang et al., 2020). This is because the usage is calculated based on the states in the page table (Gregg, 2018), while the table is shared by multiple processes. Third, the shared page table and the corresponding processes can locate on different NUMA nodes, which increases the TLB miss overhead (Achermann et al., 2020; Panwar et al., 2021). Moreover, the NUMA balance mechanism cannot work as expected due to the shared page table. Due to space limit, we discuss the working set size problem and the NUMA problem in the technical report (tec, 2022). In the following, we use the example in Table 1 to demonstrate the data leakage problem, which is the most serious one among the three problems. We also write a test program222 https://doi.org/10.5281/zenodo.7189585, Last accessed on 2022/11/13. to reproduce the example in practice.
TLB is the hardware to accelerate the translation from a virtual address to a physical address by caching recent translation results. Initially, the virtual address “V” is mapped to the physical address “X” in PTE and the mapping is cached in TLB. Note that PTE is shared between parent and child, whereas the two processes have their own TLB entries. Suppose that the memory management mechanism (e.g., memory compaction (Babka, 2016; Torvalds, 2018a), swap (Torvalds, 2018c) and NUMA balance (Torvalds, 2018b)) of OS mitigates the page from “X” to a new page frame “Y” in the parent process. Then, OS sets the mapping from “V-¿X” to “V-¿N” (None Present) to indicate that the mapping is invalid in Step 2 and flushes the parent’s TLB entry in Step 3. For other processes, the OS loops over each of them to check whether its PTEs contain ”V-¿X”; if so then set the value to ”V-¿N” and flush the TLB; otherwise, skip the process. This works well if each process has a private page table. However, ODF uses the shared page table design. When the OS checks the child process, the PTE has been set to ”V-¿N” in the parent process because the PTE is shared between the parent and child processes and therefore the OS cannot find any PTE with the value ”V-¿X” in the child process. Thus, the OS skips the update to the child in Step 4. In Step 5, the parent updates PTE to map “V” to “Y”. Although PTE has the correct mapping, the child’s TLB entry is inconsistent with PTE. Consequently, the future access to “V” in the child can lead to a data leakage problem. Despite that, we study the performance of the shared page table-based fork in our experiments for comparison purposes. As ODF (Zhao et al., 2021) is the latest work and the only one that is publicly available333 https://github.com/rssys/on-demand-fork, Last accessed on 2022/11/13. among the methods (McCracken, 2003; Dong et al., 2016; Zhao et al., 2021) adopting the shared page table design, our experiments focus on ODF.
Experiment Results. Figures 4 and 5 present the 99%-ile latency and the maximum latency of normal queries and snapshot queries, respectively. Snapshot-ODF denotes the results of using the On-Demand-Fork (Zhao et al., 2021) to take the snapshot, which is the latest shared page table-based fork method. Snapshot-DEF denotes the results of using the default fork in Linux. As shown in the figures, the latency of normal queries slightly increases with the instance size varying from 1GB to 64GB. In contrast, the value of snapshot queries grows sharply. The shared page table technique dramatically reduces the latency of the default fork, especially for the large instance. For example, on the 64GB instance size, the optimization reduces the 99%-ile latency from 911.95ms to 3.96ms and the maximum latency from 1204.78ms to 59.28ms. The latency of Snapshot-ODF is higher than that of Normal because the CoW of the page table frequently interrupts the engine process. For example, the engine process is interrupted over 7000 times on the 16GB instance, which leads to frequent out-of-service for queries. According to the analysis of existing optimization methods and the experiment results, we have the following observation.
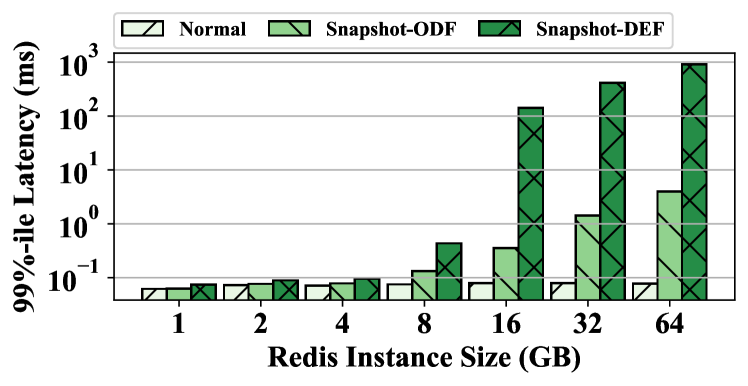
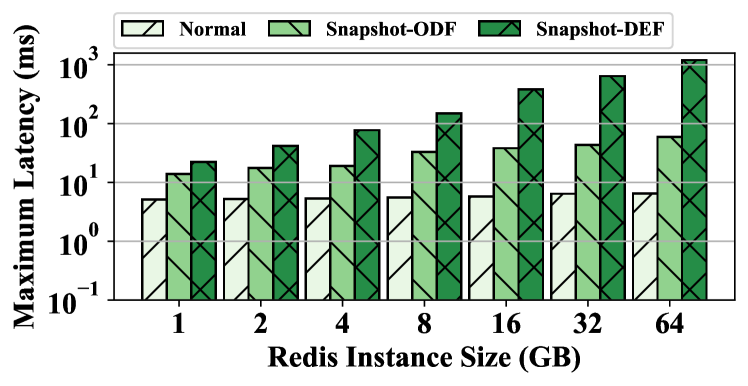
Observation 2. The fork operation has a significant impact on the latency of snapshot queries, and the tail latency of the default function is up to hundreds of milliseconds. Although the shared page table technique reduces the latency of the default fork operation, the overhead incurred by frequent interruptions is non-negligible and the shared page table introduces the potential data leakage problem.
3.3. Summary
Based on the observations, we find that copying the page table dominates the execution time of the default fork in Linux, especially, for large instances. The overhead of fork results in a long latency (up to hundreds of milliseconds) for queries issued during the invocation of fork. Although several optimization methods (Community, 2021a, b; McCracken, 2003; Dong et al., 2016; Zhao et al., 2021) of the fork operation have been proposed, they either lead to poor performance of IMKVSes, or have a data leakage problem, which potentially generates an inconsistent snapshot. Thus, these optimizations cannot be used in the fork-based snapshot mechanism in IMKVSes. As IMKVSes have a rigid requirement on the latency to serve online scenarios, a high-performance fork is required to reduce the long latency of snapshot queries.
4. Design of Async-Fork
In this section, we introduce the design of Async-fork, an operating system-based solution that effectively reduces the long latency of snapshot queries without incurring extra vulnerabilities.
4.1. General Idea
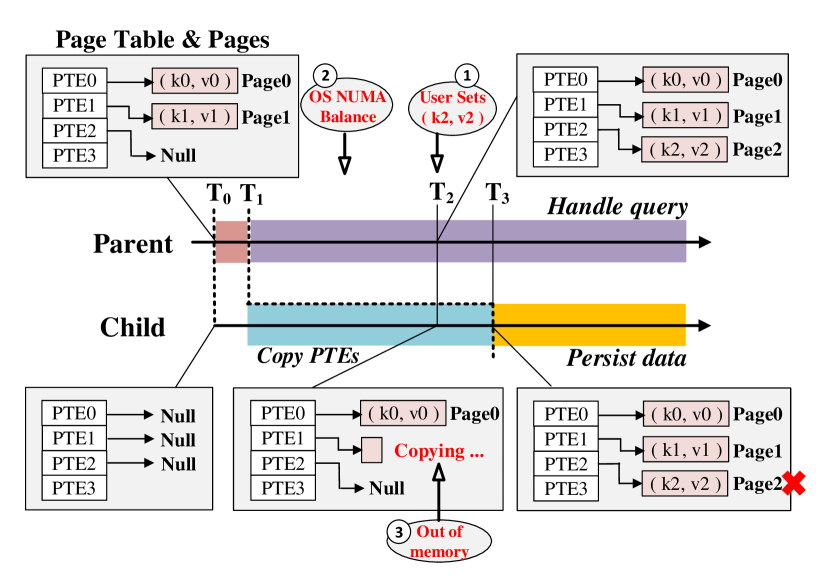
Figure 1(c) shows the general idea of Async-fork. While the parent process is responsible to copy page tables during snapshot in the default fork, as shown in the figure, Async-fork offloads the work of copying page table to the idle child process while keeping other steps in the fork unchanged. In this way, the parent process is able to handle queries while the child process copies the page table from the parent process simultaneously. However, it is non-trivial to achieve the design of Async-fork, as a snapshot may be inconsistent due to the asynchronous operations on the page table.
The inconsistency happens when the parent process modifies a PTE before the child process has copied it. Take Figure 6 as an example. The IMKVS takes a snapshot at time T0, and the in-memory data is . Suppose a user query that sets a new KV pair arrives at time T2 (① in Figure 6), and the child process is copying PTEs from time T1 to T3. The parent process handles this query, and PTE2 is modified to point to a new page (Page2) that contains . If the child process has not copied the original PTE2 before the modification, it would copy the modified PTE2, and owns the new pair in its memory space. In this way, the data is persisted, and inconsistency happens (the key-value pair does not exist when the snapshot is taken at time ).
Async-fork resolves the above inconsistency problem by using the parent process to proactively synchronize the modified PTEs to the child process. We explain the detailed steps in Section 4.2. Two main challenges have to be resolved in this solution.
Firstly, it is necessary to detect all the PTE modifications. However, besides of the user operations, many inherent memory management operations in the operating system also cause PTE modifications. For instance, the OS periodically migrates pages among NUMA nodes (Torvalds, 2018b), causing the involved PTEs to be modified as inaccessible (② in Figure 6). We describe the method to detect the PTE modifications in Section 4.3.
Secondly, errors may occur during Async-fork. For instance, the child process may fail to copy an entry due to out of memory (③ in Figure 6). In this case, error handling is necessary, as we should restore the process to the state before it calls Async-fork. We present how errors are handled in Section 4.4.
By resolving the above challenges, the time of the parent process used on fork is greatly reduced, and the latency of the snapshot queries can be reduced in consequence. Moreover, after the child process finishes copying the page table, the two processes have their complete private page table. Therefore, the Async-fork does not introduce the data leakage vulnerability.
In the following sections, we use the terminology in x86 Linux to explain our design. We also implement Async-fork on Arm Linux using similar ideas, while similar results are achieved compared with x86. Algorithm 1 describes how the parent process (Line 1 to 14) and the child process (Line 15 to 24) work in Async-fork.
4.2. Proactive Synchronization
Before introducing the proactive synchronization in detail, we first introduce how we offload the work of copying page table to the child process in Async-fork.
Copying Page Table Asynchronously. In the default fork, the parent process traverses all its VMAs and copies the corresponding parts of the page table to the child process. The page table is copied from top to bottom. In Async-fork, the parent process roughly follows the above process, but only copies PGD, P4D (if exists) and PUD entries to the child process (Lines 1 to 3 in Algorithm 1). After that, the child process starts to run, and the parent process returns to the user mode to handle queries (Lines 7 to 14). The child process then traverses the VMAs, and copies PMD entries and PTEs from the parent process. Figure 7 shows an example of the asynchronous page table copy. In the figure, the PGD/PUD entries have been copied by the parent process, but PMD entries and PTEs have not yet (some PMD entries point to “null”). The child process copies PMD entries and PTEs from the parent process (e.g., PMD0 and its PTEs).
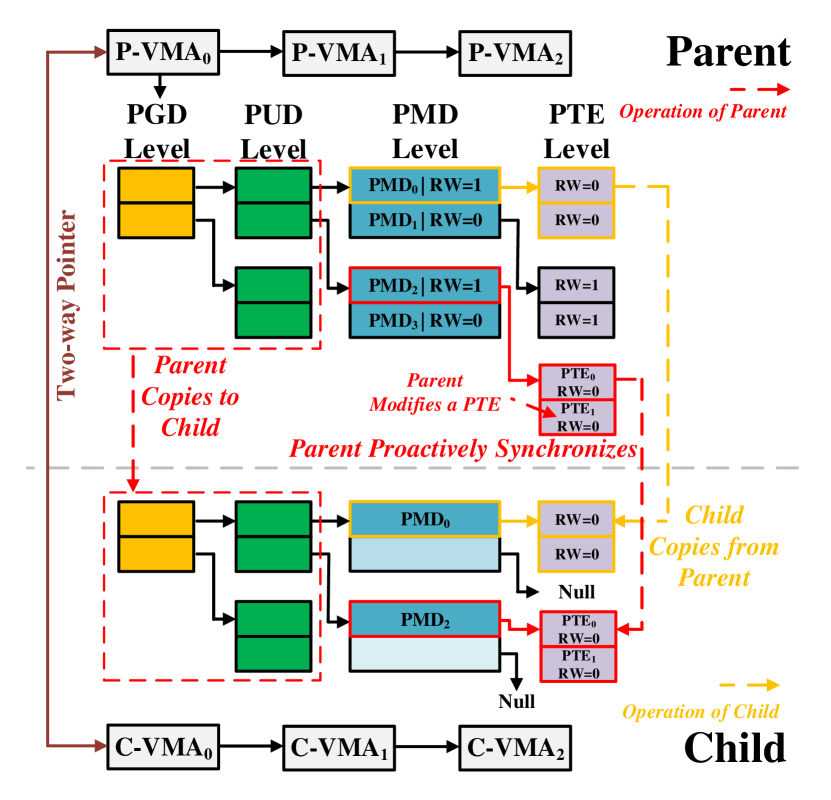
We offload the work of copying PMD entries and PTEs to the child process because the overhead of copying them is non-negligible, as analyzed in Section 3.1. Meanwhile, we keep that the parent process copies PGD/PUD entries. This is because the overhead of copying PGD/PUD entries is trivial, and it is more robust to minimize the change to the Linux kernel.
Synchronizing Modified PTEs Proactively. When the child process is responsible for copying PMD entries and PTEs, it is possible that the PTEs are modified by the parent process before they are actually copied. Note that only the parent process is aware of the modifications (the way to detect the PTE modification will be introduced in Section 4.3).
In general, there are two ways to copy the to-be-modified PTEs for the consistency. 1) the parent process proactively copies the PTEs to the child process; 2) the parent process notifies the child process to copy the PTEs and waits until the copying is finished. As both ways result in the same interruption in the parent process, we choose the former way (Lines 8 to 12 in Algorithm 1).
More specifically, when a PTE is modified during snapshot, the parent process copies not only this PTE but also all the other PTEs of a same PTE table (512 PTEs in total), as well as the parent PMD entry to the child process proactively. For instance, when PTE1 in Figure 7 is modified, the parent process proactively copies PMD2, PTE0 and PTE1 to the child process. We choose to copy the entire PTE table because we can quickly detect a range of PTEs that will be modified, but accurately identifying which one will be modified is expensive in practice.
Eliminating Unnecessary Synchronizations. Always letting the parent process copy the modified PTEs is unnecessary, as it is possible that the to-be-modified PTEs have already been copied by the child process. We identify if the PMD entries and PTEs have been copied by the child process, to avoid unnecessary synchronizations. A flag is required to track this status. We reuse the R/W flag of the PMD entry to record the status. Since the R/W flag is only used when the PMD entry points to a huge page in the x86 Linux kernel, the flag tracks the status correctly. We reuse the R/W flag because 1) this design can avoid adding new fields to the kernel data structures; and 2) the popular databases (e.g., Redis, KeyDB, MongoDB, and Couchbase) recommend disabling the huge page to improve the performance (RedisLab, 2021d; Inc., 2022d; Couchbase, 2021; Mongodb, 2021). Additionally, it is unnecessary to use Async-fork if applications use the huge page because the applications with huge page do not require PTEs but a small number of PGD/PUD/PMD entries (i.e., the page table is small).
An alternative approach is to use an unused bit in the struct page as the flag. Specifically, each PMD entry points to a PTE table, while OS maintains a data structure (struct page) for each PTE table. The struct page has bits that are not used by the current Linux kernel. Previous research uses these bits as flags, for example, ODF uses some bits in struct page as a reference counter. However, this approach requires further modification to the kernel to initialize the bit. Therefore, we do not adopt the design using the struct page.
If a PMD entry and its 512 PTEs have not been copied to the child process, the PMD entry will be set as write-protected (e.g., PMD1 in Figure 7). Note that, it does not break the CoW strategy of fork since it still triggers the page fault when the corresponding page is written on x86 (Guide, 2011). Once the PMD/PTEs have been copied to the child process (e.g., PMD0), the PMD entry is changed to be writable (the PTEs are changed to be write-protected to maintain the CoW strategy). Since both parent and child processes lock the page of the PTE table with trylock_page() when they are copying PMD entries and PTEs, they will not copy PTEs pointed by the same PMD entry at the same time.
4.3. Detecting Modified PTEs
The operations that modify PTEs in the OS can be divided into two categories: 1) VMA-wide modification. Some operations act on specific VMAs, including creating, merging, deleting VMAs and so on. The modification of a VMA may also cause the VMA’s PTEs be modified. For example, the user sends queries to delete lots of KV pairs. The IMKVS (parent process) then reclaims the corresponding virtual memory space by munmap. Some VMAs are hence split or deleted while the VMAs’ PTEs are deleted as well. A VMA is usually large because the operating system always tends to merge adjacent VMAs. It means that the VMA-wide modification usually causes extensive PTE modifications, while many VMA’s PMD entries are involved. 2) PMD-wide modification. Other operations modify the PTE directly. For example, the page of parent process can be reclaimed by the out of memory (OOM) killer. In this case, one PMD entry is involved. Note that swapping or migrating a 4KB page will change the PTE but the data will not be changed, so we will not handle it. Due to limited space, we summarize the locations where operations in the OS modify VMAs/PTEs as checkpoints in the technical report (tec, 2022).
We implement the detection by hooking the checkpoints. Once a checkpoint is reached, the parent process checks whether the involved PMD entries and PTEs have been copied (by checking the R/W flag of the PMD entry). For a VMA-wide modification, all the PMD entries of this VMA are checked, while only one PMD entry is checked for a PMD-wide modification. The uncopied PMD entries and PTEs will be copied to the child process before modifying them.
If a VMA is large, the parent process may take a relatively long time to check all PMD/PTE entries by looping over each of them. We therefore introduce a two-way pointer, which helps the parent process quickly determine whether all entries of a VMA have been copied to the child, to reduce the cost. Each VMA has a two-way pointer, which is initialized by the parent process during the invocation of the Async-fork function. The pointer in the VMA of the parent process (resp. the child process) points to the corresponding VMA of the child process (resp. the parent process). In this way, the two-way pointer maintains a connection between the VMAs of the parent and the child. The connection will be closed after all PMDs/PTEs of the VMA are copied to the child. Specifically, if no VMA-wide modification happens during the copy of PMDs/PTEs of the VMA, then the child closes the connection by setting the pointers in the VMAs of both the parent and child to null after the copy operation. Otherwise, the parent will synchronize the modification (i.e., copying the uncopied PMDs/PTEs to the child), and close the connection by setting the pointers to null after the copy operation. As both parent and child processes can access the two-way pointers, the pointers are protected by locks to keep the state consistent. When a VMA-wide modification occurs, the parent process can quickly determine whether all PMDs/PTEs of a VMA have been copied to the child by checking the pointer’s value, instead of looping over all these PMDs. Besides, the pointer is also used in handling errors (see Section 4.4).
4.4. Handling Errors
Since copying the page table involves memory allocation, some errors may occur during both the default fork and Async-fork. For instance, a process may fail to initialize a new PTE table due to out of memory. Such error may only happen in the parent process in the default fork and has a standard way to handle the error. However, the copying of page table is offloaded to the child process in Async-fork, such error may happen in the child process, and a method is required to handle such errors. Specifically, we should restore the parent process to the state before it calls Async-fork, to ensure that the parent process will not crash in the future.
As Async-fork may modify the R/W flags of the PMD entries of the parent process, we roll back these entries to be writable when errors occur in Async-fork. Errors may occur 1) when the parent process copies PGD/PUD entries, 2) when the child process copies PMD/PTEs, and 3) during a proactive synchronization. In the first case, the parent process rolls back all the write-protected PMD entries. In the second case, the child process rolls back all the remaining uncopied PMD entries. After that, we send a signal (SIGKILL) to the child process. The child process will be killed when it returns to the user mode and receive the signal. In the third case, the parent process only rolls back the PMD entries of the VMA containing the PMD entry that is being copied. The purpose is to avoid contending for the PMD entry lock with the child process. An error code is then stored into the two-way pointer of the VMA. Before (and after) copying PMDs/PTEs of a VMA, the child process will check the pointer to see whether there are errors. If so, then it stops copying PMD/PTE entries immediately and performs the rollback operations that are already described in the second case.
5. Optimization and Implementation
In this section, we present the optimization that further improves the performance of Async-fork, and the way to implement Async-fork in Linux.
5.1. Accelerating Page Table Copy
The parent process is still interrupted when a proactive PTE synchronization is triggered. A straightforward way to reduce the cost of the proactive PTE synchronization is to let the child process to first copy the PTEs potentially modified before other PTEs. However, this method is not practical because the data accessed by user queries are relatively random and the child process cannot determine which PTEs will be modified when the parent invokes Async-fork. We therefore propose to minimize the number of proactive PTE synchronizations by reducing the duration of copying the page table.
As VMAs are independent, the kernel threads can totally perform the copy in parallel and obtain near-linear speedup. Therefore, the child process may launch multiple kernel threads to copy PMD/PTEs in multiple VMAs in parallel, so that the copy completes faster. It can effectively reduce the number of proactive PTE synchronization because the synchronization only happens during the period that the child process is copying PMD/PTEs. The probability of triggering a proactive PTE synchronization gets lower when the period becomes shorter. The experiment in Section 6.3 shows the efficiency of this optimization.
Multiple kernel threads consume CPU cycles. These threads periodically check whether they should be preempted and give up CPU resources by calling cond_resched(), in order to reduce the interference on other normal processes.
5.2. Implementation of Async-fork
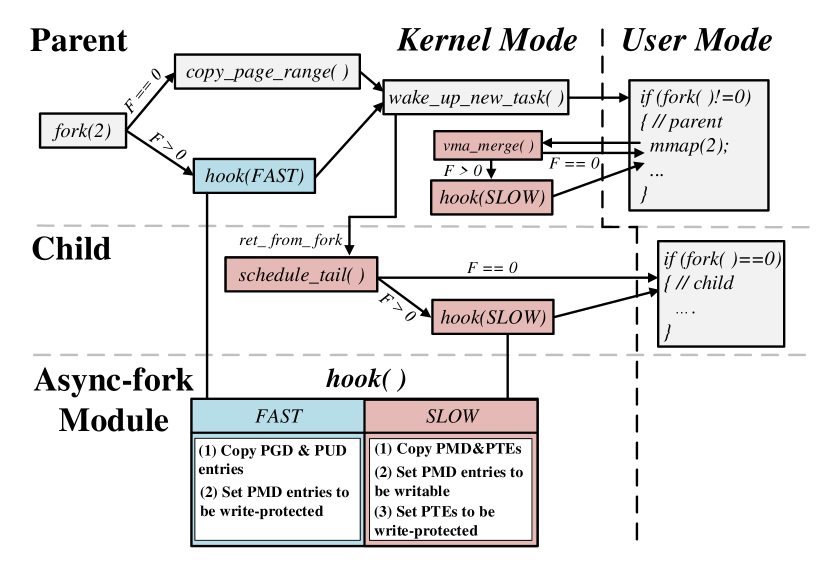
Figure 8 shows the implementation of Async-fork with a modular design. We encapsulate the code ingested to the kernel into a hook function, which is instantiated in a kernel module. We can insert/remove the module in/from the kernel as necessary. The hook function is inserted to the call path of default fork and memory subsystem in the Linux kernel (version 4.19). Users can determine the usage of the default fork and Async-fork with the parameter .
The hook function is enhanced from copy_page_range(), which accepts a flag (Fast or Slow) to control the copying of the page table. With “Fast” flag, the function copies PGD/PUD entries and sets PMD entries to be write-protected. With “Slow” flag, the function copies the write-protected PMD entries and PTEs; when the copying finishes, it sets the PMD entries to be writable and sets the PTEs to be write-protected. When Async-fork is called, the parent process copies the page table to the child process using the function with “Fast” flag. At the end of Async-fork’s invocation, the parent process puts the child process into the runqueue of a CPU and returns to the user mode. Before the child process returns to the user mode, it copies the page table using the function with “Slow” flag. The parent process proactively copies the uncopied PMD/PTEs (using the function with “Fast” flag) to the child process before modifying them.
Flexibility. For the IMKVS workload that has small memory footprint, the page table copy is already short. In this case, Async-fork brings small benefit. For these workloads, we provide an interface in memory cgroup to control whether Async-fork is enabled (as well as the number of kernel threads used to speed up copying PMD/PTEs in the child process). Specifically, when users add a process to a memory cgroup, they can pass a parameter to enable/disable Async-fork at run time (i.e., the parameter F in Figure 8). As shown in the figure, if the parameter value is 0, then the process will use the default fork. Otherwise, Async-fork is enabled. As such, users can determine which fork operation the process uses as necessary and use Async-fork without any modification in the source code of applications. The process will use the default fork if no parameter is passed in.
Memory overhead. The only memory overhead of Async-fork comes from the added pointer (8B) in each VMA of a process. In the case, the memory overhead in a process is the number of VMAs times . Considering a machine with 512GB main memory while 400 processes run simultaneously, there are roughly 760,000 VMAs according to our statistics. In this case, the memory overhead will be 7600008B 6MB. This overhead is generally negligible.
Support for ARM64. The design of Async-fork can also be implemented on ARM64. Specifically, we use the APTable[1:0] (Limited, [n.d.]) in the table descriptor of the PMD entry as the R/W flag. Async-fork can also be implemented on other architectures that support hierarchical attributes in the page table.
Consecutive Snapshots. It is possible that the parent process starts the next snapshot using Async-fork before the previous child process finishes copying PMD/PTEs, as the parent process returns to the user mode before the child process. In the current implementation, we will not block the next Async-fork call but keep a VMA’s page table be copied by only one child process at any time. When the parent process copies a VMA to the child process, it checks the two-way pointer to identify whether there exists a previous child process copying the page table of this VMA. If exists, it proactively copies the whole page table of this VMA to the previous child process. Async-fork adopts this design because supporting concurrent fork operations need to track all child processes that are copying page tables. This is hard because the kernel does not provide the information and we need to inject new data structures into the kernel to record the states and synchronize these child processes.
As Async-fork cannot support concurrent fork operations in a process (the same as the default fork in the OS), Async-fork cannot support the cases where the parent process needs to conduct the fork operation in an ultra-high frequency (e.g., in milliseconds). In spite of the limitation, Async-fork works well for database use cases because a storage engine does not create many child processes from the parent process simultaneously in practice. Specifically, conducting the fork operation frequently leads the parent to frequently turn into the kernel mode, which hurts the service quality. Moreover, many processes executing in parallel will degrade the performance due to the resource contention (e.g., IO bandwidth and CPU resources). Therefore, IMKVSes (e.g., Redis and KeyDB) do not recommend ultra-frequent data snapshots (generally 60 seconds (RedisLab, 2022b)) and have no cases requiring the parent process to invoke Async-fork in milliseconds to our knowledge. For HyPer, which uses the fork operation to support concurrent transaction processing, Async-fork can work well. This is because the parent process handles OLTP (a single updater) that has a rigid requirement on the latency, whereas the child process executes OLAP which generally has a long execution time and is more tolerant of the latency than OLTP. Moreover, HyPer notices the cost of the fork operation and designs a novel mechanism, which makes multiple OLAP queries to share a snapshot, to improve the performance.
6. Evaluation
In this section, we evaluate the effectiveness of Async-fork.
6.1. Experimental Setup
We evaluate Async-fork on a machine with two Intel Xeon Platinum 8163 processors, each of them has 24 physical cores (48 logical cores). The machine has 384GB memory, and 1TB NVMe hard drive. In terms of software setup, the experimental platform runs CentOS 7.9 with Linux 4.19. Except for the experiments in Section 6.4, all the other experiments are conducted within a single machine as described above.
Benchmarks. We use Redis (version 5.0.10) (RedisLab, 2021b) and KeyDB (version 6.2.0) (Inc., 2022a) compiled with gcc 6.5.1 as the representative IMKVS servers, and use Redis benchmark (RedisLab, 2021a) as well as Memtier benchmark (RedisLab, 2022a) to be the workload generators. The benchmarks reveal the scenario where multiple clients send requests to the IMKVS server simultaneously. Similar to prior work (Chen et al., 2019), we enhance Redis benchmark to generate queries in an open-loop mode for measuring the latency accurately (Schroeder et al., 2006; Zhang et al., 2016).
By default, the experiments are conducted with the following settings: 1) 50 clients (default settings) are used in Redis benchmark, while 50 clients are used in Memtier benchmark for consistency. 2) The key range is set to , the key size of 8B and the value size of 1024B. 3) Each experiment is repeated by five times and the average results are reported. 4) In Async-fork, the child process launches 7 additional kernel threads (together with the child process itself, there are 8 threads in total) to help it copy PMDs/PTEs faster. Our experiment in Figure 14 shows that Async-fork still outperforms the state-of-the-art solution with a single child process. 5) The KeyDB server is configured with 4 threads.
Metrics. We launch a large number of queries () to the IMKVS and record the latency of the queries that arrive in the snapshot process (start from the parent process calls fork until the child process persists all in-memory data). Specifically, we measure the 99%-ile latency because latency-sensitive services generally provide an SLA on some percentile. Moreover, we report the maximum latency because IMKVS is often used for demanding use cases that have a rigid requirement for the worst-case latency (RedisLab, 2021c). For example, the increase of the maximum latency of Redis can lead to read error on connections (Technology, 2017). Therefore, in the production environment (Gong et al., 2022), the maximum latency is an important indicator of system stability. Due to limited space, we report the experiment results of query processing throughput and total out-of-service time of the parent process in the technical report (tec, 2022). In the report, we also discuss the method of tuning IMKVSes to further improve the performance.
Baselines. We compare Async-fork with On-Demand-Fork (denoted by ODF in short) (Zhao et al., 2021), the state-of-the-art shared page table-based fork. In ODF, each time a shared PTE is modified by a process, not only one PTE but 512 PTEs located on the same PTE table will be copied at the same time. We do not report the results of the default fork in this section since it results in 10X higher latency compared with both Async-fork and ODF in most cases (already presented in Section 3.2). To accurately measure the performance of the IMKVSes in the experiments, we trigger the snapshot operation manually using the BGSAVE command.
6.2. Overall Evaluation
We first evaluate Async-fork using write-intensive workloads that require frequent snapshots for data persistence.
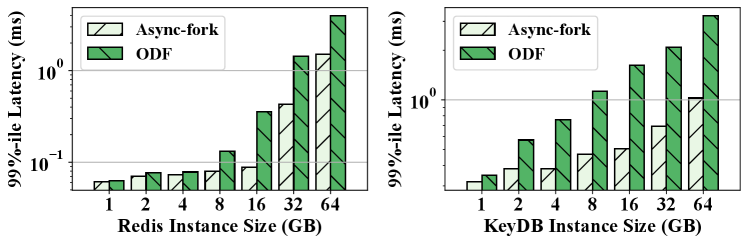
Latency Results. In this experiment, we use the Redis benchmark (RedisLab, 2021a) to generate the write-intensive workload by issuing SET queries to the IMKVSes, and configure the clients to send 50,000 such queries in a second. Since the IMKVS is often used in the context of demanding use cases, there are usually strict requirements on both the 99%-ile latency and the worst case latency (RedisLab, 2021c; Inc., 2022b).
Figure 9 shows the 99%-ile latencies of snapshot queries in Redis and KeyDB, with ODF and Async-fork. As observed, Async-fork outperforms ODF in all the cases, and the performance gap increases when the instance size gets larger. For instance, operating on a 64GB IMKVS instance, the 99%-ile latency of the snapshot queries is 3.96ms (Redis) and 3.24ms (KeyDB) with ODF, while the 99%-ile latency reduces to 1.5ms (Redis, 61.9% reduction) and 1.03ms (KeyDB, 68.3% reduction) with Async-fork.
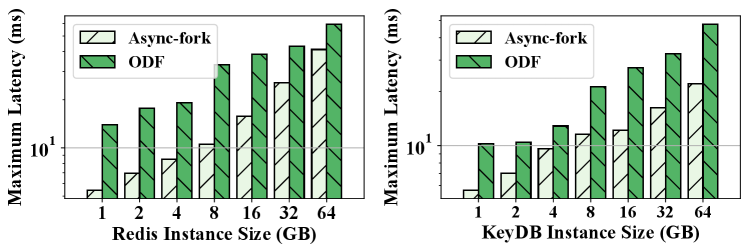
Figure 10 shows the maximum latency of the snapshot queries. As observed, Async-fork greatly reduces the maximum latency of the benchmarks compared with ODF, even if the instance size is small. For a 1GB IMKVS instance, the maximum latencies of the snapshot queries are 13.93ms (Redis) and 10.24ms (KeyDB) respectively with ODF, while the maximum latencies are decreased to 5.43ms (Redis, 60.97% reduction) and 5.64ms (KeyDB, 44.95% reduction) with Async-fork.
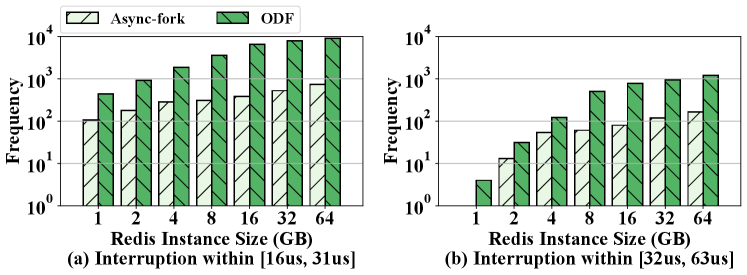
Deep Diving. The interruption of Async-fork is caused by the proactive synchronization, whereas the interruption of ODF is caused by the CoW of the page table. We measure the interruptions of the parent process during the snapshot to understand the reason that Async-fork outperforms ODF. Specifically, the parent process turns into kernel mode and is out of service for queries when executing the copy_pmd_range() function. The overhead of copy_pmd_range() dominates the cost of executing in the kernel mode. In order to examine the number of interruptions and the out-of-service time, we use the bcc tool (bcc, 2022) to count the number of copy_pmd_rage() invocations and measure the execution time of each invocation. The result of bcc is a histogram in which the bucket is the time duration and the frequency is the number of invocations whose execution time falls into the bucket. The categories [16, 31] and [32, 63] are two default buckets of bcc. In our experiments, all invocations fall into the two buckets.
Figure 11 shows the frequency of the interruptions within [16us, 31us] and [32us, 63us]. We can see that Async-fork significantly reduces the frequency of interruptions. For example, Async-fork reduces the frequency of interruptions from 7348 to 446 on the 16GB instance. Async-fork greatly reduces the interruptions because the interruptions happen only when the child process is copying PMD/PTEs (the required time is within 600ms as in Figure 15). However, the interruption can happen until all data is persisted by the child process in ODF, while the data persistence operation requires tens of seconds (e.g., persisting 8GB in-memory data takes about 40s). Under the same workload, the parent process is more vulnerable to interruption when using ODF.
6.3. Detailed Evaluation
Sensitivities to the Read/Write Patterns. Figure 12 shows the results using four workloads with different read-write patterns generated with Memtier (RedisLab, 2022a). In the figure, “1:1 (Uni.)” represents the workload with 1:1 Set:Get Ratio and the uniform random access pattern, while “1:10 (Gau.)” is the workload with 1:10 Set:Get ratio and the Gaussian distribution access pattern.
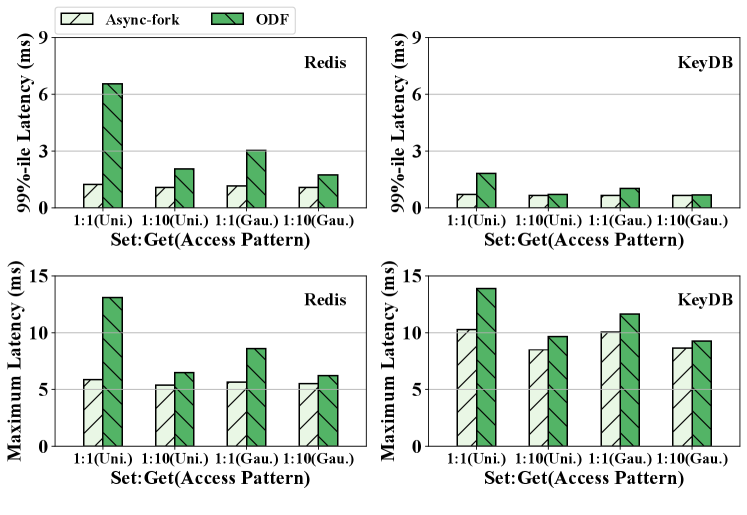
Observed from Figure 12, Async-fork still outperforms ODF. The benefit is smaller for the workload with more GET queries. This is because the serving (parent) process only copy a small number of PTEs for the GET-intensive workloads. Moreover, the modified memory is smaller in the experiment with the Gaussian distribution compared with the uniform random access pattern. With random pattern, the key-value pairs in the IMKVS have the same probability of being accessed, and parts of key-value pairs may be accessed repeatedly with the Gaussian Distribution access pattern. Since shared PTEs are copied only when they are modified for the first time in ODF, the parent process is interrupted fewer times with the Gaussian distribution access pattern.
In general, Async-fork works better for write-intensive workloads. The larger the modified memory is, the better Async-fork performs. Integrating Async-fork with CCoW (Ha and Kim, 2022) to improve the performance on write-intensive workloads is an interesting research direction because Async-fork can utilize CCoW to copy the PTEs of high-locality memory pages in advance to reduce the number of proactive synchronizations.
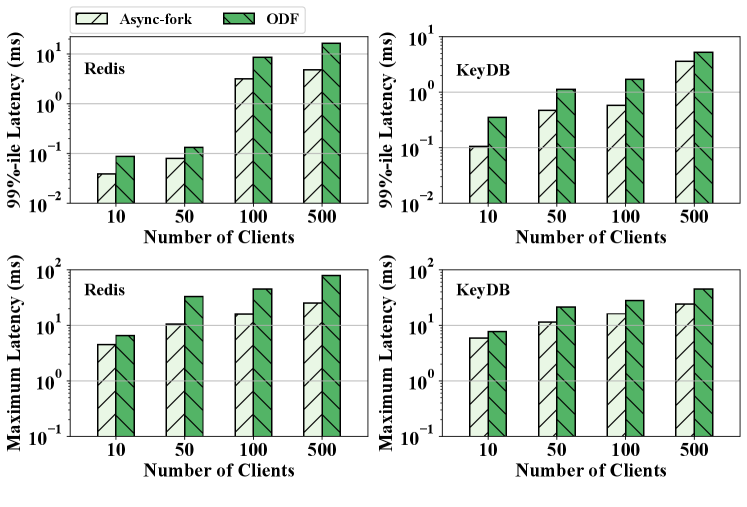
The Impact of the Number of Clients. In this experiment, we change the number of clients in Redis-benchmark while keeping sending 50, 000 SET queries every second to an 8GB IMKVS server. Figure 13 shows the results of 99%-ile and maximum latency with 10, 50, 100 and 500 clients. As observed, Async-fork outperforms ODF, while the performance gap increases as the number of clients increases. This is because more requests arrive at the IMKVS at the same time when the number of clients increases. As a result, more PTEs may be modified at the same time, and the duration of one interruption to the parent process may become longer.
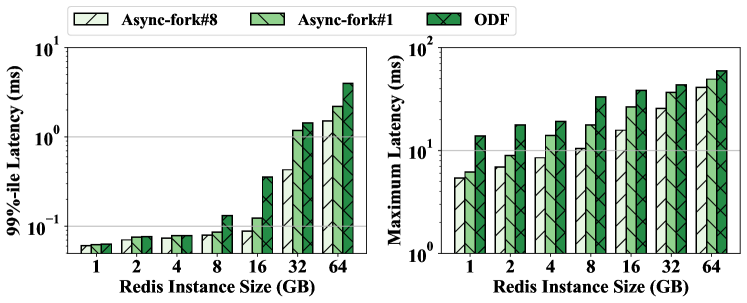
The Impact of the Number of Threads In the Child Process. In Async-fork, multiple kernel threads may be used to copy PMD/PTEs in parallel in the child process. Figure 14 shows the 99%-ile and maximum latency of snapshot queries under different Redis instance sizes. Async-fork# represents the results of using threads in total to copy the PMDs/PTEs.
Observed from Figure 14, Async-fork#1 (the child process itself) still brings shorter latency than ODF. The maximum latency of the snapshot queries is decreased by 34.3% on average, compared with ODF. We can also find that using more threads (Async-fork#8) can further decrease the maximum latency. This is because the sooner the child process finishes copying PMDs/PTEs, the lower probability the parent process is interrupted to proactively synchronize PTEs.
In more detail, Figure 15(a) shows the time that the child process takes to copy PMDs/PTEs with different numbers of kernel threads, while Figure 15(b) shows the corresponding 99%-ile and maximum latency in an 8GB Redis instance. As we can see, launching more kernel threads effectively reduces the time of copying PMDs/PTEs in the child process. The shorter the time is, the lower the latency becomes.
6.4. Evaluation in Production Environment
Async-fork has been deployed in our production Redis Clouds. We rent a Redis database from our public cloud to evaluate Async-fork in the production environment. The rented Redis server has 16GB memory and 80GB SSD. We also rent another virtual machine with 4 vCPU cores and 16GB memory from the same cloud to run the Redis benchmark as the client. The client settings are the same as previous experiments. The network bandwidth between the IMKVS server and the client is 3Gbps.
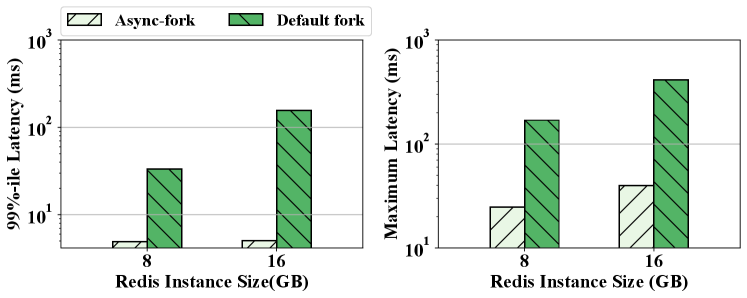
We compare Async-fork with the default fork in this subsection because ODF is not available in our cloud. Figure 16 shows the 99%-ile latency and maximum latency of the snapshot queries with the default fork and Async-fork. As observed, with an 8GB instance, the 99%-ile latency of the snapshot queries is reduced from 33.29ms to 4.92ms, and the maximum latency is reduced from 169.57ms to 24.63ms. With a 16GB instance, the former is reduced from 155.69ms to 5.02ms, while the latter is reduced from 415.19ms to 40.04ms.
Before Async-fork is deployed on our Redis Clouds, we received a large number of complaints from tenants about the long latency when taking the snapshot. Some tenants even have to disable the snapshot function, and they cannot reboot their Redis servers, otherwise the data lost. After we deploy Async-fork, no more latency complaints have been received.
7. Conclusion
In this paper, we study the latency spikes incurred by the fork-based snapshot mechanism in IMKVSes and address the problem from the operating system level. In particular, we conduct an in-depth study to reveal the impact of the fork operation on the latency spikes. According to the study, we propose Async-fork. It optimizes the fork operation by offloading the workload of copying the page table from the parent process to the child process. To guarantee data consistency between the parent and the child, we design the proactive synchronization strategy. Async-fork is implemented in the Linux kernel and deployed in production environments. Extensive experiment results show that the technique proposed in this paper can significantly reduce the tail latency of queries arriving during the snapshot period.
Acknowledgements.
This work was partially sponsored by the National Natural Science Foundation of China (62232011, 62022057), and Shanghai international science and technology collaboration project (21510713600). This work was also supported by Alibaba Group through Alibaba Innovative Research Program. Quan Chen and Minyi Guo are the corresponding authors.References
- (1)
- for ([n.d.]) [n.d.]. fork(2). https://linux.die.net/man/2/fork.
- tec (2022) 2022. Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level (Complete Version). https://drive.google.com/drive/folders/1xkwhyYmyDV5dD-X03ge1CmwUBNnGgN4X?usp=sharing.
- bcc (2022) 2022. BPF Compiler Collection (BCC). https://github.com/iovisor/bcc.
- Achermann et al. (2020) Reto Achermann, Ashish Panwar, Abhishek Bhattacharjee, Timothy Roscoe, and Jayneel Gandhi. 2020. Mitosis: Transparently self-replicating page-tables for large-memory machines. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 283–300.
- Antirez ([n.d.]) Antirez. [n.d.]. Redis persistence demystified. http://antirez.com/post/redis-persistence-demystified.html.
- Babka (2016) Vlastimil Babka. 2016. mm, compaction: introduce kcompactd. https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=698b1b30642f1ff0ea10ef1de9745ab633031377.
- Bailey et al. (2013) Katelin A Bailey, Peter Hornyack, Luis Ceze, Steven D Gribble, and Henry M Levy. 2013. Exploring storage class memory with key value stores. In Proceedings of the 1st Workshop on Interactions of NVM/FLASH with Operating Systems and Workloads. 1–8.
- Bernstein et al. (1987) Philip A Bernstein, Vassos Hadzilacos, and Nathan Goodman. 1987. Concurrency control and recovery in database systems. Vol. 370. Addison-wesley Reading.
- Bronevetsky et al. (2006) Greg Bronevetsky, Rohit Fernandes, Daniel Marques, Keshav Pingali, and Paul Stodghill. 2006. Recent advances in checkpoint/recovery systems. In Proceedings 20th IEEE International Parallel & Distributed Processing Symposium. IEEE, 8–pp.
- Cao (2013) Tuan Cao. 2013. Fault tolerance for main-memory applications in the cloud. Cornell University.
- Cao et al. (2011) Tuan Cao, Marcos Vaz Salles, Benjamin Sowell, Yao Yue, Alan Demers, Johannes Gehrke, and Walker White. 2011. Fast checkpoint recovery algorithms for frequently consistent applications. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of data. 265–276.
- Chandramouli et al. (2018) Badrish Chandramouli, Guna Prasaad, Donald Kossmann, Justin Levandoski, James Hunter, and Mike Barnett. 2018. Faster: A concurrent key-value store with in-place updates. In Proceedings of the 2018 International Conference on Management of Data. 275–290.
- Chen et al. (2019) Shuang Chen, Christina Delimitrou, and José F Martínez. 2019. Parties: Qos-aware resource partitioning for multiple interactive services. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 107–120.
- Community (2021a) The Kernel Development Community. 2021a. HugeTLB Pages. https://www.kernel.org/doc/html/latest/admin-guide/mm/hugetlbpage.html.
- Community (2021b) The Kernel Development Community. 2021b. Transparent Hugepage Support. https://www.kernel.org/doc/html/latest/admin-guide/mm/transhuge.html.
- Couchbase (2021) Couchbase. 2021. Disabling Transparent Huge Pages (THP). https://docs.couchbase.com/server/current/install/thp-disable.html.
- Diaconu et al. (2013) Cristian Diaconu, Craig Freedman, Erik Ismert, Per-Ake Larson, Pravin Mittal, Ryan Stonecipher, Nitin Verma, and Mike Zwilling. 2013. Hekaton: SQL server’s memory-optimized OLTP engine. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. 1243–1254.
- Dong et al. (2016) Xiaowan Dong, Sandhya Dwarkadas, and Alan L Cox. 2016. Shared address translation revisited. In Proceedings of the Eleventh European Conference on Computer Systems. 1–15.
- Fan et al. (2013) Bin Fan, David G Andersen, and Michael Kaminsky. 2013. Memc3: Compact and concurrent memcache with dumber caching and smarter hashing. In 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI 13). 371–384.
- Gong et al. (2022) Caixin Gong, Chengjin Tian, Zhengheng Wang, Sheng Wang, Xiyu Wang, Qiulei Fu, Wu Qin, Long Qian, Rui Chen, Jiang Qi, Ruo Wang, Guoyun Zhu, Chenghu Yang, Wei Zhang, and Feifei Li. 2022. Tair-PMem: A Fully Durable Non-Volatile Memory Database. Proc. VLDB Endow. 15, 12 (aug 2022), 3346–3358.
- Gregg (2018) Brendan Gregg. 2018. Working Set Size Estimation. https://www.brendangregg.com/wss.html.
- Guide (2011) Part Guide. 2011. Intel® 64 and ia-32 architectures software developer’s manual. Volume 3B: System programming Guide, Part 2, 11 (2011).
- Ha and Kim (2022) Minjong Ha and Sang-Hoon Kim. 2022. CCoW: Optimizing Copy-on-Write Considering the Spatial Locality in Workloads. Electronics 11, 3 (2022). https://doi.org/10.3390/electronics11030461
- Harris (2010) Alan Harris. 2010. Distributed caching via memcached. In Pro ASP. NET 4 CMS. Springer, 165–196.
- Inc. (2022a) Snap Inc. 2022a. KeyDB. https://keydb.dev/.
- Inc. (2022b) Snap Inc. 2022b. Latency Monitoring Tool. https://docs.keydb.dev/docs/latency-monitor/.
- Inc. (2022c) Snap Inc. 2022c. Persistence. https://docs.keydb.dev/docs/persistence.
- Inc. (2022d) Snap Inc. 2022d. Troubleshooting Latency Issues. https://docs.keydb.dev/docs/latency/.
- Kasture and Sanchez (2016) Harshad Kasture and Daniel Sanchez. 2016. Tailbench: a benchmark suite and evaluation methodology for latency-critical applications. In 2016 IEEE International Symposium on Workload Characterization (IISWC). 1–10.
- Kemper and Neumann (2011) Alfons Kemper and Thomas Neumann. 2011. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering. IEEE, 195–206.
- Kwon et al. (2016) Youngjin Kwon, Hangchen Yu, Simon Peter, Christopher J Rossbach, and Emmett Witchel. 2016. Coordinated and efficient huge page management with ingens. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16). 705–721.
- Li et al. (2018) Liang Li, Guoren Wang, Gang Wu, and Ye Yuan. 2018. Consistent snapshot algorithms for in-memory database systems: Experiments and analysis. In 2018 IEEE 34th International Conference on Data Engineering (ICDE). IEEE, 1284–1287.
- Liedes and Wolski (2006) A-P Liedes and Antoni Wolski. 2006. Siren: A memory-conserving, snapshot-consistent checkpoint algorithm for in-memory databases. In 22nd International Conference on Data Engineering (ICDE’06). IEEE, 99–99.
- Limited ([n.d.]) Arm Limited. [n.d.]. Arm Architecture Reference Manual Armv8, for A-profile architecture. https://developer.arm.com/documentation/ddi0487/gb/.
- McCracken (2003) Dave McCracken. 2003. Sharing page tables in the linux kernel. In Linux Symposium. 315.
- Mior and de Lara (2011) Michael J Mior and Eyal de Lara. 2011. Flurrydb: a dynamically scalable relational database with virtual machine cloning. In Proceedings of the 4th Annual International Conference on Systems and Storage. 1–9.
- Mongodb (2021) Mongodb. 2021. Disable Transparent Huge Pages (THP) — MongoDB Manual. https://docs.mongodb.com/manual/tutorial/transparent-huge-pages.
- Panwar et al. (2021) Ashish Panwar, Reto Achermann, Arkaprava Basu, Abhishek Bhattacharjee, K Gopinath, and Jayneel Gandhi. 2021. Fast local page-tables for virtualized NUMA servers with vMitosis. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 194–210.
- Panwar et al. (2018) Ashish Panwar, Aravinda Prasad, and K Gopinath. 2018. Making huge pages actually useful. In Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems. 679–692.
- Park et al. (2020) Jiwoong Park, Yunjae Lee, Heon Young Yeom, and Yongseok Son. 2020. Memory efficient fork-based checkpointing mechanism for in-memory database systems. In Proceedings of the 35th Annual ACM Symposium on Applied Computing. 420–427.
- RedisLab (2021a) RedisLab. 2021a. How fast is Redis? https://redis.io/topics/benchmarks.
- RedisLab (2021b) RedisLab. 2021b. Redis. https://redis.io/.
- RedisLab (2021c) RedisLab. 2021c. Redis latency monitoring framework. https://redis.io/topics/latency-monitor.
- RedisLab (2021d) RedisLab. 2021d. Redis Latency Problems Troubleshooting. https://redis.io/topics/latency.
- RedisLab (2021e) RedisLab. 2021e. Redis Persistence. https://redis.io/topics/persistence.
- RedisLab (2022a) RedisLab. 2022a. memtier. https://github.com/RedisLabs/memtier_benchmark.
- RedisLab (2022b) RedisLab. 2022b. redis.conf. https://github.com/redis/redis/blob/7.0/redis.conf.
- Schroeder et al. (2006) Bianca Schroeder, Adam Wierman, and Mor Harchol-Balter. 2006. Open versus closed: A cautionary tale. USENIX.
- Shafer (2012) Matthew Shafer. 2012. Memcached. https://github.com/memcached/memcached.
- Sharma et al. (2018) Ankur Sharma, Felix Martin Schuhknecht, and Jens Dittrich. 2018. Accelerating Analytical Processing in MVCC Using Fine-Granular High-Frequency Virtual Snapshotting. In Proceedings of the 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD ’18). Association for Computing Machinery, New York, NY, USA, 245–258.
- solid IT (2022) solid IT. 2022. DB-Engines Ranking of Key-value Stores. https://db-engines.com/en/ranking/key-value+store.
- Technology (2017) Trivago Technology. 2017. Learn Redis the hard way (in production). https://tech.trivago.com/2017/01/25/learn-redis-the-hard-way-in-production/.
- Torvalds (2018a) Linus Torvalds. 2018a. linux/mm/compaction.c. https://github.com/torvalds/linux/blob/v4.19/mm/compaction.c.
- Torvalds (2018b) Linus Torvalds. 2018b. linux/mm/memory.c. https://github.com/torvalds/linux/blob/v4.19/mm/memory.c.
- Torvalds (2018c) Linus Torvalds. 2018c. linux/mm/vmscan.c. https://github.com/torvalds/linux/blob/v4.19/mm/vmscan.c.
- Zhang et al. (2015) Hao Zhang, Gang Chen, Beng Chin Ooi, Kian-Lee Tan, and Meihui Zhang. 2015. In-memory big data management and processing: A survey. IEEE Transactions on Knowledge and Data Engineering 27, 7 (2015), 1920–1948.
- Zhang et al. (2020) Wei Zhang, Ningxin Zheng, Quan Chen, Yong Yang, Zhuo Song, Tao Ma, Jingwen Leng, and Minyi Guo. 2020. URSA: Precise Capacity Planning and Fair Scheduling Based on Low-Level Statistics for Public Clouds. In 49th International Conference on Parallel Processing - ICPP (Edmonton, AB, Canada) (ICPP ’20). Association for Computing Machinery, New York, NY, USA, Article 73, 11 pages.
- Zhang et al. (2016) Yunqi Zhang, David Meisner, Jason Mars, and Lingjia Tang. 2016. Treadmill: Attributing the source of tail latency through precise load testing and statistical inference. In 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA). IEEE, 456–468.
- Zhao et al. (2021) Kaiyang Zhao, Sishuai Gong, and Pedro Fonseca. 2021. On-demand-fork: a microsecond fork for memory-intensive and latency-sensitive applications. In Proceedings of the Sixteenth European Conference on Computer Systems. 540–555.
Appendix A Issues Incurred by Shared Page Table Design
We initially consider using ODF in our cloud to solve the query latency spike problem. However, we find that the shared page table design adopted in ODF (Zhao et al., 2021) (as well as previous studies (McCracken, 2003; Dong et al., 2016)) incurs several issues, which block its usage in the production environment.
Data Leakage Problem. As presented in Section 3.2, ODF has the data leakage problem due to the inconsistency between the page table and the TLB. A potential fixing method for the data leakage vulnerability works as follows: 1) for each PTE, record the processes that share it; and 2) if the PTE of a page is set to be invalid in the parent process, then the OS notifies the other processes sharing the PTE to flush the TLB entry. However, it is not easy to record all the processes that share a PTE; this problem is similar to the reverse mapping problem, i.e., mapping a physical page back to the PTEs that correspond to it. Although the reverse mapping concept looks simple and easy to implement, it is hard in practice due to the space and access efficiency problem. As introduced in the blogs444https://lwn.net/Articles/23732. Last accessed on 2022/11/13.555https://lwn.net/Articles/383162. Last accessed on 2022/11/13. by Jonathan Corbet, the author of Linux Device Drivers, each reverse mapping method requires complicated data structures and an update mechanism. Unfortunately, for each PTE, ODF records the number of processes that share it, but has no reverse mapping information. To that end, ODF cannot support the fixing method.
WSS Estimation Problem. The Linux kernel cannot accurately estimate the working set size (WSS) of a process using ODF, while WSS is an important metric, which cloud providers utilize to improve the resource utilization. Specifically, WSS is the memory size that a process actually requires in run time. A process can populate a memory space that is much bigger than the actual usage (e.g., apply for a memory pool with a fixed size at startup but do not shrink in run time). The Linux kernel estimates WSS of a process by counting how many pages the process has visited (based on the accessed bit of the PTE (Gregg, 2018)). However, the shared page table design in ODF prevents the kernel from distinguishing the visitor of a page. Consequently, the Linux kernel cannot give an accurate estimation on WSS. In practice, it is very important for public clouds to improve resource utilization because tenants generally would like to apply for more resources than their actual demands (e.g., 68.4% of memory space is wasted in our clouds (Zhang et al., 2020)).
NUMA Problem. We find that the NUMA balancing mechanism does not work as expected with ODF. Specifically, when the NUMA balancing mechanism decides to change the page location for the child process, it will set PTEs to be PROT_NONE (i.e., accessing the pages in the future triggers page faults) to ask the child process to handle the faults. However, both the parent and child processes can capture the faults due to the shared page table design. Additionally, the overhead of TLB miss increases when the processes sharing the page table run on different NUMA nodes because there is only one copy of PTEs, and some processes and the PTEs can locate into different nodes. The overhead of TLB miss can increase due to page table walk on the remote node (Achermann et al., 2020; Panwar et al., 2021). Although our experiments do not consider NUMA environments, we mention this issue to show the gap between ODF and practice.
Fixing these issues is far from trivial and requires significant efforts (e.g., adding new data structures and further modifying the kernel). This motivates us to develop a new fork mechanism that can work in the production environment. Different from the shared page table design, Async-fork has the same design as the default fork operation in which both parent and child processes have a private page table. The parent’s PTE table is locked if a PTE (belongs to this table) will be updated in the parent process. Therefore, when the PTE is updated in the parent process, either the PTE has been copied by the child process before the update or not. For the first case, both child and parent processes have their own PTEs whereby Async-fork has no data leakage issue. For the second case, the child process will copy the PTE after the update because of the lock on the parent’s PTE table. We use the example in Table 2 to demonstrate this case. The parent’s PTE table is locked during the page migration (Step 2 to Step 4). The PTE can be accessed by the child process after Step 4. Then, the child process will copy the updated PTE. As such, Async-fork does not suffer from the data leakage problem.
Nevertheless, the idea that shares a page table among multiple processes and uses CoW to keep consistent is promising because it can reduce the workload of copying the page table. It is an interesting and challenging future research to address all the above issues and develop a fork method based on the shared page table design.
| Step | Operation | Parent(P) | Child(C) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | Initial state |
|
|
||||||
| 2 |
|
|
|
||||||
| 3 | P: Flush TLB |
|
|
||||||
| 4 | P: Update PTE |
|
|
||||||
| 5 | C: Copy PTE |
|
|
||||||
| 6 | P&C: Access V |
|
|
| VMA-wide | Description | Checkpoint | PMD-wide | Description | Checkpoint | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
page fault |
|
__handle_mm_fault( ) | |||||||||||||||||||||
| expand_stack( ) |
|
|
out of memory |
|
zap_pmd_range( ) | |||||||||||||||||||||
| NUMA balance |
|
change_prot_numa( ) | get user page |
|
follow_page_pte( ) |
Appendix B Implementation Details
We summarize the operations that modify VMAs/PTEs in the OS as checkpoints. Table 3 lists the functions (i.e., checkpoints) that can modify a VMA or a PTE, through a comprehensive analysis on the Linux kernel. As shown in the table, some operations are caused by users’ queries, while others are caused by OS inherent memory management operations. Different kernel versions show quite stable call paths. Our analysis shows that only one function related to Async-fork has ever been modified from Linux kernel 2.6 to 6.0 (see Table 4). Thus, the kernel related to our work is very stable.
In practice, updating the kernel is a critical task for both cloud providers and users. They tend to stay with a kernel version for a relatively long time to keep the stability of services. Therefore, it is common for cloud providers to customize the OS kernel for important applications or specific internal needs in the production environment even the modification to the kernel cannot be upstreamed. For example, Facebook uses a customized disk cache component666https://engineering.fb.com/2013/10/09/core-data/flashcache-at-facebook-from-2010-to-2013-and-beyond. Last accessed on 2022/11/13. in the kernel to speed up MySQL, and Google adds specific rules777https://lwn.net/Articles/871195. Last accessed on 2022/11/13. for the out-of-memory killer in their kernel. The implementation of Async-fork adopts the modular design, which can be easily inserted in (or removed from) the kernel.
| Function | Lifecycle | Location |
|---|---|---|
| vma_merge() | v2.6.12 - v6.0 | mm/mmap.c |
| __split_vma( ) | v2.6.33 - v6.0 | mm/mmap.c |
| detach_vmas_to_be_unmapped( ) | v2.6.12 - v6.0 | mm/mmap.c |
| madvise_vma( ) | v2.6.12 - v5.16.20 | mm/madvise.c |
| do_mprotect_pkey( ) | v4.9 - v6.0 | mm/mprotect.c |
| mlock_fixup( ) | v2.6.12 - v6.0 | mm/mblock.c |
| vma_to_resize( ) | v2.6.33 - v6.0 | mm/mremap.c |
| expand_upwards( ) | v2.6.15 - v6.0 | mm/mmap.c |
| expand_downwards( ) | v2.6.23 - v6.0 | mm/mmap.c |
| change_prot_numa( ) | v3.8 - v6.0 | mm/mempolicy.c |
| __handle_mm_fault( ) | v3.12 - v6.0 | mm/memory.c |
| zap_pmd_range( ) | v2.6.12 - v6.0 | mm/memory.c |
| follow_page_pte( ) | v3.16 - v6.0 | mm/gup.c |
Appendix C Supplement Experiments
In this section, we first report the experiment results of query processing throughput and total out-of-service time for the parent process during the snapshot process. We then report the experiment results of using Async-fork in log rewriting. Additionally, we report the execution time of Async-fork and ODF. Lastly, we discuss the method of tuning IMKVSes to further improve the performance.
Throughput Results. This experiment measures the processing throughput of the IMKVS when taking a snapshot of the in-memory data. To do so, we use Redis benchmark (RedisLab, 2021a) to launch a great many queries and report the number of completed queries on the server side as the processing throughput.
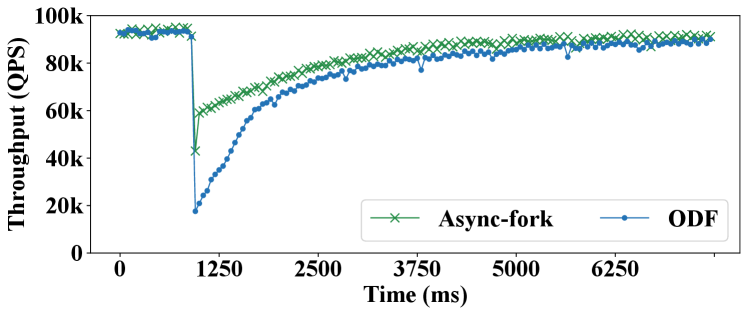
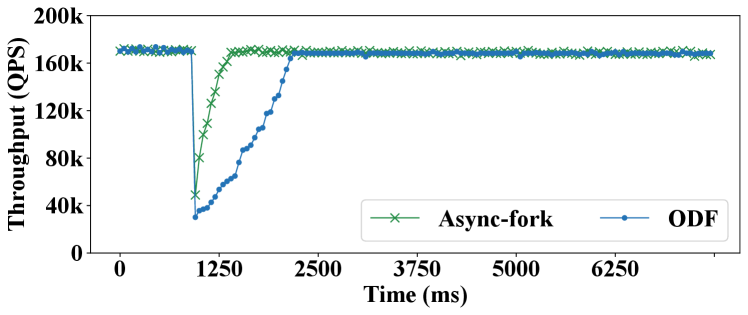
Figures 17 and 18 show the processing throughput on a 16GB Redis instance and a 16GB KeyDB instance, respectively. The throughput is reported for every 50ms. Since KeyDB handles queries with multiple threads, we measure the throughput of KeyDB as follows: 1) each thread independently measures its throughput for every 50ms and records the value with a timestamp; and 2) for each time interval (50ms), estimate the throughput of the engine by summing up the values of all threads whose timestamps fall into the interval.
As we can see, the throughput drops rapidly when the snapshot is taken while it increases gradually after that. For example, In the worst case, the throughput of Redis server drops to 17,592 queries per second (QPS) and 42,980 QPS with ODF and Async-fork respectively. Besides, the throughput increases to the normal level much faster with Async-fork than with ODF. The throughput of KeyDB is higher than that of Redis because KeyDB uses four threads to process queries in our experiments.
The experiments with other instance sizes of Redis and KeyDB show similar results. Figure 19 further shows the minimum processing throughput with different instance sizes of Redis and KeyDB. Async-fork increases the minimum throughput by 2.44x on average (up to 2.9x) compared with ODF in Redis. The minimum throughput of KeyDB is increased by 1.6x on average (up to 2.69x). Once the load exceeds the processing ability of the server, some queries queue up and suffer from a long latency. The lower the processing throughput is, the longer the latency will be, which is consistent with the results of Section 6.2.
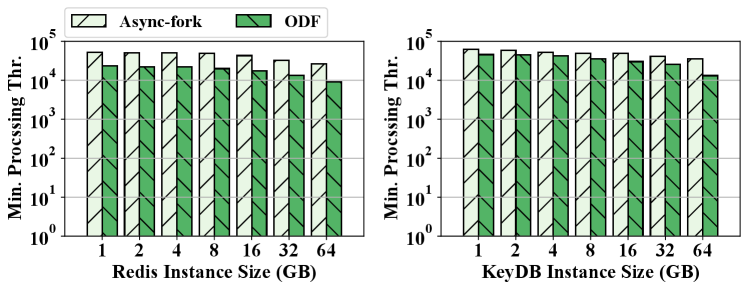
Total Out-of-service Time. As discussed in Section 6.2, the parent process is out-of-service for queries during the invocation of copy_pmd_range(). We report the total out-of-service time (the sum of the duration of each copy_pmd_range() invocation), as shown in Figure 20. Compared with Async-fork, the parent process is out-of-service for a longer time with ODF.
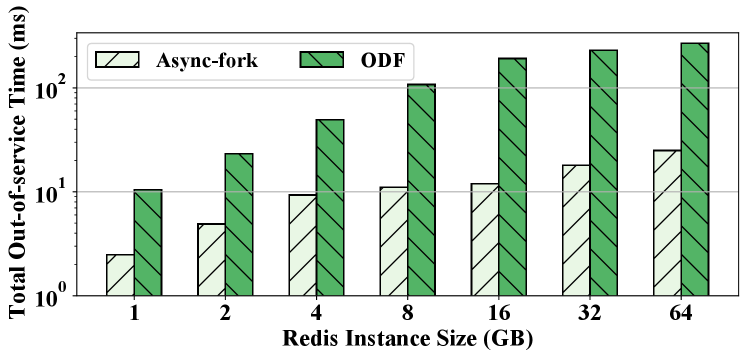
Impact of Async-fork on Log Rewriting Queries. In addition to taking the snapshot, Redis can also persist data with Append Only File (AOF). Redis logs every write operation received by the server in a file, while these operations can then be replayed again at server startup to reconstruct the original dataset. However, the AOF log file gets bigger and bigger as write operations are performed. Consequently, Redis conducts the log rewriting to optimize the AOF log file (RedisLab, 2021e). Specifically, the store engine calls fork to create a child process. The child process rebuilds the AOF file into the shortest sequence of commands needed to rebuild the current dataset in memory, while the parent process continues to serve the user’s queries. Due to the usage of fork, latency spikes will also be incurred during the log rewriting process.
In the experiments, we use the Redis benchmark (RedisLab, 2021a) to generate the workload and execute the BGREWRITEAOF command to trigger the log rewriting operation in Redis. We record the latency of the queries arriving during the period of conducting log rewriting (from the start of the fork operation to the end of log rewriting). We call these queries log rewriting queries for brevity.
Figure 21 presents the 99%-ile latency and maximum latency of log rewriting queries with different fork methods. Compared with the default fork, Async-fork reduces the 99%-ile latency of log rewriting queries by 71.81% (from 11.53ms to 3.25ms) on 1GB instance, 90.29% (from 84.03ms to 8.16ms) on 8GB instance and 97.66% (from 1093.35ms to 25.59ms) on 64GB instance. Compared with ODF, Async-fork reduces the 99%-ile latency of log rewriting queries by 39.7% (from 5.39ms to 3.25ms) on 1GB instance, 43.92% (from 14.55ms to 8.16ms) on 8GB instance and 71.09% (from 88.51ms to 25.59ms) on 64GB instance. The latency of log rewriting queries is higher than that of snapshot queries because the overall performance of Redis degrades when enabling AOF. In particular, the storage engine enabling AOF needs to synchronize the log into the disk (RedisLab, 2021e) in addition to processing queries. We observe the performance degradation of normal queries as well. When AOF is disabled, the 99%-ile latency and maximum latency of normal queries on a 16GB instance are 0.079ms and 5.78ms, respectively. In contrast, the values increase to 1.56ms and 11.3ms when AOF is enabled. Nevertheless, Async-fork significantly reduces the latency of log rewriting queries as shown in Figure 21. The results demonstrate the effectiveness of Async-fork.
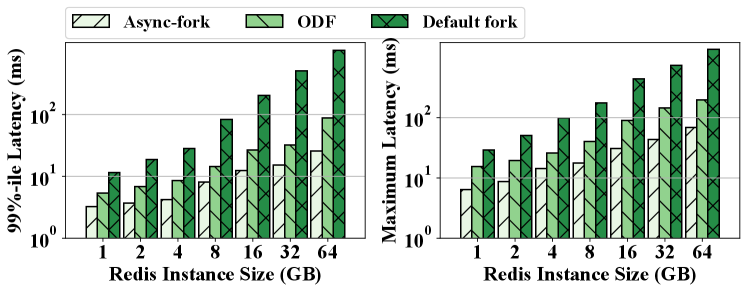
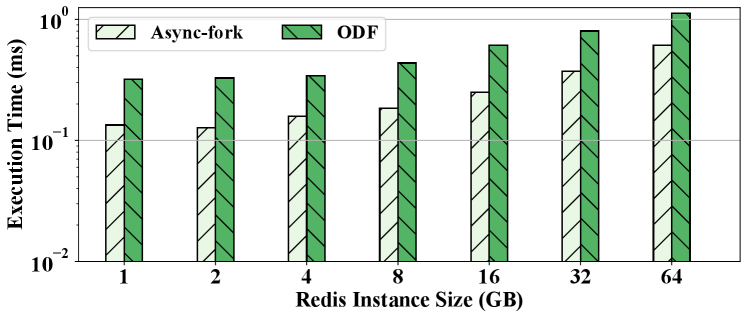
The Execution Time of Fork. The duration of the fork operation greatly impacts the latency of the snapshot queries. Figure 22 shows the time of the parent process returns from calling Async-fork and ODF at different instance sizes. Compared with the default fork (Figure 3), both Async-fork and ODF reduce the execution time of invoking the fork operation effectively. In the large 64GB instance, the parent process completes Async-fork in 0.61ms, and completes ODF in 1.1ms respectively. The time is reduced because they remove the most time-consuming phase from the default fork. We can also observe that Async-fork is slightly faster than ODF. One possible reason is that ODF introduces per-page counters to support the CoW sharing, incurring extra time cost for initialization.
Tuning IMKVSes. In our experiments, we set Redis and KeyDB to their default settings. Tuning the hyperparameters of IMKVSes may further reduce the latency of snapshot queries. In the following, we discuss the problem, while leaving it to the future studies.
By reducing the PTE modifications, the number of proactive PTE copies in Async-fork can be further reduced. The PTE modifications can be reduced by configuring the memory allocator appropriately. In general, by allocating a large enough virtual memory space for storing user data and meta information, the required mmap operations at runtime can be greatly reduced. In addition, it is better to retain the unused virtual memory for late use, rather than free them by calling munmap. Both the mmap and munmap operations cause PTE modifications. The default memory allocator jemalloc888https://github.com/jemalloc/jemalloc. Last accessed on 2022/11/13. of Redis and KeyDB supports the above configuration: 1) Pre-allocating virtual memory space through zmalloc/zfree without populating it (so that no extra physical memory is consumed). 2) Configuring the built-in property ‘retain’ to be true.