Boosting Sortition via Proportional Representation
Abstract
Sortition is based on the idea of choosing randomly selected representatives for decision making. The main properties that make sortition particularly appealing are fairness — all the citizens can be selected with the same probability— and proportional representation — a randomly selected panel probably reflects the composition of the whole population. When a population lies on a representation metric, we formally define proportional representation by using a notion called the core. A panel is in the core if no group of individuals is underrepresented proportional to its size. While uniform selection is fair, it does not always return panels that are in the core. Thus, we ask if we can design a selection algorithm that satisfies fairness and ex post core simultaneously. We answer this question affirmatively and present an efficient selection algorithm that is fair and provides a constant-factor approximation to the optimal ex post core. Moreover, we show that uniformly random selection satisfies a constant-factor approximation to the optimal ex ante core. We complement our theoretical results by conducting experiments with real data.
1 Introduction
In the last centuries, representative democracy has become synonymous with elections. However, this has not been the case throughout history. Since ancient Athens, the random selection of representatives from a given population has been proposed as a means of promoting democracy and equality Van Reybrouck (2016). Sortition has gained significant popularity in recent years, mainly because of its use for forming citizens’ assemblies, where a randomly selected panel of individuals deliberates on issues and makes recommendations. Currently, citizens’ assemblies are being implemented by more than 40 organizations in over 25 countries Flanigan et al. (2021a).
Recently, there has been a growing interest within the computer science research community in designing algorithms that select representative panels fairly and transparently Flanigan et al. (2020, 2021a, 2021b); Ebadian et al. (2022). Admittedly, a straightforward method for selecting a representative panel of size from a given population of size is to randomly select individuals uniformly Engelstad (1989). We refer to this simple procedure as uniform selection. As highlighted by Flanigan et al. (2020), two main reasons make this method particularly appealing:
-
1.
Fairness: Each citizen is included in the panel with the same probability, satisfying the requirement of equal participation. Specifically, each citizen is selected with a probability of
-
2.
Proportional Representation: The selected panel is likely to mirror the structure of the population, since if of the population has specific characteristics, then in expectation, of the panel will consist of individuals with these characteristics. For instance, if the female share of the population is , then in expectation, of the panel will be females.
Indeed, uniform selection seems to achieve proportional representation ex ante (before the randomness is realized), since in expectation the selected panel reflects the composition of the population, especially when the size of the panel is very large. However, one of the critiques of this sampling procedure is that with non-zero probability, a panel that completely excludes certain demographic groups can be selected Engelstad (1989). For example, if the population is split evenly between college-educated and non-college-educated individuals, there’s a chance that uniform selection could result in a panel consisting solely of college-educated individuals. To address such extreme cases, various strategies have been proposed to ensure proportional representation ex post (after the randomness is realized) Martin and Carson (1999).
One common strategy is the use of stratified sampling Gąsiorowska (2023). The idea is that the individuals are partitioned into disjoint groups and then a proportional number of representatives is sampled uniformly at random from each group. For example, if the population is comprised of 49% college-educated individuals and 51% non-college-educated individuals, then we can choose 49% of the representatives from the first group and the remaining representatives from the other group. This idea can be extended to ensure proportional representation across intersectional features as well. For instance, in a population characterized by the level of education and the income, we can define four groups: college-educated low-income, college-educated high-income, non-college-educated low-income, and non-college-educated high-income and then sample from each group separately. However, this approach becomes impractical when dealing with a large predefined set of features, as the number of possible groups can grow exponentially, and there may not be enough seats in the panel to represent all of them. A more general approach, extensively used in practice, is to set quotas over individual or set of features Flanigan et al. (2020); Vergne (2018). Similar to stratified sampling, when aiming for proportional representation across all intersectional features, the number of quotas can become exponential, making it infeasible to satisfy all of them concurrently. Alternatively, one may opt for setting quotas over a subset of intersectional features. For instance, quotas could be set for gender and race simultaneously, along with additional quotas for income. However, this might not ensure the representation of specific subgroups, such as high-income black women.
The presence of the above challenges in existing strategies prompts a need for alternative approaches for ensuring proportional representation. This, in turn, highlights the necessity of rigorously defining proportional representation first. Our work departs from these observations, and we aim to address the following questions:
-
1.
What is a formal definition of proportional representation of a population?
-
2.
To what extent does uniform selection satisfy proportional representation?
-
3.
Is it possible to design selection algorithms that enhance representation guarantees while maintaining fairness?
1.1 Our approach
Proportional Representation via Core.
We begin by tackling the first question posed above. Intuitively, a panel can be deemed proportionally representative if each group of size within a population of individuals is represented by members in the panel, out of the total representatives selected. Motivated by this intuition, we borrow a notion of proportional representation used by recent works on multiwinner elections, fair allocation of public goods and clustering Aziz et al. (2017); Fain et al. (2018); Conitzer et al. (2019); Cheng et al. (2020); Chen et al. (2019), called the core. The main idea of the core is: Every subset of the population is entitled to choose up to representatives. Formally, a panel is called proportionally representative, or is said to be in the core, if there does not exist a subset of the population that could choose a panel , with , under which all of them feel more represented. Note that this notion is not defined over predefined groups using particular features, but it provides proportional representation in the panel to every subset of the population.
Representation Metric Space.
A conceptual challenge is to quantify the extent to which a panel represents an individual. To address this, we use the same approach as taken by Ebadian et al. (2022) in which it is assumed that the individuals lie in an underlying representation metric space. The representation metric space can be constructed as a function of features that are of particular interest for an application at hand, such as gender, age, ethnicity and education. Intuitively, the construction of such a metric space eliminates the necessity of partitioning individuals into groups that all share exactly the same characteristics. Instead, it serves as a means of detecting large groups of individuals that share similar characteristics and are eligible to be represented proportionally. For example, a 30-year-old single, low-income black woman might still feel close to a 35-year-old married, medium-income black woman, since they share many characteristics, even if they differ in some of them.
-Cost.
Finally, to measure the degree to which an individual is represented by a panel again, we take the approach of Ebadian et al. (2022), following a recent work of Caragiannis et al. (2022) in multiwinner elections. Specifically, the cost of an individual for a panel is determined by her distance from the -th closest member in the panel, for some . We find this choice of cost suitable for applications related to sortition due to two main reasons. First, an individual may not care about her distance to all the representatives, but she may wish to ensure that there are a few with whom she can relate. For example, a woman may want to ensure that there are at least a few women on a panel to represent her, without necessarily requiring the entire panel to be composed of females, which would not be reasonable. Second, it effectively differentiates between panels containing representatives whom an individual can readily relate to and panels where representatives are more distant from her. For instance, consider an individual aged 40, a panel that includes 2 representatives aged 40, one representative aged 20, and one representative aged 60 and another panel consisting of two representatives aged 30 and two representatives aged 50. The individual may feel represented by at least two people in the former panel, and therefore for her cost would be low. While for the second panel her cost would be higher since no representative is that close to her. In contrast, natural alternatives such as the average distance would fail to capture this difference since both panels would have the same average distance from her. The choice of depends on the application at hand. However, in this work, we provide selection algorithms that do not require knowledge of the value of but offer guarantees for any value of it concurrently.
1.2 Our Contribution
Our primary conceptual contribution lies in introducing the core, in the context of sortition. Before delving into our work, we discuss the relevant literature that has provided inspiration and insights for our research. The idea of using the core as a means of measuring the proportional representation that a panel provides to a population, lying in a metric space, was first introduced by Chen et al. (2019) in a clustering setting. In our terms, Chen et al. (2019) consider the case of , i.e., each individual cares for her distance from her closest representative, while in this work, we extend the notion of core to the class of -cost functions. They show that a solution in the core is not guaranteed to exist and define a multiplicative approximation of it with respect to the cost improvement of all individuals eligible to choose a different panel. They introduce an algorithm, called Greedy Capture, that returns a solution in the -approximate core. Roughly speaking, the algorithm partitions the individuals into parts by smoothly increasing balls in the underlying metric space around each individual and greedily creating a part whenever a ball captures individuals that have not already been captured. The centers of the balls serve as the representatives.
In a sortition setting,in addition to proportional representation of all groups, it is important to ensure the fairness constraint which is that all individuals have the same chance of being included in the panel. For ensuring that, a selection algorithm should return distribution over panels of size , and not a deterministic panel as in the clustering setting. Therefore, in this work we ask for selection algorithms that are simultaneously in the ex post core, meaning that every panel that the algorithm might return, is in the core, and simultaneously is fair, meaning that each individual is included in the panel with probability equal to .
In Section 3, as one would expect, we demonstrate that uniform selection, despite satisfying fairness by its definition, falls short of achieving any reasonable approximation to the ex post core for almost any , with only exception being . This is due to the fact that when , any panel inherently belongs to the -approximate ex post core, as we will show later. We then pose the question: Is there any selection algorithm that is fair and achieves an -approximation to the ex post core? The answer is affirmative. We introduce an efficient selection algorithm, denoted as FairGreedyCapture, that is fair and is in the -approximate ex post core for every value of . In some sense, this guarantees the best of both worlds, as we provide an algorithm that preserves the positive characteristic of uniform selection, namely fairness, and additionally, it ensures that any realized panel is in the -approximate ex post core. Again loosely speaking, FairGreedyCapture creates parts using Greedy Capture which “opens” a ball in the metric space when a sufficiently number of individuals fall into it. In contrast to Greedy Capture, which selects the center of the ball as a representative, FairGreedyCapture assigns probabilities of selection to individuals within the ball, ensuring that the sum of these probabilities equals to . This ensures the selection of one representative from each ball. Additionally, to ensure fairness, a total fraction of is assigned to each individual across the balls. Then, leveraging Birkhoff’s decomposition algorithm, we find a distribution over panels of size , where each panel contains at least one representative from each ball, and each individual is selected with a probability of . We complement this result by showing that no fair selection algorithm provides an approximation better than to the ex post core.
In Section 4, we turn our attention to the question: Is uniform selection in the ex ante core? As previously mentioned, uniform selection seems to satisfy the ex ante core, at least for large panels, since, in expectation, a panel is proportionally representative. Here, we investigate whether this is true for all values of and . In particular, we define a selection algorithm to be in the ex ante core if, for any panel , the expected number of individuals who feel more represented by than panels chosen from the selection algorithms is less than . This indicates that no other panel receives significant support, in expectation. First, we show that for , uniform selection is in the ex ante core. However, for , no fair selection algorithm is in the ex ante core. Therefore, as before, we define a multiplicative approximation with respect to the cost improvement. We demonstrate that uniform selection provides an approximation of to the ex ante core. On the other hand, we show that no fair selection algorithm provides an approximation better than to the ex ante core.
In Section 5, we explore the question of whether, given a panel , there is any way to determine if it satisfies an approximation of the ex post core for a value of . This can be useful when a panel has been sampled using a selection algorithm that does not provide any guarantees for the ex post core. We show that given a panel , we can approximate, in polynomial time, how much it violates the core up to constants.
Finally, in Section 6, we empirically evaluate the approximation of uniform selection and FairGreedyCapture to the ex post core on constructed metrics derived from two demographic datasets. We notice that for large values of , uniform selection achieves an approximation to the ex post core similar to the one that FairGreedyCapture achieves. For smaller values of , when the individuals form cohesive parts, uniform selection has unbounded approximation very often. However, when the individuals are well spread in the space, uniform selection achieves a good approximation of the ex post core. Thus, the decision of using uniform selection depends on the value of and the structure of the population.
1.3 Related Work
Ebadian et al. (2022) recently considered the same question of measuring the representation that a panel or a selection algorithm achieves in a rigorous way. As we mentioned above, they also assume the existence of a representative metric space and use the distance of the -th closest representative in the panel to measure to what degree a panel represents an individual. However, they use the social cost (i.e. the sum of individual costs) to measure how much a panel represents the whole population. In Appendix A, we show that this measure of representation may fail to achieve the idea of proportional representation. Moreover, while a reasonable approximation of their notion of representation is, in some cases, incompatible with fairness (i.e., each individual is included in the panel with the same probability), in this work, we show that there are selection algorithms that achieve a constant approximation of proportional representation and fairness simultaneously.
As we discussed above, a method that is used in practice for enforcing representation is by setting quotas over features. However, a problem that appears is that only a few people volunteer to participate in a decision panel. As a result, the representatives are selected from a pool of volunteers which usually does not reflect the composition of the population, since for example highly educated people are usually more willing to participate in a decision panel than less educated people. Flanigan et al. (2021a) proposed selection algorithms that, given a biased pool of volunteers, find distributions that maximize the minimum selection probability of any volunteer over panels that satisfy the desired quotas. In this work, similar to Ebadian et al. (2022) and Benadè et al. (2019), we focus on the pivotal idea of a sortition based democracy that relies on sampling representatives directly from the underlying population Gastil and Wright (2019). However, later, we discuss how our approach can be modified for being applied in biased pools of volunteers. Benadè et al. (2019) focused on the idea of stratified sampling and asked how this strategy may affect the variance of the representation of unknown groups. Flanigan et al. (2021b) studied how the selection algorithms can become transparent as well. In a more recent work, Flanigan et al. (2024) studied the manipulability of different selection algorithms, i.e the incentives of individuals to misreport their features.
The representation of individuals as having an ideal point in a metric space has its roots to the spatial model of voting Arrow (1990); Enelow and Hinich (1984). As we mentioned above, the idea of using the core as a notion of proportional representation in a metric space was first introduced by Chen et al. (2019), and later revisited by Micha and Shah (2020), in a clustering setting. Proportional representation in clustering has also been studied by Aziz et al. (2023) and Kalayci et al. (2024). The definition by Aziz et al. (2023) is quite similar to the core, with the basic difference being that each dense group explicitly requires a sufficient number of representatives. Kalayci et al. (2024) consider a version of the core where an agent’s cost for the panel is the sum of the distance of each representative, and a group is incentivized to deviate to another solution if the overall group can reduce the sum of costs. A drawback of both the definition of the core we use in this paper and Greedy Capture, which was mentioned by Aziz et al. (2023) and Kalayci et al. (2024), is that a dense group might end up being represented by just one individual. This happens because Greedy Capture keeps expanding opened balls, and when a new individual is captured by such a ball, it disregards it by implicitly assuming that this individual is already represented. We stress that while our notion of the core does not explicitly account for this problem, FairGreedyCapture does not expand balls that are already open, and thus, it does not suffer from this weakness. More broadly, the implicitly goal of clustering is to find a set of centers that represent all the data points in an underlying metric space. As discussed by Chen et al. (2019) in their work, the classic objectives, namely -center, -means, and -median objectives, are deemed incompatible with the core. Consequently, they do not align with the notion of proportional representation desired in this work. The literature has explored various notions of fairness in clustering Chhabra et al. (2021). Recently, Kellerhals and Peters (2023) establish links among the numerous concepts related to fairness and proportionality in clustering.
Proportional representation through core has been extensively studied in the context of multiwinner elections as well Aziz et al. (2017); Faliszewski et al. (2017); Lackner and Skowron (2023); Fain et al. (2018). The problem of selecting a representative panel can be framed as a committee election problem, where the candidates are drawn from the same pool as the voters. While in these works, the voters and the candidates do not lie in a metric space, but instead the voters hold rankings over candidates, in our model, the rankings could derive from the underlying metric space. Due to impossibility results Cheng et al. (2020), relaxations of the core have been studied. The ex ante core, as defined here, was introduced by Cheng et al. (2020). They show that, without the fairness constraint, the ex ante core can be guaranteed. In this work, we show that by imposing this fairness constraint, an approximation to the ex ante -core better than is impossible, for all .
2 Preliminaries
For , let . We denote the population by . A panel is defined as a subset of the population. The individuals lie in an underlying representation metric space with distance function . The distance between individuals and is denoted as . We assume that the distances are symmetric, i.e., , and satisfy the triangle inequality, i.e., . An instance of our problem is characterized by the individuals in the population and the distances among them. Henceforth, we simply refer to such an instance as .
We consider a class of cost functions to measure the cost of an individual within a panel . For , we define the -cost of for as the distance to her -th closest member in the panel, denoted by . When , the cost of an individual is equal to her distance from her closest representative in the panel, and for , the cost is equal to her distance from her furthest representative in the panel. We denote by the set of the closest representatives of in a panel (with ties broken arbitrarily). Additionally, represents the set of individuals captured from a ball centered at with a radius of , i.e., . We may omit from the notation when clear from the context.
A selection algorithm, denoted by , is parameterized by and takes as input the metric and outputs a distribution over all panels of size . We say that a panel is in the support of , if it is implemented with positive probability under the distribution that outputs. We pay special attention to the uniform selection algorithm, denoted by , that always outputs a uniform distribution over all the subsets of the population of size .
Fairness. As mentioned above, one of the appealing properties of uniform selection is that each individual is included in the panel with the same probability. We call this property fairness and we say that a selection algorithm is fair if:
Core. Another appealing property of sortition is proportional representation. Here, we utilize the idea of the core to measure the proportional representation of a panel and, by extension, of a selection algorithm. To do so, we first introduce the following definition: For , the --preference count of with respect to is the number of individuals whose -cost under is larger than times their -cost under :
A panel is in the --core, if for any panel , . For , we say that the panel is in the -core. We define --core for , since even when , a panel in the exact -core is not guaranteed to exist (Chen et al., 2019; Micha and Shah, 2020).
Ex Post -Core.
A selection algorithm is in the ex post --core (or ex post -core, for ) if every panel in the support of is in the --core, i.e., for all drawn from and all ,
Ex Ante -Core.
A selection algorithm is in the ex ante --core (or ex ante -core, for ) if for all :
The idea of requiring a core-like property over the expected number of preference counts was introduced by Cheng et al. (2020) in a multi-winner election setting. Essentially, it states that for any panel , if, for any realized panel , we count the number of individuals that reduce their cost by a multiplicative factor of at least under , in expectation, this number is less than . Therefore, in expectation, they are not eligible to choose it.
It is easy to see that ex post -core implies ex ante -core, since if for each in the support of a distribution that returns and each , it holds that , then .
3 Fairness and Ex Post Core
In this section, we investigate if there are selection algorithms that are fair, and in addition, provide a constant approximation to the ex post -core. Unsurprisingly, uniform selection may fail to provide any bounded approximation to the ex post -core for 111 For , we show in Appendix B that all panels lie in the approximation of the -core; hence, any algorithm including uniform selection provides an ex post --core. . This happens because each panel has a nonzero probability of selection, and there may exist panels with arbitrarily large violations of the -core objective.
Theorem 1.
For any and , there exists an instance such that uniform selection is not in the ex post --core for any bounded .
Proof.
Consider an instance in which there are individuals in group and the remaining individuals are in group . Suppose that the distance between any two individuals in the same group is , and the distance between any two individuals in different groups is . Since, , uniform selection has a non-zero probability of returning a panel where all the representatives are from group . In this scenario, for any , the -cost of all the individuals in group is equal to . However, individuals in group are entitled to choose up to representatives among themselves, and if they do so, their -cost becomes , resulting in an unbounded improvement of their -cost. Therefore, uniform selection is not in the ex post --core for any bounded . ∎
Therefore, we ask: For every , is there any selection algorithm that keeps the fairness guarantee of uniform selection and ensures that every panel in its support is in the constant approximation of the -core? We answer this positively.
We present a selection algorithm, called , that is fair and in the ex post --core, for every . We highlight that the algorithm does not need to know the value of . Our algorithm leverages the basic idea of the Greedy Capture algorithm introduced by Chen et al. (2019), which returns a panel in the -approximation of the -core. Note that this algorithm is deterministic and need not satisfy fairness. Briefly, Greedy Capture starts with an empty panel and grows a ball around all individuals at the same rate. When a ball captures at least individuals for the first time, the center of the ball is included in the panel and all the captured individuals are disregarded. The algorithm keeps growing balls on all individuals, including the opened balls. As the opened balls continue to grow and capture more individuals, the newly captured ones are immediately disregarded as well. Note that the final panel can be of size less than .
At a high level, , as outlined in Algorithm 1, operates as follows: it greedily opens balls using the basic idea of the Greedy Capture algorithm, ensuring each ball contains sufficiently many individuals. In contrast to Greedy Capture, which selects the centers of the balls as the representatives, our algorithm probabilistically selects precisely one individual from each of the balls.
Before, we describe the algorithm in more detail, we define a -fractional allocation as a non-negative matrix where entries in each row sums to and entries in each column sum to , i.e., for each , , and for each , . The algorithm, during its execution, generates a -fractional allocation of individuals in into balls, where denotes the fraction of individual assigned to ball . We say that an individual is assigned to ball , if . An individual can be assigned to more than one balls.
The -fractional allocation is generated as follows. Denote the unallocated part of each individual by . Start with . This corresponds to the fairness criterion that we allocate a probability of selection to each individual. Algorithm 1 grows a ball around every individual in at the same rate. Suppose a ball captures individuals whose combined unallocated parts sum to at least . Then, we open this ball and from individuals captured by this ball with , we arbitrarily remove a total mass of exactly and assign it to the ball. This can be done in various ways, e.g., greedily pick an individual with positive and allocate fraction of it to the corresponding row (i.e. ball). This procedure terminates when the fraction of each individual is fully allocated. Note that since each time a ball opens, a total mass of is deducted from -s and, for each , starts with a fraction of , exactly balls are opened.
Sampling panels from the -fractional allocation.
Next, we show a method of decomposing , the -fractional allocation, to a distribution over panels of size that each contain at least one representative from each ball. We employ the Birkhoff’s decomposition (Birkhoff, 1946). This theorem applies over square matrices that are bistochastic. A matrix is bistochastic if every entry is nonnegative and the sum of elements in each of its rows and columns is equal to .
Theorem 2 (Birkhoff-von Neumann).
Let be a bistochastic matrix. There exists a polynomial time algorithm that computes a decomposition , with , such that for each , , is a permutation matrix and .
We cannot directly apply the theorem above, since the -fractional allocation is not bistochastic nor a square matrix. However, we can complete into a square matrix by adding rows where all entries are . Note that the resulting matrix is bistochastic. Indeed, each row of both and sums to by their definition; further, as each column of sums to and that it is followed by of entries in , the columns also sum to . Note that there are various choices of that makes a bistochastic matrix, but here we use the uniform matrix for simplicity. Then, the algorithm applies Theorem 2 and computes the decomposition . For each permutation matrix , we create a panel consisting of the individuals that have been assigned to the first rows, i.e. contains all -s with for some . Finally, the algorithm returns the distribution that selects each panel with probability equal to .
To prove that is fair and ex post --core, we need the next two lemmas.
Lemma 1.
Let , be a panel, and .
-
1.
There exists a partitioning of into disjoint sets and an individual such that for all and , and .
-
2.
There exists a partitioning of into disjoint sets and an individual such that for all and , and .
Proof.
We start by showing the first part. We partition all the individuals in into groups, denoted by iteratively as follows.
Suppose is the individual with the smallest -cost over (ties are broken arbitrary), i.e. . Then, is the set of all the individuals whose closest representatives from includes at least one member of , i.e.
Next, from the remaining individuals, suppose is the one with the smallest -cost over , i.e. . Construct from similarly by taking all the individuals whose at least one of their closest representatives in is included in . We repeat this procedure, and in round , we find that has the smallest cost over , and construct by assigning any individual in whose at least one of the closest representatives belongs in . Note that for any with , , as if at least one of the closest representatives of in is included in , then would have been assigned to and would not belong in . This means that in each round, we consider representatives that have not been considered before, and hence after rounds, less than representatives in may remain unconsidered. As a result, after at most rounds, all the individuals will have been assigned to some group, since at least one of their closest representatives has been considered.
The second part follows by simply setting to be equal to the individual in that has the largest cost over , i.e. . All the remaining arguments remain the same. ∎
Lemma 2.
For any panel and any , it holds that .
Proof.
Consider a ball centered at with radius . This ball contains at least representatives of . Hence, is less than or equal to the distance of to one of the representatives that are included in which is at most . ∎
Now, we are ready to prove the next theorem.
Theorem 3.
For every , is fair and in the ex post --core.
Proof.
Seeing that the algorithm is fair is straightforward. For a matrix , let be the submatrix induced by keeping its first rows. First, note that for each panel we choose the individuals that have been assigned to and second, recall that . The fairness of the algorithm follows by the facts that and for each , .
We proceed by showing that is in the ex post --core, for all . First, note that if an individual is assigned to a ball in some , then we must have . Now, since each individual is assigned to a ball in the permutation, we get that that at least one individual is selected from each ball.
Let be any panel that the algorithm may return. Suppose for contradiction that there exists a panel such that . This means that there exists , with , such that:
| (1) |
Let be a partition of with respect to , as given in the first part of Lemma 1. Since and , we conclude that there exists a part, say , that has size at least . From Lemma 1, we know that there exists such that for each it holds that and . Therefore, we can conclude that for each , , as following: Pick an arbitrary representative in and denote it as . Then,
This implies that the ball centered at with a radius of captures all individuals in .
Now, consider all the balls that opens and contain individuals from . Since and each ball is assigned a total fraction of , there are at least such balls. Next, we claim that least of them have radius at most . Suppose for contradiction that at most of them have radius at most . This means that a total fraction of at least from individual in is assigned to balls with radius strictly larger than . However, the ball centered at with radius would have captured this fraction, and therefore we reach a contradiction.
Next, denote with , balls that are opened, and each contain individuals from and have radius at most . Due to the definition of , each panel that is returned, contains at least one representative from each ball. Therefore, each ball contains at least one representative, denoted by . Now, note that since each contains at least one individual from , denoted by , we have that
where the first inequality follows from the triangle inequality and the last inequality follows from the facts that for each , , and each has radius at most and both and belong to this ball. Therefore, there are at least representatives in that have distance at most from . But then, which is a contradiction with Equation 1. ∎
As we discussed above, the ex post --core implies the ex ante --core which means that is also in the ex ante --core for all . In the next section, we show that no fair algorithm provides an approximation better than to the ex ante -cost, for any . Therefore, we get that no fair selection algorithm provides an approximation better than to the ex post -core either. This means that is optimal up to a factor of .
3.1 Ex Post Core and Quotas over Features
In our introduction, we discussed a common approach used to ensure proportional representation, which involves setting quotas based on individual or groups of features. For instance, a quota might mandate that at least of representatives are female. While the concept of the core aims to achieve proportional representation across intersecting features, it may not guarantee the same across individual features. For instance, a panel comprising entirely men could still meet core criteria, even if the overall population is 50% women. This raises the question of whether it’s possible to achieve both types of representation to the degree that is possible. We argue that this is feasible and show how the core requirement can be translated into a set of quotas.
As showed above, generates balls, with each individual assigned to one or more balls. The key condition for achieving an ex post --core is to have at least one representative from each ball. This condition can be transformed into quotas by introducing an additional feature, , for each individual , indicating the balls they belong to. Thus, can take values in , where represents the power set of . We then can set quotas that require the panel to contain at least one representative that belongs in ball , i.e. , for each . In other words, we can think of each ball as a subpopulation from which we want to draw a representative. We can then utilize the methods proposed by Flanigan et al. (2021a) to identify panels that meet these quotas, along with others as much as possible, while maximizing fairness. We also note that this translation allows for sampling from a biased pool of representatives using the algorithm of the aforementioned paper, as long as the characteristics of the global population are known and the balls can be constructed based on them.
4 Uniform Selection and Ex Ante Core
We have already discussed that uniform selection fails to provide any reasonable approximation to the ex post -core, for almost all values of . However, as we mentioned in the introduction, it seems to satisfy the ex ante -core, at least when is very large. In this section, we ask whether indeed uniform selection satisfies a constant approximation of the ex ante -core, in a rigorous way, for all values of and . We show that uniform selection is in the ex ante --core, for every . 222 In fact, for , uniform selection is in the ex ante -core (see Appendix C). The main reason is that, for , it suffices to show that the grand coalition does not deviate ex-ante. Since each panel is selected with non-zero probability, the marginal probabilities of deviation is strictly less than one, and the ex ante -core is satisfied.
To show this result, we use the following form of Chu–Vandermonde identity which we prove in Appendix D for completeness.
Lemma 3 (Chu–Vandermonde identity).
For any and , with , it holds
Now, we are ready to prove the following theorem.
Theorem 4.
For any , uniform selection is in the ex ante --core, i.e. for any panel
Proof.
Let be any panel. By linearity of expectation, we have that
Let be a partition of with respect to , as given in the second part of Lemma 1. For each , we reorder the individuals in in an increasing order based on their distance from , and relabel them as . This way, and are the individuals in that have the smallest and the largest distance from , respectively. Then, we get that
| (2) |
In the next lemma, we bound for each .
Lemma 4.
For each and ,
Proof.
For each , let be an arbitrary representative in . Then, we get that
| (3) |
where the last inequality follows from the fact that has the smallest cost over among all the individuals in . Now, consider the ball that is centered at and has radius . Note that this ball contains any individual with . Indeed, for each and with , we have that
where the second inequality follows form the fact that for each with , and the last inequality follows form Equation 3. This argument is drawn in Figure 1.
When , then we get that , as otherwise there would exist at least individuals in , and would be at most . Hence, we have that
where the second inequality follows from the Union Bound and the last equality follows form the fact that uniform selection chooses out of individuals uniformly at random. ∎
Then, by returning to Equation 2 we get that,
| (by Lemma 4) | ||||
| (swap summations) | ||||
where the last inequality follows from the facts that and for . ∎
In the next theorem, we show that for any , no selection algorithm that is fair, is guaranteed to achieve ex ante --core with , and hence uniform selection is optimal up to a factor of .
Theorem 5.
For any , when , there exists an instance such that no selection algorithm that is fair, is in the ex ante --core with .
Proof.
Consider a star graph with leaves and an internal node. Suppose individuals lie on the internal node, and exactly one individual lies on each of the leaves. Individuals in have a distance of from each other and a distance of from ; and, the distance between a pair of individuals from is equal to . These distances satisfy the triangle inequality.
Let be an arbitrary panel of size that does not contain . We show that for and every , we have that For any , it holds and — which is an unbounded improvement. For any individual in , since their th closest representative in would be on another leaf, while — which yields a factor improvement. Therefore, , for every .
Under any fair selection algorithm, is not included in the panel with probability . Thus, we have that
where the last inequality follows from the assumption that . ∎
5 Auditing Ex Post Core
In this section, we turn our attention to the following question: Given a panel , how much does it violate the -core, i.e. what is the maximum value of such that there exists a panel with ? This auditing question can be very useful in practice for measuring the proportional representation of a panel formed using a method that does not guarantee any panel to be in the approximate core, such as uniform selection.
Chen et al. (2019) ask the same question for the case where the cost of an individual for a panel is equal to her distance form her closest representative in the panel, i.e. when . In this case, it suffices to restrict our attention to panels of size , which are subsets of the population that individuals may prefer to be represented by. In other words, given a panel , we can simply consider every individual as a potential representative and check if a sufficiently large subset of the population prefers this individual to be their representative over . Thus, we can find the maximum such that there exists , with as following: For each , calculate which is equal to the largest value among the set containing the -cost ratios of to . Then, is equal to the maximum value among all ’s.
For , this question is more challenging. We show the possibility of approximating the value of the maximum , by generalizing the above procedure as following: For each , let be the panel that contains and its closest neighbors. Then, calculate as the largest value of among the set . Then, we return the maximum value among all ’s as . Algorithm 2 executes this procedure. We show that the maximum such that there exists a panel with is at most .
Theorem 6.
There exists an efficient algorithm that for every panel and returns --core violation that satisfies , where is the maximum amount of -core violation of .
Proof.
Suppose for contradiction that while the algorithm returns , there exists and , with , such that
First, note that if the algorithm outputs , this means that for every and , it holds that
| (4) |
as otherwise the algorithm would output a value strictly larger than .
Let be a partition of with respect to , as given in the first part of Lemma 1. Since and , we conclude that there exists a part, say , that has size at least . Moreover, since there exists such that for each , it holds that and , we can conclude that , by considering a representative in and applying the triangle inequality, i.e. , where . This means there exists a ball centered at that has radius and captures all the individuals in . Now, note that there exists such that , since otherwise for each would hold that and then which contradicts Equation 4. Hence,
where the first and the third inequalities follows from Lemma 2 and the last inequality follows from the facts that for each , , and for each since consists of the closest neighbors of . Therefore, and the theorem follows. ∎
6 Experiments
In previous sections, we examined uniform selection from a worst-case perspective and found that it cannot guarantee panels in the core for any bounded approximation ratio. But, what about the average case? How much better is FairGreedyCapture than uniform selection in terms of their approximations to the ex post core in the average case? In this section, we aim to address these questions through empirical evaluations of both algorithms using real databases.
6.1 Datasets
In accordance with the methodology proposed by Ebadian et al. (2022), we utilize the same two datasets used by the authors as a proxy for constructing the underlying metric space. These datasets capture various characteristics of populations across multiple observable features. It is reasonable to assume that individuals feel closer to others who share similar characteristics. Therefore, we construct a random metric space using these datasets.
Adult.
The first is the Adult dataset, extracted from the 1994 Current Population Survey by the US Census Bureau and available on the UCI Machine Learning Repository under a CC BY 4.0 license Kohavi and Becker (1996); Dua and Graff (2017). Our analysis focuses on five demographic features: sex, race, workclass, marital.status, and education.num. The dataset is comprised of data points, each with a sample weight attribute (fnlwgt). We identify unique data points by these features and treat the sum of the weights associated with each unique point as a distribution across them.
ESS.
The second dataset we analyze is the European Social Survey (ESS), available under a CC BY 4.0 license Report. (2021). Conducted biennially in Europe since 2001, the survey covers attitudes towards politics and society, social values, and well-being. We used the ESS Round 9 (2018) dataset, which has data points and features across 28 countries. On average, each country has around features (after removing non-demographic and country-unrelated data), with country-specific data points ranging from to . Each ESS data point has a post-stratification weight (pspwght), which we use to represent the distribution of the data points. Our analysis focuses on the ESS data for the United Kingdom (ESS-UK), which includes 2204 data points.
6.2 Representation Metric Construction
In line with the work of Ebadian et al. (2022), we apply the same approach to generate synthetic metric preferences, which are used to measure the dissimilarity between individuals based on their feature values. Our datasets consist of two types of features: categorical features (e.g. sex, race, and martial status) and continuous features (e.g. income). We define the distance between individuals and with respect to feature as follows:
where the normalization factor for continuous features ensures that for all , , and , and that the distances in different features are comparable. Next, we define the distance between two individuals as the weighted sum of the distances over different features, i.e. where the weights ’s are randomly generated. Each unique set of randomly generated feature weights results in a new representation metric.
We generate sets of randomly-assigned feature weights per dataset, calculate a representation metric for each set, and report the performance metrics averaged over instances. Given that our datasets are samples of a large population (i.e. millions) and represented through a relatively small number of unique data points (i.e. few thousands), we assume that each data point represents a group of at least people, which takes a maximum value of 40 in our study. To empirically measure ex post core violation, for each of the instances, we sample one panel from an algorithm and compute the core violation using Algorithm 2. We note that this is not exactly equal to the worst-case core violation, but a very good approximation of it.
6.3 Results
Results for Ex Post Core Violation.
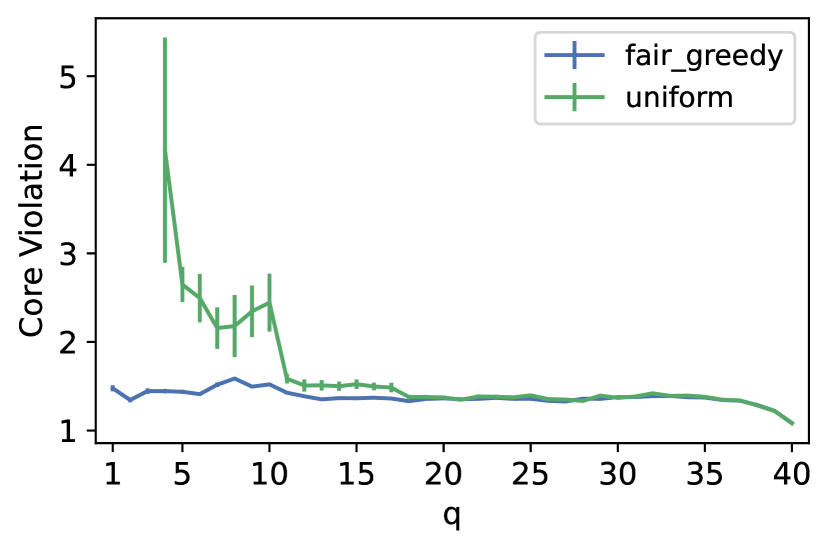
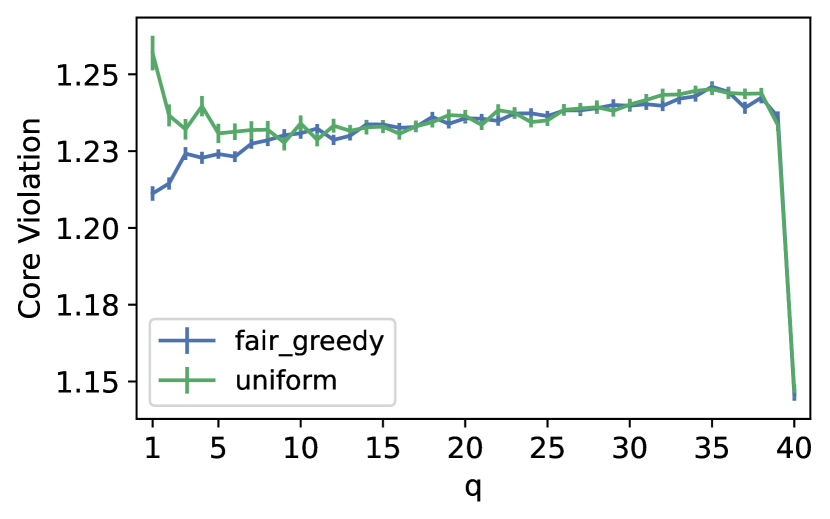
In Adult dataset, we observe an unbounded ex post core violation for Uniform when . Specifically, for , we observed unbounded core violation in , , and of the instances respectively. This happens since of the population is mapped to a single data point and that Uniform fails to select individuals from this group. When , we have , and this cohesive group is entitled to select at least members of the panel from themselves, which results in -cost of for them and an unbounded violation of the core. However, FairGreedyCapture captures this cohesive group and selects at least representatives from them. Furthermore, we see significantly higher ex post core violation for Uniform compared to FairGreedyCapture for smaller values of (up to ) and comparable performance for larger values of . This is expected as FairGreedyCapture tends to behave more similarly to Uniform as increases because it selects from fewer yet larger groups ( groups of size ).
We observe a similar pattern in ESS-UK that Uniform obtains worse ex post core violations when is smaller and similar performance as FairGreedyCapture for larger values of . However, in contrast to Adult, we do not observe similar unbounded violations for Uniform in ESS-UK. The reason is that ESS-UK consists of 250 features (compared to the we used from Adult) and any data points represent at most of the population. Thus, no group is entitled to choose enough representatives from their own to significantly improve their cost or make it . The decline in core violation for happens as it measures the minimum improvement in cost over the whole population, which is more demanding than lower values of . Lastly, FairGreedyCapture performs consistently for all values of and achieves an ex post core violation less than and in Adult and ESS-UK respectively.
Evaluating Approximation to Optimal Social Cost.
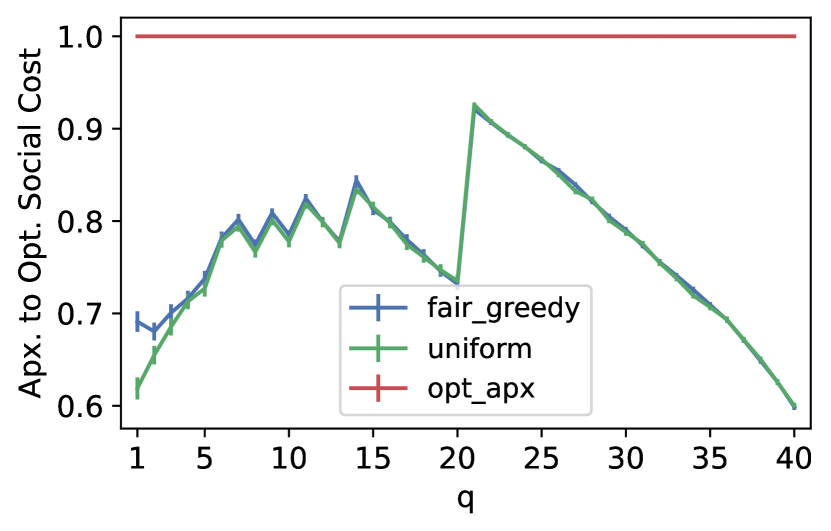
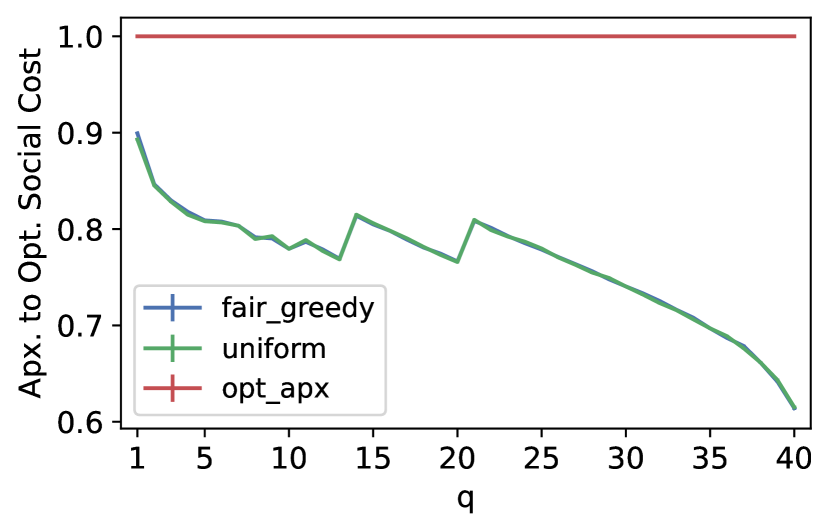
As we mentioned in the introduction, Ebadian et al. (2022) use a different approach to measure the representativeness of a panel by considering the social cost (sum of -costs) over a panel. In particular, they define the representativeness of an algorithm as the worst-case ratio between the optimal social cost and the (expected) social cost obtained by the algorithm. Ebadian et al. (2022), in their empirical analysis, measure the average approximation to the optimal social cost of an algorithm over a set of instances , defined as . Since finding the optimal panel is a hard problem and the dataset and panel sizes are large, Ebadian et al. (2022) use a proxy for the minimum social cost, specifically, an implementation of the algorithm of Kumar and Raichel (2013) for the fault-tolerant -median problem that achieves a constant factor approximation of the optimal objective — which is equivalent to minimizing the -social cost. We use the same approach and report the average approximation to the optimal social cost of FairGreedyCapture and Uniform.
In Figure 3, the reader can see the performance of the two different algorithms over this objective. For ESS-UK, we observe a similar behaviour from the two algorithms, while for Adult, FairGreedyCapture outperforms Uniform for , which is again due to FairGreedyCapture capturing the cohesive group. All considered, we observe that FairGreedyCapture can maintain at least the same level or even better optimal social cost approximation as Uniform would, while achieving significantly better empirical core guarantees in the two datasets.
7 Discussion
This work introduces a notion of proportional representation, called the core, within the context of sortition. The core serves as a metric to ensure proportional representation across intersectional features. While uniform selection achieves an ex ante --core, it fails to provide a reasonable approximation to the ex post -core. To address this, we propose a selection algorithm, FairGreedyCapture, which preserves the positive aspects of uniform selection, i.e. fairness and ex ante --core, while also meeting the ex post --core requirement. We also highlight that the use of FairGreedyCapture allows the translation of the core requirement into a set of quotas, which can be integrated with another set of quotas to ensure proportional representation across both individual and intersectional features.
It is worth to emphasize that the limitations of uniform selection in satisfying ex post guarantees arise from the potential return of non-proportionally representative panels with a positive probability. In Appendix E, we explore a natural variation where the core property is mandated to hold over the expected -costs of panels chosen from a selection algorithm. We demonstrate that this variation is incomparable with the ex post -core, and more importantly uniform selection fails to offer any meaningful multiplicative approximation to this variation, as well.
There are many directions for future work. First, there are gaps between the lower and upper bounds we provide for both the ex ante and the ex post core. Closing these gaps and investigating if there are fair selection algorithms that provide better guarantees to ex ante and/or ex post core is an immediate interesting direction. Moreover, we show Fair Greedy Capture is in the ex post --core, but we do not provide lower bounds indicating that this analysis is tight. In fact, in Appendix F, we show that for , FairGreedyCapture is in the ex post --core and this is tight. Finding tight bounds for the general case is an open question. In addition, in Appendix G, we show that if is known for an application at hand and we wish to provide guarantees with respect to ex post -core, a variation of Augmented-FairGreedyCapture provides an approximation of , which is slightly better than the approximation of . Exploring if this is tight as well is another interesting direction. Furthermore, Micha and Shah (2020) show that for , Greedy Capture (Chen et al., 2019), provides better guarantees for the Euclidean space. So, another interesting question is to see if when the metric consists of usual distance functions such as norms , and , FairGreedyCapture can provide better guarantees.
References
- Arrow [1990] K. Arrow. Advances in the spatial theory of voting. Cambridge University Press, 1990.
- Aziz et al. [2017] H. Aziz, M. Brill, V. Conitzer, E. Elkind, R. Freeman, and T. Walsh. Justified representation in approval-based committee voting. Social Choice and Welfare, 48(2):461–485, 2017.
- Aziz et al. [2023] H. Aziz, B. E Lee, and S. M. Chu. Proportionally representative clustering. arXiv preprint arXiv:2304.13917, 2023.
- Benadè et al. [2019] G. Benadè, P. Gölz, and A. D. Procaccia. No stratification without representation. In Proceedings of the 20th ACM Conference on Economics and Computation (EC), pages 281–314, 2019.
- Birkhoff [1946] G. Birkhoff. Three observations on linear algebra. Univ. Nac. Tacuman, Rev. Ser. A, 5:147–151, 1946.
- Caragiannis et al. [2022] I. Caragiannis, N. Shah, and A. A. Voudouris. The metric distortion of multiwinner voting. Artificial Intelligence, 313:103802, 2022.
- Chen et al. [2019] X. Chen, B. Fain, L. Lyu, and K. Munagala. Proportionally fair clustering. In International Conference on Machine Learning, pages 1032–1041, 2019.
- Cheng et al. [2020] Y. Cheng, Z. Jiang, K. Munagala, and K. Wang. Group fairness in committee selection. ACM Transactions on Economics and Computation (TEAC), 8(4):1–18, 2020.
- Chhabra et al. [2021] A. Chhabra, K. Masalkovaitė, and P. Mohapatra. An overview of fairness in clustering. IEEE Access, 9:130698–130720, 2021.
- Conitzer et al. [2019] V Conitzer, R Freeman, N Shah, and J. W. Vaughan. Group fairness for the allocation of indivisible goods. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI), pages 1853–1860, 2019.
- Dua and Graff [2017] D. Dua and C. Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Ebadian et al. [2022] S. Ebadian, G. Kehne, E. Micha, A. D. Procaccia, and N. Shah. Is sortition both representative and fair? In Proceedings of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS), pages 25720–25731, 2022.
- Enelow and Hinich [1984] J. M. Enelow and M. J. Hinich. The spatial theory of voting: An introduction. CUP Archive, 1984.
- Engelstad [1989] F. Engelstad. The assignment of political office by lot. Social Science Information, 28(1):23–50, 1989.
- Fain et al. [2018] B. Fain, K. Munagala, and N. Shah. Fair allocation of indivisible public goods. In Proceedings of the 19th ACM Conference on Economics and Computation (EC), pages 575–592, 2018.
- Faliszewski et al. [2017] P. Faliszewski, Piotr S., A. Slinko, and N. Talmon. Multiwinner voting: A new challenge for social choice theory. Trends in computational social choice, 74(2017):27–47, 2017.
- Flanigan et al. [2020] B. Flanigan, P. Gölz, A. Gupta, and A. D. Procaccia. Neutralizing self-selection bias in sampling for sortition. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems (NeurIPS), pages 6528–6539, 2020.
- Flanigan et al. [2021a] B. Flanigan, P. Gölz, A. Gupta, B. Hennig, and A. D. Procaccia. Fair algorithms for selecting citizens’ assemblies. Nature, 596:548–552, 2021a.
- Flanigan et al. [2021b] B. Flanigan, G. Kehne, and A. D. Procaccia. Fair sortition made transparent. In Proceedings of the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), pages 25720–25731, 2021b.
- Flanigan et al. [2024] B. Flanigan, J. Liang, A. D. Procaccia, and S. Wang. Manipulation-robust selection of citizens’ assemblies. In Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI), 2024.
- Gąsiorowska [2023] A. Gąsiorowska. Sortition and its principles: Evaluation of the selection processes of citizens’ assemblies. Journal of Deliberative Democracy, 19(1), 2023.
- Gastil and Wright [2019] J. Gastil and E. O. Wright, editors. Legislature by Lot: Transformative Designs for Deliberative Governance. Verso, 2019.
- Kalayci et al. [2024] Y. H. Kalayci, D. Kempe, and V. Kher. Proportional representation in metric spaces and low-distortion committee selection. In Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI), pages 9815–9823, 2024.
- Kellerhals and Peters [2023] L. Kellerhals and J. Peters. Proportional fairness in clustering: A social choice perspective. arXiv preprint arXiv:2310.18162, 2023.
- Kohavi and Becker [1996] R. Kohavi and B. Becker. Adult data set. UCI machine learning repository, 5:2093, 1996.
- Kumar and Raichel [2013] N. Kumar and B. Raichel. Fault tolerant clustering revisited. In Proceedings of the 25th Canadian Conference on Computational Geometry, CCCG 2013, Waterloo, Ontario, Canada, August 8-10, 2013. Carleton University, Ottawa, Canada, 2013.
- Lackner and Skowron [2023] M. Lackner and P. Skowron. Multi-winner voting with approval preferences. Springer Nature, 9783031090158, 2023.
- Martin and Carson [1999] B. Martin and L. Carson. Random selection in politics. 1999.
- Micha and Shah [2020] E. Micha and N. Shah. Proportionally fair clustering revisited. In 47th International Colloquium on Automata, Languages, and Programming (ICALP), pages 85:1–85:16, Saarbrücken, Germany, 2020. Schloss Dagstuhl.
- Report. [2021] ESS Round 9: European Social Survey (2021): ESS-9 2018 Documentation Report. Edition 3.1. bergen, european social survey data archive, nsd - norwegian centre for research data for ESS ERIC. 2021. 10.21338/NSD-ESS9-2018. URL https://www.europeansocialsurvey.org/data/.
- Van Reybrouck [2016] D. Van Reybrouck. Against Elections: The Case for Democracy. Random House, 2016.
- Vergne [2018] A. Vergne. Citizens’ participation using sortition: A practical guide to using random selection to guarantee diverse democratic participation. 2018.
- Yates [1948] F. Yates. Systematic sampling. Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences, 241(834):345–377, 1948.
Appendix A Minimizing Social Cost Fails to Provide Proportional Representation
Example 7.
Let be odd, and . Assume that there are four group of individuals, , , and . There are exactly one individual in group , and exactly one individual in group , while there are individuals in group and individuals in group . The distances between individuals in different groups is specified in the following table.
| D | ||||
|---|---|---|---|---|
It is not difficult to see that any panel with minimum social cost contains the single individuals in groups and and one individual from either group or group , as otherwise the social cost would be unbounded. This means that while the individuals in group form almost of the population, and similarly do the individuals in group , in any panel with optimal social cost, either group or is not represented at all. On the other hand, the two eccentric individuals are always part of the panel.
Appendix B Uniform Selection is in the Ex Post --Core
Next, we show that when , any panel is in the ex post --core, which implies that any algorithm including uniform selection is in the ex post --core. This is due to the fact that in this case only if the grand coalition, i.e. all the agents, has incentives to deviate, the ex post core is violated.
Theorem 8.
Every panel is in the ex post --core. Therefore, uniform selection is in the ex post -core, and this is tight.
Proof.
Consider any panel . It suffices to show that for any arbitrary panel of size , the -cost of all individuals cannot be improved by a factor of greater than .
Let and be the two individuals in the population with the maximum distance between them. Now, consider an arbitrary representative in panel . Without loss of generality, suppose that . Then, we have
| (by the choice of and ) | ||||
| (triangle inequality) | ||||
| (as ) | ||||
This implies , since the -cost for does not improve by a factor of more than two. From, this we get that any panel is in the ex post --core, and therefore uniform selection is in the ex post -core.
Next, we show that there exists an instance such that uniform selection is not in the ex post --core for . Consider the case that the individuals are assigned into three groups, , and , with , , and individuals, respectively. The distances between individuals is as specified in the following table.
The panel which consists of all the people in groups and is in the support of uniform selection. Then, for , as the -th closest representative in lies in the other group. For , the . Now, consider panel that consists of individuals from group . The -costs of all individuals improve by a factor of at least . Hence, violates ex post --core in this example. ∎
Appendix C Uniform Selection is in the Ex Ante -Core
Proposition 9.
Uniform selection is in the ex ante -core.
Proof.
To satisfy ex ante -core, for any panel of size , we should have
Essentially, this means that the ex ante -core is violated only if the grand coalition, i.e. all the agents, has incentives to deviate to , in expectation. Since for all by definition, it suffices to show that there exists a panel that is chosen with non-zero probability, and it holds that . Since, chooses any panel with non-zero probability, including , there is a non-zero probability that we realize panel for which — since the -costs do not strictly improve for any individual. Thus, the expected preference count of the panel that selected from uniform selection with respect to any other panel is strictly less than , satisfying the ex ante -core. ∎
Appendix D Proof of Chu–Vandermonde Identity
Proof.
We give a combinatorial argument for this identity. Suppose we want to select items out of a set of size . For , let be the number of such subsets in which the th picked item is item . As each subset is counted exactly once among ’s (at the position of its th item), we have . Now, we calculate . Suppose the th item is . Then, items should be selected from the first items and items should be selected from the last items. Therefore, . Then, we have
Appendix E -Core over Expected Cost
A variation of the demanding ex post -core is to ask the core property to hold with respect to the expected -cost, as it is given in the definition below.
Definition 10 (--Core over Expected Cost).
A selection algorithm is in the --core over expected cost (or in the -core over expected cost, for ) if there is no and a panel with such that
We start by showing that the ex post -core and the -core over expected cost are incomparable.
Proposition 11.
For any , ex post -core and -core over expected cost are incomparable.
Proof.
First, we show that the ex post -core does not imply the -core over expected cost. Assume that is divisible by and is divisible by . Consider an instance where there are five groups of individuals, , , , and . The first three groups contain individuals each, the fourth group contains individuals and the last group contains individuals. The table below provides the specified distances between individuals within given groups.
Suppose that a selection algorithm returns with probability a panel that contains individuals from group and the remaining representatives are from group , with probability a panel that contains individuals from group and the remaining representatives are from group and with probability a panel that contains individuals from group and the remaining representatives are from group . All these panels are in the ex post -core, since there is no sufficiently large group such that if they choose another panel, all of them reduce their distance. Now, we see that for each in or or , it holds that
while for each in , it holds that
If all the individuals in , , and choose a panel that contains individuals from , then all of them reduce their distance by a factor at least equal to .
Next, we show that the -core over expected cost does not imply the ex post -core. Consider an instance where there are four groups of individuals, , , , . Group contains individuals, group contains individuals, group contains individuals and group contains all the remaining individuals. The distance between individuals belonging to given groups is specified in the following table.
Suppose that a selection algorithm returns with probability a panel that contains individuals from group and individuals from group , and with the remaining probability returns a panel that contains individuals from group and individuals from group . Then, for each in , we have that
while for each in , we have that
Hence, this algorithm is in the -core over expected cost. But when the algorithm returns , all the individuals in and can reduce their cost by a factor of by choosing representatives in . ∎
Next, we show that as in the case of the ex post -core, uniform selection is in the --core over expected cost.
Theorem 12.
For , uniform selection is --core over expected cost.
Proof.
In the proof of Theorem 8, we show that for any and any panel , with , there exists , such that . This implies that which means that uniform selection is in the --core over expected cost. This is because to violate --core over expected cost, the -cost of the entire population would have to improve by a factor of more than , which does not hold for individual . ∎
Again as in the case of the ex post -core, we show that uniform selection does not provide any bounded multiplicative approximation to the -core over expected cost, for .
Theorem 13.
For any and , there exists an instance such that uniform selection is not in the --core over expected cost, for any bounded .
Proof.
Consider the instance as given in proof Theorem 1. As before, uniform selection may return a panel that consists only from individuals in group . Therefore, all the individuals in group have positive expected -cost under uniform selection, while if they choose a panel among themselves, they would all have a -cost of . Thus, uniform selection is not in the --core over expected cost for any bounded . ∎
Lastly, we show that is in the --core over expected cost, for every .
Theorem 14.
For every , is in the --core over expected cost.
Proof.
Let be the distribution that returns. Suppose for contradiction that there exists and , with , such that
In the proof of Theorem 3, we show that there exist such that for every in the support of the algorithm, we have that . This implies that which is a contradiction. ∎
Appendix F Analysis of for the Ex Post -Core
Theorem 15.
in the ex post --core and there exists an instance for which this bound is tight.
Proof.
Let be any panel that the algorithm may return. Suppose for contradiction that there exists a panel such that . This means that there exists , with , such that:
| (5) |
If , we can partition into groups by assigning each individual to their closest representative from , and at least one of these groups should have size at least . Therefore, without loss of generality, we can assume that and .
Let and be the individual in that has the largest distance from . Since there are sufficiently many individuals in the ball , it is possible that the algorithm opened it during its execution. If this happened, this means that there is at least one representative in that is located within this ball. Then, we get that has a distance at most equal to the diameter of the ball from her closest representative in which is at most . Hence, cannot reduce her distance by a multiplicative factor larger than by choosing , and we reach in a contradiction.
On the other hand, if the algorithm did not open this ball during its execution, this means that some of the individuals in have been allocated to different balls before the ball centered at captures sufficiently many of them. Hence, some individuals in have been captured from a different ball with radius at most . Suppose that is the first individual in that was captured from such a ball. Then, we have that within this ball there is representative in . Hence , since the distance of form any other individual in this ball is at most equal to the diameter of the ball. We consider the minimum multiplicative improvement of both and :
| (by Lemma 2) | ||||
| (as ) | ||||
To show that this bound is tight consider the case that and . Assume that the individuals form four isomorphic sets of individuals each such that each set is sufficiently far from all other sets. The distances between the individuals in one set are given in the table below.
Since and there are four isomorphic groups, there exists a group that has at most one representative in some realized panel. Note that the algorithm first opens the balls that are centered at and have radius equal to . Assume that when this ball was opened in the group that has one representative in the panel, the algorithm chooses to be included in the panel. Then, in this group the individuals , , and are eligible to choose and all of them reduce their distance by a multiplicative factor of at least as goes to zero. ∎
Appendix G Augmented-FairGreedyCapture with Known
Here, we show that there exists a version of FairGreedyCapture such that if is known, it provides an approximation of to the ex post -core. As before, our algorithm leverages the basic idea of the Greedy Capture algorithm.
, in Algorithm 3, starts with an empty panel and grows a ball around every individual in at the same rate. When a ball captures individuals (if more than individuals have been captured, it chooses exactly by arbitrarily excluding some points on the boundary), the algorithm selects of them uniformly at random, includes them in the panel , and disregards all the individuals. When this happens, we say that the algorithm detects this ball. Unlike Greedy Capture, we continue growing balls only around the individuals that are not yet disregarded, i.e. detected balls are frozen. When fewer than individuals remain, the algorithm selects the remaining representatives from among the individuals who have not yet been included in the panel as follows: each individual who has not been disregarded is selected with probability , and the remaining probability mass is allocated uniformly among the individuals who have been disregarded but not selected. This can be achieved through systematic sampling Yates [1948].
Theorem 16.
For every , is fair and in the ex post --core.
Proof.
We start by showing that the algorithm is fair.
Lemma 5.
is fair.
Proof.
Suppose that is an integer. Then, each individual that is disergarded in the while loop of the algorithm is included in the panel with probability exactly . Now, suppose that after the algorithm has detected balls, less than individuals have not been disregarded. Then, when the algorithm exits the while loop we have that and . But since,
we conclude that the remaining representatives are chosen uniformly among the individuals in . Thus, the algorithm returns a panel of size and each is chosen with probability .
Now, we focus on the case where is not an integer. In this case, note that in the while loop of the algorithm, less than representatives are included in the panel, since representatives are included in it every time that non-disregarded individuals are captured from a ball. Moreover, each individual that is disregarded is chosen with probability strictly less than . Now suppose that after exiting the while loop, there are individuals that have not been disregarded, i.e. . First, we show that the algorithm correctly chooses another representatives and outputs a panel of size . The algorithm would select each individual in with probability and allocates the remaining probability — which is equal to —uniformly among the individuals that have been disregarded but not selected in . To satisfy fairness for people in , it suffices to show that . Since for each individual we have , then we have . Thus, Hence, the algorithm outputs panels of size .
It remains to show that each individual in , which is disregarded in the while loop, is included in the panel with probability . First, note that all of them are included in the panel with the same probability. This holds, since each is selected with probability from the ball that captured them in the while loop, and, when not selected in the while loop, they get an equal chance of selection of . Since the size of the final panel returned by the algorithm is always , and by linearity of expectation, we have . By equality of ’s, we conclude that all must be equal to and each individual in is included in the panel with probability . ∎
We proceed by showing that is in the ex post --core. Let be any panel that the algorithm may return. Suppose for contradiction that there exists a panel such that . This means that there exists , with , such that:
| (6) |
Let be a partition of with respect to , as given in the first part of Lemma 1. In a similar way as in the proof of Theorem 3, we can conclude that there exists a ball centered at that has radius and captures all the individuals in . Since there are sufficiently many individuals in this ball, it is possible that the algorithm detected this ball (or a nested one) during its execution. If this happened, this means that there are representatives in that are located within the ball . Then, we get that which contradicts Equation 6.
On the other hand, if the algorithm did not detect this ball (or a nested one) during its execution, this means that some of the individuals in have been disregarded before the ball centered at captures sufficiently many of them. Hence, some individuals in have been captured from a different ball with radius at most . Suppose that is the first individual in that was captured from such a ball. Then, we get that representatives in are within this ball, which means that , since the distance of form any individual in this ball is at most equal to the diameter of the ball. We consider the minimum multiplicative improvement of both and :
| (by Lemma 2) | ||||
| (by Triangle Inequality) | ||||
| (as | ||||
| (as | ||||
which violates Equation 6 and the theorem follows. ∎