Bayesian Optimization of Hyperparameters from Noisy Marginal Likelihood Estimates
Abstract
Bayesian models often involve a small set of hyperparameters determined by maximizing the marginal likelihood. Bayesian optimization is a popular iterative method where a Gaussian process posterior of the underlying function is sequentially updated by new function evaluations. An acquisition strategy uses this posterior distribution to decide where to place the next function evaluation. We propose a novel Bayesian optimization framework for situations where the user controls the computational effort, and therefore the precision of the function evaluations. This is a common situation in econometrics where the marginal likelihood is often computed by Markov chain Monte Carlo (MCMC) or importance sampling methods, with the precision of the marginal likelihood estimator determined by the number of samples. The new acquisition strategy gives the optimizer the option to explore the function with cheap noisy evaluations and therefore find the optimum faster. The method is applied to estimating the prior hyperparameters in two popular models on US macroeconomic time series data: the steady-state Bayesian vector autoregressive (BVAR) and the time-varying parameter BVAR with stochastic volatility. The proposed method is shown to find the optimum much quicker than traditional Bayesian optimization or grid search.
1Department of Statistics, Stockholm University
2Department of Computer and Information Science, Linköping University
3Sveriges Riksbank
Keywords: acquisition strategy, Bayesian optimization, importance sampling, MCMC, steady-state BVAR, stochastic volatility, US macro.
1 Introduction
The trend in econometrics is to use increasingly more flexible models that give a richer description of the economy, particularly for prediction purposes. As the model complexity increases, the estimation problems get more involved, and computationally costly MCMC methods are often used to sample from the posterior distribution.
Most models involve a relatively small set of hyperparameters that needs to be chosen by the user. For example, consider the steady-state BVAR model (Villani,, 2009), which is widely used among practitioners and professional forecasters (Karlsson,, 2013), and used in Section 5 for illustration. The choice of the prior distribution in BVARs is often reduced to the selection of a small set of prior hyperparameters. Some of these hyperparameters can be specified subjectively by experts, for example, the steady-state is usually given a rather informative subjective prior. Other prior hyperparameters control the smoothness/shrinkage properties of the model and are less easy to specify subjectively.
Giannone et al., (2015) proposed to treat these hard-to-specify prior hyperparameters as unknown parameters and explore the joint posterior of the hyperparameters, the VAR dynamics, and the shock covariance matrix. This is a statistically elegant approach which works well when the marginal likelihood is available in closed form and is easily evaluated. However, the marginal likelihood is rarely available in closed form. The BVARs with conjugate priors considered in Carriero et al., (2012), and Giannone et al., (2015) are an exception, but already the steady-state VAR needs MCMC methods to evaluate the marginal likelihood. It is of course always an option to sample the hyperparameters jointly with the other model parameters using Metropolis-Hastings (MH) or Hamiltonian Monte Carlo (HMC), but this likely leads to inefficient samplers since the parameter spaces are high-dimensional and the posterior of the hyperparameters are often quite complex, see e.g. the application in Section 6.
Most practitioners also seem to prefer to fix the hyperparameters before estimating the other model parameters. Carriero et al., (2012) propose a brute force optimization approach where the marginal likelihood is evaluated over a grid. This is computationally demanding, especially if a simulation based method has to be used for computing the marginal likelihood. Since the marginal likelihood in Giannone et al., (2015) is available in closed form, one can readily optimize it using a standard gradient based optimizer with automatic differentiation, but this is again restricted to models with conjugate priors. The vast majority of applications instead use so-called conventional values for the hyperparameters, dating back to Doan et al., (1984), which were found to be optimal on a specific historical dataset but are likely to be suboptimal for other datasets. Hence, there is a real need for a fast method for optimizing the marginal likelihood over a set of hyperparameters when every evaluation of the marginal likelihood is a noisy estimate from a computationally costly full MCMC run.
Bayesian optimization (BO) is an iterative optimization technique originating from machine learning. BO is particularly suitable for optimization of costly noisy functions in small to moderate dimensional parameter spaces (Brochu et al.,, 2010 and Snoek et al.,, 2012) and is therefore well suited for marginal likelihood optimization. The method treats the underlying objective function as an unknown object that can be inferred by Bayesian inference by evaluating the function at a finite number of points. A Gaussian process prior expresses Bayesian prior beliefs about the underlying function, often just containing the information that the function is believed to have a certain smoothness. Bayes theorem is then used to sequentially update the Gaussian process posterior after each new function evaluation. Bayesian optimization uses the most recently updated posterior of the function to decide where to optimally place the next function evaluation. This so-called acquisition strategy is a trade-off between: i) exploiting the available knowledge about the function to improve the current maxima and ii) exploring the function to reduce the posterior uncertainty about the objective function.
Our paper proposes a novel framework for Bayesian optimization when the user can control the precision and computational cost of each function evaluation. The framework is quite general, but we focus mainly on the situation when the noisy objective function is a marginal likelihood computed by MCMC. This is a very common situation in econometrics using, for example, the estimators in Chib, (1995), Chib and Jeliazkov, (2001), and Geweke, (1999). The precision of the marginal likelihood estimate at each evaluation point is then implicitly chosen by the user via the number of MCMC iterations. This makes it possible to use occasional cheap noisy evaluations of the marginal likelihood to quickly explore the marginal likelihood over hyperparameter space during the optimization. Our proposed acquisition strategy can be seen as jointly deciding where to place the new evaluation but also how much computational effort to spend in obtaining the estimate. We implement this strategy by a stopping rule for the MCMC sampling combined with an auxiliary prediction model for the computational effort at any new evaluation point; the auxiliary prediction model is learned during the course of the optimization.
We apply the method to the steady-state BVAR (Villani,, 2009) and the time-varying parameter BVAR with stochastic volatility (Chan and Eisenstat,, 2018) and demonstrate that the new acquisition strategy finds the optimal hyperparameters faster than traditionally used acquisition functions. It is also substantially faster than a grid search and finds a better optimum.
The outline of the paper is a follows. Section 2 introduces the problem of inferring hyperparameters from an estimated marginal likelihood. Section 3 gives the necessary background on Gaussian processes and Bayesian optimization and introduces our new Bayesian optimization framework. Section 4 illustrates and evaluates the proposed algorithm in a simulation study. Sections 5 and 6 assess the performance of the proposed algorithm in empirical examples, and the final section concludes.
2 Hyperparameter estimation from an estimated marginal likelihood
To introduce the problem of using an estimated marginal likelihood for learning a model’s hyperparameters we consider the selection of hyperparameters in the popular class of Bayesian vector autoregressive models (BVARs) as our running example.
2.1 Hyperparameter estimation
Consider the standard BVAR model
| (1) |
where are iid . A simplified version of the Minnesota prior (see e.g. Karlsson, (2013)) without cross-equation shrinkage is of the form
| (2) |
with
| (3) |
where and denotes the prior mean and covariance of the coefficient matrix, is the prior scale matrix with the prior degrees of freedom, . The diagonal elements of are given by
| (4) |
where controls the overall shrinkage and the lag-decay shrinkage set by the user, denotes the estimated standard deviation of variable . The fact that we do not use the additional cross-equation shrinkage hyperparameter, , makes this prior conjugate to the VAR likelihood, a fact that will be important in the following. It has been common practice to use standard values that dates back to Doan et al., (1984), but there has been a renewed interest to find values that are optimal for the given application (see e.g. Bańbura et al., (2010), Carriero et al., (2012) and Giannone et al., (2015)). Two main approaches have been proposed. First, Giannone et al., (2015) proposed to sample from the joint posterior distribution using the decomposition
| (5) |
where and is the marginal posterior distribution of the hyperparameters. The algorithm samples from using Metropolis-Hastings (MH) and then samples directly from for each draw by drawing and from the Normal-Inverse Wishart distribution. There are some limitations to using this approach. First, the can be multimodal (see e.g. the application in Section 6) and it can be hard to find a good MH proposal density, making the sampling time-consuming. Second, practitioners tend to view hyperparameter selection as similar to model selection and want to determine a fixed value for once and for all early in the model building process.
Carriero et al., (2012) propose an exhaustive grid search to find the that maximizes and then uses that optimal throughout the remaining analysis. The obvious drawback here is that a grid search is very costly, especially if we have non-conjugate priors and more than a couple of hyperparameters.
A problem with both the approach in Giannone et al., (2015) and Carriero et al., (2012) is that for most interesting models is not available in closed form. Even the Minnesota prior with cross-equation shrinkage is no longer a conjugate prior and is intractable. In fact, most Bayesian models used in practice have intractable , including the steady-state BVAR (Villani,, 2009) and the TVP-SV BVAR (Primiceri,, 2005) used in Section 5 and 6.
When is intractable, MCMC or other simulation based methods like Sequential Monte Carlo (SMC) are typically used to obtain a noisy estimate of . Since
| (6) |
where is the marginal likelihood, this problem goes under the heading of (log) marginal likelihood estimation. We will therefore frame our method as maximizing the log marginal likelihood; maximization of is achieved by simply adding the log prior, , to the objective function.
Chib, (1995) proposes an accurate way of computing a simulation-consistent estimate of the marginal likelihood when the posterior can be obtained via Gibbs sampling, which is the case for many econometric models. We refer to Chib, (1995) for details about the marginal likelihood estimator and its approximate standard error.
Estimating the marginal likelihood for the TVP-SV BVAR is more challenging and we will adopt the method suggested by Chan and Eisenstat, (2018). The approach consists of four steps; 1) obtain a posterior sample via Gibbs sampling, 2) integrate out the time-varying VAR coefficients analytically, 3) integrate out the stochastic volatility using importance sampling to obtain the integrated likelihood, 4) integrate out the static parameters using another importance sampler. Since the algorithm makes use of two nested importance samplers, it is a special case of importance sampling squared () (Tran et al.,, 2013); see Section 6 for more details.
There are many alternative estimators that can be used in our approach, for example, the extension of Chib’s estimator to Metropolis-Hastings sampling (Chib and Jeliazkov,, 2001), and estimators based on importance sampling (Geweke,, 1999) or Sequential Monte Carlo (Doucet et al.,, 2001).
All simulation-based estimators: i) give noisy evaluations of the marginal likelihood, ii) are time-consuming, and iii) have a precision that is controlled by the user in terms of the number of MCMC or importance sampling draws. The next section explains how traditional Bayesian optimization is well suited for points i) and ii), but lacks a mechanism for exploiting point iii). Taking the user controlled precision into account brings a new perspective to the problem and we propose a class of algorithms that handle all three points above.
3 Bayesian optimization of hyperparameters
3.1 Gaussian processes
Since Bayesian optimization is a relatively unknown method in econometrics, we give an introduction here to Gaussian processes and their use in Bayesian optimization.
A Gaussian process (GP) is a (possibly infinite) collection of random variables such that any subset is jointly distributed according to a multivariate normal distribution, see e.g. Williams and Rasmussen, (2006). This process, denoted by , can be seen as a probability distribution over functions that is completely specified by its mean function, , and its covariance function, , where and are two arbitrary input values to . Note that the covariance function specifies the covariance between any two function values, and . A popular covariance function is the squared exponential (SE):
| (7) |
where is the Euclidean distance between the two inputs; the covariance function is specified by its two kernel hyperparameters, the scale parameter and the length scale . The scale parameter governs the variability of the function and the length scale determines how fast the correlation between two function values taper off with the distance , see Figure 1. The fact that any finite sampling of function values constitutes a multivariate normal distribution on allows for the convenient conditioning and marginalization properties of the multivariate normal distribution. In particular, this makes it easy to compute the posterior distribution for the function at any input .
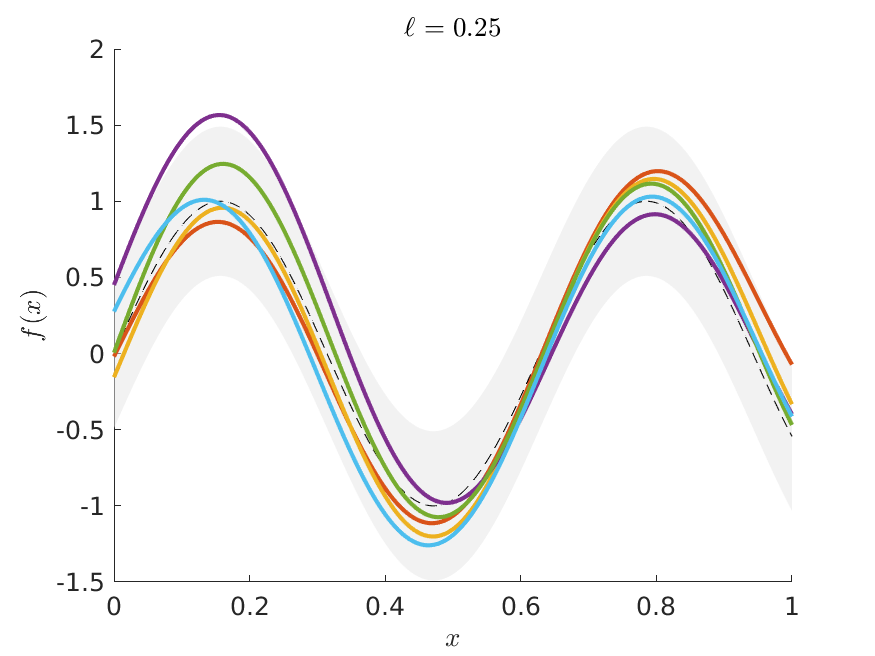
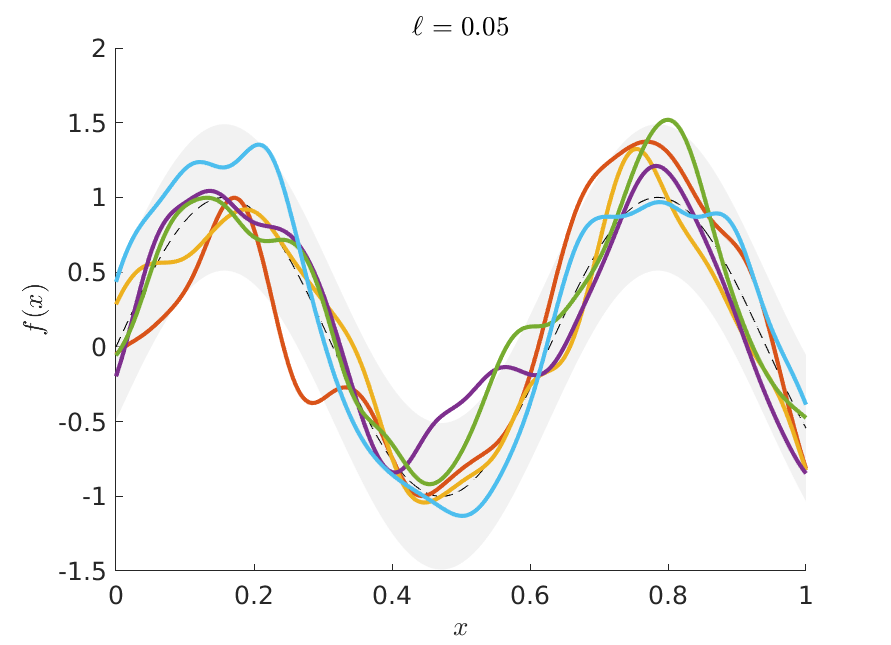
An increasingly popular alternative to the squared exponential kernel is the Matérn kernel, see e.g. Matérn, (1960) and Williams and Rasmussen, (2006). The Matérn kernel has an additional hyperparameter, >0, in addition to the length scale and scale , such that the process is times mean square differentiable if and only if . Hence, controls the smoothness of the process and it can be shown that the Matérn kernel approaches the SE kernel as (Williams and Rasmussen, (2006)). Our approach is directly applicable for any valid kernel function, but we will use the popular Matérn kernel in our applications:
| (8) |
where . The Matérn 5/2 has two continuous derivatives which is often a requirement for Newton-type optimizers (Snoek et al.,, 2012). The hyperparameters, and , are found by maximizing the marginal likelihood, see e.g. Williams and Rasmussen, (2006).
Consider the nonlinear/nonparametric regression model with additive Gaussian errors
| (9) |
and the prior . Given a dataset with observations, the posterior distribution of at a new input is (Williams and Rasmussen,, 2006)
| (10) |
where , is the -vector with covariances between at the test point and all other training inputs, is the matrix with covariances among the function values at all training inputs in . When the errors are heteroscedastic with variance for the th observation, the same formulas apply with replaced by .
3.2 Bayesian optimization
Bayesian optimization (BO) is an iterative optimization method that selects new evaluation points using the posterior distribution of conditional on the previous function evaluations. More specifically, BO uses an acquisition function, , to select the next evaluation point (Brochu et al.,, 2010 and Snoek et al.,, 2012).
An intuitively sensible acquisition rule is to select a new evaluation point that maximizes the probability of obtaining a higher function value than the current maximum, i.e. the Probability of Improvement (PI):
| (11) |
where is the maximum value of the function obtained so far. The functions and are the posterior mean and standard deviation of the estimated Gaussian process for in the point , conditional on the available function evaluations (see (10)), and denotes the cumulative standard normal distribution.
The Expected Improvement (EI) takes also the size of the improvement into consideration:
| (12) |
where denotes the density function of the standard normal distribution. The first part of (12) is associated with the size of our predicted improvement and the second part is related to the uncertainty of our function in that area. Thus, EI incorporates the trade-off between high expected improvement (exploitation) and learning more about the underlying function (exploration). Optimization of the acquisition function, to find the next evaluation point, is typically a fairly easy task since it is noise-free and cheap to evaluate, however, it can have multiple optima so some care has to be taken. An easily implemented solution is to use a regular Newton-type algorithm initiated with different starting values over the hyperparameter surface. In this paper we use particle swarm optimization, a global optimization algorithm implemented in the Optim.jl package in Julia.
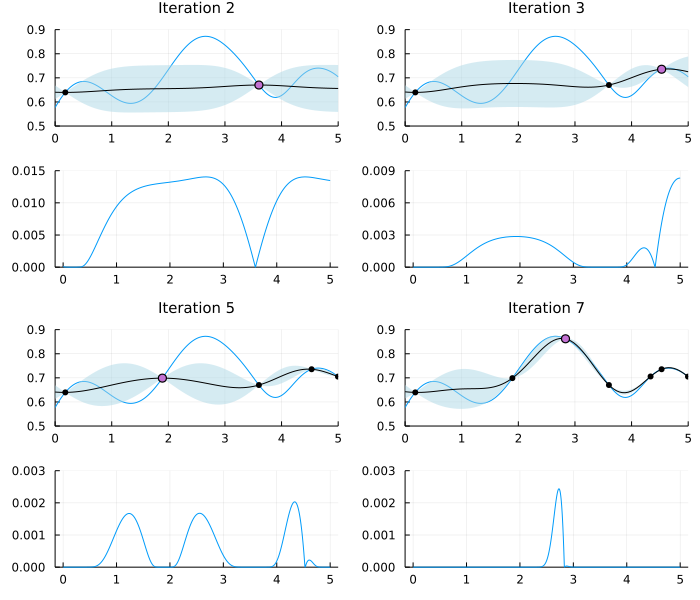
The exploitation-exploration trade-off is illustrated in Figure 2, where the blue line shows the true objective function, the black line denotes the posterior mean of the GP, and the blue-shaded regions are 95% posterior probability bands for . The black (small) dots are past function evaluations, and the violet (large) dot is the current evaluation. The first and third row in Figure 2 show the true objective function and the learned GP at four different iterations of the algorithm while the second and fourth row show the EI acquisition function corresponding to the row immediately above. At Iteration 2 in the top-left corner, we see that the EI acquisition function (second row) indicates that there is a high expected improvement by moving to either the immediate left or right of the current evaluation. At Iteration 5 the EI strategy suggests three regions worth evaluating, where the two leftmost regions are candidates because of their high uncertainty. After seven iterations, the algorithm is close to the global maximum and will now continue a narrow search for the exact location of the global maximum.
Acquisition rules like PI or EI do not consider that different evaluation points can be more or less costly. To introduce the notation of cost into the acquisition strategy, Snoek et al., (2012) proposed Expected Improvement per second, , where is a duration function that measures the evaluation time at input in seconds. More generally, we can define as an effort-aware acquisition function. The duration function is typically unknown and Snoek et al., (2012) proposed to estimate it alongside using an additional Gaussian process for .
3.3 Bayesian optimization with optimized precision
EIS assumes that the duration (or the cost) of function evaluations are unknown, but fixed for a given input ; once we visit , the cost of the function estimate is given. However, the user can often choose the duration spent to obtain a certain precision in the estimate; for example by increasing the number of MCMC iterations when the marginal likelihood is estimated by MCMC. This novel perspective opens up for strategies that not only optimize for the next evaluation point, but also optimize over the computational resources, or equivalently, the precision of the estimate . We formally extend BO by modeling the function evaluations with a heteroscedastic GP
| (13) | ||||
where the noise variance is now an explicit function of the number of MCMC iterations, , or some other duration measure. Hence the user can now choose both where to place the next evaluation and the effort spent in computing it by maximizing
| (14) |
with respect to both and , where is a baseline acquisition function, for example EI.
A complication with maximization of is that while we typically know that in Monte Carlo or MCMC, the exact numerical standard error depends on the integrated autocorrelation time (IACT) of the MCMC chain. Note that the evaluation points can, for example, be hyperparameters in the prior, where different values can give rise to varying degrees of well-behaved posteriors, so we can not expect the IACT to be constant over the hyperparameter space, hence the explicit dependence on in . Rather than maximizing with respect to both and directly, we propose to implement the algorithm in an alternative way that achieves a similar effect. The approach includes stopping the evaluation early whenever the function evaluation turns out to be hopelessly low with a low probability of improvement over the current .
For a given we let increase, in batches of a fixed size, until
| (15) |
for some small value, , or until reaches a predetermined upper bound, ; here denotes the posterior mean and standard deviation of the GP evaluated at after MCMC iterations. Note that both the posterior mean and standard deviation are functions of the noise variance, which in turn is a function of . The posterior distribution for is hence continuously updated as grows until of the posterior mass in the GP for is concentrated below , at which point the evaluation stops. The optimization is insensitive to the choice of , as long as it is a relatively small number. We now propose to maximize the following acquisition function based on early stopping
| (16) |
where is a prediction of the number of MCMC draws needed at before the evaluation stops, with the probability as the threshold for stopping. We emphasize that early stopping is here used in a subtle way, not only as a simple rule to short-circuit useless computations, but also in the planning of future computations; the mere possibility of early stopping can make the algorithm try an which does not have the highest , but which is expected to be cheap and is therefore worth a try. This effect that comes via is not present in the EIS of Snoek et al., (2012) where the cost is fixed and is not influenced by the probability model on .
Although one can use any model to predict , we will here fit a GP regression model to the logarithm of the number of MCMC draws, for in the previous evaluations
| (17) |
where is a vector of covariates. The hyperparameters, , themselves may be used as predictors of , but also and are likely to have predictive power for , as well as . We will use in our applications, where the superscript over denotes the BO iteration. The prediction for is taken to be , which corresponds to the median of the log-normal posterior for .
We will use the term Bayesian Optimization with Optimized Precision (BOOP) for BO methods that optimize in (16), and more specifically BOOP-EI when EI is used as the baseline acquisition function, . The whole procedure is described in Algorithm 1.
input
-
•
estimator of the to be maximized, and its standard error function .
-
•
initial points , a vector of corresponding function estimates, , and standard errors .
-
•
baseline acquisition function , and early stopping thresholding probability .
for from until convergence do:
-
a)
Fit the heteroscedastic GP for based on past evaluations
where .
-
b)
Fit the GP for based on past evaluations
where the elements of are functions of . Return the point prediction .
-
c)
Maximize to select the next point, .
-
d)
Compute and by early stopping at thresholding probability .
-
e)
Update the datasets in a) with and in b) with .
Note that (13) assumes that is an unbiased estimator at any . This can be ensured by using enough MCMC/importance sampling draws in the first marginal likelihood evaluation of BOOP. We performed a small simulation exercise that shows that the Chib estimator is approximately unbiased after a small number of iterations for the medium-sized VAR model in 5.4. As expected, we had to use more initial draws in the large-scale VAR in Section 5.5 and the time-varying parameter VAR with stochastic volatility in Section 6 to drive down the bias. See also Section 7 for some ideas on how to extend BOOP to estimators where the bias is still sizeable in large MCMC samples.
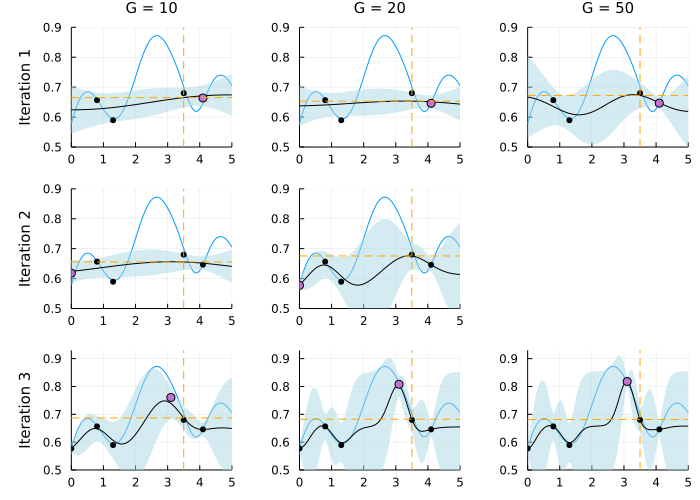
Figure 3 illustrates the early stopping part of BOOP in a toy example. The first row illustrates the first BOOP iteration and the columns show increasingly larger MCMC sample sizes (). We can see that the 95% posterior interval after MCMC draws at the current includes (dotted orange line), the highest posterior mean of the function values observed so far; it therefore worthwhile to increase the number of simulations for this . Moving one graph to the right we see that after simulations the 95% posterior interval still includes , and we move one more graph to the right for . Here we conclude that the sampled point is almost certainly not an improvement and we move on to a new evaluation point. The new evaluation point is found by maximizing the BOOP-EI acquisition function in (16) with updated effort prediction function in Equation 17 and is depicted by the violet dot in leftmost graph in the second row of Figure 3. Following the progress in the second row, we see that it takes only samples to conclude that the function value is almost certainly lower than the current maximum of the posterior mean at the second BO iteration. Finally, in the third row, we can see that the point is sampled with high variance at the beginning, but as we increase it becomes clear that this is indeed an improvement.
The code used in this paper is written in the Julia computing language (Bezanson et al.,, 2017), making use of the GaussianProcesses.jl package for estimation of the Gaussian processes and the Optim.jl package for the optimization of the acquisition functions.
4 Simulation experiment
4.1 Simulation setup
We will here assess the performance of the proposed BOOP-EI algorithm in a simulation experiment for the optimization of a non-linear function in a single variable. The simple one-dimensional setup is chosen for presentational purposes, and more challenging higher-dimensional settings are likely to show even larger advantages of our method compared to regular Bayesian optimization.
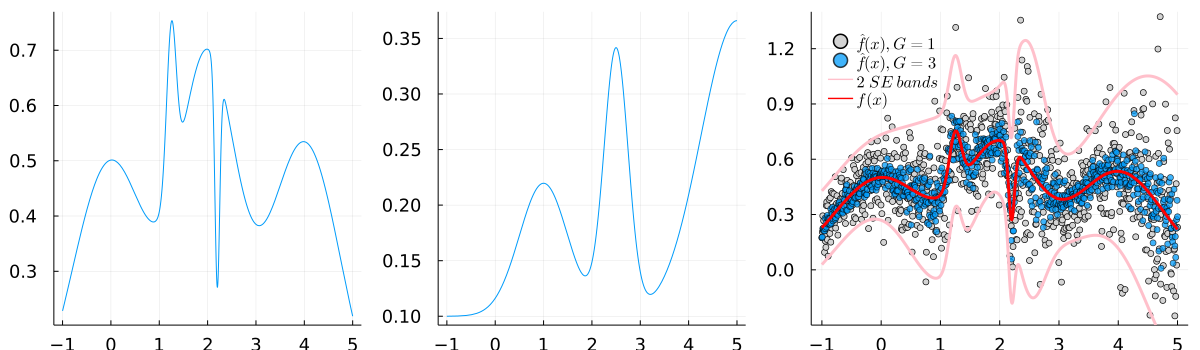
The function to be maximized is
| (18) | ||||
where denotes the density function of a variable; the function is plotted in Figure 4 (left). We further assume that can be estimated at any from noisy evaluations by a simple Monte Carlo average
| (19) |
where is a heteroscedastic standard deviation function that mimics the real world case where the variability of the marginal likelihood estimate varies over the space of hyperparameters; is plotted in Figure 4 (middle). Figure 4 (right) illustrates the noisy function evaluations (gray points) and the effect of Monte Carlo averaging evaluations for a given (blue points). We assume for simplicity here that once the algorithm decides to visit an it will get access to a noise-free evaluation of the standard error of the estimator.
4.2 Illustration of a single run of the algorithms
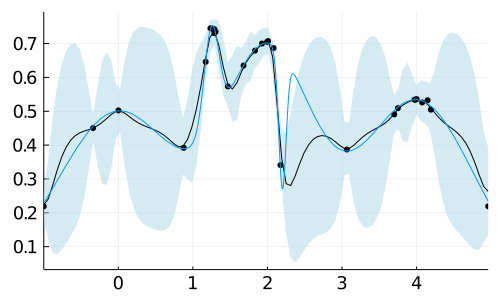
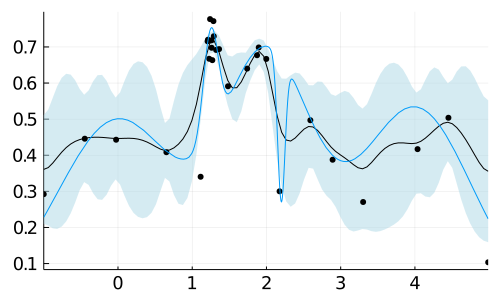
Before we conduct a small Monte Carlo experiment it is illustrative to look at the results from a single run of the EI and BOOP-EI algorithms. Figure 5 highlights the difference between the algorithms by showing the GP posterior after 25 Bayesian optimization runs. The EI algorithm has clearly wasted computations to needlessly drive down the uncertainty at (useless) low function values, while BOOP-EI tolerates larger uncertainty in such function locations.
4.3 Simulation study
We now compare the performance of a standard EI approach using a heteroscedastic GP with our BOOP-EI approach in a small simulation study. The methods will be judged by their ability to find the optimum using as few evaluations as possible. The performance will be evaluated by a Monte Carlo study where we simulate replications from each model under each simulation scenario. We investigate Bayesian optimization with EI using and samples in each iteration, BOOP-EI is allowed to stop the sampling at any time before the number of samples for the EI is reached. In each simulation we set an upper bound of Bayesian optimization iterations.
´
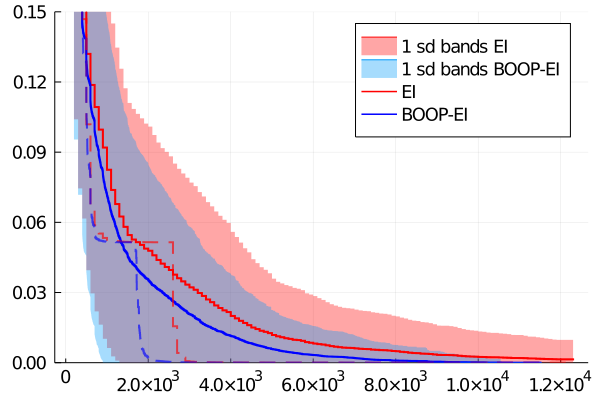
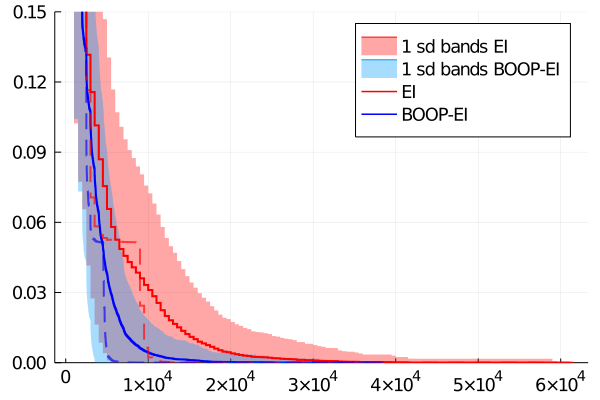
We can see from Figure 6 that BOOP finds the maximum by using fewer total number of samples in both scenarios and that the difference increases with the number of samples used when forming the estimator. We can also see from the median that both algorithms can get stuck for a while at the second greatest local maximum (which is approximately lower than the global maximum). However, BOOP gets out of the local optimum faster since it has the option to try cheap noisy evaluations and will therefore explore other parts of the function earlier than basic BO-EI. This effect seems to increase as we allow for a higher number of samples since it lowers the relative price of cheaper evaluations.
5 Application to the steady-state BVAR
In this section, we use BOOP-EI to estimate the prior hyperparameters of the steady-state BVAR of Villani, (2009). Giannone et al., (2015) show that finding the right values for the hyperparameters in BVARs can significantly improve forecasting performance. Moreover, Bańbura et al., (2010) show that different degree of shrinkage (controlled by the hyperparameters) is necessary under different model specifications.
5.1 The steady-state BVAR
The steady-state BVAR model of Villani, (2009) is given by:
| (20) |
where . In particular, if we assume that for all then has the interpretation as the overall mean of the process. We take the prior distribution to be:
| (21) | ||||
where are the mean and covariance matrix for the steady states. The prior covariance matrix for the dynamics, , is constructed using
| (22) |
where is the diagonal elements of . We also assume prior independence, following Villani, (2009). The hyperparameters that we optimize over are: the overall-shrinkage parameter , the cross-lag shrinkage , and the lag-decay parameter .
5.2 Data, prior and model settings
Table 1 describes the data used in our applications which are also used in Giannone et al., (2015). It contains 23 macroeconomic variables for which two subsets are selected to represent a medium-sized model with 7 variables and a large model that contains 22 of the variables (real investment is excluded). Before the analysis, the consumer price index and the five-year bond rate were transformed from monthly to quarterly frequency. All series are transformed such that they become stationary according to the augmented Dickey-Fuller test. This is necessary for the data to be consistent with the prior assumption of a steady-state. The number of lags is chosen according to the HQ-criteria, Hannan and Quinn, (1979) and Quinn, (1980). This resulted in lags for the medium-sized model which we also use for the large model.
We set the prior mean of the coefficient matrix, , to values that reflect some persistence on the first lag, but also that all the time series are stationary; e.g. the prior mean on the first lag of the FED interest rate and the GDP-deflator is set to 0.6, while others are set to zero in the medium-sized model. Lags longer than 1 and cross-lags all have zero prior means. The priors for the steady-states are set informative to the values listed in Table 1, these values follow suggestions from the literature for most variables, see e.g. Louzis, (2019) and Österholm, (2012). There were a few variables where we could not find theoretical values for either the mean or the standard deviation, in those cases, we set them close to their empirical counterparts.
| Variable names and transformations | |||||
|---|---|---|---|---|---|
| Variables | Mnemonic | Transform | Medium | Freq. | Prior |
| (FRED) | |||||
| Real GDP | GDPC1 | x | Q | (2.5;3.5) | |
| GDP deflator | GDPCTPI | x | Q | (1.5;2.5) | |
| Fed funds rate | FEDFUNDS | - | x | Q | (4.3,5.7) |
| Consumer price index | CPIAUCSL | M | (1.5;2.5) | ||
| Commodity prices | PPIACO | Q | (1.5;2.5) | ||
| Industrial production | INDPRO | Q | (2.3;3.7) | ||
| Employment | PAYEMS | Q | (1.5;2.5) | ||
| Employment, service sector | SRVPRD | Q | (2.5;3.5) | ||
| Real consumption | PCECC96 | x | Q | (2.3;3.7) | |
| Real investment | GPDIC1 | x | Q | (1.5;4.5) | |
| Real residential investment | PRFIx | Q | (1.5;4.5) | ||
| Nonresidential investment | PNFIx | Q | (1.5;4.5) | ||
| Personal consumption | PCECTPI | Q | (1.5;4.5) | ||
| expenditure, price index | |||||
| Gross private domestic | GPDICTPI | Q | (1.5;4.5) | ||
| investment, price index | |||||
| Capacity utilization | TCU | - | Q | (79.3;80.7) | |
| Consumer expectations | UMCSENTx | diff | Q | (-0.5, 0.5) | |
| Hours worked | HOANBS | x | Q | (2.5;3.5) | |
| Real compensation/hour | AHETPIx | x | Q | (1.5;2.5) | |
| One year bond rate | GS1 | diff | Q | (-0.5;0.5) | |
| Five years bond rate | GS5 | diff | M | (-0.5,0.5) | |
| SP 500 | S&P 500 | Q | (-2,2) | ||
| Effective exchange rate | TWEXMMTH | Q | (-1;1) | ||
| M2 | M2REAL | Q | (5.5;6.5) | ||
The table shows the 23 US macroeconomic time series from the FRED database used in the empirical analysis. The column named Prior contains the steady-state mean one standard deviation.
5.3 Experimental setup
We consider three competing optimization strategies: (I) an exhaustive grid-search, (II) Bayesian optimization with the EI acquisition function (BO-EI), and (III) our BOOP-EI algorithm. In each approach, we use the restrictions . In the grid-search, move in steps of and moves in steps of , yielding in total 100000 marginal likelihood evaluations. For the Bayesian optimization algorithm, we set the number of evaluations to 250, and we use three random draws as initial values for the GPs.
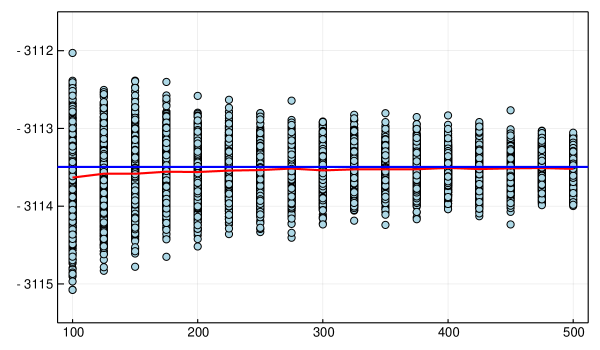
For strategies (I) and (II) we use a total of 10000 Gibbs iterations with 1000 as a burn-in sample in each model evaluation. For (III) we first draw 1100 Gibbs samples where we discard the first 1000 as burn-in and use the rest to calculate the probability of improvement PI, to ensure that the estimated marginal likelihood will be approximately unbiased; Figure 7 shows that Chib’s estimate is unbiased already after a few hundred samples. If we stop early and move on to the next BO iteration, otherwise we generate a new batch (of size 100) of Gibbs samples and again check the PI criteria. The total number of Gibbs iterations will therefore vary between 1100 and 10 000 in each of the 250 BOOP-iterations for the medium-sized model. Note that Chib’s estimator uses an estimate of the parameter for the so-called reduced Gibbs sampler run. This point estimate should preferably have a high posterior density for efficiency reasons, see Chib, (1995). The medium-sized model uses only 100 posterior samples to obtain high-density parameters for calculating Chib’s log marginal likelihood, which is enough in our set-up. For the large model, we use burn-in samples and simulations in the first batch, which gives between and MCMC iterations per evaluation point. The burn-in is likely to be excessive but is used to be conservative; a small number would make BOOP even faster in comparison to regular BO. The application is robust to the choice of , as long as it is a reasonably low number, in this study we use .
For comparison, we will also use the standard values of the hyperparameters used in e.g. the BEAR-toolbox, Dieppe et al., (2016), , as a benchmark. The methods are compared with respect to i) the obtained marginal likelihood, and ii) how much computational resources were spent in the optimization.
5.4 Results for the medium-scale steady state VAR model
| Standard | BO-EI | BOOP-EI | Grid | ||
|---|---|---|---|---|---|
| Log ML | |||||
| Gibbs iterations | |||||
| CPU-time (minutes) | |||||
| Model evaluations | |||||
The table compares different methods for hyperparameter optimization in the medium-scale steady-state BVAR. Each method is run 10 times and the reported hyperparameters for each method are the best ones over the 10 runs, rounded to two decimals. The marginal likelihood of the selected models were re-estimated using 200,000 Gibbs iterations with 40,000 as a burn-in. The duration measure is an average over the 10 runs.
Table 2 summarizes the results from ten runs of the algorithms for the medium size BVAR model. We see that all three optimization strategies find hyperparameters that yield substantially higher log marginal likelihood than the standard values. We can also see that both Bayesian optimization methods yield as good hyperparameters as the grid search at only a small fraction of the computational cost. It is also clear from Table 2 that a substantial amount of computations associated with the MCMC are saved when using BOOP. It is interesting to note that the values for are similar for all three optimization approaches but that differs to some extent. This is due to the flatness of the log marginal likelihood in that area.
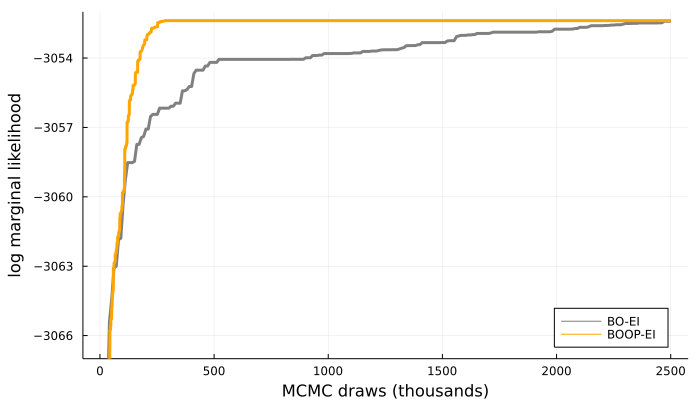
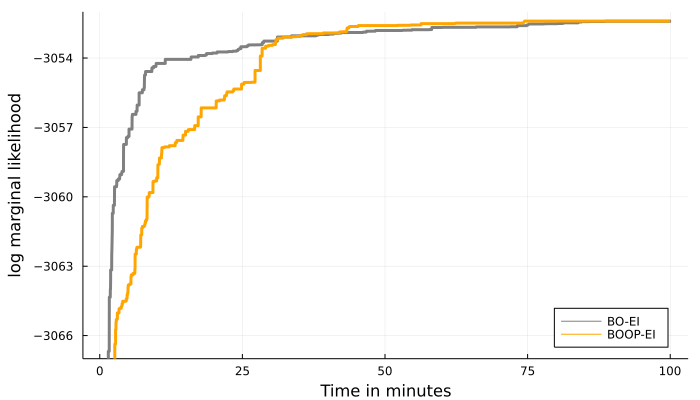
The left graph of Figure 8 shows that BOOP-EI finds higher values of the log marginal likelihood using much fewer MCMC iterations than plain BO with EI acquisitions. From Table 2 we can see that BOOP-EI uses, on average, less than a fifth of the MCMC iterations compared to BO-EI for a full run. Interesting to note is that BO-EI leads to (on average) a higher number of improvements on the way to the maximum; while BOOP-EI gives fewer improvements but of larger magnitude; the strategy of cheaply exploring new territories before locally optimizing the function pays off. The graph to the right in Figure 8 shows that for this application BO-EI is quicker in terms of CPU time to reach fairly high values for the log marginal likelihood. We see at least two explanations for this: first, BOOP-EI tries to explore more unknown territories since they are presumed to be cheap while BO-EI more greedily focuses on local optimization. Second, and more importantly, the overhead cost associated with the BOOP-EI acquisition is relatively large in this medium-sized application where the cost of evaluating the marginal likelihood itself is not excessive. The fact that BOOP can heavily reduce the number of MCMC draws while still giving similar CPU computational time suggest that it is most useful in cases where each log marginal likelihood evaluation is expensive; this will be demonstrated in the more computationally demanding models in Sections 5.5 and 6.
Figure 9 displays the log marginal likelihood surfaces over the grid of -values used in the grid search. Each sub-graph is for a fixed value of . The red dot indicates the predicted maximum log marginal likelihood for the given and the black dot in the middle sub-figure indicates the standard values. We can see that the standard values are located outside the high-density region, relatively far away from the maximum. A comparison of Figures 9 and 10 shows that the GP’s predicted log marginal likelihood surface is quite accurate already after merely 250 evaluations; this is quite impressive considering that Bayesian optimization tries to find the maximum in the fastest way, and does not aim to have high precision in low-density regions.
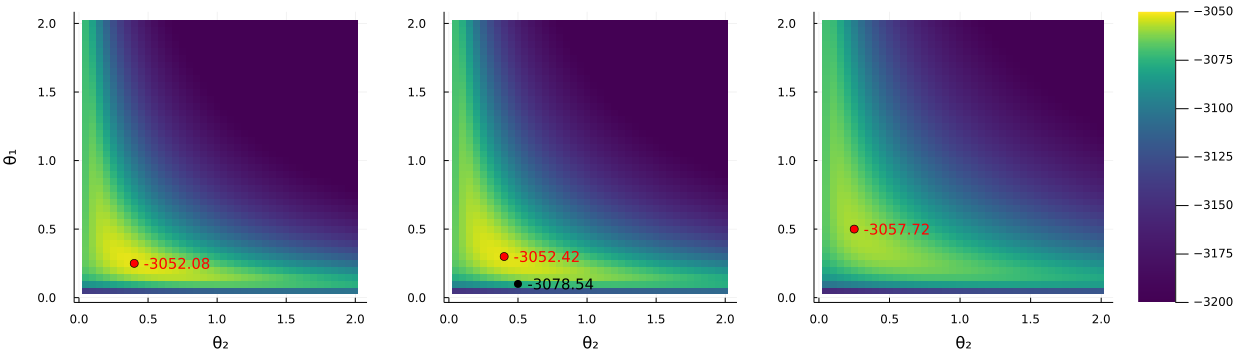
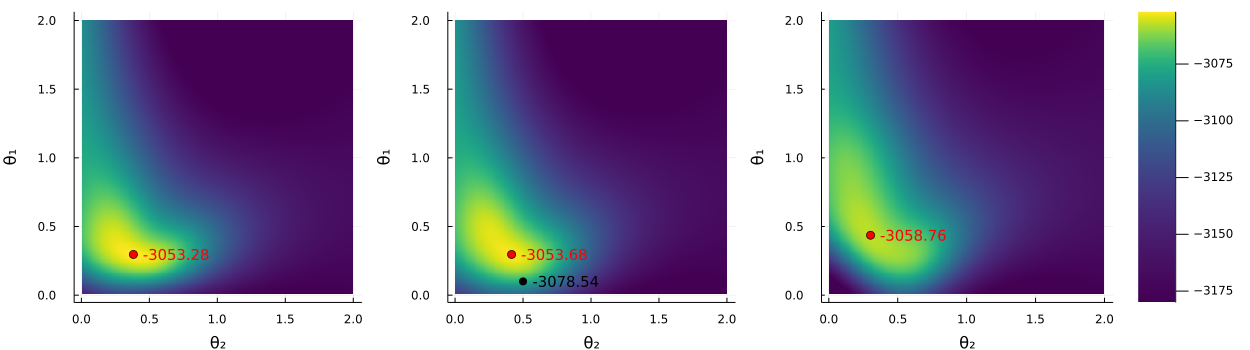
5.5 Results for the large-scale steady state VAR model
We also optimize the parameters of the more challenging large BVAR model containing the 22 different time series, using 250 iterations for both BO-EI and BOOP-EI. A complete grid search is too costly here, so we instead compare with parameters obtained from BOOP in the medium-sized BVAR in Section 5.4, which is a realistic strategy in practical work.
| Standard | BO-EI | BOOP-EI | Medium BVAR | |
|---|---|---|---|---|
| Log ML | ||||
| Sd log ML | ||||
| Gibbs iterations | ||||
| CPU-time (hours) | ||||
Hyperparameter optimization in the large-scale steady-state BVAR. The column named “Medium BVAR” are the values obtained from using BOOP-EI for the medium size model. Both optimization methods were run 5 times and the reported hyperparameters for each method are the best ones over the 5 runs, rounded to two decimals. The marginal likelihood of the selected models were re-estimated using 100,000 Gibbs iterations with 40,000 as a burn-in. The duration measures are averages over the 5 runs.
Table 3 shows that our method, again, finds optimal hyperparameters with dramatically larger log ML than standard values, and also substantially better values than those that are optimal for the medium-scale BVAR. Finally, note that the hyperparameters selected by BOOP-EI in the large-scale BVAR are quite different from those in the medium-scale model. The optimal applies less baseline shrinkage than before, but the lag decay () is higher, and in particular, the cross-lag shrinkage, , is much closer to zero, implying much harder shrinkage towards univariate AR-processes. This latter result strongly suggests that the computationally attractive conjugate prior structure is a highly sub-optimal solution since such a prior requires that . We can see that for this more computationally demanding model BOOP-EI is much faster and finish on average in a third of the time than the regular BO-EI strategy. Figure 11 show the predicted log marginal likelihood surface obtained from the last GP in a BOOP run. The rightmost graph conditions on , which is optimal for BOOP-EI, so this graph therefore has the GP with the highest accuracy.
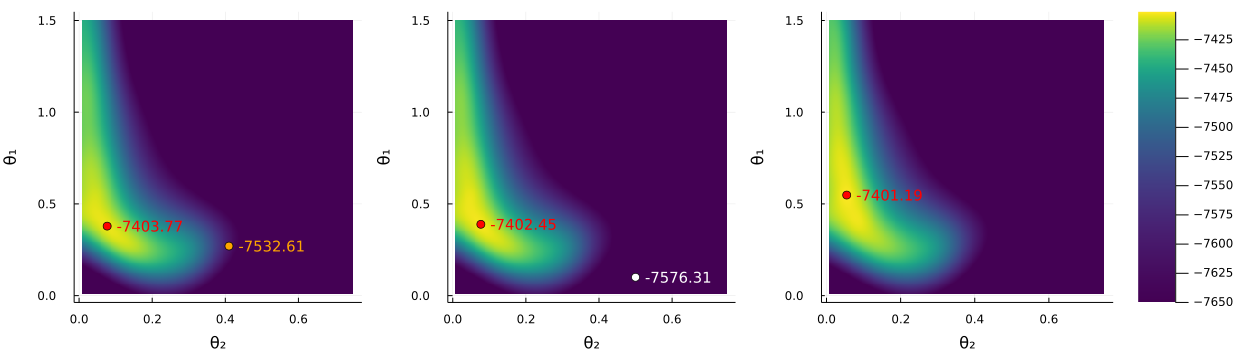
6 Time-varying parameter BVAR with stochastic volatility
6.1 Model and setup
The time-varying parameter BVAR with stochastic volatility (TVP-SV BVAR) in Chan and Eisenstat, (2018) is given by
| (23) |
where is a vector of time varying intercepts, are matrices of VAR coefficients, is a lower triangular matrix with ones on the main diagonal. The evolution of is modelled by the vector of log volatilities, , evolving as a random walk
| (24) |
where and the starting values in are parameters to be estimated. Following Chan and Eisenstat, (2018), we collect all parameters of and the matrices in a -dimensional vector and write the model in state space form as
| (25) |
where contain both current and lagged values of , and the initial values for the state variables follow and .
For comparability we choose to use the same prior setup as in Chan and Eisenstat, (2018) where the variances of the state innovations follow independent inverse-gamma distributions: if is an intercept, if is a VAR coefficient and for the innovations to the log variances. Following Chan and Eisenstat, (2018) we set , , , , and , but we use Bayesian optimization to find the optimal values for the three key hyperparameters , and which controls the degree of time-variation in the states. We collect the three optimized hyperparameter in the vector , where , and . We optimize over the domain , which allows for all cases from no time variation in any parameter to high time variation in all the model parameters.
To estimate the marginal likelihood, Chan and Eisenstat, (2018) first obtain posterior draws of using Gibbs sampling, which are then used to design efficient importance sampling proposals. The marginal likelihood is
| (26) |
where collects all the static parameters in . The inner integral w.r.t. can be solved analytically and afterwards, we can integrate out using importance sampling to obtain an estimate of the integrated likelihood
| (27) |
The last step is to integrate out the fixed parameters from the integrated likelihood
| (28) |
which is done using another importance sampler. The two nested importance samplers put the algorithm in the framework of importance sampling squared (, Tran et al., (2013)). The Chan-Eisenstat algorithm is elegantly designed, but necessarily computationally expensive with a single estimate of the marginal likelihood taking 205 minutes in MATLAB on a standard desktop (Chan and Eisenstat,, 2018). We call their MATLAB code from Julia using the MATLAB.jl package, illustrating that BOOP can plug in any marginal likelihood estimator. However, we found that the standard errors in Chan and Eisenstat, (2018) can be more robustly estimated using the bootstrap and we have done so here. The cost of bootstrapping the standard errors only has to be taken once for every Bayesian optimization iteration, and this cost is negligible compared to the computation of the log marginal likelihood estimate.
We use quarterly data for the GDP-deflator, real GDP, and the short-term interest rate in the USA from 1954Q3 to 2014Q4 from Chan and Eisenstat, (2018) for comparability. In addition, we make use of their Matlab code (with minor adjustments) for computing the marginal likelihood. This shows another strength with the BOOP approach, that it works on top of existing code.
We fix the number of Gibbs sampling iterations and the burn-in period to and respectively for both BO-EI and BOOP-EI in all evaluation points. This simplifies the implementation and does not make a practical difference since the main part of the computational cost is spent on the log marginal likelihood estimate from importance sampling. For BO-EI we use log marginal likelihood evaluations in each new evaluation point, while BOOP-EI starts with importance sampling draw and then takes batches of size until a maximum of samples has been reached. The initial 1000 draws were enough to make the estimator approximately unbiased.
6.2 Results for the TVP-SV BVAR
Table 4 shows the optimized log marginal likelihood from three independent runs of BO-EI and BOOP-EI; the hyperparameter values used in Chan and Eisenstat, (2018) are shown for reference. As expected both BO and BOOP find better hyperparameters than the ones in Chan and Eisenstat, (2018); this is particularly true for BOOP which gives an increase in the marginal likelihood of more than 10 units on the log scale on average. Interestingly, both BO and BOOP suggest that the stochastic volatilities should be allowed to move more freely than in Chan and Eisenstat, (2018), but that there should be less time variation in the intercepts and VAR coefficients. This points in the same direction as the results in Chan and Eisenstat, (2018) who find that shutting down the time variation in the intercept and VAR coefficients actually increases the marginal likelihood. Our results indicate that when carefully selecting the shrinkage parameters by optimization, the VAR-dynamics should in fact be allowed to evolve over time, but at a slower pace.
Table 4 shows a great deal of variability between runs, in particular for BO. Figure 12 shows that this is probably because the hyperparameter surface is substantially more complicated and multimodal than for the steady-state BVAR. We can also see that the log marginal likelihood is relatively insensitive to changes in around the mode while it is very sensitive to changes in .
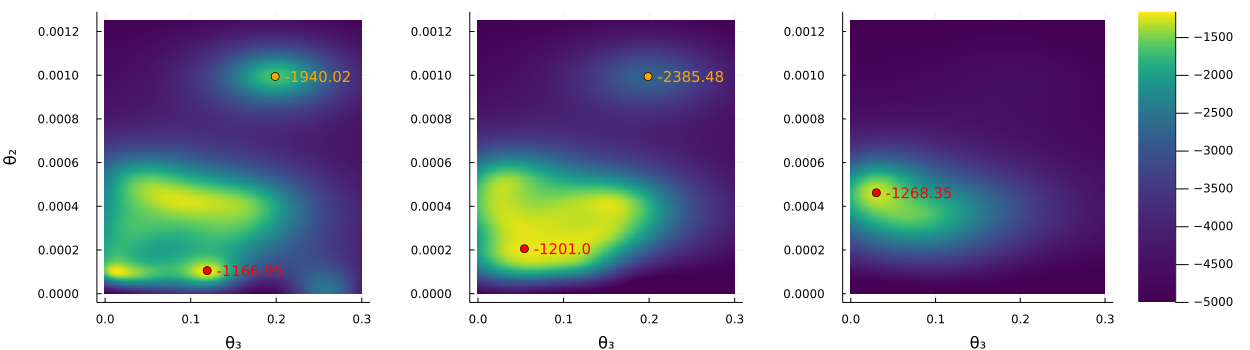
| CE | BO1 | BO2 | BO3 | BOOP1 | BOOP2 | BOOP3 | |
|---|---|---|---|---|---|---|---|
| log ML | |||||||
| SE | |||||||
| Iterations | - | ||||||
| CPU time (hours) | - |
7 Concluding remarks
We propose a new Bayesian optimization method for finding optimal hyperparameters in econometric models. The method can be used to optimize any noisy function where the precision is under the control of the user. We focus on the common situation of maximizing a marginal likelihood evaluated by MCMC or importance sampling, where the precision is determined by the number of MCMC or importance sampling draws. The ability to choose the precision makes it possible for the algorithm to take occasional cheap and noisy evaluations to explore the marginal likelihood surface, thereby finding the optimum faster.
We assess the performance of the new algorithm by optimizing the prior hyperparameters in the extensively used BVAR with stochastic volatility and time-varying parameters and the steady-state BVAR model in both a medium-sized and a large-scale VAR. The method is shown to be practical and competitive to other approaches in that it finds the optimum using a substantially smaller computational budget, and has the potential of being part of the standard toolkit for BVARs. We have focused on optimizing the marginal likelihood, but the method is directly applicable to other score functions, e.g. the popular log predictive score (Geweke and Keane,, 2007 and Villani et al.,, 2012).
Our approach builds on the assumption that the noisy estimates of the log marginal likelihoods are approximately unbiased, which we verify is a reasonable assumption in the three applications if the first BOOP evaluation is based on a marginal likelihood estimator from enough MCMC draws. The unbiasedness of the log marginal likelihood will, however, depend on the combination of MCMC sampler and marginal likelihood estimator, see Adolfson et al., (2007) for some evidence from Dynamic Stochastic General Equilibrium (DSGE) models (An and Schorfheide,, 2007). For example, the simulations in Adolfson et al., (2007) suggest that sampling with the independence Metropolis-Hastings combined with the Chib and Jeliazkov, (2001) estimator is nearly unbiased, whereas sampling with the random walk Metropolis algorithm combined with the modified harmonic estimator (Geweke,, 1999) can be severely biased, unless the posterior sample is extremely large. It would therefore be interesting to extend the method to cases with biased evaluations where the marginal likelihood estimates are persistent and only slowly approaching the true marginal likelihood. Since the marginal likelihood trajectory over MCMC iterations is rather smooth (Adolfson et al.,, 2007) one can try to predict its evolution and then correct the bias in the marginal likelihood estimates.
References
- Adolfson et al., (2007) Adolfson, M., Lindé, J., and Villani, M. (2007). Bayesian analysis of DSGE models-some comments. Econometric Reviews, 26(2-4):173–185.
- An and Schorfheide, (2007) An, S. and Schorfheide, F. (2007). Bayesian analysis of DSGE models. Econometric reviews, 26(2-4):113–172.
- Bańbura et al., (2010) Bańbura, M., Giannone, D., and Reichlin, L. (2010). Large Bayesian vector auto regressions. Journal of Applied Econometrics, 25(1):71–92.
- Bezanson et al., (2017) Bezanson, J., Edelman, A., Karpinski, S., and Shah, V. B. (2017). Julia: A fresh approach to numerical computing. SIAM review, 59(1):65–98.
- Brochu et al., (2010) Brochu, E., Cora, V. M., and De Freitas, N. (2010). A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv preprint arXiv:1012.2599.
- Carriero et al., (2012) Carriero, A., Kapetanios, G., and Marcellino, M. (2012). Forecasting government bond yields with large Bayesian vector autoregressions. Journal of Banking & Finance, 36(7):2026–2047.
- Chan and Eisenstat, (2018) Chan, J. C. and Eisenstat, E. (2018). Bayesian model comparison for time-varying parameter vars with stochastic volatility. Journal of applied econometrics, 33(4):509–532.
- Chib, (1995) Chib, S. (1995). Marginal likelihood from the Gibbs output. Journal of the American Statistical Association, 90(432):1313–1321.
- Chib and Jeliazkov, (2001) Chib, S. and Jeliazkov, I. (2001). Marginal likelihood from the Metropolis-Hastings output. Journal of the American Statistical Association, 96(453):270–281.
- Dieppe et al., (2016) Dieppe, A., Legrand, R., and Van Roye, B. (2016). The BEAR toolbox.
- Doan et al., (1984) Doan, T., Litterman, R., and Sims, C. (1984). Forecasting and conditional projection using realistic prior distributions. Econometric reviews, 3(1):1–100.
- Doucet et al., (2001) Doucet, A., De Freitas, N., Gordon, N. J., et al. (2001). Sequential Monte Carlo methods in practice. Springer.
- Geweke, (1999) Geweke, J. (1999). Using simulation methods for Bayesian econometric models: inference, development, and communication. Econometric reviews, 18(1):1–73.
- Geweke and Keane, (2007) Geweke, J. and Keane, M. (2007). Smoothly mixing regressions. Journal of Econometrics, 138(1):252–290.
- Giannone et al., (2015) Giannone, D., Lenza, M., and Primiceri, G. E. (2015). Prior selection for vector autoregressions. Review of Economics and Statistics, 97(2):436–451.
- Hannan and Quinn, (1979) Hannan, E. J. and Quinn, B. G. (1979). The determination of the order of an autoregression. Journal of the Royal Statistical Society: Series B (Methodological), 41(2):190–195.
- Karlsson, (2013) Karlsson, S. (2013). Forecasting with Bayesian vector autoregression. In Handbook of Economic Forecasting, volume 2, pages 791–897. Elsevier.
- Louzis, (2019) Louzis, D. P. (2019). Steady-state modeling and macroeconomic forecasting quality. Journal of Applied Econometrics, 34(2):285–314.
- Matérn, (1960) Matérn, B. (1960). Spatial variation. Medd. fr. St. Skogsf. Inst. 49 (5). Reprinted in Lecture Notes in Statistics no. 36.
- Österholm, (2012) Österholm, P. (2012). The limited usefulness of macroeconomic Bayesian VARs when estimating the probability of a US recession. Journal of Macroeconomics, 34(1):76–86.
- Primiceri, (2005) Primiceri, G. E. (2005). Time varying structural vector autoregressions and monetary policy. The Review of Economic Studies, 72(3):821–852.
- Quinn, (1980) Quinn, B. G. (1980). Order determination for a multivariate autoregression. Journal of the Royal Statistical Society: Series B (Methodological), 42(2):182–185.
- Snoek et al., (2012) Snoek, J., Larochelle, H., and Adams, R. P. (2012). Practical bayesian optimization of machine learning algorithms. In Advances in neural information processing systems, pages 2951–2959.
- Tran et al., (2013) Tran, M.-N., Scharth, M., Pitt, M. K., and Kohn, R. (2013). Importance sampling squared for bayesian inference in latent variable models. arXiv preprint arXiv:1309.3339.
- Villani, (2009) Villani, M. (2009). Steady-state priors for vector autoregressions. Journal of Applied Econometrics, 24(4):630–650.
- Villani et al., (2012) Villani, M., Kohn, R., and Nott, D. J. (2012). Generalized smooth finite mixtures. Journal of Econometrics, 171(2):121–133.
- Williams and Rasmussen, (2006) Williams, C. K. and Rasmussen, C. E. (2006). Gaussian processes for machine learning, volume 2. MIT Press Cambridge, MA.