Black-Litterman Portfolio Optimization with Noisy Intermediate-Scale Quantum Computers
Abstract
In this work, we demonstrate a practical application of noisy intermediate-scale quantum (NISQ) algorithms to enhance subroutines in the Black-Litterman (BL) portfolio optimization model. As a proof of concept, we implement a 12-qubit example for selecting 6 assets out of a 12-asset pool. Our approach involves predicting investor views with quantum machine learning (QML) and addressing the subsequent optimization problem using the variational quantum eigensolver (VQE). The solutions obtained from VQE exhibit a high approximation ratio behavior, and consistently outperform several common portfolio models in backtesting over a long period of time. A unique aspect of our VQE scheme is that after the quantum circuit is optimized, only a minimal number of samplings is required to give a high approximation ratio result since the probability distribution should be concentrated on high-quality solutions. We further emphasize the importance of employing only a small number of final samplings in our scheme by comparing the cost with those obtained from an exhaustive search and random sampling. The power of quantum computing can be anticipated when dealing with a larger-size problem due to the linear growth of the required qubit resources with the problem size. This is in contrast to classical computing where the search space grows exponentially with the problem size and would quickly reach the limit of classical computers.
Index Terms:
Quantum computing, Quantum machine learning, Variational quantum eigensolver, Portfolio optimization, Black-LittermanI INTRODUCTION
Portfolio optimization is a combinatorial optimization (CO) problem in finance that seeks to identify a set of assets from a pool to maximize returns while minimizing risk[1, 2]. For a continuous capital allocation case, this problem boils down to inversion of a positive semi-definite matrix (the covariance matrix), and is solvable in polynomial time. However, for a discrete case (i.e. the capital is divided into blocks), this problem becomes a combinatorial optimization (CO) problem, whose search space grows exponentially with problem size, and belongs to category of NP-hard in complexity theory. Since efficient classical algorithms are lacking for this type of problems, exploration of quantum computing as a potential solution[3, 4, 5] is prompted. Recently, quantum computers with larger scale and better fidelity have came into existence. Several studies have shown potential capability for hybrid quantum-classical methods, which is a strong candidate for application of NISQ computers, to solve portfolio optimization.
The most well known model for portfolio optimization is the modern portfolio theory (MPT) model, introduced in 1952 by Harry Markowitz[1]. MPT is also called the mean-variance model since it quantifies return and risk as mean and (co)variance of daily return, respectively. For a total N assets pool, a portfolio is represented by a vector , where denotes buying/not buying an asset. The return of a portfolio can be written as , where is the return vector that represents the expectation value of returns of each asset based on historical mean. On the other hand, risk is defined as the covariance of daily returns, and can be written as , where is the covariance matrix of the returns. The goal is to maximizes the return while minimizing the risk, and it can be achieved by minimizing the quadratic function
| (1) |
is the risk aversion coefficient that specifies the importance between minimizing risk and maximizing return. B is the budget constraint that indicates the total number of asset one should buy, and can be implement by adding a penalty term to the objective function, i.e.
| (2) |
The problem is thus a quadratic unconstrained binary optimization (QUBO).
Several studies in the realm of quantum computing have focused on solving discrete portfolio optimization with MPT using VQEs[6, 7], and quantum annealing (QA)[4]. However, despite making significant contributions to the framework of quantifying return and risk for mathematically optimizing the portfolio, MPT has shown limitations in practical cases. The MPT solution has been found to result in issues such as unintuitive and highly-concentrated portfolios, large short positions, and sensitivity to input[8, 9]. From a practical point of view, the Black-Litterman model, developed in 1992 at Goldman Sachs by Fischer Black and Robert Litterman[8], may be more appealing.
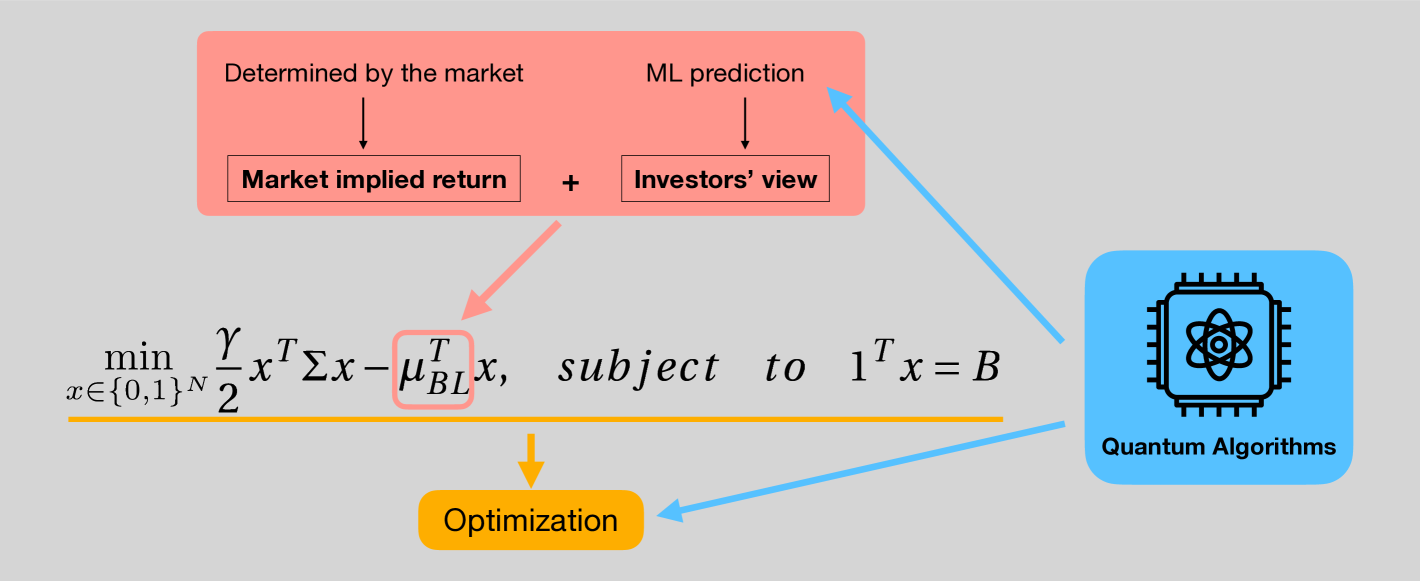
The main difference between BL and MPT model is that BL adopt the combined return vector as its return term. is a statistical combination of two distributions, market implied return and investor’s views. Market implied return is obtained through reverse optimization of the market capitalization weight, meaning that the optimal solution is given as the the capitalization weight, and the corresponding returns of each asset that lead to this solution are then calculated. Thus market implied return is entirely determined by the market itself. Investor’s view, on the other hand, can be determined in many ways, for example human predictions or other prediction models. Fortunately, previous studies have shown a way to divide these views into categories of trends[10] (e.g. very bullish, bullish, bearish, very bearish), which we can leverage classification methods in quantum machine learning (QML). We explore several quantum and classical classification models, eventually obtained with the prediction of the quantum kernel method for support vector machine (QSVM)[11] due to the higher accuracy.
After is determined, the optimization problem is similar to that of in MPT model1. The QUBO problem is mapped to Ising Hamiltonian and solved with VQE using different types of ansatz (e.g. heuristic, QAOA). Once the circuits are optimized, we point out that one can—and should—use very few final samplings to find high-quality solution. An intuition of this argument is that we will have to check the eigenvalue of each sampled eigenstate to find the best among them, and thus if the amount of samples is too large, we could just perform same amount of random samplings and will end up with very high probability to find a solution with similar ARs. Moreover, since the search space of this problem grows exponentially, the sample size we are able to check is always a small portion of it for a large size problem.
Since the scale of real quantum device today are not able to solve discrete portfolio optimization problems beyond classical computer limit (and quantum computers cannot be efficiently simulated classically), the main purpose of this work is to provide a procedure of enhancing subroutines in BL model with NISQ algorithms. We demonstrate 12 and 16 qubit case to show the capability of obtaining solutions with good backtesting performance, quantum advantage should be anticipated once we have quantum hardware with size and fidelity beyond classical capacity.
II Financial Model and Definition
II-A Black-Litterman model
BL model can be generally understood as a method to construct a new combined return vector , which is a combination of market implied return and investors’ view, to replace the in equation 1, and do portfolio optimization. The market implied return is the return we should have if the market capitalization weight is the optimal solution for a portfolio optimization, and is calculated via reverse optimization:
| (3) |
where is the risk aversion coefficient as in equation (1) that depends on investor’s preference. For a general case, we choose based on the ratio of excess return and covariance of the market index over the pass 10 years. Since is fully determined by the market, we can incorporate quantum technology into BL model via investor’s views. Investor’s views can be quantized by the following three terms :
: a matrix that identifies the assets involved in the views.
: the view vector.
: a diagonal matrix representing the uncertainty of views.
For example, if we have a view about two assets A and B, say A will have a return of 0.05 with uncertainty 0.001, and B will have a return of 0.1 with uncertainty 0.0005. The corresponding matrices are written as
Note that there are also relative views such as return of A asset will out perform B by some amount, however, in this work we consider only a direct view of every asset (thus is an identity matrix). In general, these views can be generate from any kind of resource, including financial analysts, news, or personal experience…etc. However, to take advantage of the quantum classification methods, we should treat the views quantitatively. According to [10], the uncertainty of a view about asset can be taken as proportional to the variance of the asset itself. We can thus write
| (4) |
where , is the row of , and is a constant that will not affect the final combined return vector if we use equation 4 to construct [9]. For the view vector , [10]also suggested that we can set the view in to be
| (5) |
where denotes the view as ”very bearish”, ”bearish”, ”bullish”, and ”very bullish” respectively. Here, we further defined for two binary classification models:
| (6) |
where , , and is the accurate rate of the testing data of the classifier for . Now, since we have multiplied it with a scale . This means that we will have a stronger view for the classifier with higher accuracy, and vice versa. After we constructed these matrices, the combined return vector is calculated with the result formula in the original paper [8],
| (7) |
By replacing with in equation (1), the objective function now becomes
| (8) |
and the corresponding QUBO form is
| (9) |
II-B Logarithmic Return
Many of the previous quantum finance studies either applied simple return, i.e. , by default or without giving specific form for return. However, in finance, log return is more commonly used due to it’s statistical properties (follows normal distribution) and the ability of capturing compound return (time additive). Log return is defined as
| (10) |
and when we add them along a time sequence to , it becomes . The rate of return (RoR) during this period is . On the other hand, the sum of simple return will not capture the compound return. Thus, it is more preferable to adopt log return when we are optimizing the data for a buy and hold strategy.
II-C Effective
The risk aversion coefficient is another thing that is also not discussed in quantum finance studies. In the discrete optimization case, the budget constraint, , is needed otherwise the solutions are not comparable. However, when we construct a portfolio in real cases, should always be re-normalized to 1 after we obtain the solution, i.e. . Since the variance in the objective function (equation (8)) is quadratic and the return is linear, the re-normalization will result in equivalently solving for a risk aversion coefficient . For cases that s are chosen randomly, this may not matter, nevertheless, if is estimated with historical data and has financial meaning, which is the case here, it should be carefully considered. We thus propose an effective :
| (11) |
where can be estimated with, for example, the ratio of the risk premium to the variance of index over the pass 10 years, i.e.
| (12) |
where and are the mean return and variance of the index, and is the mean risk free rate. Here we refer to the 13 week treasury bill (Yahoo Finance : ). We use rather than for solving equation (8), and when we re-normalize the optimal solution such that the sum of portfolio weights is 1, it is an optimal solution for the risk aversion coefficient that we want.
II-D Index
In the framework of BL model, the market cap weighted index is assumed to be efficient at present. For a problem of asset pool that are large enough and are all included in , we can refer the index to the index. In our case, however, we have to construct the corresponding market weighted index for our assets pool. Here, 12 individual stocks are considered, we determined the market cap by the data at closest time to the end time of the training period. Since the market cap weight is in unit of money, we first assume a total 100 unit of money (i.e. the initially normalized index level), and calculate the shares for each asset at the time of market cap data. The shares then holds as a constant, and price of the index at different time is determined by
| (13) |
where is the price of asset, and is the shares of asset.
II-E Walk-Forward Backtest
The walk-forward backtest is a common backtest method which one continuously move a window, which is consist of a training period and a following testing period, along a long period of time. We performed a walk-forward backtest for total time period from 2008/01/01 to 2021/12/31, with a 260 week (about 5 year) training period and 52 week (about 1 year) testing period, and a moving interval of 52 week to analyze the performance of BL model. Note that our moving interval is identical to the testing period, thus this backtest can also be seen as a dynamic portfolio optimization without considering the transaction fee.
III Method and Algorithms
In this section, we discussed the method and quantum algorithms we applied and the circuits we used for BL model, including A. quantum classifiers for investors’ views, and B. penalty tuning for implementing constraint, C. VQEs for optimization, and D. data sources and preprocessing.
III-A Quantum classifiers
The goal for quantum classifiers is to classify and in equation (6) after trading units (e.g. days/weeks) in the future for each asset in our pool, and predict the given feature vector at the latest date of training period to construct via equation (6), and thus the view matrix . We can represent the feature of any given date with financial indicators of that day, and labeled and according to the mean (log) return of the trading units since . The labels are given by the following rules:
| (14) | |||||
where , and is the standard deviation of of the corresponding assets. Since the testing period is 52 weeks, here.
In this work, we implemented two kinds of common quantum supervised learning models, which are quantum neural network (QNN)[12, 13], and quantum kernel method for support vector machine (QSVM)[11], and compared them with classical NN and SVM. Both quantum classifiers rely on a quantum circuit feature map that encodes classical data into Hilbert space, but the training part works in different ways. For QNN, the feature map circuit is directly followed by an ansatz circuit with trainable parameters. Every data point that are encoded with the feature map and go through the unitary transformation of the ansatz, can be measured in computational basis and output a collection samples . We interpret these measurement bit strings with a parity function that maps the samples to , resulting in a binary probability distribution. We then use classical optimizer to minimize the squared loss function and update the parameters in the ansatz circuit. For QSVM, the quantum kernel can be represented by , which the same feature maps as shown in Fig 2, followed by its own dagger. We measure the probability of , which has been shown in [11] to be equivalent to the inner product of the data points in feature space. Thus, we can apply this quantum kernel to the classical support vector machine (SVM).
We search among several kinds of feature map circuits, including the simple embedding 2(b) and the Pauli feature map 2(a), with different Pauli gates (e.g. [Z, YY], [Y, ZZ]…etc.) and entanglement structure (e.g. linear, circular, and full), finding that in our case, a simple embedding feature map without any entanglement structure (n=0) is enough to obtain high testing accurcies. QSVM with simple embedding feature map turns out to be slightly better than classical SVM with Gaussian kernel. The Pauli feature map, on the other hand, includes two-qubits rotational gates. It is more complex but did not work well on this task since we are training with only a small size and simple feature data. For predictions of more complex situations, which the feature dimension may be larger and more complex, one may be able to leverage the complexity of entangled quantum feature map. On the other hand, QNN and NN did not perform as well as SVM based ML model here.
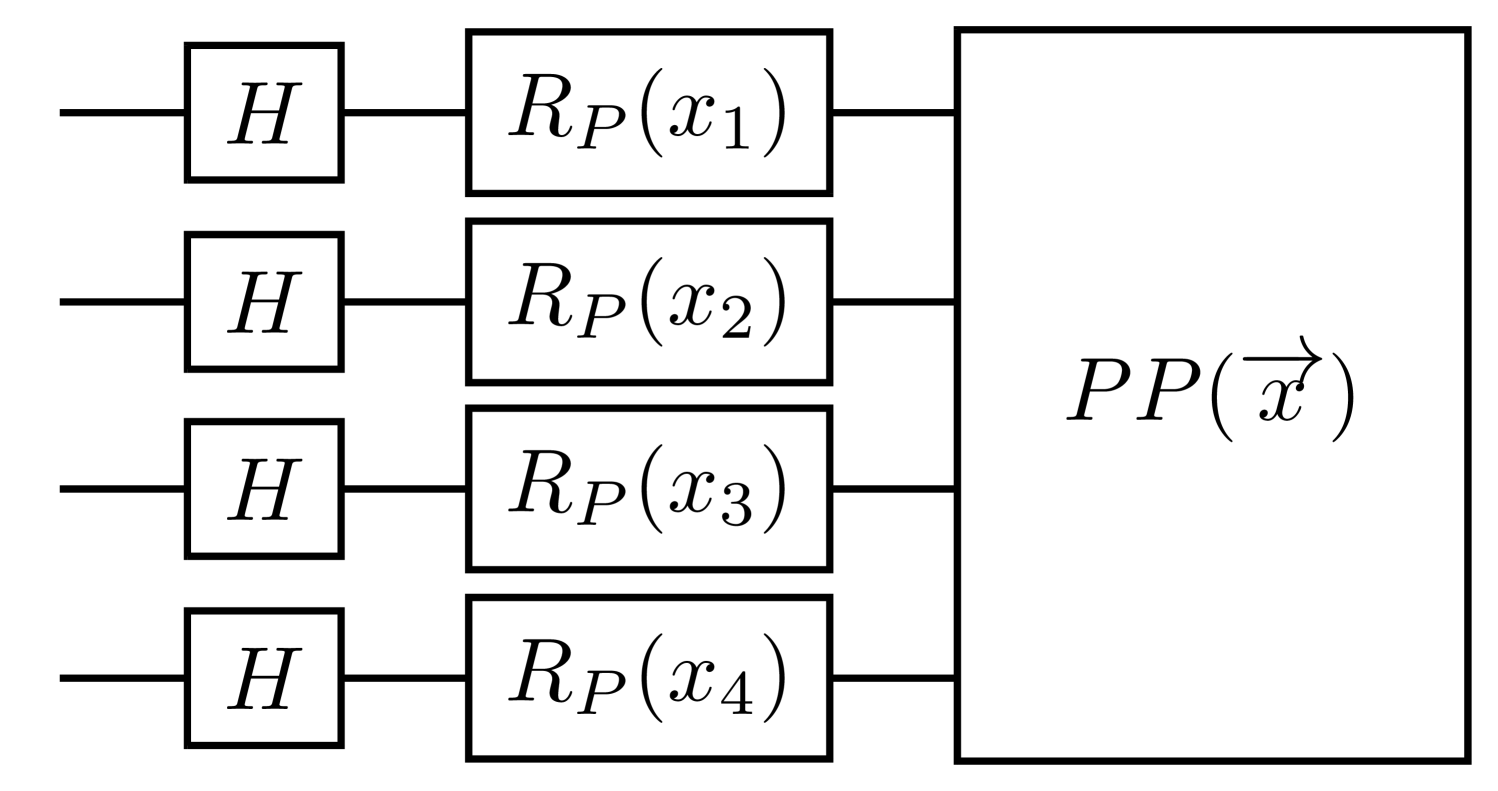
III-B Penalty tuning
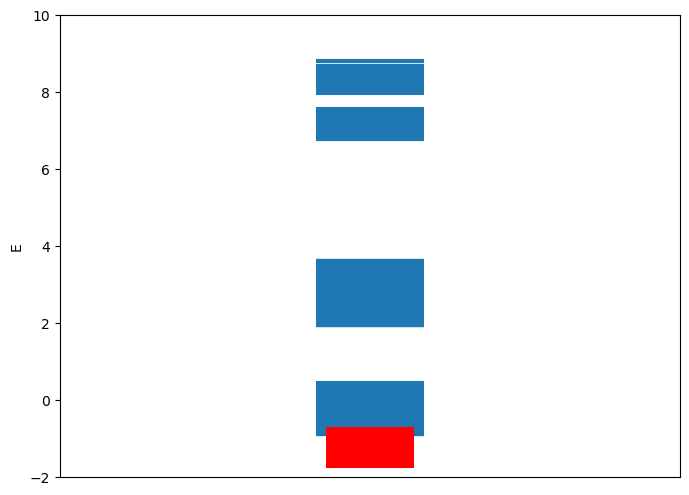
Before actually solving the QUBO objective function, i.e. equation (9), we must first determine a proper penalty . should be large enough to implement the constraint, but not unnecessarily large to dominate the Hamiltonian, making the risk-return part requires extreme precision to solve. Moreover, a large also directly increases the coefficient of the Hamiltonian, and thus we need more measurements (circuit repetitions) to evaluate the expectation value to same precision. Here we choose by empirically analyze the distribution of eigenvalue of the Hamiltonian. We believe that choosing such that the eigenvalue of the lowest eigenstate that doesn’t satisfy the constraint is at least larger than the but less than of the eigenvalue of eigenstates that satisfy the constraint, as shown in Fig 4, will be preferable for VQEs.
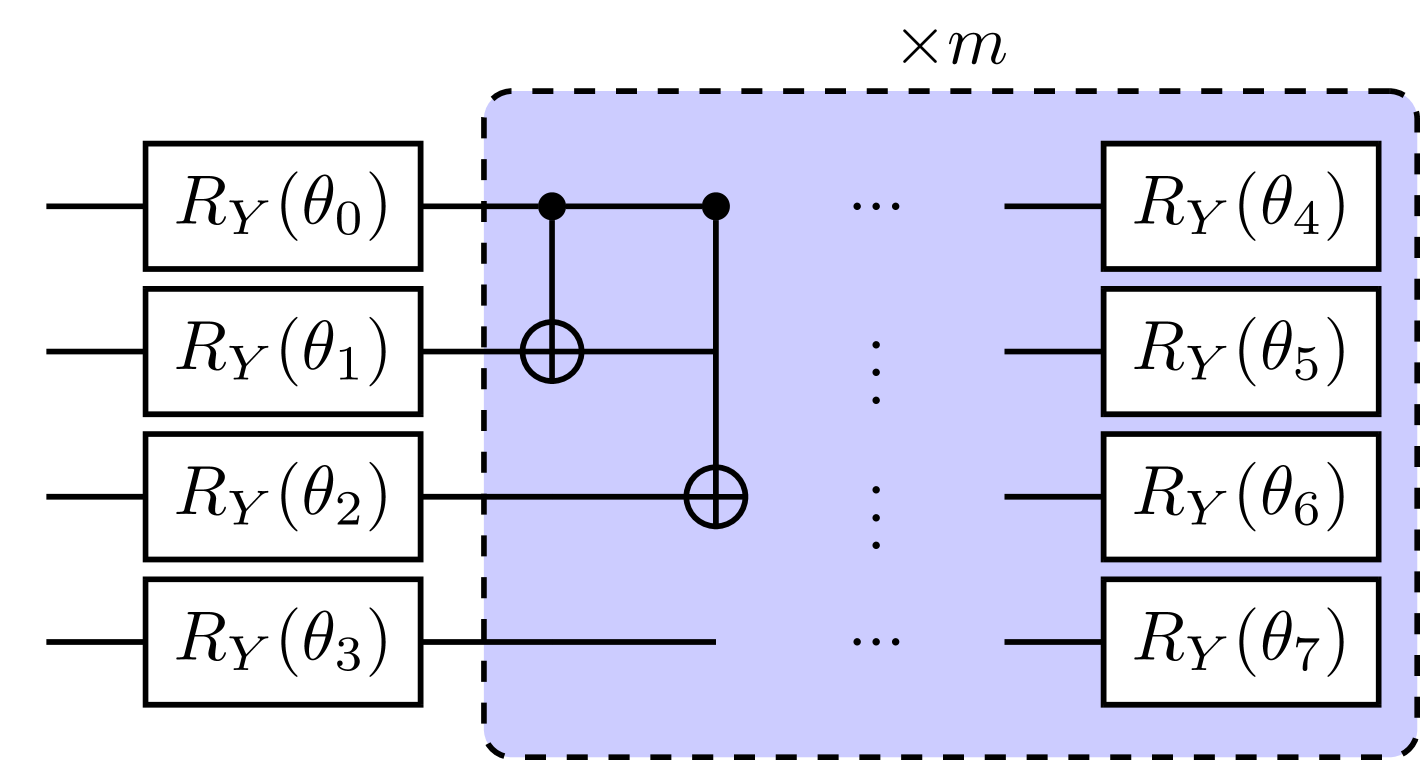
III-C VQEs
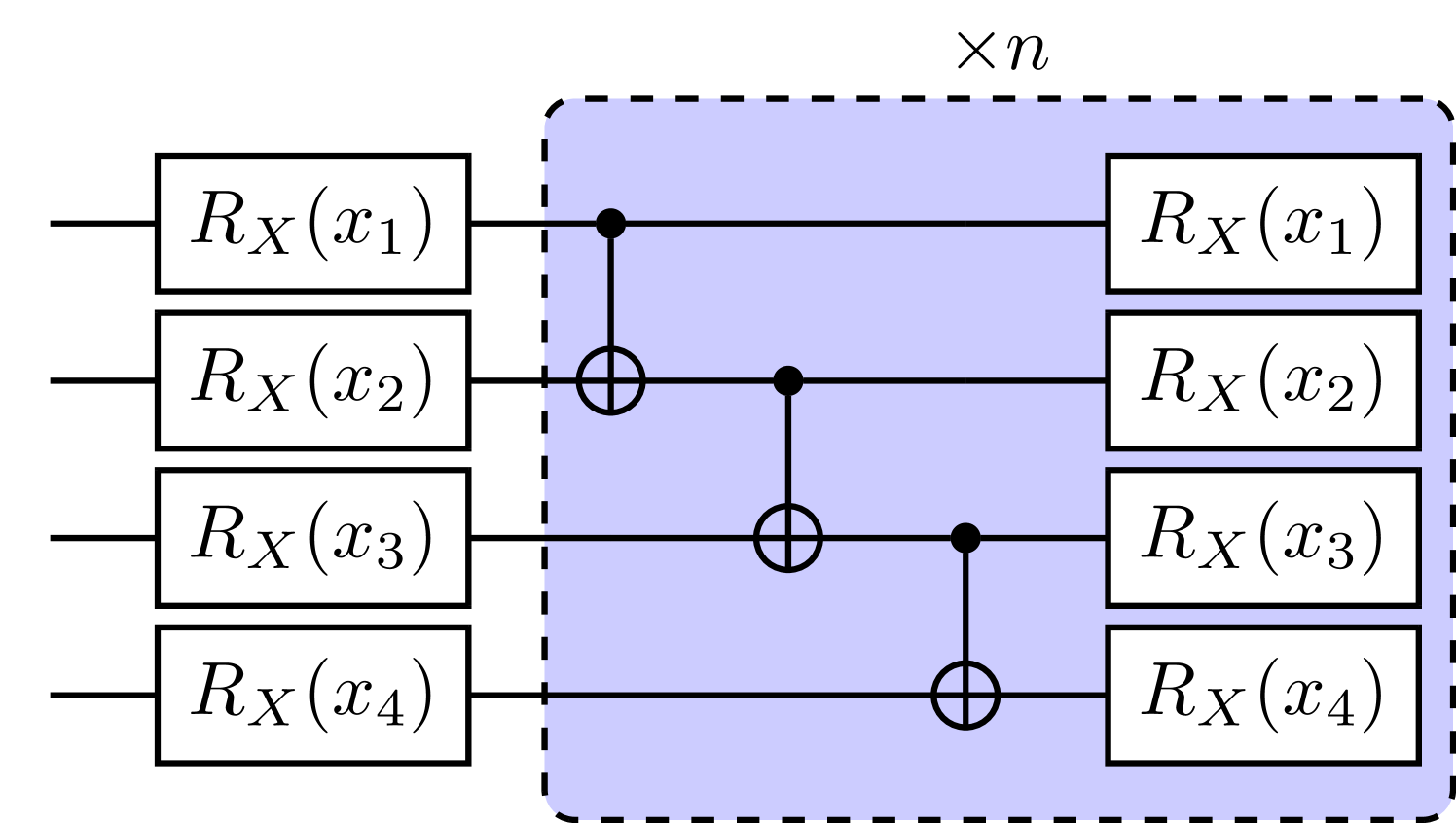
We solved equation (9) with gate-based quantum computer simulator using a heuristic circuit VQE, and QAOA[14]. QAOA is also a type of VQE that has a specific variational form that depends on the problem Hamiltonian, and is related to the quantum adiabatic algorithm. QUBO problems are natively solvable for quantum computers since the objective function can easily be mapped to an Ising Hamiltonian by , where and is the Pauli Z operator. The mapped Ising Hamiltonian of equation (9) is
| (15) |
where and are coefficients of corresponding terms and is the offset constant. This Ising Hamiltonian should in general be fully connected, unless the covariance between some of the assets are zero. With this problem Hamiltonian, we construct the heuristic ansatz for VQE shown in Fig 5, and QAOA ansatz is built following the instruction stated in [14]. From there, we then update the parameters in the circuit with Sequential Least Squares Programming (SLSQP) optimizer in order to minimize the Hamiltonian expectation value. After convergence, the optimal parameters is then fixed in the ansatz to perform final samplings, and the solution is chosen as the outcome bit string with lowest eigenvalue among the final measurements. We take only 5 measurement shots as final samplings here. There are two reasons to use such few shots, first is that once we optimized the parameter in the ansatz successfully, the probability distribution should concentrate on low energy eigenstates, thus we should expect needing only few final samplings to get a good solution with high probability. Secondly, this is also to mimic the situation of solving a large size problem, which the final shots we can get is always a tiny portion of the total search space, and should always not exceed the search space (otherwise one should rather perform a exhaustive search). Since the search space grows exponentially, a large amount of final samplings (compare to search space) is neither justified nor possible. We further analyzed the probability of getting a ”good” solution with random sampling in appendix A. We show that the probability of reaching such AR within 5 final samplings is very low, and provide a upper bound for maximum number of final sampling.
The heuristic VQE form we used requires parameters for an N assets optimization problem, where p is the repetition of the circuit. For QAOA, the entanglement has to be fully connected since the problem itself is. It might be more hardware demanding for most cases, but requires only parameters, and the performance is guaranteed to improve (or at least the same) as increases[14]. We choose for heuristic VQE and for QAOA, and take 10 and 500 initial parameter guesses for each respectively. The initial guess that is eventually optimized to the lowest expectation value will served as the optimal parameter and used to perform final sampling.
III-D Data
We applied quantum algorithms to BL model and implement it for real world stock data, with walk-forward back test framework, i.e. a 262-week (5 years) in-sample period and a 52-week (1 year) out-sample period, starting from and ends at , creating a total 9 continuous time segments. The training and testing stock price data are all downloaded from Yahoo finance weekly data, and the market capitalization data is obtained from [15]. The financial indicators for predicting investor’s views (TABLE I) are downloaded from ”Federal Reserve Bank of St. Louis” [16]. The asset pool contains 12 individual stocks randomly chosen from companies of different industries.
It requires several preprocessing before the financial indicators can become a feature vector for prediction tasks.
1. Backward moving average with a 3-week rolling window.
2. Standard normalization.
3. PCA reduce to 4 dimension.
4. Re-normalize each feature to .
We then label the these features of each week according to the rule in equation (14). In order to improve the ”trainability” of our data, we remove both feature vectors if they are too close in feature space but having different labels. The main idea of doing this is that we don’t want those feature vectors that give no information, or more specifically, require extremely high precision to distinguish each other, to distract our models. The feature vectors can then be encoded into the quantum circuit via our quantum feature map to train predictive models. We further extend the procedure to a global portfolio optimization case in Appendix B, which the asset pool contains 16 ETFs that approximately represents the global economy.
| DOW | WILL5000INDFC | VIXCLS |
| T10Y2Y | T10YIE | DCOILBRENTEU |
| DEXCHUS | DFF | EXPTOTUS |
| IGREA |
IV RESULTS & DISCUSSION
IV-A Investor’s views
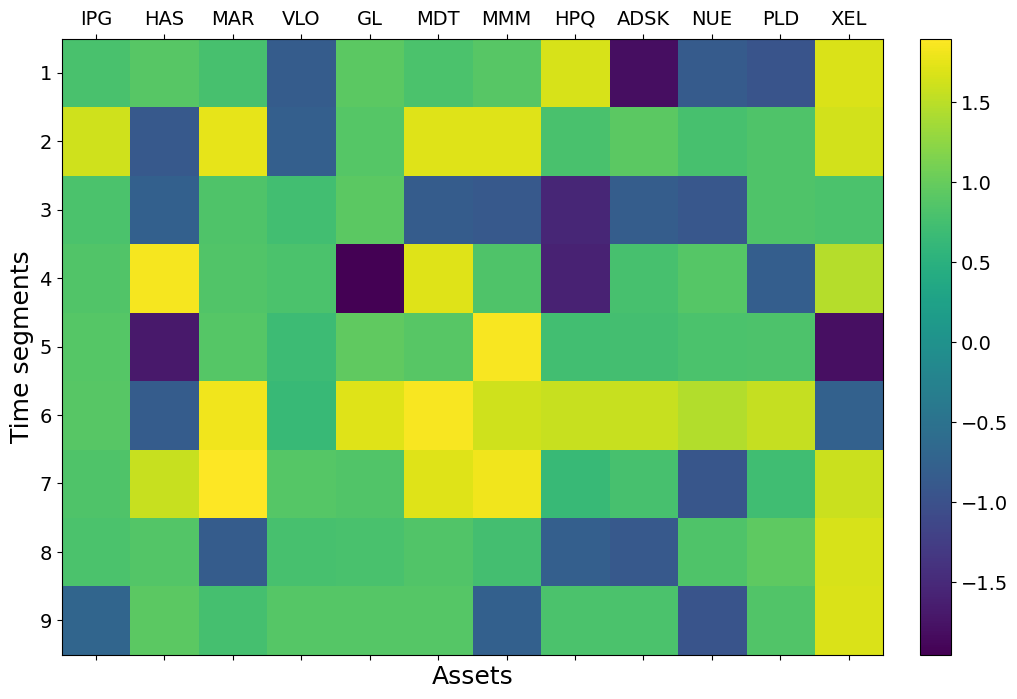
We here showcase in TABLE II the average prediction accuracy for , and over total 9 time segments of each asset. We found that in average, in terms of testing accuracy. QSVM is also much faster to train compare to QNN. Here, we chose QSVM models to predict the investor’s view for future optimizations. The corresponding predicted by QSVM for each assets is shown as a colored matrix in Fig 6.
| IPG | HAS | MAR | VLO | GL | MDT | MMM | HPQ | ADSK | NUE | PLD | XEL | mean | ||||||||||||||
| QSVM | 0.92 | 0.9 | 0.98 | 0.88 | 0.97 | 0.88 | 0.92 | 0.84 | 0.96 | 0.93 | 0.92 | 0.94 | 0.93 | 0.91 | 0.9 | 0.85 | 0.9 | 0.91 | 0.89 | 0.95 | 0.91 | 0.92 | 0.98 | 0.83 | 0.93 | 0.9 |
| QNN | 0.76 | 0.75 | 0.83 | 0.72 | 0.78 | 0.75 | 0.75 | 0.75 | 0.79 | 0.76 | 0.74 | 0.78 | 0.82 | 0.78 | 0.77 | 0.72 | 0.78 | 0.77 | 0.73 | 0.72 | 0.77 | 0.78 | 0.82 | 0.65 | 0.78 | 0.74 |
| SVM | 0.92 | 0.91 | 0.97 | 0.88 | 0.95 | 0.91 | 0.93 | 0.83 | 0.94 | 0.93 | 0.9 | 0.92 | 0.92 | 0.9 | 0.93 | 0.81 | 0.9 | 0.9 | 0.85 | 0.92 | 0.93 | 0.88 | 0.98 | 0.83 | 0.93 | 0.89 |
| NN | 0.86 | 0.87 | 0.93 | 0.76 | 0.95 | 0.82 | 0.86 | 0.75 | 0.96 | 0.86 | 0.86 | 0.87 | 0.93 | 0.86 | 0.91 | 0.74 | 0.86 | 0.86 | 0.85 | 0.93 | 0.91 | 0.83 | 0.98 | 0.71 | 0.91 | 0.82 |
Since the problem size here is not large, both classical and quantum kernel performed well. However, we may look forward to potential advantage for quantum kernel in predictions for more complex situations, as in real world use cases.
IV-B Optimization
As stated above, we applied (a) VQE circuit in Fig 5 with , (b) QAOA with , and (c) exhaustive search to solve all QUBO problems. Before we show the results, we have to first re-define the standard of measuring how good a solution is. In general, people usually refer to the approximation ratio(AR), i.e. for a minimization tasks, or the relative error, i.e. , where is the eigenvalue obtained from the algorithm, and is the exact minimum eigenvalue. However, for a portfolio optimization problem, may often be around , and thus results in unreasonably large ARs or relative errors. Moreover, after we include the constraint into the penalty term (i.e. equation (9)), the energy level of the Hamiltonian splits into chuncks, due to the large amount of extra energy a solution will gain if it violates the constraint (to different degrees), see Fig 4 as an example. Thus, if we look at the whole energy range of the Hamiltonian with penalty, which may be orders larger than the one without penalty, and construct an AR based on how close it is to the ground state, the solutions that simply meets the constrain will turn out to have very high AR and thus becomes hard to distinct a good solution from a bad one if they both meet the constraint. We thus here define AR as
| (16) |
which is equivalent to shifting the worse solution that meets the constraint to . Note that , and the solutions that violates the constraint will have negative AR (but positive AR do not necessarily meets the constraint).
The optimization result is shown in Fig 7. First, we look at the AR of the optimal circuits (7(a)), which is the corresponding AR of , where is the ansatz with optimal parameters . We see that VQE heuristic ansatzs are all solved to at least , and the mean of AR is . When we perform the final samplings, we found the outcome contains only a single eigenstates, meaning that the optimal ansatz has probability distribution highly concentrated around one or a few eigenstates. On the other hand, the optimal QAOA ansatzs wasn’t solve to AR as good as heuristic ansatzs, and the final samplings has a distribution over several eigenstates. However, we are still able to get a relatively good solution from only 5 samplings in our case, but it is not guaranteed. We further analyzed the optimal ansatzs by sampling 500000 shots and calculate the variance of eigenvalues in 7(b). As expected, the variance of VQE heuristic ansatzs are almost 0 and QAOA ansatz is large. Furthermore, although the heuristic ansatz still suffers from local minimum and is not easy to solve it to the ground state, a few number of initial guess is sufficient to solve it to a good AR. For QAOA, the result of optimization varies tremendously with the initial point, and we may usually get bad solutions (AR of ansatz ) if we don’t provide enough number of initial guesses. We are not able to determine which ansatz form is better by only looking at the AR and variance of the optimal ansatzs, since they are both able to obtain a solution with good AR within 5 final samplings. However, in terms of the amount of initial guesses, circuit depth and connectivity, and the concentration of probability, we came to a conclusion that VQE heuristic ansatz should be preferred.
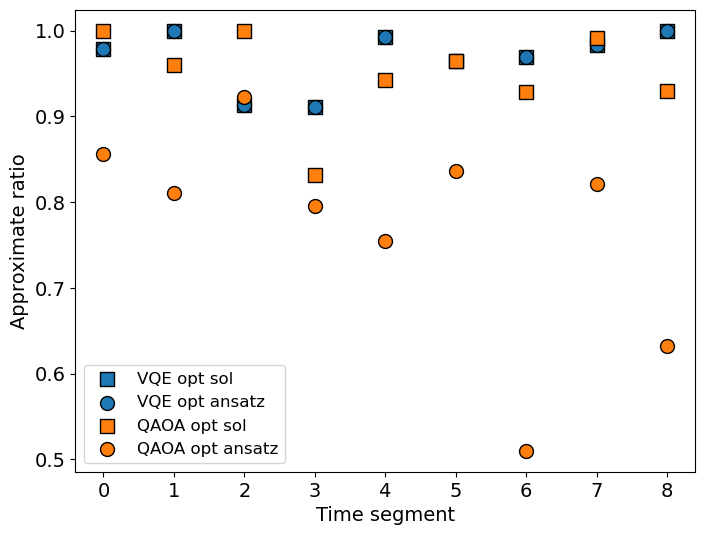
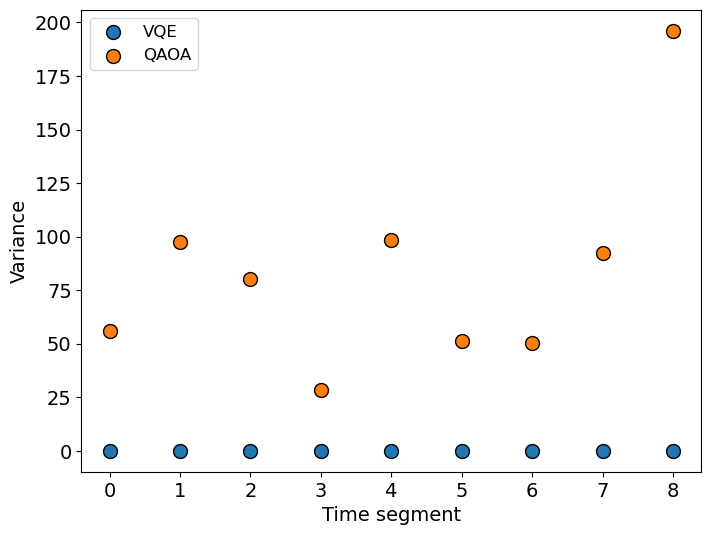
IV-C Backtesting performance
For backtesting, we adopt the view predicted by QSVM, and the show both the exact solution and the optimal solution obtain by VQE and QAOA. Here, the portfolio performance is measured by certainty-equivalent return (CER):
| (17) |
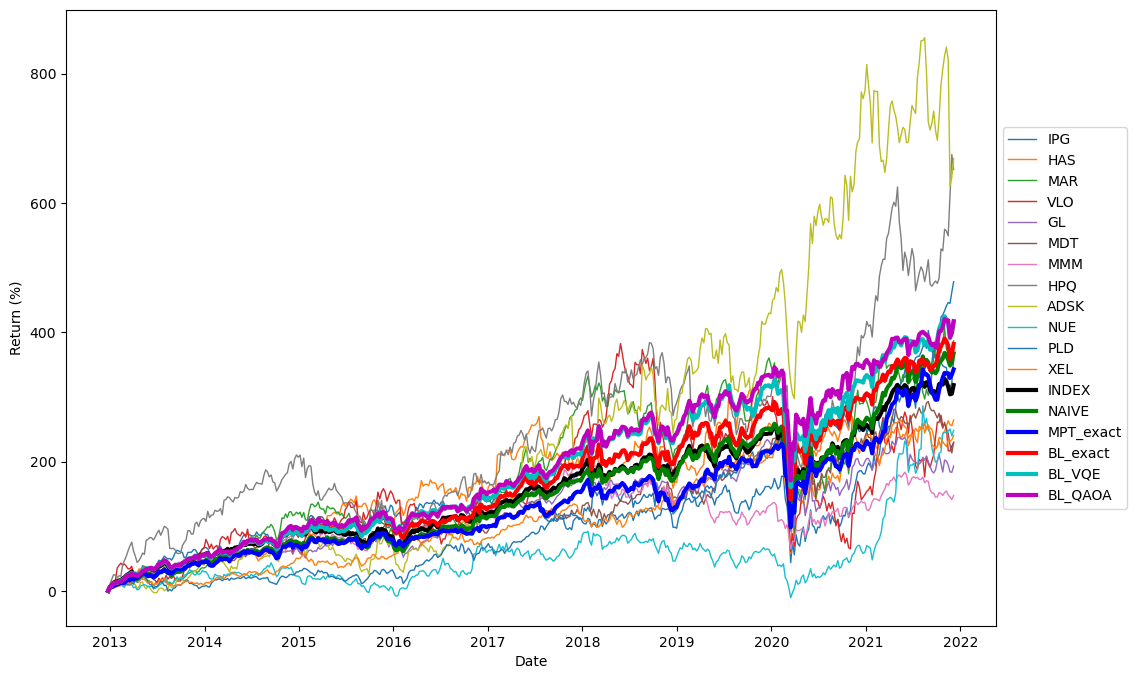
where, is the sample mean of (log) return, and is the standard deviation of the (log) return. The backtesting period covers 9 continuous 52-week time segments, and is compared to 3 kinds of common portfolios, MPT model, naive portfolio ( portfolio), and the market-cap-weighted index. In our case, BL model out performs MPT model in terms of both pure return and mean CER in a long continuous becktesting period. We also show that for VQE/QAOA solutions with high enough ARs could performed similarly as the optimal solution, and even may have a chance to outperform exact solutions. Note that we are not claiming a slightly worse solution will outperform exact solution, but a solution with high AR is enough to perform as good as exact solution. For example in the extended case in Appendix B, the performance is proportional to ARs. This means that we may not necessarily have to solve this problem to the ground state, and we can save computational cost (in terms of Hamiltonian evaluation and classical optimization) by requiring less precision.
V CONCLUSIONS
In this paper, we showcase a practical application of NISQ algorithms to enhance subroutines in the Black-Litterman model. Our results demonstrate better performance compared to several common models over an extended backtesting period. Additionally, the approximated solutions obtained from VQE/QAOA perform similarly to the exact solutions obtained by exhaustive search.
Regarding quantum machine learning, we construct investor views using QNN and QSVM. QSVM, with better testing accuracy and shorter training time, stands out. We anticipate potential advantages for quantum kernels due to their ability to extract complex features in exponential Hilbert space with linearly scaling qubits. This could become valuable for predictions in more complex situations in the future.
In the optimization part, we conclude that the heuristic circuit is preferable over QAOA due to its shallower circuit depth, requiring fewer initial guesses, and exhibiting greater stability in optimization (tendency to concentrate on one or a few eigenstates). Furthermore, we point out that one can—and should—use such few final samplings to find a high-quality solution once the ansatz is optimized. Both variational forms, when optimized, yield solutions with high ARs with only 5 final measurement shots for a 12-qubit problem size. This minimum measurement scheme reduces the number of circuit repetitions in VQE.
Potential quantum advantage is envisioned for larger problems in the future due to the ability of quantum computers to address portfolio optimization problems with linearly scaling qubits. This is in stark contrast to classical computers, which are not able to deal with exponentially growing search spaces.
References
- [1] H. Markowitz, “Portfolio selection,” The Journal of Finance, vol. 1, no. 3, p. 77–91, 1952.
- [2] A. F. Perold, “Large-scale portfolio optimization,” Management science, vol. 30, no. 10, pp. 1143–1160, 1984.
- [3] R. Orus, S. Mugel, and E. Lizaso, “Quantum computing for finance: Overview and prospects,” Reviews in Physics, vol. 4, p. 100028, 2019.
- [4] J. Alcazar, V. Leyton-Ortega, and A. Perdomo-Ortiz, “Classical versus quantum models in machine learning: insights from a finance application,” Machine Learning: Science and Technology, vol. 1, no. 3, p. 035003, 2020.
- [5] D. J. Egger, C. Gambella, J. Marecek, S. McFaddin, M. Mevissen, R. Raymond, A. Simonetto, S. Woerner, and E. Yndurain, “Quantum computing for finance: State-of-the-art and future prospects,” IEEE Transactions on Quantum Engineering, vol. 1, pp. 1–24, 2020.
- [6] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, et al., “Variational quantum algorithms,” Nature Reviews Physics, vol. 3, no. 9, pp. 625–644, 2021.
- [7] A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, “Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,” Nature, vol. 549, no. 7671, pp. 242–246, 2017.
- [8] F. Black and R. Litterman, “Global portfolio optimization,” Financial analysts journal, vol. 48, no. 5, pp. 28–43, 1992.
- [9] T. Idzorek, “A step-by-step guide to the black-litterman model: Incorporating user-specified confidence levels,” in Forecasting expected returns in the financial markets, pp. 17–38, Elsevier, 2007.
- [10] A. Meucci, “The black-litterman approach: Original model and extensions,” Shorter version in, THE ENCYCLOPEDIA OF QUANTITATIVE FINANCE, Wiley, 2010.
- [11] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum-enhanced feature spaces,” Nature, vol. 567, no. 7747, pp. 209–212, 2019.
- [12] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,” Physical Review A, vol. 98, no. 3, p. 032309, 2018.
- [13] E. Farhi and H. Neven, “Classification with quantum neural networks on near term processors,” arXiv preprint arXiv:1802.06002, 2018.
- [14] E. Farhi, J. Goldstone, and S. Gutmann, “A quantum approximate optimization algorithm,” arXiv preprint arXiv:1411.4028, 2014.
- [15] “https://companiesmarketcap.com,”
- [16] F. R. B. of St. Louis, “Fred, federal reserve economic data,” Federal Reserve Bank of St. Louis http://research.stlouisfed.org/fred2/, 1997.
Appendix A Final samplings
Here we estimate an upper bound of final measurements one could use to sample the optimal ansatz. Final measurements greater than is considered inefficient, and one would rather perform random samplings. Assuming that the probability of randomly sampling one solution with is . The probability of getting at least one solution with within random samplings is
| (18) |
Thus, the reasonable final measurements one could perform in order to solve the problem to is , such that
| (19) |
according to the standard of bounded-error probabilistic polynomial time (BPP) class algorithms. In our case, the optimal solution of VQE and QAOA with 5 final samplings is about averaging over 9 time segments. We thus assume , and is also a statistical mean over 9 cases. The maximum for justified final sampling is thus . Moreover, if we conduct only 5 final samplings, the probablity to reach such AR is . This means that our VQE/QAOA ansatzs are well solved since we only need 5 final measurement to achieve such AR.
Appendix B Global portfolio optimization
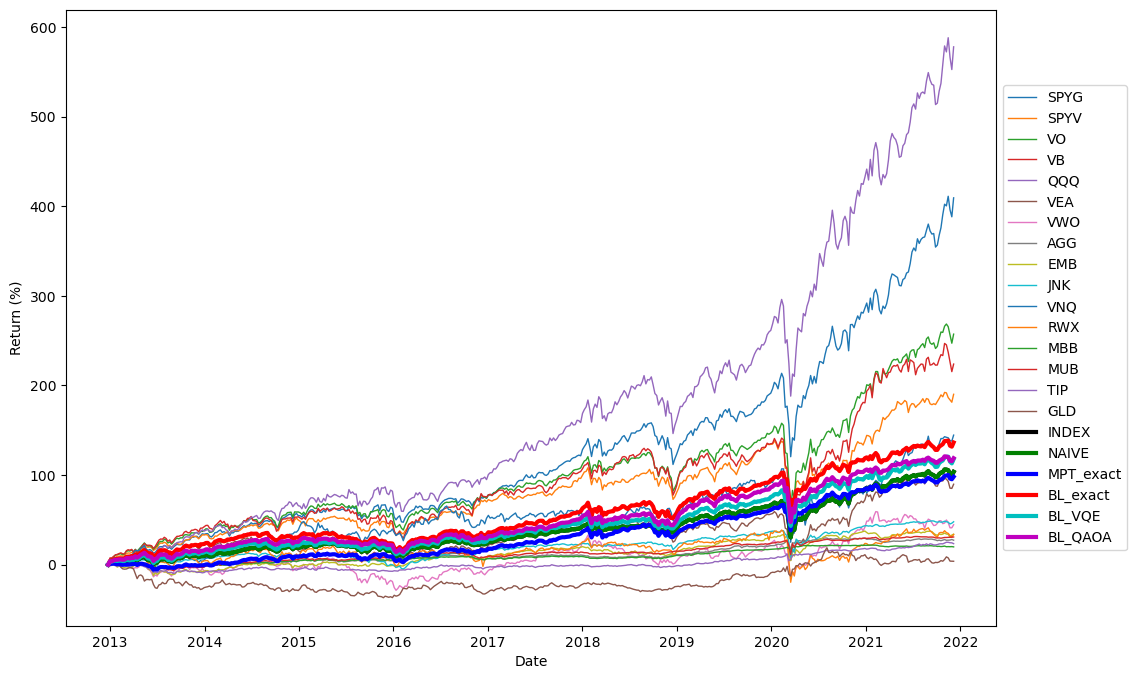
We perform our BL optimization on another case containing a 16 assets pool that approximately represents the global economy, with budget constraint . In this case, the market cap is hard to estimate, we thus consider them equal, the index here is thus identical to a naive portfolio. We applied the QSVC model also with simple embedding feature map with as investor views. The QUBO is then optimized with VQE circuit shown in Fig 5 with and 20 random initial guesses, and QAOA with and 500 initial guesses. The solution is the best among 10 final measurements taken from the optimized ansatz. We here show the backtesting results as well as mean CERs.
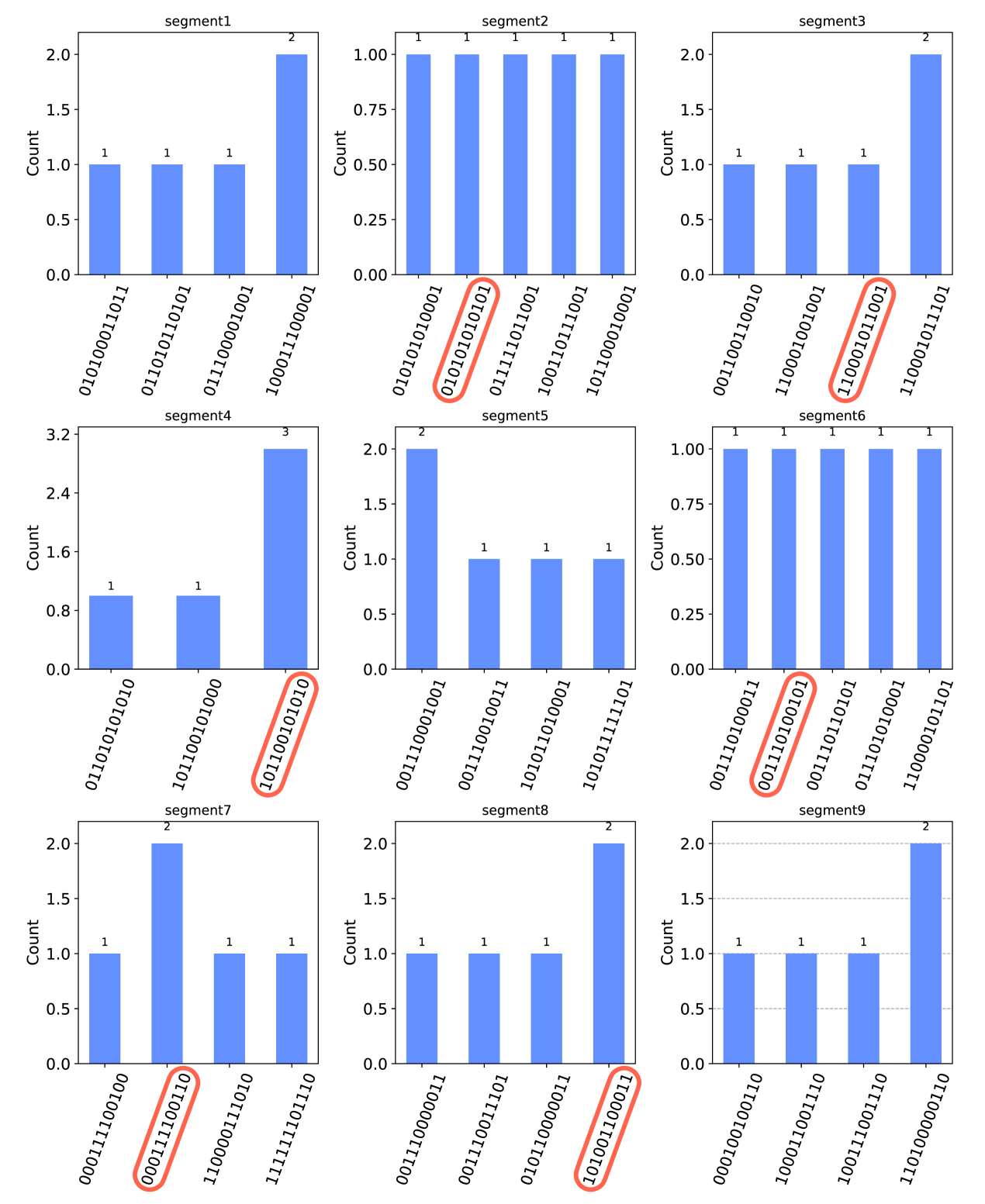
Appendix C Real device
We execute our optimized VQE heuristic circuits (12 qubits) on IBM Auckland, a 27-qubit superconducting gate based quantum computer, for the purpose of final sampling. The result is shown in Fig10 below. We are able to obtain the same solution as simulation result (red circles) within only 5 shots for 6 out of 9 cases, implying that the circuit depth remain suitable for NISQ computers today. On the other hand, the optimized QAOA circuits are much deeper and still have a distribution over a wide range of eigenstates, thus we are not able to gain useful conclusion from performing final measurements on real device.