Augmented Transformers with Adaptive n-grams Embedding for Multilingual Scene Text Recognition
Abstract
While vision transformers have been highly successful in improving the performance in image-based tasks, not much work has been reported on applying transformers to multilingual scene text recognition due to the complexities in the visual appearance of multilingual texts. To fill the gap, this paper proposes an augmented transformer architecture with n-grams embedding and cross-language rectification (TANGER). TANGER consists of a primary transformer with single patch embeddings of visual images, and a supplementary transformer with adaptive n-grams embeddings that aims to flexibly explore the potential correlations between neighbouring visual patches, which is essential for feature extraction from multilingual scene texts. Cross-language rectification is achieved with a loss function that takes into account both language identification and contextual coherence scoring. Extensive comparative studies are conducted on four widely used benchmark datasets as well as a new multilingual scene text dataset containing Indonesian, English, and Chinese collected from tourism scenes in Indonesia. Our experimental results demonstrate that TANGER is considerably better compared to the state-of-the-art, especially in handling complex multilingual scene texts.
Index Terms:
Evolutionary optimization, neural architecture search, node inheritance, attention mechanism, convolutional neural networks.I Introduction
Transformers have achieved tremendous success in computer vision [1] in a variety of image-based tasks, including object detection [2], semantic segmentation [3], and image recognition [4, 5]. Since transformers were originally developed for natural language processing [6], demanding efforts are required to design and train transformers for vision tasks [7, 8]. One attractive idea [4] is to apply a pure transformer, called ViT, directly to sequences of image patches, significantly reducing the required computational resources.
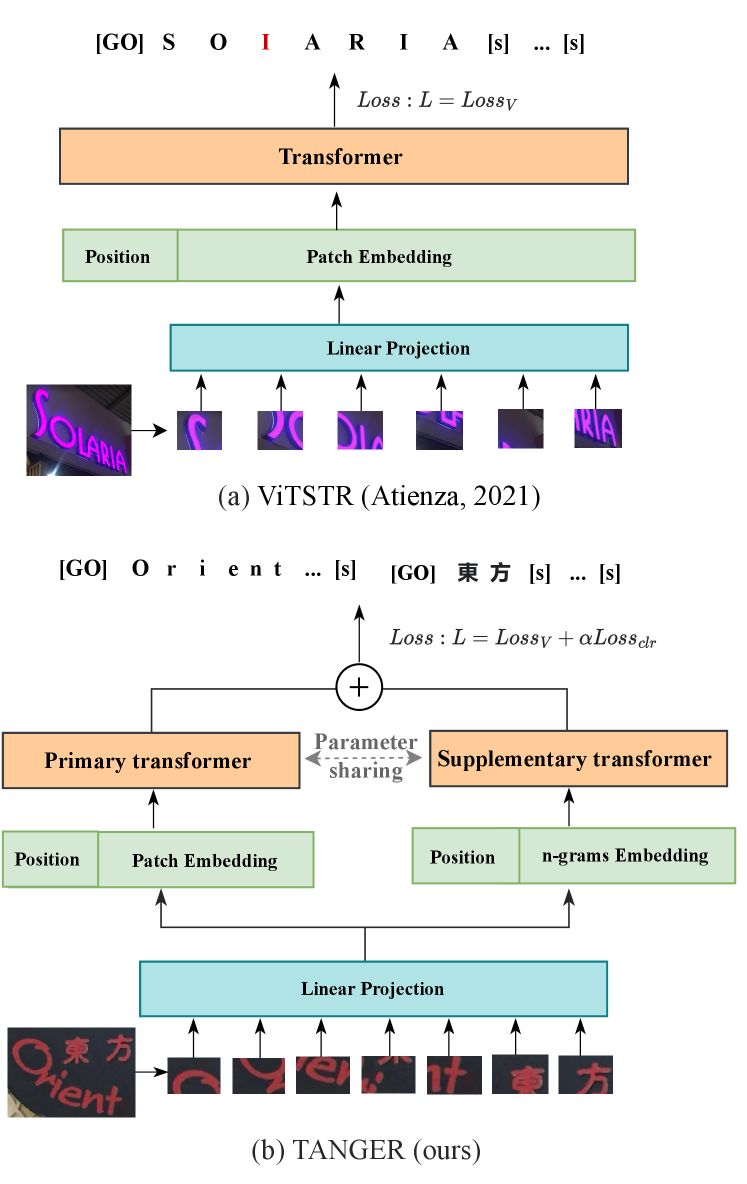
Scene text recognition (STR), one class of important and challenging tasks involving both image and text features, aims to identify texts in natural scenes such as object labels, street and road signs [9]. On the basis of ViT, an image patch-based transformer for STR, called ViTSTR, has been proposed in [5] to achieve an optimal trade-off between performance and speed. However, as illustrated in Fig. 1(a), ViTSTR works directly on sequences of single image patches without considering their associated neighbors, which may be inadequate in dealing with more complex scenes such as multilingual scene texts. Despite their potential competitive performances for STR tasks, not much attention has been paid to vision transformers to address the specific challenges encountered in multilingual scene text recognition [10].
Multilingual scene text recognition is particularly challenging in that it involves multi-scale, multi-orientation, and low-resolution images containing multiple languages. For instance, the scene texts in Fig. 1(b) contain English and Chinese, which have different sizes and orientations, making it hard for existing transformers that use single image patches to efficiently recognize multilingual scene texts.
To tackle the above challenges, we propose an augmented Transformer architecture with Adaptive N-Grams Embeddings and cross-language Rectification (TANGER) for multilingual scene text recognition. Our key hypothesis here is that adaptive patch-based n-grams embeddings can allow TANGER to deal with complex multilingual scene characters more flexibly. In addition to the single image patches for the primary vision transformer, the supplementary pyramid transformer takes various representations of the neighboring image patches as the input. The primary and supplementary vision transformers jointly learn the representation of multilingual scene text features by sharing their parameters, reducing the computational complexity of the proposed model. To further improve the performance for multilingual scene text recognition, a loss function for cross-language rectification is designed for text prediction in the presence of multiple languages by considering the language category information as well as the coherence of a sequence of characters or words.
We evaluate the proposed TANGER by comparing its performance with the state-of-the-art approaches on three public multilingual benchmark datasets including E2E-MLT [10], CTW1500 [11], and RCTW17 [12], and one monolingual dataset, Totaltext [13]. In addition, comparative experiments are carried out on a new multilingual database we collected from tourism scenes in Indonesia, called TsiText, which consists of Indonesian, English, and Chinese. Our experimental results demonstrate that TANGER achieves state-of-the-art results on all multilingual and monolingual scene text recognition tasks considered in this work.
The key contributions of this work are summarized as follows:
-
•
We propose an augmented transformer architecture (TANGER) for multilingual scene text recognition by integrating a primary vision transformer with a supplementary pyramid transformer with n-grams embeddings. To our knowledge, this is the first pure vision transformer-based method for multilingual scene text recognition.
-
•
An adaptive n-grams embedding method is designed to more flexibly extract key text features in locally related neighboring visual patches. The adaptive n-grams embedding can determine the optimal number of grams for different input image patches, which is highly beneficial for complex scent text recognition.
-
•
To further enhance TANGER’s capability of handling multilingual scene texts, we design a cross-language rectification loss function to account for language identification errors and text coherence.
II Related Work
II-A Scene Text Recognition
Existing work on STR [14] can be categorized into language-free and language-based approaches [9]. Language-free methods do not consider the linguistic information between characters and focus on the visual textures for recognition [15]. Yao et al. [16] combine various feature descriptors with localized individual characters, and present a multi-scale representation for STR. Shi et al. [17] propose a unified neural network architecture framework for STR that integrates feature extraction, sequence modeling, and transcription, considering STR as a pixel-wise classification task. Language-based methods focus on the language mode with different structures, or consider the relationship between vision and language. For example, attention-based methods [18, 19] are adopted for STR by following an end-to-end neural network model in recurrent neural networks [20]. Fang et al. [21] propose a text recognizer based on convolutional neural networks (CNNs) by fusing visual and language-based methods to boost the recognition performance.
Little work on multilingual scene text recognition has been reported with only a few exceptions. Busta et al. [10] design probably the first method, called E2E-MLT, for multilingual scene text recognition on the basis of a single fully convolutional network, which is demonstrated to be competitive even on rotated and vertical text instances. An E2E approach to script identification with different recognition heads, called Multiplexed Multilingual Mask TextSpotter, was proposed in [22], which can support the removal of existing or inclusion of new languages.
However, due to the diversity of scene texts, complexity of the background, large amounts of uncertainty [23], and different sizes of different language scripts, existing methods fail to work effectively on multilingual scene text recognition tasks.
II-B Vision Transformers for STR
To benefit from the generated visual features following linguistic rules, increased research interests have been dedicated to using transformers for STR recently [24, 4, 25], where the encoder extracts visual features and the decoder predicts characters in images. Owing to their parallel self-attention and prediction mechanisms, transformers can overcome the difficulties of sequential inference with diverse scene text features to some extent [1].
Sporadic research efforts on adapting transformers to addressing various challenges in monolingual STR have been reported. For instance, to deal with images with different resolutions, Raisi et al. [26] develop a transformer-based architecture for recognizing texts in images by using a 2D positional encoder so that the spatial information the features can be preserved. Biten et al. [27] propose a layer-aware transformer with a pre-training scheme on the basis of text and spatial cues only and show that it works well on scanned documents to handle multimodality in scene text visual question answering. Based on ViT [4], Tan et al. [28] propose a mixture experts of pure transformers for processing different resolutions for scene text recognition. Atienza [5] presents a new transformer, called ViTSTR, for scent text recognition, which only uses the encoder architecture and emphasizes the balance between the performance and computational efficiency. Recently, Wang et al. [29] explore the linguistic information between the local visual patches and propose transformer-based language rectification modules for optimizing word length and guiding rectification in monolingual scene text recognition.
Despite the progress made on the application of visual transformers to STR tasks, it remains an open question how to explicitly identify inter-patch correlations for multilingual scene text recognition containing multi-scale, multi-orientation and low-resolution texts.
III TANGER
III-A Overall Architecture
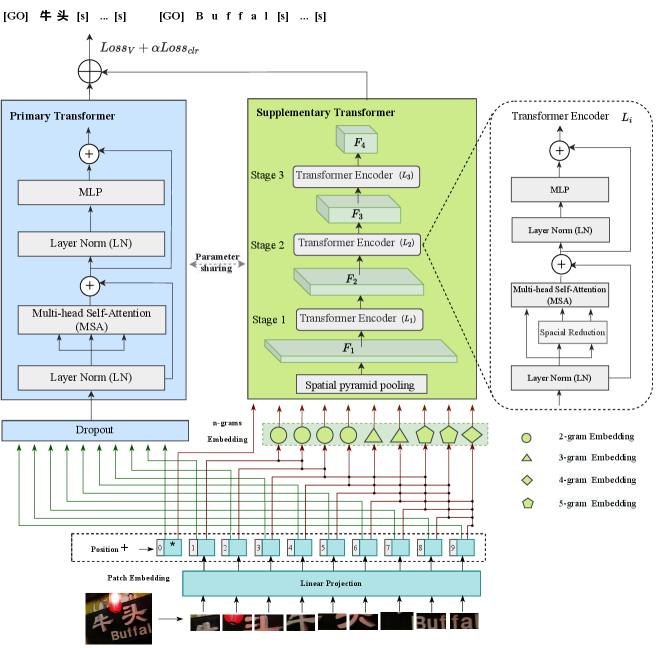
Our goal is to introduce a new vision transformer architecture for handling complex multilingual STR tasks. The proposed TANGER, as shown in Fig. 2, consists of a primary transformer, which is a normal vision transform, and a supplementary pyramid transformer with adaptive n-grams embeddings. The primary vision transform focuses on the patch-based image features without considering the associated local patches, in which a dropout layer is adopted to alleviate overfitting. The supplementary pyramid transformer concentrates on effectively extracting visual features from the neighbouring image patches with the help of the adaptive n-grams embedding, allowing us to deal with multi-scale and multi-orientation visual appearances of multilingual texts. Similar to [5], we use a single model architecture in the primary transformer, while in the supplementary transformer, three layers of pyramid transformer encoders are stacked to control the scale of feature maps in three stages. As shown in Fig. 2, , and and the feature maps extracted from the previous stage and serve as the input into encoder layers , , and , respectively. To reduce the computational complexity of TANGER, the encoder in the primary transformer and all three encoder layers in the supplementary transformer share the same parameters.
In our implementation, we first divide an input RGB image into non-overlapping patches, and the features of a patch is regarded as a concatenation of the raw pixel RGB values. For example, we use a patch size of , and split a given input image of size into patches, where , and are parameters to be defined. After that, a linear embedding layer is applied on this raw-valued feature to project it onto an arbitrary dimension for each patch. In this way, we can flexibly pass the embedded patches of different dimensions as well as a position embedding to the input of the two transformers.
III-B Patch-based Adaptive n-grams Embedding
The vision transformer in [5] only considers single image patches as a set of isolated vision words or characters without taking into account the correlation between the features in the neighboring image patches, thus limiting the model’s ability to recognize complex scene texts. For obtaining efficient relevant features of the image patches, we treat each image patch as a bag of visual words [30] to capture the relationship between neighboring patches. To this end, we introduce an adaptive -grams embedding method for determining an optimal for each image patch.
As illustrated in Fig. 2, the pyramid transformer architecture [31] with -grams embedding is employed to flexibly capture the linguistic information in the neighboring patches. However, the value of for the -th image patch must be determined individually to best capture the correlations between its neighboring patches. In this work, we set according to our pilot studies. Then, we choose the optimal for as follows:
| (1) |
where is the probability at which is correlated with its previous patches, represents sequential local visual patches. We can estimate using a feature histogram of a group of continuous patches built by using the bag of visual words (BVW) as suggested in [30, 32]:
| (2) |
where is the -th visual word, is the total number of visual words in the histogram, and refers to the frequency of features of the input image patches that is similar to each of the visual word in the histogram. An illustrative example is given in Fig. 3, in which the input image is partitioned into nine patches. To determine the number of grams for , we calculate when , respectively. Finally, the maximum probability is obtained when . Consequently, bi-gram embedding is adopted for .
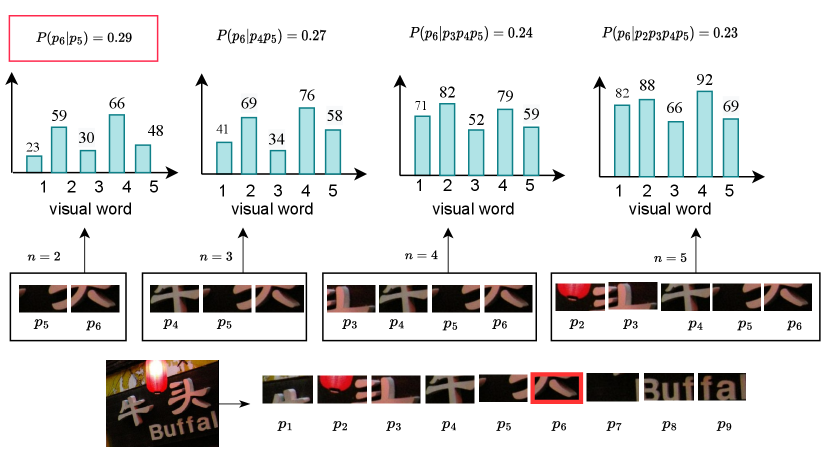
Since the length of the local patches differs from patch to patch (in the above example, the length varies from 2 to 5), we use a spatial pyramid pooling layer to obtain the final n-grams embedding representation that conforms to the input size of the transformer. This way, we can flexibly adjust the length of the local image patches most relevant to the current patch, enabling it to extract the most effective features for complex multilingual scene texts.
III-C Cross-language Rectification Loss
For multilingual scene text recognition, we must pay particular attention to the variability of the extracted features of two transformers for different languages. To achieve this, we design a loss function by including an extra cross-language rectification loss in addition to the vision loss:
| (3) |
where means the loss for the vision model, which is set following [5], represents the cross-language rectification loss, and is the weight coefficient, which is set to 0.01 based on our pilot studies. is defined as follows:
| (4) |
where is the loss of the word coherence scores, and is the loss of language class identification:
| (5) |
where is a multilayer perceptron (MLP) in the transformers that performs feature extraction, and and denote the extracted cross-language features from the vision transformer and pyramid transformer, respectively, is the soft cross entropy of language class. With the help of the supplementary transformer, the coherence scores of the predicted characters in different patches are obtained by the linear inference layer in MLP, and the loss of the word coherence scores for multilingual texts can be estimated as follow:
| (6) |
where represent inference result of the -th character, is the maximum length of the predicted characters.
III-D Discussion
Here, we discuss further the relationship between TANGER and ViTSTR [5]. Like ViTSTR, TANGER is an image-based transformer model without relying on language resources such as dictionaries or corpus. Similar to the traditional vision transformer [4], ViTSTR is mainly concerned with extracting features from a sequence of separate image patches. By contrast, TANGER explicitly takes into account the potential correlation between neighbouring visual patches, which is of paramount importance for feature extraction in complex scenes, such as multi-scale, multi-orientation and multilingual texts [33].
IV Experimental Results
In this section, we experimentally validate our proposed TANGER by comparing the performance with the state-of-the-art methods on several public datasets as well as one newly collected multilingual dataset TsiText. First, we examine the performance of TANGER for multilingual scene text recognition in comparison with two end-to-end methods [10, 22] and one dictionary-guided method [34]. Then, we compare our model with the vision transformer ViTSTR [5] in three variants, i.e., tiny, small, and base versions for monolingual scene text recognition. Finally, we present the results of ablation studies comparing TANGER with its two variants, one without the adaptive -gram patch embedding method, and the other without cross-language rectification for multilingual scene text recognition.
IV-A Experimental Settings
Datasets We validate the effectiveness of TANGER on three multilingual datasets, MLT17 [10], CTW1500 [11], RCTW17 [12], one monolingual dataset Totaltext [13], as well as a new multilingual dataset TsiText. MLT2017 [35], which comes from ICDAR 2017 Robust Reading Competition, contains 7200 training, 1800 validation and 9000 testing natural scene images in Arabic, Latin, Chinese, Japanese, Korean, and Bangla. CTW1500 [11] includes 1000 natural scene images for training and 500 for testing in English and Chinese languages. RCTW17 [12] contains 8034 training and 4229 testing images, including primarily on-scene texts in Chinese and a few in English. Totaltext [13] contains 1255 training images and 300 images for testing with 11459 annotated text instances of wild scenes in English.
TsiText contains 3600 training, 600 validation, and 1800 testing natural images collected from tourism scenes. All images in TsiText are downloaded from the Internet and do not contain sensitive information. There are an average of four text instances in per scene image, with a maximum of 61 text instances. Each text instance contains four different attributes, including position, character content, scene class, and language, and is annotated in a similar way to [11]. TsiText aims to provide complex multilingual scene texts containing rich and diverse travel-related scenes such as food, shop signs, traffic signs, directions, landmarks, and posters. It also includes multiple text types, including handwriting, print, and complex artistic styles. Finally, there is certain degrees of variety in text shapes, such as horizontal, multi-directional, curved, circular, and partially obscured texts, among others. To the best of our knowledge, this is the richest dataset for multilingual tourism scene texts.
Metrics and Parameter Configurations We adopt the character-level accuracy as the metric for comparing the algorithms on multilingual scene text recognition tasks. In addition, the frequency of the word-level edit distance between the predicted and ground truth words is employed to compare the recognition performance of the algorithms under comparison on Latin and non-Latin language scene texts. To verify the effectiveness of TANGER on monolingual scene texts, we compare it with ViTSTR in terms of model parameters, speed, FLOPS as well as accuracy.
During the training, we adopt Adam with a mini-batch size of 192 to train the transformer models for 300 epochs from scratch with a learning rate of 0.001 on two A100 GPUs.
IV-B Performance on Multilingual Scene Texts
Table I lists the performance of the proposed TANGER with three state-of-the-art algorithms for multilingual scene text recognition, namely ABCNet+D [34], E2E-MLT [10], and Multiplexed [22]. ABCNet+D [34] is a dictionary-based recognition algorithm that incorporates dictionaries before handling ambiguous cases. E2E-MLT [10] is an end-to-end approach with a single fully convolutional network applicable to both Latin and non-Latin languages for multilingual scene text. Multiplexed [22] proposes a unified loss with disentangled loss and integrated loss, and trains multiple text recognition heads in an end-to-end manner for script identification in different languages. Note that E2E-MLT and Multiplexed are end-to-end methods for both text detection and recognition, however, this work focuses on the recognition performance of the compared algorithms.
As listed in Table I, we can see that TANGER achieves the best character-level accuracy on four multilingual scene text recognition tasks. Compared with ABCNet+D, a dictionary-guided approach, TANGER can significantly improve the accuracy by 14.8%, 11.9%, 10.2%, and 10.1% on MLT17, LSVT19, RCTW17, and TsiText datasets, respectively. The impressive results of TANGER may be attributed to the fact that visual feature extraction is more effective than using lexicons when dealing with a series of multilingual texts in complex scenes. Experimental results also show that TANGER consistently outperforms two end-to-end approaches on all multilingual scene text recognition tasks. Specifically, TANGER achieves a state-of-the-art accuracy of 55.1% and 89.9% on the MLT17 and TsiText datasets, respectively. We surmise that the competitive performance of TANGER comes mainly from the more effective representation of the neighboring visual features, as well as the use of cross-language rectification for complex multilingual scene texts, which has also been verified in our ablation studies.
Figure 4 exemplifies the recognition results by TANGER on six complex testing images from the TsiText dataset. We see that TANGER can successfully recognize the texts in multiple languages in various complex scenes. On these six images, TANGER achieves an accuracy of 99.1%, while ABCNet+D, E2E-MLT, and Multiplexed achieve 91.2%, 94.6% and 95.1%, respectively, confirming the benefits of the proposed adaptive n-grams embedding and cross-language rectification mechanisms.

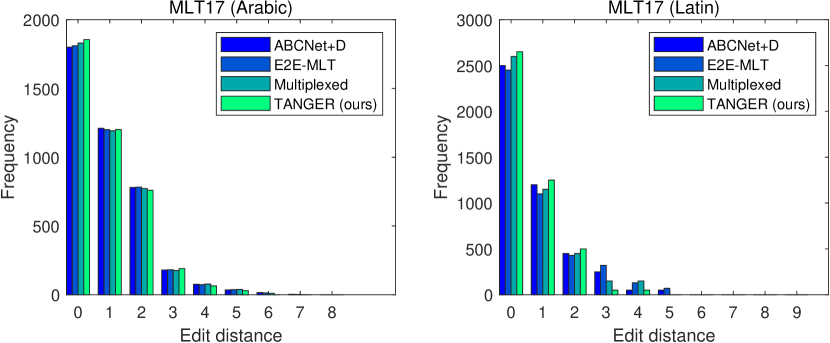
To further demonstrate the performance of TANGER for multilingual scene text recognition on both Latin and non-Latin languages, we examine the histograms of edit distance [36] between the pairs of predicted and the ground truth words for Arabic (non-Latin) and Latin language texts on the MLT17 dataset. Note that the smaller the edit distance, the smaller the recognition error of the algorithm is, and the words are recognized correctly when the edit distance is 0. From Fig. 5, we observe that TANGER can obtain the maximum frequency of occurrences at an edit distance of 0 among all compared methods for both Arabic and Latin languages. In addition, the edit distance of TANGER is always smaller than 5 for Latin languages. Overall, we can conclude that TANGER outperforms the compared methods by observing the histograms of the edit distance, further demonstrating the effectiveness of TANGER for multilingual scene text recognition.
| Method | MLT17 | CTW1500 | RCTW17 | TsiText |
|---|---|---|---|---|
| ABCNet+D [34] | 40.3 | 73.3 | 63.2 | 79.8 |
| E2E-MLT [10] | 49.1 | 65.3 | 69.2 | 84.9 |
| Multiplexed [22] | 53.2 | 80.3 | 72.2 | 88.3 |
| TANGER(ours) | 55.1 | 85.2 | 73.4 | 89.9 |
IV-C Performance on Monolingual Scene Texts
Here we evaluate TANGER for monolingual scene text recognition on the Totaltext dataset by comparing it with ViTSTR [5]. Table II reports the comparative results in terms of the accuracy, speed, model parameters, and FLOPS for three variants of the two compared models, tiny, small, and base versions. Since the transformer-based ViTSTR model is limited to Latin language text recognition we compared the two algorithms on Totaltext, which contains English texts only. From the results in Table II, we can find that TANGER enhances the recognition accuracies by 2.1%, 3.6% and 1.1% for the tiny, small and base versions, respectively, compared to ViTSTR, without considerably slowing down the inference speed.
Interestingly, we find that the coherence score loss designed for cross-language rectification in our method is also helpful for enhancing the recognition performance for monolingual tasks, which may be attributed to the supplementary transformer that takes neighboring patches into account for complex scene text extraction. Figure 6 provides some selected cases, where ViTSTR makes mistakes whilst TANGER correctly recognizes the scene texts in some artistic fonts, or multi-scale and multi-orientation texts.
| Method | Acc | Speed | Parameters | FLOPS |
|---|---|---|---|---|
| msec/image | ||||
| ViTSTR-Tiny | 80.6 | 8.1 | 5.2 | 1.6 |
| ViTSTR-Small | 81.3 | 8.5 | 21.2 | 4.6 |
| ViTSTR-Base | 84.9 | 9.1 | 83.7 | 17.3 |
| TANGER-Tiny | 82.3 | 8.1 | 5.2 | 1.7 |
| TANGER-Small | 84.2 | 9.2 | 22.4 | 5.1 |
| TANGER-Base | 85.8 | 9.5 | 84.6 | 18.2 |

IV-D Ablation Studies
In this section, we conduct ablation studies on MLT17 and TsiText datasets. Our goal is two-fold. First, to assess the importance of the proposed adaptive n-grams embeddings for multilingual text representation, we adopt different but fixed values of on local neighboring image patches for multilingual text representation compared to the proposed adaptive n-grams embeddings in TANGER. Then, we examine the effect of the proposed cross-linguistic loss function on TANGER’s recognition performance.
Adaptive n-grams Patch Embedding The proposed adaptive n-grams embedding method aims to choose an optimal for each image patch. To demonstrate its benefit, we compare the performance of TANGER variants when is set to , respectively. The comparative results are given Table III, from which we can clearly see that the adaptive n-grams embedding has led to significant improvements in the performance for multilingual scene text recognition on both MLT17 and TsiText. Specifically, the adaptive n-grams embedding can achieve a maximum performance increase of 1.9% and 3.2% on MLT17 and TsiText, respectively, compared with the best variant with a fixed . A possible explanation is that the font sizes of different scene texts in different languages may differ dramatically, which requires an adaptive setting of the n-grams embedding.
| Dataset | Method | Accuracy |
|---|---|---|
| MLT17 | TANGER(n=2) | 46.3 |
| TANGER(n=3) | 48.6 | |
| TANGER(n=4) | 53.2 | |
| TANGER(n=5 ) | 52.8 | |
| TANGER(ours) | 55.1 | |
| TsiText | TANGER(n=2) | 84.7 |
| TANGER(n=3) | 85.6 | |
| TANGER(n=4) | 86.7 | |
| TANGER(n=5) | 85.9 | |
| TANGER(ours) | 89.9 |
Cross-language Rectification Next we consider the effect of the proposed cross-language loss functions on the performance of TANGER on the MLT17 dataset. We consider two metrics for comparison, including the character-based accuracy and the frequencies of the word-level edit distance. From the results in Table IV, we see that the accuracy of TANGER has an increase of 3.5% on MLT17 and 2.3% on TsiText with cross-language rectification loss. These results indicate that the cross-language loss is able to improve recognition performance on multilingual scenes.
| Dataset |
|
||
|---|---|---|---|
| No | Yes | ||
| MLT17 | 51.6 | 55.1 | |
| TsiText | 87.6 | 89.9 | |
V Conclusions
We have proposed a novel transformer-based architecture with adaptive n-grams embeddings and cross-language rectification to tackle complex multilingual scene text recognition. To the best of our knowledge, this is the first transformer-based approach to multilingual scene text recognition. TANGER can leverage the local neighboring visual patches with the help of the proposed adaptive n-grams embedding method, which is highly beneficial for handling complex scene texts containing multi-scale and multi-orientation texts. In addition, a cross-language loss function is suggested on the basis of a primary and supplementary transformers to effectively recognize multilingual scene texts. Finally, a new database containing complex multilingual tourism scenes is introduced, providing a challenging benchmark for multilingual scene text recognition. In the future, we plan to extend the proposed method to an end-to-end approach containing text detection. In addition, we will explore the proposed augmented transformer architecture for multi-modal text recognition tasks.
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China under Grant No. 62006053 and in part by the Program of Science and Technology of Guangzhou under Grant No. 202102020878 and No. 202102080491. Y. Jin is funded by an Alexander von Humboldt Professorship for Artificial Intelligence endowed by the German Federal Ministry of Education and Research.
References
- [1] K. Han, Y. Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y. Tang, A. Xiao, C. Xu, Y. Xu et al., “A survey on visual transformer,” arXiv preprint arXiv:2012.12556, vol. 2, no. 4, 2020.
- [2] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ade20k dataset,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 633–641.
- [3] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [4] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [5] R. Atienza, “Vision transformer for fast and efficient scene text recognition,” in International Conference on Document Analysis and Recognition. Springer, 2021, pp. 319–334.
- [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [7] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in International conference on machine learning. PMLR, 2020, pp. 1691–1703.
- [8] X. Feng, H. Yao, Y. Qi, J. Zhang, and S. Zhang, “Scene text recognition via transformer,” arXiv preprint arXiv:2003.08077, 2020.
- [9] Y. Zhu, C. Yao, and X. Bai, “Scene text detection and recognition: Recent advances and future trends,” Frontiers of Computer Science, vol. 10, no. 1, pp. 19–36, 2016.
- [10] M. Bušta, Y. Patel, and J. Matas, “E2e-mlt-an unconstrained end-to-end method for multi-language scene text,” in Asian conference on computer vision. Springer, 2018, pp. 127–143.
- [11] L. Yuliang, J. Lianwen, Z. Shuaitao, and Z. Sheng, “Detecting curve text in the wild: New dataset and new solution,” arXiv preprint arXiv:1712.02170, 2017.
- [12] B. Shi, C. Yao, M. Liao, M. Yang, P. Xu, L. Cui, S. Belongie, S. Lu, and X. Bai, “Icdar2017 competition on reading chinese text in the wild (rctw-17),” in 2017 14th iapr international conference on document analysis and recognition (ICDAR), vol. 1. IEEE, 2017, pp. 1429–1434.
- [13] C. K. Ch’ng and C. S. Chan, “Total-text: A comprehensive dataset for scene text detection and recognition,” in 2017 14th IAPR international conference on document analysis and recognition (ICDAR), vol. 1. IEEE, 2017, pp. 935–942.
- [14] Z. Xie, Y. Huang, Y. Zhu, L. Jin, Y. Liu, and L. Xie, “Aggregation cross-entropy for sequence recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6538–6547.
- [15] M. Tounsi, I. Moalla, F. Lebourgeois, and A. M. Alimi, “Multilingual scene character recognition system using sparse auto-encoder for efficient local features representation in bag of features,” arXiv preprint arXiv:1806.07374, 2018.
- [16] C. Yao, X. Bai, B. Shi, and W. Liu, “Strokelets: A learned multi-scale representation for scene text recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 4042–4049.
- [17] B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 11, pp. 2298–2304, 2016.
- [18] H. Li, P. Wang, C. Shen, and G. Zhang, “Show, attend and read: A simple and strong baseline for irregular text recognition,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 8610–8617.
- [19] F. Zhan and S. Lu, “Esir: End-to-end scene text recognition via iterative image rectification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2059–2068.
- [20] B. Shi, M. Yang, X. Wang, P. Lyu, C. Yao, and X. Bai, “Aster: An attentional scene text recognizer with flexible rectification,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 9, pp. 2035–2048, 2018.
- [21] S. Fang, H. Xie, Z.-J. Zha, N. Sun, J. Tan, and Y. Zhang, “Attention and language ensemble for scene text recognition with convolutional sequence modeling,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 248–256.
- [22] J. Huang, G. Pang, R. Kovvuri, M. Toh, K. J. Liang, P. Krishnan, X. Yin, and T. Hassner, “A multiplexed network for end-to-end, multilingual ocr,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4547–4557.
- [23] Z. Qiao, Y. Zhou, D. Yang, Y. Zhou, and W. Wang, “Seed: Semantics enhanced encoder-decoder framework for scene text recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 528–13 537.
- [24] P. Lyu, Z. Yang, X. Leng, X. Wu, R. Li, and X. Shen, “2d attentional irregular scene text recognizer,” arXiv preprint arXiv:1906.05708, 2019.
- [25] B. Na, Y. Kim, and S. Park, “Multi-modal text recognition networks: Interactive enhancements between visual and semantic features,” arXiv preprint arXiv:2111.15263, 2021.
- [26] Z. Raisi, M. A. Naiel, P. Fieguth, and S. Wardell, “2D positional embedding-based transformer for scene text recognition,” Journal of Computational Vision and Imaging Systems, vol. 6, no. 1, pp. 1–4, 2020.
- [27] A. F. Biten, R. Litman, Y. Xie, S. Appalaraju, and R. Manmatha, “Latr: Layout-aware transformer for scene-text vqa,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 548–16 558.
- [28] Y. L. Tan, A. W.-K. Kong, and J.-J. Kim, “Pure transformer with integrated experts for scene text recognition,” in European Conference on Computer Vision. Springer, 2022, pp. 481–497.
- [29] Y. Wang, H. Xie, S. Fang, M. Xing, J. Wang, S. Zhu, and Y. Zhang, “Petr: Rethinking the capability of transformer-based language model in scene text recognition,” IEEE Transactions on Image Processing, vol. 31, pp. 5585–5598, 2022.
- [30] J. Yang, Y.-G. Jiang, A. G. Hauptmann, and C.-W. Ngo, “Evaluating bag-of-visual-words representations in scene classification,” in Proceedings of the international workshop on Workshop on multimedia information retrieval, 2007, pp. 197–206.
- [31] W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 568–578.
- [32] S. Tripathi, S. K. Singh, and L. H. Kuan, “Bag of visual words (bovw) with deep features–patch classification model for limited dataset of breast tumours,” arXiv preprint arXiv:2202.10701, 2022.
- [33] A. Nanda, D. S. Chauhan, P. K Sa, and S. Bakshi, “Illumination and scale invariant relevant visual features with hypergraph-based learning for multi-shot person re-identification,” Multimedia Tools and Applications, vol. 78, no. 4, pp. 3885–3910, 2019.
- [34] N. Nguyen, T. Nguyen, V. Tran, M.-T. Tran, T. D. Ngo, T. H. Nguyen, and M. Hoai, “Dictionary-guided scene text recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7383–7392.
- [35] S. Saha, N. Chakraborty, S. Kundu, S. Paul, A. F. Mollah, S. Basu, and R. Sarkar, “Multi-lingual scene text detection and language identification,” Pattern Recognition Letters, vol. 138, pp. 16–22, 2020.
- [36] R. Saluja, D. Adiga, P. Chaudhuri, G. Ramakrishnan, and M. Carman, “Error detection and corrections in indic ocr using lstms,” in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 1. IEEE, 2017, pp. 17–22.