\ul
BotSCL: Heterophily-aware Social Bot Detection with Supervised Contrastive Learning
Abstract.
Detecting ever-evolving social bots has become increasingly challenging. Advanced bots tend to interact more with humans as a camouflage to evade detection. While graph-based detection methods can exploit various relations in social networks to model node behaviors, the aggregated information from neighbors largely ignore the inherent heterophily, i.e., the connections between different classes of accounts. Message passing mechanism on heterophilic edges can lead to feature mixture between bots and normal users, resulting in more false negatives. In this paper, we present BotSCL, a heterophily-aware contrastive learning framework that can adaptively differentiate neighbor representations of heterophilic relations while assimilating the representations of homophilic neighbors. Specifically, we employ two graph augmentation methods to generate different graph views and design a channel-wise and attention-free encoder to overcome the limitation of neighbor information summing. Supervised contrastive learning is used to guide the encoder to aggregate class-specific information. Extensive experiments on two social bot detection benchmarks demonstrate that BotSCL outperforms baseline approaches including the state-of-the-art bot detection approaches, partially heterophilic GNNs and self-supervised contrast learning methods.
1. Introduction
Social bots are automated accounts that are often used for malicious purposes, such as spreading misinformation (Cresci, 2020), promoting extremism (Hamdi, 2022), and electoral interference (Deb et al., 2019; Ferrara, 2017). Bots have been widely existing in social networks and continuously evolve to tackle emerging detection techniques. A variety of advanced bot detection technologies safeguard the environment of social networks. Approaches based on extracting distinctive characteristics from Twitter accounts typically extracted tweets (Kudugunta and Ferrara, 2018), metadata (Beskow and Carley, 2019; Yang et al., 2020), and temporal features (Chavoshi et al., 2017) and fed into various classifiers. Deep neural networks with different architectures are further designed to improve classification performance. However, they fail to model the diverse relationships (e.g., following, commenting, etc.) between social accounts. Recent advancements in graph neural networks based approaches (Ali Alhosseini et al., 2019; Feng et al., 2021a; Yang et al., 2023; Feng et al., 2022a; Yang et al., 2022b) can better capture semantic relationship information. A common practice is constructing a heterogeneous graph that contains different relations before using a relational graph transformer to aggregate both intra-relational and inter-relational information. Account feature information and topological information can be therefore co-utilized to obtain richer semantic embeddings with more comprehensive information.
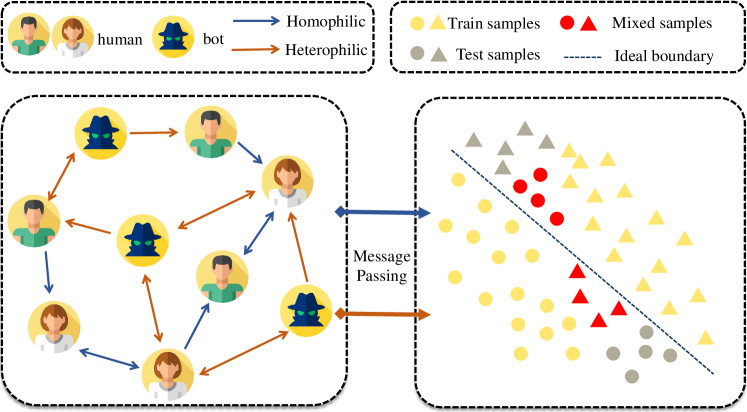
On the left side is an illustration of a graph that includes both homophilic and heterophilic relations and on the right side is the distribution of node features after message passing.
However, most of the existing graph-based methods overlook the negative impact of heterophily (i.e., the connections between different classes of accounts). Recent investigations (Williams et al., 2020; des Mesnards et al., 2022) have revealed that bots intentionally interacting more with humans inherently lead to adversarial properties of social bots: increased influence of particular information and intentional evasion of detection (Le et al., 2022). Social bots can easily establish heterophilic relationship with human beings by following normal user accounts or replying to tweets of normal users. The information aggregation mechanism used in the existing graph-based detection methods – often seen as the sum of node representations in the neighborhood – tends to make neighboring node representations similar. As shown in Figure 1, once homophilic and heterophilic interactions co-exist, message passing through heterophilic edges will assimilate node representations to those of the opposite class, leading to less distinguishable representations. As a result, such mixed representations trained with their original labels ends up with shifted classification boundary and increasing false positives.
Therefore, effective detection should make node representation pertaining to the same class as similar as possible, whilst staying away from other classes. Most of the existing works (Ali Alhosseini et al., 2019; Feng et al., 2021a, 2022a) can only assimilate the representations of nodes belonging to different categories during message passing and thus harmful for classification (Shi et al., 2022). That is to say, we first need to further extend previous relational graph neural networks in a way that enables them to freely and adaptively promote both intra-class similarity and inter-class differentiation among neighboring nodes. Supervised contrastive learning (Khosla et al., 2020) is intrinsically the effective means to characterizes inter-class discrimination. With this optimization objective, non-adjacent nodes of the same class are considered positive pairs, and nodes tend to aggregate global class-specific information rather than local information. In this way, it ensures that the node representations after message passing are closer to the category centers which is beneficial for weight matrix to classify.
In this paper, we propose BotSCL, a supervised contrastive social bot detection framework that co-considers homophilic and heterophilic relations. We devise two graph augmentation methods – including feature augmentation and topological structure augmentation – to obtain different graph views. We then propose an encoder to aggregate similar and different information on a per feature channel basis. Supervised contrastive learning is exploited in a cross-view manner to obtain class-consistent representations between different graph views. Consequently, it compels the encoder to assimilate representations of homophilic neighbors while differentiating representations from heterophilic neighbors.
In particular, this paper makes the following contributions:
-
•
We first introduce and reveal the negative impact of heterophily on social bot detection, and experimentally validate it.
-
•
We propose a detection framework that aggregates similar and differentiable information with the guidance of supervised contrastive learning.
-
•
We conduct experiments on two social bot detection benchmark datasets. The results show that our model consistently outperforms previous state-of-the-art methods.
2. Related Work
In this section, we will discuss relevant research on graph-based social bot detection, graph neural networks for heterophilic graphs, and contrastive learning (e.g., (Feng et al., 2021b, 2022a; Moghaddam and Abbaspour, 2022)).
2.1. Graph-based Social Bot Detection
Previous approaches to social bot detection primarily involve manual analysis of collected data and extraction of distinctive characteristics for input into diverse classifiers(Yang et al., 2022a). Subsequently, deep neural networks with diverse architectures are developed to enhance classification performance(Kudugunta and Ferrara, 2018; Wu et al., 2021). However, the detectability of these characteristics is vulnerable to imitation and evasion by social bots, rendering them ineffective over time. To tackle the challenge of bot disguise, graph-based social bot detection methods have been extensively studied and shown great success in social bot detection with the advent of benchmark datasets that incorporate graph information(Feng et al., 2021c, 2022b).
(Ali Alhosseini et al., 2019) is the first attempt to introduce graph convolutional networks to take advantage of both the features of the accounts and the structure of the relation graph, which takes Twitter users as nodes. Satar (Feng et al., 2021b) utilizes graph convolutional networks in a feature engineering manner and employs self-supervision to detect social robots. Relational graph convolutional networks (R-GCNs) (Schlichtkrull et al., 2018) were used by (Feng et al., 2021a) to aggregate information from different relations and (Feng et al., 2022a) later improved it with additional relations and apply graph transformer to better aggregate information from neighbors adaptively. (Yang et al., 2022b) proposed RoSGAS, a framework that leverages heterogeneous information network to effectively model multiple entities and relationships within a social network and performs subgraph embedding with reinforcement learning for social bot detection.
All of these methods are based on the assumption that both humans and bots tend to interact more with the same class, and classification benefits from smoothing the representations of neighboring nodes. However, in reality, advanced bots can easily escape graph-based detection by actively interacting with humans because none of these approaches take heterophily into account. In this paper, we propose a bot detection framework that recognizes the negative impact of heterophilic relations between bots and humans for more effective user representations to enhance the performance of bot detection.
2.2. Heterophilic GNNs
Due to the widespread existence of heterophily, graph neural networks for graphs with heterophily have received significant attention in recent years. Essentially, there are mainly two kinds of approach: 1) Aggregation of non-local neighbor information. For example, some techniques gather information from higher-order neighbors (Abu-El-Haija et al., 2019; Zhu et al., 2020b) and potential neighbors of the same class (Pei et al., 2020; Wang et al., 2022) to obtain more intra-class information. 2) Adaptive Message Passing. FAGCN (Bo et al., 2021) simultaneously aggregates high- and low-frequency information. GPRGNN (Chien et al., 2020) employs learnable weights for information aggregated from distinct hop neighbors. (Luan et al., 2021) argues that not all heterophily edges are harmful for classification and proposes Adaptive Channel Mix (ACM) to adaptively aggregate self-information, low-frequency information, and high-frequency information. Despite the emergence of numerous heterophilic GNNs, these methods primarily focus on single-relation and undirected simple graphs, particularly spectral-based GNNs. In social bot detection, bots exhibit a higher tendency towards heterophily, while humans display a higher inclination towards homophily, respectively. Therefore, directly applying heterophilic GNNs to social bot detection may not yield optimal results.
2.3. Contrastive Learning
Contrastive learning aims to learn an encoder that can generate representations consistent with different views by attracting positive pairs and repelling negative pairs. Graph contrastive learning (GCL) extends the technique to graph domain and learns the representations of nodes in a self-supervised manner due to rich information implicitly existing in the connections between nodes. GRACE (Zhu et al., 2020a) applies edge removal and feature mask to generate augmented views and treat the same node in different views as a positive pair. DGI (Velickovic et al., 2019) learns node representations by maximizing the mutual information between local and global embeddings. However, self-supervised contrastive learning methods face class collision problem – the representations of similar samples may be far apart, while the representations of dissimilar samples may be close (Zheng et al., 2021). Supervised contrastive learning (Khosla et al., 2020) firstly applied in computer vision field treats intra-class images as positive pairs, while inter-class images as negative pairs. Thus, embeddings from the same class are pulled closer than embeddings from different classes. Because this property is opposite to the feature mixing caused by message propagation on heterophilic edges, we utilize supervised contrastive loss to train an encoder that can adapt to both homophilic and heterophilic edges simultaneously to aggregate information beneficial for further classification.
3. PRELIMINARIES
We first formulate the task of graph-based social bot detection, and present an approach to measure the homophily and heterophily degree. To aid discussion, Table 1 depicts the notations used in the paper.
Definition 3.1. Graph-based Social Bot Detection. Previous graph-based approaches for detecting social bots consider social networking platform (e.g., Twitter) accounts as nodes and interactive behaviors such as follower and following as edges. Social bot detection can thus be considered as semi-supervised node classification on an attributed multi-relational graph. We define this graph as , where is the set of all nodes, represents the set of edges formed by different relations and is the feature matrix, each row of which represents the feature vector of the corresponding node. Total detection process is to use the graph and the labels of training nodes to predict the labels of test nodes :
| (1) |
Definition 3.2. Homophily and Heterophily Measure. To gain a deeper insight into the extent of homophily and heterophily in social bot detection, we further consider different relations, directionality, and classes on top of the previous metric (Zhu et al., 2020b). The class-aware homophily and heterophliy ratio of given graph in terms of relation can be defined as:
| (2) | ||||
where represents the directed edge from node to and is the label of node , 0 for human and 1 for bot. In this measurement setup, the edges are considered as the active behaviors of their start nodes. For the reason that benchmark datasets may only include a small proportion of labeled nodes, we only consider edges where both the starting and ending nodes have labels in our calculations.
| Notation | Description |
|---|---|
| ; ; ; | Graph; Node set; Edge set; Node feature matrix |
| ; ; | The node ; The edge ; |
| ; | The edge between node and ; Node ’s feature |
| ; | The relation ; Total number of relations |
| Set of edges formed by the relation | |
| Hidden state of node at layer | |
| ; | Label of node ; Node label set |
| ; | Predicted label for node ; Predicted label set |
| A class of nodes in social network graph | |
| A function to compute homophily ratio | |
| A function to compute heterophily ratio | |
| Class-aware graph augmentation function | |
| ; | The mask value of ; Mask value of |
| Bernoulli distribution | |
| Learnable model parameters at layer | |
| ; | Query weight for layer ; Key weight for layer |
| The neighborhood of node with regard to relation | |
| The attention co-efficient for at layer | |
| Hadamard product operation | |
| Nonlinear activation function | |
| The representation of node | |
| Cosine similarity function | |
| Temperature coefficient |
4. Methodology
This section presents the details of BotSCL. Same with the general framework of contrastive learning, our framework consists of a graph augmentor, an encoder, and a contrastive loss. The total pipeline of BotSCL is shown in Figure 2. First, we use two graph augmentation methods to generate two graph views. Then, nodes aggregate similar information from homophilic neighbors and adaptively discriminate representations from heterophilic neighbors for each relation. Lastly, node representations are learned through supervised contrastive learning in a cross view manner. Our goal is to train an encoder that can learn effectively from both heterophilic and homophilic edges.
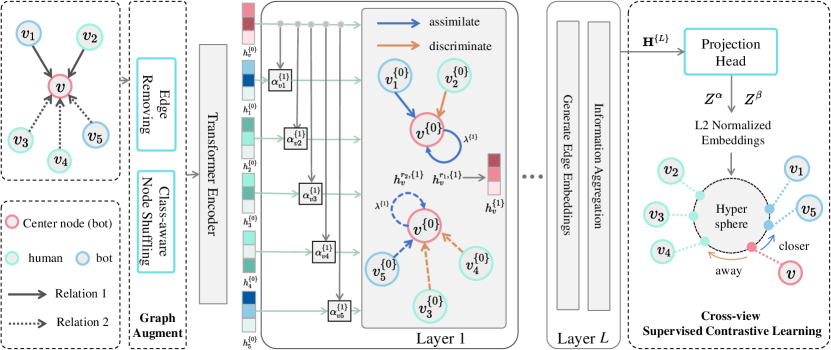
The total pipeline of BotSCL.
4.1. Augmentor
Graph contrastive learning employs multiple graph augmentation strategies, including edge addition, feature masking, and personalized pagerank diffusion, to generate various graph views (You et al., 2020). It should be noted that not all graph augmentation methods can be universally applicable to graphs with heterophily. (Yang and Mirzasoleiman, 2023) uses a low-pass filter and high-pass filter to generate graph views for self-supervised contrastive learning. However, this approach may result in the absence of directional information on relations and higher-order neighbor information. (Liu et al., 2022) first determines whether each edge belongs to within-class or between-class, and then generates a homophilic view and a heterophilic view for contrastive learning. However, error propagation will inevitably happen. This paper aims to use supervised contrastive learning loss to enable simultaneous perception of both heterophilic and heterophilic edges, instead of employing extra differentiation between the two.
As supervised contrastive learning leverages label information during the training process, we propose a class-aware node shuffling (CNS) graph augmentation method that randomly swaps nodes belonging to the same class. By using this approach, one can learn representations that are invariant to the neighborhood without excessively disrupting the graph structure. This graph augmentation method can be implemented through intra-class feature swapping:
| (3) |
Additionally, we also employed a traditional graph augmentation method, edge removing (ER), to augment the graph topology. The edge removal method can be formulated as follows:
| (4) |
where is total edge set, each element of , stands for the mask value of edge and , is the probability to remove. Through the aforementioned two graph augmentation methods, both the features and topological structure of the original graph are augmented.
4.2. Encoder
4.2.1. Feature Fusion.
Unlike other node classification tasks, the input for the social bot detection task consists of features of different types and dimensions. Therefore, it is necessary to use a multi-layer perceptron (MLP) for each type of feature to align the dimensions of feature vectors. Previous methods (Feng et al., 2021a, 2022a) further concatenate these different types of feature vectors and use another MLP to obtain the input of the graph convolutional layer.
In this study, we use TransformerEncoder (Vaswani et al., 2017) for feature fusion by treating the feature vectors of different types as token embeddings:
| (5) |
where stands for the feature vector of type of node and is the concatenation of the TransformerEnocder outputs. On top of that, we apply another MLP to and obtain the input of the graph convolutional layer :
| (6) |
where , are learnable parameters and is a nonlinear activation function. Thanks to the mechanisms of self-attention and residual connections in Transformer, we can obtain more semantically enriched node input representations.
4.2.2. Information aggregation.
After obtaining different views, BotSCL needs to use an encoder that can aggregate information from similar and dissimilar neighbors in a distinguishable manner to obtain node representations. In the spectral domain, GNNs based on the homophily assumption can be viewed as low-pass filters, while previous work (Luan et al., 2021) on graphs with heterophily has shown that high-pass filters that capture differential information are more effective for modeling heterophilic connections. On the other hand, low-pass filtering can be achieved by aggregating information from neighboring nodes, while high-pass filtering can be achieved by differentiating neighbor representations in the spatial domain. This can be formulated as:
| (7) | |||
Inspired by the above, we design a channel-wise self-attention mechanism to adaptively aggregate similar information from homophilic neighbors and differential information from heterophilic neighbors. Specifically, given a central node and its arbitrary neighbor , we first use a linear transformation and a separate element-wise multiplication across channels to obtain the query and key:
| (8) | |||
where is the weight martix of layer , are weight vectors for query and key and denotes the Hadamard product operation. and can also be calculated in the same way.
Then we calculate the channel-wise and pass-free attention coefficient for edge :
| (9) |
It is worth noting that the obtained using the above calculation method is direction- and relation-agnostic and can be also seen as the embedding of edge . Furthermore, due to the use of the tanh activation function, any element in is in the range of [-1, 1], which breaks the previous restriction on the sum of neighbor information.
Finally, we aggregate information from the neighbors using the generated channel-wise weights to obtain layer node representation :
| (10) |
| (11) |
where is the weight matrix for relation , and is the number of neighbor nodes on relation . Following (Bo et al., 2021), we apply a hyperparameter to preserve the information of the node itself. RGT (Feng et al., 2022a) uses an attention mechanism to fuse information from different relations, but here we trivially take the average of information from different relations to avoid information missing.
4.3. Contrastive Loss
Following the traditional contrastive learning framework, we use a projection head consisting of two MLP layers to obtain :
| (12) |
where is the output of last layer . Thus, we can obtain projections and of node in two graph views and in respect.
Next, we use supervised contrastive learning as the objective loss function for training. However, due to the fact that supervised contrastive learning treats all nodes of the same class in different views as positive pairs, it is prone to overfitting, where the representations of all same-class training nodes become too similar and cannot generalize to test nodes. To avoid overfitting, we use supervised contrastive learning in a cross-view manner. For a set of N samples randomly sampled from the training nodes, we obtain the projection of each node through the graph augmentation, encoder, and projection head mentioned above. Taking node in graph view as an example, we treat its projection and the projections of same-class nodes in the other view as positive pairs, and those of different-class nodes as negative pairs, to calculate the contrastive loss between them:
| (13) |
where represents the number of samples in the same class as node among samples, function is used to calculate the cosine similarity, and is the temperature coefficient which can regulate the degree of distribution uniformity.
Finally, we calculate the loss for all nodes in the sampled set of two views in the same way, and take the average:
| (14) |
Training Strategy. In this article, we follow the same two-stage training mode as previous contrastive methods (Velickovic et al., 2019; Zhu et al., 2020a; You et al., 2020). In the first stage, we employ the aforementioned method to obtain node representations and update parameters using . Due to the preservation of crucial class information in the original features (Chen et al., 2022), in the second stage, we concatenate the encoder input and the output : . Subsequently, we employ a simple machine learning classifier, i.e., Logistic Regression (LR) for training and testing with . Furthermore, due to the imbalanced distribution of classes in social bot detection, i.e., significantly fewer labeled bots compared to humans, we assign different weights to human and bot during the training process in the second stage.
Loss Comparison. In this paper, we delve into the different roles of cross-entropy and supervised contrastive learning losses in message passing. According to (Tang et al., 2022), GNNs designed for graphs with heterophily may only act as low-pass filters due to non-uniform distributions in terms of heterophily degree. We attribute this phenomenon to the fact that cross-entropy may work well in cases with a larger number of samples, but may perform poorly in some exceptional situations, especially when training graph data has non-uniform distributions at the feature and topological levels. Relatively, contrastive loss is hardness-aware (Wang and Liu, 2021), which means that during the optimization process, it automatically focuses more on challenging negative samples. Furthermore, supervised contrastive learning, through the inclusion of labels, has the ability to bring representations of the same class closer. thereby facilitating the aggregation of more class-specific information through both homophilic and heterophilic edges. In summary, compared to cross-entropy, supervised contrastive learning is more capable of dealing with abnormal distributions in terms of heterophily.
5. EXPERIMENTS
In this section, we answer the following research questions.
-
•
RQ1: Does heterophily actually worsen the performance of earlier social bot detection techniques?
-
•
RQ2: Does BotSCL outperform state-of-the-art methods for graph-based social bot detection?
-
•
RQ3: How do the designed modules of BotSCL and different graph augmentation methods enhance the prediction?
-
•
RQ4: What is the performance of BotSCL with respect to the hyperparameter?
-
•
RQ5: Can BotSCL bring representations of test nodes from the same class closer while pushing representations of test nodes from different classes apart?
5.1. Experiment Setup
5.1.1. Datasets.
Our method is graph-based and heterophily-aware, which requires relations between accounts and ground-truth labels of nodes. TwiBot-20 (Feng et al., 2021c) and TwiBot-22 (Feng et al., 2022b) containing user followers and following relations are capable of supporting our method and further experiments. Table 2 summarizes the detail of the two datasets. Compared to TwiBot-20, TwiBot-22 has a larger graph size, including more nodes and edges. We follow the same splits provided in the benchmark to ensure the results are comparable with previous works. It is worth noting that TwiBot-20 includes labels for only a small fraction of nodes, while TwiBot-22 has labels for all nodes.
5.1.2. Baselines.
To demonstrate the effectiveness of BotSCL, we compare it with homophilic GNNs, typical heterophilic GNNs, state-of-the-art graph-based social bot detection methods, and self-supervised contrastive learning methods.
Homophilic GNNs: GCN (Kipf and Welling, 2016) and GAT (Veličković et al., 2017) are typical GNNs based on the homophily assumption. Their information aggregation process can be viewed as the summation of neighbor representations.
Heterophilic GNNs: H2GCN (Zhu et al., 2020b), FAGCN (Bo et al., 2021) and GPRGNN (Chien et al., 2020) are three models designed to mitigate the impact of heterophilic edges by employing different information aggregation strategies. Compared to homophilic GNNs, these models perform better on general graph datasets with varying degrees of heterophily.
Graph-based Twtter Bot Detection:
-
•
(Ali Alhosseini et al., 2019) is the first approach to utilize graph neural networks for leveraging the graph structure information in social networks for social bot detection.
-
•
EvolveBot (Yang et al., 2013) extracts features such as betweenness centrality and clustering coefficient from the graph structure, and then performs classification on these features.
-
•
(Moghaddam and Abbaspour, 2022) proposes a type of friendship preference features, which compares the features of followers with randomly collected account features from the social network.
-
•
BotRGCN (Feng et al., 2021b) use multilayer perception to mix different types of features and then input them into an R-GCN layer twice which can make full use of follower and following relations.
-
•
RGT (Feng et al., 2022a) proposes the relational graph transformer, which utilizes self-attention mechanism to aggregate information on each relation and proposes a semantic attention module to obtain information weights on different relation views. According to experiment results from (Feng et al., 2022b), RGT achieves state-of-the-art performance among 16 different methods on TwiBot-20 relatively.
| Dataset | #nodes | #edges | class | #class | relation | homo(%) |
|---|---|---|---|---|---|---|
| TwiBot-20 | 229,580 | 227,979 | human | 5,237 | follower | 81.44 |
| following | 33.56 | |||||
| bot | 6,589 | follower | 28.99 | |||
| following | 75.27 | |||||
| TwiBot-22 | 1,000,000 | 3,743,634 | human | 860,057 | follower | 88.05 |
| following | 96.20 | |||||
| bot | 139,943 | follower | 16.55 | |||
| following | 6.25 |
| Parameter | TwiBot-20 | TwiBot-22 | Parameter | TwiBot-20 | TwiBot-22 |
| Optimizer | AdamW | AdamW | Hidden | 32 | 32 |
| LR | 0.001 | 0.0001 | Epochs | 200 | 50 |
| Batch | 128 | 512 | Temperature | 0.07 | 0.07 |
| Layer | 2 | 2 | 1 | 1 | |
| MLP dropout | 0.5 | 0.5 | 1 | 1 | |
| ATT dropout | 0.3 | 0.3 | Balance weight | 1:1 | 2:5 |
Self-supervised Contrastive Learning: DGI (Velickovic et al., 2019), GRACE (Zhu et al., 2020a), and GBT (Bielak et al., 2022) are three typical self-supervised graph contrastive learning frameworks that learn node representations in the absence of labels. SupCon (Khosla et al., 2020) stands for supervised contrastive loss, and we implement it by modifying the loss function of the GRACE.
BotSCL: bot detection method proposed by us. Compared to previous methods for bot detection, BotSCL not only considers both homophilic and heterophilic edges simultaneously but also introduces supervised contrastive learning instead of cross-entropy to guide message passing.
5.1.3. Setting of hyperparameters.
The hyperparameter settings for TwiBot-20 and TwiBot-22 are shown in the Table 3. The main difference in hyperparameter settings between the two datasets lies in the parameters related to model training. Due to the larger scale of TwiBot-22, we set it with a smaller learning rate, a larger batch size, and fewer training epochs compared to TwiBot-20. In addition, we also employ the dropout mechanism to prevent overfitting. We set the dropout rate to 0.5 for MLP and 0.3 for generated edge embeddings. Since using a small temperature coefficient in contrastive learning focuses more on challenging samples and leads to a more uniform distribution (Wang and Liu, 2021), we set the temperature coefficient to 0.07. Due to the significantly larger number of humans compared to bots in TwiBot-22, we train with a weight ratio of 2:5 for human and bot in the second stage.
5.1.4. Implementation.
For GCN, GAT, (Ali Alhosseini et al., 2019), BotRGCN, RGT and BotSCL, we use PyTorch (Paszke et al., 2019) and PyTorch Geometric (Fey and Lenssen, 2019) for implementation. For graph contrastive learning methods DGI, GRACE, GBT and SupCon, we implement them based on PyGCL (Zhu et al., 2021) and only utilize the edge removing to augment the original graph. All models are running on Python3.8.12, NVIDIA Tesla A100 GPU with 40GB memory.
5.1.5. Evaluation Metrics.
Due to the class imbalance issue in social bot detection, we employ multiple metrics including Accuracy, F1-score, Recall, and Precision to evaluate the model performance. Accuracy and F1-score provide more insights because different methods may show significant differences in terms of Recall and Precision.
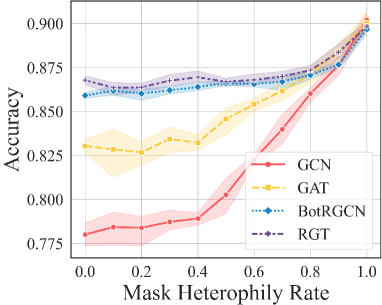
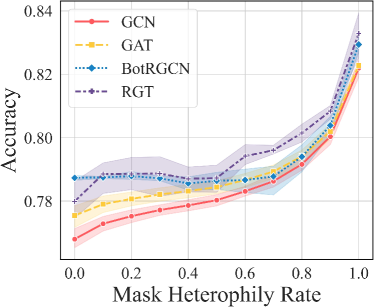
5.2. Heterophily Influence (RQ1)
Before answering RQ1, it is necessary to analyze the degree of homophily and heterophily in two datasets. As shown in Table 2, bots exhibit a evident heterophily tendency in the follower relation compared to human, while they display a stronger homophily tendency in the following relation in TwiBot-20. For TwiBot-22, bots show a high degree of heterophily in both relations, which can be attributed to the fact that the number of bots in the graph is significantly smaller than humans and bots are often surrounded with humans. This indicates that there is indeed an active tendency for social bots to interact more with humans. To answer RQ1, we visualize the curve of changes in accuracy as heterophilic edges are removed. We conduct experiments using four different models: GCN, GAT, BotRGCN, and RGT. As shown in Figure 3, the accuracy of all models gradually increases as the proportion of heterophilic edges decreases with a step size of 0.1. Furthermore, we can observe that after all heterophilic edges are removed, the performance of different models is almost the same. We suspect that the core difference between these methods lies in their varying abilities to adapt to heterophily. This experiment validates that heterophilic edges are detrimental to social bot detection. Therefore, it is necessary to consider both homophilic and heterophilic edges in graph-based social bot detection.
| Methods | Dataset | TwiBot-20 | TwiBot-22 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metrics | Accuracy | F1-score | Recall | Precision | Accuracy | F1-score | Recall | Precision | |
| Homophilic | GCN | 77.531.73 | 80.860.86 | 87.623.31 | 75.233.08 | 78.390.09 | 54.960.91 | 44.801.71 | 71.191.28 |
| GAT | 83.270.56 | 85.250.38 | 89.530.87 | 81.391.18 | 79.480.09 | 55.861.01 | 44.121.65 | 76.231.39 | |
| Heterophilic | H2GCN | 85.840.34 | 87.570.15 | 92.191.56 | 83.441.32 | OOM | OOM | OOM | OOM |
| FAGCN | 85.430.40 | 87.360.32 | 93.000.73 | 82.390.70 | 78.330.33 | 52.372.25 | 41.153.55 | 72.682.75 | |
| GPRGNN | 86.050.34 | 87.500.30 | 90.250.29 | 84.920.41 | 78.340.09 | 55.071.16 | 45.152.21 | 70.841.89 | |
| Social Bot Detection | (Ali Alhosseini et al., 2019) | 59.880.59 | 72.070.48 | 95.691.93 | 57.810.43 | 47.728.71 | 38.105.93 | \ul56.7517.69 | 29.993.08 |
| EvolveBot | 65.830.64 | 69.750.51 | 72.810.42 | 66.930.61 | 71.090.04 | 14.090.09 | 8.040.06 | 56.380.41 | |
| (Moghaddam and Abbaspour, 2022) | 74.050.80 | 77.870.71 | 84.381.03 | 72.290.67 | 73.780.01 | 32.070.03 | 21.020.07 | 67.610.10 | |
| BotRGCN | 85.750.69 | 87.250.74 | 90.191.72 | 84.520.54 | 79.660.14 | \ul57.501.42 | 46.802.76 | 74.812.22 | |
| RGT | \ul86.570.42 | \ul88.010.42 | 91.060.80 | 85.150.28 | 76.470.45 | 42.940.49 | 30.010.17 | \ul75.030.85 | |
| Contrative Learning | DGI | 84.930.31 | 87.090.36 | \ul93.941.13 | 81.170.26 | 79.610.13 | 44.061.52 | 34.451.97 | 61.280.64 |
| GRACE | 84.740.88 | 86.900.84 | 93.561.57 | 81.130.55 | \ul80.020.91 | 46.174.48 | 37.025.54 | 62.052.84 | |
| GBT | 84.740.92 | 86.870.79 | 93.281.14 | 81.290.92 | 79.750.76 | 47.273.08 | 39.104.60 | 60.873.93 | |
| SupCon | 86.100.14 | 87.670.16 | 91.370.65 | 84.270.37 | 80.000.24 | 44.413.83 | 34.585.26 | 63.522.53 | |
| Ours | BotSCL | 87.260.31 | 88.790.27 | 93.240.41 | \ul84.740.37 | 82.390.50 | 61.531.45 | 60.382.89 | 62.821.46 |
5.3. Performance Comparison (RQ2)
Table 4 summarizes the detection results of all the baseline methods and our BotSCL on TwiBot-20 and TwiBot-22. It is evident that BotSCL outperforms all the other 14 baselines in both datasets. The superior performance also indicates the significance of modeling both homophily and heterophily in finding advanced bots with the capability of actively building heterophilic edges to evade detection.
Firstly, compared to homophilic GNNs and previous graph-based social bot detection methods which simply treat interactions in social bot detection as homophilic, BotSCL has better adaptability to distinct neighborhood distributions associated with homophily and heterophily. According to Table 4, heterophilic GNNs perform better than homophilic GNNs. In addition, heterophilic GNNs achieve performance similar to previous graph-based detection methods even without the leverage of multi-relation information. Taking heterophilic edges into consideration can help uncover highly sophisticated bot accounts that are closely connected with humans.
In contrast to heterophilic GNNs, BotSCL not only considers different types of relations, but also uses supervised contrastive loss as the optimization objective, leading to improvements in both accuracy and f1-score in the two datasets. Experiments conducted by (Feng et al., 2022a) have shown that information from different types of relations can enhance model classification ability. Furthermore, with supervised contrastive learning, BotSCL enforces the aggregation of homophilic neighbor information and the differentiation of heterophilic neighbor representations.
The self-supervised contrastive learning methods perform poorly on TwiBot-20 with a large number of unlabeled nodes, while performing better on TwiBot-22. We think that the reason is due to the issue of uneven training distribution, as the second training stage uses fewer training nodes on TwiBot-20. Our method is significantly superior to these self-supervised methods, indicating that supervised signals play a vital role in adapting to both homophilic and heterophilic edges in social bot detection.
| Variants | TwiBot-20 | TwiBot-22 | ||
|---|---|---|---|---|
| Accuracy | F1-score | Accuracy | F1-score | |
| BotSCL | 87.260.31 | 88.790.27 | 82.390.50 | 61.531.45 |
| w/o Sup | 86.450.21 | 88.450.19 | 82.000.61 | 56.202.88 |
| w/o Neg | 86.900.45 | 88.480.35 | 82.120.46 | 53.431.16 |
| CE | 84.500.53 | 87.190.36 | 80.130.86 | 46.590.89 |
| CND | 87.130.17 | 88.700.20 | 81.900.26 | 58.780.84 |
| EA | 86.960.14 | 88.550.11 | 82.020.64 | 58.932.17 |
| ER | 87.110.15 | 88.670.14 | 82.170.37 | 61.461.46 |
| FM | 86.810.21 | 88.500.14 | 81.990.40 | 61.781.29 |



5.4. Ablation Study (RQ3)
To answer RQ3, we conduct an ablation study to investigate the effects of different modules and graph augmentation methods on social bot detection. Specifically, we build three ablation models: w/o Sup, w/o Neg, and CE, developed through self-supervised contrastive learning, removal of negative information aggregation, and cross-entropy loss. We also evaluate four graph augmentation methods: CNS, Edge Adding (EA), ER, and Feature Masking (FM). The results on TwiBot-20 and TwiBot-22 are shown in Table 5.
Compared to BotSCL, w/o Sup shows significant performance degradation, indicating that self-supervised methods struggle to aggregate similar or dissimilar information during message passing without labeled signals. The w/o Neg variant, using the softmax function for attention coefficients, aggregates similar information from neighbors but still performs well due to supervised contrastive learning, which limits aggregation from heterophilic neighbors. The CE variant suffers a notable performance drop, as cross-entropy loss focuses on classification, ignoring exceptional cases.
Additionally, different graph augmentation methods appear to have little impact on model performance, except for CNS and ER which are employed by BotSCL and show better performance. Under supervised conditions, CNS plays a crucial role in generating category-invariant representations. Among these different graph augmentation methods, CNS and ER, which BotSCL adopts, demonstrate better performance comparatively. FM and EA may potentially disrupt node feature information to some extent or introduce new noise.
5.5. Sensitive Analysis (RQ4)
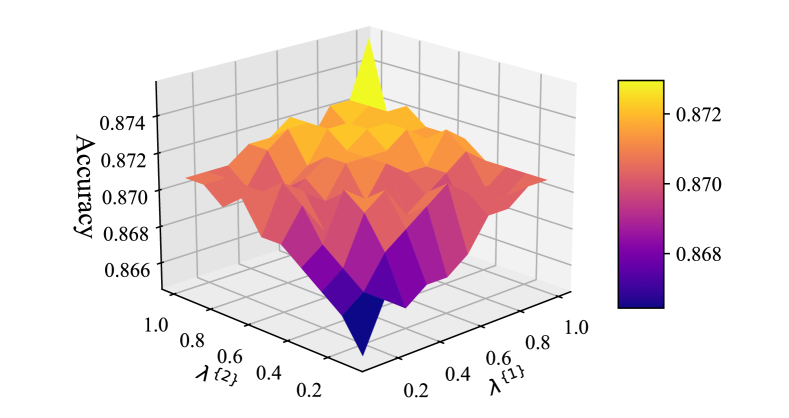
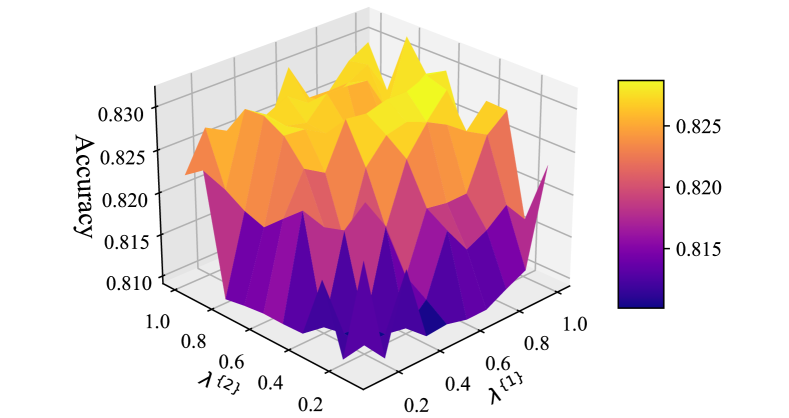
To answer RQ4, we evaluate the performance of BotSCL with regards to hyperparameters and , as we employ two layers of information aggregation. We keep the other parameters in the model unchanged and control the two parameters ranging from 0.1 to 1.0 with a step size of 0.1. The experimental results on TwiBot-20 and TwiBot-22 are shown in Figure 4a and Figure 4b, respectively.
From Figure 4, we can clearly observe that as the hyperparameters and increase, the accuracy of the model on both TwiBot-20 and TwiBot-22 gradually improves. Especially when both hyperparameters are set to 1, the model exhibits the strongest classification ability. This implies that in social bot detection, preserving the information of individual nodes is crucial for classification. Furthermore, we have found that BotSCL achieves similar performance when hyperparameters and have symmetric values. This could be because when they are set to symmetric values, their product remains the same, and the preservation of self-feature weights is equivalent after two layers of information aggregation. From Figure 4b, it can be observed that as the hyperparameter decreases to 0.8, there is a significant drop in accuracy on TwiBot-22. On the other hand, on TwiBot-20, this decrease is more gradual, and a steep drop is only observed when the hyperparameter decreases to nearly 0.4. Compared to TwiBot-20, TwiBot-22 includes labels for all nodes and suffers from the class imbalance issue, where the number of instances for each class is uneven. If the weights assigned to the original information are relatively small, the representation of the ego node is susceptible to being overwhelmed by neighbor information.
Overall, regardless of the variations in hyperparameters, the accuracy changes within the range of 0.04 for TwiBot-20 and within the range of 0.01 for TwiBot-22. This indicates that BotSCL is not highly sensitive to hyperparameters and , although the hyperparameters do have some impact on the model’s performance.
5.6. Visualization (RQ5)
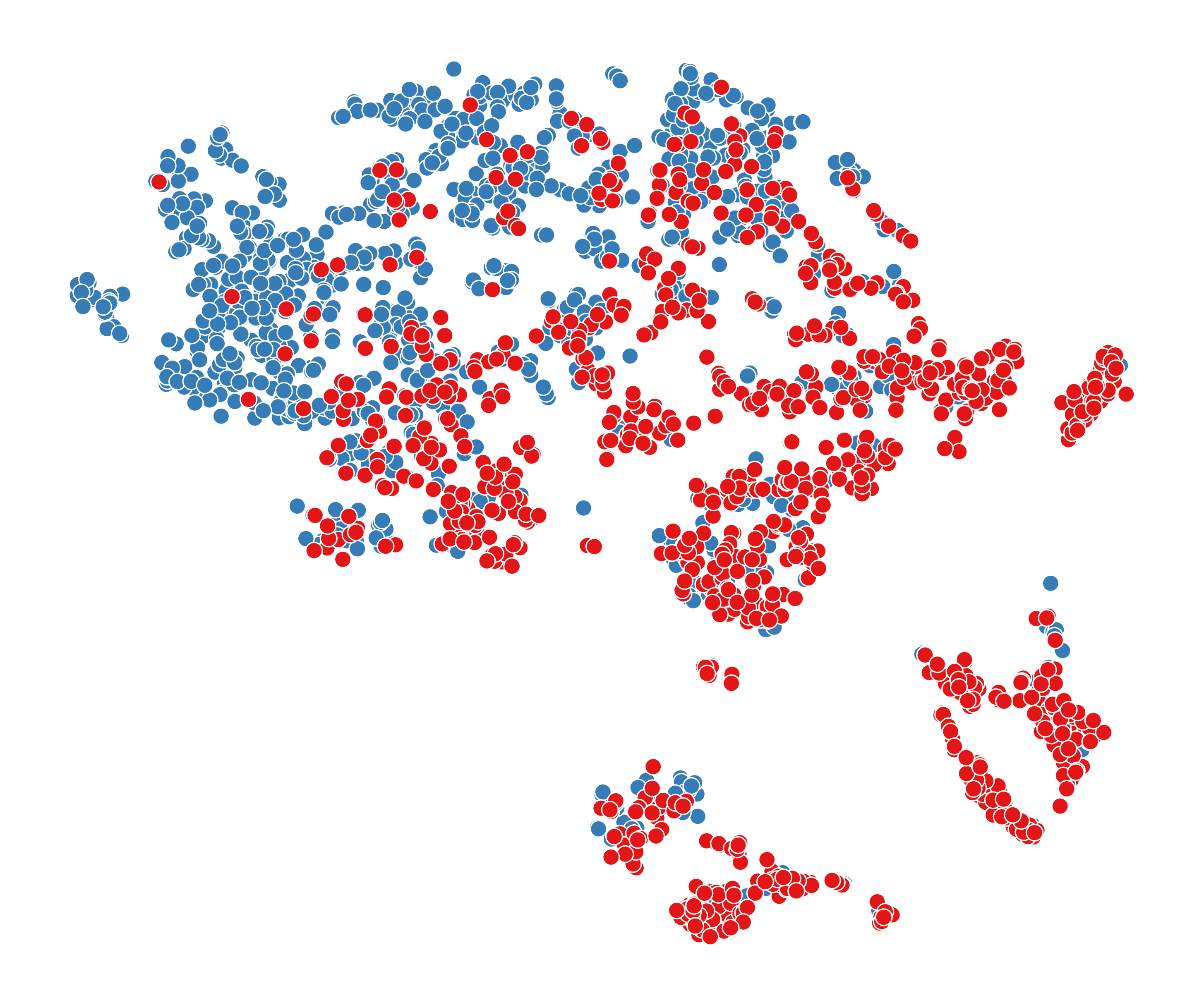
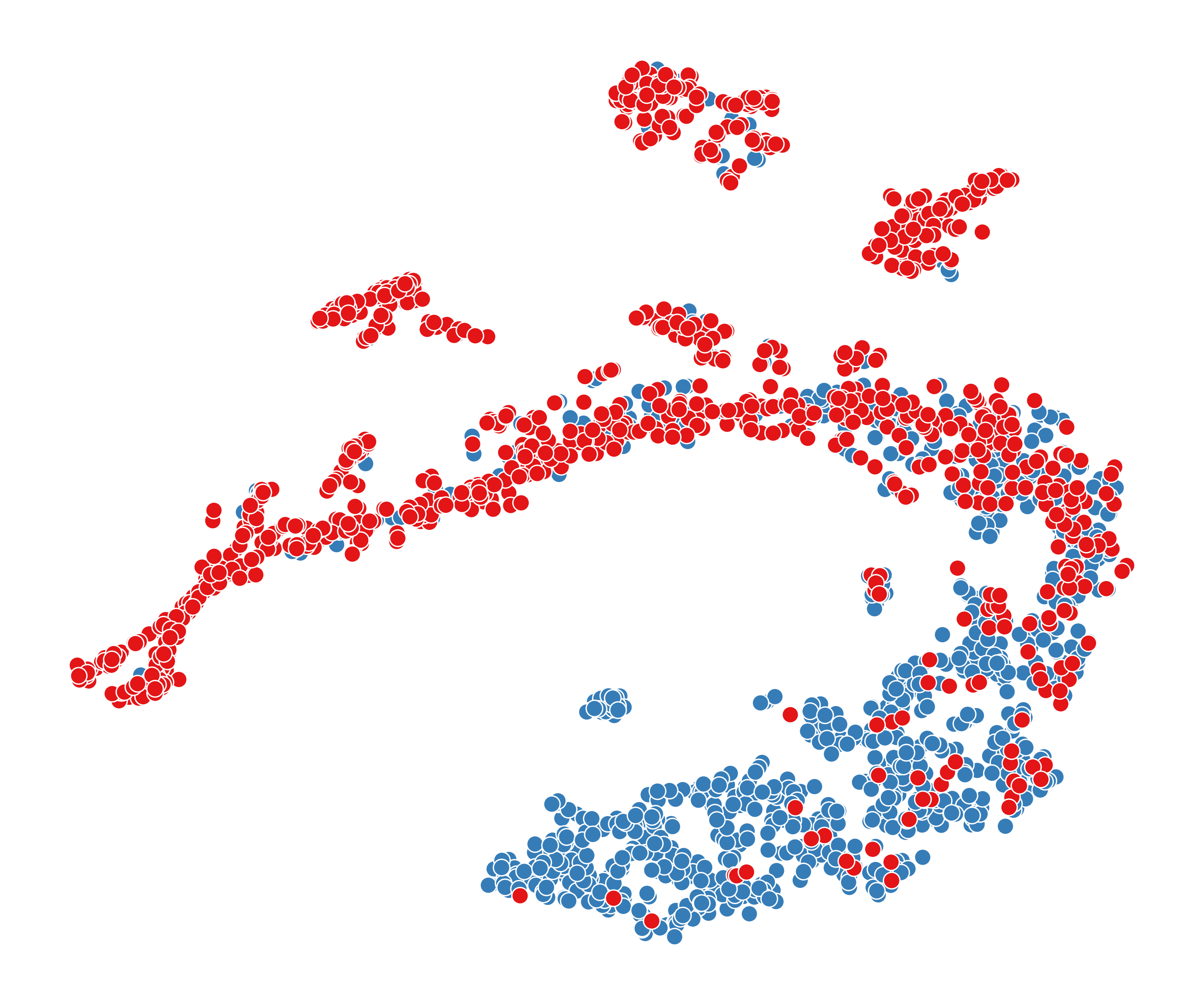
To answer RQ5, we visualize node representations obtained from six different models, including GCN, FAGCN, BotRGCN, RGT, DGI, and our method BotSCL. Due to the larger scale of TwiBot-22, it is more representative of real-world social networks. Therefore, we take it as an example for visualization. First, we obtain node representations for each model using the same implementation method as in the comparison experiments. Then, we employ the t-SNE (Van der Maaten and Hinton, 2008) to reduce the dimensionality of the representations to 2D space for visualization purposes. To facilitate better observation, we randomly select 1000 human nodes and 1000 bot nodes from the test set for visualization. The visualization results of these 6 models are shown in Figure 5.
From Figure 5, we can see that node representations obtained by homophilic GNNs (GCN, BotRGCN, RGT) are more scattered compared to those from FAGCN. These methods based on the homophily assumption can only smooth the representations of neighboring nodes without differentiation. As a result, the generated representations are primarily composed of local information, leading to a more scattered distribution. Among homophilic GNNs, RGT produces the poorest node representations on TwiBot-22, which is contrary to its performance on TwiBot-20. This suggests that the adaptive mechanism can be greatly influenced by the training data, leading to poor classification performance.
Compared to FAGCN, the node representations generated by BotSCL exhibit stronger clustering characteristics and include fewer local clusters. Although FAGCN takes into account both homophilic and heterophilic edges, using cross-entropy directly may inevitably overlook samples from less frequent distributions. Furthermore, the lack of consideration for multi-relational information is also one of the reasons for the suboptimal performance of FAGCN.
The node representations generated by DGI exhibit poor discriminative properties, as no supervised signals are used during the training process. The issue of class collision is also evident here, where the representations of bots and humans are almost mixed. In social bot detection, the problem of class collision in self-supervised contrastive learning is particularly severe. A large number of test nodes from different classes exhibit similar representations.
6. Conclusion
In this paper, we first realize that social bots can evade graph-based social bot detection methods by simply actively interacting with humans. Furthermore, through analysis of two real-world datasets, we have found strong evidence of social bots exhibiting a significant heterophily tendency. To address this, we propose BotSCL, which takes both homophilic and heterophilic edges into consideration. The key of BotSCL lies in making the encoder that can freely assimilate or discriminate neighbor representations aggregate class-specific information from neighbors. Comprehensive experiments conducted on the two real-world social bot datasets demonstrate the negative impact of heterophily on social bot detection and the effectiveness of the proposed method.
Acknowledgements.
This work was supported by the National Key Research and Development Program of China through the grants 2022YFB3105405 and 2021YFC3300502, NSFC through grants 62322202 and 61932002, Beijing Natural Science Foundation through grant 4222030, Guangdong Basic and Applied Basic Research Foundation through grant 2023B1515120020, Shijiazhuang Science and Technology Plan Project through grant 231130459A.References
- (1)
- Abu-El-Haija et al. (2019) Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. 2019. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In ICML. PMLR, 21–29.
- Ali Alhosseini et al. (2019) Seyed Ali Alhosseini, Raad Bin Tareaf, Pejman Najafi, and Christoph Meinel. 2019. Detect me if you can: Spam bot detection using inductive representation learning. In WWW. 148–153.
- Beskow and Carley (2019) David M Beskow and Kathleen M Carley. 2019. Its all in a name: detecting and labeling bots by their name. Computational and mathematical organization theory 25, 1 (2019), 24–35.
- Bielak et al. (2022) Piotr Bielak, Tomasz Kajdanowicz, and Nitesh V Chawla. 2022. Graph Barlow Twins: A self-supervised representation learning framework for graphs. Knowledge-Based Systems 256 (2022), 109631.
- Bo et al. (2021) Deyu Bo, Xiao Wang, Chuan Shi, and Huawei Shen. 2021. Beyond low-frequency information in graph convolutional networks. In AAAI. 3950–3957.
- Chavoshi et al. (2017) Nikan Chavoshi, Hossein Hamooni, and Abdullah Mueen. 2017. Temporal patterns in bot activities. In WWW. 1601–1606.
- Chen et al. (2022) Jingfan Chen, Guanghui Zhu, Yifan Qi, Chunfeng Yuan, and Yihua Huang. 2022. Towards Self-supervised Learning on Graphs with Heterophily. In CIKM. 201–211.
- Chien et al. (2020) Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. 2020. Adaptive universal generalized pagerank graph neural network. arXiv preprint arXiv:2006.07988 (2020).
- Cresci (2020) Stefano Cresci. 2020. A decade of social bot detection. Commun. ACM 63, 10 (2020), 72–83.
- Deb et al. (2019) Ashok Deb, Luca Luceri, Adam Badaway, and Emilio Ferrara. 2019. Perils and challenges of social media and election manipulation analysis: The 2018 us midterms. In WWW. 237–247.
- des Mesnards et al. (2022) Nicolas Guenon des Mesnards, David Scott Hunter, Zakaria el Hjouji, and Tauhid Zaman. 2022. Detecting bots and assessing their impact in social networks. Operations Research 70, 1 (2022), 1–22.
- Feng et al. (2022a) Shangbin Feng, Zhaoxuan Tan, Rui Li, and Minnan Luo. 2022a. Heterogeneity-aware twitter bot detection with relational graph transformers. In AAAI, Vol. 36. 3977–3985.
- Feng et al. (2022b) Shangbin Feng, Zhaoxuan Tan, Herun Wan, Ningnan Wang, Zilong Chen, Binchi Zhang, Qinghua Zheng, Wenqian Zhang, Zhenyu Lei, Shujie Yang, et al. 2022b. TwiBot-22: Towards graph-based Twitter bot detection. arXiv preprint arXiv:2206.04564 (2022).
- Feng et al. (2021b) Shangbin Feng, Herun Wan, Ningnan Wang, Jundong Li, and Minnan Luo. 2021b. Satar: A self-supervised approach to twitter account representation learning and its application in bot detection. In CIKM. 3808–3817.
- Feng et al. (2021c) Shangbin Feng, Herun Wan, Ningnan Wang, Jundong Li, and Minnan Luo. 2021c. Twibot-20: A comprehensive twitter bot detection benchmark. In CIKM. 4485–4494.
- Feng et al. (2021a) Shangbin Feng, Herun Wan, Ningnan Wang, and Minnan Luo. 2021a. BotRGCN: Twitter bot detection with relational graph convolutional networks. In SNAM. 236–239.
- Ferrara (2017) Emilio Ferrara. 2017. Disinformation and social bot operations in the run up to the 2017 French presidential election. arXiv preprint arXiv:1707.00086 (2017).
- Fey and Lenssen (2019) Matthias Fey and Jan Eric Lenssen. 2019. Fast graph representation learning with PyTorch Geometric. arXiv preprint arXiv:1903.02428 (2019).
- Hamdi (2022) Sami Abdullah Hamdi. 2022. Mining ideological discourse on Twitter: The case of extremism in Arabic. Discourse & Communication 16, 1 (2022), 76–92.
- Khosla et al. (2020) Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. Supervised contrastive learning. Advances in neural information processing systems 33 (2020), 18661–18673.
- Kipf and Welling (2016) Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
- Kudugunta and Ferrara (2018) Sneha Kudugunta and Emilio Ferrara. 2018. Deep neural networks for bot detection. Information Sciences 467 (2018), 312–322.
- Le et al. (2022) Thai Le, Long Tran-Thanh, and Dongwon Lee. 2022. Socialbots on Fire: Modeling Adversarial Behaviors of Socialbots via Multi-Agent Hierarchical Reinforcement Learning. In ACM Web Conference 2022. 545–554.
- Liu et al. (2022) Yixin Liu, Yizhen Zheng, Daokun Zhang, Vincent Lee, and Shirui Pan. 2022. Beyond Smoothing: Unsupervised Graph Representation Learning with Edge Heterophily Discriminating. arXiv preprint arXiv:2211.14065 (2022).
- Luan et al. (2021) Sitao Luan, Chenqing Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. 2021. Is Heterophily A Real Nightmare For Graph Neural Networks To Do Node Classification? arXiv preprint arXiv:2109.05641 (2021).
- Moghaddam and Abbaspour (2022) Samaneh Hosseini Moghaddam and Maghsoud Abbaspour. 2022. Friendship Preference: Scalable and Robust Category of Features for Social Bot Detection. IEEE Transactions on Dependable and Secure Computing (2022).
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
- Pei et al. (2020) Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. 2020. Geom-gcn: Geometric graph convolutional networks. arXiv preprint arXiv:2002.05287 (2020).
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In European semantic web conference. Springer, 593–607.
- Shi et al. (2022) Fengzhao Shi, Yanan Cao, Yanmin Shang, Yuchen Zhou, Chuan Zhou, and Jia Wu. 2022. H2-FDetector: A GNN-based Fraud Detector with Homophilic and Heterophilic Connections. In ACM Web Conference 2022. 1486–1494.
- Tang et al. (2022) Jianheng Tang, Jiajin Li, Ziqi Gao, and Jia Li. 2022. Rethinking Graph Neural Networks for Anomaly Detection. arXiv preprint arXiv:2205.15508 (2022).
- Van der Maaten and Hinton (2008) Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research 9, 11 (2008).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Veličković et al. (2017) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017).
- Velickovic et al. (2019) Petar Velickovic, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2019. Deep graph infomax. ICLR (Poster) 2, 3 (2019), 4.
- Wang and Liu (2021) Feng Wang and Huaping Liu. 2021. Understanding the behaviour of contrastive loss. In CVPR. 2495–2504.
- Wang et al. (2022) Tao Wang, Di Jin, Rui Wang, Dongxiao He, and Yuxiao Huang. 2022. Powerful graph convolutional networks with adaptive propagation mechanism for homophily and heterophily. In AAAI. 4210–4218.
- Williams et al. (2020) Evan M Williams, Valerie Novak, Dylan Blackwell, Paul Platzman, Ian McCulloh, and Nolan Edward Phillips. 2020. Homophily and Transitivity in Bot Disinformation Networks. In SNAMS. IEEE, 1–7.
- Wu et al. (2021) Yuhao Wu, Yuzhou Fang, Shuaikang Shang, Jing Jin, Lai Wei, and Haizhou Wang. 2021. A novel framework for detecting social bots with deep neural networks and active learning. Knowledge-Based Systems 211 (2021), 106525.
- Yang et al. (2013) Chao Yang, Robert Harkreader, and Guofei Gu. 2013. Empirical evaluation and new design for fighting evolving twitter spammers. IEEE Transactions on Information Forensics and Security 8, 8 (2013), 1280–1293.
- Yang et al. (2022a) Kai-Cheng Yang, Emilio Ferrara, and Filippo Menczer. 2022a. Botometer 101: Social bot practicum for computational social scientists. Journal of Computational Social Science (2022), 1–18.
- Yang et al. (2020) Kai-Cheng Yang, Onur Varol, Pik-Mai Hui, and Filippo Menczer. 2020. Scalable and generalizable social bot detection through data selection. In AAAI, Vol. 34. 1096–1103.
- Yang and Mirzasoleiman (2023) Wenhan Yang and Baharan Mirzasoleiman. 2023. Contrastive Learning under Heterophily. arXiv preprint arXiv:2303.06344 (2023).
- Yang et al. (2022b) Yingguang Yang, Renyu Yang, Yangyang Li, Kai Cui, Zhiqin Yang, Yue Wang, Jie Xu, and Haiyong Xie. 2022b. RoSGAS: Adaptive Social Bot Detection with Reinforced Self-Supervised GNN Architecture Search. ACM Transactions on the Web (2022).
- Yang et al. (2023) Yingguang Yang, Renyu Yang, Hao Peng, Yangyang Li, Tong Li, Yong Liao, and Pengyuan Zhou. 2023. FedACK: Federated Adversarial Contrastive Knowledge Distillation for Cross-Lingual and Cross-Model Social Bot Detection. In ACM Web Conference 2023. 1314–1323.
- You et al. (2020) Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations. Advances in neural information processing systems 33 (2020), 5812–5823.
- Zheng et al. (2021) Mingkai Zheng, Fei Wang, Shan You, Chen Qian, Changshui Zhang, Xiaogang Wang, and Chang Xu. 2021. Weakly supervised contrastive learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10042–10051.
- Zhu et al. (2020b) Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. 2020b. Beyond homophily in graph neural networks: Current limitations and effective designs. Advances in Neural Information Processing Systems 33 (2020), 7793–7804.
- Zhu et al. (2021) Yanqiao Zhu, Yichen Xu, Qiang Liu, and Shu Wu. 2021. An empirical study of graph contrastive learning. arXiv preprint arXiv:2109.01116 (2021).
- Zhu et al. (2020a) Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2020a. Deep graph contrastive representation learning. arXiv preprint arXiv:2006.04131 (2020).