Better prediction by use of co-data: Adaptive group-regularized ridge regression
Abstract
For many high-dimensional studies, additional information on the variables, like (genomic) annotation or external p-values, is available. In the context of binary and continuous prediction, we develop a method for adaptive group-regularized (logistic) ridge regression, which makes structural use of such ‘co-data’. Here, ‘groups’ refer to a partition of the variables according to the co-data. We derive empirical Bayes estimates of group-specific penalties, which possess several nice properties: i) they are analytical; ii) they adapt to the informativeness of the co-data for the data at hand; iii) only one global penalty parameter requires tuning by cross-validation. In addition, the method allows use of multiple types of co-data at little extra computational effort.
We show that the group-specific penalties may lead to a larger distinction between ‘near-zero’ and relatively large regression parameters, which facilitates post-hoc variable selection. The method, termed GRridge, is implemented in an easy-to-use R-package. It is demonstrated on two cancer genomics studies, which both concern the discrimination of precancerous cervical lesions from normal cervix tissues using methylation microarray data. For both examples, GRridge clearly improves the predictive performances of ordinary logistic ridge regression and the group lasso. In addition, we show that for the second study the relatively good predictive performance is maintained when selecting only 42 variables.
1. Department of Epidemiology and Biostatistics, VU University Medical Center, PO Box 7057, 1007 MB
Amsterdam, The Netherlands
2. Department of Mathematics, VU University, Amsterdam, The Netherlands
3. Department of Mathematics, University of Oslo, Oslo, Norway
4. Department of Pathology, VU University Medical Center, Amsterdam, The Netherlands
Keywords: Classification, logistic ridge regression, empirical Bayes, Random Forest, feature selection, methylation
Supplementary Material is available from: www.few.vu.nl/~mavdwiel/grridge.html
1 Introduction
Predicting binary or continuous response from high-dimensional data is a well-addressed problem nowadays. Many existing methods have been adapted to cope with high-dimensional data, in particular by means of regularization and new ones, e.g. based on feature extraction, have been devised Hastie et al. (2008). These methods have in common that the input is a response vector of length and a numerical design matrix, where is the number of independent samples and is the number of variables. Then, the predictor is usually learned solely from this input, possibly in combination with or followed by variable selection.
Co-data comprises of all information on the measured variables other than their numerical values for the given study. A few examples in the context of genomics are: a) Data or summaries like -values from an external study with a related objective on the same set of variables (or highly overlapping); b) Database information that summarizes the (a priori) importance of genes for a class of diseases, e.g. the Cancer Gene census Futreal et al. (2004); c) Genomic annotation, e.g. the chromosome on which a gene is located. Co-data of type a), also referred to as ‘historical data’, has been demonstrated to potentially benefit the analysis of a given clinical trial, in particular when sample size is small Neuenschwander et al. (2010). For such low-dimensional data, assigning weight(s) to the co-data, e.g. by choice of the prior in a Bayesian setting, is a difficult issue, because it usually implies a subjective setting. In a high-dimensional setting like ours, however, we show that one can use empirical Bayes principles to let the data decide how informative the co-data should be.
The empirical Bayes approach sets our approach apart from other ones that use co-data to improve prediction or variable selection, like the group-lasso Meier et al. (2008), a general multi-penalty approach Tai and Pan (2007) or a weighted lasso approach Bergersen et al. (2011). In addition, unlike those methods, our approach is able to handle co-data of many different types: the external information on the variables can be binary, nominal, ordinal or continuous plus it can manage multiple sources of co-data iteratively.
We focus mostly on logistic ridge regression to present our approach, but also demonstrate the generality of the approach by an extension to random forest classification. We start out by recapitulating logistic ridge regression and the first two moments of the parameter estimates. These are then used to derive an empirical Bayes estimate for group-specific penalties. Next, we present a more stable iterative alternative, and also address iteration on multiple partitions of the variables. If the co-data is available as a continuous summary like a vector of -values, we argue that one may use rank-based small groups of variables in combination with enforced monotony for the group-specific penalties.
A consequence of the use of group-specific penalties is that it can facilitate a posteriori variable selection. We show that effective group-regularization may result in a relatively heavy-tailed empirical distribution of the regression parameter estimates. This, as we illustrate by an example, may allow selection of a fairly sparse model with hardly any loss of predictive accuracy.
The approach is demonstrated on two cancer genomics examples. Both examples concern discriminating precancerous cervical lesions from normal cervix tissues using methylation microarray data. For the first data set, we first demonstrate that our method can automatically account for different standard deviations across variables. Next, we show that the use of annotation of the methylation probes (which are the regression variables) for group-regularization improves the prediction for 86% of the samples. The second example concerns a diagnostic setting using methylation profiles from self-collected cervico-vaginal lavages (self samples). The resulting samples are likely to be impure, which presents a challenge for discriminating the two classes. Here, we show that use of the -values from the first study, which concerns more pure samples, as a basis for group-regularization in the second study, increases the area-under-the-ROC-curve from 67% to 74%. In addition, applying variable selection on the basis of the parameter estimates of the group-regularized approach rendered an equally accurate model with only 42 variables. Together with simulated data sets, the two examples were also used to compare our method with existing ones.
We conclude with remarks on i) conceptual differences between our approach and related methods; ii) possible extensions of our method; and iii) the corresponding R-package GRridge and its computational efficiency.
1.1 Logistic ridge regression
It is well known that classical ridge regression corresponds to Bayesian ridge regression: the maximum a posteriori estimate for regression parameters corresponds to the classical estimate when using a central Gaussian prior for with a variance where is the penalty parameter in the classical ridge setting. We explore this fact to develop an empirical Bayes estimate of group-specific penalties. We explain the procedure for logistic ridge regression; the changes needed for linear ridge regression are detailed in the Supplementary Material. The results of ordinary logistic ridge regression (hence ignoring the groups) at a given value of global penalty parameter (e.g. obtained by cross-validation) are used as a starting point.
We first recapitulate some results for logistic ridge regression. For independent responses , we have
where is the design matrix and . The estimate maximizes the penalized log-likelihood:
| (1) |
where . Typically, the Newton-Raphson algorithm is used to maximize (1). Given current estimate , define and . Moreover, let and Then, the Newton-Raphson update Cule et al. (2011) is:
| (2) |
and we assume (2) has been applied until convergence. Note that penalization causes bias, so, with : . Both and can be approximated, as shown below. We will use these moments to derive an empirical Bayes estimate of the group-specific penalties.
The first-order approximation of is le Cessie and van Houwelingen (1992); Cule et al. (2011):
| (3) |
where denotes the th row (component) of any matrix (vector) . In addition, we have le Cessie and van Houwelingen (1992); Cule et al. (2011) for :
| (4) |
Calculation of both and requires the inverse of the large matrix . However, singular value decomposition (SVD) of reduces the calculation of to inversion of an matrix and matrix multiplication.
1.2 Empirical Bayes estimation of group penalties
Now, assume we have a partition of the variables into groups, , of sizes . Then, replace the penalty term in (1) by a generalized ridge penalty term Hoerl and Kennard (1970):
| (5) |
where with global penalty known and penalty multipliers to be estimated. Let us assume an independent Gaussian (and hence ridge-type) prior:
| (6) |
where denotes the group that variable belongs to. Then, for , we have, using (3) and the fact that ,
| (7) |
Next, we obtain the th estimation equation by 1) substituting by its estimate, ; 2) dividing both sides of (7) by ; 3) subtracting 1 from both sides; and 4) aggregating over all :
| (8) |
where . Let . Then, the empirical Bayes estimate for is obtained by solving the system (linear in ):
| (9) |
Naive computation of the coefficients requires calculation of the possibly very large matrix . We experienced that this may consume considerable computing time and memory. Fortunately, a much more efficient calculation is possible. To see this, first note from and (3) that is a product of an matrix, , and an matrix , where can be efficiently computed by SVD of . Matrix decomposition of and according to the groups implies that , where are the elements of with and . may still be a prohibitively large matrix, and hence we wish to avoid computing it. The following theorem provides an efficient solution for this when , because it enables computation of by element-wise multiplication of and , where both matrix products are of dimensions only.
Theorem Let and be and matrices and . Let be the Hadamard (element-wise) product of any equally-sized matrices and . Denote the sum of elements of by . Then,
| (10) |
Proof: For any quadruple of matrices and of arbitrary dimensions , respectively, we have
Substituting and completes the proof.
System (9) generally results in satisfactory solutions when is not extremely large (see also the Simulation section). For very large , however, we experienced that it may lead to extreme (and even negative) values of the estimates. Such instabilities may be caused by strong multi-collinearity between variables (likely present in high-dimensional settings), also across groups, which affects the coefficients in (8). Then, this may hamper disentangling the contributions of the various groups to each of the left-sides in (9). Therefore, we provide an iterative alternative below, but we first discuss how to obtain the group penalties from , the solutions of (9).
In order to allow re-estimation of the resulting group-specific variances, , are inverted to group-specific penalty multipliers , which are calibrated towards the mean of their inverses equalling 1. This amounts to solving for constant , with :
| (11) |
This calibration is useful to avoid (often time-consuming) re-cross-validation of . It calibrates the mean of the inverse penalty multipliers towards the mean of those inverse multipliers in the original, initial ridge regression (with multipliers all equal to 1, implying a mean of 1). In fact, we observed for the examples below that after calibration re-cross-validation hardly changes the estimate of and the predictive performance. Finally, the group-specific penalty equals
1.3 Estimation for generalized logistic ridge regression
After estimating the group-specific penalties we re-estimate , which requires maximizing (5). This is achieved by applying ordinary logistic ridge regression, i.e. iteratively applying (2), with penalty parameter to a new weighted design matrix , where is a diagonal matrix with . To see this, write the group-specific penalty term corresponding to variable in group as
Then, write the contribution of column in to the penalized likelihood (5) through as , which determines and hence also Finally, for the new estimate of , we have:
| (12) |
Here, the upper index in refers to the iteration, which will be introduced in the next section. The variance should be scaled as well: with available from (4).
1.4 An iterative alternative
Here, we provide an iterative alternative to (9). The system (9) does not make use of the fact that the initial estimates, , were implicitly (via the correspondence between the and ) already obtained under a Gaussian prior with common variance . In particular for high-dimensional data, this implicit prior has a large impact on . The proposed iterative alternative first estimates this common prior variance . For that, we simply collect all variables in one group, which renders only one equation in (9) with solution:
| (13) |
Then, we set out to estimate by first assuming for all , which is reasonable given the (implicit) common prior that was used to obtain the estimates. Now, splitting the right-side of the th equation of (9) into the contributions of group and all other groups and substituting renders the estimate:
| (14) |
In words, (14) can be considered as an estimate of that quantifies how much the observed sum of squared group parameters (scaled by their variances) deviates from the expected contributions to this summand of all variables not in group . The above solution is particularly attractive when iterating the estimation, because then the updated estimates adapt to the most recent generalized ridge estimates (12). As discussed above, these are also obtained under an implicit common prior (common ), which allows us to iteratively use (13) and (14). From , the iterative re-scaling in (12) then computes , which is on the original scale of the covariates . We experienced that this alternative solution is always very competitive with explicitly solving (9), and sometimes superior, in particular when is (very) large. The Supplementary Material provides a simulation-based comparison between the two.
Such iteration requires a stopping criterion. We simply monitor the cross-validated likelihood (CVL) and stop iterating when this decreases. The cross-validation is fast, because it only requires evaluation of the CVL for given global penalty . Moreover, we use the efficient implementation by Meijer and Goeman (2013). The resulting estimates are denoted by , where is the number of iterations before the CVL decreases.
1.5 Iterating on a new partition
More than one partition of the variables may be available, as illustrated in the second example. Suppose we have two partition with and groups, respectively. Then, the above method may simply be applied by cross-tabling the two partitions, rendering groups. However, this may render a very large number of groups and some of these groups may contain only few variables, which may deteriorate the empirical Bayes estimates. Alternatively, one may simply iterate the group-specific regularization for the second partition after the first partition was considered. A disadvantage of that approach is that the results may (somewhat) depend on the ordering of the partitions. For the iterative re-penalization solution (14), we therefore opt to embed iteration on partitions into the re-penalization iteration. Hence, partitions are considered in alternating order. The CVL-based stopping criterion formulated above is applied to both partitions with respect to the previous fit; if CVL does not improve, that particular partition does not take part in the outer re-penalization iteration anymore. If CVL does not improve for both partitions, the outer iteration is stopped as well. The group-regularization algorithm including this double iteration is depicted in Supplementary Figure 1.
Note that the new penalty multipliers will adapt to both the data and the current penalties. This is important when the partitions are not independent. Let be the estimate of for re-penalization iteration and partition . Then, the new estimate is computed by applying (12) to , using grouping variable and is computed by applying (12) to , using grouping variable . The final penalty multiplier for variable equals where the latter term is the penalty multiplier based on the second partition. These notions trivially extend to more than two partitions. The final group-regularized estimates of are denoted by . The iterative group-regularization is illustrated in the second example.
1.6 Ranking-based groups
Often, the co-data consist of external data on the same variables (e.g. genes) for an analogous, but somewhat different setting. Our second data example illustrates such a case. Then, the two data sets can not simply be pooled. However, summaries like -values or regression coefficients based on the external data may be used to define a partition of the variables into small groups which is then used as input for the group-regularized ridge on the primary data set. We enforce monotony on the penalties of those groups to avoid over-fitting, as detailed below.
First, rank the variables according to the summary, e.g. -values. Then, create groups of size , where group contains the variables with ranks . Apply (14) to obtain initial estimates for these small groups. Due to the size of the groups these estimates may be instable and not in line with the ranking based on the external data. Therefore, we force the estimates to be monotone by applying weighted isotonic regression Robertson et al. (1982) of on the index (and hence group rank) , rendering regression function . The weights account for possibly different group sizes. Then, the new estimates are set to , which are substituted into (11) to obtain group-specific penalty multipliers . Enforcing monotony highly stabilizes the estimates and interpretation of the results. In fact, even might be used, but, because the stabilizing effect of the isotonic regression is potentially less strong for the extreme ranks, this could lead to over-fitting. The latter is mitigated by using small, non-singular groups. The stabilizing effect is illustrated for the second data example in Supplementary Figure 2.
The software also allows for non-uniformly-sized groups, where one specifies a minimum group size, say , for variables corresponding to the most extreme values of the summary, and a maximum number of groups; the group size then gradually increases for variables with less extreme values of the summary. This enables the use of fewer groups (and hence faster computations) while still maintaining a good ‘resolution’ for the extreme values of the summary.
2 Generalizing the concept I: post-hoc variable selection
A nice side effect of group-specific regularization is that it may simplify post-hoc variable selection, because the empirical distribution of estimated coefficients is typically more heavy-tailed than the one from ordinary ridge regression. Hence, there is a clearer separation between ’s close to zero from those further away from zero. This is illustrated in Supplementary Figure 4 for the second data example. Also, it is known that ordinary ridge regression tends to spread mass of the parameter estimates over correlated variables. Group-specific regularization can prioritize such variables, in particular when the groups are small and the range of group-specific penalties is large. A posteriori selection could be based on an information criterion or a mixture model for the ’s. However, since we are in a prediction setting, we suggest to select directly on the basis of predictive performance by using CVL. For the purpose of prediction, variable selection is mainly desirable for potentially developing a measurement devise (e.g. based on qPCR) with much fewer variables than the original one. Hence, we allow the user to set a maximum of variables to be selected, e.g. .
A simple proposal for CVL-based selection is: sort the variables with respect to ; select top-ranking variables; re-fit the model using only those variables, but with the same fixed and ’s as for the full model; compute on this model; find ; select , with e.g. relative margin . The margin favors more sparse models: the minimization finds the model with the fewest variables such that its CVL is within a, say, 1% margin of the best. Supplementary Figure 1 depicts the entire group-regularization algorithm including variable selection, whereas Supplementary Figure 5 shows the CVL profile as a function of for the second data example.
3 Generalizing the concept II: random forest
The concept of adaptive group-regularization (or, analogous, group-weighting) can be generalized to other classifiers, also to some of very different nature than logistic ridge regression. The Supplementary Material describes the extension to the random forest classifier in detail; below we provide a summary.
A standard random forest classifier uses only variables (nodes) per node split. Typically, these variables are sampled uniformly from the entire set. Now, the idea is to weigh groups by increasing or decreasing the sampling probability according to the overall importance of variables in a group. Once a set of top-ranking variables across a forest is defined by a formal selection procedure Doksum et al. (2008) or by simply using the top (for, say, ), the observed number of top-ranking variables per group is modeled by a multinomial distribution per tree. Then, the variability of the multinomial proportions across trees is modeled by a Dirichlet distribution the parameters of which are estimated by use of empirical Bayes. This Dirichlet distribution is then used for weighted sampling of variables in the trees in a new random forest. The process of random forest classification, variable ranking, selection, estimation and weighted sampling is repeated, until the out-of-bag error does not or hardly decrease anymore.
4 Simulation results: summary
We performed simulations to compare the performances of the systems-based solution (9) and the iterative solution (14). In addition, GRridge is compared with i) ordinary logistic ridge and ii) the group lasso Meier et al. (2008). We also compared with the adaptive logistic ridge, which is the ridge version of the adaptive logistic lasso Zou (2006), simply amounting to using variable-specific penalty multipliers that are inverse proportional with the initial squared ridge parameter estimates, . However, since we found that the predictive performance of the adaptive logistic ridge was generally inferior to that of the ordinary logistic ridge, we do not present those results in detail.
We study a number of scenarios where we vary the number of groups , the size of the groups , the correlation strength in , the differential signal between the two classes of samples across groups, and the sparsity (i.e. proportion of groups without predictive signal). Performance was evaluated by computing AUC and mean Brier residuals on a large test data set (), which was generated under the same settings as the training set (). These are reported in extensive tables, supplied in the Supplementary Material; here, we summarize the results.
First, we observe that the systems-based solution and the iterative solution are very competitive for (), while the latter is superior for large In particular, the iterative solution is indeed more stable across repeated simulations for very large . The non-iterative, systems-based solution relies strongly on the parameter estimates of the initial logistic ridge regression, the bias of which may be very strong when is very large. The iterative solution, however, typically finds less extreme group penalties in the first iteration, then re-estimates the regression parameters, allowing those to adapt to the new penalties.
Generally, both GRridge versions performed at least as good as ordinary logistic ridge. As expected, we clearly observe that the gap between the performances increases with more skewed effects across groups and with increased sparsity. In addition, group lasso outperforms ordinary logistic ridge in group-sparse settings, while the reverse often holds for the non-sparse settings. GRridge generally outperforms the predictive accuracy of the group lasso, in some cases with fairly large margins, e.g. with AUCs that are 0.10 to 0.15 larger on the absolute scale. The group lasso becomes more competitive for high group-sparsity, in particular for large. Yet, it seems that GRridge adapts well to sparsity and maintains its relative good performance. Note that the weaker predictive performance of the group lasso may, for some applications, be counterbalanced by its group-selection property.
5 Examples: diagnostic classification using methylation data
DNA consists of the four nucleotides A, C, G and T. Methylation refers to the addition of a methyl-group to a C preceding a G (CpG), which can influence expression of the encoded gene. As such, methylation has a so-called epigenetic effect on the functionality of the cell, and consequently on the entire organism. It is believed to be an important molecular process in the development of cancer Laird (2003). In addition, DNA is a well-characterized and relatively stable molecule, compared to mRNA (gene expression) and many proteins. Therefore, the use of DNA methylation for diagnostic purposes is currently heavily investigated. A popular platform for measuring methylation is the Illumina™450K bead chip. This platform measures 450.000 probes per individual, where each probe corresponds uniquely to a CpG location on the genome. Each probe renders a so-called beta-value, which is the estimated proportion of methylated DNA molecules for that particular genomic location in a given tissue. Like for any microarray study, the data is preprocessed using several steps; see the Supplementary Material.
We have data sets from two similar studies on cervical cancer at our disposal. The carcinogenesis of cervical cancer is relatively well-characterized. The transformation process of normal epithelium to invasive cancer takes many years, and includes distinct stages of precursor lesions (CIN; cervical intraepithelial neoplasia). Whereas low-grade precursor lesions (CIN1/2) are known to regress back to normal, high-grade precursor lesions (CIN2/3) have a relatively high risk for progression to cancer and are usually surgically removed. Therefore, accurate detection of high-grade CIN is very important. The two studies both measure methylation for normal cervical tissue and CIN3 tissue for several independent individuals, but differ in one important aspect. The first study measures methylation on CIN3 tissue biopsies, whereas the second study considered self-collected cervico-vaginal lavages of women with underlying CIN3 lesions Gok et al. (2010). The relatively good quality of the samples in the first study may render important information about relevant methylation markers. The quality and purity of the tissues in the second study is probably inferior. This study, however, better resembles a more realistic diagnostic setting, in particular because many countries have implemented screening programs for cervical cancer. Our first example uses the data of the first study only, but compliments this with another source of information: annotation of the probes. This creates a partition of the probes into groups, which is used in the group-regularized ridge regression. The second example shows how, in addition to the annotation, the results of the first study can be used in our algorithm to improve diagnostic classification for the second study. We present the results from the iterative version of our method.
5.1 To standardize or not? - An automatic solution
A practical issue when applying penalized regression is the need or ‘no need’ for standardization of the covariates. There is no consensus on this issue Zwiener et al. (2014), because on one hand standardization has the beneficial effect of rendering a common penalty more appropriate, while on the other hand it may remove some of the (differential) signal and may lead to instabilities for variables for which the sample variances are small. Standardization is equivalent to introducing a penalty multiplier that is proportional to the variance in the unstandardized setting Zwiener et al. (2014). A potential of our method is that it can let the data decide how the variances of the variables should impact the penalties. Below, we explore this potential for the first study.
The first study Farkas et al. (2013) contains methylation profiles of 20 and 17 unrelated normal cervical and CIN3 tissues, respectively. To enable inclusion of these data in our complementary R-package GRridge, thereby allowing reproduction of the results, the computations for this and the next example were performed on a random selection of 40,000 probes. We verified, however, that all results are very similar on the entire data set, which is not surprising given the smooth nature of ridge regression and the correlations between variables.
The probes are grouped in 8 groups of 5,000 each, in increasing order of the sample variances. Note that we verified whether a different grouping (e.g. 16 groups of 2,500 or 40 groups of 1,000) would affect the results. This is not the case. In line with the argumentation above (larger penalties for probes with large variances) we imposed monotony on the 8 penalty multipliers. We observed that this constraint is not very essential here, because the estimated penalty multipliers are also nearly monotonously increasing when the constraint was not imposed. GRridge estimated the following penalty multipliers: . So, it effectively completely removes the impact of the probes with large variances (last two groups), allowing smaller penalties for the remaining 6 groups. Interestingly, GRridge with variance-based groups outperforms both ordinary standardized and unstandardized logistic ridge, in terms of ROC-curves (see Supplementary Material), AUC (0.91, 0.86, 0.76, respectively) and mean Brier residuals (defined as ; 0.14, 0.16, 0.21, respectively).
5.2 Improved classification by use of probe annotation
Our hypothesis here is that the use of a priori known annotation-based partitions of the probes may improve the classification results. This second partition, next to the variance-based one above, is based on the probe’s location in or nearby a so-called CpG-island. A CpG-island is a genomic region which is relatively rich in CG base pairs, and methylation is known to be more prevalent there than elsewhere. We used the following groups (in order of decreasing distance to CpG-islands): “CpG-island (CpG)”, “North Shore (NSe)”, “South Shore (SSe)”, “North Shelf (NSf)”, “South Shelf (SSf)”, and “Distant (D)”. If probes in CpG (or any other group of probes) are on average more important for the classification, the group-regularized ridge automatically detects this and applies a smaller penalty to all probes in this group. This may improve classification when the a priori partition was indeed informative. Note that the partition used is based on a well-accepted criterion to characterize genomic locations in methylation studies.
The group-regularized ridge used 6 iterations for re-penalizing the 6 annotation-based groups and 7 iterations for the 8 variance-based ones, which increased the CVL by 40% from -20.18 to -12.03. The final penalty multipliers for the annotation-based groups ( inverse weights) are: , , , , and . The group-specific penalties clearly affect the regression parameter estimates , because larger values of result in smaller values of . Hence, these values imply that GRridge effectively only uses the CpG and SSe probes for the predictions. The results confirm the importance of probes on CpG islands. The variance-based penalty multipliers are . These are largely in line with the results above, although somewhat compressed, because they adapted to the annotation-based multipliers. Please note that one should be careful with interpreting the exact values of the group penalties. As indicated above, these may depend on the presence of another partition due to overlap between groups. In addition, in the Supplementary Material we show that for the annotation-based groups above the penalties vary somewhat with respect to sizes of the groups. The order of the group-penalties seems to be fairly stable, however, so we recommend to interpret the group-penalties in terms of their ranking.
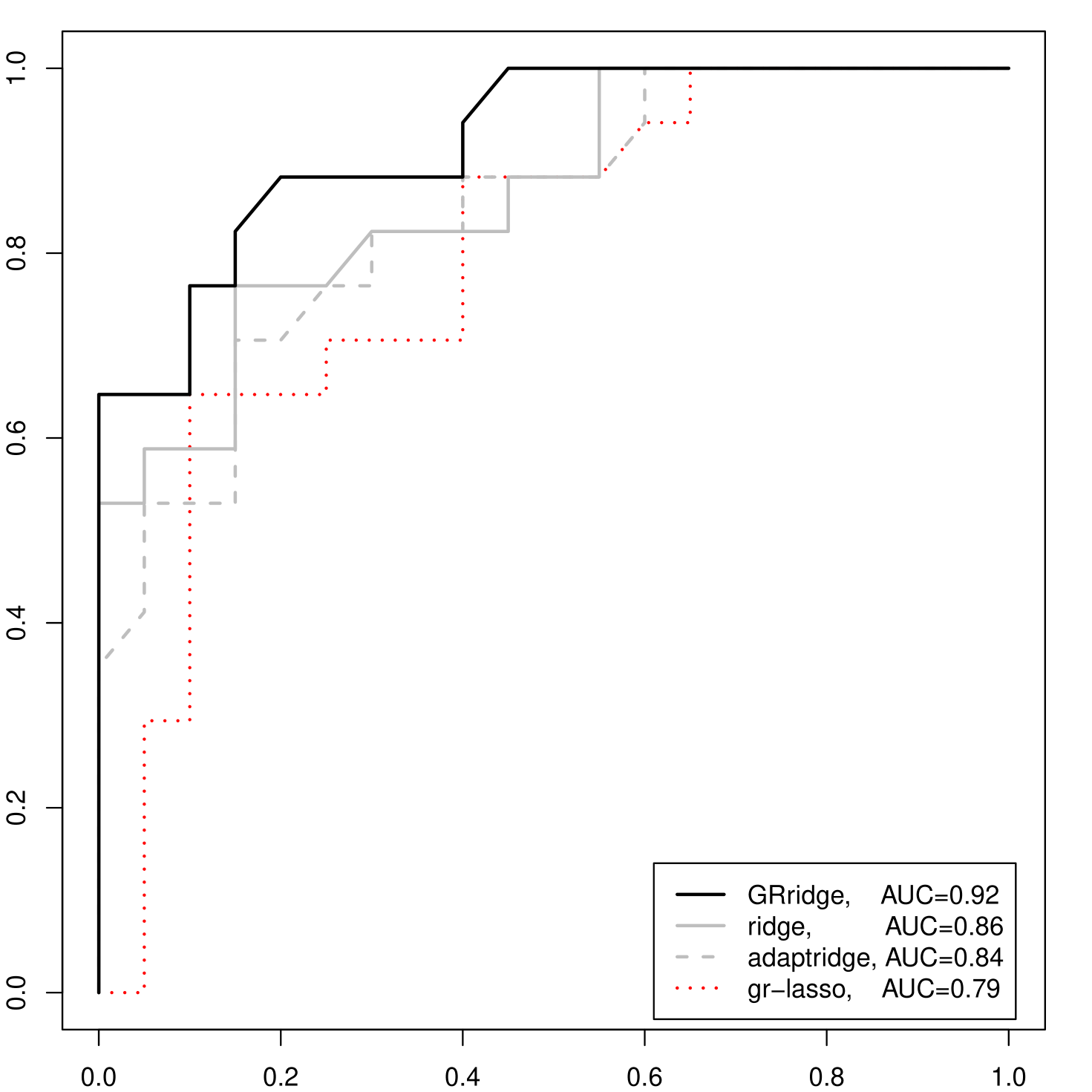
To assess whether the group-regularized ridge improves classification with respect to ordinary ridge, we computed ROC curves obtained by 10-fold cross-validation. Here, we compare with ridge regression on standardized covariates, because the latter was superior to the unstandardized version, as demonstrated above. In addition, we compare with the group lasso Meier et al. (2008), as implemented in the R package grpreg, using the same annotation-based groups as for GRridge. The last competitor is the adaptive ridge, as discussed above. Also these two methods are applied to the standardized covariates (which were verified to be superior to their unstandardized counterparts). Group lasso selected only the SSe group, but, surprisingly, not the CpG group.
The resulting ROC curves depict the False Positive Rate (FPR) versus the True Positive Rate (FPR) for a dynamic cut-off for the predicted probability on CIN3. Figure 1(a) shows the results. We clearly observe superior performance of GRridge, with AUC = 0.92 (and 0.86, 0.84, 0.79 for ordinary ridge, adaptive ridge and group lasso, respectively). With respect to ordinary ridge, predictions improved for 33 out of 37 observations, as displayed in Figure 1(b). Note that adding the annotation-based groups to the variance-based groups improved the AUC only slightly, from 0.91 to 0.92, probably because AUC is a rank-based criterion. In fact, the predictions did improve for 32 out of 37 observations, leading to a relatively larger improvement (decrease) for the mean Brier residual, from 0.143 to 0.116.
5.3 Improved diagnostic classification by use of external data
The second study contains methylation profiles of self-collected cervico-vaginal lavages (or self-samples) corresponding to 15 women with an unaffected (normal) cervix and 29 women with CIN3 lesions, all unrelated. Here, it is important to note that the samples of the affected cervices may be contaminated with normal cells and cells of other origins (mostly vaginal cells and lymphocytes), due to imprecise sampling. Hence, the differential signal may be diluted. We aim to use the results of the first study for the group penalties in the second study.
In principle, we could use the results of the group-regularized ridge regression fitted on the first study, as presented in the previous section. However, the effect of the (possible) contamination may vary considerably across probes. For example, the differential signal of probes with hypo-methylation (affected normal) in the first study is diluted more than that of hyper-methylated probes. This can be illustrated in a simple deterministic setting. In case of hypo-methylation, consider a true ratio affected/normal = 0.4/0.8 = 1/2. Assume a contamination of 50%, then the measured ratio will be (0.4/2 + 0.8/2)/0.8 = 3/4, hence the ratio is 50% too large. Using the same numbers for hyper-methylation renders a measured ratio that is only 33% too small. In addition, it is well-known that ridge regression distributes differential signal over parameters corresponding to correlated probes. Hence, the magnitude of a particular coefficient also depends on other probes. Since the dilution in Study 2 affects probes differently, the applicability of Study 1 ridge regression results for analyzing Study 2 may be limited.
Therefore, we propose to use group penalties that are simply based on -test -values as obtained by applying limma Smyth (2004) on Study 1. These -values are then used to define a ranking-based partition with 100 groups of probes of minimal size (size gradually increasing with the -value) as described above. To stabilize the estimates of weights for Study 2 are forced to be monotonously decreasing with increasing Study 1 -values as described above. The function pava of the R library Iso is used for this purpose, which is illustrated in Supplementary Figure 2. In this setting, it is reasonable to precede our method by a mild prior filtering: only include those probes with and a mean absolute difference larger than 0.1 (on log-scale) in Study 1. Then, our method applies group-specific regularization to the 9491 probes surviving these thresholds.
Given the earlier argument about a stronger dilution effect on hypo- than on hyper-methylated probes (as detected in Study 1), we also considered a second sign-based partition that distinguishes those two groups of probes. Finally, we added the variance-based and annotation-based partitions introduced in the first example. This illustrates the ability of our method to operate on multiple partitions. For this example, the adaptive group-regularized ridge used 3 re-penalization iterations. The CVL increased from -28.91 to -27.54, hence a 5% improvement. The sign-based and variance-based partitions had no effect on the results (hence rendering group-specific penalties equal to 1) on top of the -value-based partition, illustrating the adaptive nature of the algorithm. The partition based on external -values produced 100 group-specific penalties ranging from to for , so indeed a large range (see also Supplementary Figure 3), illustrating the relevance of this partition. The annotation-based partition rendered , and much larger penalty multipliers for the other 5 classes. So, also for this data set the probes on the CpG-islands correspond to smaller penalties, which is biologically plausible.
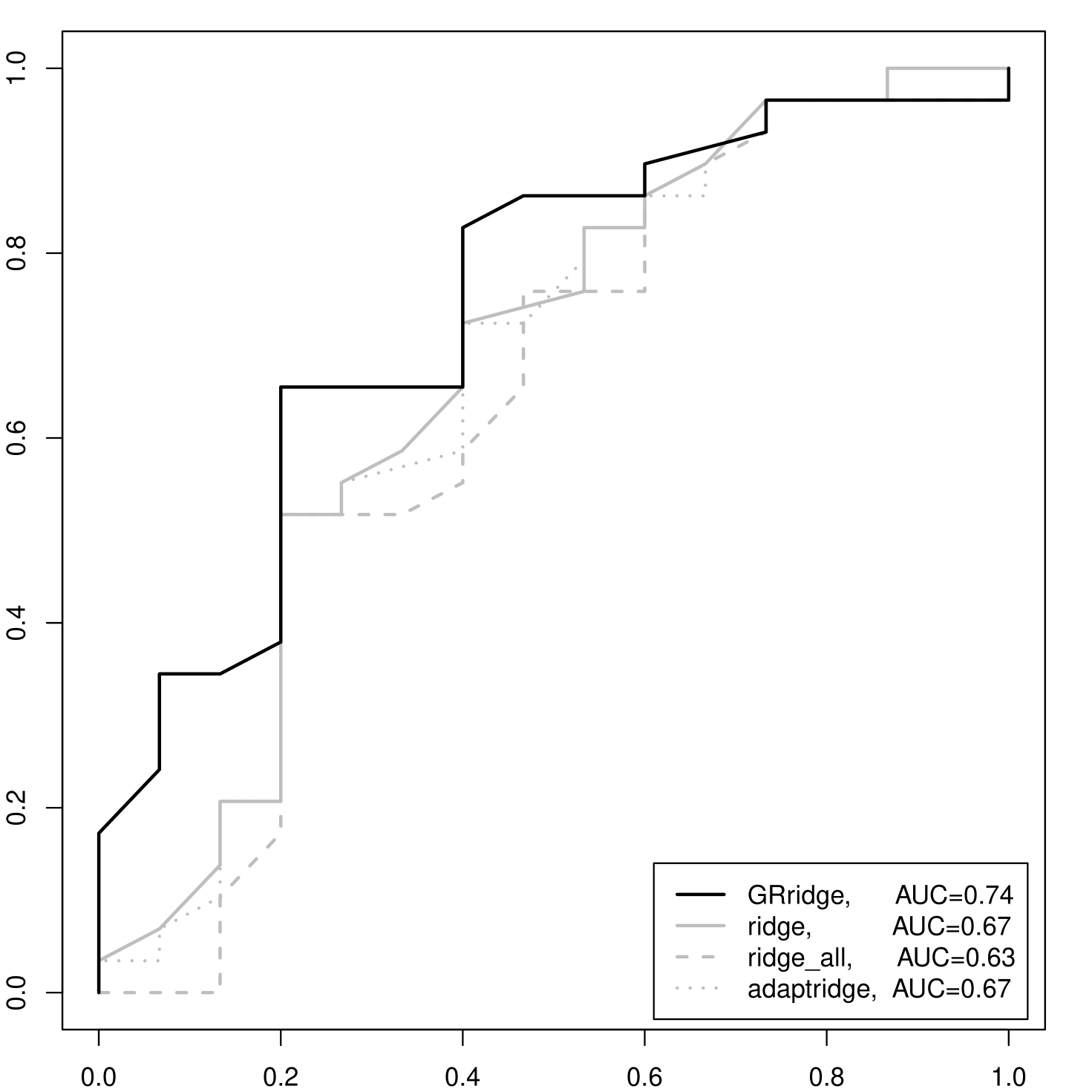
We compared GRridge with: i) ordinary ridge; ii) adaptive ridge; iii) group lasso with the same 100 -value based groups (all three also applied to the filtered probe set); and iv) ordinary ridge on the entire, non-filtered probe set. For this data set, the group lasso did not select any group. Hence, no variable was selected either, rendering inferior prediction results. Probably, the weak differential signal per variable in this challenging data set caused the absence of selections for the group lasso. The ROC curves for the other three methods were obtained by applying leave-one-out cross-validation (LOOCV). Figure 2(a) shows the results: GRridge has a markedly higher AUC (0.74) than the ones corresponding to i) 0.67, ii) 0.67 and iv) 0.63.
We also checked whether the order in which the four partitions are used within each re-penalization iteration matters for the results. The final CVLs for all 24 possible orderings show very little variation: the range is . Hence, we conclude that the sensitivity of the performance with respect to the ordering is very small for this data set.
5.4 Variable selection
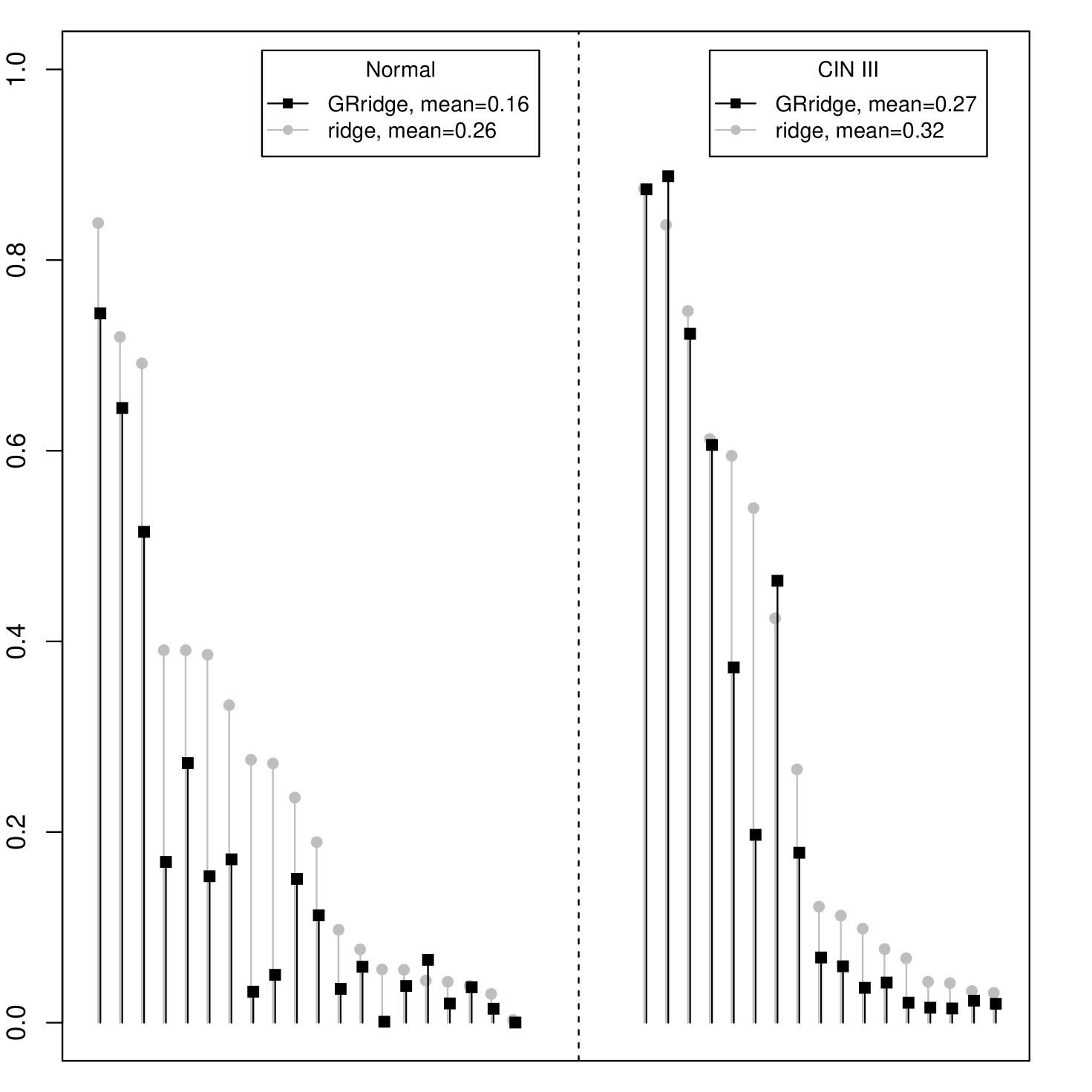
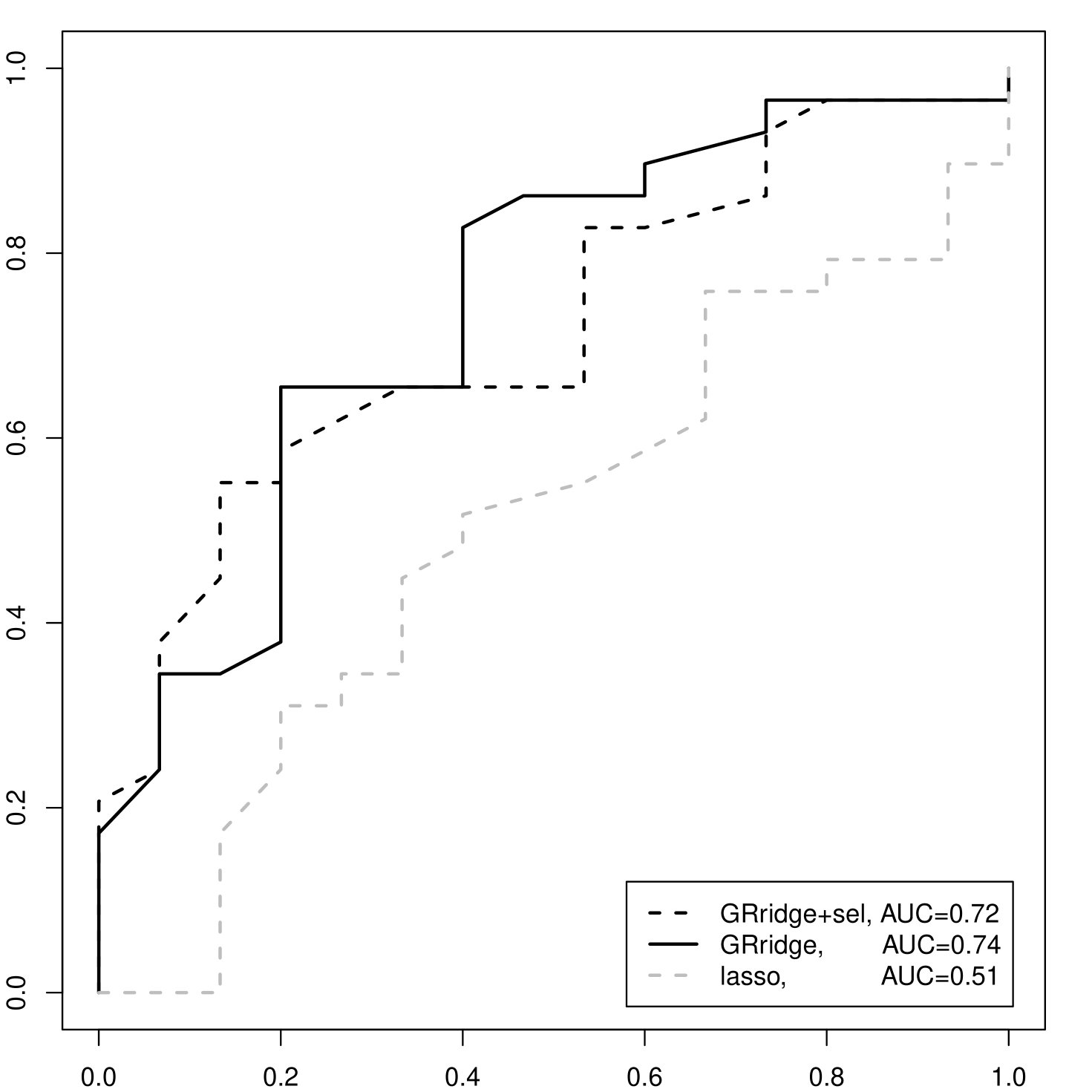
Supplementary Figure 4 shows that the most extreme coefficients of the group-regularized ridge regression are relatively much larger than those of ordinary logistic ridge regression. In fact, for the former, the 1% most extreme coefficients account for 61% of the total sum of absolute values of the coefficients, whereas for the latter this drops to only 3%. We applied the proposed a posteriori variable selection to which rendered a model with 42 selected variables, termed GRridge+sel. Figure 2(b) depicts the ROC-curves and AUCs for GRridge+sel, GRridge and lasso, as obtained by LOOCV. First, note that the much more parsimonious GRridge+sel model predicts nearly as well as the full GRridge model in this case (AUC = 0.72 vs AUC = 0.74). Second, to illustrate the beneficial effect of group-specific regularization in this variable selection context, we also compare GRridge+sel with the lasso (Goeman, 2010, R package penalized) on the same filtered data set. The lasso renders a somewhat more parsimonious model with 17 variables, but performs much worse in terms of prediction: Figure 2(b) depicts the ROC-curves and AUCs. Of course, the lasso could possibly be improved by adapting group-regularized principles as well (see Discussion).
6 Discussion
Our method is weakly adaptive in the sense that the penalties adapt in a group-specific sense only. This is an important conceptual difference with strongly adaptive methods such as adaptive lasso Zou (2006) and enriched random forests Amaratunga et al. (2008), which aim to learn variable-specific penalties from the same data as the data used for classification. Such methods strongly rely on sparsity. While this may be a fairly natural assumption for some applications, we believe it to be less realistic for complex genomic traits like cancer. In fact, we observed that for both applications the adaptive lasso did not outperform the ordinary lasso, and hence performed worse than the adaptive group-regularized ridge regression.
The adaptive group-regularized ridge shares the philosophy of accounting for group structure with the group lasso Meier et al. (2008). The latter, however, selects entire groups using a lasso penalty on the group-wise sum of coefficients and then spreads the coefficients within a group using a ridge penalty within a group. The group lasso is particularly attractive for selecting relatively small, interpretable groups of variables, e.g. gene pathways. However, it is less useful and suitable when the groups tend to be large (and not necessarily homogenous) as in the first example, or when the groups have no clear biological interpretation, as for the ranking-based small groups in the second example. In addition, for both simulated and real data sets we show that the predictive performance of GRridge is often superior to that of the group lasso. Group-specific regularization was also discussed by Tai and Pan (2007) in the context of nearest shrunken centroids and partial least squares classifiers. Their results support our claim that such regularization can improve classification performance. Their approach, however, requires cross-validation on all group-penalties or, when this is too computationally demanding, a priori fixing of weights (inverse penalties). Also, unlike GRridge, their method does not make use of multiple partitions of the variables, which are often available in practice.
As discussed, group-regularization helps to better discriminate small and large coefficients, and the model after variable selection may be fairly parsimonious. Yet, extension of our method to sparse methods like lasso may be desirable in some cases. These methods usually render only few non-zero coefficients, which may lead to unstable group penalties. This may be mitigated by re-sampling or by using a power transformation of ridge-based penalties, as suggested by Bergersen et al. (2011) in another setting. Alternatively, one may consider a Bayesian set-up with a selection prior, for example a Laplace prior Park and Casella (2008) or a horseshoe prior Carvalho et al. (2009). The hyper-parameters of such priors would be estimated per group of variables, e.g. by empirical Bayes. Then, the entire posterior of each , rather than just the point estimate, impacts the penalty (represented by the group-wise prior) of the group that variable belongs to.
It is possible to shrink towards the corresponding estimates of the external study rather than to zero, i.e. targeting shrinkage Gruber (1998). However, unless the two experiments are expected to be very similar in terms of design, quality, effect size distribution, and the exact meaning of the two corresponding ’s, this may do more harm than good. For example, our illustration on the joint use of the two methylation studies does clearly not satisfy these conditions: due to the dilution, the ’s in Study 2 are bound to be weaker than those in Study 1, and likely in a non-uniform way. Yet, in very well-controlled settings targeted shrinkage may be a useful extension.
We end with some practical remarks. The adaptive group-regularized logistic and linear ridge procedures are implemented in the R-package GRridge, available via www.few.vu.nl/~mavdwiel/grridge.html. It depends on the package penalized Goeman (2010), which is used for model fitting and cross-validation. GRridge provides all functionality described in this paper, including: both versions (the non-iterative, systems-based one and the iterative one), adaptive regularization on multiple partitions, variable selection, estimation of predictive accuracy by cross-validation and convenience functions to create partitions of the variables using co-data. In addition, it allows for including non-penalized variables, e.g. clinical information. It also includes both data sets discussed here. The iterative version is the default, but based on the simulations we believe one can safely use the faster, non-iterative version for . The iterative algorithm, however, is also fairly fast. For the first example (, 7 iterations on two partitions), constructing the group-regularized ridge classifiers took 3m01s and 3m27s, for tuning the global penalty by LOOCV and group-regularization, respectively. Hence, 6m28s in total on a 3GHz laptop with 3.5Mb RAM. The second example (, 3 iterations on four partitions) took 31s, 23s and 14s for -cross-validation, group-regularization and selection, respectively, so 1m08s in total. The code used to produce the results of GRridge in this paper is included in the Supplementary Material.
7 Acknowledgements
We are particularly grateful to Tristan Mary-Huard for his critical comments and suggestions on earlier versions of this manuscript. In addition, we thank Sanja Farkas for providing the raw data of her study Farkas et al. (2013) and Carel Peeters for discussing several aspects of ridge regression. This study was partly supported by the OraMod project, which received funding from the European Community under the Seventh Framework Programme, grant no. 611425. DNA methylation data of the self-samples were obtained as part of a project supported by the European Research Council (ERC advanced 2012-AdG, proposal 322986; Mass-care), by which also Wina Verlaat and Saskia M. Wilting were supported.
References
- Amaratunga et al. (2008) Amaratunga, D. et al. (2008). Enriched random forests. Bioinformatics, 24, 2010–2014.
- Bergersen et al. (2011) Bergersen, L.C. et al. (2011). Weighted lasso with data integration. Stat. Appl. Genet. Mol. Biol., 10.
- Carvalho et al. (2009) Carvalho, C. et al. (2009). Handling sparsity via the horseshoe. J. Mach. Learn. Res., W&CP, pages 73–80.
- Cule et al. (2011) Cule, E. et al. (2011). Significance testing in ridge regression for genetic data. BMC Bioinf., 12, 372.
- Doksum et al. (2008) Doksum, K. et al. (2008). Nonparametric variable selection: the EARTH algorithm. J. Amer. Statist. Assoc., 103, 1609–1620.
- Farkas et al. (2013) Farkas, S. et al. (2013). Genome-wide DNA methylation assay reveals novel candidate biomarker genes in cervical cancer. Epigenetics, 8, 1213–1225.
- Futreal et al. (2004) Futreal, P. et al. (2004). A census of human cancer genes. Nat. Rev. Cancer, 4, 177–183.
- Goeman (2010) Goeman, J. (2010). L1 penalized estimation in the Cox proportional hazards model. Biom. J., 52, 70–84.
- Gok et al. (2010) Gok, M. et al. (2010). HPV testing on self collected cervicovaginal lavage specimens as screening method for women who do not attend cervical screening: cohort study. BMJ, 340, c1040.
- Gruber (1998) Gruber, M. (1998). Improving Efficiency by Shrinkage: The James–Stein and Ridge Regression Estimators. Statistics: A Series of Textbooks and Monographs.
- Hastie et al. (2008) Hastie, T. et al. (2008). The elements of statistical learning, 2nd ed. Springer, New York.
- Hoerl and Kennard (1970) Hoerl, A.E. and Kennard, R.W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12, 55–67.
- Laird (2003) Laird, P. (2003). The power and the promise of DNA methylation markers. Nat. Rev. Cancer, 3, 253–266.
- le Cessie and van Houwelingen (1992) le Cessie, S. and van Houwelingen, J. (1992). Ridge estimators in logistic regression. Applied Statistics, 41, 191–201.
- Meier et al. (2008) Meier, L. et al. (2008). The group Lasso for logistic regression. J. R. Stat. Soc. Ser. B Stat. Methodol., 70, 53–71.
- Meijer and Goeman (2013) Meijer, R. and Goeman, J. (2013). Efficient approximate k-fold and leave-one-out cross-validation for ridge regression. Biom. J., 55, 141–155.
- Neuenschwander et al. (2010) Neuenschwander, B. et al. (2010). Summarizing historical information on controls in clinical trials. Clin. Trials, 7, 5–18.
- Park and Casella (2008) Park, T. and Casella, G. (2008). The Bayesian lasso. J. Amer. Statist. Assoc., 103, 681–686.
- Robertson et al. (1982) Robertson, T. et al. (1982). Order Restricted Statistical Inference. Wiley, New York.
- Smyth (2004) Smyth, G.K. (2004). Linear models and empirical Bayes methods for assessing differential expression in microarray experiments. Stat. Appl. Genet. Mol. Biol., 3, Art. 3.
- Tai and Pan (2007) Tai, F. and Pan, W. (2007). Incorporating prior knowledge of predictors into penalized classifiers with multiple penalty terms. Bioinformatics, 23, 1775–1782.
- Zou (2006) Zou, H. (2006). The adaptive lasso and its oracle properties. J. Amer. Statist. Assoc., 101, 1418–1429.
- Zwiener et al. (2014) Zwiener, I. et al. (2014). Transforming RNA-Seq data to improve the performance of prognostic gene signatures. PLoS ONE, 9, e85150.
Figures