Blind Fingerprinting
Abstract
We study blind fingerprinting, where the host sequence into which fingerprints are embedded is partially or completely unknown to the decoder. This problem relates to a multiuser version of the Gel’fand-Pinsker problem. The number of colluders and the collusion channel are unknown, and the colluders and the fingerprint embedder are subject to distortion constraints.
We propose a conditionally constant-composition random binning scheme and a universal decoding rule and derive the corresponding false-positive and false-negative error exponents. The encoder is a stacked binning scheme and makes use of an auxiliary random sequence. The decoder is a maximum doubly-penalized mutual information decoder, where the significance of each candidate coalition is assessed relative to a threshold that trades off false-positive and false-negative error exponents. The penalty is proportional to coalition size and is a function of the conditional type of host sequence. Positive exponents are obtained at all rates below a certain value, which is therefore a lower bound on public fingerprinting capacity. We conjecture that this value is the public fingerprinting capacity. A simpler threshold decoder is also given, which has similar universality properties but also lower achievable rates. An upper bound on public fingerprinting capacity is also derived.
Index Terms. Fingerprinting, traitor tracing, watermarking, data hiding, randomized codes, universal codes, method of types, maximum mutual information decoder, minimum equivocation decoder, channel coding with side information, random binning, capacity, error exponents, multiple access channels, model order selection.
I Introduction
Content fingerprinting finds applications to document protection for multimedia distribution, broadcasting, and traitor tracing [1, 2, 3, 4]. A covertext—image, video, audio, or text—is to be distributed to many users. A fingerprint, a mark unique to each user, is embedded into each copy of the covertext. In a collusion attack, several users may combine their copies in an attempt to “remove” their fingerprints and to forge a pirated copy. The distortion between the pirated copy and the colluding copies is bounded by a certain tolerance level. To trace the forgery back to the coalition members, we need fingerprinting codes that can reliably identify the fingerprints of those members. Essentially, from a communication viewpoint, the fingerprinting problem is a multiuser version of the watermarking problem [5, 6, 7, 8, 9, 10]. For watermarking, the attack is by one user and is based on one single copy, whereas for fingerprinting, the attack is modeled as a multiple-access channel (MAC). The covertext plays the role of side information to the encoder and possibly to the decoder.
Depending on the availability of the original covertext to the decoder, there are two basic versions of the problem: private and public. In the private fingerprinting setup, the covertext is available to both the encoder and decoder. In the public fingerprinting setup, the covertext is available to the encoder but not to the decoder, and thus decoding performance is generally worse. However public fingerprinting presents an important advantage over private fingerprinting, in that it does not require the vast storage and computational resources that are needed for media registration in a large database. For example, a DVD player could detect fingerprints from a movie disc and refuse to play it if fingerprints other than the owner’s are present. Or Web crawling programs can be used to automatically search for unauthorized content on the Internet or other public networks [3].
The scenario considered in this paper is one where a degraded version of each host symbol is available to the decoder. Private and public fingerprinting are obtained as special cases with and , respectively. We refer to this scenario as either blind or semiprivate fingerprinting. The motivation is analogous to semiprivate watermarking [11], where some information about the host signal is provided to the receiver in order to improve decoding performance. This may be necessary to guarantee an acceptable performance level when the number of colluders is large.
The capacity and reliability limits of private fingerprinting have been studied in [7, 8, 9, 10]. The decoder of [10] is a variation of Liu and Hughes’ minimum equivocation decoder [12], accounting for the presence of side information and for the fact that the number of channel inputs is unknown. Two basic types of decoders are of interest: detect-all and detect-one. The detect-all decoder aims to catch all members of the coalition and an error occurs if some colluder escapes detection. The detect-one decoder is content with catching at least one of the culprits and an error occurs only when none of the colluders is identified. A third type of error (arguably the most damaging one) is a false positive, by which the decoder accuses an innocent user.
In the same way as fingerprinting is related to the MAC problem, blind fingerprinting is related to a multiuser extension of the Gel’fand-Pinsker problem. The capacity region for the latter problem is unknown. An inner region, achievable using random binning, was given in [13].
This paper derives random-coding exponents and an upper bound on detect-all capacity for semiprivate fingerprinting. Neither the encoder nor the decoder know the number of colluders. The collusion channel has arbitrary memory but is subject to a distortion constraint between the pirated copy and the colluding copies. Our fingerprinting scheme uses random binning because, unlike in the private setup, the availability of side information to the encoder and decoder is asymmetric. To optimize the error exponents, we propose an extension of the stacked-binning scheme that was developed for single-user channel coding with side information [11]. Here the codebook consists of a stack of variable-size codeword-arrays indexed by the conditional type of the covertext sequence. The decoder is a minimum doubly-penalized equivocation (M2PE) decoder or equivalently, a maximum doubly-penalized mutual information (M2PMI) decoder.
The proposed fingerprinting system is universal in that it can cope with unknown collusion channels and unknown number of colluders, as in the private fingerprinting setup of [10]. A tunable parameter trades off false-positive and false-negative error exponents. The derivation of these exponents combines techniques from [10] and [11]. A preliminary version of our work, assuming a fixed number of colluders, was given in [14, 15].
I-A Organization of This Paper
A mathematical statement of our generic fingerprinting problem is given in Sec. II, together with the basic definitions of error probabilities, capacity, error exponents, and fair coalitions. Sec. III presents our random coding scheme. Sec. IV presents a simple but suboptimal decoder that compares empirical mutual information scores between received data and individual fingerprints, and outputs a guilty decision whenever the score exceeds a certain tunable threshold. Sec. V presents a joint decoder that assigns a penalized empirical mutual information score to candidate coalitions and selects the coalition with the highest score. Sec. VI establishes an upper bound on blind fingerprinting capacity under the detect-all criterion. Finally, conclusions are given in Sec. VII. The proofs of the theorems are given in appendices.
I-B Notation
We use uppercase letters for random variables, lowercase letters for their individual values, calligraphic letters for finite alphabets, and boldface letters for sequences. We denote by the set of sequences of arbitrary length (including 0) whose elements are in . The probability mass function (p.m.f.) of a random variable is denoted by . The entropy of a random variable is denoted by , and the mutual information between two random variables and is denoted by . Should the dependency on the underlying p.m.f.s be explicit, we write the p.m.f.s as subscripts, e.g., and . The Kullback-Leibler divergence between two p.m.f.s and is denoted by ; the conditional Kullback-Leibler divergence of and given is denoted by . All logarithms are in base 2 unless specified otherwise.
Denote by the type, or empirical p.m.f. induced by a sequence . The type class is the set of all sequences of type . Likewise, we denote by the joint type of a pair of sequences and by the type class associated with . The conditional type of a pair of sequences () is defined by for all such that . The conditional type class given , is the set of all sequences such that . We denote by the empirical entropy of the p.m.f. , by the empirical conditional entropy, and by the empirical mutual information for the joint p.m.f. .
We use the calligraphic fonts and to represent the set of all p.m.f.s and all empirical p.m.f.’s, respectively, on the alphabet . Likewise, and denote the set of all conditional p.m.f.s and all empirical conditional p.m.f.’s on the alphabet . A special symbol will be used to denote the feasible set of collusion channels that can be selected by a size- coalition.
Mathematical expectation is denoted by the symbol . The shorthands and denote asymptotic relations in the exponential scale, respectively and . We define and . The indicator function of a set is denoted by . Finally, we adopt the convention that the minimum of a function over an empty set is and the maximum of a function over an empty set is 0.
II Statement of the Problem
II-A Overview
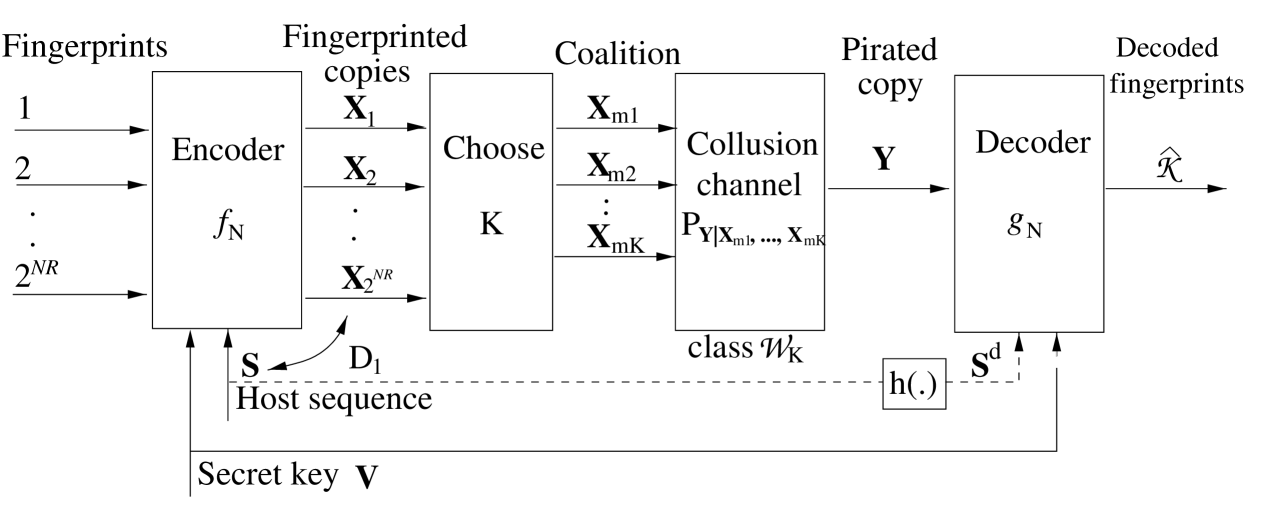
Our model for blind fingerprinting is diagrammed in Fig. 1. Let , , and be three finite alphabets. The covertext sequence consists of independent and identically distributed (i.i.d.) samples drawn from a p.m.f. , . A random variable taking values in an alphabet is shared between encoder and decoder, and not publicly revealed. The random variable is independent of and plays the role of a cryptographic key. There are users, each of which receives a fingerprinted copy:
| (2.1) |
where is the encoding function, and is the index of the user. The encoder binds each fingerprinted copy to the covertext via a distortion constraint. Let be the distortion measure and the extension of this measure to length- sequences. The code is subject to the distortion constraint
| (2.2) |
Let be a coalition of users, called colluders. No constraints are imposed on the formation of coalitions. The colluders combine their copies to produce a pirated copy . Without loss of generality, we assume that is generated stochastically as the output of a collusion channel . Fidelity constraints are imposed on to ensure that is “close” to the fingerprinted copies . These constraints can take the form of distortion constraints, analogously to (2.2). They are formulated below and result in the definition of a feasible class of attacks.
The decoder knows neither nor selected by the colluders and has access to the pirated copy , the secret key , as well as to , a degraded version of the host . To simplify the exposition, the degradation arises via a deterministic symbolwise mapping . The sequence could represent a coarse version of , or some other features of . Two special cases are private fingerprinting where , and public fingerprinting where . The decoder produces an estimate
| (2.3) |
of the coalition. A possible decision is the empty set, , which is the reasonable choice when an accusation would be unreliable. To summarize, we have
Definition II.1
A randomized rate- length- fingerprinting code with embedding distortion is a pair of encoder mapping and decoder mapping .
The randomization is via the secret key and can take the form of permutations of the symbol positions , permutations of the fingerprint assignments, and an auxiliary time-sharing sequence, as in [6]—[10], [16].
We now state the attack models and define the error probabilities, capacities, and error exponents.
II-B Collusion Channels
The conditional type is a random variable whose conditional distribution given depends on the collusion channel . Our fidelity constraint on the coalition is of the general form
| (2.4) |
where is a convex subset of . That is, the empirical conditional p.m.f. of the pirated copy given the marked copies is restricted. Examples of are given in [10], including hard distortion constraints on the coalition:
| (2.5) |
where is a (possible randomized) permutation-invariant estimator of each host signal sample based on the corresponding marked samples; is the coalition’s distortion function; is a reference p.m.f.; and is the maximum allowed distortion. Another possible choice for is obtained using the Boneh-Shaw constraint [1, 10].
Fair Coalitions. Denote by a permutation of the elements of . The set of fair, feasible collusion channels is the subset of consisting of permutation-invariant channels:
| (2.6) |
The collusion channel is said to be fair if . For any fair collusion channel, the conditional type is invariant to permutations of the colluders.
Strongly exchangeable collusion channels [7]. Now denote by a permutation of the samples of a length- sequence. For strongly exchangeable channels, is independent of , for every . The channel is defined by a probability assignment on the conditional type classes. The distribution of conditioned on is uniform:
| (2.7) |
II-C Error Probabilities
Let be the actual coalition and the decoder’s output. The three error probabilities of interest in this paper are the probability of false positives (one or more innocent users are accused),
the probability of failing to catch a single colluder,
and the probability of failing to catch the full coalition:
These three probabilities are obtained by averaging over , , and the output of the collusion channel . In each case the worst-case probability is denoted by
| (2.8) |
where denotes either , or , and the maximum is over all feasible collusion channels, i.e., such that (2.4) holds.
II-D Capacity and Random-Coding Exponents
Definition II.2
A rate is achievable for embedding distortion , collusion class , and detect-one criterion if there exists a sequence of randomized codes with maximum embedding distortion , such that both and vanish as .
Definition II.3
A rate is achievable for embedding distortion , collusion class , and detect-all criterion if there exists a sequence of randomized codes with maximum embedding distortion , such that both and vanish as .
Definition II.4
Fingerprinting capacities and are the suprema of all achievable rates with respect to the detect-one and detect-all criteria, respectively.
For random codes the error exponents corresponding to (2.8) are defined as
| (2.9) |
We have and because an error event for the detect-one problem is also an error event for the detect-all problem.
III Overview of Random-Coding Scheme
A brief overview of our scheme is given in this section. The decoders will be specified later. The scheme is designed to achieve a false-positive error exponent equal to and assumes a nominal value for coalition size. Two arbitrarily large integers and are selected, defining alphabets and , respectively. The parameters are used to identify a certain optimal type class and conditional type classes , and for every possible . Optimality is defined relative to either the thresholding decoder of Sec. IV or the joint decoder of Sec. V. The secret key consists of a random sequence and the collection (3.1) of random codebooks indexed by .
III-A Codebook
A random constant-composition code
| (3.1) |
is generated for each pair of sequences and conditional type by drawing random sequences independently and uniformly from an optimized conditional type class , and arranging them into an array with columns and rows. Similarly to [11] (see Fig. 2 therein), we refer to as the depth parameter of the array.
III-B Encoding Scheme
Prior to encoding, a sequence is drawn independently of and uniformly from , and shared with the receiver. Given , the encoder determines the conditional type and performs the following two steps for each user .
-
1.
Find such that . If more than one such exists, pick one of them randomly (with uniform distribution). Let . If no such can be found, generate uniformly from the conditional type class .
-
2.
Generate uniformly distributed over the conditional type class , and assign this marked sequence to user .
III-C Worst Collusion Channel
The fingerprinting codes used in this paper are randomly-modulated (RM) codes [10, Def. 2.2]. For such codes we have the following proposition, which is a straightforward variation of [10, Prop. 2.1] with in place of at the decoder.
Proposition III.1
To derive error exponents for such channels, it suffices to use the following upper bound:
| (3.2) |
which holds uniformly over all feasible probability assignments to conditional type classes .
III-D Encoding and Decoding Errors
The array depth parameter takes the form
where is any element of , and is an arbitrarily small number. The analysis shows that given any , the probability of encoding errors vanishes doubly exponentially.
The analysis also shows that the decoding error probability is dominated by a single joint type class . Denote by an arbitrary representative of that class. The normalized logarithm of the size of the array is given by
and the probability of false positives vanishes as .
IV Threshold Decoder
IV-A Decoding
The decoder has access to but does not know the conditional type realized at the encoder. The decoder evaluates the users one at a time and makes an innocent/guilty decision on each user independently of the other users. Specifically, the receiver outputs an estimated coalition if and only if satisfies the following condition:
| (4.1) |
If no such is found, the receiver outputs . This decoder outputs all user indices whose empirical mutual information score, penalized by , exceeds the threshold .
IV-B Error Exponents
Define the following set of conditional p.m.f.’s for given :
i.e., the conditional marginal p.m.f. is the same for each . Also define the sets
| (4.2) | |||||
where in (4.2) the random variables , are conditionally i.i.d. given .
Define for each the set of conditional p.m.f.’s
| (4.3) | |||||
and the pseudo sphere packing exponent
| (4.4) | |||||
Taking the maximum and minimum of above over , we respectively define
| (4.5) | |||||
| (4.6) |
For a fair coalition (), is independent of , and the two expressions above coincide. Define
| (4.7) | |||||
Denote by and the maximizers in (4.7), the latter to be viewed as a function of . Both and implicitly depend on and . Finally, define
| (4.8) | |||||
| (4.9) |
The terminology pseudo sphere-packing exponent is used because despite its superficial similarity to a real sphere-packing exponent, (4.4) does not provide a fundamental asymptotic lower bound on error probability.
Theorem IV.1
The decision rule (4.1) yields the following error exponents.
- (i)
-
The false-positive error exponent is
(4.10) - (ii)
-
The detect-all error exponent is
(4.11) - (iii)
-
The detect-one error exponent is
(4.12) - (iv)
-
A fair collusion strategy is optimal under the detect-one error criterion:
- (v)
-
The detect-one and detect-all error exponents are the same when the colluders emply a fair strategy: .
- (vi)
-
For , the supremum of all rates for which the detect-one error exponent of (4.12) is positive is
(4.13)
V Joint Fingerprint Decoder
The fundamental improvement over the simple thresholding strategy for decoding in Sec. IV resides in the use of a joint decoding rule. Specifically, the decoder maximizes a penalized empirical mutual information score over all possible coalitions of any size. The penalty depends on the conditional host sequence type , as in Sec. IV, and is proportional to the size of the coalition, as in [10, Sec. V]. We call this blind fingerprint decoder the maximum doubly-penalized mutual information (M2PMI) decoder.
Mutual Information of Random Variables. The mutual information of random variables is defined as the sum of their individual entropies minus their joint entropy [21, p. 57] or equivalently, the divergence between their joint distribution and the product of their marginals:
The symbol is used to distinguish it from ordinary mutual information between two random variables. Similarly one can define a conditional mutual information conditioned on , and an empirical mutual information between sequences , conditioned on , as the conditional mutual information with respect to the joint type of . Some properties of are given in [10, Sec. V.A].
Recall that denotes and that the codewords in (3.1) take the form . In the following, we shall use the compact notation , and
V-A M2PMI Criterion
Given , the decoder seeks the coalition size , the conditional host sequence type , and the codewords in that maximize the M2PMI criterion below. The column indices , corresponding to the decoded words form the decoded coalition . If the maximizing in (5.2) is zero, the receiver outputs .
The Maximum Doubly-Penalized Mutual Information criterion is defined as
| (5.2) |
where
| (5.3) |
V-B Properties
The following lemma shows that 1) each subset of the estimated coalition is significant, and 2) any further extension of the coalition would fail a significance test. The proof parallels that of Lemma 5.1 in [10] and is therefore omitted.
V-C Error Exponents
Define for each the set of conditional p.m.f.’s
| (5.6) | |||||
and the pseudo sphere packing exponent
| (5.7) | |||||
Taking the maximum 111 The property that achieves is established in the proof of Theorem V.2, Part (iv). and the minimum of above over all subsets of , we define
| (5.8) | |||||
| (5.9) |
Now define
| (5.10) | |||||
Denote by and the maximizers in (5.10), where the latter is to be viewed as a function of . Both and implicitly depend on and . Finally, define
| (5.11) | |||||
| (5.12) |
Theorem V.2
The decision rule (5.2) yields the following error exponents.
- (i)
-
The false-positive error exponent is
(5.13) - (ii)
-
The detect-all error exponent is
(5.14) - (iii)
-
The detect-one error exponent is
(5.15) - (iv)
-
.
- (v)
-
.
- (vi)
-
If , the supremum of all rates for which the error exponent of (5.15) and (5.14) are positive is
(5.16) under the “detect-one” criterion, and by
(5.17) under the “detect-all” criterion. If the colluders select a fair collusion channel, as is their collective interest, the minimization is restricted to in (5.17), and then
For the special case of private fingerprinting (), the term in (5.16) is zero. Since , it suffices to choose and to achieve the maximum in (5.16). The resulting expression coincides with the capacity formula in [10, Theorem 3.2]. Similarly to the single-user case [11], when the binning scheme is degenerate.
V-D Bounded Coalition Size
Assume now that is known not exceed some maximum value . The same random coding scheme can be used. In the evaluation of the M2PMI criterion of (5.2), the maximization is now limited to . In Lemma 5.5, property (5.4) holds, and property (5.5) now holds for every disjoint with , and of size . Following the derivation of the error exponents in the appendix, we see that these exponents remain the same as those given by Theorem V.2.
Blind watermarking. The case represents blind watermark decoding with a guarantee that the false-positive exponent is at least equal to . In this scenario, there is no need for a time-sharing sequence , and the decoder’s input is either an unwatermarked sequence () or a watermarked sequence (). The M2PMI criterion of (5.3) reduces to
The resulting false-positive and false-negative exponents are given by and , respectively.
VI Upper Bounds on Public Fingerprinting Capacity
Deriving public fingerprinting capacity is a challenge because the capacity region for the Gel’fand-Pinsker version of the MAC is still unknown, in fact an outer bound for this region has yet to be established. Even in the case of a MAC with side information causally available at the transmitter but not at the receiver, the expressions for the inner and outer capacity regions do not coincide [23]. Likewise, the expression derived below is an upper bound on public fingerprinting capacity under the detect-all criterion.
Recall the definition of the set in (4.2), where and are random variables defined over alphabets and , respectively. Here we define the larger set
| (6.1) | |||||
where , are still conditionally i.i.d. given but the random variables , are generally conditionally dependent.
Define
| (6.2) | |||||
Using the same derivation as in Lemma 2.1 of [11], it can be shown that is a nondecreasing function of and and converges to a finite limit. Moreover, the gap to the limit may be bounded by a polynomial function of and , see [11, Sec. 3.5] for a similar derivation.
Theorem VI.1
Public fingerprinting capacity is upper-bounded by
| (6.3) |
under the “detect-all” criterion.
Proof: see appendix.
We conjecture that the upper bound on capacity given by Theorem VI.1 is generally not tight. The insight here is that the upper bound remains valid if the class of encoding functions is enlarged to include feedback from the receiver: for . It can indeed be verified that all the inequalities in the proof and the Markov chain properties hold. The question is now whether feedback can increase public fingerprinting capacity. We conjecture the answer is yes, because feedback is known to increase MAC capacity [24].
VII Conclusion
We have proposed a communication model and a random-coding scheme for blind fingerprinting. While a standard binning scheme for communication with asymmetric side information at the transmitter and the receiver may seem like a reasonable candidate, such a scheme would be unable to trade false-positive error exponents against false-negative error exponents. Our proposed binning scheme combines two ideas. The first is the use of a stacked binning scheme as in [11], which demonstrated the advantages (in terms of decoding error exponents) of selecting codewords from an array whose size depends on the conditional type of the host sequence. The second is the use of an auxiliary time-sharing random variable as in [10]. The blind fingerprint decoders of Secs. IV and V combine the advantages of both methods and provide positive error exponents for a range of code rates. The tradeoff between the two fundamental types of error probabilities is determined by the value of the parameter .
Appendix A Proof of Theorem IV.1
We derive the error exponents for the thresholding rule (4.1). We have and . Fix some arbitrarily small . Define for all
| (A.1) | |||||
| (A.2) | |||||
where (A.2) is obtained by application of the chain rule for divergence. Also define
| (A.5) | |||||
Denote by and the maximizers above, the latter viewed as a function of . Both maximizers depend implicitly on and . Let
| (A.6) | |||||
| (A.7) |
The exponents (A.2)—(A.7) differ from (4.4)—(4.9) in that the optimizations are performed over conditional types instead of general conditional p.m.f.’s. We have
| (A.8) | |||||
| (A.9) |
by continuity of the divergence and mutual-information functionals.
Consider the maximization over the conditional type in (A.5). As a result of this maximization, we may associate the following:
-
•
to any , a conditional type class ;
-
•
to any , a conditional type class ;
-
•
to any and , a conditional type class ;
-
•
to any type , a conditional mutual information where are any three sequences with joint type .
Codebook. Define the function
A random constant-composition code
is generated for each , , and by drawing random sequences independently and uniformly from the conditional type class , and arranging them into an array with columns and rows.
Encoder. Prior to encoding, a sequence is drawn independently of and uniformly from , and shared with the receiver. Given , the encoder determines the conditional type and performs the following two steps for each user .
-
1.
Find such that . If more than one such exists, pick one of them randomly (with uniform distribution). Let . If no such can be found, generate uniformly from the conditional type class .
-
2.
Generate uniformly distributed over the conditional type class .
Collusion channel. By Prop. III.1, it is sufficient to restrict our attention to strongly exchangeable collusion channels in the error probability analysis.
Decoder. Given , the decoder outputs if and only if (4.1) is satisfied.
Encoding errors. Analogously to [11], the probability of encoding errors vanishes doubly exponentially with because . Indeed an encoding error for user arises under the following event:
The probability that a sequence uniformly distributed over also belongs to is equal to on the exponential scale. Therefore the encoding error probability, conditioned on type class , satisfies
| (A.11) | |||||
where the inequality follows from .
The derivation of the decoding error exponents is based on the following two asymptotic equalities which are special cases of (C.2) and (C.5) established in Lemma C.1.
1) Fix and draw uniformly from some fixed type class, independently of . Then
| (A.12) |
2) Given , draw , i.i.d. uniformly from a conditional type class , and then draw uniformly over a single conditional type class . For any , we have
| (A.13) |
(i). False Positives. From (4.1), the occurrence of a false positive implies that
| (A.14) |
By construction of the codebook, is independent of for . For any given , there are at most possible values for and possible values for in (A.14). Hence the probability of false positives, conditioned on the joint type class , is
| (A.15) | |||||
where (a) is obtained by application of (A.12) with , and (b) because the number of conditional types is at most .
Averaging over all type classes , we obtain , from which (4.10) follows.
(ii). Detect-One Error Criterion (Miss All Colluders). We first derive the error exponent for the event that the decoder misses a specific colluder . Any coalition that contains fails the test (4.1), i.e., for any such ,
| (A.16) |
This implies that
| (A.17) |
where is the row index actually selected by the encoder, and is the actual host sequence conditional type. The probability of the miss- event, given the joint type , is therefore upper-bounded by the probability of the event (A.17):
where (a) follows from (A.13) with .
The miss-all event is the intersection of the miss- events over . Its conditional probability is
| (A.18) | |||||
Averaging over , we obtain
which establishes (4.12). Here (a) follows from (C.3) and (A.18), (b) from (LABEL:eq:Emax-tilde-simple-N) and (A.6), and (c) from (A.8).
(iii). Detect-All Error Criterion (Miss Some Colluders).
The miss-some event is the union of the miss- events over . Given the joint type , the probability of this event is
| (A.20) | |||||
Averaging over , we obtain
which establishes (4.11). Here (a) follows from (C.3) and (A.20), (b) from (A.7) and (LABEL:eq:Emin-tilde-simple-N), and (c) from (A.9).
(iv). Fair Collusion Channels. The proof parallels that of [10, Theorem 4.1(iv)], using the conditional divergence in place of .
(v). Immediate, because in this case.
(vi). Positive Error Exponents. From Part (v) above, we may restrict our attention to . Consider any and that is positive over its support set (if it is not, reduce the value of accordingly.) For any , the minimand in the expression (4.4) for , is zero if and only if
Such is feasible for (4.3) if and only if is such that . It is not feasible, and thus a positive exponent is guaranteed, if . The supremum of all such is given by (4.13) and is achieved by letting , , and .
Appendix B Proof of Theorem V.2
We derive the error exponents for the M2PMI decision rule (5.2). Define for all
| (B.1) | |||||
| (B.2) | |||||
| (B.3) | |||||
| (B.4) | |||||
Denote by and the maximizers in (LABEL:eq:Epsp-N), the latter viewed as a function of . Both maximizers depend implicitly on , , and . Let
| (B.7) | |||||
| (B.8) |
The exponents (B.3)—(B.8) differ from (5.7)—(5.12) in that the optimizations are performed over conditional types instead of general conditional p.m.f.’s. We have
| (B.9) | |||||
| (B.10) |
by continuity of the divergence and mutual-information functionals.
The codebook and encoding procedure are exactly as in the proof of Theorem IV, the difference being that and are solutions to the optimization problem (LABEL:eq:Epsp-N) instead of (A.5). The decoding rule is the M2PMI rule of (5.2).
To analyze the error probability for this random-coding scheme, it is again sufficient to restrict our attention to strongly-exchangeable channels and use the bound (3.2) on the conditional probability of the collusion channel output. We also use Lemma C.1.
(i). False Positives. By application of (5.4), a false positive occurs if and
| (B.11) | |||||
The probability of this event is upper-bounded by the probability of the larger event
| (B.12) | |||||
Denote by the conditional type of the host sequence and by the row indices selected by the encoder. To each triple , we associate a unique subset of defined as follows:
-
•
If then
-
•
If then is the (possibly empty) set of all indices such that .
Thus is the set of colluder indices for which the decoder correctly identifies the conditional host sequence type and the codewords that were assigned by the encoder. Denoting by the set of pairs associated with , we rewrite (B.12) as
| (B.13) | |||||
Define the complement set which is comprised of all incorrectly accused users as well as any colluder such that or . Since and there is at least one innocent user in , the cardinality of is at least equal to 1. By construction of the codebook and definition of and , is independent of and . The probability of the event (B.13) is upper-bounded by the probability of the larger event
| (B.14) |
Hence the probability of false positives, conditioned on , satisfies
| (B.15) | |||||
where
| (B.16) | |||||
By definition of , there are at most possible values for and possible values for in (B.16). Hence
| (B.17) | |||||
where (a) is obtained by application of (C.2) with in place of .
Combining (B.15) and (B.17) we obtain
Averaging over all joint type classes , we obtain , from which (5.13) follows.
(ii). Detect-All Criterion. (Miss Some Colluders.)
Under the miss-some error event, any coalition that contains fails the test. By (5.4), this implies
| (B.18) | |||||
In particular, for we have
| (B.19) |
where are the row indices actually selected by the encoder, and is the actual host sequence conditional type. The probability of the miss-some event, conditioned on , is therefore upper bounded by the probability of the event (B.19):
| (B.20) | |||||
where (a) follows from (C.5) with .
Averaging over , we obtain
which proves (5.14). Here (a) follows from (C.3) and (B.20), (b) from the definitions (LABEL:eq:Emin-tilde-N) and (B.3), (c) from (B.8), and (d) from the limit property (B.10).
(iii). Detect-One Criterion (Miss All Colluders.) Either the estimated coalition is empty, or it is a set of innocent users (disjoint with ). Hence . The first probability, conditioned on , is bounded as
where (a) follows from (C.5) with . To bound , we use property (5.5) with and , which yields
Since
combining the two inequalities above yields
The probability of this event is again given by (B); we conclude that
(iv). Optimal Collusion Channels are Fair. The proof parallels that of [10, Theorem 4.1(iv)] and is omitted.
(v). Detect-All Exponent for Fair Collusion Channels. The proof parallels that of [10, Theorem 4.1(v)] and is omitted.
(vi). Achievable Rates. Consider any and that is positive over its support set (if it is not, reduce the value of accordingly.) For any , the divergence to be minimized in the expression (5.7) for is zero if and only if
These p.m.f.’s are feasible for (5.6) if and only if the inequality below holds:
They are infeasible, and thus positive error exponents are guaranteed, if
From Part (iv) above, we may restrict our attention to under the detect-one criterion. Since the p.m.f. of is permutation-invariant, by application of [10, Eqn. (3.3)] with in place of , we have
| (B.22) |
Hence the supremum of all for error exponents are positive is given by in (5.16) and is obtained by letting , and .
For any , under the detect-all criterion, the supremum of all for which error exponents are positive is given by in (5.17) and is obtained by letting , and . Since the optimal conditional p.m.f. is not necessarily permutation-invariant, (B.22) does not hold in general. However, if , (B.22) holds, and the same achievable rate is obtained for the detect-one and detect-all problems.
Appendix C
Lemma C.1
1) Fix and , and draw i.i.d. uniformly over a common type class , independently of . We have the asymptotic equality
| (C.1) |
| (C.2) |
2) Given , draw i.i.d. . We have [21]
| (C.3) |
3) Given , draw , i.i.d. uniformly from a conditional type class , and then draw uniformly from a single conditional type class . We have
| (C.4) | |||||
For any feasible, strongly exchangeable collusion channel, for any and , we have
| (C.5) | |||||
Appendix D Proof of Theorem VI.1
Let be size of the coalition and a sequence of length-, rate- randomized codes. We show that for any sequence of such codes, reliable decoding of all fingerprints is possible only if . Recall that the encoder generates marked copies for and that the decoder outputs an estimated coalition . We use the notation and .
To prove that is an upper bound on capacity, it suffices to identify a family of collusion channels for which reliable decoding is impossible at rates above . As shown in [10], it is sufficient to derive such a bound for the compound family of memoryless channels.
Our derivation is an extension of the single-user compound Gel’fand-Pinsker problem [11] to the multiple-access case. A lower bound on error probability is obtained when an oracle informs the decoder that the coalition size is at most .
There are possible coalitions of size . We represent such a coalition as , where , are drawn i.i.d. uniformly from .
Given a memoryless channel , the joint p.m.f. of is given by
| (D.1) |
Our derivations make repeated use of the identity
which follows from the chain rule for conditional mutual information and holds for any .
The total error probability (including false positives and false negatives) for the detect-all decoder is
| (D.2) |
when collusion channel is in effect.
Step 1. Following the derivation of [10, Eqn. (B.20)] with in place of at the receiver, for the error probability to vanish for each , we need
| (D.3) |
Step 2. Define the i.i.d. random variables
| (D.4) |
Also define the random variables
| (D.5) |
where and . Hence
| (D.6) |
The following properties hold for each :
- •
-
•
The random variables , are conditionally i.i.d. given .
-
•
Due to the term in (D.5), the random variables , are conditionally dependent given .
The joint p.m.f. of may thus be written as
| (D.7) |
Step 3. Consider a time-sharing random variable that is uniformly distributed over and independent of the other random variables, and define the tuple of random variables as . Also let and , , which are defined over alphabets of respective cardinalities
and
Since forms a Markov chain, so does . From (D.7), the joint p.m.f. of takes the form
| (D.8) |
In (6.1) we have defined the set
| (D.9) | |||||
where and . Observe that defined in (D.8) belongs to , .
Define the collection of indices and the following functionals indexed by :
| (D.10) |
Step 4. We have
| (D.11) | |||||
where (a) holds because are mutually independent, and (b) follows from the chain rule for mutual information, (c) from [20, Lemma 4], using and in place of and , respectively, (d) holds because , and (e) by definition of .
For all , we have
| (D.13) |
where (a) and (b) hold because , , and are mutually independent, the equality (c) is proved at the end of this section, and (d) follows from the definition of .
Combining (D.3), (D.11), and (D.13), we obtain
| (D.14) | |||||
where (a) holds because the functionals are nondecreasing in , (b) uses the definition of in (6.2), and (c) the fact that the sequence is nondecreasing.
Proof of (D). Recall the definitions of and in (D.5) and the recursion (D.6) for . We prove the following inequality:
| (D.15) | |||||
Then summing both sides of this equality from to , cancelling terms, and using the properties and yields (D).
The first of the six terms in (D.15) may be expanded as follows:
| (D.16) | |||||
Similarly for the second term, replacing with in the above derivation, we obtain
| (D.17) |
The six terms in (D.15) can be expanded using the chain rule for mutual information, in the same way as in [20, Lemma 4.2]:
| (D.18) | |||||
| (D.19) | |||||
| (D.20) | |||||
| (D.21) | |||||
| (D.22) | |||||
Moreover, expanding the conditional mutual information in two different ways, we obtain
| (D.24) | |||||
Substracting the sum of (D.17), (D.18), (D.20), (D.22), (D.24) from the sum of (D.16), (D.19), (D.21), (LABEL:eq:GP-6), and cancelling terms, we obtain (D.15), from which the claim follows.
References
- [1] D. Boneh and J. Shaw, “Collusion–Secure Fingerprinting for Digital Data,” in Advances in Cryptology: Proc. CRYPTO’95, Springer–Verlag, New York, 1995.
- [2] I. J. Cox, J. Killian, F. T. Leighton and T. Shamoon, “Secure Spread Spectrum Watermarking for Multimedia,” IEEE Trans. Image Proc., Vol. 6, No. 12, pp. 1673—1687, Dec. 1997.
- [3] M. Wu, W. Trappe, Z. J. Wang and K. J. R. Liu, “Collusion-Resistant Fingerprinting for Multimedia,” IEEE Signal Processing Magazine, Vol. 21, No. 2, pp. 15—27, March 2004.
- [4] K. J. R. Liu, W. Trappe, Z. J. Wang, M. Wu and H. Zhao, Multimedia Fingerprinting Forensics for Traitor Tracing, EURASIP Book Series on Signal Processing, 2006.
- [5] P. Moulin and A. Briassouli, “The Gaussian Fingerprinting Game,” Proc. Conf. Information Sciences and Systems, Princeton, NJ, March 2002.
- [6] P. Moulin and J. A. O’Sullivan, “Information-theoretic analysis of information hiding,” IEEE Trans. on Information Theory, Vol. 49, No. 3, pp. 563—593, March 2003.
- [7] A. Somekh-Baruch and N. Merhav, “On the capacity game of private fingerprinting systems under collusion attacks,” IEEE Trans. Information Theory, vol. 51, no. 3, pp. 884—899, Mar. 2005.
- [8] A. Somekh-Baruch and N. Merhav, “Achievable error exponents for the private fingerprinting game,” IEEE Trans. Information Theory, Vol. 53, No. 5, pp. 1827—1838, May 2007.
- [9] N. P. Anthapadmanabhan, A. Barg and I. Dumer, “On the Fingerprinting Capacity Under the Marking Assumption,” submitted to IEEE Trans. Information Theory, arXiv:cs/0612073v2, July 2007.
- [10] P. Moulin, “Universal Fingerprinting: Capacity and Random-Coding Exponents,” submitted to IEEE Trans. Information Theory. Available from arxiv:0801.3837v1 [cs.IT] 24 Jan 2008.
- [11] P. Moulin and Y. Wang, “Capacity and Random-Coding Exponents for Channel Coding with Side Information,” IEEE Trans. on Information Theory, Vol. 53, No. 4, pp. 1326—1347, Apr. 2007.
- [12] Y.-S. Liu and B. L. Hughes, “A new universal random coding bound for the multiple-access channel,” IEEE Trans. Information Theory, vol. 42, no. 2, pp. 376 –386, Mar. 1996.
- [13] A. Somekh-Baruch and N. Merhav, “On the Random Coding Error Exponents of the Single-User and the Multiple-Access Gel’fand-Pinsker Channels,” Proc. IEEE Int. Symp. Info. Theory, p. 448, Chicago, IL, June-July 2004.
- [14] Y. Wang and P. Moulin, “Capacity and Random-Coding Error Exponent for Public Fingerprinting Game,” Proc. Int. Symp. on Information Theory, Seattle, WA, July 2006.
- [15] Y. Wang, Detection- and Information-Theoretic Analysis of Steganography and Fingerprinting, Ph. D. Thesis, ECE Department, University of Illinois at Urbana-Champaign, Dec. 2006.
- [16] G. Tardos, “Optimal Probabilistic Fingerprinting Codes,” STOC, 2003.
- [17] R. Ahlswede, “Multiway Communication Channels,” Proc. ISIT, pp. 23—52, Tsahkadsor, Armenia, 1971.
- [18] H. Liao, “Multiple Access Channels,” Ph. D. dissertation, EE Department, U. of Hawaii, 1972.
- [19] A. Lapidoth and P. Narayan, “Reliable Communication Under Channel Uncertainty,” IEEE Trans. Information Theory, Vol. 44, No. 6, pp. 2148—2177, Oct. 1998.
- [20] S. I. Gel’fand and M. S. Pinsker, “Coding for Channel with Random Parameters,” Problems of Control and Information Theory, Vol. 9, No. 1, pp. 19—31, 1980.
- [21] I. Csiszár and J. Körner, Information Theory: Coding Theory for Discrete Memoryless Systems, Academic Press, NY, 1981.
- [22] A. Das and P. Narayan, “Capacities of Time-Varying Multiple-Access Channels With Side Information,” IEEE Trans. Information Theory, Vol. 48, No. 1, pp. 4—25, Jan. 2002.
- [23] S. Sigurjónsson and Y.-H. Kim, “On Multiple User Channels with State Information at the Transmitters,” Proc. ISIT 2005.
- [24] N. T. Gaarder and J. K. Wolf, “The Capacity Region of a Multiple-Access Discrete Memoryless Channel Can Increase with Feedback,” IEEE Trans. Information Theory, Vol. 21, No. 1, pp. 100—102, Jan. 1975.