Benchmarking Augmentation Methods for Learning Robust Navigation Agents: the Winning Entry of the 2021 iGibson Challenge
Abstract
Recent advances in deep reinforcement learning and scalable photorealistic simulation have led to increasingly mature embodied AI for various visual tasks, including navigation. However, while impressive progress has been made for teaching embodied agents to navigate static environments, much less progress has been made on more dynamic environments that may include moving pedestrians or movable obstacles. In this study, we aim to benchmark different augmentation techniques for improving the agent’s performance in these challenging environments. We show that adding several dynamic obstacles into the scene during training confers significant improvements in test-time generalization, achieving much higher success rates than baseline agents. We find that this approach can also be combined with image augmentation methods to achieve even higher success rates. Additionally, we show that this approach is also more robust to sim-to-sim transfer than image augmentation methods. Finally, we demonstrate the effectiveness of this dynamic obstacle augmentation approach by using it to train an agent for the 2021 iGibson Challenge at CVPR, where it achieved 1st place for Interactive Navigation.
I INTRODUCTION
Mobile robots must be able to skillfully navigate through their environments to operate effectively in the real world. For example, home assistant robots must be able to go from room to room in order to help humans with daily chores. However, autonomous navigation is a difficult challenge that typically requires robots to understand and reason about their surroundings using visual sensors. Fortunately, several recent works using deep reinforcement learning have shown promising results by deploying robots that can successfully navigate in novel environments in the real world [1, 2].
One well-studied task, PointGoal Navigation [3], challenges the agent to reach a target coordinate location in its environment. However, it typically assumes the environment is static and devoid of dynamic objects, a far-cry from real homes and offices that may contain moving humans and pets or small movable obstacles and furniture. The recent iGibson Challenge [4] at the 2021 CVPR conference was designed to encourage researchers to investigate two modified versions of PointNav that are more difficult: Interactive Navigation (InteractiveNav) and Social Navigation (SocialNav). In InteractiveNav, the agent must reach the goal while pushing aside movable obstacles that obstruct the path. For SocialNav, the agent must reach the goal while avoiding collisions with humans walking across the environment that may not yield.
These dynamic tasks impose new challenges that are absent in static navigation settings. For InteractiveNav, the agent must distinguish between moveable and unmovable objects, and learn how to push movable ones if necessary in the proper directions to form shorter paths to the goal. For SocialNav, the agent must avoid the trajectories of nearby pedestrians and reach the goal without colliding with any of them. Another factor that makes dynamic navigation tasks even more difficult is the sparsity of data available for simulating dynamic environments; while there are large datasets for static 3D environments such as Gibson [5] and HM3D [6], datasets for dynamic environments that include individually interactable and properly arranged furniture are much sparser. For the 2021 iGibson Challenge, only eight training scenes were available.

To address the challenges of dynamic navigation and constraints on the availability of training scenes, we aim to provide a benchmark and analysis of augmentation techniques for visual navigation such that other researchers can leverage our findings from the iGibson Challenge. In particular, we show that simply adding several dynamic obstacles (pedestrians) to the scene during training improves the agent’s test-time success rate in novel environments significantly, even for navigation tasks that do not involve dynamic obstacles in the environment, such as PointNav and InteractiveNav. We conduct a systematic analysis in which we sweep through both the amount of training data available and the number of dynamic pedestrians used during training.
We then compare this dynamic obstacle augmentation method against two image augmentation methods, Crop and Cutout, which was shown by Laskin et al. [7] to significantly improve test-time generalization (up to 4x performance improvement) on various benchmarks for visual tasks [8, 9]. We show that dynamic obstacle augmentation can be combined synergistically with image augmentations to further improve performance. We also show that in contrast, combining different image augmentation methods can reduce performance gains, an observation that is also made by Laskin et al.
Additionally, we show that dynamic obstacle augmentation is also more robust to sim-to-sim transfer. After training our agents on a dataset of 3D scans of real-world indoor scenes in the Habitat simulator [10], we test them on a dataset of fully synthetic scenes composed by 3D artists in the iGibson simulator [11]. We find that agents trained with dynamic obstacle augmentation are more robust to the sim-to-sim transfer, as they are able to confer higher gains in navigation performance in these synthetic scenes than agents that are trained with image augmentations.
We demonstrate the effectiveness of dynamic obstacle augmentation by participating in the 2021 iGibson Challenge at CVPR, where our agent ranked 1st place for InteractiveNav. This feat was accomplished without using any rewards specific to InteractiveNav; only a basic PointNav reward and dynamic obstacle augmentation was used. Despite this, our approach achieved a 4% (absolute percentage) higher success rate than the 2nd place team.
II RELATED WORK
II-A PointGoal Navigation
PointGoal Navigation (PointNav), as formally defined by Anderson et al. in [3], is a task in which the robot must navigate from a start position to a goal coordinate in the environment. This is a challenging task to perform in a novel scene containing obstacles, especially when the agent only has access to an egocentric camera and an egomotion sensor. Despite these constraints, Wijmans et al. [12] proved that a near-perfect (97% success) PointNav agent could be trained in simulation with deep reinforcement learning. However, this work leveraged a large amount of training scenes; in this work, we focus on how augmentation methods can improve performance in scenarios in which only a small amount of scenes are available, and show that training an agent to reach the same levels of success in such scenarios is not yet solved.
II-B Navigation in Dynamic Environments
Though there has been a large amount of work on autonomous robot navigation, a very small subset of this research has focused on navigation requiring the robot to interact directly with dynamic elements in the environment. The recent work by Xia et al. [11] introduced a new task, InteractiveNav, in which the robot interacts with displaceable objects in order to reach the goal. This does not require the robot to use a manipulator; the robot can simply push past the objects using its base as it moves. InteractiveNav evaluates how well the robot can balance taking the shortest path to the goal and how much it disrupts the obstacles present in the environment. Their work showed that it is possible to teach an agent to complete this task with deep reinforcement learning, though they supply the agent with the next ten waypoints to the goal position as observations at each step. In this work, we seek to investigate performance for this task using only egocentric vision and an egomotion sensor and how it can be improved using augmentation methods.
SocialNav is another task that requires the robot to maneuver around dynamic elements in the environment, in which the robot must reach the goal without colliding with nearby moving pedestrians. Similar to our work, several recent works have used deep reinforcement learning to avoid colliding with pedestrians, such as SA-CADRL [13] and SARL [14], which use the positions of the pedestrians as observations to their policy, and the work by Pérez-D’Arpino et al. [15] which uses a motion planner that has access to a map of the environment and LiDAR data. In contrast to these works, we aim to complete the task of SocialNav without a motion planner or LiDAR, and investigate how performance can be improved using augmentation methods for visual deep reinforcement learning. We believe this setup is better suited for deployment in novel environments, where accurate localization of pedestrian positions or providing a map to a motion planner may be difficult or infeasible.
II-C Enhancing visual navigation performance
Several recent works have studied techniques to improve generalization to novel environments for visual navigation. Ye et al. [16] build upon the work by Wijman et al. [12] through the use of self-supervised auxiliary tasks, which proved to significantly improve sample efficiency. Sax et al. [17] incorporate visual priors about the world to confer performance gains over training end-to-end from scratch without priors. Chaplot et al. [18, 19] improve sample efficiency compared to typical end-to-end agents by having the agent infer information about mapping and localization, which can be supervised using privileged information from the simulator.
Unlike the works mentioned above, we study methods that yield significant improvement for visual navigation without the use of additional auxiliary losses, extra network heads, or additional sensory information (e.g., local occupancy map). In this work, we focus on augmentation methods that can be applied to virtually any visual deep reinforcement learning approach to improve test-time generalization. We study how these methods improve navigation both when used on their own and when combined with each other.
III METHOD
III-A Augmentation Methods for Visual Navigation
Training an effective visual navigation agent requires a large dataset (70 3D apartment scans) to avoid overfitting [12]. However, it can be difficult to have access to a diverse set of interactive training environments, especially for dynamic environments in which each object is individually interactable and must be arranged within the environment in a realistic manner, such as the synthetic scenes in the iGibson dataset, which contains only 15 scenes. For the 2021 iGibson Challenge, only eight training scenes were available. In such data-constrained scenarios, augmentation methods can be vital in improving the capability of the agent to generalize to novel environments at test-time.
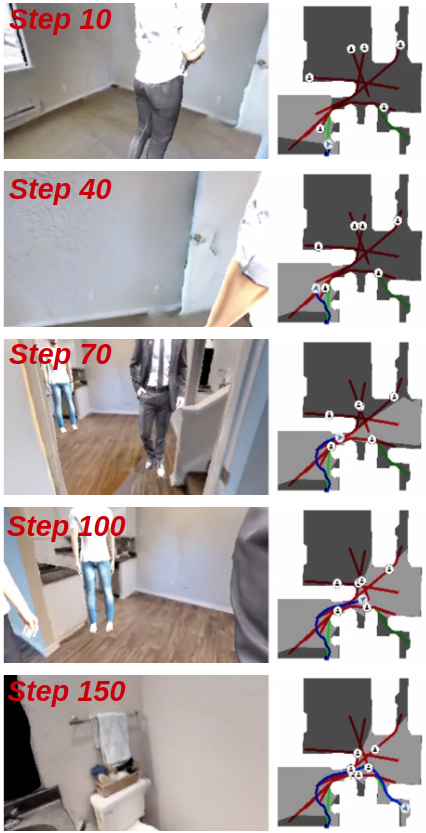
Dynamic Obstacle Augmentation. To improve the test-time generalization of the agent for visual navigation, we introduce several moving pedestrians into the environment (illustrated in Figures 1 and 2). This approach aims to prevent the agent from learning to overfit to the environments it sees during training; with a large number of moving visual distractors present in the scene, it is more difficult for the agent to memorize the layout of the training environment using observations from its camera. Additionally, unlike image augmentation methods that simply perturb the agent’s visual inputs, this method forces the agent to learn a larger variety of paths for a given episode’s pair of start-goal positions. Because the paths that the pedestrians take are newly generated each time the environment is reset, the agent is not able to always take the same path between the same pair of start-goal positions without colliding into a pedestrian.
During training, these moving pedestrians are treated as dynamic obstacles that the agent is not allowed to collide with. If a collision between the agent and a pedestrian occurs, the episode is simply terminated. Between 3 to 12 pedestrians represented by a 3D model of a standing human from the iGibson Challenge [4] is used, which we have found to be sufficiently large (for visual occlusion) while having a small enough radius for the agent to maneuver around in most situations. At the start of an episode, for each pedestrian, two navigable points at least 3 meters apart are randomly sampled from the environment. Throughout the episode, each pedestrian moves back and forth along the shortest obstacle-free path connecting these points. It has the same maximum linear and angular speed as the agent, but its speed is randomly decreased from the maximum value by up to 10% on a per-episode basis, such that different pedestrians within the same episode can be moving at different velocities.
Comparison with Image-based Data Augmentation. Image augmentation is one of the most popular approaches to improving sample efficiency for vision-based learning. Image augmentation aims to inject priors of invariance using random perturbations, such as cropping, erasing, or rotation. In particular, Laskin et al. [7] showed that the Crop and Cutout image augmentations (see Figure 3) are among the most effective for visual deep reinforcement learning performance improvement. Crop extracts a random patch from the original frame; similar to Laskin et al., we crop the frame at a random location such that the resulting image is 8% shorter in height and width (i.e., it maintains the original aspect ratio). Cutout, detailed by Zhong et al. [20], inserts a black rectangle of a random shape, aspect ratio, and location into the original frame. We use the same parameters as Zhong et al., in which the rectangle’s aspect ratio can be between , and its scale relative to the original frame can be between . In addition, we investigate Crop&Cutout, which combines Crop and Cutout by applying them sequentially.

III-B Problem Formulation and Learning Method
Observation and Action Spaces. At each step, the policy observes an egocentric (first-person) depth image and its relative distance and heading to the goal point as input. As the goal point is specified relative to the agent’s initial position, and the egomotion sensor indicates the agent’s relative distance and heading from its initial position, they can be used to calculate the agent’s current relative distance and heading to the goal. We choose to use only depth vision rather than depth and RGB vision together, as Wijmans et al. [12] has shown that including RGB can hurt performance relative to using depth alone. The policy outputs a two-dimensional diagonal Gaussian action distribution, from which a pair of actions are sampled (linear and angular velocity). The maximum speeds are 0.5 m/s and 90°/s, and the policy is polled at 10 Hz. If the magnitude of the velocities are below a certain threshold (10% of their maximum values for our experiments), it is perceived as the agent invoking a stop action, which ends the episode.
Reward Function. The reward function used for all our experiments are the same regardless of what augmentation method is used, if any at all:
where is the change in geodesic distance to the goal since the previous state, and , , and are binary flags indicating whether the agent has moved backwards, collided with the environment, or terminated the episode successfully (see Success Criteria in Subsection III-B), respectively. serves as a constant slack penalty incurred at each step to encourage the agent to minimize episode completion time. , , and are set to 0.002, 0.02, and 10.0. Backward motion is penalized because we have observed that it often leads to poor visual navigation performance. However, we do not prevent it altogether, as backward movement can be helpful for avoiding an incoming obstacle that suddenly appears into the robot’s view.
Success Criteria. For all tasks, episodes are considered successful only if the agent both (1) invokes a stop action that terminates the episode, and (2) the agent is within m of the goal point. Episodes are terminated and deemed unsuccessful after steps, or if the agent collides with a dynamic pedestrian either for SocialNav or when training with dynamic obstacle augmentation. A collision with a pedestrian is deemed to have occurred if the agent is within 0.3 m of it.
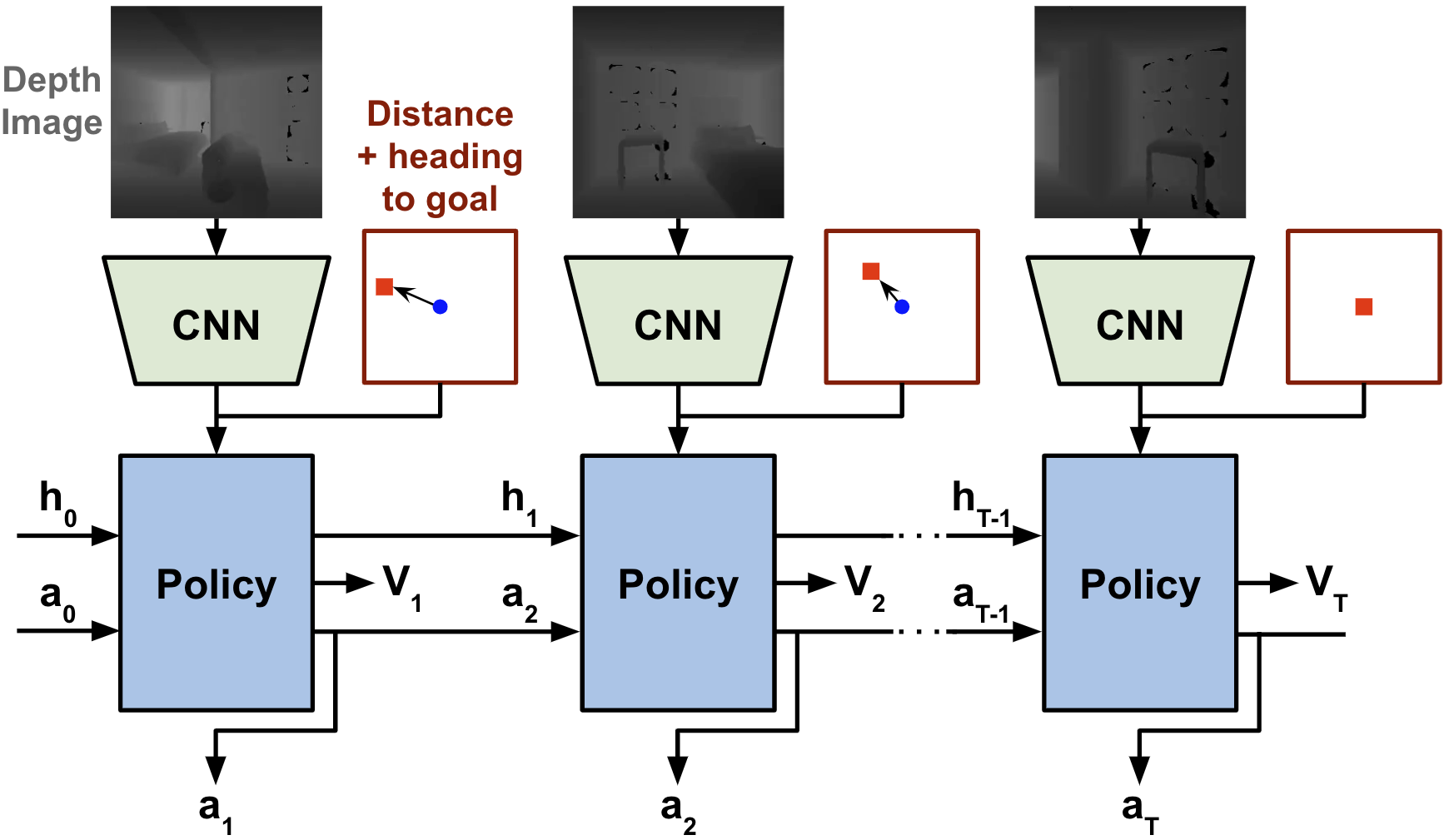
Network Architecture and Training. Our network architecture has two main components; a visual encoder and a recurrent policy. The visual encoder is a ResNet-18 [21] convolutional neural net which extracts visual features from the depth image. The policy is a 2-layer LSTM [22] with a 512-dimensional hidden state. The policy receives the visual features, the relative distance and heading to the goal, the previous action, and its previous LSTM hidden state. In addition to a head that outputs actions, the policy has a critic head that outputs an estimate of the state’s value, which is used for Proximal Policy Optimization (PPO) reinforcement learning as described by Schulman et al. in [23]. We use Decentralized Distributed PPO by Wijmans et al. [12] to train our agents using parallelization, and use the same learning hyperparameters. We train 8 workers per GPU, using 8 GPUs for a total of 64 workers collecting experience in parallel. Each agent is trained for 500M steps (~280 GPU hours, or ~35 hours wall-clock).
IV EXPERIMENTAL SETUP

IV-A Simulator and dataset
All of our agents are trained within Habitat [24], a high-performance photorealistic 3D simulator that provides the virtual robot with first-person visual data. Habitat can reach speeds of up to 3,000 frames per second per simulator instance, while the iGibson simulator used in the iGibson Challenge runs at approximately 100 frames per second [10]. Habitat also readily supports parallelization of simulator instances and gradient updates across multiple GPUs. Its speed and scalability allow us to train many agents very quickly and save a significant amount of time.
In this work, we use both the Gibson-4+ and iGibson datasets (depicted in Figure 5). We use the Gibson-4+ dataset [24] for training and evaluation, which contains 86 high quality 3D scans of real-world indoor spaces curated manually from the larger Gibson dataset [5]. All scenes in the Gibson-4+ dataset have been rated 4 or above on a quality scale from 0 to 5 by a human, and are free of significant reconstruction artifacts such as holes in texture or cracks in floor surfaces. The training split contains 3.6M episodes distributed across the 72 scenes (50k per scene), while the validation split contains 994 episodes across 14 scenes (71 per scene). In order to select checkpoints and evaluate our agents, we randomly select (without replacement) 7 out of the 14 scenes in the validation set to form a val1 and val2 set, such that each set contains 497 episodes.
For the 2021 iGibson Challenge, instead of the Gibson-4+ dataset we train on the iGibson dataset of synthetic scenes (8 scenes total) imported into Habitat. We also use the iGibson dataset to evaluate agents trained on the Gibson-4+ dataset for the task of sim-to-sim transfer on InteractiveNav using the iGibson simulator.
IV-B Evaluation Details
During evaluation, the agent’s behavior was set to be deterministic for reproducibility, by sampling only the means from the policy’s output Gaussian action distribution. We trained each agent configuration three times using different seeds. For each seed, the checkpoint that yielded the highest success rate on val1 was selected, and reported evaluation metrics are based on that checkpoint’s performance on val2. There are no pedestrians present during PointNav evaluation, and three pedestrians for SocialNav evaluation. For InteractiveNav, objects from the YCB dataset [26] are placed on the shortest obstacle-free path from the start to the goal spaced 0.5 m apart.
IV-C Evaluation Metrics
We use success rate as our primary evaluation metric. Apart from success, to evaluate InteractiveNav performance in iGibson, we use Success weighted by inverse Path Length (SPL) [3], as well as Effort Efficiency and Interactive Navigation Score (INS) [27]. SPL and Effort Efficiency are both scores between 0 and 1, with 1 being the best. SPL measures how short the agent’s path is relative to the length of the shortest path between the start and goal. Effort Efficiency penalizes displacement and forces that are applied to objects in the environment by the robot. INS is simply the average of SPL and Effort Efficiency.
V RESULTS
This section evaluates the effects of different augmentation methods for learning various visual navigation tasks. We design the experiments to answer the following questions:
-
1.
How does dynamic obstacle augmentation affect navigation performance across a wide range of training data availability?
-
2.
What are the effects of combining dynamic obstacle augmentation with image augmentation techniques?
-
3.
How well does each augmentation method handle the gap from the Gibson 4+ to the iGibson dataset?
We present all metrics multiplied by 100 for readability.
| # of | # of dynamic pedestrians during training | ||||
|---|---|---|---|---|---|
| train | (baseline) | ||||
| scenes | 0 ppl | 3 ppl | 6 ppl | 12 ppl | 18 ppl |
| 1 | 74.931.91 | 73.903.26 | 78.641.76 | 76.532.65 | 78.120.57 |
| 2 | 81.412.03 | 80.851.30 | 81.220.89 | 81.691.17 | 82.861.26 |
| 4 | 82.390.87 | 86.150.57 | 84.371.79 | 84.322.07 | 85.770.61 |
| 8 | 87.891.31 | 91.410.80 | 88.971.65 | 90.991.52 | 89.440.34 |
| 16 | 91.601.68 | 90.990.98 | 91.690.53 | 92.070.81 | 91.690.70 |
| 32 | 90.800.78 | 92.680.40 | 93.900.65 | 92.681.33 | 92.390.69 |
| 72 | 94.841.50 | 95.260.46 | 93.431.16 | 94.930.83 | 94.080.61 |
| # of | # of dynamic pedestrians during training | |||
|---|---|---|---|---|
| train | (baseline) | |||
| scenes | 3 ppl | 6 ppl | 12 ppl | 18 ppl |
| 1 | 65.262.47 | 68.780.35 | 65.403.77 | 68.402.26 |
| 2 | 68.970.96 | 69.202.92 | 72.682.03 | 71.311.66 |
| 4 | 74.601.45 | 77.320.64 | 76.100.24 | 75.771.52 |
| 8 | 80.381.27 | 80.891.04 | 79.913.37 | 78.641.04 |
| 16 | 83.001.37 | 83.710.59 | 82.961.61 | 80.470.63 |
| 32 | 84.041.09 | 84.410.74 | 83.991.29 | 81.270.87 |
| 72 | 85.261.27 | 84.791.33 | 86.431.75 | 83.102.93 |
V-A Performance with Dynamic Obstacle Augmentation
We evaluated the performances of many training configurations, in which both the amount of available training scenes and number of dynamic pedestrians used during training are varied. Table I represents the success rates for PointNav, while Table II shows the success rates for SocialNav. We did not evaluate agents trained with zero pedestrians for SocialNav due to their inability to adapt to the presence of dynamic obstacles at test-time, which led to poor performance.
Finding 1: Dynamic obstacle augmentation improves visual navigation performance, even when the environment is static. Our results indicate that dynamic obstacle augmentation improves performance for both visual navigation tasks, as the best performance is achieved when dynamic pedestrians were added in the training environments. An interesting observation is that dynamic obstacle augmentation improves test-time generalization even for PointNav, where the environment is completely static and there are no dynamic obstacles at test-time.
Finding 2: Dynamic obstacle augmentation is more effective with a small number of training scenes. Both tables also show that the performance gains provided by dynamic obstacle augmentation are more substantial when only a small number (8 or less) of training scenes are available. As the number of available training scenes increases, the gap between the baseline agents and those trained with added dynamic pedestrians decreases. For instance, the difference between the baseline and the best agents is % with eight training scenes but the difference is only % with training scenes in Table I. This trend indicates that the limited number of training scenes causes the agent to overfit, but can be mitigated by dynamic obstacle augmentation.
V-B Comparison with Image Augmentation Methods
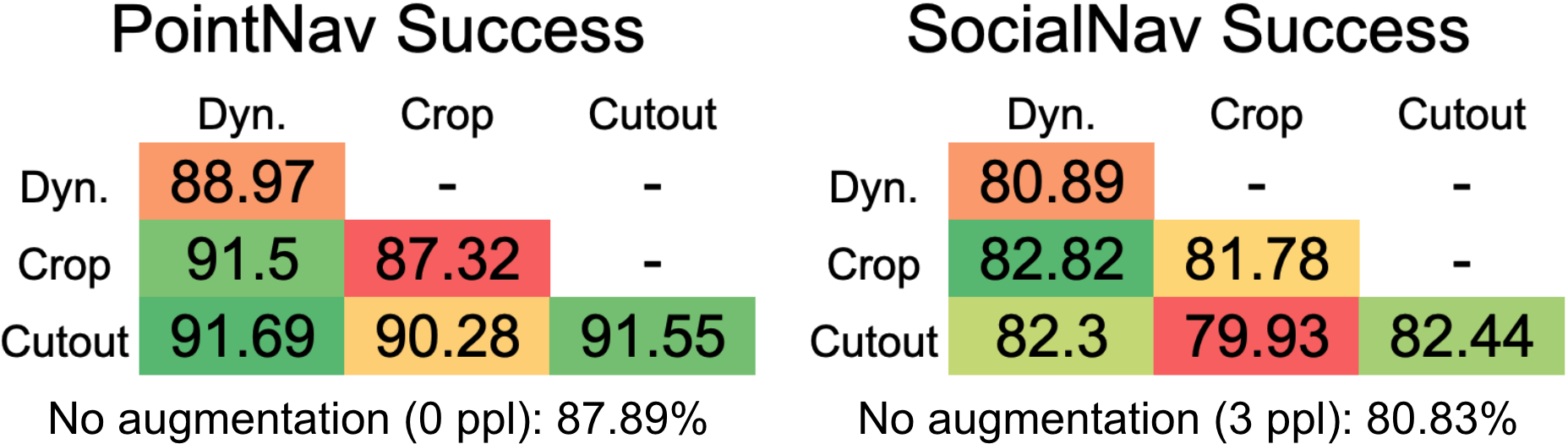
In this section, we compare our technique against image augmentation techniques, Crop and Cutout, as defined in Section III-A. To narrow the scope of our investigation and evaluate how well each technique mitigates overfitting, we limit experiments to agents trained with only eight scenes. When dynamic obstacle augmentation is used, six pedestrians are added during training. Otherwise agents were trained with zero pedestrians for PointNav, or three pedestrians for SocialNav.
Finding 3: Image augmentation can improve test-time success rate as well, yet combining them can decrease performance gains. We find that Crop and Cutout can also improve test-time success when each augmentation is used alone as shown in Figure 6, with the exception of Crop for PointNav. We find that using Cutout alone outperforms dynamic obstacle augmentation by a slight margin for both tasks. We also evaluate the effects of combining the image augmentation techniques. When training with deep reinforcement learning, applying different data augmentation techniques in conjunction does not necessarily improve performance over a single isolated technique. Laskin et al. [7] showed that the best results on the DeepMind Control Suite [8] are achieved when only Crop is used, and performance would only drop when combined with other image augmentation techniques. Similarly, we observe that combining Cutout and Crop (bottom-middle cells) only leads to worse performance than simply using Cutout alone.
Finding 4: Combining dynamic obstacle and image augmentation techniques can further increase success rates. However, as shown in Figure 6, when dynamic obstacle augmentation is combined with either the Crop or Cutout image augmentations, we find that the success rate can improve even further than using either method alone. While combining image augmentation methods hurts performance, combining Dyn with Crop (middle-left cells) yields a higher success rate than using either method alone. This combination achieves the highest success rate for both tasks, tying with Cutout for PointNav and surpassing it for SocialNav. Combining Cutout with Dyn (bottom-left cells) does not affect performance over using Cutout alone, in contrast to the performance decrease that occurs when Crop is added to Cutout.
V-C Sim-to-Sim Transfer for iGibson InteractiveNav
| Success | SPL | EffortEfficiency | INS | |
|---|---|---|---|---|
| No Augmentation | 51.008.03 | 13.102.47 | 92.701.28 | 52.901.85 |
| Dynamic | 61.993.30 | 15.580.91 | 94.151.09 | 54.860.74 |
| Dynamic+crop | 61.206.80 | 15.512.11 | 92.831.30 | 54.171.70 |
| Dynamic+cutout | 60.543.87 | 14.770.62 | 93.041.19 | 53.770.65 |
| Crop | 56.111.32 | 14.020.52 | 92.640.86 | 53.400.61 |
| Cutout | 54.962.35 | 13.781.01 | 92.831.30 | 53.041.13 |
| Crop+Cutout | 52.403.56 | 13.131.99 | 92.201.45 | 52.661.66 |
Though we can evaluate our agents for PointNav and SocialNav in Habitat, emulating the InteractiveNav task in Habitat requires a large amount of engineering and remained out of our reach for this work, despite prolonged effort. Instead, we evaluate the agents trained in Habitat directly in iGibson for InteractiveNav in a zero-shot manner (no adaptation). This is the same approach we used to achieve 1st place in the iGibson Challenge.
As in the previous subsection, all agents were trained with eight Gibson-4+ scenes, and those trained with dynamic obstacle augmentation were trained with six pedestrians (no pedestrians otherwise). We evaluate our agents in the eight iGibson scenes from the training set for the InteractiveNav task; currently, the evaluation set from the iGibson Challenge is not public.
Finding 5: Dynamic obstacle augumentation is more robust to sim-to-sim transfer from Gibson-4+ to iGibson scenes. As shown in Table III, while all augmentation methods improve performance over using no augmentation at all, dynamic obstacle augmentation did so by the greatest amount (~11% more success). Notably, in contrast to the results in the previous subsection, the results yielded by the image augmentation methods are much less competitive against dynamic obstacle augmentation. In fact, when using Crop or Cutout in conjunction with our method, performance is actually slightly reduced. Whereas Cutout by itself conferred one of the highest gains in performance in the previous subsection, it now provides the least gains over the baseline, beating only Crop&Cutout.
We attribute this to the visual gap between the iGibson scenes and the Gibson-4+ scenes that our agents were trained on; Gibson-4+ scenes are collected from the real world using a 3D camera and may contain some irregularities or artifacts, whereas iGibson scenes are completely synthetic, comprised wholly by 3D computer-aided design (CAD) files made by artists, and thus contain no artifacts and have much more geometric surfaces and edges (see Figures 1 and 5 for comparison).
Because image augmentation methods encourage the agent to infer the removed information from the remaining context available in the visual input, agents trained with these methods are more sensitive to visual changes in that context. In contrast, dynamic obstacle augmentation maintains a substantial performance gain. We conjecture that it allows agents to learn a better spatial understanding of their surroundings by dodging obstacles and recalculating new paths, as opposed to simply teaching the agents to use existing visual context to recover from visual perturbations.
| Team | InteractiveNav | SocialNav |
|---|---|---|
| Ours | 31% | 26% |
| LPAIS | 27% | 26% |
| NICSEFC | 26% | 28% |
| LPACSI | - | 28% |
| SYSU | 26% | - |
| Fractal | - | 25% |
V-D Results on 2021 iGibson Challenge
For the agent we submitted to the 2021 iGibson Challenge, we train on the 8 provided iGibson dataset scenes, not on Gibson-4+ scenes using the Habitat simulator. We submitted the same agent to both the InteractiveNav and SocialNav tracks. The results of the top five teams for each track are shown in Table IV. Dynamic obstacle augmentation was the only augmentation used, with 12 pedestrians being present during training. For InteractiveNav, we achieved 4% more success than the 2nd place team, who used image augmentation and a reward function very similar to ours, except with added terms designed to encourage the robot to seek alternative paths when blocked [28]. Additionally, their agent is trained natively in iGibson, precluding any issues that may arise from sim-to-sim transfer from Habitat to iGibson (which we discuss at the end of this section). For SocialNav, we attain a success rate only 2% lower than the 1st place team.
Episode visualizations and metrics for causes of episode failure on the challenge scenes were not shown to participants. Upon asking the organizers, we were informed that the large majority of episodes across all entries failed due to timeout (71% for InteractiveNav and 63% for SocialNav). We speculate that the large difference between the success rates on the challenge scenes (around %) and the experiment results seen in subsections V-B and V-C (around % and %), in which only eight training scenes were also used (albeit from Gibson-4+, not iGibson), may be due to the size and layout of the challenge scenes and the sim-to-sim gap from Habitat to the iGibson simulator. Scenes from the iGibson dataset tend to be relatively small (see Figure 5), especially compared to the real-world scans of the Gibson-4+ dataset used to train the agents in subsections V-B and V-C. The size and furniture layout of the challenge scenes may have restricted the robot to narrower paths that caused it to get caught on obstacles more often, or accidentally block a path to the goal with moveable furniture or obstacles (especially for InteractiveNav, where there is also clutter), or make passing an incoming pedestrian along a narrower path much more difficult for SocialNav.
Additionally, we “freeze” the iGibson training scenes in Habitat to maintain high simulation speeds when training our agents. In other words, furniture in the scene such as chairs and lamps could not be moved by the robot in the Habitat simulator, whereas they could be moved in either InteractiveNav or SocialNav upon deployment in the iGibson simulator. Our agents avoid pushing larger objects because these objects cannot move in training, and thus the agents learn to simply try to circumvent them entirely. This may have also contributed to making navigation more difficult for the robot in the iGibson Challenge, as it may not have been able to adapt to cases in which colliding with the environment caused an obstacle to block the path to the goal.
VI CONCLUSION AND FUTURE WORK
In this work, we conducted a systematic analysis on augmentation methods to improve the performance of deep reinforcement learning methods for visual navigation tasks: PointNav, SocialNav, and InteractiveNav. We show that the dynamic obstacle augmentation approach detailed in this work can significantly improve test-time generalization, be synergistically combined with image augmentation methods for further improvements in success, and are more robust to sim-to-sim transfer than image augmentation methods.
There are several directions in which our work can be extended. We suspect that while using dynamic pedestrians can boost performance, overcrowding can make the agent overly conservative and result in suboptimal behaviors. In the future, we plan to introduce curriculum learning to gradually increase the number of pedestrians during training, in order to potentially increase the number of pedestrians that will maximize performance.
We also plan to investigate sim-to-real transfer of the proposed technique by deploying it to real-world with pedestrians. However, we expect that the sim-to-real gap will lead to significant drops in performance, especially because pedestrians used within simulation are single rigid bodies (i.e., limbs are not independently animated). This could be addressed by adding more realistic motions and gestures for simulated humans to reduce the sim-to-real gap.
VII Acknowledgements
The Georgia Tech effort was supported in part by NSF, ONR YIPs, ARO PECASE. The views and conclusions are those of the authors and should not be interpreted as representing the U.S. Government, or any sponsor.
References
- [1] A. Kadian, J. Truong, A. Gokaslan, A. Clegg, E. Wijmans, S. Lee, M. Savva, S. Chernova, and D. Batra, “Sim2real predictivity: Does evaluation in simulation predict real-world performance?” IEEE Robotics and Automation Letters (RA-L), 2020.
- [2] N. Yokoyama, S. Ha, and D. Batra, “Success weighted by completion time: A dynamics-aware evaluation criteria for embodied navigation,” 2021.
- [3] P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V. Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva et al., “On evaluation of embodied navigation agents,” arXiv preprint arXiv:1807.06757, 2018.
- [4] C. Li, J. Jang, F. Xia, R. Martín-Martín, C. D’Arpino, A. Toshev, A. Francis, E. Lee, and S. Savarese. (2021) iGibson Challenge 2021. [Online]. Available: http://svl.stanford.edu/igibson/challenge.html
- [5] F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese, “Gibson env: Real-world perception for embodied agents,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [6] S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. M. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y. Zhao, and D. Batra, “Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. [Online]. Available: https://openreview.net/forum?id=-v4OuqNs5P
- [7] M. Laskin, K. Lee, A. Stooke, L. Pinto, P. Abbeel, and A. Srinivas, “Reinforcement learning with augmented data,” arXiv preprint arXiv:2004.14990, 2020.
- [8] M. Laskin, A. Srinivas, and P. Abbeel, “Curl: Contrastive unsupervised representations for reinforcement learning,” Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, PMLR 119, 2020, arXiv:2004.04136.
- [9] K. Cobbe, C. Hesse, J. Hilton, and J. Schulman, “Leveraging procedural generation to benchmark reinforcement learning,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 2048–2056. [Online]. Available: https://proceedings.mlr.press/v119/cobbe20a.html
- [10] A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y. Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymets, A. Gokaslan, V. Vondrus, S. Dharur, F. Meier, W. Galuba, A. Chang, Z. Kira, V. Koltun, J. Malik, M. Savva, and D. Batra, “Habitat 2.0: Training home assistants to rearrange their habitat,” CoRR, vol. abs/2106.14405, 2021. [Online]. Available: https://arxiv.org/abs/2106.14405
- [11] F. Xia, W. B. Shen, C. Li, P. Kasimbeg, M. E. Tchapmi, A. Toshev, R. Martín-Martín, and S. Savarese, “Interactive gibson benchmark: A benchmark for interactive navigation in cluttered environments,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 713–720, 2020.
- [12] E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,” arXiv, pp. arXiv–1911, 2019.
- [13] Y. F. Chen, M. Everett, M. Liu, and J. P. How, “Socially aware motion planning with deep reinforcement learning,” 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1343–1350, 2017.
- [14] C. Chen, Y. Liu, S. Kreiss, and A. Alahi, “Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 6015–6022.
- [15] C. Pérez-D’Arpino, C. Liu, P. Goebel, R. Martín-Martín, and S. Savarese, “Robot navigation in constrained pedestrian environments using reinforcement learning,” 2021.
- [16] J. Ye, D. Batra, E. Wijmans, and A. Das, “Auxiliary tasks speed up learning pointgoal navigation,” arXiv preprint arXiv:2007.04561, 2020.
- [17] A. Sax, B. Emi, A. R. Zamir, L. Guibas, S. Savarese, and J. Malik, “Mid-level visual representations improve generalization and sample efficiency for learning visuomotor policies,” arXiv preprint arXiv:1812.11971, 2018.
- [18] D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov, “Learning to explore using active neural slam,” arXiv preprint arXiv:2004.05155, 2020.
- [19] D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [20] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 13 001–13 008.
- [21] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” CoRR, vol. abs/1512.03385, 2015. [Online]. Available: http://arxiv.org/abs/1512.03385
- [22] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [23] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [24] Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A Platform for Embodied AI Research,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [25] A. Gupta, A. Murali, D. Gandhi, and L. Pinto, “Robot learning in homes: Improving generalization and reducing dataset bias,” CoRR, vol. abs/1807.07049, 2018. [Online]. Available: http://arxiv.org/abs/1807.07049
- [26] B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar, “The YCB object and model set: Towards common benchmarks for manipulation research,” in 2015 international conference on advanced robotics (ICAR). IEEE, 2015, pp. 510–517.
- [27] F. Xia, W. B. Shen, C. Li, P. Kasimbeg, M. E. Tchapmi, A. Toshev, R. Martín-Martín, and S. Savarese, “Interactive gibson benchmark: A benchmark for interactive navigation in cluttered environments,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 713–720, 2020.
- [28] iGibson Challenge LPAIS Spotlight CVPR 2021 Embodied AI Workshop. YouTube, Jun 2021. [Online]. Available: https://www.youtube.com/watch?v=x5ewIkkgYuQ