Body-Part Joint Detection and Association via Extended Object Representation
Abstract
The detection of human body and its related parts (e.g., face, head or hands) have been intensively studied and greatly improved since the breakthrough of deep CNNs. However, most of these detectors are trained independently, making it a challenging task to associate detected body parts with people. This paper focuses on the problem of joint detection of human body and its corresponding parts. Specifically, we propose a novel extended object representation that integrates the center location offsets of body or its parts, and construct a dense single-stage anchor-based Body-Part Joint Detector (BPJDet). Body-part associations in BPJDet are embedded into the unified representation which contains both the semantic and geometric information. Therefore, BPJDet does not suffer from error-prone association post-matching, and has a better accuracy-speed trade-off. Furthermore, BPJDet can be seamlessly generalized to jointly detect any body part. To verify the effectiveness and superiority of our method, we conduct extensive experiments on the CityPersons, CrowdHuman and BodyHands datasets. The proposed BPJDet detector achieves state-of-the-art association performance on these three benchmarks while maintains high accuracy of detection. Code is in https://github.com/hnuzhy/BPJDet.
Index Terms— Association, body-part joint detection, object detection, object representation
1 Introduction
Human body detection [1, 2, 3] is a research hotspot in computer vision. Accurate and fast human detection in an arbitrary scene can support many down-stream vision tasks such as pedestrian re-id, person tracking and human pose estimation. Also, the detection of body parts like face [4, 5], head [6, 7] and hands [8, 9] is equally important. They may serve as precursors to specific missions like face recognition, crowd counting and hand pose estimation. Although the detection performance of human bodies and related parts has been significantly improved due to breakthroughs of deep CNN-based general object detection (e.g., Faster R-CNN [10], FPN [11], RetinaNet [12] and YOLO [13]) and construction of large-scale high-quality datasets (e.g., COCO [14], CityPersons [15] and CrowdHuman [16]), the joint discovery of human body and its parts is still challenging but meaningful.
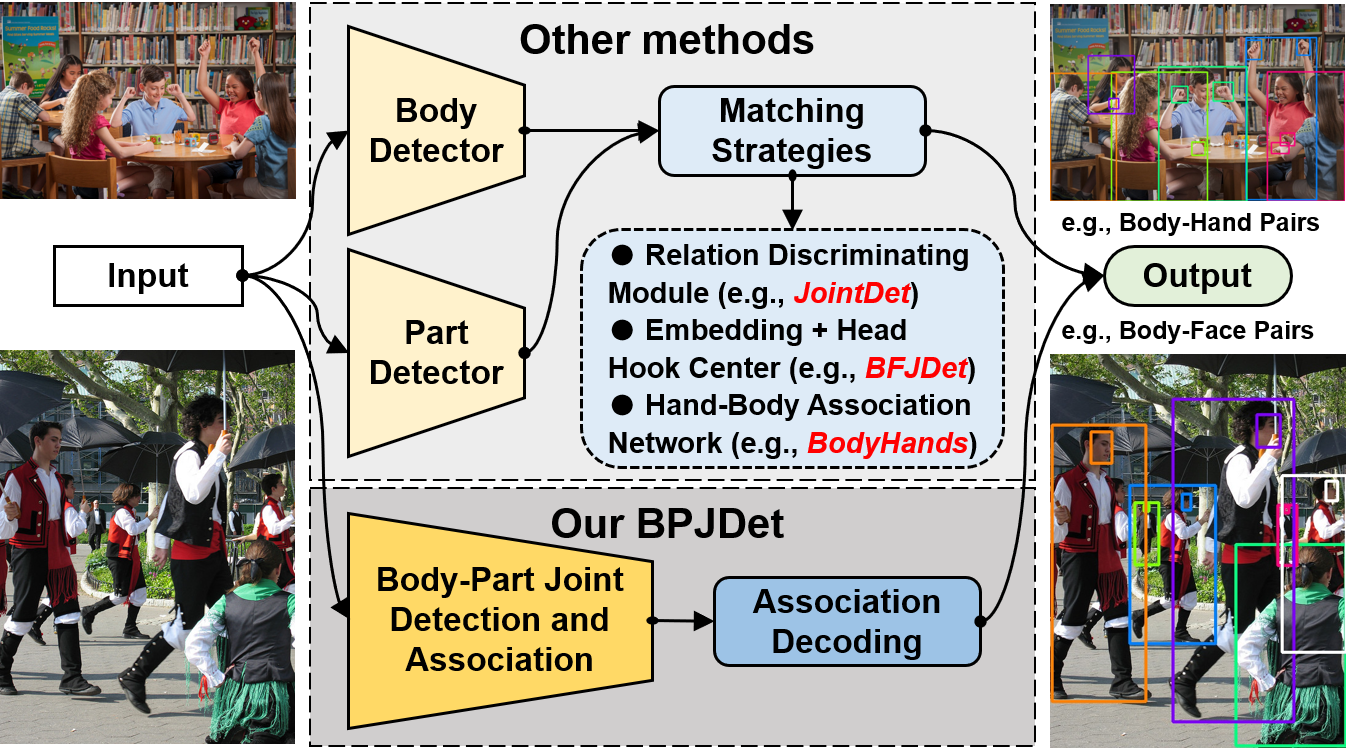
In this paper, we study the problem of body-part joint detection and propose a Body-Part Joint Detector (BPJDet). As shown in Fig. 1, the body part can be a face or hand. Our goal is to improve the body-part association accuracy on the premise of ensuring the detection precision. Prior to ours, several researches have attempted to address the joint body and part detection problem. DA-RCNN [19] and JointDet [17] focus on joint body-head detection. BFJDet [18] concentrates on the similarity body-face joint detection task. BodyHands [9] and [8] tackle the problem of detecting hands and finding the location of the corresponding person.
Unlike above methods using explicit strategies to model body-part relationships by exploiting heuristic post-matching or learning branched association networks, as illustrated in Fig. 1, we propose a novel extended object representation that can be harmlessly applied to single-stage anchor-based detectors like YOLO series [13, 20, 21]. Besides bounding boxes, confidence and objectness contained in the classic object representation, our extension adds location offsets of body parts. Regressing offsets is popular in object detection [22, 23] and human pose estimation [24, 25, 26, 27]. Our simple yet efficient innovation has at least three advantages. 1) The relational learning of body-part can benefit from the training of general detectors without painstakingly designing association subnets. 2) The final prediction naturally implies the detected body bounding boxes and their associated parts, which avoids error-prone and tedious association post-processing. 3) This general representation enables us to jointly detect arbitrary body part such as face and hand without major modifications. In experiments, we performed extensive tests on three public datasets to verify the superiority of our method.
To sum up, we mainly have following three contributions: 1) We propose a novel end-to-end trainable Body-Part Joint Detector (BPJDet) by extending the classic object representation with regressing offsets of body parts. 2) We reveal the feasibility and expedience of joint training of bounding boxes and offsets with designing suitable multi-task loss functions. 3) We achieve state-of-the-art body-part association performance on three public benchmarks while maintaining high detection accuracy of body and parts.
2 Related Work
Human Body and Part Detection: We here discuss emerging powerful CNN-based detectors that achieve promising results over traditional approaches using hand-crafted features. For human body detection, it belongs to either general object detection containing the person category [10, 11, 12, 13, 20, 22, 23, 21] trained on common datasets like COCO [14], or pedestrian detection [1, 2, 3, 28, 29] trained on specific benchmarks CityPersons [15] and CrowdHuman [16]. A key challenge in human body detection is occlusion. Therefore, many researches propose customized loss functions [1, 2], improved NMS [28, 3] or tailored distribution model [29] for alleviating problems of crowded people detection. On the other hand, detection of body part has also been intensively and extensively studied. Face detection [4, 5] and head detection [6, 7] are two mostly vigorous fields. Face detectors are usually based on well-designed networks and trained on dedicated datasets. Head detectors are rarely studied alone, and often used for facilitating crowd counting, enhancing crowd human detection or preprocessing of head pose estimation. Besides, some literatures present detection of hands such as hand-raisers [8] or body-hand pairs [9].
Body-Part Joint Detection: We mainly pay attention to the joint detection of face, head and hands body part. First of all, body-head joint detection is the most popular couple, because the human head is a salient structural body part and plays a vital role in recognizing people, especially when it is occluded. For example, DA-RCNN [19] proposes to handle the crowd occlusion problem in human detection by capturing and cross-optimizing body and head parts in pairs with double anchor RPN. JointDet [17] presents a head-body relationship discriminating module to perform relational learning between heads and human bodies. Recently, BFJDet [18] investigates the performance of body-face joint detection for the first time, and proposes a bottom-up scheme that outputs body-face pairs for each pedestrian. It also adopts independent detection followed by pairwise association. For body-hand joint detection, [8] devises heuristic strategies to match hand-raising gestures with body skeletons [24] in classroom scenes. BodyHands [9], in unconstrained conditions, proposes a novel association network to jointly detect hands and the body location, and introduces a new corresponding hand-body association dataset. Unlike all of them, our approach BPJDet is not restricted to a certain body part, and tackles detection and association in an end-to-end way.
Representation of Object Detection: Most modern object detection systems including anchor-based [10, 11, 12] and anchor-free [13, 20, 23, 21] detectors represent objects with bounding boxes. CenterNet [22] models objects using heatmap-based center points and represents human poses as a 2K-dimensional property of the center point. It firstly extends the traditional object representation, and reveals essential overlap between the tasks of object detection and human pose estimation. Similarly, for instance, FCPose [26] adapts single-stage object detector FCOS [23] with proposed dynamic filters to process person detections by predicting keypoint heatmaps and regressing offsets. Other single-stage pose estimators SPM [25] and AdaptivePose [27] also learn to regress keypoints as series of joint offsets. These works motivate us to detect human body with regressing its parts jointly by an extended object representation.
3 Our Method
3.1 Extended Object Representation
In our proposed BPJDet, we train a dense single-stage anchor-based detector to directly predict a set of objects , which contains human body set and body-part set concurrently. A typical prediction is concatenated of the bounding box and corresponding center point displacement . It locates an object with a tight bounding box where coordinates are the center position, and are the width and height of , respectively. It also records the relative displacement of center point of body-part () or affiliated body () to each . Considering that body-part may be more than one component (e.g., both hands part with ), we allow to be compatible with -dimensional 2D offsets. For these regressed offsets, we will explain how to decode them for the body-part association with fusing detected body-part set in Section 3.4.
Intuitively, we can benefit a lot from this extended representation. On one hand, an appropriate large body bounding box possesses both strong local characteristics and weak global features (such as surrounding background and anatomical position) for its body part offset regression. This enables the network to learn their intrinsic relationships. On the other hand, compared to methods [17, 18, 9] training multiple subnetworks or stages, mixing and up can be leveraged directly in BPJDet without the need of complicated post-processing. By designing a one-stage network that uses shared heads to jointly predict and , our approach can achieve high accuracy with minimal computational burden during training and inference.
3.2 Overall Network Architecture
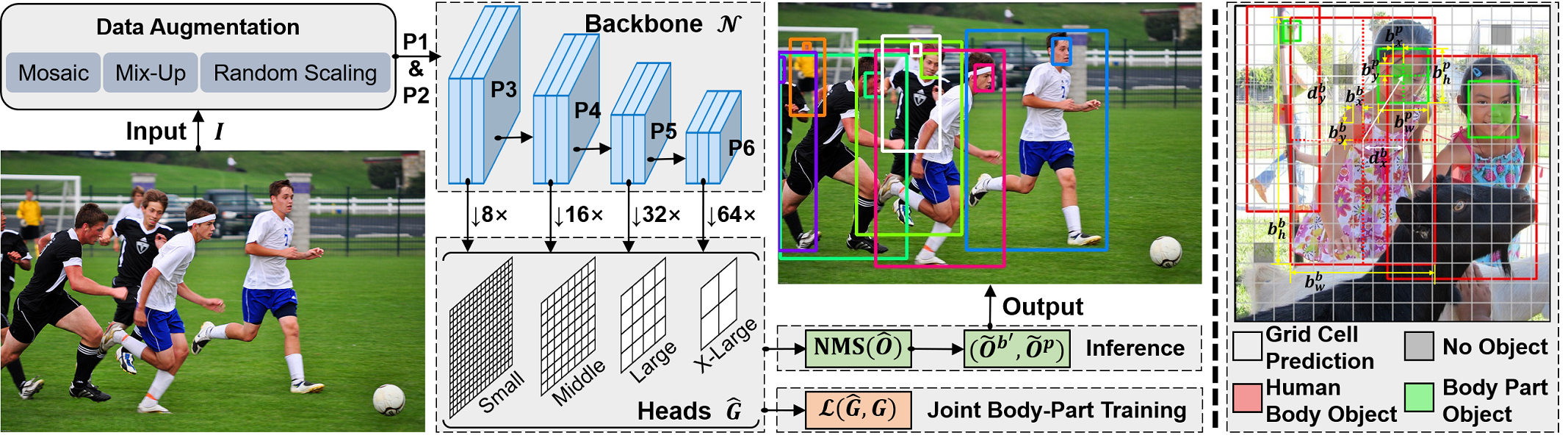
Our network structure is shown in Fig. 2 left. We choose the recently most cost-effective one-stage YOLOv5 [21] as the basic backbone . Specifically, following YOLOv5, we feed one RGB image as the input, keep its beneficial data augmentation strategies (e.g., Mosaic and MixUp), and output four grids from four multi-scale heads. Each grid contains dense object outputs produced from anchor channels and output channels. Supposing that one target object is centered at in the feature map , the corresponding grid at cell should be highly confident. When having defined anchor boxes for the grid , we will generate anchor channels at each cell . Furthermore, to obtain robust capability, YOLOv5 allows detection redundancy of multiple objects and four surrounding cells matching for each cell. This redundancy makes sense to the detection of body or part position , but it is not completely facilitative to the regression of offsets . We interpret this in Section 3.3.
Then, we explain the arrangement of one prediction from output channels of which is related to -th anchor box at grid cell . As shown in the example of grid cells in Fig. 2 right, one typical predicted embedding consists of four parts: the objectness or probability that an object exists, the candidate bounding box , the object classification score , and the candidate of body-part offsets . Thus, . To transform the candidate into coordinates relative to the grid cell , we apply conversions as below:
| (1) | ||||
where is the sigmoid function that limits model predictions in the range . Similarly, this detection strategy can be extended to the offset of body-part. A body-part’s intermediate offsets are predicted in the grid coordinates and relative to the grid cell origin using:
| (2) |
In the way, and are constrained to and , respectively. To learn and , losses are applied in the grid space. Sample targets of and are shown in Fig. 2 right.
3.3 Multi-Loss Functions
For a set of predicted grids , we firstly build target grids set following formats introduced in Section 3.2. Then, we mainly compute following four loss components:
| (3) | |||
| (4) | |||
| (5) | |||
| (6) |
For the bounding box regression loss , we adopt the complete intersection over union (CIoU) across four grids . in the objectness loss and classification loss is the binary cross-entropy. The multiplier in is used for penalizing candidates without hitting target grid cells (), and encouraging candidates around target anchor ground-truths (). The is a balance weight for different grid level. Finally, we utilize the mean squared error (MSE) to measure offset outputs and normalized targets in body-part displacement loss . Before that, we apply a filter with the visibility label of body-part to remove out those false-positive offset predictions from . Finally, we calculate the total training loss as follows:
| (7) |
where is the batch size. The , , and are weights of losses , , and , respectively.
3.4 Association Decoding
In inference, we need to process the predicted objects set to get final results. First of all, we apply the conventional Non-Maximum Suppression (NMS) to filter out false-positive and redundant bounding boxes of both body and part objects:
| (8) |
where and are thresholds for object confidence and IoU overlap, respectively. We fetch confidence of each predicted object by , where for body object and for part object. Then, we rescale and in and to obtain real and by below transformations:
| (9) |
where and are offsets from grid cell centers. The maps the box and offset size back to the original image shape.
Finally, we update associated body parts of each left body object in by fusing its regressed center point offsets () with the remaining candidate part objects . Specifically, we search each box in part objects with its nearest body-part offset belonging to body object. The part box that has a large inner IoU () with the body box will be selected. The updated body objects set is denoted as . We report all evaluation results on and .
4 Experimental Results
4.1 Experiment and Training Settings
Datasets: We mainly expect to evaluate the association quality of BPJDet, while maintaining high object detection accuracy. Three public datasets including CityPersons [15], CrowdHuman [16] and BodyHands [9] are chosen. The former two are for pedestrian detection tasks. In CityPersons, it has 2,975 and 500 images for training and validation, respectively. In CrowdHuman, there are 15,000 images for training and 4,375 images for validation. Following BFJDet [18], we use its re-annotated box labels of visible faces for conducting corresponding experiments. The last dataset BodyHands is for hand-body associations tasks. It has 18,861 and 1,629 images in train-set and test-set with annotations for hand and body locations and correspondences. We implement body-hand joint detection task in it for comparing.
Evaluation Metric: For evaluation metrics, we report the standard VOC Average Precision (AP) metric with IoU=0.5 for object detection of body, face and hands. We also present the log-average miss rate (MR-2) of body and its parts. For the association quality of BPJDet, we report the log-average miss matching rate (mMR-2) as proposed by BFJDet [18] of body-face pairs, and present Conditional Accuracy and Joint AP defined by BodyHands [9] of body-hand pairs.
Implementation Details: We adopt the PyTorch 1.10 and 4 RTX-3090 GPUs for training. Depending on the dataset complexity and scale, we train on the CityPersons, CrowdHuman and BodyHands datasets for 100, 150 and 100 epochs using the SGD optimizer, respectively. Following the original YOLOv5 [21] architecture, we train three kinds of models including BFJDet-S/M/L by controlling the depth and width of bottlenecks in . The shape of input images is resized and zero-padded to following settings in JointDet [17] and BFJDet [18]. We adopt the data training augmentation but leave out test time augmentation (TTA). As for many hyperparameters, we keep most of them unchanged, including adaptive anchors boxes , the grid balance weight , and the loss weights , and . We set based on ablation studies. When testing, we use thresholds , , , and for applying on .
| Methods | AP body | AP face | mMR | |||
| Reasonable | Partial | Bare | Heavy | |||
| RetinaNet+POS [12, 18] | 78.5 | 35.3 | 40.0 | 42.8 | 38.7 | 67.0 |
| RetinaNet+BFJ [12, 18] | 79.3 | 36.2 | 39.5 | 41.5 | 38.5 | 63.1 |
| FPN+POS [11, 18] | 80.6 | 65.5 | 33.5 | 32.7 | 34.1 | 56.6 |
| FPN+BFJ [11, 18] | 84.4 | 68.0 | 32.7 | 30.6 | 33.0 | 53.5 |
| BPJDet-S (Ours) | 75.1 | 58.2 | 29.3 | 28.9 | 29.3 | 57.2 |
| BPJDet-M (Ours) | 76.7 | 58.8 | 27.5 | 31.6 | 24.9 | 55.8 |
| BPJDet-L (Ours) | 75.5 | 61.0 | 26.4 | 27.7 | 25.5 | 46.2 |
| Methods | Stage | MR-2 body | MR-2 face | AP body | AP face | mMR |
| RetinaNet+POS [12, 18] | One | 52.3 | 60.1 | 79.6 | 58.0 | 73.7 |
| RetinaNet+BFJ [12, 18] | One | 52.7 | 59.7 | 80.0 | 58.7 | 63.7 |
| FPN+POS [11, 18] | Two | 43.5 | 54.3 | 87.8 | 70.3 | 66.0 |
| FPN+BFJ [11, 18] | Two | 43.4 | 53.2 | 88.8 | 70.0 | 52.5 |
| CrowdDet+POS [3, 18] | Two | 41.9 | 54.1 | 90.7 | 69.6 | 64.5 |
| CrowdDet+BFJ [3, 18] | Two | 41.9 | 53.1 | 90.3 | 70.5 | 52.3 |
| BPJDet-S (Ours) | One | 41.3 | 45.9 | 89.5 | 80.8 | 51.4 |
| BPJDet-M (Ours) | One | 39.7 | 45.0 | 90.7 | 82.2 | 50.6 |
| BPJDet-L (Ours) | One | 40.7 | 46.3 | 89.5 | 81.6 | 50.1 |
| Methods | Hand AP | Cond. Accuracy | Joint AP |
| OpenPose [24] | 39.7 | 74.03 | 27.81 |
| Keypoint Communities [30] | 33.6 | 71.48 | 20.71 |
| MaskRCNN+Feature Distance [31, 9] | 84.8 | 41.38 | 23.16 |
| MaskRCNN+Feature Similarity [31, 9] | 84.8 | 39.12 | 23.30 |
| MaskRCNN+Locaction Distance [31, 9] | 84.8 | 72.83 | 50.42 |
| MaskRCNN+IoU [31, 9] | 84.8 | 74.52 | 51.74 |
| BodyHands [9] | 84.8 | 83.44 | 63.48 |
| BodyHands* [9] | 84.8 | 84.12 | 63.87 |
| BPJDet-S (Ours) | 84.0 | 85.68 | 77.86 |
| BPJDet-M (Ours) | 85.3 | 86.80 | 78.13 |
| BPJDet-L (Ours) | 85.9 | 86.91 | 84.39 |
4.2 Quantitative and Visual Comparison
Ablation Studies: We mainly investigate the hyperparameter . For simplicity, we conduct all ablation experiments on the CityPersons dataset using BPJDet-S and training about joint body-face detection task. The input shape is . Total epoch is expanded to 150 for searching the best result. We uniformly sample from 0.005 to 0.030 with step 0.005 for training, and report metrics including MR-2s and average mMR-2 of each best model. As in Fig. 3, we can clearly find that the model performance is optimal when . A larger or smaller will lead to inferior results. More ablation studies are provided in our supplementary material.
Results on CityPersons and CrowdHuman: We compare joint body-face detection performance of BPJDet with method BFJDet [18] on these two benchmarks. Table 1 shows results on the val-set of CityPersons. Following [2, 18], results are reported on four subsets of Reasonable (occlusion 35%), Partial (10% occlusion 35%), Bare (occlusion 10%) and Heavy (occlusion 35%). Comparing with RetinaNet+BFJ which obtains similar body AP but far inferior face AP to ours, BPJDet-L exceeds it of mMR-2 by 13.1%, 13.8%, 13.0% and 16.9% in four subsets, respectively. Comparing with FPN+BFJ that has similar face AP but higher body AP to ours, BPJDet-L also surpasses it of mMR-2 by 6.3%, 2.9%, 7.5% and 7.3% in four subsets. Especially, in the Heavy subset, our association superiority is the most prominent, which reveals that our BPJDet has an advantage for addressing miss-matchings in crowded scenes.
Table 2 shows results on the more challenging CityPersons. Our method BPJDet achieves considerable gains in all metrics comparing with BFJDet based on one-stage RetinaNet [12] or two-stage FPN [11] and CrowdDet [3]. Remarkably, BPJDet-L has achieved the lowest mMR-2 value 50.1%, which is 2.2% lower than the previous best method CrowdDet+BFJ. These again demonstrate the superiority of our method. More persuasive visual results of BPJDet-L trained on CrowdHuman and tested on complicated overcrowded scenes are shown in Fig. 4.










Results on BodyHands: We conduct joint body-hand detection experiments on BodyHands [9], and compare our BPJDet with several methods proposed in BodyHands. As shown in Table 3, our BPJDet outperforms all other methods by a significant margin. With achieving highest hand AP 85.9% and conditional accuracy 86.91% of body, BPJDet-L largely improves the previous best Joint AP of body and hands by 20.52%. We give more qualitative comparisons of joint body-hand detection trained on BodyHands in Fig. 5. The compared masked images are fetched from BodyHands paper. Our BPJDet can detect many unlabeled objects, and associate hands that method proposed in BodyHands fails to match. This illustrates why we have an overwhelming Joint AP advantage. All these results further validate the generalizability of our extended object representation and its impressive strength on body and part relationship discovery.
5 Conclusion
In this paper, we propose a novel body-part joint detector named BPJDet to address the challenging paired object detection and association problem. Inspired by offset regression in general object detection and human pose estimation, we attempt to extend the traditional object representation by appending body-part displacements, and design favorable multi-loss functions to enable joint training. Furthermore, BPJDet is not limited to a specific or single body part. Quantitative SOTA results and impressive qualitative performance on three public datasets suffice to demonstrate the robustness, adaptability and superiority of our proposed BPJDet.
References
- [1] Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, and Stan Z Li, “Occlusion-aware r-cnn: detecting pedestrians in a crowd,” in ECCV, 2018, pp. 637–653.
- [2] Xinlong Wang, Tete Xiao, Yuning Jiang, Shuai Shao, Jian Sun, and Chunhua Shen, “Repulsion loss: Detecting pedestrians in a crowd,” in CVPR, 2018, pp. 7774–7783.
- [3] Xuangeng Chu, Anlin Zheng, Xiangyu Zhang, and Jian Sun, “Detection in crowded scenes: One proposal, multiple predictions,” in CVPR, 2020, pp. 12214–12223.
- [4] Peiyun Hu and Deva Ramanan, “Finding tiny faces,” in CVPR, 2017, pp. 951–959.
- [5] Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou, “Retinaface: Single-shot multi-level face localisation in the wild,” in CVPR, 2020, pp. 5203–5212.
- [6] Tuan-Hung Vu, Anton Osokin, and Ivan Laptev, “Context-aware cnns for person head detection,” in ICCV, 2015, pp. 2893–2901.
- [7] Chao Le, Huimin Ma, Xiang Wang, and Xi Li, “Key parts context and scene geometry in human head detection,” in ICIP. IEEE, 2018, pp. 1897–1901.
- [8] Huayi Zhou, Fei Jiang, and Ruimin Shen, “Who are raising their hands? hand-raiser seeking based on object detection and pose estimation,” in ACML. PMLR, 2018, pp. 470–485.
- [9] Supreeth Narasimhaswamy, Thanh Nguyen, Mingzhen Huang, and Minh Hoai, “Whose hands are these? hand detection and hand-body association in the wild,” in CVPR, 2022, pp. 4889–4899.
- [10] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” NIPS, vol. 28, 2015.
- [11] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie, “Feature pyramid networks for object detection,” in CVPR, 2017, pp. 2117–2125.
- [12] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár, “Focal loss for dense object detection,” in ICCV, 2017, pp. 2980–2988.
- [13] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, “You only look once: Unified, real-time object detection,” in CVPR, 2016, pp. 779–788.
- [14] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick, “Microsoft coco: Common objects in context,” in ECCV. Springer, 2014, pp. 740–755.
- [15] Shanshan Zhang, Rodrigo Benenson, and Bernt Schiele, “Citypersons: A diverse dataset for pedestrian detection,” in CVPR, 2017, pp. 3213–3221.
- [16] Shuai Shao, Zijian Zhao, Boxun Li, Tete Xiao, Gang Yu, Xiangyu Zhang, and Jian Sun, “Crowdhuman: A benchmark for detecting human in a crowd,” arXiv preprint arXiv:1805.00123, 2018.
- [17] Cheng Chi, Shifeng Zhang, Junliang Xing, Zhen Lei, Stan Z Li, and Xudong Zou, “Relational learning for joint head and human detection,” in AAAI, 2020, vol. 34, pp. 10647–10654.
- [18] Junfeng Wan, Jiangfan Deng, Xiaosong Qiu, and Feng Zhou, “Body-face joint detection via embedding and head hook,” in ICCV, 2021, pp. 2959–2968.
- [19] Kevin Zhang, Feng Xiong, Peize Sun, Li Hu, Boxun Li, and Gang Yu, “Double anchor r-cnn for human detection in a crowd,” arXiv preprint arXiv:1909.09998, 2019.
- [20] Joseph Redmon and Ali Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [21] Glenn Jocher, Alex Stoken, Jirka Borovec, A Chaurasia, and L Changyu, “ultralytics/yolov5,” Github Repository, YOLOv5, 2020.
- [22] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl, “Objects as points,” arXiv preprint arXiv:1904.07850, 2019.
- [23] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He, “Fcos: Fully convolutional one-stage object detection,” in ICCV, 2019, pp. 9627–9636.
- [24] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in CVPR, 2017, pp. 7291–7299.
- [25] Xuecheng Nie, Jiashi Feng, Jianfeng Zhang, and Shuicheng Yan, “Single-stage multi-person pose machines,” in ICCV, 2019, pp. 6951–6960.
- [26] Weian Mao, Zhi Tian, Xinlong Wang, and Chunhua Shen, “Fcpose: Fully convolutional multi-person pose estimation with dynamic instance-aware convolutions,” in CVPR, 2021, pp. 9034–9043.
- [27] Yabo Xiao, Xiao Juan Wang, Dongdong Yu, Guoli Wang, Qian Zhang, and HE Mingshu, “Adaptivepose: Human parts as adaptive points,” in AAAI, 2022, vol. 36, pp. 2813–2821.
- [28] Songtao Liu, Di Huang, and Yunhong Wang, “Adaptive nms: Refining pedestrian detection in a crowd,” in CVPR, 2019, pp. 6459–6468.
- [29] Zixuan Xu, Banghuai Li, Ye Yuan, and Anhong Dang, “Beta r-cnn: Looking into pedestrian detection from another perspective,” NIPS, vol. 33, pp. 19953–19963, 2020.
- [30] Duncan Zauss, Sven Kreiss, and Alexandre Alahi, “Keypoint communities,” in ICCV, 2021, pp. 11057–11066.
- [31] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick, “Mask r-cnn,” in ICCV, 2017, pp. 2961–2969.