Boilerplate Detection via Semantic Classification of TextBlocks
Abstract
We present a hierarchical neural network model called SemText to detect HTML boilerplate based on a novel semantic representation of text blocks. We train SemText on three published datasets of news webpages and fine-tune it using a small number of development data in CleanEval and GoogleTrends-2017. We show that SemText achieves the state-of-the-art accuracy on these datasets. We then demonstrate the robustness of SemText by showing that it also detects boilerplate effectively on out-of-domain community-based Q&A webpages.
Index Terms:
content extraction, sequence labeling, boilerplate detection, word embedding, neural networksI Introduction
How to detect HTML boilerplate accurately and efficiently is a continuing quest for search engines and other applications. Methods that worked well on earlier webpages may not work well on contemporary webpages due to new structure and presentation style.
Structures of contemporary webpages have two types: The type-1 structure keeps the main content in one place, surrounded by boilerplate contents, while the type-2 structures scatters the main text across the entire webpage. News articles and blogs are type-1, and community-based Q&A webpages are type-2, which display lists of questions followed by one or more answers to each question (see Fig. 1).
Constructing a spiderbot (a.k.a. spider or crawler) for a given webpage is the most accurate method to extract the main text. However, it involves tedious manual inspection of the layout of the page, and its accuracy is sensitive to even the slightest change of the underlying structure of the webpage. To avoid laborious construction and maintenance of spiders, researchers have pursued a different approach known as boilerplate detection based on common features, which are less sensitive to structural change of webpages.
Boilerplate-detection methods have mainly targeted at type-1 pages; extracting main contents from type-2 webpages has not attracted much attention. However, there is a need to extract question-answer pairs from community Q&A websites for constructing a domain-specific chatbot (e.g., [1]). Recent success of neural-network research has made it possible to construct a boilerplate detection model to handle webpages of both types. We present such a model called SemText that requires no handcrafted features, and demonstrate that it is a promising approach.
SemText is a hierarchical neural-network model based on a semantic representation of text. To obtain this representation we partition the text contained in an HTML file into a sequence of text blocks, and represent each text block uniquely with three sequences: (1) a sequence of HTML tags on the path from the root of the DOM-tree of the page to the text block, (2) a sequence of class names on the path from the root to the text block, and (3) a text string (content) enclosed in the text block. HTML tags have semantic meanings, so do class names if web developers follow the conventional naming rules. We take advantage of these meanings by replacing each HTML tag with the underlying word and each class name with an appropriate sequence of words. We view a word string as a sentence with certain meanings, and so semantic representations of words such as word-embedding vectors may be used. Next, we feed the resulting strings to a depthwise CNN model to produce a feature map of a text block. We then apply a Bi-LSTM-CRF sequence-labeling model to classify feature maps using the semantics registered inside and between them.
We train SemText in an end-to-end fashion on a dataset that combines three published type-1 webpages collected from 2008 to 2020, then fine-tune it using a small number of cross-domain webpages for development provided by CleanEval [2] and GoogleTrends-2017 [3]. We show that SemText achieves the highest F1 score over previous methods on these datasets. We then evaluate SemText on a collection of type-2 webpages and show that SemText also works well.
II Related Work
Previous boilerplate-detection methods can be divided into rule-based, website-based, and machine learning algorithms.
II-1 Rule-based and heuristic methods
They are based on shallow features such as text length or text-over-tag density. For example, the main content could be located at a “plateau” area where the amount of text increases dramatically while the number of tags only changes a little [4]. The main content could also be in an area with the highest text density defined by the number of tokens over the number of tags or lines [5, 6, 7, 8]. These methods, while achieving high accuracy on certain webpages such as news articles, do not work well on contemporary webpages with running ads separating the main text into multiple segments. Contemporary webpages would present multiple “plateaus” or multiple clusters of the same highest density.
II-2 Website-based methods
They are based on the observation that webpages on the same website would follow the same style. For example, merging the DOM-trees of single webpages on the same website in a top-down fashion, the main content could be a sequence of nodes with more presentation styles and more diverse content types [9]. A boilerplate may also be viewed as a common subtree of DOM-trees of the webpages at the same website, and so boilerplate detection is reduced to finding a common subtree from a set of given trees [10]. These methods can detect website templates with high accuracy, applicable to both type-1 and type-2 webpages. In reality, however, most applications only have a single webpage as a data source without the needed website information.
II-3 Machine-learning methods
They can be categorized into regression, classification, and sequence labeling.
Regression methods rank or score text blocks. For example, using a vision-based page segmentation method [11] to visually separate a webpage into several blocks by the center pixel coordinate, width, height, and other visual information, a radial-basis-function network can perform regression to score text blocks [12]. However, most published datasets do not provide ranking or scoring of extractions to support regression, which hinders this approach.
Classification methods represent and classify each text block independently based on handcrafted features. For example, a total of 67 handcrafted textual features are used for block classification [13]. Similarily, FIASCO[14] represents a text block using linguistic, structural, and visual features, and uses SVM for classification. However, classifying text blocks without considering context or the interrelations between them is error-prone, especially those with limited content. For example, to classify a text block that says “limited time 20 percent off” without context is difficult, for it could be a boilerplate or the main text depending on the context.
Sequence-labeling methods, such as Conditional Random Field (CRF) [15, 16], use relations between neighboring text blocks to jointly decode the best chain of labels for text blocks. To enrich conventional features, a CNN model may be added to sequence labeling. For example, Web2text [17] applies CNN to learn unary and pairwise classification potentials for the sequence of text blocks, maximizing the joint probability using the Viterbi algorithm. But the CNN model is used to refine 128 hand-crafted features instead of learning feature representations.
Machine-learning methods rely on handcrafted features, ranging from textual to structural and from linguistic to visual; handcrafted features are sensitive to structure change. Moreover, most handcrafted features were designed specifically for type-1 webpages with simpler layouts. To avoid handcrafted features, deep learning models have recently been used to detect boilerplate. BoilerNet [3], for example, is a neural sequence-labeling model that represents each text block as a vector, encoding both HTML tags and words in the text block. Each index in the vector indicates the token count for a specific tag or word. A bi-directional LSTM model is adopted for sequence labeling. BoilerNet outperforms or matches previous models.
How to represent a text block is critical. Counting tokens may work for HTML tags, for the number of tags is limited. But it may not work well for words. In particular, if a token in the testing webpages has never been seen in the training set, the vector fails to represent the text block properly. Although it is possible to represent text with limited tokens by carefully selecting them, it is akin to using handcrafted features. Furthermore, a counting-based representation discards the most important semantic information registered inside the text. Such information is often used by humans when distinguishing the main content from boilerplate.
III SemText
We model boilerplate detection as a text-sequence labeling problem, where a webpage is divided into a sequence of text blocks and each text block is encoded using semantic representations of three word strings: (1) a sequence of HTML tags, (2) a sequence of class names, and (3) a sequence of text in the text block. We seek to produce a globally-optimal label sequence for , where denotes the classification label (“main” or “boilerplate”) assigned to block at time on input .
III-A Generation of text block sequence
We present an algorithm called Search-and-Combine Segmentation (SCS) to generate a sequence of text blocks in two phases: the search phase and the combine phase. In the search phase, SCS traverses the DOM-tree of a given HTML file using depth-first search (DFS) and identifies leaf nodes that contain text. On each path during the search phase, SCS removes text-formatting tags and the corresponding closing tags, but not the enclosed text. In the combine phase, starting from the first text block, SCS recursively compares the current text block with the next text block and merge them into a new block if they are siblings and with the same presentation style. Merging text blocks provides needed semantic information for more accurate classification and helps to prevent vanishing gradients during training.
The search phase
HTML tags are categorized into three groups. Tags in group-1 and the enclosed text (if any) do not contribute to the main text. These tags include all document-metadata tags (e.g., head, meta), all scripting tags, almost all content-embedding tags (e.g., img, audio), all form tags, among a few others. Tags in group-2 contain text that may or may not contribute to the main content, but the tags should be excluded from a text block. These include most of the text-formatting tags (e.g., em, strong), and some tabular-tags (tbody, thead). Tags in group-3 and the enclosed text should all be included in a text block. These include all section tags, some grouping tags (e.g., div, p), all list tags, some tabular tags (e.g., table, caption), and a few others.
Let be an HTML file. SCS() performs a depth-first search (DFS) on ’s DOM-tree, finding a path from the root node to each leaf node. For each path during search, remove every tag in group-1, together with its closing tag (if any) and the content enclosed. Also removed is every tag in group-2 and its closing tag (if any), but not the enclosed text.
SCS() creates a text block when it encounters a group-3 tag, opening or closing, by extracting the text between this tag and the next group-3 tag, opening or closing; and stores it with the sequence of opening tags and the sequence of class names on the path from the root to this block registered by the DFS search. Remove closing tags. If the text extracted is empty or invalid, do not create a text block. Thus, the sequence of text blocks produced by SCS in the order of DFS-traversal is a partition of the valid text portion of in its original order, where each text block consists of three strings of text: , , and , with tag() being the sequence of the group-3 tags on the path from the root to the block, class the sequence of class names on the same path, and text the text enclosed in .
Given a character string , denote by the number of characters contained in . Let be the height of the DOM-tree for . For a well-balanced DOM-tree, we have . Without loss of generality, assume that for any . All webpages we have encountered satisfy this property. Note that the length of each tag and each class name is bounded above by a constant. The following lemma is straightforward.
Lemma 1
Let be the sequence of text blocks generated by SCD(). We have and .
The combine phase
Let be an array of text blocks created in the search phase in the order of DFS-traversal, and the -th text block in . Then SCS, where is defined recursively as follows, and is stored right before :
Case 1
and are leaf siblings with the same tag sequence and the same class-name sequence. Then and belong together. That is, is a new block with , , and .
Case 2
is a leaf and a single child of , class() = class(), tag() is a prefix of tag(), and . They and belong together. That is ,combine them into a new text block as in Case 1.
Case 3
is a leaf, is either a sibling of or a parent of a single child , then don’t combine. That is, This “don’t-combine” rule can be justified as follows: If and are leaf siblings with , then the two blocks may have different structures. If and are leaf siblings with , then the two blocks may have different presentation styles. If is a leaf single child of , but , then the child would have a different intention with the parent.
Case 4
None of the above and is not the last stored. Let be its next text block in the order of DFS-traversal. Then let
Theorem 1
SCS runs in time.
Proof sketch. In the search phase, DFS runs in linear time in terms of the number of nodes of the DOM-tree for , which is determined by the number of opening tags contained in it.Let denote the number of the temporary text blocks produced by the search phase. While is much smaller than , the search phase may still need to read through the entire file. Thus, it follows from Lemma 1 that the search phase incurs a running time . The combine phase is a linear recursion on non-overlapping text blocks,and so its running time is .
Remark
It is reasonable to assume that a text block generated during the search phase will not contain both main and boilerplate contents; otherwise, even humans cannot distinguish the main text from boilerplate without inspecting the semantics of the corresponding text, which defies the purpose of the webpage. Likewise, the combine phase will in general not combine a text block for boilerplate and a text block for the main content, because to combine them, they would be siblings with the same tags and class names, which violates the general practice that the main text and boilerplate are distinguishable by humans based on their looks. Our experimental results affirm this observation.
III-B Word replacement for tags and class names
We observe that using semantics contained in the text enclosed in a text block can help identify boilerplate. For the text enclosed inside a text block, if “The US president …” is in one block and “limited time 20% off” in another, then it is easier to tell that the former text block is part of the main content and the latter a boilerplate according to their meanings. To bring in semantics to a text block, we replace each tag with the underlying word or phrase to produce a “sentence” of words. For example, p is replaced by “paragraph”, div by “division”, and h1 by “primary headline”. Similarly, class names, especially in HTML files that follow conventional naming rules for understanding and reusing codes are often formed by words or meaningful word abbreviations. Fig. 2 is an example of the DOM-tree for an ABC news webpage, where the main text—the darkened part with the news text omitted—has a sequence of class names like, after text cleansing, “story feed item scrollspy container article flex story article content story”. For the blocks around the main content, we can see class names with words of “header”, “footer”, and “sponsored headline”.
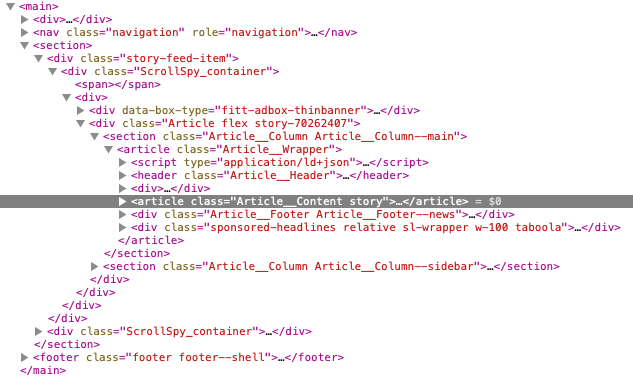
We remove hyphens, dashes, and other delimiters from class names, separate camel-case words, discard numbers, and expand abbreviations to their original words. A class name that cannot be converted to a word string (note that this is rare) is left as is. We recommend keeping these class names to prevent information loss. Another thing worth mentioning is that the ID attributes may be added to the class-name sequence to form an ID-class-name sequence, as used by CSS for manipulating the element with a specific ID. ID-class-name sequences are treated in the same way as class-name sequences.

Fig. 3 depicts an example of converting tag sequences and class-name sequences into string of words for two neighboring text blocks.
III-C Sequence labeling
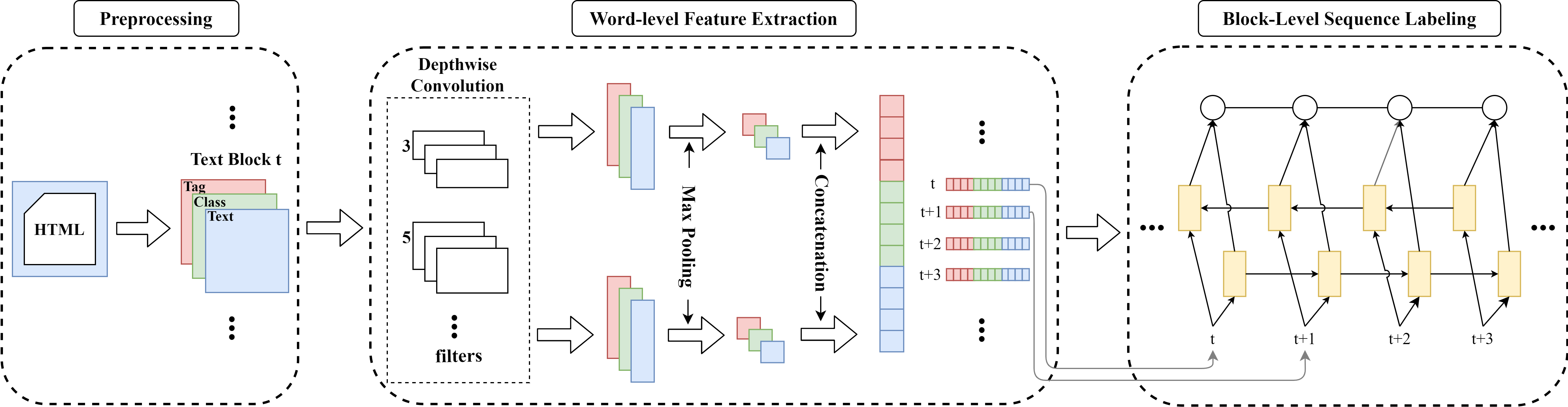
Figure 4 depicts the architecture of SemText. The preprocessing component is responsible for generating text blocks from a given HTML file. The word-level-feature-extraction component is a depth-wise CNN model that takes text blocks as input and generates a feature map for each text block. The block-level-sequence-labeling component is a Bi-LSTM-CRF model that labels each feature map as “main” or “boilerplate”.
III-D Preprocessing
Word embedding
SemText removes stop words from each word string obtained from Section B above, and replaces each remaining word with its word-embedding representation to bring in useful semantic and syntactic information. If a word does not appear in the pre-trained dataset, such as the unidentifiable class names aforementioned, SemText obtains an embedding representaton for it using Subword [18], a method that overcomes this problem.
Text-block truncation
Long text blocks are undesirable because of intense computation needed to process them. On the other hand, it is not necessary to have long text blocks for the purpose of classifying them. What is needed is a reasonable amount of text in each word string. Thus, for each text block, SemText keeps the first (e.g., ) words (after removing stop words) in each word string and removes the rest.
Preprocessing time complexity
Let be an HTML file for SemText. Generating a sequence of text blocks from using SCS takes time (Theorem 1). The time for carrying out word replace and replacing a word with its word-embedding vector is constant. Truncating a text block is time. Thus, SemText runs in time for preprocessing.
III-E Word-level depth-wise CNN encoding
We construct a CNN encoder to extract word-level features, motivated by Kim’s one-layer CNN model with 1-dimensional convolution [19]. An input has three word strings with at most words in each string, denoted by , where each word is a -d embedding vector. If () has less than words, then fill in the rest of the word slots by 0-vectors. Thus, each becomes an matrix , where is the feature map number and a -d vertical vector.
Unlike regular CNNs that apply convolution filters to all feature maps to form a single result, our CNN model uses different feature maps to represent different aspects of a text block not necessarily having any cross-feature-map relation with others, and uses different convolution filters on different feature maps. Thus, we perform depthwise 1-d convolution instead of combining them. An added benefit of doings so is that it significantly reduces the number of parameters. In particular, our depthwise 1-d convolution first splits the input to form different feature maps, then carries out convolution operations on each feature map with a filter , where is the filter width. Let denote a filter-size block that contains word-embedding vectors, then the corresponding feature map for the current window is where denotes a bias factor. Sliding the filter in the vertical direction, we obtain a feature map as follows: Convoluting each feature map with the corresponding filter, and then perform max-pooling over each feature map that extracts the largest number in the map, resulting in a 3-tuple of numerical values for . ;
Repeat the above procedure for different filters with different kernel sizes to produce 3-tuples of numerical values. Group them according to feature maps and flatten the results into a 1-d output, denoted by , to produce the final feature map of . Figure 4 illustrates the data flow of this process in the word-level feature extraction module.
III-F Block-level Bi-LSTM-CRF sequence labeling
At the block-level, SemText uses the Bi-LSTM-CRF [20] architecture to capture context for the block sequence. To learn a contextual representation and a context dependency , the feature map generated by the CNN model at time , as well as the previous block information and , are fed to a long-short-term memory (LSTM) unit [21]. LSTM units are connected forwardly, thus previous block information can be captured, which may impact the representation and output for the current input block. LSTM is designed to resolve the gradient vanishing problem that can be encountered when training a traditional recurrent-neural-network model, allowing long-term dependencies being captured. It uses a set of gates to decide when a certain dependence should be remembered, forgotten, or outputted.
LSTM, however, has a forward-only direction capable of capturing the past context only. To make use of forward and backward information, bidirectional LSTM (Bi-LSTM) [22] puts two LSTM together, one in the forward direction and one in the backward direction. Thus, the contextual representation of the -th text block can be rewritten as . To make effective use of past and future prediction results, a CRF layer is added to the output of Bi-LSTM for jointly decoding the best chain of labels. Let denote the contextual representation generated by Bi-LSTM through time, that is, The CRF layer maximizes conditional probability to find the highest-scored result over all possible label sequences, where represent a possible sequence and is a log potential function with being an emission potential and a transition potential. The emission potential is defined by a fully-connected layer, transferring the output of Bi-RNN at timestamp to a score. The transition potential denote a transition probability from the previous tag to the current tag . Adding the CRF layer is helpful to cultivate strong correlations that exist between labels of adjacent neighborhoods.
IV Evaluation
IV-A Datasets
The CleanEval dataset [2] is a cross-domain benchmark, consisting of 55 webpages for training (development) and 676 webpages for evaluation. The “clean text file” for each webpage does not align properly between text blocks of the two files, and so cannot be used directly for analysing HTML files at the tag level. We adopt Vogels et al.’s method [17] to make proper alignment. The latest GoogleTrends-2017 dataset [3] published in 2020, consists of 180 documents randomly sampled from a larger pool of websites retrieved from the top Google queries with the corresponding main text. It is customary to use 80 webpages for training and the remaining 100 webpages for testing when using GoogleTrends-2017.
These two datasets, however, are insufficient to train a neural network. It is also more desirable to have a training dataset mixing of past and contemporary webpages from a wider range of domains. To this end, we combine the following three published type-1 datasets: (1) the dataset annotated by Uzun E. et al. [23], consisting of 1,170 webpages from 573 domains published from 2008 to 2011; (2) the dataset annotated by Peters M. and Lecocq D. [24], consisting of 1,381 webpages collected in late 2012 from RSS feeds, news articles, and blogs; (3) the TECO Benchmark Suite, presented by Alarte J. [25], consisting of webpages collected from 130 domains during the period from 2013 to 2020. TECO is a multilingual dataset made for testing language independent features and we remove non-English and non-type-1 webpages from it. We train SemText on this combined dataset, then fine-tune it using the 55 training webpages in CleanEval and 80 webpages in GoogleTreands-2017. This allows us to demonstrate the robustness of SemText on webpages of different structures across a wider spectrum.
We also evaluate SemText on 250 type-2 webpages consisting of 70 pages sampled from the TECO Forum dataset with non-English pages removed111This dataset is available at https://github.com/dreamlegends/Semtext., and 180 webpages collected from nine large Q&A sites including Quora and Yahoo Answer, with main content extracted by custom-built spiders.
IV-B Model Setup
Let be the maximum number of words for each word-string component (without stopwords). For each text block , we translate HTML tags in using the W3C HTML5 reference222https://dev.w3.org/html5/html-author/. Class names in class() are processed as described in Section III-B. While we have not seen any text block with tag or class containing more than 50 words, it is common for text to exceed the 50-word limit and so truncation is used to trim it down to 50. With an average of 10 to 15 words per sentence in the main text (with stopwords removed), 50 words can cover 4–5 sentences, sufficient for representing the semantics of a text block.
Let be the upper bound for the number of text blocks produced by SCS, which is adequate to cover 90% of news articles and would not cause excessive computation. If SCS produces more than 85 text blocks for an HTML file, we divide them into sub-sequences in the same order as evenly as possible so that the number of text blocks in each sub-sequence is the largest possible bounded above by 85.
We use kernels of sizes of 3, 5, and 7 for the word-level CNN encoder, with the corresponding numbers of filters being 128, 128, and 256, for a total number of filters . This setting covers consecutive words in almost every aspect to capture the essential meaning of a text block. There are 512 hidden units for a single Bi-LSTM. Parameter optimization is performed using stochastic gradient descent (SGD) with a batch size of 64.
We divide at random the combined dataset with a 75-25 split into a training set and a validation set, and choose the checkpoint with the highest F1 score on the validation set. Our model is implemented on Pytorch and trained on a single NVIDIA GeForce GTX 2080Ti GPU.
IV-C Comparison results
We compare SemText with BoilerNet [3], Web2Text [17], and BoilerPipe [13], the best models so far, under the measures of average precision and recall. To provide fair comparison, we train and test these models as we train SemText using the same combined dataset and fine-tune them using the same development data of CleanEval and GoodTrends (except BoilerPipe that is not built for fine-tuning). We name the models trained this way as, respectively, BoilerNet-C, Web2Text-C, and BoilerPipe-C. We also train these models using the original development data of CleanEval to obtain, respectively, three models named BoilerNet-1, Web2Text-1, and BoilerPipe-1; and using the original development data of GoogleTrends to obtain, respectively, three models named BoilerNet-2, Web2Text-2, and BoilderPipe-2.
We test all models on the same test data of CleanEval and GoogleTrends. Evaluation is carried out at the text-block level and blocks are treated equally with the same weight. Table I shows the evaluation results, where 12 means that the results of the corresponding model version 1 (e.g., BoilerPipe-1) are under the CleanEval column and version 2 (e.g., BoilerPipe-2) are under the GoogleTrends column. The numbers in boldface are the highest.
| Methods | CleanEval | GoogleTrends | ||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| BoilerPipe-C | 0.81 | 0.67 | 0.73 | 0.74 | 0.61 | 0.69 |
| Web2Text-C | 0.80 | 0.76 | 0.78 | 0.76 | 0.73 | 0.74 |
| BoilerNet-C | 0.88 | 0.85 | 0.86 | 0.87 | 0.86 | 0.87 |
| BoilerPipe-12 | 0.87 | 0.73 | 0.79 | 0.80 | 0.66 | 0.72 |
| Web2Text-12 | 0.85 | 0.82 | 0.83 | 0.82 | 0.74 | 0.78 |
| BoilerNet-12 | 0.85 | 0.80 | 0.82 | 0.86 | 0.82 | 0.84 |
| SemText | 0.91 | 0.89 | 0.90 | 0.92 | 0.86 | 0.89 |
Indications of these results are summarized below:
-
1.
SemText outperforms the previous models under each category except that SemText and BoilerNet-C have the same recall on GoogleTrends.
-
2.
BoilerNet-C is substantially better than BoilerPipe-C and Web2Text-C on both datasets.
-
3.
BoilerPipe-C and Web2Text-C on GoogleTrends are substantially worse than themselves on CleanEval. Likewise, BoilerPipe-2 and Web2Text-2 are substantially worse than BoilerPipe-1 and Web2Text-1, respectively.
-
4.
Web2Text-1 is slightly better than BoilerNet-1, and Web2Text-2 is substantially lower than BoilerNet-2.
-
5.
The results of SemText and BoilerNet are consistent on both datasets, but the results of BoilerPipe and Web2Text are not.
A possible cause of inconsistency of BoilerPipe and Web2Text across different datasets is that some of their handcrafted features are sensible to webpage structure. For example, both web structure and tag usage have changed gradually in the past ten years, and placing ads from a sidebar to the main content area can increase the link density and decrease the text density, making the text-density feature fail on contemporary webpages. Tag TD, which was widely used before 2009, was replaced by tag DIV in the web evolution. Thus, BoilerPipe and Web2Text would provide anticipated performance only when they are trained and tested on datasets from the same period. BoilerNet, on the other hand, does benefit from the combined dataset, which indicates that neural network models can indeed provide a better and more robust representation. The combined dataset also provides a large vocabulary size to alleviate the Out-of-Vocabulary problem mentioned in the last paragraph of Section II. Since each tag is treated as a token in the BoilerNet, the change of tag usage may still affect the model. SemText mitigates this drawback by taking advantage of the semantics registered inside the tags.
SemText also performs reasonably well on type-2 webpages without any training on type-2 webpages and is substantially better than BoilerNet-C, which in turn is substantially better than Web2Text-C and BoilerPipc-C (see the upper part of Table II).
| Methods | P | R | F1 |
|---|---|---|---|
| BoilerPipe-C | 0.93 | 0.12 | 0.21 |
| Web2Text-C | 0.59 | 0.73 | 0.65 |
| BoilerNet-C | 0.66 | 0.81 | 0.72 |
| SemText | 0.79 | 0.84 | 0.82 |
| BoilerPipe-C1 | 0.92 | 0.19 | 0.32 |
| Web2Text-C1 | 0.63 | 0.75 | 0.68 |
| BoilerNet-C1 | 0.72 | 0.87 | 0.79 |
| SemText-1 | 0.85 | 0.87 | 0.86 |
Next, we retrain all models by including type-2 webpages in the training dataset and evaluate how well they perform on type-2 pages. To this end, we randomly select 50 webpages from the type-2 dataset and add them to the combined dataset of type-1 pages. The remaining 200 type-2 webpages are used for evaluation. We obtain SemText-1, BoilerNet-C1, BoilerPipe-C1, and Web2Text-C1, with the evaluation results shown in the lower part of Table II. It can be seen that all models have improved performance with the same performance ranking as before. In particular, under the F1 measure, SemText-1 is 8.87% higher than BoilerNet-C1. While SemText-1 and BoilerNet-C1 have the same recall, SemText-1’s precision is much higher. As shown in Fig 5, BoilerNet-C1 mistakenly labels the question list in the sidebar and part of the text in the header as the main content, and SemText-1 successfully removes the side bar and the header completely. We observe that the mislabeled text is similar to the main content. The improvement of SemText can be attributed to adding class info (e.g. question list, sidebar) to the representation of the question-list text blocks in the side bar. BoilerPipe has extremely high precision with extremely low recall because BoilerPipe only extracts the first block of the main content.
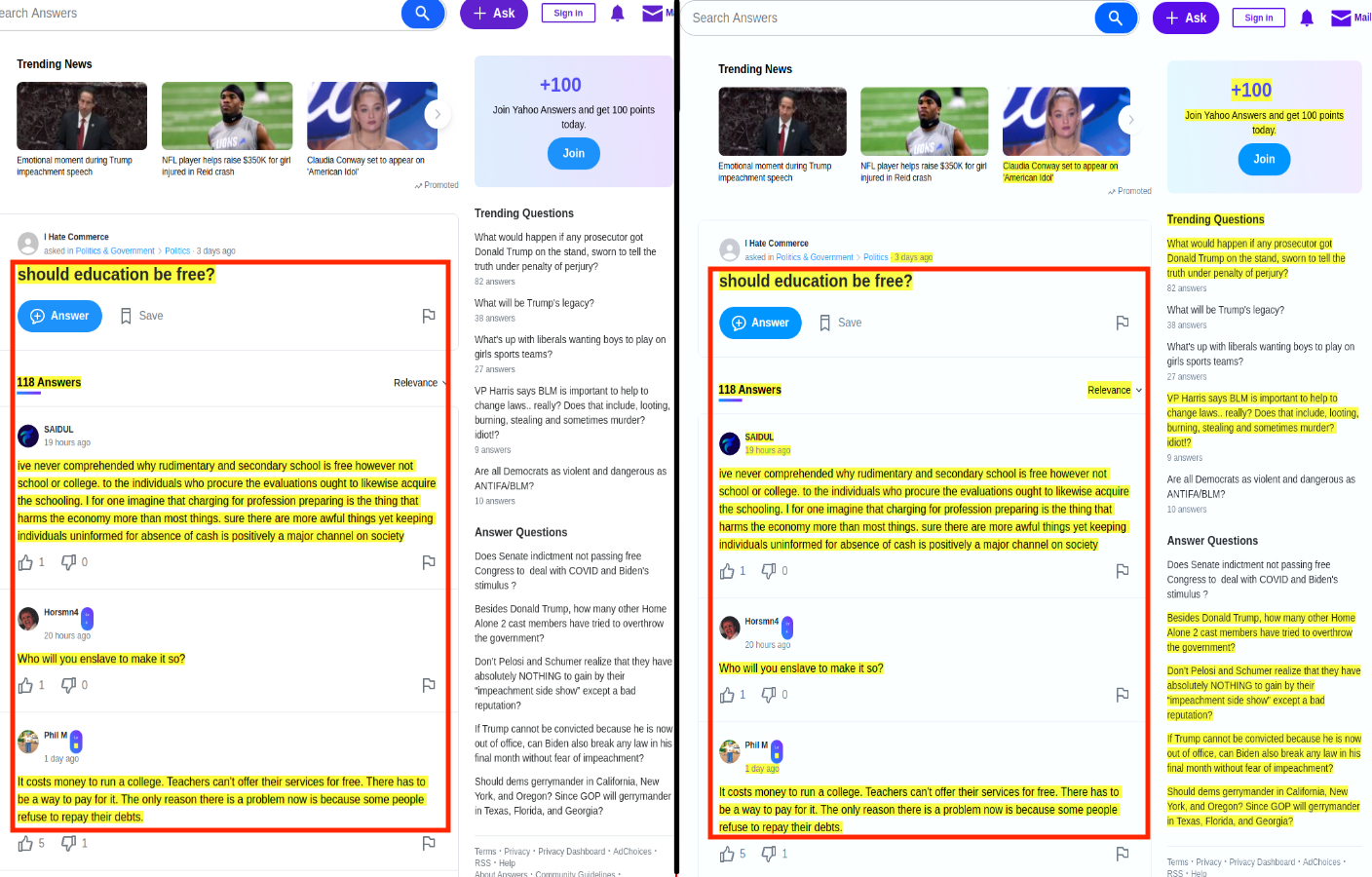
| (a) SemText-1 | (b) BoilerNet-C1 |
IV-D Ablation study
Let SemText_TXT denote the baseline of SemText with only text sequence, Semtext_TAG = SemText_TXT plus tag sequence, and SemText_CLS = SemText_TXT plus class sequence. Evaluation results are shown in Table III.
| Methods | P | R | F1 |
|---|---|---|---|
| SemText_TXT | 0.82 | 0.87 | 0.84 |
| SemText_TAG | 0.90 | 0.84 | 0.87 |
| SemText_CLS | 0.89 | 0.85 | 0.87 |
| SemText | 0.92 | 0.86 | 0.89 |
We can see that SemText_TXT has the lowest F1 score, while SemText_TAG and SemText_CLS each improves the F1 score over SemTexT_TXT, indicating that adding a tag sequence and a class sequence for a text block each contributes to the improvement of the baseline model. A possible cause of the lowest precision score of SemText_TXT is that it tends to mislabel text blocks that are similar to the main content. On the other hand, SEMText_TXT has a higher recall, which is expected. Adding a tag sequence and a class sequence both contribute to a higher precision, as indented; but they also slightly decrease the recall scores.
In summary, SemText consistently achieves substantially higher F1 scores across type-1 and type-2 webpages over all the evaluated models. Moreover, all models, after trained, run about the same time on the evaluation data. In particular, it takes an average of 38 ms for SemText to extract the main text on a single NVIDIA GeForce GTX 2080Ti GPU, with an average of 683 DOM nodes per page in the evaluation data.
V Conclusion and Final Remarks
We have shown that using the semantic representation of text blocks proposed in the paper and classifying them by a hierarchical neural network model is promising on boilerplate detection. It would be interesting to explore if this approach may be beneficial to other applications dealing with webpages.
Analyzing the labeling results, we find that mislabeled blocks by SemText often appear at the beginning of a sub-sequence. This phenomenon has a natural explanation: A text block without labels of previous text blocks would more likely be misclassified, and occurs more often on the type-2 dataset. Thus, it would be interesting to investigate how to label the “entire sequence” of text blocks without needing to break it into sub-sequences.
A long sequence is unavoidable on community-based Q&A webpages. On the other hand, the sequencing-labeling model confines the length of an input sequence for effective training, and we break a long sequence into sub-sequences somewhat arbitrarily to meet this requirement. Considering that we have already achieved the highest F1 scores over previous methods even with such a simple strategy, it would make sense to investigate how to make use of labels generated from a previous sub-sequence. For example, we may directly use a few text blocks in the previous sequence with their generated labels. An obstacle in this approach is that some of these labels may be incorrect. Thus, we would need to figure out how many previous text blocks should be used to minimize the negative impact of incorrect labels. This would likely become a combinatorial pursuit similar to those for achieving fault tolerance. We may also break a long sequence of text blocks into overlapping sub-sequences. In this direction we would need to investigate how much overlap would be appropriate and how to resolve conflicting labels on overlapped text blocks.
Finally, we may explore a tree-structured LSTM-neural-network model to label text blocks. This approach might be more appropriate for labeling sibling blocks that have the same structure with the same look. This direction would likely require more sophisticated modeling efforts.
The code for SemText is available at https://github.com/dreamlegends/Semtext.
References
- [1] W. Yang and J. Wang, “Generating appropriate question-answer pairs for chatbots using data harvested from community-based qa sites,” in Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, November 1–3, 2017.
- [2] M. Baroni, F. Chantree, A. Kilgarriff, and S. Sharoff, “Cleaneval: a competition for cleaning web pages.” in Lrec, 2008.
- [3] J. Leonhardt, A. Anand, and M. Khosla, “Boilerplate removal using a neural sequence labeling model,” in Companion Proceedings of the Web Conference 2020, 2020, pp. 226–229.
- [4] A. Finn, N. Kushmerick, and B. Smyth, “Fact or fiction: Content classification for digital libraries.” in DELOS, 2001.
- [5] C. Kohlschütter and W. Nejdl, “A densitometric approach to web page segmentation,” in Proceedings of the 17th ACM conference on Information and knowledge management, 2008, pp. 1173–1182.
- [6] T. Weninger, W. H. Hsu, and J. Han, “Cetr: content extraction via tag ratios,” in Proceedings of the 19th international conference on World wide web, 2010, pp. 971–980.
- [7] F. Sun, D. Song, and L. Liao, “Dom based content extraction via text density,” in Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, 2011, pp. 245–254.
- [8] J. Wang and J. Wang, “qRead: A fast and accurate article extraction method from web pages using partition features optimizations,” in 2015 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), vol. 1. IEEE, 2015, pp. 364–371.
- [9] L. Yi, B. Liu, and X. Li, “Eliminating noisy information in web pages for data mining,” in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, 2003, pp. 296–305.
- [10] K. Vieira, A. S. Da Silva, N. Pinto, E. S. De Moura, J. M. Cavalcanti, and J. Freire, “A fast and robust method for web page template detection and removal,” in Proceedings of the 15th ACM international conference on Information and knowledge management, 2006, pp. 258–267.
- [11] D. Cai, S. Yu, J.-R. Wen, and W.-Y. Ma, “Vips: a vision-based page segmentation algorithm,” 2003.
- [12] R. Song, H. Liu, J.-R. Wen, and W.-Y. Ma, “Learning block importance models for web pages,” in Proceedings of the 13th international conference on World Wide Web, 2004, pp. 203–211.
- [13] C. Kohlschütter, P. Fankhauser, and W. Nejdl, “Boilerplate detection using shallow text features,” in Proceedings of the third ACM international conference on Web search and data mining, 2010, pp. 441–450.
- [14] D. Bauer, J. Degen, X. Deng, P. Herger, J. Gasthaus, E. Giesbrecht, L. Jansen, C. Kalina, T. Kräger, R. Märtin et al., “Fiasco: Filtering the internet by automatic subtree classification, osnabruck,” in Building and Exploring Web Corpora: Proceedings of the 3rd Web as Corpus Workshop, incorporating CleanEval, vol. 4, 2007, pp. 111–121.
- [15] M. Spousta, M. Marek, and P. Pecina, “Victor: the web-page cleaning tool,” in 4th Web as Corpus Workshop (WAC4)-Can we beat Google, 2008, pp. 12–17.
- [16] M. Neunerdt, E. Reimer, M. Reyer, and R. Mathar, “Enhanced web page cleaning for constructing social media text corpora,” in Information science and applications. Springer, 2015, pp. 665–672.
- [17] T. Vogels, O.-E. Ganea, and C. Eickhoff, “Web2text: Deep structured boilerplate removal,” in European Conference on Information Retrieval. Springer, 2018, pp. 167–179.
- [18] P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, “Enriching word vectors with subword information,” Transactions of the Association for Computational Linguistics, vol. 5, pp. 135–146, 2017.
- [19] Y. Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882, 2014.
- [20] Z. Huang, W. Xu, and K. Yu, “Bidirectional lstm-crf models for sequence tagging,” arXiv preprint arXiv:1508.01991, 2015.
- [21] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [22] A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” in 2013 IEEE international conference on acoustics, speech and signal processing. IEEE, 2013, pp. 6645–6649.
- [23] E. Uzun, H. V. Agun, and T. Yerlikaya, “A hybrid approach for extracting informative content from web pages,” Information Processing & Management, vol. 49, no. 4, pp. 928–944, 2013.
- [24] M. E. Peters and D. Lecocq, “Content extraction using diverse feature sets,” in Proceedings of the 22Nd International Conference on World Wide Web, 2013, pp. 89–90.
- [25] J. Alarte, D. Insa, J. Silva, and S. Tamarit, “Temex: the web template extractor,” in Proceedings of the 24th International Conference on World Wide Web, 2015, pp. 155–158.