Beyond and Free from Diffusion: Invertible Guided Consistency Training
Abstract
Guidance in image generation steers models towards higher-quality or more targeted outputs, typically achieved in Diffusion Models (DMs) via Classifier-free Guidance (CFG). However, recent Consistency Models (CMs), which offer fewer function evaluations, rely on distilling CFG knowledge from pretrained DMs to achieve guidance, making them costly and inflexible. In this work, we propose invertible Guided Consistency Training (iGCT), a novel training framework for guided CMs that is entirely data-driven. iGCT, as a pioneering work, contributes to fast and guided image generation and editing without requiring the training and distillation of DMs, greatly reducing the overall compute requirements. iGCT addresses the saturation artifacts seen in CFG under high guidance scales. Our extensive experiments on CIFAR-10 (Krizhevsky, 2012) and ImageNet64 (Chrabaszcz et al., 2017) show that iGCT significantly improves FID and precision compared to CFG. At a guidance of 13, iGCT improves precision to 0.8, while DM’s drops to 0.47. Our work takes the first step toward enabling guidance and inversion for CMs without relying on DMs.

1 Introduction
Diffusion Models (DMs) have emerged as a powerful class of generative models, demonstrating state-of-the-art performance in tasks such as image synthesis (Ho et al., 2020; Song & Ermon, 2020; Song et al., 2021, 2022; Rombach et al., 2022; Podell et al., 2023; Lin et al., 2023) conditional generation (Avrahami et al., 2022; Meng et al., 2022; Mou et al., 2023; Bar-Tal et al., 2023; Bashkirova et al., 2023; Huang et al., 2023; Zhang et al., 2023; Ni et al., 2023; Podell et al., 2023), and precise image editing (Mokady et al., 2023; Miyake et al., 2023; Wallace et al., 2023; Han et al., 2024; Garibi et al., 2024; Huberman-Spiegelglas et al., 2024). Unlike GANs, which rely on adversarial training to generate samples (Goodfellow et al., 2014; Metz et al., 2016; Gulrajani et al., 2017; Arjovsky & Bottou, 2017; Karras et al., 2018; Brock et al., 2019; Karras et al., 2019, 2020, 2021), diffusion models (DMs) use a stochastic process that incrementally adds Gaussian noise to data, then reverses this process to generate new samples. This iterative approach, while computationally intensive, enables greater control over sample quality and diversity through guided sampling methods (Ho & Salimans, 2022; Dieleman, 2022; Ho et al., 2022; Meng et al., 2023; Karras et al., 2024a). In contrast, GANs often suffer from mode collapse (Gulrajani et al., 2017; Arjovsky & Bottou, 2017; Metz et al., 2016), which hinders output diversity and training stability. Diffusion-based algorithms can thus offer a key advantage by balancing quality-diversity tradeoffs, frequently achieved with Classifier-free Guidance (CFG) (Ho & Salimans, 2022). Both the role of diffusion noise scheduling and the network’s convergence properties are essential for improving performance and applicability (Karras et al., 2022; Lu et al., 2022, 2023; Zheng et al., 2023; Karras et al., 2024c; Salimans & Ho, 2022; Park et al., 2024; Karras et al., 2024b).
Consistency Models (CMs), designed to accelerate the diffusion process, provide a more efficient alternative by reducing the number of function evaluations (NFE) needed for generation (Song et al., 2023; Kim et al., 2023, 2024; Li & He, 2024; Heek et al., 2024; Lu & Song, 2024; Lee et al., 2025). These models achieve this by aligning data points along the Probability-flow (PF) ODE of the stochastic forward process, using either consistency distillation (CD) or consistency training (CT) (Song et al., 2023). While CD models have been widely applied in real-time image synthesis and fast editing via distillation (Luo et al., 2023; Starodubcev et al., 2024), the development of CT models remain relatively unexplored. This is primarily because CT, as a fully self-supervised and data-driven approach, requires a well-crafted training curriculum to be trained successfully (Song & Dhariwal, 2023; Geng et al., 2024).
CT, however, offers distinct advantages. First, unlike CD, CT can be trained with any underlying diffusion schedulers. The design space for DM training, sampling, and preconditioning (Karras et al., 2022) is an ongoing area of research that has attracted researchers interest ever since the diffusion surge. Therefore, CT’s flexibility to train with improved designs makes it more attractive than CD by dropping the dependence of a state-of-the-art DM. An improved diffusion scheduler can be directly utilized in CT, while CD depends on the existence of a DM (Fig. 2). Second, recent studies show that CT, when improved with advanced training techniques, outperforms CD in image generation on FID metrics (Song & Dhariwal, 2023; Geng et al., 2024). This underscores its potential to surpass CD in both efficiency and quality, making CT as a promising alternative for advancing fast generative modeling.
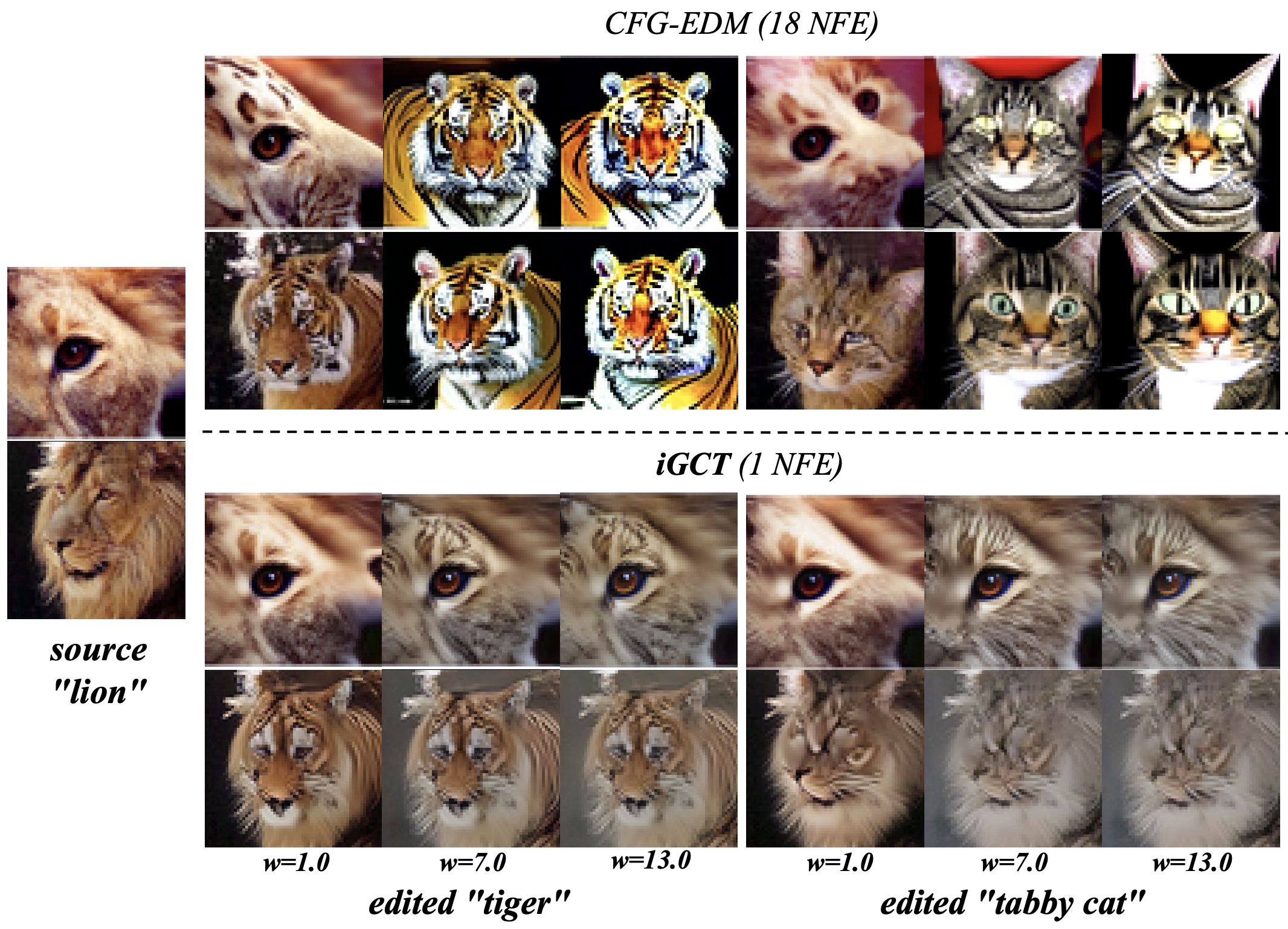
Our study fills the missing piece in establishing a comprehensive theory for CT, a data-driven approach for guidance learning in 1-step/few-step image generation. We present Invertible Guided Consistency Training (iGCT), a novel framework that enables CMs to perform guided generation without requiring DM distillation at training. In training, iGCT decouples the target clean sample from the source to capture effects of both unconditional and conditional noise. For invertibility, iGCT incorporates an independent component, the noiser, which maps images to noise in a single step. This same-dimensional noise, termed as noise latent in our paper, serves as a deterministic representation of the input image. Removing the dependency on a teacher DM, iGCT provides greater flexibility and efficiency by eliminating the need of a two-stage training procedure. We show that guidance learned via iGCT removes the high-contrast artifacts (Figs. 1 and 3), a well-known limitation observed for CFG trained DMs (Ho et al., 2022; Saharia et al., 2022; Bradley & Nakkiran, 2024; Kynkäänniemi et al., 2024; Karras et al., 2024a). Consequently, iGCT achieves higher FID’s and Precision/Recall under guided generation compared to multi-step DMs and their distilled CM counterparts. In line with the parallel work on few-step image editing from iCD (Starodubcev et al., 2024), we demonstrate that iGCT is effective for 1-step image editing. Following common editing frameworks that applies high guidance after DDIM inversion (Mokady et al., 2023; Miyake et al., 2023; Han et al., 2024; Starodubcev et al., 2024), iGCT is able to match the target class semantics while preserving features inversed from the source image. To summarize, our contributions are as follows:
-
•
We introduce invertible Guided Consistency Training (iGCT), a DM independent approach that incorporates guidance into CMs (Sec. 3 and Appendix Beyond and Free from Diffusion: Invertible Guided Consistency Training).
- •
-
•
We present iGCT’s invertibility, a disjoint contribution that enables efficient inversion and generation using class conditioning, offering a promising framework for real-time image editing (Sec. 4.2).
2 Background and Preliminaries
This section introduces the foundational concepts relevant to our methodology and baselines on CMs, CFG, and inversion-based image editing. In the remaining discussion, we denote as a sample from the target data distribution, denoted as .
2.1 EDM and Consistency Models
In this paper, we mainly consider EDM (Karras et al., 2022), a popular formulation of DM, diffusion scheduler, and ODE widely used by CMs (Song et al., 2023; Song & Dhariwal, 2023; Li & He, 2024; Geng et al., 2024). We introduce two ways of learning discrete-time CMs, CD and CT, originally in the first CM paper (Song et al., 2023), as well as the continuous-time CM from ECT (Geng et al., 2024).
EDM. The stochastic forward process of EDM is described by, , where , and denotes the Brownian motion. With a sample from the dataset, , and a random noise, , EDM learns the reverse process via the denoising objective,
| (1) |
where , is a weighting function w.r.t. , and is further parametrized by , allowing the network to predict residual information from the signal and noise mixture. Besides, the preconditioning terms, , ensure unit variance of both the model’s target and input. For readers interested in the derivations, please refer to Appendix B.6 from the EDM paper.
Discrete-time CM. We focus our discussion on the family of CMs that model the same ODE as EDM. CMs aim to inference the solution of the PF-ODE at directly or with few NFEs. To achieve this, CMs are optimized against the consistency objective,
| (2) |
where is the discrete timestep sequence defined throughout the course of training, and is the distance function. The noisier term is given by , while the cleaner term can be obtained from the instantaneous change at using a pretrained EDM or by , sharing the same noise direction . The former approach, known as Consistency Distillation (CD), distills knowledge from a pretrained EDM, while the latter data-driven method is called Consistency Training (CT). At training, gradient updates are applied only to the weights predicting the noisier term, while the weights for the cleaner term, denoted , remains frozen. In CMs, the preconditioning terms look nearly identical to the ones used in EDM to ensure the boundary condition of the consistency objective: at , , with , and , where is the lowest noise at training for stability (Song et al., 2023).
Continuous-time CM. We focus on continuous-time CMs introduced in ECT (Geng et al., 2024). ECT is a consistency training/tuning algorithm replacing the discrete timesteps with a continuous-time schedule. ECT samples noise scales following a lognormal distribution, where , optimizing Eq. 2 between noisy samples and along the same noise direction. Throughout training, ECT reduces to via an exponentially decreasing schedule with a base of , e.g., , where is the training and doubling iterations, and is a sigmoid adjusting function. Our iGCT is trained under the same continuous-time schedule used by ECT. To establish DM independence, iGCT’s training curriculum begins with diffusion training by setting .
2.2 Classifier-free Guidance
CFG is a technique in DMs that improves image quality by jointly optimizing an unconditional and conditional denoising objective (Ho & Salimans, 2022). At inference, guidance is achieved by extrapolating conditional and unconditional passes using factor .
| (3) |
when , the update direction is encouraged by the conditional term, , and discouraged from the unconditional term, . In practice, high guidance enables high-fidelity image generation (Rombach et al., 2022; Podell et al., 2023; Dieleman, 2022; Ho et al., 2022; Meng et al., 2023) and precise image editing (Mokady et al., 2023; Miyake et al., 2023; Han et al., 2024; Garibi et al., 2024; Huberman-Spiegelglas et al., 2024; Starodubcev et al., 2024). High CFG guidance causes deviation from the original PF-ODE, leading to mode drop and overly saturated images (Saharia et al., 2022; Kynkäänniemi et al., 2024; Bradley & Nakkiran, 2024). Further comparisons of guidance are provided in Sec. 3.1 and Fig. 3.
Guidance in Latent Consistency Models. Latent CMs (Luo et al., 2023) are distilled from latent DMs that synthesizes high-resolution images requiring 2-4 NFEs. At distillation, the cleaner term relies on an ODE solver, , a teacher DM, , to compute the incorporated CFG knowledge into the consistency objective (Eq. 2), e.g.,
| (4) | ||||
where the guidance range is chosen as a hyper-parameter during distillation.
2.3 Inversion-based Image Editing
Inversion-based editing aims to modify subjects in real images by aligning the forward process of diffusion models with the DDIM inversion trajectory (Song et al., 2022). Previous works achieve this by tuning learnable representations during the editing process, which often requires time-consuming per-image optimization (Dong et al., 2023; Li et al., 2023; Mokady et al., 2023). While BCM (Li & He, 2024), a CM that demonstrates capabilities in both image generation and inversion, iGCT distinguishes itself by decoupling the inversion module from the generation. This separation allows for the flexibility for guidance generation with iGCT’s denoiser. Despite these advancements, achieving inversion-based editing in one-step guided CMs remains an unexplored challenge. As a pioneering work, iGCT addresses this challenge by focusing on category-based editing, offering a novel approach to the problem. Further analysis and results are provided in Section 4.2.
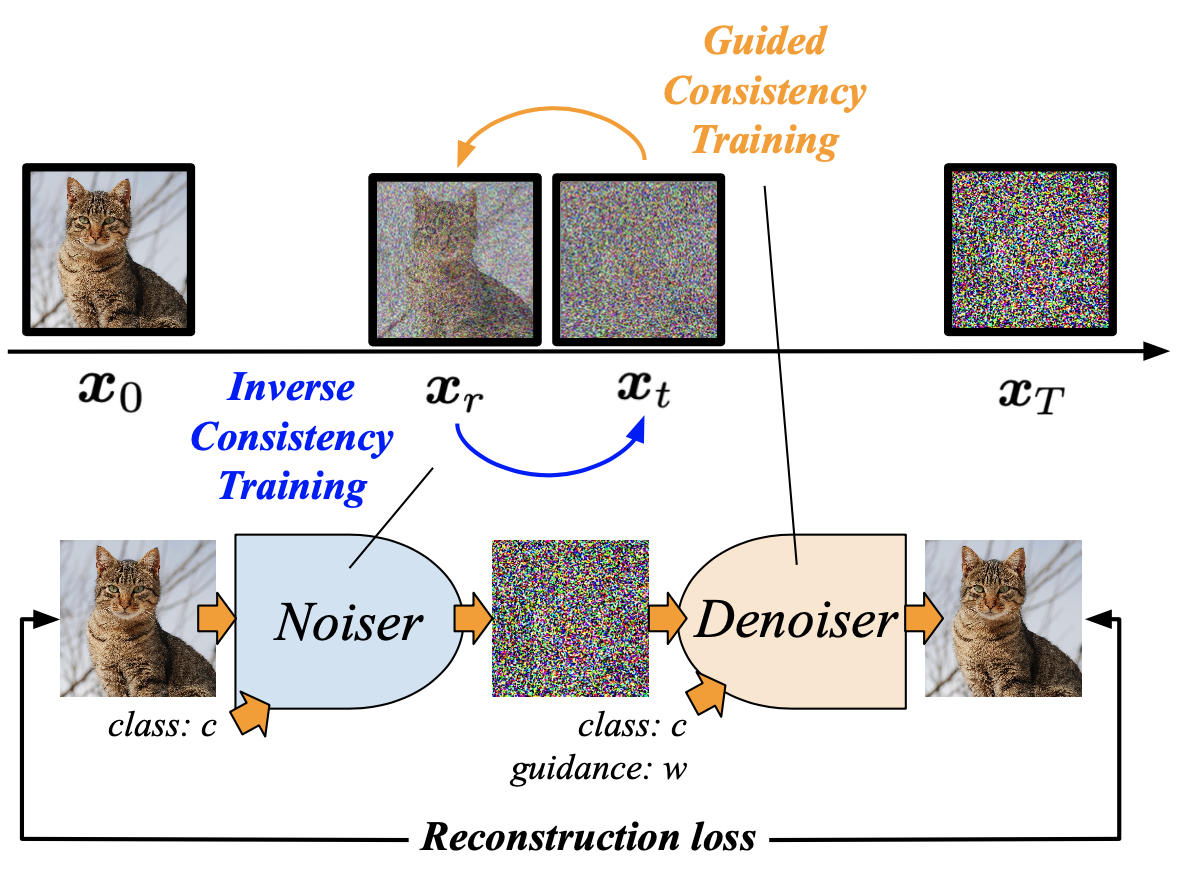
3 Invertible Guided Consistency Training
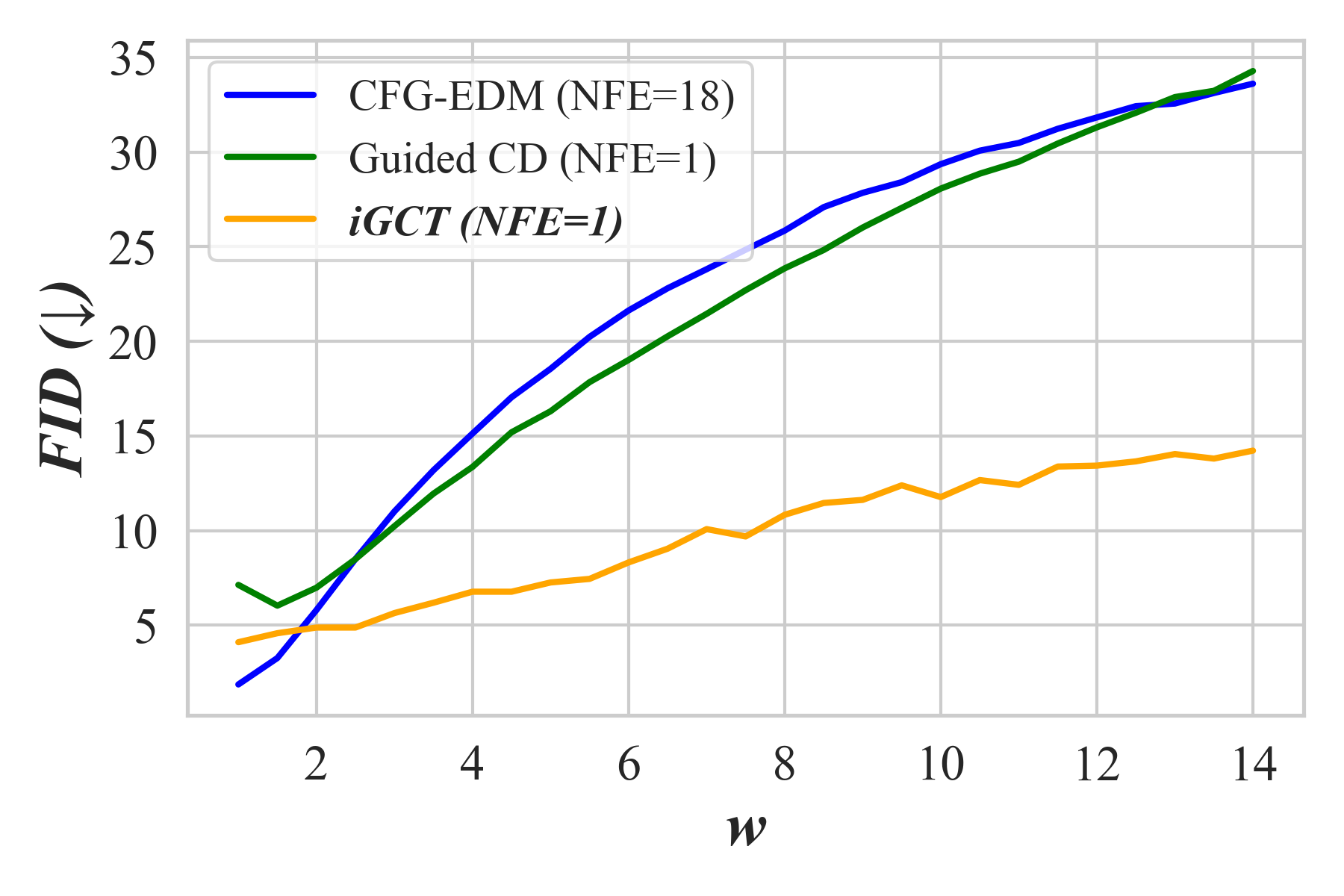
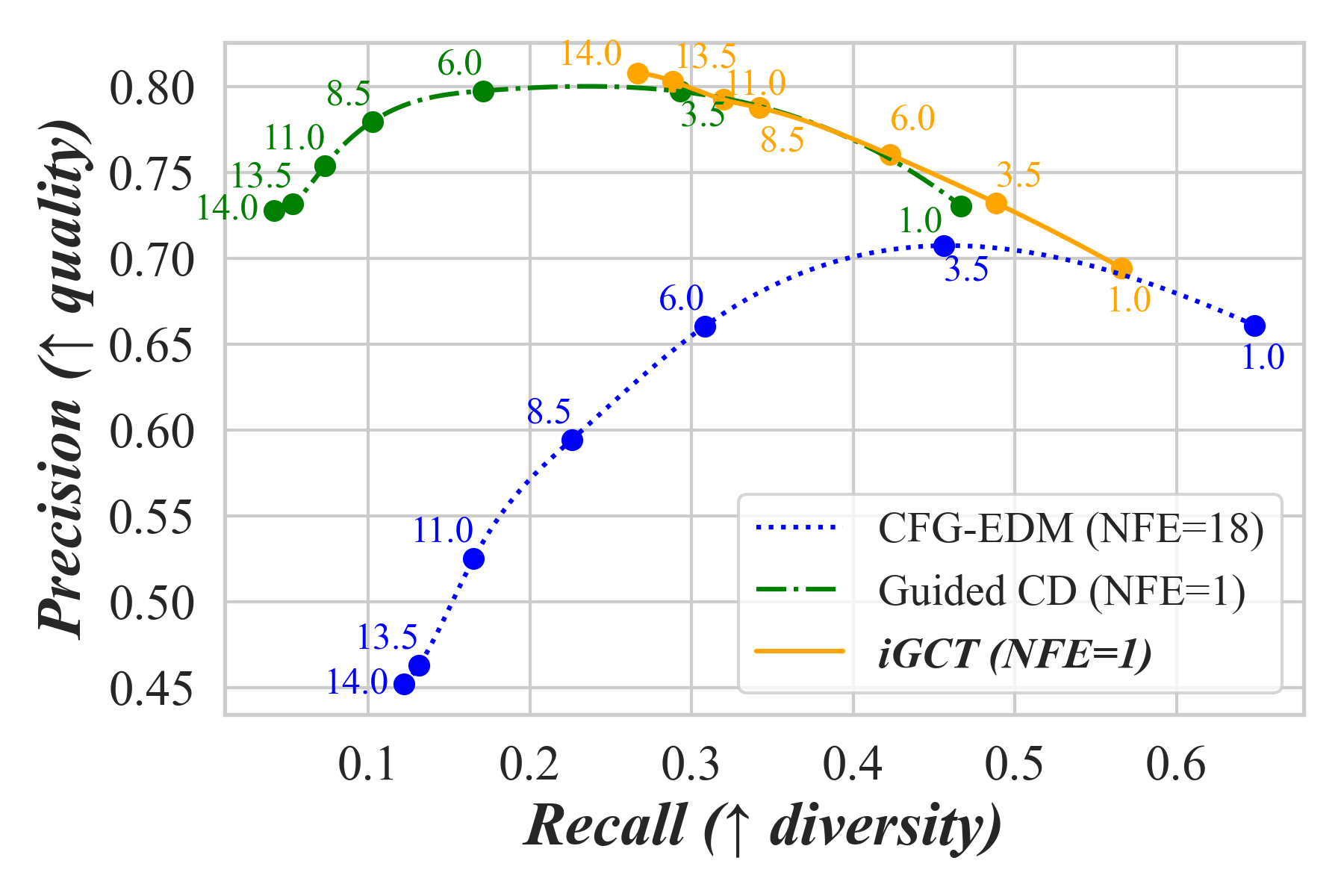
This section begins by introducing the approach for data-driven guidance learning with CT, followed by a discussion on the invertible aspect. All together, we present Invertible Guided Consistency Training (iGCT), a one-stage training framework that supports few step, guided image generation and image editing (Fig. 4). iGCT requires less gpu training hours compared to the total time required for the two-stage framework, i.e., optimizing CFG EDM + guided CD (Table A3). The resulting iGCT achieves higher precision (Kynkäänniemi et al., 2019) compared to a CFG trained DM and a CM distilled from it (Song et al., 2023; Luo et al., 2023), allowing better FID under high guidance (Fig. 7).
3.1 The ”Curse of Uncondition” and Guided CT
For distillation-based CM, guidance is achieved by emphasizing the conditional while negating the unconditional score predicted by a teacher DM. Associated with the input condition , the same random noise that is used to produce the noisy sample guides toward its original clean image in conditional CT. Following the notation of continuous-time CM in Sec. 2.1, as with progressively finer discretization during training, the expected instantaneous change from random noise converges to the underlying true conditional noise, denoted as .
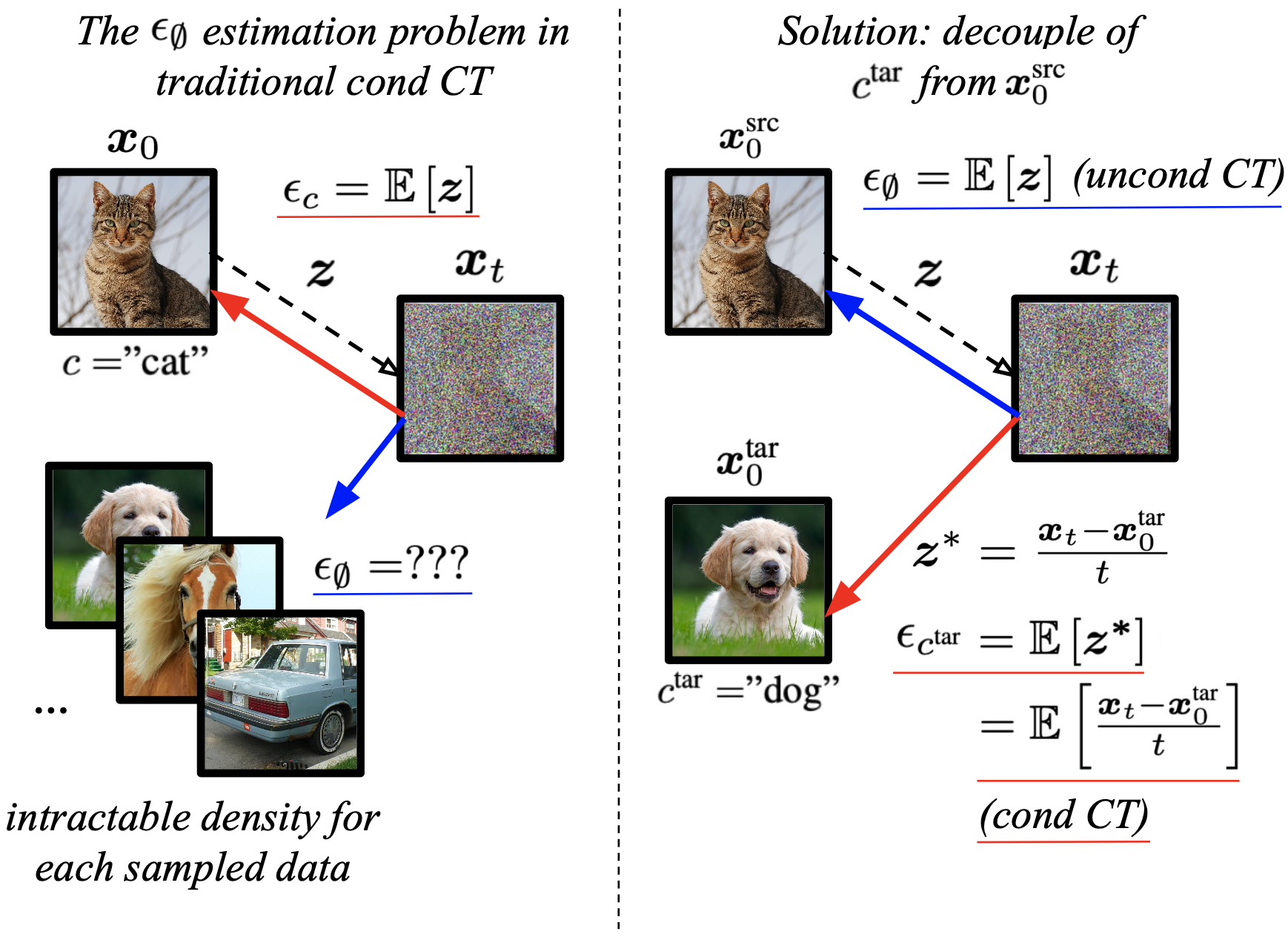
However, finding the true unconditional noise is challenging without a DM model. Since guided CMs are defined as , the sampled noise that generated inherently depends on , making it unsuitable as an unconditional noise estimate. In other words, associates with the class inevitably. Prior works address this by training the CM on a denoising objective with the condition masked (Hu et al., 2024), i.e., , , allowing it to function as a DM when unconditioned, and switch back to CM when conditioned. To further highlight this challenge, a tempting approach is to approximate the unconditional noise by averaging among random data; however, this requires the conditional density of source samples given , which is effectively what a DM model is trained to model in the absence of class labels.
To address these challenges, we decouple the condition from the source image that generated . We denote as the target condition and as the source image before diffusion, i.e., . As originates from data independent of , we can treat the noise as an estimate of the true unconditional noise. The direction from to a random sample associated with serves as an estimate of the true conditional noise. Thus, we define the guided direction as the extrapolation between and , yielding as the input to the target for the consistency objective (Fig. 5).
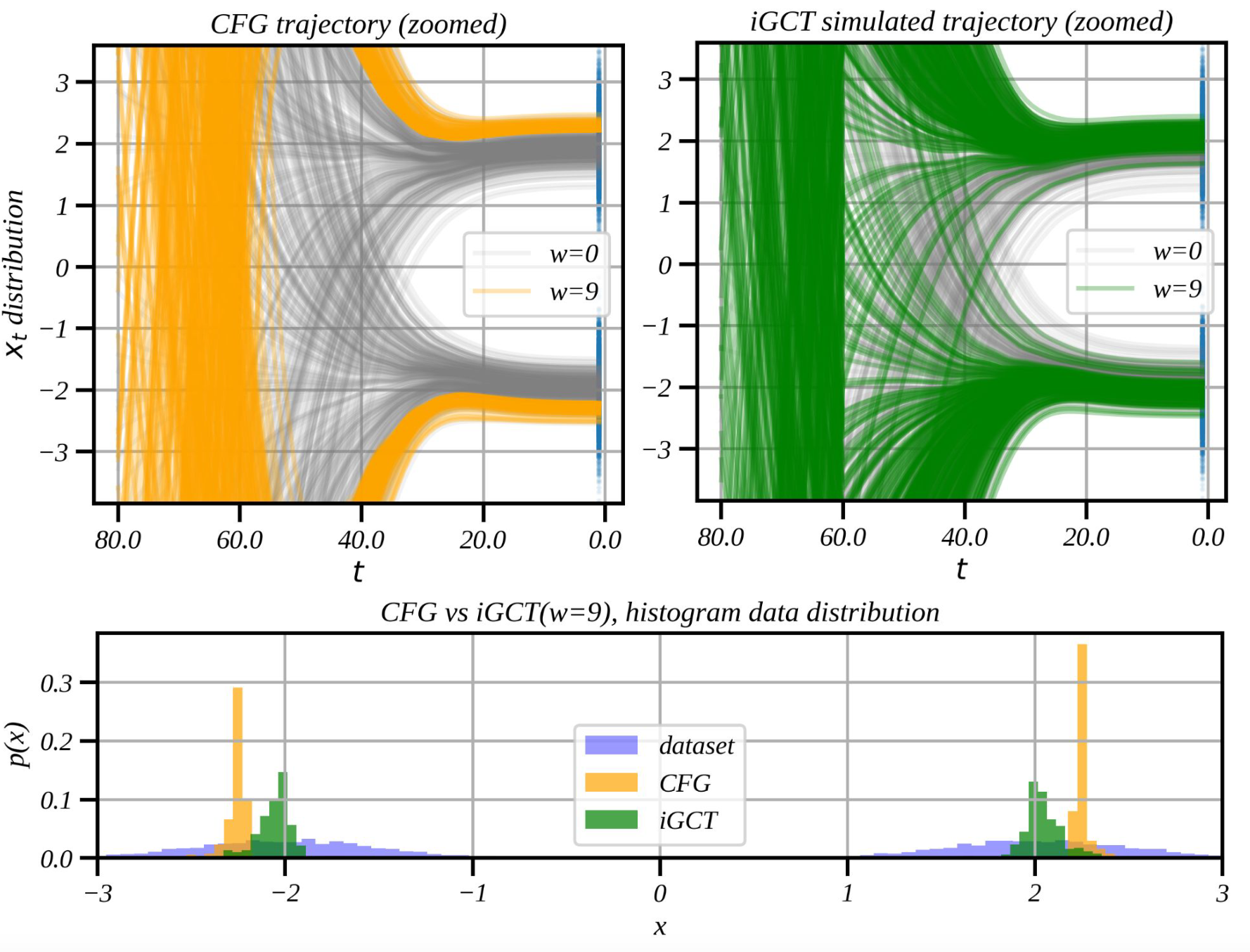
To effectively span the PF-ODE trajectory with sampled data and as a coherent chain, our loss function incorporates both guided consistency training and the original CT objective (Eq. 2) under a continuous-time schedule. Specifically, for high noise levels , the target is more likely generated through the above decoupled approach, serving as the target for to learn guidance. For low noise samples, is generated solely via the shared noise assuming that and are indistinguishable when the sample closely resembles the clean image. We compare the guidance logic of CFG and iGCT using a 1D diffusion toy example with target modes at and (Fig. 3). CFG shows an overshooting trajectory and generates extreme values away from the modes. In contrast, iGCT produces modes that align with the data distribution. The guided CT loss is formulated as follows:
| (5) |
, where is the weighting function defined by the reciprocal of the step following ECT (Geng et al., 2024).
3.2 Inverse Consistency Training
Besides few-step guided image generation with CT, we introduce inverse CT, which leverages the consistency objective in reverse to map the target distribution back to Gaussian. This deterministic inverse mapping facilitates precise image editing, traditionally performed via DDIM requiring numerous NFEs. By training on the consistency objective, our model directly infers the PF-ODE endpoint efficiently. We define the model that maps images to noise as the noiser, denoted .
Following ECT (Geng et al., 2024), we sample , and set by progressively reducing over training. This approach emphasizes importance sampling of pairs and in the lower region, where learning the PF-ODE path is more complex and challenging compared to higher noise levels (Karras et al., 2022; Song & Dhariwal, 2023). As oppose to ECT, we define the weighting function as , and treat as the target for inverse CT, optimizing the objective . Similar to EDM and CMs, our noiser is further preconditioned. We define , where , and , serving as the boundary conditions while preserving the unit variance property. The proof of unit variance is provided in Appendix B. The inverse CT loss is given by:
| (6) |
Following iCD (Starodubcev et al., 2024), we found that adding a reconstruction loss is critical to aligning the noiser’s latent output with the denoiser’s input noise. The reconstruction loss is defined as:
| (7) |
Putting them all together, the summarized loss terms for our invertible Guided Consistency Training is, . Please refer to Appendix Beyond and Free from Diffusion: Invertible Guided Consistency Training and Table A2 for the full training algorithm and hyperparameters.

4 Experiments: Fast Style-Preserving Guided Generation and Editing
To understand the effect of guidance and inversion of iGCT, we first introduce our baselines, then, present a series of experiments on CIFAR-10 (Krizhevsky, 2012) and ImageNet64 (Chrabaszcz et al., 2017) across various guidance scales for image generation (Sec. 4.1) and class-based editing (Sec. 4.2). Our analysis mainly focuses on CIFAR-10 compared against CFG and few-step distillation methods as baselines. For training and implementation details on iGCT, please see Appendix C.
Baselines. We compare iGCT with two key baselines: EDM (Karras et al., 2022) and CD (Song et al., 2023), both widely adopted frameworks for DMs and CMs respectively. The goal is to evaluate iGCT’s performance against multi-step classifier-free guidance (CFG) in DMs, as well as few-step guided CMs. Prior to our work, guidance in consistency models was exclusively achieved through consistency distillation from pretrained DMs, as demonstrated by guided-CD and iCD (Luo et al., 2023; Starodubcev et al., 2024). As of writing this paper, iGCT is the first framework to incorporate guidance directly into consistency training, eliminating the need for distillation. Given this, EDM and guided-CD serve as our primary baselines for evaluating guidance performance on CIFAR-10 (Krizhevsky, 2012). Additionally, we conduct image editing experiments using EDM as a baseline by leveraging its invertibility and guidance capabilities.
We also present results on ImageNet64 (Chrabaszcz et al., 2017), using EDM as the primary baseline. Due to resource constraints, we exclude guided-CD from this comparison, as distilling a DM model for guided-CD would require approximately twice the computational cost of iGCT from our CIFAR-10 experiments (see Table A3). This estimate is based on implementing guided-CD following the best configurations outlined in (Song et al., 2023) and (Luo et al., 2023). For iGCT, we adopt a smaller ADM architecture (Dhariwal & Nichol, 2021), reducing the width dimensions compared to the default EDM. This adjustment allows us to lower the burden in training iGCT in 190 GPU days on A100 clusters. Additional details about the reimplementation of guided baselines, including CFG-EDM and guided-CD, can be found in Appendix C.
4.1 Guidance
| W Scale | Methods | NFE | FID / Precision / Recall |
| w=1 | CFG-EDM (Karras et al., 2022) | 18 | 1.9 / 0.66 / 0.64 |
| Guided-CD (Song et al., 2023) | 1 | 7.1 / 0.74 / 0.47 | |
| 2 | 3.9 / 0.71 / 0.53 | ||
| iGCT (ours) | 1 | 4.1 / 0.69 / 0.57 | |
| 2 | 3.8 / 0.69 / 0.59 | ||
| w=7 | CFG-EDM | 18 | 23.8 / 0.63 / 0.27 |
| Guided-CD | 1 | 21.5 / 0.79 / 0.14 | |
| 2 | 21.3 / 0.76 / 0.20 | ||
| iGCT | 1 | 10.1 / 0.77 / 0.38 | |
| 2 | 9.2 / 0.76 / 0.42 | ||
| w=13 | CFG-EDM | 18 | 32.6 / 0.47 / 0.13 |
| Guided-CD | 1 | 33.0 / 0.74 / 0.05 | |
| 2 | 32.5 / 0.72 / 0.10 | ||
| iGCT | 1 | 14.0 / 0.80 / 0.28 | |
| 2 | 12.6 / 0.78 / 0.35 |
| W Scale | Methods | NFE | FID / Precision / Recall |
| w=1 | CFG-EDM (Karras et al., 2022) | 18 | 3.38 / 0.66 / 0.64 |
| iGCT | 1 | 13.16 / 0.46 / 0.40 | |
| 2 | 11.67 / 0.43 / 0.47 | ||
| w=7 | CFG-EDM | 18 | 29.19 / 0.63 / 0.27 |
| iGCT | 1 | 15.45 / 0.54 / 0.22 | |
| 2 | 11.18 / 0.50 / 0.29 | ||
| w=13 | CFG-EDM | 18 | 29.03 / 0.47 / 0.13 |
| iGCT | 1 | 20.78 / 0.60 / 0.14 | |
| 2 | 13.37 / 0.54 / 0.23 |
We evaluate iGCT using FID, precision and recall (Kynkäänniemi et al., 2019) on CIFAR-10 and ImageNet64 across various guidance scales . All three metrics are computed by comparing 50k generated samples with 50k dataset samples. These metrics provide a consistent basis for evaluating a model’s performance on quality and diversity. Fig. 6 compares guidance methods based on CFG and iGCT. When , both CFG-based methods and iGCT exhibit a trade-off between diversity and quality, with increased unification in background tone and color compared to , i.e., unguided conditional generation. Notably, CFG tends to produce high-contrast colors at higher guidance levels, while iGCT maintains a consistent style. Consequently, iGCT achieves lower FID compared to CD and EDM under high guidance. Adjusting the scale for iGCT also consistently enhances precision, while CFG shows declines in both quality and diversity beyond a certain threshold. We plot the FID and precision/recall tradeoff on CIFAR-10 in Fig. 7 and provide additional metric results for both CIFAR-10 and ImageNet64 in Table 1.
4.2 Inversion-based Image Editing
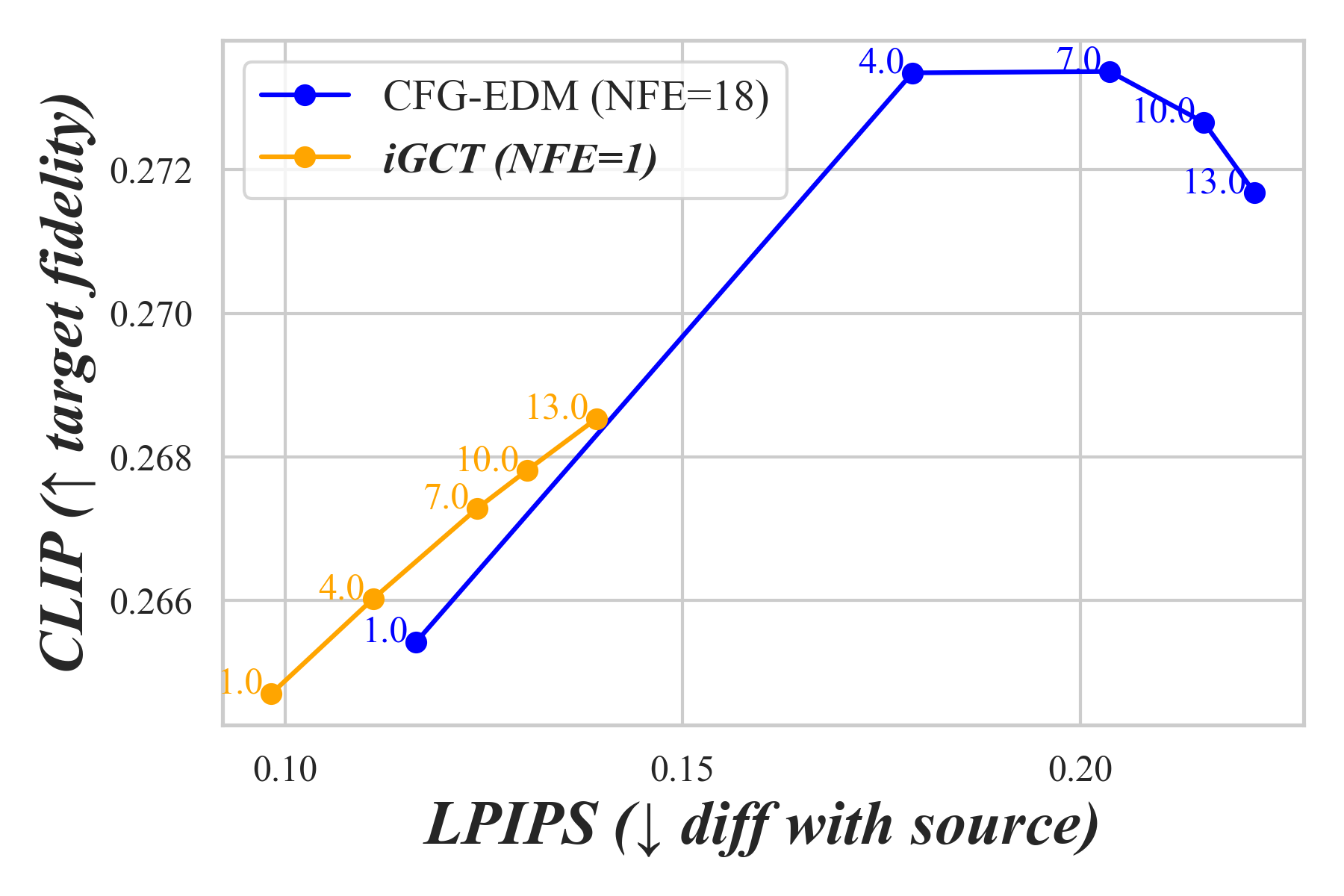
To validate iGCT’s effectiveness in image editing, we conduct inversion-based editing experiments on CIFAR-10 and ImageNet64. We compare class-based editing results across various guidance scales on the inversed noise latent. We train a CFG-EDM as baseline that infers the noise latent of a source image with DDIM inversion (Mokady et al., 2023) without fine-tuning. The edited image is then generated conditionally on a target class. To perform image editing with iGCT, the noiser predicts the noise latent of a source image, then generates the edited image conditioned on the target class. Our baseline EDM requires 18 NFEs for both inversion and generation, whereas iGCT computes the noise latent in a single step, highlighting its potential for real-time image editing.
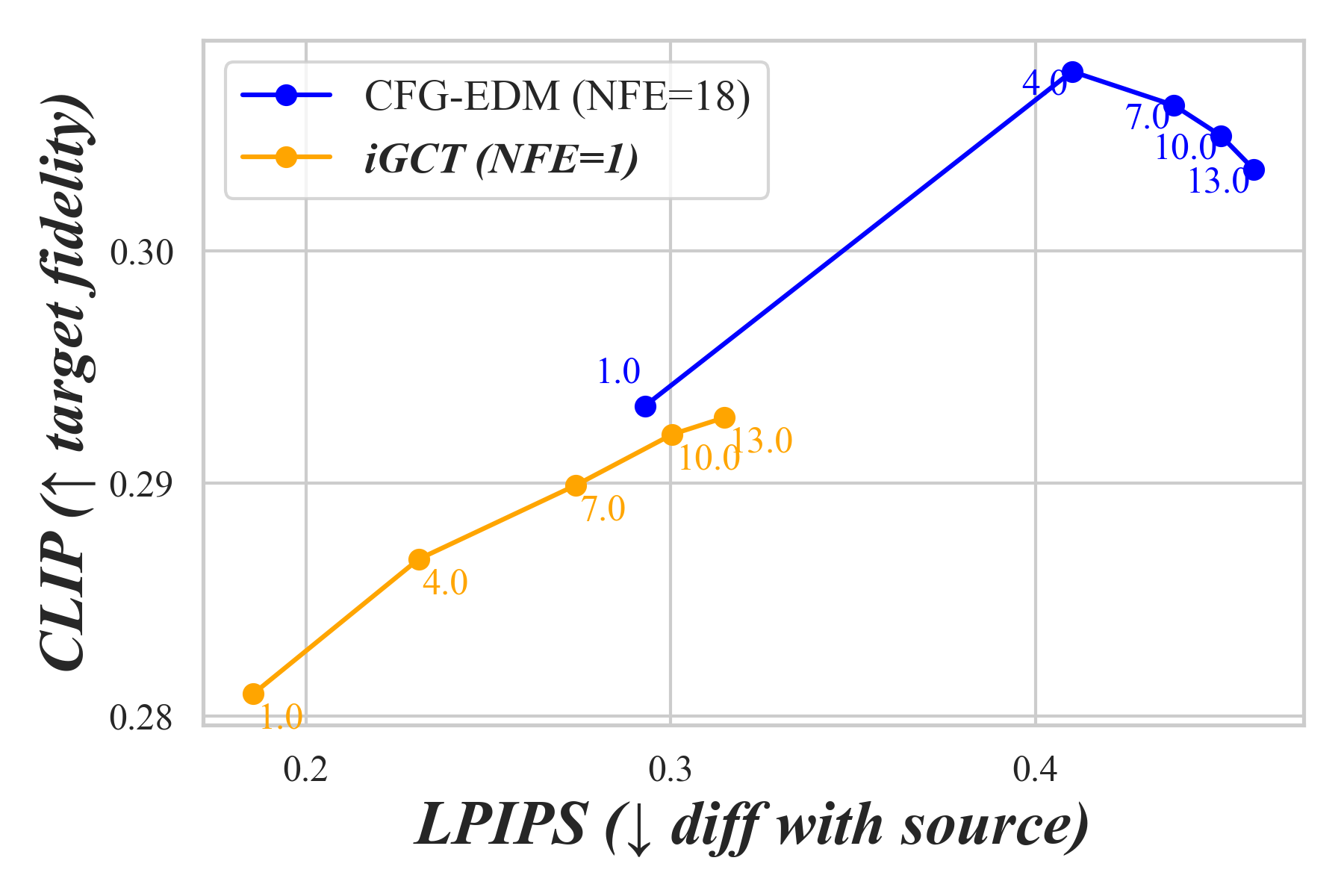
For CIFAR-10, we perform cross-class editing by transforming a source image into each target class. With LPIPS, edits are evaluated by measuring how much feature is preserved from the source. With CLIP, we measure the edit’s alignment with the target prompt ”a photo of a ”. We average LPIPS and CLIP scores across edits for each and plot the metrics for both iGCT and the baseline in 2D, illustrating the effects of guidance strength in image editing (Fig. 8). While EDM achieves a higher CLIP score, it alters the style of the original dataset and deviates from the source image. This shift makes the edited result less relevant to the original content, not to mention its cost in inversion and generation. iGCT presents strong potential for fast inversion-based editing by aligning source semantics well and achieving rapid edits in a single step.
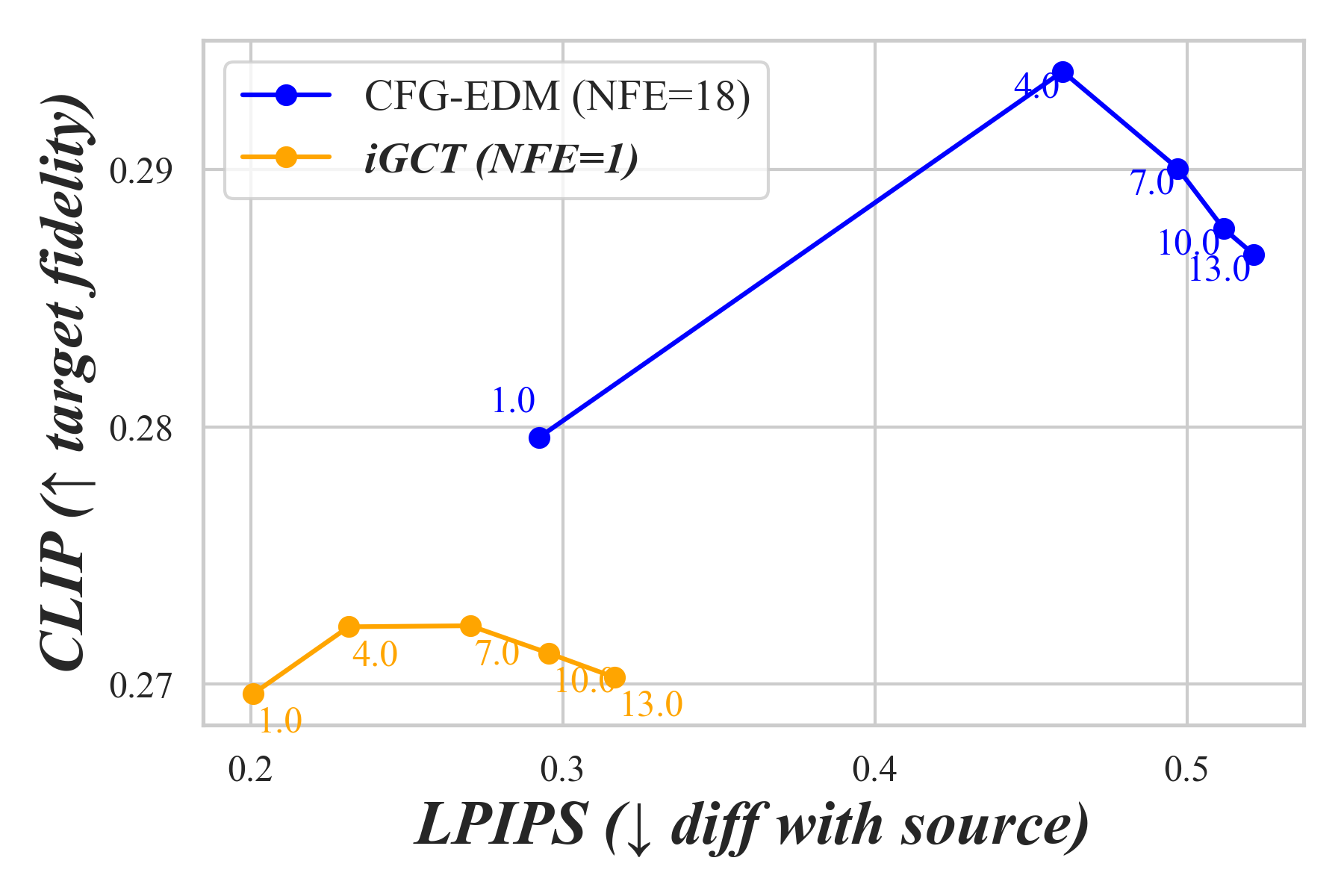
With 1,000 classes in ImageNet64, we evaluate cross-class editing within 6 predefined subgroups: automobiles, bears, cats, dogs, vegetables, and wild herbivores from the validation set. For image-editing within each subgroup, we chose 5 distinct classes, e.g., black bear is a class in the bears subgroup, and 50 images per class. Results are shown in Fig. 9, where LPIPS and CLIP scores are plotted on different for the editing tasks. Similar to findings on CIFAR-10, CFG drastically alters the style and semantics of the source image under high guidance. In contrast, iGCT aligns essential features with both the source and target classes.


5 Conclusion and Limitation
Our proposed iGCT reduces color saturation and artifacts at high guidance levels, offering a data-driven solution for guided image generation in CMs without relying on DMs. We also introduce a novel noiser component for efficient image-to-noise mapping, that also enhances the alignment between edited and source images in image editing compared to naive DDIM.
However, iGCT faces several limitations that warrant further exploration. The performance on ImageNet64, for instance, falls short of existing approaches. Additionally, the theory for guided consistency training remains intuitive and informal. Establishing a theoretical mathematical formulation would help clarify why it outperforms alternatives like CFG. Addressing these areas in future work would solidify the method’s contributions and open new research directions in this domain.
Impact Statement
The societal implications of this work are largely positive, as it contributes to creative industries, education, and research. However, as with any image generation technology, there is a risk of misuse, such as the creation of misleading or harmful content. We encourage the responsible use of this technology and emphasize the importance of ethical considerations in its deployment.
In summary, while our work primarily aims to advance the field of machine learning, we acknowledge the broader societal implications and encourage ongoing dialogue about the ethical use of image generation technologies.
References
- Arjovsky & Bottou (2017) Arjovsky, M. and Bottou, L. Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862, 2017.
- Avrahami et al. (2022) Avrahami, O., Lischinski, D., and Fried, O. Blended diffusion for text-driven editing of natural images. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, June 2022. doi: 10.1109/cvpr52688.2022.01767. URL http://dx.doi.org/10.1109/CVPR52688.2022.01767.
- Bar-Tal et al. (2023) Bar-Tal, O., Yariv, L., Lipman, Y., and Dekel, T. Multidiffusion: Fusing diffusion paths for controlled image generation, 2023. URL https://arxiv.org/abs/2302.08113.
- Bashkirova et al. (2023) Bashkirova, D., Lezama, J., Sohn, K., Saenko, K., and Essa, I. Masksketch: Unpaired structure-guided masked image generation, 2023. URL https://arxiv.org/abs/2302.05496.
- Bradley & Nakkiran (2024) Bradley, A. and Nakkiran, P. Classifier-free guidance is a predictor-corrector, 2024. URL https://arxiv.org/abs/2408.09000.
- Brock et al. (2019) Brock, A., Donahue, J., and Simonyan, K. Large scale gan training for high fidelity natural image synthesis, 2019. URL https://arxiv.org/abs/1809.11096.
- Chrabaszcz et al. (2017) Chrabaszcz, P., Loshchilov, I., and Hutter, F. A downsampled variant of imagenet as an alternative to the cifar datasets, 2017. URL https://arxiv.org/abs/1707.08819.
- Dhariwal & Nichol (2021) Dhariwal, P. and Nichol, A. Diffusion models beat gans on image synthesis, 2021. URL https://arxiv.org/abs/2105.05233.
- Dieleman (2022) Dieleman, S. Guidance: a cheat code for diffusion models, 2022. URL https://benanne.github.io/2022/05/26/guidance.html.
- Dong et al. (2023) Dong, W., Xue, S., Duan, X., and Han, S. Prompt tuning inversion for text-driven image editing using diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7430–7440, 2023.
- Garibi et al. (2024) Garibi, D., Patashnik, O., Voynov, A., Averbuch-Elor, H., and Cohen-Or, D. Renoise: Real image inversion through iterative noising. arXiv preprint arXiv:2403.14602, 2024.
- Geng et al. (2024) Geng, Z., Luo, W., Pokle, A., and Kolter, Z. Consistency models made easy, 2024. URL https://gsunshine.notion.site/Consistency-Models-Made-Easy-954205c0b4a24c009f78719f43b419cc?pvs=4.
- Goodfellow et al. (2014) Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial networks, 2014. URL https://arxiv.org/abs/1406.2661.
- Gulrajani et al. (2017) Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. C. Improved training of wasserstein gans. Advances in neural information processing systems, 30, 2017.
- Han et al. (2024) Han, L., Wen, S., Chen, Q., Zhang, Z., Song, K., Ren, M., Gao, R., Stathopoulos, A., He, X., Chen, Y., et al. Proxedit: Improving tuning-free real image editing with proximal guidance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 4291–4301, 2024.
- He et al. (2015) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385.
- Heek et al. (2024) Heek, J., Hoogeboom, E., and Salimans, T. Multistep consistency models. arXiv preprint arXiv:2403.06807, 2024.
- Ho & Salimans (2022) Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. (2020) Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models, 2020. URL https://arxiv.org/abs/2006.11239.
- Ho et al. (2022) Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D. P., Poole, B., Norouzi, M., Fleet, D. J., and Salimans, T. Imagen video: High definition video generation with diffusion models, 2022. URL https://arxiv.org/abs/2210.02303.
- Hu et al. (2024) Hu, M., Zhu, M., Zhou, X., Yan, Q., Li, S., Liu, C., and Chen, Q. Efficient text-driven motion generation via latent consistency training, 2024. URL https://arxiv.org/abs/2405.02791.
- Huang et al. (2023) Huang, L., Chen, D., Liu, Y., Shen, Y., Zhao, D., and Zhou, J. Composer: Creative and controllable image synthesis with composable conditions, 2023. URL https://arxiv.org/abs/2302.09778.
- Huberman-Spiegelglas et al. (2024) Huberman-Spiegelglas, I., Kulikov, V., and Michaeli, T. An edit friendly ddpm noise space: Inversion and manipulations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12469–12478, 2024.
- Karras et al. (2018) Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation, 2018. URL https://arxiv.org/abs/1710.10196.
- Karras et al. (2019) Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks, 2019. URL https://arxiv.org/abs/1812.04948.
- Karras et al. (2020) Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., and Aila, T. Training generative adversarial networks with limited data, 2020. URL https://arxiv.org/abs/2006.06676.
- Karras et al. (2021) Karras, T., Aittala, M., Laine, S., Härkönen, E., Hellsten, J., Lehtinen, J., and Aila, T. Alias-free generative adversarial networks. In Proc. NeurIPS, 2021.
- Karras et al. (2022) Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. Advances in Neural Information Processing Systems, 35:26565–26577, 2022.
- Karras et al. (2024a) Karras, T., Aittala, M., Kynkäänniemi, T., Lehtinen, J., Aila, T., and Laine, S. Guiding a diffusion model with a bad version of itself. arXiv preprint arXiv:2406.02507, 2024a.
- Karras et al. (2024b) Karras, T., Aittala, M., Kynkäänniemi, T., Lehtinen, J., Aila, T., and Laine, S. Guiding a diffusion model with a bad version of itself, 2024b. URL https://arxiv.org/abs/2406.02507.
- Karras et al. (2024c) Karras, T., Aittala, M., Lehtinen, J., Hellsten, J., Aila, T., and Laine, S. Analyzing and improving the training dynamics of diffusion models, 2024c. URL https://arxiv.org/abs/2312.02696.
- Kendall et al. (2018) Kendall, A., Gal, Y., and Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7482–7491, 2018.
- Kim et al. (2024) Kim, B., Kim, J., Kim, J., and Ye, J. C. Generalized consistency trajectory models for image manipulation. arXiv preprint arXiv:2403.12510, 2024.
- Kim et al. (2023) Kim, D., Lai, C.-H., Liao, W.-H., Murata, N., Takida, Y., Uesaka, T., He, Y., Mitsufuji, Y., and Ermon, S. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. arXiv preprint arXiv:2310.02279, 2023.
- Kingma & Ba (2017) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980.
- Krizhevsky (2012) Krizhevsky, A. Learning multiple layers of features from tiny images. University of Toronto, 05 2012.
- Kynkäänniemi et al. (2024) Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., and Lehtinen, J. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. arXiv preprint arXiv:2404.07724, 2024.
- Kynkäänniemi et al. (2019) Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. Improved precision and recall metric for assessing generative models, 2019. URL https://arxiv.org/abs/1904.06991.
- Kynkäänniemi et al. (2024) Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., and Lehtinen, J. Applying guidance in a limited interval improves sample and distribution quality in diffusion models, 2024. URL https://arxiv.org/abs/2404.07724.
- Lee et al. (2025) Lee, S., Xu, Y., Geffner, T., Fanti, G., Kreis, K., Vahdat, A., and Nie, W. Truncated consistency models, 2025. URL https://arxiv.org/abs/2410.14895.
- Li & He (2024) Li, L. and He, J. Bidirectional consistency models. arXiv preprint arXiv:2403.18035, 2024.
- Li et al. (2023) Li, S., van de Weijer, J., Hu, T., Khan, F. S., Hou, Q., Wang, Y., and Yang, J. Stylediffusion: Prompt-embedding inversion for text-based editing. arXiv preprint arXiv:2303.15649, 2023.
- Lin et al. (2023) Lin, C.-H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.-Y., and Lin, T.-Y. Magic3d: High-resolution text-to-3d content creation, 2023. URL https://arxiv.org/abs/2211.10440.
- Liu et al. (2019) Liu, S., Liang, Y., and Gitter, A. Loss-balanced task weighting to reduce negative transfer in multi-task learning. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pp. 9977–9978, 2019.
- Lu & Song (2024) Lu, C. and Song, Y. Simplifying, stabilizing and scaling continuous-time consistency models, 2024. URL https://arxiv.org/abs/2410.11081.
- Lu et al. (2022) Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps, 2022. URL https://arxiv.org/abs/2206.00927.
- Lu et al. (2023) Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models, 2023. URL https://arxiv.org/abs/2211.01095.
- Luo et al. (2023) Luo, S., Tan, Y., Huang, L., Li, J., and Zhao, H. Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378, 2023.
- Meng et al. (2022) Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.-Y., and Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations, 2022. URL https://arxiv.org/abs/2108.01073.
- Meng et al. (2023) Meng, C., Rombach, R., Gao, R., Kingma, D., Ermon, S., Ho, J., and Salimans, T. On distillation of guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14297–14306, June 2023.
- Metz et al. (2016) Metz, L., Poole, B., Pfau, D., and Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv preprint arXiv:1611.02163, 2016.
- Miyake et al. (2023) Miyake, D., Iohara, A., Saito, Y., and Tanaka, T. Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models. arXiv preprint arXiv:2305.16807, 2023.
- Mokady et al. (2023) Mokady, R., Hertz, A., Aberman, K., Pritch, Y., and Cohen-Or, D. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6038–6047, 2023.
- Mou et al. (2023) Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y., and Qie, X. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models, 2023. URL https://arxiv.org/abs/2302.08453.
- Ni et al. (2023) Ni, H., Shi, C., Li, K., Huang, S. X., and Min, M. R. Conditional image-to-video generation with latent flow diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18444–18455, 2023.
- Nichol & Dhariwal (2021) Nichol, A. and Dhariwal, P. Improved denoising diffusion probabilistic models, 2021. URL https://arxiv.org/abs/2102.09672.
- Park et al. (2024) Park, Y.-H., Lai, C.-H., Hayakawa, S., Takida, Y., and Mitsufuji, Y. Jump Your Steps: Optimizing sampling schedule of discrete diffusion models, 2024. URL https://arxiv.org/abs/2410.07761.
- Podell et al. (2023) Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., and Rombach, R. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URL https://arxiv.org/abs/2307.01952.
- Rombach et al. (2022) Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
- Saharia et al. (2022) Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S. K. S., Ayan, B. K., Mahdavi, S. S., Lopes, R. G., Salimans, T., Ho, J., Fleet, D. J., and Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding, 2022. URL https://arxiv.org/abs/2205.11487.
- Salimans & Ho (2022) Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models, 2022. URL https://arxiv.org/abs/2202.00512.
- Song et al. (2022) Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models, 2022. URL https://arxiv.org/abs/2010.02502.
- Song & Dhariwal (2023) Song, Y. and Dhariwal, P. Improved techniques for training consistency models. arXiv preprint arXiv:2310.14189, 2023.
- Song & Ermon (2020) Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution, 2020. URL https://arxiv.org/abs/1907.05600.
- Song et al. (2021) Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations, 2021. URL https://arxiv.org/abs/2011.13456.
- Song et al. (2023) Song, Y., Dhariwal, P., Chen, M., and Sutskever, I. Consistency models. arXiv preprint arXiv:2303.01469, 2023.
- Starodubcev et al. (2024) Starodubcev, N., Khoroshikh, M., Babenko, A., and Baranchuk, D. Invertible consistency distillation for text-guided image editing in around 7 steps. arXiv preprint arXiv:2406.14539, 2024.
- Wallace et al. (2023) Wallace, B., Gokul, A., and Naik, N. Edict: Exact diffusion inversion via coupled transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22532–22541, 2023.
- Yang et al. (2023) Yang, S., Xiao, W., Zhang, M., Guo, S., Zhao, J., and Shen, F. Image data augmentation for deep learning: A survey, 2023. URL https://arxiv.org/abs/2204.08610.
- Zhang et al. (2023) Zhang, L., Rao, A., and Agrawala, M. Adding conditional control to text-to-image diffusion models, 2023. URL https://arxiv.org/abs/2302.05543.
- Zheng et al. (2023) Zheng, K., Lu, C., Chen, J., and Zhu, J. Dpm-solver-v3: Improved diffusion ode solver with empirical model statistics. Advances in Neural Information Processing Systems, 36:55502–55542, 2023.
Our Appendix is organized as follows. First, we present the pseudocode for the key components of iGCT. We also include the proof for unit variance and boundary conditions in preconditioning iGCT’s noiser. Next, we detail the training setups for our CIFAR-10 and ImageNet64 experiments. Additionally, we provide ablation studies on using guided synthesized images as data augmentation in image classification. Finally, we present more uncurated results comparing iGCT and CFG-EDM on inversion, editing and guidance, thoroughly of iGCT.
Appendix A Pseudocode for iGCT
iGCT is trained under a continuous-time scheduler similar to the one proposed by ECT (Geng et al., 2024). Our noise sampling function follows a lognormal distribution, , with and . At training, the sampled noise is clamped at and . Step function , is used to compute the step size from the sampled noise , with being the current training iteration and the number of iterations for halfing , and is a sigmoid adjusting function.
In Guided Consistency Training, the guidance mask function determines whether the sampled noise should be supervised for guidance training. With probability , the update is directed towards the target sample ; otherwise, no guidance is applied. In practice, is higher in noisier regions and zero in low-noise regions,
| (A1) |
where and . For the range of guidance strength, we set and . Guidance strengths are sampled uniformly at training, with means no guidance applied.
A noiser trained under Inverse Consistency Training maps an image to its latent noise in a single step. In contrast, DDIM Inversion requires multiple steps with a diffusion model to accurately produce an image’s latent representation. Since the boundary signal is reversed, spreading from down to , we design the importance weighting function to emphasize higher noise regions, defined as:
| (A2) |
where the step size is proportional to the sampled noise level , and is a constant that normalizes the scale of the inversion loss. The noise sampling function and the step function used in computing both and are the same.
Together, iGCT jointly optimizes the two consistency objectives , and aligns the noiser and denoiser via a reconstruction loss, . To improve training efficiency, is computed every , reducing the computational cost of back-propagation through both the weights of the denoiser and the noiser . Alg. 3 provides an overview of iGCT.
Appendix B Preconditioning for Noiser
We define
| (A3) |
where , , and . This setup naturally serves as a boundary condition. Specifically:
-
•
When ,
(A4) emphasizing that the model’s noise prediction dominates the residual information given a relatively clean sample.
-
•
When ,
(A5) satisfying the condition that outputs at the maximum time step.
We show that these preconditions ensure unit variance for the model’s input and target. First, , so setting normalizes the input variance to 1. Second, we require the training target to have unit variance. Given the noise target for is , by moving of terms, the effective target for can be written as,
| (A6) |
When , , we verify that target is unit variance,
| (A7) | ||||
Appendix C Baselines & Training Details
For our diffusion model baseline, we follow EDM’s official repository (https://github.com/NVlabs/edm) instructions for training and set label_dropout to 0.1 to optimize a CFG (classifier-free guided) DM. We will use this DM as the teacher model for our consistency model baseline via consistency distillation.
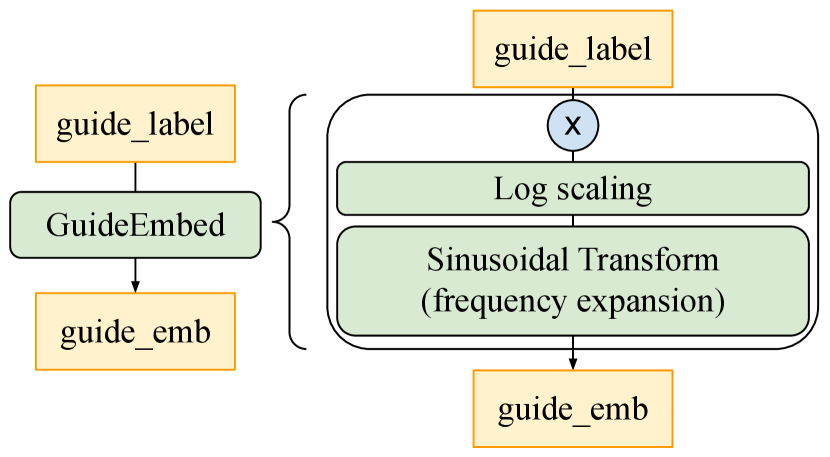
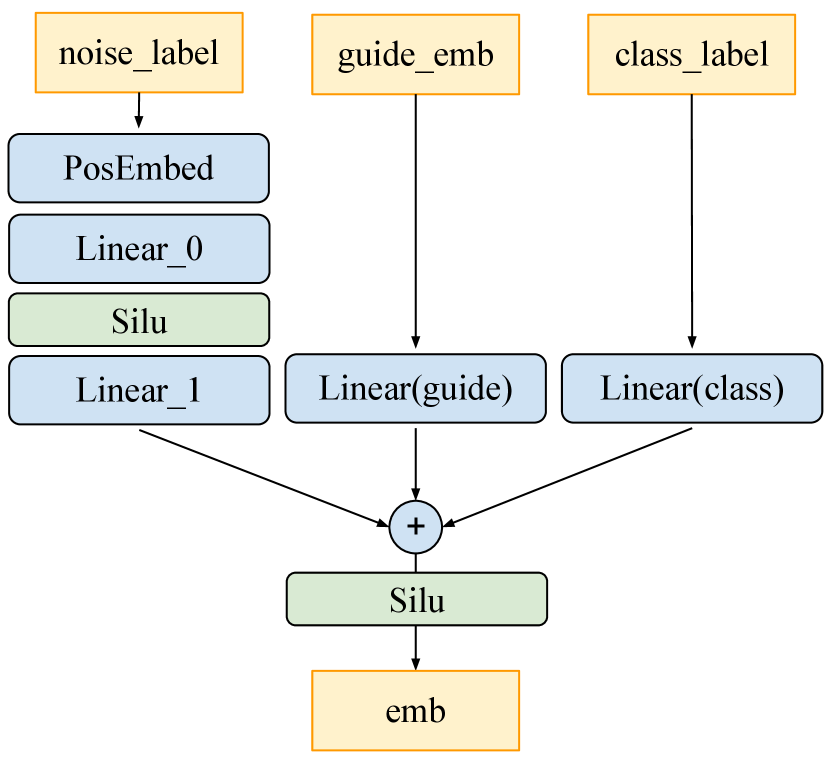
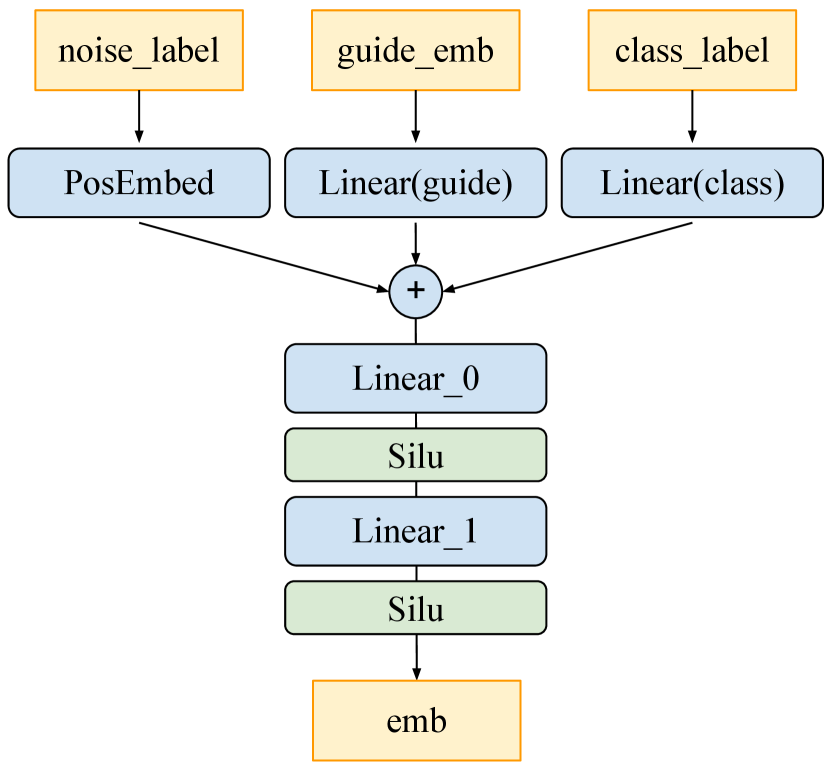
The consistency model baseline Guided CD is trained with a discrete-time schedule. We set the discretization steps and use a Heun ODE solver to predict update directions based on the CFG EDM, as in (Song et al., 2023). Following (Luo et al., 2023), we modify the model’s architecture and iGCT’s denoiser to accept guidance strength by adding an extra linear layer. See the detailed architecture design for guidance conditioning of consistency model in Fig. A1. A range of guidance scales is uniformly sampled at training. Following (Song & Dhariwal, 2023), we replace LPIPS by Pseudo-Huber loss, with determining the breadth of the smoothing section between L1 and L2. See Table A1 for a summary of the training configurations for our baseline models.
| CIFAR-10 | ImageNet64 | ||
| EDM | Guided-CD | EDM | |
| Arch. config. | |||
| model arch. | NCSN++ | NCSN++ | ADM |
| channels mult. | 2,2,2 | 2,2,2 | 1,2,3,4 |
| UNet size | 56.4M | 56.4M | 295.9M |
| Training config. | |||
| lr | 1e-3 | 4e-4 | 2e-4 |
| batch | 512 | 512 | 4096 |
| dropout | 0.13 | 0 | 0.1 |
| label dropout | 0.1 | (n.a.) | 0.1 |
| loss | L2 | Huber | L2 |
| training iterations | 390k | 800k | 800K |
| CIFAR-10 | ImageNet64 | |
| iGCT | iGCT | |
| Arch. config. | ||
| model arch. | NCSN++ | ADM |
| channels mult. | 2,2,2 | 1,2,2,3 |
| UNet size | 56.4M | 182.4M |
| Total size | 112.9M | 364.8M |
| Training config. | ||
| lr | 1e-4 | 1e-4 |
| batch | 1024 | 1024 |
| dropout | 0.2 | 0.3 |
| loss | Huber | Huber |
| 0.03 | 0.06 | |
| 40k | 40k | |
| -1.1 | -1.1 | |
| 2.0 | 2.0 | |
| 2e-5 | 2e-5, ( 180k) 4e-5, ( 200k) 6e-5, ( 260k) | |
| 10 | 10 | |
| training iterations | 360k | 260k |

iGCT is trained with a continuous-time scheduler inspired by ECT (Geng et al., 2024). To rigorously assess its independence from diffusion-based models, iGCT is trained from scratch rather than fine-tuned from a pre-trained diffusion model. Consequently, the training curriculum begins with an initial diffusion training stage, followed by consistency training with the step size halved every iterations. In practice, we adopt the same noise sampling distribution , same step function , and same distance metric for both guided consistency training and inverse consistency training.
For CIFAR-10, iGCT adopts the same UNet architecture as the baseline models. However, the overall model size is doubled, as iGCT comprises two UNets: one for the denoiser and one for the noiser. The Pseudo-Huber loss is employed as the distance metric, with a constant parameter . Consistency training is organized into nine stages, each comprising 400k iterations with the step size halved from the last stage. We found that training remains stable when the reconstruction weight is fixed at throughout the entire training process.
For ImageNet64, iGCT employs a reduced ADM architecture (Dhariwal & Nichol, 2021) with smaller channel sizes to address computational constraints. A higher dropout rate and Pseudo-Huber loss with is used, following prior works (Geng et al., 2024; Song & Dhariwal, 2023). During our experiments, we observed that training on ImageNet64 is sensitive to the reconstruction weight. Keeping fixed throughout training leads to inversion collapse, with significant signal leaked to the latent noise (see Fig. A2). We found that increasing to at iteration 1800 and to at iteration 2000 effectively stabilizes training and prevents collapse. This suggests that the reconstruction loss serves as a regularizer for iGCT. Additionally, we observed diminishing returns when training exceeded 240k iterations, leading us to stop at 260k iterations for our experiments. These findings indicate that alternative training strategies, such as framing iGCT as a multi-task learning problem (Kendall et al., 2018; Liu et al., 2019), and conducting a more sophisticated analysis of loss weighting, may be necessary to enhance stability and improve convergence. See Table A2 for a summary of the training configurations for iGCT.
| Methods | A100 (40G) GPU hours |
| CFG-EDM (Karras et al., 2022) | 312 |
| Guided-CD (Song et al., 2023) | 3968 |
| iGCT (ours) | 2032 |
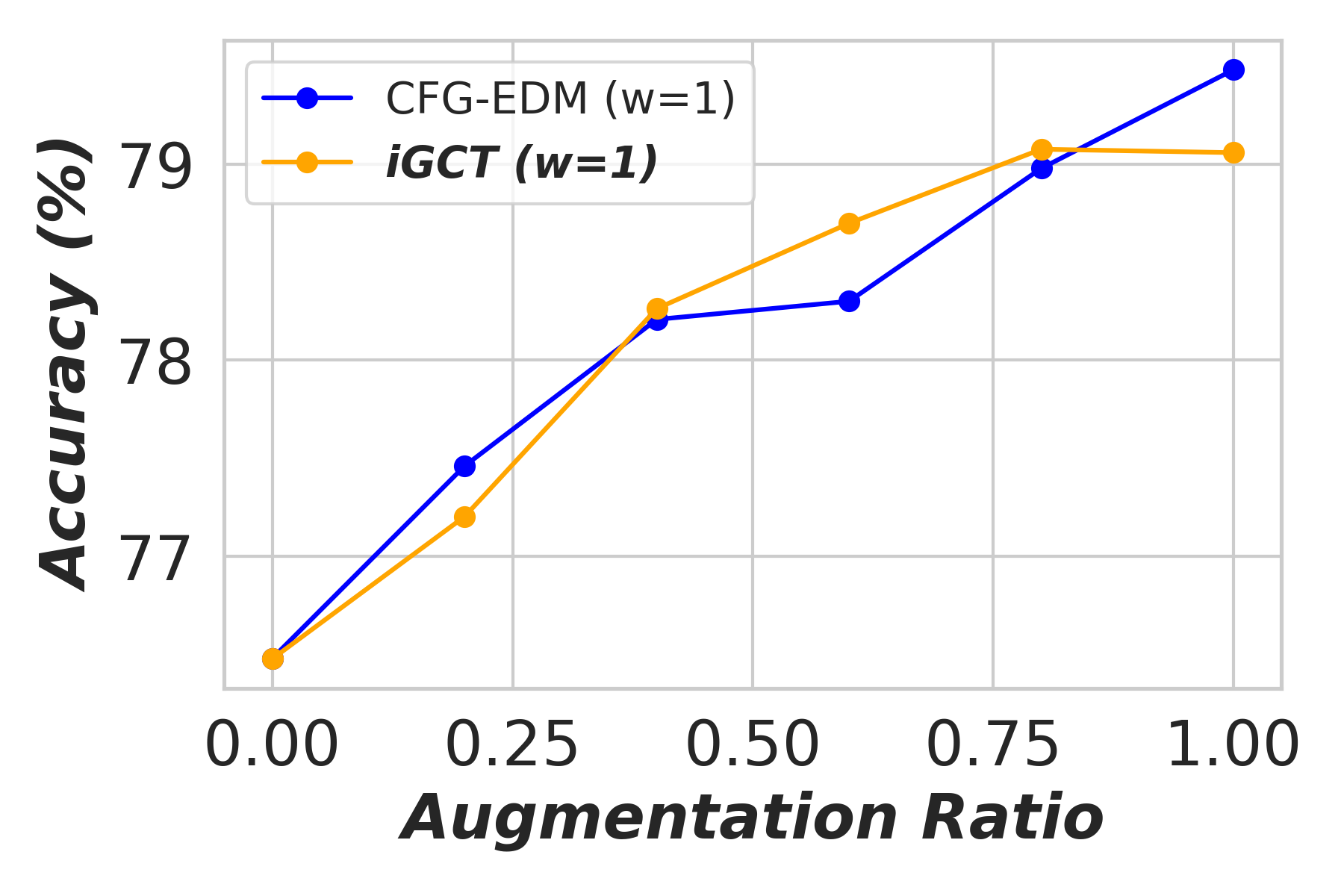
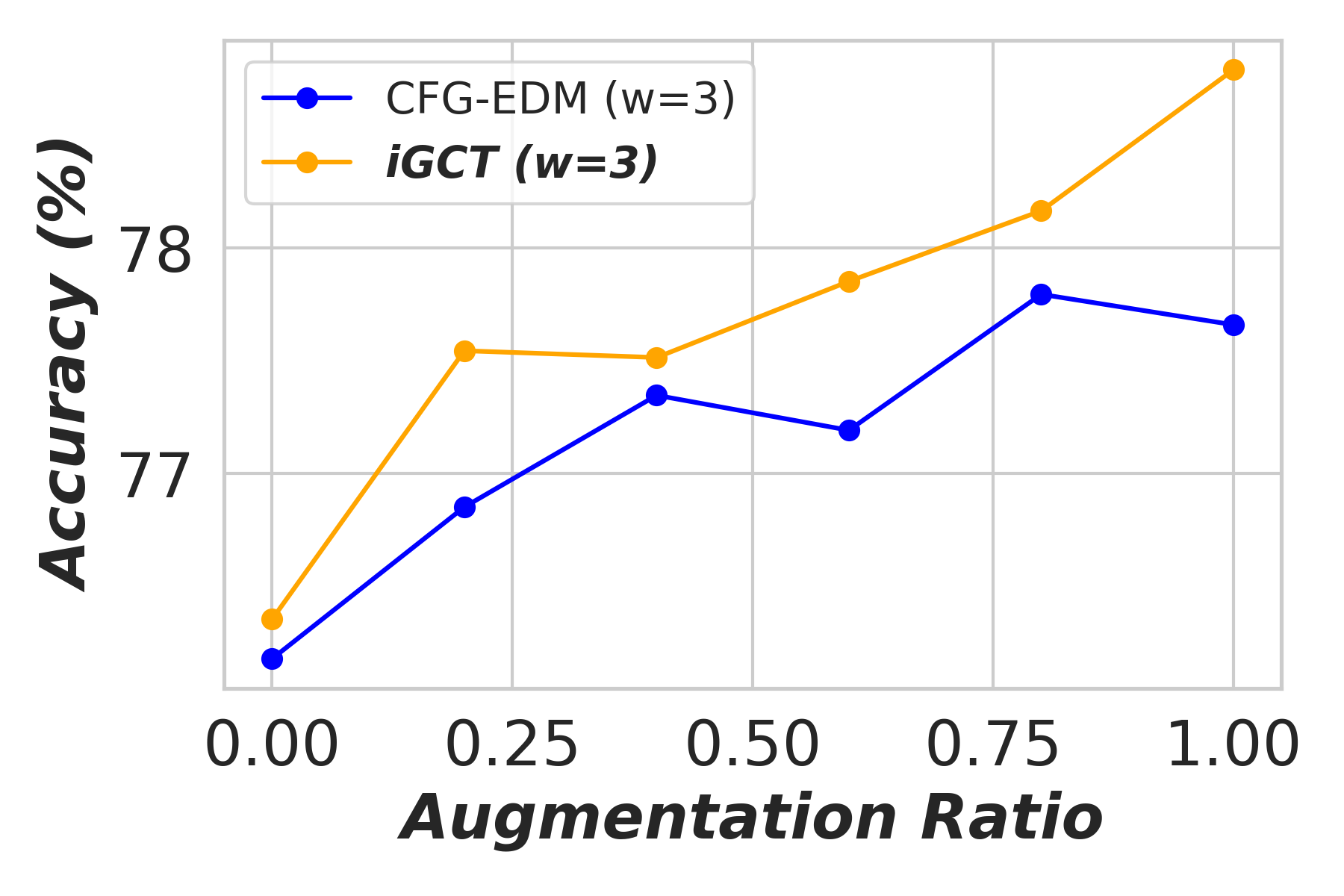
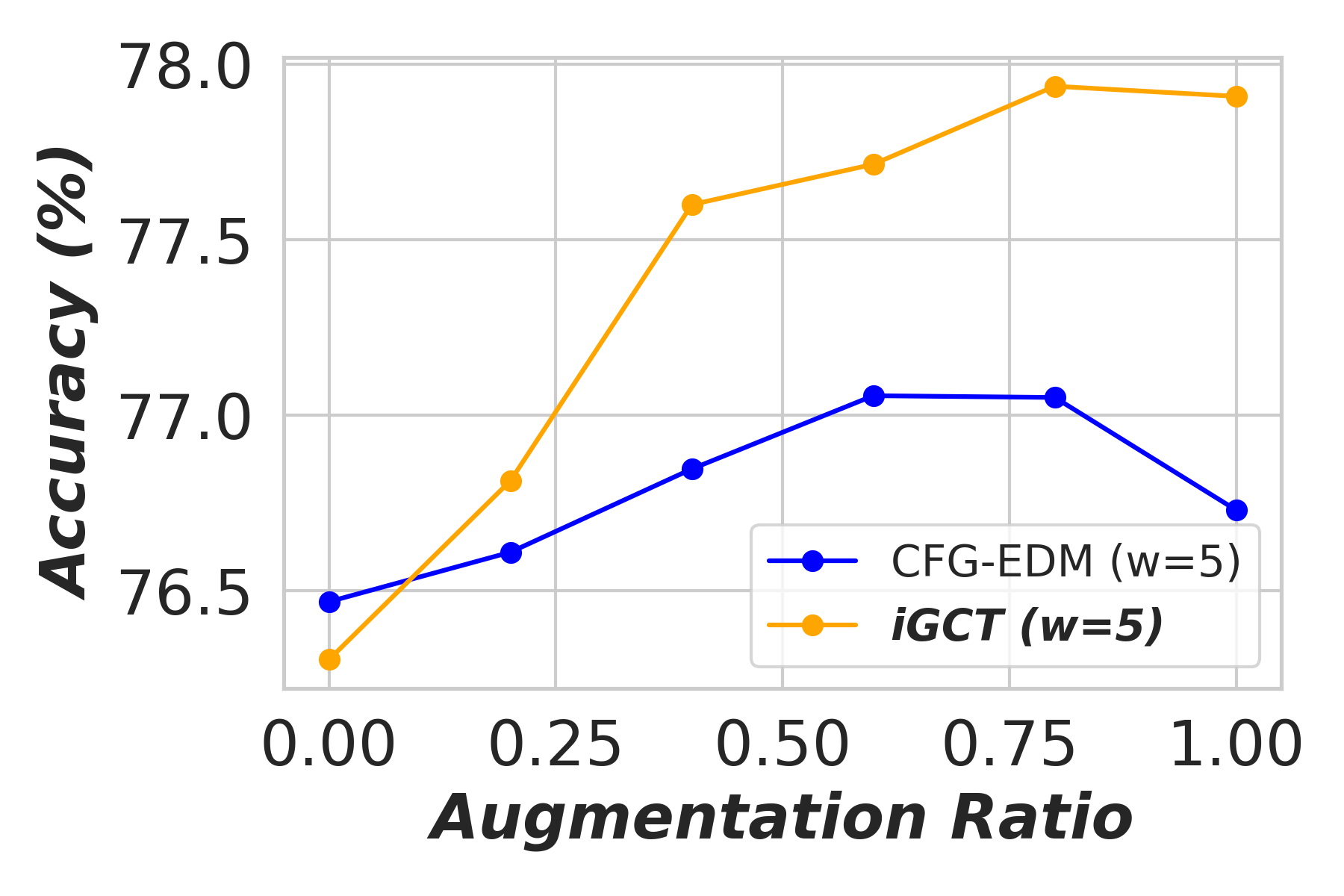
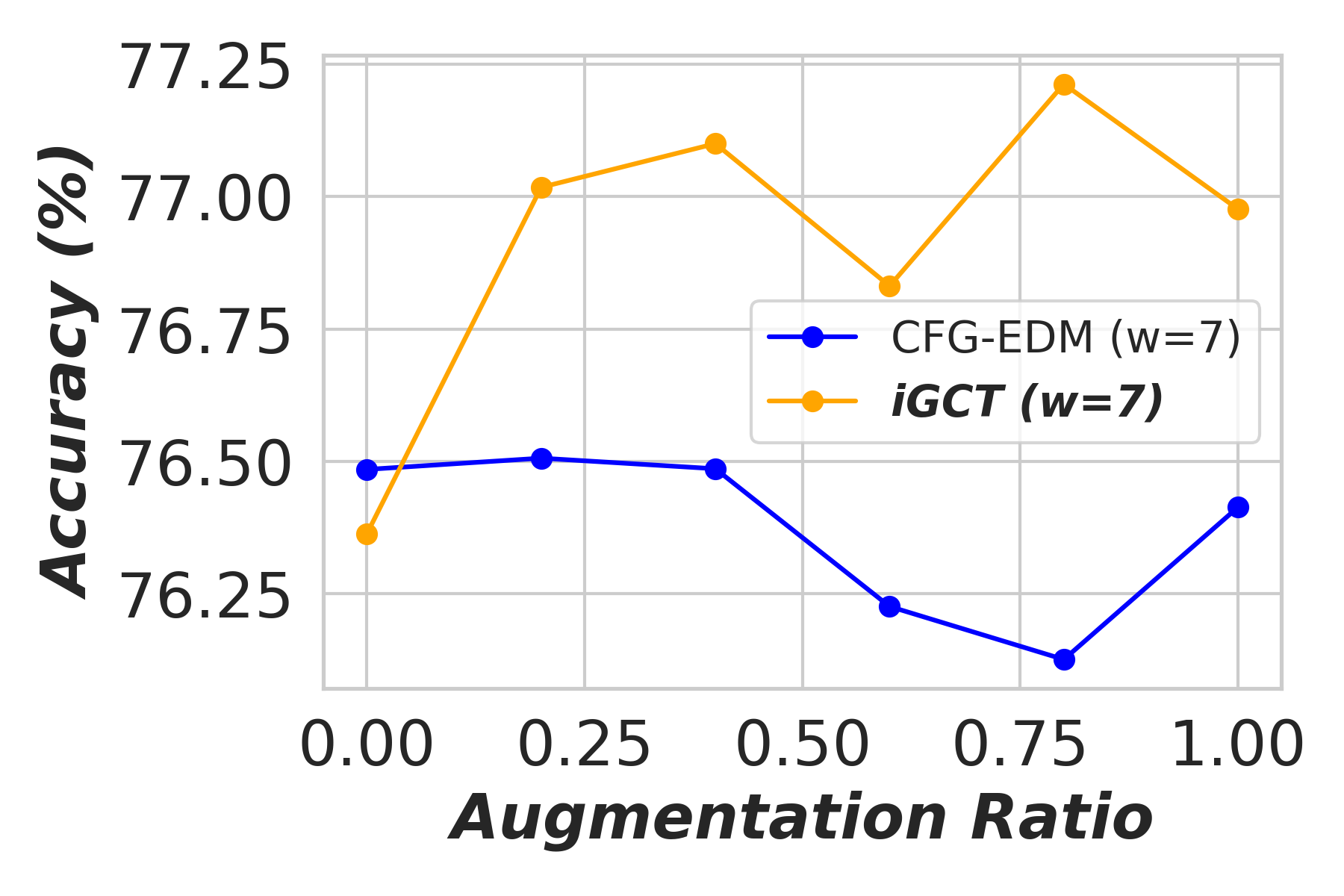
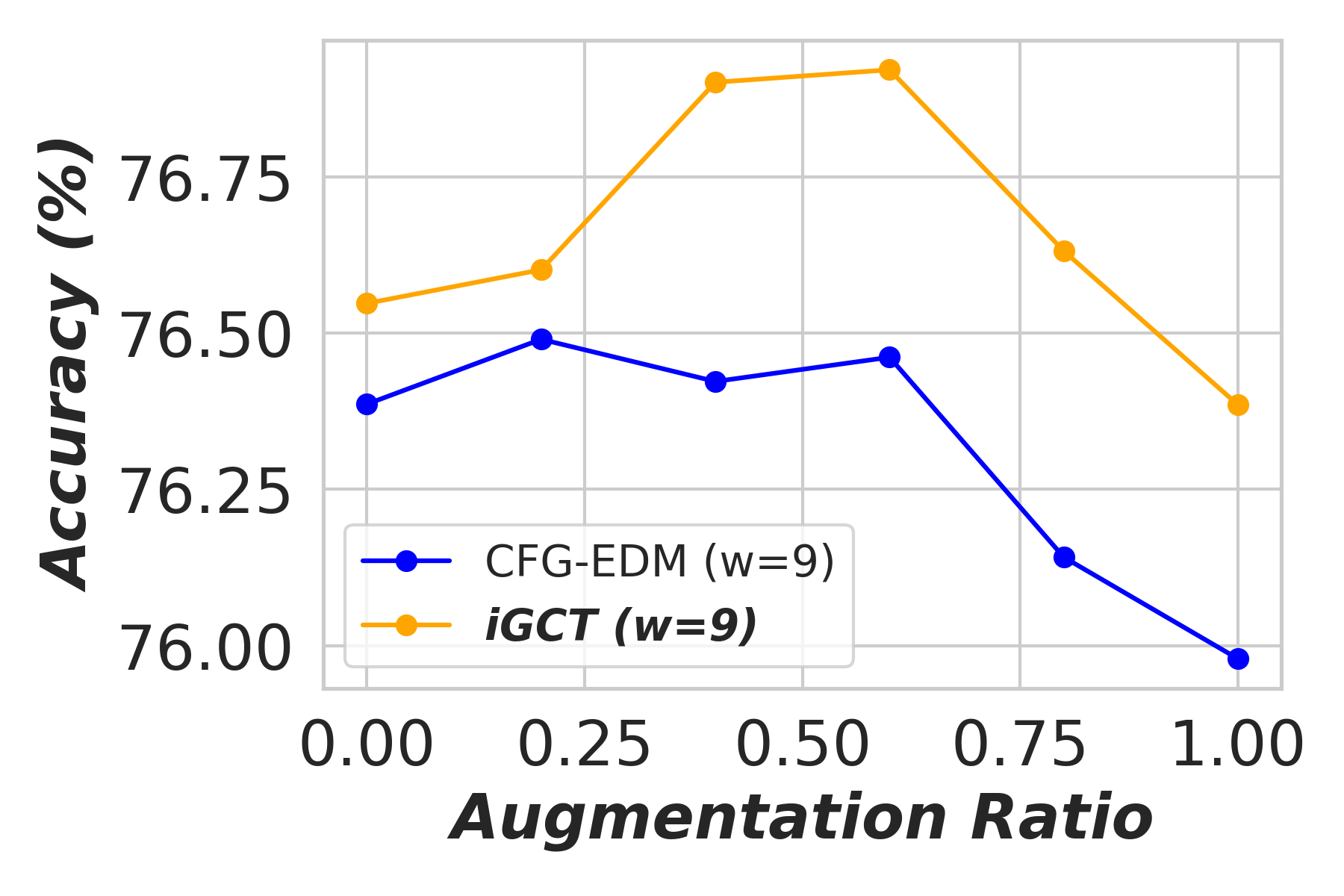
Appendix D Application: Data Augmentation Under Different Guidance
In this section, we show the effectiveness of data augmentation with diffusion-based models, CFG-EDM and iGCT, across varying guidance scales for image classification on CIFAR-10 (Krizhevsky, 2012). High quality data augmentation has been shown to enhance classification performance (Yang et al., 2023). Under high guidance, augmentation data generated from iGCT consistently improves accuracy. Conversely, augmentation data synthesized from CFG-EDM offers only limited gains. We describe the ratios of real to synthesized data, the classifier architecture, and the training setup in the following.
Training Details. We conduct classification experiments trained on six different mixtures of augmented data synthesized by iGCT and CFG-EDM: , , , , and . The ratio represents . For example, indicates that the training and validation sets contain only 50k of real samples from CIFAR-10, and includes 50k real and 10k synthesized samples. In terms of guidance scales, we choose to synthesize the augmented data using iGCT and CFG-EDM. The augmented dataset is split 80/20 for training and validation. For testing, the model is evaluated on the CIFAR-10 test set with 10k samples and ground truth labels.
The standard ResNet-18 (He et al., 2015) is used to train on all different augmented datasets. All models are trained for 250 epochs, with batch size 64, using an Adam optimizer (Kingma & Ba, 2017). For each augmentation dataset, we train the model six times under different seeds and report the average classification accuracy.
Results. The classifier’s accuracy, trained on augmented data synthesized by CFG-EDM and iGCT, is shown in Fig. A3. With (no guidance), both iGCT and CFG-EDM provide comparable performance boosts. As guidance scale increases, iGCT shows more significant improvements than CFG-EDM. At high guidance and augmentation ratios, performance drops, but this effect occurs later for iGCT (e.g., at augmentation and ), while CFG-EDM stops improving accuracy at . This experiment highlights the importance of high-quality data under high guidance, with iGCT outperforming CFG-EDM in data quality.
Appendix E Uncurated Results
In this section, we present additional qualitative results to highlight the performance of our proposed iGCT method compared to the multi-step EDM baseline. These visualizations include both inversion and guidance tasks across the CIFAR-10 and ImageNet64 datasets. The results demonstrate iGCT’s ability to maintain competitive quality with significantly fewer steps and minimal artifacts, showcasing the effectiveness of our approach.
E.1 Inversion Results
We provide additional visualization of the latent noise on both CIFAR-10 and ImageNet64 datasets. Fig. LABEL:fig:CIFAR-10_inversion_reconstruction and Fig. LABEL:fig:im64_inversion_reconstruction compare our 1-step iGCT with the multi-step EDM on inversion and reconstruction.
E.2 Editing Results
E.3 Guidance Results
In Section 4.1, we demonstrated that iGCT provides a guidance solution without introducing the high-contrast artifacts commonly observed in CFG-based methods. Here, we present additional uncurated results on CIFAR-10 and ImageNet64. For CIFAR-10, iGCT achieves competitive performance compared to the baseline diffusion model, which requires multiple steps for generation. See Figs. A9–A18. For ImageNet64, although the visual quality of iGCT’s generated images falls slightly short of expectations, this can be attributed to the smaller UNet architecture used—only 61% of the baseline model size—and the need for a more robust training curriculum to prevent collapse, as discussed in Section C. Nonetheless, even at higher guidance levels, iGCT maintains style consistency, whereas CFG-based methods continue to suffer from pronounced high-contrast artifacts. See Figs. A19–A22.











































































