Bamboo: Boosting Training Efficiency for Real-Time Video Streaming via Online Grouped Federated Transfer Learning
1. Introduction
Recently, learning-based bitrate adaptation algorithms have emerged, eliminating the reliance on handcrafted rules. For example, they utilize deep reinforcement learning (RL) to train their learning agents for the generation of proper bitrate adaptation policies in a simple simulation environment.
Existing works primarily involve offline and online learning methods. Most of them are limited to the offline mode, applying the “learning offline, running online” strategy (Zhang et al., 2020), which inevitably suffers from the simulation-to-reality gap. Compared with offline learning, online learning supports the training along with video streaming service, continuously refining RL models in response to new environments instead of relying on pre-trained models. Although online learning can better adapt to dynamic scenes, it faces the slow training convergence challenge. On the one hand, acquiring the training data is relatively slow as environmental observations are not available for collection until the completion of a video streaming session. In this case, only one actual learning agent can be used for online learning at a time. On the other hand, it is impractical to wait for the online model to be fully trained before making decisions, considering that a real-time video streaming session enforces the prompt response (rep, 2023).
To this end, this paper proposes Bamboo, a novel online grouped federated transfer learning framework for real-time video streaming to boost training efficiency. Bamboo utilizes user grouping for intra-group federated learning and mitigates RL’s trial-and-error impacts through online transfer. As a result, Bamboo can complete the online training within a user’s real-time video session.
We implement Bamboo on a WebRTC-based real-time video conferencing testbed111We develop the testbed based on an open-source WebRTC framework which is available at https://github.com/yuanrongxi/razor. which uses the Linux traffic control (TC) tool to control the network condition. Our experimental results show that Bamboo remarkably improves online training efficiency by up to 302% compared to other reinforcement learning algorithms across various network conditions while ensuring the quality of experience (QoE) of real-time video streaming.
2. Bamboo Design
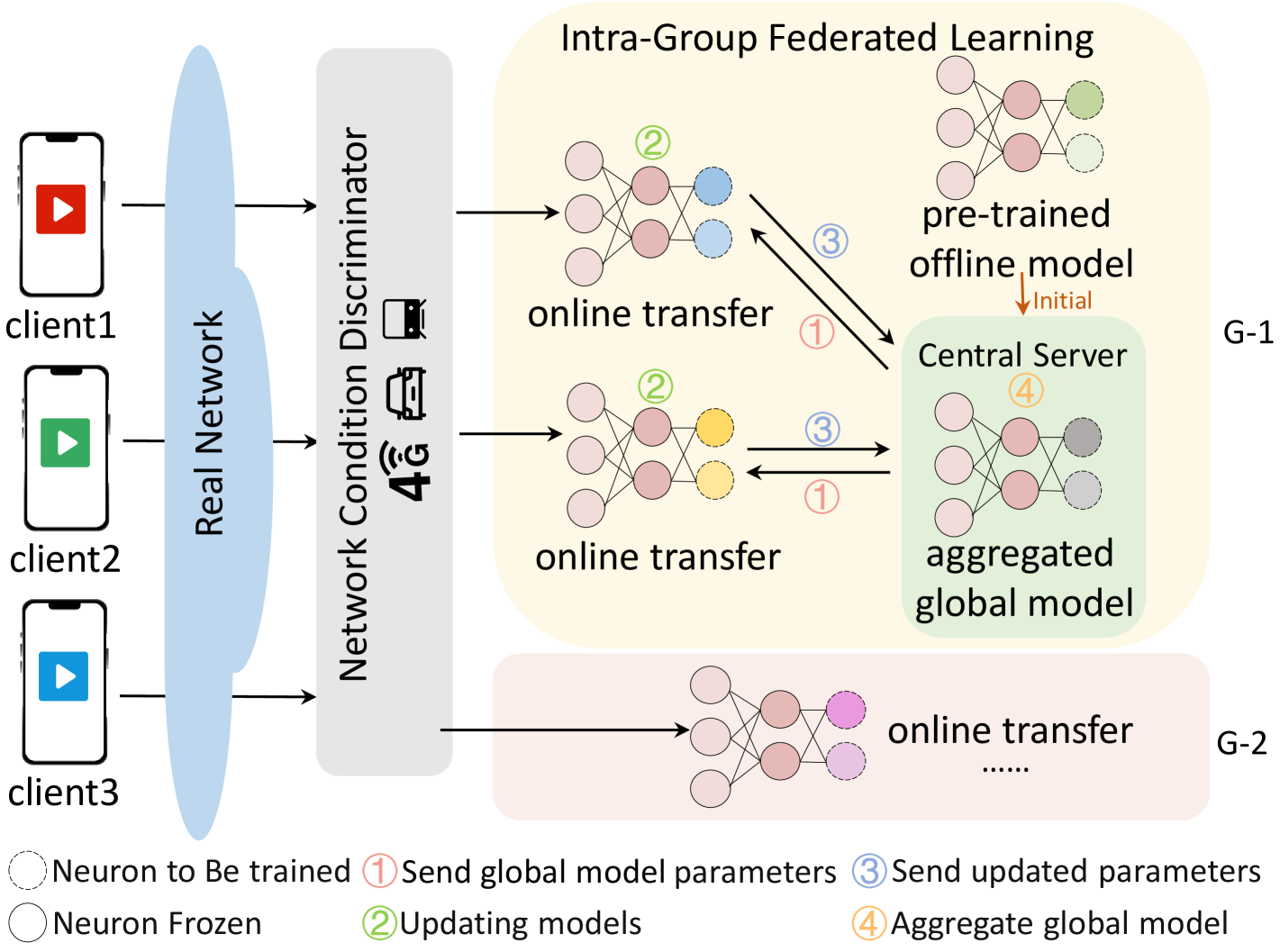
Figure 1 gives an overview of Bamboo. We first design a dynamic network condition discriminator to identify each user’s network type and transportation mode. Especially, the network type (e.g., 3G, 4G, and WiFi) can be directly obtained from internet service providers (ISP) (Zhang et al., 2022), and the transportation mode (e.g., car, bus, ferry, and train) can be detected using mobile sensors (e.g., GPS, accelerometers or microphones) (Wang and Jiang, 2022). Users are classified into 12 groups (labeled as , which can be extended to the more general group classification) as depicted in Table 1. Users within the same group engage in intra-group federated learning.
Intra-Group Federated Learning. Without loss of generality, we assume two users and one central server are in one group, which can be extended to more general cases. The framework primarily comprises four procedures. Firstly, offline training involves training a well-generalized fixed neural network model using extensive datasets in a simulator, which is then deployed on the central server. Secondly, the pre-trained offline model is distributed to users, enabling them to train their own models using local network conditions. Thirdly, each user locally updates the model parameters and periodically shares them with the central server. The central server aggregates these parameters to construct an aggregated global model of the group. Finally, users can train personalized models by incorporating the central server model with their own previous models. The aggregated global model undergoes iterative updates through interactive exchanges with the users in a cyclic iterative process. This accelerates batch writing of user data and facilitates RL model training within the same group.
| -1: | 3G & foot | -5: | 4G & foot | -9: | WIFI & foot |
|---|---|---|---|---|---|
| -2: | 3G & car | -6: | 4G & car | -10: | WIFI & car |
| -3: | 3G & ferry | -7: | 4G & ferry | -11: | WIFI & ferry |
| -4: | 3G & train | -8: | 4G & train | -12: | WIFI & train |
Specifically, the federal learning method we adopt enhances the A3C (Mnih et al., [n. d.]) algorithm to synchronously optimize the neural network of each user by averaging the optimization of neural network gradients within the same group. Users dynamically interact with the real-time video streaming environment, undergo training, and make decisions. The integration of federated learning techniques not only mitigates communication overhead resulting from data transmission but also simultaneously enhances model accuracy and generalization performance.
Efficient Online Transfer. In the final step, to mitigate the discrepancy between the offline pre-trained model and the user’s online model caused by the simulation-to-reality gap, we use online transfer training to fine-tune the pre-trained model to better adapt to the real network conditions and video content characteristics. In model transfer, the low-level layers for common feature extraction are frozen. In contrast, the parameters of high-level task-specific layers are updated to adapt to the new network environment.
Through efficient offline pre-training, the basic knowledge of the real-time video streaming environment is learned and the scarcity of real samples is alleviated. In the following online training, transfer learning is leveraged to fully utilize past experiences for mitigating early-stage “trial-and-error” and expediting the training process for new network environments, which significantly benefits computational resource savings without degrading model generalization.
Overall, the dynamic network condition discriminator periodically identifies the group to which a user belongs, and the user continuously interacts with the central server within the same group to exchange the model parameters. Such flexible grouping and iterative training endow Bamboo to handle instantaneous changes in network conditions and enhance its generalization performance.
3. EVALUATION & FUTURE WORK
We built a WebRTC-based real-time video conferencing testbed to evaluate Bamboo. We created a network trace corpus from HSDPA (Riiser et al., 2013), NYU (Mei et al., 2020), FCC (Commission, 2016), and used the Linux TC tool to reproduce the real-world network dynamics recorded in these traces. The corpus was randomly divided into training and testing datasets, with 80% of the data used for training Bamboo and 20% for testing all algorithms by default. Within the training set, 80% of data were used to train pre-trained offline models, while the remaining 20% were used to train online fine-tuning models. We compare Bamboo to the following schemes, which represent the state-of-the-art in bitrate adaptation: (a) ARS (Chen et al., 2019), a learning-based bitrate adaptation algorithm with its model trained offline; (b) OnRL (Zhang et al., 2020), which employs online training from scratch to improve its model performance; (c) Bamboo-transfer, a variant of Bamboo with transfer learning enabled but intra-group federated learning disabled. Note that we use the same neural network architecture for these baselines as Bamboo for a fair comparison.
| 3G | 4G | WIFI | |
| OnRL | 2.54 | 2.65 | 2.57 |
| Bamboo-transfer | 1.56 | 1.28 | 1.51 |
| Bamboo | 0.80 | 0.53 | 0.60 |
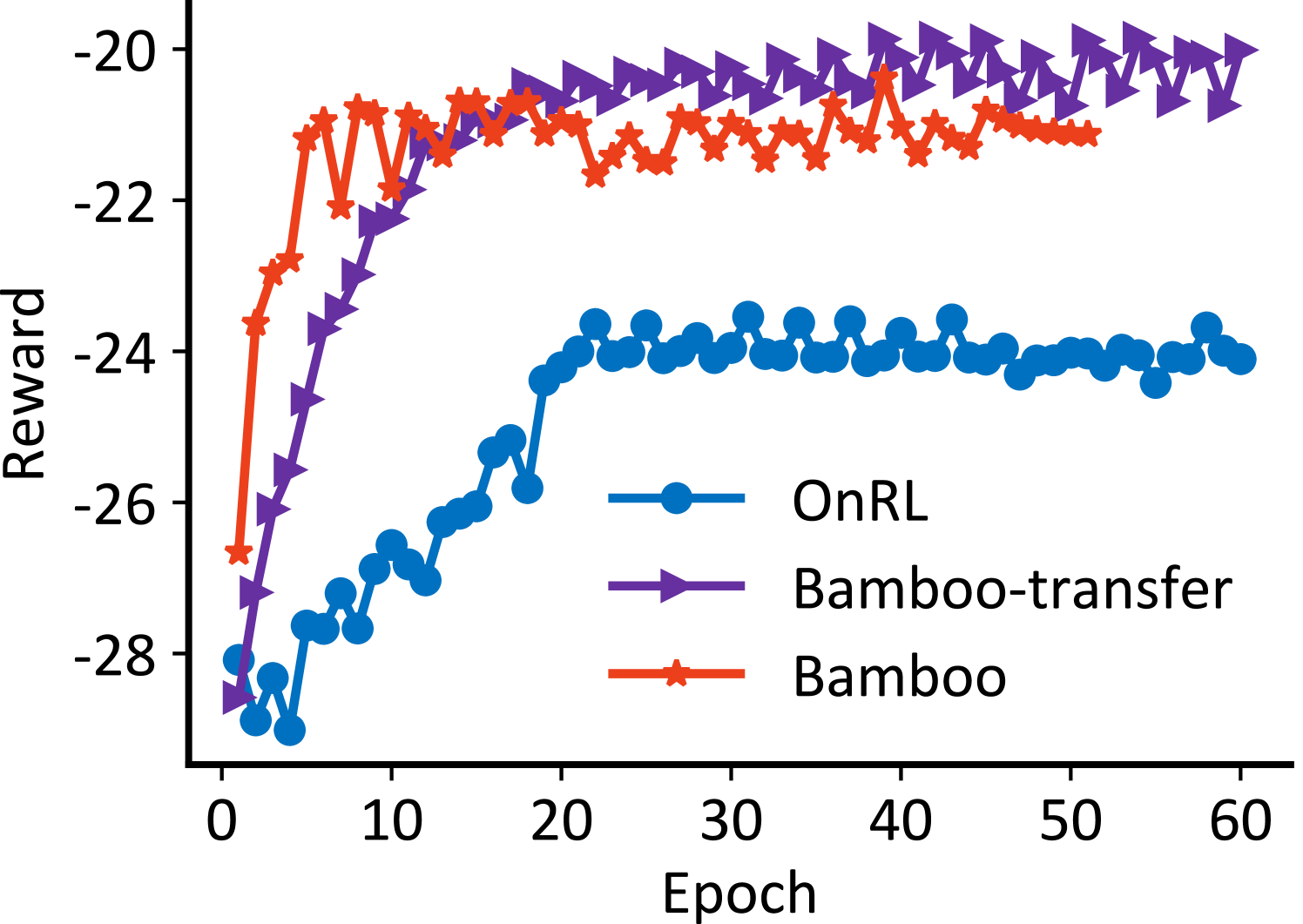
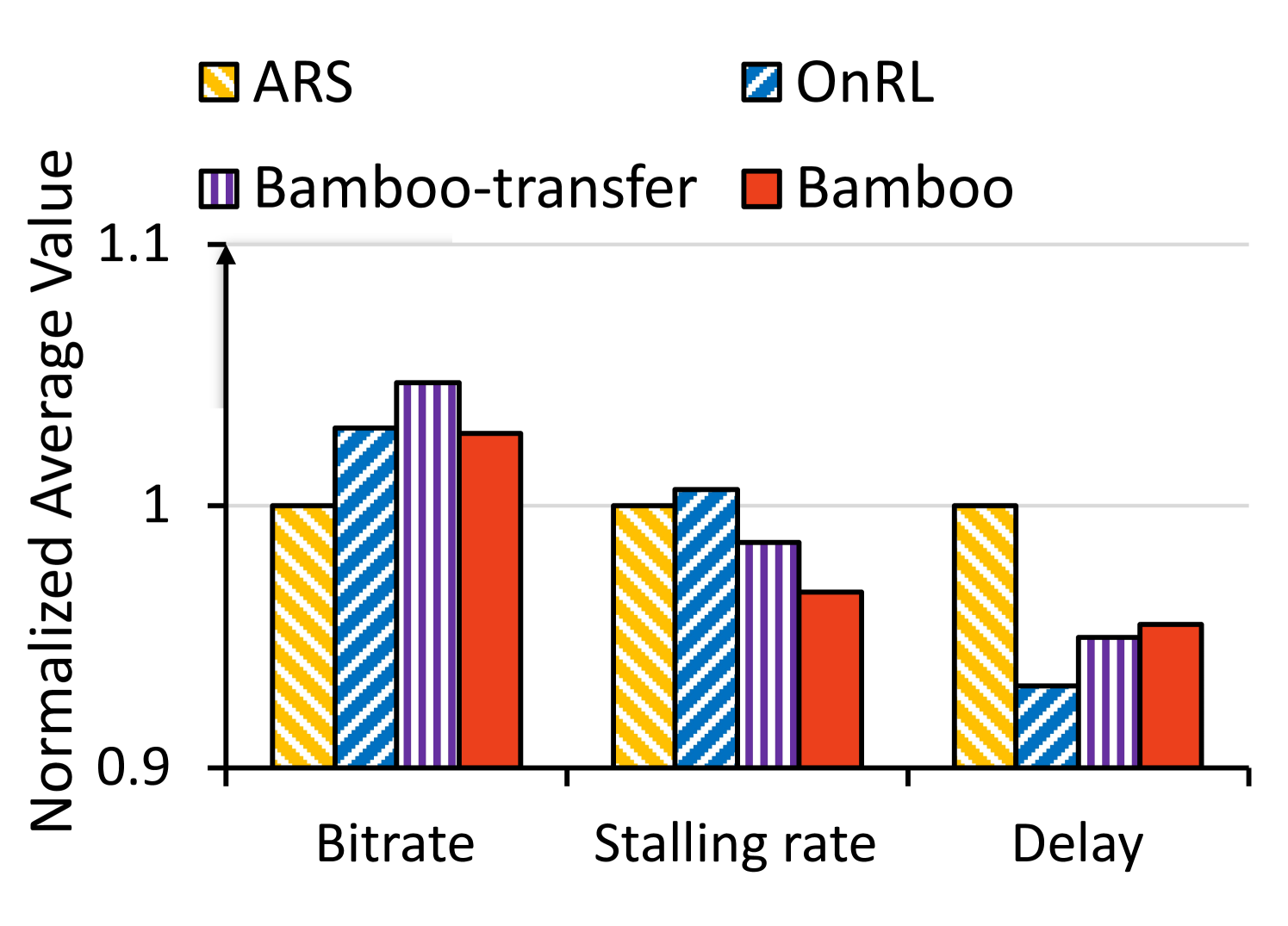
Table 2 and Figure 3 illustrate the training efficiency of Bamboo. We evaluate the performance of Bamboo and other methods under the same test trace lasting for 300s and plot the normalized average value of QoE metrics (e.g., bitrate, stalling rate, and delay) in Figure 3. We observe that Bamboo’s online transfer and grouped federated training improve the online model training efficiency by 43.9% and 55.6%, respectively. Furthermore, when compared to the ARS anchor across all trace sets, these mechanisms increase the bitrate by 0.7%-3.7% and reduce the stalling rate by 2.3%-2.9% as well as delay by 2.3%-4.7%. These findings demonstrate Bamboo’s proficiency in knowledge transfer and its generalization ability by mitigating RL’s trial-and-error impacts and expediting training data acquisition. Consequently, Bamboo outperforms existing approaches by 302% in terms of average convergence time and ensures a satisfactory QoE in real-time video streaming.
In the future, we will consider more practical issues (e.g., robust hybrid learning mechanism, determining whether the online training can be terminated) and conduct more testbed experiments.
References
- (1)
- rep (2023) 2023. The state of video conferencing 2022. https://www.dialpad.com/blog/video-conferencing-report/.
- Chen et al. (2019) Hao Chen, Xu Zhang, et al. 2019. T-Gaming: A Cost-Efficient Cloud Gaming System at Scale. IEEE Trans. Parallel Distrib. Syst. (2019).
- Commission (2016) Federal Communications Commission. 2016. Raw Data-Measuring Broadband America 2016. https://www.fcc.gov/reports-research/reports/measuring-broadband-america/raw-data-measuring-broadband-america-2016
- Mei et al. (2020) Lifan Mei, Runchen Hu, et al. 2020. Realtime mobile bandwidth prediction using LSTM neural network and Bayesian fusion. Comput. Netw. (2020).
- Mnih et al. ([n. d.]) Volodymyr Mnih, Adria Puigdomenech Badia, et al. [n. d.]. Asynchronous Methods for Deep Reinforcement Learning. In Proc. ICML.
- Riiser et al. (2013) Haakon Riiser, Paul Vigmostad, et al. 2013. Commute Path Bandwidth Traces from 3G Networks: Analysis and Applications. In Proc. ACM MMSys.
- Wang and Jiang (2022) Pu Wang and Yongguo Jiang. 2022. Transportation Mode Detection Using Temporal Convolutional Networks Based on Sensors Integrated into Smartphones. Sensors (2022).
- Zhang et al. (2020) Huanhuan Zhang, Anfu Zhou, et al. 2020. OnRL: Improving Mobile Video Telephony via Online Reinforcement Learning. In Proc. ACM MobiCom.
- Zhang et al. (2022) Huanhuan Zhang, Anfu Zhou, et al. 2022. Improving Mobile Interactive Video QoE Via Two-level Online Cooperative Learning. IEEE. Trans. Mob. Comput. (2022).