AugRmixAT: A Data Processing and Training Method for Improving Multiple Robustness and Generalization Performance
Abstract
Deep neural networks are powerful, but they also have shortcomings such as their sensitivity to adversarial examples, noise, blur, occlusion, etc. Moreover, ensuring the reliability and robustness of deep neural network models is crucial for their application in safety-critical areas. Much previous work has been proposed to improve specific robustness. However, we find that the specific robustness is often improved at the sacrifice of the additional robustness or generalization ability of the neural network model. In particular, adversarial training methods significantly hurt the generalization performance on unperturbed data when improving adversarial robustness. In this paper, we propose a new data processing and training method, called AugRmixAT, which can simultaneously improve the generalization ability and multiple robustness of neural network models. Finally, we validate the effectiveness of AugRmixAT on the CIFAR-10/100 and Tiny-ImageNet datasets. The experiments demonstrate that AugRmixAT can improve the model’s generalization performance while enhancing the white-box robustness, black-box robustness, common corruption robustness, and partial occlusion robustness.
Index Terms— Deep neural networks, robustness, data processing, generalization ability
1 Introduction
Deep neural networks have achieved remarkable success in a variety of fields and have been widely used in areas where reliability and security are critical, such as medical image processing [1], autonomous driving [2], and face recognition [3]. Unfortunately, recent studies [4, 5] have shown that artificially adding an imperceptible adversarial perturbation to the input image can significantly reduce the recognition ability of the neural network or guide the neural network to identify it as the characteristic wrong target. In addition to artificially designed adversarial examples, there are various common corruptions [6] and occlusions [7] in real-world environments that also affect the robustness and reliability of neural networks.
Many methods [4, 5, 8, 9, 10] have recently been proposed for defending against adversarial attacks. Among such defense methods, adversarial training has proven to be one of the most promising methods [5, 9, 10]. However, adversarial training also has a huge drawback in that it drastically reduces the generalization ability of neural networks on the original data [5, 9]. Furthermore, we find that adversarial training is similarly detrimental to occlusion robustness. Previous studies [11, 12] have also shown that improving one specific robustness is not necessarily beneficial or even harmful to another specific robustness. In our experiments, we can also discover that CutMix [13] can effectively enhance the occlusion robustness but is detrimental to noise robustness and adversarial robustness. However, for security-sensitive applications in practice, we cannot consider only a single specific robustness, but multiple aspects of robustness and generalization performance of neural network models.
To address the above issues, we propose AugRmixAT, a new data processing and training method that can simultaneously improve the multiple robustness and generalization performance of neural network models. AugRmixAT utilizes traditional data augmentation, mixed data augmentation [14, 13, 15, 16] between different samples, and data augmentation with added adversarial perturbation to process and generate multiple different sets of augmented data. To ensure the generalization performance on clean data (standard test data), AugRmixAT uses both soft cross-entropy and Jensen-Shannon divergence [17] consistent loss to train multiple sets of augmented data in a surrogate manner. Finally, we experimented on CIFAR-10/100 and Tiny-ImageNet [18] and showed that AugRmixAT can simultaneously improve white-box robustness, black-box robustness, 19 common corruption robustness on CIFAR-10/100, 15 common corruption robustness on Tiny-ImageNet, partial occlusion robustness, and generalization performance on clean data.
2 Related Work
Data Augmentation. Data augmentation is a very practical and powerful technique to increase the diversity of training datasets, enhance the generalization ability of neural networks and prevent overfitting [19]. For instance, some of the most commonly used data augmentations in computer vision are geometric transformations, flipping, color modification, cropping, rotation, translation, noise injection and random erasing [20]. Recently, mixed sample data augmentation methods have gained tremendous attention and a series of mixed sample data augmentation methods [14, 13, 15, 16] have been proposed. Mixup [14] is the first proposed mixed sample data augmentation that mixes two different samples in a convex combination to generate a new training sample and corresponding label. Combining the ideas of Mixup and Cutout [7], CutMix [13] uses cutting and pasting patches between training images for mixing, and ground truth labels are also proportionally mixed with patch regions. Fmix [15] uses a random binary mask obtained by applying a threshold to low-frequency images sampled from Fourier space to further improve the shape of CutMix mixed patches. To solve the problem of label misallocation and object information missing in CutMix, ResizeMix [16] mixes training data by directly resizing the source image to a small patch and then pasting it on another image. AugMix [21] is proposed to improve both the generalization performance and the corruption robustness by mixing common data augmentation.
Adversarial Training (AT). Adversarial training, which augments training dataset with adversarial examples, is one of the most effective methods of defending against adversarial attacks [4, 5, 9, 10]. Therefore, we can also consider adversarial training as a data augmentation technique. Goodfellow et al. [4] proposed the Fast Gradient Sign Method (FGSM), which is a simple and fast method to generate adversarial examples for adversarial training. Projected Gradient Descent (PGD) [5] adversarial training leverages the PGD attack to generate adversarial examples and trains only with the adversarial examples. Zhang et al. [9] proposed TRADES to specifically maximize the trade-off of adversarial training between adversarial robustness and standard accuracy. Lamb et al. [10] proposed Interpolated Adversarial Training(IAT), which trains on interpolations of adversarial examples along with interpolations of unperturbed examples and improves adversarial robustness without sacrificing too much standard accuracy.
3 AugRmixAT
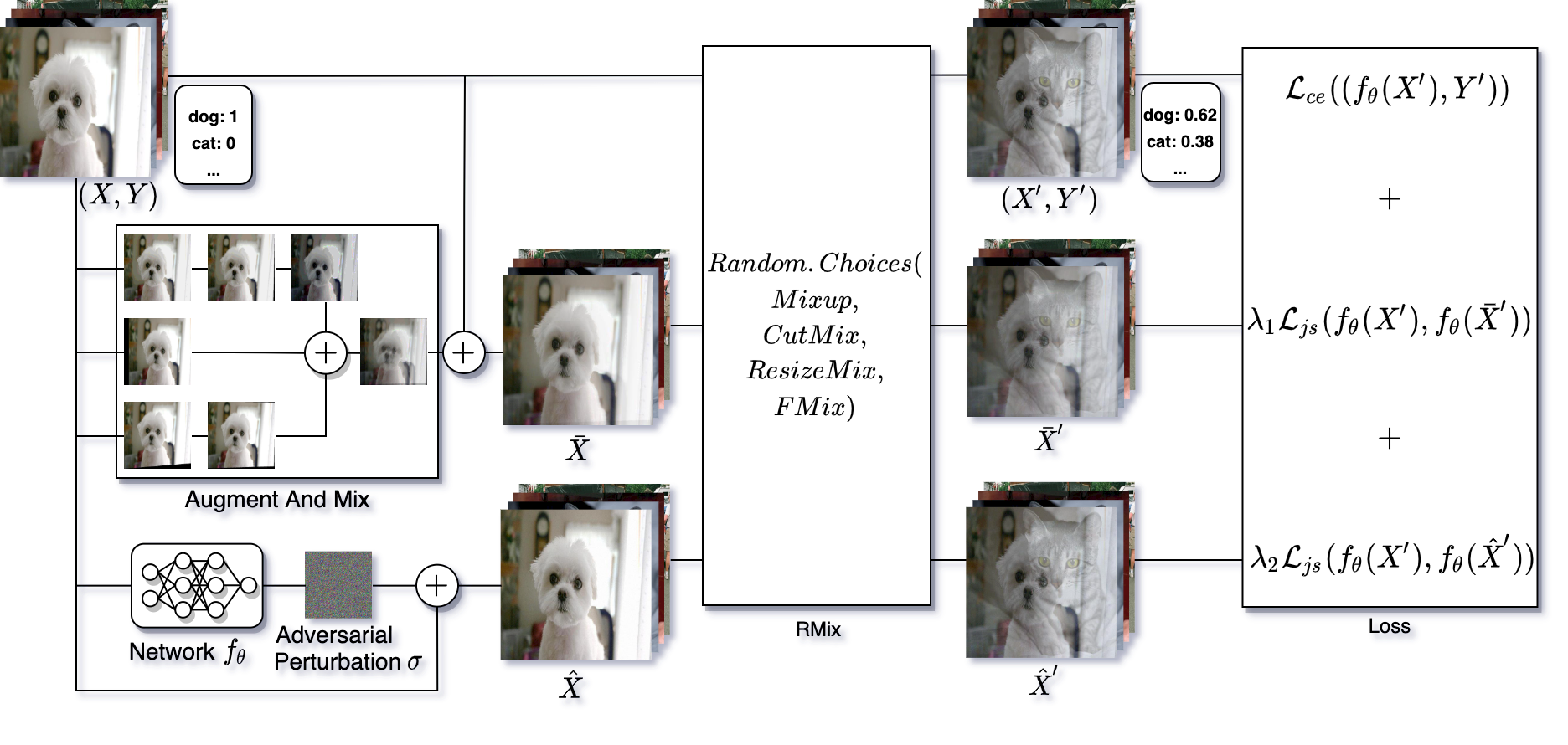
Previous data augmentation [14, 13, 21] and adversarial training [5, 9, 10] methods can effectively improve specific robustness or generalization performance, but they are difficult to improve multiple robustness and generalization abilities of deep neural network models simultaneously. In particular, most adversarial training [5, 9, 10] tends to sacrifice standard accuracy when enhancing adversarial robustness. AugRmixAT is an image data processing and training method that can simultaneously improve multiple robustness and generalization performance of models and is easy to slot into existing training pipelines. Figure 1 shows an example of AugRmixAT. First, a batch of input images is used to generate data by “Augment And Mix” data augmentation and to generate adversarial samples by adding adversarial perturbations, respectively. Next, , , and are processed with mixed sample data augmentation to generate , , and . The corresponding mixed labels are also generated using the labels . Finally, we use a soft cross-entropy loss and Jensen-Shannon divergence consistent loss to train , , and .
Augment And Mix. We use the same “Augment And Mix” operation as AugMix [21]. The “Augment And Mix” operation starts by randomly selecting multiple augmentations from the base augmentation set to form multiple augmentation chains and producing multiple augmentation samples through the augmentation chains. Then, multiple augmentation samples are mixed through a random convex combination sampled from a Dirichlet() distribution. Finally, we combine this mixed sample with the original sample through a second random convex combination sampled from a Bata() distribution. In the experiment, we put to 1 and the number of augmentation chains to 3. Each augmentation chain consists of 1 to 3 random base augmentation operations. Our base data augmentation set contains , , , , , .
Adversarial examples. We apply PGD [5] adversarial attacks to generate adversarial examples, which can be expressed as
| (1) | ||||
where is the Gaussian distribution function with zero mean and identity variance, is the adversarial perturbation budget, is the perturbation step size, represents a neighborhood of , is the sign function, is the KL divergence loss function, denotes the neural network with parameters .
Mixed Sample Data Augmentation. To further obtain more diverse training data, we simultaneously perform the same mixed sample data augmentation operation on the original images , the “Augment And Mix” enhanced images , and the adversarial examples . In our work, we integrate multiple mixed sample data augmentation [5, 9, 10] in a randomly chosen manner. Our mixed sample data augmentation operates as follows,
| (2) | ||||
where is the random permutation function, is the random choice function, is the corresponding mixing ratio.
Loss Function. To ensure the generalization ability of the model and to improve the robustness of the model, we use the Jensen-Shannon divergence consistent loss function to train the mixed “Augment And Mix” enhanced data and mixed adversarial examples in a surrogate manner. Our loss function is defined as
| (3) | ||||
where and are two regularization hyperparameters. The detailed algorithm is described in Algorithm Block 1.
| Noise | Blur | Weather | Digital | |||||||||||||||||
| Model | Gauss. | Shot | Impulse | Speckle | Defocus | Glass | Motion | Zoom | Gauss. | Snow | Frost | Fog | Spatter | Bright | Contrast | Elastic | Pixel | Saturate | JPEG | mCE |
| Standard | 52.64 | 39.49 | 48.86 | 35.44 | 14.13 | 43.36 | 18.18 | 16.10 | 20.71 | 14.29 | 16.96 | 9.13 | 14.24 | 5.11 | 18.80 | 14.00 | 22.41 | 6.73 | 20.83 | 22.71 |
| Mixup | 32.40 | 29.68 | 33.39 | 27.11 | 11.03 | 32.4 | 13.61 | 14.13 | 22.27 | 8.16 | 7.52 | 7.83 | 6.53 | 4.06 | 21.97 | 11.38 | 22.01 | 5.56 | 17.23 | 17.65 |
| CutMix | 79.40 | 68.68 | 61.24 | 66.91 | 15.87 | 44.70 | 19.06 | 20.45 | 28.56 | 12.25 | 18.48 | 8.16 | 7.85 | 4.84 | 13.36 | 14.74 | 30.25 | 7.04 | 29.93 | 29.04 |
| AugMix | 16.38 | 11.83 | 9.83 | 10.41 | 4.17 | 19.17 | 5.46 | 5.22 | 4.63 | 7.67 | 7.66 | 5.65 | 5.18 | 3.85 | 5.81 | 8.08 | 10.29 | 5.54 | 11.50 | 8.33 |
| PGDAT | 18.29 | 16.98 | 30.43 | 17.06 | 18.49 | 20.33 | 22.84 | 19.59 | 21.06 | 19.46 | 22.85 | 41.16 | 17.97 | 16.50 | 55.51 | 19.44 | 15.34 | 16.81 | 15.41 | 22.40 |
| TRADES () | 17.75 | 16.60 | 27.94 | 16.73 | 18.15 | 20.35 | 22.38 | 19.40 | 20.59 | 19.44 | 23.75 | 40.06 | 17.53 | 16.57 | 54.54 | 19.35 | 15.10 | 16.63 | 15.04 | 22.00 |
| TRADES () | 19.56 | 18.62 | 29.35 | 19.04 | 19.82 | 21.51 | 24.30 | 20.81 | 22.00 | 21.08 | 25.46 | 40.96 | 19.44 | 18.41 | 56.47 | 20.91 | 16.84 | 18.41 | 16.85 | 23.68 |
| IAT | 15.48 | 13.78 | 27.68 | 14.08 | 8.73 | 15.18 | 10.90 | 10.33 | 13.61 | 10.05 | 9.23 | 10.29 | 7.59 | 6.63 | 19.30 | 9.67 | 11.73 | 7.59 | 11.32 | 12.27 |
| AugRmixAT-1-1 | 13.71 | 11.19 | 7.33 | 10.54 | 3.10 | 18.56 | 5.45 | 4.11 | 3.82 | 5.45 | 6.18 | 4.26 | 3.03 | 2.97 | 8.05 | 5.98 | 15.26 | 3.93 | 10.73 | 7.56 |
| AugRmixAT-1-32 | 14.69 | 13.67 | 17.46 | 13.76 | 15.09 | 17.87 | 18.56 | 16.11 | 16.91 | 16.70 | 19.46 | 32.36 | 14.39 | 14.07 | 49.29 | 16.46 | 12.97 | 14.39 | 13.21 | 18.25 |
| White-box attacks | |||||
| Model | Clean | FGSM | PGD10 | PGD20 | CW20 |
| Standard | 96.06 | 56.30 | 5.10 | 0.76 | 0.22 |
| Mixup | 97.12 | 65.71 | 14.21 | 2.99 | 0.99 |
| CutMix | 96.90 | 41.40 | 4.37 | 1.63 | 0.55 |
| AugMix | 96.49 | 53.38 | 4.01 | 0.23 | 0.09 |
| PGDAT | 87.06 | 59.04 | 62.13 | 51.11 | 50.81 |
| TRADES () | 87.37 | 59.21 | 61.46 | 50.50 | 50.27 |
| TRADES () | 85.35 | 59.37 | 61.84 | 51.79 | 52.70 |
| IAT | 95.27 | 86.59 | 63.39 | 53.49 | 54.15 |
| AugRmixAT-1-1 | 98.17 | 88.01 | 66.22 | 53.21 | 54.33 |
| AugRmixAT-1-32 | 89.14 | 65.88 | 67.81 | 57.50 | 56.47 |
| Defense | Attack model | |||
|---|---|---|---|---|
| model | Standard | PGDAT | TRADES | IAT |
| PGDAT | 86.40 | - | 69.38 | 77.44 |
| TRADES () | 86.60 | 68.69 | - | 76.87 |
| IAT | 89.81 | 77.01 | 76.70 | - |
| AugRmixAT-1-1 | 91.96 | 87.37 | 87.53 | 83.57 |
| AugRmixAT-1-32 | 88.49 | 75.20 | 74.69 | 79.60 |
| Model | Untargeted | Targeted | Mean |
|---|---|---|---|
| Standard | 77.58 | 76.41 | 77.00 |
| Mixup | 81.24 | 82.69 | 81.97 |
| CutMix | 90.95 | 92.59 | 91.77 |
| AugMix | 78.47 | 77.60 | 78.03 |
| PGDAT | 56.49 | 66.22 | 61.36 |
| TRADES () | 57.77 | 63.14 | 58.95 |
| TRADES () | 54.77 | 63.14 | 58.95 |
| IAT | 69.63 | 78.87 | 74.25 |
| AugRmixAT-1-1 | 91.04 | 93.66 | 92.35 |
| AugRmixAT-1-32 | 75.44 | 80.79 | 78.12 |
4 Experiments
4.1 Implementation Details
We use the same neural network architecture as in previous works [5, 9], i.e., WideResNet-34-10 [22], for experiments on CIFAR-10/100 and PreAct-ResNet18 [23] for experiments on Tiny-ImageNet [18]. Except for the different neural network architecture, other settings and hyperparameters are the same for all datasets. We apply the momentum stochastic gradient descent optimizer on both CIFAR-10/100 and Tiny-ImageNet. The initial learning rate is set to 0.1 and decays with the cosine annealing schedule [24]. We set the momentum as 0.9 and use the weight decay of . The batch size for training is set to and the maximum number of epochs is set to 200. The following is the setting of our main comparison method in the experiment.
Standard: The model trained on the original data does not use any data augmentation methods.
Mixup, CutMix, AugMix: The models trained using data augmentation methods Mixup [14], CutMix [13] and AugMix [21] respectively.
PGDAT, TRADES, IAT: The models trained using PGD Adversarial Training (PGDAT) [5], TRADES [9], and Interpolated Adversarial Training (IAT) [10] respectively, where the perturbation budget are set to 0.031, the perturbation step size are set to 0.007, and the number of iterations are set to 10. The way of combining examples in IAT is Mixup.
AugRmixAT-1-1, AugRmixAT-1-32: The models trained using our proposed method, in which the perturbation budget , the perturbation step size , and the number of iterations are set the same as in PGDAT, TRADES, and IAT. “-1-1” means . “-1-32” means .
Additionally, all experiments were implemented and evaluated on the PyTorch [25] platform with four NVIDIA Tesla V100 GPUs.
4.2 CIFAR-10
Evaluation on White-box Robustness. The results of the white-box robustness on CIFAR-10 are shown in Table 2. We evaluate the robustness of all models against three types of white-box attacks for CIFAR-10, i.e., FGSM [4], PGD [5], and CW [26] (PGD with CW loss). For FGSM, we set the perturbation budget as 0.031. For PGD10, PGD20, and CW20, we set the perturbation budget to 0.031 and the perturbation step size to 0.003. PGD10 set the number of iterations as 10. PGD20 and CW20 set the number of iterations as 20.
We can see from Table 2 that all the compared adversarial training methods reduce the Clean accuracy, but the AugRmixAT-1-1 model trained by our method can improve the Clean accuracy. Moreover, it is 1.05% higher than the Mixup. Under the FSGM attack, the AugRmixAT-1-1 model has the best robust accuracy. Under the attacks of PGD10, PGD20 and CW20 respectively, the AugRmixAT-1-32 model achieves the best robust accuracy. In particular, the robust accuracy rate on PGD20 of the AugRmixAT-1-32 model is 6.39% higher than PGDAT, 5.71% higher than TRADES (), and 4.01% higher than IAT.
Evaluation on Black-box Robustness. We use transfer-based black-box attacks [27] to evaluate the black-box robustness of the model. We first use each trained model to construct adversarial examples by PGD and then apply these adversarial examples to other models and evaluate their performance. We set the perturbation budget as 0.031, the perturbation step size as 0.003, and the number of iterations as 10. The results of the black-box robustness on CIFAR-10 are reported in Table 3. Again, the AugRmixAT-1-1 model trained by our method achieves higher robustness than the other models.
Evaluation on Common Corruptions Robustness. We evaluate the robustness of various common corruptions on the CIFAR-10-C [6], which consists of 19 types of corruption. Moreover, each type of corruption has 5 levels of severity.
Following prior works [6, 21], we adopt Corruption Error (CE) [6] to measure the common corruption robustness and mCE denotes the mean Corruption Error of the 19 corruption. As shown in Table 1, the AugRmixAT-1-1 model trained by our proposed method achieves the lowest CE on 15 of 19 common corruptions. Moreover, the mCE of AugRmixAT-1-1 is also the lowest, 0.77% lower than Augmix, 15.15% lower than Standard, 14.84% lower than PGDAT, and 4.71% lower than IAT.
Evaluation on Partial Occlusion Robustness. Compared to corruption and adversarial example attacks, partial occlusion should be more common. We use untargeted random partial occlusion and targeted random partial occlusion to evaluate the robustness of the model under partial occlusion attacks. Untargeted occlusion blocks are filled with 0 and targeted occlusion blocks are from other objects. For untargeted partial occlusion we used the Top1 robust accuracy metric and for targeted partial occlusion we used the Top2 robust accuracy. From Table 4, we can find that the previous adversarial training methods PGDAT, TRADES and IAT are difficult to defend against partial occlusion attacks and are even detrimental to the robustness of partial occlusion. In contrast, our method can not only effectively improve both targeted and untargeted occlusion robust accuracy, but also has a robust accuracy rate of 0.09% higher than CutMix in the untargeted occlusion and 1.07% higher than CutMix in the targeted occlusion. Furthermore, AugRmixAT-1-1 achieves the best performance under partial occlusion attacks, and far outperformed the models trained by other adversarial training methods.
| CIFAR-100 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| White-box attacks | Black-box attacks | ||||||||
| Model | Clean | FGSM | PGD10 | PGD20 | CW20 | Standard | PGDAT | Corr | Occ |
| Standard | 80.12 | 24.26 | 2.09 | 0.55 | 0.25 | - | 62.38 | 51.53 | 54.64 |
| Mixup | 82.53 | 40.19 | 0.52 | 0.05 | 0.00 | 56.44 | 68.03 | 58.49 | 60.73 |
| CutMix | 82.38 | 19.73 | 0.66 | 0.12 | 0.00 | 34.46 | 61.47 | 48.20 | 71.95 |
| AugMix | 80.21 | 19.54 | 1.52 | 0.38 | 0.14 | 68.42 | 68.63 | 68.75 | 54.65 |
| PGDAT | 61.16 | 30.76 | 33.95 | 26.48 | 25.43 | 60.79 | - | 48.72 | 35.12 |
| TRADES () | 60.60 | 30.83 | 33.74 | 26.67 | 25.99 | 60.01 | 43.22 | 48.50 | 33.61 |
| TRADES () | 56.30 | 29.63 | 32.64 | 25.78 | 25.53 | 55.75 | 41.83 | 45.63 | 30.79 |
| IAT | 75.79 | 58.07 | 33.79 | 24.95 | 20.27 | 68.94 | 53.55 | 61.49 | 50.15 |
| AugRmixAT-1-1 | 84.83 | 66.50 | 36.51 | 25.94 | 22.15 | 76.89 | 71.55 | 71.31 | 74.21 |
| AugRmixAT-1-32 | 65.93 | 37.59 | 38.49 | 30.18 | 28.50 | 65.05 | 49.58 | 55.20 | 56.38 |
| Tiny-ImageNet | |||||||||
| White-box attacks | Black-box attacks | ||||||||
| Model | Clean | FGSM | PGD10 | PGD20 | CW20 | Standard | PGDAT | Corr | Occ |
| Standard | 63.90 | 1.07 | 0.10 | 0.00 | 0.00 | - | 48.45 | 24.31 | 49.34 |
| Mixup | 64.66 | 0.94 | 0.00 | 0.00 | 0.00 | 20.68 | 51.07 | 27.84 | 50.62 |
| CutMix | 67.78 | 2.75 | 0.02 | 0.00 | 0.00 | 13.80 | 53.44 | 24.63 | 62.26 |
| AugMix | 62.46 | 2.83 | 0.16 | 0.03 | 0.00 | 30.69 | 47.19 | 33.57 | 45.35 |
| PGDAT | 45.86 | 15.60 | 18.78 | 12.64 | 12.55 | 44.08 | - | 18.24 | 28.06 |
| TRADES () | 47.60 | 14.93 | 18.36 | 11.95 | 11.63 | 41.39 | 32.47 | 18.74 | 30.02 |
| TRADES () | 43.08 | 19.65 | 23.14 | 17.69 | 14.89 | 44.09 | 31.56 | 18.09 | 26.93 |
| IAT | 54.20 | 17.37 | 20.64 | 13.00 | 10.99 | 41.40 | 38.05 | 24.39 | 34.67 |
| AugRmixAT-1-1 | 69.64 | 42.79 | 14.42 | 7.13 | 3.48 | 44.91 | 54.14 | 35.93 | 62.66 |
| AugRmixAT-1-32 | 52.90 | 26.27 | 28.70 | 22.20 | 16.96 | 50.24 | 39.22 | 24.56 | 42.91 |
| White-box attacks | ||||||||
|---|---|---|---|---|---|---|---|---|
| Clean | FGSM | PGD10 | PGD20 | CW20 | Corr | Occ | ||
| 1 | 1 | 96.91 | 79.81 | 62.43 | 49.23 | 47.12 | 89.28 | 90.16 |
| 2 | 1 | 96.89 | 80.66 | 61.20 | 46.95 | 44.41 | 90.34 | 89.01 |
| 3 | 1 | 96.95 | 80.42 | 58.84 | 40.69 | 36.88 | 90.27 | 89.85 |
| 4 | 1 | 96.94 | 80.63 | 57.99 | 40.33 | 36.74 | 90.64 | 88.65 |
| 5 | 1 | 96.82 | 79.88 | 57.43 | 39.00 | 34.69 | 91.05 | 89.33 |
| 1 | 2 | 96.34 | 79.68 | 65.20 | 52.78 | 50.78 | 89.46 | 88.98 |
| 1 | 4 | 94.33 | 77.26 | 65.12 | 52.59 | 50.21 | 87.55 | 85.87 |
| 1 | 8 | 89.94 | 59.73 | 63.16 | 50.70 | 48.19 | 82.50 | 78.10 |
| 1 | 16 | 88.05 | 60.03 | 64.18 | 53.17 | 50.06 | 79.93 | 73.88 |
| 1 | 32 | 84.81 | 59.61 | 63.66 | 54.86 | 51.83 | 76.41 | 69.52 |
4.3 CIFAR-100 and Tiny-ImageNet
We also verify the effectiveness of our method on CIFAR-100 and Tiny-ImageNet. The results are presented in Table 5. In Tables 5, “Corr” is the common corruptions robustness, evaluated using the mean corruption accuracy (mCAmCE), “Occ” is the partial occlusion robustness, evaluated using the mean of Top1 untargeted occlusion robust accuracy and Top2 targeted occlusion robust accuracy. The other settings are the same as on the CIFAR-10.
4.4 Sensitivity of hyperparameters and
We apply PreAct-ResNet18 [23] to implement regularization hyperparameters and sensitivity experiments on CIFAR-10. The other settings are the same as the above experiments. We can observe from Table 6 that as the hyperparameters parameter increases, the common corruptions robust accuracy increases while the adversarial robust accuracy decreases. Moreover, as the hyperparameters parameter increases, the clean accuracy, the common corruptions robust accuracy, and the partial occlusion robust accuracy decrease while the adversarial robust accuracy increases. This also verifies that when improving only one specific robustness, it is often detrimental to the robustness of another one or more. In practical applications, we recommend setting both regularization hyperparameters and to 1, which can effectively improve the generalization performance and multiple robustness of the model.
5 Conclusion
We propose AugRmixAT, which is a new image data processing and training method. Unlike previous data augmentation and adversarial training, our method not only improves the generalization performance of neural network models but also improves a variety of robustness including white-box robustness, black-box robustness, common corruption robustness, and partial occlusion robustness. Moreover, AugRmixAT can be easily inserted into existing training pipelines, and we believe it can make neural networks used in real-world applications more reliable and secure.
References
- [1] Dinggang Shen, Guorong Wu, and Heung-Il Suk, “Deep learning in medical image analysis,” Annual review of biomedical engineering, vol. 19, pp. 221–248, 2017.
- [2] Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu, “A survey of deep learning techniques for autonomous driving,” Journal of Field Robotics, vol. 37, no. 3, pp. 362–386, 2020.
- [3] Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter, “Adversarial generative nets: Neural network attacks on state-of-the-art face recognition,” arXiv preprint arXiv:1801.00349, 2017.
- [4] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
- [5] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu, “Towards deep learning models resistant to adversarial attacks,” in International Conference on Learning Representations (ICLR), 2018.
- [6] Dan Hendrycks and Thomas Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,” International Conference on Learning Representations (ICLR), 2019.
- [7] Terrance DeVries and Graham W Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv:1708.04552, 2017.
- [8] Ali Dabouei, Sobhan Soleymani, Fariborz Taherkhani, Jeremy Dawson, and Nasser M Nasrabadi, “Exploiting joint robustness to adversarial perturbations,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1122–1131.
- [9] Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan, “Theoretically principled trade-off between robustness and accuracy,” in International Conference on Machine Learning (ICML), 2019.
- [10] Alex Lamb, Vikas Verma, Juho Kannala, and Yoshua Bengio, “Interpolated adversarial training: Achieving robust neural networks without sacrificing too much accuracy,” in Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, 2019.
- [11] Ludwig Schmidt, Shibani Santurkar, Dimitris Tsipras, Kunal Talwar, and Aleksander Madry, “Adversarially robust generalization requires more data,” in Neural Information Processing Systems (NeurIPS), 2018.
- [12] Logan Engstrom, Brandon Tran, Dimitris Tsipras, Ludwig Schmidt, and Aleksander Madry, “Exploring the landscape of spatial robustness,” in International Conference on Machine Learning (ICML), 2019.
- [13] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” IEEE International Conference on Computer Vision (ICCV), 2019.
- [14] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz, “mixup: Beyond empirical risk minimization,” International Conference on Learning Representations (ICLR), 2018.
- [15] Ethan Harris, Antonia Marcu, Matthew Painter, Mahesan Niranjan, and Adam Prügel-Bennett Jonathon Hare, “Fmix: Enhancing mixed sample data augmentation,” International Conference on Learning Representations (ICLR), 2021.
- [16] Jie Qin, Jiemin Fang, Qian Zhang, Wenyu Liu, Xingang Wang, and Xinggang Wang, “Resizemix: Mixing data with preserved object information and true labels,” arXiv preprint arXiv:2012.11101, 2020.
- [17] Dominik Maria Endres and Johannes E Schindelin, “A new metric for probability distributions,” IEEE Transactions on Information theory, 2003.
- [18] Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter, “A downsampled variant of imagenet as an alternative to the cifar datasets,” arXiv preprint arXiv:1707.08819, 2017.
- [19] Christopher M Bishop, “Pattern recognition,” 2006.
- [20] Connor Shorten and Taghi M Khoshgoftaar, “A survey on image data augmentation for deep learning,” Journal of Big Data, vol. 6, no. 1, pp. 1–48, 2019.
- [21] Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan, “AugMix: A simple data processing method to improve robustness and uncertainty,” International Conference on Learning Representations (ICLR), 2020.
- [22] Sergey Zagoruyko and Nikos Komodakis, “Wide residual networks,” arXiv preprint arXiv:1605.07146, 2016.
- [23] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Identity mappings in deep residual networks,” in European Conference on Computer Vision (ECCV), 2016.
- [24] I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,” in International Conference on Learning Representations (ICLR), 2017.
- [25] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer, “Automatic differentiation in pytorch,” 2017.
- [26] Nicholas Carlini and David Wagner, “Towards evaluating the robustness of neural networks,” in IEEE Symposium on Security and Privacy (SP), 2017.
- [27] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami, “Practical black-box attacks against machine learning,” in Proceedings of the 2017 ACM on Asia conference on computer and communications security, 2017.