Beyond Ansätze: Learning Quantum Circuits
as Unitary Operators
Abstract
This paper explores the advantages of optimizing quantum circuits on wires as operators in the unitary group . We run gradient-based optimization in the Lie algebra and use the exponential map to parametrize unitary matrices. We argue that is not only more general than the search space induced by an ansatz, but in ways easier to work with on classical computers. The resulting approach is quick, ansatz-free and provides an upper bound on performance over all ansätze on wires.
1 Introduction
Quantum machine learning (QML) continues to be one of the most compelling application areas of quantum computing, particularly in the noisy, intermediate scale quantum (NISQ) era [Preskill, 2018]. The field has already seen a broad range of QML applications investigated, including image classification [Wilson et al., 2018; Adachi and Henderson, 2015], predicting quantum states associated with a one-dimensional symmetry-protected topological phase [Cong et al., 2019], election forecasting [Henderson et al., 2019], financial applications [Alcazar et al., 2019; Kashefi et al., 2020], synthetic weather modeling [Enos et al., 2021] or Earth observation [Henderson et al., 2020; Sebastianelli et al., 2021]. The unique properties of quantum computers powering QML applications are tested against classical algorithms, with the goal of observing higher accuracy, faster training, fewer required training samples, or other beneficial improvements.
While some QML applications have theoretical advantages over classical algorithms, empirically showing advantages on NISQ devices remains a challenge for several reasons. One issue is in optimal approaches for embedding classical data into QML devices, since noise can lead to incorrect, unstable outputs. Research into methods for determining which embeddings minimize the impact of this noise for particular problems offers an appealing approach forward [LaRose and Coyle, 2020]. Another problem is that of data dimensionality, as NISQ devices are extremely limited in qubit count compared to the typical dimensionality of input classical data. Various approaches to mitigate this limitation have been explored, including linear encoding a large amount of classical data into a few control parameters [Wilson et al., 2018], running the circuit on subsets of the entire input [Henderson et al., 2020, 2021], and re-uploading data using deeper circuits [Pérez-Salinas et al., 2019]. While there are additional obstacles in performing QML applications in practice, we finish with an extremely important one and the focus of this paper: dealing with circuit ansatz selection and training times.
The circuit ansatz is the structure of the quantum gates that comprise the quantum circuit, which fundamentally define the types of functions that the quantum circuit can compute; this is analogous to the types of layers that form the architecture of a neural network. The ansatz can be considered as an extra assumption on the form of the problem and usually comes from an educated guess. Finding good circuit ansätze which are effective on near term devices is extremely challenging for QML applications, as it is often unclear for various datasets how different circuit ansätze will perform. Additionally, once a circuit ansatz is chosen, it will typically have tunable parameters which need to be optimized in order to generate the best performance possible. Methods of parameter-shift rule have been developed and improved upon for calculating quantum gradients to update these parameters [Mitarai et al., 2018; Schuld et al., 2018], but the computational cost becomes extremely taxing even using state-of-the-art software implementations [Bergholm et al., 2020] as the problem size scales up. Ideally, better approaches for determining optimal circuit ansatz with hardware amenable structure and low numbers of variational parameters would be ideal.
This work focuses on a methodological approach which uses powerful machine learning libaries to try and learn the coefficients of unitary matrices. The goal is to provide an approach which can theoretically hone in on extremely good, problem-specific unitary mappings, that allow researchers to qucikly estimate the performance of QML applications without having to choose an ansatz. In Section 2, we walk through a more detailed account of current problems and solutions for selecting and training circuit ansatz for QML applications. In Section 3, we explain the approach laid out in this work, and show the performance of our approach compared to other best-in-class software in Section 4. Finally, in Section 5 we address ways in which this work may be extended and improved upon that could further benefit the QML research community.
2 Motivation
2.1 Existing quantum simulations are slow
While the future of quantum computation is in quantum computational hardware, the currently available hardware is expensive and accessibly limited; this is noted at the core reason for the work of Padilha et al. [2019], which is one of many advances in designing classical software simulators of quantum computational systems. While these quantum simulators allow the research community to experiment on toy problems, even the best simulators pose major problems for many QML applications.
Focusing in on the circuit ansatz challenge, we may consider on the application area of quantum chemistry. Within quantum chemistry, there are some some algorithms wherein “problem-inspired" circuit ansatz exists, but due to the current quantum computational hardware constraints, a “hardware efficient ansatz" is used instead. This is a practical compromise; a circuit ansatz which performs well in simulation but fits no current hardware may be traded off for a circuit ansatz which has a slew of theoretical problems but can be experimented with on NISQ devices.
QML applications in this sense have an extreme disadvantage: unlike quantum chemistry problems which are built on strong foundations, there are no known theoretical ansatz which work well on arbitrary machine learning problems. By their very nature, machine learning applications can have arbitrary datasets with patterns that do not match any clear physical model. In this case, there is no clear answer between “what does the ideal anstaz look like?" vs “what is close to the ideal we can fit on hardware?" but rather “what ansatz is useful on this particular dataset within this particular application?"
2.2 A quantum circuit is just a unitary transformation
The key observation that motivated this paper is that a quantum system of qubits can be described by a state vector in and every quantum circuit is a unitary transformation on this state space. This implies that every machine learning algorithm that optimizes a quantum circuit on wires can be viewed as a optimization process in (a subspace of) the space of -dimensional unitaries, denoted by . Note that this a fundamentally different from classical machine learning where the space of all possible networks is infinite dimensonal. In the quantum case, the unitary group has real dimension and allows to fully parametrize the possible quantum circuits on wires.
3 Unitary optimization
We want to perform gradient descent in the space of unitary matrices without having to choose an ansatz for the architecture. Such an approach would have the advantage of not losing any expressivity of the quantum network by constraining the optimization to a fixed architecture.
Moreover, directly optimizing the unitary enables the full use of differentiable programming frameworks. In particular, we can efficiently process batch of inputs in a single pass of the neural network and make use of GPUs for faster training.
3.1 Parametrizing via the Lie algebra
The Lie algebra of the unitary group is the space of skew-Hermitian matrices
This space is of real dimension . Moreover, since is connected and compact, the (matrix-)exponential map is surjective [Hall, 2015, Corollary 11.10], i.e. every unitary transformation can be written as the exponential of some skew-Hermitian .
Motivated by this result, we propose to parametrise the Lie algebra , and use the exponential map to obtain unitary transformations. Since the exponential map is differentiable, we can propagate gradients all the way back to the Lie algebra and do gradient based optimization there.
Note that is significantly eases the optimization process. The reason for this is that the Lie group of unitary transformations has non-trivial geometry and doing gradient descent is cumbersome on such spaces. On the other hand, the Lie algebra is a vector space, where gradient descent can shine.
Since PyTorch [Paszke et al., 2017] has built-in support both for complex-valued tensors and the matrix exponential, random unitary transformations can be generated with just a few lines of Python code:
Parametrising a unitary transformation on dimensions requires scalar parameters, and the dimension of an qubit system is . It follows that the use our approach on wires requires trainable parameters.
3.2 Reducing the parameter count
Since the dimension of the group of unitary transformations scales exponentially as we increase the number of qubits, it is impractical to optimize unitary operators on a large number of wires. Restraining to optimization to subsets of can ease this computational issue. One interesting subgroup is , i.e. applying one unitary to the first wires, and a second one to the last wires. This of course can be generalized by a different partitioning of the wires. For instance, consider the following alternatives:
-
•
Optimizing directly on qubits requires parameters to train.
-
•
Optimizing unitary operators on wires requires parameters. This, of course, does not allow any interaction between qubits belonging to different partitions. To overcome this, one could repeat the same procedure with a different partitioning of the wires into groups of size . Repeating this times results in trainable parameters, which only scales linearly in .
Working with subspaces of the unitary group in order to shrink the optimization space is an effective way of cutting the computational costs. It is important to note that every such reduction of the number of parameters (and in turn the search space) trades off generality for a computational speedup. Moreover, training speed is not a monotonically decreasing function of the parameter count, a large number of parameters may be faster if the resulting map is simple to compute (such as the exponential of a single skew-symmetric matrix) than a mapping with a lower parameter count but with a long chain of simple ingredients, that need to be composed every time the parameters change (such as a long ansatz).
3.3 Connection to circuits with a given ansatz
Taking the idea of the previous section to the extreme, we can recover the traditional approach of first choosing an ansatz of predefined quantum gates and optimizing their parameters. As an example, consider a two-qubit quantum system. Our approach would optimize the parameters generating the full unitary group :
| (1) |
where denotes the complex unit.
Now, let us restrict our attention to the ansatz with an RX-gate on the first wire and an RY-gate on the second one. Optimizing this circuit amounts to training resulting in the following family of unitaries:
| (2) |
Note that family of unitaries in (2) is a strict subset of the unitaries in (1), i.e. our method can find quantum circuits that the approach with a given ansatz would not be able to find. The price to pay for that is an increased number of parameters, a bigger search space to optimize in.
As with all ansätze, if there is a good reason to believe that the optimal circuit belongs to a certain subclass of unitaries, then it makes a lot of sense to to only consider functions that satisfy the ansatz. Otherwise, keeping the search space as big as possible (and practically still feasible) is a reasonable thing to do.
3.4 Bound on the performance of all ansätze
In the previous section we argued that an ansatz is equivalent to a particular restriction of the search space. Conversely, optimization over all unitaries is at least as general as any choice of ansatz, which in turn implies that the optimum of full unitary optimization represents the best possible quantum circuit that any ansatz could have found111Note that in practice life is more complicated. Local minima, gradient step size, etc. can have an effect on the optimization process. The statement here is simply that if a search space is contained in an other one, then the global optimum of the latter one cannot be worse than that of the first one.. To put it differently:
Theorem 1
Optimization in the full unitary group provides an upper bound on performance over all possible ansätze on wires.
This is particularly useful when trying to answer questions such as
Question 2
Given some machine learning task , is there a quantum circuit on wires that performs better than some predefined performance threshold ?
Whether is the performance of some classical approach (looking for quantum advantage) or not, our method separates these issues from the choice of an ansatz and provides a way to answer them easily. If the answer to a question such as Question 2 is affirmative, there is hope that a (simple) ansatz can also perform well on . Otherwise one doesn’t have to worry about ansätze as none of them will reach performance .
4 Experiments
4.1 Toy experiments
We compare our approach to PennyLane [Bergholm et al., 2020] by running the same training procedure (number of qubits, datapoints and training epochs) in both frameworks. The space of unitary transformations on qubits is dimensional. It follows that our PyTorch model contains trainable parameters. Accordingly, we initizalize a PennyLane model containing a single RandomLayer with trainable parameters.
In our experiments, we generate a classical dataset and use rotations to encode the classical data into a quantum representation, apply the quantum circuit and perform measurements on the wires to decode from the quantum to a classical representation. We are not interested in accuracy of the trained networks, only in training speed, so we just train the networks to learn the identity function.
Comparing to PennyLane
In the first experiment, the dataset is just 1 datapoint of some fixed dimension . We train for 10 epochs both in PennyLane and PyTorch and log the wall-clock time after every epoch. The results are plotted in Figure (1(a)). Our approach is significantly faster than PennyLane which we explain by the fact that our approach optimizes a single unitary matrix and does not have to compose exponentially many gates.
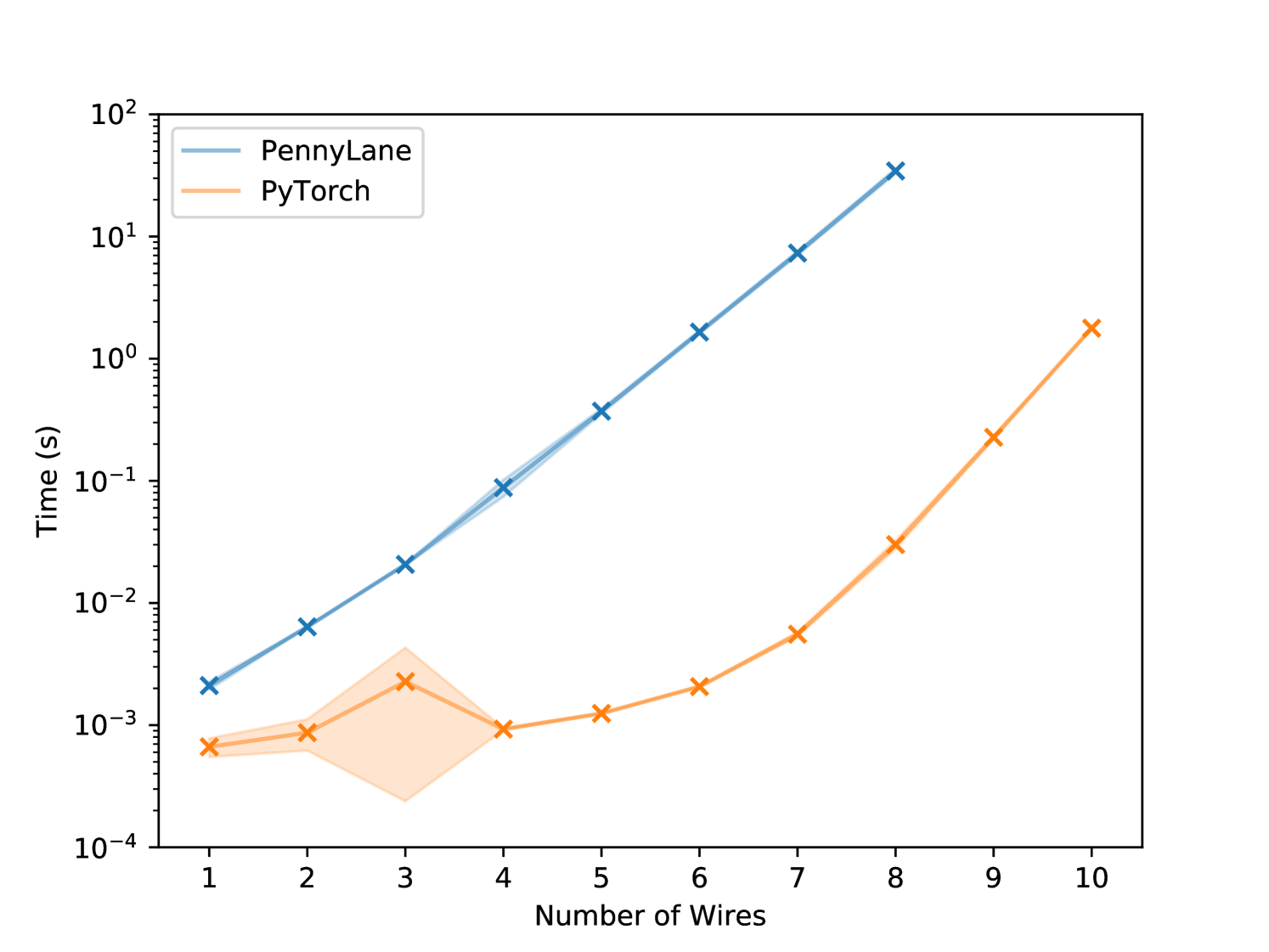
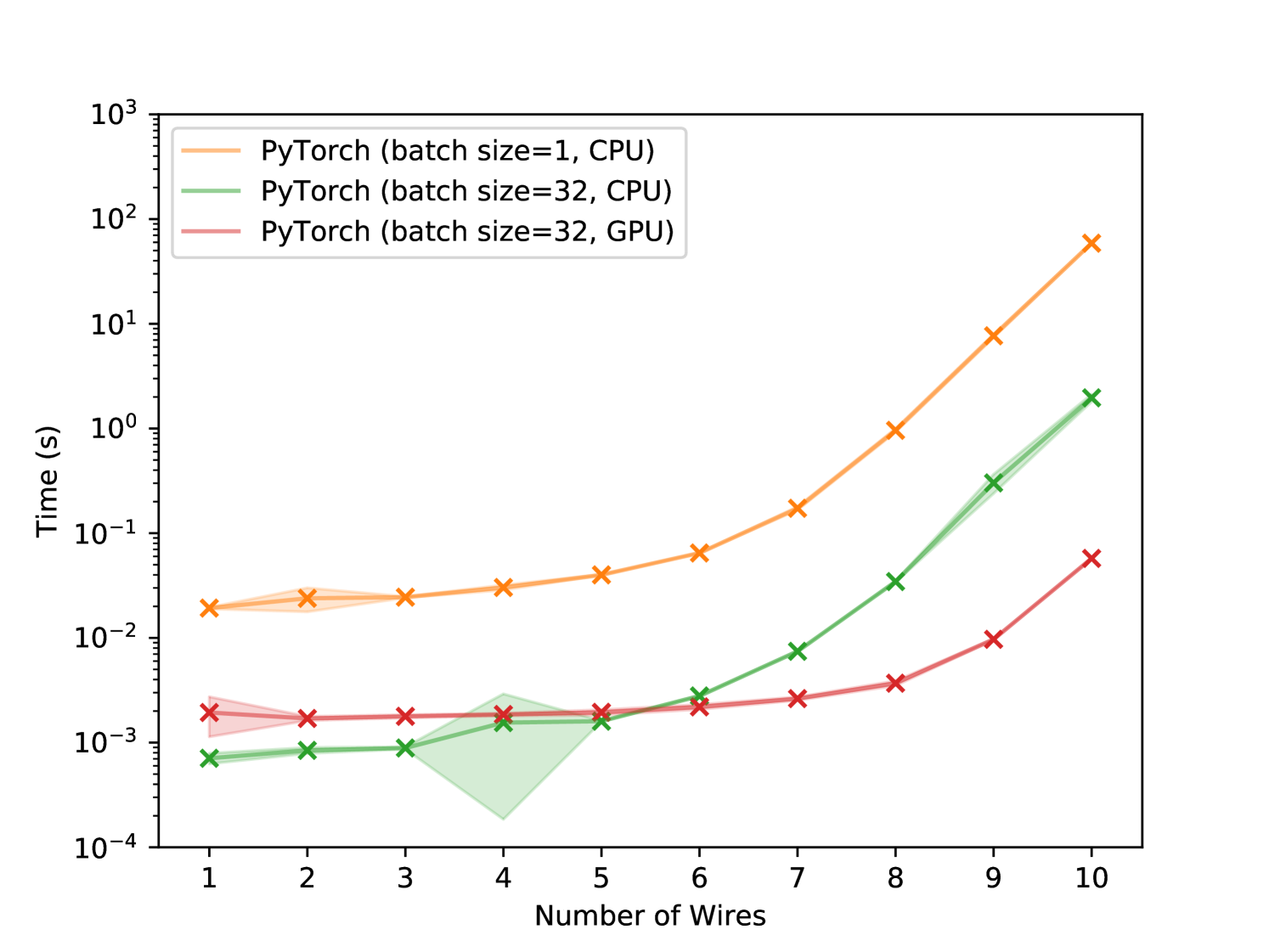
The effect of batching and using GPUs
We gain an additional speedup by minibatch training and by using a GPU. To demonstrate this, we build a dataset of 32 datapoints and we train for 10 epochs using 3 different setups:
-
1.
PyTorch with batch size 1, train on the CPU
-
2.
PyTorch with batch size 32, train on the CPU
-
3.
PyTorch with batch size 32, train on the GPU
The results are plotted in Figure (1(b)). Batching consistently improves speed by a factor comparable to the batch size. Working on the GPU also helps if the circuit is large enough. We explain this by the overhead of invoking GPU kernels, and copying data between CPU and GPU. It’s only worth to pay this price above a certain number of wires. All numerical values are reported in Table (1).
4.2 Quanvolutional networks on MNIST and SAT-6
In this section we run experiments along the lines of §3.4 and test quantum circuits on two image classification tasks, MNIST and SAT-6222The SAT-6 dataset [Basu et al., 2015] consists of satellite images of 4-channels (red, green, blue, near infrared) each belonging to one of 6 categories (barren land, trees, grassland, roads, buildings and water bodies).. Quanvolutional networks [Henderson et al., 2020] generalize the concept of convolutions by having a quantum circuit sliding through the input image and evaluating it at every patch of the input. By construction they inherit the translation equivariance property of convolutional networks, therefore are a fitting architecture for image processing tasks.
In both experiments we compare two networks, one classical and one classical-quantum hybrid. The overall number of parameters of the networks are comparable, the architectures are shown in Figure LABEL:fig:architecture. The quanvolutional layer maps from 16 to 8 channels using 2-by-2 filters, resulting in a total of 32 quantum circuits on 4 qubits.
The results are summarized in Figure 2. We see that the quanvolutional architecture trained by full unitary optimization does not yield an accuracy benefit over the classical network and conclude that no ansatz exists for the 4 qubit circuits that would outperform the classical network given that the classical part of the hybrid architecture is not changed, only retrained with the ansatz.
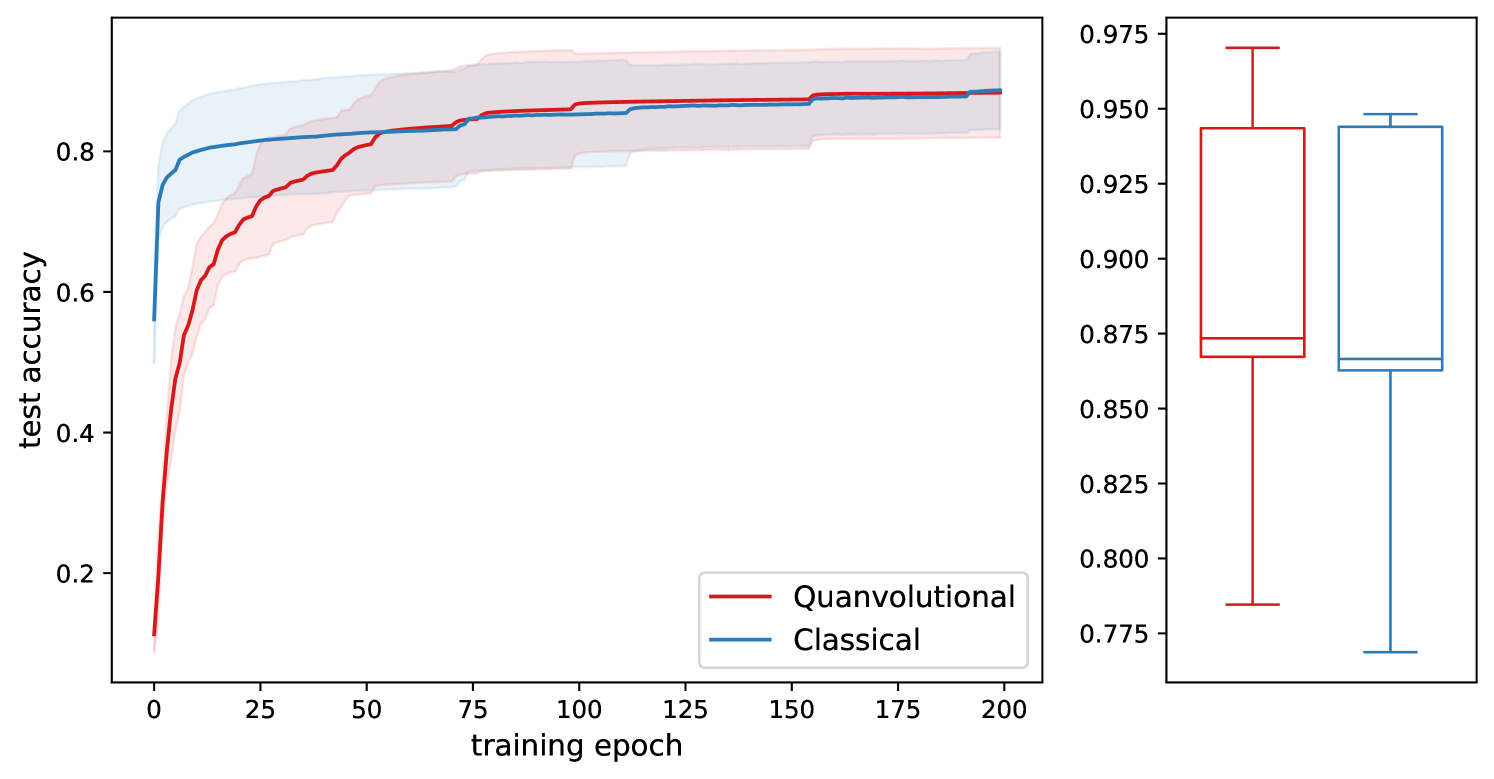
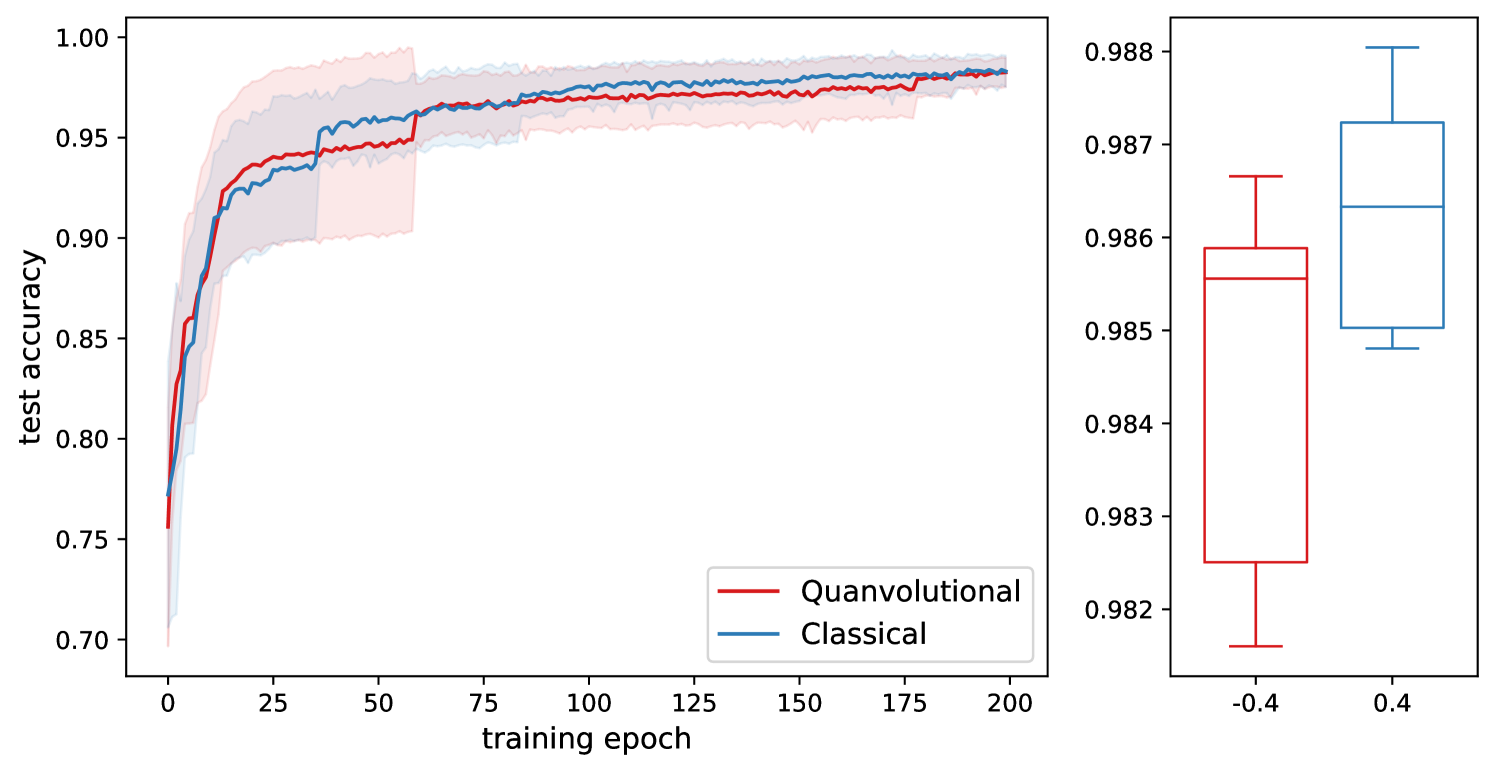
5 Future Work and Conclusion
5.1 Decomposing unitary transformations to canonical quantum gates
If our approach finds a useful unitary transformation, it needs to be decomposed into a sequence of elementary operations to execute it on a quantum computer. This section summarizes the relevant results.
Any unitary transformation on wires can be written as a composition of 1 and 2-qubit gates [Nielsen and Chuang, 2010, 4.5.2]. An exact decomposition of a general unitary operator will almost surely not have a simple form, and would require many gates to implement it. However, at the moment we need very shallow circuits to avoid noise challenges. Therefore, a more fitting approach is to do an approximate decomposition where the goal is to keep the decomposition simple while still staying close to the original unitary map. The Solovay-Kitaev algorithm [Kitaev, 1997; Dawson and Nielsen, 2005] performs an approximate decomposition, but uses only a finite set of gates. Since continuously parametrized gates are not included, a long sequence of elementary gates are necessary to closely approximate an arbitrary unitary matrix. The authors are not aware of an efficient algorithm that performs approximate decomposition while keeping the resulting circuits shallow.
5.2 Conclusion
While the arbitrary structure of input datasets makes theoretical claims of quantum machine learning applications challenging, the widespread adoption of machine learning in virtually every business sector creates a strong research motivation to explore potential QML applications. While this incentive guides QML research to approach applications from the “what can we do with the hardware we have?" perspective, this work investigates a framework which focuses on the functional question: “with an ideal quantum computer, are there circuit ansätze in the given architecture which outperform classical comparisons with the same amount of resources?" The framework in this paper is not absolute, but provides flexibility to quickly analyze the space of possible ansätze for a particular number of qubits within a given QML architecture with considerably favorable scaling compared to other state-of-the-art software packages, and can be extended with different architectures, encoding protocols, and decoding protocols than the ones shown in this work. The goal of this work is to provide a practical tool to the QML research community that can assist in guiding researchers towards effective ansatz structures for particular applications, or prevent researchers from over-investing in QML designs which have no clear advantage. As a framework, this methodology would be for the following open questions:
-
•
For the datasets explored in this work, would there be some set of architecture decisions which would lead to an benefit? This would involve exploring different sized quantum circuit ansätze, different numbers of layers of quantum transformations, and different positions of the operations in the stack.
-
•
Could better circuit ansätze be found for previous algorithms? For instance, the quantum kitchen sinks [Wilson et al., 2018] algorithm is very amenable to this approach. In that work, classical data is mapped into a single layer of Rx gates, with quantum circuit ansätze preceding and/or following this parameterized layer; using this framework, one could test if there were more appropriate ansätze to improve results found in the original paper.
-
•
In the event that a set of useful ansätze is found for a particular dataset and architecture, how do we approximate it using available hardware? While there is a rich body of research highlighted in this work concerning decomposition, at the time of writing there are only a few solutions for approximating decomposing quantum circuits while also taking into account the impact of noise [Cincio et al., 2021] and this constitutes a promising field of research.
In classical machine learning, this work relates with Neural Architecture Search (NAS) [Elsken et al., 2019] which aims to automatically find the best network model for a given task and dataset e.g., image classification [Zoph and Le, 2017]. Combination of neural and quantum architecture search would allow optimal design of hybrid classical-quantum architectures.
6 Acknowledgments and Disclosure of Funding
Bálint Máté was supported by the Swiss National Science Foundation under grant number FNS-193716 “Robust Deep Density Models for High-Energy Particle Physics and Solar Flare Analysis (RODEM)". This work was also inspired through collaboration and connection formed through the Quantum Open Source Foundation (https://qosf.org/).
Appendix A Quantitative results of Experiment 4.1
| qubits | PennyLane | PyTorch | PyTorch | PyTorch |
|---|---|---|---|---|
| batching | batching, GPU | |||
| 1 | 6.75e-02 5.02e-03 | 2.13e-02 3.70e-03 | 7.08e-04 8.17e-05 | 1.94e-03 8.01e-04 |
| 2 | 2.04e-01 8.44e-04 | 2.78e-02 7.95e-03 | 8.43e-04 5.57e-05 | 1.70e-03 7.85e-05 |
| 3 | 6.62e-01 5.30e-03 | 7.27e-02 6.51e-02 | 8.88e-04 2.35e-05 | 1.78e-03 6.43e-05 |
| 4 | 2.81e+00 4.48e-01 | 2.97e-02 5.41e-04 | 1.55e-03 1.37e-03 | 1.85e-03 5.48e-05 |
| 5 | 1.19e+01 5.57e-01 | 3.99e-02 3.21e-04 | 1.60e-03 1.58e-05 | 1.95e-03 1.15e-04 |
| 6 | 5.28e+01 1.55e+00 | 6.62e-02 7.45e-04 | 2.79e-03 4.59e-05 | 2.19e-03 1.19e-04 |
| 7 | 2.34e+02 9.33e+00 | 1.78e-01 7.38e-03 | 7.44e-03 1.06e-04 | 2.63e-03 9.95e-05 |
| 8 | 1.10e+03 5.05e+01 | 9.62e-01 7.60e-02 | 3.45e-02 3.97e-04 | 3.69e-03 1.95e-04 |
| 9 | 7.27e+00 2.44e-01 | 3.02e-01 6.27e-02 | 9.69e-03 1.58e-04 | |
| 10 | 5.68e+01 7.12e-01 | 1.96e+00 1.59e-01 | 5.75e-02 7.01e-04 |
References
- Preskill [2018] John Preskill. Quantum Computing in the NISQ era and beyond. jan 2018. doi: 10.22331/q-2018-08-06-79. URL http://arxiv.org/abs/1801.00862http://dx.doi.org/10.22331/q-2018-08-06-79.
- Wilson et al. [2018] C. M. Wilson, J. S. Otterbach, N. Tezak, R. S. Smith, G. E. Crooks, and M. P. da Silva. Quantum Kitchen Sinks: An algorithm for machine learning on near-term quantum computers. jun 2018. URL http://arxiv.org/abs/1806.08321.
- Adachi and Henderson [2015] Steven H. Adachi and Maxwell P. Henderson. Application of Quantum Annealing to Training of Deep Neural Networks. oct 2015. URL http://arxiv.org/abs/1510.06356.
- Cong et al. [2019] Iris Cong, Soonwon Choi, and Mikhail D Lukin. Quantum convolutional neural networks. Nature Physics, 15(12):1273–1278, 2019. ISSN 1745-2481. doi: 10.1038/s41567-019-0648-8. URL https://doi.org/10.1038/s41567-019-0648-8.
- Henderson et al. [2019] Maxwell Henderson, John Novak, and Tristan Cook. Leveraging Quantum Annealing for Election Forecasting. Journal of the Physical Society of Japan, 88(6):61009, mar 2019. ISSN 0031-9015. doi: 10.7566/JPSJ.88.061009. URL https://doi.org/10.7566/JPSJ.88.061009.
- Alcazar et al. [2019] Javier Alcazar, Vicente Leyton-Ortega, and Alejandro Perdomo-Ortiz. Classical versus Quantum Models in Machine Learning: Insights from a Finance Application. aug 2019. URL https://arxiv.org/abs/1908.10778.
- Kashefi et al. [2020] Brian Coyle Kashefi, Maxwell Henderson, Justin Chan Jin Le, Niraj Kumar, Marco Paini, and Elham. Quantum versus classical generative modelling in finance. Quantum Science and Technology, 2020. ISSN 2058-9565. URL http://iopscience.iop.org/article/10.1088/2058-9565/abd3db.
- Enos et al. [2021] Graham R. Enos, Matthew J. Reagor, Maxwell P. Henderson, Christina Young, Kyle Horton, Mandy Birch, and Chad Rigetti. Synthetic weather radar using hybrid quantum-classical machine learning. nov 2021. URL https://arxiv.org/abs/2111.15605.
- Henderson et al. [2020] Maxwell Henderson, Samriddhi Shakya, Shashindra Pradhan, and Tristan Cook. Quanvolutional neural networks: powering image recognition with quantum circuits. Quantum Machine Intelligence, 2(1):1–9, 2020. ISSN 2524-4914. doi: 10.1007/s42484-020-00012-y. URL https://doi.org/10.1007/s42484-020-00012-y.
- Sebastianelli et al. [2021] A. Sebastianelli, D. A. Zaidenberg, D. Spiller, B. Le Saux, and S.L. Ullo. On circuit-based hybrid quantum neural networks for remote sensing imagery classification. Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 15:565–580, 2021. doi: 10.1109/JSTARS.2021.3134785.
- LaRose and Coyle [2020] Ryan LaRose and Brian Coyle. Robust data encodings for quantum classifiers. Physical Review A, 102(3):32420, sep 2020. doi: 10.1103/PhysRevA.102.032420. URL https://link.aps.org/doi/10.1103/PhysRevA.102.032420.
- Henderson et al. [2021] Max Henderson, Jarred Gallina, and Michael Brett. Methods for accelerating geospatial data processing using quantum computers. Quantum Machine Intelligence, 3(1):4, 2021. ISSN 2524-4914. doi: 10.1007/s42484-020-00034-6. URL https://doi.org/10.1007/s42484-020-00034-6.
- Pérez-Salinas et al. [2019] Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and José I. Latorre. Data re-uploading for a universal quantum classifier. jul 2019. URL http://arxiv.org/abs/1907.02085.
- Mitarai et al. [2018] Kosuke Mitarai, Makoto Negoro, Masahiro Kitagawa, and Keisuke Fujii. Quantum Circuit Learning. mar 2018. doi: 10.1103/PhysRevA.98.032309. URL http://arxiv.org/abs/1803.00745http://dx.doi.org/10.1103/PhysRevA.98.032309.
- Schuld et al. [2018] Maria Schuld, Ville Bergholm, Christian Gogolin, Josh Izaac, and Nathan Killoran. Evaluating analytic gradients on quantum hardware. nov 2018. doi: 10.1103/physreva.99.032331. URL https://arxiv.org/abs/1811.11184.
- Bergholm et al. [2020] Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, M. Sohaib Alam, Shahnawaz Ahmed, Juan Miguel Arrazola, Carsten Blank, Alain Delgado, Soran Jahangiri, Keri McKiernan, Johannes Jakob Meyer, Zeyue Niu, Antal Száva, and Nathan Killoran. PennyLane: Automatic differentiation of hybrid quantum-classical computations, 2020. URL https://arxiv.org/abs/1811.04968.
- Padilha et al. [2019] Dan Padilha, Serge Weinstock, and Mark Hodson. QxSQA: GPGPU-Accelerated Simulated Quantum Annealer within a Non-Linear Optimization and Boltzmann Sampling Framework. 2019. URL https://www.qxbranch.com/wp-content/uploads/2019/06/Padilha-2019-QxSQA_GPGPU_Accelerated_Simulated_Quantum_Annealer-2.pdf.
- Hall [2015] B. Hall. Lie Groups, Lie Algebras, and Representations: An Elementary Introduction. Graduate Texts in Mathematics. Springer International Publishing, 2015.
- Paszke et al. [2017] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. 2017. URL https://arxiv.org/abs/1912.01703.
- Basu et al. [2015] Saikat Basu, Sangram Ganguly, Supratik Mukhopadhyay, Robert DiBiano, Manohar Karki, and Ramakrishna Nemani. Deepsat - a learning framework for satellite imagery, 2015.
- Nielsen and Chuang [2010] Michael A. Nielsen and Isaac L. Chuang. Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, 2010. doi: 10.1017/CBO9780511976667.
- Kitaev [1997] A. Yu Kitaev. Quantum computations: algorithms and error correction. Russian Mathematical Surveys, 52(6):1191–1249, December 1997. doi: 10.1070/RM1997v052n06ABEH002155.
- Dawson and Nielsen [2005] Christopher M. Dawson and Michael A. Nielsen. The solovay-kitaev algorithm, 2005.
- Cincio et al. [2021] Lukasz Cincio, Kenneth Rudinger, Mohan Sarovar, and Patrick J. Coles. Machine learning of noise-resilient quantum circuits. PRX Quantum, 2:010324, Feb 2021. doi: 10.1103/PRXQuantum.2.010324. URL https://link.aps.org/doi/10.1103/PRXQuantum.2.010324.
- Elsken et al. [2019] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, 20(55):1–21, 2019. URL http://jmlr.org/papers/v20/18-598.html.
- Zoph and Le [2017] Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. In Proc. Int. Conf. on Learning Representations (ICLR), 2017.