Beat: Bi-directional One-to-Many Embedding Alignment for Text-based Person Retrieval
Abstract.
Text-based person retrieval (TPR) is a challenging task that involves retrieving a specific individual based on a textual description. Despite considerable efforts to bridge the gap between vision and language, the significant differences between these modalities continue to pose a challenge. Previous methods have attempted to align text and image samples in a modal-shared space, but they face uncertainties in optimization directions due to the movable features of both modalities and the failure to account for one-to-many relationships of image-text pairs in TPR datasets. To address this issue, we propose an effective bi-directional one-to-many embedding paradigm that offers a clear optimization direction for each sample, thus mitigating the optimization problem. Additionally, this embedding scheme generates multiple features for each sample without introducing trainable parameters, making it easier to align with several positive samples. Based on this paradigm, we propose a novel Bi-directional one-to-many Embedding Alignment (Beat) model to address the TPR task. Our experimental results demonstrate that the proposed Beat model achieves state-of-the-art performance on three popular TPR datasets, including CUHK-PEDES (65.61 R@1), ICFG-PEDES (58.25 R@1), and RSTPReID (48.10 R@1). Furthermore, additional experiments on MS-COCO, CUB, and Flowers datasets further demonstrate the potential of Beat to be applied to other image-text retrieval tasks.
1. Introduction
The task of text-based person retrieval (TPR) (Li et al., 2017b) is of critical importance as it aims to seek a specific person from a vast image gallery through a natural language description query. Unlike traditional image-based or attribute-based person retrieval methods, TPR leverages language descriptions that are more easily accessible and provide more comprehensive information. However, due to the significant difference between the visual and linguistic modalities, TPR is also a more challenging task than image-based or attribute-based person retrieval.
To address the significant modality gap, numerous previous works (Li et al., 2017b; Zhu et al., 2021; Han et al., 2021) have adopted a modal-shared one-to-one embedding paradigm. This paradigm involves embedding images and textual descriptions into a joint space through a one-to-one projection function, which is then used to investigate semantic alignment between image and text pairs. While this paradigm is theoretically elegant and has been widely used for decades, it suffers from two limitations in optimization and alignment.
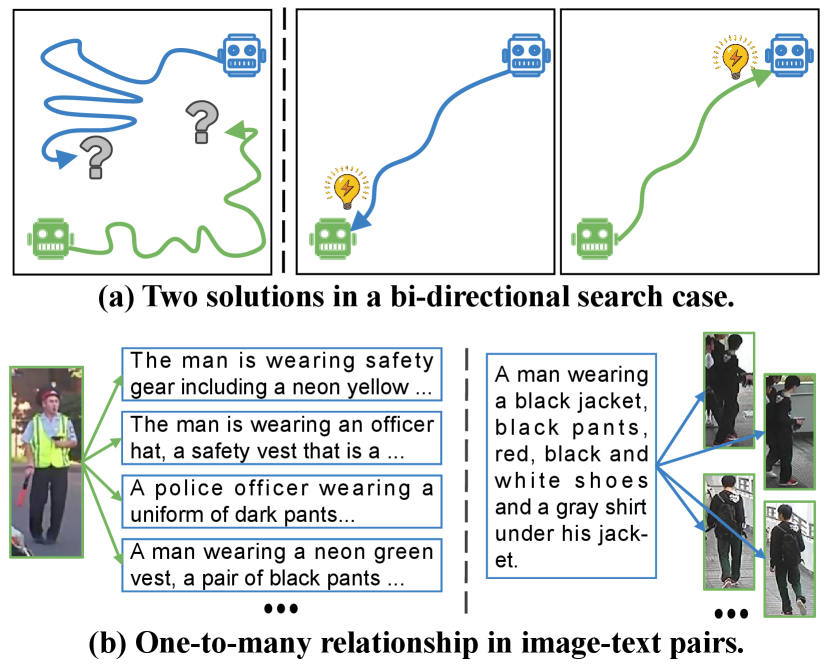
Firstly, the modal-shared embedding technique in this paradigm presents a significant challenge in optimizing the model. This is due to the fact that both visual and textual features are trainable, leading to fluctuations in the optimization direction. This can be likened to a bi-directional search scenario. As illustrated in Fig. 1(a), when both agents are movable, it is difficult for them to find each other due to the uncertain meeting location. Similarly, when features of both modalities are movable during alignment, the uncertainty in optimization direction becomes even more pronounced. Consequently, the conventional modal-shared embedding paradigm is less effective than alternative solutions that fix one modality and only optimize the other.
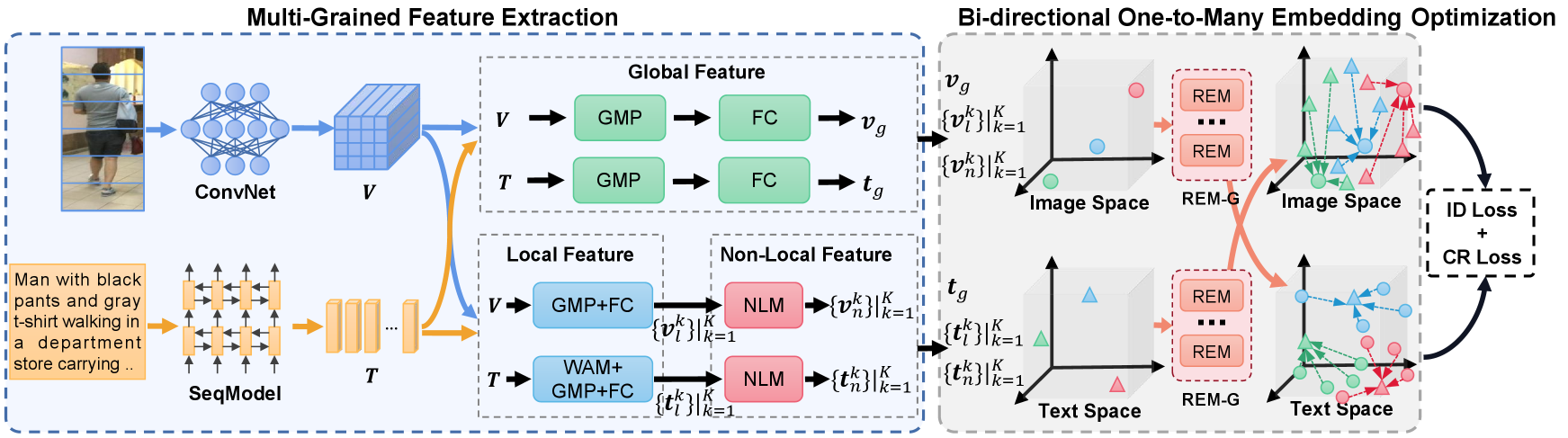
To address the optimization challenge of the modal-shared embedding paradigm, we propose a novel and effective approach called the bi-directional embedding paradigm. This approach involves separately projecting images and text into modality-specific spaces for matching, as illustrated in Fig. 2. We first extract multi-grained textual and visual features using established methods (Ding et al., 2021). Unlike the conventional modal-shared embedding paradigm that aligns both visual and textual features in a modal-shared space where both modalities are trainable, the proposed bi-directional embedding paradigm aligns samples in both image and text spaces. Specifically, we use a projection function to embed visual features into the text space and align them with textual features based on cosine similarity, where textual features are fixed in the text space. Similarly, the same operation is performed for textual features. This approach enables us to achieve effective alignment between the two modalities while mitigating the optimization problem that arises when both modalities are trainable.
Secondly, the one-to-one embedding scheme employed in prior studies (Li et al., 2017b; Zhu et al., 2021; Han et al., 2021; Fei et al., 2022) inadequately accounts for the one-to-many relationship inherent in image-text pairs. This issue is demonstrated in Fig. 1(b), where an image of a person may be associated with a varied range of textual descriptions that emphasize different aspects of the individual or depict them in diverse styles. Likewise, a textual description may correspond to multiple images of the same person due to the possibility of being captured by different cameras. This phenomenon presents a significant challenge in aligning a query with multiple positive samples since the traditional one-to-one embedding paradigm only maps the query to a single feature.
To tackle the challenge of aligning one query sample with multiple positive samples, we propose a novel approach called the one-to-many embedding paradigm, which provides multiple embedding features for each sample. Our approach utilizes a residual embedding module group (REM-G), which comprises several residual embedding modules (REMs). Each REM performs one-to-one projection, enabling the REM-G to perform one-to-many embedding. It is worth noting that due to the bottleneck structure used for each REM, the one-to-many embedding does not introduce additional parameters. By generating multiple embedding features for each query sample, our approach allows several positive samples to align with the most suitable feature, thereby alleviating the difficulty of one-to-many alignment.
Based on the proposed bi-directional one-to-many embedding paradigm, we introduce a new model called the Bi-directional one-to-many Embedding Alignment (Beat) model to tackle the challenging TPR task. To evaluate the proposed approach, we conduct extensive experiments on three TPR datasets: CUHK-PEDES (Li et al., 2017b), ICFG-PEDES (Ding et al., 2021), and RSTPReID (Zhu et al., 2021). Our results consistently demonstrate that the proposed Beat model outperforms existing state-of-the-art (SOTA) approaches significantly. Moreover, our proposed paradigm also yields benefits on other image-text retrieval datasets, such as MS-COCO (Lin et al., 2014), CUB (Reed et al., 2016), and Flowers (Reed et al., 2016).
In summary, the main contributions of our work include:
-
•
We present a novel approach that uses a bi-directional embedding paradigm to align visual and textual samples in TPR, which addresses the issue of uncertain optimization direction in the traditional paradigm.
-
•
We notice that the images and their corresponding representations in the TPR dataset exhibit a one-to-many relationship. Hence, we propose a one-to-many embedding paradigm that models this relationship in image-text pairs, thereby improving one-to-many alignment for TPR.
-
•
Building on the proposed bi-directional one-to-many embedding paradigm, we propose the Beat model, which achieves SOTA performance on three TPR datasets and consistently improves other image-text retrieval tasks.
2. Related Work
2.1. Text-based Person Retrieval
The text-based person retrieval (TPR) task (Xu et al., 2023; Jiang and Ye, 2023; Ding and Mang, 2023; Wang et al., 2023b; Chen et al., 2023; Wang et al., 2022c, b, a), which retrieves a person through natural language descriptions, differs from conventional image-based or attribute-based methods. Considerable research has been dedicated to this task, with Li et al. (Li et al., 2017b) proposing a CNN-LSTM network with gated neural attention, and Li et al. (Li et al., 2017a) introducing an identity-aware two-stage framework to improve retrieval performance. Other approaches include Jing et al. (Jing et al., 2020a), who leverage pose information as a soft attention signal to locate important and discriminative regions, and Niu et al. (Niu et al., 2020), who propose a multi-granularity image-text alignments model to mitigate the cross-modal fine-grained problem. Liu et al. (Liu et al., 2019b) introduce a novel A-GANet to exploit semantic scene graphs, while Zhu et al. (Zhu et al., 2021) propose deep surroundings-person separation learning to extract and match person information while reducing interference from surrounding information. Jing et al. (Jing et al., 2020b) propose a moment alignment network to solve cross-modal cross-domain person search, while Wu et al. (Wu et al., 2021) adopt two color reasoning sub-tasks to improve model sensitivity to fine-grained cross-modal information.
All previous TPR methods employ the modal-shared one-to-one embedding paradigm, where image and text are embedded into a unified space for similarity evaluation via a one-to-one projection function. In this paper, we propose a novel bi-directional one-to-many embedding paradigm that reduces optimization difficulty and adapts to the one-to-many relationship in image-text pairs.
2.2. Visual-Textual Embedding
The field of visual-textual embedding technology is gaining increasing attention from researchers due to the rapid growth of vision and language data. In particular, several methods have been proposed to align visual and textual samples. Frome et al. (Frome et al., 2013) proposed a visual semantic embedding (VSE) framework that aligns images with sentences using ranking loss. Faghri et al. (Faghri et al., 2017) improved the VSE model by focusing on computing the hardest negative examples, with the aim of improving computational efficiency. Huang et al. (Huang et al., 2017) introduced a novel multi-modal context-modulated attention scheme, implemented using a multi-modal LSTM network, to attend to an image-text pair at each timestep. Lee et al. (Lee et al., 2018) proposed the stacked cross attention network (SCAN) which employs a fine-grained attention mechanism to embed images and sentences. Aside from the conventional image-text matching task, visual-textual embedding has also benefited many other multi-modal tasks, such as image captioning (IC)(Ji et al., 2022; Ma et al., 2022; Hu et al., 2022; Fang et al., 2022) and visual question answering (VQA)(Jing et al., 2022; Ding et al., 2022; Cascante-Bonilla et al., 2022; Chun et al., 2021). For example, Anderson et al. (Anderson et al., 2018) proposed bottom-up top-down attention for IC and VQA, while Jiang et al. (Jiang et al., 2020) explored the grid representation of the object detector to further improve the performance of VQA.
In this context, our work proposes a bi-directional one-to-many embedding paradigm for visual-textual embedding. This approach is complementary to the aforementioned works and has the potential to enhance the performance of a range of multi-modal tasks (Wang et al., 2022d; Fei et al., 2023; Lin et al., 2020; Wang et al., 2023a).
3. The Proposed Method
In this section, we elaborate on each component of the proposed Beat, which is illustrated in Fig. 2. Specifically, we first introduce the problem formulation of the TPR task in Sec. 3.1. Then, we explain how to extract the multi-grained visual and textual features in Sec. 3.2. We show the details of the key bi-directional one-to-many embedding paradigm REM-G in Sec. 3.3. Finally, we describe the optimization of our proposed framework in Sec. 3.4.
3.1. Problem Formulation
The goal of the proposed Beat is to calculate the semantic similarity scores between the description queries and the images in TPR. Formally, a TPR dataset consists of image-text pairs, which are denoted as . Each image-text pair is also provided with a identity (ID) label . The set of all IDs is denoted as with , where is the number of distinct IDs for all pedestrians. Given a textual description , a TPR model aims to retrieve images with the same ID as from a large-scale image gallery.
3.2. Multi-Grained Feature Extraction
As TRP is a fine-grained retrieval task, it is insufficient to extract only coarse-grained features to differentiate detailed information among pedestrians. To address this challenge, we follow previous research (Ding et al., 2021; Shao et al., 2022) and extract multi-grained features from both images and texts to enable comprehensive perception. This approach allows us to capture more nuanced information and better distinguish between similar-looking pedestrians in the dataset.
Backbone. Given an image , we use the pre-trained ResNet (He et al., 2016) backbone on ImageNet (Deng et al., 2009) to extract the visual representation , where , and are the height, width, and channel dimension of , respectively.
For a description sentence , we adopt a pre-trained frozen BERT (Devlin et al., 2018) and a trainable Bi-LSTM model to extract the textual feature following (Wang et al., 2022c), where and refer to the length and channel dimension of the textual representation.
Global Feature Extraction. To obtain global visual and textual features, we employ a global max pooling (GMP) operation on the visual feature map and the textual feature map to eliminate spatial dimensions. We then pass the resulting feature vectors through fully connected (FC) layers for embedding. This process can be expressed mathematically as follows:
| (1) |
| (2) |
where and are the trainable parameter matrices of FC layers. is the channel dimension of the global feature. and refer to the obtained global visual and textual features, respectively.
Local Feature Extraction. To obtain local visual features, we first uniformly split into non-overlapping parts, which is denoted as with . For textual features, we adopt the word attention module (WAM) (Ding et al., 2021) to obtain textual features .
Then, for the -th part features and , we use GMP modules and FC layers to obtain the local visual feature and textual feature :
| (3) |
| (4) |
where .
Non-local Feature Extraction. For non-local interactions, we introduce the non-local module (NLM) (Ding et al., 2021) to perform modeling between local features to obtain non-local features. Specifically, we first calculate the cosine similarity score between and after linear embedding:
| (5) |
where . Then, we aggregate local visual features based on similarity scores as follows:
| (6) |
where . The final non-local visual feature is denoted as follows:
| (7) |
where . The non-local textual feature could be obtained in the same way.
3.3. Bi-directional One-to-Many Embedding
The conventional modal-shared one-to-one embedding paradigm (Zhu et al., 2021; Zheng et al., 2020a; Ding et al., 2021; Chen et al., 2018) involves embedding visual and textual samples into a joint space for alignment using a one-to-one projection function. However, this approach overlooks the challenges posed by uncertain optimization and the one-to-many relationships present in image-text pairs. To overcome these limitations, we propose a novel bi-directional one-to-many embedding paradigm. In this section, we provide detailed explanations of both the bi-directional embedding and one-to-many embedding techniques that we employ in our proposed approach.
Bi-directional Embedding. As analyzed in Sec. 1, since features of both modalities are movable in the joint space, the conventional modal-shared projection leads to the problem of uncertain optimization direction, thus increasing the difficulty of optimization. To address the challenges posed by the movable features in the joint space, we propose a bi-directional embedding paradigm that projects the features of each modality into their respective modal-specific spaces. Specifically, we first fix the textual features and project only the visual features into the textual feature space for matching. This approach provides the visual features with a clear optimization direction. We also fix the visual features and only project textual features into the image space for alignment. Formally, the bi-directional embedding for global features can be expressed as follows:
| (8) |
| (9) |
where and represent the global visual feature in text space and the global textual feature in image space, respectively. To project visual features into text space, we employ an embedding function denoted by , while for projecting textual features into image space, we use the embedding function . The next section provides detailed information about the specific forms of these embedding functions.
One-to-Many Embedding. The one-to-many relationship between image and text pairs is a widely recognized fact, and the conventional one-to-one projection may yield suboptimal outcomes in TPR datasets. The reason behind this is that the multiple positive samples of a query may have slight variations. If only the one-to-one projection is employed on query samples, it becomes challenging for multiple positive samples to align with the unique embedding feature of the query. To address this issue and account for the one-to-many relationship in image-text pairs, we propose a residual embedding module group (REM-G) as and . This module group is capable of performing one-to-many embedding. Our proposed REM-G consists of residual embedding modules (REMs). Each REM incorporates a residual-based linear embedding. The -th REM for global features is formulated as follows:
| (10) |
| (11) |
where and are trainable parameter matrices of the -th REM. is ReLU activation function. and are the global visual features in the text space and the global textual features in the image space, which are projected by the -th REM. Since REM-G consists of REMs, the outputs of REM-G are a list of visual and textual features, i.e., and .
Similarly, following the bi-directional one-to-many embedding paradigm, local and non-local features also yield multiple embedding features in both text and image spaces.
3.4. Optimization
To optimize the model effectively, we employ two widely used objectives, namely, the identity (ID) loss and the compound ranking (CR) loss, which have been previously used in (Ding et al., 2021).
ID Loss. We regard pedestrians with different IDs as different classes and cluster images into groups according to their IDs via ID loss. ID loss is formulated as follows:
| (12) | |||
where , , and are visual features, textual features, and the corresponding IDs, respectively. are trainable parameter matrices. is the operation that takes the value according to the index. is the channel dimension of input features and is the number of person IDs in the training set.
CR Loss. The ranking-based loss has shown its strength in image-text matching (Lee et al., 2018; Faghri et al., 2017). Following (Ding et al., 2021), we adopt CR loss as a matching objective:
| (13) | ||||
where . and represent matched image-text pairs. , , and are unmatched pairs. is the text for another image with the same identity as . and refer to the margins and indicates the weight for the weak supervision terms.
In the conventional methods, there is only one feature for each sample in the modal-shared space, so is just the cosine similarity between the two samples. However, in our method, there are two modal-specific spaces for alignment, and each sample produces features after projection. To this end, we sum the similarity scores computed on multiple embedded features in these two spaces as the final similarity score, which is formulated as:
| (14) |
where is the number of REMs in REM-G. and are the visual feature in the text space and the textual feature in the image space projected by the -th REM, is the cosine similarity function. and include global, local and non-local features.
The final loss function is the sum of ID loss and CR loss:
| (15) |
4. Experiment
4.1. Datasets
To evaluate the effectiveness of Beat, we conducted experiments on three widely-used TRP datasets: CUHK-PEDES (Li et al., 2017b), ICFG-PEDES (Ding et al., 2021), and RSTPReID (Zhu et al., 2021). In addition, to verify the generality of Beat, we also evaluated its performance of three other image-text retrieval datasets: MS-COCO (Lin et al., 2014), Caltech-UCSD Birds (CUB) (Reed et al., 2016), and Oxford-102 Flowers (Flowers) (Reed et al., 2016). Further details on these datasets are available in the supplementary materials.
| Model | R@1 | R@5 | R@10 |
| CNN-RNN (Reed et al., 2016) | 8.07 | - | 32.47 |
| GNA-RNN (Li et al., 2017b) | 19.05 | - | 53.64 |
| PWM-ATH (Chen et al., 2018) | 27.14 | 49.45 | 61.02 |
| GLA (Chen et al., 2018) | 43.58 | 66.93 | 76.26 |
| MIA (Niu et al., 2020) | 53.10 | 75.00 | 82.90 |
| A-GANet (Liu et al., 2019b) | 53.14 | 74.03 | 81.95 |
| ViTAA (Wang et al., 2020a) | 55.97 | 75.84 | 83.52 |
| IMG-Net (Wang et al., 2020d) | 56.48 | 76.89 | 85.01 |
| CMAAM (Aggarwal et al., 2020) | 56.68 | 77.18 | 84.86 |
| HGAN (Zheng et al., 2020a) | 59.00 | 79.49 | 86.60 |
| DSSL (Zhu et al., 2021) | 59.98 | 80.41 | 87.56 |
| MGEL (Wang et al., 2021a) | 60.27 | 80.01 | 86.74 |
| SSAN (Ding et al., 2021) | 61.37 | 80.15 | 86.73 |
| NAFS (Gao et al., 2021) | 61.50 | 81.19 | 87.51 |
| TBPS (Han et al., 2021) | 61.65 | 80.98 | 86.78 |
| LapsCore (Wu et al., 2021) | 63.40 | - | 87.80 |
| Beat | 64.23 | 82.91 | 88.65 |
| Beat* | 65.61 | 83.45 | 89.57 |
4.2. Experimental Settings
We conduct the experiments on RTX3090 24GB GPUs using the PyTorch library. We set the maximum sentence length to 100 and resize the input images to with random horizontal flipping augmentation. We empirically set to 4 and adopt the values of from previous work (Ding et al., 2021; Wang et al., 2020a), specifically 6, 2048, 1024, 1024, 512, 0.2, and 0.1, respectively. is set to 8. We optimize the Beat model for 80 epochs using the Adam optimizer (Kingma and Ba, 2014) with a batch size of 64 and a learning rate of 0.001. We weight the loss functions for global, local, and non-local features as 2, 1, and 1, respectively. During inference, we calculate the cosine similarity between the query feature and candidate features in each space, and select the maximum value as the similarity in this space. The final similarity is the sum of the similarities calculated in the two spaces. In the following experimental results (i.e., Tab. 4 and Fig. 4, 6), the only difference between the base model and Beat is that the base model uses the modal-shared one-to-one embedding paradigm (Ding et al., 2021) using the plain linear layer, while Beat adopts a bi-directional one-to-many embedding paradigm.
4.3. Performance Comparison
To demonstrate the effectiveness and generalizability of our proposed method, we conducted extensive experiments and compared it against previous state-of-the-art (SOTA) models on three widely-used benchmarks: CUHK-PEDES, ICFG-PEDES, and RSTPReID. Our results, as shown in Tab. 1-3, consistently demonstrate that Beat outperforms the strongest competitors by a significant margin. Specifically, we achieved 65.61 R@1, 58.25 R@1, and 48.10 R@1 on these datasets, respectively. It is noteworthy that previous TPR methods only produce a single feature for each sample and calculate cross-modal similarity score in the modal-shared space, whereas our proposed Beat is a pioneer work that explores the bi-directional one-to-many embedding paradigm for cross-modal alignment. Our significant performance gain clearly shows that this new paradigm is highly effective in aligning multi-modal samples and improving the TPR task’s overall performance.
| Model | R@1 | R@5 | R@10 |
| Dual Path (Zheng et al., 2020b) | 38.99 | 59.44 | 68.41 |
| CMPM+CMPC (Zhang and Lu, 2018) | 43.51 | 65.44 | 74.26 |
| MIA (Niu et al., 2020) | 46.49 | 67.14 | 75.18 |
| SCAN (Lee et al., 2018) | 50.05 | 69.65 | 77.21 |
| ViTAA (Wang et al., 2020a) | 50.98 | 68.79 | 75.78 |
| SSAN (Ding et al., 2021) | 54.23 | 72.63 | 79.53 |
| Beat | 57.62 | 75.04 | 81.53 |
| Beat* | 58.25 | 75.92 | 81.96 |
| Model | R@1 | R@5 | R@10 |
| IMG-Net (Wang et al., 2020d) | 37.60 | 61.15 | 73.55 |
| AMEN (Wang et al., 2021b) | 38.45 | 62.40 | 73.80 |
| DSSL (Zhu et al., 2021) | 32.43 | 55.08 | 63.19 |
| ASPD-Net (Wang et al., 2022a) | 39.90 | 65.15 | 74.40 |
| SUM (Wang et al., 2022b) | 41.38 | 67.48 | 76.48 |
| Beat | 47.30 | 69.65 | 79.20 |
| Beat* | 48.10 | 73.10 | 81.30 |
4.4. Ablation Study
| Model | Params | Speed | R@1 |
| Base | 230.13M | 31.38 ms/txt | 62.78 |
| Beat | 230.13M | 34.93 ms/txt | 64.23 |
Efficiency and Parameter Comparison. Tab. 4 presents a comparison of the efficiency and parameters between the base model and Beat. By adopting a bottleneck structure, Beat maintains the same number of parameters as the base model. Thus, the performance gain does not come from the increase of trainable parameters. Due to the one-to-many embedding of Beat, cross-modal similarity calculations are performed multiple times, which may affect the model efficiency. Nevertheless, our experimental results demonstrate that the impact on efficiency (+3.55 ms/txt) can be disregarded, given the significant performance improvements achieved (+1.45 R@1).
Effect of Embedding Space. To gain a deeper understanding of the bi-directional embedding paradigm, we conducted a series of ablation studies on the CUHK-PEDES dataset, in which we aligned image and text samples in different spaces, namely the image space, text space, and modal-shared space. Our analysis of the results presented in Tab. 5 led us to the following observations:
-
•
We found that aligning samples in both image and text spaces (Exp7) outperforms aligning them in either space alone (Exp4, Exp5) by a margin of 1.72 R@1 and 2.05 R@1, respectively. This indicates that the alignment results in the image and text spaces can complement each other and lead to better retrieval performance, thereby demonstrating the superiority of our proposed bi-directional embedding paradigm.
-
•
To eliminate the effect of the number of alignment spaces, we further conducted experiments by aligning samples in different numbers of modal-shared spaces (Exp1, Exp2, Exp3). Our analysis reveals that the retrieval performance declines slightly as the number of modal-shared spaces (MSS) increases. This finding indicates that the performance improvement of our bi-directional embedding paradigm is not solely attributable to the increase in the number of alignment spaces, but rather to the effectiveness of the paradigm itself.
-
•
To further explore the impact of alignment in MSS, we conducted an experiment (Exp6) by aligning visual and textual samples in all three spaces. However, we found that the performance of Exp6 was worse than that of Exp7, suggesting that alignment in MSS leads to performance degradation. The main reason for this may be that alignment in MSS results in the problem of uncertain optimization direction, as explained in Sec. 1.
-
•
By comparing Exp1, Exp4, and Exp5, we observed that aligning samples in the text space performs slightly worse than aligning them in either the image or modal-shared space. This could be because the expression of text is often abstract and general, making it more challenging to align samples in the text space compared to the image space and modal-shared space.
| ID | MSS | IS | TS | R@1 | R@5 | R@10 |
| Exp1 | ✓ | 62.78 | 81.43 | 87.52 | ||
| Exp2 | ✓✓ | 62.46 | 80.99 | 87.64 | ||
| Exp3 | ✓✓✓ | 62.43 | 80.45 | 87.46 | ||
| Exp4 | ✓ | 62.51 | 82.02 | 87.85 | ||
| Exp5 | ✓ | 62.18 | 81.22 | 86.81 | ||
| Exp6 | ✓ | ✓ | ✓ | 63.01 | 81.60 | 87.82 |
| Exp7 | ✓ | ✓ | 64.23 | 82.91 | 88.65 | |
| ID Loss | CR Loss | R@1 | R@5 | R@10 |
| ✓ | 47.43 | 70.86 | 80.04 | |
| ✓ | 37.23 | 59.47 | 69.57 | |
| ✓ | ✓ | 64.23 | 82.91 | 88.65 |
Effect of Loss Function. To explore the impact of the loss function, we also conduct ablation studies by adopting different loss functions. Beat is equipped with two loss functions, i.e., ID loss and CR loss, to both minimize the intra-class distance and maximize the inter-class distance. As shown in Tab. 6, we observe that both ID loss and CR loss are critical for retrieval performance. In particular, the lack of CR loss and ID loss leads to significant performance degradation of 16.80 R@1 and 27.00 R@1, respectively.

| Local | Non-local | Global | R@1 | R@5 | R@10 |
| ✓ | 59.31 | 79.48 | 86.57 | ||
| ✓ | 61.37 | 80.80 | 87.22 | ||
| ✓ | 57.81 | 77.45 | 84.34 | ||
| ✓ | ✓ | 61.61 | 81.12 | 87.31 | |
| ✓ | ✓ | 61.92 | 81.14 | 87.91 | |
| ✓ | ✓ | 61.84 | 80.88 | 87.59 | |
| ✓ | ✓ | ✓ | 64.23 | 82.91 | 88.65 |
| Model | Image-to-Text | Text-to-Image | rSum | ||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| SCAN (Lee et al., 2018) | 72.7 | 94.8 | 98.4 | 58.8 | 88.4 | 94.8 | 507.9 |
| BFAN (Liu et al., 2019a) | 74.9 | 95.2 | - | 59.4 | 88.4 | - | 317.9 |
| PVSE (Song and Soleymani, 2019) | 69.2 | 91.6 | 96.6 | 55.2 | 86.5 | 93.7 | 492.8 |
| CVSE (Wang et al., 2020c) | 69.2 | 93.3 | 97.5 | 55.7 | 86.9 | 93.8 | 496.4 |
| DPRNN (Chen and Luo, 2020) | 75.3 | 95.8 | 98.6 | 62.5 | 89.7 | 95.1 | 517.0 |
| SGM (Wang et al., 2020b) | 73.4 | 93.8 | 97.8 | 57.5 | 87.3 | 94.3 | 504.1 |
| IMRAM (Chen et al., 2020) | 76.7 | 95.6 | 98.5 | 61.7 | 89.1 | 95.0 | 516.6 |
| SMFEA (Ge et al., 2021) | 75.1 | 95.4 | 98.3 | 62.5 | 90.1 | 96.2 | 517.6 |
| SHAN (Ji et al., 2021) | 76.8 | 95.4 | 98.7 | 62.6 | 89.6 | 95.8 | 519.8 |
| NAAF (Zhang et al., 2022) | 78.1 | 96.1 | 98.6 | 63.5 | 89.6 | 95.3 | 521.2 |
| NAAF + REM-G | 79.0 | 96.9 | 98.9 | 64.1 | 90.2 | 95.5 | 524.7 |
Effect of Multi-grained Features. To explore the impact of multi-grained features, we conduct ablation studies incrementally. As reported in Tab. 7, the retrieval performance will gradually improve as more multi-grained features are adopted. These facts demonstrate that multi-grained features may provide complementary information to represent images and descriptions. Besides, we observe that if only one type of feature is used, non-local features (61.37 R@1) outperform global (57.81 R@1) and local (59.31 R@1) features significantly. This may be because non-local features not only contain part-level information but also have global information through non-local interaction.
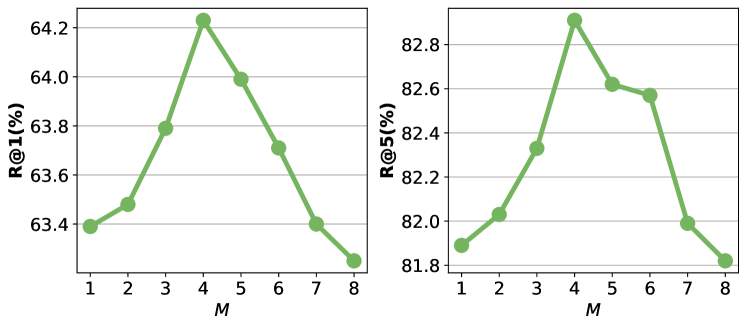
Effect of . We propose REM-G to implement one-to-many embedding and each REM-G consists of REMs, so determines the number of embedded features for each sample. To explore the impact of (i.e., the number of REMs in each REM-G), we conduct experiments by increasing it from 1 to 8. As shown in Fig. 3, we observe that increasing in an appropriate range (i.e., from 1 to 4) can improve the retrieval performance significantly. This can be because the proposed one-to-many embedding strategy handles the scenario of the one-to-many relationship in image-text pairs. However, when is greater than 4, performance begins to drop. The reason may be that too many embedded features increase the difficulty of optimization.
4.5. Qualitative Analysis
Heat map. To provide a deeper understanding of the visual and textual alignment, we have presented heat maps in Fig. 4. These heat maps illustrate the similarity scores between the global textual feature and all grids of the visual feature map , where the brighter parts indicate higher similarity scores. Notably, the description queries in both models mainly focus on the person’s body. It is worth noting that the proposed Beat model accurately localizes the person, even capturing their outline. On the other hand, the base model can only locate the general area of the person (as seen in row 1, column 2 of Fig. 4). Thus, owing to the bi-directional one-to-many embedding paradigm, Beat achieves stronger cross-modal semantic alignment capability compared to the base model.
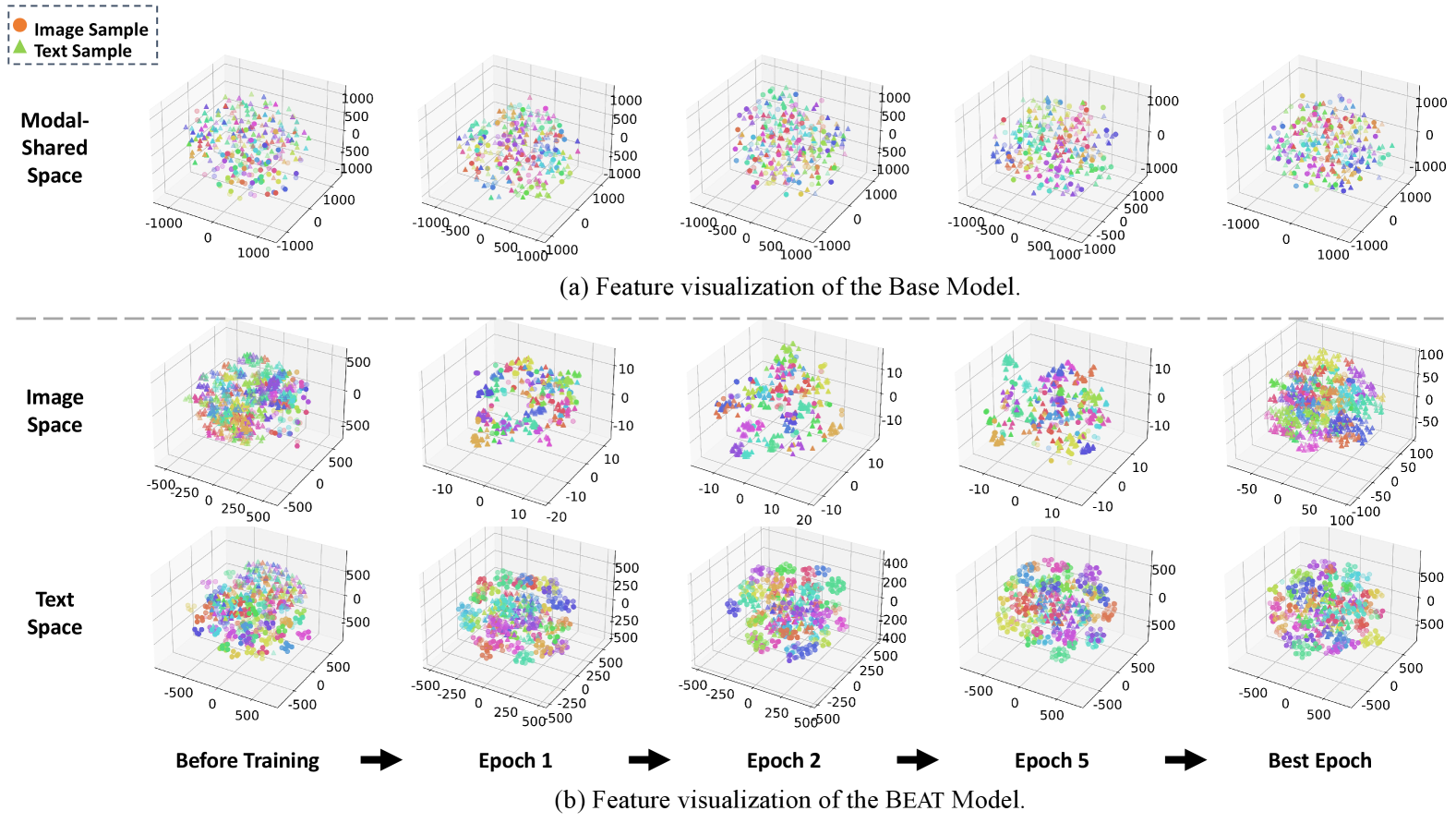
t-SNE Visualization. We randomly sample the images and descriptions of 30 classes and visualize the visual and textual features of different training epochs via t-SNE (Van der Maaten and Hinton, 2008) in Fig. 5 and obtain the following observations:
-
•
Before training, a significant gap exists between visual and textual modalities, and the distance between image and text samples of the same identity (ID) is large in either image or text space. After several training epochs, samples with the same ID are clustered together, and the modality gap is gradually eliminated. Finally, the samples with the same ID converge to a center, and the modality gap almost disappears.
-
•
Compared with the base model, textual and visual features with the same ID generated by Beat achieve better clustering results, which can be observed in the last column of Fig.5.
5. generalizability verification
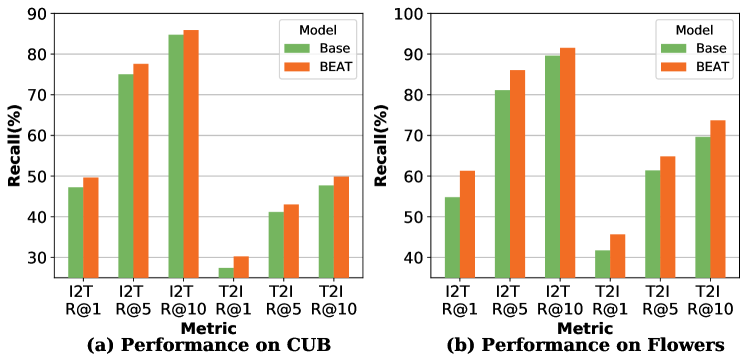
To verify the generalization of our method, we also conduct experiments on several image-text retrieval datasets, including MS-COCO, CUB, and Flowers. Tab. 8 lists the SOTA performance comparison on MS-COCO. We equip the proposed REM-G on the previous SOTA model, i.e., NAAF (Zhang et al., 2022). It can be observed that NAAF+REM-G is +0.9 R@1 (I2T) and +0.6 R@1 (T2I) higher than NAAF. Furthermore, we conduct experiments on CUB (Reed et al., 2016) and Flowers (Reed et al., 2016) to compare the base model and Beat. As shown in Fig. 6, a consistent performance gain is also achieved via adopting the bi-directional one-to-many embedding paradigm, which demonstrates that the proposed paradigm is effective and universal for several types of multi-modal retrieval tasks.
6. Conclusion
This paper presents a novel Beat model, which is the first work on exploring the bi-directional one-to-many embedding paradigm for TPR. Beat achieves state-of-the-art performance on several text-based person retrieval datasets, including CUHK-PEDES, ICFG-PEDES, and RSTPReID. Besides, the proposed bi-directional one-to-many embedding paradigm also attains consistent performance improvement on several image-text retrieval datasets, i.e., MS-COCO, CUB, and Flowers. In the future, we will look forward to investigating its usage on uni-modal retrieval (e.g., image retrieval) and other multi-modal tasks (e.g., image captioning).
Acknowledgement
This work was supported by National Key R&D Program of China (No.2022ZD0118201), the National Science Fund for Distinguished Young Scholars (No.62025603), the National Natural Science Foundation of China (No. U21B2037, No. U22B2051, No. 62176222, No. 62176223, No. 62176226, No. 62072386, No. 62072387, No. 62072389, No. 62002305 and No. 62272401), China Postdoctoral Science Foundation (No.2023M732948), and the Natural Science Foundation of Fujian Province of China (No.2021J01002, No.2022J06001).
References
- (1)
- Aggarwal et al. (2020) Surbhi Aggarwal, Venkatesh Babu Radhakrishnan, and Anirban Chakraborty. 2020. Text-based person search via attribute-aided matching. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2617–2625.
- Anderson et al. (2018) Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. 2018. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6077–6086.
- Cascante-Bonilla et al. (2022) Paola Cascante-Bonilla, Hui Wu, Letao Wang, Rogerio S Feris, and Vicente Ordonez. 2022. Simvqa: Exploring simulated environments for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5056–5066.
- Chen et al. (2023) Cuiqun Chen, Mang Ye, and Ding Jiang. 2023. Towards Modality-Agnostic Person Re-Identification With Descriptive Query. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15128–15137.
- Chen et al. (2018) Dapeng Chen, Hongsheng Li, Xihui Liu, Yantao Shen, Jing Shao, Zejian Yuan, and Xiaogang Wang. 2018. Improving deep visual representation for person re-identification by global and local image-language association. In Proceedings of the European conference on computer vision (ECCV). 54–70.
- Chen et al. (2020) Hui Chen, Guiguang Ding, Xudong Liu, Zijia Lin, Ji Liu, and Jungong Han. 2020. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12655–12663.
- Chen and Luo (2020) Tianlang Chen and Jiebo Luo. 2020. Expressing objects just like words: Recurrent visual embedding for image-text matching. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 10583–10590.
- Chun et al. (2021) Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Yannis Kalantidis, and Diane Larlus. 2021. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8415–8424.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Ding and Mang (2023) Jiang Ding and Ye Mang. 2023. Transformer Network for Cross-modal Text-to-Image Person Re-identification. JOURNAL OF IMAGE AND GRAPHICS (2023). https://doi.org/10.11834/jig.220620
- Ding et al. (2022) Yang Ding, Jing Yu, Bang Liu, Yue Hu, Mingxin Cui, and Qi Wu. 2022. MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5089–5098.
- Ding et al. (2021) Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. 2021. Semantically self-aligned network for text-to-image part-aware person re-identification. arXiv preprint arXiv:2107.12666 (2021).
- Faghri et al. (2017) Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler. 2017. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612 (2017).
- Fang et al. (2022) Zhiyuan Fang, Jianfeng Wang, Xiaowei Hu, Lin Liang, Zhe Gan, Lijuan Wang, Yezhou Yang, and Zicheng Liu. 2022. Injecting semantic concepts into end-to-end image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18009–18019.
- Fei et al. (2023) Hao Fei, Qian Liu, Meishan Zhang, Min Zhang, and Tat-Seng Chua. 2023. Scene Graph as Pivoting: Inference-time Image-free Unsupervised Multimodal Machine Translation with Visual Scene Hallucination. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5980–5994.
- Fei et al. (2022) Hao Fei, Shengqiong Wu, Yafeng Ren, and Meishan Zhang. 2022. Matching Structure for Dual Learning. In Proceedings of the International Conference on Machine Learning, ICML. 6373–6391.
- Frome et al. (2013) Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. 2013. Devise: A deep visual-semantic embedding model. Advances in neural information processing systems 26 (2013).
- Gao et al. (2021) Chenyang Gao, Guanyu Cai, Xinyang Jiang, Feng Zheng, Jun Zhang, Yifei Gong, Pai Peng, Xiaowei Guo, and Xing Sun. 2021. Contextual non-local alignment over full-scale representation for text-based person search. arXiv preprint arXiv:2101.03036 (2021).
- Ge et al. (2021) Xuri Ge, Fuhai Chen, Joemon M Jose, Zhilong Ji, Zhongqin Wu, and Xiao Liu. 2021. Structured multi-modal feature embedding and alignment for image-sentence retrieval. In Proceedings of the 29th ACM International Conference on Multimedia. 5185–5193.
- Han et al. (2021) Xiao Han, Sen He, Li Zhang, and Tao Xiang. 2021. Text-based person search with limited data. arXiv preprint arXiv:2110.10807 (2021).
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Hu et al. (2022) Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. 2022. Scaling Up Vision-Language Pre-Training for Image Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 17980–17989.
- Huang et al. (2017) Yan Huang, Wei Wang, and Liang Wang. 2017. Instance-aware image and sentence matching with selective multimodal lstm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2310–2318.
- Ji et al. (2022) Jiayi Ji, Yiwei Ma, Xiaoshuai Sun, Yiyi Zhou, Yongjian Wu, and Rongrong Ji. 2022. Knowing What to Learn: A Metric-Oriented Focal Mechanism for Image Captioning. IEEE Transactions on Image Processing 31 (2022), 4321–4335. https://doi.org/10.1109/TIP.2022.3183434
- Ji et al. (2021) Zhong Ji, Kexin Chen, and Haoran Wang. 2021. Step-wise hierarchical alignment network for image-text matching. IJCAI (2021).
- Jiang and Ye (2023) Ding Jiang and Mang Ye. 2023. Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2787–2797.
- Jiang et al. (2020) Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, and Xinlei Chen. 2020. In defense of grid features for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10267–10276.
- Jing et al. (2022) Chenchen Jing, Yunde Jia, Yuwei Wu, Xinyu Liu, and Qi Wu. 2022. Maintaining Reasoning Consistency in Compositional Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5099–5108.
- Jing et al. (2020a) Ya Jing, Chenyang Si, Junbo Wang, Wei Wang, Liang Wang, and Tieniu Tan. 2020a. Pose-guided multi-granularity attention network for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 11189–11196.
- Jing et al. (2020b) Ya Jing, Wei Wang, Liang Wang, and Tieniu Tan. 2020b. Cross-modal cross-domain moment alignment network for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10678–10686.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Lee et al. (2018) Kuang-Huei Lee, Xi Chen, Gang Hua, Houdong Hu, and Xiaodong He. 2018. Stacked cross attention for image-text matching. In Proceedings of the European conference on computer vision (ECCV). 201–216.
- Li et al. (2017a) Shuang Li, Tong Xiao, Hongsheng Li, Wei Yang, and Xiaogang Wang. 2017a. Identity-aware textual-visual matching with latent co-attention. In Proceedings of the IEEE International Conference on Computer Vision. 1890–1899.
- Li et al. (2017b) Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. 2017b. Person search with natural language description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1970–1979.
- Lin et al. (2020) Jialiang Lin, Yao Yu, Yu Zhou, Zhiyang Zhou, and Xiaodong Shi. 2020. How many preprints have actually been printed and why: a case study of computer science preprints on arXiv. Scientometrics 124, 1 (2020), 555–574.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European conference on computer vision. Springer, 740–755.
- Liu et al. (2019a) Chunxiao Liu, Zhendong Mao, An-An Liu, Tianzhu Zhang, Bin Wang, and Yongdong Zhang. 2019a. Focus your attention: A bidirectional focal attention network for image-text matching. In Proceedings of the 27th ACM International Conference on Multimedia. 3–11.
- Liu et al. (2019b) Jiawei Liu, Zheng-Jun Zha, Richang Hong, Meng Wang, and Yongdong Zhang. 2019b. Deep adversarial graph attention convolution network for text-based person search. In Proceedings of the 27th ACM International Conference on Multimedia. 665–673.
- Ma et al. (2022) Yiwei Ma, Jiayi Ji, Xiaoshuai Sun, Yiyi Zhou, Yongjian Wu, Feiyue Huang, and Rongrong Ji. 2022. Knowing what it is: Semantic-enhanced Dual Attention Transformer. IEEE Transactions on Multimedia (2022), 1–1. https://doi.org/10.1109/TMM.2022.3164787
- Niu et al. (2020) Kai Niu, Yan Huang, Wanli Ouyang, and Liang Wang. 2020. Improving description-based person re-identification by multi-granularity image-text alignments. IEEE Transactions on Image Processing 29 (2020), 5542–5556.
- Reed et al. (2016) Scott Reed, Zeynep Akata, Honglak Lee, and Bernt Schiele. 2016. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 49–58.
- Shao et al. (2022) Zhiyin Shao, Xinyu Zhang, Meng Fang, Zhifeng Lin, Jian Wang, and Changxing Ding. 2022. Learning Granularity-Unified Representations for Text-to-Image Person Re-identification. arXiv preprint arXiv:2207.07802 (2022).
- Song and Soleymani (2019) Yale Song and Mohammad Soleymani. 2019. Polysemous visual-semantic embedding for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1979–1988.
- Van der Maaten and Hinton (2008) Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, 11 (2008).
- Wang et al. (2021a) Chengji Wang, Zhiming Luo, Yaojin Lin, and Shaozi Li. 2021a. Text-based Person Search via Multi-Granularity Embedding Learning.. In IJCAI. 1068–1074.
- Wang et al. (2023b) Guanshuo Wang, Fufu Yu, Junjie Li, Qiong Jia, and Shouhong Ding. 2023b. Exploiting the Textual Potential from Vision-Language Pre-training for Text-based Person Search. arXiv preprint arXiv:2303.04497 (2023).
- Wang et al. (2023a) Haowei Wang, Jiayi Ji, Yiyi Zhou, Yongjian Wu, and Xiaoshuai Sun. 2023a. Towards real-time panoptic narrative grounding by an end-to-end grounding network. arXiv preprint arXiv:2301.03160 (2023).
- Wang et al. (2020c) Haoran Wang, Ying Zhang, Zhong Ji, Yanwei Pang, and Lin Ma. 2020c. Consensus-aware visual-semantic embedding for image-text matching. In European Conference on Computer Vision. Springer, 18–34.
- Wang et al. (2020b) Sijin Wang, Ruiping Wang, Ziwei Yao, Shiguang Shan, and Xilin Chen. 2020b. Cross-modal scene graph matching for relationship-aware image-text retrieval. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 1508–1517.
- Wang et al. (2020a) Zhe Wang, Zhiyuan Fang, Jun Wang, and Yezhou Yang. 2020a. Vitaa: Visual-textual attributes alignment in person search by natural language. In European Conference on Computer Vision. Springer, 402–420.
- Wang et al. (2022a) Zijie Wang, Jingyi Xue, Xili Wan, Aichun Zhu, Yifeng Li, Xiaomei Zhu, and Fangqiang Hu. 2022a. ASPD-Net: Self-aligned part mask for improving text-based person re-identification with adversarial representation learning. Engineering Applications of Artificial Intelligence 116 (2022), 105419.
- Wang et al. (2021b) Zijie Wang, Jingyi Xue, Aichun Zhu, Yifeng Li, Mingyi Zhang, and Chongliang Zhong. 2021b. AMEN: Adversarial Multi-space Embedding Network for Text-Based Person Re-identification. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 462–473.
- Wang et al. (2022b) Zijie Wang, Aichun Zhu, Jingyi Xue, Daihong Jiang, Chao Liu, Yifeng Li, and Fangqiang Hu. 2022b. SUM: Serialized Updating and Matching for text-based person retrieval. Knowledge-Based Systems 248 (2022), 108891.
- Wang et al. (2022c) Zijie Wang, Aichun Zhu, Jingyi Xue, Xili Wan, Chao Liu, Tian Wang, and Yifeng Li. 2022c. CAIBC: Capturing All-round Information Beyond Color for Text-based Person Retrieval. arXiv preprint arXiv:2209.05773 (2022).
- Wang et al. (2022d) Zijie Wang, Aichun Zhu, Jingyi Xue, Xili Wan, Chao Liu, Tian Wang, and Yifeng Li. 2022d. Look before you leap: Improving text-based person retrieval by learning a consistent cross-modal common manifold. In Proceedings of the 30th ACM International Conference on Multimedia. 1984–1992.
- Wang et al. (2020d) Zijie Wang, Aichun Zhu, Zhe Zheng, Jing Jin, Zhouxin Xue, and Gang Hua. 2020d. IMG-Net: inner-cross-modal attentional multigranular network for description-based person re-identification. Journal of Electronic Imaging 29, 4 (2020), 043028.
- Wu et al. (2021) Yushuang Wu, Zizheng Yan, Xiaoguang Han, Guanbin Li, Changqing Zou, and Shuguang Cui. 2021. LapsCore: Language-guided Person Search via Color Reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1624–1633.
- Xu et al. (2023) Wenhao Xu, Zhiyin Shao, and Changxing Ding. 2023. Mining False Positive Examples for Text-Based Person Re-identification. arXiv preprint arXiv:2303.08466 (2023).
- Zhang et al. (2022) Kun Zhang, Zhendong Mao, Quan Wang, and Yongdong Zhang. 2022. Negative-Aware Attention Framework for Image-Text Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15661–15670.
- Zhang and Lu (2018) Ying Zhang and Huchuan Lu. 2018. Deep cross-modal projection learning for image-text matching. In Proceedings of the European conference on computer vision (ECCV). 686–701.
- Zheng et al. (2020a) Kecheng Zheng, Wu Liu, Jiawei Liu, Zheng-Jun Zha, and Tao Mei. 2020a. Hierarchical gumbel attention network for text-based person search. In Proceedings of the 28th ACM International Conference on Multimedia. 3441–3449.
- Zheng et al. (2020b) Zhedong Zheng, Liang Zheng, Michael Garrett, Yi Yang, Mingliang Xu, and Yi-Dong Shen. 2020b. Dual-path convolutional image-text embeddings with instance loss. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 16, 2 (2020), 1–23.
- Zhu et al. (2021) Aichun Zhu, Zijie Wang, Yifeng Li, Xili Wan, Jing Jin, Tian Wang, Fangqiang Hu, and Gang Hua. 2021. DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval. In Proceedings of the 29th ACM International Conference on Multimedia. 209–217.