Attention-Guided Multi-scale Interaction Network for Face Super-Resolution
Abstract
Recently, CNN and Transformer hybrid networks demonstrated excellent performance in face super-resolution (FSR) tasks. Since numerous features at different scales in hybrid networks, how to fuse these multi-scale features and promote their complementarity is crucial for enhancing FSR. However, existing hybrid network-based FSR methods ignore this, only simply combining the Transformer and CNN. To address this issue, we propose an attention-guided Multi-scale interaction network (AMINet), which contains local and global feature interactions as well as encoder-decoder phases feature interactions. Specifically, we propose a Local and Global Feature Interaction Module (LGFI) to promote fusions of global features and different receptive fields’ local features extracted by our Residual Depth Feature Extraction Module (RDFE). Additionally, we propose a Selective Kernel Attention Fusion Module (SKAF) to adaptively select fusions of different features within LGFI and encoder-decoder phases. Our above design allows the free flow of multi-scale features from within modules and between encoder and decoder, which can promote the complementarity of different scale features to enhance FSR. Comprehensive experiments confirm that our method consistently performs well with less computational consumption and faster inference.
Index Terms:
Face super-resolution, Hybrid networks, Multi-scale interaction, Attention-guided.I Introduction
Face super-resolution (FSR), also known as face hallucination, aims at restoring high-resolution (HR) face images from low-resolution (LR) face images [1]. In contrast to standard image super-resolution, the primary objective of FSR is to reconstruct as many facial structural features as possible (i.e. the shape and contour of facial components). In practical scenarios, a range of face-specific tasks such as face detection [2] and face recognition [3] require HR face images. However, The quality of captured face images is frequently diminished due to variations in hardware configuration, positioning, and shooting angles of the imaging devices, seriously affecting the above downstream tasks. Therefore, FSR has gained increased attention in recent years.
Recently, since the advantages exhibited by hybrid networks [5] of CNNs and Transformers in FSR, this type of method has gained increased attention. Specifically, CNN-based FSR methods [6] generally do not require large computational consumption. Still, they specialize in extracting local details, such as the local texture of the face, color, etc., and are unable to model long-range feature interaction, such as the global profile of the face. Transformer-based FSR methods [7] can simulate global modeling well, but their computational consumption is huge. Hybrid-based FSR methods leverage the strengths of both CNN and Transformer, facilitating models to accomplish the extraction of local and global facial features while maintaining a manageable computational cost, which is not possible with CNN or Transformer alone. The impressive performance of hybrid-based FSR methods comes from numerous features extracted inside their networks at different scales, such as global features from self-attention, local features from convolution, and features from different stages of the encoder-decoder, which facilitates models to refine local facial details and global facial contours.
However, while existing hybrid-based FSR methods consider utilizing features from different scales to improve FSR, they ignore the problem of how we fuse these multi-scale features to make their properties better complement each other. For example, Faceformer [8] simply parallelizes the connected CNN modules and the window-based Transformer [9] modules. SCTANet [10] also only juxtaposes spatial attention-based residual blocks and multi-head self-attention in designed modules. CTCNet [5] simply connects the CNN module in tandem with the Transformer module. None of the above methods realize the importance of effectively blending different scales and facilitating the free flow of features at different scales within the module to refine facial details.
To address this problem, we propose an Attention-Guided Multi-scale Interaction Network (AMINet) for FSR in this work. Our AMINet fuses multi-scale features in two main ways, including the fusion of features obtained from self-attention and convolution and the fusion of features at different stages of the encoder-decoder. Specifically, we design a Local and Global Feature Interaction Module (LGFI) to adaptively fuse global facial and local features with different receptive fields obtained by convolutions. In LGFI, self-attention is responsible for extracting global features, our proposed Residual Depth Feature Extraction Module (RDFE) extracts local features at different scales using separable convolutional kernels of different sizes, and our proposed Selective Kernel Attention Fusion Module (SKAF) is responsible for weighted fusion of these two parts of features for our model to adaptively perform selective fusion during training. In addition, we also utilize our proposed SKAF as a crucial fusion module in our Encoder and Decoder Feature Fusion Module (EDFF) to further perform feature communications of our method by fusing features at different scales from the encoder-decoder processes.
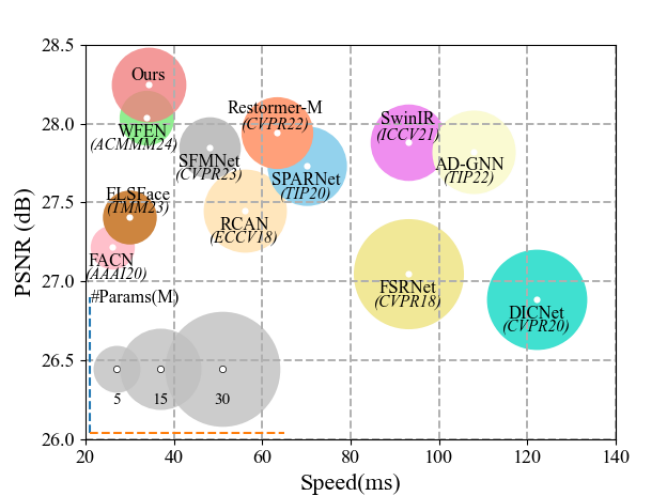
Our above design greatly enhances the flow and exchange of features at different scales within the model and improves the representation of our model. As a result, our method can obtain a more powerful feature representation than existing FSR methods. As shown in Fig. 1, our method can achieve the best FSR performance with a smaller size and faster inference speed, demonstrating our method’s effectiveness. In summary, the main contributions are as follows:
-
•
We design an LGFI to differ from the traditional Transformer by allowing free flow and adaptive selective fusion of local and global features within the module.
-
•
We design an RDFE, which enables better refinement of facial details by fusion and refinement of local features extracted by convolutional kernels of different sizes.
-
•
We design the SKAF to help selective fusions of different scale features within LGFI and EDFF by selecting appropriate convolutional kernels.
-
•
Comprehensive experiments confirm that our method consistently achieves good FSR performance with less cost by exploring multiple levels of feature interactions.
In the following sections, we will introduce related work and discuss their disadvantages in Section II. Then, we will introduce our method and proposed core modules in Section III. Next, we will evaluate our method and analyze our ablation experiments in Section IV. Finally, we will conclude this paper according to our experiments in Section V.
II Related Work
II-A Face Super-Resolution
Early deep learning approaches focused on leveraging facial priors as guidance to enhance FSR [11] accuracy. For instance, Chen et al. [12] developed an end-to-end prior-based network that utilized facial landmarks and heatmaps to generate FSR images. Similarly, Kim et al. [13] employed a face alignment network for landmark extraction in conjunction with a progressive training technique to produce realistic face images. Ma et al. [14] introduced DICNet, which integrates facial landmark priors iteratively to enhance image quality at each step. Hu et al. [15] explored the use of 3D shape priors to better capture and define sharp facial structures. While these methods have advanced FSR, they require additional labeling of training datasets. Moreover, inaccuracies in prior estimation can significantly diminish FSR performance, especially when dealing with highly blurred face images.
Attention-based FSR methods have been proposed to promote FSR to avoid the adverse effects of inaccurate prior estimates on FSR. Zhang et al. [16] proposed a supervised pixel-by-pixel generation of the adversarial network to improve face recognition performance during FSR. Chen et al. [17] proposed the SPARNet, which can focus on important facial structure features adaptively by using spatial attention in residual blocks. Lu et al. [18] proposed a partial attention mechanism to enhance the consistency of the fidelity of facial detail and facial structure. Bao et al. [19] introduced the equalization texture enhancement module to enhance the facial texture detail through histogram equalization. Wang et al. [20]critical introduced Fourier transform into FSR, fully exploring the correlation between spatial domain features and frequency domain features. Shi et al. [21] designed a two-branch network, which introduces convolution based on local changes to enhance the ability of convolution. Liu et al. [10] improve the interaction ability of regional and global features through designed hybrid attention modules. Li et al. [22] designed a wavelet-based network to reduce the loss of downsampling in the encoder-decoder. Although the above methods can reconstruct reasonable FSR images, they cannot promote the efficient fusion of local features with global features and different features at different stages of the encoder-decoder, affecting FSR’s efficiency and accuracy.
II-B Attention-based Super-Resolution
The attention mechanism can improve the super-resolution accuracy of models due to its flexibility in focusing on key areas of facial features. In the super-resolution [23] task, different variants of the attention mechanism include self-attention, spatial attention, channel attention, and hybrid attention.
Zhang et al. [24] inserted channel attention into residual blocks to enhance model representation. Xin et al. [25] utilized channel attention plus residual mechanisms to combine a multi-level information fusion strategy. Chen et al. [17] enhance FSR by utilizing an improved facial spatial attention cooperated with the hourglass structure. Gao et al. [26] performed shuffling to hybrid attention. Wang et al. [27] constructed a simplified feed-forward network using spatial attention to reduce parameters and computational complexity. To model long-range feature interaction, the self-attention in Transformer [28, 29] has been widely used in super-resolution. Gao et al. [30] reduced costs by utilizing the recurse mechanism on self-attention. Li et al. [31, 32] combined self-attention and convolutions to complement each other’s required features. Zeng et al. [33] introduced a self-attention network that investigates the relationships among features at various levels. Shi et al. [21] enhance FSR by mitigating the adverse effects of inaccurate prior estimates through a parallel self-attention mechanism, effectively capturing both local and non-local dependencies. To combine the advantages of different attentions, Yang et al. [34] integrated channel attention with spatial attention to enhance feature acquisition and correlation modeling. Bao et al. [10] and Gao et al. [5] employed spatial attention and self-attention to capture facial structure and details. Zhang et al. [35] employed a hybrid attention module that combines self-attention, spatial attention, and channel attention to optimize fine-grained facial details and broad facial structure. Unlike the above attention-based methods that significantly enhance model representation, we utilize attention to learn feature maps from different receptive fields, allowing our network to adaptively select the appropriate convolutional kernel size to match the multi-scale feature fusion. This design enables our network to effectively perform multi-scale feature extraction. Furthermore, it improves the integration of features across various scales, leading to enhanced performance and greater adaptability.
III Proposed Method
In this section, we first describe the overall architecture of the proposed Attention-Guided Multi-scale Interaction Network (AMINet). Then, we introduce our local and global feature interaction module (LGFI) and encoder and decoder feature fusion module (EDFF) in our AMINet in detail. Finally, since we provide a GAN version of our AMINet, called AMIGAN, we further introduce the loss functions used to supervise AMIGAN during training.
III-A Overview of AMINet
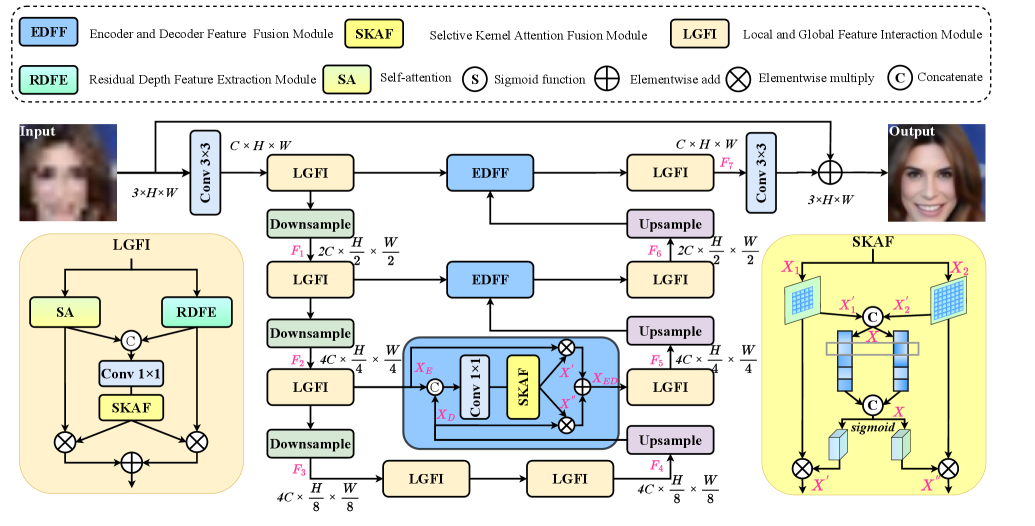
As illustrated in Fig. 2, our proposed AMINet features a U-shaped CNN-Transformer hierarchical architecture with three distinct stages: encoding, bottleneck, and decoding. For an LR input face image , in the encoding stage, our network aims to extract features at different scales and capture multi-scale feature representations of the input image to get the facial feature . Then, the bottleneck stage network continues to refine the feature and provides a more informative representation to get the refined feature for the subsequent reconstruction phase. In decoding, the network focuses on feature upsample and facial detail reconstruction. Meanwhile, an interactive connection is used between the encoding and decoding stages to ensure the features are fully integrated throughout the network. We can get the reconstructed face feature with rich facial details through the above operators. Finally, through a convolution with reduced channel dimensions plus a residual connection, we get the HR output face image .
III-A1 Encoding stage
The encoding stage in our network aims to extract facial features of different scales. In this stage, given a degraded face image , first, a convolution is used to extract facial shallow features. Then, extracted facial features are further fined by three encoder stages. Each encoder comprises our designed Local and Global Feature Interaction Module (LGFI) and a downsampling operator. After each encoder, the input face feature’s channel counts will be doubled, and the size of the image of the input face feature will be halved. As shown in Fig. 2, the features obtained after three encoders are as follows: , , .
III-A2 Bottleneck stage
In the bottleneck stage between the encoding and decoding stages, obtained encoding features are designed to be fine-grained. is obtained through the bottleneck stage. In this stage, we continue to use two LGFIs to refine and enhance encoding features to ensure they are better utilized in the decoding stage. After this stage, our model can continuously enhance the information about the facial structure at different scales, thus improving the perception of facial details.
III-A3 Decoding stage
In the decoding stage, there are three decoders. We focus on multi-scale feature fusion, aiming at reconstructing high-quality face images at this stage. As depicted in Fig. 2, each decoder includes an upsampling operation, an EDFF, and an LGFI. Each upsampling operator halves the input feature channel counts while doubling the width and weight of the input facial feature. Compared to encoding stages, decoding stages additionally use our proposed SKAF to adaptively selectively fuse different scale features from the encoder and decoder stages. Through this design, different scale features can interact to recover more detailed face features. The features obtained after three decoders are as follows: , , . Finally, a convolution unit is utilized to transform our obtained deep facial feature into output FSR image .
As for the loss of our AMINet, given a dataset , we optimize our AMINet by minimizing the pixel-level loss function:
| (1) |
where denotes paired training face image counts. and are the face LR image and HR image of the -th pair, respectively. Meanwhile, and denote the AMINet and the number of parameters of AMINet, respectively.
III-B Local and Global Feature Interaction Module (LGFI)
In our AMINet, LGFI is mainly used for local and global facial feature extraction. As shown in Fig. 2, LGFI consists of Self-attention(SA), a Residual Depth Feature Extraction Module (RDFE), and a Selective Kernel Attention Fusion Module (SKAF), used for local and global feature fusion and interaction, respectively. The SA is designed to extract global features. At the same time, RDEM is designed to extract local features at different scales and enrich local facial details through multiple convolutional kernels under numerous receptive fields. It is worth mentioning that the local and global branches output features through SKAF, which can obtain the corresponding weight of input face information, separate and multiply it with the two branches separately, which can better promote the interaction of channel information and improve the performance of face restoration.
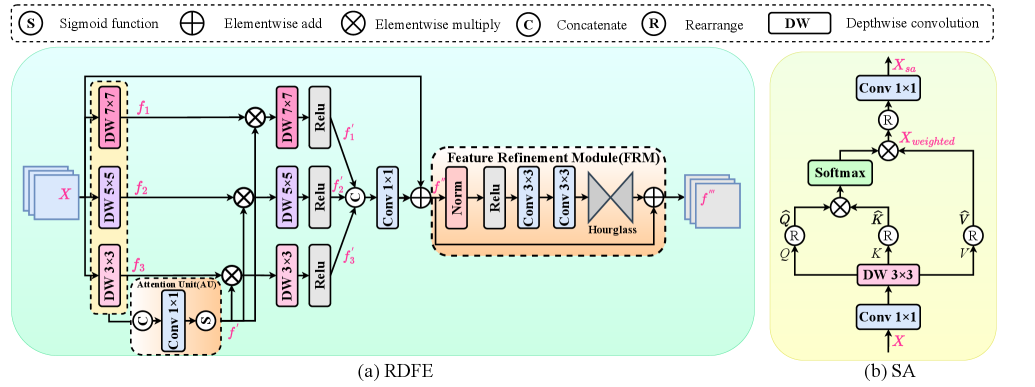
III-B1 Self-attention (SA)
We utilize Self-attention (SA) to extract global facial features, which can effectively model the relationships between distant features. Meanwhile, through the multi-head mechanism in SR, features can be captured from different subspaces, improving the robustness and generalization ability of the model. As illustrated in Fig. 3 (b), we start by applying a convolutional layer followed by a depth-wise convolutional layer to combine pixel-level cross-channel information and extract channel-level spatial context. From this spatial context, we then generate . For an input facial feature , the process of obtaining can be described as:
| (2) |
| (3) |
| (4) |
where is the pointwise convlution and is the depthwise convlution.
Next, we reshape , , and into , , and , respectively. After that, the dot product is multiplied by to obtain weights , which facilitates the capturing of the important local context in SA. Finally, we rearrange into . The above operations can be expressed as:
| (5) |
| (6) |
where is the attention map of SA, is a factor used to scale the dot product of and , stands for the rearrange operation, denotes the output of SA.
III-B2 Residual depth feature extraction module (RDFE)
As shown in Fig. 3 (a), we design RDFE to extract local facial features at different scales. Compared with the traditional feed-forward network (FFN), our RDFE is beneficial for processing more complex features and multi-scale features flexibly. Specifically, for the input feature , we use depthwise convolutions of , , and to parallelly extract three scales facial features, which depthwise convolution can reduce the computational complexity of the model, while convolution with different kernel sizes can effectively extracting rich face details. The above operations can be expressed as:
| (7) |
where , , and are , , and depthwise convlution, respectively. Additionally, we use an attention unit to calculate the feature weight of the fusion feature of three branches. Then, we use calculated weight to perform multiplications with the three branch features at different scales. This operation enables our model to adaptively allocate weights to extract important facial information under different receptive fields, improving our model’s performance and generalization ability. Next, we use , , and depthwise convolutions to further reconstruct selected important facial features. The above operations can be expressed as:
| (8) |
| (9) |
where is a concat operator. Then, we aggregate the three branches’ features to combine facial detail information under different receptive fields. This process can be described as:
| (10) |
where represents convolution. Finally, we utilize a Feature Refinement Module to refine features obtained from previous multiple branches. Specifically, we begin by applying normalization and multiple convolutional layers to refine the local facial context. Afterward, the hourglass block further integrates multi-scale information to capture global and local relationships. The above operations can be expressed as:
| (11) |
where indicates feature refinement module.
III-B3 Selctive Kernel Attention Fusion Module (SKAF)
Inspired by SKNet [36] and LSKNet [37], as shown in Fig. 2, we design a SKAF module to make our model with the ability to select local and global features required for reconstruction for fusion interaction. Specifically, given global feature obtained by the SA and local features obtained by the RDFE, we first fuse the local and global features extracted by a convolution and a convolution to get a hybrid feature . This operation can be expressed as:
| (12) |
| (13) |
where represents convolution, represents convolution, indicates the concat operation along the channel dimension. Then, we impose pooling to learn the weight of obtained hybrid features, where the weight reflects the importance of features under different receptive fields. The process of obtaining the weight for selecting required facial features is as follows:
| (14) |
where indicates the average pooling operation, indicates the max pooling operation. Finally, we multiply the weights obtained from the above calculations with the local and global features, respectively. Thus, our SKAF can adaptively select the important local and global information required for reconstruction. The process of obtaining important local and global features , by adaptive weight selection can be expressed as:
| (15) |
where indicates the feature separation operation along the channel dimension. Through the above operators, we can get the adaptive selected local and global features.
III-C Encoder and Decoder Feature Fusion Module (EDFF)
To fully utilize the multi-scale features extracted from the encoding and decoding stage, we introduce an EDFF to fuse different features, enabling our AMINet with better feature propagation and representation capabilities. As shown in Figure. 2, our EDFF mainly utilizes our proposed SKAF to fuse and select different scale features required for reconstruction. Given the feature the feature from the decoding stage and the encoding stage, respectively. Firstly, we concatenate features from the encoding and decoding stages along the channel dimension. Then, a convolution is used to reduce the channel counts and reduce the process’s computational costs to obtain two weights through our SKAF. These operations can be expressed as:
| (16) |
where represents Selective Kernel Attention Fusion Module, stands for the convolutional layer, denotes the operation of concatenating features across the channel dimension. Next, we feed the obtained two weights into two branches for multiplication. Through this operator, we obtain the selected facial features from hybrid features obtained by fusing the encoding and decoding features. Finally, we add the features of the two branches. The process is:
| (17) |
through the above operators, we can complete the process of the adaptive fusion of encoding features and decoding features.
III-D Model Extension
Since the GAN-based methods [38, 39] can get better perceptual qualities, we expand our AMINet to AMIGAN to generate more high-quality SR results. The loss function used in training AMIGAN consists of the following three parts:
III-D1 Pixel loss
Pixel-level loss is used to reduce the pixel difference between the SR and HR images. This loss is expressed as:
| (18) |
where indicates the AMIGAN generator.
III-D2 Perceptual loss
To enhance the visual quality of super-resolution images, we apply perceptual loss. This involves using a pre-trained VGG19 [40] model to extract facial features from both the HR images and our generated FSR images. Then, we compare the obtained perceptual features of HR and FSR images to constrain the generation of FSR features. Therefore, the perceptual loss can be described as:
| (19) |
where represents the feature map from the -th layer of the VGG network, is the total number of layers in VGG, and indicates the quantity of elements within that feature map.
| Methods | PSNR | SSIM | VIF | LPIPS |
|---|---|---|---|---|
| LGFI w/o SA | 27.75 | 0.7944 | 0.4652 | 0.1886 |
| LGFI w/o RDFE | 27.51 | 0.7840 | 0.4495 | 0.2085 |
| LGFI w/o SKAF | 27.74 | 0.7932 | 0.4611 | 0.1979 |
| LGFI | 27.83 | 0.7961 | 0.4725 | 0.1821 |
| Methods | Parameters | PSNR | SSIM | VIF | LPIPS |
|---|---|---|---|---|---|
| Transformer | 11.32M | 27.73 | 0.7952 | 0.4511 | 0.1878 |
| LGFI | 12.62M | 27.83 | 0.7961 | 0.4725 | 0.1821 |
III-D3 Adversarial loss
GANs have been shown to be effective in reconstructing photorealistic images [38, 39]. GAN generates FSR results through the generator while using the discriminator to distinguish between ground truth and FSR results, which ultimately enables the generator to generate realistic FSR results in the process of constant confrontation. This process is:
| (20) |
additionally, the generator tries to minimize:
| (21) |
thus, AMIGAN is refined by minimizing the following total objective function:
| (22) |
where , , and represent the weighting factors for the corresponding pixel loss, perceptual loss, and adversarial loss, respectively.
| Methods | Parameters | PSNR | SSIM | VIF | LPIPS |
|---|---|---|---|---|---|
| FFN | 12.11M | 27.72 | 0.7931 | 0.4578 | 0.1922 |
| RDFE | 12.62M | 27.83 | 0.7961 | 0.4725 | 0.1821 |
| Methods | PSNR | SSIM | VIF | LPIPS |
|---|---|---|---|---|
| Single path ( dw) | 27.73 | 0.7934 | 0.4619 | 0.1915 |
| Single path ( dw) | 27.71 | 0.7912 | 0.4587 | 0.1944 |
| Single path ( dw) | 27.72 | 0.7926 | 0.4602 | 0.1922 |
| RDFE w/o AU | 27.76 | 0.7951 | 0.4673 | 0.1846 |
| RDFE w/o FRM | 27.75 | 0.7941 | 0.4643 | 0.1928 |
| RDFE | 27.83 | 0.7961 | 0.4725 | 0.1821 |
| conv | conv | Avgpool | Maxpool | PSNR | SSIM |
|---|---|---|---|---|---|
| 27.69 | 0.7919 | ||||
| 27.76 | 0.7955 | ||||
| 27.73 | 0.7946 | ||||
| 27.74 | 0.7931 | ||||
| 27.79 | 0.7951 | ||||
| 27.78 | 0.7946 | ||||
| 27.83 | 0.7961 |
IV Experiments
This section will introduce the experimental setting, our ablation studies, and comparisons with current advanced FSR methods to thoroughly demonstrate the advantages of our approach on both synthetic and real test datasets.
IV-A Datasets and Evaluation Metrics
In our studies, we utilize the CelebA [4] dataset for training and evaluation on CelebA [4], Helen [41], and SCface [42] datasets, respectively. We center-crop the aligned face images and resize them to pixels to obtain high-resolution (HR) versions. These HR images are then downsampled to pixels using bicubic interpolation, producing the corresponding low-resolution (LR) images. For our experiments, we randomly choose 18,000 CelebA images for training and 1,000 for testing. In addition, We also utilize the SCface test set as a real-world evaluation dataset. To measure the quality of the FSR results, we use five metrics: PSNR [43], SSIM [43], LPIPS [44], VIF [45], and FID [46].
IV-B Implementation details
We implement our model using the PyTorch framework on an NVIDIA GeForce RTX 3090. The network is optimized using the Adam optimizer, with parameters set to and . The initial learning rate is , with separate learning rates for the generator and discriminator set at and , respectively. The loss function weights are configured as , , and .
| Methods | ||||||||
|---|---|---|---|---|---|---|---|---|
| PSRN | SSIM | VIF | LPIPS | PSNR | SSIM | VIF | LPIPS | |
| Bicubic | 23.61 | 0.6779 | 0.1821 | 0.4899 | 22.95 | 0.6762 | 0.1745 | 0.4912 |
| SAN [47] | 27.43 | 0.7826 | 0.4553 | 0.2080 | 25.46 | 0.7360 | 0.4029 | 0.3260 |
| RCAN [24] | 27.45 | 0.7824 | 0.4618 | 0.2205 | 25.50 | 0.7383 | 0.4049 | 0.3437 |
| HAN [48] | 27.47 | 0.7838 | 0.4673 | 0.2087 | 25.40 | 0.7347 | 0.4074 | 0.3274 |
| SwinIR [9] | 27.88 | 0.7967 | 0.4590 | 0.2001 | 26.53 | 0.7856 | 0.4398 | 0.2644 |
| FSRNet [12] | 27.05 | 0.7714 | 0.3852 | 0.2127 | 25.45 | 0.7364 | 0.3482 | 0.3090 |
| DICNet [14] | - | - | - | - | 26.15 | 0.7717 | 0.4085 | 0.2158 |
| FACN [49] | 27.22 | 0.7802 | 0.4366 | 0.1828 | 25.06 | 0.7189 | 0.3702 | 0.3113 |
| SPARNet [17] | 27.73 | 0.7949 | 0.4505 | 0.1995 | 26.43 | 0.7839 | 0.4262 | 0.2674 |
| SISN [18] | 27.91 | 0.7971 | 0.4785 | 0.2005 | 26.64 | 0.7908 | 0.4623 | 0.2571 |
| AD-GNN [50] | 27.82 | 0.7962 | 0.4470 | 0.1937 | 26.57 | 0.7886 | 0.4363 | 0.2432 |
| Restormer-M [51] | 27.94 | 0.8027 | 0.4624 | 0.1933 | 26.91 | 0.8013 | 0.4595 | 0.2258 |
| LAAT [52] | 27.91 | 0.7994 | 0.4624 | 0.1879 | 26.89 | 0.8005 | 0.4569 | 0.2255 |
| ELSFace [53] | 27.41 | 0.7922 | 0.4451 | 0.1867 | 26.04 | 0.7873 | 0.4193 | 0.2811 |
| SFMNet [20] | 27.96 | 0.7996 | 0.4644 | 0.1937 | 26.86 | 0.7987 | 0.4573 | 0.2322 |
| SPADNet [54] | 27.82 | 0.7966 | 0.4589 | 0.1987 | 26.47 | 0.7857 | 0.4295 | 0.2654 |
| AMINet | 28.26 | 0.8091 | 0.4893 | 0.1755 | 27.01 | 0.8042 | 0.4694 | 0.2067 |

IV-C Ablation Studies
IV-C1 Study of LGFI
LGFI is proposed to extract local features and global relationships of images, which represents a new attempt to interact with local and global information. To verify the reasonableness of our design of LGFI, as shown in Table I, we design four ablation models. The first model removes the SA, labeled “LGFI w/o SA”. The second model removes RDFE, labeled as “LGFI w/o RDFE”. The third model removes SKAF, labeled as “LGFI w/o SKAF”. We have the following observations: (a) introducing SA, and RDFE alone can improve model performance. This is because the above two modules can capture local and global features to promote facial feature reconstruction, including facial details and overall overall contours; (b) Model performance has been significantly increased by introducing the SKAF to capture the relationship between local and global facial features. This is because our SKAF can promote interaction between our SA and RDFE, integrating richer information and providing supplementary information for the final FSR image reconstruction. In our LGFI, using only one module can not achieve optimal results, validating the effectiveness of LGFI.
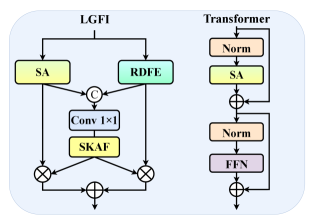
IV-C2 Comparison between LGFI and Transformer
As shown in Figure 4, LGFI uses a dual branch structure to interact with representing the local and global features. In contrast, the traditional Transformer in Restormer [55] uses a serial structure to link the local and global features. To verify the effectiveness of LGFI, we replace all LGFIs in the network with Transformers and conduct comparative experiments with similar parameters between the two models. From Table II, we can see that the network’s performance using LGFI is better when the two networks maintain similar parameters. This is because LGFI utilizes the features of both local and global branches for interaction, facilitating the communication of multi-scale facial information.
IV-C3 Comparison between RDFE and FFN
The feed-forward network (FFN) performs independent nonlinear transformations of the inputs at each position to help the Transformer capture local features, but it lacks the ability to extract multi-scale features, which is not favorable for accurate FSR. In contrast, our RDFE can extract multi-scale local features well. To compare RDFE and FFN, we replace RDFE with FFN while keeping the parameters of the two models similar. As shown in Table III, since FFN’s ability to capture feature interactions is limited compared to our RDFE that utilizes multiple branches to capture different receptive field facial features, our RDFE performs much better than FFN with similar computational consumption.
IV-C4 Effectiveness of RDFE
In RDFE, a three-branch network guided by an attention mechanism is used for deep feature extraction, and the feature refinement module is used to enrich feature representation. To verify the effectiveness of RDFE, we conduct multiple ablation experiments. We design five improved models. The first model adopts a single branch structure of depthwise convolution, labeled as “Single path ( dw)”. The second model adopts a single branch structure of depthwise convolution, labeled as “Single path ( dw)”. The third model adopts a single branch structure of depthwise convolution, labeled as “Single path ( dw)”. The fourth model removes attention units labeled as ”w/o AU”. The fifth model removes the feature refinement module, labeled as ”w/o FRM”. From the Table IV, we have the following observations: (a) By comparing the first three rows and the last row of the table, it can be seen that multi-scale branching facilitates the model’s performance due to its ability to extract face features at different levels; (b) From the comparison between the second and the last rows of the table and the last row, it can be seen that using attention units (AU) to guide three-branch feature extraction can enable the model to adaptively allocate weights, enhance the representation of important facial information, and thus improve model performance; (c) From the last two rows of the table, we can conclude that the feature refinement module (FRM) module can further integrate multi-scale information, refine multi-scale fusion features, and thus improve performance.

IV-C5 Effectiveness of SKAF
SKAF is an important component of LGFI, facilitating information exchange between local and global branches. We perform a series of ablation experiments to validate the impact of our SKAF module and assess the practicality of the combined approach. Since SKAF consists of dual branch convolutional layers, maximum pooling layers, and average pooling layers, we verify the effectiveness of module components in SKAF. From Table V, we have the following observations: (a) From the last three rows of the table, we find that using a single pooling branch results in reduced performance, while using average pooling alone results in lower performance than using maximum pooling alone. This is because the salient features of the face are the key to facial recovery, with maximum pooling focusing on salient facial feature information. In contrast, average pooling focuses on the overall information of the face. (b) Compared to the third and fifth rows,, it can be concluded that using both and simultaneously can improve performance and fully utilize key facial information under different receptive fields.
IV-C6 Study of EDFF
This section presents a set of experiments to validate the effectiveness of our EDFF, a module tailored for fusing multi-scale features. We add EDFF to SPARNet [17], which uses EDFF to connect the encoding and decoding stages in SPARNet and send them to the next decoding stage. Additionally, we add EDFF to SFMNet [20], and the specific operation is the same as in SPARNet. From the results of Table VI, we can see that although the parameters of both models increase slightly, the performance of the models improves, which precisely proves that EDFF is helpful for feature fusion in encoding and decoding stages.
| Methods | PSNR | SSIM | VIF | FID |
|---|---|---|---|---|
| FSRGAN [12] | 25.02 | 0.7279 | 0.3400 | 146.55 |
| DICGAN [14] | 25.59 | 0.7398 | 0.3925 | 144.25 |
| SPARGAN [17] | 25.86 | 0.7518 | 0.3932 | 149.54 |
| SFMGAN [20] | 25.96 | 0.7618 | 0.4019 | 141.23 |
| AMIGAN (Ours) | 26.35 | 0.7769 | 0.4101 | 122.43 |
IV-D Comparison with Other Methods
This section compares our AMINet and its GAN-based variant with leading FSR methods currently available, including SAN [47], RCAN [24], HAN [48], SwinIR [9], FSRNet [12], DICNet [14], FACN [49], SPARNet [17], SISN [18], AD-GNN [50], Restormer-M [51], LAAT [52], ELSFace [53], SFMNet [20] and SPADNet [54].


IV-D1 Comparison on CelebA dataset
We conduct a quantitative comparison of AMINet against existing FSR methods on the CelebA test set, as detailed in Table VII. Our AMINet outperforms all other evaluation metrics, including PSNR, SSIM, LPIPS, and VIF, which fully demonstrates its efficiency. This strongly validates the effectiveness of AMINet. Additionally, the visual comparison in Fig. 5 reveals that previous FSR methods struggled to accurately reproduce facial features like the eyes and mouth. In contrast, AMINet excels at preserving the facial structure and producing more precise results, proving its effectiveness.
IV-D2 Comparison on Helen dataset
We evaluate our method on the Helen test set to further assess AMINet’s versatility. Table VII provides a quantitative comparison of 8 FSR results about it, where AMINet achieves the better performance. Visual comparisons in Fig. 6 indicate that existing FSR methods struggle to maintain accuracy, leading to blurred shapes and a loss of facial details. In contrast, AMINet successfully preserves facial contours and details, reinforcing its effectiveness and adaptability across different datasets.
IV-D3 Comparison with GAN-based methods
We present AMIGAN as an innovative approach to bolster the visual fidelity of image restoration tasks. To substantiate its superiority, we have conducted a rigorous comparison of AMIGAN against state-of-the-art GAN-based methodologies, namely FSRGAN [12], DICGAN [14], SPARGAN [17], and SFMGAN [20]. As a complementary assessment metric, we introduce the FID [46] to quantitatively evaluate the GANs’ performance. The outcomes presented in Table VIII, derived from tests on the Helen dataset, reveal that AMIGAN outpaces its competitors considerably. Furthermore, the visual inspection illustrated in Fig. 7 underscores AMIGAN’s exceptional capabilities. Unlike existing FSR methods, which exhibit visible artifacts in generated facial images, AMIGAN meticulously restores critical facial features and intricate texture details around the mouth and nose, which underscores AMIGAN’s prowess in facial texture restoration, resulting in a notable enhancement in clarity and overall visual realism.
IV-D4 Comparison on Real-world surveillance faces
All the above comparisons are tested on synthetic test sets, which fail to simulate real-world scenarios accurately. To further evaluate our model’s performance in real-world conditions, we also conduct experiments using low-quality face images from the SCface dataset [42]. As shown in Fig. 8, we visually compare reconstruction results. From this figure, We find that the reconstruction results of face prior-based methods are not satisfactory. The challenge lies in accurately estimating priors from real-world LR facial images. Incorrect prior information can lead to misleading guidance during the reconstruction process. In contrast, our AMINet can restore clearer face details and faithful face structures. This result fully demonstrates our method’s effectiveness in real scenarios.
IV-E Model Complexity Analysis
In addition to the performance indicators mentioned earlier, the number of model parameters and inference time are crucial factors in evaluating performance. As shown in Fig. 1, we compare our model with existing ones in terms of parameters, PSNR values, and inference speed. We can see that AMINet still performs well while maintaining a fast inference time and a small parameter count.
V Conclusions
This work proposes an attention-guided Multi-scale interaction network for face super-resolution. Specifically, we design an LGFI, which allows accessible communication of global features obtained from self-attention and local features obtained from our designed RDFE. To enhance the variegation of local features in RDFE, we employ a multi-scale depth separable convolutional kernel coupled with attention mechanisms to extract and refine local features. Furthermore, to adaptively fuse features at different scales, we propose an RDFE to utilize the attention mechanism to select a convolutional kernel of the appropriate size to promote feature fusion. Extensive experiments on the synthetics and real test sets show our designed modules significantly improve the communication of features at different scales with modules, allowing our proposed method to outperform existing methods regarding FSR performance, model size, and inference speed.
References
- [1] L. Liu, R. Lan, and Y. Wang, “Discriminative face hallucination via locality-constrained and category embedding representation,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 51, no. 12, pp. 7314–7325, 2021.
- [2] D. Mamieva, A. B. Abdusalomov, M. Mukhiddinov, and T. K. Whangbo, “Improved face detection method via learning small faces on hard images based on a deep learning approach,” Sensors, vol. 23, no. 1, p. 502, 2023.
- [3] G. Hu, Y. Yang, D. Yi, J. Kittler, W. Christmas, S. Z. Li, and T. Hospedales, “When face recognition meets with deep learning: an evaluation of convolutional neural networks for face recognition,” in ICCVW, 2015, pp. 142–150.
- [4] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in ICCV, 2015, pp. 3730–3738.
- [5] G. Gao, Z. Xu, J. Li, J. Yang, T. Zeng, and G.-J. Qi, “Ctcnet: A cnn-transformer cooperation network for face image super-resolution,” IEEE Transactions on Image Processing, vol. 32, pp. 1978–1991, 2023.
- [6] E. Zhou, H. Fan, Z. Cao, Y. Jiang, and Q. Yin, “Learning face hallucination in the wild,” in AAAI, vol. 29, no. 1, 2015.
- [7] J. Shi, Y. Wang, S. Dong, X. Hong, Z. Yu, F. Wang, C. Wang, and Y. Gong, “Idpt: Interconnected dual pyramid transformer for face super-resolution.” in IJCAI, 2022, pp. 1306–1312.
- [8] Y. Wang, T. Lu, Y. Zhang, Z. Wang, J. Jiang, and Z. Xiong, “Faceformer: Aggregating global and local representation for face hallucination,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 6, pp. 2533–2545, 2022.
- [9] J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” in ICCV, 2021, pp. 1833–1844.
- [10] Q. Bao, Y. Liu, B. Gang, W. Yang, and Q. Liao, “Sctanet: A spatial attention-guided cnn-transformer aggregation network for deep face image super-resolution,” IEEE Transactions on Multimedia, vol. 25, pp. 8554–8565, 2023.
- [11] W. Li, M. Wang, K. Zhang, J. Li, X. Li, Y. Zhang, G. Gao, W. Deng, and C.-W. Lin, “Survey on deep face restoration: From non-blind to blind and beyond,” arXiv:2309.15490, 2023.
- [12] Y. Chen, Y. Tai, X. Liu, C. Shen, and J. Yang, “Fsrnet: End-to-end learning face super-resolution with facial priors,” in CVPR, 2018, pp. 2492–2501.
- [13] D. Kim, M. Kim, G. Kwon, and D.-S. Kim, “Progressive face super-resolution via attention to facial landmark,” arXiv:1908.08239, 2019.
- [14] C. Ma, Z. Jiang, Y. Rao, J. Lu, and J. Zhou, “Deep face super-resolution with iterative collaboration between attentive recovery and landmark estimation,” in CVPR, 2020, pp. 5569–5578.
- [15] X. Hu, W. Ren, J. LaMaster, X. Cao, X. Li, Z. Li, B. Menze, and W. Liu, “Face super-resolution guided by 3d facial priors,” in ECCV. Springer, 2020, pp. 763–780.
- [16] M. Zhang and Q. Ling, “Supervised pixel-wise gan for face super-resolution,” IEEE Transactions on Multimedia, vol. 23, pp. 1938–1950, 2020.
- [17] C. Chen, D. Gong, H. Wang, Z. Li, and K.-Y. K. Wong, “Learning spatial attention for face super-resolution,” IEEE Transactions on Image Processing, vol. 30, pp. 1219–1231, 2020.
- [18] T. Lu, Y. Wang, Y. Zhang, Y. Wang, L. Wei, Z. Wang, and J. Jiang, “Face hallucination via split-attention in split-attention network,” in ACMMM, 2021, pp. 5501–5509.
- [19] Q. Bao, R. Zhu, B. Gang, P. Zhao, W. Yang, and Q. Liao, “Distilling resolution-robust identity knowledge for texture-enhanced face hallucination,” in ACMMM, 2022, pp. 6727–6736.
- [20] C. Wang, J. Jiang, Z. Zhong, and X. Liu, “Spatial-frequency mutual learning for face super-resolution,” in CVPR, 2023, pp. 22 356–22 366.
- [21] J. Shi, Y. Wang, Z. Yu, G. Li, X. Hong, F. Wang, and Y. Gong, “Exploiting multi-scale parallel self-attention and local variation via dual-branch transformer-cnn structure for face super-resolution,” IEEE Transactions on Multimedia, vol. 26, pp. 2608–2620, 2023.
- [22] W. Li, H. Guo, X. Liu, K. Liang, J. Hu, Z. Ma, and J. Guo, “Efficient face super-resolution via wavelet-based feature enhancement network,” in ACMMM, 2024.
- [23] J. Li, Z. Pei, W. Li, G. Gao, L. Wang, Y. Wang, and T. Zeng, “A systematic survey of deep learning-based single-image super-resolution,” ACM Computing Surveys, vol. 56, no. 10, pp. 1–40, 2024.
- [24] Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y. Fu, “Image super-resolution using very deep residual channel attention networks,” in ECCV, 2018, pp. 286–301.
- [25] J. Xin, N. Wang, X. Gao, and J. Li, “Residual attribute attention network for face image super-resolution,” in AAAI, vol. 33, no. 01, 2019, pp. 9054–9061.
- [26] G. Gao, W. Li, J. Li, F. Wu, H. Lu, and Y. Yu, “Feature distillation interaction weighting network for lightweight image super-resolution,” in AAAI, vol. 36, no. 1, 2022, pp. 661–669.
- [27] Y. Wang, Y. Li, G. Wang, and X. Liu, “Multi-scale attention network for single image super-resolution,” in CVPR, 2024, pp. 5950–5960.
- [28] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPs, 2017, pp. 5998–6008.
- [29] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018.
- [30] G. Gao, Z. Wang, J. Li, W. Li, Y. Yu, and T. Zeng, “Lightweight bimodal network for single-image super-resolution via symmetric cnn and recursive transformer,” arXiv:2204.13286, 2022.
- [31] W. Li, J. Li, G. Gao, W. Deng, J. Zhou, J. Yang, and G.-J. Qi, “Cross-receptive focused inference network for lightweight image super-resolution,” IEEE Transactions on Multimedia, vol. 26, pp. 864–877, 2023.
- [32] W. Li, J. Li, G. Gao, W. Deng, J. Yang, G.-J. Qi, and C.-W. Lin, “Efficient image super-resolution with feature interaction weighted hybrid network,” arXiv:2212.14181, 2022.
- [33] K. Zeng, Z. Wang, T. Lu, J. Chen, J. Wang, and Z. Xiong, “Self-attention learning network for face super-resolution,” Neural Networks, vol. 160, pp. 164–174, 2023.
- [34] Y. Yang and Y. Qi, “Image super-resolution via channel attention and spatial graph convolutional network,” Pattern Recognition, vol. 112, p. 107798, 2021.
- [35] Z. Zhang and C. Qi, “Feature maps need more attention: A spatial-channel mutual attention-guided transformer network for face super-resolution,” Applied Sciences, vol. 14, no. 10, p. 4066, 2024.
- [36] X. Li, W. Wang, X. Hu, and J. Yang, “Selective kernel networks,” in CVPR, 2019, pp. 510–519.
- [37] Y. Li, Q. Hou, Z. Zheng, M.-M. Cheng, J. Yang, and X. Li, “Large selective kernel network for remote sensing object detection,” in ICCV, 2023, pp. 16 794–16 805.
- [38] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in CVPR, 2017, pp. 4681–4690.
- [39] X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao, and C. Change Loy, “Esrgan: Enhanced super-resolution generative adversarial networks,” in ECCVW, 2018, pp. 1–16.
- [40] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv:1409.1556, 2014.
- [41] V. Le, J. Brandt, Z. Lin, L. Bourdev, and T. S. Huang, “Interactive facial feature localization,” in ECCV, 2012, pp. 679–692.
- [42] M. Grgic, K. Delac, and S. Grgic, “Scface–surveillance cameras face database,” Multimedia Tools and Applications, vol. 51, no. 3, pp. 863–879, 2011.
- [43] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
- [44] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018, pp. 586–595.
- [45] H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” IEEE Transactions on Image Processing, vol. 15, no. 2, pp. 430–444, 2006.
- [46] A. Obukhov and M. Krasnyanskiy, “Quality assessment method for gan based on modified metrics inception score and fréchet inception distance,” in CoMeSySo, 2020, pp. 102–114.
- [47] T. Dai, J. Cai, Y. Zhang, S.-T. Xia, and L. Zhang, “Second-order attention network for single image super-resolution,” in CVPR, 2019, pp. 11 065–11 074.
- [48] B. Niu, W. Wen, W. Ren, X. Zhang, L. Yang, S. Wang, K. Zhang, X. Cao, and H. Shen, “Single image super-resolution via a holistic attention network,” in ECCV. Springer, 2020, pp. 191–207.
- [49] J. Xin, N. Wang, X. Jiang, J. Li, X. Gao, and Z. Li, “Facial attribute capsules for noise face super resolution,” in AAAI, vol. 34, no. 07, 2020, pp. 12 476–12 483.
- [50] Q. Bao, B. Gang, W. Yang, J. Zhou, and Q. Liao, “Attention-driven graph neural network for deep face super-resolution,” IEEE Transactions on Image Processing, vol. 31, pp. 6455–6470, 2022.
- [51] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” in CVPR, 2022, pp. 5728–5739.
- [52] G. Li, J. Shi, Y. Zong, F. Wang, T. Wang, and Y. Gong, “Learning attention from attention: Efficient self-refinement transformer for face super-resolution.” in IJCAI, 2023, pp. 1035–1043.
- [53] H. Qi, Y. Qiu, X. Luo, and Z. Jin, “An efficient latent style guided transformer-cnn framework for face super-resolution,” IEEE Transactions on Multimedia, vol. 26, pp. 1589–1599, 2024.
- [54] C. Wang, J. Jiang, K. Jiang, and X. Liu, “Structure prior-aware dynamic network for face super-resolution,” IEEE Transactions on Biometrics, Behavior, and Identity Science, 2024.
- [55] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” in CVPR, 2022, pp. 5728–5739.