BayeSED-GALAXIES I. Performance test for simultaneous photometric redshift and stellar population parameter estimation of galaxies in the CSST wide-field multiband imaging survey
Abstract
The forthcoming CSST wide-field multiband imaging survey will produce seven-band photometric spectral energy distributions (SEDs) for billions of galaxies. The effective extraction of astronomical information from these massive datasets of SEDs relies on the techniques of both SED synthesis (or modeling) and analysis (or fitting). We evaluate the performance of the latest version of BayeSED code combined with SED models with increasing complexity for simultaneously determining the photometric redshifts and stellar population parameters of galaxies in this survey. By using an empirical statistics-based mock galaxy sample without SED modeling errors, we show finding that the random observational errors in photometries are more important sources of errors than the parameter degeneracies and Bayesian analysis method and tool. By using a Horizon-AGN hydrodynamical simulation-based mock galaxy sample with SED modeling errors about the star formation histories (SFHs) and dust attenuation laws (DALs), the simple typical assumptions lead to significantly worse parameter estimation with CSST photometries only.The SED models with more flexible (or complicated) forms of SFH/DAL do not necessarily lead to better estimation of redshift and stellar population parameters. We discuss the selection of the best SED model by means of Bayesian model comparison in different surveys. Our results reveal that the Bayesian model comparison with Bayesian evidence may favor SED models with different complexities when using photometries from different surveys. Meanwhile, the SED model with the largest Bayesian evidence tends to give the best performance of parameter estimation, which is more clear for photometries with larger discriminative power.
1 Introduction
Understanding the complex ecosystem of stars, interstellar gas and dust, and supermassive black holes in galaxies is one of the most important challenges in modern astrophysics (National Academies of Sciences, Engineering, and Medicine, 2021). The new generation of space and ground telescopes and the corresponding large surveys will provide vast amounts of multi-band data for understanding the cosmic ecosystems and all the complex physical processes involved. For example, the James Webb Space Telescope (JWST, Rieke et al., 2005; Gardner et al., 2006; Beichman et al., 2012) is able to detect the earliest stages of galaxies from infrared at unprecedented depths, and is expected to provide decisive observations of the first generation of stars and galaxies (Beichman et al., 2012; Robertson, 2022). Meanwhile, forthcoming deep and wide field surveys with the Chinese Space Station Telescope (CSST, Zhan, 2011, 2018, 2021), the Euclid Space Telescope (Laureijs et al., 2011; Joachimi, 2016), the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al., 2019; Breivik et al., 2022), and the Nancy Grace Roman Space Telescope (NGRST, Green et al., 2012; Dore et al., 2019) will provide multi-band photometric and spectroscopic information for billions of galaxies. Especially, the CSST wide-field multiband imaging survey is set to image approximately 17,500 square degrees of the sky using NUV, u, g, r, i, z, and y bands in about 10 years of orbital time, which aims to achieve a limiting magnitude of 26 (AB mag) or higher for point sources in the g and r bands. How to effectively and reliably measure the redshift and the properties of various physical components of galaxies from the obtained huge amount of photometric spectral energy distributions (SEDs) data has become an urgent task to be done. A new generation of SED synthesis and analysis methods and tools are strongly demanded to effectively extract physical information from those massive datasets of observational SEDs.
The SED synthesis and analysis of galaxies are two aspects that are both opposite and unified in nature. The reliability and efficiency of the SED synthesis and analysis methods and tools will directly determine the reliability and efficiency of physical information extraction from the massive multi-wavelength datasets. In terms of SED synthesis of galaxies, the evolutionary synthesis technique of stellar population has become the core method from the pioneering works of Tinsley & Gunn (1976); Tinsley (1978). Nowadays, the stellar population synthesis models of BC03 (Bruzual & Charlot, 2003), M05 (Maraston, 2005), FSPS (Conroy et al., 2009), BPASS (Eldridge & Stanway, 2009), among others are widely used in the study of the formation and evolution of galaxies. However, in the SED synthesis models of galaxies, many important uncertainties remain in almost all the model ingredients (Conroy et al., 2009, 2010; Conroy & Gunn, 2010; Conroy, 2013), such as the initial stellar mass function (IMF) (Padoan et al., 1997; Hoversten & Glazebrook, 2008; van Dokkum, 2008; Bastian et al., 2010; Cappellari et al., 2012; Ferreras et al., 2013; Gennaro et al., 2018), the physics of stellar evolution (Thomas & Maraston, 2003; Zhang et al., 2005; Maraston et al., 2006; Han et al., 2007; Marigo et al., 2008; Bertelli et al., 2008; Brott et al., 2011; Hernández-Pérez & Bruzual, 2013), stellar spectral libraries (Coelho, 2009; Choi et al., 2019; Knowles et al., 2019; Coelho et al., 2020; Knowles et al., 2021; Yan et al., 2019), the complex star formation and metallicity enrichment histories (SFHs and MEHs) (Debsarma et al., 2016; Iyer et al., 2019; Carnall et al., 2019; Leja et al., 2019; Aufort et al., 2020; Wang & Lilly, 2020; Iyer et al., 2020; Côté et al., 2016; Maiolino & Mannucci, 2019; Valentini et al., 2019), the reprocessing by the interstellar gas and dust (Draine, 2003, 2010; Galliano et al., 2018; Kewley et al., 2019; Salim & Narayanan, 2020; Tacconi et al., 2020), and the possible contribution from active galactic nuclei (AGNs) at the center of galaxies (Antonucci, 1993, 2012; Netzer, 2015; Hickox & Alexander, 2018; Brown et al., 2019a, b; Lyu & Rieke, 2022). Different choices of these model ingredients will lead to very different estimation of the redshifts and physical parameters of galaxies, as well as different and even conflicting conclusions about the formation and evolution of galaxies. Therefore, the proper selection of these model ingredients is an essential step in any SED analysis work of galaxies (Han & Han, 2019; Han et al., 2020).
In terms of SED analysis of galaxies, the Bayesian method has been widely adopted in the last decade. For example, the widely used and actively developing SED fitting codes, such as MAGPHYS (da Cunha et al., 2008), CIGALE (Noll et al., 2009; Boquien et al., 2019), GalMC (Acquaviva et al., 2011), BayeSED (Han & Han, 2012, 2014), BEAGLE (Chevallard & Charlot, 2016), Prospector (Leja et al., 2017), BAGPIPES (Carnall et al., 2018), and ProSpect (Robotham et al., 2020) are all based on the Bayesian methods. Besides, a long list of new SED fitting codes, such as MCSED (Bowman et al., 2020), piXedfit (Abdurro’uf et al., 2021), gsf (Morishita, 2022), and Lightning (Doore et al., 2023) among others, are build along this way. The application of Bayesian methods implies that the SED analysis of galaxies is considered as a more general Bayesian inference problem instead of the previous Chi-square minimization-based optimization problem known as SED fitting. For the parameter estimation of a give SED model, the Bayesian approach provides the complete posterior probability distribution of parameters as the solution to the SED analysis problem, which is computationally more demanding but allows a more formal and simultaneous estimation of parameter values and their uncertainties. More importantly, for the selection of model ingredients, the Bayesian approach also provides the very useful Bayesian evidence which can be considered as a quantified Occam’s razor for effective model selection.
A noteworthy difference among the Bayesian SED analysis tools is that the earlier tools (e.g. MAGPHYS and CIGALE) are based on irregular or regular grid search, while the newer generation of tools (e.g. GalMC and BayeSED) are based on more advanced random sampling techniques such as Markov Chain Monte Carlo (MCMC, Sharma, 2017; Hogg & Foreman-Mackey, 2018) and Nested Sampling (NS, Skilling, 2006; Buchner, 2021; Ashton et al., 2022). The advantage of the grid-based Bayesian approach is that an SED library with regular or irregular model grids can be built in advance for only once. Besides, the prior probabilities can be set more freely during this procedure. Then it can be used in the analysis of a large sample of galaxies of any size without the generation of new SEDs. However, the size of SED library needs to be very large to allow a reasonable parameter estimation for all galaxies in the sample, especially in the case with regular grids where the number of required grids will increase dramatically with the number of free parameters. In contrast, a sampling-based Bayesian approach allows for a more detailed and efficient sampling of the parameter space for each galaxy and allows for a finer reconstruction of the posterior, leading to more reliable parameter estimates. However, the theoretical SED synthesis needs to be done in real-time and repeated many times, which could be very computationally expensive for the analysis of very large samples of galaxies. Fortunately, a much more efficient synthesis SED models can be achieved with the help of machine learning techniques. For example, in Han & Han (2014) we have employed the artificial neural network (ANN) and K-nearest neighbor (KNN) searching techniques to speed up the sampling-based Bayesian approach. The combination of sampling-based Bayesian inference and machine learning techniques enables the detailed Bayesian SED analysis of very large samples of galaxies (Han et al., 2019). Although the training phase of machine-learning-based SED synthesis method could be very time-consuming, especially for very complex SED models with many free parameters and the accurate synthesis of high-resolution SED, it is very promising with more advanced training techniques (Alsing et al., 2020; Gilda et al., 2021; Qiu & Kang, 2022; Hahn & Melchior, 2022) and worthwhile to carry out further exploration in this direction.
For the study of galaxy formation and evolution, the ideal SED synthesis and analysis tool should be able to simultaneously account for the contributions of stars, interstellar gas and dust, and AGN components, and to provide accurate and efficient estimates of the redshift and the physical properties of all components. However, in practice, it is very difficult, if not impossible, to fully satisfy all of these requirements. Therefore, a good SED synthesis and analysis tool should attempt to achieve a reasonable balance among these requirements as much as possible. This is what we are trying to achieve during the development of the BayeSED code (Han & Han, 2012, 2014, 2019; Han et al., 2019, 2020). In this work, we will rigorously test the performance of the latest version of BayeSED code combined with SED models with increasing complexity for simultaneous photometric redshift and stellar population parameter estimation of galaxies, so as to be ready for the analysis of the forthcoming massive datasets from the CSST wide-field multiband imaging survey and others.
We begin in §2 by introducing the methods we have employed for the generation of empirical statistics-based (§2.1) and hydrodynamical simulation-based (§2.2) mock catalog of galaxies, observational error modeling (§2.3) and the selection of samples (§2.4) that will be used for the performance test. In §3, we briefly describe the Bayesian approach of photometric SED analysis methods, including parameter estimation (§3.1) and model selection (§3.2). Especially, in §3.3, we will introduce some runtime parameters of MultiNest algorithm which is the core engine of BayeSED. They need to be properly tuned to improve the performance of BayeSED. We present the results of performance test for the case without SED modeling errors using an empirical statistics-based mock galaxy sample in §4. In §5, by employing the simplest SED model, we present the results of performance test for the case with SED modeling errors about the SFH and DAL of galaxies using a Horizon-AGN hydrodynamical simulation-based mock galaxy sample for CSST-like imaging survey. In §6, we discuss the effectiveness of more flexible (or complex) forms of SFH and DAL of galaxies for improving the performance of simultaneous redshift and stellar parameter estimation in CSST-like (§6.1), CSST+Euclid-like (§6.2), and COSMOS-like (§6.3) surveys with increasing discriminative power, respectively. Especially, we also discuss the relation between the metrics of the quality of parameter estimation and Bayesian evidence, as well as how they depend on the different surveys. Finally, a summary of our results and conclusions is presented in §7.
2 Bayesian photometric SED synthesis with BayeSED
The SED synthesis (or modeling) module is an essential part in any Bayesian SED fitting code. In BayeSED-V3, we have added more functions for SED synthesis, especially for the simulation of mock observation of galaxies in a Bayesian way. This is not just crucial for the current work, but also lays the foundation for future applications of machine learning and simulation-based Bayesian inference methods in Bayesian SED fitting (Hahn & Melchior, 2022; Hahn et al., 2022). For this work, we use the empirical statistics-based (§2.1) and hydrodynamical simulation-based (§2.2) methods to generate mock photometric catalog, add noise with a simple magnitude limit-based approach (2.3), and select a sample (2.4) similar to previous works for the performance test in the next two sections. In the following, we introduce them in more detail.
2.1 Empirical statistics-based photometric mock catalog
The first method to generate mock photometric catalog is built by randomly draw samples from the parameter space of a particular SED model while under the constraints of some empirical statistical properties of galaxies. The sampling is performed with the same nested sampler MultiNest as in the Bayesian SED analysis mode of BayeSED. A sample from this catalog will be used in §4 to test the performance of redshift and stellar population parameter estimation in the case where the SED modeling is perfect, since exactly the same SED modeling method will be used in the Bayesian SED analysis of it.
2.1.1 SED modeling
As in Han & Han (2019), the SED of a galaxy is modeled as the luminosity of starlight from stellar populations of varying ages and metallicities, transmitted through the Interstellar Medium (ISM) and the Intergalactic Medium (IGM) to the observer. Specifically, the luminosity emitted at wavelength by a galaxy with can be given as:
| (1) | ||||
| (2) |
where is the star formation history (SFH) describing the SFR as a function of the time , and is the luminosity emitted per unit wavelength per unit mass by a simple stellar population (SSP) of age and metallicity .
is the transmission function of the ISM (Charlot & Longhetti, 2001), which is contributed by two components:
| (3) |
where and are the transmission functions of the ionized gas and the neutral ISM, respectively. The transmission through ionized gas can be modeled with photoionization code such as CLOUDY. However, we set in this work to be consistent with the hydrodynamical-simulation based catalog (§2.2). A detailed modeling of with CLOUDY to account for the combined effects of starlight absorption, nebular line emission, ionized continuum emission, and possible emission from warm dust within HII regions will be presented in a companion paper. Meanwhile, the transmission functions of the neutral ISM is considered with a simple time-independent dust attenuation law (DAL) and uniformly applied to the whole galaxy.
is the stellar metallicity as a function of the time , which describe the chemical evolution history of the galaxy. In previous works, we assume a time-independent metallicity, i.e. , as in many SED fitting codes of galaxy. To properly consider the evolution of stellar metallicity, we additionally employ a linear SFH-to-metallicity mapping model(Driver et al., 2013; Robotham et al., 2020; Thorne et al., 2021; Alsing et al., 2023):
| (4) |
Generally, the main ingredients for our SED modeling of galaxies are the SSP model, SFH, CEH and DAL. In this work,as the construction of the Horizon-AGN hydrodynamical-simulation based catalog (§2.2), we use the SSP model assuming a Chabrier (2003) stellar IMF from the widely used stellar population synthesis model of Bruzual & Charlot (2003). The SFH of galaxies is typically parameterized as the exponentially declining form: (hereafter model). The model only describes the SFH of galaxies in a closed box without inflow of pristine gas and outflow of processed gas, where the gases are converted to stars at a rate proportional to the remaining gas and with a fixed efficiency (Schmidt, 1959; Tinsley, 1980). It is widely discussed in the literature that this simple assumption may lead to systematically biased estimation of stellar population parameters, especially for galaxies at (Lee et al., 2009, 2010; Reddy et al., 2012; Ciesla et al., 2017; Carnall et al., 2018). Therefore, some more flexible and physically inspired form of models have been suggested to improve the measurement of SFHs of galaxies and the estimation of their stellar population parameters and photometric redshift (Pacifici et al., 2012; Ciesla et al., 2017; Iyer & Gawiser, 2017; Carnall et al., 2019; Leja et al., 2019; Iyer et al., 2019; Lower et al., 2020; Suess et al., 2022).
In the present work, we employ three extension of the model with different complexity. The first one is described as:
| (5) |
which is just an extended form of the delayed- model (Lee et al., 2010). Apparently, the typical model and delayed- model are just two special cases of this model (hereafter - model) with and , respectively. The second one is the - model combined with a quenching (or rejuvenation) component which is described as (Ciesla et al., 2016):
| (6) |
where is the time when the star formation is quenched () or rejuvenated (), and is the ratio between and :
| (7) |
This model (hereafter --r model) is a further extension of the - model with the latter being the special case with . The third one is the double power-law model (Diemer et al., 2017; Carnall et al., 2018; Alsing et al., 2023) combined with a quenching (or rejuvenation) component which is described as:
| (8) |
where and are the falling and rising slopes, respectively, and is related to the time at which star formation peaks, which is defined as for the age of the galaxy . A major advantage of the double-power-law model is the decoupling of the rising and falling parts of the SFH. Therefore, this model (hereafter ---r model) is even more flexible than the --r model.
The dust attenuation law (DAL) is another very important ingredient for the SED modeling of galaxies (Walcher et al., 2011; Conroy, 2013). When deriving the photometric redshift and physical properties of galaxies from the analysis of their photometric or spectroscopic observations, a universal DAL as a simple uniform screen is commonly assumed. However, different choices of the universal law may lead to very different estimation of photometric redshift and physical parameters of galaxies (Pforr et al., 2012, 2013; Salim & Narayanan, 2020). Especially, many studies show that the dust attenuation curve of different galaxies are very different (Kriek & Conroy, 2013; Reddy et al., 2015; Salmon et al., 2016; Salim & Boquien, 2019; Shivaei et al., 2020), and therefore there is no universal DAL as expected on theoretical grounds (Witt & Gordon, 2000; Seon & Draine, 2016; Narayanan et al., 2018; Lower et al., 2022). By a detailed study of the dust attenuation curves of about 230,000 individual galaxies in the local universe using photometric data covering from UV to IR bands, Salim et al. (2018) presented new forms of attenuation laws that are suitable for normal star-forming galaxies, high-z analogs, and quiescent galaxies (See also Noll et al., 2009). In this work, we additionally employ this new form of DAL which is parameterized as following:
| (9) |
where is the Calzetti et al. (2000) DAL with . The power law term with an exponent is introduced to deviate from the slope of the Calzetti et al. (2000) DAL. is the -dependent ratio of total to selective extinction for the modified law. The term is introduced to add a UV bump. The relationship between and is given by:
| (10) |
The UV bump following a Drude profile (Fitzpatrick, 1986) is represented as:
| (11) |
with the amplitude , fixed central wavelength and width .
In total, we have considered six different combinations of SFH, CEH, and DAL with increasing complexity. A summary of these models, their parameters and priors are shown in Table 1.
| Model | Parameter | Range | Prior | |
| U | ||||
| U | ||||
| ccfootnotemark: | U | |||
| U | ||||
| SFH=,CEH=no | U | |||
| DAL=Cal+00aafootnotemark: | U | |||
| SFH=,CEH=yes | U | |||
| DAL=Cal+00aafootnotemark: | U | |||
| SFH=,CEH=yes | U | |||
| DAL=Sal+18bbfootnotemark: | U | |||
| U | ||||
| U | ||||
| SFH=- | U | |||
| CEH=yes | U | |||
| DAL=Sal+18bbfootnotemark: | U | |||
| U | ||||
| U | ||||
| SFH=--r | U | |||
| CEH=yes | U | |||
| DAL=Sal+18bbfootnotemark: | rSFR | LUddfootnotemark: | ||
| U | ||||
| U | ||||
| U | ||||
| U | ||||
| SFH=---r | U | |||
| CEH=yes | U | |||
| DAL=Sal+18bbfootnotemark: | LU | |||
| LU | ||||
| rSFR | LUddfootnotemark: | |||
| U | ||||
| U | ||||
| U |
Finally, we also include the effect of IGM absorption with the description of Madau (1995). Other other more recent consideration of IGM absorption are also available in BayeSED. However, the exploration of the effects of different choices of IGM absorption models on the redshift and stellar population parameter estimation is beyond the scope of this work, which will not change the conclusions given here.
2.1.2 Galaxy population modeling
To model the galaxy population, we need to set the joint probability distribution that characterizes the statistical properties of the galaxy population. The statistical properties of the galaxy population are the results of the complex physical procedures happened during the formation and evolution of galaxies. In this work, we employ some widely discussed empirical statistical properties of galaxies to model the galaxy population phenomenologically. It should be mentioned that there are large uncertainties in these statistical properties, and we do not attempt to use the most up-to-date results for all of them in this work. The other choices of statistical properties of galaxies will not change the conclusions of this work.
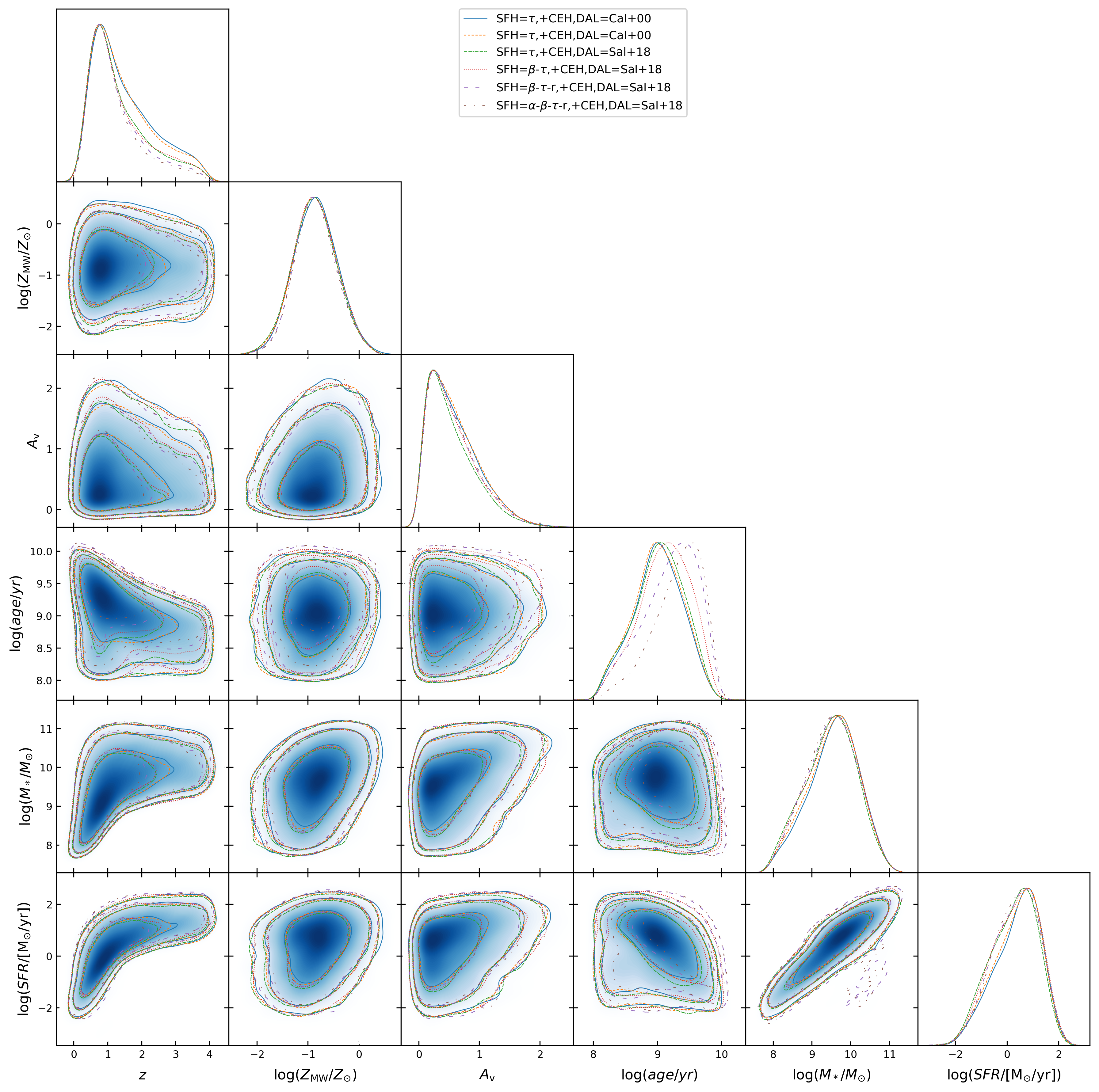
Similar to Tanaka (2015)(See also Alsing et al., 2023), we assume that the joint probability distribution of the stellar population parameters and redshift of galaxy population can be factorized as
| (12) | ||||
The joint distribution of stellar mass and redshift is defined as
| (13) |
where is the unnormalized stellar mass function and is the differential comoving volume element. We employ the recent measurement of stellar mass function and its redshift evolution from Leja et al. (2020), while a WMAP-5 (Spergel et al., 2003) cosmology for the comoving volume element.
Following Tanaka (2015), we assume that can be expressed as the sum of two Gaussians to represent two distinct sequences formed by star forming and quiescent galaxies:
| (14) |
where is the mean SFR of star forming galaxies given by
| (15) |
with
| (16) |
and the fraction of quiescent galaxies is given as a function of stellar mass and redshift (Behroozi et al., 2013):
| (17) |
As in Tanaka (2015), the dust attenuation is considered to positively correlate with SFR:
| (18) |
where , and
| (19) |
| (20) |
Then, we use the relation between and to obtain .
The probability of the age of a galaxy is described conditionally on the stellar mass and redshift:
| (21) |
where
| (22) |
This lead to a low probability for a massive galaxy with young age, while a high probability for a low-mass galaxy with the same age.
Finally, the probability of mass weighted stellar metallicity is modeled as:
| (23) |
where , and
| (24) |
is the redshift dependent stellar mass and metallicity relation (Ma et al., 2016) which is predicted by using the high-resolution cosmological zoom-in simulations from the Feedback in Realistic Environment (FIRE) project (Hopkins et al., 2014).
To generate empirical statistics-based mock catalog of galaxies, we employ the MultiNest algorithm to draw samples from the joint probability distribution of the stellar population parameters and redshift of galaxy population by setting in Equation 12 to be the likelihood function. Besides, to simulate a magnitude-limited sample, we can additionally set the likelihood function to be when the magnitude in a given band is larger than a given value. Since the sampling points with likelihood to be will be ignored by MultiNest, the obtained posterior sample can be used to buid a magnitude-limited sample of mock galaxies with some physical constraints from the empirical statistical properties of galaxies. More details about the selection of magnitude-limited sample is presented in §2.4. The mock catalog can be build with the posterior sample of redshift and all physical parameters given by MultiNest. However, this is a weighted sample (Yallup et al., 2022), which can not be directly used as a mock sample of galaxies. To build a more realistic mock sample of galaxies, we use bootstrap resampling method to obtain an unweighted sample.
In total, we have build six mock catalog of galaxies by employing SED models with different combinations of SFH, CEH, and DAL and increasing complexity as shown in Table 1, respectively. The employed priors of redshift and stellar population parameters are listed in the same Table for each model, respectively. In Figure 1, we show the joint distributions of redshift and physical parameters of the six empirical statistics-based mock galaxy population. Although the sampe set of empirical are employed, different SED models lead to slightly different distribution of parameters, especially for redshift and galaxy age. This is likely due to different mapping relations from free parameters to derived parameters. For example, different forms of SFH may lead to different relations between the age of galaxy and its recent SFR.
2.2 Hydrodynamical simulation-based photometric mock catalog
The second method to generate mock photometric catalog is based on an SED library which is built by the post-processing of galaxies from a hydrodynamical simulation. This catalog will be used in §5 to test the performance of redshift and stellar population parameter estimation in the case where the SED modeling is imperfect, since the SED modeling method employed in the Bayesian SED analysis will be very different from the one used to built it.
We start from the rest-frame spectra of galaxies which are produced using the light-cone from the cosmological hydrodynamical simulation Horizon-AGN (Dubois et al., 2014). The computation of these spectra, which accounts for the complex star formation history and metal enrichment of Horizon-AGN galaxies, and consistently includes dust attenuation, is described in details by Laigle et al. (2019) and Davidzon et al. (2019). The dust attenuation of galaxies in Horizon-AGN simulation is modelled for each stellar particle, assumed to be a SSP, by using the gas metal mass distribution as an approximation of the dust mass distribution, assuming a constant dust-to-metal mass ratio (Laigle et al., 2019). Besides, to obtain the amount of extinction at a given wavelength, the Weingartner & Draine (2001) model of Milky Way dust grain with and the prominent -graphite bump is employed for post-processing the simulated galaxies. As mentioned in Laigle et al. (2019), the overall attenuation curve becomes less steep and the bump tends to be reduced when summing up the contribution of all the SSPs to obtain the resulting galaxy spectrum. They also noticed that the averaged attenuation curve in Horizon-AGN simulation can not be well reproduced by either the model of Calzetti et al. (2000) or Arnouts et al. (2013). The more flexible form of DAL as given by Equation 9 is more likely to reproduce the attenuation curves of galaxies in the Horizon-AGN simulation. In order to isolate the possible differences in the convolution with filter response function, observational error modeling, and consideration of IGM absorption, we choose to convert their rest-frame spectra of mock galaxies to corresponding mock photometries with BayeSED, instead of using their virtual photometries directly111We have compared the two set of photometries careful and found that they are actually very similar, only with some differences at the very faint end.. The consideration for the effects of IGM absorption is the same as in §2.1.1.Therefore, the difference between the empirical statistics-based (§2.1) and hydrodynamical simulation-based photometric mock catalog are only driven by the different SFH, CEH, DAL of mock galaxies and their different distribution of redshift and physical parameters.
2.3 Observational error modeling
The modeling of realistic errors on the flux is crucial for a meaningful performance test of redshift and stellar population parameter estimation. Here, we introduce the method we have employed to compute flux errors of mock galaxies and perturb their fluxes accordingly. The flux error for a wavelength band with N AB magnitude limit is given by:
| (25) |
where the flux limit and the systematic flux error are in unit of . From the relation that magnitude error and signal-to-noise ratio , we can obtain:
| (26) |
As in Cao et al. (2018), we assume a systematic magnitude error . The final mock flux is obtained by the original flux perturbed by a Gaussian noise . In practice, the magnitude limit may have a dispersion for galaxies with different sizes. So, the actually used magnitude limit is drawn from the Gaussian distribution . In this work, we set . We have generated three sets of mock catalog for CSST-like, Euclid-like, and COSMOS-like surveys, respectively. A summary of the adopted depths in all bands of the three surveys is shown in Table 2. The response functions and modeled relation between magnitude and magnitude error are shown in the panels of Figure 2 for the 7 CSST bands, 3 Euclid bands and 26 COSMOS bands, respectively. To separate the effects of observational errors on the accuracy of parameter estimation, we also generated another two sets of mock catalog without adding observational errors. In this case (the no noise case in Figure 2), the magnitude errors are all fixed to be , but the photometries have not been perturbed accordingly.
| Survey | band | depth |
|---|---|---|
| CSST-like | ||
| depthbbfootnotemark: | ||
| Euclid-like | ||
| depthaafootnotemark: | ||
| COSMOS-like | ||
| depth aafootnotemark: | ||
2.4 Sample selection
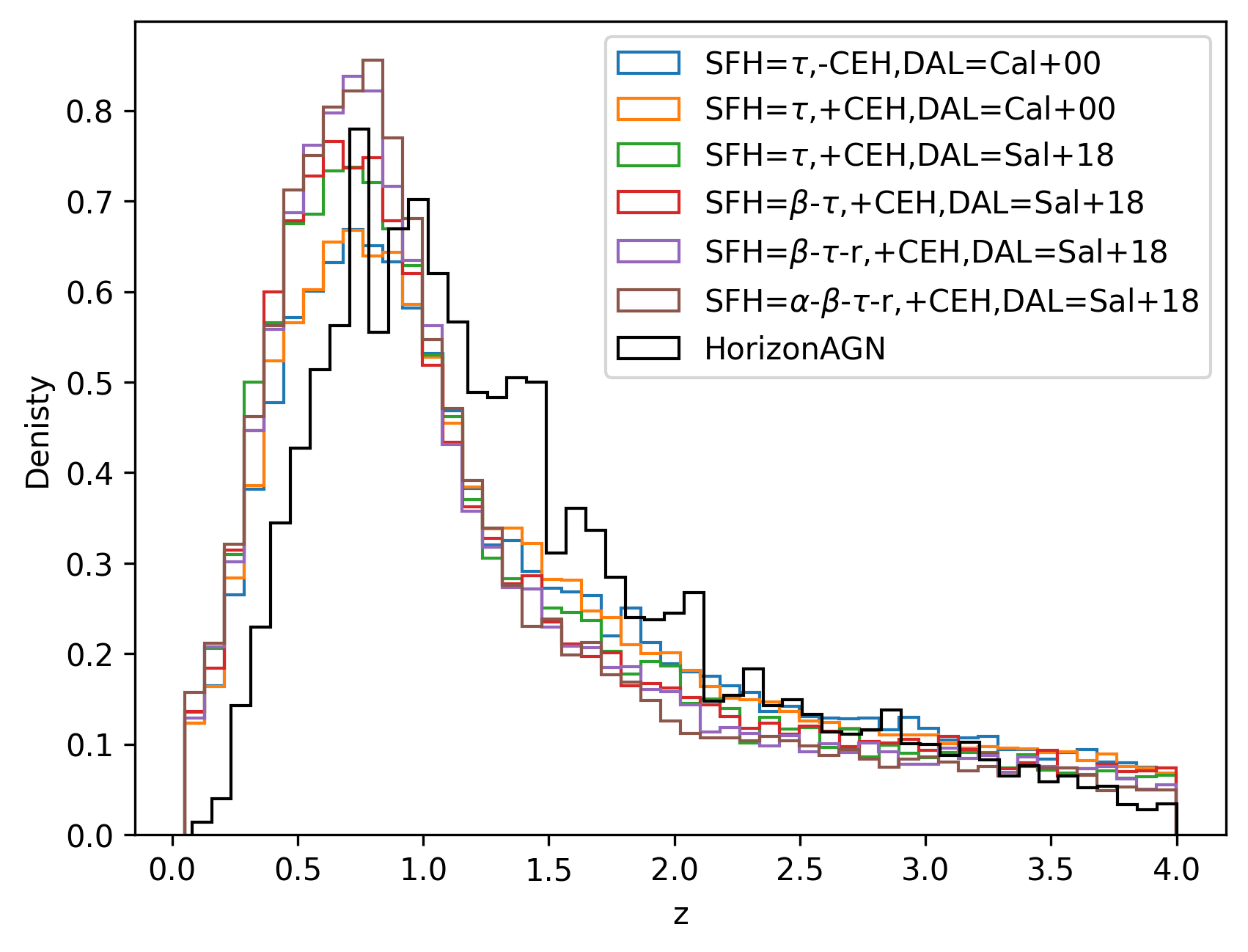
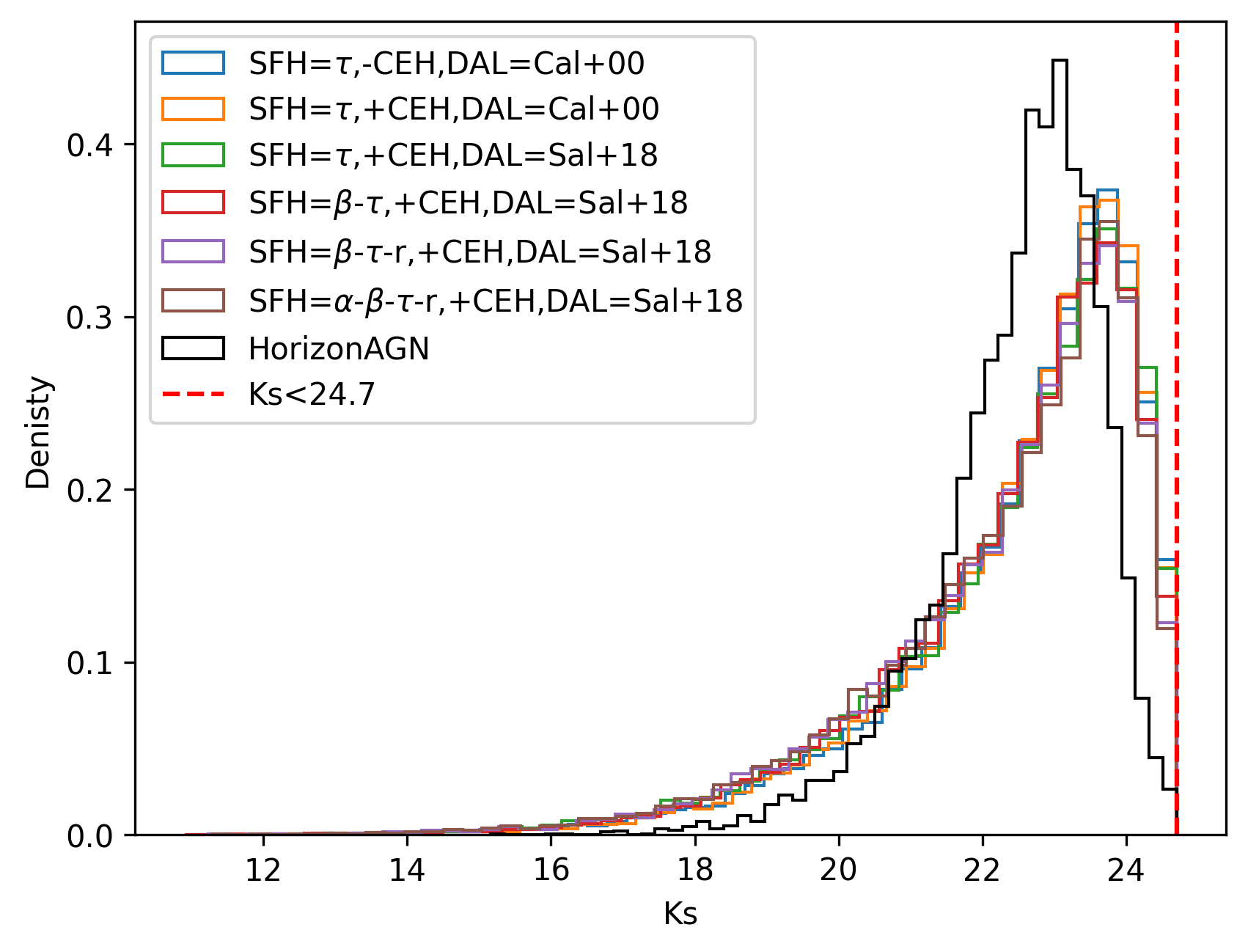
To test the performance of BayeSED, we selected two sets of samples of galaxies with (Laigle et al., 2019) and (Cao et al., 2018)222In Cao et al. (2018) and Zhou et al. (2022a, b), only the high-quality sources with the in g or i band were selected to test the performance of photometric redshift estimation. This selection is not used in this work to obtain a more full picture for the performance of the CSST wide-field multiband imaging survey. from the empirical statistics-based mock catalog (§2.1) and the hydrodynamical simulation-based mock catalog (§2.2), respectively. The first set of samples are obtained directly with BayeSED combined with SED models with different complexity by using the method present in §2.1.2. The second sample is selected from the Horizon-AGN hydrodynamical simulation-based photometric catalogs for COSMOS-like configuration333https://www.horizon-simulation.org/PHOTOCAT/HorizonAGN_LAIGLE-DAVIDZON+2019_COSMOS_v1.6.fits which contains galaxies. We find that a sample with galaxies is large enough to obtain stable results for the performance tests as presented in §4 and §5. The redshift and magnitude distributions of the two samples are presented in Figure 3. When employing different SED models with different complexity and the same set of empirical statistics, the empirical statistics-based samples show some differences, especially the redshift distribution. This is likely due to the different mapping relations from physical parameters to photometries and from free parameters to derived parameters for different SED models. Generally, the hydrodynamical simulation-based sample is consistent with the empirical statistics-based samples. We attribute the difference between the two set of samples to the different modeling of the SFH, CEH and DAL of galaxies and their different distribution of redshift and physical parameters.

3 Bayesian photometric SED analysis with BayeSED
The general method for the application of Bayesian inference to photometric SED analysis of galaxies is the same as in Han & Han (2014, 2019). In this section, we introduce some special aspects of Bayesian parameter estimation (§3.1) and model selection (§3.2) which are relevant to the current work.
3.1 Bayesian parameter estimation
For the Bayesian analysis of the mock data generated in the last section, we employ the same SED modeling procedure and setting of priors for free parameters as in §2.1.1, while the commonly used Gaussian form of likelihood function is employed. The performance of this Bayesian analysis, including its speed and quality, is crucial for the analysis of large sample of galaxies in the big data era. We need some metrics to quantify the performance of parameter estimation which is the main subject of this work.
While the speed of parameter estimation can be easily quantified by the running time, some metrics for the quality of parameter estimation are required. Similar to Acquaviva et al. (2015), we use three metrics to quantify the quality of parameter estimation. Bias, which characterizes the median separation between the predicted and the true values, is defined as:
| (27) |
while the precision, which describes the scatter between predicted and the true values, is defined as:
| (28) |
where for redshift (Ilbert et al., 2009; Dahlen et al., 2013; Salvato et al., 2018), and for other parameters. The median-base definition makes them to be less sensitive to outliers (sources with unexpectedly large errors). The fraction of outliers is defined as:
| (29) |
3.2 Bayesian model selection
An important advantage of nested sampling-based algorithm, such as MultiNest, over MCMC-based method is the ability to carry out a simultaneous parameter estimation and model selection. While the main subject of this work is parameter estimation, it is also interesting to explore the effects of sampling parameters (namingly, and ) of MultiNest on the computation of Bayesian evidence, the quantity which is crucial for Bayesian model selection.
In Han & Han (2019), we presented a mathematical framework to discriminate the different assumptions about SSP, DAL and SFH in the SED modeling of galaxies based on the Bayesian evidence for a sample of galaxies. In this work, since the SSP model employed in the generation of mock data is the same as that employed in their Bayesian analysis, we do not need to consider the different choices of SSP. So, the problem is significantly simplified. In this work, we focus on the computation of the Bayesian evidence for the SED modeling of a sample of galaxies with SSP, SFH, and DAL all being assumed to be universal (i.e. -like model (See Section 5.1 of Han & Han, 2019).) The sample Bayesian evidence in this case (as Equation 33 of Han & Han (2019)) is:
| (30) |
Although the detailed SFH and DAL of different galaxies can vary significantly, the sample Bayesian evidence computed in this manner remains valuable for identifying the most efficient combination of SFH and DAL for analyzing a vast sample of galaxies, such as the one provided by the CSST wide-field imaging survey.
In practice, the natural logarithmic of Bayesian evidence is commonly used for Bayesian model selection. Therefore, Equation 30 can be rewritten as:
| (31) |
where , the Bayesian evidence for an individual galaxy, can be directly obtained in BayeSED with MultiNest. However, the individual Bayesian evidences estimated with MultiNest contain errors. A more strict Bayesian model selection should consider the effects of error propagation. In our case, the error of the sample Bayesian evidence is simply the sum of errors for individual galaxies which is provided by MultiNest as well.
The minimum method is also widely used for model selection. For the case with Gaussian observational errors, there is only a constant difference between the minimum and the natural logarithmic of maximum likelihood. The sample maximum likelihood (as Equation 32 of Han & Han (2019)) is:
| (32) |
Then, the natural logarithmic of sample maximum likelihood is:
| (33) |
where , the natural logarithmic of maximum likelihood for an individual galaxy, can be directly obtained in BayeSED with MultiNest. Similar to the model selection with Bayesian evidence, only the difference of between different models is useful for the model selection. Therefore, the model selection with is equivalent to that with minimum . In §6, we will discuss the difference between the two model selection methods.
3.3 Runtime parameters of MultiNest algorithm
As the Bayesian inference engine of BayeSED, MultiNest has some runtime parameters. The values of these runtime parameters have very important effects on the performance of BayeSED for redshift and stellar population parameter estimation of galaxies. Here, we briefly introduce the meaning of these runtime parameters of MultiNest algorithm.
Nested sampling (NS) (Skilling, 2004, 2006), as a Monte Carlo (MC) method primarily designed for the efficient computation of the Bayesian evidence, allows posterior inference as a by-product at the same time. So, it provides a way to carry out simultaneous Bayesian parameter estimation and model selection. As an algorithm built on the NS framework, MultiNest (Feroz & Hobson, 2008; Feroz et al., 2009) is special for its efficiency in sampling from posteriors that may contain several modes and/or degeneracies. It has been improved further by the implementation of importance nested sampling (INS) (Cameron & Pettitt, 2014; Feroz et al., 2019) to increase the efficiency for evidence computation. In the latest version of BayeSED, the V3.12 version of MultiNest, which includes the implementation of INS, is employed.
Similar to most nested sampling algorithms, MultiNest explores the posterior distribution by maintaining a fixed number (See also Higson et al., 2019; Speagle, 2020, for new methods using variable number) of samples drawn from the prior distribution, called live points, and iteratively replaces the point with the lowest likelihood value (the dead point) with another point drawn from the prior but has a higher value of likelihood. While there are many runtime parameters of MultiNest which can be set in BayeSED, only two of them are of particular importance. They largely determined the accuracy and computational cost for the running of MultiNest algorithm and therefore BayeSED. The first one is the total number of live points (), which determines the effective sampling resolution. The second one is the target sampling efficiency (), which determines the ratio of points accepted to those sampled. Generally, the larger and lower lead to more accurate posteriors and evidence values but higher computational cost. The optimal value of and should be problem-dependent, although equals to and are recommended by the authors of MultiNest for parameter estimation and evidence evalutaion, respectively.
4 Results of performance tests using empirical statistics-based mock galaxy sample
In this section, we present the results of performance tests of photometric redshift and stellar population parameter estimation by using empirical statistics-based mock galaxy sample for CSST wide-field multiband imaging survey. Since the SED model employed in the Bayesian parameter estimation is exactly the same as that used in the generation of mock observations, the error of parameter estimation is mainly contributed by the random error in the data, parameter degeneracies, the stochastic nature of the employed MultiNest sampling algorithm and other potential errors in the BayeSED code. To separate out the effects of the random photometric error in the data, we will consider the two cases with and without adding random noise to the photometric data. Besides, to find out the optimal run parameters, we have considered six different choices of the target sampling efficiency () and eight choices of the number of live points () for the MultiNest sampling algorithm. Furthermore, we compare the performance of different SED models with increasing complexity in terms of running time and quality of parameter estimation.
4.1 Photometric redshift estimation
The results of performance tests for photometric redshift estimation are shown in Figure 4. In Figure 4(a), we show the results for only the simplest SED model (SFH=,-CEH,DAL=Cal+00) employed in this work. As shown in the top right panel of this figure, in the case without noise, there is a clear anti-correlation between the computation time (or the sampling resolution ) and the error (defined in Equation 28) of photometric redshift estimation. Meanwhile, a smaller makes the anti-correlation converge faster with the increasing of . There is a clear lower limit for the value of , which is about . As shown in the top left panel of Figure 4(a), in the case with noise, the error of photometric redshift estimation does not always decrease with the sampling resolution . When we set , the lowest error () of redshift estimation is obtained when is about .When , the error of redshift estimation start to increase with and finally converge to . This is most likely due to the overfitting to the noise added to the mock data.
The middle two panels of Figure 4(a) show the relation between the computation time (or ) and the bias (defined in Equation 27) of photometric redshift estimation. In the case with noise, the relation between the computation time (or ) and bias has almost the opposite profile of that of the error . However, the bias of photometric redshift estimation is generally very small, which is almost zero in the noise-free case.
The bottom two panels of Figure 4(a) show the relation between the computation time (or ) and the fraction of outliers OLF (defined in Equation 29) of photometric redshift estimation. Similar to that for , in the noise-free case, there is a clear anti-correlation between the computation time (or ) and OLF. In this case, the lower limit for the value of OLF is about . In the case with noise, the relation between the computation time (or ) and OLF has the same profile as that of the error . When we set , the lowest OLF () of redshift estimation is also obtained when is about . When , the OLF of redshift estimation start to increase with and finally converge to .
In Figure 4(b), we show the results for all of the six SED models with increasing complexity. Here, only the results with are shown. In the case without noise, as shown in the top right panel of this figure, the error of photometric redshift estimation tends to converge to a larger value when more complicated SED model is employed. This is not strange, since more complicated SED models have more free parameters and thus suffer from more severe parameter degeneracies. Besides, more complicated SED models apparently require longer running time. The bias of redshift estimation is always very small no matter which SED is employed. In general, when more complicated SED model is employed, the OLF of redshift estimation also increases significantly, and decreases much slower with the increasing of .
In the case with noise, as shown in the left panels of Figure 4(b), the results are a little more complicated. For the first three simplest SED models, the error of photometric redshift estimation apparently increases with the increasing of model complexity. However, when more complicated forms of SFH is considered, start to decreases with the increasing of model complexity, although not very significantly. Meanwhile, the most complicated SED model (SFH=---r,+CEH,DAL=Sal+18) lead to the smallest absolute value of bias, although the bias is actually very small in all cases. The situation for OLF is somewhat similar to that of . No matter which SED model is employed, when , both and OLF of redshift estimation start to increase, and then slowly decrease to a stable value.
4.2 Stellar population parameter estimation
In this subsection, we show the results of performance tests for the photometric stellar population parameter estimation. While the estimates of many stellar population parameter are available, we only show the results for stellar mass and SFR, which are two of the most important physical parameters for the study of the formation and evolution of galaxies.
4.2.1 Stellar mass
The results of performance tests for stellar mass estimation are shown in Figure 5. In Figure 5(a), we show the results for only the simplest SED model (SFH=,-CEH,DAL=Cal+00) employed in this work. As shown in the top right panel of this figure, in the case without noise, there is also a clear anti-correlation between the computation time (or the sampling resolution ) and the error of photometric stellar mass estimation. The behavior of error of stellar mass with respect to the change of efr is similar to that of photometric redshift. There is also a clear lower limit for the value of , which is about . As shown in the top left panel of Figure 5(a), in the case with noise, the error of stellar mass estimation does not always decrease with the sampling resolution as well. When we set , the lowest error () of stellar mass estimation is also obtained when is about . When , the error of stellar mass estimation only slightly increase with . The error of stellar mass is about two times larger than that of photometric redshift estimation. The bias of stellar mass estimation is also larger, but still very small when comparing with . In the noise-free case, there is also a clear anti-correlation between the computation time (or ) and the OLF of stellar mass estimation, where the lower limit for the value of OLF is about . In the case with noise, when we set , the lowest OLF () of stellar mass estimation is also obtained when is about . When , the OLF of stellar mass estimation only slightly increase with as well. The OLF of stellar mass estimation is slightly larger than that of photometric redshift estimation.
In Figure 5(b), we show the results for all of the six SED models with increasing complexity, where only the results with are shown. In the two cases with or without noise, as shown in the top right panel of this figure, the error of photometric stellar mass estimation tends to converge to a larger value when more complicated SED model is employed. The same is true for the OLF of photometric stellar mass estimation. The behavior of bias is somewhat different, but it is generally very small when comparing with . Besides, in the case with noise, for the most complicated SED model (SFH=---r,+CEH,DAL=Sal+18) used in this work, the , bias and OLF of stellar mass estimation increases significantly when . This should be a very clear indication of overfitting to the noise in the data. In general, more complicated SED models lead to worse quality of stellar mass estimation.
4.2.2 Star-formation rate
The results of performance tests for SFR estimation are shown in Figure 6. In Figure 6(a), we show the results for only the simplest SED model (SFH=,-CEH,DAL=Cal+00) employed in this work. Similar to the results for photometric redshift and stellar mass estimation, in the case without noise, there is also a clear anti-correlation between the computation time (or the sampling resolution ) and the error of photometric stellar mass estimation. The behavior of error of SFR with respect to the change of efr is similar to that of photometric redshift and stellar mass. There is also a clear lower limit for the value of , which is about . As shown in the top left panel of Figure 5(a), in the case with noise, the error of SFR estimation increases apparently when the sampling resolution . Generally, the error of SFR estimation is slightly smaller than that of stellar mass estimation. The bias of SFR estimation is also slightly smaller, and ignorable with respect to . In the noise-free case, the relation between the computation time (or ) and the OLF of SFR estimation is somewhat different from that of photometric redshift and stellar mass. Even with , the OLF of SFR estimation still does not seem to converge. The lower limit for the value of OLF seems near . In the case with noise, the OLF of SFR estimation converge much faster to about when we set . This is slightly smaller than that of stellar mass estimation.
In Figure 6(b), we show the results for all of the six SED models with increasing complexity, where only the results with are shown. In the two cases with or without noise, as shown in the top right panel of this figure, the error of SFR estimation tends to converge to a larger value when more complicated SED model is employed, and is more sensitive to the selection of SED model than that of stellar mass. The same is true for the OLF of SFR estimation. The behavior of bias is somewhat different, but it is generally very small when comparing with . Besides, in the case with noise, for the four most complicated SED models used in this work, the , bias and OLF of SFR estimation significantly increases with . This is another even more clear indication of overfitting to the noise in the data. In general, more complicated SED models lead to worse quality of SFR estimation.
4.3 Computation of Bayesian evidence
In this subsection, we present the results of performance test for the computation of Bayesian evidence, a quantity which is crucial for Bayesian model selection.
In Figure 7(a), we show the results for only the simplest SED model (SFH=,-CEH,DAL=Cal+00) employed in this work. As shown in the top and middle panels of this figure, the Bayesian evidence computed with importance sampling is more stable than that without importance sampling, especially in the case with noise. So, hereafter and especially in §5 and 6, all mentioned Bayesian evidences are computed with importance sampling. The value of Bayesian evidence increases with the number of live points () which determines the effective sampling resolution. In all cases, it eventually converges to a stable value when is very large, while a smaller sampling efficiency () leads to faster convergence rate. A good balance between the speed and quality of Bayesian evidence estimation can be achieved when the MultiNest runtime parameters equals to and equals to .
On the other hand, as shown in the bottom panels of Figure 7(a), the error of Bayesian evidence decreases with , while a larger sampling efficiency () also leads to faster convergence rate. However, unlike the value of Bayesian evidence, the error of Bayesian evidence converges slower with the increasing of in all cases. As a result, if we set and , the error of Bayesian evidence would be overestimated. A much larger value of seems required to obtain a more reliable estimation for the error of Bayesian evidence with MultiNest, which would be very computationally expansive and not suitable for the analysis of massive photometric data. However, in practice, this may not be a serious issue, since an overestimated error of Bayesian evidence only leads to a more conservative conclusion about model comparison. We just need to keep this in mind.
In Figure 7(b), we show the results for all SED models with increasing complexity, where only the results with are shown. Although the data used for the computation of Bayesian evidence is different for different SED models, the value of Bayesian evidence clearly decreases with the increasing of the complexity of SED model. This is reasonable. Since the same SED model is employed for the generation of mock data and their Bayesian analysis, the mock data can always be interpreted well. However, a more complicated SED model is penalized for being distributed over a larger space, of which only a smaller fraction is useful for the given mock data.
5 Results of performance tests using hydrodynamical simulation-based mock galaxy sample
In this section, we present the results of performance tests of photometric redshift and stellar population parameter estimation by using hydrodynamical simulation-based mock galaxy sample for CSST-like imaging survey. Only the results obtained with the simplest SED model are shown. In §6, we will discuss the effect of more flexible SFH and DAL for CSST-like, CSST+Euclid-like and COSMOS-like surveys, respectively.
As mentioned in §2.2, the generation of this mock galaxy sample accounts for the complex SFH and metal enrichment of Horizon-AGN galaxies, and consistently includes dust attenuation. However, for the Bayesian analysis of this more theoretical mock galaxy sample, we firstly employ the widely used assumptions about SFH (exponentially declining), metal enrichment history (constant but free), and dust attenuation (uniform foreground dust screen with Calzetti et al. (2000) DAL). The results in this section will help us to quantify the systematic errors resulting from these simplified assumptions. Besides, as mentioned in §2.4, galaxies in the mock sample used here are selected with and . In the literature, it is quite common to exclude some pathological cases with a kind of selection (Davidzon et al., 2017; Caputi et al., 2015; Laigle et al., 2019) before presenting the results of performance test. However, no such cut was made here because the pathological cases are precisely what we want to investigate.
5.1 Photometric redshift estimation
In Figure 8, we investigate the performance of BayeSED combined with the simplest SED model to estimate the photometric redshifts of hydrodynamical simulation-based mock galaxy sample for CSST-like imaging survey. Aa a reference, the panel a of this figure show the ideal case without observational noise and SED modeling errors. So, in this case, the effects of parameter degeneracies, the stochastic nature of MultiNest sampling algorithm and other potential errors in the BayeSED code are the sources of error. As shown clearly, the total error from all of these sources is very small. By comparing panels a and b of this figure, with only the observational noise added, the of photometric redshift estimation increases by eight times and the OLF increases by more than forty times. The bias also increases, but is ignorable with respect to . By comparing panels a and c of this figure, with only the error from the imperfect SED modeling added, the of photometric redshift estimation increases by more than three times and the OLF decreases slightly. Besides, there are some additional systematic patterns in the relation between true and estimated values of photometric redshift. The bias also increases and is comparable to . In general, the observational noise is more important source of error for the photometric redshift estimation of galaxies, although the other one is also very important.
Finally, as shown in panel d of Figure 8, when all sources of error are included, the of photometric redshift estimation increases to , the OLF increases to , and the bias becomes . The systematic patterns shown in panel c seems being hidden due to the added noise. The algorithm seems to be struggling to estimate the photometric redshifts correctly by only using the seven-band photometries from CSST-like imaging survey, especially for galaxies with redshift larger than one.
5.2 Stellar population parameter estimation
In Figure 9, we investigate the performance of BayeSED combined with the simplest SED model to estimate the stellar population parameters of hydrodynamical simulation-based mock galaxies for CSST-like imaging survey. Aa a reference, the panel a of this figure show the ideal case without observational noise and SED modeling errors. In this ideal case, the , bias and OLF of stellar mass estimation are , and , respectively. As shown in panel b, with only the observational noise added, the results become , and , respectively. As shown in panel c, with only the error from the imperfect SED modeling added, the results become , and , respectively. By comparing panels a and c, the performance of stellar mass estimation is severely affected by the simplified assumptions in the SED modeling. However, by comparing panels b and c, the observational noise is more important source of error for the photometric stellar mass estimation of galaxies, although the other one is also very important. Finally, as shown in panel d of this figure, when all sources of error are included, the of photometric stellar mass estimation increases to , the bias increases to , and the OLF increases to . The algorithm seems to be even more struggling to estimate the photometric stellar mass correctly by only using the seven-band photometries from CSST-like imaging survey.
Similarly, Figure 10 shows the performance of BayeSED combined with the simplest SED model to estimate the SFR of hydrodynamical simulation-based mock galaxy sample for CSST-like imaging survey. Comparing with the results for stellar mass estimation in Figure 9, the photometric SFR estimation is even more severely affected by the simplified assumptions in the SED modeling. Actually, by comparing panels b and c of this figure, it is clear that the error from the imperfect SED modeling is more important source of error for the photometric SFR estimation of galaxies, although the other one is also very important. Finally, it becomes even more struggling to estimate the photometric SFR correctly by only using the seven-band photometries from CSST-like imaging survey.
6 Discussion
By comparing the results of performance tests for simultaneous photometric redshift and stellar parameters estimation using empirical statistics-based mock galaxy sample (§4) and hydrodynamical simulation-based mock galaxy sample(§5), especially those presented in Figures 8, 9 and 10, it is clear that the simple typical assumptions about the SFH and DAL of galaxies have severe impact on the performance of photometric parameter estimation of galaxies for CSST-like imaging survey. It is not very surprising, since the SFHs and MEHs of galaxies in the cosmic hydrodynamical simulation, such as Horizon-AGN (Volonteri et al., 2016; Beckmann et al., 2017a; Kaviraj et al., 2017; Beckmann et al., 2017b), are much more complex and diverse (See also Iyer et al., 2020) than the simple assumptions that have been employed in the previous Bayesian analysis of photometric mock data.
In this section, we will discuss the effects of more flexible forms of SFH and DAL on the performance of simultaneous photometric redshift and stellar population parameter estimation of galaxies. As in Han & Han (2012, 2014, 2019) (See also Salmon et al., 2016; Dries et al., 2016, 2018; Lawler & Acquaviva, 2021), we mainly employ the Bayesian model comparison method to compare six different combinations of these model ingredients with increasing complexity (See Table 1 for details). In addition to the CSST-like survey (§6.1) where only the photometries from seven broad-bands are available, we also discuss the results obtained by using mock data for CSST+Euclid-like (§6.2) and COSMOS-like surveys (§6.3) with increasing discriminative power, respectively.
6.1 Effects of more flexible SFH and DAL for CSST-like survey
| survey | noise | SFH | DAL | ln(BE) | ln(ML) | parameter | NMAD | BIA | OLF |
|---|---|---|---|---|---|---|---|---|---|
| 0.024 | 0.011 | 0.003 | |||||||
| CSST | - | ,-CEH | Cal+00 | -880425936 | 127197 | 0.103 | 0.003 | 0.141 | |
| 0.140 | -0.117 | 0.436 | |||||||
| 0.023 | 0.010 | 0.002 | |||||||
| CSST | - | ,+CEH | Cal+00 | -741285973 | 144380 | 0.092 | -0.010 | 0.141 | |
| 0.148 | -0.141 | 0.491 | |||||||
| 0.016 | 0.014 | 0.004 | |||||||
| CSST | - | ,+CEH | Sal+18 | 588785823 | 282267 | 0.086 | 0.041 | 0.170 | |
| 0.153 | -0.019 | 0.390 | |||||||
| 0.015 | 0.014 | 0.004 | |||||||
| CSST | - | -,+CEH | Sal+18 | 563435780 | 283410 | 0.079 | 0.041 | 0.150 | |
| 0.133 | 0 | 0.370 | |||||||
| 0.017 | 0.011 | 0.006 | |||||||
| CSST | - | --r,+CEH | Sal+18 | 342135867 | 275861 | 0.097 | 0.052 | 0.227 | |
| 0.257 | 0.045 | 0.579 | |||||||
| 0.016 | 0.010 | 0.005 | |||||||
| CSST | - | ---r,+CEH | Sal+18 | 330445800 | 275886 | 0.098 | 0.051 | 0.239 | |
| 0.214 | 0.065 | 0.544 | |||||||
| 0.097 | 0.003 | 0.264 | |||||||
| CSST | + | ,-CEH | Cal+00 | -188712649 | 49807 | 0.135 | -0.034 | 0.341 | |
| 0.157 | 0.011 | 0.371 | |||||||
| 0.096 | 0.005 | 0.264 | |||||||
| CSST | + | ,+CEH | Cal+00 | -186612649 | 49469 | 0.135 | -0.034 | 0.344 | |
| 0.155 | 0 | 0.366 | |||||||
| 0.098 | 0.012 | 0.263 | |||||||
| CSST | + | ,+CEH | Sal+18 | -260982956 | 54493 | 0.158 | -0.023 | 0.387 | |
| 0.201 | 0 | 0.468 | |||||||
| 0.099 | 0.011 | 0.263 | |||||||
| CSST | + | -,+CEH | Sal+18 | -281412904 | 54484 | 0.161 | -0.029 | 0.396 | |
| 0.194 | 0.028 | 0.472 | |||||||
| 0.100 | 0.013 | 0.268 | |||||||
| CSST | + | --r,+CEH | Sal+18 | -350483020 | 54444 | 0.171 | -0.037 | 0.415 | |
| 0.232 | 0.041 | 0.544 | |||||||
| 0.104 | 0.007 | 0.290 | |||||||
| CSST | + | ---r,+CEH | Sal+18 | -339832869 | 54440 | 0.177 | -0.052 | 0.430 | |
| 0.224 | 0.080 | 0.570 |
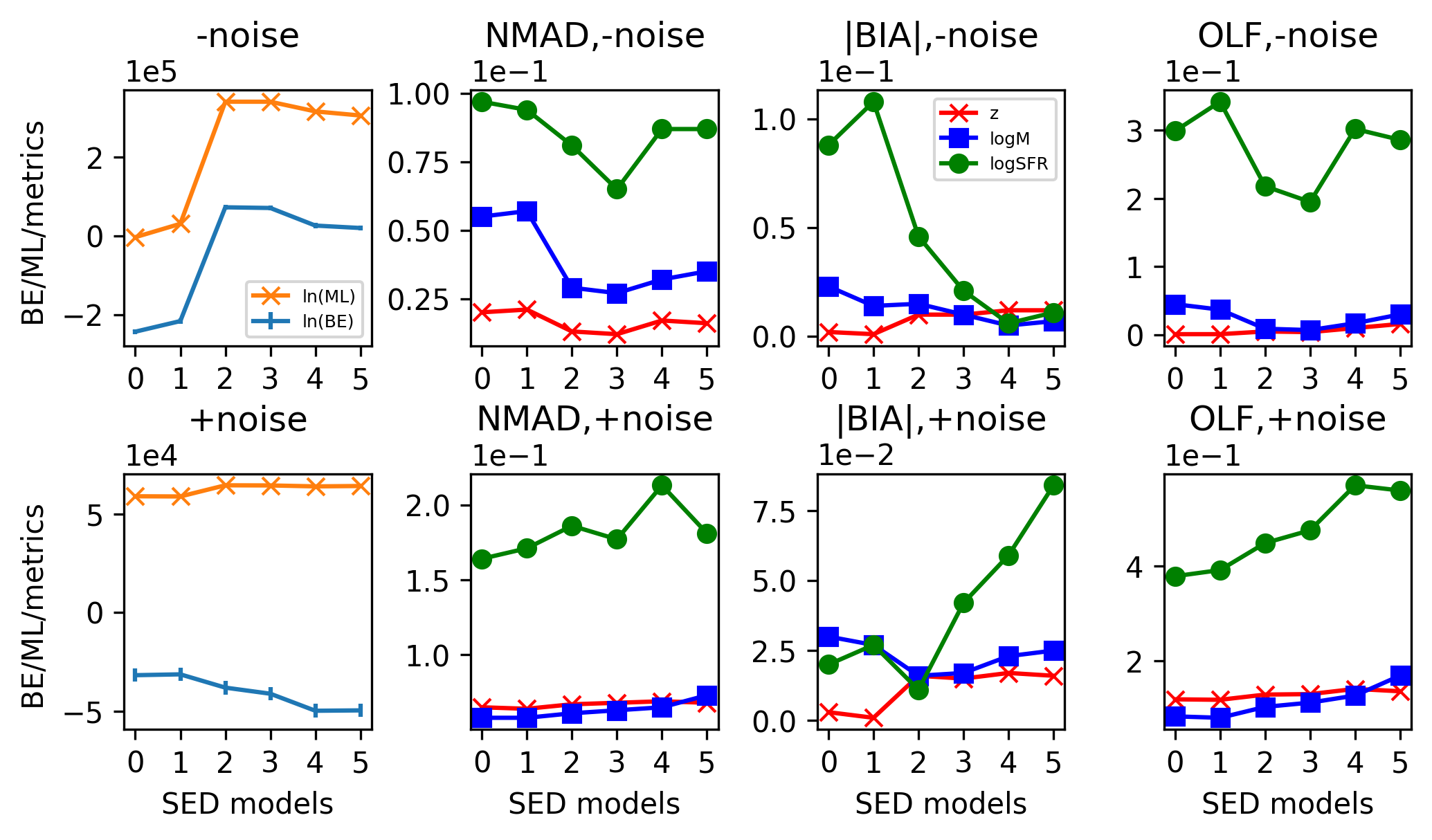
In Table 3, we present a summary of the Bayesian evidences, maximum likelihoods and metrics of the quality of parameter estimation from the Bayesian analysis of the hydrodynamical simulation-based mock galaxy sampe for CSST-like survey by employing six different combinations of SFH and DAL with increasing complexity, as well as for the cases with and without noise. The same results are also shown more clearly in Figure 11.
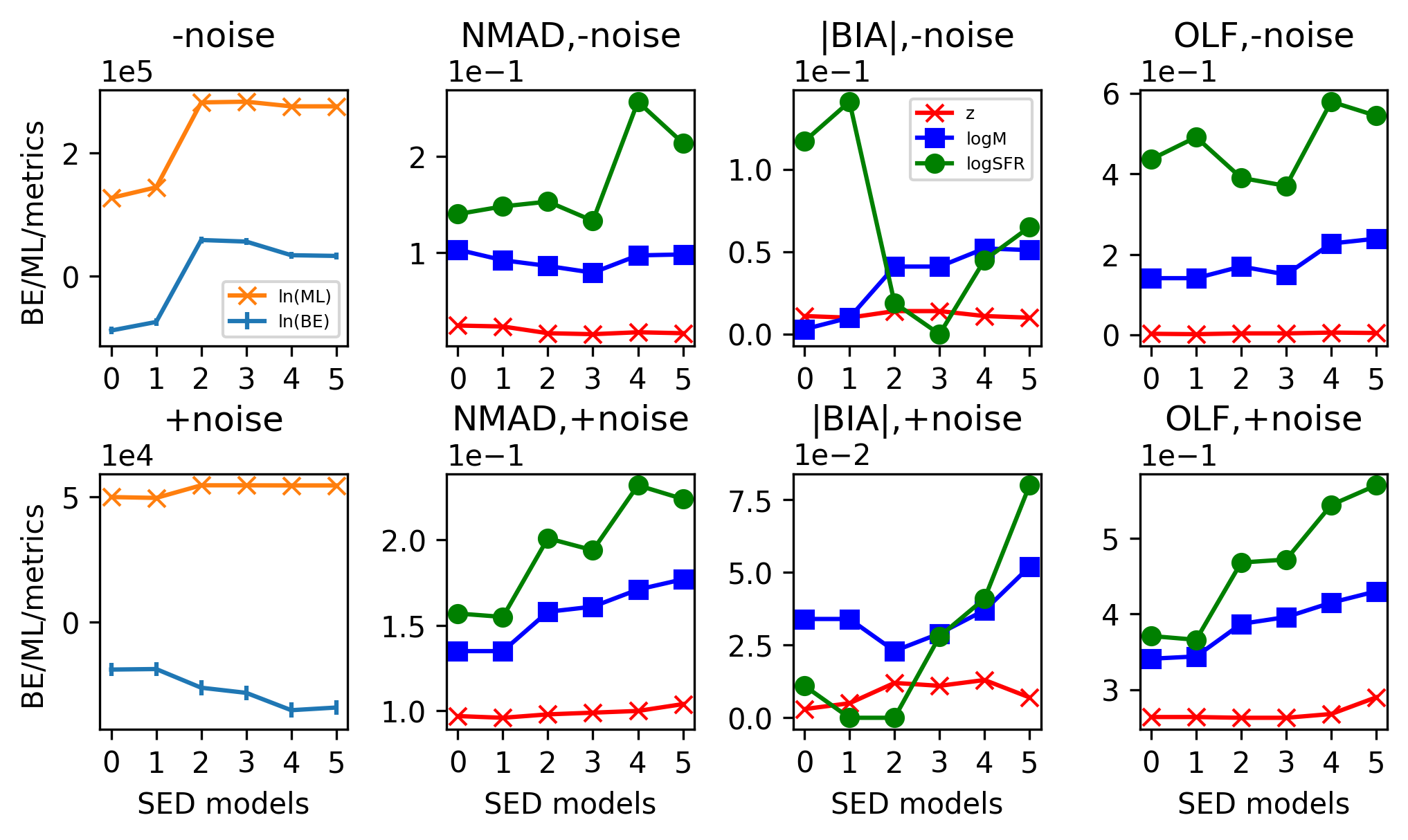
6.1.1 Model comparison
In the case without noise, as shown in the top left panel of Figure 11, the simplest model “SFH=,-CEH,DAL=Cal+18” has the lowest Bayesian evidence of . With the additional consideration of metallicity evolution, the Bayesian evidence of the model “SFH=,+CEH,DAL=Cal+18” increases to . Then, with the adoption of the DAL of Salim et al. (2018), the Bayesian evidence of the model “SFH=,+CEH,DAL=Sal+18” increases significantly to . Apparently, the DAL of Salim et al. (2018) is a much better choice than that of Calzetti et al. (2000) for the hydrodynamical simulation-based mock galaxy sampe in CSST-like survey. Furthermore, by employing a more complicated - form of SFH, the Bayesian evidence of the model “SFH=-,+CEH,DAL=Sal+18” seems decreases a little to . Actually, the latter two SED models (“SFH=,+CEH,DAL=Sal+18” and “SFH=-,+CEH,DAL=Sal+18”) have the largest Bayesian evidences which are comparable within error bar. They are neither the simplest nor the most complex models. With a quenching (or rejuvenation) component added to the SFH, the Bayesian evidence of the model “SFH=--r,+CEH,DAL=Sal+18” obviously decreases to . It seems that, while the rejuvenation or rapid quenching events may happen in some galaxies, this additional component of SFH is not very effective for most of the galaxies in the sample. Finally, by employing a even more flexible double power-law form of SFH, the Bayesian evidence of the model “SFH=---r,+CEH,DAL=Sal+18” seems decreases a little to . However, the latter two SED models are actually comparable within error bar. On the other hand, it is worth to mention that the model selection with maximum likelihood (or equivalently minimum ) lead to similar results.
In the case with noise, as shown in the bottom left panel of Figure 11, the two simplest SED models “SFH=,-CEH,DAL=Cal+00” and “SFH=,+CEH,DAL=Cal+00” have the largest Bayesian evidences of and , respectively. Although the latter which has additionally considered the metallicity evolution seems better, their Bayesian evidences are actually comparable within error bar. Then, with the adoption of the DAL of Salim et al. (2018), the Bayesian evidence of the model “SFH=,+CEH,DAL=Sal+18” decreases significantly to , exactly the opposite of the situation without noise. It is likely that the more complicated form of DAL does not give a better fit to the noisier data. By employing a more complicated - form of SFH, the Bayesian evidence of the model “SFH=-,+CEH,DAL=Sal+18” seems decreases further to , although comparable with the former within error bar. With a quenching (or rejuvenation) component added to the SFH, the Bayesian evidence of the model “SFH=--r,+CEH,DAL=Sal+18” obviously decreases to , which is similar to the case without noise. Finally, by employing a even more flexible double power-law form of SFH, the Bayesian evidence of the model “SFH=---r,+CEH,DAL=Sal+18” seems increases a little to , although comparable with the former within error bar. On the other hand, it is very interesting to notice that the model selection with maximum likelihood (or equivalently minimum ) lead to exactly the opposite results, where the more complex (or flexible) models are always more favored.
6.1.2 Parameter estimation
In the right three panels of Figure 11, we show the three metrics of the quality of photometric redshift, stellar mass and SFR estimation for different SED models, respectively. In general, in the case without noise, the SED models “SFH=,+CEH,DAL=Sal+18” and “SFH=-,+CEH,DAL=Sal+18” which are just the two with largest Bayesian evidence give the highest quality parameter estimates. In the case with noise, the two simplest SED models “SFH=,-CEH,DAL=Cal+00” and “SFH=,+CEH,DAL=Cal+00” which are also the two with the largest Bayesian evidences give the highest quality parameter estimates. In the following, we discuss these results in more detail.
The detailed results of photometric redshift estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 12. In the case without noise, by comparing the results in panel c of Figure 8 with that in panel a of Figure 12, it is clear that, with the additional consideration of metallicity evolution and the adoption of the DAL of Salim et al. (2018), the of photometric redshift estimation is obviously reduced while the bias and OLF are only slightly increased. Meanwhile, the systematic patterns in the former results are also largely reduced. However, as shown in panel c of Figure 12, by additionally employing a more complicated - form of SFH, the of photometric redshift estimation is only slightly reduced while the bias and OLF are exactly the same. Besides, as shown in Table 3 and Figure 11, the other two even more complicated forms of SFH lead to similar quality of photometric redshift estimation. In the case with noise, the best two models are quite similar in the quality of photometric redshift estimation. Besides, with the increasing of the complexity of SED models, the quality of photometric redshift estimation tend to decrease, although not very significantly.
The detailed results of photometric stellar mass estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 13. In the case without noise, by comparing the results in panel c of Figure 9 with that in panel a of Figure 13, it is clear that, with the additional consideration of metallicity evolution and the adoption of the DAL of Salim et al. (2018), the of photometric stellar mass estimation is reduced, although the bias and OLF are somewhat increased. By additionally employing a more complicated - form of SFH, as shown in panel c of Figure 13, the quality of photometric stellar mass estimation increase further. However, as shown in Table 3 and Figure 11, with the increasing of the complexity of SED models, the quality of photometric stellar mass stimation decreases obviously. In the case with noise, the best two models are exactly the same in the quality of photometric stellar mass estimation. Meanwhile, with the increasing of the complexity of SED models, the quality of photometric stellar mass stimation decreases even more obviously.
The detailed results of photometric SFR estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 14. In the case without noise, by comparing with the results in panel c of Figure 10 with that in panel a of Figure 14, it is clear that, with the additional consideration of metallicity evolution and the adoption of the DAL of Salim et al. (2018), the systematic bias and OLF of photometric redshift estimation are largely reduced while the is slightly increased. By additionally employing a more complicated - form of SFH, as shown in panel c of Figure 14, the quality of photometric SFR estimation increase to the best. However, as shown in Table 3 and Figure 11, with a additional quenching (or rejuvenation) component, the --r form of SFH lead to a much worse quality of photometric SFR estimation. Finally, the most complicated ---r form of SFH lead to a slightly better SFR estimation. In the case with noise, the best two models are also very similar in the quality of photometric stellar mass estimation. Meanwhile, with the increasing of the complexity of SED models, the quality of photometric SFR stimation increases significantly.
For photometric redshift, stellar mass and SFR, their accurate estimation becomes increasingly difficult. Besides, the latter two are also more sensitive to the selection of SED models. Generally, the quality of parameter estimates is closely related to the level of Bayesian evidence, which is especially clear in the more realistic case with noise. Meanwhile, the model selection with maximum likelihood (or equivalently minimum ), where the more complex (or flexible) models are always more favored, is not consistent with the measurements of the quality of parameter estimation. In practice, the direct measurements of the quality of parameter estimation as indicated by NMAD, BIA and OLF are usually unavailable. So, the Bayesian model comparison with Bayesian evidence can be used to find the best SED model which is not only the most efficient but also give the best parameter estimation.
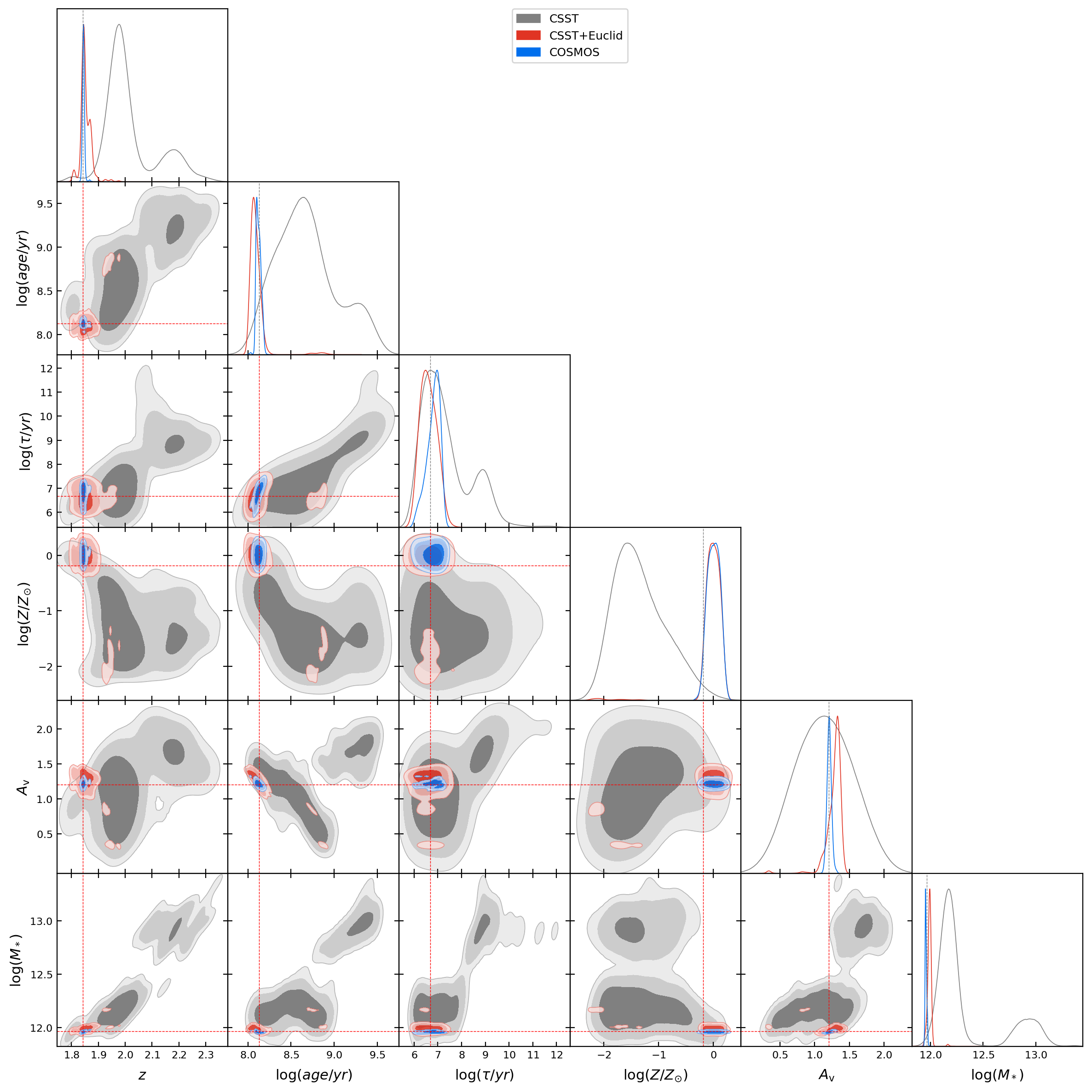
6.2 Effects of more flexible SFH and DAL for CSST+Euclid-like survey
The results of both model comparison and parameter estimation are strongly dependent on the used datasets which may have very different discriminative powers. In Figure 15, we show an example of 1D and 2D posterior probability distribution functions (PDFs) of free parameters obtained from the Bayesian analysis of the photometric data of a mock galaxy in the CSST-like, CSST-like+Euclid-like, and COSMOS-like surveys, respectively. It is clear that different datasets lead to very different PDFs, due to their very different discriminative powers. In this section and §6.3, we discuss the effects of more flexible SFH and DAL for CSST+Euclid-like and COSMOS-like surveys, respectively. The addition of Euclid data extends the wavelength coverage of the data to the longer NIR band than with CSST-only data, which should be useful for enhancing the discriminative power of model comparison and the quality of the parameter estimation.
| survey | noise | SFH | DAL | ln(BE) | ln(ML) | parameter | NMAD | BIA | OLF |
|---|---|---|---|---|---|---|---|---|---|
| 0.020 | 0.002 | 0.001 | |||||||
| CSST+Euclid | - | ,-CEH | Cal+00 | -2435276307 | -3717 | 0.055 | -0.023 | 0.045 | |
| 0.097 | -0.088 | 0.299 | |||||||
| 0.021 | 0.001 | 0.001 | |||||||
| CSST+Euclid | - | ,+CEH | Cal+00 | -2166136390 | 30195 | 0.057 | -0.014 | 0.037 | |
| 0.094 | -0.108 | 0.342 | |||||||
| 0.013 | 0.010 | 0.005 | |||||||
| CSST+Euclid | - | ,+CEH | Sal+18 | 720926475 | 340038 | 0.029 | -0.015 | 0.009 | |
| 0.081 | -0.046 | 0.218 | |||||||
| 0.012 | 0.010 | 0.004 | |||||||
| CSST+Euclid | - | -,+CEH | Sal+18 | 703406409 | 339916 | 0.027 | -0.010 | 0.007 | |
| 0.065 | -0.021 | 0.195 | |||||||
| 0.017 | 0.012 | 0.010 | |||||||
| CSST+Euclid | - | --r,+CEH | Sal+18 | 257286566 | 315401 | 0.032 | -0.005 | 0.017 | |
| 0.087 | 0.006 | 0.302 | |||||||
| 0.016 | 0.012 | 0.016 | |||||||
| CSST+Euclid | - | ---r,+CEH | Sal+18 | 195606454 | 305020 | 0.035 | -0.007 | 0.030 | |
| 0.087 | 0.011 | 0.286 | |||||||
| 0.065 | -0.003 | 0.119 | |||||||
| CSST+Euclid | + | ,-CEH | Cal+00 | -317833314 | 58861 | 0.058 | -0.030 | 0.083 | |
| 0.164 | -0.020 | 0.379 | |||||||
| 0.064 | -0.001 | 0.118 | |||||||
| CSST+Euclid | + | ,+CEH | Cal+00 | -313473302 | 58766 | 0.058 | -0.027 | 0.080 | |
| 0.171 | -0.027 | 0.392 | |||||||
| 0.067 | 0.016 | 0.129 | |||||||
| CSST+Euclid | + | ,+CEH | Sal+18 | -380813529 | 64421 | 0.061 | -0.016 | 0.103 | |
| 0.186 | 0.011 | 0.449 | |||||||
| 0.068 | 0.015 | 0.130 | |||||||
| CSST+Euclid | + | -,+CEH | Sal+18 | -411643437 | 64349 | 0.063 | -0.017 | 0.112 | |
| 0.177 | 0.042 | 0.476 | |||||||
| 0.069 | 0.017 | 0.141 | |||||||
| CSST+Euclid | + | --r,+CEH | Sal+18 | -497963561 | 63873 | 0.065 | -0.023 | 0.127 | |
| 0.213 | 0.059 | 0.571 | |||||||
| 0.068 | 0.016 | 0.136 | |||||||
| CSST+Euclid | + | ---r,+CEH | Sal+18 | -496083426 | 64065 | 0.073 | -0.025 | 0.169 | |
| 0.181 | 0.084 | 0.560 |
In Table 4, we present a summary of the Bayesian evidences, maximum likelihoods and metrics of the quality of parameter estimation from the Bayesian analysis of the hydrodynamical simulation-based mock galaxy sampe for CSST+Euclid-like survey by employing six different combinations of SFH and DAL with increasing complexity, as well as for the cases with and without noise. The same results are also shown more clearly in Figure 16.
6.2.1 Model comparison
In the case without noise, as shown in the top left panel of Figure 16, the simplest model “SFH=,-CEH,DAL=Cal+18” has the lowest Bayesian evidence of . With the additional consideration of metallicity evolution, the Bayesian evidence of the model “SFH=,+CEH,DAL=Cal+18” increases to . Then, with the adoption of the DAL of Salim et al. (2018), the Bayesian evidence of the model “SFH=,+CEH,DAL=Sal+18” increases significantly to . Apparently, the DAL of Salim et al. (2018) is also a much better choice than that of Calzetti et al. (2000) for the hydrodynamical simulation-based mock galaxy sampe in CSST+Euclid-like survey. Furthermore, by employing a more complicated - form of SFH, the Bayesian evidence of the model “SFH=-,+CEH,DAL=Sal+18” seems decreases a little to . As in the case for CSST-like survey, the latter two SED models (“SFH=,+CEH,DAL=Sal+18” and “SFH=-,+CEH,DAL=Sal+18”) have the largest Bayesian evidences which are comparable within error bar. With a quenching (or rejuvenation) component added to the SFH, the Bayesian evidence of the model “SFH=--r,+CEH,DAL=Sal+18” decreases significantly to . Finally, by employing a even more flexible double power-law form of SFH, the Bayesian evidence of the model “SFH=---r,+CEH,DAL=Sal+18” seems decreases a little to which is comparable with the former within error bar. On the other hand, the model selection with maximum likelihood (or equivalently minimum ) lead to similar results.
In the case with noise, the two simplest SED models “SFH=,-CEH,DAL=Cal+00” and “SFH=,+CEH,DAL=Cal+00” have the largest Bayesian evidences of and , respectively. Then, with the adoption of the DAL of Salim et al. (2018), the Bayesian evidence of the model “SFH=,+CEH,DAL=Sal+18” decreases significantly to . By employing a more complicated - form of SFH, the Bayesian evidence of the model “SFH=-,+CEH,DAL=Sal+18” seems decreases further to , although comparable with the former within error bar. With a quenching (or rejuvenation) component added to the SFH, the Bayesian evidence of the model “SFH=--r,+CEH,DAL=Sal+18” obviously decreases to , which is similar to the case without noise. Finally, by employing a even more flexible double power-law form of SFH, the Bayesian evidence of the model “SFH=---r,+CEH,DAL=Sal+18” seems increases a little to , although comparable with the former within error bar. However, the model selection with maximum likelihood (or equivalently minimum ) lead to exactly the opposite results, where the more complex (or flexible) models are always more favored.
In general, all of these results are very similar to that for CSST-like survey. The model selection with Bayesian evidence is still more consistent with the measurements of the quality of parameter estimation. However, the relative error of Bayesian evidences have been reduced, especially in the case without noise.
6.2.2 Parameter estimation
In the right three panels of Figure 16, we show the three metrics of the quality of photometric redshift, stellar mass and SFR estimation for different SED models, respectively. In general, in the case without noise, the SED models “SFH=,+CEH,DAL=Sal+18” and “SFH=-,+CEH,DAL=Sal+18” which are just the two with largest Bayesian evidence give the highest quality parameter estimates. In the case with noise, the two simplest SED models “SFH=,-CEH,DAL=Cal+00” and “SFH=,+CEH,DAL=Cal+00” which are also the two with the largest Bayesian evidences give the highest quality parameter estimates. In the following, we discuss these results in more detail.
The detailed results of photometric redshift estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 17. By comparing with the results for CSST-like survey in Figure 12, it is clear that the quality of photometric redshift estimation has been obviously increased in both the cases with and without noise. Especially, in the more realistic case with noise, the outliers caused by the mis-identification of Lyman and Balmer break features have been largely reduced. This suggest that, the inclusion of J, H and Y bands from Euclid is helpful for improving the photometric redshift estimation. However, the more complicated - form of SFH is not very helpful for improving the quality of photometric redshift estimation.
The detailed results of photometric stellar mass estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 18. By comparing with the results for CSST-like survey in Figure 13, it is clear that the quality of photometric stellar mass estimation has been significantly improved in both the cases with and without noise. Apparently, the inclusion of J, H and Y bands from Euclid is crucial for a more accurate estimation of stellar mass. With the more complicated - form of SFH, the quality of photometric stellar mass estimation is slightly improved. However, as shown in Table 4 and Figure 16, the even more complicated forms of SFH is still not helpful for improving the quality of photometric stellar mass estimation.
The detailed results of photometric SFR estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 19. In the case without noise, by comparing with the results for CSST-like survey in Figure 14, it is clear that the and OLF of photometric SFR estimation are largely reduced, although the bias is slightly increased. However, in the case with noise, all of the , bias and OLF of photometric SFR estimation slightly increase. So, the inclusion of J, H and Y bands from Euclid is not very helpful for improving the photometric SFR estimation.
6.3 Effects of more flexible SFH and DAL for COSMOS-like survey
The COSMOS-like survey covers many more bands than CSST-like data. Although there is no NUV data, it extends to the longer wavelengths and includes some intermediate bands (IBs) (Laigle et al., 2016). Since the COSMOS-like mock data has much stronger discriminative power than CSST-like and CSST+Euclid-like mock data, the Bayesian evidence of different SED models should show much larger difference, and the photometric redshift and stellar population parameter estimation should be better.
| survey | noise | SFH | DAL | ln(BE) | ln(ML) | parameter | NMAD | BIA | OLF |
|---|---|---|---|---|---|---|---|---|---|
| 0.007 | -0.002 | 0 | |||||||
| COSMOS | - | ,-CEH | Cal+00 | -17106046811 | -1431790 | 0.030 | -0.026 | 0.013 | |
| 0.110 | -0.062 | 0.290 | |||||||
| 0.006 | -0.002 | 0 | |||||||
| COSMOS | - | ,+CEH | Cal+00 | -14996186997 | -1207887 | 0.032 | -0.017 | 0.010 | |
| 0.101 | -0.082 | 0.299 | |||||||
| 0.002 | 0 | 0 | |||||||
| COSMOS | - | ,+CEH | Sal+18 | 3545817310 | 681554 | 0.023 | -0.022 | 0.012 | |
| 0.069 | -0.068 | 0.124 | |||||||
| 0.002 | 0 | 0 | |||||||
| COSMOS | - | -,+CEH | Sal+18 | 3870097273 | 717135 | 0.020 | -0.011 | 0.006 | |
| 0.047 | -0.041 | 0.057 | |||||||
| 0.003 | 0.001 | 0 | |||||||
| COSMOS | - | --r,+CEH | Sal+18 | 2550697552 | 613256 | 0.028 | -0.003 | 0.017 | |
| 0.070 | -0.001 | 0.124 | |||||||
| 0.003 | 0.001 | 0 | |||||||
| COSMOS | - | ---r,+CEH | Sal+18 | 2751297218 | 612401 | 0.031 | -0.005 | 0.012 | |
| 0.067 | -0.006 | 0.121 | |||||||
| 0.017 | -0.003 | 0.004 | |||||||
| COSMOS | + | ,-CEH | Cal+00 | 998814881 | 259510 | 0.044 | -0.020 | 0.006 | |
| 0.127 | -0.032 | 0.282 | |||||||
| 0.017 | -0.004 | 0.003 | |||||||
| COSMOS | + | ,+CEH | Cal+00 | 1070094896 | 268492 | 0.044 | -0.012 | 0.005 | |
| 0.126 | -0.044 | 0.288 | |||||||
| 0.015 | 0.002 | 0.003 | |||||||
| COSMOS | + | ,+CEH | Sal+18 | 1315785115 | 313110 | 0.042 | -0.017 | 0.036 | |
| 0.107 | -0.021 | 0.211 | |||||||
| 0.015 | 0.002 | 0.003 | |||||||
| COSMOS | + | -,+CEH | Sal+18 | 1307665064 | 315205 | 0.037 | -0.012 | 0.029 | |
| 0.090 | 0.002 | 0.176 | |||||||
| 0.016 | 0.006 | 0.004 | |||||||
| COSMOS | + | --r,+CEH | Sal+18 | 1095725116 | 305267 | 0.044 | -0.021 | 0.052 | |
| 0.102 | 0.063 | 0.321 | |||||||
| 0.015 | 0.005 | 0.003 | |||||||
| COSMOS | + | ---r,+CEH | Sal+18 | 1109095006 | 306387 | 0.045 | -0.020 | 0.066 | |
| 0.097 | 0.055 | 0.304 |
In Table 5, we present a summary of the Bayesian evidences, maximum likelihoods and metrics of the quality of parameter estimation from the Bayesian analysis of the hydrodynamical simulation-based mock galaxy sampe for COSMOS-like survey by employing six different combinations of SFH and DAL with increasing complexity, as well as for the cases with and without noise. The same results are also shown more clearly in Figure 20.
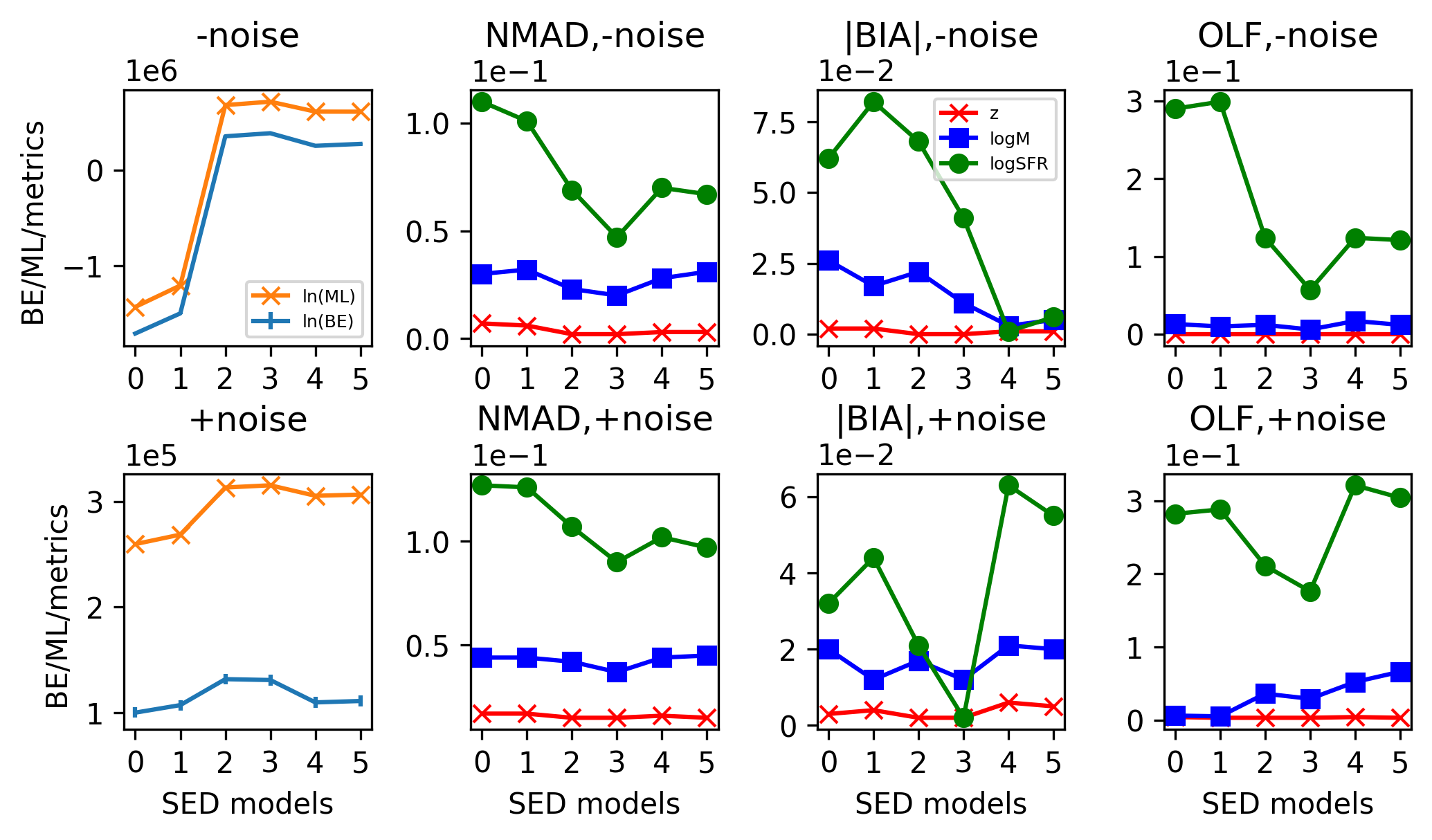
6.3.1 Model comparison
In the case without noise, as shown in the top left panel of Figure 20, the simplest model “SFH=,-CEH,DAL=Cal+18” has the lowest Bayesian evidence of . With the additional consideration of metallicity evolution, the Bayesian evidence of the model “SFH=,+CEH,DAL=Cal+18” increases to . Then, with the adoption of the DAL of Salim et al. (2018), the Bayesian evidence of the model “SFH=,+CEH,DAL=Sal+18” increases significantly to . Apparently, the DAL of Salim et al. (2018) is also a much better choice than that of Calzetti et al. (2000) for the hydrodynamical simulation-based mock galaxy sampe in COSMOS-like survey. Furthermore, by employing a more complicated - form of SFH, the Bayesian evidence of the model “SFH=-,+CEH,DAL=Sal+18” increases further to . However, with a quenching (or rejuvenation) component added to the SFH, the Bayesian evidence of the model “SFH=--r,+CEH,DAL=Sal+18” significantly decreases to , which is similar to the case without noise. Finally, by employing a even more flexible double power-law form of SFH, the Bayesian evidence of the model “SFH=---r,+CEH,DAL=Sal+18” increases to . As in the cases for CSST-like and CSST+Euclid-like surveys, the model selection with maximum likelihood (or equivalently minimum ) lead to similar results.
In the case with noise, as shown in the bottom left panel of Figure 20, almost the same conclusions about SED model comparison are obtained, although the detailed values of Bayesian evidence are apparently different. Unlike the cases for CSST-like and CSST+Euclid-like surveys, the model selection with Bayesian evidence and maximum likelihood (or equivalently minimum ) lead to similar results. In general, for COSMOS-like survey, we can obtain more clear results of SED model comparison. Meanwhile, in the more realistic case with noise, the more complicated SED models are more favored than in the cases for CSST-like and CSST+Euclid-like survey. This is reasonable, since COSMOS-like survey has much stronger discriminative power than CSST-like and CSST+Euclid-like surveys.
6.3.2 Parameter estimation
In the right three panels of Figure 20, we show the three metrics of the quality of photometric redshift, stellar mass and SFR estimation for different SED models, respectively. In the cases with and without noise, the same SED model “SFH=-,+CEH,DAL=Sal+18” which is just the one with largest Bayesian evidence give the highest quality parameter estimates. In the following, we discuss these results in more detail.
The detailed results of photometric redshift estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 21. By comparing with the results for CSST-like survey in Figure 12 and that for for CSST+Euclid-like survey in Figure 17, it is clear that the quality of photometric redshift estimation has been significantly increased in both the cases with and without noise. Meanwhile, in both cases, the best two SED models given identical quality of photometric redshift estimation. In the case without noise, the bias and OLF of photometric redshift estimation are almost zero while the is only 0.002. In this case, the errors from parameter degeneracy and SED model error should be largely reduced. This suggest that the contribution of errors from the stochastic nature of MultiNest sampling algorithm and other potential errors in the BayeSED code should be less than 0.002. In the more realistic case with noise, the outliers caused by the mis-identification of Lyman and Balmer break features have been largely resolved. Finally, as in the cases for CSST-like and CSST+Euclid-like surveys, the more complicated SED models are not very helpful for improving the quality of photometric redshift estimation.
The detailed results of photometric stellar mass estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 22. By comparing with the results for CSST+Euclid-like survey in Figure 18, it is clear that the quality of photometric stellar mass estimation has been improved further in both the cases with and without noise. Besides, the more complicated - form of SFH makes the quality of photometric stellar mass estimation a little better. However, as shown in Table 5 and Figure 16, the even more complicated forms of SFH make the quality of photometric stellar mass estimation worse.
The detailed results of photometric SFR estimation obtained by employing the two models with the largest Bayesian evidences are shown in Figure 23. By comparing with the results for CSST+Euclid-like survey in Figure 18, it is clear that the quality of photometric SFR estimation has been significantly improved in both the cases with and without noise. Besides, the more complicated - form of SFH makes the quality of photometric SFR estimation much better. However, as shown in 20, with a quenching (or rejuvenation) component added to the SFH, the quality of photometric SFR estimation becomes obviously worse. Finally, by employing a even more flexible double power-law form of SFH, the quality of photometric SFR estimation becomes a little better.
7 Summary and conclusion
In this work, based on the Bayesian SED synthesis and analysis techniques employed in the BayeSED-V3 code, we present a comprehensive and systematic test of its performance for simultaneous photometric redshift and stellar population parameter estimation of galaxies when combined with six SED models with increasing complexity in the form of SFH and DAL. The main purpose is to make a systematic analysis of various factors affecting the simultaneous photometric redshift and stellar population parameter estimation of galaxies in the context of Bayesian SED fitting, so as to provide clues for further improvement.
To separate the different factors which could contribute to the errors of photometric redshift and stellar population parameter estimation of galaxies, the empirical statistics-based and hydrodynamical simulation-based approaches have been employed to generate mock photometric sample of galaxies with or without noise for CSST-like, COSMOS-like and CSST+Euclid-like surveys, respectively. We compare the difference in performance of photometric parameter estimation with different run parameters of Bayesian analysis algorithm, different assumptions about the SFH and DAL of galaxies, and different observational datasets. Our main findings are as follows.
For the performance tests using empirical statistics-based mock galaxy sample with idealized SED modeling:
-
1.
The performance of photometric redshift and stellar population parameter estimation, in terms of speed and quality, is sensitive to the runtime parameters (the target sampling efficiency and the number of live points ) of MultiNest algorithm.
-
2.
A good balance among the speed, quality of parameter estimation, and accuracy of model comparison can be achieved when adopting the MultiNest runtime parameters equals to and equals to .
-
3.
By employing the optimized runtime parameters of MultiNest and simplest SED modeling, a speed of () can be achieved for a detailed Bayesian analysis of photometries from CSST-like survey, which is sufficient for the analysis of massive photometric data. Meanwhile, a quality of photometric redshift estimation with , , , a quality of photometric stellar mass estimation with , , , and a quality of photometric SFR estimation with , , can be achieved.
-
4.
With the optimized runtime parameters of MultiNest, the value of Bayesian evidence which is crucial for Bayesian model comparison can also be well estimated, although the error of Bayesian evidence tends to be overestimated, which may lead to a more conservative conclusion about model comparison.
-
5.
The random observational errors in photometries are more important sources of errors than the parameter degeneracies and Bayesian analysis method and tool.
-
6.
More complicated SED models apparently require longer running time. They also tend to overfit noisy photometries and lead to worse quality of photometric redshift, stellar mass and SFR estimation, which is likely due to more free parameters and more severe parameter degeneracies.
-
7.
The value of Bayesian evidence clearly decreases with the increasing of the complexity of the SED model in both of the cases with and without noise.
For the performance tests using hydrodynamical simulation-based mock galaxy sample without idealized SED modeling:
-
1.
The commonly used simple assumptions about the SFH and DAL of galaxies have severe impact on the quality of photometric parameter estimation of galaxies, especially for CSST-like survey with only photometries from seven broad-bands.
-
2.
The performance of both Bayesian parameter estimation and model comparison highly depends on the discriminative power of the observational photometries. With more informative photometries, more clear results about SED model comparison and higher quality of photometric parameter estimation can be obtained.
-
3.
While the SED model comparison with Bayesian evidence may favor SED models with very different complexities when using photometries from different surveys, the maximum likelihood (or equivalently minimum ) tend to favor more complex models. For photometries with strong enough discriminative power, the two methods lead to more consistent results. However, for photometries without strong enough discriminative power, the two methods may lead to contradictory results. In both cases, the results of model selection with Bayesian evidence are more consistent with the measurements of the quality of parameter estimation.
-
4.
In both of the cases with and without noise, the additional consideration of metallicity evolution helps to improve the quality of photometric redshift and stellar parameter estimation of galaxies, and increases the Bayesian evidence of corresponding SED model.
-
5.
In the case without noise, the DAL of Salim et al. (2018) is a much better choice than that of Calzetti et al. (2000) for the hydrodynamical simulation-based mock galaxy sampe in CSST-like, CSST+Euclid-like and COSMOS-like surveys. However, in the more realistic case with noise, it is only more favored in the COSMOS-like survey with Bayesian evidence-based model selection. With maximum likelihood (or equivalently minimum )-based model selection, it could be more favored, but lead to worse parameter estimation.
-
6.
In the case without noise, the more flexible forms of SFH lead to better quality of parameter estimation and increase the Bayesian evidence of corresponding SED model. However, in the more realistic case with noise, they are only more favored in the COSMOS-like survey.
-
7.
With a quenching (or rejuvenation) component added to the SFH, the quality of parameter estimation and the Bayesian evidence of corresponding SED model decrease in all cases. Although the rejuvenation or rapid quenching events may happen in some galaxies, this additional component of SFH is not very effective for most of the galaxies in the hydrodynamical simulation-based mock galaxy sample.
-
8.
The quality of parameter estimation is closely related to the level of Bayesian evidence such that the SED model with largest Bayesian evidence tends to give the best quality of parameter estimation, which is more clear for photometries with larger discriminative power. By using photometries without strong enough discriminative power, the quality of parameter estimation, especially that of stellar mass and SFR estimation, tend to decrease with the increasing of SED model complexity
-
9.
Since the direct measurements of the quality of parameter estimation as indicated by NMAD, BIA and OLF are usually unavailable, the Bayesian model comparison with Bayesian evidence can be used to find the best SED model which is not only the most efficient but also give the best parameter estimation.
-
10.
For photometric redshift, stellar mass and SFR, their accurate estimation becomes increasingly difficult, while the latter two are also more sensitive to the selection of SED models.
-
11.
For the photometric redshift estimation of galaxies in CSST-like survey, the observational noise is the more important source of error than the imperfect SED modeling. However, for the photometric stellar mass and SFR estimation of galaxies, the opposite is true.
-
12.
The combination of photometries from CSST-like and Euclid-like surveys is helpful for improving the quality of photometric redshift estimation and crucial for the more accurate stellar mass estimation, but not very useful for SFR estimation.
-
13.
With photometries in 26 bands from COSMOS-like surveys, by employ the same SED model, BayeSED-V3 can achieve similar quality of photometric redshift, stellar mass and SFR estimation to previous works. Besides, with photometries in 26 bands from COSMOS-like surveys, more complicated SED models tend to be more favored, which is very different from the two cases with only photometries from CSST-like (7 bands) or CSST+Euclid-like (10 bands) surveys.
We conclude that the latest version of BayeSED is capable of achieving a good balance among speed, the quality of simultaneous photometric redshift and stellar population parameter estimation of galaxies and the reliable SED model comparison. This makes it suitable for the analysis of existing and forthcoming massive photometric data of galaxies in CSST wide-field multiband imaging survey and others.
Generally, the current main bottleneck that limits the performance of the Bayesian approach for the simultaneous photometric redshift and stellar population parameter estimation of galaxies is the reliability of the SED synthesis (or modeling) procedure. Assuming a more flexible model is not a complete solution. We need a SED model that is not only more flexible but also more precisely accurate. It can be achieved by gradually adding more informative priors and physical constraints to the SED synthesis (modeling) procedure of galaxies, which is the subject of future works. The Bayesian model selection method with Bayesian evidence, a quantified Occam’s razor, is very helpful to identify the best SED model which is not only the most efficient but also give the best parameter estimation.
The results about simultaneous photometric redshift and stellar population estimation presented in this work are not yet optimal, especially those about CSST. The contributions of nebular lines and continuum emission to the SED, which may help break some parameter degeneracies, are still mising in this work. It is also worth to mention that the results of Bayesian SED model comparison and the metrics (OLF, BIA or NMAD) of parameter estimation highly depend on the selected samples. In this paper, we have chosen a relative broader sample to test the overall performance in the CSST wide-field imaging survey. For a differently selected sample which is designed for answering a more specific scientific question, the results could be different.
Finally, in addition to multi-bands photometries, we may need more informations from other forms of data, such as slitless spectroscopy and morphology parameters from the imaging to break the severe parameter degeneracies. More advanced methods may be able to take advantage of all information to give better redshift and/or stellar population parameter estimation of galaxies. These will be the subjects of future works as well.
References
- Abdurro’uf et al. (2021) Abdurro’uf, Lin, Y.-T., Wu, P.-F., & Akiyama, M. 2021, ApJS, 254, 15, doi: 10.3847/1538-4365/abebe2
- Acquaviva et al. (2011) Acquaviva, V., Gawiser, E., & Guaita, L. 2011, ApJ, 737, 47, doi: 10.1088/0004-637X/737/2/47
- Acquaviva et al. (2015) Acquaviva, V., Raichoor, A., & Gawiser, E. 2015, ApJ, 804, 8, doi: 10.1088/0004-637X/804/1/8
- Alsing et al. (2023) Alsing, J., Peiris, H., Mortlock, D., Leja, J., & Leistedt, B. 2023, ApJS, 264, 29, doi: 10.3847/1538-4365/ac9583
- Alsing et al. (2020) Alsing, J., Peiris, H., Leja, J., et al. 2020, ApJS, 249, 5, doi: 10.3847/1538-4365/ab917f
- Antonucci (1993) Antonucci, R. 1993, ARA&A, 31, 473, doi: 10.1146/annurev.aa.31.090193.002353
- Antonucci (2012) —. 2012, Astronomical and Astrophysical Transactions, 27, 557. https://arxiv.org/abs/1210.2716
- Arnouts et al. (2013) Arnouts, S., Le Floc’h, E., Chevallard, J., et al. 2013, A&A, 558, A67, doi: 10.1051/0004-6361/201321768
- Ashton et al. (2022) Ashton, G., Bernstein, N., Buchner, J., et al. 2022, Nature Reviews Methods Primers, 2, 39, doi: 10.1038/s43586-022-00121-x
- Astropy Collaboration et al. (2013) Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068
- Astropy Collaboration et al. (2018) Astropy Collaboration, Price-Whelan, A. M., Sipőcz, B. M., et al. 2018, AJ, 156, 123, doi: 10.3847/1538-3881/aabc4f
- Aufort et al. (2020) Aufort, G., Ciesla, L., Pudlo, P., & Buat, V. 2020, A&A, 635, A136, doi: 10.1051/0004-6361/201936788
- Bastian et al. (2010) Bastian, N., Covey, K. R., & Meyer, M. R. 2010, ARA&A, 48, 339, doi: 10.1146/annurev-astro-082708-101642
- Beckmann et al. (2017a) Beckmann, R. S., Devriendt, J., Slyz, A., et al. 2017a, MNRAS, 472, 949, doi: 10.1093/mnras/stx1831
- Beckmann et al. (2017b) —. 2017b, ArXiv e-prints. https://arxiv.org/abs/1701.07838
- Behroozi et al. (2013) Behroozi, P. S., Wechsler, R. H., & Conroy, C. 2013, ApJ, 770, 57, doi: 10.1088/0004-637X/770/1/57
- Beichman et al. (2012) Beichman, C. A., Rieke, M., Eisenstein, D., et al. 2012, in Space Telescopes and Instrumentation 2012: Optical, Infrared, and Millimeter Wave, ed. M. C. Clampin, G. G. Fazio, H. A. MacEwen, & J. M. O. Jr., Vol. 8442, International Society for Optics and Photonics (SPIE), 84422N, doi: 10.1117/12.925447
- Bertelli et al. (2008) Bertelli, G., Girardi, L., Marigo, P., & Nasi, E. 2008, A&A, 484, 815, doi: 10.1051/0004-6361:20079165
- Boquien et al. (2019) Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103, doi: 10.1051/0004-6361/201834156
- Bowman et al. (2020) Bowman, W. P., Zeimann, G. R., Nagaraj, G., et al. 2020, ApJ, 899, 7, doi: 10.3847/1538-4357/ab9f3c
- Breivik et al. (2022) Breivik, K., Connolly, A. J., Ford, K. E. S., et al. 2022, arXiv e-prints, arXiv:2208.02781. https://arxiv.org/abs/2208.02781
- Brott et al. (2011) Brott, I., de Mink, S. E., Cantiello, M., et al. 2011, A&A, 530, A115, doi: 10.1051/0004-6361/201016113
- Brown et al. (2019a) Brown, A., Nayyeri, H., Cooray, A., et al. 2019a, ApJ, 871, 87, doi: 10.3847/1538-4357/aaf73b
- Brown et al. (2019b) Brown, M. J. I., Duncan, K. J., Landt, H., et al. 2019b, MNRAS, 489, 3351, doi: 10.1093/mnras/stz2324
- Bruzual & Charlot (2003) Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000, doi: 10.1046/j.1365-8711.2003.06897.x
- Buchner (2021) Buchner, J. 2021, arXiv e-prints, arXiv:2101.09675. https://arxiv.org/abs/2101.09675
- Calzetti et al. (2000) Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682, doi: 10.1086/308692
- Cameron & Pettitt (2014) Cameron, E., & Pettitt, A. 2014, Statistical Science, 29, 397 , doi: 10.1214/13-STS465
- Cao et al. (2018) Cao, Y., Gong, Y., Meng, X.-M., et al. 2018, MNRAS, 480, 2178, doi: 10.1093/mnras/sty1980
- Cappellari et al. (2012) Cappellari, M., McDermid, R. M., Alatalo, K., et al. 2012, Nature, 484, 485, doi: 10.1038/nature10972
- Caputi et al. (2015) Caputi, K. I., Ilbert, O., Laigle, C., et al. 2015, ApJ, 810, 73, doi: 10.1088/0004-637X/810/1/73
- Carnall et al. (2019) Carnall, A. C., Leja, J., Johnson, B. D., et al. 2019, ApJ, 873, 44, doi: 10.3847/1538-4357/ab04a2
- Carnall et al. (2018) Carnall, A. C., McLure, R. J., Dunlop, J. S., & Davé, R. 2018, MNRAS, 480, 4379, doi: 10.1093/mnras/sty2169
- Chabrier (2003) Chabrier, G. 2003, PASP, 115, 763, doi: 10.1086/376392
- Charlot & Longhetti (2001) Charlot, S., & Longhetti, M. 2001, MNRAS, 323, 887, doi: 10.1046/j.1365-8711.2001.04260.x
- Chevallard & Charlot (2016) Chevallard, J., & Charlot, S. 2016, MNRAS, 462, 1415, doi: 10.1093/mnras/stw1756
- Choi et al. (2019) Choi, J., Conroy, C., & Johnson, B. D. 2019, ApJ, 872, 136, doi: 10.3847/1538-4357/aaff67
- Ciesla et al. (2017) Ciesla, L., Elbaz, D., & Fensch, J. 2017, A&A, 608, A41, doi: 10.1051/0004-6361/201731036
- Ciesla et al. (2016) Ciesla, L., Boselli, A., Elbaz, D., et al. 2016, A&A, 585, A43, doi: 10.1051/0004-6361/201527107
- Coelho (2009) Coelho, P. 2009, in American Institute of Physics Conference Series, Vol. 1111, American Institute of Physics Conference Series, ed. G. R. M. L. L. A. A. N. M. . E. B. G. Giobbi, A. Tornambe, 67–74, doi: 10.1063/1.3141624
- Coelho et al. (2020) Coelho, P. R. T., Bruzual, G., & Charlot, S. 2020, MNRAS, 491, 2025, doi: 10.1093/mnras/stz3023
- Collette et al. (2023) Collette, A., Kluyver, T., Caswell, T. A., et al. 2023, h5py/h5py: 3.8.0-aarch64-wheels, 3.8.0-aarch64-wheels, Zenodo, doi: 10.5281/zenodo.7568214
- Conroy (2013) Conroy, C. 2013, ARA&A, 51, 393, doi: 10.1146/annurev-astro-082812-141017
- Conroy & Gunn (2010) Conroy, C., & Gunn, J. E. 2010, ApJ, 712, 833, doi: 10.1088/0004-637X/712/2/833
- Conroy et al. (2009) Conroy, C., Gunn, J. E., & White, M. 2009, ApJ, 699, 486, doi: 10.1088/0004-637X/699/1/486
- Conroy et al. (2010) Conroy, C., White, M., & Gunn, J. E. 2010, ApJ, 708, 58, doi: 10.1088/0004-637X/708/1/58
- Côté et al. (2016) Côté, B., Ritter, C., O’Shea, B. W., et al. 2016, ApJ, 824, 82, doi: 10.3847/0004-637X/824/2/82
- da Cunha et al. (2008) da Cunha, E., Charlot, S., & Elbaz, D. 2008, MNRAS, 388, 1595, doi: 10.1111/j.1365-2966.2008.13535.x
- Dahlen et al. (2013) Dahlen, T., Mobasher, B., Faber, S. M., et al. 2013, ApJ, 775, 93, doi: 10.1088/0004-637X/775/2/93
- Davidzon et al. (2017) Davidzon, I., Ilbert, O., Laigle, C., et al. 2017, A&A, 605, A70, doi: 10.1051/0004-6361/201730419
- Davidzon et al. (2019) Davidzon, I., Laigle, C., Capak, P. L., et al. 2019, MNRAS, 489, 4817, doi: 10.1093/mnras/stz2486
- Debsarma et al. (2016) Debsarma, S., Chattopadhyay, T., Das, S., & Pfenniger, D. 2016, MNRAS, doi: 10.1093/mnras/stw1909
- Diemer et al. (2017) Diemer, B., Sparre, M., Abramson, L. E., & Torrey, P. 2017, ApJ, 839, 26, doi: 10.3847/1538-4357/aa68e5
- Doore et al. (2023) Doore, K., Monson, E. B., Eufrasio, R. T., et al. 2023, ApJS, 266, 39, doi: 10.3847/1538-4365/accc29
- Dore et al. (2019) Dore, O., Hirata, C., Wang, Y., et al. 2019, BAAS, 51, 341. https://arxiv.org/abs/1904.01174
- Draine (2010) Draine, B. 2010, Physics of the Interstellar and Intergalactic Medium, Princeton Series in Astrophysics (Princeton University Press). https://books.google.co.kr/books?id=FycJvKHyiwsC
- Draine (2003) Draine, B. T. 2003, ARA&A, 41, 241, doi: 10.1146/annurev.astro.41.011802.094840
- Dries et al. (2016) Dries, M., Trager, S. C., & Koopmans, L. V. E. 2016, MNRAS, 463, 886, doi: 10.1093/mnras/stw2049
- Dries et al. (2018) Dries, M., Trager, S. C., Koopmans, L. V. E., Popping, G., & Somerville, R. S. 2018, MNRAS, 474, 3500, doi: 10.1093/mnras/stx2979
- Driver et al. (2013) Driver, S. P., Robotham, A. S. G., Bland-Hawthorn, J., et al. 2013, MNRAS, 430, 2622, doi: 10.1093/mnras/sts717
- Dubois et al. (2014) Dubois, Y., Pichon, C., Welker, C., et al. 2014, MNRAS, 444, 1453, doi: 10.1093/mnras/stu1227
- Eldridge & Stanway (2009) Eldridge, J. J., & Stanway, E. R. 2009, MNRAS, 400, 1019, doi: 10.1111/j.1365-2966.2009.15514.x
- Feroz & Hobson (2008) Feroz, F., & Hobson, M. P. 2008, MNRAS, 384, 449, doi: 10.1111/j.1365-2966.2007.12353.x
- Feroz et al. (2009) Feroz, F., Hobson, M. P., & Bridges, M. 2009, MNRAS, 398, 1601, doi: 10.1111/j.1365-2966.2009.14548.x
- Feroz et al. (2019) Feroz, F., Hobson, M. P., Cameron, E., & Pettitt, A. N. 2019, The Open Journal of Astrophysics, 2, 10, doi: 10.21105/astro.1306.2144
- Ferreras et al. (2013) Ferreras, I., La Barbera, F., de la Rosa, I. G., et al. 2013, MNRAS, 429, L15, doi: 10.1093/mnrasl/sls014
- Fitzpatrick (1986) Fitzpatrick, E. L. 1986, AJ, 92, 1068, doi: 10.1086/114237
- Galliano et al. (2018) Galliano, F., Galametz, M., & Jones, A. P. 2018, ARA&A, 56, 673, doi: 10.1146/annurev-astro-081817-051900
- Gardner et al. (2006) Gardner, J. P., Mather, J. C., Clampin, M., et al. 2006, Space Sci. Rev., 123, 485, doi: 10.1007/s11214-006-8315-7
- Gennaro et al. (2018) Gennaro, M., Tchernyshyov, K., Brown, T. M., et al. 2018, ApJ, 855, 20, doi: 10.3847/1538-4357/aaa973
- Gilda et al. (2021) Gilda, S., Lower, S., & Narayanan, D. 2021, ApJ, 916, 43, doi: 10.3847/1538-4357/ac0058
- Gong et al. (2019) Gong, Y., Liu, X., Cao, Y., et al. 2019, ApJ, 883, 203, doi: 10.3847/1538-4357/ab391e
- Green et al. (2012) Green, J., Schechter, P., Baltay, C., et al. 2012, arXiv e-prints, arXiv:1208.4012. https://arxiv.org/abs/1208.4012
- Hahn & Melchior (2022) Hahn, C., & Melchior, P. 2022, ApJ, 938, 11, doi: 10.3847/1538-4357/ac7b84
- Hahn et al. (2022) Hahn, C., Kwon, K. J., Tojeiro, R., et al. 2022, arXiv e-prints, arXiv:2202.01809. https://arxiv.org/abs/2202.01809
- Han & Han (2012) Han, Y., & Han, Z. 2012, ApJ, 749, 123, doi: 10.1088/0004-637X/749/2/123
- Han & Han (2014) —. 2014, ApJS, 215, 2, doi: 10.1088/0067-0049/215/1/2
- Han & Han (2019) —. 2019, ApJS, 240, 3, doi: 10.3847/1538-4365/aaeffa
- Han et al. (2019) Han, Y., Han, Z., & Fan, L. 2019, in The Art of Measuring Galaxy Physical Properties, 5, doi: 10.5281/zenodo.3553688
- Han et al. (2020) Han, Y., Han, Z., & Fan, L. 2020, in IAU Symposium, Vol. 341, IAU Symposium, ed. M. Boquien, E. Lusso, C. Gruppioni, & P. Tissera, 143–146, doi: 10.1017/S1743921319002746
- Han et al. (2007) Han, Z., Podsiadlowski, P., & Lynas-Gray, A. E. 2007, MNRAS, 380, 1098, doi: 10.1111/j.1365-2966.2007.12151.x
- Hernández-Pérez & Bruzual (2013) Hernández-Pérez, F., & Bruzual, G. 2013, MNRAS, 431, 2612, doi: 10.1093/mnras/stt368
- Hickox & Alexander (2018) Hickox, R. C., & Alexander, D. M. 2018, ARA&A, 56, 625, doi: 10.1146/annurev-astro-081817-051803
- Higson et al. (2019) Higson, E., Handley, W., Hobson, M., & Lasenby, A. 2019, Statistics and Computing, 29, 891, doi: 10.1007/s11222-018-9844-0
- Hogg & Foreman-Mackey (2018) Hogg, D. W., & Foreman-Mackey, D. 2018, ApJS, 236, 11, doi: 10.3847/1538-4365/aab76e
- Hopkins et al. (2014) Hopkins, P. F., Kereš, D., Oñorbe, J., et al. 2014, MNRAS, 445, 581, doi: 10.1093/mnras/stu1738
- Hoversten & Glazebrook (2008) Hoversten, E. A., & Glazebrook, K. 2008, ApJ, 675, 163, doi: 10.1086/524095
- Hunter (2007) Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90, doi: 10.1109/MCSE.2007.55
- Ilbert et al. (2009) Ilbert, O., Capak, P., Salvato, M., et al. 2009, ApJ, 690, 1236, doi: 10.1088/0004-637X/690/2/1236
- Ivezić et al. (2019) Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111, doi: 10.3847/1538-4357/ab042c
- Iyer & Gawiser (2017) Iyer, K., & Gawiser, E. 2017, ApJ, 838, 127, doi: 10.3847/1538-4357/aa63f0
- Iyer et al. (2019) Iyer, K. G., Gawiser, E., Faber, S. M., et al. 2019, ApJ, 879, 116, doi: 10.3847/1538-4357/ab2052
- Iyer et al. (2020) Iyer, K. G., Tacchella, S., Genel, S., et al. 2020, MNRAS, 498, 430, doi: 10.1093/mnras/staa2150
- Joachimi (2016) Joachimi, B. 2016, in Astronomical Society of the Pacific Conference Series, Vol. 507, Multi-Object Spectroscopy in the Next Decade: Big Questions, Large Surveys, and Wide Fields, ed. I. Skillen, M. Balcells, & S. Trager, 401
- Kaviraj et al. (2017) Kaviraj, S., Laigle, C., Kimm, T., et al. 2017, MNRAS, 467, 4739, doi: 10.1093/mnras/stx126
- Kewley et al. (2019) Kewley, L. J., Nicholls, D. C., & Sutherland, R. S. 2019, ARA&A, 57, 511, doi: 10.1146/annurev-astro-081817-051832
- Knowles et al. (2021) Knowles, A. T., Sansom, A. E., Allende Prieto, C., & Vazdekis, A. 2021, MNRAS, 504, 2286, doi: 10.1093/mnras/stab1001
- Knowles et al. (2019) Knowles, A. T., Sansom, A. E., Coelho, P. R. T., et al. 2019, MNRAS, 486, 1814, doi: 10.1093/mnras/stz754
- Kriek & Conroy (2013) Kriek, M., & Conroy, C. 2013, ApJ, 775, L16, doi: 10.1088/2041-8205/775/1/L16
- Laigle et al. (2016) Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24, doi: 10.3847/0067-0049/224/2/24
- Laigle et al. (2019) Laigle, C., Davidzon, I., Ilbert, O., et al. 2019, MNRAS, 486, 5104, doi: 10.1093/mnras/stz1054
- Laureijs et al. (2011) Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints. https://arxiv.org/abs/1110.3193
- Lawler & Acquaviva (2021) Lawler, A. J., & Acquaviva, V. 2021, MNRAS, 502, 3993, doi: 10.1093/mnras/stab138
- Lee et al. (2010) Lee, S.-K., Ferguson, H. C., Somerville, R. S., Wiklind, T., & Giavalisco, M. 2010, ApJ, 725, 1644, doi: 10.1088/0004-637X/725/2/1644
- Lee et al. (2009) Lee, S.-K., Idzi, R., Ferguson, H. C., et al. 2009, ApJS, 184, 100, doi: 10.1088/0067-0049/184/1/100
- Leja et al. (2019) Leja, J., Carnall, A. C., Johnson, B. D., Conroy, C., & Speagle, J. S. 2019, ApJ, 876, 3, doi: 10.3847/1538-4357/ab133c
- Leja et al. (2017) Leja, J., Johnson, B. D., Conroy, C., van Dokkum, P. G., & Byler, N. 2017, ApJ, 837, 170, doi: 10.3847/1538-4357/aa5ffe
- Leja et al. (2020) Leja, J., Speagle, J. S., Johnson, B. D., et al. 2020, ApJ, 893, 111, doi: 10.3847/1538-4357/ab7e27
- Lower et al. (2020) Lower, S., Narayanan, D., Leja, J., et al. 2020, ApJ, 904, 33, doi: 10.3847/1538-4357/abbfa7
- Lower et al. (2022) —. 2022, ApJ, 931, 14, doi: 10.3847/1538-4357/ac6959
- Lyu & Rieke (2022) Lyu, J., & Rieke, G. 2022, Universe, 8, 304, doi: 10.3390/universe8060304
- Ma et al. (2016) Ma, X., Hopkins, P. F., Faucher-Giguère, C.-A., et al. 2016, MNRAS, 456, 2140, doi: 10.1093/mnras/stv2659
- Madau (1995) Madau, P. 1995, ApJ, 441, 18, doi: 10.1086/175332
- Maiolino & Mannucci (2019) Maiolino, R., & Mannucci, F. 2019, A&A Rev., 27, 3, doi: 10.1007/s00159-018-0112-2
- Maraston (2005) Maraston, C. 2005, MNRAS, 362, 799, doi: 10.1111/j.1365-2966.2005.09270.x
- Maraston et al. (2006) Maraston, C., Daddi, E., Renzini, A., et al. 2006, ApJ, 652, 85, doi: 10.1086/508143
- Marigo et al. (2008) Marigo, P., Girardi, L., Bressan, A., et al. 2008, A&A, 482, 883, doi: 10.1051/0004-6361:20078467
- Morishita (2022) Morishita, T. 2022, gsf: Grism SED Fitting package, Astrophysics Source Code Library, record ascl:2211.012. http://ascl.net/2211.012
- Narayanan et al. (2018) Narayanan, D., Conroy, C., Davé, R., Johnson, B. D., & Popping, G. 2018, ApJ, 869, 70, doi: 10.3847/1538-4357/aaed25
- National Academies of Sciences, Engineering, and Medicine (2021) National Academies of Sciences, Engineering, and Medicine. 2021, Pathways to Discovery in Astronomy and Astrophysics for the 2020s (The National Academies Press), doi: 10.17226/26141
- Netzer (2015) Netzer, H. 2015, ARA&A, 53, 365, doi: 10.1146/annurev-astro-082214-122302
- Noll et al. (2009) Noll, S., Burgarella, D., Giovannoli, E., et al. 2009, A&A, 507, 1793, doi: 10.1051/0004-6361/200912497
- Oke (1974) Oke, J. B. 1974, ApJS, 27, 21, doi: 10.1086/190287
- Pacifici et al. (2012) Pacifici, C., Charlot, S., Blaizot, J., & Brinchmann, J. 2012, MNRAS, 421, 2002, doi: 10.1111/j.1365-2966.2012.20431.x
- Padoan et al. (1997) Padoan, P., Nordlund, A., & Jones, B. J. T. 1997, MNRAS, 288, 145
- Pforr et al. (2012) Pforr, J., Maraston, C., & Tonini, C. 2012, MNRAS, 422, 3285, doi: 10.1111/j.1365-2966.2012.20848.x
- Pforr et al. (2013) —. 2013, MNRAS, 435, 1389, doi: 10.1093/mnras/stt1382
- Qiu & Kang (2022) Qiu, Y., & Kang, X. 2022, ApJ, 930, 66, doi: 10.3847/1538-4357/ac63a1
- Reddy et al. (2012) Reddy, N. A., Pettini, M., Steidel, C. C., et al. 2012, ApJ, 754, 25, doi: 10.1088/0004-637X/754/1/25
- Reddy et al. (2015) Reddy, N. A., Kriek, M., Shapley, A. E., et al. 2015, ApJ, 806, 259, doi: 10.1088/0004-637X/806/2/259
- Rieke et al. (2005) Rieke, M. J., Kelly, D., & Horner, S. 2005, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 5904, Cryogenic Optical Systems and Instruments XI, ed. J. B. Heaney & L. G. Burriesci, 1–8, doi: 10.1117/12.615554
- Robertson (2022) Robertson, B. E. 2022, ARA&A, 60, 121, doi: 10.1146/annurev-astro-120221-044656
- Robotham et al. (2020) Robotham, A. S. G., Bellstedt, S., Lagos, C. d. P., et al. 2020, MNRAS, 495, 905, doi: 10.1093/mnras/staa1116
- Salim & Boquien (2019) Salim, S., & Boquien, M. 2019, ApJ, 872, 23, doi: 10.3847/1538-4357/aaf88a
- Salim et al. (2018) Salim, S., Boquien, M., & Lee, J. C. 2018, ApJ, 859, 11, doi: 10.3847/1538-4357/aabf3c
- Salim & Narayanan (2020) Salim, S., & Narayanan, D. 2020, ARA&A, 58, 529, doi: 10.1146/annurev-astro-032620-021933
- Salmon et al. (2016) Salmon, B., Papovich, C., Long, J., et al. 2016, ApJ, 827, 20, doi: 10.3847/0004-637X/827/1/20
- Salvato et al. (2018) Salvato, M., Ilbert, O., & Hoyle, B. 2018, Nature Astronomy, doi: 10.1038/s41550-018-0478-0
- Schmidt (1959) Schmidt, M. 1959, ApJ, 129, 243, doi: 10.1086/146614
- Seon & Draine (2016) Seon, K.-I., & Draine, B. T. 2016, ApJ, 833, 201, doi: 10.3847/1538-4357/833/2/201
- Sharma (2017) Sharma, S. 2017, ARA&A, 55, 213, doi: 10.1146/annurev-astro-082214-122339
- Shivaei et al. (2020) Shivaei, I., Reddy, N., Rieke, G., et al. 2020, ApJ, 899, 117, doi: 10.3847/1538-4357/aba35e
- Skilling (2004) Skilling, J. 2004, in American Institute of Physics Conference Series, Vol. 735, American Institute of Physics Conference Series, ed. . U. V. T. R. Fischer, R. Preuss, 395–405, doi: 10.1063/1.1835238
- Skilling (2006) Skilling, J. 2006, Bayesian Analysis, 1, 833
- Speagle (2020) Speagle, J. S. 2020, MNRAS, 493, 3132, doi: 10.1093/mnras/staa278
- Spergel et al. (2003) Spergel, D. N., Verde, L., Peiris, H. V., et al. 2003, ApJS, 148, 175, doi: 10.1086/377226
- Suess et al. (2022) Suess, K. A., Leja, J., Johnson, B. D., et al. 2022, ApJ, 935, 146, doi: 10.3847/1538-4357/ac82b0
- Tacconi et al. (2020) Tacconi, L. J., Genzel, R., & Sternberg, A. 2020, ARA&A, 58, 157, doi: 10.1146/annurev-astro-082812-141034
- Tanaka (2015) Tanaka, M. 2015, ApJ, 801, 20, doi: 10.1088/0004-637X/801/1/20
- Thomas & Maraston (2003) Thomas, D., & Maraston, C. 2003, A&A, 401, 429, doi: 10.1051/0004-6361:20030153
- Thorne et al. (2021) Thorne, J. E., Robotham, A. S. G., Davies, L. J. M., et al. 2021, MNRAS, 505, 540, doi: 10.1093/mnras/stab1294
- Tinsley (1978) Tinsley, B. M. 1978, ApJ, 222, 14, doi: 10.1086/156116
- Tinsley (1980) —. 1980, Fund. Cosmic Phys., 5, 287, doi: 10.48550/arXiv.2203.02041
- Tinsley & Gunn (1976) Tinsley, B. M., & Gunn, J. E. 1976, ApJ, 203, 52, doi: 10.1086/154046
- Valentini et al. (2019) Valentini, M., Borgani, S., Bressan, A., et al. 2019, MNRAS, 485, 1384, doi: 10.1093/mnras/stz492
- van der Walt et al. (2011) van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Computing in Science & Engineering, 13, 22, doi: 10.1109/MCSE.2011.37
- van Dokkum (2008) van Dokkum, P. G. 2008, ApJ, 674, 29, doi: 10.1086/525014
- Volonteri et al. (2016) Volonteri, M., Dubois, Y., Pichon, C., & Devriendt, J. 2016, MNRAS, 460, 2979, doi: 10.1093/mnras/stw1123
- Walcher et al. (2011) Walcher, J., Groves, B., Budavári, T., & Dale, D. 2011, Ap&SS, 331, 1, doi: 10.1007/s10509-010-0458-z
- Wang & Lilly (2020) Wang, E., & Lilly, S. J. 2020, ApJ, 892, 87, doi: 10.3847/1538-4357/ab7b7d
- Weingartner & Draine (2001) Weingartner, J. C., & Draine, B. T. 2001, ApJ, 548, 296, doi: 10.1086/318651
- Witt & Gordon (2000) Witt, A. N., & Gordon, K. D. 2000, ApJ, 528, 799, doi: 10.1086/308197
- Yallup et al. (2022) Yallup, D., Janßen, T., Schumann, S., & Handley, W. 2022, European Physical Journal C, 82, 678, doi: 10.1140/epjc/s10052-022-10632-2
- Yan et al. (2019) Yan, R., Chen, Y., Lazarz, D., et al. 2019, ApJ, 883, 175, doi: 10.3847/1538-4357/ab3ebc
- Zhan (2011) Zhan, H. 2011, Scientia Sinica Physica, Mechanica & Astronomica, 41, 1441, doi: 10.1360/132011-961
- Zhan (2018) Zhan, H. 2018, in 42nd COSPAR Scientific Assembly, Vol. 42, E1.16–4–18
- Zhan (2021) —. 2021, Chinese Science Bulletin, 66, 1290
- Zhang et al. (2005) Zhang, F., Han, Z., Li, L., & Hurley, J. R. 2005, MNRAS, 357, 1088, doi: 10.1111/j.1365-2966.2005.08739.x
- Zhou et al. (2022a) Zhou, X., Gong, Y., Meng, X.-M., et al. 2022a, arXiv e-prints, arXiv:2206.13696. https://arxiv.org/abs/2206.13696
- Zhou et al. (2022b) —. 2022b, MNRAS, 512, 4593, doi: 10.1093/mnras/stac786