BEV-MODNet: Monocular Camera based Bird’s Eye View
Moving Object Detection for Autonomous Driving
Abstract
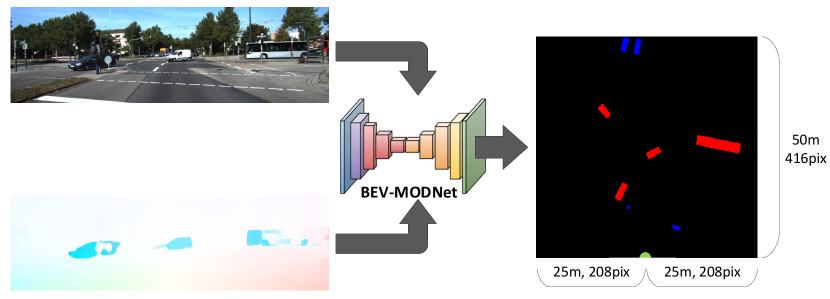
Detection of moving objects is a very important task in autonomous driving systems. After the perception phase, motion planning is typically performed in Bird’s Eye View (BEV) space. This would require projection of objects detected on the image plane to top view BEV plane. Such a projection is prone to errors due to lack of depth information and noisy mapping in far away areas. CNNs can leverage the global context in the scene to project better. In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes. The dataset is intended to be used for class agnostic motion cue based object detection and classes are provided as meta-data for better tuning. We design and implement a two-stream RGB and optical flow fusion architecture which outputs motion segmentation directly in BEV space. We compare it with inverse perspective mapping of state-of-the-art motion segmentation predictions on the image plane. We observe a significant improvement of 13% in mIoU using the simple baseline implementation. This demonstrates the ability to directly learn motion segmentation output in BEV space. Qualitative results of our baseline and the dataset annotations can be found in https://sites.google.com/view/bev-modnet.
I INTRODUCTION
Moving object detection has gained significant attention recently especially for autonomous driving applications [6]. Motion information can be used as a signal for class-agnostic detection. For example, current systems come with appearance based vehicle and pedestrian detectors. They won’t be able detect unseen classes like animals which can cause accidents. Motion cues can be used to detect any moving object regardless of its class, and hence the system can use it to highlight unidentified risks. Moving objects also need to be detected for their removal in SLAM systems [24].
Sensor fusion is typically used to obtain an accurate and robust perception. A common representation for all sensors fusion is the BEV map which defines the location of the objects relative to the ego-vehicle from top-view perspective. BEV maps also provides a better representation than image view as they minimize the occlusions between objects that lie on the same line of sight with the sensor. In case of visual perception on image view, a projection function is applied to map them to the top-view BEV space.
Such a projection is usually error prone due to the absence of depth information. Deep learning on the other hand can be used to improve this inaccuracy by learning the objects representation directly in BEV representation. There has been efforts to explore deep learning performance for BEV object detection using camera sensor and there has been also efforts in motion segmentation on front view. However, there is no literature in end-to-end learning of BEV motion segmentation. In this work, we attempt to tackle such limitation through the following contributions:
-
•
We create a dataset comprising of 12.9k images containing BEV pixel-wise annotation for moving and static vehicles for 5 classes.
-
•
We design and implement a simple end-to-end baseline architecture demonstrating reasonable performance.
-
•
We compare our results against conventional Inverse Perspective Mapping (IPM) [12] approach and show a significant improvement of over 13%.
II RELATED WORK
 (a) (a)
(a) (a)
 (b) (b)
(b) (b)
(c) (c)
 (d) (d)
(d) (d)
Motion segmentation has been explored through classical approaches such as [14]. Classical methods usually make use of complex algorithmic pipelines which accumulate the errors of each step to the final result providing less accuracy compared to deep learning approaches. Foreground segmentation has been explored by [9] using optical flow, however the algorithm is generic and it does not predict enough information to classify if the object is moving or static. Video object segmentation has been explored in [5, 23] using complex approaches that are not applicable to our application as they use heavy models such as R-CNN [5] and DeepLab [23] which provide 8 fps only. On the other hand, [22, 21] explored moving object detection using CNNs. Appearance features are obtained from RGB images and motion features are obtained from the corresponding optical flow images which encode the scene motion. InstanceMotSeg [15] extended it to obtain motion segmentation at instance level. MOD has been also explored on fisheye images in [26] using wide angle cameras and higher distortion levels relative to conventional images. The approach has been evaluated on [27] dataset which provides fisheye images from 4 surround-view cameras and their corresponding MOD annotations captured from real AD scenes.
In a typical AD pipeline, planning and prediction are done on a top-view map, where height information is usually discarded due to its low importance relative to to BEV information. Many recent algorithms attempted to explore environment perception on BEV such as [3, 1, 7]. Most of this work focus mainly on scenes obtained by LiDAR sensor which is an expensive sensor for commercial vehicles to deploy. Time-of-flight (ToF) sensors such as LiDAR provide depth information which makes projection of the scene onto a BEV map relatively easier without explicit assumptions. On the other hand, due to the fact that camera is a low cost sensor which unlike LiDAR provides dense scene perception, the prediction of BEV images has recently gained a huge attention. Inverse Perspective Mapping (IPM) is a standard method to project images on BEV map. To perform such a method, 4 corresponding point pairs in a source and target frame have to be determined to compute a homography matrix for such transformation. The approach assumes flat ground surface and fixed camera extrinsic parameters which is not realistic in a lot of scenarios. Moreover, it provides noisy estimates and breaks down in occluding scenarios. In [20], end-to-end 3D object detection from monocular images have been explored through explicit projection inside the network. The approach is computationally heavy and not suitable for real-time applications. Later, the authors expanded to semantic segmentation [19]. In [13], an encoder-decoder architecture has been used to predict BEV directly from monocular scenes, where authors showed that CNNs are able to predict such representation without explicit projection inside the network. All the mentioned methods study BEV object detection and semantic segmentation. However, BEV motion segmentation is not explored.
 (a) (a)
(a) (a)

(b) (b)
 (c) (c)
(c) (c)
 (d) (d)
(d) (d)
III PROPOSED METHOD
In this section, we describe the proposed method including dataset generation and our network architecture.
III-A Inverse Perspective Mapping
To be able to project a scene from image view into BEV, one would need 8 points to perform such operation. Four points have to be determined in the source frame and the corresponding 4 points have to be identified in the target frame. A homography matrix is computed to transform the source image into the target image, which is usually done in an iterative approach. For the application of autonomous driving, one interesting feature would be the lanes of the road. They can be used so that they become parallel to each other in the final projection. Due to the lack of 3D information, the projected image is not realistic and there is a lot of noise in the output. Figure 3 demonstrate a sample image of KITTI dataset when projected on BEV using IPM [12] in (d). We also evaluate predicting MOD using image view and then doing projection on top view using IPM in (c). As observed in the image, (c) provides very noisy output relative to (b) which is the representation we would like to learn end-to-end. To learn such representation directly using a deep network, one would need a dataset with such representation which is not available in the public datasets. Hence, we created our own dataset having MOD annotations on BEV.
III-B Dataset Generation
In general, there is a limitation of large scale MOD datasets in autonomous driving. In [25], 255 images on KITTI dataset have been manually labeled for motion segmentation task. Additionally, around 3k images on Cityscapes dataset have been annotated. These numbers are relatively low, and they are only performed on image view of the camera sensor. In [22], 1.3k images have been weakly annotated for MOD, and it has been extended by [18] where more KITTI sequences have been annotated for moving vehicles only. All these methods provide only image view annotation which cannot be used directly on top-view predictions. Hence, we create our own dataset which consists of 12.9k images including pixel-wise annotations for static and moving objects. Our dataset is labeled for 5 classes, and it will be released for all classes, however in our experiments we focus on training the network with vehicle class only to simplify the problem. We choose KITTI dataset because of the extensive prior work on MOD to enable comparison. Another alternative is NuScenes [2] dataset. It is a more recent larger dataset which provides motion attribute for vehicles and pedestrians but not for cyclists and motorcyclists.
We adapt the approach by [18] to create our dataset, where we make use of KITTI raw sequences as they provide IMU/GPS measurements for ego-motion, LiDAR point clouds for depth and 3D boxes of the objects relative to the ego-vehicle in each frame. First, we use the IMU/GPS to compute the ego-vehicle motion in LiDAR coordinates system. We use the tracking information to compute the difference in objects positions between each two sequential frames. We project the objects into world co-ordinate system and we compute the difference between ego-vehicle and other objects motion. Using thresholding techniques, we are able to classify the surrounding objects into moving or static ones. We project the 3D points in the 3D camera co-ordinate system onto the plane to obtain the BEV representation of the surrounding scene.
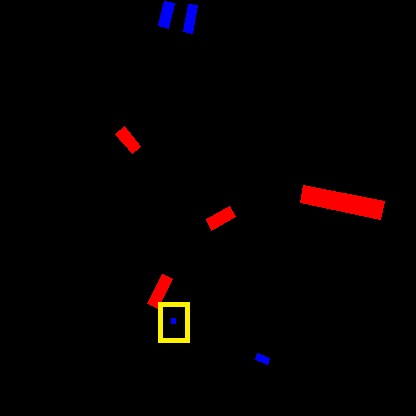
At first, we obtained the max distance of the furthest object in the dataset and set it as maximum distance to make sure all objects are included in the dataset. However, we observe that most of the objects are closer to the ego-vehicle and most of the output maps are mostly empty because of the sparsity of very far objects. Hence, we keep the maximum distance to to maintain reasonable resolution of the output maps. We observe that there are still false positives and negatives in our moving/static labels due to thresholding errors. We fix such errors by manual refinement of the false labels. The main task we target is motion segmentation, so we provide the annotations as pixel-wise masks for moving objects. We also provide masks for static objects which may be used to improve the motion segmentation prediction. Figure 2 represents samples of our generated dataset. The blue boxes refer to static objects from BEV viewpoint and the red ones correspond to moving ones. Table I demonstrates details about our generated dataset. We provide annotations for 5 classes and we provide details about both static and moving objects in each class.
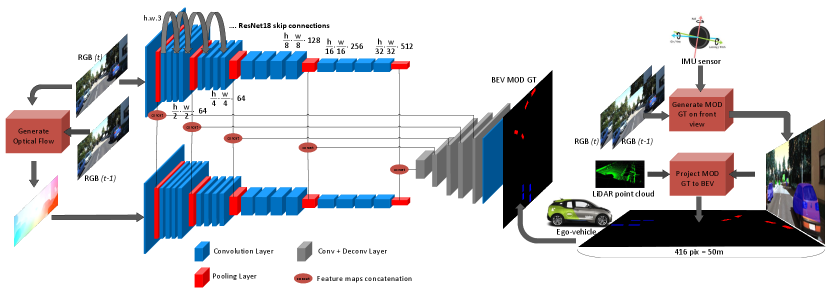
III-C Network Architecture
As proposed by [13], an encoder-decoder architecture is able to learn a BEV representation of the surrounding scene. We follow a similar approach and make use of the architecture in [10] for its high inference rate and low weight. The model in [13] is able to predict BEV map without focusing on moving vs static object classification using a single monocular image. On the other hand, the model in [10] takes two sequential images as input and tries to understand motion implicitly. This approach has been proven by [16] that it provides less accuracy than feeding optical flow explicitly. We create another encoder which accepts optical flow as input and we perform feature fusion [17] between multi-scale feature maps of both encoders and then feed the resulted tensors into the decoder. The decoder consists of 5 deconvolution layers which are preceded by convolution layers [4]. The final output is a binary mask which predicts a class for each pixel among the two classes (Moving and Static).
IV EXPERIMENTS
In this section, we provide details of our experimental setup and the analysis of the obtained results.
IV-A Experimental Setup
We use ResNet18 as backbone for feature extraction, where we create another encoder for capturing motion features from optical flow. We initialize our network with the ResNet18 pre-trained weights and we set the batch size to 16. The network is trained using the Ranger (RAdam[11] + LookAhead [28]) optimizer. We train all the models using weighted binary cross-entropy loss function for 60 epochs. We use transposed convolution layers for upsampling purpose to finally reach the original input size. Finally, a weighted binary cross entropy loss function is used to obtain the final predictions for each pixel as a classification task among two classes, i.e, Moving and Static.
 (a) (a)
(a) (a)

(b) (b)
 (c) (c)
(c) (c)
 (d) (d)
(d) (d)



IV-B Results
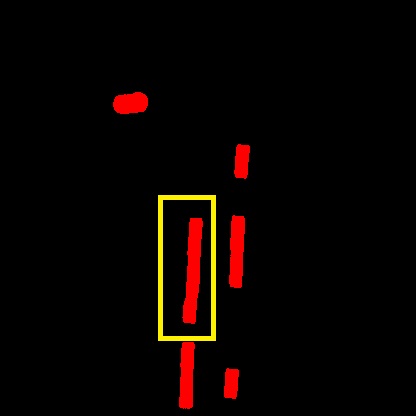
Table III demonstrate the results using our baseline network to predict BEV MOD end-to-end vs doing the prediction on Front view and performing IPM afterwards. We evaluate both predictions vs our generated ground truth and we obtain significant improvement over IPM approach by approx 7% in mIoU. Figure 5 demonstrates the output of our network in 2nd row vs the ground truth from our dataset in 3rd row. It is shown that CNN is able to predict BEV directly through an encoder-decoder architecture as proposed by [13]. However, the network is not able to distinguish between vehicles in some cases as described in the first column. In the second column, the object highlighted in yellow is very hard to predict where most of the object is occluded behind the front vehicle. On the other hand, the static object highlighted in blue has been suppressed correctly which shows the importance of optical flow to capture the motion information in the scene. The third and fourth columns demonstrate our results for multiple objects in the scene. Results show decent output where the model can be used a baseline for benchmarking. However, the length of some objects are not captured perfectly and some of the objects are mis-classified as false static objects, which shows that there is still room for improvement. Perhaps one approach to explore is to define an explicit learning-based BEV projection model inside the network to overcome such inaccuracies.
| Type/Class | Car | Truck | Van | Pedestrian | Cyclist |
|---|---|---|---|---|---|
| Static | 28001 | 323 | 2984 | 920 | 177 |
| Moving | 8527 | 982 | 1410 | 1356 | 1301 |
| Total | 36528 | 1305 | 4394 | 2276 | 1478 |
| Experiment | mIoU | fps |
|---|---|---|
| {RGB + Optical Flow} + IPM re-projection | 47.9 | 73 |
| {RGB + RGB (prev)} end-to-end BEV output | 53.3 | 85 |
| {RGB + Optical Flow} end-to-end BEV output | 54.5 | 85 |
| Detection Range | mIoU |
|---|---|
| 0-10m | 51.8 |
| 10-20m | 53.5 |
| 20-30m | 55.2 |
| 30-40m | 55.8 |
| 40-50m | 53.8 |
We also observe that accuracy of the predictions decrease with increasing the depth from the camera sensor. To evaluate that quantitatively, we divide the view range into 5 bins, 10m each, and we compute mIoU over all the images for the 5 bins separately, where the results are tabulated in Table III. We observe that very close objects are not captured entirely and this is expected because very close moving objects are usually moving in the same direction with almost same speed of the ego-vehicle such as passing vehicles. Due to motion parallax problem, such vehicles appear almost fixed relative to the ego-vehicle and hence very hard to detect. Accuracy of the model reaches its maximum in the middle ranges from 10m to 30m from the camera sensor and then decrease again as we go far away from the sensor. This is intuitive because as we go far away from the camera sensor, the vehicles appear smaller and moving slowly from the viewpoint of the ego-vehicle. This makes the optical flow vectors associated with such vehicles are small compared to the closer vehicles, and hence they are harder to detect. Moreover, due to absence of depth sensor, ambiguity increases with increased depth which might cause inaccurate predictions. We also observe that using the same input modalities and same architecture, the network learns motion segmentation in front view in a better accuracy. This is expected because in BEV approach the network learns an additional task to motion segmentation which is BEV projection. However, overall, BEV end-to-end learning provides better accuracy than learning in front view then projecting using IPM as demonstrated in Table III. Using more complex models than our model, better representation can be learnt using our dataset with higher accuracy.
V CONCLUSION
In this work, we explore the idea of learning moving object detection directly in BEV space. We create a dataset that consists of 12.9k images having annotations for MOD on 5 classes. We design a deep network to predict such representation directly and we compare our results with standard IPM approach, where we show a significant improvement of 13% in mIoU. However, our qualitative results illustrate that there are significant gaps and more research is needed to improve the performance compared to our simple baseline. Thus, we release the dataset publicly and we hope it motivates further research in class agnostic moving object detection.
References
- [1] M. Bansal, A. Krizhevsky, and A. Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv preprint arXiv:1812.03079, 2018.
- [2] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- [3] S. Casas, W. Luo, and R. Urtasun. Intentnet: Learning to predict intention from raw sensor data. In Conference on Robot Learning, pages 947–956. PMLR, 2018.
- [4] A. Das., S. Kandan., S. Yogamani., and P. Křížek. Design of real-time semantic segmentation decoder for automated driving. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 5: VISAPP,, pages 393–400. SciTePress, 2019.
- [5] B. Drayer and T. Brox. Object detection, tracking, and motion segmentation for object-level video segmentation. arXiv preprint arXiv:1608.03066, 2016.
- [6] J. Horgan, C. Hughes, J. McDonald, and S. Yogamani. Vision-based driver assistance systems: Survey, taxonomy and advances. In 2015 IEEE 18th International Conference on Intelligent Transportation Systems, pages 2032–2039. IEEE, 2015.
- [7] J. Houston, G. Zuidhof, L. Bergamini, Y. Ye, A. Jain, S. Omari, V. Iglovikov, and P. Ondruska. One thousand and one hours: Self-driving motion prediction dataset. arXiv preprint arXiv:2006.14480, 2020.
- [8] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2462–2470, 2017.
- [9] S. D. Jain, B. Xiong, and K. Grauman. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. In 2017 IEEE conference on computer vision and pattern recognition (CVPR), pages 2117–2126. IEEE, 2017.
- [10] V. R. Kumar, S. Yogamani, H. Rashed, G. Sitsu, C. Witt, I. Leang, S. Milz, and P. Mäder. Omnidet: Surround view cameras based multi-task visual perception network for autonomous driving. IEEE Robotics and Automation Letters, 6(2):2830–2837, 2021.
- [11] L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han. On the variance of the adaptive learning rate and beyond. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
- [12] H. A. Mallot, H. H. Bülthoff, J. Little, and S. Bohrer. Inverse perspective mapping simplifies optical flow computation and obstacle detection. Biological cybernetics, 64(3):177–185, 1991.
- [13] K. Mani, S. Daga, S. Garg, S. S. Narasimhan, M. Krishna, and K. M. Jatavallabhula. Monolayout: Amodal scene layout from a single image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1689–1697, 2020.
- [14] M. Menze and A. Geiger. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3061–3070, 2015.
- [15] E. Mohamed, M. Ewaisha, M. Siam, H. Rashed, S. Yogamani, W. Hamdy, M. Helmi, and A. El-Sallab. Monocular instance motion segmentation for autonomous driving: Kitti instancemotseg dataset and multi-task baseline. arXiv preprint arXiv:2008.07008, 2020.
- [16] M. Ramzy, H. Rashed, A. E. Sallab, and S. Yogamani. Rst-modnet: Real-time spatio-temporal moving object detection for autonomous driving. NeurIPS Workshop on Autonomous Driving, 2019.
- [17] H. Rashed, A. El Sallab, S. Yogamani, and M. ElHelw. Motion and depth augmented semantic segmentation for autonomous navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- [18] H. Rashed, M. Ramzy, V. Vaquero, A. El Sallab, et al. Fusemodnet: Real-time camera and lidar based moving object detection for robust low-light autonomous driving. In Proc. of the IEEE International Conference on Computer Vision Workshops, 2019.
- [19] T. Roddick and R. Cipolla. Predicting semantic map representations from images using pyramid occupancy networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11138–11147, 2020.
- [20] T. Roddick, A. Kendall, and R. Cipolla. Orthographic feature transform for monocular 3d object detection. arXiv preprint arXiv:1811.08188, 2018.
- [21] M. Siam, S. Eikerdawy, M. Gamal, M. Abdel-Razek, M. Jagersand, and H. Zhang. Real-time segmentation with appearance, motion and geometry. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5793–5800. IEEE, 2018.
- [22] M. Siam, H. Mahgoub, M. Zahran, S. Yogamani, M. Jagersand, and A. El-Sallab. MODNet: Motion and appearance based moving object detection network for autonomous driving. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), pages 2859–2864, 2018.
- [23] P. Tokmakov, K. Alahari, and C. Schmid. Learning video object segmentation with visual memory. In Proceedings of the IEEE International Conference on Computer Vision, pages 4481–4490, 2017.
- [24] N. Tripathi and S. Yogamani. Trained trajectory based automated parking system using Visual SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021.
- [25] J. Vertens, A. Valada, and W. Burgard. Smsnet: Semantic motion segmentation using deep convolutional neural networks. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 582–589. IEEE, 2017.
- [26] M. Yahiaoui, H. Rashed, L. Mariotti, G. Sistu, I. Clancy, et al. FisheyeMODNet: Moving object detection on surround-view cameras for autonomous driving. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019.
- [27] S. Yogamani, C. Hughes, J. Horgan, G. Sistu, P. Varley, et al. WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9308–9318, 2019.
- [28] M. R. Zhang, J. Lucas, J. Ba, and G. E. Hinton. Lookahead optimizer: k steps forward, 1 step back. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, 2019.