Asynchronous Distributed Protocol for Service Provisioning in the Edge-Cloud Continuum
Abstract
In the edge-cloud continuum, datacenters provide microservices (MSs) to mobile users, with each MS having specific latency constraints and computational requirements. Deploying such a variety of MSs matching their requirements with the available computing resources is challenging. In addition, time-critical MSs may have to be migrated as the users move, to keep meeting their latency constraints. Unlike previous work relying on a central orchestrator with an always-updated global view of the available resources and of the users’ locations, this work envisions a distributed solution to the above issues. In particular, we propose a distributed asynchronous protocol for MS deployment in the cloud-edge continuum that (i) dramatically reduces the system overhead compared to a centralized approach, and (ii) increases the system stability by avoiding having a single point of failure as in the case of a central orchestrator. Our solution ensures cost-efficient feasible placement of MSs, while using negligible bandwidth.
I Introduction
Today’s networks offer bulk virtualized resources, embodied as a collection of datacenters on the continuum from the edge to the cloud [1, 2, 3, 4]. These datacenters host a plethora of applications with versatile computational requirements and latency constraints. For example, such time-critical services as road safety applications require low latency, which may dictate processing them in an edge datacenter, close to the user. In contrast, infotainment tasks require larger computational resources, but looser latency constraints and therefore may be placed on a cloud datacenter with abundant and affordable computation resources [5, 2]. Placing services over the cloud-edge continuum is thus challenging. It becomes even more complex when changes in the users’ mobility or traffic demand require migrating services to reduce latency.
Most of the existing solutions [1, 6, 7, 3, 8, 9, 2] rely on a central orchestrator to make all placement and migration decisions. The orchestrator periodically (i) gathers information about the state of resources and migration requirements, (ii) calculates new placement and resource allocation, and (iii) instructs datacenter local controllers accordingly. This centralized synchronous approach has several shortcomings. First, it does not scale well, thus failing to manage systems with multiple datacenters efficiently. In practice, gathering fresh state information causes significant communication bottlenecks, even within a single cloud datacenter [10]. Secondly, the orchestrator is a natural single point of failure, compromising the system’s stability. Finally, the datacenters may be operated by distinct operators [11, 12], which are typically unwilling to share proprietary information and implementation details with competitors.
Our Contribution. We present a solution, named Distributed Asynchronous Placement Protocol for the Edge-Cloud Continuum (DAPP-ECC), that effectively and efficiently overcomes the above issues. DAPP-ECC is carefully crafted to decrease communication overhead by using simple single-hop control messages transmitted by a node to only relevant neighbors. Furthermore, DAPP-ECC requires no out-of-band communication or synchronization tools. DAPP-ECC can find a feasible solution even with restricted resources, where a feasible placement necessitates migrating also already-placed MSs. Finally, and very importantly, our solution allows multiple datacenters – possibly of distinct providers – to cooperate without exposing proprietary information.
Paper organization. We introduce the system model in Sec. II and formulate the placement and migration problem in Sec. III. Sec. IV describes our algorithmic solution. Sec. V evaluates the performance of DAPP-ECC in various settings, using real-world mobility traces and antenna locations. Finally, Sec. VI reviews relevant related work, and Sec. VII draws some conclusions.
II System Model
We consider a fat-tree cloud-edge continuum architecture, which comprises [5]: (i) a set of datacenters, , denoting generic computing resources, (ii) switches, and (iii) radio Points of Access (PoA). Datacenters are connected through switches, and PoAs have a co-located datacenter [13]. Each user is connected to the network through a PoA, and they can change PoA as they move.
We model such logical multi-tier network as a directed graph , where the vertices are the datacenters, while the edges are the directed virtual links connecting them. We assume the existence of a single predetermined loop-free path between each pair of datacenters.
Let us consider a generic user generating a service request , originating at the PoA , to which the user is currently connected. Each request is served by placing an instance of a microservice (MS) on a datacenter. Denote the instance of the MS for service request by . Let denote the set of service requests, and the set of corresponding MSs that are currently placed, or need to be placed, on datacenters.
Each service is associated with an SLA, which specifies its requirements in terms of KPI target values [14]. Let us consider latency as the most relevant KPI, although our model could be extended to others, like throughput and energy consumption. Due to these latency constraints, each request is associated with a list of delay-feasible datacenters . The delay-feasible servers in are not too far from ’s PoA (), or, more formally, their list is a prefix of the path from to the root [1, 4, 6]. The top delay-feasible datacenter of request is denoted by .
To successfully serve request on datacenter , should allocate (at least) CPU units, where is an integer multiple of a basic CPU speed. As there exists a known method to calculate and given the characteristics of [6], we refer to and as known input parameters. Each datacenter has a total processing capacity , expressed in number of CPU cycles/s.
III The Placement and Migration Problem
The delay experienced by an MS may vary over time due to either (i) a change in the user’s PoA, which changes the network delay, or (ii) a fluctuation in the traffic, and hence in the processing latency [15]. Each user continuously monitors its Quality of Experience (QoE) and warns its PoA as its latency approaches the maximum acceptable value111If the user can predict its near-future location, it can inform the PoA before the target delay is violated.. The PoA then checks the request, and if the user is indeed critical – namely, its latency constraint is about to be violated – the PoA triggers a migration algorithm. The PoA also handles new requests that are yet to be served.
Decision variables. Let be the Boolean placement decision variables, i.e., if MS is scheduled to run on datacenter . Any choice for the values of such variables provides a solution to the Placement and Migration Problem (PMP), determining (i) where to deploy new MSs, (ii) which existing MSs to migrate, and (iii) where to migrate them.
Constraints. The following constraints hold:
| (1) | |||||
| (2) |
Constraint (1) ensures that at any point in time, each MS is associated with a single scheduled placement. (2) assures that the capacity of each datacenter is not exceeded.
Costs. The system costs are due to migration and computational resource usage, as detailed below.
Migrating MS from datacenter to datacenter incurs a migration cost . Let denote the current placement indicator parameters222 are not decision variables, as they indicate the current deployment., i.e., iff MS is currently placed on datacenter . We assume that a user does not become critical again before it finishes being placed based on the decision made by any previous run of the algorithm solving the PMP. The migration cost incurred by a critical MS is then:
Placing MS on datacenter incurs a computational cost . As computation resources in the cloud are cheaper [5, 2], we assume that if is an ancestor of , placing MS on is cheaper than placing on .
Following Proposition 2 in [6], it is easy to see that PMP is NP-hard. We are interested in a distributed solution, where no single datacenter (or any other entity) has a complete fresh view of the status (e.g., the current place of each MS, or the amount of available resources in each datacenter). Instead, the placement and migration protocol should run on an as small as possible subset of the datacenters. Furthermore, the solution should be asynchronous, as distinct PoAs may independently invoke different, simultaneous runs of the protocol.
IV The DAPP-ECC Algorithmic Framework
In this section, we present our algorithmic solution to PMP, named Distributed Placement Protocol for the Edge-Cloud Continuum (DAPP-ECC). We start with a high-level description and then provide the details of the single algorithms. In our description, we let .proc() denote a run of procedure proc() on datacenter . As our protocol is distributed, each datacenter maintains its local variables, denoted by a sub-script . We will use the procedure Sort() that sorts MSs in non-increasing timing criticality, realized by a non-decreasing , i.e., the number of ancestor datacenters on which the MS may be placed. Sort() breaks ties by non-decreasing and breaks further ties by users’ FIFO order.
IV-A Protocol overview
Following the intuition, one would reduce the system costs by placing MSs in the network continuum as close as possible to the cloud, since cloud resources are cheaper and this may prevent future migrations. However, such an approach may make the algorithm fail to find feasible solutions, even when they exist [6].
Our solution to this conflict between feasibility and cost-efficiency is inspired to [6]. The proposed DAPP-ECC algorithm initially assigns – or, better, reserves – CPU for each request as close as possible to the edge. We dub this stage Seek a Feasible Solution (SFS). Once such a solution is found, the protocol Pushes Up (PU) the MSs as much as possible towards the cloud, to reduce costs. If SFS cannot find a feasible solution, non-critical MSs will be migrated via the Push-Down (PD) procedure, to make room for a critical MS.
IV-B The DAPP-ECC algorithms
We now detail the algorithmic framework we developed. We will denote by a list of currently unassigned requests, and by a list of assigned requests that may be pushed-up to a closer-to-the-cloud datacenter, to reduce costs. Let denote a set of push-down requests. denotes the available capacity on datacenter . Upon system initialization, each datacenter assigns and .
Seek for a feasible solution
.SFS() is presented in Alg. 1. It handles the unassigned MSs as follows. If the locally available capacity suffices to locally place an unassigned MS (Ln. 4), reserves capacity for (Ln. 6). If cannot be placed higher in the tree (Ln. 7), .SFS() not only assigns , but also locally places it. Otherwise, the procedure inserts to the set of potentially-placed MSs, which will later propagate to its parent. If .SFS() fails to place a request that cannot be placed higher, it calls .PD() (Lines 12-15). The arguments for .PD() are (i) the identity of the initiator datacenter, ; (ii) a list of MSs that asks its descendants to push-down, and (iii) deficitCPU, namely, the amount of CPU resources that must be freed from to find a feasible solution.
In Lines 16-17, .SFS() checks whether there exist MSs that are not yet assigned, or may be pushed-up to an ancestor. If so, .SFS() initiates a run of SFS() on ’s parent (Ln. 18). If there are no pending push-up requests from its ancestors, initiates a push-up (Lines 20-21).
Push-Up
.PU(), detailed in Alg. 2, first displaces and regains the CPU resources for all the MSs pushed-up from to a higher-level datacenter. Next, .PU() handles all the push-up requests as follows. Consider a request to push up MS , currently placed on datacenter that is a descendent of . If has enough available capacity for that request, then .PU() locally places (Lines 4-5) and updates the relevant record in (Ln. 6). This record will later be propagated to which will identify that was pushed up, and regain the resources allocated for it. In Lines 7-11, propagates the push-up requests to its children. To reduce communication overhead, each push-up request in is propagated only to the child that is delay-feasible for the MS in question.
Push-Down
.PD(), in Alg. 3, runs the same when either a parent calls its child, or vice versa. denotes the initiator of the PD procedure currently handled by datacenter . If no PD procedure is currently handled by , then =null. Note that several parallel simultaneous runs of PD may exist in the system. Each such run is unequivocally identified by its initiator . At any time instant, each such run is associated with a single current value of deficitCpu. PD runs sequentially, in a DFS manner, in the sub-tree rooted by , and terminates once deficitCPU is nullified.
If .PD() is invoked while takes part in another run of PD() (realized by a different initiator ), the procedure replies with the minimal data necessary to retain liveness (Lines 1-3). Otherwise, .PD() adds to the given set of requests its locally assigned MSs. To reduce the number of migrations, the locally assigned MSs are added to the end of , so that the procedure will migrate already-placed MSs only if necessary for finding a feasible solution. In Lines 7-13, serially requests its children to push-down MSs, to free space in . The amount of space to be freed from is deficitCpu. Before each such call, checks whether nullifying deficitCpu without calling an additional child is possible. If the answer is positive, skips calling its children (Lines 8-9). Upon receiving a reply from child , the procedure updates deficitCpu and ’s state variables according to the MSs that were pushed-down to ’s sub-tree (Lines 11-13). In Lines 14-15, .PD() tries to push-down to MSs from the push-down list, . Later, if is not the initiator of this push-down procedure, it calls its parent (Lines 16-17). Finally, .PD() calls SFS in -mode (described below) to place all its yet-unassigned MSs, if such exist.
The following theorem assures the convergence of DAPP-ECC (proof omitted due to space constraints).
Theorem 1.
If there are no new requests, the protocol either fails or finds a feasible solution after exchanging a finite number of messages.
IV-C Reducing the communication overhead
F-mode. Intuitively, a run of .PD() indicates that a recent run of SFS() – either in , or in an ancestor of – failed, and hence called PD(). Since in such a case, there is a high risk of failing again, the algorithm should focus on finding a feasible solution, rather than reducing costs: it does not make sense to push-up MSs just to push them back down slightly later. Hence, we define an F (feasibility)-mode of the protocol. Each time .PD() is called, enters -mode (if it was not already in -mode), and remains so for some pre-configured F-mode period. While in -mode, DAPP-ECC does not initiate new push-up requests, and only replies to existing push-up requests with the minimum necessary details to prevent deadlocks. If .SFS() does not find a feasible solution while is in -mode, DAPP-ECC terminates with a failure.
Accumulation delay. Theoretically, each attempt to place a single MS may result in a unique run of PD that involves all the datacenters, thus incurring excessive overhead. To avoid such case, observe that, typically, several users move together in the same direction (e.g., cars moving simultaneously on the road, on the same trajectory). Naively, such a scenario may translate to multiple invocations of DAPP-ECC, each of them for placing a single request. To tackle this problem, we introduce short accumulation delays to our protocol. We let each datacenter receiving a SFS message wait for a short SFS accumulation delay before it begins handling the new request. To deter long service delays or even deadlocks, each datacenter maintains a single SFS accumulation delay timer that operates as follows: if a run of SFS reaches Ln. 3 in Alg. 1 while no SFS accumulation delay timer is ticking, the procedure initiates a new SFS accumulation delay timer. This current run of SFS, as well as all the subsequent runs, halt. After the SFS accumulation delay terminates, only a single SFS process resumes (see Alg. 1, Ln. 3).
Likewise, to initiate fewer runs of PD(), we let each datacenter retain a single PD accumulation delay mechanism that works similarly to the SFS accumulation delay timer. Significantly, the accumulation delay only impacts the time until the protocol finds a new feasible placement, not the delay experienced by applications in the data plane. We assess the impact of the accumulation delay in Sec. V-B.
V Numerical Evaluation
V-A Simulation settings
Service area, network, and datacenters. We consider two mobility traces, representing real-world scenarios with distinct characteristics: the vehicular traffic within the centers of the cities of (i) Luxembourg [16], and (ii) the Principality of Monaco [17]. For the PoAs, we rely on real-world antenna locations, publicly available in [18]. For each simulated area, we consider the antennas of the cellular telecom provider having the largest number of antennas in the simulated area. For both traces, we consider the 8:20-8:30 am rush hour period. Further details about the mobility traces can be found in [6, 16, 17].
Network and datacenters. The cloud-edge continuum is structure as a 6-height tree; a topology level is denoted by . The leaves (level 0) are the datacenters co-located with the PoAs (antennas). Similarly to [9, 8, 12], the higher levels recursively partition the simulated area. In both Luxembourg and Monaco, if no PoAs exist in a particular rectangle, the respective datacenters are pruned from the tree. The CPU capacity increases with the level to reflect the larger computational capacity in datacenters closer to the cloud. Denoting the CPU capacity at each leaf datacenter by , the CPU capacity in level is .
Services and costs. Each vehicle that enters the considered geographical area is randomly marked as requesting either real time (RT) or non-RT services, with some probability defined later. We calculate , , and for each using the GFA algorithm and the same data-plane latency parameters as in [6]. We thus obtain the following values. Each RT request can be placed on levels 0, 1, or 2 in the tree, requiring CPU of 17, 17, and 19 GHz, associated with costs of 544, 278, and 164, respectively. Each non-RT request can be placed on any level, with a fixed allocated CPU of 17 GHz and associated costs of 544, 278, 148, 86, 58, and 47 for placing the MS on levels 0, 1, 2, 3, 4 and 5, respectively. The migration cost is for every request and datacenters .
Delays. The delay experienced by each packet consists of (i) transmission delay and (ii) propagation delay.
The transmission delay is calculated as the packet’s size over the capacity allocated for the control plane at each link, through a dedicated network slice. We assume that this capacity is 10 Mbps. We now detail the size of each field in the messages exchanged by DAPP-ECC. As DAPP-ECC uses only single-hop packets, we assume a fixed 80-bits header. The IDs of datacenters, and requests, are represented using 12-bits, and 14-bits. Each MS belongs to a concrete class of timing constraint, expressed through a 4-bit classId. The CPU allocation of an MS on a datacenter is represented through a 5-bits field. deficitCpu is at most the highest capacity of any single datacenter; we assume that this requires 16 bits. For the propagation delay, we use a pessimistic approach, where the length of every single link in the network corresponds to the diameter of the simulated area, and the propagation speed is . Consequently, the propagation delay of each link in Luxembourg and Monaco is and (resp.). For a datacenter at level , SFS accumulation delay, and PD accumulation delay are , and (resp.). We assign ms and ms. -mode period (recall Sec. IV-C) is 10 s.
Benchmark algorithms. We are unaware of any fully distributed, asynchronous algorithm for the PMP. Hence, we consider centralized placement schemes that identify the currently critical and new users once in a second and solve the respective PMP. We will consider the following algorithms.
Lower Bound (LBound): An optimal solution to the PMP that can place fractions of an MS on distinct datacenters. Also, the LP formulation considers all MSs in the system every 1 s period, not just critical MSs. Hence, it serves as a lower bound on the cost of any feasible solution to the problem.
F-Fit: It places each request on the lowest datacenter in that has sufficient available resources to place MS . This is an adaptation to our problem of the placement algorithm proposed in Sec. IV.B in [19].
BUPU [6]: It consists of two stages. At the bottom-up, it places all the critical and new MSs as low as possible. If this stage fails to place an MS while considering datacenter , the algorithm re-places all the MSs associated with ’s sub-tree from scratch. Later, BUPU performs a push-up stage similar to our DAPP-ECC’s PU() procedure.
Simulation methodology. We simulate users’ mobility using SUMO [20]. The benchmark algorithms use the Python code publicly available in [21]. DAPP-ECC is implemented using OMNeT++ network simulator [22]. Each new user, or an existing user which becomes critical, invokes a run of DAPP-ECC datacenter co-located with the user’s PoA. DAPP-ECC’s code is available in [23]. LBound is computed using Gurobi optimizer [24].
V-B Resources required for finding a feasible solution
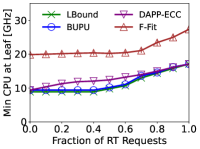
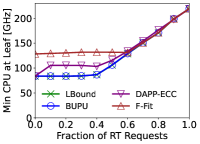
We now study the amount of resources each algorithm requires to find a feasible solution. We vary the fraction of RT MSs with respect to the total MSs. For each setting, a binary search is used to find the minimum amount of resources needed by the algorithm in question to successfully place all the critical MSs along the trace. Fig. 1 presents the results of this experiment. The amount of CPU required by BUPU is almost identical to the optimal value. Despite being fully distributed and asynchronous, the amount of CPU needed by DAPP-ECC is only slightly higher than BUPU. Finally, F-Fit requires a processing capacity that is 50% to 100% higher than LBound to provide a feasible solution.
V-C Communication overhead
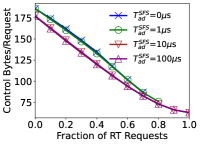
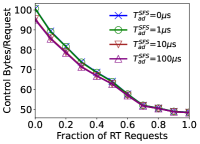
For each simulated scenario, we now set the CPU resources to 10% above the amount of resources required by LBound to find a feasible solution when 100% of the requests are RT. While maintaining this amount of CPU resources, we vary the ratio of RT requests, and measure the overall amount of data for signaling used by DAPP-ECC. Fig. 2 presents the per-request signaling overhead, defined as the overall signaling data exchanged by DAPP-ECC (“control bytes”) over the overall number of critical/new requests along the trace. We consider several values of the SFS accumulation delay parameter . A run of PD() may migrate also non-critical MSs, thus incurring a higher overhead than PU(). Hence, we set . The results show that increasing the fraction of RT requests decreases the signaling overhead. The reason is that RT requests can be placed only in the three lowest levels in the tree, thus avoiding any signaling message between higher-level datacenters. When increasing the accumulation delays, the protocol aggregates more requests before sending a message, thus decreasing the signaling overhead. However, an accumulation delay of about suffices. We stress that the accumulation delay only impacts the time until the protocol finds a new feasible placement, not the delay experienced by the user’s application. Indeed, delaying the migration decision may deteriorate the user’s QoE. However, this performance deterioration can be mitigated using an efficient prediction mechanism for the user’s mobility. Furthermore, in practical scenarios, an accumulation delay of about may be negligible compared to the more considerable delay incurred by the migration process. Finally, in all the settings considered, the signaling overhead associated with each request is about bytes. Thus, we can claim a very low overhead for DAPP-ECC.
V-D Cost comparison
In our next experiment, we compare the cost of various solutions for the PMP. We set the ratio of RT requests to 30%, and vary the resource augmentation.
The results (not detailed here due to lack of space) show that the costs obtained by BUPU and DAPP-ECC are almost identical, and both are up to 10% higher than LBound (depending on the concrete setting). That is, despite being distributed and asynchronous, DAPP-ECC obtain costs that are almost identical to those obtained by BUPU, which relies on a centralized controller with an always-accurate view of the system state. F-Fit typically only finds any feasible solution when resources are abundant, in which case all the placement algorithms easily obtain close-to-optimal costs.
VI Related Work
State-of-the-art solutions to the PMP [25, 8, 2, 9]. assume a centralized orchestrator that possesses a fresh, accurate information about the locations, trajectories, and computational demands of all users, and the available resources at all the datacenters. Such an assumption may be impractical in a large system, possibly operated by several distinct operators.
Other solutions [25, 12] independently select an optimal destination for each migration request, based on multiple considerations, such as topological distance, availability of resources at the destination, and the data protection level in the destination. However, such a selfish user-centric approach may fail to provide a feasible system-level solution when multiple RT users compete for resources in the edge.
The work [19] uses dynamic clustering of datacenters to handle multiple simultaneous independent placement requests. However, the complex dynamic clustering mechanism may result in significant communication and computational overhead. Also, [19] does not consider migrating non-critical requests to make room for a new user, as we do.
The PMP combines several properties of the Multiple Knapsack problem [26] with added restrictions typical for bin-packing problems (e.g., each item can be packed only on a subset of the knapsacks, and a feasible solution must pack all the items). However, in contrast to the usual settings of such problems, we aim at a distributed and asynchronous scheme that runs independently on multiple datacenters (“knapsacks”), using only little communication between them.
The work [27] optimizes lower-level implementational details of the migration process, to decrease its overhead. LSTM [28] considers learning algorithms that predict future service requests. These solutions are orthogonal to the PMP and hence could be incorporated into our solution to boost performance.
VII Conclusions
We proposed a distributed asynchronous protocol for service provisioning in the cloud-edge continuum. Our solution is carefully designed to reduce signaling overhead by using only small control messages between immediate neighbor datacenters. Numerical results, derived using realistic settings, show that our approach may provide a feasible solution while using only slightly higher computing resources than a centralized scheduler, which may be impractical for large communication networks. Also, our protocol obtains reduced costs and incurs only a small communication overhead.
References
- [1] B. Kar et al., “QoS violation probability minimization in federating vehicular-fogs with cloud and edge systems,” IEEE Transactions on Vehicular Technology, vol. 70, no. 12, pp. 13 270–13 280, 2021.
- [2] D. Zhao et al., “Mobile-aware service function chain migration in cloud–fog computing,” Future Generation Computer Systems, vol. 96, pp. 591–604, 2019.
- [3] S. Svorobej et al., “Orchestration from the cloud to the edge,” The Cloud-to-Thing Continuum, pp. 61–77, 2020.
- [4] Y.-D. Lin, C.-C. Wang, C.-Y. Huang, and Y.-C. Lai, “Hierarchical cord for NFV datacenters: resource allocation with cost-latency tradeoff,” IEEE Network, vol. 32, no. 5, pp. 124–130, 2018.
- [5] L. Tong, Y. Li, and W. Gao, “A hierarchical edge cloud architecture for mobile computing,” in IEEE INFOCOM, 2016, pp. 1–9.
- [6] I. Cohen et al., “Dynamic service provisioning in the edge-cloud continuum with bounded resources,” IEEE Transaction on Networking, in press, 2023.
- [7] H. Yu, J. Yang, and C. Fung, “Elastic network service chain with fine-grained vertical scaling,” in IEEE GLOBECOM, 2018, pp. 1–7.
- [8] I. Leyva-Pupo et al., “Dynamic scheduling and optimal reconfiguration of UPF placement in 5G networks,” in ACM MSWiM, 2020, pp. 103–111.
- [9] X. Sun and N. Ansari, “PRIMAL: Profit maximization avatar placement for mobile edge computing,” in IEEE ICC, 2016, pp. 1–6.
- [10] I. Cohen et al., “Parallel VM deployment with provable guarantees,” in IFIP Networking, 2021, pp. 1–9.
- [11] A. De La Oliva et al., “Final 5g-crosshaul system design and economic analysis,” 5G-Crosshaul public deliverable, 2017.
- [12] T. Ouyang et al., “Adaptive user-managed service placement for mobile edge computing: An online learning approach,” in IEEE INFOCOM, 2019, pp. 1468–1476.
- [13] S. Wang et al., “Dynamic service migration in mobile edge-clouds,” in IEEE IFIP Networking, 2015, pp. 1–9.
- [14] Martín-Pérez et al., “OKpi: All-KPI network slicing through efficient resource allocation,” in IEEE INFOCOM, 2020, pp. 804–813.
- [15] M. Nguyen, M. Dolati, and M. Ghaderi, “Deadline-aware SFC orchestration under demand uncertainty,” IEEE Transactions on Network and Service Management, pp. 2275–2290, 2020.
- [16] L. Codecá et al., “Luxembourg SUMO traffic (LuST) scenario: Traffic demand evaluation,” IEEE Intelligent Transportation Systems Magazine, pp. 52–63, 2017.
- [17] L. Codeca and J. Härri, “Monaco SUMO traffic (MoST) scenario: A 3D mobility scenario for cooperative ITS,” EPiC Series in Engineering, vol. 2, pp. 43–55, 2018.
- [18] “Opencellid,” https://opencellid.org/, accessed on 3.10.2021.
- [19] M. Goudarzi, M. Palaniswami, and R. Buyya, “A distributed application placement and migration management techniques for edge and fog computing environments,” in IEEE FedCSIS, 2021, pp. 37–56.
- [20] P. Alvarez et al., “Microscopic traffic simulation using sumo,” in IEEE International Conference on Intelligent Transportation Systems, 2018.
- [21] “Service function chains migration.” [Online]. Available: https://github.com/ofanan/SFC_migration
- [22] “OMNeT++ discrete event simulator,” 2023. [Online]. Available: https://omnetpp.org
- [23] “Distributed SFC migration.” [Online]. Available: https://github.com/ofanan/Distributed_SFC_migration
- [24] “Gurobi optimizer reference manual,” 2023. [Online]. Available: https://www.gurobi.com
- [25] C. Puliafito et al., “Companion fog computing: Supporting things mobility through container migration at the edge,” in IEEE SMARTCOMP, 2018, pp. 97–105.
- [26] M. S. Hung and J. C. Fisk, “An algorithm for 0-1 multiple-knapsack problems,” Naval Research Logistics Quarterly, vol. 25, no. 3, pp. 571–579, 1978.
- [27] K. Ha et al., “You can teach elephants to dance: Agile VM handoff for edge computing,” in ACM/IEEE SEC, 2017, pp. 1–14.
- [28] T. Subramanya and R. Riggio, “Centralized and federated learning for predictive VNF autoscaling in multi-domain 5G networks and beyond,” IEEE TNSM, vol. 18, no. 1, pp. 63–78, 2021.