Benchmarking Quantum Processor Performance at Scale
Abstract
As quantum processors grow, new performance benchmarks are required to capture the full quality of the devices at scale. While quantum volume is an excellent benchmark, it focuses on the highest quality subset of the device and so is unable to indicate the average performance over a large number of connected qubits. Furthermore, it is a discrete pass/fail and so is not reflective of continuous improvements in hardware nor does it provide quantitative direction to large-scale algorithms. For example, there may be value in error mitigated Hamiltonian simulation at scale with devices unable to pass strict quantum volume tests. Here we discuss a scalable benchmark which measures the fidelity of a connecting set of two-qubit gates over qubits by measuring gate errors using simultaneous direct randomized benchmarking in disjoint layers. Our layer fidelity can be easily related to algorithmic run time, via defined in Ref. [1] that can be used to estimate the number of circuits required for error mitigation. The protocol is efficient and obtains all the pair rates in the layered structure. Compared to regular (isolated) RB this approach is sensitive to crosstalk. As an example we measure a qubit layer fidelity on a 127 qubit fixed-coupling “Eagle” processor (ibm_sherbrooke) of 0.26(0.19) and on the 133 qubit tunable-coupling “Heron” processor (ibm_montecarlo) of 0.61(0.26). This can easily be expressed as a layer size independent quantity, error per layered gate (EPLG), which is here for ibm_sherbrooke and for ibm_montecarlo.
The development of quantum benchmarks enables improvements to be tracked across devices and technologies so that reasonable inferences on performance can be made. In Ref. [2], some properties of quantum benchmarks were discussed, and that a suite of benchmarks should be designed to address quality, speed and scale, altogether describing performance. There are few suggested speed benchmarks besides CLOPS [3]; however, for quality and scale there are many proposals. Generally, the quality is signified by having high fidelity gates (the underlying operations of the device) over a large set of connected qubits with low crosstalk. The size of the set is a benchmark of scale. Such quality can be measured discretely, by individually benchmarking the gate, or holistically, e.g., by running large representative circuits with well known outputs.
Individual gate quality is typically measured by variants of randomized benchmarking [4, 5] (RB). For RB, one selects a random sequence of Clifford gates, constructs a circuit by appending the inverse of the sequence (also a Clifford), decomposes this circuit into the native gate set of a device, and then runs the circuit on said device. The decay of the measured polarization (of any Pauli- operator) versus sequence length averaged over many random sequences is straightforwardly related to the average gate error. Because these sequence lengths can be very deep, small errors can be measured that are not dependent on state-preparation and measurement (unlike tomography). Measured in this way, we obtain fine-grained information about the device since we have error rates on each discrete gate element. However, important features of the noise can be missed depending on the way these are measured. Specifically, in a connected device, if we measure isolated two-qubit (2Q) gate pairs using RB, we potentially overlook crosstalk terms. This issue was addressed in the simultaneous RB protocol [6], yet there are still ambiguities in the implementation.
Conversely, running test algorithms/structured circuits can give a holistic view of gate quality; however, it is very specific to the type of circuits selected. There have been proposed families of circuits as benchmarks [7, 8, 9, 10, 11, 12, 13, 14, 15, 16]; however, it remains an open question how to connect performance on one such benchmark to another. As such, benchmarks based on randomized circuits, such as quantum volume (QV) [17], cross-entropy benchmarking (XEB) [18], mirror RB [19], and inverse-free (binary) RB [20], are often believed to give a better overview of average performance. In particular, QV is a stringent test of the device which is defined as QV when some subset of qubits can pass the QV test – to measure a heavy output probability greater than for circuits with random, all-to-all connected, SU(4) layers. It is straightforward to compare QV across different qubit technologies, and its performance has been linked to the performance of quantum error correcting codes [21].
However, as with all benchmarks, there are limits to QV. For one, it reports on the performance of the best subset of qubits on a device; it is a “high-flier” benchmark. For devices with more qubits than log2(QV), QV is not a good representative number of overall quality. For example, in superconducting qubits the largest quantum volume is 512 (9 qubits) [22] and in ion traps 524288 (19 qubits) [23]. Yet, there are devices being constructed at scales far beyond these thresholds and so QV is not capturing quality across the full scale of the device. Secondly, QV (and also XEB) requires classical computation of the circuits, and so is limited to scales where that is tractable – generally thought to be about 50 qubits and 50 layers of gates (see recent review Ref. [24] and simulation on advanced high-performance computing (HPC) [25]). And thirdly, as a discrete benchmark, QV does not indicate continuous changes in gate improvement. Finally, QV measures a specific type of unstructured square circuit; however, many near term algorithms, such as the variational quantum eigensolver (VQE), quantum approximate optimization algorithm (QAOA), and Trotterized dynamics (see, e.g., Ref [26] for a review), are based on the idea of a repetitive layer of gates. Similarly, quantum error correction (QEC) relies on a repetitive structure of the application of parallel gates and measurements to perform code checks and detect errors (see, e.g., Ref. [27] for a QEC inspired benchmark).
Layered circuits lend themselves well to applying the techniques of error migitation [1, 28]. Error mitigation is a post processing technique that makes a tradeoff with speed to improve quality, i.e., by running more instances of the circuit with different noise profiles to purify the final result. Therefore, there are compelling reasons to provide a benchmark that spans across an entire device via layered circuits and which reveals continuous information as a complement to QV. While XEB, mirror RB and binary RB can probe layered circuits, they require high-weight measurements that do not reveal information about individual gates. Furthermore, XEB has similar classical computational limitations as QV and the output fidelity can be optimized over any N-qubit unitary in each layer. This adds flexibility to XEB, but makes device to device and application to application comparisons difficult.
To address these points, we propose an alternative benchmark called layer fidelity (), which combines the ideas of simultaneous [6] and direct [29] randomized benchmarking and is summarized graphically in Fig. 1. For a given fully connected set of 2Q gates, we partition them into layers where the 2Q gates are disjoint. When in disjoint layers, we can construct simultaneous direct randomized benchmarking sequences for these gates with alignment barriers and measure individual 1Q and 2Q fidelities. From these disjoint fidelities we can use the product to estimate the full layer fidelity over qubits. Given this measurement we have enough information to estimate the layer fidelity of all embedded layers of size . To normalize to a size-independent quantity, we introduce error per layered gate (EPLG), where is the number of two-qubit gates (typically for a linear chain of qubits), which is representative of the process error of a gate in these layered circuits. A similar quantity, the dressed two-qubit pauli error (measured from XEB), was defined in Ref. [30]. Lending support to the , Ref. [30] shows a threshold between a quantity similar to and the ability to classically simulate random circuits with layered structure.
We will discuss the full algorithm in § I and show data on two IBM devices (127 qubit and 133 qubit) in § II. In contrast to other protocols that Pauli-twirl a repeated layer [1, 31, 32, 33, 34], the procedure for calculating requires fewer circuits. However, we can still relate to a mitigation metric under most conditions, ; links noise to the number of probabalistic error cancellation circuits [1] required for a depth circuit, 111 here is the number of repeated full layers which are used to compute . If is the traditionally defined circuit depth, is a geometric mean over the disjoint layers and is computed from as such.. We show data comparing LF and in § A and further discussion of the bounds is in § E. is similarly linked to the quantity measured by mirror RB [19]; we show data comparing and mirror RB in § A, and we compare simulations of RB, and mirror in § B.
I Layer Fidelity Protocol
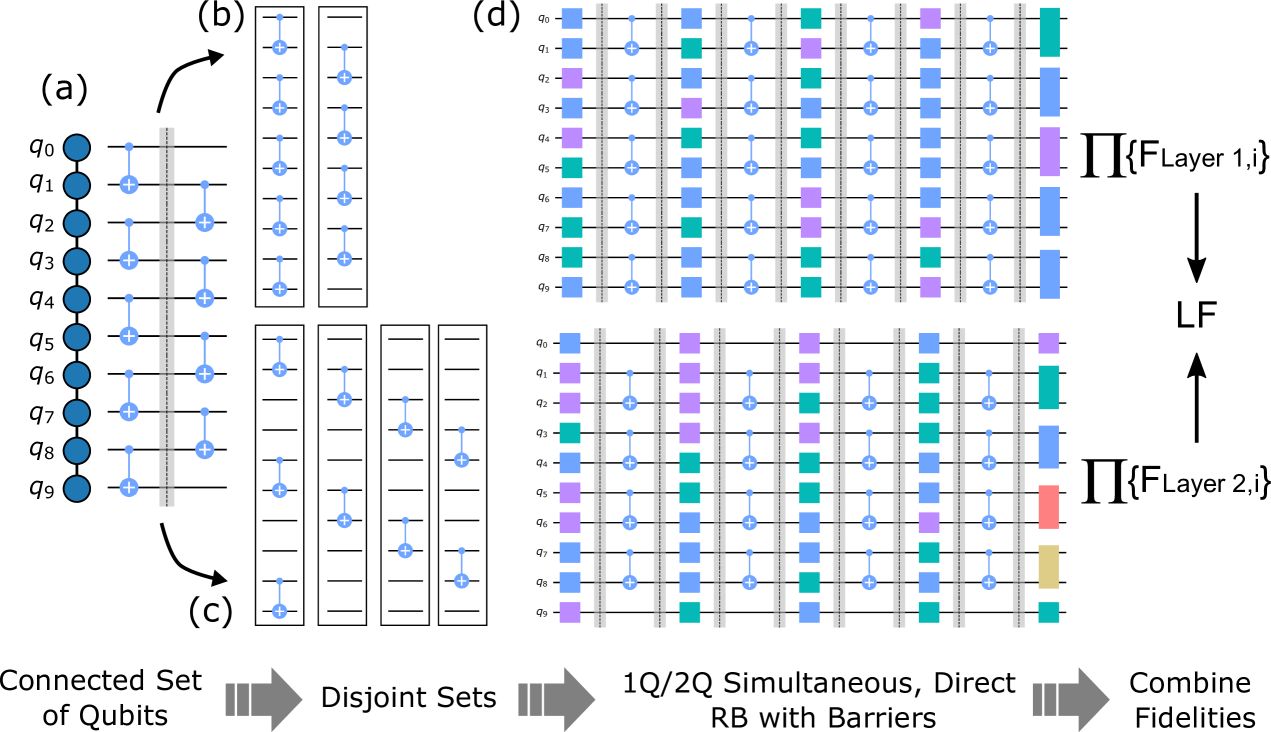
An overview of the protocol is visualized in Fig. 1, and here we outline the steps of the protocol,
-
1.
Select a set of qubits with a connected set of Clifford two qubit gates (e.g., CNOT) such that the set of two qubit gates plus arbitrary single-qubit gates define a universal gate set over . Part (a) of Fig. 1.
-
2.
Split the full layer into disjoint layers with such that where have no overlapping qubits. The set of idle qubits are . Example disjoint layers shown in (b) and (c) of Fig. 1.
-
3.
Measure the errors on and in the disjoint layers using simultaneous direct randomized benchmarking sequences, (d) of Fig. 1.
-
4.
From each measured decay we obtain a process fidelity where is the dimension of the decay space ( for 1Q, for 2Q) and is the RB decay rate. The layer fidelity per disjoint layer is
(1) and the full layer fidelity is
(2) We define a normalized quantity, the error per layered gate,
(3) where is the number of 2Q gates in all the layers, e.g., for the minimal set of connected gates
There are a few considerations for the protocol:
-
•
are typical two-qubit gates such as CNOT, CZ, and iSWAP and variations from those that differ by single qubit gates, e.g., ECR ().
-
•
There is no unique decomposition of disjoint layers, but the error of all qubits must be measured, including idle qubits, i.e., qubits without a two-qubit gate in that disjoint layer. We show some data comparing different disjoint layer decompositions in § A.
-
•
A requirement of the protocol is that barriers must be enforced at the layer of two-qubit gates (all gates before the barrier must complete before the circuit can proceed). That is, we apply a set of randomizing single qubit Clifford gates on all qubits, a barrier across all qubits, the layer of disjoint two-qubit gates, then another barrier, and repeat this times. At the end, we invert each disjoint set, and measure the ground state population of each akin to simultaneous randomized benchmarking [6]. Since the sub-layers are disjoint there is no mixing and we get well-defined decay curves of the ground state population versus . The use of barriers keeps each layer consistent with how it would appear in the full (i.e. non-disjoint) layer.
-
•
Dynamic decoupling is allowed.
-
•
makes a Markovianity assumption and is a benchmark insensitive to state preparation and measurement (SPAM) errors; however, the contribution of measurement error can be trivially added by taking the product of the measurement assignment fidelities.
-
•
The layer fidelity of a device for qubits is defined as the maximum layer fidelity measured on the device (practical considerations are discussed in § II).
The goal of the protocol is to measure the fidelity of the full layer defined in the first step of the protocol, for example, (a) of Fig. 1. Formally, the fidelity of that layer is the trace of the Pauli Transfer Matrix (PTM) between the noisy experimental map and the inverse ideal map,
| (4) |
where , are the Pauli matrices, and is the process map for the layer. In the limit of no crosstalk, Eqn. 1 is exact, but Eqn. 2 is not because the product of traces is not the trace of the product; however, for small errors this is a good approximation (§ D) and is a lower bound. This is also true for the layer fidelity: after repetitions of the layer, is approximately the true fidelity until gets small. With crosstalk, Eqn. 2 and Eqn. 4 are not identical and for specific crosstalk terms (see § C) the layer fidelity will be a lower bound (the crosstalk error terms are double counted). Because a general treatment of all cases is not possible, we turn to numerics (§ B) with various noise models. We compare layer fidelity to theory (Eqn. 4) and to the fidelity measured from mirror RB [19], which is a protocol to measure the layer fidelity by building a circuit of layers to which the reverse circuit is appended, and the polarization of the output is measured versus .
The advantage of mirror circuit RB is that it does capture all crosstalk terms; however with two distinct disadvantages compared to layer. First, with layer fidelity we obtain more information: a detailed set of error rates for each and . Second, the signal to noise of layer fidelity is higher since we are measuring the individual error rates versus the error rate of the entire layer (a weight- measurement). Any protocol that requires the estimation of high-weight observables, which avoids, is unscalable because, with enough qubits, the signal will be unmeasurably small even for short protocol depths. Overall, the numerics support the assertion that layer fidelity is capturing the majority of the crosstalk terms for realistic noise models, and layer fidelity and mirror RB agree well in an experimental test (§ A). By fitting all decay terms [36, 37] available to us in our layer fidelity benchmark, we could properly better account for some of these crosstalk terms. However, the added complexity, exposure to measurement errors, and loss of signal-to-noise need more careful consideration. As an aside, the advantages shown here for layer fidelity over mirror benchmarking should also hold for binary RB [20] as well.
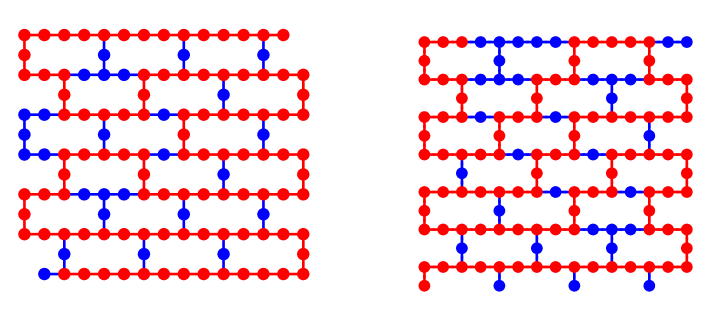
As mentioned, one advantage of the layer fidelity protocol is that it gives access to the discrete fidelities of the underlying gates. One utility of this is that we can easily measure the layer fidelity on smaller subsets of the measured set . We can simply calculate the smaller subset by omitting qubits outside the set in the calculation of , i.e., change the indices of Eqn. 1. A gate may extend outside the new subset, so we assume that the gate fidelity is shared equally between those subsets and calculate the fidelity of that qubit in the layer as . In most geometries the layer fidelity is optimally measured on a long 1D line of qubits (chain of qubits) as this only requires two disjoint layers, i.e., the gates first starting at (even set) and then at (odd set) as shown in (b) of Fig. 1. When defined on a line, measuring subsets is particularly straightforward as it is a sliding window of qubits inside the larger 1D chain. Although it is not guaranteed that we find the optimal value of layer fidelity using this subspace method, this can be used as a lower bound. While the line is the densest application of gates possible, based on the definition set forth, the gates can be measured over more disjoint layers, so long as idle qubit errors are accounted for; we show data in § A that splitting over more layers is worse due to the increased duration. In certain geometries, such as a star, more disjoint layers will necessarily be required: this problem is equivalent to constructing an edge-coloring of the coupling graph, and Vizing’s theorem guarantees that we require no more distinct layers than the degree of the graph plus one.
Layer fidelity can be easily related to other metrics which quantify the error models on a layer, such as [1], which is defined as
| (5) |
where are the Pauli generator terms in the Lindblad model of the Pauli-twirled noise. While in general all Pauli-twirled error terms exist in Eqn. 5, approximations are made to make the calculation tractable, for example, in Ref. [1] the terms are truncated to all physical connections in the device, and Pauli benchmarking is required to learn them. Even still, this requires many more circuits than are required to measure layer fidelity. The two quantities are easily related for well-behaved noise; for depolarizing noise is given by,
| (6) | |||||
which in the limit of close to 1 is,
| (7) |
We derive this and discuss the bounds in § E, and we show some data comparing and in § A. Note that this is defined over the disjoint layers used to measure layer fidelity, which are at least depth 2. To estimate on a qubit ( even), depth 1 layer (), we can use EPLG (Eqn. 3),
| (8) |
and
| (9) |
The accuracy of this estimate will depend on the the layer structures being similar between the layer for and the layer used to measure /EPLG. If is defined on the same disjoint layer as used for the layer fidelity measurement, then it can also be calculated directly from the disjoint layer fidelity Eqn. 1.
II Data
|
|
|
|
As mentioned, the layer fidelity for a subset of qubits on a device () is defined as the maximum layer fidelity over all K (-qubit) subsets. Practically it will be impossible to measure all sets on a large device, for example the number of length 100 chains on a 127Q heavy hex device such as ibm_sherbrooke is 313,980. Therefore, in practice we need heuristic methods to measure the optimal layer fidelity. Initial estimates of the layer fidelity can be made with the isolated two-qubit fidelities [38] and from there candidate sets can be measured. One of the bigger considerations here is that the layer fidelity imposes a fixed length on all gates of the disjoint layer equal to the longest gate (see the simulations in the appendix § B), and so the estimates from isolated RB fidelities must take that into consideration. Typically, this is done by omitting edges of the graph with gates that are much longer than the average. We use a heuristic protocol given by the following procedure:
-
1.
Assuming a list of gate errors measured from isolated RB is available, calculate the layer fidelity for each qubit linear string, where is selected to be at least the length of the longest desired chain. In this step long gates may be omitted from the graph as they are known to make the layer fidelity much worse. Find the set with the highest predicted (set 1), then find the set with the least overlap with set 1 and the highest predicted of that subset (set 2). Repeat this again to find a third set.
- 2.
-
3.
For each value of take the largest from all the subchains measured. For example, if and then there are 150 possible sub-chains.
-
4.
Plot vs , convert to error per layered gate (EPLG) as where is the number of 2Q gates.
-
5.
Since this covers a heuristic number of chains, more chains at different lengths can be measured “ad-hoc” and if the of those chains is larger, they will supplant the previously measured values.
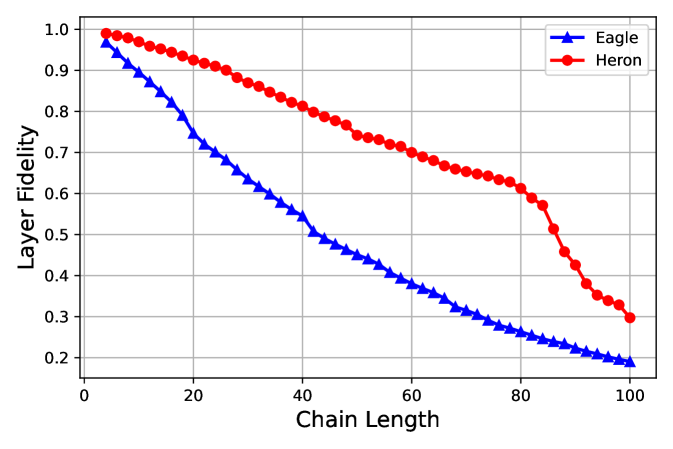
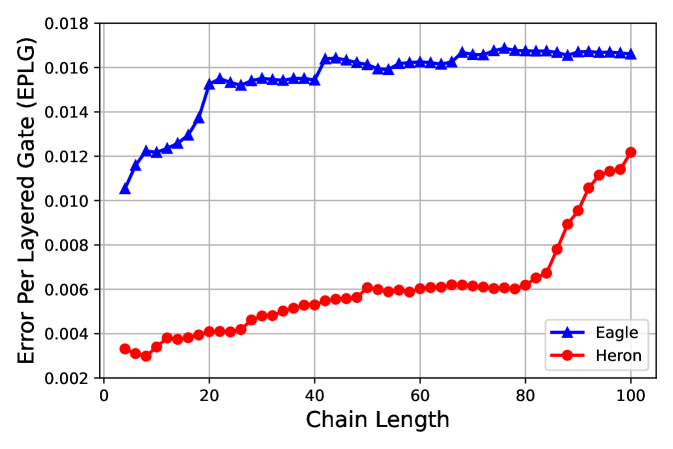
We show typical data taken on a 127 qubit “Eagle” processor ibm_sherbrooke (native two-qubit CX gate using cross-resonance) and 133 qubit “Heron” processor ibm_montecarlo (native two-qubit CZ gate using tunable-coupler actuation) in Fig. 2. To measure the fidelities we perform the simultaneous direct RB sequences described previously with 300 shots per circuit, 6 randomizations and [1, 10, 20, 30, 40, 60, 80, 100, 125, 150, 200, 400] (Eagle) and [1, 10, 20, 30, 40, 60, 80, 100, 125, 150, 200, 400, 750] (Heron). For ibm_sherbrooke most gate lengths are 533 ns, but as described in the heuristics for picking the gate sets, three edges with gate lengths 700 ns were removed from consideration. For ibm_montecarlo the gate lengths were about an equal mix of 84 ns and 104 ns and none were removed from consideration due to gate length. All circuits were generated in Qiskit and run through the IBM Quantum cloud interface. In the top plot we show the layer fidelity and the error per layered gate as a function of chain length. The chain of qubits on the ibm_sherbrooke and ibm_montecarlo devices for the data is shown in red on the bottom right plot.
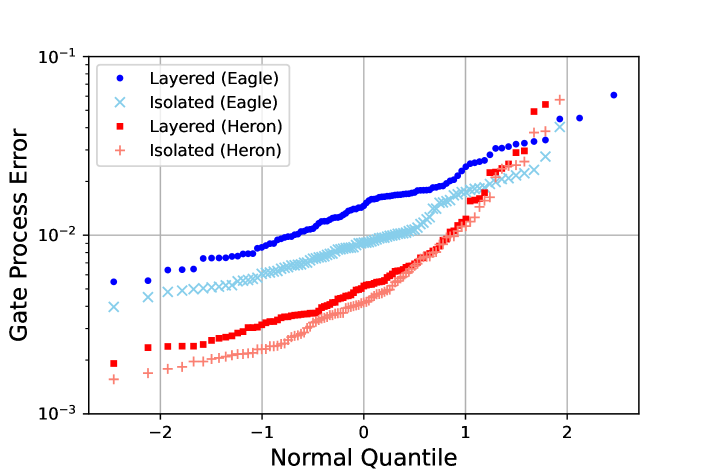
One of the advantages of this layer fidelity measurement is the access to individual gate errors which can be used for further analysis or fidelity estimates. In particular, we can perform a comparison between isolated RB and the errors from layer fidelity RB which can be a proxy for crosstalk errors. We note here that the isolated RB data is, in fact, a variant of simultaneous RB where there is a distance of at least one idle qubit between all two qubit gate pairs and there are no barriers. As we show in simulations in the appendix § B isolated RB trivially eliminates some crosstalk, such as always on ZZ between pairs of qubits for fixed coupling architectures. The data bears this out as the middle plot of Fig. 2 shows a distinct increase in the error per gate on the “Eagle” processor when run in layers versus isolated RB mode. Conversely, these errors are greatly alleviated in the “Heron” processor since the coupling between neighboring qubits can be turned off when not required for two-qubit gate operation.
III Conclusions
In this manuscript we discussed a benchmark for quantum processors at scale - the layer fidelity. The layer fidelity follows naturally from standard randomized benchmarking procedures, is crosstalk aware, fast to measure over a large number of qubits, has high signal to noise and gives fine-grained information. We demonstrated the key components of the layer fidelity metric with measurements on the 127 qubit Eagle processor ibm_sherbrooke and 133 qubit Heron processor ibm_montecarlo. Using simulation and data we showed (§ A and § B) that there is good agreement with mirror randomized benchmarking - a complementary technique for measuring layers - over a number of error models. The layer fidelity links easily with other methods of characterizing layers, such as Pauli learning for . We leave a few open questions outside the scope of this manuscript, such as whether more advanced data fitting can improve agreement with the exact layer fidelity, the predictive power of with differently structured circuits, the limits of twirling in , and how to extend to layered circuits with mid-circuit measurements. Finally, we note that, like all benchmarks layer fidelity should be considered as one piece of information towards full device characterization.
Acknowledgements.
The authors would like to thank Andrew Wack for helpful discussions, Kevin Krsulich for Qiskit help, Samantha Barron for help with the Pauli learning, and James Wootton and Blake Johnson for manuscript comments. Research was sponsored by the Army Research Office and was accomplished under Grant Number W911NF-21-1-0002. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.References
- Berg et al. [2022] E. v. d. Berg, Z. K. Minev, A. Kandala, and K. Temme, Probabilistic error cancellation with sparse pauli-lindblad models on noisy quantum processors, arXiv preprint arXiv:2201.09866 (2022).
- Amico et al. [2023] M. Amico, H. Zhang, P. Jurcevic, L. Bishop, P. Nation, A. Wack, and D. C. McKay, Defining standard strategies for quantum benchmarks, arXiv preprint arXiv:2303.02108 (2023).
- Wack et al. [2021] A. Wack, H. Paik, A. Javadi-Abhari, P. Jurcevic, I. Faro, J. M. Gambetta, and B. R. Johnson, Quality, speed, and scale: three key attributes to measure the performance of near-term quantum computers, arXiv preprint arXiv:2110.14108 (2021).
- Magesan et al. [2012] E. Magesan, J. M. Gambetta, and J. Emerson, Characterizing quantum gates via randomized benchmarking, Phys. Rev. A 85, 042311 (2012).
- Helsen et al. [2022] J. Helsen, I. Roth, E. Onorati, A. Werner, and J. Eisert, General framework for randomized benchmarking, PRX Quantum 3, 020357 (2022).
- Gambetta et al. [2012] J. M. Gambetta, A. D. Córcoles, S. T. Merkel, B. R. Johnson, J. A. Smolin, J. M. Chow, C. A. Ryan, C. Rigetti, S. Poletto, T. A. Ohki, M. B. Ketchen, and M. Steffen, Characterization of addressability by simultaneous randomized benchmarking, Phys. Rev. Lett. 109, 240504 (2012).
- Lubinski et al. [2021] T. Lubinski, S. Johri, P. Varosy, J. Coleman, L. Zhao, J. Necaise, C. H. Baldwin, K. Mayer, and T. Proctor, Application-oriented performance benchmarks for quantum computing, arXiv preprint arXiv:2110.03137 (2021).
- Mesman et al. [2021] K. Mesman, Z. Al-Ars, and M. Möller, Qpack: Quantum approximate optimization algorithms as universal benchmark for quantum computers, arXiv preprint arXiv:2103.17193 (2021).
- Finžgar et al. [2022] J. R. Finžgar, P. Ross, L. Hölscher, J. Klepsch, and A. Luckow, Quark: A framework for quantum computing application benchmarking, in 2022 IEEE International Conference on Quantum Computing and Engineering (QCE) (IEEE, 2022) pp. 226–237.
- Tomesh et al. [2022] T. Tomesh, P. Gokhale, V. Omole, G. S. Ravi, K. N. Smith, J. Viszlai, X.-C. Wu, N. Hardavellas, M. R. Martonosi, and F. T. Chong, Supermarq: A scalable quantum benchmark suite, in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) (IEEE, 2022) pp. 587–603.
- Zhang and Nation [2023] V. Zhang and P. D. Nation, Characterizing quantum processors using discrete time crystals, arXiv preprint arXiv:2301.07625 (2023).
- Kurlej et al. [2022] A. Kurlej, S. Alterman, and K. M. Obenland, Benchmarking and analysis of noisy intermediate-scale trapped ion quantum computing architectures, in 2022 IEEE International Conference on Quantum Computing and Engineering (QCE) (IEEE, 2022) pp. 247–258.
- Lubinski et al. [2023] T. Lubinski, C. Coffrin, C. McGeoch, P. Sathe, J. Apanavicius, and D. E. B. Neira, Optimization applications as quantum performance benchmarks, arXiv preprint arXiv:2302.02278 (2023).
- Kordzanganeh et al. [2022] M. Kordzanganeh, M. Buchberger, M. Povolotskii, W. Fischer, A. Kurkin, W. Somogyi, A. Sagingalieva, M. Pflitsch, and A. Melnikov, Benchmarking simulated and physical quantum processing units using quantum and hybrid algorithms, arXiv preprint arXiv:2211.15631 (2022).
- Mundada et al. [2022] P. S. Mundada, A. Barbosa, S. Maity, T. Stace, T. Merkh, F. Nielson, A. R. Carvalho, M. Hush, M. J. Biercuk, and Y. Baum, Experimental benchmarking of an automated deterministic error suppression workflow for quantum algorithms, arXiv preprint arXiv:2209.06864 (2022).
- Li et al. [2022] A. Li, S. Stein, S. Krishnamoorthy, and J. Ang, Qasmbench: A low-level quantum benchmark suite for nisq evaluation and simulation, ACM Transactions on Quantum Computing 10.1145/3550488 (2022).
- Cross et al. [2019] A. W. Cross, L. S. Bishop, S. Sheldon, P. D. Nation, and J. M. Gambetta, Validating quantum computers using randomized model circuits, Physical Review A 100, 032328 (2019).
- Boixo et al. [2018] S. Boixo, S. V. Isakov, V. N. Smelyanskiy, R. Babbush, N. Ding, Z. Jiang, M. J. Bremner, J. M. Martinis, and H. Neven, Characterizing quantum supremacy in near-term devices, Nature Physics 14, 595 (2018).
- Proctor et al. [2022] T. Proctor, S. Seritan, K. Rudinger, E. Nielsen, R. Blume-Kohout, and K. Young, Scalable randomized benchmarking of quantum computers using mirror circuits, Phys. Rev. Lett. 129, 150502 (2022).
- Hines et al. [2023] J. Hines, D. Hothem, R. Blume-Kohout, B. Whaley, and T. Proctor, Fully scalable randomized benchmarking without motion reversal (2023), arXiv:2309.05147 [quant-ph] .
- Baldwin et al. [2022] C. H. Baldwin, K. Mayer, N. C. Brown, C. Ryan-Anderson, and D. Hayes, Re-examining the quantum volume test: Ideal distributions, compiler optimizations, confidence intervals, and scalable resource estimations, Quantum 6, 707 (2022).
- Gambetta [2022] J. Gambetta, Qv 512 announcement (2022).
- Quantinuum [2023] Quantinuum, Quantinuum h-series quantum computer accelerates through 3 more performance records for quantum volume: , , and (2023).
- Xu et al. [2023] X. Xu, S. Benjamin, J. Sun, X. Yuan, and P. Zhang, A herculean task: Classical simulation of quantum computers (2023).
- Liu et al. [2022] Y. Liu, Y. Chen, C. Guo, J. Song, X. Shi, L. Gan, W. Wu, W. Wu, H. Fu, X. Liu, D. Chen, G. Yang, and J. Gao, Validating quantum-supremacy experiments with exact and fast tensor network contraction (2022).
- Dalzell et al. [2023] A. M. Dalzell, S. McArdle, M. Berta, P. Bienias, C.-F. Chen, A. Gilyén, C. T. Hann, M. J. Kastoryano, E. T. Khabiboulline, A. Kubica, G. Salton, S. Wang, and F. G. S. L. Brandão, Quantum algorithms: A survey of applications and end-to-end complexities (2023), arXiv:2310.03011 [quant-ph] .
- Liepelt et al. [2023] M. Liepelt, T. Peduzzi, and J. R. Wootton, Enhanced repetition codes for the cross-platform comparison of progress towards fault-tolerance (2023), arXiv:2308.08909 [quant-ph] .
- Ferracin et al. [2022] S. Ferracin, A. Hashim, J.-L. Ville, R. Naik, A. Carignan-Dugas, H. Qassim, A. Morvan, D. I. Santiago, I. Siddiqi, and J. J. Wallman, Efficiently improving the performance of noisy quantum computers (2022), arXiv:2201.10672 [quant-ph] .
- Proctor et al. [2019] T. J. Proctor, A. Carignan-Dugas, K. Rudinger, E. Nielsen, R. Blume-Kohout, and K. Young, Direct randomized benchmarking for multiqubit devices, Phys. Rev. Lett. 123, 030503 (2019).
- Morvan and et. al [2023] A. Morvan and et. al, Phase transition in random circuit sampling (2023), arXiv:2304.11119 [quant-ph] .
- Erhard et al. [2019] A. Erhard, J. J. Wallman, L. Postler, M. Meth, R. Stricker, E. A. Martinez, P. Schindler, T. Monz, J. Emerson, and R. Blatt, Characterizing large-scale quantum computers via cycle benchmarking, Nat. Comm. 10, 5347 (2019).
- Helsen et al. [2019] J. Helsen, X. Xue, L. M. K. Vandersypen, and S. Wehner, A new class of efficient randomized benchmarking protocols, npj Quantum Inf 5, 71 (2019).
- Kimmel et al. [2014] S. Kimmel, M. P. da Silva, C. A. Ryan, B. R. Johnson, and T. Ohki, Robust extraction of tomographic information via randomized benchmarking, Phys. Rev. X 4, 011050 (2014).
- Carignan-Dugas et al. [2023] A. Carignan-Dugas, D. Dahlen, I. Hincks, E. Ospadov, S. J. Beale, S. Ferracin, J. Skanes-Norman, J. Emerson, and J. J. Wallman, The error reconstruction and compiled calibration of quantum computing cycles (2023).
- Note [1] here is the number of repeated full layers which are used to compute . If is the traditionally defined circuit depth, is a geometric mean over the disjoint layers and is computed from as such.
- McKay et al. [2020] D. C. McKay, A. W. Cross, C. J. Wood, and J. M. Gambetta, Correlated randomized benchmarking (2020).
- Harper et al. [2020] R. Harper, S. Flammia, and J. Wallman, Efficient learning of quantum noise, Nat. Phys. 16, 1184 (2020).
- Nation and Treinish [2022] P. D. Nation and M. Treinish, Suppressing quantum circuit errors due to system variability, arXiv preprint arXiv:2209.15512 (2022).
- Murali et al. [2019] P. Murali, J. M. Baker, A. Javadi-Abhari, F. T. Chong, and M. Martonosi, Noise-adaptive compiler mappings for noisy intermediate-scale quantum computers, in Proceedings of the twenty-fourth international conference on architectural support for programming languages and operating systems (2019) pp. 1015–1029.
- Emerson et al. [2005] J. Emerson, R. Alicki, and K. Życzkowski, Scalable noise estimation with random unitary operators, Journal of Optics B: Quantum and Semiclassical Optics 7, S347 (2005).
- Pedersen et al. [2007] L. H. Pedersen, N. M. Møller, and K. Mølmer, Fidelity of quantum operations, Physics Letters A 367, 47 (2007).
- Wei et al. [2022] K. X. Wei, E. Magesan, I. Lauer, S. Srinivasan, D. F. Bogorin, S. Carnevale, G. A. Keefe, Y. Kim, D. Klaus, W. Landers, N. Sundaresan, C. Wang, E. J. Zhang, M. Steffen, O. E. Dial, D. C. McKay, and A. Kandala, Hamiltonian engineering with multicolor drives for fast entangling gates and quantum crosstalk cancellation, Phys. Rev. Lett. 129, 060501 (2022).
- Mitchell et al. [2021] B. K. Mitchell, R. K. Naik, A. Morvan, A. Hashim, J. M. Kreikebaum, B. Marinelli, W. Lavrijsen, K. Nowrouzi, D. I. Santiago, and I. Siddiqi, Hardware-efficient microwave-activated tunable coupling between superconducting qubits, Phys. Rev. Lett. 127, 200502 (2021).
- Greenbaum [2015] D. Greenbaum, Introduction to quantum gate set tomography (2015), arXiv:1509.02921 [quant-ph] .
- Nielsen [2002] M. A. Nielsen, A simple formula for the average gate fidelity of a quantum dynamical operation, Physics Letters A 303, 249 (2002).
Appendix A Additional Data
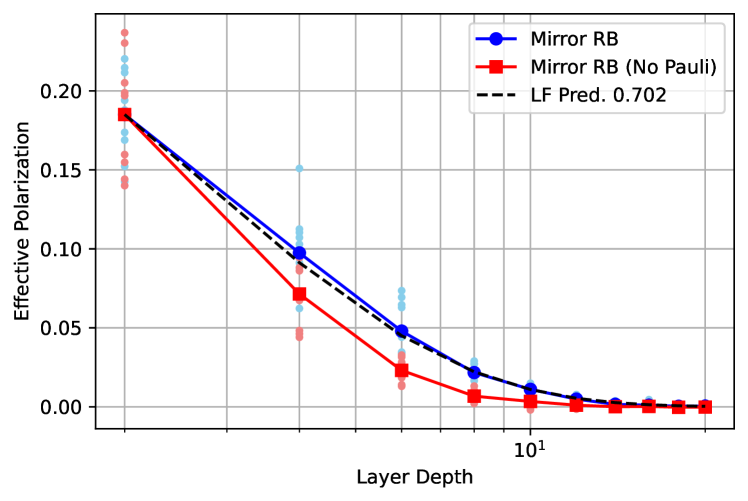
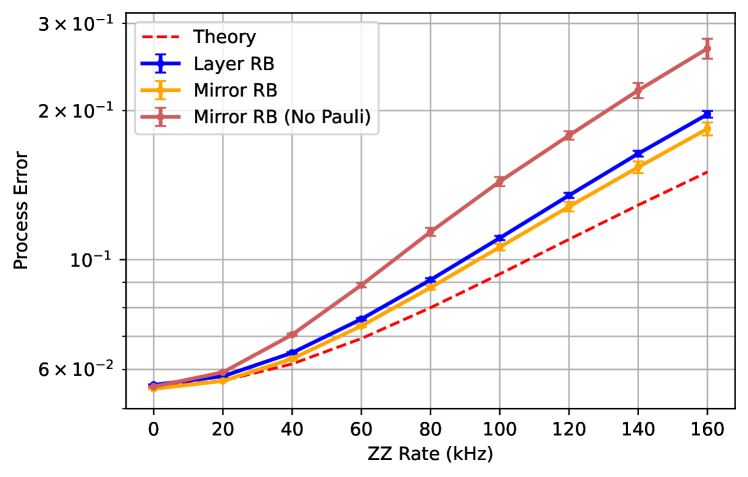
Here we provide some additional support for layer fidelity by comparing to the mirror RB protocol [19] which embeds the full layer directly in a mirror circuit. Our specific mirror circuit is comprised of a random 1Q Clifford layer, then the first disjoint layer of two-qubit gates, a second random 1Q Clifford layer, then the second disjoing layer of two-qubit gates. In this way the number of 1Q gates is the same between mirror RB and layer RB when constructing the full layer fidelity. We consider two versions of mirror, one which is a direct mirror (just the forward and reverse circuit) and the second version, more faithful to Ref. [19], includes a random Pauli layer between the forward and reverse circuits. We measure the polarization as defined in Ref. [19]. Our data comparison is on 20 qubits of the ibm_peekskill device, which is a 27 qubit fixed-coupling “Falcon” processor and the path is shown in Fig. 3. We perform 10 randomizations and measure 2000 shots. We compare to layer fidelity data from 6 randomization and 300 shots. We can see that the agreement between mirror and layer is quite good and that there is some discrepancy between mirror with and without the Pauli layer. Since our error model in the device is fixed, we investigate the comparison of layer and mirror further with simulations in § B.
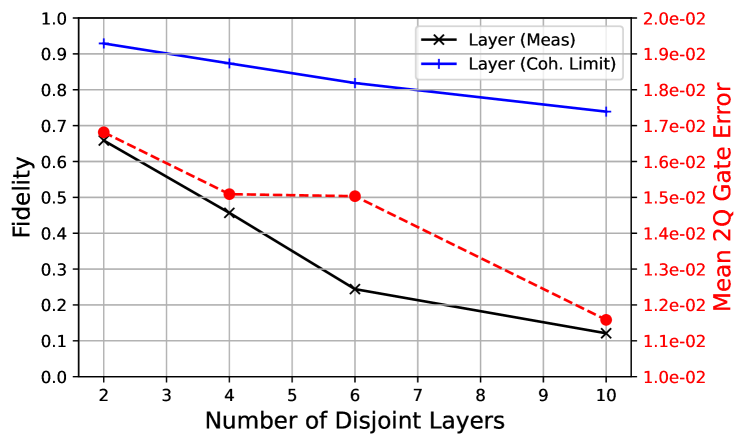
Another aspect of the layer protocol is that the choice of disjoint sets is not unique, as shown in Fig. 1 for 2 versus 4 layers of the chain. Therefore, we take data in the same set of qubits as above splitting the layer fidelity into 2, 4, 6 and 10 disjoint layers. Because of the increased total duration, more disjoint layers leads to lower fidelity. However, this statement will be architecture dependent; there are certain types of crosstalk terms that occur during simultaneous gates that are large enough to offset the longer duration of the circuit, e.g., this was probed on IBM devices in Ref. [39]. In this case, splitting into more disjoint layers is a sensible approach. Another scenario is that the architecture does not allow more than a certain number of simultaneous gates at a time.
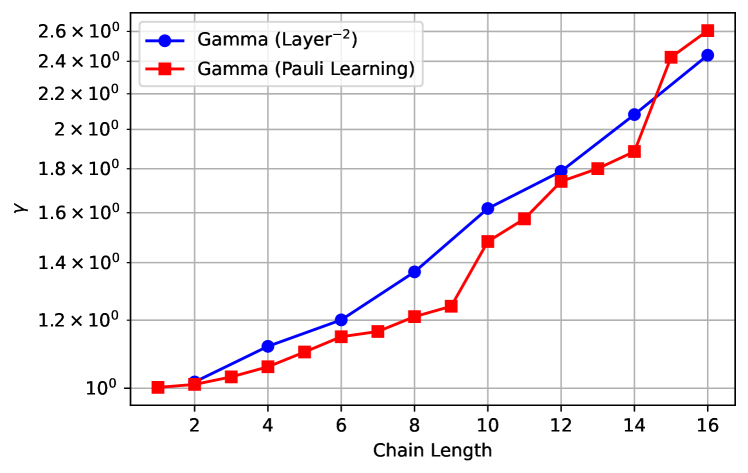
In the main text we relate the layer fidelity to a quantity relevant for error mitigation, , defined in Eqn. 5. The relation is given in Eqn. 7, and although supported in theory by well behaved noise models (see § E), here we do an experimental comparison on a 16 qubit section of ibm_peekskill. The layer fidelity data is taken according to the procedure outlined in the main text and the direct data is taken according to the procedure in Ref. [1]. For the LF data we take 178 circuits (13 depth points 6 randomizations 2 disjoint layers) and for the data we take 14,000 circuits (14 depth points 1000 basis rotations randomizations). This ratio of circuits demonstrates why layer fidelity is a quick method for estimating gamma. The data is shown in Fig. 4 and the agreement is reasonable; a more comprehensive study including error bars and minimizing time variations of the device properties is left for a future study.
Appendix B Simulations
Here we compare simulations between isolated RB, simultaneous RB, layer fidelity RB, and mirror RB with a variety of error models. The circuits are generated as gates (in the decomposition of , [idle], [arbitrary Z rotations] and gates) and then converted to a schedule based on the single-qubit gate being the smallest unit of time; the two-qubit gates are converted into fractional time steps of either 5 or 8 single-qubit gate times. Because the gates are zero time, they are considered their own gate slices, and so a finite time step can consist of the 3 possible gates on each qubit and so for four qubits there are roughly 81 unique four qubit unitaries to construct. We may add coherent error terms to each unitary, e.g., an overrotation or a crosstalk. We then perform a density matrix simulation, where at each time step the unitary is applied followed by a discrete / map on each qubit. Breaking the unitary and incoherent evolution into time steps is an implementation of Trotterized simulation of their concurrent evolution. We compare the error extracted from these sequences to the theoretical errors by adding the coherent [40, 41] and incoherent errors,
| (10) | |||||
| (11) | |||||
where is the gate length and both these errors are process errors.
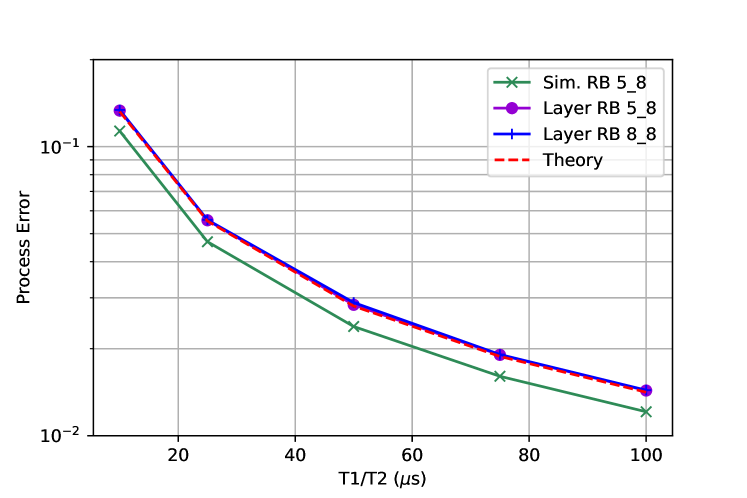
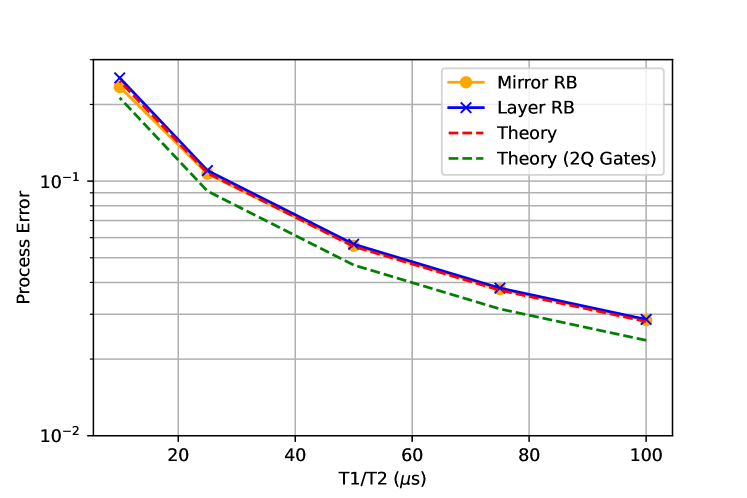
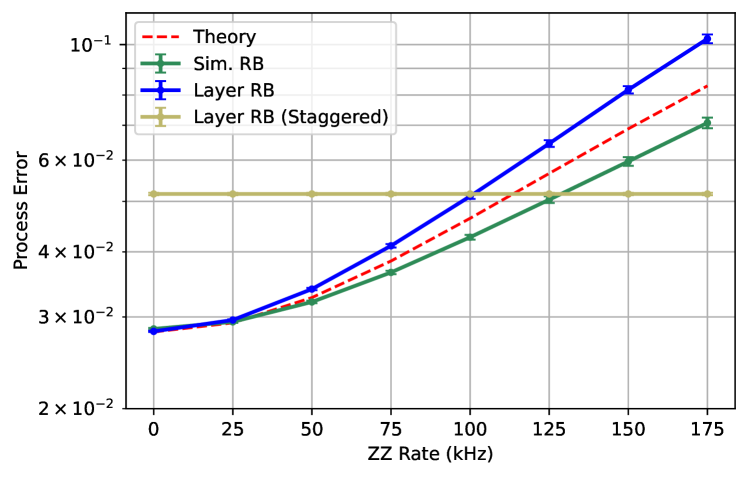
In the first set of simulations we only consider incoherent errors and perform the simulation on the even layer of the 4Q set as shown in the top of Fig. 5. We consider two different scenarios, one where the two gates in the layer ( and ) are different lengths (5 time units for and 8 time units for ) and another scenario where both gates are 8 time units. Trivially, simultaneous RB gives the wrong answer for the error of the layer because there are no enforced barriers between the different two-qubit gates. The different layer fidelities are the same because of the barrier. This illustrates how the layer fidelity enforces the layer to be as long as the longest gate for all qubits. The theory agrees well, once we include the 1.5 single qubit gates per layer (so the layer is considered 8+1.5 units in length). The length unit is 50 ns. We then continue the simulation for both layers (with all three gates having length 8) and compare to mirror RB (bottom of Fig. 5). For comparison here the mirror layer has a set of random 1Q Cliffords before each layer of two-qubit gates so that the total gate counts are the same in layer and mirror. The agreement between the two is near exact.
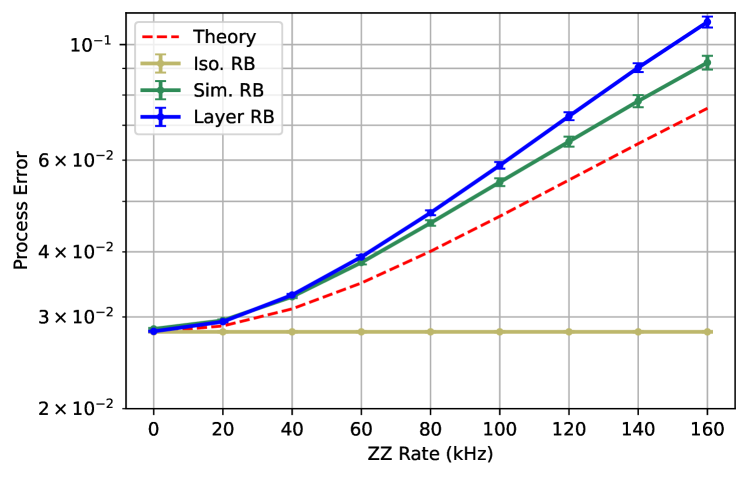
Next we investigate the more interesting case of coherent crosstalk error. We take (same unit time length as before, 50 ns) and vary the interaction rate, , between qubits 0 and 3 () and qubits 1 and 2 (). This error is out of the disjoint subspace. We consider two versions of this crosstalk; one version where the is “always-on”, and another where it only occurs during simultaneous two-qubit gate operation. All the gate lengths are the same (8 units).
First, we look at just layer 1 (top Fig. 6) with always-on and compare isolated RB, simultaneous RB and layer RB. Trivially the isolated RB is not affected by the ZZ interaction, demonstrating that it’s a poor method for assessing crosstalk. Simultaneous RB and Layer RB are reasonably similar, with the caveat from Fig. 5 that if the gate lengths are different simultaneous RB will not reflect the layer properly.
Next we consider the full layer with always-on and compare layer RB to mirror RB. We look at two flavors of mirror RB, the first is to exactly mirror the circuit (“no pauli”) and the second is to more faithfully execute the mirror circuit with a random Pauli layer between the original circuit and its mirror. For this crosstalk the “no Pauli” mirror reports a much higher error whereas the layer and mirror (with Pauli) are in very close agreement.
Finally, we look at layer 1, with that is only activated by simultaneous 2Q gates, noting that such a crosstalk could be activated by the physics described in Ref. [42, 43]. Here there is a greater divergence between the layer fidelity and simultaneous RB results because simultaneous RB does not enforce strictly running the 2Q gates at the same time. Furthermore, we see that if we run a layer where the 2Q gates are staggered, this crosstalk term trivially vanishes, although the layer has higher baseline error since it’s longer. This elucidates why sometimes it can be beneficially to run non-simultaneous gates for crosstalk as seen in Ref. [39]. This particular version of crosstalk is not necessarily representative, but serves as an example for a family of similar crosstalk terms that activate with simultaneous 2Q gates. We note that there is some ambiguity in calculating the theory curves for these plots, we use Eqn. 10, but since the errors are in the single qubit layer as well we approximate the errors by assuming the single layers and two qubit layers add.
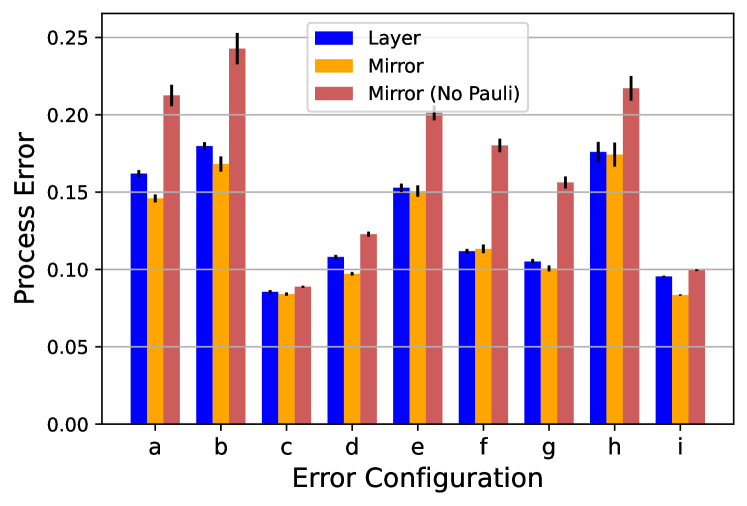
Ultimately the comparison we desire is between layer fidelity and mirror fidelity. In the plots we see the two are fairly close, but the space of possible unitary errors is very large. Therefore, we take a scattershot look at a variety of different error terms and compare between the two methods, as summarized in Fig. 7. The general trend appears is that layer and mirror measure very similar errors, layer fidelity tends to measure slightly higher error than mirror (consistent with the discussion in the next section), whereas without the Pauli layer mirror always measures a larger error.
Appendix C Crosstalk and Layer Fidelity
Here we consider the layer fidelity protocol with a single Pauli weight-2 coherent crosstalk term. There are two subspaces and that both have and qubits and there is a crosstalk term of the form,
| (12) |
where is a weight-2 Pauli spanning and and is small so we take the small expansion. The true fidelity of the layer (idles and this crosstalk term) is
| (13) | |||||
| (14) |
Now, what if we do simultaneous RB and are able to twirl and (mythically here without additional problems), from the simultaneous paper we know that the decay parameter is where are the Pauli’s just in (e.g. if , this would be the 15 ). Calculating the PTM terms (remember we only need the on-diagonal terms) and leaving off the in front of the trace,
| (15) | |||||
| (17) | |||||
| (18) |
because the middle terms have trace zero. So if then the above is 1, and if they don’t commute then the above is . In the space for the decay parameter of then, there are elements with (because there are 2 Pauli’s in that don’t commute with which is weight 2 but only has 1 weight in ) and the rest are 1. The fidelity in space is then
| (19) | |||||
| (20) |
So the estimate is independent of and therefore . And then since we multiply the two fidelities together to estimate ,
| (21) | |||||
| (22) |
which is a lower fidelity than the true fidelity Eqn. 14.
This analysis also holds by the same arguments for a Pauli stochastic error channel of the form
| (23) |
with defined as before. For this error channel we again find that , and , such that the layer fidelity is a lower bound for the true process fidelity .
Appendix D Combining Process Fidelities
Here we summarize some properties of the process fidelity which have been shown in other sources for reference. The process fidelity is defined as the trace of the superoperators (see, e.g. Ref [44] for a summary), in Pauli form,
| (24) | |||||
| (25) |
which is related to the average gate fidelity [45]
| (26) |
where is the average gate error and is often quoted from the gate error from randomized benchmarking. If there are two disjoint subspaces that have process fidelities and , then the fidelity of the combined system is , which is the property we have used to build up each disjoint layer fidelity. It is, however, not true that process fidelities multiply across layers (for simplicity assuming the ideal is the identity),
| (27) | |||||
| (28) |
However this is approximately true for small errors of diagonal maps, which can be shown by a simple expansion. Practically this means that the the fidelity of the layer repeated to multiple depths is fairly well approximated until the fidelity drops below a percent.
Appendix E Relating to
In this section we relate the to as defined in Ref. [1]. This is a useful metric for error mitigation since it indicates the number of circuit randomizations required to perform probabilistic error mitigation. is defined for Pauli diagonal noise model, and although we define for a depolarizing model, we will do a general comparison here for a Pauli diagonal noise model. As a reminder the definition of in terms of the PTM elements defined in the above section is,
| (29) | |||||
| (30) | |||||
| (31) |
where is the sum over where and are generators of a Lindblad equation that are small for small errors. In that limit, it’s straightforward to expand the exponentials,
| (32) | |||||
| (33) | |||||
| (34) | |||||
| (35) | |||||
| (36) |
using the fact that and .
Next we explore the correspondence of to more commonly used gate metrics such as the diamond norm or the average gate fidelity with more rigor and provide bounds. For a Pauli channel, both the average gate fidelity and the diamond norm have simple deviations from the spectral properties of the process matrix , where [4]. In particular, for a Pauli Channel we can write the average gate error and diamond norm as
| (37) | ||||
| (38) |
For a Pauli channel, we can derive either metric from the arithmetic average of the eigenvalues of .
Note that the form in Eqn. 5 is derived from a Lindbladian generator, . This allows us to express in terms of the spectrum of . That is
| (40) |
Through the exponential map we arrive at
| (41) |
That is gamma is related to the geometric mean of the eigenvalues of .
E.1 depolarizing channels
For a depolarizing channel, the spectrum of is a single and , ’s. In this case
| (42) | ||||
| (43) |
In the limit of large these both converge to . In terms of this depolarizing parameter we have,
| (44) | ||||
| (45) | ||||
| (46) |
Alternatively, we can express the gate fidelity and diamond norm in terms of gamma as
| (47) | ||||
| (48) |
E.2 The small error limit
Let’s assume is very close to the identity, i.e., the spectrum contains terms . Let’s define .
| (49) | ||||
| (50) |
Once again we are in the limit where the arithmetic and geometric means are the same, which again yields
| (51) | ||||
| (52) |
E.3 Bounds
The process fidelity of a superoperator is the arithmetic mean of its eigenvalues. On the other hand, Eqn. 41 established that is equal to the geometric mean of the eigenvalues. To make and more easily comparible this section chooses to work in terms of
We start with Theorem 1 which provides upper and lower bounds for in terms of . Although the lower bound appears complicated, it is extremely close to on all of , which can therefore be used as a proxy for most practical purposes. Especially note that both the upper and lower bounds are independent of the dimension . Following the theorem, we provide natural families of channels that saturate the upper bound, and nearly saturate the lower bound. For high fidelity layers, say above , it will be seen that .
Theorem 1.
Suppose is a CPTP Pauli channel with a process fidelity , and . Then it holds that
| (53) |
where
| (54) |
Proof.
The upper bound on follows directly from a standard application of Jensen’s inequality; the geometric mean of positive numbers cannot exceed their arithmetic mean.
To show the lower bound, first observe that all of the Pauli fidelities of lie in the interval . This was shown in Ref. [31], but we repeat the brief argument here for completeness. We can express the Pauli fidelity in terms of the Kraus probabilities as
| (55) |
where we have used the CPTP condition to write the sum of those where does not commute with as one minus the sum of those that do. Now clearly , and moreover , hence
| (56) |
We can now apply Lemma 1 (below) with and to get the stated inequality. ∎
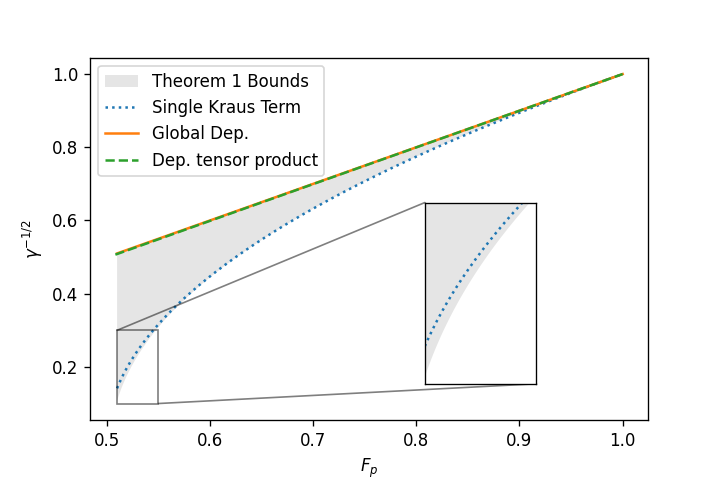
The geometric mean and arithmetic mean agree exactly when their arguments are equal, which means that exactly when all of the Pauli fidelities are equal, which, for TP channels, only happens with the identity channel. However, globally depolarizing channels are the next best thing as all values but one are equal. For a globally depolarizing channel with non-trivial Pauli fidelities , we have
| (57) |
which are very close to equal even for moderate ; see the upper curve in Fig. 8.
The next family of channels we consider are tensor products of two-qubit depolarizing channels, each with strength . Assuming is even and we have the tensor product of such channels, we get
| (58) |
which, as with global depolarizing channels (see Fig. 8), are very close to equal even for moderate .
The previous two families of channels have had Pauli fidelites that are tightly concentrated. To saturate the lower bound of Theorem 1, we will need to instead choose a channel that maximizes the variance of the Pauli fidelities. As seen in the proof of Lemma 1, this is done by making the Pauli fidelities strongly bimodal, concentrating roughly half of them at 1, and the other half at another value less than 1. This can be done by choosing a to have a Kraus map with only one non-trivial Pauli,
| (59) |
In this case, whenever commutes with , but otherwise. In this case we get
| (60) |
where we note the independence of . A physically relevant example of such a noise model is one where a single subsystem has a high error that dominates every other error, for example, by taking , where the first qubit is faulty. The geometric mean (viz. ) is good at capturing this outlier, but the arithmetic mean (viz. ) is not.
Lemma 1.
Suppose that are real numbers and fix a positive integer . Define by and by . Then restricting to the hyperrectangular region , we have
| (61) |
where and
| (62) |
Proof.
Since is linear and is concave, must be convex. Therefore, the maximum of is acheived on the extreme points of the convex set , which are given by . That is, we have .
Now, for any , there exists some such that . Therefore, . Standard calculus show that is concave on and acheives a maximum value at , which proves the inequality of this lemma. ∎