Batch Bayesian optimisation via density-ratio estimation with guarantees
Abstract
Bayesian optimisation (BO) algorithms have shown remarkable success in applications involving expensive black-box functions. Traditionally BO has been set as a sequential decision-making process which estimates the utility of query points via an acquisition function and a prior over functions, such as a Gaussian process. Recently, however, a reformulation of BO via density-ratio estimation (BORE) allowed reinterpreting the acquisition function as a probabilistic binary classifier, removing the need for an explicit prior over functions and increasing scalability. In this paper, we present a theoretical analysis of BORE’s regret and an extension of the algorithm with improved uncertainty estimates. We also show that BORE can be naturally extended to a batch optimisation setting by recasting the problem as approximate Bayesian inference. The resulting algorithms come equipped with theoretical performance guarantees and are assessed against other batch and sequential BO baselines in a series of experiments.
1 Introduction
Bayesian optimisation (BO) algorithms provide flexible black-box optimisers for problems involving functions which are noisy or expensive to evaluate [1]. Typical BO approaches place a probabilistic model over the objective function which is updated with every new observation in a sequential decision-making process. Most methods are based on Gaussian process (GP) surrogates [2], which provide closed-form analytic expressions for the model’s posterior distribution and allow for a number of theoretical performance guarantees [3, 4, 5]. However, GP surrogates have a number of limitations, such as not easily scaling to high-dimensional domains, high computational complexity and requiring a careful choice of covariance function and hyper-parameters [2]. Non-GP-based BO methods have also been proposed in the literature, such as BO methods based on neural networks [6, 7] and random forests [8] regression models.
As an alternative to improving the model, Tiao et al. [9] focus on the acquisition function, which in BO frameworks represents the guide that takes the model predictions into account. They show that one can derive the acquisition function directly without an implicit model by reinterpreting the expected improvement [4, 1] via a density-ratio estimation problem. Applying this perspective, the acquisition function can then be derived as a classification model, which can be represented by flexible parametric models, such as deep neural networks, and efficiently trained via stochastic gradient descent. The resulting method, called Bayesian optimisation via density-ratio estimation (BORE) is then shown to outperform a variety of traditional GP-based and non-GP baselines.
Despite the significant performance gains, BORE has only been applied to a sequential setting and not much is known about the method’s theoretical guarantees. Batch BO methods have the potential to speed up optimisation in settings where multiple queries to the objective function can be evaluated simultaneously [10, 11, 12, 13]. Given its flexibility to apply models which can scale to large datasets, it is therefore a natural question as to whether BORE can be readily extended to the batch setting in a computationally efficient way.
In this paper, we extend the BORE framework to the batch setting and analyse its theoretical performance. To derive theoretical guarantees, we first show that the original BORE can be improved by accounting for uncertainty in the classifier’s predictions. We then propose a novel method, called BORE++, which uses an upper confidence bound over the classifier’s predictions as its acquisition function. The method comes equipped with guarantees in the probabilistic least-squares setting. We provide extensions for both BORE and BORE++ to the batch setting. Lastly, we present experimental results demonstrating the performance of the proposed algorithms in practical optimisation problems.
2 Background
We consider a global optimisation problem over a compact search space of the form:
| (1) |
where is assumed to be a black-box objective function, i.e., we have no access to gradients nor analytic formulations of it. In addition, we are only allowed to run up to rounds of function evaluations, where we might collect single points or batches of observations , which are corrupted by additive noise , for .
2.1 Bayesian optimisation
Bayesian optimisation (BO) algorithms approach the problem in Equation 1 via sequential decision making [1]. At each iteration, BO selects a query point by maximising an acquisition function :
| (2) |
The acquisition function encodes information provided by the observations collected so far using a probabilistic model over , typically a Gaussian process (GP) [2], conditioned on the data. After collecting an observation , the dataset is updated with the new query-observation pair . This process then repeats for a given number of iterations .
2.2 Bayesian optimisation via density-ratio estimation (BORE)
The expected improvement (EI) [4, 14] is a popular acquisition function in the BO literature and the basis for many BO algorithms. At each iteration , one can define as an incumbent target. EI is then defined as:
| (3) |
In the case of a GP prior on , the EI is available in closed form as a function of the GP posterior. However, the EI may be reformulated without the need for a prior.
Under mild assumptions, Bergstra et al. [15] showed that the EI can be formulated as a density ratio between two probability distributions. Let represent the probability density over conditioned on the observation being below a threshold . Conversely, let . For , the -relative density ratio between these two densities is:
| (4) |
noting that leads to the ordinary probability density ratio definition, . Now if we choose , where represents the cumulative distribution function of the marginal distribution of observations,111Note that , where we may assume uniform. for , and then replace in Equation 3, Bergstra et al. [15] have shown that222Bergstra et al. [15] and Tiao et al. [9] also rely on the mild assumption that for all . , for . Based on this fact, Tiao et al. [9] showed:
| (5) |
where can be approximated by a probabilistic classifier trained with a proper scoring rule, such as the binary cross-entropy loss:
| (6) |
Other examples of proper scoring rules include the least-squares loss, which leads to probabilistic least-squares classifiers [16], and the zero-one loss. We refer the reader to Gneiting and Raftery [17] for a review and theoretical analysis on this topic.
BORE is summarised in Algorithm 1. As seen, the marginal observations distribution CDF is replaced by the empirical approximation and its corresponding quantile function . At each iteration, observations are labelled according to the estimated th quantile , and a classifier is trained by minimising the loss over the data points . A query point is chosen by maximising the classifier’s probabilities, which in our case corresponds to maximising the expected improvement. A new observation is collected, and the algorithm continues running up to a given number of iterations . As demonstrated, no explicit probabilistic model for is needed, only a classifier, which can be efficiently trained via, e.g., stochastic gradient descent.
3 Analysis of the BORE framework
In this section, we analyse limitations of the BORE framework in modelling uncertainty and analyse its effects on the algorithm’s performance. As presented in Section 2.2, at each iteration , the original BORE framework trains a probabilistic classifier to approximate , where denotes the th quantile of the marginal observations distribution, i.e., . This approach leads to a maximum likelihood estimate for the classifier , which may not properly account for the uncertainty in the classifier’s approximation.
Since BORE is based on probabilistic classifiers, instead of regression models as in traditional BO frameworks [1], a natural first question to ask is whether a classifier can guide it to the global optimum of the objective function. The following lemma answers this question and is a basis for our analysis.
Lemma 1.
Let be a continuous function over a compact space . Assume that, for any , we observe , where is i.i.d. noise with a strictly monotonic cumulative distribution function . Then, for any , we have:
| (7) |
Proof.
As the observation noise CDF is monotonic, by basic properties of the , we have:
| (8) |
which concludes the proof. ∎
According to this lemma, maximising class probabilities is equivalent to optimising the objective function when the classifier is optimal, i.e., it has perfect knowledge of . This result holds for any given threshold . We only make a mild assumption on the CDF of the observation noise , which is satisfied for any probability distribution with support covering the real line (e.g. Gaussian, Student-T, Cauchy, etc.).333This result could also be easily extended to distributions with bounded support as long as their CDF is monotonic within it. However, we keep the support as for simplicity, and the extension is left for future work.
To analyse BORE’s optimisation performance, we will aim to bound the algorithm’s instant regret:
| (9) |
and its cumulative version . Sub-linear bounds on lead to a no-regret algorithm, since and .
Assuming that there is an optimal classifier , which is such that , for a given , we can directly relate the classifier probabilities to the objective function values, since:
| (10) |
The existence of the inverse is ensured by the strict monotonicity assumption on in 1. Under this observation, the algorithm’s regret at any iteration can be bounded in terms of classifier probabilities:
| (11) |
where is any Lipschitz constant for , which exists since is compact. Therefore, we should be able to bound BORE’s regret by analysing the approximation error for at each iteration .
Although approximation guarantees for classification algorithms under i.i.d. data settings are well known [18], each observation in BORE depends on the previous ones via the acquisition function. This process is also not necessarily stationary, so that we cannot apply known results for classifiers under stationary processes [19]. In the next section, we consider a particular setting for learning a classifier which allows us to bound the prediction error under BORE’s data-generating process.
3.1 Probabilistic least-squares classifiers
We consider the case of probabilistic least-squares (PLS) classifiers [20, 21]. In particular, we model a probabilistic classifier as an element of a reproducing kernel Hilbert space (RKHS) associated with a positive-definite kernel . A RKHS is a space of functions equipped with inner product and norm [22]. For the purposes of this analysis, we will also assume that , for all .444This assumption can always be satisfied by proper scaling. This setting allows for both linear and non-parametric models. Gaussian assumptions on the function space would lead us to GP-based PLS classifiers [2], but we are not restricted by Gaussianity in our analysis. If the kernel is universal, as is injective, we can also see that the RKHS assumption allows for modelling any continuous function.
For a given , a PLS classifier is obtained by minimising the regularised squared-error loss:
| (12) |
where is a given regularisation factor and . In the RKHS case, the solution to the problem above is available in closed form [23, 16] as:
| (13) |
where , and . This PLS approximation may not yield a valid classifier, since it is possible that for some . However, it allows us to place a confidence interval on the optimal classifier’s prediction, as presented in the following theorem, which is based on theoretical results from the online learning literature [24, 25]. Our proofs can be found in the supplement.
Theorem 1.
Given , assume is such that , and . Let be a -valued discrete-time stochastic process predictable with respect to the filtration . Let be a real-valued stochastic process such that is -sub-Gaussian conditionally on , for all . Then, for any , with probability at least , we have that:
| (14) |
where , with denoting the determinant of matrix , and
3.2 Regret analysis for BORE
We now consider BORE with a PLS classifier. For this analysis, we will assume an ideal setting where is fixed, possibly corresponding to the true th quantile of the observations distribution. However, our results hold for any choice of and can therefore be assumed to approximately hold for a varying which is converging to a fixed value. In this setting, the algorithm’s choices are: given by:
| (15) |
where is the estimator in Equation 13. we can then apply Theorem 1 to the classifier-based regret in Equation 11 to obtain a regret bound. For this result, we will also need the following quantity:
| (16) |
where the maximisation is taken over the discrete set of locations and . This quantity denotes the maximum information gain of a Gaussian process model after observations. We are now ready to state our theoretical result regarding BORE’s regret.
Theorem 2.
Under the conditions in Theorem 1, with probability at least , , the instant regret of the BORE algorithm with a PLS classifier after iterations is bounded by:
| (17) |
and the cumulative regret by:
| (18) |
As Theorem 2 shows, the regret of the BORE algorithm in the PLS setting is comprised of two components. The first term is related to the regret of a GP-UCB algorithm [see 26, Thr. 3] and its known to grow sub-linearly for a few popular kernels, such as the squared exponential and the Matérn class [3, 27]. The second term, however, reflects the uncertainty of the algorithm around the optimum location . If the algorithm never samples at that location, this second summation might have a mostly linear growth, which will not lead to a vanishing regret. In fact, if we consider Equation 13 and a RKHS with a translation-invariant kernel, we see that, as soon as an observation is collected at a location , that location will constitute the maximum of the classifier output. Then the algorithm would keep returning to that same location, missing opportunities to sample at .
It is worth noting that Theorem 2 reflects the regret of BORE in an idealistic setting where the algorithm uses the optimal PLS estimator in the function space . However, if we train a parametric classifier, such as a neural network, via gradient descent, the behaviour will not necessarily be the same, and the algorithm might still achieve a good performance. In the original BORE paper, for instance, a parametric classifier is trained by minimising the binary cross-entropy loss [9] and leads to a successful performance in experiments. Neural network models trained via stochastic gradient descent are known to provide approximate samples of a posterior distribution [28, 29], instead of an optimal best-fit predictor, which might make BORE behave like Thompson sampling [30] (see discussion in the appendix). Nevertheless, Theorem 2 still shows us that BORE may get stuck into local optima, which is not ideal for BO methods. In the next section, we present an extension of the BORE framework which addresses this shortcoming.
4 BORE++: improved uncertainty estimates
As discussed in the previous section, the lack of uncertainty quantification in the estimation of the classifier for the original BORE might lead to sub-optimal performance. To address this shortcoming, we present an approach for uncertainty quantification in the BORE framework which leads to improvements in performance and theoretical optimality guarantees. Our approach is based on using an upper confidence bound (UCB) on the predicted class probabilities as the acquisition function for BORE. Due to its improved uncertainty estimates, we call this approach BORE++.
4.1 Class-probability upper confidence bounds
We propose replacing in Algorithm 1 by an upper confidence bound which is such that:
| (19) |
which with probability greater than , given . Therefore, represents an upper quantile over the optimal class probability . BORE++ selects .
To derive an upper confidence bound on a classifier’s predictions , we can take a few different approaches. For a parametric model , a Bayesian model updating the posterior leads to a corresponding predictive distribution over . This is the case of ensemble models [31], for instance, where we approximate predictions with . Instead of using the expected class probability, however, BORE++ uses an (empirical) quantile approximation for to ensure Equation 19 holds. Bayesian neural networks [32], random forests [33], dropout methods, etc. [34], also constitute valid approaches for predictive uncertainty estimation. An alternative approach is to place a non-parametric prior over , such as a Gaussian process model [2], which allows for the modelling of uncertainty directly in the function space where lies. In the next section, we present a concrete derivation of BORE++ for the PLS classifier setting which takes the non-parametric perspective and allows us to derive theoretical performance guarantees.
4.2 BORE++ with PLS classifiers
In the PLS setting, the result in Theorem 1 gives us a closed-form expression for a classifier upper confidence bound satisfying the condition in Equation 19. Given , we set:
| (20) |
where and are set according to Theorem 1. We then obtain the following result for BORE++.
Theorem 3.
Under the assumptions in Theorem 1, running the BORE++ algorithm with a PLS classifier as defined above yields, with probability at least , an instant regret bound of:
| (21) |
and a cumulative regret bound after iterations:
| (22) |
According to Theorem 3, the regret of BORE++ vanishes if the maximum information gain grows sub-linearly, since and . Sub-linear growth is known to be achieved for popular kernels, such as the squared exponential, the Matérn family and linear kernels [3, 27]. This result also tells us that theoretically BORE++ performs no worse than GP-UCB since they share similar regret bounds [3, 26]. However, in practice, the BORE++ framework offers a series of practical advantages over GP-UCB, such as no need for an explicit surrogate model, and a classifier which does not need to be a GP and can therefore be more flexible and scalable to high-dimensional problems and large amounts of data. The connection with GP-UCB, instead, brings us new insights into how the density-ratio BO algorithm can still share some of the well known guarantees of traditional BO methods.
5 Batch BORE
This section proposes an extension of the BORE framework which allows for multiple queries to the objective function to be performed in parallel. Although many methods for batch BO have been previously proposed in the literature, we here focus on approaching batch optimisation as an approximate Bayesian inference problem. Instead of having to derive complex heuristics to approximate the utility of a batch of query points, we can view points in a batch as samples from a posterior probability distribution which uses the acquisition function as a likelihood.
5.1 BORE batches via approximate inference
Applying an optimisation-as-inference perspective to BORE, we can formulate a batch BO algorithm which does not require an explicit regression model for . The classifier naturally turns out as a likelihood function over query locations . Since the search space is compact, we can assume a uniform prior distribution . Also note that the normalisation constant in this case is simply . Our posterior distribution then becomes:
| (23) |
Therefore, we formulate a batch version of BORE as an inference problem aiming for:
| (24) |
where denotes the Kullback-Leibler (KL) divergence between and , and represents the space of probability distributions over . Sampling from would allow us to obtain the points of interest in the search space, including the optimum and other locations where . However, as the true is unknown, we instead formulate a proxy inference problem with respect to a surrogate target distribution based on the classifier model. For BORE, we set , while for BORE++ the setting is . In contrast to , the normalisation constant for the surrogate distributions is unknown, leading us to a proxy problem of minimising at each iteration . This variational inference problem above can be efficiently solved via Stein variational gradient descent (SVGD) [35], described next.
5.2 Batch sampling via Stein variational gradient descent
In our implementation, we apply SVGD to approximately sample a batch of points from . Other approximate inference algorithms could also be applied. One of the main advantages of SVGD, however, is that it encourages diversification in the batch, capturing the possible multimodality of . Given the batch locations, observations can be collected in parallel and then added to the dataset to update the classifier model.
SVGD is an approximate inference algorithm which represents a variational distribution as a set of particles [35]. The particles are initialised as i.i.d. samples from an arbitrary base distribution and then optimised via a sequence of smooth transformations towards the target distribution, which in our case corresponds to . The SVGD steps are given by:
| (25) | ||||
| (26) |
where is a positive-definite kernel, and is a small step size. Intuitively, the first term in the definition of guides the particles to the modes of , while the second term encourages diversification by repelling nearby particles. Theoretical convergence guarantees [36, 37] and practical extensions, such as second-order methods [38, 39] and derivative-free approaches [40], have been proposed in the literature. Further details on SVGD can be found in Liu and Wang [35].
5.3 Regret bound for Batch BORE++ with PLS classifiers
We follow the derivations in Oliveira et al. [41] to derive a distributional regret bound for batch BORE++ with respect to its target sampling distribution , which is presented in the following result.
Theorem 4.
Under the same assumptions in Theorem 1, running batch BORE++ with set as in Equation 20, we obtain a bound on the instantaneous distributional regret:
| (27) |
where , and on the cumulative distributional regret at :
| (28) |
both of which hold with probability at least .
As in the case of non-batch BORE++, the distributional regret bounds for the batch algorithm also grow sub-linearly for most popular kernels, leading to an asymptotically vanishing simple regret. Although different, to compare the distributional regret of batch BORE++ with the non-distributional regret bounds for BORE++, we may consider a case where is set to the function minimum and the observation noise is small. In this case, the batch sampling distribution would converge to a Dirac at the optimum, so that . Compared to the regret of non-batch BORE++ (Theorem 3) after collecting an equivalent number of observations , the expected regret of the batch version of BORE++ after iterations is then lower by a factor of , noting that . Therefore, batch BORE++ should be able to achieve lower regret per runtime than sequential BORE++ with an equivalent number of observations.
6 Related work
Since their proposal by Schonlau et al. [42], batch Bayesian optimisation methods have appeared in various forms in the literature. Many methods are based on heuristics derived from estimates given by a Gaussian process regression model [11, 12, 43]. Others are based on Monte Carlo estimates of multi-query acquisition functions [10, 13], optimising points over GP posterior samples [44], solving local optimisation problems [45], or optimising over ensembles of acquisition functions [46]. Despite that, the prevalent approaches to batch BO are still based on a GP regression model, which require prior knowledge about the objective function and do not scale to high-dimensional problems. We instead take a different approach by viewing BO as a density-ratio estimation problem following the BORE framework by Tiao et al. [9]. For batch design, we take an optimisation-as-inference approach [47, 48] by applying Stein variational gradient descent, a non-parametric approximate inference method [35], which has been recently combined with GP-based BO [49, 50]. Our theoretical results, however, are agnostic to the choice of inference algorithm. In contrast to traditional batch BO methods, the inference approach does not require solving inter-dependent optimisation problems for each batch point, as in heuristic-based approaches [43, 11, 12], Monte Carlo integration over the GP posterior [10, 13], nor sampling from it [44]. SVGD allows batch selection to be solved in a vectorised way, which can take advantage of hardware accelerators, such as GPUs.
7 Experiments
This section presents experiments assessing the theoretical results and demonstrating the practical performance of batch BORE on a series of global optimisation benchmarks. We compared our methods against GP-based BO baselines in both experiments sets. Additional experimental results, including the sequential setting (Appendix E), a description of the experiments setup (Appendix E), and further discussions on theoretical aspects can be found in the supplementary material.555Code will be made available at https://github.com/rafaol/batch-bore-with-guarantees
Theory assessment.
We first present simulated experiments assessing the theoretical results in practice, testing BORE and BORE++ in the PLS setting. As a baseline, we compare both methods against GP-UCB. This experiment was run by generating a random base classifier in the RKHS and then a corresponding objective function via the inverse noise CDF . The search space was set as a uniformly-sampled finite subset of the unit interval . We applied the theory-backed settings for BORE++ (Section 2.2) and GP-UCB [25], while BORE employed the optimal PLS classifier (Equation 13).
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/b471e28e-b8b8-4758-a905-e0cc6b8e94c3/theory-regret-1D.png) \captionof
\captionof
figure[Theory assessment]Regret in theory assessment experiment. Results were averaged over 10 trials, and the shaded area indicates the 95% confidence interval.666Linear interpolation is applied to obtain the plotted confidence intervals when the number of trials is small.
As the results in footnote 6 show, BORE using an optimal PLS classifier simply gets stuck at a its initial point, resulting in constant regret. BORE++, however, is able to progress in the optimisation problem towards the global optimum, outperforming the GP-UCB baseline.
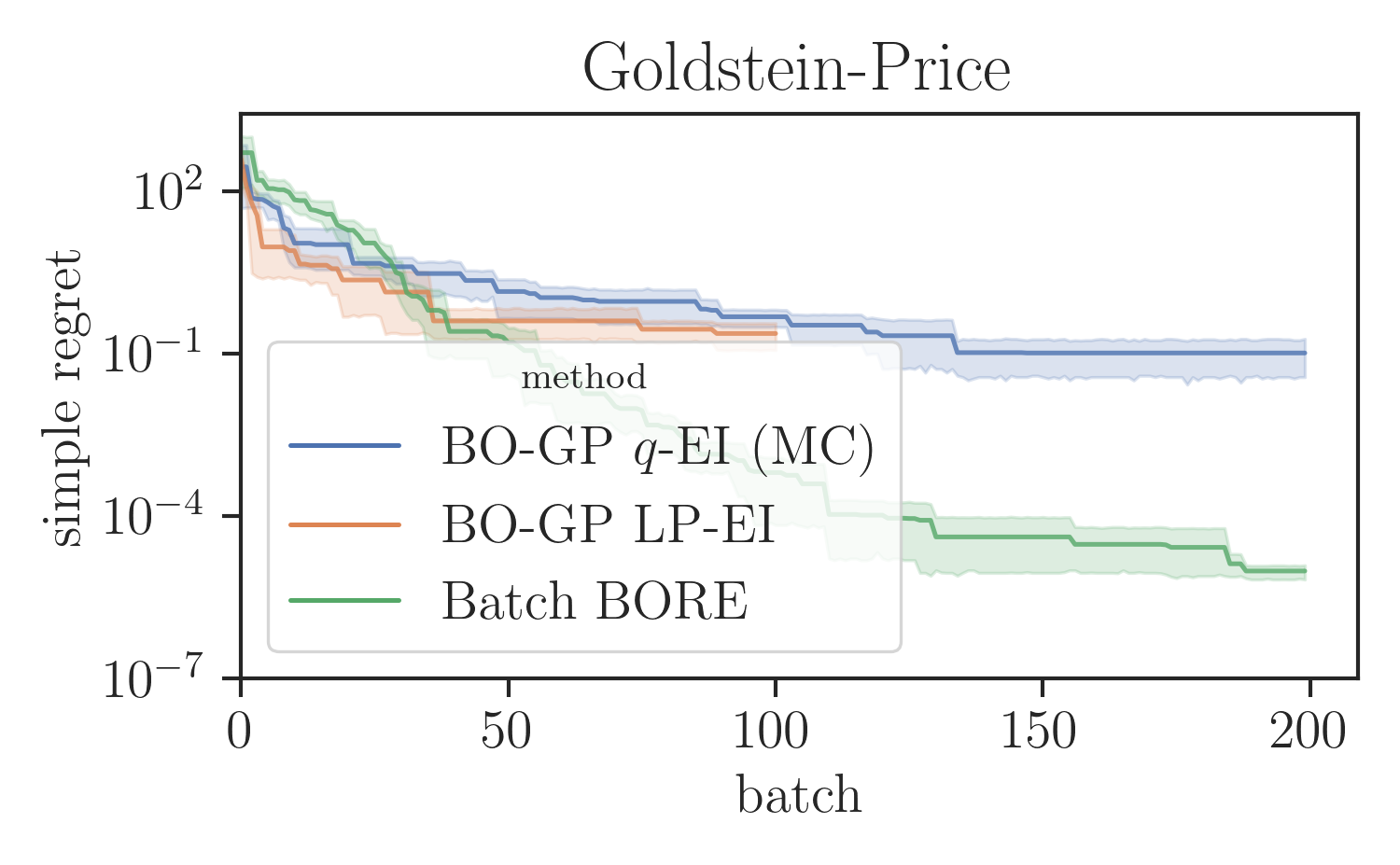
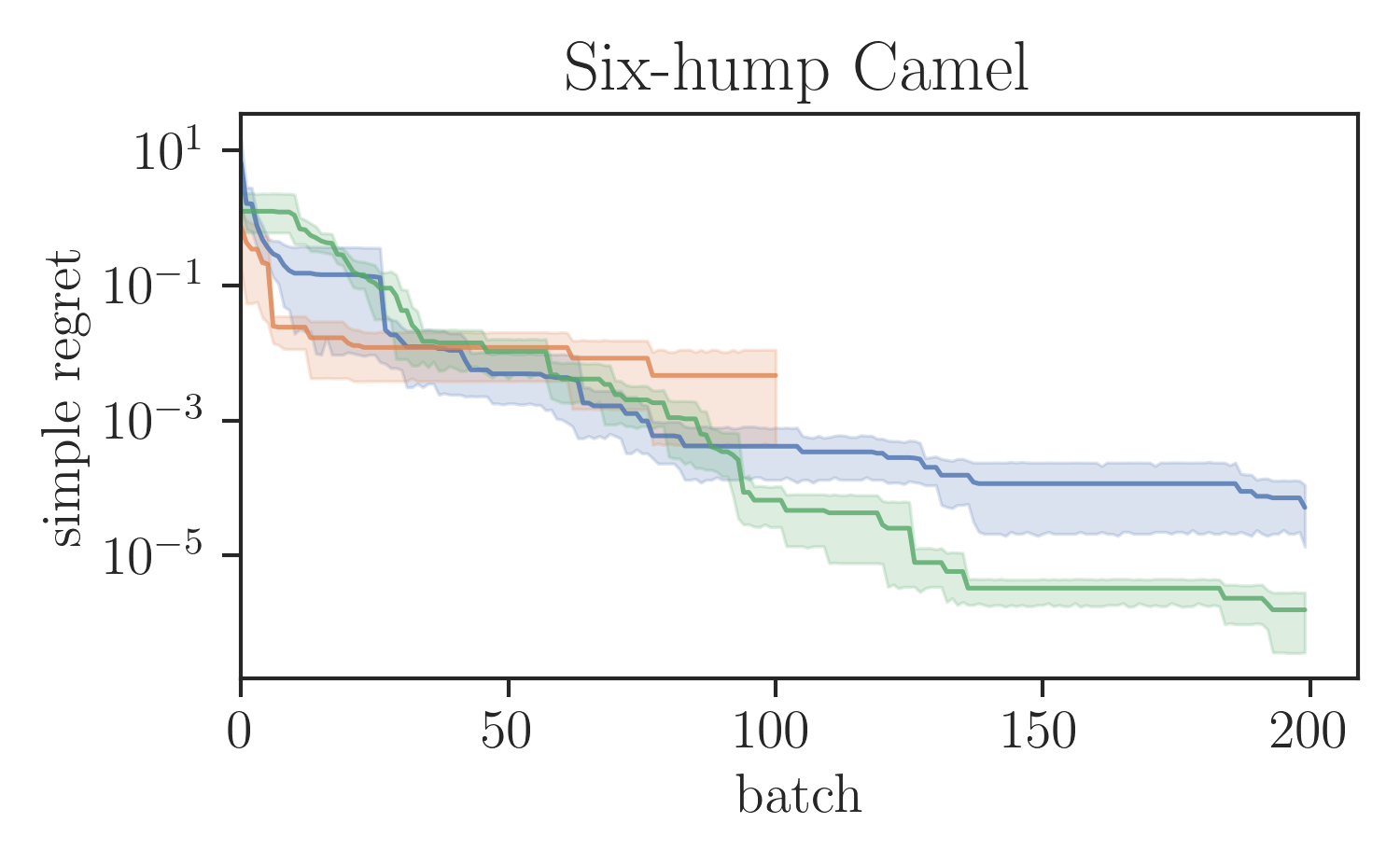
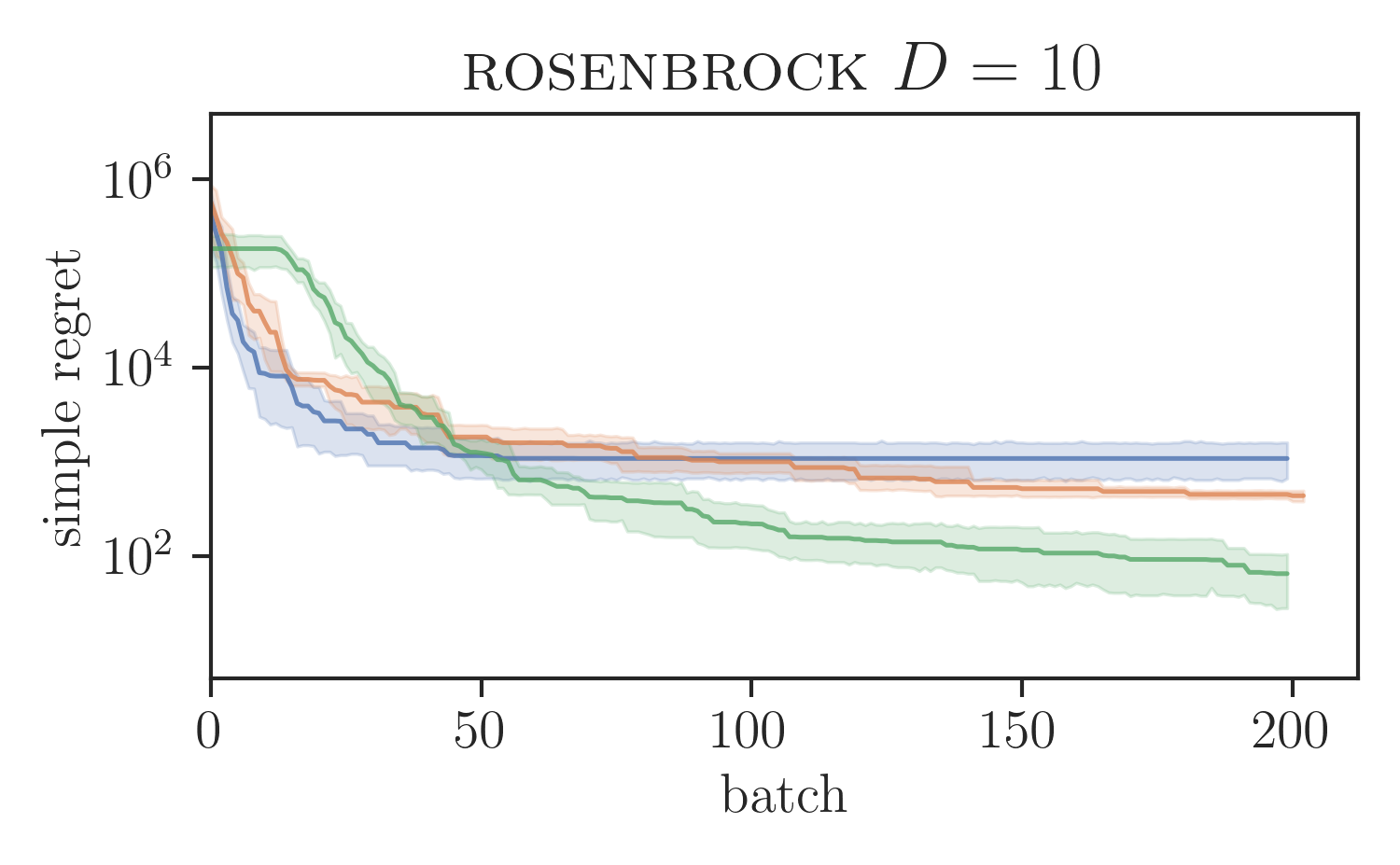
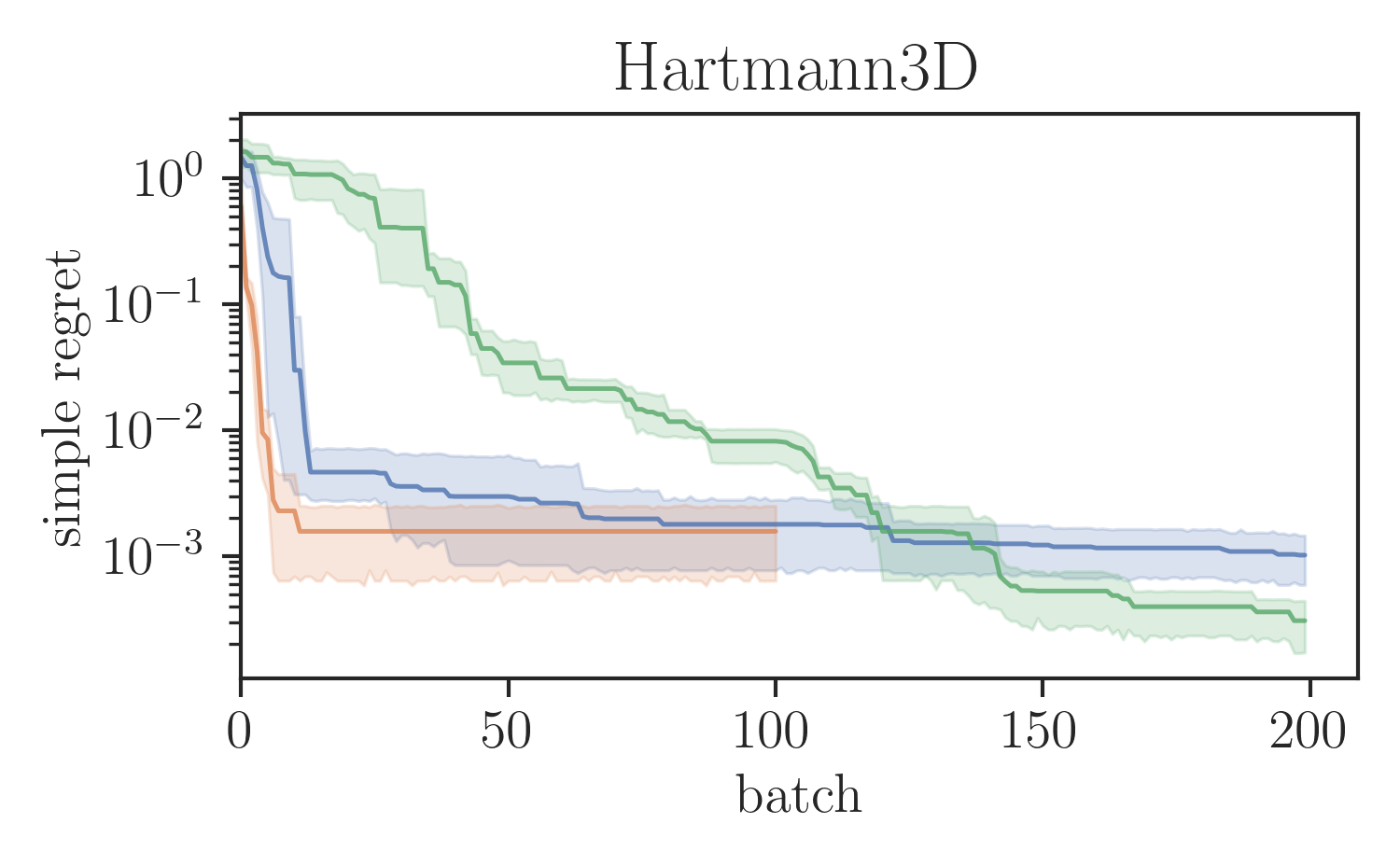
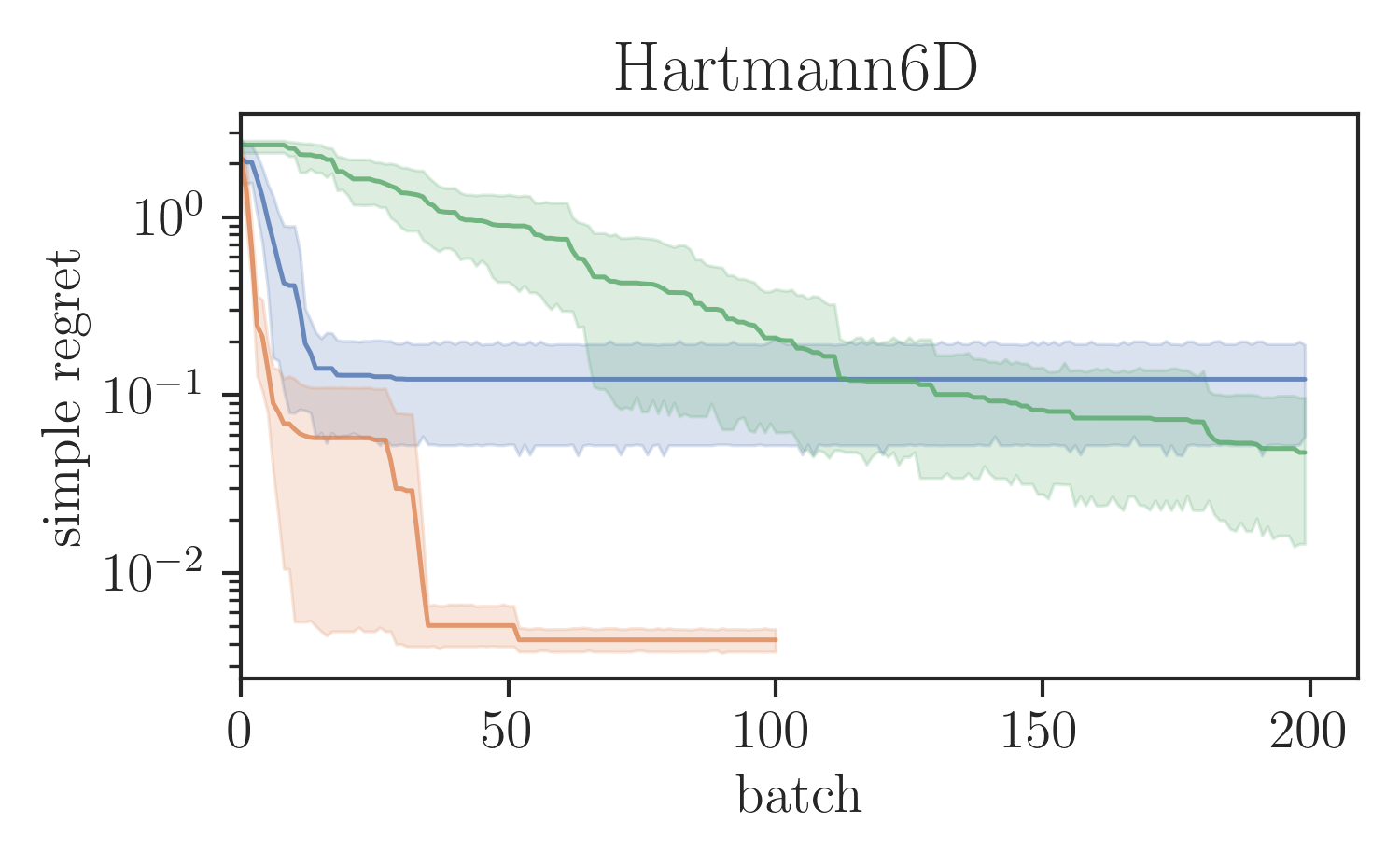
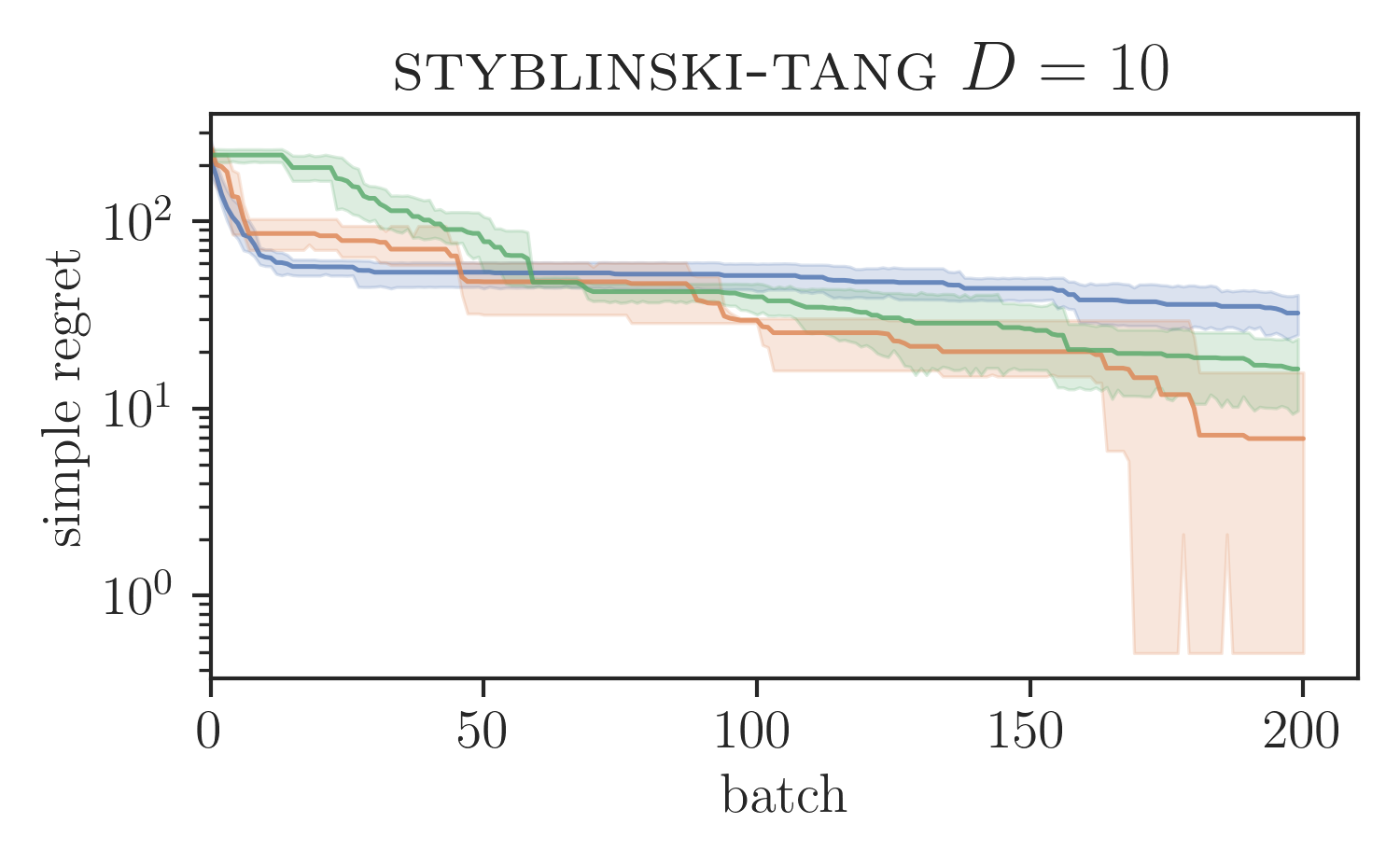
Global optimisation benchmarks.
We evaluated the proposed SVGD-based batch BORE method in a series of test functions for global optimisation comparing it against other BO baselines. In particular, for our comparisons, we ran the locally penalised EI (LP-EI) method [11] and the Monte Carlo based -EI method [10], which are both based on the EI algorithm, like BORE. Results are presented in Figure 1. All methods ran for iterations and used of batch size of 10 evaluations per iteration. Additional experimental details are deferred to the supplementary material.
As Figure 1 shows, batch BORE is able to outperform its baselines on most of the global optimisation benchmarks. We also note that, in some case, due to its complexity the LP-EI method becomes computationally infeasible after 100 iterations, having to be aborted halfway through the optimisation. Batch BORE, however, is able to maintain steady performance throughout its runs.
Real-data benchmarks.
Lastly, we compared the sequential version of BORE++ against BORE and other baselines, including traditional BO methods, such as GP-UCB and GP-EI [1], the Tree-structured Parzen Estimator (TPE) [15], and random search, on real-data benchmarks. In particular, we assessed the algorithms on some of the same benchmarks present in the original BORE paper [9].
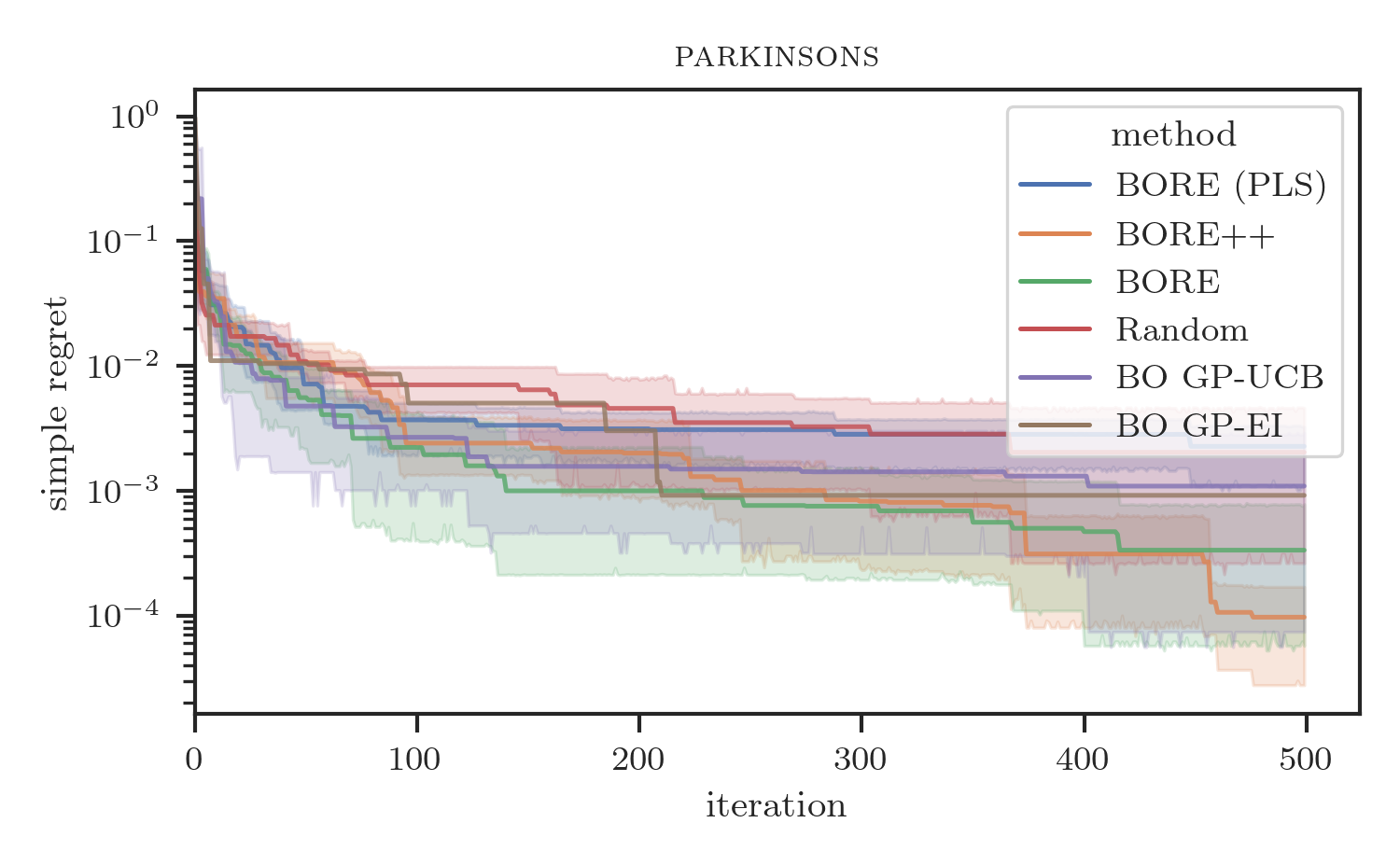
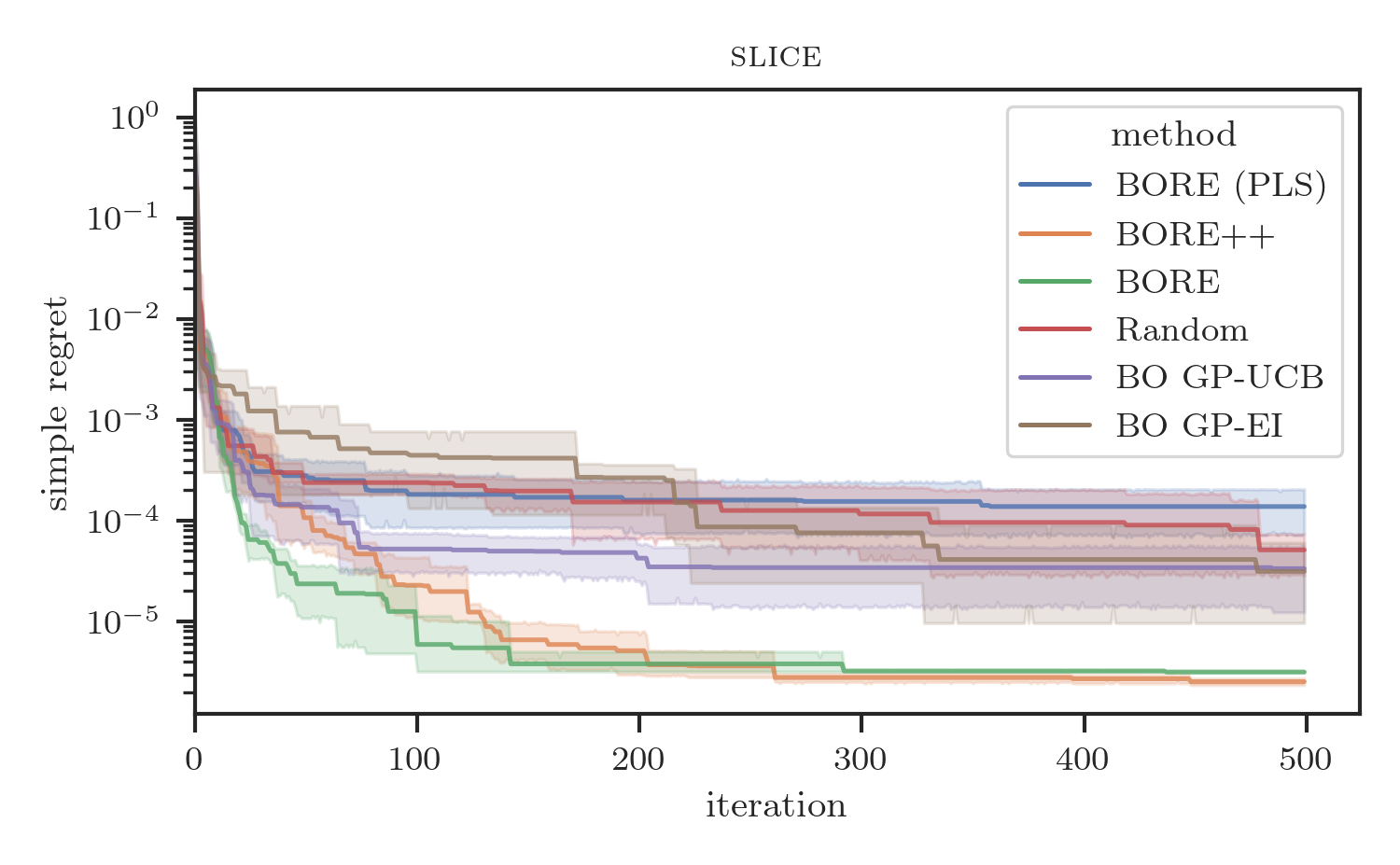
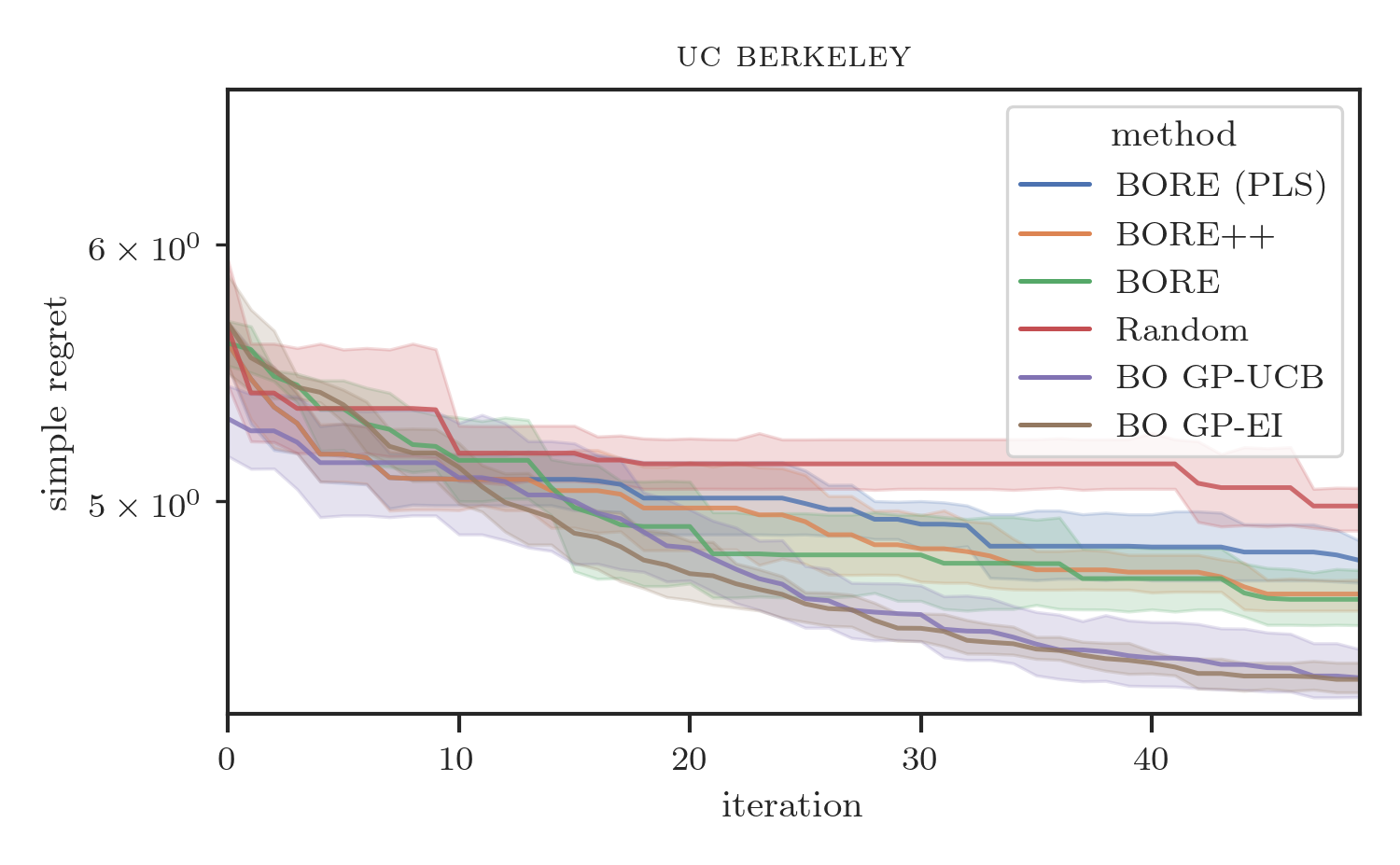
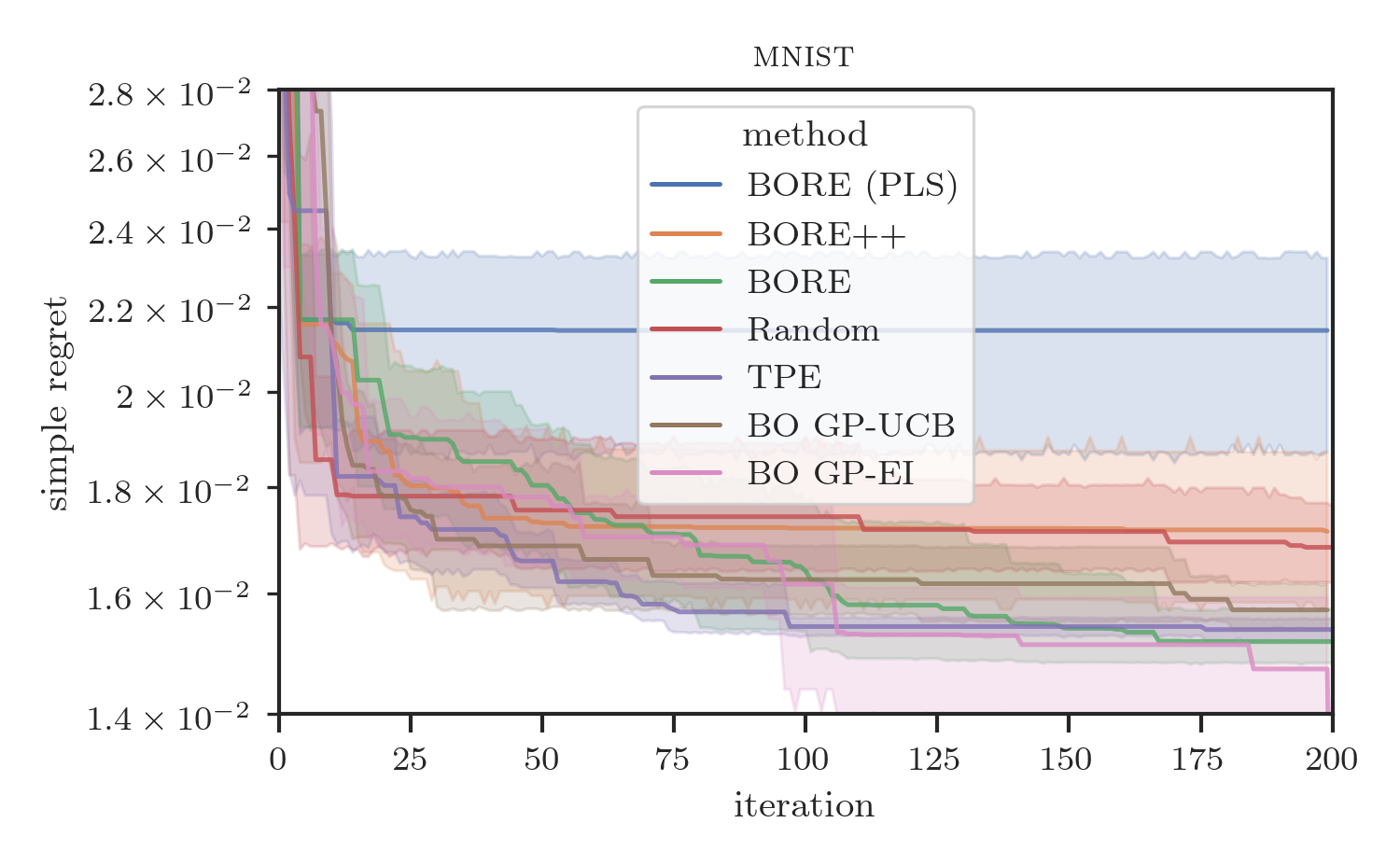
Results are presented in Figure 2. As the plots show, BORE++ presents significantly better performance than BORE in the probabilistic least-squares (PLS) setting (i.e., ), as the theoretical results suggested. In fact, it is possible to note that BORE (PLS) performs comparably to (or at times worse than) random search, indicating that the optimal least-squares classifier by itself is unable to properly capture the epistemic uncertainty. By using a neural network classifier trained via gradient descent and a different loss function (cross-entropy), the original BORE is still able to achieve top performance in most benchmarks. Both BORE versions are only surpassed by traditional GP-based BO on the racing line optimisation problem, as observed in Tiao et al. [9], due to the inherent smoothness the problem, and in the final iterations of the neural architecture search problem by GP-EI. Interestingly, even though restricted to the kernel-based PLS setting, we observe that BORE++ is able to surpass the original BORE in the neural network hyper-parameter tuning problems (slice and parkinsons), while maintaining similar performance in other tasks. These results confirm that improved uncertainty estimates can lead to practical performance gains.
8 Conclusion
This paper presented an extension of the BORE framework to the batch setting alongside the theoretical analysis of the proposed extension and an improvement over the original BORE. Theoretical results in terms of regret bounds and experiments show that BORE methods are able to maintain performance guarantees while outperforming traditional BO baselines. The main purpose of this work, however, was to establish the theoretical foundations for the analysis and derivation of new algorithmic frameworks for Bayesian optimisation via density-ratio estimation, equipping BO with new tools based on probabilistic classification, instead of regression models.
As future work, we plan to investigate the theoretical properties of BORE under different loss functions and analyse other batch design strategies, e.g., sampling methods for combinatorial domains. The theoretical contributions of this work can also be extended to other versions of BORE, such as its recent multi-objective version [51], and provide insights into other likelihood-free BO methods [52]. Finally, we consider integrating BORE++ with other probabilistic classification models equipped with predictive uncertainty estimates, such as neural network ensembles [53], random forests [54], and Bayesian generalised linear models, which should lead to improvements in scalability and additional performance gains.
Acknowledgments and Disclosure of Funding
Rafael Oliveira was supported by the Medical Research Future Fund Applied Artificial Intelligence in Health Care grant (MRFAI000097) by the Australian Department of Health and Aged Care.
References
- Shahriari et al. [2016] Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando De Freitas. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1):148–175, 2016.
- Rasmussen and Williams [2006] Carl E. Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning. The MIT Press, Cambridge, MA, 2006.
- Srinivas et al. [2010] Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias Seeger. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), pages 1015–1022, 2010.
- Bull [2011] Adam D. Bull. Convergence Rates of Efficient Global Optimization Algorithms. Journal of Machine Learning Research (JMLR), 12:2879–2904, 2011.
- Wang et al. [2018] Zi Wang, Beomjoon Kim, and Leslie Kaelbling. Regret bounds for meta Bayesian optimization with an unknown Gaussian process prior. In Conference on Neural Information Processing Systems, Montreal, Canada, 2018.
- Snoek et al. [2015] Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, M Patwary, Prabhat, and R Adams. Scalable Bayesian optimization using deep neural networks. In International Conference on Machine Learning (ICML), Lille, France, 2015.
- Springenberg et al. [2016] Jost Tobias Springenberg, Klein Aaron, Stefan Falkner, and Frank Hutter. Bayesian optimization with robust Bayesian neural networks. In Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 2016.
- Hutter et al. [2011] Frank Hutter, Holger H Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In International conference on learning and intelligent optimization, pages 507–523. Springer, 2011.
- Tiao et al. [2021] Louis C Tiao, Aaron Klein, Matthias Seeger, Edwin V Bonilla, Cédric Archambeau, and Fabio Ramos. Bayesian Optimization by Density-Ratio Estimation. In Proceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR, Jul 2021.
- Snoek et al. [2012] Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practical bayesian optimization of machine learning algorithms. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 2951–2959. Curran Associates, Inc., 2012.
- Gonzalez et al. [2016] Javier Gonzalez, Zhenwen Dai, Philipp Hennig, and Neil D. Lawrence. Batch Bayesian optimization via local penalization. In International Conference on Artificial Intelligence and Statistics (AISTATS), pages 648–657, Cadiz, Spain, 2016.
- Wang et al. [2017] Zi Wang, Chengtao Li, Stefanie Jegelka, and Pushmeet Kohli. Batched high-dimensional Bayesian optimization via structural kernel learning. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3656–3664, International Convention Centre, Sydney, Australia, 2017. PMLR.
- Wilson et al. [2018] James T. Wilson, Frank Hutter, and Marc Peter Deisenroth. Maximizing acquisition functions for Bayesian optimization. In 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada, 2018.
- Jones et al. [1998] D. R. Jones, M. Schonlau, and W. J. Welch. Efficient global optimization of expensive black-box functions. Journal of Global Optimization, 13:455–492, 1998.
- Bergstra et al. [2011] James S Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for Hyper-parameter Optimization. In Advances in Neural Information Processing Systems, pages 2546–2554, 2011.
- Sugiyama et al. [2012] Masashi Sugiyama, Hirotaka Hachiya, Makoto Yamada, Jaak Simm, and Hyunha Nam. Least-squares probabilistic classifier: A computationally efficient alternative to kernel logistic regression. In Proceedings of International Workshop on Statistical Machine Learning for Speech Processing (IWSML2012), Kyoto, Japan, 2012.
- Gneiting and Raftery [2007] Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007.
- Barron [1994] Andrew R Barron. Approximation and estimation bounds for artificial neural networks. Machine learning, 14(1):115–133, 1994.
- Steinwart and Christmann [2009] Ingo Steinwart and Andreas Christmann. Fast learning from Non-i.i.d. observations. In Advances in Neural Information Processing Systems 22, pages 1768–1776, 2009.
- Selten [1998] Reinhard Selten. Axiomatic characterization of the quadratic scoring rule. Experimental Economics, 1(1):43–62, 1998.
- Suykens and Vandewalle [1999] J. A. K. Suykens and J. Vandewalle. Least squares support vector machine classifier. Neural Processing Letters, 9:293–300, 1999.
- Schölkopf and Smola [2002] Bernhard Schölkopf and Alexander J. Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT Press, Cambridge, Mass, 2002.
- Abbasi-Yadkori et al. [2010] Yasin Abbasi-Yadkori, David Pal, and Csaba Szepesvari. Improved Algorithms for Linear Stochastic Bandits. In Advances in Neural Information Processing Systems (NIPS), pages 1–19, 2010.
- Abbasi-Yadkori [2012] Yasin Abbasi-Yadkori. Online Learning for Linearly Parametrized Control Problems. Phd, University of Alberta, 2012.
- Durand et al. [2018] Audrey Durand, Odalric-Ambrym Maillard, and Joelle Pineau. Streaming kernel regression with provably adaptive mean, variance, and regularization. Journal of Machine Learning Research, 19(1):650–683, 2018.
- Chowdhury and Gopalan [2017] Sayak Ray Chowdhury and Aditya Gopalan. On Kernelized Multi-armed Bandits. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 2017.
- Vakili et al. [2021] Sattar Vakili, Kia Khezeli, and Victor Picheny. On information gain and regret bounds in gaussian process bandits. In Arindam Banerjee and Kenji Fukumizu, editors, Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 82–90. PMLR, 13–15 Apr 2021.
- Bardsley et al. [2014] Johnathan M Bardsley, Antti Solonen, Heikki Haario, and Marko Laine. Randomize-then-optimize: A method for sampling from posterior distributions in nonlinear inverse problems. SIAM Journal on Scientific Computing, 36(4):A1895 – A1910, 2014.
- Mandt et al. [2017] Stephan Mandt, Matthew D. Hoffman, and David M. Blei. Stochastic gradient descent as approximate Bayesian inference. Journal of Machine Learning Research, 18, 2017.
- Russo and Van Roy [2016] Daniel Russo and Benjamin Van Roy. An Information-Theoretic Analysis of Thompson Sampling. Journal of Machine Learning Research (JMLR), 17:1–30, 2016.
- Rokach [2010] Lior Rokach. Ensemble-based classifiers. Artificial intelligence review, 33(1):1–39, 2010.
- Penny and Roberts [1999] William D Penny and Stephen J Roberts. Bayesian neural networks for classification: how useful is the evidence framework? Neural networks, 12(6):877–892, 1999.
- Amit and Geman [1997] Yali Amit and Donald Geman. Shape quantization and recognition with randomized trees. Neural Computation, 9(7):1545–1588, 07 1997.
- Polson and Sokolov [2017] Nicholas G. Polson and Vadim Sokolov. Deep learning: A Bayesian perspective. Bayesian Analysis, 12(4):1275–1304, 2017.
- Liu and Wang [2016] Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose Bayesian inference algorithm. In Advances in Neural Information Processing Systems (NIPS), 2016.
- Liu [2017] Qiang Liu. Stein variational gradient descent as gradient flow. In Advances in Neural Information Processing Systems, pages 8854–8863, Long Beach, CA, USA, 2017.
- Korba et al. [2020] Anna Korba, Adil Salim, Michael Arbel, Giulia Luise, and Arthur Gretton. A non-asymptotic analysis for Stein variational gradient descent. In Advances in Neural Information Processing Systems, Vancouver, Canada, 2020.
- Detommaso et al. [2018] Gianluca Detommaso, Tiangang Cui, Alessio Spantini, Youssef Marzouk, and Robert Scheichl. A Stein variational Newton method. In 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada, 2018.
- Liu et al. [2019] Chang Liu, Jingwei Zhuo, Pengyu Cheng, Ruiyi Zhang, Jun Zhu, and Lawrence Carin. Understanding and accelerating particle-based variational inference. In 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, 2019.
- Han and Liu [2018] Jun Han and Qiang Liu. Stein variational gradient descent without gradient. In 35th International Conference on Machine Learning (ICML 2018), 2018.
- Oliveira et al. [2021] Rafael Oliveira, Lionel Ott, and Fabio Ramos. No-regret approximate inference via Bayesian optimisation. In Cassio de Campos and Marloes H. Maathuis, editors, Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, volume 161 of Proceedings of Machine Learning Research, pages 2082–2092. PMLR, 27–30 Jul 2021.
- Schonlau et al. [1998] Matthias Schonlau, William J. Welch, and Donald R. Jones. Global versus local search in constrained optimization of computer models. New Developments and Applications in Experimental Design, 34:11–25, 1998.
- Azimi et al. [2010] Javad Azimi, Alan Fern, and Xiaoli Z. Fern. Batch Bayesian optimization via simulation matching. In Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010 (NIPS 2010), 2010.
- Kandasamy et al. [2018] Kirthevasan Kandasamy, Akshay Krishnamurthy, Jeff Schneider, and Barnabas Poczos. Parallelised Bayesian optimisation via Thompson sampling. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), Lanzarote, Spain, 2018.
- Eriksson et al. [2019] David Eriksson, Michael Pearce, Jacob R Gardner, Ryan Turner, and Matthias Poloczek. Scalable global optimization via local Bayesian optimization. In 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), 2019.
- Zhang et al. [2022] Shuhan Zhang, Fan Yang, Changhao Yan, Dian Zhou, and Xuan Zeng. An efficient batch-constrained Bayesian optimization approach for analog circuit synthesis via multiobjective acquisition ensemble. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 41(1), 2022.
- Todorov [2008] Emanuel Todorov. General duality between optimal control and estimation. In Proceedings of the 47th IEEE Conference on Decision and Control, Cancun, Mexico, 2008.
- Fellows et al. [2019] Matthew Fellows, Anuj Mahajan, Tim G. J. Rudner, and Shimon Whiteson. VIREL: A variational inference framework for reinforcement learning. In 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 2019.
- Gong et al. [2019] Chengyue Gong, Jian Peng, and Qiang Liu. Quantile Stein Variational Gradient Descent for Batch Bayesian Optimization. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 2019.
- Oliveira et al. [2019] Rafael Oliveira, Lionel Ott, and Fabio Ramos. Distributional Bayesian optimisation for variational inference on black-box simulators. In 2nd Symposium on Advances in Approximate Bayesian Inference, Vancouver, Canada, 2019.
- De Ath et al. [2022] George De Ath, Tinkle Chugh, and Alma A. M. Rahat. MBORE: Multi-objective Bayesian optimisation by density-ratio estimation. GECCO ’22, page 776–785, New York, NY, USA, 2022. Association for Computing Machinery.
- Song et al. [2022] Jiaming Song, Lantao Yu, Willie Neiswanger, and Stefano Ermon. A general recipe for likelihood-free Bayesian optimization. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 20384–20404. PMLR, 17–23 Jul 2022.
- Lakshminarayanan et al. [2017] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In Neural Information Processing Systems (NIPS), 2017.
- Balog and Teh [2015] Matej Balog and Yee Whye Teh. The Mondrian Process for Machine Learning. Technical report, University of Oxford, 2015.
- Boucheron et al. [2013] Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. Concentration inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013.
- Munkres [1975] James Raymond Munkres. Topology: a first course. Prentice Hall, Edgewood Cliffs, NJ, 1975.
- Jacot et al. [2018] Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in Neural Information Processing Systems, Montreal, Canada, 2018.
- de G. Matthews et al. [2018] Alexander G. de G. Matthews, Jiri Hron, Mark Rowland, Richard E. Turner, and Zoubin Ghahramani. Gaussian Process Behaviour in Wide Deep Neural Networks. In International Conference on Learning Representations, Vancouver, Canada, 2018. OpenReview.net.
- Grünewälder et al. [2010] Steffen Grünewälder, Jean Yves Audibert, Manfred Opper, and John Shawe-Taylor. Regret bounds for Gaussian process bandit problems. In Journal of Machine Learning Research, volume 9, pages 273–280, 2010.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- Byrd et al. [1995] Richard H Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization. SIAM Journal on scientific computing, 16(5):1190–1208, 1995.
- authors [2016] The GPyOpt authors. GPyOpt: A Bayesian optimization framework in python. http://github.com/SheffieldML/GPyOpt, 2016.
- Balandat et al. [2020] Maximilian Balandat, Brian Karrer, Daniel R. Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Eytan Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. In Advances in Neural Information Processing Systems 33, 2020.
- Kingma and Ba [2015] Diederik P Kingma and Jimmy Lei Ba. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations (ICLR), 2015.
- Virtanen et al. [2020] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Moore, Jake VanderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Tsanas et al. [2009] Athanasios Tsanas, Max Little, Patrick McSharry, and Lorraine Ramig. Accurate telemonitoring of parkinson’s disease progression by non-invasive speech tests. Nature Precedings, pages 1–1, 2009.
- Graf et al. [2011] Franz Graf, Hans-Peter Kriegel, Matthias Schubert, Sebastian Pölsterl, and Alexander Cavallaro. 2d image registration in ct images using radial image descriptors. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 607–614. Springer, 2011.
- Dua and Graff [2017] Dheeru Dua and Casey Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Eggensperger et al. [2021] Katharina Eggensperger, Philipp Müller, Neeratyoy Mallik, Matthias Feurer, Rene Sass, Aaron Klein, Noor Awad, Marius Lindauer, and Frank Hutter. Hpobench: A collection of reproducible multi-fidelity benchmark problems for hpo. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
- Liniger et al. [2015] Alexander Liniger, Alexander Domahidi, and Manfred Morari. Optimization-based autonomous racing of 1:43 scale RC cars. OPTIMAL CONTROL APPLICATIONS AND METHODS, 36:628–647, 2015.
- Jain and Morari [2020] Achin Jain and Manfred Morari. Computing the racing line using Bayesian optimization. In Proceedings of the 59th IEEE Conference on Decision and Control (CDC), 2020.
- Deng [2012] Li Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- Falkner et al. [2018] Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: Robust and efficient hyperparameter optimization at scale. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1437–1446. PMLR, 10–15 Jul 2018.
- Rahimi and Recht [2007] Ali Rahimi and Ben Recht. Random features for large-scale kernel machines. In Advances in Neural Information Processing (NIPS), 2007.
Appendix
This appendix complements the main paper with proofs, experiment details and additional experiments and discussions. Appendix A presents full proofs for the main theoretical results in the paper. In Appendix B, we discuss an approach to derive alternative regret bounds for BORE under a Thompson sampling perspective. We discuss the theoretical analysis of BORE with its non-constant approximation for the observations quantile in Appendix C. In Appendix D, we present further details on the experiments setup. Finally, Appendix E presents an additional experiment assessing dimensionality effects.
Appendix A Proofs
This section presents proofs for the main theoretical results in the paper. We start with a few auxiliary results from the GP-UCB literature [3, 26], following up with the proofs for the main theorems.
A.1 Auxiliary results
Lemma A.1 (Srinivas et al. [3, Lemma 5.3]).
The information gain for a sequence of observations , where , , can be expressed in terms of the predictive variances. Namely, if , then the information gain provided by the observations is such that:
| (A.1) |
where and .
Lemma A.2 (Chowdhury and Gopalan [26, Lemma 4]).
Following the setting of A.1, the sum of predictive standard deviations at a sequence of points is bounded in terms of the maximum information gain:
| (A.2) |
Lemma A.3.
Let be a finite set of points where a function was evaluated, so that the GP posterior covariance function and the corresponding variance are given by:
| (A.3) | ||||
| (A.4) |
where and . Then, for any given set of evaluations of , we have:
| (A.5) |
Proof.
The result follows by observing that the GP posterior given observations at is a prior for the GP with the new observations at the complement . Then we obtain, for all :
| (A.6) |
since is non-negative. ∎
A.2 Proof of Theorem 1
Proof of Theorem 1.
A.3 Proof of Theorem 2
To prove Theorem 2, we will follow the procedure of GP-UCB proofs [3, 26] by bounding the approximation error via a confidence bound (Theorem 1) and then applying it to the instant regret. From the instant regret to the cumulative regret, the bounds are extended by means of the maximum information gain introduced in the main text. One of the differences with our proof, however, is that BORE with a PLS classifier is not following the optimal UCB policy, but instead a pure-exploitation approach by following the maximum of the mean estimator , which does not account for uncertainty.
Proof of Theorem 2.
Recalling the classifier-based bound in Section 4 and that for any the result in Lemma 1 holds, we have:
| (A.7) |
According to Theorem 1, working with the confidence bounds on , we then have that the instant regret is bounded with probability at least by:
| (A.8) |
since . Now we can apply A.2, yielding with probability at least :
| (A.9) |
since for all . This concludes the proof. ∎
A.4 Proof of Theorem 3
Again, we will be following standard GP-UCB proofs for this result using the bound in Theorem 1.
Proof of Theorem 3.
Extending the bound in Equation A.7 with Theorem 1, we have with probability at least :
| (A.10) |
since . Turning our attention to the cumulative regret, with the same probability, we have:
| (A.11) |
which concludes the proof. ∎
A.5 Proof of Theorem 4
Proof.
Starting with the regret definition, we can define a bound in terms of the discrepancy between the two sampling distributions:
| (A.12) |
where the last line is due to Pinsker’s inequality [55] applied to the total variation distance between and (third line).
Tp obtain a bound on , starting from the definition of the terms, with probability at least , we have that:
| (A.13) |
which follows from . Now, by the mean value theorem [56], for all , we have that the following holds with the same probability:
| (A.14) |
since for all , and by Theorem 1. The first result in the theorem then follows.
For the second part of the result, we first note that:
| (A.15) |
Following the previous derivations, it holds with probability at least that:
| (A.16) |
since , for all , and expectations are linear operations. Considering the predictive variances above, recall that, at each iteration , the algorithm selects a batch of i.i.d. points , sampled from , where to evaluate the objective function . The predictive variance is conditioned on all previous observations, which are grouped by batches. We can then decompose, for any :
| (A.17) |
where we use the notation introduced in A.3, and:
| (A.18) | ||||
| (A.19) | ||||
Therefore, the predictive variance of the batched algorithm is not the same as the predictive variance of a sequential algorithm, and we cannot direcly apply A.2 to bound the last term in Equation A.16.
A.3 tells us that the predictive variance given a set of observations is less than the predictive variance given a subset of observations. Selecting only the first point from within each batch and applying A.3, we get, for :
| (A.20) |
where , with , . Note that the right-hand side of the equation above is simply the non-batched GP predictive variance. Furthermore, sample points within a batch are i.i.d., so that and are identically distributed. We can now apply A.2, yielding:
| (A.21) |
Combining this result with Equation A.16, we obtain:
| (A.22) |
Lastly, from the definition of , we have:
| (A.23) |
where:
| (A.24) |
for . Therefore, the cumulative sum of divergences is such that:
| (A.25) |
which concludes the proof. ∎
Appendix B Bayesian regret bounds for BORE as Thompson sampling
Although in our main results we considered BORE using an optimal classifier according to a least-squares loss, we may instead consider that, in practice, the trained classifier might be sub-optimal due to training via gradient descent. In particular, in the case of stochastic gradient descent, Mandt et al. [29] showed that parameters learnt this way can be seen as approximate samples of a Bayesian posterior distribution. This is, therefore, the case of Thompson (or posterior) sampling [30]. If we consider that the posterior over the model’s function space is Gaussian, e.g., as in the case of infinitely-wide deep neural networks [57, 58], we may instead analyse the original BORE as a GP-based Thompson sampling algorithm. We can then apply theoretical results from Russo and Van Roy [30] to use general GP-UCB approximation guarantees [3, 59] to bound BORE’S Bayesian regret. Note, however, that this is a different type of analysis compared to the one presented in this paper, which considered a frequentist setting where the objective function is fixed, but unknown.
Appendix C Analysis with a non-constant quantile approximation
Our main theoretical results so far relied upon the quantile being fixed throughout all iterations , though in practice we have to approximate the quantile based on the empirical observations distribution up to time . In this section, we discuss the plausibility of the theoretical results under this practical scenario.
The main impact of a time-varying quantile , and the corresponding classifier , in theoretical results is in the UCB approximation error (Theorem 1). This result depends on the observation noise as perceived by a GP model with observations , , to be sub-Gaussian when conditioned on the history. Hence, a few challenges originate from there. Firstly, the past observations in the vector are changing across iterations, due to the update in . Secondly, the latent function is stochastic, as the quantile depends on the current set of observations . Lastly, it is not very clear how to define a filtration for the resulting stochastic process such that the GP noise is sub-Gaussian. Nevertheless, as the number of observations increases, converges to a fixed value, making our asymptotic results valid.
Appendix D Experiment details
This section presents details of our experiments setup. We used PyTorch [60] for our implementation of batch BORE and BORE++, which we plan to make publicly available in the future.
D.1 Theory assessment
For this experiment, we generated a random classifier as an element of the RKHS defined by the kernel as:
| (D.1) |
where and the weights were i.i.d. sampled from a unit uniform distribution , with . The norm of is given by:
| (D.2) |
where and . To ensure , we normalised the weights according to the classifier norm, i.e., , so that , and consequently , for all . The kernel was set as the squared exponential (RBF) with a length-scale of .
Given a threshold , the objective function corresponding to satisfies:
| (D.3) |
For this experiment, we set . Each trial had a different objective function generated for it. An example of classifier and objective function pair is presented in Figure 1b (main paper). Observations were composed as function evaluations corrupted by zero-mean Gaussian noise with variance .
The search space was configured as a finite set by sampling points from a unit uniform distribution. The number of points in the search space was set as . As the search space is finite, we also know .
| Parameter | Setting |
|---|---|
| 0.025 | |
| 0.1 | |
| 0 |
| Parameter | Setting |
|---|---|
| 0.01 | |
| 0.1 | |
| 0.01 |
Regarding algorithm hyper-parameters, although any upper bound would work for setting up , BORE++ was configured with the RKHS norm as the first term in the setting for (see Theorem 1). To configure GP-UCB according to its theoretical settings [25, Thm. 1], we computed the RKHS norm of the resulting in the RKHS. We can compute the norm of as an element of by solving the following constrained optimisation problem:
| (D.4) |
As the search space is finite, the solution to this problem is available in closed form as:
| (D.5) |
where , and . We set . For both BORE++ and GP-UCB, the information gain was recomputed at each iteration. Lastly, the regularisation factor was set as for GP-UCB and as for BORE++, which was found by grid search. In summary, for this experiment, the settings for BORE++ can be found in Table D.1 and, for GP-UCB, in Table D.2.
D.2 Global optimisation benchmarks
For each problem, all methods used 10 initial points uniformly sampled from the search space. As performance indicator, we measured the simple regret:
| (D.6) |
as the global minimum of each of the considered benchmark functions is known. All objective function evaluations were provided free of noise to the algorithms.
| Parameter | Setting |
|---|---|
| Optimiser | Adam |
| Batch size | 64 |
| Steps | 100* |
| Parameter | Setting |
|---|---|
| Step size | 0.001 |
| Decay rate | 0.9 |
| Number of steps |
Batch BORE was run with a percentile , which was applied to estimate the empirical quantile at every iteration . The method’s classifier model was composed of a multilayer perceptron neural network model with 2 hidden layers of 32 units each, which was trained to minimise the binary cross-entropy loss. The activation function was set as the rectified linear unit (ReLU) with exception for the Hartmann 3D and the Six-hump Camel problem, which were run with an exponential linear unit (ELU), instead. Training for the neural networks was performed via stochastic gradient descent, whose settings are presented in Table D.3. SVGD was run applying Adadelta to configure its steps according to the settings in Table D.4. The SVGD kernel was set as the squared exponential (RBF) using the median trick to adjust its lengthscale [35].
D.3 Comparisons on real-data benchmarks
We here present experiments comparing the sequential version of BORE++ against BORE and other baselines, including traditional BO methods, such as GP-UCB and GP-EI [1], the Tree-structured Parzen Estimator (TPE) [15], and random search, on real-data benchmarks. In particular, we assessed the algorithms on some of the same benchmarks present in the original BORE paper [9].
D.3.1 Algorithm settings
All versions of BORE were set with . The original BORE algorithm used a 2-layer, 32-unit fully connected neural network as a classifier. The network was trained via stochastic gradient descent using Adam [64]. As in the other experiments in this paper, we followed the same scheme that keeps the number of gradient steps per epoch fixed [see 9, Appendix J.3], set in our case as 100, and a mini-batch of size 64. The probabilistic least-squares version of BORE and BORE++ were configured with a GP classifier using the rational quadratic kernel [2, Ch. 4] with output scaling and independent length scales per input dimension. All GP-based algorithms used the same type of kernel. GP hyper-parameters were estimated by maximising the GP’s marginal likelihood at each iteration using BoTorch’s hyper-parameter estimation methods, which apply L-BFGS by default [63]. BORE++ was set with a fixed value for its parameter , the regularisation factor was set as . Acquisition function optimisation was run for 500 to 1000 iterations via L-BFGS with multiple restarts using SciPy’s toolkit [65]. Lastly, for the experiment with the MNIST dataset, we also used the Tree-structured Parzen Estimator (TPE) by Bergstra et al. [15] set with default settings from the HyperOpt package. All algorithms were run for a given number of independent trials and results are presented with their 95% confidence intervals777Confidence intervals are calculated via linear interpolation when the number of trials is small.
D.3.2 Benchmarks
Neural network hyper-parameter tuning.
We first considered two of the neural network (NN) tuning problems found in Tiao et al. [9], where a two-layer feed-forward NN is trained for regression. The NN is trained for 100 epochs with the ADAM optimizer [64], and the objective is the validation mean-squared error (MSE). The hyper-parameters are the initial learning rate, learning rate schedule, batch size, along with the layer-specific widths, activations, and dropout rates. In particular, we considered Parkinson’s telemonitoring [66] and the CT slice localisation [67] datasets, available at UCI’s machine learning repository [68], and utilize HPOBench [69], which tabulates, for each dataset, the MSEs resulting from all possible (62,208) configurations. The datasets and code are publicly available888Tabular benchmarks: https://github.com/automl/nas_benchmarks. Each algorithm was run for 500 iterations across 10 independent trials.
Racing line optimisation.
We compare the different versions of BORE against a random search baseline in the UC Berkeley racing line optimisation benchmark [70] using the code provided by Jain and Morari [71]. The task consists of finding the optimal racing line across a given track by optimising the positions of a set of 10 waypoints on the Cartesian plane along the track’s centre line which would reduce the lap time for a given car, resulting in a 20-dimensional problem. For this track, the car model is based on UC Berkeley’s 1:10 scale miniature racing car open source model999Open source race car: https://github.com/MPC-Berkeley/barc/tree/devel-ugo. Each algorithm was run for 50 iterations across 5 independent trials.
Neural architecture search.
Lastly, we compare all algorithms on a neural network architecture search problem. The task consists of optimising hyper-parameters which control the training process (initial learning rate, batch size, dropout, exponential decay factor for learning rate) and the architecture (number of layers and units per layer) of a feed forward neural network on the MNIST hand-written digits classification task [72]. The objective is to minimise the NN classification error. To allow for a wide range of hyper-parameter evaluations, this task uses a random forest surrogate trained with data obtained by training the actual NNs on MNIST [73]. For this experiment, each method was run for 200 iterations across 10 independent trials.
Appendix E Dimensionality effect on batch BORE vs. batch BORE++ performance
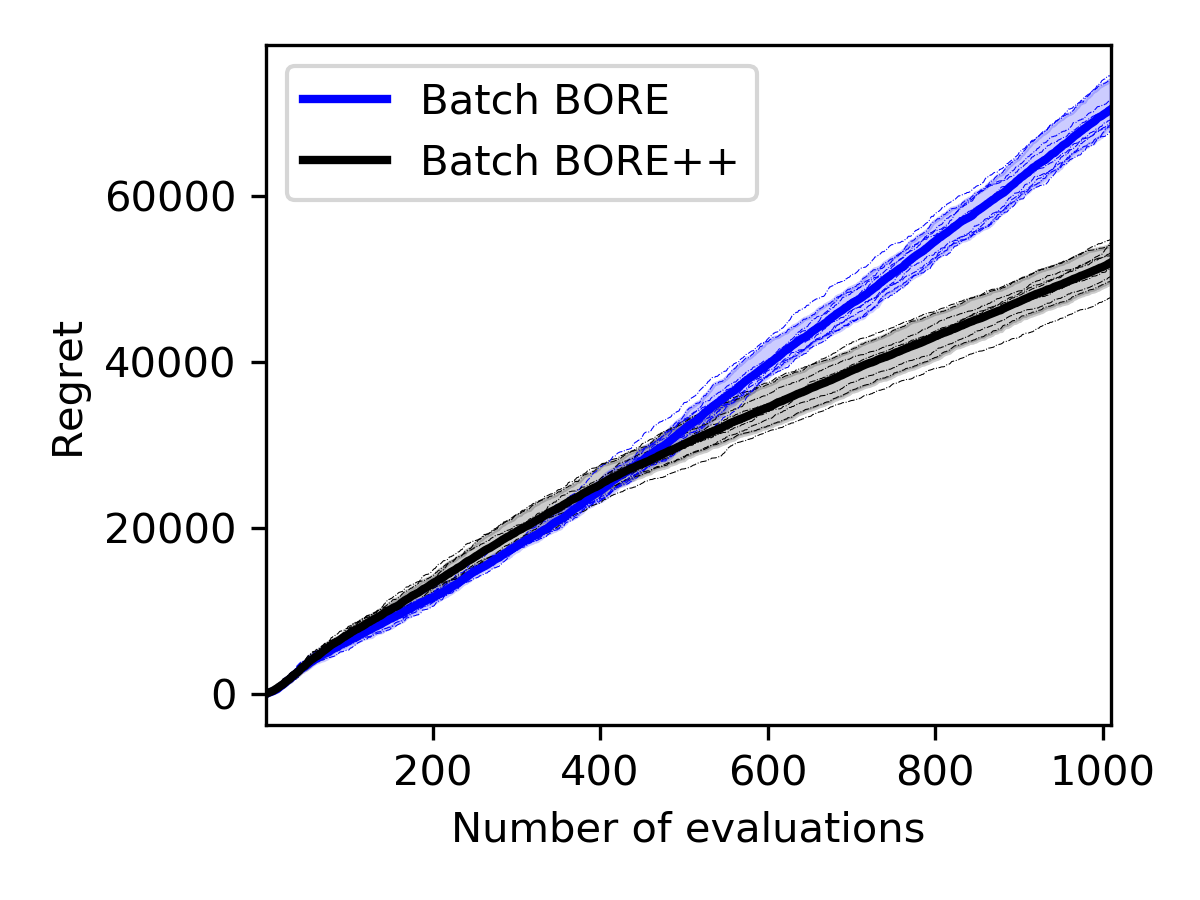
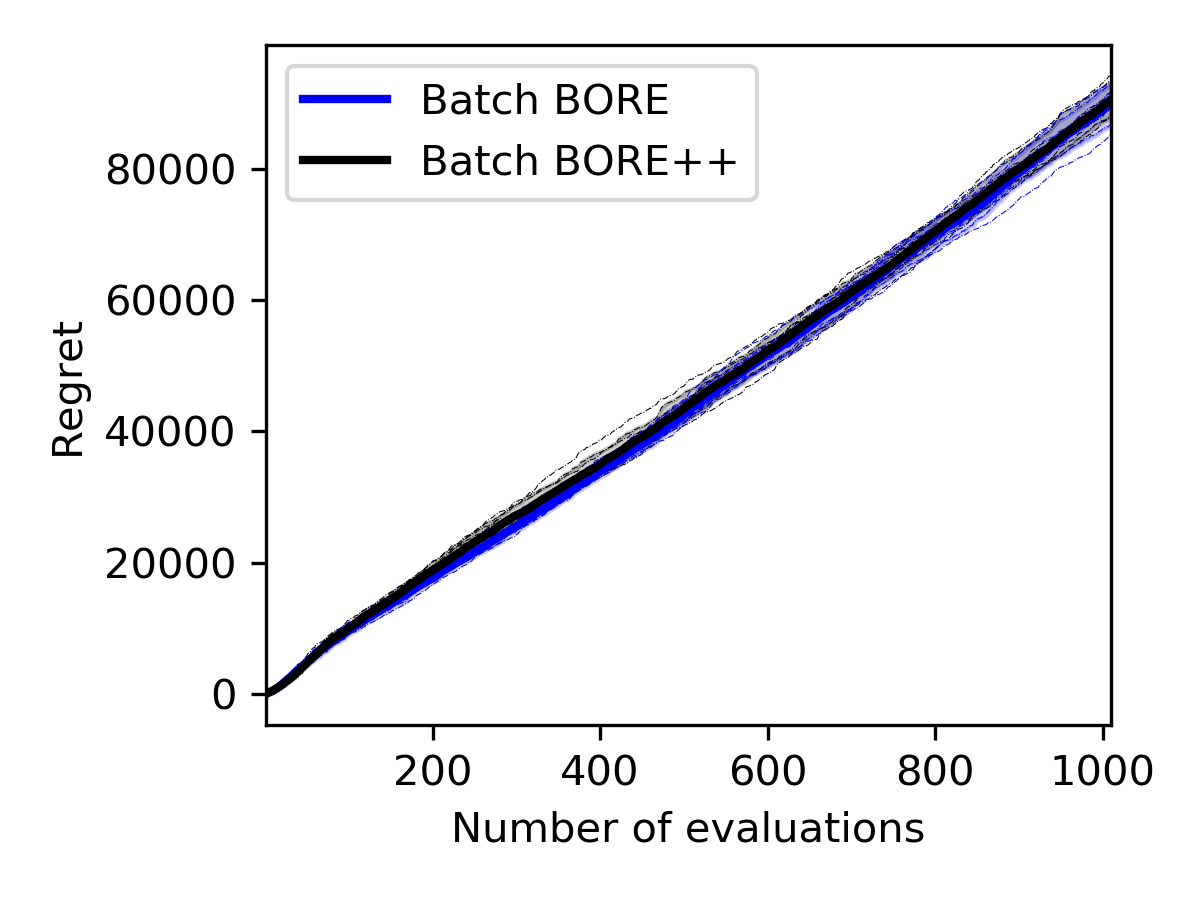
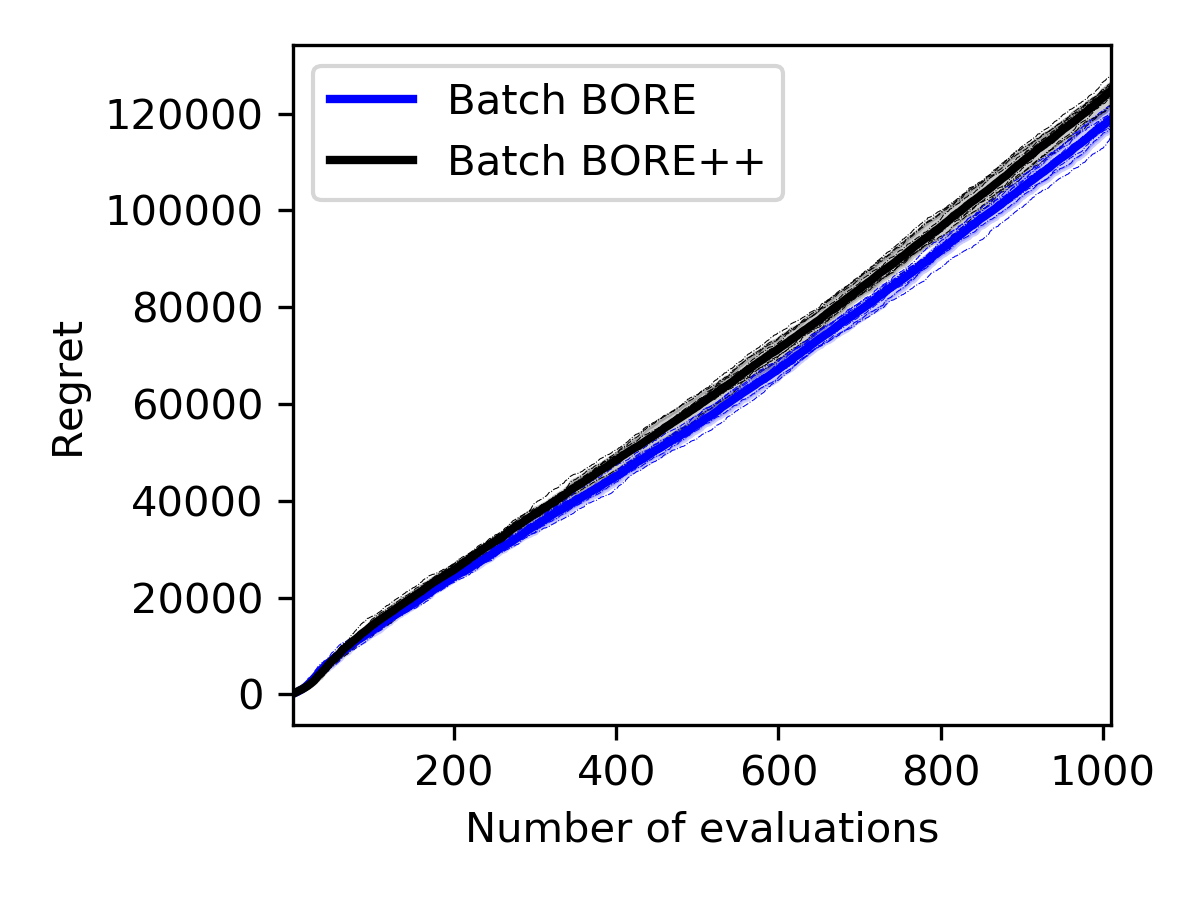
We compared batch BORE against the batch BORE++ algorithm on a synthetic optimisation problem with the Rosenbrock function. The dimensionality of the search space was varied. The cumulative regret curves for each algorithm are presented in Figure E.1.
Both algorithms were configured with a Bayesian logistic regression classifier applying random Fourier features [74] as feature maps based on the squared-exponential kernel. The number of features was set as 300, and the classifier was trained via expectation maximisation. Observations were corrupted by additive Gaussian noise with zero mean and a small noise variance , and each model was set accordingly. To demonstrate the practicality of the method, the UCB parameter for BORE++ was fixed at across all iterations , instead of applying the theoretical setup. SVGD was configured as its second-order version [38] applying L-BFGS to adjust its steps [61].
As the results show in Figure E.1, batch BORE++ has a clear advantage over batch BORE in low dimensions. However, the performance gains become less obvious at higher dimensionalities and eventually deteriorate. One of the factors explaining this behaviour is that, as the dimensionality increases, uncertainty estimates become less useful. Distances between data points largely increase and affect the posterior variance estimates provided by translation-invariant kernels, such as the squared-exponential kernel our feature maps were based on. Other classification models may lead to different behaviours, and their investigation is left for future work.