Attack Impact Evaluation for Stochastic Control Systems through Alarm Flag State Augmentation
Abstract
This note addresses the problem of evaluating the impact of an attack on discrete-time nonlinear stochastic control systems. The problem is formulated as an optimal control problem with a joint chance constraint that forces the adversary to avoid detection throughout a given time period. Due to the joint constraint, the optimal control policy depends not only on the current state, but also on the entire history, leading to an explosion of the search space and making the problem generally intractable. However, we discover that the current state and whether an alarm has been triggered, or not, is sufficient for specifying the optimal decision at each time step. This information, which we refer to as the alarm flag, can be added to the state space to create an equivalent optimal control problem that can be solved with existing numerical approaches using a Markov policy. Additionally, we note that the formulation results in a policy that does not avoid detection once an alarm has been triggered. We extend the formulation to handle multi-alarm avoidance policies for more reasonable attack impact evaluations, and show that the idea of augmenting the state space with an alarm flag is valid in this extended formulation as well.
Index Terms:
Attack impact evaluation, chance constraint, control system security, stochastic optimal control.I INTRODUCTION
The security of control systems has become a pressing concern due to the increased connectivity of modern systems. There have been indeed numerous reported incidents in industrial control systems [1], and some critical infrastructures that have been seriously damaged [2, 3, 4, 5]. Security risk assessment is a crucial step in preventing such incidents from occurring. For general information systems, risk assessment is typically conducted by identifying potential scenarios, quantifying their likelihoods, and evaluating the potential impacts [6, 7].
Evaluating the impact of attacks to control systems is a challenging task because the defender must specify harmful attack signals. Many studies have attempted to address this issue by quantifying impact as the solution of a constrained optimal control problem or the reachable set under a constraint (see e.g., [8, 9]). These constraints often describe the stealthiness of the attack throughout the considered time horizon. However, a common problem with these formulations is that they are limited in the types of systems that they can handle. Existing studies often assume specific forms of the attack detector, such as the detector and the cumulative sum (CUSUM) detector [10]. However, other types of detectors are also used in practice with distinct properties in terms of detection performance and computational efficiency [11]. While some works provide a universal bound for all possible detectors by using the Kullback-Leibler divergence between the observed output and the nominal signal [12], this approach can lead to overly conservative evaluations when the implemented detector is specified.
This study aims to provide a framework for evaluating the impact of attacks that can be applied to a wide range of systems and detectors. We use a constrained optimal control formulation, in which the stealth condition is represented as a temporally joint chance constraint. This constraint limits the probability that an alarm is triggered at least once throughout the entire time horizon. However, because the chance constraint is joint over time, the optimal policy depends not only on the current state, but also the entire history. As a result, the size of the search space increases exponentially with the length of the horizon, making the problem intractable even for small instances.
In this note, we propose a reformulation of the attack impact evaluation problem in a computationally tractable form. Our key insight is that the information of whether an alarm has been triggered, in addition to the current state, is sufficient to identify the worst attack at each time step. We refer to this binary extra information as an alarm flag. By augmenting the alarm flag state to the original state space, we show that the optimal value can be attained by Markov policies. The reformulated problem is a standard constrained stochastic optimal control problem, which can be solved using exiting numerical methods if the dimension of the spaces is not too large. Additionally, we note that the adversary does not avoid detection once an alarm has been triggered at least once. However, this behavior may not be reasonable in practice due to the presence of false alarms. To address this, we generalize the formulation to handle multi-alarm avoidance policies, providing a more realistic attack impact evaluation. We also demonstrate that the idea of flag state augmentation is valid in this extended formulation.
Related Work
The attack impact evaluation problem for control systems has been considerably studied [8, 13, 12, 14, 15, 9, 16, 10, 17, 18, 19, 20, 21, 22]. These works formulate the problem as a constrained optimal control problem, but the computation approaches differ based on the type of system, detector, and the objective function used to quantify the attack impact. To the best of our knowledge, this study is the first work to handle general systems and detectors.
Our idea of alarm flag state augmentation is to add information sufficient for determining the optimal decision at each time step. A similar concept has been proposed in previous studies especially in the context of risk-averse Markov decision process (MDP) [23, 24, 25]. The work [23] treats a non-standard MDP where the objective function is given not by expectation but by conditional-value-at-risk (CVaR), to which value iteration can be applied by considering an augmented state space for CVaR. In [24], this idea is generalized to chance-constrained MDP. The work [25] proposes risk-aware reinforcement learning based on state space augmentation. Moreover, linear temporal logic specification techniques can handle general properties, such as safety, invariant, and liveness for discrete event systems [26]. However, our study provides a clear interpretation of the augmented state in the context of control system security, leading to a reasonable extension to the multi-alarm avoidance problem discussed in Sec. IV. Additionally, we consider a continuous state space, whereas existing studies mainly focus on finite or discrete state spaces.
Temporally joint chance constraints in optimal control have also been studied [27, 28, 29], but these methods rely on approximating the chance constraint. Furthermore, they do not discuss the state space augmentation of the decision at each time step. Finally, a continuous-time optimal control problem with a joint-chance constraint is considered in [30, 31] although the process stops once the state reaches the unsafe region in their formulation.
Organization and Notation
This note is organized as follows. Sec. II defines the system model, clarifies the threat model, and formulates the attack impact evaluation problem. In Sec. III, the difficulty of the formulated problem is explained. Subsequently, we propose a problem reformulation in a tractable form by introducing the alarm flag state augmentation. Sec. IV first provides a characterization of the optimal policy after an alarm is triggered. Based on the observation, we extend the formulation to be able to handle multi-alarm avoidance policies and show that the proposed idea is still valid in the extended variant. In Sec. V, the theoretical results are verified through numerical simulation, and finally, Sec. VI concludes and summarizes this note.
We denote the set of real numbers by , the -dimensional Euclidean space by , the -ary Cartesian power of the set for a positive integer by , the complement of a set by , the tuple by , and the Borel algebra of a topological space by .
II ATTACK IMPACT EVALUATION PROBLEM
II-A System Model
Consider a discrete-time nonlinear stochastic control system of the form
with where is the state, is the attack signal, and is an independent random process noise. The distribution of the initial state is denoted by . An attack detector equipped with the control system triggers an alarm when the state reaches the alarm region .
Remark: This model includes control systems with the typical cascade structure illustrated by Fig. 1. Let the dynamics of the control system and the detector be given by
respectively, with the state spaces and . The binary signal describes whether an alarm is triggered, or not, at the time step. It is clear that the cascade system can be described in the form by taking and .
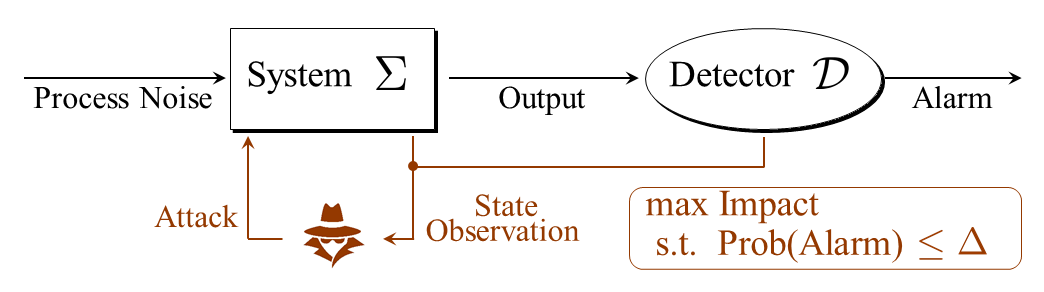
II-B Threat Model
In this study, we consider the following threat model:
-
•
The adversary has succeeded in intruding into the system and can execute any attack signal in a probabilistic manner at every time step.
-
•
The adversary has perfect model knowledge.
-
•
The adversary possesses infinite memory and computation resources.
-
•
The adversary can observe the state at every time step.
-
•
The attack begins at and ends at .
The threat model implies that the adversary can implement an arbitrary history-dependent randomized policy , where is a tuple of policies at every time step. Let denote the history. The policy at each time step is a stochastic kernel on given denoted by . It is well known that a policy uniquely induces a probability measure on [33, Chap. 11]. The probabilities are specifically given by
where and and is the state transition kernel on given induced by and the distribution of [34, Chap. 8]. The expectation operator with respect to is denoted by .
The objective of the adversary is to maximize a cumulative attack impact while avoiding detection. Let the impact be quantified as
The adversary keeps herself stealthy over the considered time period . Specifically, the probability the event that an alarm is triggered at some time step defined by
is made less than or equal to a given constant .
II-C Problem Formulation
The attack impact evaluation problem is formulated as a stochastic optimal control problem with a temporally joint chance constraint:
Problem 1
The attack impact evaluation problem is given by
| (1) |
with a given constant .
In the subsequent section, we explain its difficulty and propose an equivalent reformulation in a tractable form.
III EQUIVALENT REFORMULATION to TRACTABLE PROBLEM
III-A Alarm Flag State Augmentation
It is well known that Markov policies, which depend only on the current state, can attain the optimal value for unconstrained stochastic optimal control problems [34, Proposition 8.1]. However, Problem 1 has a temporally joint chance constraint that cannot be decomposed with respect to time steps. Hence Markov policies cannot attain the optimal value in general, an example of which is provided in the Appendix. As a result, the size of the search space grows exponentially with the time horizon length, making the problem intractable even for small instances.
The key idea in this paper to overcome this challenge is to augment the alarm history information into the state space. We define the augmented state space and the induced augmented system next.
Definition 1
The augmented state is referred to as the alarm flag, since indicates that the alarm has been triggered before the time step , whereas indicates otherwise. For the augmented system, we denote the set of histories by , the set of history-dependent randomized policies by , the probability measure on induced by by , and the expectation operator with respect to by .
By using the alarm flag, we can rewrite the temporally joint chance constraint in (1) as an isolated chance constraint on the state only at the final time step. It is intuitively true that , the event that an alarm is triggered at some time step, is equivalent to , the event that the alarm flag takes the value at the final time step. This idea yields the reformulated problem
| (2) |
The most significant aspect of this formulation is that the chance constraint depends on the marginal distribution with respect to the final time step only. Hence, the optimal value of (2) can be attained by Markov policies for augmented state space [34, Proposition 8.1]. Thus, the problem (2) can be reduced to
| (3) |
where the search space is replaced with , the set of Markov policies for the augmented system.
III-B Equivalence
We justify the reformulation in a formal manner. First, we show the following lemma.
Lemma 1
For any there exists such that
for any and .
Proof:
We say to be consistent with when satisfies
It is clear that a state trajectory deterministically specifies the consistent alarm flag trajectory , denoted by . Note that if and zero otherwise, where denotes the probability mass function on conditioned on under the policy .
For a given , determine by
| (4) |
for . We confirm next that the policy above satisfies the condition in the lemma statement. From the definition of and (4), we have
∎
Lemma 1 implies that the stochastic behaviors of the original system and the augmented one are identical with appropriate policies related to each other through (4).
The following theorem is the main result of this paper.
Proof:
Denote the optimal values of (1), (2), and (3) by and , respectively. We first show . Since the policy set of of the augmented system includes that of the original system, clearly holds. Fix a feasible policy for (2) and take the corresponding policy for the original system according to (4). From Lemma 1, the marginal distributions of the state and the action with the policies coincide. From the dynamics of we have , and hence is feasible in (1). Therefore, which leads to . Finally, is a direct conclusion of [34, Proposition 8.1]. ∎
IV EXTENSION: MULTI-ALARM AVOIDANCE POLICY
In this section, we observe that the adversary does not avoid detection once an alarm has been triggered at least once based on the previous section’s result. However, this behavior may not be reasonable because of the presence of false alarms. We generalize the formulation to be able to handle multi-alarm avoidance policies, providing a more reasonable evaluation of the attack impact.
IV-A Optimal Policy after Alarm Triggered
We observe that the optimal policy after an alarm is triggered is characterized using an optimal policy of an unconstrained problem. Consider the problem
| (5) |
and assume that there exists a unique optimal Markov policy, denoted by , for simplicity.
We first show the following lemma, which claims that the probability of the alarm flag is invariant as long as the policy conditioned by is invariant.
Lemma 2
Let and be Markov policies for the augmented system. If for any and , then for any .
Proof:
Since for , we have
∎
Based on Lemma 2, we can show the following proposition, which partially characterizes the optimal policy for (3).
Proposition 1
Let be the optimal Markov policy for the problem (3). Then
for .
Proof:
For a fixed Markov policy , take such that
for . Note that is feasible for the problem (3) if is feasible from Lemma 2.
Define the value functions associated with recursively by and
for . We show that
| (6) |
for any by induction. It is clear that (6) holds for . Assume that (6) holds for . Consider the case with . Then replacing with yields
From the monotonicity of the Bellman operator, the hypothesis derives
On the other hand, for the case with ,
which is the Bellman expectation operator for the unconstrained problem (5). Since is the optimal policy for (5), we get .
Proposition 1 implies that the adversary cares about being detected when there have been no alarms so far, but does no longer care once an alarm has been triggered. In reality, however, a single alarm may not result in counteractions by the defender due to the presence of false alarms, and a different strategy that avoids serial alarms can possibly be more reasonable. Therefore, it is more preferable to extend our problem formulation (1) to be able to handle multiple alarms.
IV-B Multi-alarm Avoidance Policy
We define the event that alarms are triggered more than or equal to times,
where
The extended version of the attack impact evaluation problem for multi-alarm avoidance strategies is formulated as follows.
Problem 2
The attack impact evaluation problem for multi-alarm avoidance strategies is given by
| (7) |
with given constants for .
The same idea of the alarm flag state augmentation proposed in Sec. III can be applied to Problem 2 as well by augmenting information on the number of alarms instead of the binary information. The augmented state space and the augmented system for Problem 2 are defined as follows.
Definition 2
The augmented state space of for Problem 2 is defined as with . The augmented system is defined as
The alarm number augmentation naturally leads to an equivalent problem
| (8) |
where the search space is the set of Markov policies for the state space augmented with the number of alarms. The following theorem is the correspondence of Theorem 1.
Proof:
The claim can be proven in a manner similar to that of Theorem 1. ∎
Moreover, the correspondence of Proposition 1 is described as follows.
Proposition 2
Proof:
The claim can be proven in a manner similar to that of Proposition 1. ∎
Proposition 2 means that the adversary does not avoid detection after the number of alarms reaches .
Remark: The constraint in the extended problem (7) restricts the probability distribution of the number of alarms. In other words, the formulation utilizes a risk measure on a probability distribution instead of a typical statistic. Several risk measures have been proposed, such as CVaR, which is one of the most commonly used coherent risk measures [36]. Those risk measures compress risk of a random variable with a distribution into a scalar value. Because our formulation uses the full information of the distribution, the constraint can be regarded as a fine-grained version of standard risk measures.
V NUMERICAL EXAMPLE
V-A Simulation Setup
Consider the one-dimensional discrete-time integrator
with the CUSUM attack detector [37, Chap. 2]
with the bias and the threshold , where . The state space and the alarm region are constructed according to Sec. II-A. The process noise follows the white Gaussian distribution with mean zero and variance . The adversary’s objective is to drive the system state around a reference value . Accordingly, the objective function is set to a quadratic function
The constants are specifically set to and . We compute based on discretization of the state and input spaces and use a standard linear programming approach for solving the resulting constrained finite MDP [38]. On the other hand, we analytically compute as the unconstrained discrete-time linear quadratic regulator [39, Chap. 4] based on Proposition 1.
V-B Simulation Results
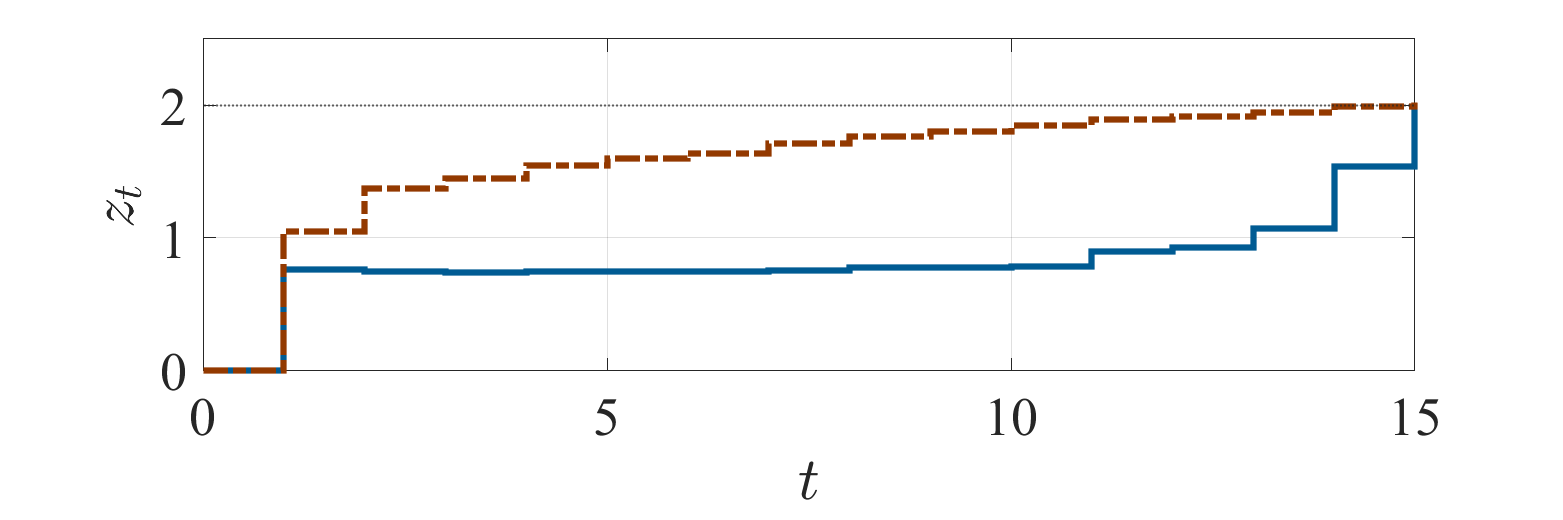
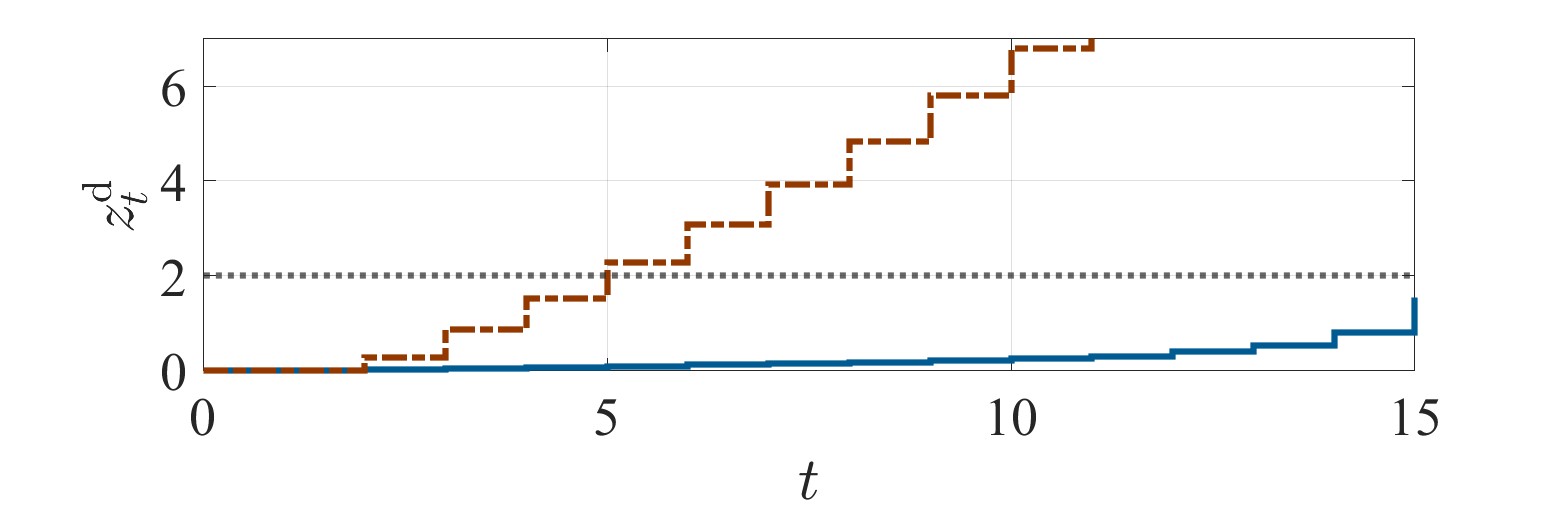
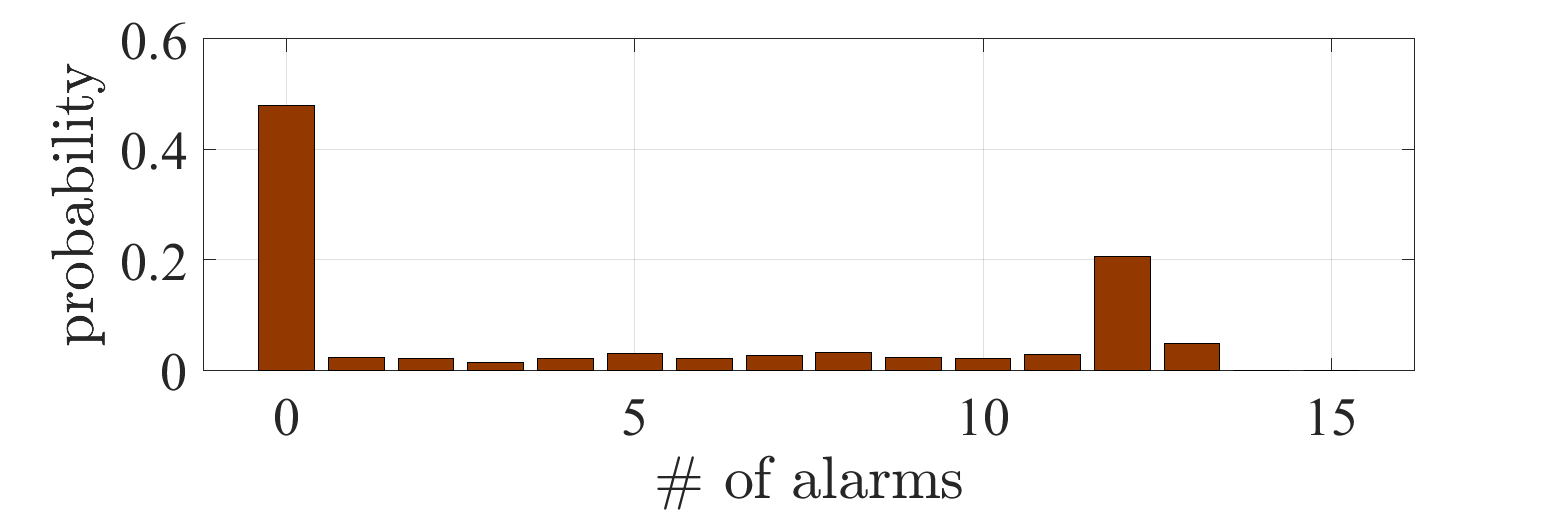
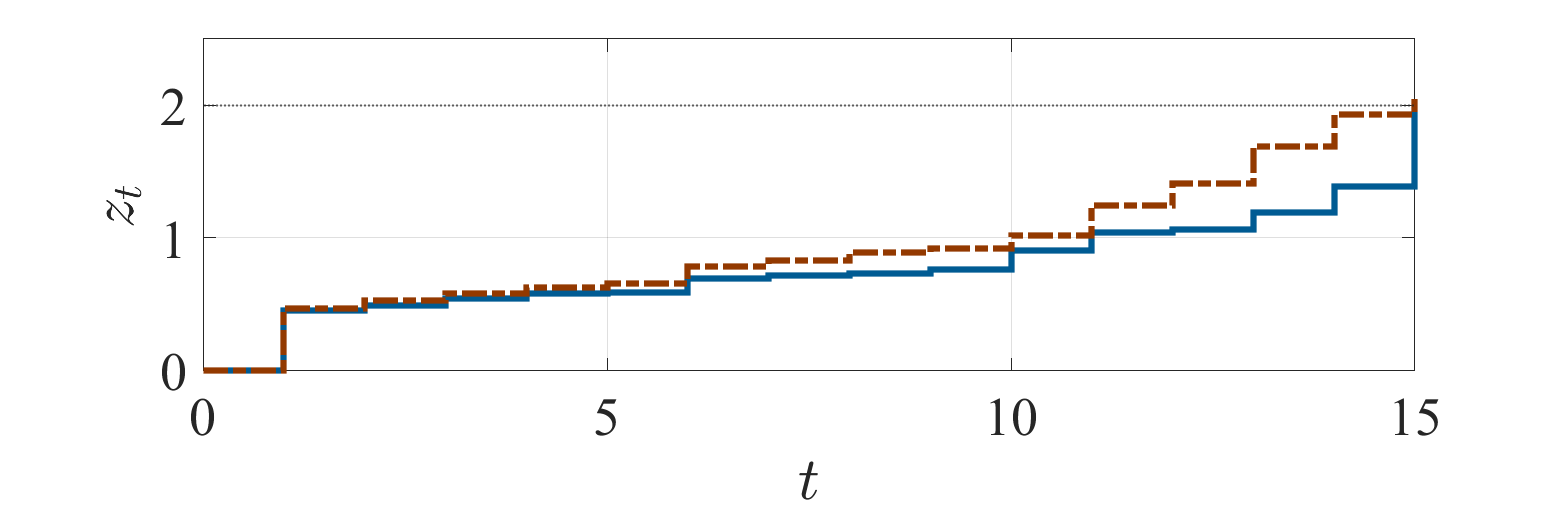
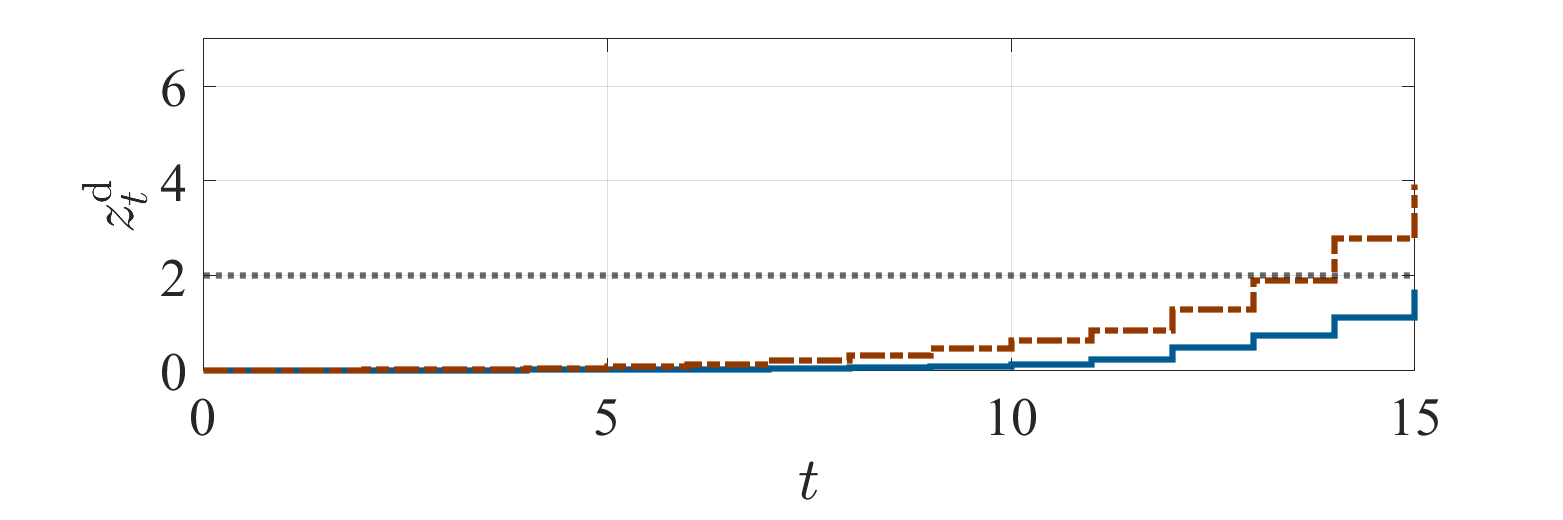
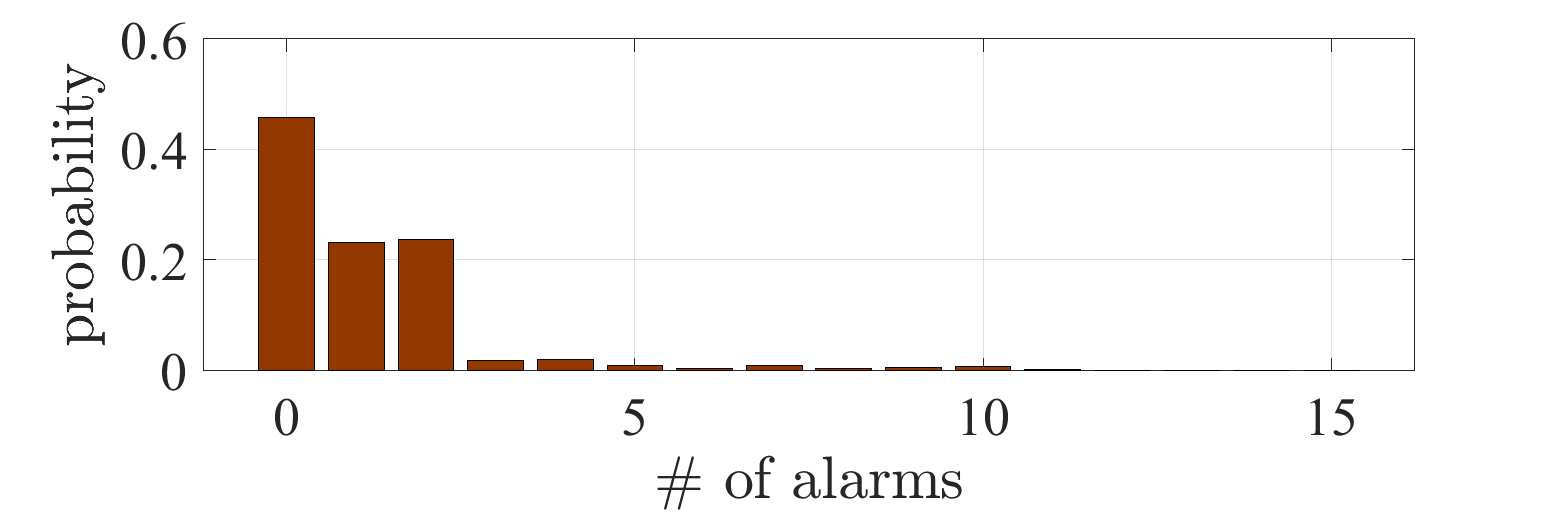
We first treat the formulation of Problem 1. Set the constant on the stealth condition by . Fig. 2 shows the simulation results with the optimal policy obtained by solving the equivalent problem (3). Figs. 2a and 2b depict the empirical means of and conditioned by whether an alarm is triggered at least once during the process, or not, respectively. It can be observed that increases even after an alarm is triggered, as claimed in Sec. IV-A. Fig. 2c depicts the probabilities with respect to the total number of alarms during the process. It can be observed that a large number of alarms occur with a high probability. The result indicates that the formulation of Problem 1 leads to a policy such that the number of alarms becomes large once an alarm is triggered.
We next treat the formulation of Problem 2. Set the constants on the stealth condition by
with . Fig. 3 shows the simulation results. The subfigures correspond to those in Fig. 2. It can be observed that the trajectory of is kept less than the detection threshold over almost the entire period. Accordingly, the probability depicted in Fig. 3 suggests that the obtained policy avoids multiple alarms.
VI CONCLUSION
This note has addressed the attack impact evaluation problem for stochastic control systems. The problem is formulated as an optimal control problem with a temporally joint chance constraint. The difficulty to solve the optimal control problem lies in the explosion of the search space owing to the dependency of the optimal policy on the entire history. In this note, we have shown that the information whether an alarm has been triggered or not is sufficient for determining the optimal decision. By augmenting the alarm flag with the original state space, we can obtain an equivalent optimal control problem in a computationally tractable form. Moreover, the formulation is extended to handle multi-alarm avoidance policies by taking the number of alarms into account.
Future research directions include development of a numerical algorithm that efficiently solves the reformulated problem. Although the search space is hugely reduced by the proposed method, it still suffers from the curse of dimensionality occurring from space discretization. In addition, it is interesting to clarify the relationship between the chance constraint considered in our formulation and existing risk measures, such as CVaR. Although we have used full information of the probability distribution, coherent risk measures can effectively compress the information, the property of which can possibly be used for efficient numerical algorithms.
We provide an example for which Markov policies cannot attain the optimal value in the formulation (1). Consider the finite MDP illustrated by Fig. 4. The adversary can inject an input only at . When the input is selected, the state reaches with probability one and the resulting attack impact is . On the other hand, when the input is selected, the state reaches or with equal probabilities. The impact is 10 in the case of , while there is no impact in the case of . The alarm region is given as . The input can be interpreted as a risky action in the sense that it leads to large impact in expectation but may trigger an alarm.
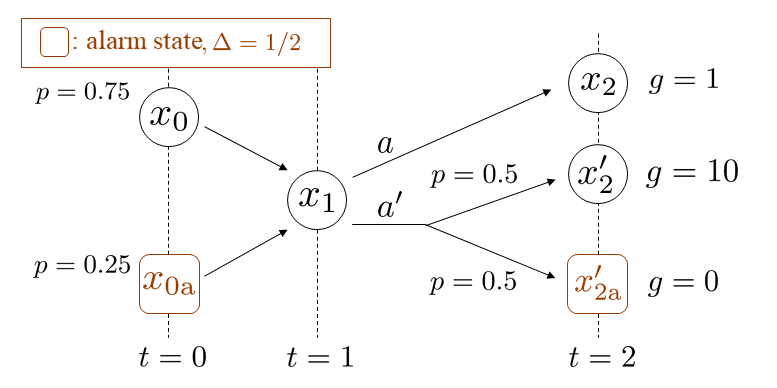
We derive the optimal policy. The history-dependent policies can be parameterized by and with parameters . The joint chance constraint is written by Thus the feasible region of is . The objective function is written by Because this is monotonically increasing with respect to and , the optimal values are which leads to
On the other hand, the Markov policies can be parameterized by with . The joint chance constraint imposes and the objective function is . Thus the optimal policy is given by namely Denoting the value of the objective function with a policy by we have which implies that Markov policies cannot attain the optimal value for this instance.
The optimal history-dependent policy means that the adversary reduces the risk when no alarm has been triggered while she selects the risky input when an alarm has been triggered. In other words, the decision making at the state depends on the alarm flag. This observation leads to the hypothesis that this binary information in addition to the current state is sufficient for optimal decision making, giving rise to the idea of alarm flag state augmentation.
References
- [1] K. E. Hemsley and D. R. E. Fisher, “History of industrial control system cyber incidents,” U.S. Department of Energy Office of Scientific and Technical Information, Tech. Rep. INL/CON-18-44411-Rev002, 2018.
- [2] N. Falliere, L. O. Murchu, and E. Chien, “W32. Stuxnet Dossier,” Symantec, Tech. Rep., 2011.
- [3] Cybersecurity & Infrastructure Security Agency, “Stuxnet malware mitigation,” Tech. Rep. ICSA-10-238-01B, 2014, [Online]. Available: https://www.us-cert.gov/ics/advisories/ICSA-10-238-01B.
- [4] ——, “HatMan - safety system targeted malware,” Tech. Rep. MAR-17-352-01, 2017, [Online]. Available: https://www.us-cert.gov/ics/MAR-17-352-01-HatMan-Safety-System-Targeted-Malware-Update-B.
- [5] ——, “Cyber-attack against Ukrainian critical infrastructure,” Tech. Rep. IR-ALERT-H-16-056-01, 2018, [Online]. Available: https://www.us-cert.gov/ics/alerts/IR-ALERT-H-16-056-01.
- [6] S. Kaplan and B. J. Garrick, “On the quantitative definition of risk,” Risk Analysis, vol. 1, no. 1, pp. 11–27, 1981.
- [7] S. Sridhar, A. Hahn, and M. Govindarasu, “Cyber–physical system security for the electric power grid,” Proc. IEEE, vol. 100, no. 1, pp. 210–224, 2012.
- [8] A. Teixeira, K. C. Sou, H. Sandberg, and K. H. Johansson, “Secure control systems: A quantitative risk management approach,” IEEE Control Systems Magazine, vol. 35, no. 1, pp. 24–45, Feb 2015.
- [9] C. Murguia and J. Ruths, “On reachable sets of hidden CPS sensor attacks,” in 2018 Annual American Control Conference (ACC), 2018, pp. 178–184.
- [10] C. Murguia and J. Ruths, “On model-based detectors for linear time-invariant stochastic systems under sensor attacks,” IET Control Theory Applications, vol. 13, no. 8, pp. 1051–1061, 2019.
- [11] A. A. Cárdenas, S. Amin, Z.-S. Lin, Y.-L. Huang, C.-Y. Huang, and S. Sastry, “Attacks against process control systems: Risk assessment, detection, and response,” in Proc. the 6th ACM ASIA Conference on Computer and Communications Security, 2011.
- [12] C.-Z. Bai, F. Pasqualetti, and V. Gupta, “Data-injection attacks in stochastic control systems: Detectability and performance tradeoffs,” Automatica, vol. 82, pp. 251 – 260, 2017.
- [13] Y. Mo and B. Sinopoli, “On the performance degradation of cyber-physical systems under stealthy integrity attacks,” IEEE Trans. Autom. Control, vol. 61, no. 9, pp. 2618–2624, Sep. 2016.
- [14] D. Umsonst, H. Sandberg, and A. A. Cárdenas, “Security analysis of control system anomaly detectors,” in Proc. 2017 American Control Conference (ACC), May 2017, pp. 5500–5506.
- [15] N. H. Hirzallah and P. G. Voulgaris, “On the computation of worst attacks: A LP framework,” in 2018 Annual American Control Conference (ACC), 2018, pp. 4527–4532.
- [16] Y. Chen, S. Kar, and J. M. F. Moura, “Optimal attack strategies subject to detection constraints against cyber-physical systems,” IEEE Trans. Contr. Netw. Systems, vol. 5, no. 3, pp. 1157–1168, 2018.
- [17] A. M. H. Teixeira, “Optimal stealthy attacks on actuators for strictly proper systems,” in 2019 IEEE 58th Conference on Decision and Control (CDC), 2019, pp. 4385–4390.
- [18] J. Milošević, H. Sandberg, and K. H. Johansson, “Estimating the impact of cyber-attack strategies for stochastic networked control systems,” IEEE Trans. Control Netw. Syst., vol. 7, no. 2, pp. 747–757, 2019.
- [19] C. Fang, Y. Qi, J. Chen, R. Tan, and W. X. Zheng, “Stealthy actuator signal attacks in stochastic control systems: Performance and limitations,” IEEE Trans. Autom. Control, vol. 65, no. 9, pp. 3927–3934, 2019.
- [20] T. Sui, Y. Mo, D. Marelli, X. Sun, and M. Fu, “The vulnerability of cyber-physical system under stealthy attacks,” IEEE Trans. Autom. Control, vol. 66, no. 2, pp. 637–650, 2020.
- [21] X.-L. Wang, G.-H. Yang, and D. Zhang, “Optimal stealth attack strategy design for linear cyber-physical systems,” IEEE Trans. on Cybern., vol. 52, no. 1, 2022.
- [22] A. Khazraei, H. Pfister, and M. Pajic, “Resiliency of perception-based controllers against attacks,” in Proc. Learning for Dynamics and Control Conference, 2022, pp. 713–725.
- [23] N. Bäuerle and J. Ott, “Markov decision processes with average-value-at-risk criteria,” Mathematical Methods of Operations Research, vol. 74, no. 3, pp. 361–379, 2011.
- [24] W. B. Haskell and R. Jain, “A convex analytic approach to risk-aware Markov decision processes,” SIAM Journal on Control and Optimization, vol. 53, no. 3, pp. 1569–1598, 2015.
- [25] Y. Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk-constrained reinforcement learning with percentile risk criteria,” The Journal of Machine Learning Research, vol. 18, no. 1, pp. 6070–6120, 2017.
- [26] C. Baier and J.-P. Katoen, Principles of Model Checking. MIT Press, 2008.
- [27] M. Ono, Y. Kuwata, and J. Balaram, “Joint chance-constrained dynamic programming,” in Proc. IEEE Conference on Decision and Control (CDC), 2012, pp. 1915–1922.
- [28] M. Ono, M. Pavone, Y. Kuwata, and J. Balaram, “Chance-constrained dynamic programming with application to risk-aware robotic space exploration,” Autonomous Robots, vol. 39, no. 4, pp. 555–571, 2015.
- [29] A. Thorpe, T. Lew, M. Oishi, and M. Pavone, “Data-driven chance constrained control using kernel distribution embeddings,” in Proc. Learning for Dynamics and Control Conference, 2022, pp. 790–802.
- [30] A. Patil, A. Duarte, A. Smith, F. Bisetti, and T. Tanaka, “Chance-constrained stochastic optimal control via path integral and finite difference methods,” in Proc. IEEE Conference on Decision and Control (CDC), 2022, pp. 3598–3604.
- [31] A. Patil, A. Duarte, F. Bisetti, and T. Tanaka, “Chance-constrained stochastic optimal control via HJB equation with Dirichlet boundary condition,” 2022, [Online]. Available: https://sites.utexas.edu/tanaka/files/2022/07/Chance_Constrained_SOC.pdf.
- [32] H. Sasahara, T. Tanaka, and H. Sandberg, “Attack impact evaluation by exact convexification through state space augmentation,” in Proc. IEEE Conference on Decision and Control (CDC), 2022, pp. 7084–7089.
- [33] K. Hinderer, Foundations of Non-stationary Dynamic Programming with Discrete Time Parameter. Springer, 1970.
- [34] D. Bertsekas and S. Shreve, Stochastic Optimal Control: The Discrete-Time Case. Athena Scientific, 1996.
- [35] R. Munos and A. Moore, “Variable resolution discretization in optimal control,” Machine Learning, vol. 49, no. 2, pp. 291–323, 2002.
- [36] P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath, “Coherent measures of risk,” Mathematical Finance, vol. 9, no. 3, pp. 203–228, 1999.
- [37] M. Basseville, I. V. Nikiforov et al., Detection of Abrupt Changes: Theory and Application. Prentice Hall Englewood Cliffs, 1993.
- [38] E. Altman, Constrained Markov Decision Processes. Chapman and Hall/CRC, 1999.
- [39] D. Bertsekas, Dynamic Programming and Optimal Control: Volume I. Athena Scientific, 2012.