Back-stepping Experience Replay with Application to Model-free Reinforcement Learning for a Soft Snake Robot
Abstract
In this paper, we propose a novel technique, Back-stepping Experience Replay (BER), that is compatible with arbitrary off-policy reinforcement learning (RL) algorithms. BER aims to enhance learning efficiency in systems with approximate reversibility, reducing the need for complex reward shaping. The method constructs reversed trajectories using back-stepping transitions to reach random or fixed targets. Interpretable as a bi-directional approach, BER addresses inaccuracies in back-stepping transitions through a distillation of the replay experience during learning. Given the intricate nature of soft robots and their complex interactions with environments, we present an application of BER in a model-free RL approach for the locomotion and navigation of a soft snake robot, which is capable of serpentine motion enabled by anisotropic friction between the body and ground. In addition, a dynamic simulator is developed to assess the effectiveness and efficiency of the BER algorithm, in which the robot demonstrates successful learning (reaching a 100% success rate) and adeptly reaches random targets, achieving an average speed 48% faster than that of the best baseline approach.
Index Terms:
Deep reinforcement learning, experience replay, soft robot, snake robot, locomotion, navigation.I Introduction
As a promising decision-making approach, reinforcement learning (RL) has drawn increasing attention for its ability to solve complex control problems and achieve generalization in both virtual and physical tasks, as evidenced in various applications, such as chess games [1], quadrupedal locomotion [2], and autonomous driving [3, 4]. Considering the inherent infinite degrees of freedom of soft robots and their complicated interactions with environments [5], RL approaches were adopted for the control of soft robots, such as soft manipulators [6] and wheeled soft snake robots [7].
As a typical challenge for RL, especially in tasks where complicated behaviors are involved, the learning efficiency suffers from the relatively large search space and the inherent difficulties of the tasks, which usually requires delicate reward shaping [8] to guide the policy optimization and to constrain the learning directions or the behavior styles. The RL agents have to successfully reach their goals for efficient learning before getting lost in numerous inefficient failure trials. Multiple strategies were proposed to address the hard exploration challenge with sparse rewards, including improving the exploration techniques for more versatile trajectories from intrinsic motivations [9, 10, 11, 12], and exploiting the information acquired from the undesired trails [13, 14, 15].
Compatible with these techniques that might improve learning efficiency, the motivation of BER proposed for off-policy RL is the human ability to solve problems forward (from the beginning to goal) and backward (from the goal to the beginning) simultaneously, which is different from the standard model-free RL algorithms that mostly rely on forward exploration. For example, in proving a complicated mathematical equation, an effective method is to derive the equation from both sides where the information of both the left-hand side (beginning) and the right-hand side (goal) is utilized, to which the reasoning process and the mechanism of BER are similar.
In this paper, a BER algorithm is introduced that allows the RL agent to explore bidirectionally, which is compatible with arbitrary off-policy RL algorithms. It is applicable for systems with approximate reversibility and with fixed or random goal setups. After an evaluation of BER with a toy task, it is applied to the locomotion and navigation task of a soft snake robot. The developed algorithm is validated on a physics-based dynamic simulator with a computationally efficient serpentine locomotion model based on the system characteristic. Comprehensive experimental results demonstrate the effectiveness of the proposed RL framework with BER in learning the locomotion and navigation skills of the soft snake robot compared with other state-of-the-art benchmarks, indicating the potential of BER in general off-policy RL and robot control applications.
The remainder of the paper is structured as follows. Section \@slowromancapii@ introduces the BER algorithm with an evaluation of a toy task. Section \@slowromancapiii@ details the BER application in locomotion and navigation of a soft snake robot with the performance comparisons with other benchmarks, and Section \@slowromancapiv@ concludes the paper.
II Back-stepping Experience Replay
II-A Background
II-A1 Reinforcement Learning
A standard RL formalism is adopted where an agent (e.g. a robot) interacts with an environment and learns a policy according to the perceptions and rewards.
In each episode, the system starts with an initial state with a distribution of , and the agent observes a current state in the environment at each time step . Then, an action is generated to control the agent based on the current policy and the observations. Afterward, the system evolves to a new state based on the action and transition dynamics , and a reward is collected by the agent for the learning before the termination of the episode. During the training process, the RL agent learns an optimal policy mapping states to actions that maximize the expected return. The return is defined as the accumulated discounted reward , where is a discount factor.
The state value function represents the expected return starting from state following the current policy , and the action value function represents the expected return starting from the state with an immediate action by following the current policy . All optimal policies share the same optimal Q-function , according to the Bellman equation [16]:
|
|
(1) |
II-A2 Deep Q-Networks (DQN) and Deep Deterministic Policy Gradient (DDPG)
The Deep Q-Network (DQN) is a model-free, off-policy RL approach suitable for agents operating in discrete action spaces [16]. It typically employs a neural network to approximate the optimal Q-function , selecting optimal actions: . Exploration is often facilitated by the -greedy algorithm. To stabilize training, a replay buffer stores transition data () and is used to optimize with a loss , where the target is calculated by using a periodically updated target network : , and using transitions in the replay buffer.
Deep Deterministic Policy Gradient (DDPG) [17] is an off-policy RL algorithm that simultaneously learns a Q-function and a policy, tailored specifically for environments with continuous action spaces. DDPG interweaves the learning process of an approximator to , with an approximator to select , offering a unique adaptation for continuous action scenarios.
II-B Algorithm for BER
The above classical off-policy RL algorithms often face challenges with systems characterized by sparse rewards or challenging tasks with rewards hard to reshape. In such scenarios, RL agents rarely achieve informative standard forward explorations due to a low success rate in reaching goals in complex problems without precise guidance [13]. To address these challenges, we propose a novel Back-stepping Experience Replay (BER) algorithm for tasks with different goals (Alg. 1), designed to enhance the learning efficiency of off-policy RL algorithms. This is achieved by incorporating exploration methods in both forward and backward directions.
The BER algorithm requires at least an approximate reversibility of the system. This means that from a standard transition , a back-stepping transition can be constructed, which is similar to a real transition in the environment, i.e., . The action in the back-stepping transition is calculated as , where function is dependent on the environment. The approximate reversibility is evaluated by a small upper bound for all transitions during back-stepping calculation:
| (2) |
There exists a perfect reversibility when with a probably complex function , while an approximate reversibility might be achieved with a slightly larger and a simpler and solvable function .
The idea of BER is simple yet effective: instead of solely relying on forward explorations (navy blue solid line in Fig. 1) from initial states to goals, which depend heavily on the randomness of forward trajectories to reach these goals, RL agents also navigate backward from the goals to the initial states in the tasks (sky blue solid line in Fig. 1). The standard transitions are sampled from the standard forward and backward exploration trajectories (solid lines in Fig. 1), where the initial states of themselves are included. Then, the back-stepping transitions are calculated based on the standard transitions to constitute the reversed trajectories (dashed lines in Fig. 1), where the virtual goals are set to be the original initial state in their corresponding standard trajectories, such that the reversed trajectories are guaranteed to reach their virtual goals and contribute to the learning efficiency.
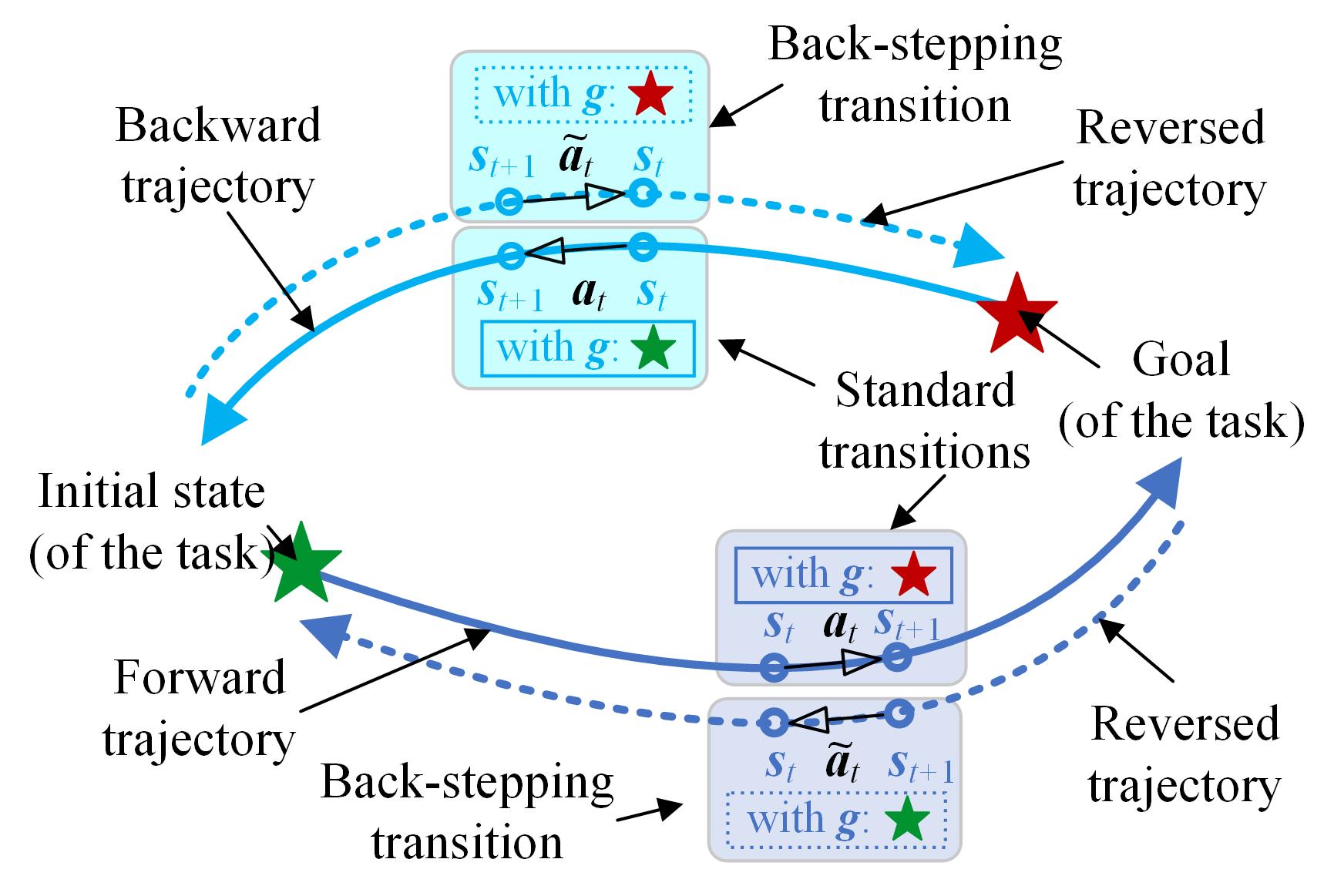
During the explorations, the standard and the back-stepping transitions are collected and stored in separate replay buffers for training. A strategy is used to sample the transitions from the standard replay with a probability and from the back-stepping replay with a probability , where . For a system with imperfect reversibility, gradually drops to zero to distill the transition set for training because of the inaccurate back-stepping transition. The details of BER are shown in Alg. 1. It should be noticed that the operator between the states and the goals also indicates the modification of the sequential data (e.g., the history data) when the back-stepping transitions are constructed.
The BER accelerates the estimation of Q-functions of the RL agent by using the reversed successful trajectories to bootstrap the networks. One interpretation of BER is a bi-directional search method for standard off-policy RL approaches, with a higher convergence rate and learning efficiency. The distillation strategy of the transitions for training needs to be carefully tuned and might be combined with other exploration tricks, to reach an accurate policy learning in the end and avoid the limitations brought by the bi-directional search method, e.g., non-trivial sub-optimum.
In the practical learning tasks, the accuracy and the complexity of the function , which calculates the actions in the back-stepping transitions , need to be balanced. An accurate yields better reversibility (with smaller in Eq. (2)) with more accurate back-stepping transitions and brings less bias and noise, while itself could be computationally expensive or even unsolvable. On the other hand, a moderate relaxation of the accuracy of might boost the efficiency of the calculation of back-stepping transitions, when the larger bias and the noises brought by the approximate reversibility (with larger ) are managed by the distillation mechanism in BER.
II-B1 A case study of BER
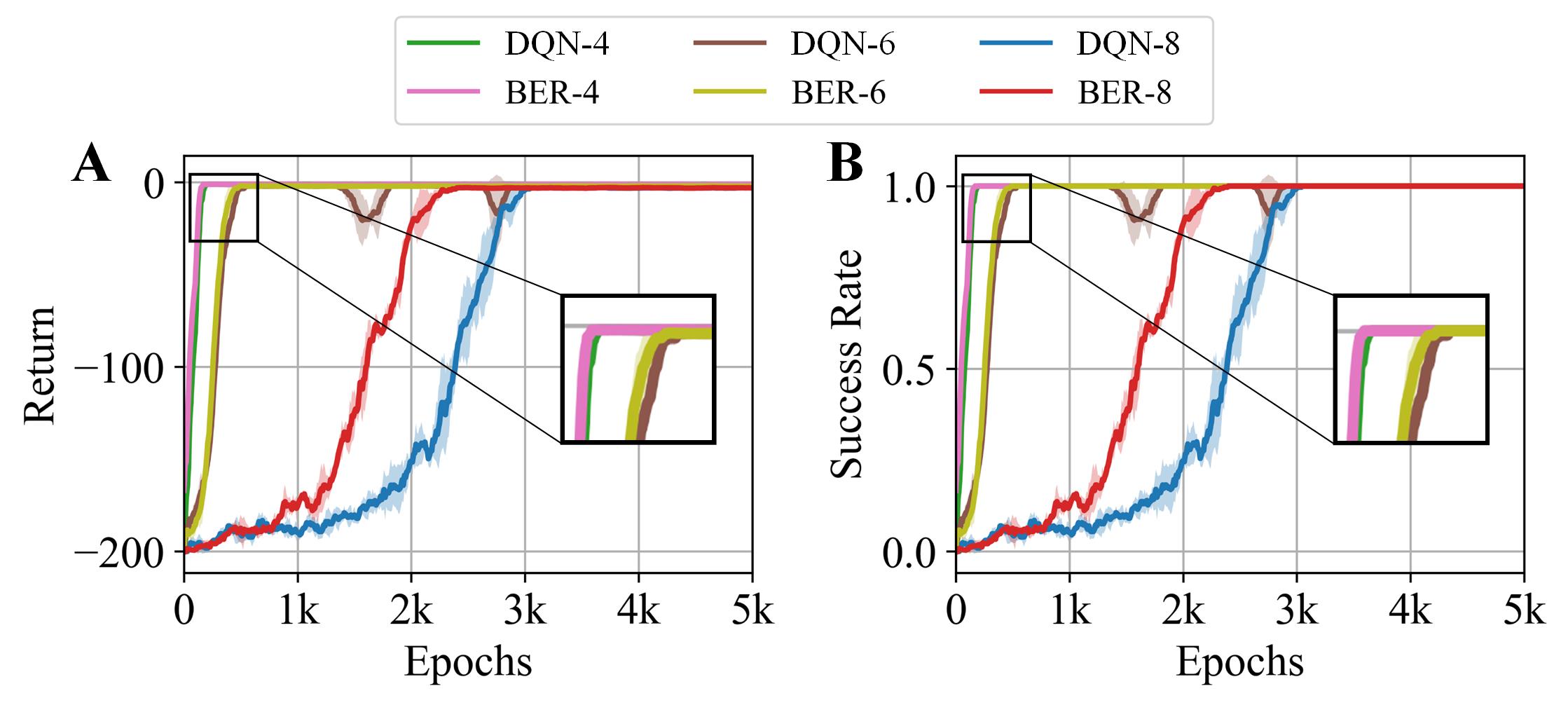
To illustrate the effectiveness and generality of BER, a general binary bit flipping game [13] with bits was considered as an environment for the RL agent, where the state was the bit value array , , and the action was the index of the chosen bit that was flipped. It was noticed that the game was completely reversible and for any time step and transition. The initial state and the goal were sampled uniformly and randomly, with a sparse non-negative reward: . The game is terminated once .
A simple ablation study was designed where a DQN and a DQN with BER were used for training when . The fully activated backward exploration and the use of back-stepping transitions were stopped after 1k epochs directly. The experimental result (Fig. 2) showed that BER facilitated an effective and efficient policy learning for a general DQN approach, and contributed more when the problem became more complex (i.e., was larger).
III BER in Model-free RL for a Soft Snake Robot
In this section, a locomotion and navigation task for a compact pneumatic soft snake robot with snake skins in our previous works [18, 19] is utilized to evaluate the effectiveness and efficiency of BER with a model-free RL approach, where the robot learns both movement skills and efficient strategies to reach different challenging targets.
III-A Soft Snake Robot and Serpentine Locomotion
Compared with soft snake robots where each air chamber was controlled independently [20], in this paper, a more compact soft snake robot with snake skins [18] is considered. There are only four independent air paths to generate the traveling-wave deformation of the robot, which enables the robot to traverse complex environments more easily by reducing the number of pneumatic tubing. The body of the robot consists of six bending actuators and each actuator is divided into four air chambers (Figs. 3A, 3D) that connect to four air paths (Fig. 3B). Four sinusoidal waves with 90-degree phase differences and the same amplitude can be used as references of pressures in air paths to generate traveling-wave deformation (Fig. 3C), when the biases of waves induce unbalance actuation for steering of the robot.
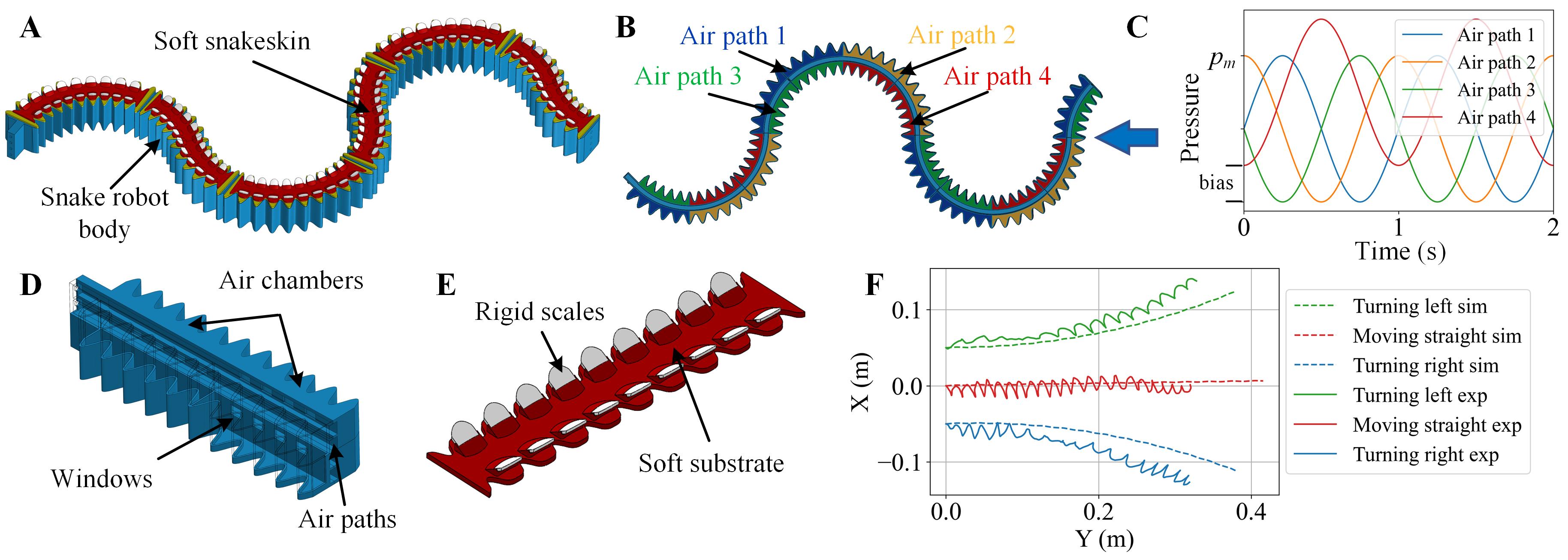
Serpentine locomotion is adopted for the movement of the soft snake robot, where the anisotropic friction between the snake skins and the ground propels the robot during the traveling-wave deformation [21]. The artificial snake skins are designed with a soft substrate and embedded rigid scales (Fig. 3E); see [19] for more details.
To describe the serpentine locomotion of the robot, the dynamic model in [21] is adopted, where the body of the robot is modeled as an inextensible curve in a 2D plane with a total length and a constant density per unit length. The position of each point on the robot at time is defined as:
| (3) |
where is the curve length measured from the tail of the robot.
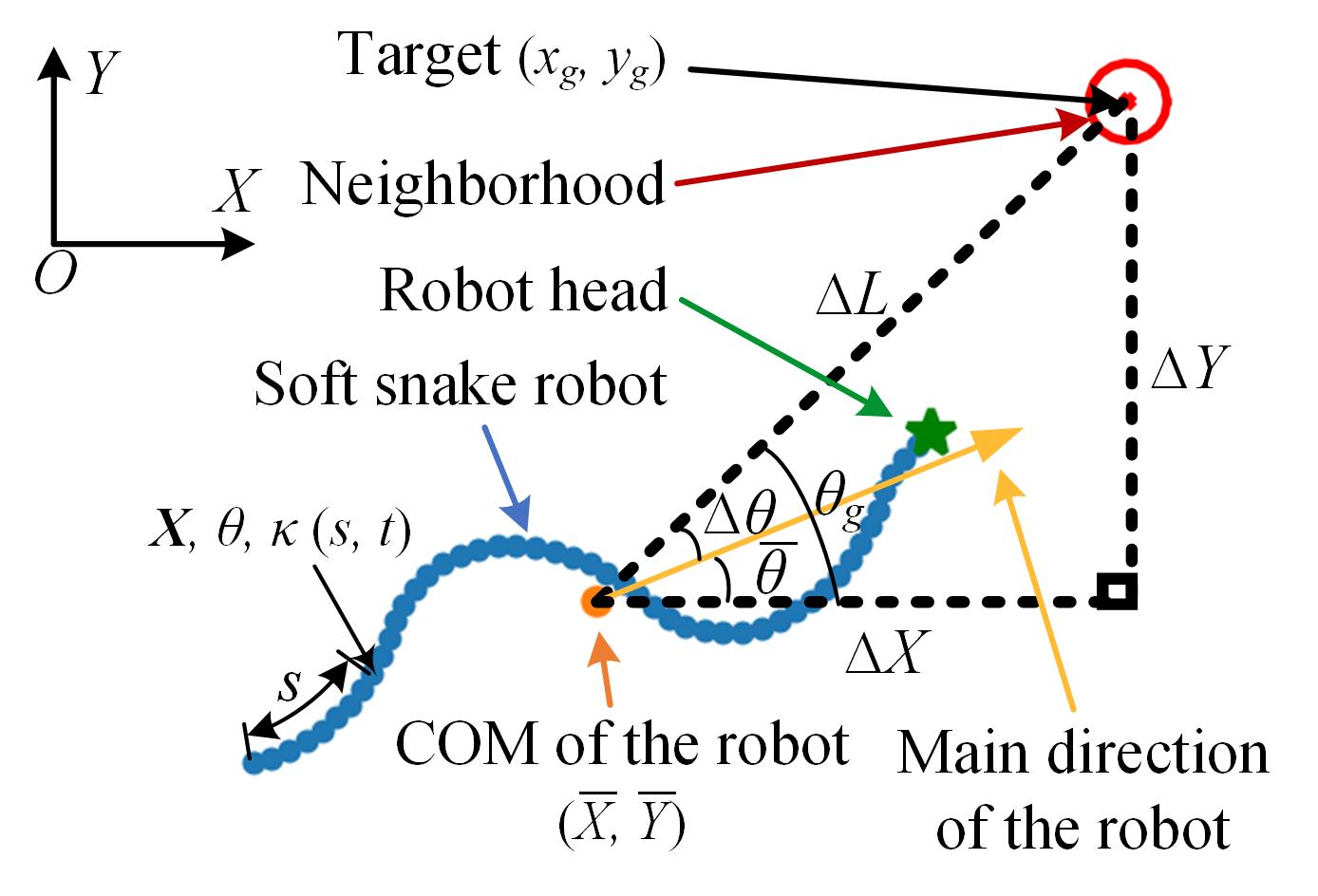
By utilizing a mean-zero anti-derivative [22] ( ), the position and the orientation (the angle between the local tangent direction and the X-axis of the inertial frame) of each point are described as a function of the position and orientation (Fig. 4) of the center of mass (COM) of the robot:
| (4) |
| (5) |
where and is the local curvature. , . The curvature is related to the local pneumatic pressure via:
| (6) |
where is the proportional constant and is the pressure difference between the two air chambers at point .
The anisotropic friction between the snake skins and the ground is described as a weighted average of the independent components in different local directions (forward , backward , transverse ):
| (7) |
where represents the direction of the local velocity, , , and are the friction coefficients of the snakeskin in , backward , and directions, respectively. , where is the signum function.
The dynamics of each point of the snake robot is determined by Newton’s second law:
| (8) |
where is the internal force in the robot body, which includes internal air pressure, bending elastic force, et al, with observations: and .
Finally, the dynamics for the COM of the robot are derived using the equation (3)-(8) with the observations of ; see [22] for more details.
Based on the dynamic model of the robot, which simplifies a dynamic system for all points of the robot to a single dynamic system for the COM of the robot, a simulator is designed with proper discretizations and numerical techniques for RL training. The simulation results matched the experimental results [19] of the soft snake robot when different pressure biases were applied for the robot’s steering (Fig. 3F), where the wavy trajectories in the experiments were attributed to the limited number (25) of the tracking markers in the tests.
III-B RL formulation of Locomotion and Navigation of the Robot
In this paper, the locomotion and navigation of the soft snake robot is formulated as a Markov Decision Process (MDP) and solved with a model-free RL. The is defined as a tuple :
-
1.
Action space: Compared with a random Central Pattern Generator (CPG) [7], more constrained sinusoidal waves are used to generate a smoother traveling-wave deformation of the robot for better locomotion efficiency. Besides, the learned controller of the robot is limited to avoid high-frequency pressure change, i.e., the RL agent is only able to generate an action to change the parameters of the waveform at the beginning of each actuation period that is same as the period of the sinusoidal waves, and one episode consists of multiple connected actuation periods. The sinusoidal pressure for -th channel of the robot is designed as:
(9) where is the relative time in one actuation period. and are the fixed magnitude and bias of the sinusoidal waves for the -th channel, respectively, . is a one-step history of the wave bias for the -th channel with at the initial state. is a variable to control the propagation direction of the traveling-wave deformation and thus can change the movement direction of the robot.
The action space of the RL agent for locomotion and navigation of the robot is designed as:
(10) where ’s are constructed by and :
(11) At the beginning of each actuation period, based on the current policy, the RL agent observes the state and generates an action, which specifies the waveform of the pressures in that period to propel the snake robot. The wave design guarantees the continuity of the pressures across different actuation periods to avoid impractical sudden changes in the pressures and the robot’s body shape.
-
2.
State space: A goal-conditioned state is used for the learning of the RL agent for adapting to different random targets. Specifically, a relative representation of the snake robot’s position and orientation with respect to the target is used as part of the state (Fig. 4):
(12) where , denote the relative position of the target to the COM of the snake robot, represents the relative direction of the target to the main direction of the robot, and is the angle between the line from the COM of the robot to the target and the X-axis, and are two-step histories of the action and , respectively, with an initial setting of .
The velocities of COM of the robot are not included as part of the state because the value of the Froude number [22] in serpentine locomotion of the snake robot is small, indicating that the frictional and gravitational effects dominate the inertial effect. Two-step histories (longer than one step) are introduced to compensate for the omission of the velocity state.
-
3.
Reward function: The reward function is pivotal for the RL agent to learn the desired behaviors. The training objective in this work is to drive the COM of the snake robot to reach a random target as soon as possible, with a preference for serpentine locomotion where the robot approaches the target along its main direction. Therefore, the reward assigned to the agent at time is designed as:
(13) where and are non-positive coefficients, is a large sparse positive success reward once the COM of the robot enters a neighborhood of the target with a radius of . is the distance between the COM of the robot and target at time , and when . The deflection is used in the reward to allow the robot to approach the target in a backward direction as well:
(14) -
4.
Transition probabilities: The transition probability, , characterizes the underlying dynamics of the robot system in the environment. In this study, we do not assume any detailed knowledge of this transition probability while developing our RL algorithm.
III-C Experiments of RL algorithms
III-C1 Experimental Setups
The RL experiments for the locomotion and navigation of the snake robot were conducted in a customized dynamic simulator which was developed based on the aforementioned serpentine locomotion model (Sec. III. A). The soft snake robot had a length of 0.5 m with a linear density of 1.08 kg/m. The frictional anisotropy between the snake skins and the ground was set as , and the maximum of the pressure bias was set as the same as kPa. The proportional constant between the applied pressure difference and the curvature was set as 0.058 kPam. The period of the actuation and the sinusoidal waves was 1 s.
The serpentine locomotion of the soft snake robot demonstrated approximate reversibility (Fig. 5A) when the function was designed as: when . The trajectories in the simulation results (Fig. 5A) suggested a small (in Eq. (2)) for locomotion and navigation of the soft snake robot when the above function was used.
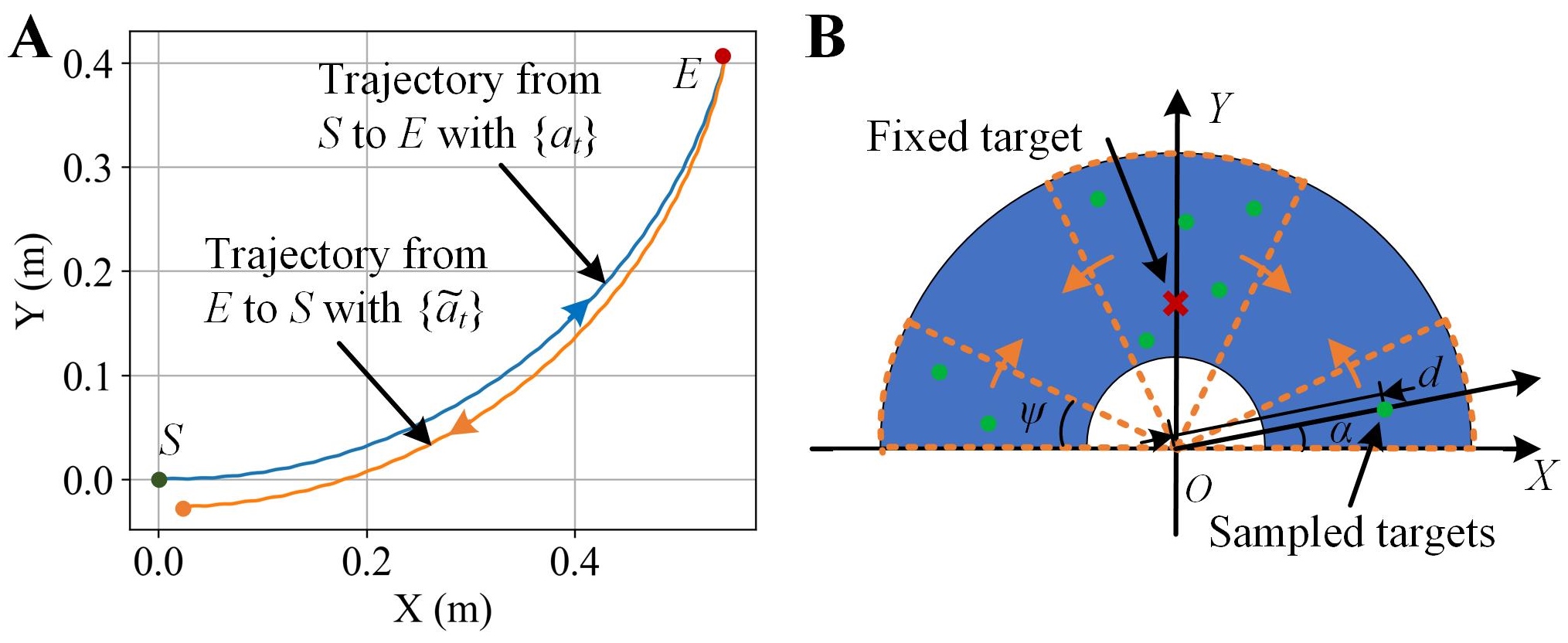
The soft snake robot was initialized in the simulator by using a horizontal static curved shape () with zero-value action histories and a target (with neighborhoods: m), whose control policies was learned by using BER (with DDPG) and several state-of-art benchmark algorithms, including DDPG, HER [13], and PPO [23]. The number of total training epochs was 10k and the strategy to sample the transitions was when the index of epoch , when , and , . The coefficients of the reward were set as , , and the termination condition for one episode was either the COM of the robot entering a neighborhood of the target and receiving a success reward () or the exploration time exceeding 150 s.
The return, success rate, average distance (the averaged for each time step ), and average deflection (the averaged for each time step ) were used to evaluate the algorithms during the training, with moving-window averaging for training with different seeds ( epochs). Three training experiments with different random seeds (for parameter initialization) were conducted to evaluate each algorithm, where the solid line and the shaded area showed the mean and the standard deviation, respectively (Figs. 6 and 8). An AMD 9820X processor with 64 GB memory and Ubuntu 18.04 was used for the training.
III-C2 Locomotion and Navigation with a Fixed Target
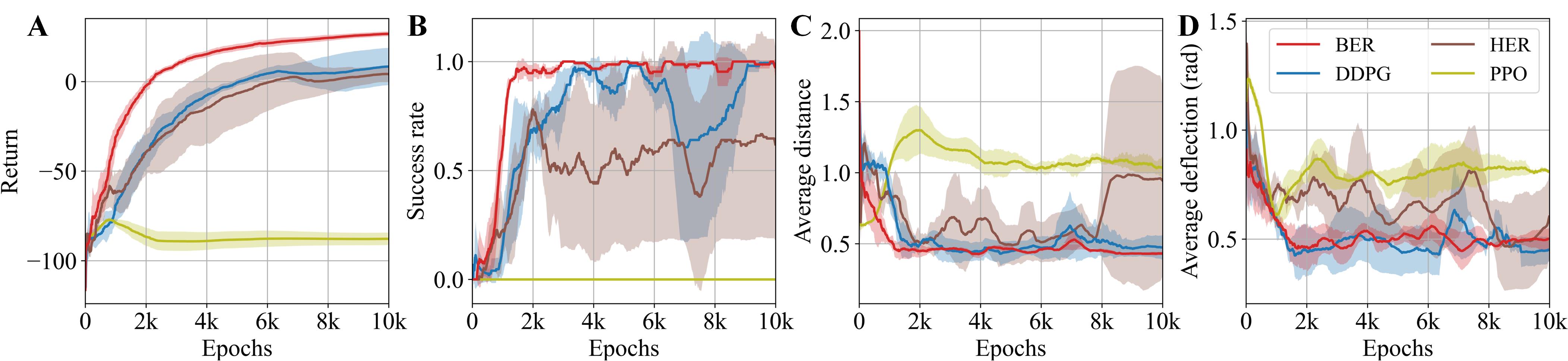
The performance of the algorithms was initially evaluated on the locomotion and navigation task of the robot, targeting a challenging fixed point (Fig. 5B). The experiment results of the training showed that both DDPG and BER were able to solve the task and learn policies to reach the fixed target successfully, while HER had worse stability and PPO was unable to solve the task within the epoch limitation (Fig. 6). It was also shown that BER had a faster convergence rate and better stability compared with other baseline algorithms.
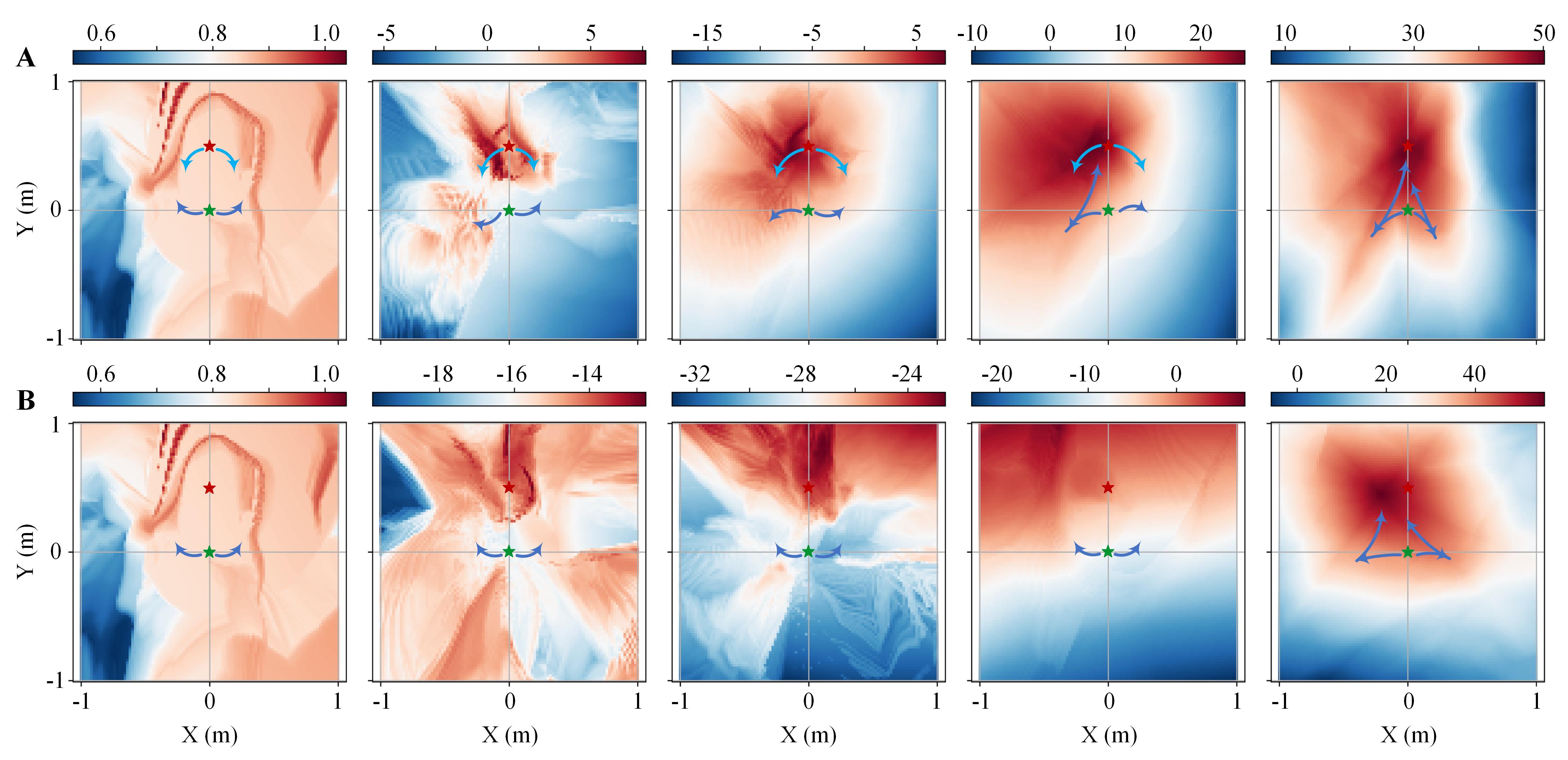
The evolution of the maximum Q-value at different locations for the algorithms during the training process (with the same seed) revealed the underlying mechanism and the advantage of BER (Fig. 7). It was shown that the effective Q-values in the training with BER were estimated from both the start and the target locations, expediting the successful explorations and the convergence of the estimation. The BER learned a more informative Q-value distribution after 500 epochs than that of the baseline DDPG after 1000 epochs. The final Q-value distribution of BER was also more accurate than that of the baseline DDPG, manifested by their shapes and the positions of the Q-value’s peaks.
III-C3 Locomotion and Navigation with Random Targets
A locomotion and navigation task of the soft snake robot with random targets was then explored by using different RL algorithms, where a half ring was used to randomly sample the target because of the system symmetry: (Fig. 5B). Besides, a strategy was designed where the targets were sampled uniformly from gradually expanding areas for the -th training epoch within the total epochs: , .
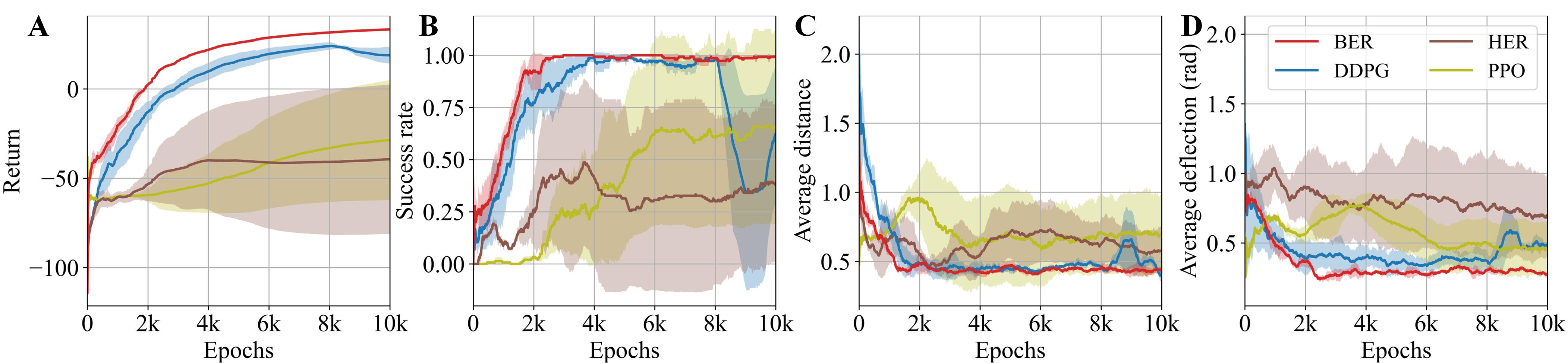
The training results revealed that BER outperformed all other benchmark algorithms tested (Fig. 8). BER achieved the highest return and success rate during training, exhibiting more stable behavior and a smaller average deflection. In contrast, the baseline DDPG’s performance declined when introduced to a variety of targets, despite its strong early-stage performance. HER struggled to learn to reach targets in different areas, whereas PPO gradually learned an effective policy, a process that benefited from the random-goal training setup involving progressively changing targets.
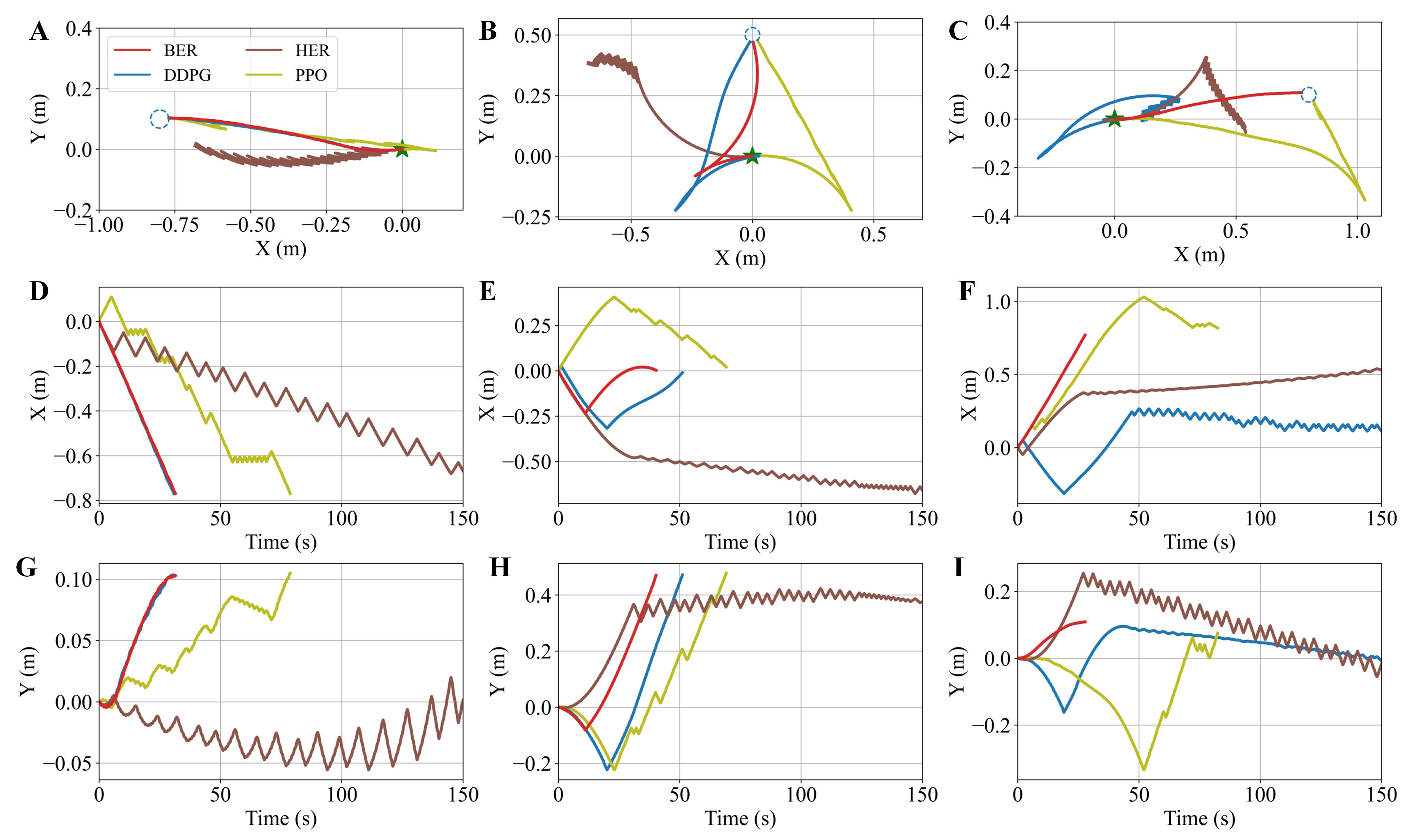
The robot’s trajectories further demonstrated BER’s efficiency (Fig. 9), where controllers with median success rates from each algorithm were used for control. A video for these experiments can be viewed at https://youtu.be/Z0da6rVu9j8. Three representative targets were tested: m m for moving backward, m for moving towards a lateral target, m m for moving forward. The BER controller successfully and smoothly guided the robot to all targets. In contrast, the DDPG and HER controllers exhibited inefficient oscillations, possibly due to less accurate Q-function estimation. While the PPO controller managed to reach all targets, it also displayed inefficient oscillation and adopted a sub-optimal policy for the forward target m m.
The quantitative results of the algorithms (Table I) were the average values tested by using the controllers trained with different seeds, and using 50 random targets sampled from the half-ring area (Fig. 5B). The average velocity (, : episode length) indicated the efficiency of the learned controllers. Notably, the average velocity of the robot with the BER controller (0.0169 m/s) was approximately 48% faster than that of the DDPG baseline (0.0114 m/s), and significantly higher compared to other benchmarks.
Besides, compared to other algorithms, BER not only learned an efficient controller based on the primary reward (highest average deflection: rad), but was also able to sacrifice the secondary reward to some extent (second highest average distance: m/m) for better performance. The success rate of BER reached 100 while that of the other baselines did not exceed 65, which exhibited the advantage of BER in the locomotion and navigation learning of the soft snake robot.
| Metrics | PPO | HER | DDPG | BER |
|---|---|---|---|---|
| Average velocity (m/s) | 0.0061 | 0.0080 | 0.0114 | 0.0169 |
| Average distance (m/m) | 0.6241 | 0.5202 | 0.3903 | 0.4002 |
| Average deflection (rad) | 0.4049 | 0.6702 | 0.3915 | 0.2920 |
| Success rate (%) | 64.44 | 43.33 | 61.11 | 100 |
IV Conclusions and Discussions
A novel technique, Back-stepping Experience Replay, was proposed in this paper, which exploited the back-stepping transitions constructed by using the standard transitions in both forward and backward exploration trajectories, improving the learning efficiencies in off-policy RL algorithms for the approximate reversible systems. The BER was compatible with arbitrary off-policy RL algorithms, demonstrated by combining with DQN and DDPG in a bit-flip task and locomotion and navigation task for a soft snake robot, respectively.
A model-free RL framework was proposed for locomotion and navigation of a soft snake robot as an application of the proposed BER, where a conventional locomotion model for real snakes was adopted to describe the serpentine locomotion of the soft snake robot and to design a simulator for learning. An RL formulation for locomotion and navigation of the soft snake robot was built based on the characteristics of the robot. Extensive experiments showed that the proposed RL approach was able to learn an efficient controller that drove the soft snake robot approaching fixed or even random targets by using serpentine locomotion. For the tasks with random targets, the controller learned by using BER achieved a 100 success rate and the robot’s average speed was 48 faster than that of the best baseline RL benchmark.
For future work, we will apply the proposed RL approach with BER to a physical soft snake robot system, where the data from the physical system will be used for learning. Besides, we will also study the influence of the approximate reversibility of general systems to BER, and analyze the convergence properties of BER for proper state-of-the-art off-policy RL algorithms.
References
- [1] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al., “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016.
- [2] X. Liu, R. Gasoto, Z. Jiang, C. Onal, and J. Fu, “Learning to locomote with artificial neural-network and cpg-based control in a soft snake robot,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7758–7765, IEEE, 2020.
- [3] D. Chen, L. Jiang, Y. Wang, and Z. Li, “Autonomous driving using safe reinforcement learning by incorporating a regret-based human lane-changing decision model,” in 2020 American Control Conference (ACC), pp. 4355–4361, IEEE, 2020.
- [4] M. Hua, D. Chen, X. Qi, K. Jiang, Z. E. Liu, Q. Zhou, and H. Xu, “Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects,” arXiv preprint arXiv:2312.11084, 2023.
- [5] C. Lee, M. Kim, Y. J. Kim, N. Hong, S. Ryu, H. J. Kim, and S. Kim, “Soft robot review,” International Journal of Control, Automation and Systems, vol. 15, pp. 3–15, 2017.
- [6] A. Gupta, C. Eppner, S. Levine, and P. Abbeel, “Learning dexterous manipulation for a soft robotic hand from human demonstrations,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3786–3793, IEEE, 2016.
- [7] X. Liu, C. D. Onal, and J. Fu, “Reinforcement learning of cpg-regulated locomotion controller for a soft snake robot,” IEEE Transactions on Robotics, 2023.
- [8] A. Y. Ng, D. Harada, and S. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” in International Conference on Machine Learning, vol. 99, pp. 278–287, Citeseer, 1999.
- [9] G. Ostrovski, M. G. Bellemare, A. Oord, and R. Munos, “Count-based exploration with neural density models,” in International Conference on Machine Learning, pp. 2721–2730, PMLR, 2017.
- [10] D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-driven exploration by self-supervised prediction,” in International Conference on Machine Learning, pp. 2778–2787, PMLR, 2017.
- [11] L. Choshen, L. Fox, and Y. Loewenstein, “Dora the explorer: Directed outreaching reinforcement action-selection,” arXiv preprint arXiv:1804.04012, 2018.
- [12] A. P. Badia, P. Sprechmann, A. Vitvitskyi, D. Guo, B. Piot, S. Kapturowski, O. Tieleman, M. Arjovsky, A. Pritzel, A. Bolt, et al., “Never give up: Learning directed exploration strategies,” arXiv preprint arXiv:2002.06038, 2020.
- [13] M. Andrychowicz et al., “Hindsight experience replay,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [14] M. Fang, C. Zhou, B. Shi, B. Gong, J. Xu, and T. Zhang, “Dher: Hindsight experience replay for dynamic goals,” in International Conference on Learning Representations, 2018.
- [15] Y. Ding, C. Florensa, P. Abbeel, and M. Phielipp, “Goal-conditioned imitation learning,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [16] V. Mnih, A. K. others, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [17] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971, 2015.
- [18] X. Qi, H. Shi, T. Pinto, and X. Tan, “A novel pneumatic soft snake robot using traveling-wave locomotion in constrained environments,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1610–1617, 2020.
- [19] X. Qi, T. Gao, and X. Tan, “Bioinspired 3d-printed snakeskins enable effective serpentine locomotion of a soft robotic snake,” Soft Robotics, vol. 10, no. 3, pp. 568–579, 2023.
- [20] M. Luo, M. Agheli, and C. D. Onal, “Theoretical modeling and experimental analysis of a pressure-operated soft robotic snake,” Soft Robotics, vol. 1, no. 2, pp. 136–146, 2014.
- [21] D. L. Hu, J. Nirody, T. Scott, and M. J. Shelley, “The mechanics of slithering locomotion,” Proceedings of the National Academy of Sciences, vol. 106, no. 25, pp. 10081–10085, 2009.
- [22] D. L. Hu and M. Shelley, “Slithering locomotion,” in Natural locomotion in fluids and on surfaces: swimming, flying, and sliding, pp. 117–135, Springer, 2012.
- [23] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.