Automatically Generating Counterfactuals for Relation Classification
Abstract
The goal of relation classification (RC) is to extract the semantic relations between/among entities in the text. As a fundamental task in natural language processing, it is crucial to ensure the robustness of RC models. Despite the high accuracy current deep neural models have achieved in RC tasks, they are easily affected by spurious correlations. One solution to this problem is to train the model with counterfactually augmented data (CAD) such that it can learn the causation rather than the confounding. However, no attempt has been made on generating counterfactuals for RC tasks.
In this paper, we formulate the problem of automatically generating CAD for RC tasks from an entity-centric viewpoint, and develop a novel approach to derive contextual counterfactuals for entities. Specifically, we exploit two elementary topological properties, i.e., the centrality and the shortest path, in syntactic and semantic dependency graphs, to first identify and then intervene on the contextual causal features for entities. We conduct a comprehensive evaluation on four RC datasets by combining our proposed approach with a variety of backbone RC models. The results demonstrate that our approach not only improves the performance of the backbones, but also makes them more robust in the out-of-domain test.
1 Introduction
Relation classification (RC) aims to extract the semantic relations between/among entities in the text. It serves as a fundamental task in natural language processing (NLP), which facilitates a range of downstream applications such as knowledge graph construction and question answering. Deep neural models have made substantial progress in many communities like computer vision and NLP. However, existing studies (Jo and Bengio, 2017; Zhou et al., 2016a) have shown that neural models are likely to be unstable due to the spurious correlations. A typical example is the dog on the grass or in the sea, where the head of the dog is the causation and the grass is a confounding. The robustness and generalization of the models can be severely affected by spurious correlations. Consequently, it is desirable to train robust models by identifying what features would need to change for the model to produce a specified output (label).
One solution to train a robust neural model is to generate counterfactually augmented data (CAD) (Kaushik et al., 2020) such that the model can distinguish causal and spurious patterns. There has been an increasing interest in generating counterfactuals in many subfields of NLP, including sentiment classification (Yang et al., 2021; Chen et al., 2021; Wang and Culotta, 2021), named entity recognition (Zeng et al., 2020), dialogue generation (Zhu et al., 2020), and cross-lingual understanding (Yu et al., 2021). Early research often employs human annotators and designs human-in-the-loop systems (Kaushik et al., 2020; Srivastava et al., 2020). Most of recent studies automatically generate counterfactuals with semantic interventions using templates, lexical and paraphrase changes, and text generation methods (Madaan et al., 2021; Fern and Pope, 2021; Robeer et al., 2021), and a few of them incorporate the syntax into language models (Yu et al., 2021).
Despite the emerging trend of casual analysis in the NLP field, automatically generating CAD for RC tasks has received little attention. The key challenge is that the RC task involves two or more entities which should remain unchanged during the intervention, otherwise the problem itself also changes. Existing semantic intervention methods tend to select content words for generating counterfactuals. The reason is that they follow “the minimal change” principle (Kaushik et al., 2020; Yang et al., 2021), where the content words like entities have a larger probability to be replaced since they convey more information than function words. This is not desirable in our task. The syntactic intervention method (Yu et al., 2021) replaces each type of dependency relation between two words with a randomized one. Such a method cannot flip the label in our RC task, either.
In view of this, we introduce the problem of automatically generating CAD into RC tasks for the first time. To meet the condition of invariant entities, we formulate it from an entity-centric viewpoint. We then develop a novel approach to derive counterfactuals for the contexts of entities. Instead of directly manipulating the raw text, we deploy semantic dependency graph (SemDG) and syntactic dependency graph (SynDG) as they contain abundant information. We exploit two elementary topological properties to identify contextual casual features for entities. In particular, the centrality measures the importance of the word in the SynDG, which helps us recognize structurally similar entities in two samples. Meanwhile, the shortest path between two entities in SemDG captures the basic relation between them. We then generate CAD by intervening on the contextual words around one specific entity and those along the shortest path between two entities.
The contributions of this study are summarized as follows.
To the best of our knowledge, we are the first to investigate the problem of automatical generation of CAD in RC tasks, which can improve the model robustness and is an essential property for real applications.
We propose a novel approach which exploits the topology structures in both the semantic and syntactic dependency graphs to generate more human-like counterfactuals for each original sample.
Extensive experiments on four benchmark datasets prove that our approach significantly outperforms the state-of-the-art baselines. It is also more effective for alleviating spurious associations and improving the model robustness.
2 Related Work
Relation Classification
Deep learning models have been successfully employed in RC tasks, either for extracting better semantic features from word sequences (Zhou et al., 2016b; Zhang et al., 2017), or incorporating syntactic features over the dependency graph (Guo et al., 2019; Mandya et al., 2020). More recently, pre-trained language model (PLM) based models have become the mainstream (Qin et al., 2021; Yamada et al., 2020).
Despite the remarkable performance deep neural models have achieved in RC, their realization in practical applications still faces big challenges. One particular concern is that these models might learn unexpected behaviors that are associated with spurious patterns.
Counterfactual Reasoning
There has been a growing line of research to learn casual associations using casual inference. Early work attempts to achieve model robustness with the help of human-in-the-loop systems to generate counterfactual augmented data (Kaushik et al., 2020; Srivastava et al., 2020). Recently, automatically generating counterfactuals has received more and more attention. For example, Wang and Culotta (2021); Yang et al. (2021) identify causal features and generate counterfactuals by substituting them with other words for sentiment analysis and text classification. Yu et al. (2021) generate counterfactually examples by randomly replacing syntactic features to implicitly force the networks to learn semantics and syntax. Another line of work deploys PLMs to obtain a universal counterfactual generator for texts (Fern and Pope, 2021; Robeer et al., 2021; Madaan et al., 2021; Wu et al., 2021; Tucker et al., 2021).
Overall, the problem of automatical generation of CAD has not been explored in RC tasks. Our work makes the first attempt on it. Furthermore, our proposed framework takes advantage of both syntax and semantic information in dependency graphs, which allows us to generate grammatically correct and semantically readable counterfactuals.
3 Preliminary
3.1 Task Definition
Relation Classification (RC)
Relation classification tasks are mainly categorized into three types: sentence-level RC, cross-sentence -ary RC, and document-level RC. Our proposed model is targeted for the first two types and can be extended to the last one which we leave for the future work. Formally, let = [, …, ] be a text consisting of sentence(s) with tokens and two or three entity mentions. = {, …, , } ( = None) is a predefined relation set. The RC task can be formulated as a classification problem of determining whether a relation holds for entity mentions.
Generating Counterfactuals in RC
Given a RC dataset {(,)} and the model f: , we aim to generate a set of counterfactuals {(,)} () without changing entities. For the purpose of training a robust model, it is desirable to make as similar to as possible (Yang et al., 2021), i.e., is syntactic-preserving and semantic-reasonable.
3.2 Structural Causal Model
We introduce the structure casual model (SCM) (Judea, 2000) to investigate the casual relationship between data and the RC model, where random variables are vertices and an edge denotes the direct causation between two variables. Before start, we first propose our casual questions to guide the generation of SCM. (1) What would happen if the important syntactic structure SY around the entity is changed? (2) What would happen if the semantic path SE between two entities in the text changes?
Based on the casual questions, we consider two important factors and as variables in SCM to capture the casual relation in the text. As shown in Figure 1(a), there is a confounding variable that influences the generation of and , is the label variable, and represents the unmeasured variable. means there exits a direct effect from to . Furthermore, the path / denotes / has an indirect effect on via a mediator . can be calculated from the values of its ancestor nodes, which is formulated as: , where is the value function of .
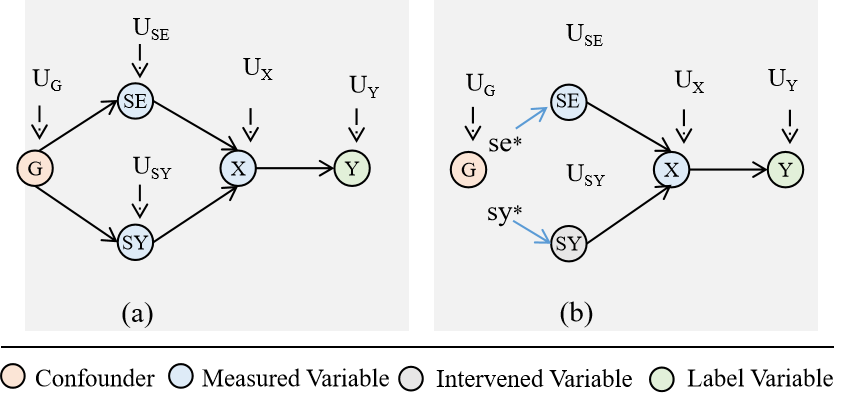
In order to estimate the casual effects of the variable / on the target variable , we need to block the influence of the confounding variable on /, and see how is changed by a unit intervention when fixing the value of / as ∗/∗, as shown in Figure 1(b).
4 Model Overview
This section presents our approach for automatically generating counterfactuals by substituting casual compositions with candidate ones to enhance the robustness of RC models. One of our key insights is adopting the graph formulation to incorporate the rich information in syntactic dependency graph (SynDG) and semantic dependency graph (SemDG).
SynDG pays attention to the role of non-substantive words such as prepositions in the sentence. Existing work (Guo et al., 2019) has shown the effectiveness by applying SynDGs to RC models with graph convolutional networks. We also exploit SynDG in this study but our goal is to identify causal syntactic features. Moreover, we introduce SemDG into the field of causality analysis. Our intuition is that SemDG reveals the semantic relationship between substantive words, and crosses the constraints of the surface syntactic structure. In other words, SemDG provides complementary information for SynDG.
A counterfactual, denoted as , is a sample which has the most similar semantic or syntactic structure with the original sample but has a different label. Recall that we cannot change the entities during the interventions for samples in RC tasks, hence we propose our entity-centric framework to generate counterfactuals by first identifying and then intervening on contextual casual features for entities via topological based analysis in SynDG and SemDG. The identification of causal features consists of two main steps.
-
•
To identify the syntactic casual composition around the entity, we conduct the centrality analysis for entities in two samples since centrality measures how importance a node is in the graph.
-
•
To identify the semantic casual composition between two entities, we employ the shortest dependency path (SDP) between them since SDP retains the most relevant information while eliminating irrelevant words (noises) in the sentence (Xu et al., 2015).
4.1 Generating Syntactic Counterfactuals
Since a counterfactual should flip the label of the original sample , the candidate substitute which will be used for identifying causal features is randomly chosen from the training samples with different class labels 111In our implementation, we randomly select three candidate substitutes for the original sample. If none of generated candidates meets the requirements, they will all be discarded. If there are multiple candidates qualified as counterfactuals, one of them is chosen at random.. Moreover, since entities are of the most importance in RC tasks, the entities in the substitute should be most similar with those in . In view of this, we first identify the syntactically similar entity nodes in SynDG using the centrality metric, which is proposed to account for the importance of nodes in a graph (network). We employ three types of centralities including betweenness centrality (BC), closeness centrality (CC), and degree centrality (DC) for this purpose. After that, we generate the contextual counterfactual for these syntactically similar entities to meet the condition of invariant entities, i.e., instead of changing entities, we intervene on their contexts. We term this proposed method SynCo as the substitution of casual features is based on the syntactic graph SynDG.
We take two samples for illustration: an original sample “They drank wine produced by wineries.” with “Product-Producer” relation, and a candidate sample “They bought the grapes from farms” with “Entity-Origin”. Their SynDGs and the intervention procedure are shown in Figure 2. The main procedure for SynCo is summarized below.
1. We first calculate the average score for three centrality metrics of the entity and denote it as avgC(entity), e.g., avgC(wineo) and avgC(grapesc) is 1.24 and 1.17.
2. We then calculate the topological distance (TD) of two entities by minusing their avgC values. If TD is smaller than a predefined topological distance threshold (TDT), they form a candidate entity pair for substitute structures. For example, given TD(avgC(wineo), avgC(grapesc)) = 0.07 TDT and TD(avgC(wineo), avgC(farmsc)) = 0.68 TDT, the entity ‘grapes’ in and the entity ‘wine’ in form a candidate entity pair.
3. We now generate the candidate syntactic counterfactual. We calculate the cosine similarity of the syntactic features (POS and dependency relation embedding) for entities in the candidate entity pair. We denote it as FS. If it is greater than a predefined feature similarity threshold (FST), we substitute the first-order neighbors around the entity in with those of the candidate entity in . These neighbors should have the same type of POS tags to ensure the correctness of the syntax. Moreover, if there are several words around entities and they all have the same type, we will replace the one with the smallest TD. For example, given FS(wineo, grapesc) = 0.877 FST, we can substitute the verb-type neighbors ‘dranko’ and ‘producedo’ of ‘wine’ with the same type neighbor ‘boughtc’ of ‘grapes’. Moreover, since TD(avgC(dranko), avgC(boughtc)) = 0.57 and TD(avgC(producedo), avgC(boughtc)) = 0.50, we replace ‘producedo’ with ‘boughtc’ and retain ‘dranko’ unchanged.
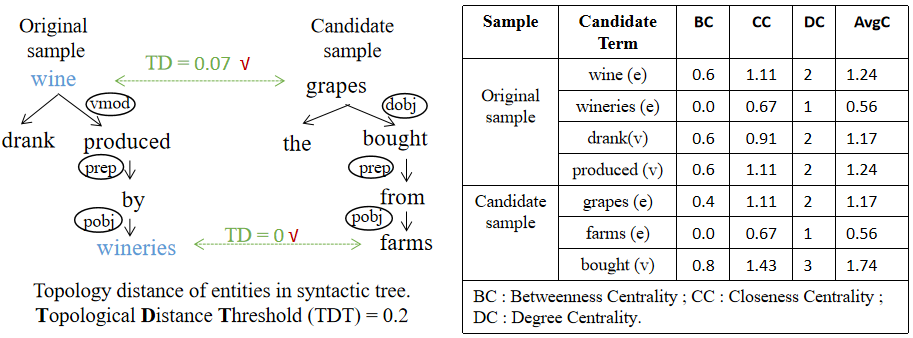
4. After substituting the contexts of the candidate entity pair and adding the label of , a candidate counterfactual is produced. In order to ensure that the sample we generate is a real counterfactual, we put it into the trained backbone model and re-predict its label. If the label is indeed changed, we treat it as the counterfactual of . For example, “They drank wine bought from wineries.” with “Entity-Origin” relation is a counterfactual sample after SynCo.
4.2 Generating Semantic Counterfactuals
This section presents our semantically intervened counterfactual generator SemCo. We prefer to replace the contexts between entities in with words of the most similar semantics and get a different label. To this end, we exploit the shortest path in SemDG for identifying semantically similar contexts between entities.
As shown in Figure 3, we first obtain the SemDG of an original sample “Wine is in the bottle” with “Content-Container” label and that of a candidate sample “Letter is from the city” with “Entity-Origin” label. We then extract the SDP between entities in and . We propose to calculate the cosine similarity of averaged word embeddings between two paths. If the similarity score is larger than the semantic similarity threshold (SST), we replace the semantic path in with that in . Similar to SynCo, we put the generated semantic counterfactual into the trained backbone model and re-predict its label. We consider the new sample as a counterfactual of if the label is changed.
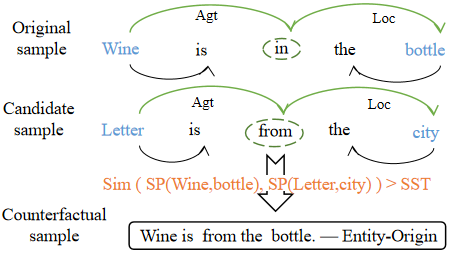
Finally, the generated semantic counterfactuals, as well as the syntactic counterfactuals, are used to augment the original data to train a robust classifier.
5 Datasets and Evaluation Protocol
5.1 Datasets
We briefly introduce four datasets in our experiments.
In-Domain Data
We adopt three in-domain datasets on two RC tasks including cross-sentence -ary RC and sentence-level RC. For cross-sentence -ary RC, we use the PubMed dataset which contains 4 relation labels and 1 special none label. For sentence-level RC task, we follow the experiment settings in (Guo et al., 2019) to evaluate our model on two datasets. (1) SemEval 2010 Task 8 dataset contains 9 directed relations and 1 Other class. (2) TACRED dataset contains 41 relation types and 1 no_relation class.
Out-of-Domain Data
We employ one dataset to verify the model robustness with CAD: the ACE 2005 dataset with 6 relation types and 1 special none class. It has 6 different domains including broadcast conversation (bc), broadcast news (bn), conversational telephone conversation (cts), newswire (nw), usenet (un), and webblogs (wl).
5.2 Evaluation Protocol
We evaluate our model with a dedicated protocol. We first adopt three typical RC methods as the backbone, which will be used as the encoder for the input and for training the base classifier for the prediction of the candidate counterfactual. Moreover, the backbone is used for training the final classifier on the original data and CAD. The backbone RC methods include PA-LSTM (Zhang et al., 2017), AGGCN (Guo et al., 2019), and R-BERT (Wu and He, 2019). They are chosen as the representative of sequence based models, graph-based models, and the PLMs methods, respectively. R-BERT is the best among the state-of-the-art BERT methods. Note the backbone methods will be combined with all counterfactual generation methods including ours and the baselines.
We further compare our model with automatical counterfactual generation baselines. These methods are either general text generator or designed for other tasks. For the general methods (Madaan et al., 2021; Fern and Pope, 2021; Robeer et al., 2021), we directly generate counterfactuals on RC datasets using their generator, and we avoid masking entities for a fair comparison with our model. Among the specific methods, COSY (Yu et al., 2021) is for the cross-lingual understanding task, and we follow it to build a counterfactual dependency graph by maintaining the graph structure, and replacing each type of relation with a randomized one and randomly selecting a POS tag. RM/REP-CT (Yang et al., 2021) is proposed for sentiment classification tasks. We employ its self-supervised context decomposition and select the human-like counterfactuals using MoverScore.
For models with static word embedding, we initialize word vectors with 300-dimension GloVe embeddings provided by Pennington et al. (2014). For models with contextualized word embedding, we adopt BERT as the PLM. The embeddings for POS and dependency relation are initialized randomly and their dimension is set to 30. We adopt the Stanford CoreNLP (Manning et al., 2014) as the syntactic parser and use semantic dependency parsing (Dozat and Manning, 2018) to generate semantic dependency graph. We use SGD as the optimizer with a 0.9 decay rate. The L2-regularization coefficient is 0.002 222Please refer to Appendix for detailed information for datasets and baselines, as well as the hyper-parameter setting for three thresholds..
| Model | Binary-class | Multi-class | ||||
|---|---|---|---|---|---|---|
| T | B | T | B | |||
| Single | Cross | Single | Cross | Cross | Cross | |
| PA-LSTM | 84.9 | 85.8 | 85.6 | 85.0 | 78.1 | 77.0 |
| COSY | 85.2 | 86.1 | 85.8 | 85.4 | 78.4 | 77.3 |
| RM/REP-CT | 85.0 | 84.9 | 84.9 | 85.0 | 77.7 | 76.9 |
| GYC | 85.1 | 85.9 | 85.4 | 85.3 | 78.2 | 77.2 |
| CLOSS | 84.9 | 84.6 | 85.7 | 85.2 | 77.4 | 76.9 |
| CounterfactualGAN | 84.6 | 85.7 | 85.1 | 85.2 | 78.0 | 77.1 |
| CoCo | 87.0∗‡ | 86.9 | 87.5† | 86.8∗‡ | 80.5∗‡ | 80.0∗‡ |
| AGGCN | 87.1 | 87.0 | 85.2 | 85.6 | 79.7 | 77.4 |
| COSY | 87.6 | 87.8 | 86.3 | 86.2 | 80.7 | 78.4 |
| RM/REP-CT | 87.1 | 87.0 | 85.3 | 85.5 | 79.7 | 77.0 |
| GYC | 87.2 | 87.1 | 85.4 | 85.6 | 79.8 | 77.6 |
| CLOSS | 76.4 | 86.3 | 85.0 | 84.3 | 79.2 | 76.4 |
| CounterfactualGAN | 87.1 | 87.1 | 85.1 | 85.4 | 80.1 | 77.2 |
| CoCo | 89.0∗‡ | 89.1∗‡ | 88.0∗‡ | 87.7∗† | 84.1∗‡ | 81.1∗‡ |
| R-BERT | 88.6 | 88.7 | 88.1 | 87.9 | 85.1 | 84.2 |
| COSY | 88.6 | 88.8 | 88.3 | 87.9 | 85.3 | 84.5 |
| RM/REP-CT | 88.5 | 88.6 | 87.9 | 87.6 | 85.0 | 84.2 |
| GYC | 88.7 | 88.9 | 88.0 | 87.8 | 85.2 | 84.3 |
| CLOSS | 87.2 | 87.5 | 87.1 | 86.7 | 83.8 | 83.4 |
| CounterfactualGAN | 88.1 | 88.2 | 87.4 | 87.3 | 84.8 | 84.1 |
| CoCo | 89.1 | 89.3 | 88.7 | 88.4 | 86.2† | 85.8† |
| Model | TACRED | SemEval | ||
|---|---|---|---|---|
| P | R | Micro-F1 | Macro-F1 | |
| PA-LSTM | 65.7 | 64.5 | 65.1 | 82.7 |
| COSY | 65.8 | 64.6 | 65.2 | 83.1 |
| RM/REP-CT | 66.9 | 63.3 | 65.0 | 80.1 |
| GYC | 65.2 | 64.1 | 64.6 | 82.9 |
| CLOSS | 64.2 | 63.9 | 64.0 | 81.3 |
| CounterfactualGAN | 64.9 | 63.7 | 64.3 | 82.4 |
| CoCo | 66.3 | 66.1 | 66.2∗† | 84.2∗‡ |
| AGGCN | 71.9 | 64.0 | 67.7 | 85.7 |
| COSY | 71.8 | 64.2 | 67.8 | 85.9 |
| RM/REP-CT | 71.0 | 63.9 | 67.6 | 84.8 |
| GYC | 71.3 | 63.9 | 67.4 | 85.6 |
| CLOSS | 70.2 | 63.3 | 66.6 | 84.8 |
| CounterfactualGAN | 71.0 | 63.3 | 66.9 | 85.4 |
| CoCo | 72.4 | 64.8 | 68.4† | 86.6† |
| R-BERT | 69.7 | 70.1 | 69.9 | 88.6 |
| COSY | 69.6 | 70.1 | 69.8 | 88.5 |
| RM/REP-CT | 69.2 | 69.8 | 69.5 | 87.2 |
| GYC | 69.5 | 70.5 | 70.0 | 88.6 |
| CLOSS | 68.0 | 67.9 | 67.9 | 87.5 |
| CounterfactualGAN | 68.9 | 69.3 | 69.1 | 87.5 |
| CoCo | 70.2 | 70.5 | 70.4 | 89.0 |
6 Results and Discussions
We first compare our method with the backbone and the state-of-art automatical counterfactual generation methods on three in-domain datasets. We also provide an ablation study to focus on the contribution of single component in our model. Notably, we evaluate our model on the out-of-domain data for the generalization test. Furthermore, we present a case study of counterfactuals for a detailed comparison of the counterfactuals generated by baselines and our model.
6.1 Main Comparison Results
The comparison results for cross-sentence -ary and sentence-level tasks are shown in Table 1 and Table 2, respectively. From these results, we make the following observations.
(1) Our CoCo model significantly improves the performance of all the backbones across three datasets. Specifically, CoCo outperforms two backbone approaches PA-LSTM and AGGCN by around 2-3 absolute percentage points in terms of accuracy on PubMed. It also improves F1 scores by 1-2 absolute percentage points on TACRED and SemEval. More importantly, our model boosts the performance of R-BERT on all three datasets especially on PubMed, which is impressive because it is a very strong backbone, and also because most baselines damage the performance of R-BERT.
(2) Our model achieves the state-of-the-art performance in terms of a counterfactual generator for RC. For example, CoCo outperforms the syntax-based model COSY and the best semantics-based model GYC by 1-3 absolute percentage points. COSY randomly replaces syntactic features which cannot flip the label and makes little sense for RC. CounterfactualGAN and GYC get a slight increase on PubMed with PA-LSTM and AGGCN, but their other results are unsatisfactory. The results of RM/REP-CT on three datasets fluctuate. On PubMed, some of them keep the same as the original ones and some of them decline, while on SemEval and TACRED they all decline. The poor results of the baseline counterfactual generators can be due to the lack of grammar constraint and the lack of entity-centric viewpoint. We will illustrate this in our case study.
| Input Sentence | RM/REP-CT | CounterfactualGAN | CoCo | ||||||||||||||||
|
|
|
|
||||||||||||||||
| Input Sentence | CLOSS | GYC | CoCo | ||||||||||||||||
|
|
|
|
| Model | PubMed_B | PubMed_T | TACRED | SemEval |
|---|---|---|---|---|
| Acc. | Acc. | Micro-F1 | Macro-F1 | |
| PA-LSTM | 77.0 | 78.1 | 65.1 | 82.7 |
| + SynCo | 79.4 | 79.6 | 65.6 | 83.9 |
| + SemCo | 79.7 | 79.8 | 65.7 | 84.0 |
| + Syn-TED | 77.6 | 78.4 | 65.2 | 83.0 |
| + Sem-BA | 77.4 | 78.3 | 65.3 | 83.2 |
| AGGCN | 77.4 | 79.7 | 67.7 | 85.7 |
| + SynCo | 80.3 | 82.8 | 67.9 | 86.3 |
| + SemCo | 80.7 | 83.1 | 68.2 | 86.5 |
| + Syn-TED | 77.6 | 79.9 | 67.7 | 85.8 |
| + Sem-BA | 77.8 | 79.8 | 67.8 | 86.1 |
| R-BERT | 84.2 | 85.1 | 69.9 | 88.6 |
| + SynCo | 85.1 | 85.6 | 70.1 | 88.7 |
| + SemCo | 85.6 | 85.8 | 70.3 | 88.7 |
| + Syn-TED | 84.3 | 85.1 | 70.0 | 88.5 |
| + Sem-BA | 84.6 | 85.2 | 70.0 | 88.3 |
| Different Training Data | |||
| PA-LSTM | AGGCN | R-BERT | |
| Micro-avg. F1 on bc domain. | |||
| Ori. | 48.5 | 62.5 | 68.5 |
| Ori. & CAD (GYC) | 48.7 | 63.1 | 68.6 |
| Ori. & CAD (COSY) | 48.6 | 62.4 | 68.6 |
| Ori. & CAD (CoCo) | 52.6∗ | 64.4∗ | 69.0∗ |
| Micro-avg. F1 on cts domain. | |||
| Ori. | 42.5 | 63.1 | 69.4 |
| Ori. & CAD (GYC) | 42.6 | 63.8 | 69.8 |
| Ori. & CAD (COSY) | 42.3 | 63.2 | 69.7 |
| Ori. & CAD (CoCo) | 46.2∗ | 65.3∗ | 70.4 |
| Micro-avg. F1 on wl domain. | |||
| Ori. | 38.8 | 53.4 | 59.5 |
| Ori. & CAD (GYC) | 39.1 | 53.6 | 59.7 |
| Ori. & CAD (COSY) | 38.1 | 53.7 | 59.2 |
| Ori. & CAD (CoCo) | 41.1∗ | 55.2∗ | 60.2 |
6.2 Ablation Study
Our model has two unique characteristics. Firstly, it utilizes both syntactic and sematic information. Secondly, it takes advantage of the graph topological property. We hence design two types of ablation study. One is performing one separate component only, i.e., SynCo or SemCo. The other is replacing our graph topology based intervention methods with other syntactic/semantic ones, i.e., tree edit distance (TED) (Zhang and Shasha, 1989) which measures the syntactic closeness between the candidate and the original text and BERT-attack (BA) (Li et al., 2020) which generates substitutes for the vulnerable words in a semantic-preserving way. We present the ablation results on three datasets in Table 4.
We find that a single SynCo or SemCo is already good enough to enhance the performance of the backbone. In addition, we observe that our single SynCo/SemCo outperforms the baselines in Table 1 and Table 2. Moreover, SynCo and SemCo have almost the same effects on the model. For example, the backbone PA-LSTM has an accuracy score 77.0 on PubMed_B. After SynCo/SemCo, its accuracy rises up to 79.4/79.7, showing a similar 2.4/2.7 absolute increase. These results demonstrate that both SynCo and SemCo contribute to our model, and their combination CoCo is more powerful.
The replacement of SynCo with TED and SemCo with BA hurts the performance. For example, on SemEval with AGGCN as the backbone, TED results in a 0.5 F1 decrease (SynCo 86.3 vs. Syn-TED 85.8). On TACRED with R-BERT as the backbone, BA brings about a 0.3 (SemCo 70.3 vs. Syn-TED 70.0) absolute decrease. The reason might be that TED only considers the causal words from the whole syntactic tree while our SynCo exploits the topological structure and syntactic feature of the words. Meanwhile, BA is unable to capture casual associations when generating adversarial samples since it only replaces the words with similar ones generated by BERT.
6.3 Robustness in the Generalization Test
To evaluate the model robustness, we perform the generalization test on ACE2005 dataset by using the training and test data from different domains. Following the settings for fine-grained RC tasks (Yu et al., 2015), we use the union of the news domains (nw and bn) for training, and hold out half of the bc domain as development data, and finally evaluate on the remainder of bc, cts, and wl domains. We choose two best baselines GYC and COSY for comparison.
As can be seen in Table 5, our proposed CoCo model enhances the performance of all backbones on the combined CAD and the original (Ori.) data, i.e., PA-LSTM (+4.1%, +3.7%, +2.3% ), AGGCN (+1.9%, +2.2%, +1.8%), and R-BERT (+0.5%, +1.0%, +0.7%) on three different target domains. It is worthy of noting that our improvements over three backbones (including R-BERT) are statistically significant on all generalization tests. In contrast, two baselines GYC and COSY only get very small improvements or even decrease the performance of backbones in some cases. All these clearly prove that our method can enhance the robustness of backbone methods with the generated counterfactuals.
6.4 Case Study
To have a close look, we select two samples from SemEval for case study and present results by different models in Table 3. RM/REP-CT deletes the important preposition ‘from’ to change the label and results in an incomplete sample. CounterfactualGAN employs an adversarial attack method. Its generated ‘sleep’ is ungrammatical and the sample is low-quality as it is inconsistent with the flipped label. GYC and CLOSS generate the counterfactual with a specified target label and the substitution tends to be common words in the specified class like ‘community’, which makes the sentence unreadable. Moreover, the word ‘almost’ identified by GYC is out of the scope of two entities and is not a causal feature.
Overall, the results by other methods are very uncontrollable, and it is easy for them to generate sentences with semantic or syntactic errors. In contrast, our model not only identifies the correct causal features, but also produces human-like counterfactuals, which can force the classifier to better distinguish between causation and confounding.
7 Conclusion
In this paper, we introduce the problem of automatic counterfactual generation into the RC task. We aim to produce the most human-like, i.e., grammatically correct and semantically readable, counterfactuals, while keeping the entities unchanged. To this end, we design an entity-centric framework which employs semantic and syntactic dependency graphs and exploits two topological properties in these two graphs to first identify and then intervene on contextual casual features for entities. Extensive experimental results on four datasets prove that our model significantly outperforms the state-of-the-art baselines, and is more effective for alleviating spurious associations and improving the model robustness.
References
- Chen et al. [2021] Hao Chen, Rui Xia, and Jianfei Yu. Reinforced counterfactual data augmentation for dual sentiment classification. In EMNLP, 2021.
- Dozat and Manning [2018] Timothy Dozat and Christopher D. Manning. Simpler but more accurate semantic dependency parsing. In ACL, 2018.
- Fern and Pope [2021] Xiaoli Z. Fern and Quintin Pope. Text counterfactuals via latent optimization and shapley-guided search. In EMNLP, 2021.
- Guo et al. [2019] Zhijiang Guo, Yan Zhang, and Wei Lu. Attention guided graph convolutional networks for relation extraction. In ACL, 2019.
- Jo and Bengio [2017] Jason Jo and Yoshua Bengio. Measuring the tendency of cnns to learn surface statistical regularities. CoRR, abs/1711.11561, 2017.
- Judea [2000] Pearl Judea. Cambridge University Press, 2000.
- Kaushik et al. [2020] Divyansh Kaushik, Eduard H. Hovy, and Zachary Chase Lipton. Learning the difference that makes A difference with counterfactually-augmented data. In ICLR, 2020.
- Li et al. [2020] Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. BERT-ATTACK: adversarial attack against BERT using BERT. In EMNLP, 2020.
- Madaan et al. [2021] Nishtha Madaan, Inkit Padhi, Naveen Panwar, and Diptikalyan Saha. Generate your counterfactuals: Towards controlled counterfactual generation for text. In AAAI, 2021.
- Mandya et al. [2020] Angrosh Mandya, Danushka Bollegala, and Frans Coenen. Graph convolution over multiple dependency sub-graphs for relation extraction. In COLING, 2020.
- Manning et al. [2014] Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Rose Finkel, Steven Bethard, and David McClosky. The stanford corenlp natural language processing toolkit. In ACL, 2014.
- Noh and Kavuluru [2021] Jiho Noh and Ramakanth Kavuluru. Joint learning for biomedical NER and entity normalization: encoding schemes, counterfactual examples, and zero-shot evaluation. In BCB, pages 55:1–55:10, 2021.
- Pennington et al. [2014] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global vectors for word representation. In EMNLP, 2014.
- Qin et al. [2021] Yujia Qin, Yankai Lin, Ryuichi Takanobu, Zhiyuan Liu, Peng Li, Heng Ji, Minlie Huang, Maosong Sun, and Jie Zhou. ERICA: improving entity and relation understanding for pre-trained language models via contrastive learning. In ACL, 2021.
- Robeer et al. [2021] Marcel Robeer, Floris Bex, and Ad Feelders. Generating realistic natural language counterfactuals. In EMNLP Findings, 2021.
- Srivastava et al. [2020] Megha Srivastava, Tatsunori B. Hashimoto, and Percy Liang. Robustness to spurious correlations via human annotations. In ICML, 2020.
- Tucker et al. [2021] Mycal Tucker, Peng Qian, and Roger Levy. What if this modified that? syntactic interventions with counterfactual embeddings. In Findings of the ACL, 2021.
- Wang and Culotta [2021] Zhao Wang and Aron Culotta. Robustness to spurious correlations in text classification via automatically generated counterfactuals. In AAAI, 2021.
- Wu and He [2019] Shanchan Wu and Yifan He. Enriching pre-trained language model with entity information for relation classification. In CIKM, 2019.
- Wu et al. [2021] Tongshuang Wu, Marco Túlio Ribeiro, Jeffrey Heer, and Daniel S. Weld. Polyjuice: Generating counterfactuals for explaining, evaluating, and improving models. In ACL, 2021.
- Xu et al. [2015] Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, and Zhi Jin. Classifying relations via long short term memory networks along shortest dependency paths. In EMNLP, 2015.
- Yamada et al. [2020] Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, and Yuji Matsumoto. LUKE: deep contextualized entity representations with entity-aware self-attention. In EMNLP, 2020.
- Yang et al. [2021] Linyi Yang, Jiazheng Li, Padraig Cunningham, Yue Zhang, Barry Smyth, and Ruihai Dong. Exploring the efficacy of automatically generated counterfactuals for sentiment analysis. In ACL, 2021.
- Yu et al. [2015] Mo Yu, Matthew R. Gormley, and Mark Dredze. Combining word embeddings and feature embeddings for fine-grained relation extraction. In NAACL, 2015.
- Yu et al. [2021] Sicheng Yu, Hao Zhang, Yulei Niu, Qianru Sun, and Jing Jiang. COSY: counterfactual syntax for cross-lingual understanding. In ACL, 2021.
- Zeng et al. [2020] Xiangji Zeng, Yunliang Li, Yuchen Zhai, and Yin Zhang. Counterfactual generator: A weakly-supervised method for named entity recognition. In EMNLP, 2020.
- Zhang and Shasha [1989] Kaizhong Zhang and Dennis E. Shasha. Simple fast algorithms for the editing distance between trees and related problems. SIAM J. Comput., 1989.
- Zhang et al. [2017] Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D. Manning. Position-aware attention and supervised data improve slot filling. In EMNLP, 2017.
- Zhou et al. [2016a] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, 2016.
- Zhou et al. [2016b] Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, and Bo Xu. Attention-based bidirectional long short-term memory networks for relation classification. In ACL, 2016.
- Zhu et al. [2020] Qingfu Zhu, Wei-Nan Zhang, Ting Liu, and William Yang Wang. Counterfactual off-policy training for neural dialogue generation. In EMNLP, 2020.