Besov Function Approximation and Binary Classification on Low-Dimensional Manifolds Using Convolutional Residual Networks
Abstract
Most of existing statistical theories on deep neural networks have sample complexities cursed by the data dimension and therefore cannot well explain the empirical success of deep learning on high-dimensional data. To bridge this gap, we propose to exploit low-dimensional geometric structures of the real world data sets. We establish theoretical guarantees of convolutional residual networks (ConvResNet) in terms of function approximation and statistical estimation for binary classification. Specifically, given the data lying on a -dimensional manifold isometrically embedded in , we prove that if the network architecture is properly chosen, ConvResNets can (1) approximate Besov functions on manifolds with arbitrary accuracy, and (2) learn a classifier by minimizing the empirical logistic risk, which gives an excess risk in the order of , where is a smoothness parameter. This implies that the sample complexity depends on the intrinsic dimension , instead of the data dimension . Our results demonstrate that ConvResNets are adaptive to low-dimensional structures of data sets.
1 Introduction
Deep learning has achieved significant success in various practical applications with high-dimensional data set, such as computer vision (Krizhevsky et al., 2012), natural language processing (Graves et al., 2013; Young et al., 2018; Wu et al., 2016), health care (Miotto et al., 2018; Jiang et al., 2017) and bioinformatics (Alipanahi et al., 2015; Zhou and Troyanskaya, 2015).
The success of deep learning clearly demonstrates the great power of neural networks in representing complex data. In the past decades, the representation power of neural networks has been extensively studied. The most commonly studied architecture is the feedforward neural network (FNN), as it has a simple composition form. The representation theory of FNNs has been developed with smooth activation functions (e.g., sigmoid) in Cybenko (1989); Barron (1993); McCaffrey and Gallant (1994); Hamers and Kohler (2006); Kohler and Krzyżak (2005); Kohler and Mehnert (2011) or nonsmooth activations (e.g., ReLU) in Lu et al. (2017); Yarotsky (2017); Lee et al. (2017); Suzuki (2019). These works show that if the network architecture is properly chosen, FNNs can approximate uniformly smooth functions (e.g., Hölder or Sobolev) with arbitrary accuracy.
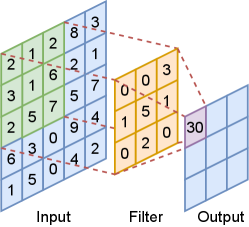
In real-world applications, convolutional neural networks (CNNs) are more popular than FNNs (LeCun et al., 1989; Krizhevsky et al., 2012; Sermanet et al., 2013; He et al., 2016; Chen et al., 2017; Long et al., 2015; Simonyan and Zisserman, 2014; Girshick, 2015). In a CNN, each layer consists of several filters (channels) which are convolved with the input, as demonstrated in Figure 1(a). Due to such complexity in the CNN architecture, there are limited works on the representation theory of CNNs (Zhou, 2020b, a; Fang et al., 2020; Petersen and Voigtlaender, 2020). The constructed CNNs in these works become extremely wide (in terms of the size of each layer’s output) as the approximation error goes to 0. In most real-life applications, the network width does not exceed 2048 (Zagoruyko and Komodakis, 2016; Zhang et al., 2020).
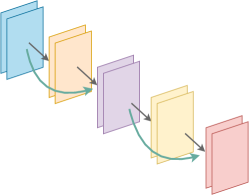
Convolutional residual networks (ConvResNet) is a special CNN architecture with skip-layer connections, as shown in Figure 1(b). Specifically, in addition to CNNs, ConvResNets have identity connections between inconsecutive layers. In many applications, ConvResNets outperform CNNs in terms of generalization performance and computational efficiency, and alleviate the vanishing gradient issue. Using this architecture, He et al. (2016) won the 1st place on the ImageNet classification task with a 3.57% top 5 error in 2015.
| Network type | Function class | Low dim. structure | Fixed width | Training | |
| Yarotsky (2017) | FNN | Sobolev | ✗ | ✗ | difficult to train due to the cardinality constraint |
| Suzuki (2019) | FNN | Besov | ✗ | ✗ | |
| Chen et al. (2019b) | FNN | Hölder | ✓ | ✗ | |
| Petersen and Voigtlaender (2020) | CNN | FNN | ✗ | ✗ | |
| Zhou (2020b) | CNN | Sobolev | ✗ | ✗ | can be trained without the cardinality constraint |
| Oono and Suzuki (2019) | ConvResNet | Hölder | ✗ | ✓ | |
| Ours | ConvResNet | Besov | ✓ | ✓ |
Recently, Oono and Suzuki (2019) develops the only representation and statistical estimation theory of ConvResNets. Oono and Suzuki (2019) proves that if the network architecture is properly set, ConvResNets with a fixed filter size and a fixed number of channels can universally approximate Hölder functions with arbitrary accuracy. However, the sample complexity in Oono and Suzuki (2019) grows exponentially with respect to the data dimension and therefore cannot well explain the empirical success of ConvResNets for high dimensional data. In order to estimate a function in with accuracy , the sample size required by Oono and Suzuki (2019) scales as , which is far beyond the sample size used in practical applications. For example, the ImageNet data set consists of 1.2 million labeled images of size . According to this theory, to achieve a 0.1 error, the sample size is required to be in the order of which greatly exceeds 1.2 million. Due to the curse of dimensionality, there is a huge gap between theory and practice.
We bridge such a gap by taking low-dimensional geometric structures of data sets into consideration. It is commonly believed that real world data sets exhibit low-dimensional structures due to rich local regularities, global symmetries, or repetitive patterns (Hinton and Salakhutdinov, 2006; Osher et al., 2017; Tenenbaum et al., 2000). For example, the ImageNet data set contains many images of the same object with certain transformations, such as rotation, translation, projection and skeletonization. As a result, the degree of freedom of the ImageNet data set is significantly smaller than the data dimension (Gong et al., 2019).
The function space considered in Oono and Suzuki (2019) is the Hölder space in which functions are required to be differentiable everywhere up to certain order. In practice, the target function may not have high order derivatives. Function spaces with less restrictive conditions are more desirable. In this paper, we consider the Besov space , which is more general than the Hölder space. In particular, the Hölder and Sobolev spaces are special cases of the Besov space:
for any and . For practical applications, it has been demonstrated in image processing that Besov norms can capture important features, such as edges (Jaffard et al., 2001). Due to the generality of the Besov space, it is shown in Suzuki and Nitanda (2019) that kernel ridge estimators have a sub-optimal rate when estimating Besov functions.
In this paper, we establish theoretical guarantees of ConvResNets for the approximation of Besov functions on a low-dimensional manifold, and a statistical theory on binary classification. Let be a -dimensional compact Riemannian manifold isometrically embedded in . Denote the Besov space on as for and . Our function approximation theory is established for . For binary classification, we are given i.i.d. samples where and is the label. The label follows the Bernoulli-type distribution
for some . Our results (Theorem 1 and 2) are summarized as follows:
Theorem (informal).
Assume .
-
1.
Given , we construct a ConvResNet architecture such that, for any , if the weight parameters of this ConvResNet are properly chosen, it gives rises to satisfying
-
2.
Assume . Let be the minimizer of the population logistic risk. If the ConvResNet architecture is properly chosen, minimizing the empirical logistic risk gives rise to with the following excess risk bound
where denotes the excess logistic risk of against and is a constant independent of .
We remark that the first part of the theorem above requires the network size to depend on the intrinsic dimension and only weakly depend on . The second part is built upon the first part and shows a fast convergence rate of the excess risk in terms of where the exponent depends on instead of . Our results demonstrate that ConvResNets are adaptive to low-dimensional structures of data sets.
Related work. Approximation theories of FNNs with the ReLU activation have been established for Sobolev (Yarotsky, 2017), Hölder (Schmidt-Hieber, 2017) and Besov (Suzuki, 2019) spaces. The networks in these works have certain cardinality constraint, i.e., the number of nonzero parameters is bounded by certain constant, which requires a lot of efforts for training.
Approximation theories of CNNs are developed in Zhou (2020b); Petersen and Voigtlaender (2020); Oono and Suzuki (2019). Among these works, Zhou (2020b) shows that CNNs can approximate Sobolev functions in for with an arbitrary accuracy . The network in Zhou (2020b) has width increasing linearly with respect to depth and has depth growing in the order of as decreases to 0. It is shown in Petersen and Voigtlaender (2020); Zhou (2020a) that any approximation error achieved by FNNs can be achieved by CNNs. Combining Zhou (2020a) and Yarotsky (2017), we can show that CNNs can approximate functions in with arbitrary accuracy . Such CNNs have the number of channels in the order of and a cardinality constraint. The only theory on ConvResNet can be found in Oono and Suzuki (2019), where an approximation theory for Hölder functions is proved for ConvResNets with fixed width.
Statistical theories for binary classification by FNNs are established with the hinge loss (Ohn and Kim, 2019; Hu et al., 2020) and the logistic loss (Kim et al., 2018). Among these works, Hu et al. (2020) uses a parametric model given by a teacher-student network. The nonparametric results in Ohn and Kim (2019); Kim et al. (2018) are cursed by the data dimension, and therefore require a large number of samples for high-dimensional data.
Binary classification by CNNs has been studied in Kohler et al. (2020); Kohler and Langer (2020); Nitanda and Suzuki (2018); Huang et al. (2018). Image binary classification is studied in Kohler et al. (2020); Kohler and Langer (2020) in which the probability function is assumed to be in a hierarchical max-pooling model class. ResNet type classifiers are considered in Nitanda and Suzuki (2018); Huang et al. (2018) while the generalization error is not given explicitly.
Low-dimensional structures of data sets are explored for neural networks in Chui and Mhaskar (2018); Shaham et al. (2018); Chen et al. (2019b, a); Schmidt-Hieber (2019); Nakada and Imaizumi (2019); Cloninger and Klock (2020); Chen et al. (2020); Montanelli and Yang (2020). These works show that, if data are near a low-dimensional manifold, the performance of FNNs depends on the intrinsic dimension of the manifold and only weakly depends on the data dimension. Our work focuses on ConvResNets for practical applications.
The networks in many aforementioned works have a cardinality constraint. From the computational perspective, training such networks requires substantial efforts (Han et al., 2016, 2015; Blalock et al., 2020). In comparison, the ConvResNet in Oono and Suzuki (2019) and this paper does not require any cardinality constraint. Additionally, our constructed network has a fixed filter size and a fixed number of channels, which is desirable for practical applications.
As a summary, we compare our approximation theory and existing results in Table 1.
2 Preliminaries
Notations: We use bold lower-case letters to denote vectors, upper-case letters to denote matrices, calligraphic letters to denote tensors, sets and manifolds. For any , we use to denote the smallest integer that is no less than and use to denote the largest integer that is no larger than . For any , we denote . For a function and a set , we denote the restriction of to by . We use to denote the norm of . We denote the Euclidean ball centered at with radius by .
2.1 Low-dimensional manifolds
We first introduce some concepts on manifolds. We refer the readers to Tu (2010); Lee (2006) for details. Throughout this paper, we let be a -dimensional Riemannian manifold isometrically embedded in with . We first introduce charts, an atlas and the partition of unity.
Definition 1 (Chart).
A chart on is a pair where is open and is a homeomorphism (i.e., bijective, and are both continuous).
In a chart , is called a coordinate neighborhood and is a coordinate system on . A collection of charts which covers is called an atlas of .
Definition 2 ( Atlas).
A atlas for is a collection of charts which satisfies , and are pairwise compatible:
are both for any . An atlas is called finite if it contains finitely many charts.
Definition 3 (Smooth Manifold).
A smooth manifold is a manifold together with a atlas.
The Euclidean space, the torus and the unit sphere are examples of smooth manifolds. functions on a smooth manifold are defined as follows:
Definition 4 ( functions on ).
Let be a smooth manifold and be a function on . We say is a function on , if for every chart on , the function is a function.
We next define the partition of unity which is an important tool for the study of functions on manifolds.
Definition 5 (Partition of Unity).
A partition of unity on a manifold is a collection of functions with such that for any ,
-
1.
there is a neighbourhood of where only a finite number of the functions in are nonzero, and
-
2.
.
An open cover of a manifold is called locally finite if every has a neighbourhood which intersects with a finite number of sets in the cover. The following proposition shows that a partition of unity for a smooth manifold always exists (Spivak, 1970, Chapter 2, Theorem 15).
Proposition 1 (Existence of a partition of unity).
Let be a locally finite cover of a smooth manifold . There is a partition of unity such that .
Let be a atlas of . Proposition 1 guarantees the existence of a partition of unity such that is supported on .
The reach of introduced by Federer (Federer, 1959) is an important quantity defined below. Let be the distance from to .
Definition 6 (Reach (Federer, 1959; Niyogi et al., 2008)).
Define the set
The closure of is called the medial axis of . The reach of is defined as

We illustrate large and small reach in Figure 2.
2.2 Besov functions on a smooth manifold
We next define Besov function spaces on , which generalizes more elementary function spaces such as the Sobolev and Hölder spaces. To define Besov functions, we first introduce the modulus of smoothness.
Definition 7 (Modulus of Smoothness (DeVore and Lorentz, 1993; Suzuki, 2019)).
Let . For a function be in for , the -th modulus of smoothness of is defined by
Definition 8 (Besov Space ).
For , define the seminorm as
The norm of the Besov space is defined as . The Besov space is .
Definition 9 ( Functions on ).
Let be a compact smooth manifold of dimension . Let be a finite atlas on and be a partition of unity on such that . A function is in if
| (1) |
Since is supported on , the function is supported on . We can extend from to by setting the function to be on . The extended function lies in the Besov space (Triebel, 1992, Chapter 7).
2.3 Convolution and residual block
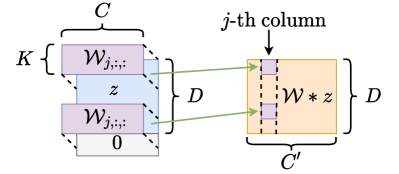
In this paper, we consider one-sided stride-one convolution in our network. Let be a filter where is the output channel size, is the filter size and is the input channel size. For , the convolution of with gives such that
| (2) |
where and we set for , as demonstrated in Figure 3(a).
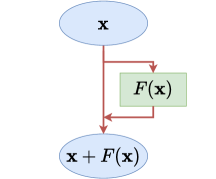
The building blocks of ConvResNets are residual blocks. For an input , each residual block computes
where is a subnetwork consisting of convolutional layers (see more details in Section 3.1). A residual block is demonstrated in Figure 3(b).
3 Theory
In this section, we first introduce the ConvResNet architecture, and then present our main results.
3.1 Convolutional residual neural network
We study the ConvResNet with the rectified linear unit () activation function: . The ConvResNet we consider consists of a padding layer and several residual blocks followed by a fully connected feedforward layer.
We first define the padding layer. Given an input , the network first applies a padding operator for some integer such that
Then the matrix is passed through residual blocks.
In the -th block, let and be a collection of filters and biases. The -th residual block maps a matrix from to by
where is the identity operator and
| (3) |
with applied entrywise. Denote
| (4) |
For networks only consisting of residual blocks, we define the network class as
| (5) |
where denotes norm of a vector, and for a tensor , .
Based on the network in (4), a ConvResNet has an additional fully connected layer and can be expressed as
| (6) |
where and are the weight matrix and the bias in the fully connected layer. The class of ConvResNets is defined as
| (7) |
Sometimes we do not have restriction on the output, we omit the parameter and denote the network class by .
3.2 Approximation theory
Our approximation theory is based on the following assumptions of and the object function .
Assumption 1.
is a -dimensional compact smooth Riemannian manifold isometrically embedded in . There is a constant such that for any , .
Assumption 2.
The reach of is .
Assumption 3.
Let , . Assume and for a constant . Additionally, we assume for a constant .
Assumption 3 implies that is Lipschitz continuous (Triebel, 1983, Section 2.7.1 Remark 2 and Section 3.3.1).
Our first result is the following universal approximation error of ConvResNets for Besov functions on .
Theorem 1.
Assume Assumption 1-3. For any and positive integer , there is a ConvResNet architecture such that, for any , if the weight parameters of this ConvResNet are properly chosen, the network yields a function satisfying
| (8) |
Such a network architecture has
| (9) |
The constant hidden in depend on , ,, , , and the surface area of .
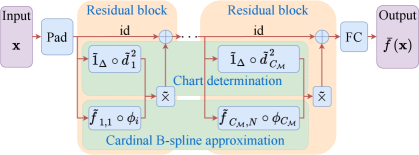
The architecture of the ConvResNet in Theorem 1 is illustrated in Figure 4. It has the following properties:
-
•
The network has a fixed filter size and a fixed number of channels.
-
•
There is no cardinality constraint.
-
•
The network size depends on the intrinsic dimension , and only weakly depends on .
Theorem 1 can be compared with Suzuki (2019) on the approximation theory for Besov functions in by FNNs as follows: (1) To universally approximate Besov functions in with error, the FNN constructed in Suzuki (2019) requires depth, width and nonzero parameters. By exploiting the manifold model, our network size depends on the intrinsic dimension and weakly depends on . (2) The ConvResNet in Theorem 1 does not require any cardinality constraint, while such a constraint is needed in Suzuki (2019).
3.3 Statistical theory
We next consider binary classification on . For any , denote its label by . The label follows the following Bernoulli-type distribution
| (10) |
for some .
We assume the following data model:
Assumption 4.
We are given i.i.d. sample , where , and the ’s are sampled according to (10).
In binary classification, a classifier predicts the label of as . To learn the optimal classifier, we consider the logistic loss . The logistic risk of a classifier is defined as
| (11) |
The minimizer of is denoted by , which satisfies
| (12) |
For any classifier , we define its logistic excess risk as
| (13) |
In this paper, we consider ConvResNets with the following architecture:
| (14) |
where are some parameters to be determined.
The empirical classifier is learned by minimizing the empirical logistic risk:
| (15) |
We establish an upper bound on the excess risk of :
Theorem 2.
Theorem 2 shows that a properly designed ConvResNet gives rise to an empirical classifier, of which the excess risk converges at a fast rate with an exponent depending on the intrinsic dimension , instead of .
4 Proof of Theorem 1
We provide a proof sketch of Theorem 1 in this section. More technical details are deferred to Appendix C.
We prove Theorem 1 in the following four steps:
-
1.
Decompose as a sum of locally supported functions according to the manifold structure.
-
2.
Locally approximate each using cardinal B-splines.
-
3.
Implement the cardinal B-splines using CNNs.
-
4.
Implement the sum of all CNNs by a ConvResNet for approximating .
Step 1: Decomposition of .
Construct an atlas on . Since the manifold is compact, we can cover by a finite collection of open balls for , where is the center of the ball and is the radius to be chosen later. Accordingly, the manifold is partitioned as with . We choose such that is diffeomorphic to an open subset of (Niyogi et al., 2008, Lemma 5.4). The total number of partitions is then bounded by
where is the surface area of and is the average number of ’s that contain a given point on (Conway et al., 1987, Chapter 2 Equation (1)).
On each partition, we define a projection-based transformation as
where the scaling factor and the shifting vector ensure , and the column vectors of form an orthonormal basis of the tangent space . The atlas on is the collection for . See Figure 5 for a graphical illustration of the atlas.

Decompose according to the atlas. We decompose as
| (17) |
where is a partition of unity with . The existence of such a is guaranteed by Proposition 1. As a result, each is supported on a subset of , and therefore, we can rewrite (17) as
| (18) |
where is the indicator function of . Since is a bijection between and , is supported on . We extend on by 0. The extended function is in (see Lemma 4 in Appendix C.1). This allows us to use cardinal B-splines to locally approximate each as detailed in Step 2.
Step 2: Local cardinal B-spline approximation. We approximate using cardinal B-splines as
| (19) |
where is a coefficient and denotes a cardinal B-spline with indecies . Here is a scaling factor, is a shifting vector, is the degree of the B-spline and is the dimension (see a formal definition in Appendix C.2).
Since (by Assumption 3), setting in Lemma 5 (see Appendix C.3) and applying Lemma 4 gives
| (20) |
for some constant depending on and .
Step 3: Implement local approximations in Step 2 by CNNs. In Step 2, (21) gives a natural approximation of . In the sequel, we aim to implement all ingredients of using CNNs. In particular, we show that CNNs can implement the cardinal B-spline , the linear projection , the indicator function , and the multiplication operation.
Implement by CNNs. Recall our construction of in Step 1. For any , we have if ; otherwise .
To implement , we rewrite it as the composition of a univariate indicator function and the distance function :
| (22) |
We show that CNNs can efficiently implement both and . Specifically, given and , there exist CNNs that yield functions and satisfying
| (23) |
and
| (24) |
We also characterize the network sizes for realizing and : The network for has layers, channels and all weight parameters bounded by ; the network for has layers, channels and all weight parameters bounded by . More technical details are provided in Lemma 9 in Appendix C.6.
Implement by CNNs. Since is a linear projection, it can be realized by a single-layer perceptron. By Lemma 8 (see Appendix C.5), this single-layer perceptron can be realized by a CNN, denoted by .
For , Proposition 3 (see Appendix C.8) shows that for any and , there exists a CNN with
such that when setting , we have
| (25) |
where is a constant depending on and . The constant hidden in depends on . The CNN class is defined in Appendix B.
Implement the multiplication by a CNN. According to Lemma 7 (see Appendix C.4) and Lemma 8, for any , the multiplication operation can be approximated by a CNN with error :
| (26) |
Such a CNN has layers, channels. All parameters are bounded by .
Step 4: Implement by a ConvResNet. We assemble all CNN approximations in Step 3 together and show that the whole approximation can be realized by a ConvResNet.
Assemble all ingredients together. Assembling all CNN approximations together gives an approximation of as
| (27) |
After substituting (27) into (21), we approximate the target function by
| (28) |
The approximation error of is analyzed in Lemma 12 (see Appendix C.9). According to Lemma 12, the approximation error can be bounded as follows:
where and are defined in (25), (26), (24) and (23), respectively. For any , with properly chosen and as in (53) in Lemma 12, one has
| (29) |
With these choices, the network size of each CNN is quantified in Appendix C.10.
Realize by a ConvResNet. Lemma 17 (see Appendix C.15) shows that for every , there exists with such that for any . As a result, the function in (28) can be expressed as a sum of CNNs:
| (30) |
where is chosen of (see Proposition 3 and Lemma 12). Lemma 18 (see Appendix C.16) shows that can be realized by with
5 Conclusion
Our results show that ConvResNets are adaptive to low-dimensional geometric structures of data sets. Specifically, we establish a universal approximation theory of ConvResNets for Besov functions on a -dimensional manifold . Our network size depends on the intrinsic dimension and only weakly depends on . We also establish a statistical theory of ConvResNets for binary classification when the given data are located on . The classifier is learned by minimizing the empirical logistic loss. We prove that if the ConvResNet architecture is properly chosen, the excess risk of the learned classifier decays at a fast rate depending on the intrinsic dimension of the manifold.
Our ConvResNet has many practical properties: it has a fixed filter size and a fixed number of channels. Moreover, it does not require any cardinality constraint, which is beneficial to training.
Our analysis can be extended to multinomial logistic regression for multi-class classification. In this case, the network will output a vector where each component represents the likelihood of an input belonging to certain class. By assuming that each likelihood function is in the Besov space, we can apply our analysis to approximate each function by a ConvResNet.
References
- Alipanahi et al. (2015) Alipanahi, B., Delong, A., Weirauch, M. T. and Frey, B. J. (2015). Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nature Biotechnology, 33 831–838.
- Barron (1993) Barron, A. R. (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information theory, 39 930–945.
- Blalock et al. (2020) Blalock, D., Ortiz, J. J. G., Frankle, J. and Guttag, J. (2020). What is the state of neural network pruning? arXiv preprint arXiv:2003.03033.
- Chen et al. (2017) Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K. and Yuille, A. L. (2017). DeepLAB: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40 834–848.
- Chen et al. (2019a) Chen, M., Jiang, H., Liao, W. and Zhao, T. (2019a). Efficient approximation of deep ReLU networks for functions on low dimensional manifolds. In Advances in Neural Information Processing Systems.
- Chen et al. (2019b) Chen, M., Jiang, H., Liao, W. and Zhao, T. (2019b). Nonparametric regression on low-dimensional manifolds using deep ReLU networks. arXiv preprint arXiv:1908.01842.
- Chen et al. (2020) Chen, M., Liu, H., Liao, W. and Zhao, T. (2020). Doubly robust off-policy learning on low-dimensional manifolds by deep neural networks. arXiv preprint arXiv:2011.01797.
- Chui and Mhaskar (2018) Chui, C. K. and Mhaskar, H. N. (2018). Deep nets for local manifold learning. Frontiers in Applied Mathematics and Statistics, 4 12.
- Cloninger and Klock (2020) Cloninger, A. and Klock, T. (2020). ReLU nets adapt to intrinsic dimensionality beyond the target domain. arXiv preprint arXiv:2008.02545.
- Conway et al. (1987) Conway, J. H., Sloane, N. J. A. and Bannai, E. (1987). Sphere-packings, Lattices, and Groups. Springer-Verlag, Berlin, Heidelberg.
- Cybenko (1989) Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems, 2 303–314.
- DeVore and Lorentz (1993) DeVore, R. A. and Lorentz, G. G. (1993). Constructive Approximation, vol. 303. Springer Science & Business Media.
- DeVore and Popov (1988) DeVore, R. A. and Popov, V. A. (1988). Interpolation of Besov spaces. Transactions of the American Mathematical Society, 305 397–414.
- Dispa (2003) Dispa, S. (2003). Intrinsic characterizations of Besov spaces on lipschitz domains. Mathematische Nachrichten, 260 21–33.
- Dũng (2011) Dũng, D. (2011). Optimal adaptive sampling recovery. Advances in Computational Mathematics, 34 1–41.
- Fang et al. (2020) Fang, Z., Feng, H., Huang, S. and Zhou, D.-X. (2020). Theory of deep convolutional neural networks II: Spherical analysis. Neural Networks, 131 154–162.
- Federer (1959) Federer, H. (1959). Curvature measures. Transactions of the American Mathematical Society, 93 418–491.
- Geer and van de Geer (2000) Geer, S. A. and van de Geer, S. (2000). Empirical Processes in M-estimation, vol. 6. Cambridge University press.
- Geller and Pesenson (2011) Geller, D. and Pesenson, I. Z. (2011). Band-limited localized parseval frames and Besov spaces on compact homogeneous manifolds. Journal of Geometric Analysis, 21 334–371.
- Girshick (2015) Girshick, R. (2015). Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision.
- Gong et al. (2019) Gong, S., Boddeti, V. N. and Jain, A. K. (2019). On the intrinsic dimensionality of image representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Graves et al. (2013) Graves, A., Mohamed, A.-r. and Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE.
- Hamers and Kohler (2006) Hamers, M. and Kohler, M. (2006). Nonasymptotic bounds on the error of neural network regression estimates. Annals of the Institute of Statistical Mathematics, 58 131–151.
- Han et al. (2016) Han, S., Pool, J., Narang, S., Mao, H., Gong, E., Tang, S., Elsen, E., Vajda, P., Paluri, M., Tran, J. et al. (2016). Dsd: Dense-sparse-dense training for deep neural networks. arXiv preprint arXiv:1607.04381.
- Han et al. (2015) Han, S., Pool, J., Tran, J. and Dally, W. J. (2015). Learning both weights and connections for efficient neural networks. arXiv preprint arXiv:1506.02626.
- He et al. (2016) He, K., Zhang, X., Ren, S. and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Hinton and Salakhutdinov (2006) Hinton, G. E. and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313 504–507.
- Hu et al. (2020) Hu, T., Shang, Z. and Cheng, G. (2020). Sharp rate of convergence for deep neural network classifiers under the teacher-student setting. arXiv preprint arXiv:2001.06892.
- Huang et al. (2018) Huang, F., Ash, J., Langford, J. and Schapire, R. (2018). Learning deep resnet blocks sequentially using boosting theory. In International Conference on Machine Learning.
- Jaffard et al. (2001) Jaffard, S., Meyer, Y. and Ryan, R. D. (2001). Wavelets: tools for science and technology. SIAM.
- Jiang et al. (2017) Jiang, F., Jiang, Y., Zhi, H., Dong, Y., Li, H., Ma, S., Wang, Y., Dong, Q., Shen, H. and Wang, Y. (2017). Artificial intelligence in healthcare: past, present and future. Stroke and vascular neurology, 2 230–243.
- Kim et al. (2018) Kim, Y., Ohn, I. and Kim, D. (2018). Fast convergence rates of deep neural networks for classification. arXiv preprint arXiv:1812.03599.
- Kohler and Krzyżak (2005) Kohler, M. and Krzyżak, A. (2005). Adaptive regression estimation with multilayer feedforward neural networks. Nonparametric Statistics, 17 891–913.
- Kohler et al. (2020) Kohler, M., Krzyzak, A. and Walter, B. (2020). On the rate of convergence of image classifiers based on convolutional neural networks. arXiv preprint arXiv:2003.01526.
- Kohler and Langer (2020) Kohler, M. and Langer, S. (2020). Statistical theory for image classification using deep convolutional neural networks with cross-entropy loss. arXiv preprint arXiv:2011.13602.
- Kohler and Mehnert (2011) Kohler, M. and Mehnert, J. (2011). Analysis of the rate of convergence of least squares neural network regression estimates in case of measurement errors. Neural Networks, 24 273–279.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I. and Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems.
- LeCun et al. (1989) LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W. and Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural Computation, 1 541–551.
- Lee et al. (2017) Lee, H., Ge, R., Ma, T., Risteski, A. and Arora, S. (2017). On the ability of neural nets to express distributions. In Conference on Learning Theory.
- Lee (2006) Lee, J. M. (2006). Riemannian manifolds: an introduction to curvature, vol. 176. Springer Science & Business Media.
- Long et al. (2015) Long, J., Shelhamer, E. and Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Lu et al. (2017) Lu, Z., Pu, H., Wang, F., Hu, Z. and Wang, L. (2017). The expressive power of neural networks: A view from the width. In Advances in Neural Information Processing Systems.
- McCaffrey and Gallant (1994) McCaffrey, D. F. and Gallant, A. R. (1994). Convergence rates for single hidden layer feedforward networks. Neural Networks, 7 147–158.
- Mhaskar and Micchelli (1992) Mhaskar, H. N. and Micchelli, C. A. (1992). Approximation by superposition of sigmoidal and radial basis functions. Advances in Applied mathematics, 13 350–373.
- Miotto et al. (2018) Miotto, R., Wang, F., Wang, S., Jiang, X. and Dudley, J. T. (2018). Deep learning for healthcare: review, opportunities and challenges. Briefings in Bioinformatics, 19 1236–1246.
- Montanelli and Yang (2020) Montanelli, H. and Yang, H. (2020). Error bounds for deep ReLU networks using the Kolmogorov–Arnold superposition theorem. Neural Networks, 129 1–6.
- Nakada and Imaizumi (2019) Nakada, R. and Imaizumi, M. (2019). Adaptive approximation and estimation of deep neural network with intrinsic dimensionality. arXiv preprint arXiv:1907.02177.
- Nitanda and Suzuki (2018) Nitanda, A. and Suzuki, T. (2018). Functional gradient boosting based on residual network perception. In International Conference on Machine Learning.
- Niyogi et al. (2008) Niyogi, P., Smale, S. and Weinberger, S. (2008). Finding the homology of submanifolds with high confidence from random samples. Discrete & Computational Geometry, 39 419–441.
- Ohn and Kim (2019) Ohn, I. and Kim, Y. (2019). Smooth function approximation by deep neural networks with general activation functions. Entropy, 21 627.
- Oono and Suzuki (2019) Oono, K. and Suzuki, T. (2019). Approximation and non-parametric estimation of ResNet-type convolutional neural networks. In International Conference on Machine Learning.
- Osher et al. (2017) Osher, S., Shi, Z. and Zhu, W. (2017). Low dimensional manifold model for image processing. SIAM Journal on Imaging Sciences, 10 1669–1690.
- Park (2009) Park, C. (2009). Convergence rates of generalization errors for margin-based classification. Journal of Statistical Planning and Inference, 139 2543–2551.
- Petersen and Voigtlaender (2020) Petersen, P. and Voigtlaender, F. (2020). Equivalence of approximation by convolutional neural networks and fully-connected networks. Proceedings of the American Mathematical Society, 148 1567–1581.
- Schmidt-Hieber (2017) Schmidt-Hieber, J. (2017). Nonparametric regression using deep neural networks with ReLU activation function. arXiv preprint arXiv:1708.06633.
- Schmidt-Hieber (2019) Schmidt-Hieber, J. (2019). Deep ReLU network approximation of functions on a manifold. arXiv preprint arXiv:1908.00695.
- Sermanet et al. (2013) Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R. and LeCun, Y. (2013). Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229.
- Shaham et al. (2018) Shaham, U., Cloninger, A. and Coifman, R. R. (2018). Provable approximation properties for deep neural networks. Applied and Computational Harmonic Analysis, 44 537–557.
- Shen and Wong (1994) Shen, X. and Wong, W. H. (1994). Convergence rate of sieve estimates. The Annals of Statistics 580–615.
- Simonyan and Zisserman (2014) Simonyan, K. and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Spivak (1970) Spivak, M. D. (1970). A comprehensive introduction to differential geometry. Publish or Perish.
- Suzuki (2019) Suzuki, T. (2019). Adaptivity of deep ReLU network for learning in besov and mixed smooth besov spaces: optimal rate and curse of dimensionality. In International Conference on Learning Representations.
- Suzuki and Nitanda (2019) Suzuki, T. and Nitanda, A. (2019). Deep learning is adaptive to intrinsic dimensionality of model smoothness in anisotropic besov space. arXiv preprint arXiv:1910.12799.
- Tenenbaum et al. (2000) Tenenbaum, J. B., De Silva, V. and Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. Science, 290 2319–2323.
- Triebel (1983) Triebel, H. (1983). Theory of Function Spaces. Modern Birkhäuser Classics, Birkhäuser Basel.
- Triebel (1992) Triebel, H. (1992). Theory of function spaces II. Monographs in Mathematics, Birkhäuser Basel.
- Tu (2010) Tu, L. (2010). An Introduction to Manifolds. Universitext, Springer New York.
- Wu et al. (2016) Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K. et al. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144.
- Yarotsky (2017) Yarotsky, D. (2017). Error bounds for approximations with deep ReLU networks. Neural Networks, 94 103–114.
- Young et al. (2018) Young, T., Hazarika, D., Poria, S. and Cambria, E. (2018). Recent trends in deep learning based natural language processing. IEEE Computational Intelligence Magazine, 13 55–75.
- Zagoruyko and Komodakis (2016) Zagoruyko, S. and Komodakis, N. (2016). Wide residual networks. arXiv preprint arXiv:1605.07146.
- Zhang et al. (2020) Zhang, H., Wu, C., Zhang, Z., Zhu, Y., Zhang, Z., Lin, H., Sun, Y., He, T., Mueller, J., Manmatha, R. et al. (2020). ResNeSt: Split-attention networks. arXiv preprint arXiv:2004.08955.
- Zhou (2020a) Zhou, D.-X. (2020a). Theory of deep convolutional neural networks: Downsampling. Neural Networks, 124 319–327.
- Zhou (2020b) Zhou, D.-X. (2020b). Universality of deep convolutional neural networks. Applied and Computational Harmonic Analysis, 48 787–794.
- Zhou and Troyanskaya (2015) Zhou, J. and Troyanskaya, O. G. (2015). Predicting effects of noncoding variants with deep learning–based sequence model. Nature Methods, 12 931–934.
Supplementary Materials for Besov Function Approximation and Binary Classification on
Low-Dimensional Manifolds Using Convolutional Residual Networks
Notations: Throughout our proofs, we define the following notations: For two functions and defined on some domain , we denote if there is a constant such that for all . Similarly, we denote if there is a constant such that for all . We denote if and . We use to denote the set of all nonnegative integers. For a real number , we denote and .
The proof of Theorem 1 is sketched in Section 4. In this supplementary material, we prove Theorem 2 in Section A. We define convolutional network and multi-layer perceptrons classes in Section B, based on which the lemmas used in Section 4 are proved in Section C. The lemmas used in Section A are proved in Section D.
Appendix A Proof of Theorem 2
A.1 Basic definitions and tools
We first define the bracketing entropy and covering number which are used in the proof of Theorem 2.
Definition 10 (Bracketing entropy).
A set of function pairs is called a -bracketing of a function class with respect to the norm if for any , and for any , there exists a pair such that . The -bracketing number is defined as the cardinality of the minimal -bracketing set and is denoted by . The -bracketing enropy, denoted by , is defined as
Definition 11 (Covering number).
Let be a set with metric . A -cover of is a set such that for any , there exists for some such that . The -covering number of is defined as
It has been shown (Geer and van de Geer, 2000, Lemma 2.1) that for any ,
The proof of Theorem 2 relies on the following proposition which is a modified version of Kim et al. (2018, Theorem 5):
Proposition 2.
Let be a surrogate loss function for binary classification. Let be defined as in (12) and (13), respectively. Assume the following regularity conditions:
-
(A1)
is Lipschitz: for any and some constant .
-
(A2)
For a positive sequence for some , there exists a sequence of function classes such that as ,
for some .
-
(A3)
There exists a sequence with such that .
-
(A4)
There exists a constant such that for any and any ,
for some constant only depending on and .
-
(A5)
For a positive constant , there exists a sequence such that
for in (A2), in (A3) and in (A4).
Let . Then the empirical -risk minimizer over satisfies
| (31) |
for some constants .
Proposition 2 is proved in Appendix D.1. In Proposition 2, condition (A1) requires the surrogate loss function to be Lipschitz. This condition is satisfied in Theorem 2 since is the logistic loss. (A2) is a condition on the bias of . Take as the number of samples. (A2) requires the bias to decrease in the order of for some . (A3) requires all functions in the class to be bounded. (A4) and (A5) are conditions relate to the variance of . Condition (A4) for logistic loss can be verified using the following lemma:
Lemma 1 (Lemma 6.1 in Park (2009)).
Let be the logistic loss. Given a function class which is uniformly bounded by , for any function , we have
for some constant .
A.2 Proof of Theorem 2
Proof of Theorem 2.
A truncation technique.
Recall that . As goes to 0 (resp. 1), goes to (resp. ). Note that (A3) requires the function class to be bounded by . To study the approximation error of with respect to , we consider a truncated version of defined as
| (33) |
Verification of (A2) and (A3).
The following lemma is a very important lemma on approximating by ConvResNets. It also provides the covering number of the network class which will be used to verify (A5).
Lemma 2.
Lemma 2 is proved in Section D.2. By Lemma 2, fix the network architecture , for , there exists a ConvResNet such that In the following, we choose .
Next we check conditions (A2) and (A3) by estimating . Denote
We have
| (34) |
where we used on . In (34), represents the approximation error of , and is the truncation error. Since ,
| (35) |
A bound of is provided by the following lemma (see a proof in Appendix D.3):
Lemma 3.
Verification of (A5).
For (A5), we only need to check that for some constant . According to Lemma 2 with our choices of and , we have
Substituting our choice gives rise to
| (37) |
for some depending on and the surface area of . Therefore (A5) is satisfied.
Estimate the excess risk.
Since (A1)-(A5) are satisfied, Proposition 2 gives
| (38) |
with and being the minimizer of the empirical risk in (11). Here is a constant depending on and the surface area of .
Note that (A5) is also satisfied for any . Thus
| (39) |
for any . Integrating (39), we estimate the expected excess risk as
| (40) |
for some constants depending on and the surface area of . ∎
Appendix B Convolutional neural networks and muli-layer perceptrons
The proofs of the main results utilize properties convolutional neural networks (CNN) and multi-layer perceptrons (MLP) with the ReLU activation. We consider CNNs in the form of
| (41) |
where is defined in (3), is the weight matrix of the fully connected layer, are sets of filters and biases, respectively. We define the class of CNNs as
| (42) | ||||
| Each convolutional layer has filter size bounded by . | ||||
For MLP, we consider the following form
| (43) |
where and are weight matrices and bias vectors of proper sizes, respectively. The class of MLP is defined as
| (44) | ||||
In some cases it is necessary to enforce the output of the MLP to be bounded. We define such a class as
In some case we do not need the constraint on the output, we denote such MLP class as .
Appendix C Lemmas and proofs in Section 4
C.1 Lemma 4 and its proof
Lemma 4.
To prove Lemma 4, we first give an equivalent definition of Besov functions:
Definition 12.
Let be a Lipschitz domain in . For and , is the set of functions
where denotes the restriction of on . The norm is defined as .
According to Dispa (2003, Theorem 3.18), for any Lipschitz domain , the norm in Definition 8 is equivalent to in Definition 12. Thus .
C.2 Cardinal B-splines
We give a brief introduction of cardinal B-splines.
Definition 13 (Cardinal B-spline).
Let be the indicator function of . The cardinal B-spline of order m is defined by taking -times convolution of :
where .
Note that is a piecewise polynomial with degree and support . It can be expressed as (Mhaskar and Micchelli, 1992)
For any , let , which is the rescaled and shifted cardinal B-spline with resolution and support . For and , we define the dimensional cardinal B-spline as . When , we denote .
C.3 Lemma 5
For any , let and the quasi-norm of the coefficient for be
| (45) |
The following lemma, resulted from DeVore and Popov (1988); Dũng (2011), gives an error bound for the approximation of functions in by cardinal B-splines.
Lemma 5 (Lemma 2 in Suzuki (2019); DeVore and Popov (1988); Dũng (2011)).
Assume that and satisfying . Let be the order of the Cardinal B-spline basis such that . For any , there exists satisfying
for some constant with . is in the form of
| (46) |
where for and . The real numbers and are two absolute constants chosen to satisfy , which are to . Moreover, we can choose the coefficients such that
for some constant .
Lemma 6.
C.4 Lemma 7
Lemma 7 (Proposition 3 in Yarotsky (2017)).
For any and . If , there is an MLP, denoted by , such that
Such a network has layers and parameters. The width of each layer is bounded by 6 and all parameters are bounded by .
C.5 Lemma 8
The following lemma is a special case of Oono and Suzuki (2019, Theorem 1). It shows that each MLP can be realized by a CNN:
Lemma 8 (Theorem 1 in Oono and Suzuki (2019)).
Let be the dimension of the input. Let be positive integers and . For any , any MLP architectures can be realized by a CNN architecture with
Specifically, any can be realized by a CNN . Furthermore, the weight matrix in the fully connected layer of has nonzero entries only in the first row.
C.6 Lemma 9 and its proof
Lemma 9.
Let and be defined as in (22). For any and , there exists a CNN approximating such that
and a CNN approximating with
for . The CNN for has layers, channels and all weights parameters are bounded by . The CNN for has layers, channels. All weight parameters are bounded by .
As a result, for any , gives an approximation of satisfying
Proof.
We first show the existence of . Here is the sum of univariate quadratic functions. Each quadratic function can be approximated by an multi-layer perceptron (MLP, see Appendix B for the definition) according to Lemma 7. Let be an MLP approximation of for with error , i.e., . We define
as an approximation of , which gives rise to the approximation error . Such a MLP has layers, and width . All weight parameters are bounded by . According to Lemma 8, can be realized by a CNN, which is denoted by . Such a CNN has layers, channels. All weight parameters are bounded by .
To show the existence of , we use the following function to approximate :
We implement based on the basic step function defined as: . Define
We set which can be realized by a CNN (according to Lemma 8). Such a CNN has layers, channels. All weight parameters are bounded by . The number of compositions is chosen to satisfy which gives .
∎
C.7 Lemma 10 and its proof
Lemma 10 shows that each cardinal B-spline can be approximated by a CNN with arbitrary accuracy. This lemma is used to prove Proposition 3.
Lemma 10.
Let be any number in and be any element in . There exists a constant depending only on and such that, for and and , there exists a CNN with and such that for any and ,
and for all .
The proof of Lemma 10 is based on the following lemma:
Lemma 11 (Lemma 1 in Suzuki (2019)).
Let be any number in and be any element in . There exists a constant depending only on and such that, for all , there exists an MLP with and such that for any and ,
and for all .
C.8 Proposition 3 and its proof
Proposition 3 shows that if and are properly chosen, can approximate with arbitrary accuracy.
Proposition 3.
Proof of Proposition 3.
Based on the approximation (19), for each , we construct CNN to approximate it.
Note that with some coefficient and index where is a -dimensional cardinal B-spline. Lemma 10 shows that can be approximated by a CNN with arbitrary accuracy. Therefor can be approximated by a CNN with arbitrary accuracy. Assume for some . Then with
| (50) |
The rest proof follows that of Suzuki (2019, Proposition 1) in which we show that with properly chosen and , can approximate with arbitrary accuracy.
We decompose the error as
| (51) |
where is defined in (19). We next derive an error bound for each term.
Let be the order of the Cardianl B-spline basis. Set . According to (20) and Lemma 5,
| (52) |
for some constant depending on and , some universal constant with for , and . By setting , we have .
Next we consider the second term in (51). For any , we have
with being some constant depending on .
In the second inequality, if and it equals to otherwise. The third inequality follows from the fact that for each , there are basis functions which are non-zero at and . In the fourth inequality we use and , and the last inequality follows from . Setting
proves the error bound.
C.9 Lemma 12
Lemma 12 estimates the approximation error of .
Lemma 12.
Proof of Lemma 12.
In the error decomposition, measures the error from :
for some constant depending on .
measures the error from CNN approximation of Besov functions. According to Proposition 3, .
measures the error from CNN approximation of the chart determination function. The bound of can be derived using Chen et al. (2019b, Proof of Lemma 4.5) since is a Lipschitz function and its domain is in . ∎
C.10 CNN size quantification of
Let be defined as in (28). Under the choices of in Lemma 12, we quantify the size of each CNN in as follows:
-
•
has layers, channels and all weights parameters are bounded by .
-
•
has layers with channels. All weights are bounded by .
-
•
has layers with channels. All weights are of .
-
•
has layers with channels. All weights are in the order of where is defined in Lemma 5.
-
•
has layers and channels. All weights are bounded by .
In the above network architectures, the constant hidden in depend on and the surface area of . In particular, the constant depends on linearly.
C.11 Lemma 13 and its proof
Lemma 13 shows that the composition of two CNNs can be realized by another CNN. Lemma 13 is used to prove Lemma 17.
Lemma 13.
Let be a CNN architecture from and be a CNN architecture from . Assume the weight matrix in the fully connected layer of and has nonzero entries only in the first row. Then there exists a CNN architecture from with
such that for any and , there exists such that . Furthermore, the weight matrix in the fully connected layer of has nonzero entries only in the first row.
In Lemma 13 and the following lemmas, the subscript of are used to distinguish different network architectures.
Proof of Lemma 13.
Compared to a CNN, directly composing and gives a network with an additional intermediate fully connected layer. In our network construction, we will design two convolutaionl layers to replace and realize this fully connected layer.
Denote and by
where are sets of filters and biases and are defined in (3). In the rest of this proof, we will choose proper weight parameters in and such that is in the form of
and satisfies .
For , we set .
For , to realize the fully connected layer of by a convolutional layer, we set
and . Here is a size-one filter with two output channels, where is the number of input channels of . The output of the -th layer of has the form
where denotes some elements that will not affect the result.
Since the input of is a real number, all filters of has size 1. The weight matrix in the fully connected layer and all biases only have one row. For the -th layer, we set
where varies from 1 to the number of output channels of . Here is a size-one filter whose number of output channels is the same as that of .
For , we set
For , we set
With the above settings, the lemma is proved. ∎
C.12 Lemma 14 and its proof
Lemma 14.
Let be a CNN from and be a CNN from . Assume the weight matrix in the fully connected layer of and have nonzero entries only in the first row. Then there exists a set of filters and biases such that
Such a network has layers, each filter has size at most and at most channels. All parameter are bounded by .
Proof of Lemma 14.
For simplicity, we assume all convolutional layers of have channels and all convolutional layers of have channels. If some filters in (or ) have channels less than (or ), we can add additional channels with zero filters and biases. Without loss of generality, we assume .
Denote and by
where are sets of filters and biases and are defined in (3). In the rest of this proof, We will choose proper weight parameters in such that
For , we set
Each is a filter with size and output channels. When , we pad the smaller filter by zeros. For example when , we set
such that has size filters.
For the -th layer, we set
is a filter with size and output channels.
For , we set
For the -th layer, we set
and . ∎
C.13 Lemma 15 and its proof
Lemma 15.
Let be positive integers. For any , define
For any CNN architecture from , there exists a CNN architecture from such that for any , there exists with . Furthermore, the fully connected layer of has nonzero entries only in the first row.
Proof of Lemma 15.
Denote as
where are sets of filters and biases and is defined in (3). For simplicity, we assume all convolutional layers of have channels . If some filters in have less than channels, we can add additional channels with zero filters and biases.
We next choose proper weight parameters in and such that
and .
For the first layer, i.e., , we design and since is a vector in , the filter has 1 input channel and output channel. For and , we set
where is of size , is a zero matrix of size .
For and , we set
where is of size . The bias is set as
We next choose weight parameters for . For and , we set
where is of size , is a zero matrix of size .
For and , we set
where is of size . The bias is set as
For the fully connected layer, we set
With these choices, the lemma is proved. ∎
C.14 Lemma 16 and its proof
Lemma 16 shows that for any CNN, if we scale all weight parameters in convolutional layers by some factors and scale the weight parameters in the fully connected layer properly, the output will remain the same. Lemma 16 is used to prove Lemma 17.
Lemma 16.
Let . For any , there exists such that .
Proof of Lemma 16.
This lemma is proved using the linear property of and convolution. Let be any CNN in . Denote its architecture as
Define and as
for any . Set
We have and since for any . ∎
C.15 Lemma 17 and its proof
Lemma 17.
Proof of Lemma 17.
According to Lemma 13, there exists a CNN realizing and a CNN realizing . Using Lemma 14, one can construct a CNN excluding the fully connected layer, denoted by , such that
| (54) |
Here has channels.
Since the input of is Lemma 15 shows that there exists a CNN which takes (54) as the input and outputs .
Note that only contains convolutional layers. The composition , denoted by , is a CNN and for any , . We have with
and can be any integer in .
We next rescale all parameters in convolutional layers of to be no larger than 1. Using Lemma 16, we can realize by for any . Set where is a constant such that . With this , we have with
∎
C.16 Lemma 18 and its proof
Lemma 18 shows that the sum of a set of CNNs can be realized by a ConvResNet.
Lemma 18.
Let be any CNN architecture from to . Assume the weight matrix in the fully connected layer of has nonzero entries only in the first row. Let be a positive integer. There exists a ConvResNet architecture such that for any , there exists with
Proof of Lemma 18.
Denote the architecture of by
with In , denote the weight matrix and bias in the fully connected layer by and the set of filters and biases in the -th block by and , respectively. The padding layer in pads the input from to by zeros. Here each column denotes a channel.
We first show that for each , there exists a subnetowrk such that for any in the form of
| (55) |
we have
| (56) |
where denotes some entries that we do not care.
For any , the first layer of takes input in . As a result, the filters in are in . We pad these filters by zeros to get filters in and construct as
For any in the form of (55), we have . For the filters in the following layers and all biases, we simply set
In , another convolutional layer is constructed to realize the fully connected layer in . According to our assumption, only the first row of has nonzero entries. We set and as size one filters with three output channels in the form of
Under such choices, (56) is proved and all parameters in are bounded by .
By composing all residual blocks, one has
The fully connect layer is set as
The weights in the fully connected layer are bounded by .
Such a ConvResNet gives
∎
Appendix D Proof of Lemmas and Propositions in Section A
D.1 Proof of Proposition 2
The proof of Proposition 2 relies on the following large-deviation inequality:
Lemma 19 (Theorem 3 in Shen and Wong (1994)).
Let be i.i.d. samples from some probability distribution. Let be a class of functions whose magnitude is bounded by . Let be a constant. Assume there are constants such that
-
(B1)
,
-
(B2)
,
-
(B3)
if , then
Then
Proof of Proposition 2.
Let be constants defined in Proposition 2. Set . For each defined in (A2), define
| (57) |
Note that by (A2). Since is the minimizer of , we have
We decompose the set into disjoint subsets for in the form of
Note that and for all . Therefore, for any , we have
which implies is an empty set for . We set . Then we have . Since , we have
Denote . We have
where is defined in (57). Then we will bound each summand on the right-hand side using Lemma 19. First, using (A4), we have
Define . For any , . Since , we have .
To apply Lemma 19 on , we set and with
Since and , we have and . We first check the validation of (B2). Since ,
when is large enough. Thus (B2) is satisfied.
For (B3), note that for where , . We have
where the second inequality comes from . Since is a non-increasing function of ,
where in the third inequality we used (A5). (B3) is satisfied when is large enough.
To verify (B1), we use (B2) and (B3). From (B2), since , we have which implies . Thus the condition in (B3) is satisfied. From (B3), we derive
where in the third inequality we used . Again from (B2), . Therefore
and (B1) is verified.
D.2 Proof of Lemma 2
The proof of Lemma 2 consists of two steps. We first show that there exists a composition of networks such that . Then we show that can be realized by a ConvResNet .
Lemma 20 shows the existence of .
Lemma 20.
Assume Assumption 1 and 2. Assume , , . There exists a network composition architecture
| (58) |
where with
with
and
For any with for some constant , let be defined as in (33). For any and , there exists a composition of networks such that
Proof of Lemma 20.
According to Theorem 1, for any and , there is a ConvResNet architecture with
such that there exists with
Since , we have with
The function can be realized by . Then is an approximation of .
Define
for which is a Lipschitz function with Lipschitz constant . According to Chen et al. (2019b, Theorem 4.1), there exists an MLP such that with
Let . Then such that with
Let We define
as an approximation of . Then the error of can be decomposed as
Choosing gives rise to . With this choice, we have
Setting proves the lemma. ∎
To show that can be realized by a ConvResNet class and to derive its covering number, we need the following lemma to bound the covering number of ConvResNets.
Lemma 21.
Let be the ConvResNet structure defined in Theorem 1. Its covering number is bounded by
Lemma 21 is proved based on the following lemma:
Lemma 22 (Lemma 4 of Oono and Suzuki (2019)).
Let be a class of ConvResNet architecture from to . Let . For , we have
where
with and .
Proof of Lemma 21.
The following lemma shows that can be realized by a ConvResNet class and estimates the covering number of the class of .
Lemma 23.
Proof of Lemma 23.
In this proof, we show that each part of in Lemma 20 can be realized by ConvResNet architectures. Specifically, we show that can be realized by residual blocks , and can be realized by a ConvResNet . In the following, we show the existence of each ingredient.
Realize by residual blocks.
In Lemma 20, with
By Lemma 21, the covering number of this architecture is bounded by
Excluding the final fully connected layer, denote all of the residual blocks of by , then with and
We denote the -th row (the -th element of all channels) of the output of the residual-blocks by . In the proof of Theorem 1, the input in is padded into by 0’s. The output of has the form . Here denotes some number that does not affect the result. In this proof, instead of padding the input into size , we pad it into size . The weights in the first blocks of is the same as that of except we need to pad the filters and biases by 0 to be compatible with the additional channels. Then the output of is .
Realize by residual blocks.
To realize , we add another block with 4 layers with filters and biases where . We set the parameters in the first layer as
and . This layer scales the output of back to . Then we use the other 4 layers to realize . The second layer is set as
The third layer is set as
The forth layer is set as
The output of is stored as the first element in the forth channel of the output of :
We have where with
According to Lemma 22, the covering number of is bounded as
Substituting the expressions of into the expression above gives rise to and .
Realize by residual blocks.
To realize , from the construction of and using Oono and Suzuki (2019, Corollary 4), we can realize by with
and
where , and is the Lipschitz constant of . According to Lemma 22, the covering number of this class is bounded by
Note that such is from to . Since the information we need from the output of is only the first element in the forth channel, we can follow the proof of Oono and Suzuki (2019, Theorem 6) to construct by padding the elements in the filters and biases by 0 so that all operations work on the forth channel and store results on the fifth and sixth channel. Substituting and yields
and
Similar to , denote all residual blocks of by . We have
Realize by a ConvResNet.
We then add another residual block of 3 layers followed by a fully connected layer to realize . Denote the parameters in this block and the fully connected layer by and , respectively. Here and .
The first layer is set as
This layer scales the output of back to . The rest layers are used to realize .
The second layer is set as
The third layer is set as
The first row of the output of the third layer is
Then the fully connected layer is set as
and .
Thus with and
According to Lemma 22, substituting the expressions of gives rise to .
The resulting network is a ConvResNet and
for any . Denote the class of the architecture of by . Its covering number is bounded by
The constants hidden in depend on and the surface area of . ∎
D.3 Proof of Lemma 3
Proof of Lemma 3.
We divide into two regions: and . A bound of is derived by bounding the integral on both regions.
Let us first consider the region . Since , we have
| (59) |
On this region, . Thus
| (60) |
| (61) |
Now consider the region , we have
| (62) |
On this region, . Thus
| (63) |
| (64) |