Average value estimation in nonadiabatic holonomic quantum computation
Abstract
Nonadiabatic holonomic quantum computation has been attracting continuous attention since it was proposed. Until now, various schemes of nonadiabatic holonomic quantum computation have been developed and many of them have been experimentally demonstrated. It is known that at the end of a computation, one usually needs to estimate the average value of an observable. However, computation errors severely disturb the final state of a computation, causing erroneous average value estimation. Thus for nonadiabatic holonomic quantum computation, an important topic is to investigate how to better give the average value of an observable under the condition of computation errors. While the above topic is important, the previous works in the field of nonadiabatic holonomic quantum computation pay woefully inadequate attention to it. In this paper, we show that rescaling the measurement results can better give the average value of an observable in nonadiabatic holonomic quantum computation when computation errors are considered. Particularly, we show that by rescaling the measurement results, of the computation errors can be reduced when using depolarizing noise model, a widely adopted noise model in quantum computation community, to analyse the benefit of our method.
I Introduction
Unlike classical computation, quantum computation can use quantum parallelism to process information encoded in physical systems. For this reason, quantum computation can solve many problems, such as factoring large integers and searching unsorted databases, much faster than classical computation Nielsen2001 . However, while the advantages of quantum computation are attracting, achieving them in practice is difficult. The main reason is that compared to classical systems, quantum systems are much easier to be affected by noise, so that quantum computation, which builds on quantum systems, is difficult to be realized with high fidelity. To overcome the noise problem and thereby realize high-fidelity quantum computation, researchers pay continuous attention to investigate robust quantum computation and until now impressive progresses have been made in this direction.
Geometric phases are important both in theory and application. The first kind of geometric phases discovered by researchers were adiabatic and Abelian geometric phases Berry . This kind of geometric phases can be acquired by evolving a quantum system in a nondegenerate eigenstate adiabatically and cyclicly. Soon after, the notion of adiabatic and Abelian geometric phases was gradually generalized: a quantum system with degenerate eigenstates undergoing adiabatic cyclic evolution can acquire adiabatic and non-Abelian geometric phases or adiabatic quantum holonomies Wilczek ; a quantum system with nondegenerate eigenstates undergoing nonadiabatic cyclic evolution can acquire nonadiabatic and Abelian geometric phases Aharonov ; a quantum system with degenerate eigenstates undergoing nonadiabatic cyclic evolution can acquire nonadiabatic and non-Abelian geometric phases or nonadiabatic quantum holonomies Anandan . Besides the above seminal works, there are also other remarkable works enriching the field of geometric phases Sjoqvist2000 ; Tong2004 .
Since geometric phases are only dependent on the path in which the quantum system evolves but independent of its evolutional details, quantum computations based on geometric phases are robust against certain control errors. As one important geometric quantum computation paradigm, nonadiabatic holonomic quantum computation Sjoqvist2012 ; Xu2012 builds its gates on nonadiabatic and non-Abelian geometric phases Anandan . Moreover, nonadiabatic holonomic quantum computation does not have the constraint of adiabatic evolution condition Tong2005 ; Tong2007 ; Tong2010 and thereby has the feature of being implemented with high-speed. Because of the above features, nonadiabatic holonomic quantum computation has been attracting continuous attention since it was proposed. Until now, a number of relevant schemes have been put forward Abdumalikov ; Feng ; Arroyo ; Zu ; Liang ; Zhang1 ; Mousolou ; Xue ; Xu3 ; Sjoqvist2 ; Herterich ; Zhang2 ; Wang ; Sun ; Xue2017 ; Li2017 ; Sekiguchi ; Zhou2017 ; Hong2018 ; Zhao2019 ; danilin18 ; Xu2018 ; Zhang2019 ; Ramberg ; Liu2019 ; Zhu2019 ; Yan2019 ; Ai2020 ; Xu2021 ; Zhao2021 ; Liang2022 ; Shen2023 ; Zhang2023 , and some schemes have been experimentally demonstrated in circuit QED Abdumalikov ; danilin18 ; Xu2018 ; Yan2019 ; Zhang2019 , nuclear magnetic resonance systems Feng ; Li2017 ; Zhu2019 , nitrogen-vacancy centers Arroyo ; Zu ; Sekiguchi ; Zhou2017 and trapped ions Ai2020 .
When using quantum computation to implement a computational task, an important step is to estimate the average value of an observable at the end. However, computation errors can disturb the final state of the computation, thereby affecting the estimation of the average value. When implementing a computational task, many nonadiabatic holonomic gates are needed. While these nonadiabatic holonomic gates have robustness, they can not be perfect in practice. And these imperfections can accumulate, resulting in severe computation errors. Thus for nonadiabatic holonomic quantum computation, it is of significance to investigate how to better give the average value of an observable when the above computation errors are taken into account.
In this paper, we show that when computation errors in nonadiabatic holonomic quantum computation are considered, rescaling the measurement results is a better way to give the average value of an observable than the conventional way. Our proposal is based on the fact that while the ideal final state of nonadiabatic holonomic quantum computation resides in the logical space, the support of the noisy final state can occupies the whole Hilbert space. We also use depolarizing noise model, which is a widely adopted noise model in quantum computation community, to conduct the analysis and find that of the computation errors can be reduced when using the rescaling method to give the average value.
II the framework
We now start to illustrate our framework. Before proceeding further, we first briefly review how to realize a nonadiabatic holonomic gate. We consider an -dimensional quantum system governed by Hamiltonian , of which the evolution operator is denoted as with being time ordering. We use to represent orthonormal solutions of the Schrödinger equation . Assume there is an -dimensional subspace evolving cyclicly with the period , i.e. , and satisfying the parallel transport condition, i.e., , . The computational basis can be then encoded into and the final evolution operator acting on is a nonadiabatic holonomic gate.
From the above review, one can readily see that to realize a nonadiabatic holonomic gate, the logical space needs to be smaller than the whole Hilbert space, i.e., the logical space is just a subspace of the whole Hilbert space. Thus, instead of using two-level systems, one usually uses three-level systems to build nonadiabatic holonomic quantum computation and for each three-level system, only two of its three internal states are used as logical states Sjoqvist2012 .
Clearly, when using nonadiabatic holonomic quantum computation to implement a specific computational task, one needs more than one three-level systems, and without loss of generality, we assume the required number is .
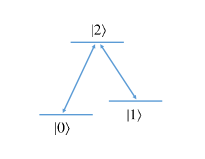
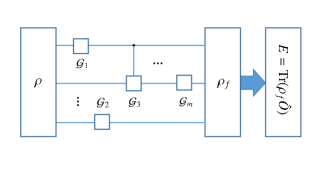
As shown in Fig. 1, for each of these three-level systems, we denote its three states by , and , respectively. Between these three states, the transitions and are allowed, while the transition is forbidden. Of these three states, the states and are used as logical states and the state is used as an auxiliary state. When implementing a computational task, these three-level systems are first prepared in an initial state , i.e., the initial state of the computation. Then a family of nonadiabatic holonomic gates ’s are performed on , generating the final state of the computation. That is,
| (1) |
where is the number of the performed nonadiabatic holonomic gates in the computation. At the end, a measurement is performed on the final state , aiming to give the average value of some observable. That is,
| (2) |
where is the observable whose average value we want to estimate and denotes the average value. The above procedure can also be seen from Fig. 2.
However, while nonadiabatic holonomic quantum gates have robustness, they can not be perfect in practice i.e., they can be noisy Solinas ; Johansson . Particularly, many nonadiabatic holonomic quantum gates are needed for implementing a computational task, and the imperfections of these gates can be accumulated, seriously affecting the quality of the final state . Specifically, in practice we can not get the ideal final state , but instead we get a final state written as
| (3) |
where represents the -th noisy nonadiabatic holonomic gate and represents the noisy final state of the computation. In this case, if the conventional way is used to estimate the average value of , one will get
| (4) |
instead of the desired average value .
Clearly, is not a good estimation of the desired average value . To improve the estimation, we analyse the difference between the ideal final state and the noisy final state . Recall that for each of the three-level systems, the states and are used to encode the logical information, while the state is used as an auxiliary state. Thus, for these three-level systems, the whole Hilbert space is , while the logical space is . As it is well known, if a nonadiabatic holonomic gate is perfect, it transforms states in the logical space to states in the logical space. Thus, the support of the ideal final state is a subspace of the logical space . On the other hand, when the performed nonadiabatic holonomic gates ’s are noisy, we do not expect the support of the noisy final state to be a subspace of the logical space because the computation errors can cause the logical information to leak from the logical space. And the leakage problem can be induced by either the inaccuracy of the system Hamiltonian Spiegelberg ; Alves or decoherence. Generally, the relation between and can be simply expressed as
| (5) |
where is a probability describing the strength of the computation errors and is a noisy state. Note that the support of is a subspace of the logical space , but the support of can be the whole Hilbert space . Thus, if we detect the state outside the logical space, we known errors have occurred. This inspires us to use the quantum error detection principle to reduce the errors Nielsen2001 . Specifically, based on the difference between and , we consider the following projector
| (6) |
According to Eqs. (5) and (6), one can see that the weight of the ideal final state within is higher than that within , where is a normalization factor. The reason for the above is that under the action of the projector , the ideal final state is totally retained, i.e., , while the noisy state is only partly retained. The above discussion indicates that it is better to extract the information of the average value of from than from .
To proceed further, we analyse the properties of the observable . Because is an observable, we can choose the eigenvectors of so that these eigenvectors constitute an orthonormal basis for the whole Hilbert space . Without loss of generality, we denote the eigenvectors of the observable by and the eigenvalue corresponding to by . As mentioned before, constitute an orthonormal basis for the whole Hilbert space . Since the support of is a subspace of the logical space , we can always appropriately choose so that they can be divided into two parts: some of the eigenvectors are in the logical space and the others are in the subspace , where is the subspace orthogonal to the logical subspace. Then extracting the information of the average value of from is equivalent to the following formula
| (7) |
where and by , we mean the summation is only calculated for the eigenvectors belonging to the logical space . With the eigenvectors of denoted by and eigenvalues denoted by , we can also rewrite in Eq. (4) as follows
| (8) |
According to Eqs. (7) and (8), one can readily see the difference: one is the summation range and the other is that the probabilities in Eq. (7) are rescaled by the factor while the probabilities in Eq. (8) are not rescaled.
In the above, we have shown that extracting the information of the average value of the observable from is better than from , that is, Eq. (7) is better to estimate the desired average value of the observable than Eq. (8). In the following, we will analyse to what extent one can get benefit from using the rescaling method, i.e., Eq. (7).
It is known that depolarizing noise model is widely used to describe computation errors in quantum computation community. Thus we here adopt this noise model to conduct our analysis. As shown in Fig. 2, a family of nonadiabatic holonomic gates ’s are used in the computation. Usually, these nonadiabatic holonomic gates are one-qubit and two-qubit gates. That is, only one-qubit and two-qubit gates are used to process the information. Moreover, these gates are not perfect but experience depolarizing noise Bhattacharyya . Since the quality of the gates is high, it is reasonable to assume only one gate in the computation is erroneous. Because one-qubit gates are much more reliable than two-qubit gates, the erroneous gate in the computation can be assumed to be a two-qubit gate.
Without loss of generality, we assume the erroneous two-qubit gate acts on the three-level systems and , that is,
| (9) |
where , represents the ideal gate, and represents the errors. It is very important to note that is not a fixed number. Recall that we have assumed only one gate in the computation is erroneous. But this does not mean a fixed gate is erroneous every time we implement the computation. Instated, this means that every time we implement the computation, one of the performed gates is erroneous but which one is erroneous is not fixed.
has the possible values described by the generalized Pauli operators
| (10) |
In the above, operators and respectively act on three-level systems and , where , and , with . According to Eq. (10), one can see that has possible values in total: error-free operator and error operators. The error-free operator is given by and it is in fact the identity operator acting on three-level systems and . Because the depolarizing noise model is symmetric, these error operators are equally likely.
Usually, the initial state of a computation is chosen to be a very easily prepared state. Thus, the fidelity of the initial state is very high. So, we can think of the initial state of the computation as a pure state residing in the logical space , and we denote this initial state by . After the action of the nonadiabatic holonomic gates, the final state of the computation can be written as
| (11) |
where and respectively represent the gates performed before and after , and .
We first consider the action of and on . Since the gates and are ideal, is a pure state residing in the logical space. Without loss of generality, this pure state can be written as
| (12) | |||||
where , , , are normalization coefficients, while , , , are the states of the three-level systems except for and , with , , , being bit strings consisting of and .
We next consider the action of on . Recall that has possible values: error-free operator and error operators. Before proceeding further, we divide these error operators into four subsets: , , and . The subset contains the following error operators
| (13) |
where . The subset contains the following error operators
| (14) |
The subset contains the following error operators
| (15) |
For subset , it contains all the rest of error operators not contained in subsets , and . That is, the subset contains the following error operators
| (16) |
Consider the case where one of the error operators in subset occurs, and without loss of generality, we assume this error operator is , that is, . Note that here and are some fixed numbers. In this case, the action of on , i.e., , is equivalent to . By calculation, one can get that reads
| (17) | |||||
From the above equation, one can see that while the first component resides in the logical space , the left three components reside in the subspace , i.e., the subspace orthogonal to .
In the above, we have discussed the action of , and on , i.e., , where is assumed to have the value of the error operator . We then consider the action of , that is, . Specifically, after the action of , the state turns into
| (18) | |||||
It is known that the gates are ideal: transform states in the logical space to state in the logical space , and transform states in the subspace to states in the subspace . Thus, after the action of , the first component still resides in the logical space , while the left three components still reside in the subspace .
We now analyse to what extent one can get benefit from using the rescaling method, i.e., Eq. (7), under the condition that . In this case, using the rescaling method is equivalent to ruling out the components of residing in the subspace . Note that it is the error operator that causes the appearance of the components of residing in the subspace . Thus, ruling out the components of residing in the subspace is equivalent to ruling out the error operator . By calculation, the probability of ruling out the error operator reads
| (19) | |||||
where is the identity operator acting on the whole Hilbert space . Note that the above probability is a conditional probability and the condition is that is assumed to be the error operator . That is, under the condition of the error operator occurring, with probability a measurement yields an eigenstate which does not belong to the logical subspace.
With a similar discussion, we can get the conditional probabilities , , and that respectively describe the possibilities of ruling out the error operators , and in the subset . Specifically, these conditional probabilities read
| (20) |
With a similar discussion, we can also get the conditional probabilities corresponding to the error operators in the subsets , and . For example, consider the case where the error operator occurs, i.e., . Then after the action of the operator, the state turns into
| (21) | |||||
Then after the action of , the above state turns into
| (22) | |||||
According to the above equation, we can get that the conditional probability corresponding to the error operator reads
| (23) | |||||
To sum up, the other conditional probabilities can also be got similarly and they can be written as
| (24) |
For the error operators in the subset , they do not cause the logical information to leak from the logical space because these error operators are formed by using only the generalized Pauli operator . So, the corresponding conditional probabilities have the value of zero.
We have got the conditional probabilities corresponding to each error operator. And we know that the depolarizing noise model is symmetric and therefore these error operators are equally likely. Using the above information, we can get the probability ruling out the depolarizing noise and it reads
| (25) |
where is the sum of the conditional probabilities corresponding to the error operators in the subset , is the sum of the conditional probabilities corresponding to the error operators in the subset and is the sum of the conditional probabilities corresponding to the error operators in the subset . So, of the computation errors can be reduced when using the rescaling method to estimate the average value of the observable. While we assume that the depolarizing noise model is symmetric in the above, our method can also be applicable in the asymmetric case. Note that the error operators are formed by the generalized Pauli operators and , and is the reason for the logical information to leak out the logical space. Thus, if occurs with high probability and occurs with low probability, the efficiency of our method will be increased. But if occurs with low probability and occurs with high probability, the efficiency of our method will be decreased.
III Conclusion
In conclusion, we put forward a way to estimate the average value of an observable in nonadiabatic quantum computation. The specific procedure is to perform a measurement with respect to the observable and then rescale the measurement results so that one can get a better estimation of the average value of the observable. Our way is based on the fact that while the support of the ideal final state of nonadiabatic holonomic quantum computation is a subspace of the logical subspace, the support of the noisy final state can be the whole Hilbert space. Thus projecting the noisy final state onto the logical space can increase the weight of the ideal final state, making the estimation of the average value more accurate. We use the depolarizing noise model, which is a widely adopted noise model in quantum computation, to specifically analyse to what extent one can benefit from using the rescaling method, and we find that of the computation errors can be reduced when assuming that one gate in the computation is erroneous. While our method is illustrated with system based nonadiabatic holonomic quantum computation, its application may be generalized to other quantum computation paradigms. For a quantum system used to build a qubit, it usually has many levels and two of these levels are chosen to encode the logical information. If the logical information can leak out to other levels when the quantum system experiencing inaccuracy evolutions, the logical space cannot be seen as the whole Hilbert space and our method is applicable.
Acknowledgments
The authors acknowledge support from the National Natural Science Foundation of China through Grant No. 12174224.
References
- (1) M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, Cambridge, 2001).
- (2) M. V. Berry, Proc. R. Soc. London A 392, 45 (1984).
- (3) F. Wilczek and A. Zee, Phys. Rev. Lett. 52, 2111 (1984).
- (4) Y. Aharonov and J. Anandan, Phys. Rev. Lett. 58, 1593 (1987).
- (5) J. Anandan, Phys. Lett. A 113, 171 (1988).
- (6) E. Sjöqvist, A. K. Pati, A. Ekert, J. S. Anandan, M. Ericsson, D. K. L. Oi, and V. Vedral, Phys. Rev. Lett. 85, 2845 (2000).
- (7) D. M. Tong, E. Sjöqvist, L. C. Kwek, and C. H. Oh, Phys. Rev. Lett. 93, 080405 (2004).
- (8) E. Sjöqvist, D. M. Tong, L. M. Andersson, B. Hessmo, M. Johansson, and K. Singh, New J. Phys. 14, 103035 (2012).
- (9) G. F. Xu, J. Zhang, D. M. Tong, E. Sjöqvist, and L. C. Kwek, Phys. Rev. Lett. 109, 170501 (2012).
- (10) D. M. Tong, K. Singh, L. C. Kwek, and C. H. Oh, Phys. Rev. Lett. 95, 110407 (2005).
- (11) D. M. Tong, K. Singh, L. C. Kwek, and C. H. Oh, Phys. Rev. Lett. 98, 150402 (2007).
- (12) D. M. Tong, Phys. Rev. Lett. 104, 120401 (2010).
- (13) J. Zhang, L. C. Kwek, E. Sjöqvist, D. M. Tong, and P. Zanardi, Phys. Rev. A 89, 042302 (2014).
- (14) Z. T. Liang, Y. X. Du, W. Huang, Z. Y. Xue, and H. Yan, Phys. Rev. A 89, 062312 (2014).
- (15) Z. Y. Xue, J. Zhou, and Z. D. Wang, Phys. Rev. A 92, 022320 (2015).
- (16) C. F. Sun, G. C. Wang, C. F. Wu, H. D. Liu, X. L. Feng, J. L. Chen, and K. Xue, Sci. Rep. 6, 20292 (2016).
- (17) B. J. Liu, X. K. Song, Z. Y. Xue, X. Wang, and M. H. Yung, Phys. Rev. Lett. 123, 100501 (2019).
- (18) J. Zhang, T. H. Kyaw, D. M. Tong, E. Sjöqvist, and L. C. Kwek, Sci. Rep. 5, 18414 (2015).
- (19) G. F. Xu, C. L. Liu, P. Z. Zhao, and D. M. Tong, Phys. Rev. A 92, 052302 (2015).
- (20) E. Sjöqvist, Phys. Lett. A 380, 65 (2016).
- (21) E. Herterich and E. Sjöqvist, Phys. Rev. A 94, 052310 (2016).
- (22) Y. Wang, J. Zhang, C. Wu, J. Q. You, and G. Romero, Phys. Rev. A 94, 012328 (2016).
- (23) Z. Y. Xue, F. L. Gu, Z. P. Hong, Z. H. Yang, D. W. Zhang, Y. Hu, and J. Q. You, Phys. Rev. Applied 7, 054022 (2017).
- (24) Z. P. Hong, B. J. Liu, J. Q. Cai, X. D. Zhang, Y. Hu, Z. D. Wang, and Z. Y. Xue, Phys. Rev. A 97, 022332 (2018).
- (25) P. Z. Zhao, G. F. Xu, and D. M. Tong, Phys. Rev. A 99, 052309 (2019).
- (26) N. Ramberg and E. Sjöqvist, Phys. Rev. Lett. 122, 140501 (2019).
- (27) V. A. Mousolou, C. M. Canali, and E. Sjöqvist, New J. Phys. 16, 013029 (2014).
- (28) A. A. Abdumalikov, J. M. Fink, K. Juliusson, M. Pechal, S. Berger, A. Wallraff, and S. Filipp, Nature (London) 496, 482 (2013).
- (29) S. Danilin, A. Vepsäläinen, and G. S. Paraoanu, Phys. Scr. 93, 055101 (2018).
- (30) Y. Xu, W. Cai, Y. Ma, X. Mu, L. Hu, Tao Chen, H. Wang, Y. P. Song, Z. Y. Xue, Z. Q. Yin, and L. Sun, Phys. Rev. Lett. 121, 110501 (2018).
- (31) T. X. Yan, B. J. Liu, K. Xu, C. Song, S. Liu, Z. S. Zhang, H. Deng, Z. G. Yan, H. Rong, K. Q. Huang, M. H. Yung, Y. Z. Chen, and D. P. Yu, Phys. Rev. Lett. 122, 080501 (2019).
- (32) Z. X. Zhang, P. Z. Zhao, T. H. Wang, L. Xiang, Z. L. Jia, P. Duan, D. M. Tong, Y. Yin, and G. P. Guo, New J. Phys. 21, 073024 (2019).
- (33) G. R. Feng, G. F. Xu, and G. L. Long, Phys. Rev. Lett. 110, 190501 (2013).
- (34) H. Li, Y. Liu, and G. L. Long, Sci. China-Phys. Mech. Astron. 60, 080311 (2017).
- (35) Z. N. Zhu, T. Chen, X. D. Yang, J. Bian, Z. Y. Xue, and X. H. Peng, Phys. Rev. Applied 12, 024024 (2019).
- (36) S. Arroyo-Camejo, A. Lazariev, S. W. Hell, and G. Balasubramanian, Nat. Commun. 5, 4870 (2014).
- (37) C. Zu, W. B. Wang, L. He, W. G. Zhang, C. Y. Dai, F. Wang, and L. M. Duan, Nature (London) 514, 72 (2014).
- (38) Y. Sekiguchi, N. Niikura, R. Kuroiwa, H. Kano, and H. Kosaka, Nature Photon. 11, 309 (2017).
- (39) B. B. Zhou, P. C. Jerger, V. O. Shkolnikov, F. J. Heremans, G. Burkard, and D. D. Awschalom, Phys. Rev. Lett. 119, 140503 (2017).
- (40) M. Z. Ai, S. Li, Z. B. Hou, R. He, Z. H. Qian, Z. Y. Xue, J. M. Cui, Y. F. Huang, C. F. Li, and G. C. Guo, Phys. Rev. Applied 14, 054062 (2020).
- (41) G. F. Xu, P. Z. Zhao, E. Sjöqvist, and D. M. Tong, Phys. Rev. A 103, 052605 (2021).
- (42) P. Z. Zhao, G. F. Xu, and D. M. Tong, Chin. Sci. Bull. 66, 1935 (2021).
- (43) Y. Liang, P. Shen, T. Chen, and Z. Y. Xue, Phys. Rev. Appl. 17, 034015 (2022).
- (44) P. Shen, Y. Liang, T. Chen, and Z. Y. Xue, Phys. Rev. A 108, 032601 (2023).
- (45) J. Zhang, T. H. Kyaw, S. Filipp, L. C. Kwek, E. Sjöqvist, and D. M. Tong, Physics Reports 1027, 1-53 (2023).
- (46) P. Solinas, M. Sassetti, P. Truini, and N. Zanghì, New Journal of Physics 14, 093006 (2012).
- (47) M. Johansson, E. Sjöqvist, L. M. Andersson, M. Ericsson, B. Hessmo, K. Singh, and D. M. Tong, Physical Review A 86, 062322 (2012).
- (48) J. Spiegelberg and E. Sjöqvist, Physical Review A 88, 054301 (2013).
- (49) G. O. Alves and E. Sjöqvist, Physical Review A 106, 032406 (2022).
- (50) S. Bhattacharyya and S. Bhattacharyya, Entropy (Basel) 24, 1593 (2022).