Availability Adversarial Attack and Countermeasures for Deep Learning-based Load Forecasting
Abstract
The forecast of electrical loads is essential for the planning and operation of the power system. Recently, advances in deep learning have enabled more accurate forecasts. However, deep neural networks are prone to adversarial attacks. Although most of the literature focuses on integrity-based attacks, this paper proposes availability-based adversarial attacks, which can be more easily implemented by attackers. For each forecast instance, the availability attack position is optimally solved by mixed-integer reformulation of the artificial neural network. To tackle this attack, an adversarial training algorithm is proposed. In simulation, a realistic load forecasting dataset is considered and the attack performance is compared to the integrity-based attack. Meanwhile, the adversarial training algorithm is shown to significantly improve robustness against availability attacks. All codes are available at https://github.com/xuwkk/AAA_Load_Forecast.
Index Terms:
load forecasting, adversarial attack, availability attack, adversarial training.I Introduction
I-A Load Forecasting
Load forecasting plays an essential role in the operation and control of the power system. With more distributed resources embedded in the grid, accurate load forecasting also benefits the demand-side response. Plenty of researches have been done for load forecasting, both deterministic and probabilistic [1]. Regression-based models and their variants dominates the long-term forecasting while machine learning algorithms, such as artificial neural network (ANN) gains more attention for short-term forecasting due to its efficiency on feature extraction [2]. For instance, feedforward neural network is applied in [3]. In addition, long short-term memory (LSTM) and convolutional neural net (CNN) are used to remember temporal information, which can result in state-of-the-art accuracy [4].
I-B Adversarial Attack
The concept of adversarial attack against deep neural network was firstly discovered by Szegedy et al. [5] where it has been shown that a small amount of perturbation on the image pixels can result in wrong classification. To generate the attack, fast gradient sign method (FGSM) was proposed by assuming the local linearity of the loss surface [6]. Although the FGSM can reduce the computational burden, it can only produces sub-optimal attack vectors. Projected gradient descent (PGD) extends the idea of FGSM in which the attack vector is solved in a multistep manner to approach the global optima [7]. In addition, the most effective approach to combating adversarial attacks is to minimize the loss of adversarial examples generated at each epoch, which is named adversarial training [7].
Recently, adversarial attacks on time series, especially the load forecasting applications, have gained more attention [8]. Starting from the linear model, Luo et al. compares four load forecasting algorithms that can easily fail under data integrity attacks [9]. The authors then introduce regularization to address the challenge [10]. However, the integrity attacks considered in [9, 10] are not specifically designed by the forecasting model. In [11], a robust linear regression for data availability attack is proposed through min-max optimization. In the deep learning era, a cost-oriented integrity attack is established to maximize operational cost [12]. In [13], the robustness of the deep load forecasting model is guaranteed through Bayesian inference.
I-C Contribution
We observe that the integrity attack is the main source of adversarial attacks in deep learning-based load forecasting models, and the availability attack is only considered for linear models. Considering a ‘man-in-the-middle’ scenario, availability attack is much cheaper than integrity attack as the attacker does not need to manipulate the data and repackage the packets [14]. Meanwhile, missing data are more common, as measurements can be temporally unavailable due to equipment failure. To fill this research gap, first, we design the availability adversarial attack targeting on piecewise linear neural network (PLNN). The optimality of the attack is guaranteed by reformulating the PLNN into mixed integer linear programming (MILP). Second, an adversarial training algorithm is proposed that considers both clean and attack accuracy to improve the robustness of the PLNN. In the simulation, we compare the performance of the availability adversarial attack with its integrity counterpart and demonstrate the effectiveness of the proposed adversarial training algorithm in a realistic load forecasting task.
II Load Forecasting Model
Load forecasting problem is defined as a supervised learning task where the input to the model is a collection of features, such as temperature, and the output is the true load consumption. Define a dataset space where represents the input space and represents the target load space. To train a load forecasting model, a dataset can be sample from where and . In this paper, the dataset from [15] is used which consists of data from the four-year metropolitan load at a resolution of one hour. The forecast features include K1: air pressure (kW), K2: cloud cover in %, K3: humidity in %, K4: temperature in , K5: wind direction in degrees, k6: wind speed in km/h, and K7: temporal information. Temporal information that includes the month, date, and time is further converted into sine and cosine values on the basis of different periods. Consequently, the above setting results in number of features.
A deep neural network parameterized on can be trained to minimize the mean squared error (MSE) loss between the targeted and predicted loads:
| (1) |
Stochastic gradient descent (SGD) is broadly used to find the local minima of (1). At each epoch, the gradient is found in a batch of the dataset:
| (2) |
where is a user-defined learning rate.
Specifically, this paper considers a piecewise linear neural network structure with ReLU activation functions before the last layer. Therefore, the neural network with layers () can be explicitly written as:
| (3) |
where and are the weight and bias of the -th layer.
III Adversarial Attacks on Load Forecasting
In the literature, adversarial attack commonly refers to maliciously perturbing a small value in the input data , that is, integrity adversarial attack. The ‘adversarial’ implies that the attacker can maliciously design the attack vector for a specific trained ANN and data instance under a white-box assumption. However, in this paper, we propose availability adversarial attack where the attacker can block part or all of the input features.
III-A Integrity Adversarial Attacks
Referring to the loss function (1), the objective of the adversarial attack is to increase the forecast error by perturbing on the input subject to a predefined ball . After obtaining the trained model , the integrity adversarial attack on can be written as
| (4) |
Projected gradient descent (PGD)111Though the objective of (4) is to maximize the loss; it is common to name it descent in the literature. can be used to solve (4). At each iteration, normalized gradient ascents are operated and the resulting data is clamped by the norm ball [7].
Although PGD has proven to be efficient, it is hard to obtain the global optima due to the non-convexity of the neural network. To approach the global optimality, multi-run strategy can be applied. However, it is possible to find global optima for small sized neural network under certain structure. Firstly, since the square loss in (4) is convex, to formulate a convex problem, we can maximize and minimize the forecast values. Second, -norm is considered in which each feature can be maximally injected by . Referring to (3), (4) can be rewritten as:
| (5) |
The optimization problem (5) is non-convex due to the maximization constraint caused by ReLU. However, it can be easily transformed into an MILP using the big-M method. Specifically, (5) is equivalent to [16]:
| (6) |
where is the auxiliary integer variable related to the ReLU activation functions; and are the upper and lower bounds for the output of the -th layer, i.e., , which are designed by the user. All the inequality constraints in (6) are element-wise. If the inequality is satisfied for some optimal solution of (5), then the optimal solution of (6) is also an optimal solution of (5) [17]. A detailed conversion from (5) to (6) can be found in [18].
III-B Availability Adversarial Attack
The integrity attack with the MILP reformulation has been well studied in the literature. However, it requires the attackers not only hijack the sensor measurements from the remote server, but also have the ability to manipulate their values and send them back to the operator. Compared to the integrity attack, the availability attack is much cheaper, as it only requires the attackers to block measurements [14].
First, the temporal information, such as month, date and time, cannot be attacked as it can be easily obtained and verified by the operator. Therefore, only K1-K6 features are prone to attack (flexible feature, indexed by ) while the temporal feature is fixed (indexed by ). Second, once the K1-K6 features are blocked, the operator can have different choices to impute the missing value(s). In detail, defining an integer vector and vector , the imputed input data can be represented as where and are all one and zero vectors with proper dimensions222Without losing generality, we assume that the flexible features are concatenated in front of the fixed features.. The imputed vector reflects the operator’s choice to compensate for the missing features. When , this feature is unavailable and . For simplicity, can be chosen as or the average value in this paper.
Similarly to (5), the optimal availability adversarial attack can be obtained by solving the following optimization problem:
| (7) |
in which the last constraint represents the attacker’s budget. For example, at most number of features can be blocked.
The user-defined layer output bounds and are essential to solve (7). First, the solution of (8) may be sub-optimal to (7) if the bounds do not cover the output of layer at the optimal value of (7). Second, if the bounds are too large, the MILP can be slow to converge. To inform proper bounds on the output of each linear layer, convex bound propagation can be applied as follows. First, define . Then the initial bounds on can be defined as follows:
| (9) |
Considering (3), the bounds on the output of each layer before the last can be propagated by
| (10) |
for . By the above formulation, there should be at least two layers in the network. Otherwise, the ANN will become a linear regression.
Remark 1
A small value can be subtracted and added on and respectively to avoid numerical instability when solving MILP.
IV Adversarial Training against Availability Attack
To overcome the availability attack defined in (7) and (8), adversarial training can be implemented in which the loss of the worst-case attack is minimized in each epoch. Defining , the adversarial loss function is written as
| (11) |
According to Danskin’s Theorem [7], the gradient of the maximization problem equals the gradient of the loss function at the maxima. Therefore,
| (13) |
where is calculated from the optimal solution of the adversarial loss (11). Consequently, the loss function of adversarial training for availability attacks can be written as
| (14) |
In (14), , , and represent the clean loss, maximization, and minimization of adversarial loss (11) respectively. Instead of solely training on the adversarial instance, the clean loss is also added to improve the accuracy on clean dataset [19].
Remark 2
Although the proposed availability adversarial attack and adversarial training are based on feedforward neural networks, they can also be extended to other types of piecewise linear layer, such as the convolutional layer. Due to the page limit, the discussion on convolutional neural networks will be left for future work.
V Simulation and Result
The optimal integrity and availability adversarial attacks are constructed using CVXPY [20] with Gurobi solver. Python muti-processing is used to accelerate the MILP optimization in (6) and (8). The deep load forecasting model is trained using PyTorch on an RTX 3090 graphic card. The outputs of the layers in ANN are 40-20-10-1. Adam optimizer is used with initial learning rate of 0.0005 and cosine annealing. For the original dataset [15], outliers beyond three-sigma are removed and we randomly separate the dataset into train and test with proportion 8:2. Flexible features are scaled into [0,1]. We train the model for 150 epochs and store the weights with best test set performance. For adversarial training, the hyperparameters are set to . The accuracy of the load forecasting model is reported by mean absolute percentage error (MAPE). For clean samples, we measure the distance between forecasted and ground-truth loads:
| (15) |
For adversarial samples, we use the mean percentage error (MPE) to evaluate their output against the output of the clean sample:
| (16) |
as the adversarial attack is formulated on the trained neural network.
In the following discussion, the model trained on clean dataset is referred as Clean Model, while the model trained through adversarial training is referred as Adver Model. Furthermore, to distinguish different attack attempts, we use AVAI(mode, , ) to represent the availability adversarial attack with mode{max,min} and . Similarly, INTE(mode, ) represents the integrity adversarial attack with attack strength .
V-A Performance of Availability Adversarial Attack
Fig. 1 compares the MPE deviation on the clean model under the availability adversarial attacks. In each of the box plot, the box represents the inter-quartile range (IQR) extending from the first quartile to the third of the data. The median of the data is indicated by the orange line. The whiskers cover the whole range of data. First, increasing the attack budget can increase the output deviations. However, this trend is not significant when . The output deviations with zero imputation is more intense than average imputation as no feature information can be extracted. Second, different data can have different vulnerabilities on the availability attack. For example, some samples can maintain the output with MPE=0 while others are altered significantly.
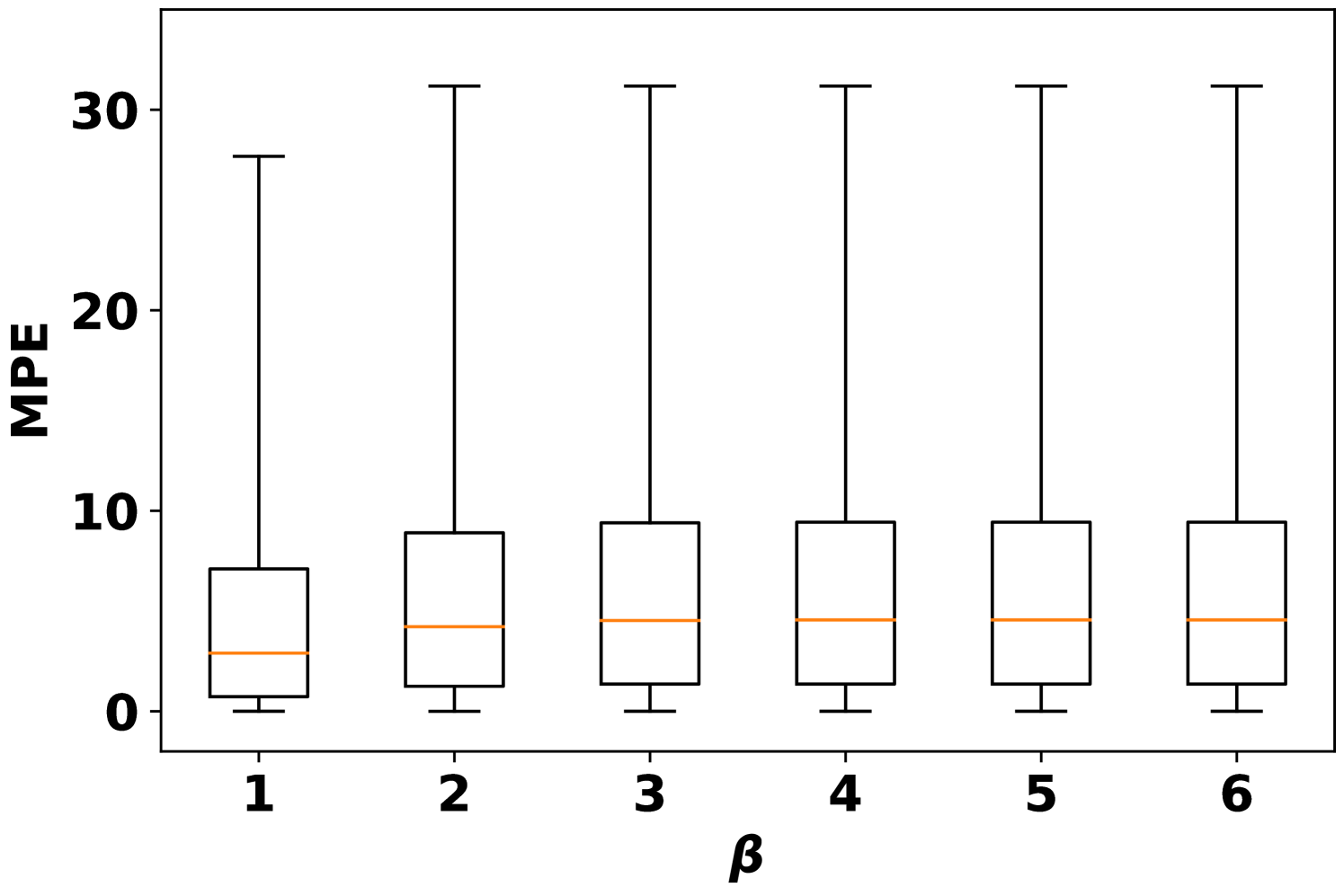
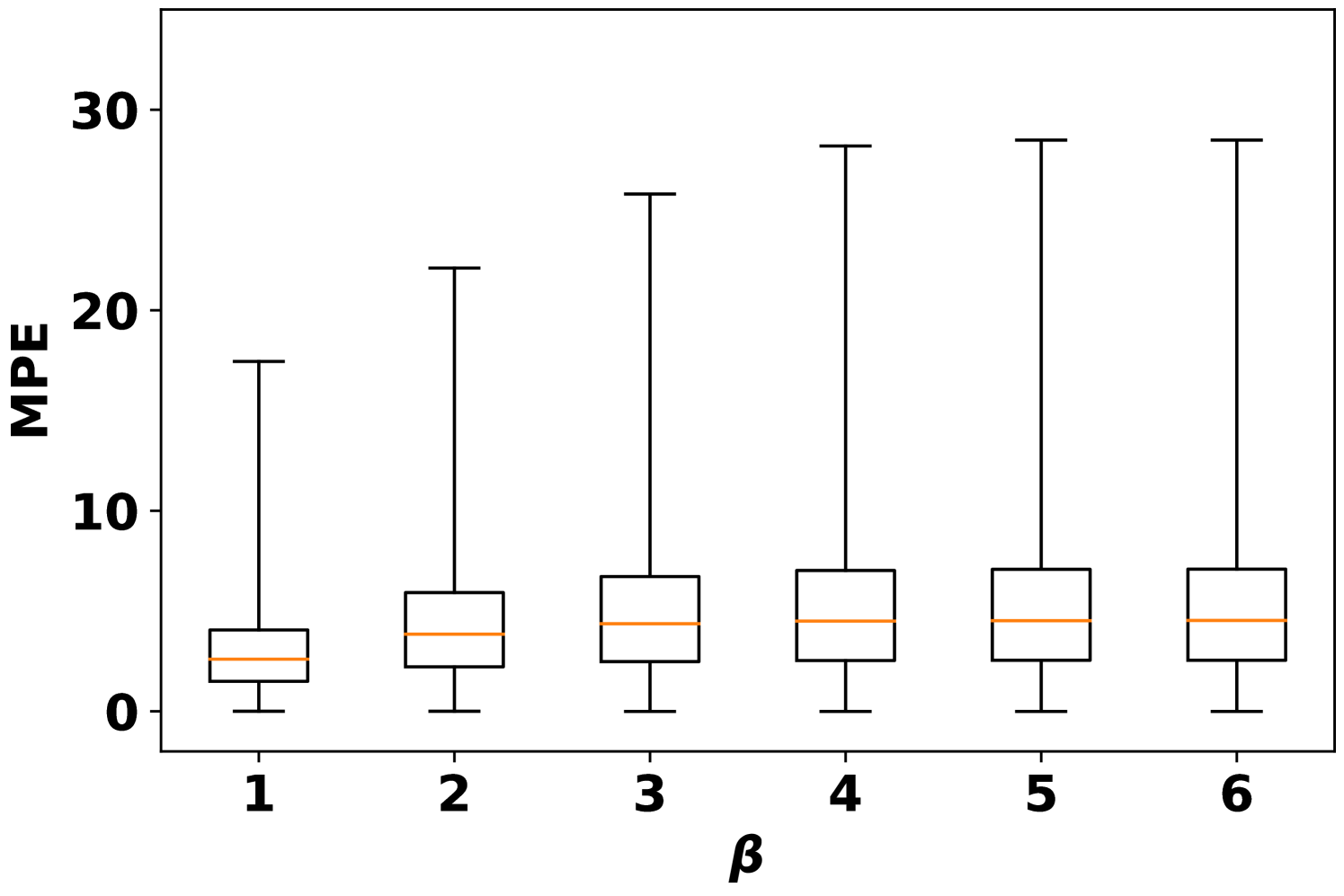
To better see the dependency of attack performance on the attack budget , Fig. 2 records the number of actual missing features under AVAI(min, mean, ) attack (corresponding to Fig. 1(d)). First, it is clearly shown that a small proportion of data cannot be attacked regardless of the choices of , which results in MPE=0. These data points are least sensitive to AVAI(min, mean, ) attack, as blocking any subset of their features can only increase the load forecast. Second, most of the actual missing numbers locate at 3 even when . This further implies that in most cases, blocking more features may not result in a stronger attack, although increasing can have more flexibility to allocate the attack position.
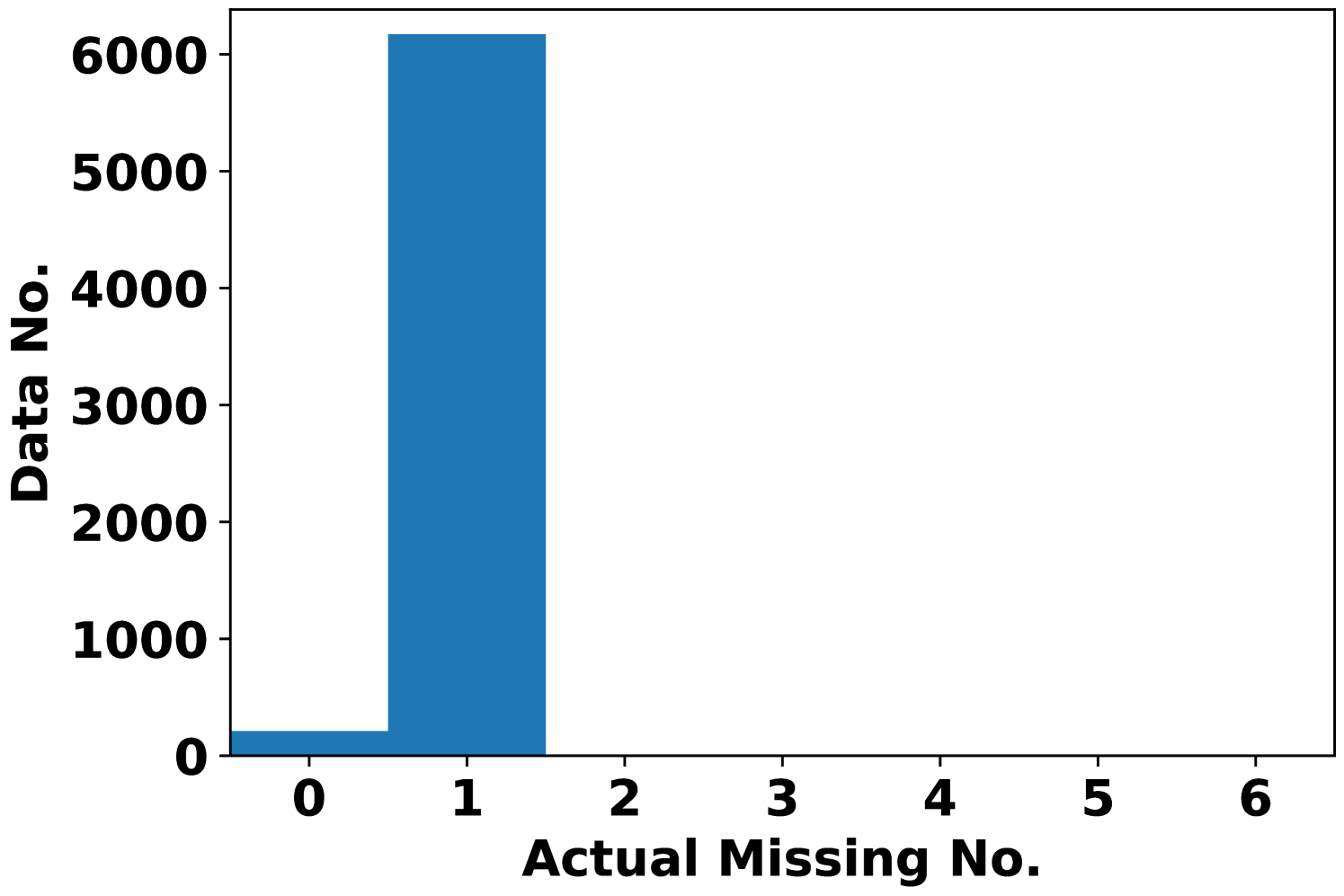
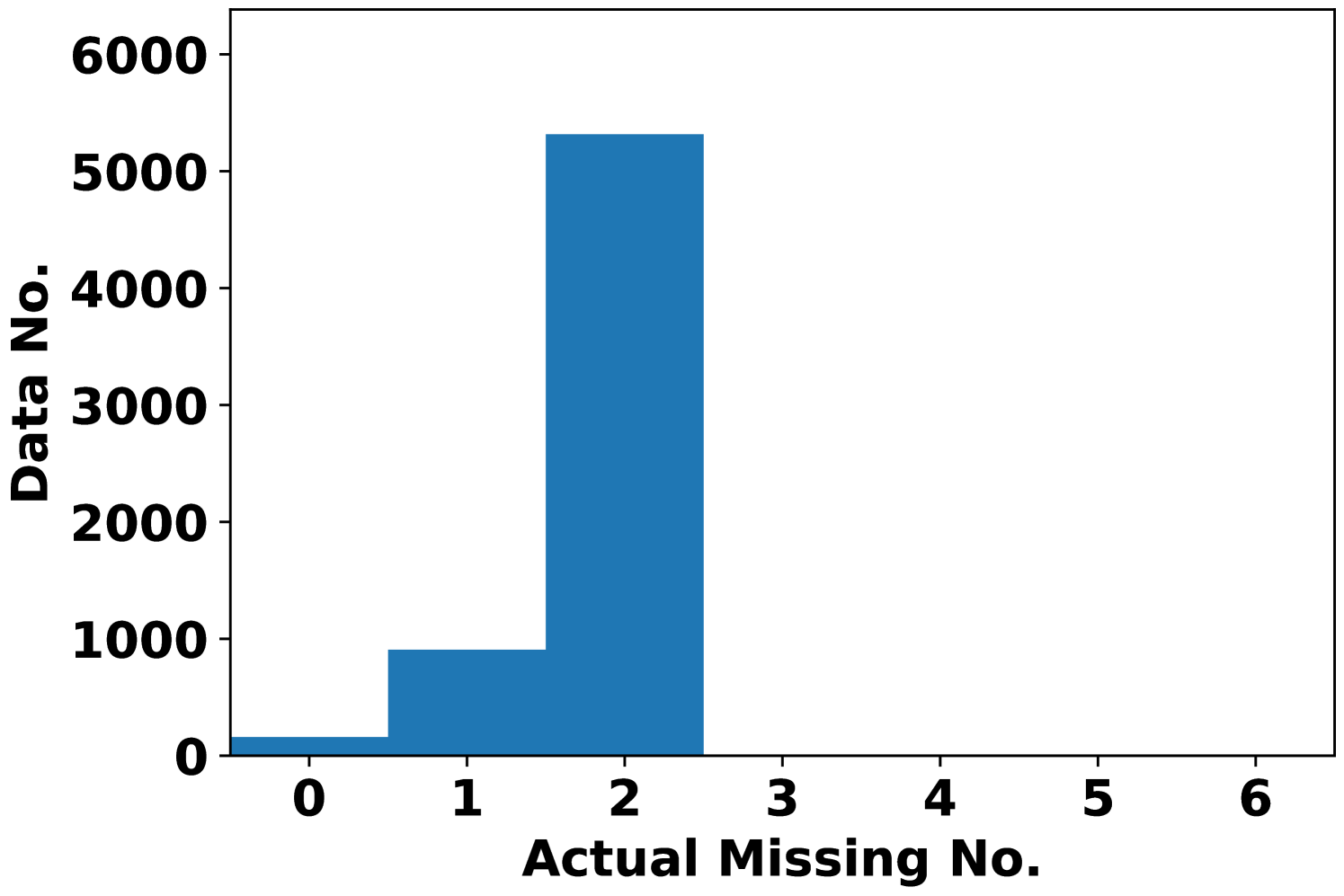
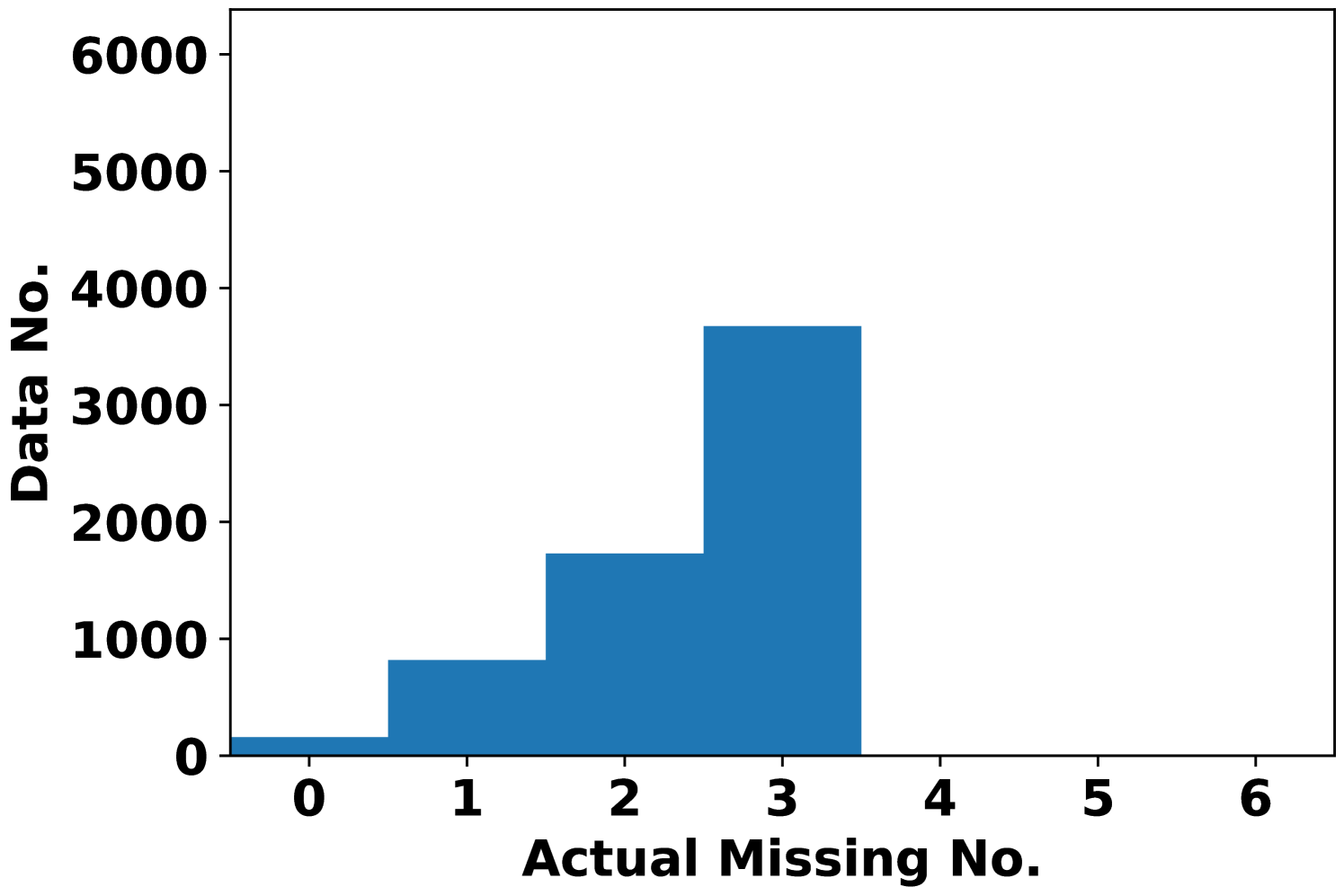
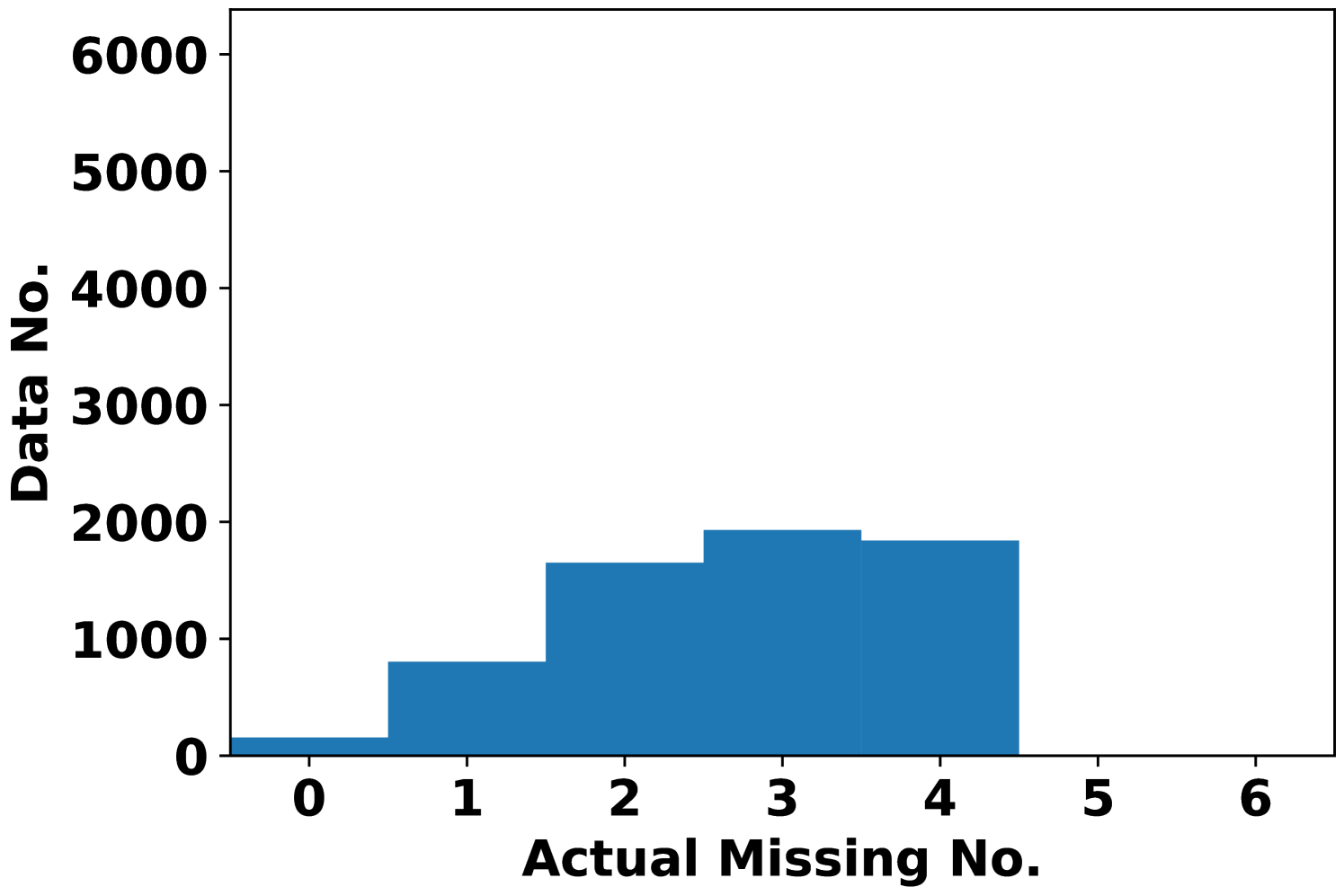
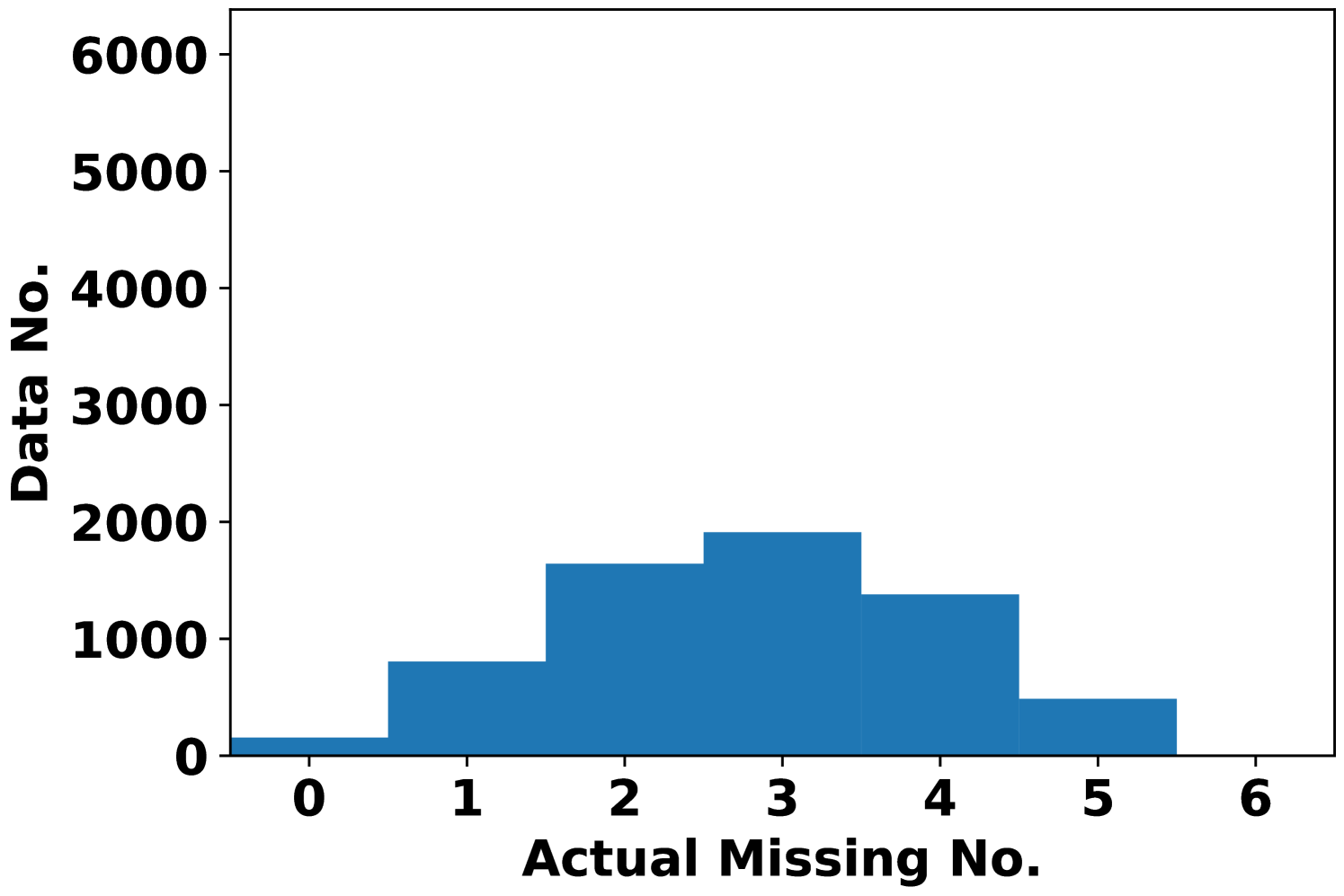
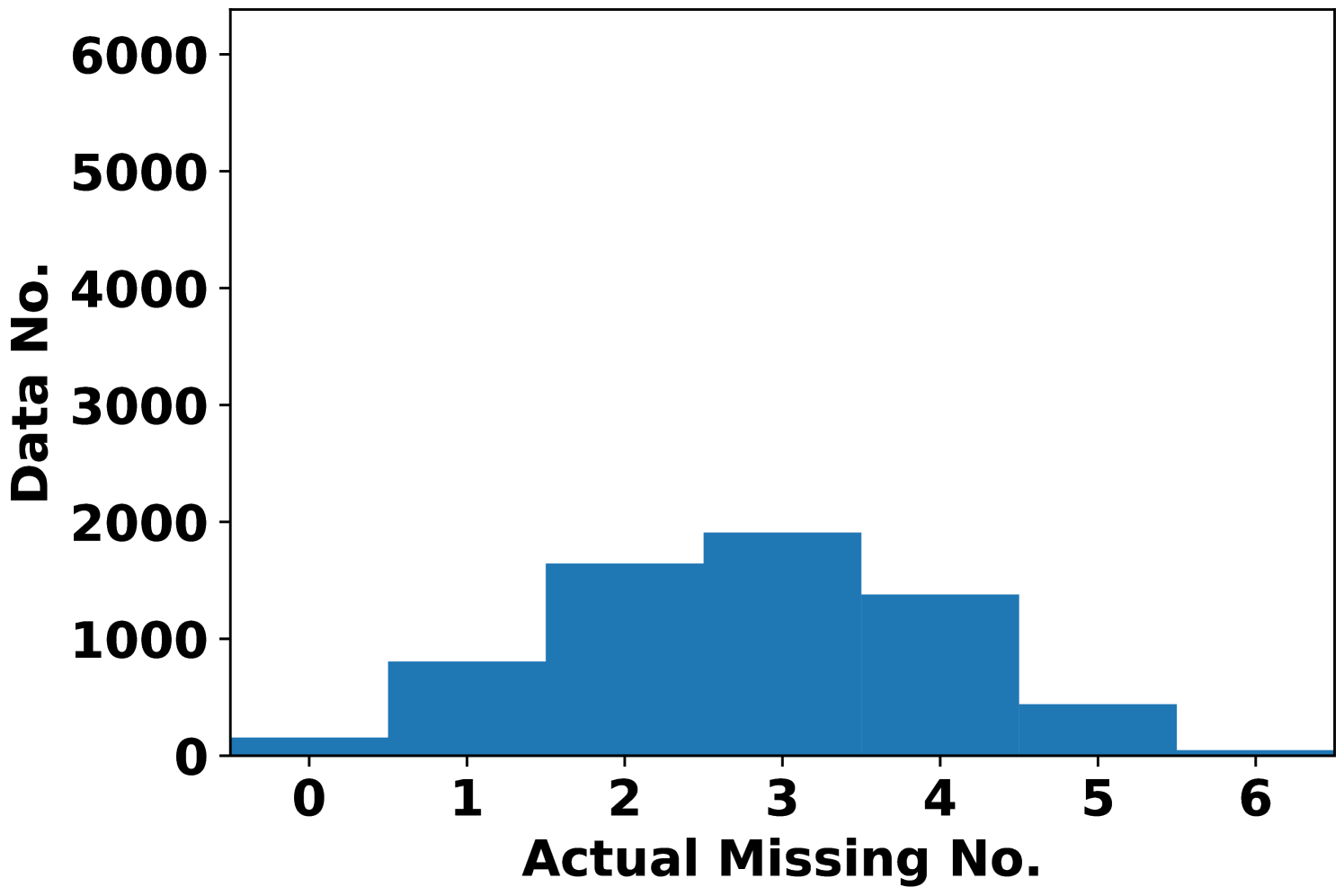
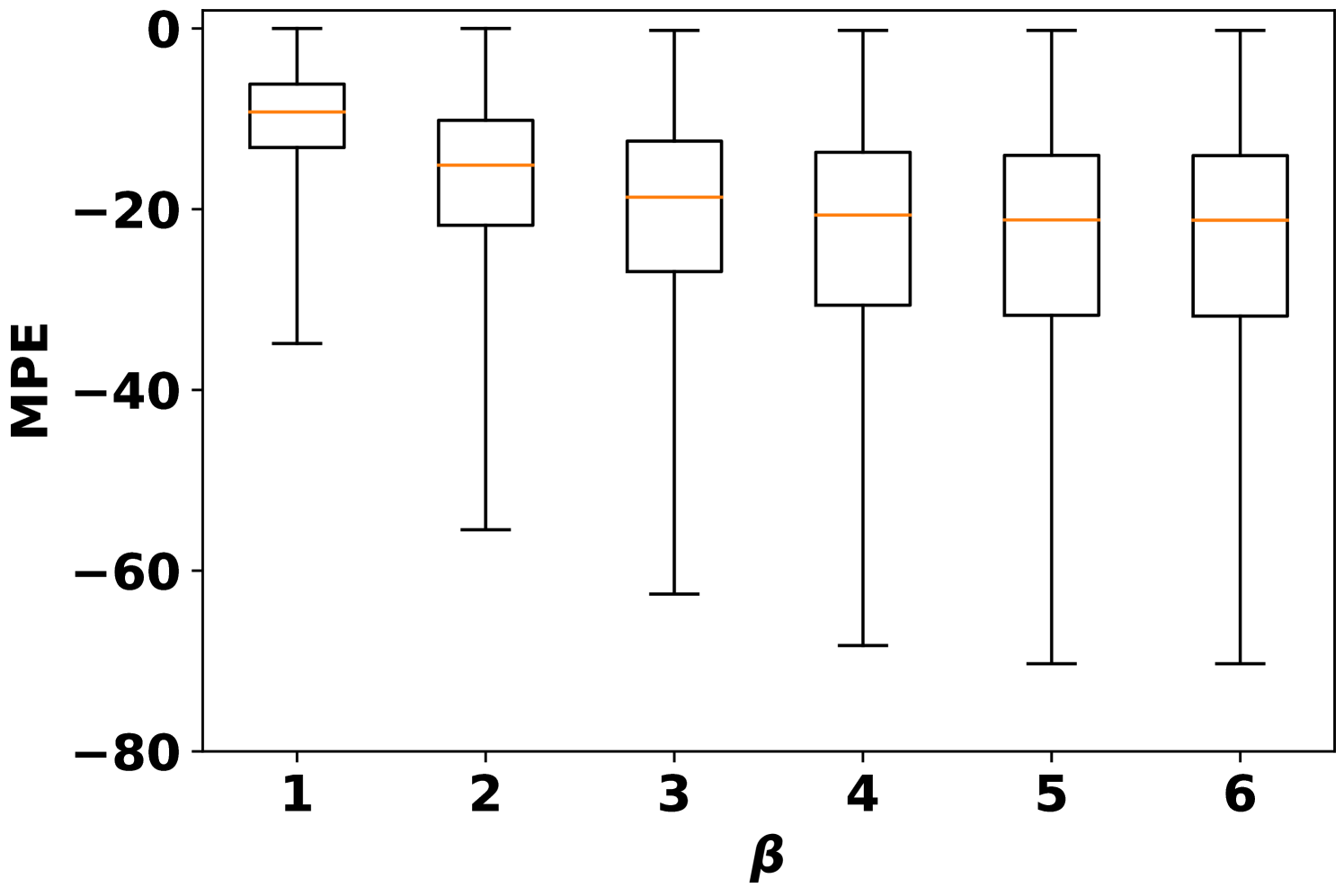
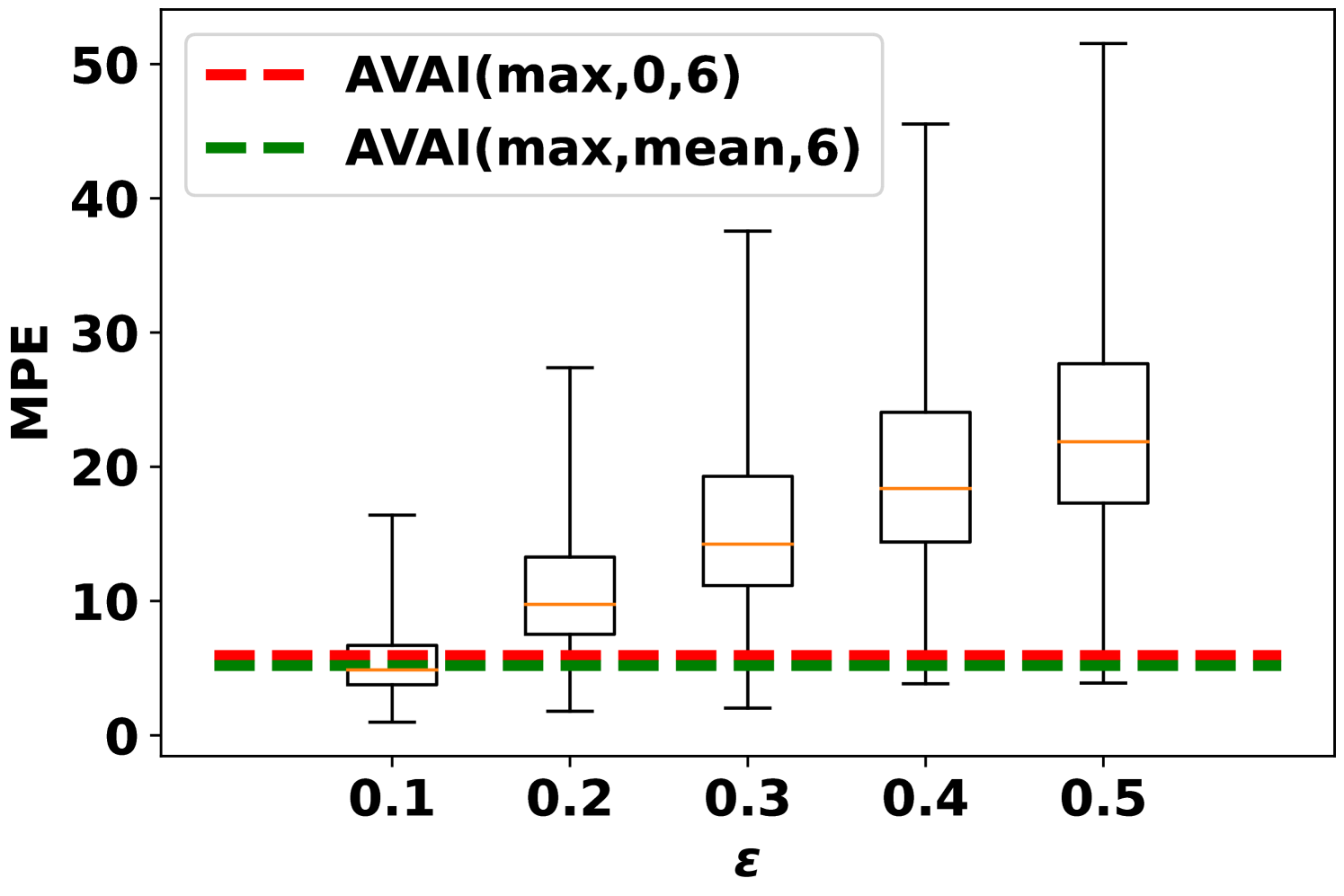
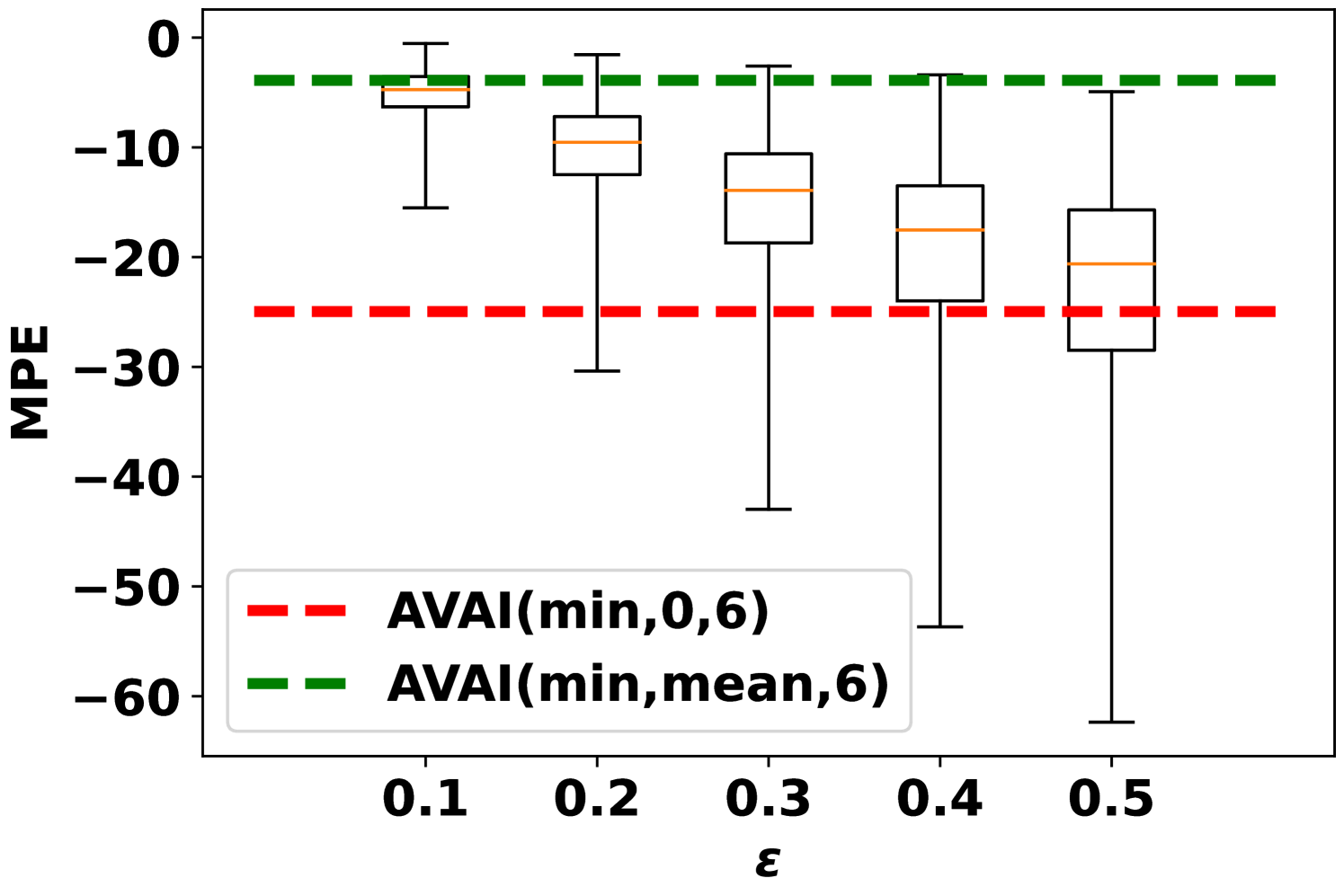
Fig. 3 records the MPE of integrity adversarial attacks solved by MILP (6). The median MPEs of availability attacks with are also plotted as a reference. When maximizing the load forecast (Fig. 3(a)), availability attacks can give output deviations comparable to integrity attacks when is small, e.g. with . However, when increases, the MPE of the integrity attack is much higher than the availability attacks. When minimizing the load forecast (Fig. 3(b)), AVAI(min, mean, 6) can persistently outperform integrity attacks. Since the input features are scaled into , it is not realistic to have larger than 0.2. Meanwhile, as it is is much cheaper than the integrity attack, the availability attack is a promising attack strategy for the attacker. However, how to balance the cost and impact of this attack is unsolved and we will leave it for future work.
Solving the MILP can be time consuming, especially when the number of integer variables is large. The computational time of both availability attacks are summarized in Table I. As adversarial training requires solving the optimal availability attacks, faster computation is beneficial to efficient training. Recall that the size of the dataset is 32k, which requires half hour to train single epoch. After using parallel computation, the computational time is significantly reduced to 1.7 min/epoch, which is acceptable for a real-time application.
| Attack Types | Time |
|---|---|
| AVAI-Parallel | 3.16 |
| AVAI-Sequential | 49.73 |
V-B Performance of Adversarial Training
Adversarial training is implemented in this section. Since there are two imputation strategies discussed in this paper, the performances are reported on both models trained adversarially with and . In addition, the attack budget is set to in adversarial training.
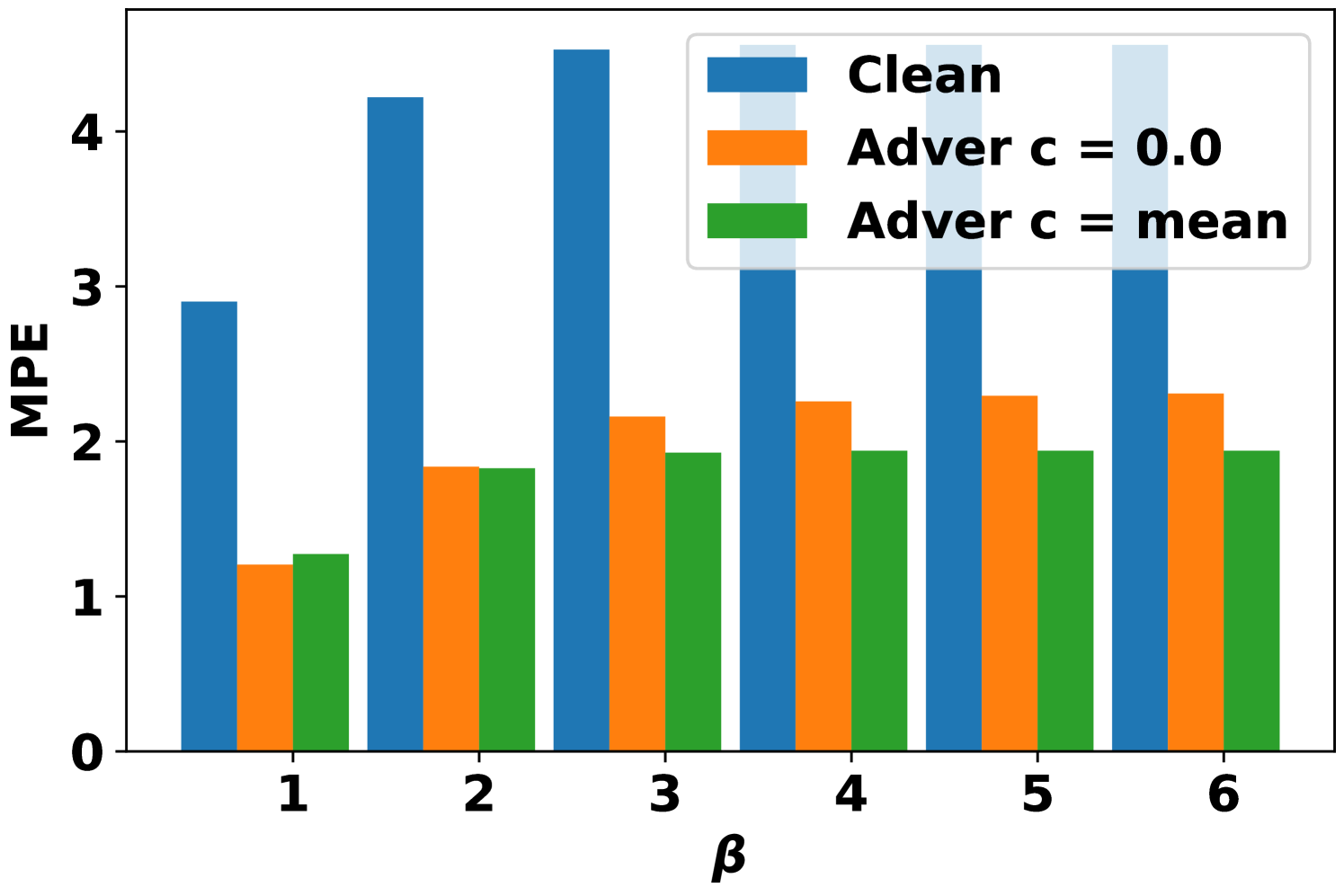
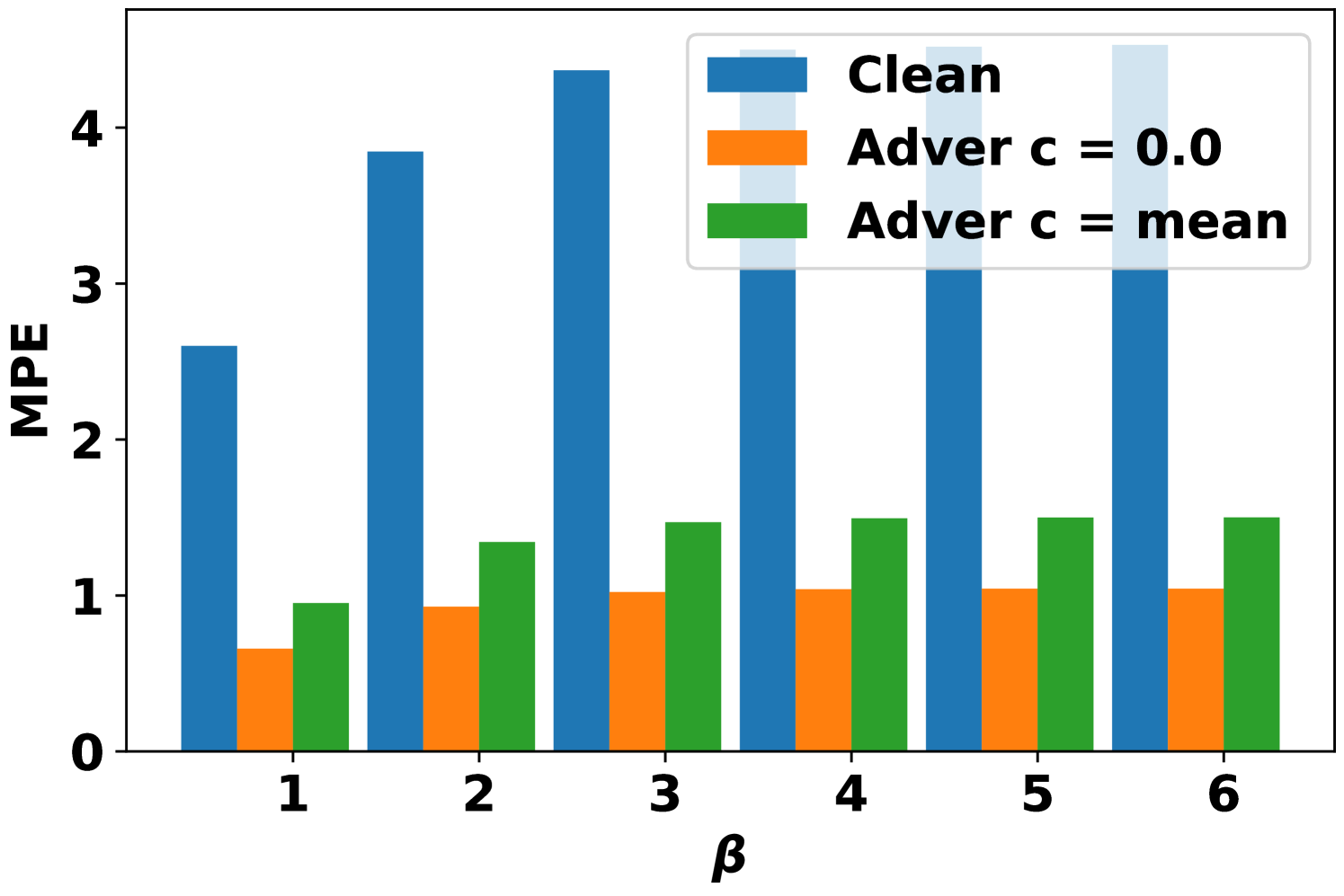
First, the MAPEs on the clean samples for both clean model and adversarial model are summarized in Table II. Adversarial training can inevitably deteriorate the performance of the model in clean samples by 1.0%. As is a stronger attack attempt than , model trained on AVAI(mode, 0, 6) has higher MAPE than it trained on AVAI(mode, mean, 6).
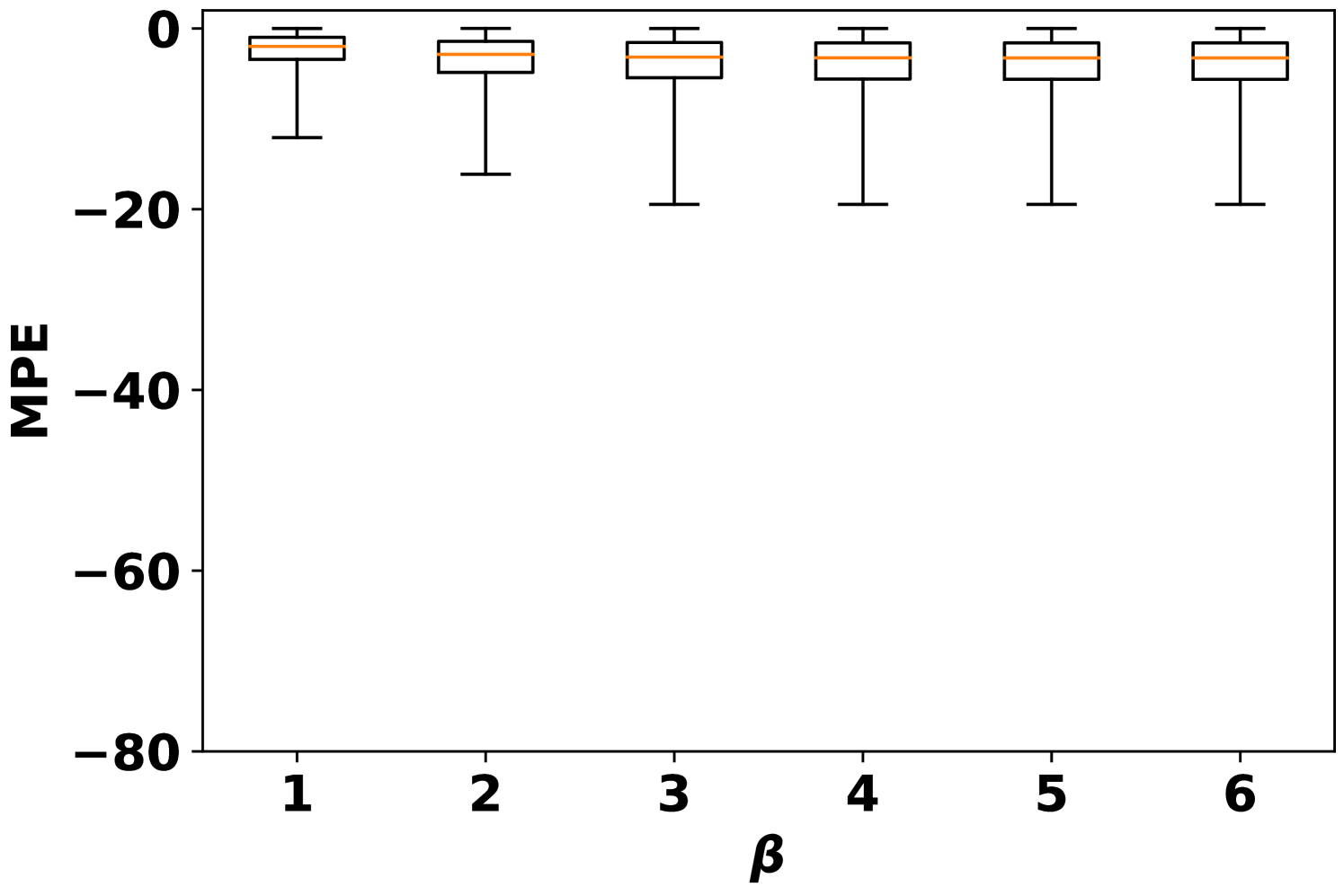
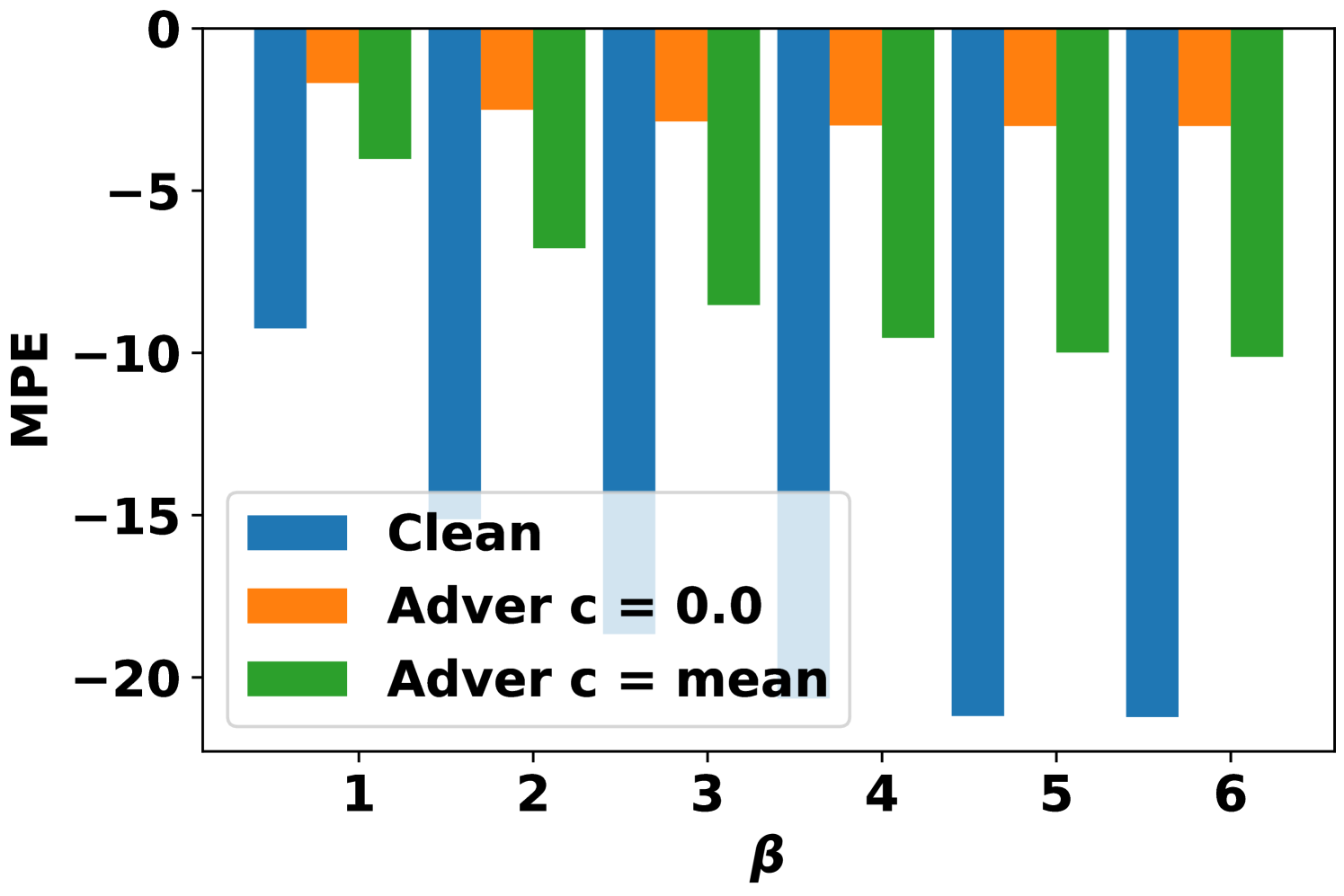
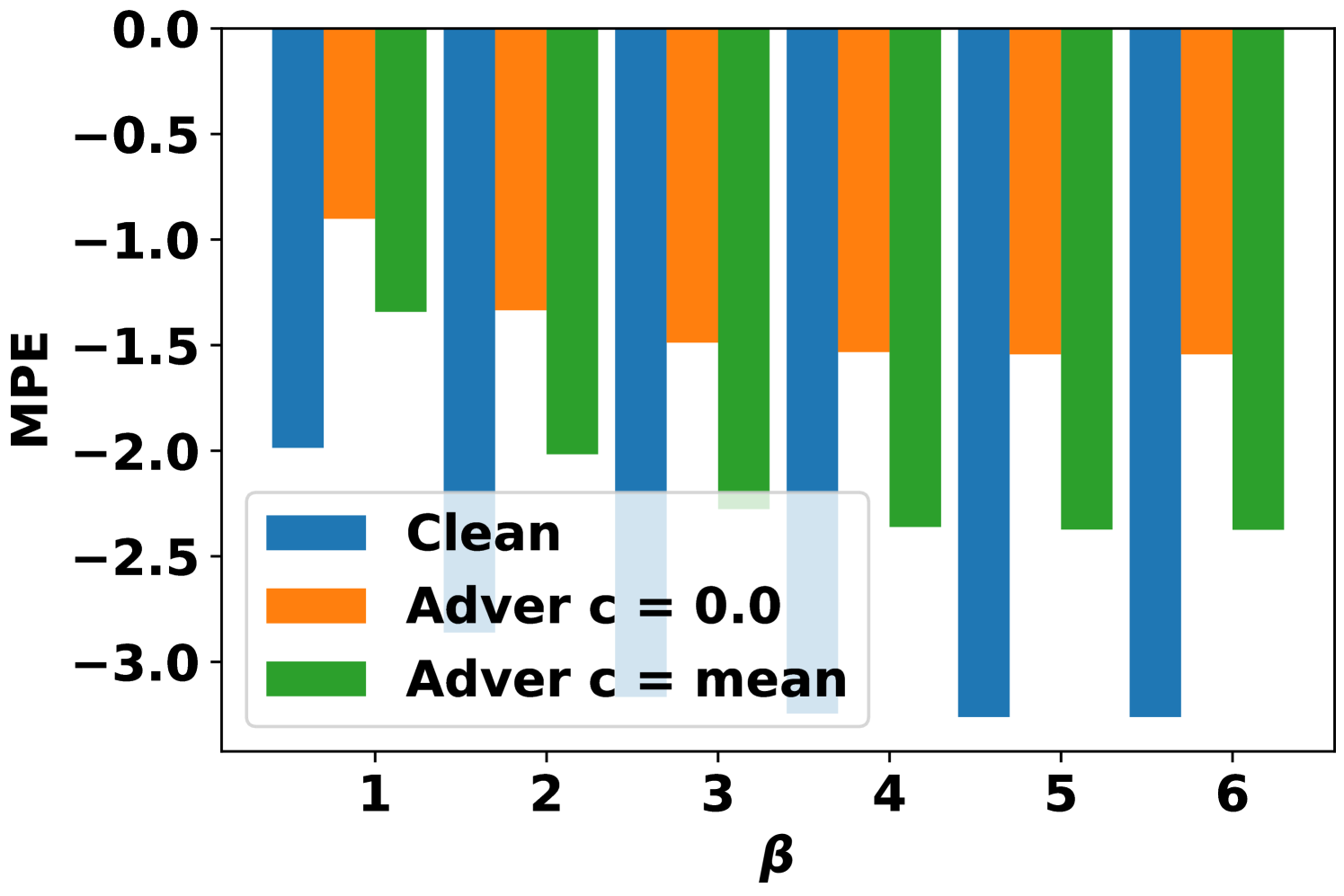
Second, the MPE on the adversarially attacked samples under different training situations are summarized in Fig. 4. After the adversarial training, the MPEs are reduced by more than 50% in general. The stronger adversarial training situation with can have better robustness, but sacrifices more in clean accuracy (Table II). It is interesting to observe that the model trained with can also have better performance on AVAI(mode, mean, 6) than the model trained directly with . Moreover, the performance of model trained with has slightly higher MPEs than the model trained with . Referring to (14), both AVAI(max, , 6) and AVAI(min, , 6) attacks contribute equally to the adversarial loss function. Therefore, the gradient descent tries to balance them during the training, although the AVAI(min, 0, 6) is much stronger than AVAI(max, 0, 6). To solve the problem, the hyperparameters can be set to in (14).
| Clean | Adver (c=0) | Adver (c=mean) | |
|---|---|---|---|
| Train | 5.81 | 6.83 | 6.76 |
| Test | 6.07 | 6.95 | 6.88 |
VI Conclusion
This paper proposes a new availability adversarial attack on load forecasting model constructed by piece-wise linear neural network. The attack is optimally found through MILP subject to certain attack budget, and a countermeasure is given through adversarial training. The simulation results show that the availability attack can achieve attack performance comparable to that of the integrity counterpart. Meanwhile, adversarial training can effectively reduce MPE by more than 50% on the adversarial samples while only increasing 1% MAPE on the clean samples.
References
- [1] T. Hong and S. Fan, “Probabilistic electric load forecasting: A tutorial review,” International Journal of Forecasting, vol. 32, no. 3, pp. 914–938, 2016.
- [2] C. Kuster, Y. Rezgui, and M. Mourshed, “Electrical load forecasting models: A critical systematic review,” Sustainable cities and society, vol. 35, pp. 257–270, 2017.
- [3] J. Zhang, Y. Wang, and G. Hug, “Cost-oriented load forecasting,” Electric Power Systems Research, vol. 205, p. 107723, 2022.
- [4] S. H. Rafi, Nahid-Al-Masood, S. R. Deeba, and E. Hossain, “A short-term load forecasting method using integrated cnn and lstm network,” IEEE Access, vol. 9, pp. 32 436–32 448, 2021.
- [5] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv preprint arXiv:1312.6199, 2013.
- [6] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
- [7] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv preprint arXiv:1706.06083, 2017.
- [8] H. I. Fawaz, G. Forestier, J. Weber, L. Idoumghar, and P.-A. Muller, “Adversarial attacks on deep neural networks for time series classification,” in 2019 International Joint Conference on Neural Networks (IJCNN). IEEE, 2019, pp. 1–8.
- [9] J. Luo, T. Hong, and S.-C. Fang, “Benchmarking robustness of load forecasting models under data integrity attacks,” International Journal of Forecasting, vol. 34, no. 1, pp. 89–104, 2018.
- [10] ——, “Robust regression models for load forecasting,” IEEE Transactions on Smart Grid, vol. 10, no. 5, pp. 5397–5404, 2018.
- [11] A. Stratigakos, P. Andrianesis, A. Michiorri, and G. Kariniotakis, “Towards resilient energy forecasting: A robust optimization approach,” 2022.
- [12] Y. Chen, M. Sun, Z. Chu, S. Camal, G. Kariniotakis, and F. Teng, “Vulnerability and impact of machine learning-based inertia forecasting under cost-oriented data integrity attack,” IEEE Transactions on Smart Grid, 2022.
- [13] Y. Zhou, Z. Ding, Q. Wen, and Y. Wang, “Robust load forecasting towards adversarial attacks via bayesian learning,” IEEE Transactions on Power Systems, 2022.
- [14] K. Pan, A. Teixeira, M. Cvetkovic, and P. Palensky, “Cyber risk analysis of combined data attacks against power system state estimation,” IEEE Transactions on Smart Grid, vol. 10, no. 3, pp. 3044–3056, 2018.
- [15] M. Farrokhabadi, J. Browell, Y. Wang, S. Makonin, W. Su, and H. Zareipour, “Day-ahead electricity demand forecasting competition: Post-covid paradigm,” IEEE Open Access Journal of Power and Energy, vol. 9, pp. 185–191, 2022.
- [16] X. Liu, X. Han, N. Zhang, and Q. Liu, “Certified monotonic neural networks,” Advances in Neural Information Processing Systems, vol. 33, pp. 15 427–15 438, 2020.
- [17] A. Teixeira, K. C. Sou, H. Sandberg, and K. H. Johansson, “Secure control systems: A quantitative risk management approach,” IEEE Control Systems Magazine, vol. 35, no. 1, pp. 24–45, 2015.
- [18] Z. Kolter and A. Madry, “Adversarial robustness - theory and practice,” 2022. [Online]. Available: https://adversarial-ml-tutorial.org/
- [19] H. Zhang, Y. Yu, J. Jiao, E. Xing, L. El Ghaoui, and M. Jordan, “Theoretically principled trade-off between robustness and accuracy,” in International conference on machine learning. PMLR, 2019, pp. 7472–7482.
- [20] S. Diamond and S. Boyd, “Cvxpy: A python-embedded modeling language for convex optimization,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2909–2913, 2016.