Boosting Adversarial Transferability via
Commonality-Oriented Gradient Optimization
Abstract
Exploring effective and transferable adversarial examples is vital for understanding the characteristics and mechanisms of Vision Transformers (ViTs). However, adversarial examples generated from surrogate models often exhibit weak transferability in black-box settings due to overfitting. Existing methods improve transferability by diversifying perturbation inputs or applying uniform gradient regularization within surrogate models, yet they have not fully leveraged the shared and unique features of surrogate models trained on the same task, leading to suboptimal transfer performance. Therefore, enhancing perturbations of common information shared by surrogate models and suppressing those tied to individual characteristics offers an effective way to improve transferability. Accordingly, we propose a commonality-oriented gradient optimization strategy (COGO) consisting of two components: Commonality Enhancement (CE) and Individuality Suppression (IS). CE perturbs the mid-to-low frequency regions, leveraging the fact that ViTs trained on the same dataset tend to rely more on mid-to-low frequency information for classification. IS employs adaptive thresholds to evaluate the correlation between backpropagated gradients and model individuality, assigning weights to gradients accordingly. Extensive experiments demonstrate that COGO significantly improves the transfer success rates of adversarial attacks, outperforming current state-of-the-art methods.
Keywords:
Adversarial Example Vision Transformer.1 Introduction
Vision Transformer (ViT) [dosovitskiy2020image] and its variants [liu2021swin, raghu2021vision, touvron2021training, wu2020visual, zhang2024mg] have demonstrated strong performance in computer vision tasks by effectively capturing long-range dependencies and contextual information. However, ViTs are highly vulnerable to adversarial attacks: even small and well-designed perturbations can lead to severe misclassifications, seriously compromising their reliability in safety-critical applications [goodfellow2014explaining, liu2024image, madry2017towards, shao2021adversarial]. Exploring and developing universal and effective adversarial attack strategies is essential for improving model robustness. In this context, transfer-based adversarial attacks on ViTs have drawn increasing attention, as they do not require the internal structure or setting of the target model [goodfellow2014explaining, inkawhich2020transferable], making them more applicable to real-world scenarios [liu2016delving, papernot2017practical].
Transfer-based adversarial examples generated by surrogate models often encode excessive surrogate-specific information, leading to poor generalization to unseen target models, a phenomenon commonly referred to as adversarial overfitting [hamdi2020advpc, moosavi2017universal, tramer2017ensemble, wu2020skip]. To alleviate this issue, gradient ascent is commonly enhanced with input diversity and gradient regularization. For instance, High-Frequency Adaptation (HFA) [zhuenhancing] introduces input diversity by amplifying high-frequency components through random noise. However, it neglects the fact that surrogate models strongly depend on mid-to-low frequency information for classification. Meanwhile, methods like token gradient regularization (TGR) [zhang2023transferable] and Gradient Normalization Scaling (GNS) [zhuenhancing] regularize gradients more strategically: TGR suppresses extreme gradients, and GNS enhances moderate ones. Despite their effectiveness, these methods uniformly adjust gradients based solely on statistical properties, without considering the correlation between gradients and model-specific characteristics. In other words, if gradient regularization is guided by the objective of weakening surrogate-specific features, it can enhance transferability; otherwise, it remains constrained by surrogate-specific biases, ultimately compromising black-box performance.
Building on this insight, we turn our attention to leveraging features that are commonly shared across diverse ViTs. Although prior studies have shown that ViTs are vulnerable to high-frequency perturbations, this vulnerability reflects architectural sensitivity rather than common decision behavior, since high-frequency responses differ significantly across models. In contrast, ViTs trained on the same dataset tend to rely consistently on mid-to-low frequency components, which encode shape and semantic structures, as the primary basis for classification [kim2024exploring, shao2021adversarial, zhang2024mlip]. These components therefore serve as a better representation of model commonality. However, identifying such commonality directly in black-box scenarios is difficult due to the inaccessibility of target gradients. To address this, we propose applying frequency-aware perturbations to the mid-to-low frequency components of input images, where the perturbation strength is adapted based on their semantic importance. This encourages the generated adversarial examples to exploit features that are commonly used across different ViTs, thereby achieving commonality enhancement.
From a complementary perspective, suppressing the individuality of surrogate models also contributes to optimizing for commonality. Due to architectural differences, various ViTs extract features in distinct ways and thus learn heterogeneous representations even when trained on the same dataset [han2021transformer, touvron2021training]. This leads to varying gradient sensitivities, resulting in different adversarial perturbations across models, as illustrated in Figure 1. When perturbations are generated based on surrogate gradients, some components correspond to shared decision patterns and support transferability, while others reflect surrogate-specific biases and hinder it. Therefore, explicitly reducing the influence of these individual-specific gradients is crucial for promoting transfer-friendly perturbations through individuality suppression.

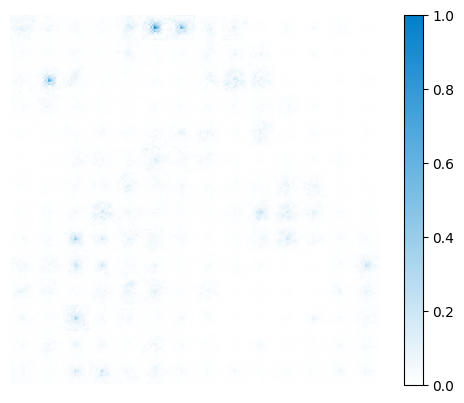

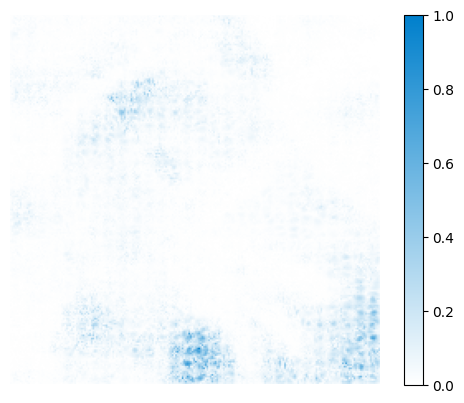
In this paper, we propose Commonality-Oriented Gradient Optimization (COGO), a novel strategy to enhance adversarial transferability by focusing on shared decision patterns of ViTs trained on the same dataset and task, while considering structural differences that cause gradient inconsistencies. COGO consists of two key components: Commonality Enhancement (CE) and Individuality Suppression (IS). During forward propagation, CE amplifies mid-to-low frequency components by applying frequency energy enhancement via Discrete Cosine Transform (DCT). In backward propagation, IS employs adaptive thresholds to identify and suppress gradients linked to surrogate-specific features, preserving those aligned with shared model characteristics to guide perturbation updates. By simultaneously emphasizing shared semantic features and mitigating surrogate-specific biases, COGO offers a principled approach to improve adversarial transferability across various ViTs.
Experiments demonstrate that COGO significantly improves the transferable attack success rate, outperforming the advanced method GNS-HFA by up to 16.1%. In summary, our contributions are as follows:
-
•
We adopt a commonality-oriented optimization that accounts for the relationship between gradients and model characteristics, moving beyond traditional uniform gradient adjustment methods.
-
•
We propose COGO, a novel strategy combining Commonality Enhancement (CE) and Individuality Suppression (IS). It leverages frequency-domain energy enhancement and an adaptive threshold mechanism to strengthen model commonality while suppressing surrogate-specific individuality.
-
•
COGO significantly outperforms state-of-the-art methods, including GNS-HFA and ATT, demonstrating its effectiveness.
2 Related Work
2.1 Vision Transformers
ViTs [dosovitskiy2020image], inspired by the self-attention mechanism in NLP, have transformed deep learning and demonstrated strong performance across a wide range of domains [liu2025aligning, wan2025srpo, wan2025d2o, zhang2025enhancing]. Since their introduction, numerous variants have emerged, including Visformer [chen2021visformer], DeiT [touvron2021training], PiT [heo2021rethinking], CaiT [touvron2021going], TNT [han2021transformer] and MG-ViT [zhang2024mg].
In this work, we categorize ViT variants based on their dominant design priorities. One group focuses on computational efficiency by simplifying attention operations or integrating convolutions to reduce inference cost, as seen in Visformer [chen2021visformer] and PiT [heo2021rethinking]. The other group emphasizes data efficiency by improving representation capacity and generalization, often through mechanisms such as knowledge distillation or deeper attention stacks, as in DeiT [touvron2021training] and CaiT [touvron2021going]. It is important to note that this categorization is not mutually exclusive—many models exhibit traits from both categories. However, we analyze and group them based on their most salient characteristics to guide the design of our method. Although these models are typically trained on the same datasets and tasks and tend to form shared decision patterns, their architectural differences lead to diverse gradient behaviors. This heterogeneity can reduce adversarial transferability, motivating the need to craft perturbations that emphasize shared patterns while suppressing surrogate-specific biases.
2.2 Transfer-Based Black-Box Adversarial Attack
In transfer-based black-box attacks, adversarial examples generated on a surrogate model are designed to exploit cross-model vulnerabilities and transfer to attack unknown target models [liu2016delving]. Numerous methods have been developed to improve adversarial transferability.
Methods targeting CNNs as surrogate models have a long history. Early methods like BIM [kurakin2018adversarial], PGD [madry2017towards], and MIM [dong2018boosting] focused on stabilizing gradient directions, while DIM [xie2019improving] and TIM [dong2019evading] improved transferability via input transformations. Recently, SSA [long2022frequency] explored frequency-domain vulnerabilities comprehensively, but did not design frequency-aware perturbations specifically to enhance transferability. Additionally, HFA [zhuenhancing], inspired by SSA, only adapts high-frequency components, neglecting mid-to-low frequencies. These limitations lead to suboptimal results on ViTs, motivating our method to leverage a broader frequency spectrum tailored for ViTs to improve transferability.
Recent methods such as TGR [zhang2023transferable] and GNS-HFA [zhuenhancing] have advanced adversarial transferability on ViTs by mitigating gradient overfitting. TGR reduces the variance of gradients within the surrogate model by suppressing extreme gradient values, hypothesizing that these outliers drive overfitting. This effectively decreases internal gradient variance. Conversely, GNS-HFA posits that moderate gradients are more crucial for transferability, regularizing gradients towards a Gaussian distribution and amplifying those below a threshold to promote uniformity. It also employs high-frequency adaptation to enhance input diversity and further improve transferability.
Nevertheless, both approaches focus solely on homogenizing the gradient distribution within the surrogate model, without explicitly perturbing the shared decision patterns across different architectures. Consequently, their adversarial examples achieve only suboptimal transferability, as these methods inevitably incorporate some ineffective gradient updates. Furthermore, experiments show a notable performance drop when transferring attacks to CNN-based targets, reflecting the intrinsic gap between ViTs and CNNs in adversarial robustness.
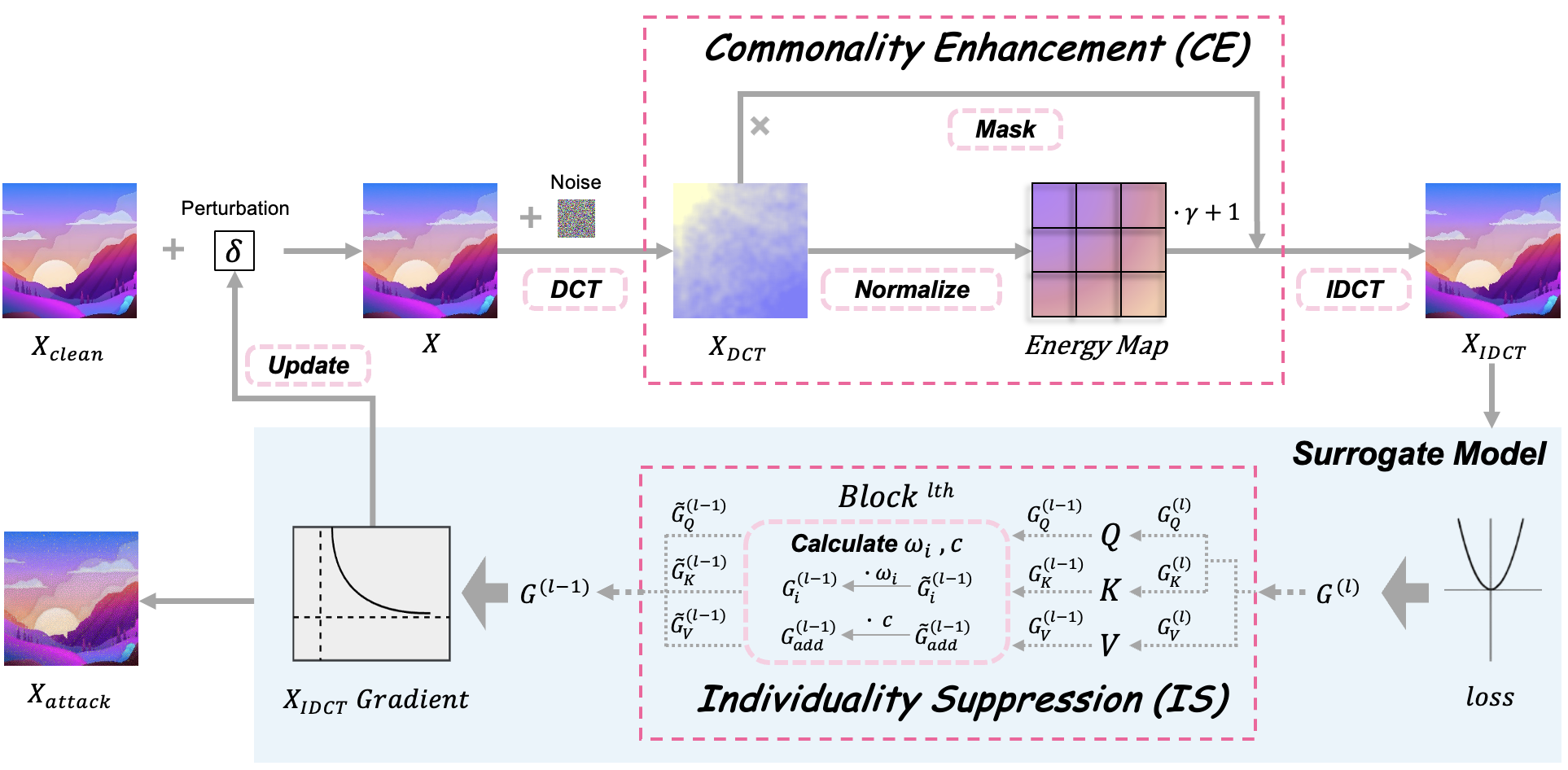
3 Method
3.1 Overview
We provide an overview of the COGO strategy in Figure 2, illustrating the process of a single iteration.
Starting with a zero-initialized perturbation added to the input, we apply a Discrete Cosine Transform (DCT) to project it into the frequency domain. There, the Commonality Enhancement (CE) module selectively amplifies mid-to-low frequency components based on an energy map, guiding the perturbation toward shared decision patterns across architectures. The modified frequency representation is then converted back to the spatial domain via Inverse DCT (IDCT) and passed through the surrogate model.
During backpropagation, the Individuality Suppression (IS) module adaptively suppresses surrogate-specific gradients using a thresholding mechanism, reducing overfitting and promoting transferable directions. This process iterates until convergence, producing the final adversarial example.

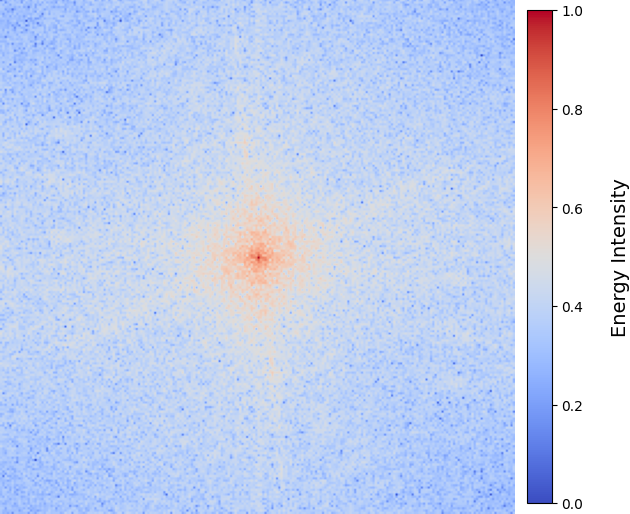
3.2 Commonality Enhancement
In the forward process of adversarial example generation, most existing methods focus on high-frequency perturbations [zhuenhancing]. However, recent studies [zhang2024mlip] show that ViTs rely more on mid-to-low frequency components, which encode essential structural and semantic information. As illustrated in Figure 3, these components dominate the energy spectrum, which are important in feature representation. Enhancing them not only reinforces ViT decision signals but also promotes gradients aligned with shared patterns, thereby improving adversarial transferability.
To leverage this property, our CE module adaptively enhances mid-to-low frequency components using the energy distribution of each input sample. Starting from a clean input , we add the current perturbation (initialized as zero) to obtain:
| (1) |
Gaussian noise is added to increase frequency diversity, and we apply the Discrete Cosine Transform (DCT) to map the perturbed sample to the frequency domain:
| (2) | ||||
| (3) |
where represents the normalized energy map. We then enhance the frequency representation in energy-dominant regions:
| (4) |
with controlling the enhancement strength. Finally, the enhanced frequency sample is converted back to the spatial domain using IDCT. We apply a spatial mask , inherited from HFA [zhuenhancing], to introduce additional perturbation diversity:
| (5) |
and feed into the surrogate model.
3.3 Individuality Suppression
Gradient Suppression Location.
We apply Information Suppression (IS) to the module, as it directly controls token-to-token interactions in ViTs and plays a central role in capturing both common and model-specific patterns. Compared to other modules like the Feed-Forward Network (FFN), which processes each token independently, the module enables global information flow via attention. Suppressing gradients here thus has a broader impact, making it more effective for reducing surrogate-specific biases. Empirical comparisons with alternative locations are provided in Appendix A.
Two types of features requiring gradient suppression.
Inspired by the optimization approaches of ViT variants in Section 2.1, we identify two types of features requiring gradient suppression: (1) those associated with redundant representations in structurally optimized ViTs, and (2) those linked to additional knowledge in data-efficient variants. The suppression algorithm is shown in Appendix B.
IS for Redundant Features.
For structurally optimized ViTs, we address the issue of feature redundancy, where multiple channels capture overlapping information, leading to imbalanced gradient updates that overemphasize certain feature directions and thus reduce adversarial transferability. To quantify redundancy, we utilize widely accepted metrics Mutual Information (MI) and Pearson Correlation (PC) between gradient channel pairs, which effectively measure shared information and linear dependence, respectively.
Specifically, we randomly select a subset of channel pairs and compute their MI and PC values based on their gradients and at layer . Instead of fixed thresholds, we define adaptive thresholds and as:
| (6) | |||
| (7) |
where and are scaling factors controlling sensitivity.
If the MI or the absolute PC between a channel pair exceeds its respective threshold, this pair is considered redundant and contributes to suppressing the corresponding channel gradients. The suppression weight for channel in layer is computed by aggregating redundancy indicators and from all sampled pairs :
| (8) |
where is a fixed reduction factor. To prevent excessive suppression, the weight is truncated:
| (9) |
Finally, the gradient is adjusted by
| (10) |
This adaptive and fine-grained suppression effectively reduces redundant gradient directions, lowering surrogate-specific overfitting and improving adversarial sample transferability.
IS for Additional Knowledge.
In data-efficient ViTs, supplementary tokens such as distillation tokens provide extra information that enhances model accuracy but often encode surrogate-specific patterns which harm adversarial transferability.
To mitigate this, we propose an adaptive gradient scaling mechanism for these additional knowledge tokens. Considering the self-attention interaction between primary and additional tokens, the attention can be formulated as
| (11) |
where , , and represent the query, key, and value matrices respectively.
We compute a scaling factor via the sigmoid function on the ratio of L2 norms of their gradients
| (12) |
which adaptively adjusts the magnitude of gradients from additional tokens:
| (13) |
This reduces the influence of surrogate-specific information encoded in additional tokens, effectively enhancing the transferability of generated adversarial examples.
4 Experiments
4.1 Experiment Setting
To validate the effectiveness of COGO, we conducted extensive experiments in various models. In this section, we describe the details of our experimental setup, including datasets, models, adversarial attack methods, evaluation metrics, and hyperparameter settings.
Datasets.
Following TGR [zhang2023transferable] and other prior works, we use 1,000 randomly sampled images from the ILSVRC 2012 validation set [russakovsky2015imagenet], a common setting for fair comparison in transfer-based attack studies.
Models.
We evaluate the transferability of adversarial examples generated by different source models in two scenarios: intra-architecture transferability, where ViT-based source and target models are used, and cross-architecture transferability, where ViT-based models are applied to attack CNN target models.
For our experiments, we selected four source models: Visformer-S [chen2021visformer], DeiT-B [touvron2021going], CaiT-S/24 [touvron2021going] and ViT-B/16 [dosovitskiy2020image]. And the target models include additional ViT architectures, such as TNT-S [han2021transformer] and ConViT-B [d2021convit]. For CNN target models, we used both defended and undefended versions. Undefended models include well-known architectures such as Inception-v3 [szegedy2016rethinking], Inception-v4 [szegedy2017inception], Inception-ResNet-v2 [szegedy2017inception], and ResNet-101 [he2016deep], while the defended models employ adversarial training and other defense techniques [madry2017towards], including ensembles of adversarially trained Inception-v3 and Inception-ResNet-v2 models.
Attack Methods.
We evaluate the effectiveness of our COGO by comparing it with several competitive baselines. The primary baseline is TGR [zhang2023transferable], which is specifically designed to generate transferable adversarial attacks on ViTs. We also include two state-of-the-art methods, GNS-HFA [zhuenhancing] and ATT [ming2024boosting]. In addition, we compare against other strong baselines, including MIM [dong2018boosting], SINI-FGSM [lin2019nesterov], PNA [wei2022towards], and SSA [long2022frequency].
Evaluation Metrics.
We measure the attack success rate (ASR) of adversarial examples on different models, which quantifies the proportion of successful attacks that lead to misclassifications by the target model. This is expressed as:
| (14) |
Hyperparameter Settings.
In all experiments, hyperparameters were carefully chosen to ensure fairness. Each attack ran for 10 iterations with a maximum -norm perturbation of (scale 0–255).
4.2 Results
In this section, we evaluate the performance of our proposed methods against three categories of models: undefended ViTs, undefended CNNs, and adversarially trained CNNs. Specifically, we generate adversarial examples using a given surrogate model and attack other models in a black-box scenario, as well as the surrogate model itself in a white-box scenario. The results are shown in Table 1, where the best values in each column are highlighted in bold, and the second-best are underlined.
First, we evaluate transferability across different ViT models. In black-box settings, our strategy achieves an average improvement of 7.2% in attack success rates over GNS-HFA and an 10.1% enhancement over the ATT method.
Next, we evaluate the effectiveness of COGO against both undefended and adversarially trained CNNs to assess cross-architecture transferability. Despite the significant architectural differences between ViTs and CNNs, COGO achieves an average improvement of 2.3% over GNS-HFA and 10.5% over ATT.
| Model | Attack | ViT-based Models | CNN-based Models | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT-B/16 | CaiT-S/24 | Visformer-S | DeiT-B | TNT-S | ConViT-B | Inc-v3 | Inc-v4 | IncRes-v2 | Res | |||||
| Visformer-S | MIM | 18.5 | 24.9 | 99.6 | 20.8 | 41.9 | 23.3 | 31.2 | 31.9 | 22.4 | 25.0 | 11.5 | 10.7 | 6.9 |
| SINI-FGSM | 25.8 | 35.6 | 99.7 | 34.1 | 53.7 | 35.9 | 42.3 | 43.0 | 32.7 | 35.4 | 21.0 | 18.1 | 14.5 | |
| PNA | 19.4 | 28.3 | 100.0 | 23.6 | 49.9 | 24.4 | 37.4 | 36.0 | 23.7 | 30.9 | 11.3 | 8.9 | 6.2 | |
| SSA | 22.8 | 28.2 | 96.3 | 27.1 | 55.4 | 26.3 | 43.8 | 44.6 | 33.4 | 32.1 | 21.1 | 16.7 | 12.5 | |
| TGR | 30.3 | 41.4 | 100.0 | 36.8 | 66.2 | 35.3 | 49.6 | 54.1 | 34.8 | 50.4 | 22.8 | 18.9 | 11.3 | |
| GNS-HFA | 49.1 | 58.1 | 99.9 | 54.1 | 81.3 | 52.3 | 71.6 | 71.3 | 57.9 | 68.4 | 48.7 | 47.0 | 34.2 | |
| ATT | 34.7 | 47.2 | 99.7 | 39.6 | 71.5 | 38.9 | 58.4 | 60.3 | 40.7 | 57.0 | 29.4 | 24.0 | 16.5 | |
| COGO | 55.2 | 66.9 | 100.0 | 64.9 | 85.5 | 62.0 | 71.8 | 72.4 | 59.1 | 72.7 | 50.5 | 47.9 | 36.2 | |
| DeiT-B | MIM | 65.0 | 90.8 | 51.2 | 100.0 | 68.9 | 90.8 | 40.2 | 37.6 | 30.1 | 31.5 | 22.1 | 19.4 | 14.6 |
| SINI-FGSM | 68.3 | 90.2 | 53.4 | 99.9 | 72.8 | 90.3 | 43.9 | 39.8 | 34.2 | 33.1 | 26.8 | 24.3 | 18.2 | |
| PNA | 61.3 | 80.8 | 52.1 | 91.1 | 67.0 | 81.0 | 42.1 | 38.8 | 32.0 | 34.0 | 22.2 | 19.6 | 15.0 | |
| SSA | 68.9 | 92.0 | 44.7 | 99.9 | 75.2 | 90.5 | 47.9 | 45.2 | 40.3 | 30.5 | 25.0 | 20.5 | 16.9 | |
| TGR | 82.0 | 93.3 | 65.3 | 99.9 | 84.0 | 93.1 | 52.9 | 49.5 | 40.6 | 45.9 | 32.9 | 30.4 | 22.4 | |
| GNS-HFA | 82.9 | 93.6 | 69.2 | 99.5 | 87.2 | 93.6 | 61.9 | 56.8 | 50.9 | 52.1 | 42.0 | 33.8 | 25.7 | |
| ATT | 82.5 | 94.7 | 69.2 | 99.8 | 84.9 | 94.9 | 56.3 | 51.5 | 41.6 | 49.8 | 34.1 | 32.2 | 24.5 | |
| COGO | 87.6 | 96.0 | 73.9 | 99.9 | 91.3 | 96.4 | 64.6 | 60.1 | 52.9 | 56.2 | 45.3 | 35.4 | 27.6 | |
| CaiT-S/24 | MIM | 48.8 | 99.2 | 34.4 | 69.7 | 54.2 | 68.7 | 33.6 | 29.6 | 22.4 | 21.8 | 15.1 | 12.6 | 9.8 |
| SINI-FGSM | 52.2 | 98.3 | 35.0 | 71.5 | 54.7 | 70.3 | 35.9 | 33.3 | 25.8 | 22.3 | 17.8 | 15.8 | 11.8 | |
| PNA | 44.3 | 82.3 | 33.5 | 61.8 | 52.6 | 60.8 | 32.8 | 29.6 | 22.7 | 22.9 | 14.2 | 11.0 | 8.8 | |
| SSA | 52.5 | 96.0 | 34.0 | 72.6 | 62.1 | 68.4 | 39.5 | 38.0 | 31.9 | 24.6 | 19.7 | 16.5 | 12.2 | |
| TGR | 78.9 | 99.9 | 60.1 | 90.0 | 82.6 | 89.7 | 49.6 | 48.0 | 35.8 | 38.8 | 26.9 | 23.6 | 16.2 | |
| GNS-HFA | 79.7 | 99.6 | 65.2 | 88.4 | 84.3 | 88.2 | 61.9 | 57.6 | 47.9 | 47.8 | 38.9 | 38.5 | 28.9 | |
| ATT | 78.0 | 99.4 | 63.7 | 89.1 | 83.9 | 88.3 | 56.2 | 52.1 | 40.1 | 45.3 | 30.8 | 29.1 | 20.7 | |
| COGO | 84.8 | 99.8 | 68.6 | 93.0 | 89.5 | 92.9 | 64.0 | 60.6 | 49.5 | 50.0 | 42.0 | 39.2 | 28.4 | |
| ViT-B/16 | MIM | 99.6 | 53.7 | 23.1 | 51.2 | 55.3 | 54.4 | 30.9 | 30.6 | 24.8 | 16.0 | 13.4 | 10.7 | 8.0 |
| SINI-FGSM | 98.8 | 56.4 | 27.9 | 55.5 | 61.0 | 56.9 | 36.2 | 35.7 | 29.2 | 16.7 | 15.7 | 13.2 | 9.2 | |
| PNA | 97.1 | 62.1 | 30.5 | 60.0 | 62.6 | 60.5 | 34.6 | 32.4 | 28.3 | 19.9 | 12.4 | 11.0 | 8.7 | |
| SSA | 99.4 | 51.8 | 21.5 | 47.5 | 62.0 | 50.5 | 34.6 | 31.4 | 28.6 | 13.5 | 11.1 | 10.0 | 7.5 | |
| TGR | 99.4 | 56.2 | 30.6 | 54.2 | 66.3 | 57.8 | 37.3 | 36.3 | 29.7 | 19.7 | 16.1 | 14.3 | 10.4 | |
| GNS-HFA | 98.8 | 65.7 | 38.2 | 64.6 | 73.1 | 67.2 | 44.5 | 41.6 | 37.8 | 25.9 | 21.1 | 19.8 | 15.0 | |
| ATT | 99.5 | 69.0 | 40.4 | 67.2 | 73.1 | 68.0 | 41.8 | 40.9 | 35.0 | 25.6 | 19.0 | 17.2 | 13.0 | |
| COGO | 99.8 | 81.5 | 48.2 | 80.7 | 80.4 | 81.2 | 50.3 | 50.3 | 41.8 | 35.9 | 27.9 | 26.1 | 19.4 | |
4.3 Analysis
To better understand the impact of COGO, we analyzed the gradient flow in ViT models during adversarial example generation. Without COGO, gradients in the module were highly concentrated on specific tokens and channels tied to dominant surrogate model features, causing perturbations to be overly model-specific and less transferable.
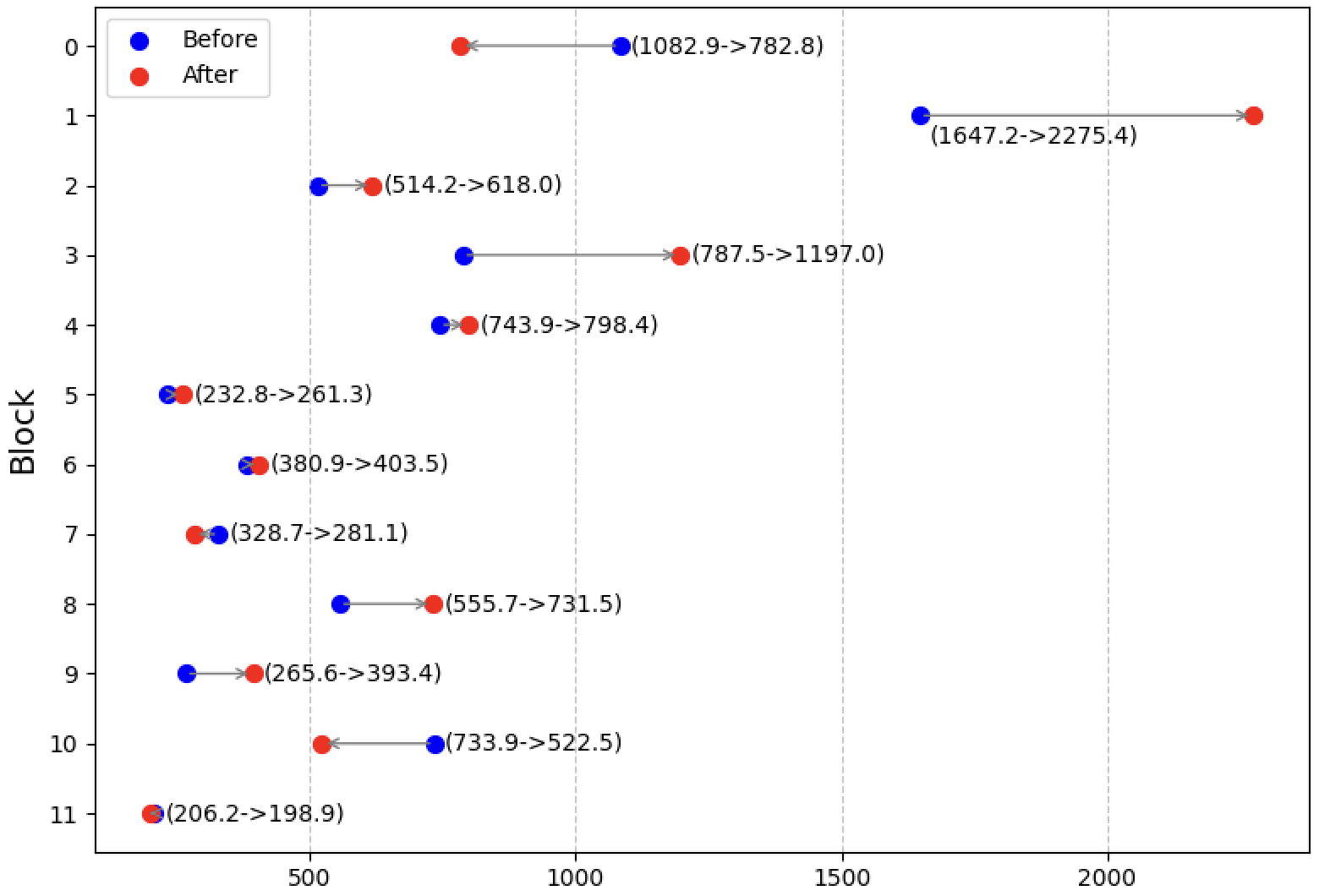
Applying COGO resulted in a more diverse gradient distribution across model blocks. To quantify this, we computed a dispersion-related indicator by flattening and normalizing gradient magnitudes into a probability-like vector and summing its log-weighted elements. This value reflects how broadly the gradients are spread across different dimensions. A larger value indicates a more balanced distribution and reduced dependence on surrogate-specific features. As shown in Figure 4, most blocks show increased values after applying COGO, suggesting improved gradient diversity. A few blocks, such as blocks[0] and blocks[10], show slightly reduced values due to the CE component, which enhances shared mid-to-low frequency features and causes gradient concentration in those regions. This complementarity between IS and CE promotes more transferable and model-common features.
Overall, the more balanced and diverse gradient landscape induced by COGO helps generate adversarial perturbations that better capture transferable features, thus improving attack success rates across different models.
| CE | IS | ViTs | CNNs | CNNs-adv |
|---|---|---|---|---|
| - | - | 46.64 | 30.45 | 9.80 |
| - | 72.56 (+25.92) | 56.18 (+25.73) | 32.15 (+22.35) | |
| - | 62.38 (+15.74) | 45.85 (+15.40) | 22.77 (+12.97) | |
| 77.97 (+31.33) | 63.73 (+33.28) | 36.75 (+26.95) |
| ViT-based Models | CNN-based Models | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT-B/16 | CaiT-S/24 | Visformer-S | DeiT-B | TNT-S | ConViT-B | Inc-v3 | Inc-v4 | IncRes-v2 | Res | ||||
| -0.25 | 100.0 | 72.5 | 41.1 | 73.3 | 76.6 | 73.7 | 49.0 | 44.7 | 41.7 | 27.7 | 23.2 | 20.6 | 14.8 |
| -0.1 | 100.0 | 78.9 | 46.5 | 78.3 | 78.3 | 78.7 | 52.2 | 47.4 | 42.6 | 32.6 | 25.4 | 21.8 | 17.1 |
| 0 | 98.8 | 65.7 | 38.2 | 64.6 | 73.1 | 67.2 | 44.5 | 41.6 | 37.8 | 25.9 | 21.1 | 19.8 | 15.0 |
| 0.1 | 99.6 | 71.9 | 43.5 | 70.9 | 76.9 | 73.7 | 49.7 | 45.9 | 39.6 | 29.3 | 22.8 | 21.1 | 16.7 |
| 0.25 | 99.6 | 74.6 | 45.6 | 73.9 | 79.0 | 76.4 | 50.4 | 48.1 | 41.0 | 31.3 | 25.1 | 22.9 | 18.7 |
| 0.5 | 99.5 | 77.4 | 46.1 | 76.2 | 79.9 | 78.4 | 50.2 | 48.0 | 40.6 | 33.7 | 26.2 | 24.8 | 18.2 |
| 0.75 | 99.4 | 74.8 | 45.8 | 74.5 | 79.4 | 75.3 | 48.6 | 47.3 | 39.7 | 32.2 | 26.0 | 23.1 | 18.0 |
| 1 | 99.8 | 81.5 | 48.2 | 80.7 | 80.4 | 81.2 | 50.3 | 50.3 | 41.8 | 35.9 | 27.9 | 26.1 | 19.4 |
| 1.5 | 97.9 | 67.6 | 38.0 | 67.6 | 73.2 | 65.7 | 44.6 | 44.5 | 37.9 | 28.4 | 22.7 | 21.0 | 15.7 |
4.4 Ablation Study
Impact of CE and IS.
Ablation results in Table 2 demonstrate that both CE and IS significantly improve attack success rates on ViTs, CNNs, and adversarially trained CNNs. Among them, CE has a more pronounced effect. Combining CE and IS achieves the highest success rates, highlighting their complementary roles. This indicates that guiding perturbations deliberately is most effective when the main challenges are clearly addressed.





Impact of enhancement coefficient in CE.
The parameter controls the strength of perturbations applied to mid-to-low frequency DCT coefficients (Eq. 4). Table 3 shows that yields the best balance between perturbation strength and transferability, outperforming both higher () and lower () values, which either cause over-perturbation or insufficient enhancement.
Impact of iteration number .
As illustrated in Figure 5, increasing the number of iterations leads to more complex perturbations. However, improvements plateau around . Therefore, to balance computational cost and attack effectiveness, we choose as the default setting.
Impact of other hyperparameters.
We also examined other hyperparameters such as the number of selected channels, reduction thresholds for MI and PC, and the step size constant. Detailed results and analyses are provided in Appendix C.
5 Conclusion
In this paper, we propose COGO, a commonality-oriented gradient optimization strategy to enhance adversarial attack transferability on ViTs. Our method improves transferability by boosting perturbations related to features shared across surrogate models via frequency-domain noise injection (CE) and suppressing gradients linked to surrogate-specific characteristics using adaptive thresholding (IS). Extensive experiments on ViTs and CNNs demonstrate that COGO significantly outperforms existing approaches.
A Architectural Module Analysis
In this section, we provide a detailed analysis of the key modules within ViTs that are potential targets for perturbation application. The analysis is organized in the order that data flows through these modules, examining each module’s role and the impact of gradient adjustments systematically.
Layers
Query , Key , and Value layers are essential components of the attention mechanism. They determine how tokens interact with one another to form the Attention Map. Adjusting gradients alters token-to-token query relationships, which can redistribute focus across tokens. Adjusting gradients modifies the Attention Map distributions, influencing how features are weighted globally. Adjusting gradients directly affects the token output representations, which propagate through the network as features.
Attention Projection Layer
The Attention Projection Layer is responsible for linearly projecting the output of the multi-head attention mechanism back to the token feature space. It consolidates the information processed by all attention heads. Adjusting gradients in this module allows fine-tuning of the final feature distribution derived from the Attention Map, ensuring that perturbations affect a wider range of features rather than over-relying on specific heads or tokens. This makes it a critical target for balancing attention diversity and improving perturbation generalization.
Attention Dropout
Applied to the Attention Map, dropout reduces the dependency on specific token-to-token relationships. Manipulating gradients here disperses the token importance distribution, increasing the diversity of features targeted by the perturbation.
Layers
Multi-Layer Perceptrons process each token independently, providing non-linear transformations to enrich token features. Gradient adjustments in layers influence token-level transformations, complementing the global adjustments made in the Attention mechanism.
| modules | ViTs | CNNs | CNNs-adv | Average |
|---|---|---|---|---|
| 66.90 | 69.00 | 37.90 | 57.93 | |
| + | 66.92 | 68.98 | 37.86 | 57.92 |
| + | 57.54 | 57.10 | 28.82 | 47.82 |
| + | 50.82 | 59.79 | 28.50 | 46.37 |
From the analysis above, it is evident that some modules play a more critical role in determining the effectiveness and transferability of generated perturbations. Among these, the layers in the Multi-Head Attention mechanism are the most impactful, as they directly influence the Attention Map by controlling token-to-token interactions and feature representations. Extreme gradients or redundant features arising in these layers are more likely to affect the generated perturbations, embedding characteristics that are overly specific to the substitute model.
To further explore the impact of gradient adjustments in other modules, we designed three combinations: layers with the Attention Projection Layer, layers with Attention Dropout, and layers with the layers. For each combination, we applied our gradient adjustment method and compared the results to the baseline method in our paper, where adjustments were limited to the layers. These experiments illustrated as Table 4 allow us to evaluate the collaborative effects of gradient adjustments across multiple modules and their contributions to the overall perturbation transferability.
B Algorithm
The IS algorithm has been demonstrated in the Algorithm 1.
C Hyperparameter Ablation Study
C.1 Impact of the Number of Selected Channel Pairs
To investigate the effect of the number of selected channel pairs () on gradient adjustments, we carried out experiments by varying for mutual information and correlation calculations. The default setting in our paper uses 5 channel pairs. However, we first tested additional settings with . The results, summerized in Table 5 and visualized in Figure 6, show that the attack success rates remain largely consistent across different values of . While minor fluctuations are observed, increasing the number of selected channel pairs does not significantly improve the attack success rates.
To ensure this consistency was not due to selecting too few channel pairs, we further conducted an experiment with a significantly larger value, , and summarized the results in Table 6.Interestingly, the results for are comparable to, or even slightly worse than, the results for , suggesting that selecting a larger number of channel pairs does not provide additional benefits. Furthermore, even with , where only a single randomly selected channel pair is used for adjustments, the attack success rates are nearly on par with those achieved using larger values of .
| ViTs | CNNs | CNNs-adv | Average | |
|---|---|---|---|---|
| 1 | 66.92 | 68.95 | 37.82 | 57.90 |
| 3 | 66.94 | 69.00 | 37.88 | 57.94 |
| 5 | 66.90 | 69.00 | 37.90 | 57.93 |
| 7 | 66.84 | 68.93 | 37.85 | 57.87 |
| 9 | 66.96 | 69.10 | 37.92 | 57.99 |
| ViTs | CNNs | CNNs-adv | Average | |
| 50 | 66.90 | 69.05 | 37.92 | 57.96 |
| ViTs | CNNs | CNNs-adv | ||
|---|---|---|---|---|
| 0.3 | 0.5 | 66.7 | 68.5 | 37.6 |
| 0.5 | 0.7 | 66.9 | 69.0 | 37.9 |
| 0.7 | 0.9 | 66.2 | 68.4 | 37.2 |
This phenomenon can be attributed to the nature of high-dimensional feature spaces, where most critical gradient information is often concentrated in a small subset of channels. Channels with higher mutual information or strong correlations tend to dominate the gradient flow, as they represent key relationships in the feature representation learned by the model. By adjusting even a small number of these channel pairs, it becomes possible to effectively disrupt redundant and overrepresented features in the gradient signal, thereby optimizing the perturbation’s impact.
| ViTs | CNNs | CNNs-adv | Average | |
|---|---|---|---|---|
| 0.0 | 88.84 | 57.85 | 35.52 | 60.74 |
| 0.1 | 89.04 | 58.45 | 36.10 | 61.20 |
| 0.3 | 88.98 | 58.33 | 36.06 | 61.12 |
| 0.5 | 88.96 | 58.03 | 35.85 | 60.95 |
| 0.7 | 88.74 | 57.95 | 35.60 | 60.76 |
| 1.0 | 88.26 | 57.38 | 35.35 | 60.33 |
Moreover, increasing beyond a certain point introduces diminishing returns because additional channel pairs often contribute redundant or low-variance information. In high-dimensional spaces, features are inherently structured such that a few dominant channels encode the majority of the relevant information, while others serve auxiliary roles or capture noise. Randomly selected channel pairs, even in small numbers, are likely to intersect with these dominant channels due to the distributional sparsity of critical features. This explains why the observed success rates remain consistent even with randomly chosen channel pairs, as the adjustments tend to influence significant regions of the feature space regardless of the specific pairs selected.
These findings show two important conclusions. First, the effectiveness of our gradient adjustment method depends more on its ability to mitigate redundancy in a targeted manner than on the exact number of selected channel pairs. Second, the method’s primary impact stems from its application itself rather than the specific channels being adjusted, with the critical distinction being between using this method and not using it at all. This robustness to the number of selected pairs underscores the generalizability and efficiency of our approach in optimizing perturbation transferability.
C.2 Impact of and in Mutual Information (MI) and Pearson correlation (PC)
Although we adopted an adaptive threshold setting method, we evaluated different configurations of these thresholds to obtain more intuitive information.
The results, presented in Table 7, indicate that the selected threshold values of 0.5 for mutual information and 0.7 for correlation achieve the highest success rate across ViTs, CNNs, and adversarially trained CNNs. Lower or higher threshold values lead to decreased effectiveness. These findings provide valuable insights for our subsequent, more fine-grained research.
| ViTs | CNNs | CNNs-adv | Average | |
|---|---|---|---|---|
| 0.5 | 31.72 | 18.83 | 9.60 | 20.05 |
| 0.75 | 56.24 | 31.6 | 15.42 | 34.42 |
| 1.0 | 67.50 | 40.83 | 19.82 | 42.72 |
| 1.25 | 68.70 | 42.05 | 21.15 | 43.97 |
| 1.5 | 69.90 | 42.70 | 21.30 | 44.63 |
| 1.75 | 70.38 | 42.6 | 21.22 | 44.73 |
| 2.0 | 70.46 | 42.08 | 21.15 | 44.56 |
C.3 Impact of Additional Knowledge Gradient Suppression Factor
To further investigate the impact of suppressing the gradient of additional knowledge features in ViT variants, we conducted experiments by varying the scaling factor applied to the additional knowledge gradient. The scaling factors were set to , and the resulting attack success rates were evaluated on ViTs, CNNs, and adversarially trained CNNs.
Table 8 presents the attack success rates across different scaling factors. The results demonstrate that achieves the best average attack success rate (61.20%) among all tested settings. This finding demonstrates that not only enhances the attack success rate across different model types but also achieves a balanced suppression of the additional knowledge gradient. In contrast, completely nullifying the additional knowledge gradient () or leaving it unadjusted () results in lower success rates, as these extremes either disregard the auxiliary knowledge provided by the additional features or overemphasize it, reducing the transferability of the perturbations. These results prove the importance of carefully tuning the additional knowledge gradient’s contribution to optimize adversarial attack performance.
C.4 Impact of Step Size Constant
To evaluate the effect of the step size constant on attack success rates, we conducted experiments with varying values: 0.5, 0.75, 1.0, 1.25, 1.5, 1.75, and 2.0. The objective was to identify the optimal balance between perturbation strength and transferability for adversarial attacks.
The results in Table 9 and Figure 7 show a clear trend where smaller step sizes () result in weaker perturbations, leading to lower attack success rates. As increases to moderate values (), the success rates improve significantly across all models, indicating that the perturbations are becoming more effective. This improvement can be attributed to the fact that appropriately increasing the step size introduces a degree of randomness to the generated perturbations, enhancing their generalization and reducing excessive reliance on precise gradient information.
However, for larger step sizes (), the performance plateaus or slightly declines, particularly for CNNs and adversarially trained CNNs. This suggests that over-amplifying the step size causes the gradient information to lose its guiding role in determining the perturbation direction, ultimately reducing the transferability of the perturbations. This observation underscores the importance of using a step size that is neither too conservative nor overly aggressive.
These findings prove that moderate step sizes, such as , are optimal to achieve a balance between perturbation strength and transferability. By ensuring sufficient perturbation strength without over-amplification, this step size allows for effective attacks across different model architectures while maintaining robustness and generalization.