Blind Face Restoration for Under-Display Camera via Dictionary Guided Transformer
Abstract
By hiding the front-facing camera below the display panel, Under-Display Camera (UDC) provides users with a full-screen experience. However, due to the characteristics of the display, images taken by UDC suffer from significant quality degradation. Methods have been proposed to tackle UDC image restoration and advances have been achieved. There are still no specialized methods and datasets for restoring UDC face images, which may be the most common problem in the UDC scene. To this end, considering color filtering, brightness attenuation, and diffraction in the imaging process of UDC, we propose a two-stage network UDC Degradation Model Network named UDC-DMNet to synthesize UDC images by modeling the processes of UDC imaging. Then we use UDC-DMNet and high-quality face images from FFHQ and CelebA-Test to create UDC face training datasets FFHQ-P/T and testing datasets CelebA-Test-P/T for UDC face restoration. We propose a novel dictionary-guided transformer network named DGFormer. Introducing the facial component dictionary and the characteristics of the UDC image in the restoration makes DGFormer capable of addressing blind face restoration in UDC scenarios. Experiments show that our DGFormer and UDC-DMNet achieve state-of-the-art performance.
Index Terms:
Blind face restoration, image synthesis, under-display camera, transformerI Introduction
In recent years, the technique of Under-Display Camera (UDC) has been widely used in smart devices, which can provide a better experience for users. For example, the smartphone using UDC can achieve true full screen without punch holes or notches. Laptops or tablets that place cameras under the center of the displays can enable a more natural gaze to focus when people use the camera. However, placing the camera below the display (e.g., OLED screen) can seriously degrade the quality of the images, e.g., blur [1], noise [2], low light [3], etc. Enhancing imaging quality can be achieved through the redesign of the display panel’s physical structure, including optimizations in the spatial arrangement of the opening. However, the development costs associated with the refining of OLED display panels can be prohibitively high. An alternative and cost-effective approach involves harnessing deep learning techniques for the restoration of images captured via Under-Display Cameras (UDC). Consequently, image restoration beneath UDC has emerged as a prominent focal point within the realm of computer vision.
A large number of methods [4, 5, 6, 7, 8, 9, 10, 11] have been proposed for image restoration under UDC. For example, DISCNet [5] puts the prior knowledge of an accurately measured PSF in the network design to help restore UDC images. Koh et al. [8] first regard the process of recovery of UDC images as low-spatial-frequency restoration and high-spatial-frequency restoration. Then, they propose a two-branch network called BNUDC to deal with the UDC restoration problem. Although these existing UDC restoration methods work well in the natural UDC image restoration problem, these methods do not fully consider UDC face images. Directly applying these general UDC restoration methods to UDC face images, the recovered results may lack the richness of face details.
On the other hand, existing blind face restoration methods [12, 13, 14, 15, 16, 17, 18] trained on face datasets (e.g., FFHQ [19]) cannot restore the UDC face images very well. Because these datasets and methods do not take into account the characteristics of UDC images, where UDC-degraded images generally suffer from diverse and complicated degradation, e.g., low light, blur, and noise [20, 8, 10, 3]. Thus, existing blind face restoration methods are not applicable for restoring UDC face images. Besides, to the best of our knowledge, there is still no benchmark and specialized method for restoring UDC face images, which may be the most common problem in the UDC scene.

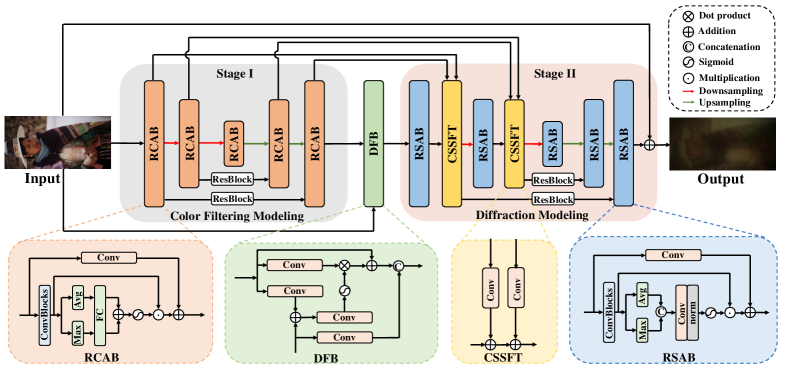
To investigate the UDC face restoration problem, we first propose a synthesis method for synthesizing UDC images with reference to the UDC imaging process. Based on our synthesis method, we build the first UDC face image datasets using the ordinary face dataset FFHQ [19] and CelebA-Test dataset [21]. Finally, we propose a face restoration method specifically for the UDC scene. Specifically, for UDC degradation synthesis, inspired by previous works [22, 4], we propose an end-to-end image synthesis method named UDC Degradation Modeling Network (UDC-DMNet) to simulate the UDC imaging degradation process from existing paired real-world UDC dataset [23]. In particular, UDC-DMNet is a two-stage network, and its two stages are designed for modeling the color filtering and diffraction degradation processes of UDC images, respectively. In addition, the network also uses cross-stage affine transformation and feature fusion to connect the two stages.
To construct UDC face datasets, we first train our UDC-DMNet on two UDC image datasets T-OLED and P-OLED [23], respectively. Then we use high-quality face images from FFHQ [19] as inputs to the trained UDC-DMNet to synthesize corresponding low-quality face images from the training dataset named FFHQ-P and FFHQ-T for UDC face restoration. In the end, we use high-quality face images from CelebA-Test [21] dataset to synthesize corresponding low-quality face images of the testing dataset, CelebA-Test-P, and CelebA-Test-T. Exemplar images of our built dataset are shown in Fig. 1.
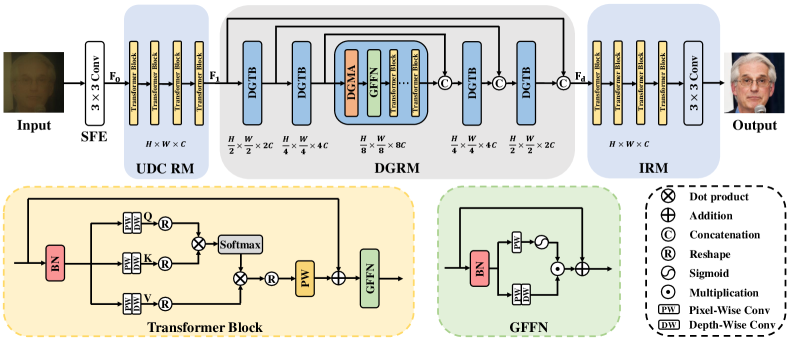
Based on our built UDC face datasets, we propose a Dictionary-Guide Transformer called DGFormer for UDC face restoration. DGFormer uses the facial component dictionary as the face prior and takes into account the characteristics of UDC images to achieve effective UDC face restoration. To be specific, our DGFormer consists of four modules: Shallow Feature Extractor (SFE), UDC Restoration Module (UDCRM), Dictionary-Guided Restoration Module (DGRM), and Image Reconstruction Module (IRM). SFE extracts image features and UDCRM achieves coarse-grained UDC degradation removal by several transformer blocks designed considering UDC characteristics. DGRM adopts the proposed dictionary-guided transformer blocks containing facial dictionaries, which can provide diverse facial component textures for fine-grained restoration. IRM reconstructs the fine-grained feature to a clear image. The comprehensive experiments show that our UDC-DMNet and our DGFormer achieve state-of-the-art performance. We hope that DGFormer and UDC-DMNet can benefit the community.
Overall, our contributions can be summarized as follows:
-
•
We propose UDC-DMNet to simulate the UDC imaging degradation process from the existing paired real-world UDC dataset. With UDC-DMNet, we build the first UDC face restoration datasets, FFHQ-P/T for training and CelebA-Test-P/T for evaluation of UDC face. To the best of our knowledge, we are the first to build UDC face datasets.
-
•
We propose a method called DGFormer for UDC face image restoration. DGFormer comprehensively considers the face prior information and the characteristics of the UDC image, achieving effective UDC face restoration.
-
•
According to extensive experimental studies, the UDC image synthesis method UDC-DMNet and the UDC face restoration method DGFormer are state-of-the-art compared with existing methods.
The subsequent sections of this paper are structured as follows: In Section II, we review pertinent research encompassing UDC imaging, UDC image restoration, and blind face restoration. Section III illustrates our UDC-DMNet and DGFormer models. Section IV provides a comprehensive account of the experimental results and their corresponding analyses. Ultimately, our conclusion and future work are encapsulated in Section V.
II Related Work
In this section, we present a brief literature review of UDC imaging, UDC image restoration, and blind face restoration.
II-A UDC Imaging and Degradation Model
Zhou et al. [10] first analyze the UDC optical system and then establish the physical model of the degradation of images captured by UDC. Specifically, in the UDC imaging system, before being captured by the sensor, the light emitted from a point light source is modulated by the OLED and camera lens. Due to the diffraction effects, light transmission rate, camera noise, and other problems caused by OLED and camera lenses, UDC images always tend to be blurry, low-light, and noisy. The degradation processing of UDC imaging is typically modeled by
| (1) |
where is the clean real world image, and is the degraded UDC image. represents the intensity scaling factor which simultaneously relates to the physical light transmission rate of the display and the changing ratio of the average pixel values. is the Point Spread Function (PSF) which depends on the type of display. is additive noise, and denotes the convolution operator. Based on the above model, several works [5, 11, 9] make various changes considering different aspects of UDC. For example, considering proper dynamic range for the scenes and camera sensor, Feng et al. [5] turn the input image into an HDR image. Considering that the PSF is not valid for the corners of the image, where the light is obliquely incident on the panel, Kown et al. [9] use PSF from different angles. Besides, Koh et al. [8] consider the different transmission rates of wavelengths by the thin-film layers of an OLED and further simplify the degradation process into two stages. It can be formulated as
| (2) |
where represents color filtering and spatially variant attenuation caused by thin-film layers of the OLEDs and is diffraction which can be represented by a PSF caused by the pixel definition layer of the OLEDs.
II-B UDC Image Restoration
In the work of UDC image restoration, Zhou et al. [10] propose a UDC dataset with paired low-quality and high-quality images which are captured with Monitor-Camera Imaging System (MCIS) devised by the authors. There are some works in the ECCV challenge [23] trying to solve the UDC image restoration problem. Feng et al. [5] construct a new UDC image dataset that uses HDR images as input and measures the PSF of the UDC system to generate UDC images. They also propose DISCNet to address the UDC image restoration problem. The MIPI challenge [24] aims to tackle the problem of UDC image restoration and attracts more and more attention. Besides, by achieving a deep learning approach that performs a RAW-to-RAW image restoration, Qi et al. [25] propose an image-restoration pipeline that is ISP-agnostic and successfully accomplishes superior quantitative performance. Kwon et al. [9] tackle this problem as denoising and deblur utilizing pixel-wise UDC-specific kernel representation and a noise estimator, achieving higher perceptual quality. Koh et al. [8] introduce a deep neural network with two branches to reverse each type of degradation of UDC. Their network outperforms existing methods on all three datasets of UDC images. Considering the deployment of the mobile terminal, Li et al. [26] propose a lightweight method and further distill the proposed model.
Although the above methods have been used to deal with the natural UDC image restoration problem, there is still no specialized method or dataset for the restoration of face images in the UDC scenery, which may be the most common problem in the UDC scene. Thus, we propose a method for synthesizing UDC images with reference to the UDC imaging process. With this synthesis method, we build UDC facial image datasets using the ordinary face dataset FFHQ [19] and CelebA-Test [21] and propose a face restoration method specifically for the UDC scene.
II-C Blind Face Restoration
Due to the wide application scenarios of face images, face image restoration has received a lot of attention in all aspects. e.g., face super resolution [27, 28, 29], blind face restoration [12, 30, 31], face inpainting [32, 33, 34], etc. Among them, blind face restoration (BFR) aims to restore high-quality face images from low-quality ones without the knowledge of degradation types or parameters [35]. In the literature, BFR methods can be approximately divided into two categories: prior-based restoration methods and non-prior-based restoration methods. Some non-prior-based methods [14] perform BFR by learning the mapping function between low-quality and high-quality facial images. Because of the high degree of face structures, most blind face restoration methods use face priors to recover facial images with clearer facial structures, such as generative prior [36, 37, 13, 38], reference prior [30, 18, 17, 39], and geometric prior [40, 41, 42, 43].
Generative prior used in BFR methods mainly include using GAN inversion [36] and pre-training facial GAN models [12, 13, 37] such as StyleGAN [44] to provide richer and more diverse facial information. However, these methods based on generative prior do not consider identity information during the training and the methods are limited to the latent space of generators. Although these methods show good performance in terms of image generation metrics and detail texture, their restored images lack fidelity. Several reference prior based methods [30, 17, 39, 18] guide the face restoration process by using the facial structure or facial component dictionary obtained from additional high-quality face images as a reference prior. Li et al. [30] propose a deep face dictionary network (DFDNet) for face restoration, which uses a dictionary of facial components extracted from high-quality images as a reference prior. Then, they select the most similar component features from the component dictionary to transfer the details to low-quality face images for face restoration. While VQFR [18] and RestoreFormer [17] using VQGAN [45] pretrain a high-quality codebook on entire faces, acquiring rich expressiveness. The unique geometric shape and spatial distribution information of faces in the images are used to help the model gradually recover high-quality face images in geometric prior-based methods, which mainly include facial landmarks [40, 46], facial heatmaps [42], and facial parsing maps [16]. In these methods, geometric priors usually need to be extracted from degraded face images, but the degraded face images cannot obtain the prior information accurately. In addition, geometric priority cannot provide rich details for face restoration.
III Methodology
In this section, We first introduce our method for synthesizing face UDC images. Based on the proposed synthetic method, we build the first UDC face datasets (i.e., FFHQ-P/T for training, and CelebA-Test-P/T for testing) by using FFHQ and CelebA-Test datasets. Moreover, with these synthetic UDC face datasets, we further propose a dictionary guide transformer restoration network called DGFormer for blind face restoration in UDC.
III-A UDC Degradation Synthesis and Datasets
III-A1 Degradation Synthesis
Existing methods usually use the UDC degradation model in Eq. (1) to synthesize UDC-degraded images. However, there exists a big gap between this approximate degradation model and the real UDC degradation. For example, the parameters in degradation (intensity scale factor and PSF ) are different in UDC configurations, which requires extensive human effort to obtain these parameters in advance [10, 5, 9]. Thus, we design an end-to-end UDC degradation modeling network called UDC-DMNet to directly learn the UDC degradation process with the existing real-world paired data.
As shown in Fig. 2, our UDC-DMNet models the UDC degradation process as two stages [8] i.e., color filtering and brightness attenuation modeling, and diffraction modeling. Correspondingly, our UDC-DMNet is a two-stage network, where the first stage is used for color filtering and brightness attenuation modeling, and the second stage is designed for diffraction modeling.
Color Filtering and Brightness Attenuation Modeling. When the light is normally incident on the OLED display, part of the light will be absorbed by the display, because the thin-film layers of an OLED have different transmission rates for different wavelengths. Thus, a clean image first exhibits color filtering and brightness attenuation in the UDC imaging process and the degradation is highly related to the channels of the image. To model this degradation process, as shown in Fig. 2, we first use one convolutional layer in the first stage of our UDC-DMNet to extract the initial features. Then, those features are fed into an encoder-decoder architecture with four downsampling and upsampling operations to derive multi-scale information. In each scale, we use a Residual Channel Attention Block (RCAB) [47, 48] to adaptively learn the process of brightness attenuation. In particular, RCAB consists of three convolution layers and one channel attention layer. With the help of RCAB, the first stage of our UDC-DMNet can fully simulate the brightness and color of the UDC image.
Diffraction Modeling. In the second stage of UDC imaging, the light will be incident on the pixel definition layer (PDL). PDL that has a periodic window pattern acts as a planar diffraction grating [49, 50]. And images formed under PDL will be blurry. Previous works [10, 5, 9] usually estimate the PSF to simulate this process. However, PSF is highly complicated, and the measured PSF is usually not universal. Thus, in this work, we also choose encoder-decoder architecture to model this diffraction process. To better cover the PSF of various scales, we use a convolution with the stride of 2 to downsample and use a transposed convolution to upsample the feature maps. Specifically, in each scale, we adopt a residual block with spatial attention [48] named Residual Spatial Attention Block (RSAB) as the basic layer to build the second stage of our UDC-DMNet. With the help of RSAB, our UDC-DMNet can well simulate the blur caused by spatial changes in the second stage.
Moreover, considering that the degradation of the first stage may affect the diffraction of the second stage and a long series of convolution operations are likely to cause blurring of edge features. Thus, as shown in Fig. 2, we propose a Cross-Stage Spatial Feature Transform (CSSFT) to connect two stages of our UDC-DMNet. CSSFT can help simplify the information flow among stages to address the above problem [51, 52]. Specifically, CSSFT can be formulated as follows,
| (3) |
where and are both convolution. and are the same scale features from the encoder and decoder in the first stage, respectively. , are the parameters of the spatial feature transform, which can be defined as
| (4) |
where is the output of RSAB, and represents the output of the spatial feature transform.
In addition, as shown in Fig. 2, we introduce a Degradation Fusion Block (DFB) between the first and second stages of our UDC-DMNet to fuse color-filtering degraded features with the input image, which makes the second stage of UDC-DMNet better focus on diffraction modeling.
III-A2 Loss Function
We first select the Peak Signal-to-Noise Ratio (PSNR) loss as the main supervision [53]. However, the PSNR loss function merely measures the pixel-wise distance and cannot properly describe the similarity of the degradation of two images. The generated degraded image will be over-smooth. Therefore, we further select perceptual loss [54] and adversarial loss [55] to learn the degradation patterns in training. We adopt three losses to train UDC-DMNet: PSNR loss , perceptual loss and adversarial loss . The PSNR loss is defined as:
| (5) |
where and refer to the generated degraded image and ground-truth degraded image respectively. Then the perceptual loss is used to help our model produce visually pleasing results. We adopt a pre-trained VGG19 [56] to extract the perceptual features from the layer of VGG19, and then use the loss function to calculate the difference in the feature space between the generated degraded image and their corresponding ground-truth degraded image. Specifically, the perceptual loss is as follows:
| (6) |
We use adversarial loss on the output of the generator of UDC-DMNet to distinguish real and fake degraded images. This is helpful to make the UDC-DMNet model the degradation process better and narrow the gap between the generated distribution and the real-world distribution. Specifically, we adopt the discriminator of PatchGAN [57] for adversarial training:
| (7) |
The final loss function to train our proposed UDC-DMNet is shown as follows:
| (8) |
where and are hyper-parameters used to balance these three losses. In our experiments, they are both set to .
III-A3 Building UDC Face Datasets
We train our UDC-DMNet on the P-OLED and T-OLED datasets [23], respectively. Both datasets have pairs of degraded UDC images captured using a UDC device in the real world and the corresponding ground truth images. Each image is of resolution . After the model training, we leverage the FFHQ dataset [19], which consists of high-quality face images as inputs to the trained UDC-DMNet to synthesize UDC face datasets, FFHQ-P and FFHQ-T, which will be specifically employed for the training of our proposed UDC face image restoration model illustrated in the following. For evaluation of UDC face image restoration, we use high-quality face images in CelebA-Test dataset [21] as inputs of the trained UDC-DMNet to synthesize CelebA-Test-P and CelebA-Test-T.
III-B Dictionary Guide Transformer
To better restore facial images in the UDC scenery, we further propose a transformer-based network with dictionary guidance, named DGFormer.
III-B1 Overall Architecture
As shown in Fig. 3, DGFormer consists of four modules: shallow feature extractor, UDC restoration module, dictionary-guided restoration module, and image reconstruction module. Specifically, give a degraded UDC face image , the shallow feature extractor, consisting of a simple convolution, first extracts features from the input image . Then, the feature is fed into the subsequent UDC restoration module to achieve coarse-grained UDC degradation removal. The UDC restoration module is composed of several specially designed transformer blocks. After that, the output feature of the UDC restoration module is forwarded into the dictionary-guided restoration module for fine-grained restoration. The dictionary-guided restoration module is a symmetric encoder-decoder structure, which is mainly built by our proposed dictionary-guided transformer blocks. Finally, the fine-grained feature is reconstructed to a clear image by the image reconstruction module. The UDC restoration module, dictionary-guided restoration module, and image reconstruction module are core modules of our DGFormer, thus we detail them in the following.
III-B2 UDC Restoration Module
The UDC image usually has diverse and complicated degradation (e.g., low light, blur, noise etc.), thus directly restoring clear images from UDC images is difficult. In addition, the complex degradation in UDC input images causes difficulty in extracting face priors, which influences the performance. Thus, we propose a UDC Restoration Module as the successor of the shallow extractor to achieve coarse-grained UDC degradation removal. Previous work [4] claims that the UDC restoration network should consider global and local information in the network design because removing low light and color filtering degradation in UDC images requires global information in each color channel, and local information is more favorable for noise and blur removal. Thus, as shown in Fig. 3, we propose a new transformer block as the basic unit to build our UDC Restoration Module. The proposed transformer block considers both global and local information for feature processing. Specifically, in the proposed transformer block, we first use a pixel-wise convolution [58] and a depth-wise convolution [59] to generate query, key, and value which are helpful to enrich the local context. Then, we perform self-attention across channels [60] to generate an attention map encoding the global context implicitly. Finally, we resort to the gating mechanism in the feed-forward network named Gating Feed Forward Network (GFFN) to further improve the expressive capability of networks. Specifically, the gating mechanism is formulated as the element-wise product of two parallel paths. In the first path, we adopt a pixel-wise convolution and a depth-wise convolution to strengthen the locality. In the second path, we adopt a pixel-wise convolution followed by a Sigmoid function as a gating signal. The UCD restoration module can be formulated as
| (9) |
where is the UDC Restoration module that contains several transformer blocks, represents output features of the shallow feature extractor, and is output features.

III-B3 Dictionary-guided Restoration Module
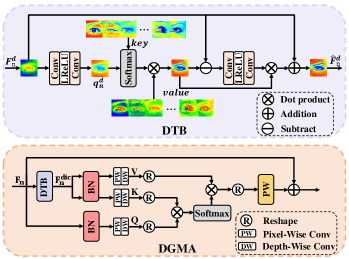
To achieve fine-grained UDC face restoration, we exploit the face dictionary as extra facial prior knowledge in the proposed dictionary-guided restoration module to further help restore face details of the face images. The dictionary-guided restoration module is designed under an encoder-decoder structure with skip connections, which can fully exploit both multi-scale features and face dictionary prior for effective face restoration. In our dictionary-guided restoration module, we propose a novel Dictionary-Guided Transformer Block (DGTB) as the basic block of the encoder-decoder structure to restore the facial details of the image. As shown in Fig. 3, the DGTB consists of a Dictionary-Guide Muti-head Attention (DGMA), a GFFN in the UDC Restoration Module, and several transformer blocks. DGMA has facial component dictionaries and queries these dictionaries through Dictionary Transform Block (DTB). By storing the high-quality textures of the eyes, nose, and mouth in the facial component dictionary in advance, we can significantly improve the model’s ability to restore face details.
DGMA is our core component, which is shown in Fig. 5. The facial component dictionary in each DGMA can be expressed as follows
| (10) |
where is the number of key values in the dictionary. To make sure the dictionary can be end-to-end optimized by the final loss, we set the in the dictionary as learnable parameters. The size of the and are related to the scale where DGMA is located. Taking the eye dictionary as an example, in the DGMA with an input feature size of , the size of each key and value is , where is the size of the detected eye landmark box. Supposing the input feature of DGMA is , DGMA first takes the obtained into DTB. DTB first obtains facial component features such as eyes and mouth from through RoIAlign operation and detected facial landmarks. Then query features is obtained through a series of convolution operations on features . Then DTB queries the component dictionary in a similar way as the attention mechanism. After that, DTB fuses the original component features and the component features queried in the dictionary, then copies and pastes fused component features into the original features through reverse RoIAlign operation to obtain features . Then, instead of using self-attention directly to features , our DGMA takes input features as queries , while the keys and values are generated from output feature of DTB , where is a pixel-wise convolution and is a depth-wise convolution. Finally, we adopt the attention mechanism to conduct face restoration. Overall, the DGMA process is defined as
| (11) |
where is a learnable scaling parameter. With the guidance of the face dictionary prior, our DGMA can fuse the information from the features and its corresponding high-quality face texture features . They can respectively provide identity information and high-quality facial details for face restoration. While normal self-attention usually can only consider the feature of a single information source.
For the DGTB of each scale, after using a DGMA and a GFFN, we choose to use several transformer blocks mentioned in UDCRM to refine the features of this scale instead of continuing to use DGMA. Because we find that the use of the DGMA query dictionary repeatedly can cause model performance to decline.
III-B4 Image Reconstruction Module
Following the Dictionary Guided Restoration Module, deep features are put into the image reconstruction module. In this module, we use four consecutive transformer blocks and a convolution to transform into the final clear face image. To simplify our DGFormer, we use the same transformer block that is used in the UDC restoration module.
III-B5 Loss Function
To train our DGFormer, we use L1 loss between the recovered images and the ground truth images.


IV Experiment
In this section, we conducted a series of experiments to compare our synthesis methods with the existing synthesis methods and the real-world datasets, and compare our restoration methods with existing UDC restoration and face restoration methods. The results of quantitative and qualitative experiments prove the effectiveness of both synthesis and restoration methods. Furthermore, we have performed an ablation study to validate the efficacy of each module within our network architecture.
IV-A Implementation Details
In this work, the training settings of the two networks are different. For UDC-DMNet, we train it using Adam optimizer [61] with , to minimize a weighted combination of PSNR loss [53], perceptual loss [54], and the adversarial loss [62] for iterations. We choose PatchGANDiscriminator [57] as the discriminator. The initial learning rates are set to both for the generator and discriminator. The learning rate is decayed with a cosine annealing schedule [63], where the learning rate is decreased to . The batch size is set to , and we apply horizontal flipping and rotation as data augmentation and crop image patch of for training. And as for DGFormer, the number of transformer blocks in the UDC Restoration Module and Image Reconstruction Module are both . The number of transformer blocks in each layer of the Dictionary Guided Restoration Module is , and attention heads are . We use AdamW [64] optimizer (, , weight decay 0.01) with the cosine annealing strategy to train the DGFormer, where the learning rate gradually decreases from the initial learning rate to for epochs. We choose loss and perceptual loss as the final loss and the training batch size is set to .
| Data from | P-OLED [23] | T-OLED [23] | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| Real world [23] | 27.79 | 0.8446 | 32.98 | 0.9248 |
| DAGF [22] | 21.20 | 0.6554 | 24.20 | 0.8031 |
| MPGNet [4] | 21.77 | 0.7471 | 32.66 | 0.9240 |
| UDC-DMNet | 27.03 | 0.8217 | 32.86 | 0.9244 |
| Real world+UDC-DMNet | 28.36 | 0.8595 | 33.93 | 0.9375 |


IV-B Analysis of Synthesis Method
Since our UDC-DMNet is proposed to simulate a degradation process in generating UDC images, in this work, we mainly compare with two related works, i.e., DAGF [22], MPGNet [4] which are both representative methods for synthesizing UDC images. Besides, we also compare with real-world UDC images [23].
The qualitative comparisons are shown in Fig. 5. For the P-OLED scene, the results demonstrate that DAGF cannot simulate the noise, and P-OLED UDC images synthesized by DAGF are over-smooth. In this regard, images generated by our method and MPGNet are closer to the ground truth. While MPGNet cannot simulate the brightness of P-OLED UDC images. As the results show, the P-OLED UDC images synthesized by MPGNet tend to be darker. Besides, MPGNet and DAGF cannot simulate color-shift well. For the T-OLED scene, the blurred details of the UDC images synthesized by MPGNet and DAGF are different from the real-world UDC images. And they cannot simulate the striped shadows in T-OLED UDC images compared with ours.
We use different synthetic datasets and real-world UDC datasets to train an identical restoration model, NAFNet [65]. For a fair comparison, the model is trained on different data sources by epochs with the same training parameters. After training, we evaluate the restoration model on real-world UDC images. The quantitative results for different data sources are shown in Table I. For P-OLED, the model trained with our synthetic dataset achieves the closest PSNR and SSIM to the real-world dataset and is significantly higher than other results with synthetic datasets generated by DAGF and MPGNet. For T-OLED, the model trained with our dataset still slightly outperforms others and is closest to the real-world dataset. At the same time, when we combine our dataset and real-world dataset to train the restoration model, the performance of the model is improved compared to the counterpart with only the real-world dataset. It shows that the dataset we build can play the role of supplement and thus improve the generalization of the model. The qualitative results across diverse data sources are shown in Fig 6 and 7. For P-OLED, when compared to MPGNet, images restored by NAFNet, trained with UDC-DMNet’s synthetic P-OLED datasets, perform a closer match in brightness to images restored by NAFNet trained with real-world datasets. Furthermore, images restored by NAFNet, trained with both synthetic and real-world datasets, are closer to clean images in comparison to NAFNet trained only on real-world datasets. In the case of T-OLED, NAFNet trained with UDC-DMNet’s synthetic T-OLED datasets performs superior capability in removing striped shadows when contrasted with MPGNet. Simultaneously, the synthetic dataset serves to complement the real-world datasets, thereby contributing to the overall enhancement of the restoration model’s performance.
IV-C Comparison with SOTA Restoration Methods
| Method | PSNR | SSIM | LPIPS | Deg. | LMD |
|---|---|---|---|---|---|
| input | 9.84 | 0.4448 | 0.6808 | 68.89 | 3.50 |
| GFPGAN[12] | 28.04 | 0.8359 | 0.2766 | 22.71 | 1.17 |
| VQFR[18] | 24.14 | 0.6629 | 0.3270 | 43.40 | 2.72 |
| PSFR-GAN[16] | 23.39 | 0.7001 | 0.4464 | 37.36 | 1.87 |
| RestoreFormer[17] | 24.66 | 0.6994 | 0.3349 | 27.91 | 1.76 |
| BNUDC[8] | 31.58 | 0.8993 | 0.2342 | 21.03 | 0.96 |
| DAGF[22] | 30.47 | 0.8678 | 0.2909 | 22.41 | 1.07 |
| DWFormer[4] | 30.83 | 0.8869 | 0.2629 | 22.96 | 1.05 |
| ResUNet[6] | 31.84 | 0.9010 | 0.2280 | 20.66 | 0.92 |
| DGFormer (Ours) | 32.69 | 0.9094 | 0.2015 | 18.97 | 0.85 |
We compare the performance of the proposed DGFormer with several state-of-the-art UDC restoration methods: BNUDC [8], DAGF [22], ResUNet [6], DWFromer [4] and several state-of-the-art face restoration methods: GFPGAN [12], PSFRGAN [16], VQFR [18], RestoreFormer [17] on the synthetic UDC face dataset. To ensure a fair comparison, all methods are trained under the same training settings. For evaluation, we employ pixel-wise metrics (PSNR and SSIM) and the perceptual metric (LPIPS [66]). And we measure the identity distance with angels in the ArcFace [67] feature embedding as the identity metric, which is denoted by ‘Deg.’. We also adopt landmark distance (LMD) as the fidelity metric to better measure the fidelity with accurate facial positions and expressions.
The quantitative comparisons in terms of the above metrics are reported in Table II and Table III. The results show that our method achieves state-of-the-art performance on both CelebA-Test-P and CelebA-Test-T. Specifically, DGFormer achieves the best performance regarding PSNR and SSIM. Moreover, DGFormer achieves the lowest LPIPS, indicating that the perceptual quality of restored faces is closest to ground truth. DGFormer also achieves the best Deg. and LDM, showing that it can recover accurate facial parts and details. In addition, some restoration methods based on face priors perform poorly. We suspect that this is mainly due to the difference between UDC degradation and normal degradation. UDC degradation is a combination of multiple degradations such as low light, blur, and noise, which is distinct from normal degradation. Therefore, if the specific characteristics of the UDC image are not considered when introducing the face prior in the network, the prior may not work well.
| Method | PSNR | SSIM | LPIPS | Deg. | LMD |
|---|---|---|---|---|---|
| input | 25.56 | 0.7673 | 0.3796 | 32.22 | 1.99 |
| GFPGAN[12] | 31.09 | 0.9479 | 0.1705 | 13.01 | 0.78 |
| VQFR[18] | 24.84 | 0.6841 | 0.3354 | 31.67 | 2.04 |
| PSFR-GAN[16] | 31.09 | 0.8750 | 0.2294 | 15.43 | 0.86 |
| RestoreFormer[17] | 27.42 | 0.7505 | 0.2419 | 16.22 | 1.00 |
| BNUDC[8] | 36.49 | 0.9498 | 0.1232 | 8.98 | 0.36 |
| DAGF[22] | 33.63 | 0.9131 | 0.1826 | 11.79 | 0.48 |
| DWFormer[4] | 36.68 | 0.9533 | 0.1194 | 8.72 | 0.35 |
| ResUNet[6] | 37.38 | 0.9604 | 0.0951 | 7.55 | 0.30 |
| DGFormer (Ours) | 38.35 | 0.9678 | 0.0720 | 6.49 | 0.27 |
The qualitative results are presented in Fig. 8, 9. Compared with UDC restoration methods, thanks to our special design dictionary-guided restoration module, our method recovers faithful details in the eyes, mouth, etc. On the contrary, face images restored by normal UDC restoration methods are over-smooth and lose facial details. Compared with face restoration methods, some of them do not remove the degradation of UDC face images well (see the second column in Fig. 8, 9). And some of them introduce texture information that does not belong to the original face (see the third and fourth columns in Fig. 8, 9). In contrast, our method performs better in both aspects. This is attributed to the fact that the characteristics of UDC degradation are taken into consideration when designing the network.
IV-D Ablation Studies
| Configurations | PSNR | SSIM |
|---|---|---|
| only PSNR Loss | 24.31 | 0.6179 |
| PSNR Loss + Perceptual Loss | 26.10 | 0.7917 |
| PSNR Loss + GAN Loss | 26.69 | 0.8131 |
| w/o RSAB | 26.02 | 0.8052 |
| w/o RCAB | 25.92 | 0.7989 |
| w/o CSSFT | 26.58 | 0.7943 |
| w/o DFB | 25.85 | 0.7896 |
| Single Stage | 24.96 | 0.7885 |
| Full method | 27.03 | 0.8217 |
IV-D1 UDC-DMNet
In the ablation of UDC-DMNet, we analyze the effectiveness of its components. We use UDC-DMNet with different settings to synthesize different P-OLED datasets to train an identical restoration model, NAFNet [65]. For a fair comparison, the model is trained on different datasets by epochs with the same training parameters. After training, we evaluate the restoration model on real-world P-OLED UDC images. Table IV reports the performance of different settings.
We first perform ablation experiments on the loss function. When using only PSNR loss to train the network, the performance of the network declines significantly. The reason is that images generated by UDC-DMNet are too smooth, and UDC-DMNet fails to generate any noise degradation in the generated images. The restoration model trained with such synthetic data cannot remove UDC degradation well. Then ablation experiments are carried out on perceptual loss and adversarial loss respectively. Compared to using only PSNR loss, adding both losses can improve the utility of the synthetic dataset and make the restoration model trained by it perform better.
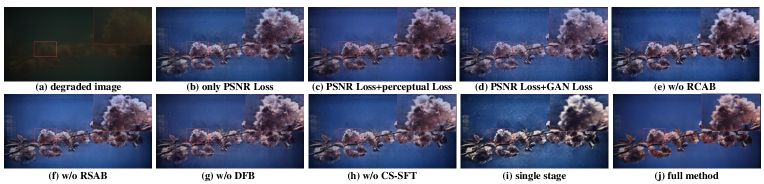
Secondly, we perform ablation experiments on each component in the UDC-DMNet structure. Specifically, we first remove RSAB and RCAB respectively, adopting a normal residual block [68] in each stage. Removing RSAB causes a drop of dB in terms of PSNR and removing RCAB causes a drop of dB in terms of PSNR. It demonstrates that both kinds of attention blocks are useful for simulating degradation. Then we remove the Cross-Stage Spatial Feature Transform (CSSFT), and the performance drops by about dB regarding PSNR. Then we remove the Degradation Fusion Block (DFB), and the performance drops by about dB in terms of PSNR. All the ablation studies demonstrate the effectiveness of our proposed UDC-DMNet for UDC image synthesis. Furthermore, we modify the network to single-stage to explore the effectiveness of multi-stage modeling of the degradation process. This leads to a significant drop in performance, indicating that multi-stage modeling affects the synthesis performance significantly. The qualitative results for different configurations are shown in Fig. 10. UDC-DMNET, without any of the concerned components, can hardly simulate real-world UDC degradation. As shown in the figure, this leads to poor performance of the restoration model trained on these synthetic datasets.
| Configuration | PSNR | SSIM |
|---|---|---|
| use ResBlock | 30.88 | 0.8870 |
| w/o UDCRM | 32.37 | 0.9062 |
| w/o IRM | 32.26 | 0.8998 |
| w/o DTB in DGTB | 32.20 | 0.9038 |
| Replace DGMA with self-attention | 32.11 | 0.9012 |
| Replace transformer blocks with DGMA+GFFN | 31.89 | 0.9002 |
| Full method | 32.69 | 0.9094 |
IV-D2 DGFormer
We further analyze and discuss the effectiveness of the internal modules in our DGFormer. Table V shows the results, where all models are trained on FFHQ-P and tested on CelebA-Test-P.
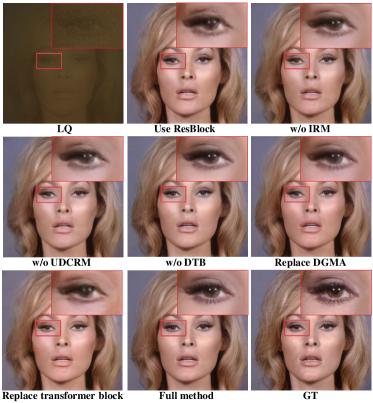
Firstly, we replace the transformer blocks with residual blocks [69, 68] for training, leading to a significant drop in performance. It implies that transformer blocks are important for the integration of global information and local information. Secondly, we remove the UDC Restoration Module (UDCRM) and Image Reconstruction Module (IRM) respectively, which both result in a performance drop, implying that both coarse-grained UDC degradation removal and image feature refinement are indispensable. Thirdly, we remove the Dictionary Transform Block (DTB) in each Dictionary-Guided Transformer Block (DGTB). In this way, we will not use the facial component dictionary in the network. This also causes performance drop, and the facial details are easily lost, demonstrating that dictionaries are helpful in the restoration of facial component details. Fourth, we replace DGMA with normal self-attention, which results in a performance drop. This shows that DGMA, which combines low-quality features and features enhanced by prior information, is more conducive to image restoration than self-attention using only a single feature as an information source. Finally, we replace the normal transformer block in DGTB with DGMA + GFFN, causing a performance drop, which shows that the repeated use of the dictionary has a negative impact on the restoration of details.
The visual results of varying configurations are presented in Fig. 11. Regarding ‘use Resblocks’ and ‘w/o UDCRM’ in the figure, the absence of a transformer structure and UDCRM cannot fully eliminate UDC degradation, leading to blurring and noise artifacts in the restored images. For ‘w/o DTB’ in the figure, the restoration model without the dictionary component struggles to effectively restore eye details. In addition, as shown in the ‘Replace transformer block’ of the figure, when we replace the transformer block in DGTB with DGMA + GFFN, the eyes of the restored image become blurrier. Furthermore, in comparison with ‘w/o IRM’ and ‘Replace DGMA’, images restored by full DGFormer showcase more comprehensive and detailed eye features. This illustrates the refinement effect of IRM and DGMA on image features.
V Conclusion and Future Work
In this work, we tackle the UDC face restoration problem for the first time. We first introduce a two-stage network called UDC-DMNet for synthesizing UDC images by simulating the color filtering and brightness attenuation process and the diffraction process in UDC imaging. Experiments show that our UDC-DMNet can synthesize realistic UDC images, which are also superior to images synthesized by other methods in training the restoration model. Furthermore, we propose a novel dictionary-guide transformer named DGFormer which takes both UDC characteristics and face priors into account. Extensive experiments show that our DGFormer achieves superior performance than existing UDC restoration methods and face restoration methods in UDC scenarios.
In the future, we will consider the following challenges for UDC Face restoration. Firstly, considering that the predominant utilization of UDC occurs in mobile phones, it is necessary to devise a more lightweight face restoration model and optimize it for the hardware architecture of mobile devices. Secondly, it’s essential to consider the evolving landscape of real-world UDC face images, where additional complexities such as glare and reflections can emerge based on the specific capture contexts. Consequently, It is still necessary to collect real-world UDC images of more scenes.
References
- [1] K. Zhang, T. Wang, W. Luo, W. Ren, B. Stenger, W. Liu, H. Li, and M.-H. Yang, “Mc-blur: A comprehensive benchmark for image deblurring,” IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2023.
- [2] B. Jiang, Y. Lu, B. Zhang, and G. Lu, “Few-shot learning for image denoising,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 9, pp. 4741–4753, 2023.
- [3] T. Wang, K. Zhang, T. Shen, W. Luo, B. Stenger, and T. Lu, “Ultra-high-definition low-light image enhancement: a benchmark and transformer-based method,” in AAAI Conference on Artificial Intelligence, 2023, pp. 2654–2662.
- [4] Y. Zhou, Y. Song, and X. Du, “Modular degradation simulation and restoration for under-display camera,” in Asian Conference on Computer Vision, 2022, pp. 265–282.
- [5] R. Feng, C. Li, H. Chen, S. Li, C. C. Loy, and J. Gu, “Removing diffraction image artifacts in under-display camera via dynamic skip connection network,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 662–671.
- [6] Q. Yang, Y. Liu, J. Tang, and T. Ku, “Residual and dense unet for under-display camera restoration,” in European Conference on Computer Vision Workshop, 2021, pp. 398–408.
- [7] H. Panikkasseril Sethumadhavan, D. Puthussery, M. Kuriakose, and J. Charangatt Victor, “Transform domain pyramidal dilated convolution networks for restoration of under display camera images,” in European Conference on Computer Vision Workshop, 2020, pp. 364–378.
- [8] J. Koh, J. Lee, and S. Yoon, “Bnudc: A two-branched deep neural network for restoring images from under-display cameras,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 1950–1959.
- [9] K. Kwon, E. Kang, S. Lee, S.-J. Lee, H.-E. Lee, B. Yoo, and J.-J. Han, “Controllable image restoration for under-display camera in smartphones,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 2073–2082.
- [10] Y. Zhou, D. Ren, N. Emerton, S. Lim, and T. Large, “Image restoration for under-display camera,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 9179–9188.
- [11] X. Liu, J. Hu, X. Chen, and C. Dong, “Udc-unet: Under-display camera image restoration via u-shape dynamic network,” in European Conference on Computer Vision Workshop, 2023, pp. 113–129.
- [12] X. Wang, Y. Li, H. Zhang, and Y. Shan, “Towards real-world blind face restoration with generative facial prior,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 9168–9178.
- [13] T. Yang, P. Ren, X. Xie, and L. Zhang, “Gan prior embedded network for blind face restoration in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 672–681.
- [14] L. Yang, S. Wang, S. Ma, W. Gao, C. Liu, P. Wang, and P. Ren, “Hifacegan: Face renovation via collaborative suppression and replenishment,” in Proceedings of the ACM International Conference on MultiMedia, 2020, pp. 1551–1560.
- [15] X. Li, S. Zhang, S. Zhou, L. Zhang, and W. Zuo, “Learning dual memory dictionaries for blind face restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [16] C. Chen, X. Li, L. Yang, X. Lin, L. Zhang, and K.-Y. K. Wong, “Progressive semantic-aware style transformation for blind face restoration,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 896–11 905.
- [17] Z. Wang, J. Zhang, R. Chen, W. Wang, and P. Luo, “Restoreformer: High-quality blind face restoration from undegraded key-value pairs,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 512–17 521.
- [18] Y. Gu, X. Wang, L. Xie, C. Dong, G. Li, Y. Shan, and M.-M. Cheng, “Vqfr: Blind face restoration with vector-quantized dictionary and parallel decoder,” in European Conference on Computer Vision, 2022, pp. 126–143.
- [19] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
- [20] T. Wang, X. Zhang, R. Jiang, L. Zhao, H. Chen, and W. Luo, “Video deblurring via spatiotemporal pyramid network and adversarial gradient prior,” Computer Vision and Image Understanding, vol. 203, p. 103135, 2021.
- [21] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in IEEE International Conference on Computer Vision, 2015, pp. 3730–3738.
- [22] V. Sundar, S. Hegde, D. Kothandaraman, and K. Mitra, “Deep atrous guided filter for image restoration in under display cameras,” in European Conference on Computer Vision Workshop, 2020, pp. 379–397.
- [23] Y. Zhou, M. Kwan, K. Tolentino, N. Emerton, S. Lim, T. Large, L. Fu, Z. Pan, B. Li, Q. Yang et al., “Udc 2020 challenge on image restoration of under-display camera: Methods and results,” in European Conference on Computer Vision Workshop, 2020, pp. 337–351.
- [24] R. Feng, C. Li, S. Zhou, W. Sun, Q. Zhu, J. Jiang, Q. Yang, C. C. Loy, J. Gu, Y. Zhu et al., “Mipi 2022 challenge on under-display camera image restoration: Methods and results,” in European Conference on Computer Vision Workshop, 2023, pp. 60–77.
- [25] M. Qi, Y. Li, and W. Heidrich, “Isp-agnostic image reconstruction for under-display cameras,” arXiv preprint arXiv:2111.01511, 2021.
- [26] Y. Li, J. Wu, and Z. Shi, “Lightweight neural network for enhancing imaging performance of under-display camera,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- [27] L. Chen, J. Pan, R. Hu, Z. Han, C. Liang, and Y. Wu, “Modeling and optimizing of the multi-layer nearest neighbor network for face image super-resolution,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- [28] C. Wang, J. Jiang, Z. Zhong, and X. Liu, “Propagating facial prior knowledge for multitask learning in face super-resolution,” IEEE Transactions on Circuits and Systems for Video Technology, 2022.
- [29] Wang, Chenyang and Jiang, Junjun and Zhong, Zhiwei and Liu, Xianming, “Spatial-frequency mutual learning for face super-resolution,” in IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 356–22 366.
- [30] X. Li, C. Chen, S. Zhou, X. Lin, W. Zuo, and L. Zhang, “Blind face restoration via deep multi-scale component dictionaries,” in European Conference on Computer Vision, 2020, pp. 399–415.
- [31] P. Zhang, K. Zhang, W. Luo, C. Li, and G. Wang, “Blind face restoration: Benchmark datasets and a baseline model,” arXiv preprint arXiv:2206.03697, 2022.
- [32] H. Li, W. Wang, C. Yu, and S. Zhang, “Swapinpaint: Identity-specific face inpainting with identity swapping,” IEEE Transactions on Circuits and Systems for Video Technology, 2022.
- [33] W. Luo, S. Yang, and W. Zhang, “Reference-guided large-scale face inpainting with identity and texture control,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- [34] S. Sola and D. Gera, “Unmasking your expression: Expression-conditioned gan for masked face inpainting,” in IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 5907–5915.
- [35] T. Wang, K. Zhang, X. Chen, W. Luo, J. Deng, T. Lu, X. Cao, W. Liu, H. Li, and S. Zafeiriou, “A survey of deep face restoration: Denoise, super-resolution, deblur, artifact removal,” arXiv preprint arXiv:2211.02831, 2022.
- [36] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “Pulse: Self-supervised photo upsampling via latent space exploration of generative models,” in IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 2437–2445.
- [37] Y. Hu, Y. Wang, and J. Zhang, “Dear-gan: Degradation-aware face restoration with gan prior,” IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- [38] F. Zhu, J. Zhu, W. Chu, X. Zhang, X. Ji, C. Wang, and Y. Tai, “Blind face restoration via integrating face shape and generative priors,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 7662–7671.
- [39] X. Li, W. Li, D. Ren, H. Zhang, M. Wang, and W. Zuo, “Enhanced blind face restoration with multi-exemplar images and adaptive spatial feature fusion,” in IEEE Conference on Computer Vision and Pattern Recognition.
- [40] Y. Chen, Y. Tai, X. Liu, C. Shen, and J. Yang, “Fsrnet: End-to-end learning face super-resolution with facial priors,” in IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2492–2501.
- [41] A. Bulat and G. Tzimiropoulos, “Super-fan: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans,” in IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 109–117.
- [42] X. Yu, B. Fernando, B. Ghanem, F. Porikli, and R. Hartley, “Face super-resolution guided by facial component heatmaps,” in European Conference on Computer Vision, 2018, pp. 217–233.
- [43] Y. Yu, P. Zhang, K. Zhang, W. Luo, C. Li, Y. Yuan, and G. Wang, “Multi-prior learning via neural architecture search for blind face restoration,” arXiv preprint arXiv:2206.13962, 2022.
- [44] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
- [45] P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 873–12 883.
- [46] D. Kim, M. Kim, G. Kwon, and D.-S. Kim, “Progressive face super-resolution via attention to facial landmark,” in British Machine Vision Conference, 2019.
- [47] Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y. Fu, “Image super-resolution using very deep residual channel attention networks,” in European Conference on Computer Vision, 2018, pp. 286–301.
- [48] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” in European Conference on Computer Vision, 2018, pp. 3–19.
- [49] A. Yang and A. C. Sankaranarayanan, “Designing display pixel layouts for under-panel cameras,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [50] Z. Zhang, “14.4: Diffraction simulation of camera under display,” in SID Symposium Digest of Technical Papers, 2021, pp. 93–96.
- [51] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 821–14 831.
- [52] X. Wang, K. Yu, C. Dong, and C. C. Loy, “Recovering realistic texture in image super-resolution by deep spatial feature transform,” in IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 606–615.
- [53] L. Chen, X. Lu, J. Zhang, X. Chu, and C. Chen, “Hinet: Half instance normalization network for image restoration,” in IEEE Conference on Computer Vision and Pattern Recognition, 2021, pp. 182–192.
- [54] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in European Conference on Computer Vision, 2016, pp. 694–711.
- [55] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems, 2014.
- [56] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [57] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in IEEE International Conference on Computer Vision, 2017, pp. 2223–2232.
- [58] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [59] M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International Conference on Machine Learning, 2019, pp. 6105–6114.
- [60] A. Ali, H. Touvron, M. Caron, P. Bojanowski, M. Douze, A. Joulin, I. Laptev, N. Neverova, G. Synnaeve, J. Verbeek, and J. Hervé, “Xcit: Cross-covariance image transformers,” in Advances in Neural Information Processing Systems, 2021, pp. 20 014–20 027.
- [61] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [62] J. H. Lim and J. C. Ye, “Geometric gan,” arXiv preprint arXiv:1705.02894, 2017.
- [63] Loshchilov, Ilya and Hutter, Frank, “Sgdr: Stochastic gradient descent with warm restarts,” in International Conference on Learning Representations, 2017.
- [64] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2019.
- [65] L. Chen, X. Chu, X. Zhang, and J. Sun, “Simple baselines for image restoration,” in European Conference on Computer Vision, 2022, pp. 17–33.
- [66] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 586–595.
- [67] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4690–4699.
- [68] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [69] B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee, “Enhanced deep residual networks for single image super-resolution,” in IEEE Conference on Computer Vision and Pattern Recognition Workshop, 2017, pp. 136–144.