11email: gorbatovski@itmo.ru, 11email: kovalchuk@itmo.ru
Bayesian Networks for Named Entity Prediction in Programming Community Question Answering
Abstract
Within this study, we propose a new approach for natural language processing using Bayesian networks to predict and analyze the context and how this approach can be applied to the Community Question Answering domain. We discuss how Bayesian networks can detect semantic relationships and dependencies between entities, and this is connected to different score-based approaches of structure-learning. We compared the Bayesian networks with different score metrics, such as the BIC, BDeu, K2 and Chow-Liu trees. Our proposed approach out-performs the baseline model at the precision metric. We also discuss the influence of penalty terms on the structure of Bayesian networks and how they can be used to analyze the relationships between entities. In addition, we examine the visualization of directed acyclic graphs to analyze semantic relationships. The article further identifies issues with detecting certain semantic classes that are separated in the structure of directed acyclic graphs. Finally, we evaluate potential improvements for the Bayesian network approach.
Keywords:
Bayesian networks Context prediction Natural language generation Natural language processing Question answering1 Introduction
Increasing interest in natural language processing (NLP) presented automated solutions to different human problems, such as text classification, text summarization and generation either with quality comparable to human solutions [1]. Still, there remains the problem of context addition. To solve this problem we aim to predict the entire context or basic entities to get the coherent and cohesive text meaning [2]. Usually a part of the full text, such as the key words or some description, are available. On the one hand it is a more complicated task than a language modeling problem, because there are limits to extrapolating the context from a small part or a description [3]. Furthermore, the semantic gap between the original text and what is recovered is not as unambiguous as in the summarization problem [4].
This may also be applied to search insights by titles or recovery of text contents when the author is not available. Another application is feature extraction for better text generation or context reconstruction for dialogues [5]. On the other hand, there are topics in the analysis and use of human code generation quality assessment [6] and community question answering (CQA), in which the Bayesian approach could prove a great tool. The CQA domain needs to emphasize information from questions or shorter titles, to generate answers more accurately. Such tasks mostly obtain good results by complex and sophisticated neural network architectures, such as LSTM [2] or transformers [7]. However, there are issues with this application of neural networks [8]. For example, well known GPT-like models used for text generation need huge amounts of textual data and time, and they are too complex for fine tuning [9].
In this paper, we present a Bayesian approach for context prediction. Bayesian networks (BNs) allow us to recover the meaning of a full text by knowing the conditional probability distributions (CPDs) of named entities. A named entity in our case is the class of one of the semantically meaningful words in the programming domain obtained as a result of named entity recognition (NER). These entities present informative units that carry information about the context.
Additionally, the directed acyclic graph (DAG) provided by BN show links between entity classes. In most cases, entities from the title part directly affect the appearance of the entity in question. Besides, it detects links between significant elements of the programming domain, such as code blocks with error names or class and function entity classes. In practice, because of probable errors of the NER model used to annotate the text content, there may be incorrect relationships, but in an ideal case, BN specify more precise relationships and give information about semantics and causal relationships.
2 Methodology
In this section, we describe different components of the proposed BN approach for context prediction. Figure 1, shows the overall process consists of several parts: 1) Semantic entity recognition by the NER model; 2) Learning the Bayesian network as a causal model; 3) Predicting and evaluating entities in question by title.
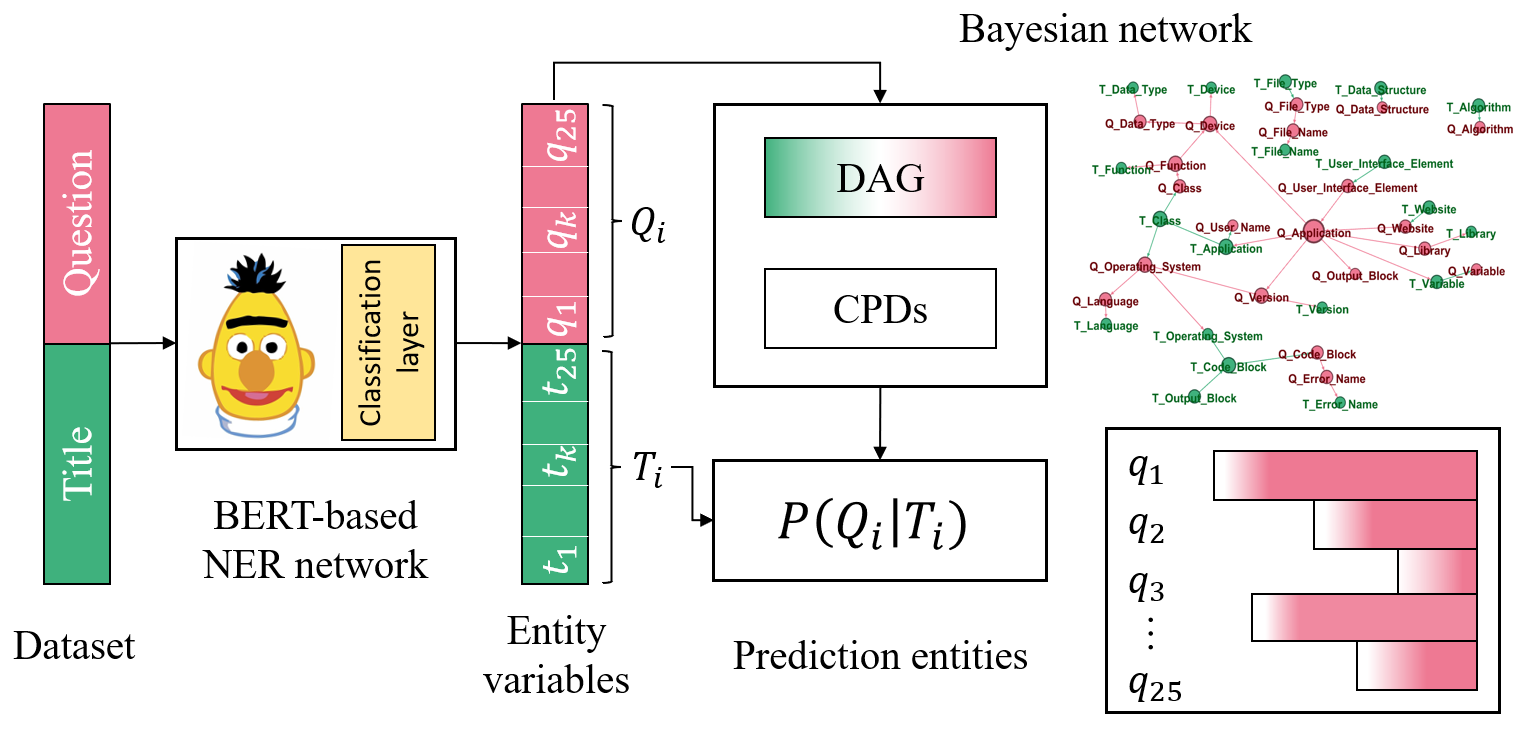
2.1 Problem Statement
As shown in Figure 1, we need to predict the semantic meaningful classes of questions with BN as a multilabel classification problem. For this problem we have textual data, presented as vectors.
More formally, assume we are given two sets of Questions and Titles , where - is the number of samples in our dataset. For each title we have dimension vector, , where represents the entity class of the title and , where corresponds to the absence of the class entity in title, and corresponds to the existence of the class entity in title. For the questions it is the same, for each question there are 25 dimension vectors, , where represents the entity class of the question and , where corresponds to the absence of the class entity in question, and corresponds to existence of the class entity in question. We solve the multi label classification problem by predicting for each question its entity classes by titles entity classes.
2.2 Dataset
The dataset we use is based on 10% of the Stack Overflow111https://stackoverflow.com Q&A 3 years ago222https://www.kaggle.com/datasets/stackoverflow/stacksample. For the set of questions we apply the following filtering operations: select questions with tag "android", select questions with a length less than 200 words and related to the API Usage category proposed by Stefanie et al. [10]. Moreover, we selected questions without links and images, because information from those types of content is unavailable for Bayesian networks. Thus, we received pairs of title and question .
2.3 Semantic Entities Recognition
For extracting domain specific entities from text content we used the open source CodeBERT [11] realization trained for the NER problem [12] on Stack Overflow data, since this is the most popular resource for programmers to find answers to questions. The model was tuned to detect 25 entity classes defined by Jeniya et al. [13]. They represent the following classes: ALGORITHM, APPLICATION, CLASS, CODE BLOCK, DATA STRUCTURE, DATA TYPE, DEVICE, ERROR NAME, FILE NAME, FILE TYPE, FUNCTION, HTML XML TAG, KEYBOARD IP, LANGUAGE, LIBRARY, LICENSE, OPERATING SYSTEM, ORGANIZATION, OUTPUT BLOCK, USER INTERFACE ELEMENT, USER NAME, VALUE, VARIABLE, VERSION, WEBSITE. Each class is domain specific and defines context semantics [14].
Declared precision of the open-source model is 0.60333https://huggingface.co/mrm8488/codebert-base-finetuned-stackoverflow-ner, hence markup could not be ideal because of model mistakes. Figure 2 shows the Hugging face model inference example. So, annotation models sometimes break a word into several parts and define for each its own class. To smooth out these inaccuracies, we decided to combine parts of words into one entity according to the class of the first defined part. While, entities detected by the model might be ambiguous, testing the key words of sentences mostly results in correct detection. All pairs are vectorized as one-hot encoding, thus each title and question is represented by a k-dimension vector, as there are defined classes.

2.4 Bayesian Networks
A Bayesian network is a probabilistic model that encodes a joint probability distribution over a set of variables , which, in our case, presents entity classes. We consider only discrete variables. Formally, a Bayesian network is a pair , where is a directed acyclic graph called "structure". Each node corresponds to one of the variables from . is a set of probabilities defined on . It specifies the conditional probability distribution , where are the parents of the variable. The lack of edge between the variables encodes the conditional independence. With BN, it is possible to get the joint probability distribution of all variables, given as:
| (1) |
2.4.1 Structure Learning
BNs are a suitable tool for the problem, providing excellent means to structure complex domains and draw inferences. To determine semantic relationships and dependencies, we chose a score-based approach of structure-learning; otherwise, a constraint-based approach needs expert knowledge. In a score-based approach, a scoring function is used to measure how well a given structure fits the data. Formally, the learning problem is to find :
| (2) |
where is the given dataset. The score-based approach is essentially a search problem, hence there are two parts: the search algorithm and a score metric.
2.4.2 Searching Algorithm
Chickering showed that learning an optimal BN from is an NP-hard problem [15]. Solving the learning problem precisely becomes impractical, which is why we decided to use the local search algorithm. In our case, the number of variables is equal to 50, because question and title entity classes have 25 each. The search algorithm selected the greedy hill climbing approach [16]. There are also other algorithms that are enabled to learn optimal structure for datasets with dozens of variables[17, 18, 19], based on dynamic programming, branch and bound, linear and integer programming (LP), and heuristic search.
2.4.3 Scoring Metrics
We used the Bayesian information criterion (BIC) [20], Bayesian Dirichlet equivalent uniform prior(BDeu) and K2 [21] as metrics. The BIC is based on the Schwarz Information Criterion and consists of a log-likelihood term and a penalty term, defined as while the score is defined as follows:
| (3) |
In this way, the influence of model complexity decreases as increases, and we get regularized DAG, as the log-likelihood score usually overfits and tends to favor complete graphs.
BDeu and K2 are scores from the family of Bayesian Dirichlet score functions. Under some assumptions, such as parameter independence, parameter modularity, exchangeable data and Dirichlet prior probabilities it is possible to say that penalty term for BDeu is
| (4) |
where is the number of possible values of , is the number of possible values for , is the number of times and in , and is a parameter based on the user-specified . is a heuristic constant that under the likelihood-equivalent assumption proposes the same distribution, described in general terms by Heckerman, Geiger and Chickering (1995). This is called the equivalent sample size, and low values typically result in sparse networks. We used equals to 5, as default value.
After learning structure and finding a local optimum, BNs were pruned by Chi-Square Test Independence [22] to detect more specific semantic relationships.
Additionally, we used the Chow-Liu Algorithm [23]. It finds the maximum-likelihood tree-structured graph (i.e., each node has exactly one parent, except for parentless root node). The score is simply the log-likelihood and there is no penalty term for graph structure complexity as it is regularized by tree structure.
2.4.4 Predicting & Evaluating networks
For BNs using BIC, BDeu and K2 scores, we predicted question’ entities using the Maximum Likelihood Estimation (MLE). A natural estimate for the CPDs is to simply use the relative frequencies, with each variable state that has occurred following Formula 1.
For BNs having tree structures we tried different probabilistic inference approaches. Algorithms such as Variable Elimination (VE), Gibbs Sampling (GS), Likelihood Weighting (LW) and Rejection Sampling (RS) are detailed in respective articles [24, 25]. Each label in question is predicted by a one-vs-rest strategy, by all entities of its title from the pair.
For evaluation we selected common multilabel classification metrics. We preferred macro and weighted averaging because existing classes are imbalanced, and it is important to evaluate each class with its number of instances. The formulas for those metrics are
| (5) |
| (6) |
where , is the number of samples of class, TP is the number of predictions that correctly reports a positive result, and FP is the number of predictions that incorrectly reports a false positive.
3 Results
In this section we analyze classification metrics of BNs based on BIC, BDeu and K2 scores as well as Chow-Liu trees. Each score defines a different structure of DAG, which means different semantic dependencies. We compared DAGs and analyzed the penalty terms of each score and its relationships reflected in graphs, as well as the detected relations.
3.1 Comparison of Evaluation Metrics
We used a common train-test split for evaluation. With the dataset described above, we composed the test dataset as random 30% samples of the whole set. The random seed is defined in a specific way whereby classes from the test set are in the train set as well.
| Precision | Recall | F1-score | ||||
|---|---|---|---|---|---|---|
| Model | Macro | Weighted | Macro | Weighted | Macro | Weighted |
| CatBoost | 0.41 | 0.58 | 0.19 | 0.35 | 0.24 | 0.41 |
| BIC based | 0.56 | 0.66 | 0.20 | 0.33 | 0.28 | 0.42 |
| BDeu based | 0.48 | 0.63 | 0.20 | 0.35 | 0.26 | 0.43 |
| K2 based | 0.51 | 0.66 | 0.24 | 0.34 | 0.29 | 0.43 |
| CL trees VE | 0.47 | 0.63 | 0.21 | 0.33 | 0.25 | 0.41 |
| CL trees LW | 0.48 | 0.63 | 0.17 | 0.29 | 0.22 | 0.37 |
| CL trees GS | 0.41 | 0.57 | 0.13 | 0.25 | 0.18 | 0.33 |
| CL trees RS | 0.23 | 0.44 | 0.07 | 0.15 | 0.10 | 0.22 |
Table 1 shows the main evaluation results according to the selected classification metrics. We prefer to accentuate precision, because precision of individual classes is most important for information extraction and context prediction, and wrong class predictions caused context misunderstanding.
Our approach shows better precision metrics than the baseline - CatBoost model [26], 0.56 vs 0.41 macro precision and 0.66 vs 0.58 weighted precision, comparing the BIC score-based network and baseline.
We observe the highest precision in the BIC score-based model, while the K2-based model shows the better recall metric and comparable precision, hence the best network from the F1-score perspective is the K2-based one. As expected, the BIC regularizes the log-likelihood stronger than the BDeu and K2-specific penalty terms. As a result, BDeu and K2-based DAGs detect more relationships that allow to classify more instances of each class correctly, hence the growth of recall.
We see that the Chow-Liu tree-based networks are comparable to other models if Variable Elimination is used as a sampling algorithm. This causes the limitation that each node has exactly one parent, except parents root nodes, and it is non-redundant for the DAG to fit the data. Other sampling algorithms approximating solutions to the inference problem show worse results.
3.2 Visual DAG representation
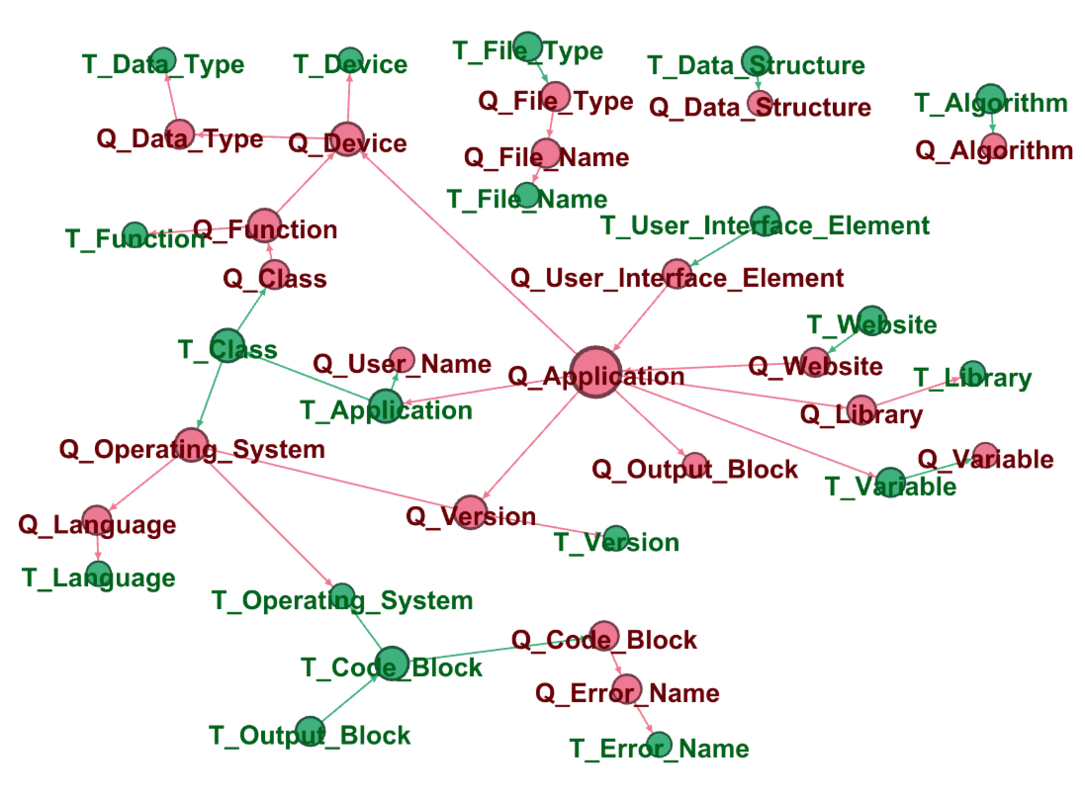
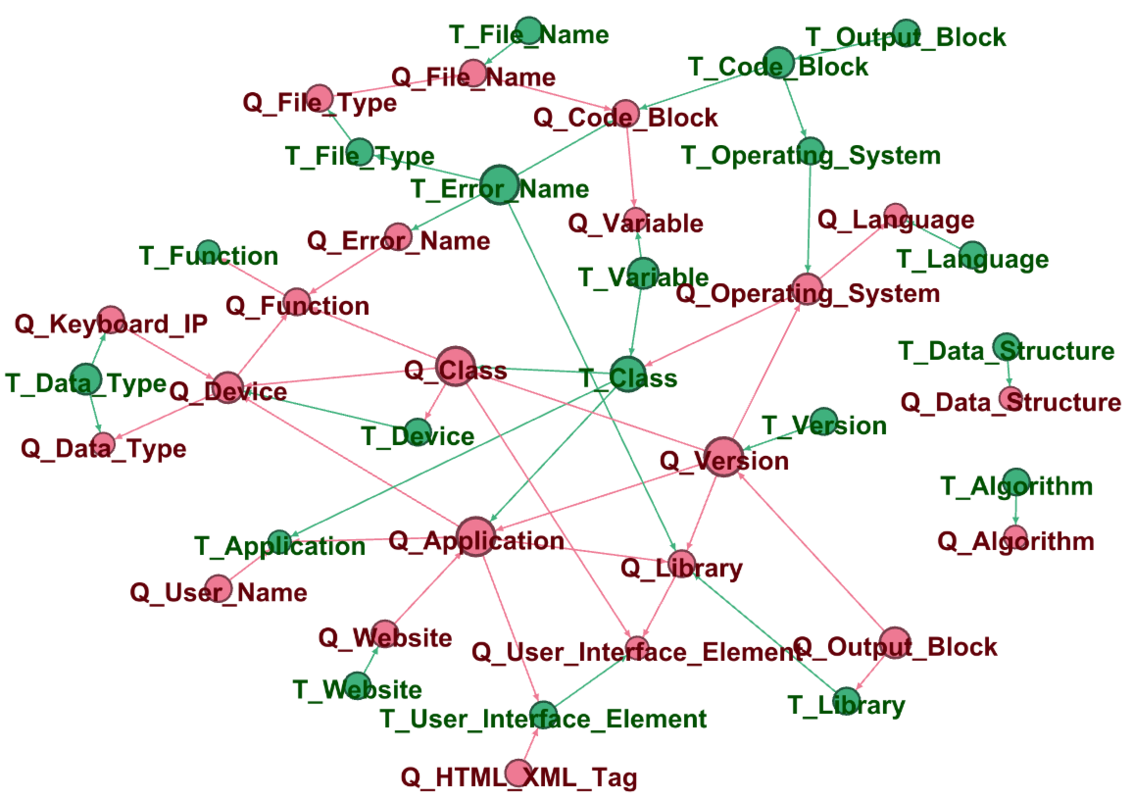
We visualized DAGs from each Bayesian network to see relationships that a BN allows to detect. A BN has causal structure, and we use this property to analyze connections of different semantic entities, describing the context. Figure 4 shows structures learned by described methods. The graphs provide information about the relations between significant parts of the context.
As expected, graphs of K2 (3(b)) and BDeu (4(a)) -based networks detect more relationships and are more complete, in contrast to the BIC (3(a)) -based graph. At each DAG there are semantic links between the same title and question entity classes. The structure of the Chow-Liu trees (4(b)) shows this very well.
Additionally, analysis shows different clusters of semantic entities. This way, DATA STRUCTURE and ALGORITHM separated in each of the four graphs. Furthermore, there is a link between FILE NAME and FILE TYPE, CODE BLOCK and OUTPUT BLOCK. This indicates the logic and validity of BN DAGs structures.
It is noteworthy that the tree structured DAG defines causation from Question ALGORITHM to Title USER NAME and from Title ALGORITHM to Question CLASS without establishing a causal relationship between entities of the same names. More likely, these are outliers, as the NER model is not ideal.


3.3 Predictions analysis
Finally, we compared semantic entities detected by the NER model and predicted by BN based on the K2 metric. Below in Table 2, there are several examples of predictions. Matched to the DAG described above, we observe that overall, predicted entities coincide to target one in the first example. In some cases, BN could not detect semantic instances, as in the second and third rows of Table 2. On Graph (3(b)) VERSION and USER NAME have consequence relations from APPLICATION at both question and title. Similarly, OPERATING SYSTEMS connected to APPLICATION and LANGUAGE in the graph. It is likely that the value of conditional probability was not enough to consider whether these entities would be in the question context.
| Title | Question | Questions entities | Predicted entities |
|---|---|---|---|
| How to send email with attachment using GmailSender in android | I want to know about how to send email with attachment using GmailSender in android. | APPLICATION, OPERATING SYSTEM | APPLICATION, OPERATING SYSTEM |
| Intel XDK build for previous versions of Android | I have just started developing apps in Intel XDK and was just wondering how to build an app for a specific version of Android OS. The emulator I select "Samsung Galaxy S" is using the version 4.2 of android. My application works fine for Galaxy s3 but not on galaxy Ace 3.2 . I could not find a way to add more devices to the emulator list. How can I achieve this. Regards, Shankar. | APPLICATION, OPERATING SYSTEM, VERSION, USER NAME | APPLICATION, OPERATING SYSTEM |
| Automatic update database of android application | I’m making an quiz application in android.But If there are changes in database then how can user get updated with this changes.I read about GCM and php.But can anyone tell me how to do that?Any helpful tutorial? Thanks. | OPERATING SYSTEM, APPLICATION, LANGUAGE | OPERATING SYSTEM |
4 Discussion
As mentioned above, Bayesian networks are one of the methods to predict and analyze the context. This method may be especially useful at the CQA domain for information extraction and semantic causation in the analysis of the important parts of a question and how clear it is for answering [27]. Results show that BN are able to capture the main trend of using meaningful entities, in particular in the programming domain. The recovery task might be an efficient way to determine heuristics as an improvement of the BN approach for context prediction and meaning, as shown by Mehmet et al. Global Uniform parameter priors [28], because we have no knowledge about prior distribution. Conversely, an additional penalty term could fare better in structure learning and detect more relevant relations. Finally, using the mentioned optimal search algorithm should show better defined metrics.
Another approach is work with data. On the one hand, expanding data and not specifying the android tag could allow the BN to determine more general dependencies because of Bayesian inference. It is also possible to change data representation, and focus on specific meaningful words or verbal constructions as opposed general classes of entities. It could lead to the growth of variables power depending on penalty term structure capacity, due to context uncertainty.
Furthermore, there are techniques of query expansion based on relevant documents feedback, especially in information retrieval systems [29]. Neural systems lack interoperability, whereas Bayesian networks have a clarify causal inference and could potentially be a good tool for query expansion and reformulations by providing context representation from the given query-reformulation pairs [30].
5 Conclusion and Future Directions
In this paper we proposed a new application for Bayesian networks in CQA. Bayesian networks could be used as a tool for context prediction and context information extraction. Applying BN to CQA and programming domain in this way, we recognized causal semantic relationships on the set of SO questions and related titles. More precisely, we received the DAGs based on different approaches, making it possible to analyze interrelations. Moreover, we defined that BNs identify entities acceptably, mostly correctly but with issues detecting semantic classes that are separated in the DAG structure.
In future work we plan to build an end-to-end artificial neural network based on the existing NER model. In addition, it seems interesting to compare the NER model and the Bayesian network approach on a small dataset, as done in this article. With this in mind, we would use LSTM with attention to predict semantic entities. Additionally, we are planning to compare the BN and LDA (Latent Dirichlet allocation) approaches for the problems of thematic modeling and information extraction CQA.
References
- [1] Khurana, D., Koli, A., Khatter, K., Singh, S.: Natural language processing: State of the art, current trends and challenges. Multimedia tools and applications pp. 1–32 (2022)
- [2] Santhanam, S.: Context based text-generation using lstm networks. arXiv preprint arXiv:2005.00048 (2020)
- [3] Pillutla, K., Swayamdipta, S., Zellers, R., Thickstun, J., Welleck, S., Choi, Y., Harchaoui, Z.: Mauve: Measuring the gap between neural text and human text using divergence frontiers. Advances in Neural Information Processing Systems 34, 4816–4828 (2021)
- [4] Nallapati, R., Zhou, B., Gulcehre, C., Xiang, B., et al.: Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv preprint arXiv:1602.06023 (2016)
- [5] Yang, W., Qiao, R., Qin, H., Sun, A., Tan, L., Xiong, K., Li, M.: End-to-end neural context reconstruction in chinese dialogue. In: Proceedings of the First Workshop on NLP for Conversational AI. pp. 68–76 (2019)
- [6] Kovalchuk, S.V., Lomshakov, V., Aliev, A.: Human perceiving behavior modeling in evaluation of code generation models. In: Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). pp. 287–294. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid) (Dec 2022), https://aclanthology.org/2022.gem-1.24
- [7] Williams, J., Tadesse, A., Sam, T., Sun, H., Montañez, G.D.: Limits of transfer learning. In: Nicosia, G., Ojha, V., La Malfa, E., Jansen, G., Sciacca, V., Pardalos, P., Giuffrida, G., Umeton, R. (eds.) Machine Learning, Optimization, and Data Science. pp. 382–393. Springer International Publishing, Cham (2020)
- [8] Liu, L., Liu, X., Gao, J., Chen, W., Han, J.: Understanding the difficulty of training transformers. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 5747–5763. Association for Computational Linguistics, Online (Nov 2020)
- [9] Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T.J., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., Amodei, D.: Language models are few-shot learners. ArXiv abs/2005.14165 (2020)
- [10] Beyer, S., Macho, C., Di Penta, M., Pinzger, M.: What kind of questions do developers ask on stack overflow? a comparison of automated approaches to classify posts into question categories. Empirical Software Engineering 25, 2258–2301 (2020)
- [11] Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M., Shou, L., Qin, B., Liu, T., Jiang, D., et al.: Codebert: A pre-trained model for programming and natural languages. arXiv preprint arXiv:2002.08155 (2020)
- [12] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., Dyer, C.: Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360 (2016)
- [13] Tabassum, J., Maddela, M., Xu, W., Ritter, A.: Code and named entity recognition in StackOverflow. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4913–4926. Association for Computational Linguistics, Online (Jul 2020)
- [14] Dash, N.S.: Context and contextual word meaning. SKASE Journal of Theoretical Linguistics (2008)
- [15] Chickering, D.M.: Learning bayesian networks is np-complete. Learning from data: Artificial intelligence and statistics V pp. 121–130 (1996)
- [16] Heckerman, D.: A tutorial on learning with Bayesian networks. Springer (1998)
- [17] Koivisto, M., Sood, K.: Exact bayesian structure discovery in bayesian networks. The Journal of Machine Learning Research 5, 549–573 (2004)
- [18] Jaakkola, T., Sontag, D., Globerson, A., Meila, M.: Learning bayesian network structure using lp relaxations. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. pp. 358–365. JMLR Workshop and Conference Proceedings (2010)
- [19] Yuan, C., Malone, B.: An improved admissible heuristic for learning optimal bayesian networks. arXiv preprint arXiv:1210.4913 (2012)
- [20] Schwarz, G.: Estimating the dimension of a model. The annals of statistics pp. 461–464 (1978)
- [21] Heckerman, D., Geiger, D., Chickering, D.M.: Learning bayesian networks: The combination of knowledge and statistical data. Machine learning 20, 197–243 (1995)
- [22] Argyrous, G.: The chi-square test for independence, pp. 257–284. Macmillan Education UK, London (1997)
- [23] Chow, C., Liu, C.: Approximating discrete probability distributions with dependence trees. IEEE transactions on Information Theory 14(3), 462–467 (1968)
- [24] Koller, D., Friedman, N.: Probabilistic graphical models: principles and techniques. MIT press (2009)
- [25] Hrycej, T.: Gibbs sampling in bayesian networks. Artificial Intelligence 46(3), 351–363 (1990)
- [26] Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A.V., Gulin, A.: Catboost: unbiased boosting with categorical features. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018)
- [27] Arora, U., Goyal, N., Goel, A., Sachdeva, N., Kumaraguru, P.: Ask it right! identifying low-quality questions on community question answering services. In: 2022 International Joint Conference on Neural Networks (IJCNN). pp. 1–8 (2022)
- [28] Kayaalp, M., Cooper, G.F.: A bayesian network scoring metric that is based on globally uniform parameter priors. In: Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence. p. 251–258. UAI’02, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (2002)
- [29] Kandasamy, S., Cherukuri, A.K.: Query expansion using named entity disambiguation for a question-answering system. Concurrency and Computation: Practice and Experience 32(4), e5119 (2020), https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.5119, e5119 CPE-18-1119.R1
- [30] Adolphs, L., Huebscher, M.C., Buck, C., Girgin, S., Bachem, O., Ciaramita, M., Hofmann, T.: Decoding a neural retriever’s latent space for query suggestion (2022), https://arxiv.org/abs/2210.12084