*\minimiseminimise \DeclareMathOperator*\argmaxargmax \DeclareMathOperator*\argminargmin
Bounded Robustness in Reinforcement Learning
via Lexicographic Objectives
Abstract
Policy robustness in Reinforcement Learning may not be desirable at any cost: the alterations caused by robustness requirements from otherwise optimal policies should be explainable, quantifiable and formally verifiable. In this work we study how policies can be maximally robust to arbitrary observational noise by analysing how they are altered by this noise through a stochastic linear operator interpretation of the disturbances, and establish connections between robustness and properties of the noise kernel and of the underlying MDPs. Then, we construct sufficient conditions for policy robustness, and propose a robustness-inducing scheme, applicable to any policy gradient algorithm, that formally trades off expected policy utility for robustness through lexicographic optimisation, while preserving convergence and sub-optimality in the policy synthesis.
1 Introduction
Consider a dynamical system where we need to synthesise a controller (policy) through a model-free Reinfrocement Learning (Sutton and Barto, 2018) approach. When using a simulator for training we expect the deployment of the controller in the real system to be affected by different sources of noise, possibly not predictable or modelled (e.g. for networked components we may have sensor faults, communication delays, etc). In safety-critical systems, robustness (in terms of successfully controlling the system under disturbances) should preserve formal guarantees, and plenty of effort has been put on developing formal convergence guarantees on policy gradient algorithms (Agarwal et al., 2021; Bhandari and Russo, 2019). All these guarantees vanish under regularization and adversarial approaches, which are aimed to produce more robust policies. Therefore, for such applications one needs a scheme to regulate the robustness-utility trade-off in RL policies, that on the one hand preserves the formal guarantees of the original algorithms, and on the other attains sub-optimality conditions from the original problem. Additionally, if we do not know the structure of the disturbance (which holds in most applications), learning directly a policy for an arbitrarily disturbed environment will yield unexpected behaviours when deployed in the true system.
Lexicographic Reinforcement Learning (LRL)
Recently, lexicographic optimisation (Isermann, 1982; Rentmeesters et al., 1996) has been applied to the multi-objective RL setting (Skalse et al., 2022b). In an LRL setting some objectives may be more important than others, and so we may want to obtain policies that solve the multi-objective problem in a lexicographically prioritised way, i.e., “find the policies that optimise objective (reasonably well), and from those the ones that optimise objective (reasonably well), and so on”.
Previous Work
In robustness against model uncertainty, the MDP may have noisy or uncertain reward signals or transition probabilities, as well as possible resulting distributional shifts in the training data (Heger, 1994; Xu and Mannor, 2006; Fu et al., 2018; Pattanaik et al., 2018; Pirotta et al., 2013; Abdullah et al., 2019), connecting to ideas on distributionally robust optimisation (Wiesemann et al., 2014; Van Parys et al., 2015). For adversarial attacks or disturbances on policies or action selection in RL agents (Gleave et al., 2020; Lin et al., 2017; Tessler et al., 2019; Pan et al., 2019; Tan et al., 2020; Klima et al., 2019; Liang et al., 2022), recently Gleave et al. (2020) propose to attack RL agents by swapping the policy for an adversarial one at given times. For a detailed review on Robust RL see Moos et al. (2022). Our work focuses in robustness versus observational disturbances, where agents observe a disturbed state measurement and use it as input for the policy (Kos and Song, 2017; Huang et al., 2017; Behzadan and Munir, 2017; Mandlekar et al., 2017; Zhang et al., 2020, 2021). Zhang et al. (2020) propose a state-adversarial MDP framework, and utilise adversarial regularising terms that can be added to different deep RL algorithms to make the resulting policies more robust to observational disturbances, and Zhang et al. (2021) study how LSTM increases robustness with optimal state-perturbing adversaries.
Contributions
Most existing work on RL with observational disturbances proposes modifying RL algorithms at the cost of explainability (in terms of sub-optimality bounds) and verifiability, since the induced changes in the new policies result in a loss of convergence guarantees. Our main contributions are summarised in the following points.
-
•
We consider general unknown stochastic disturbances and formulate a quantitative definition of observational robustness that allows us to characterise the sets of robust policies for any MDP in the form of operator-invariant sets. We analyse how the structure of these sets depends on the MDP and noise kernel, and obtain an inclusion relation providing intuition into how we can search for robust policies more effectively.111There are strong connections between Sections 2-3 in this paper and the literature on planning for POMDPs (Spaan and Vlassis, 2004; Spaan, 2012) and MDP invariances (Ng et al., 1999; van der Pol et al., 2020; Skalse et al., 2022a), as well as recent work concerning robustness misspecification (Korkmaz, 2023).
-
•
We propose a meta-algorithm that can be applied to any existing policy gradient algorithm, Lexicographically Robust Policy Gradient (LRPG) that (1) Retains policy sub-optimality up to a specified tolerance while maximising robustness, (2) Formally controls the utility-robustness trade-off through this design tolerance, (3) Preserves formal guarantees.
Figure 1 represents a qualitative interpretation of the results in this work.
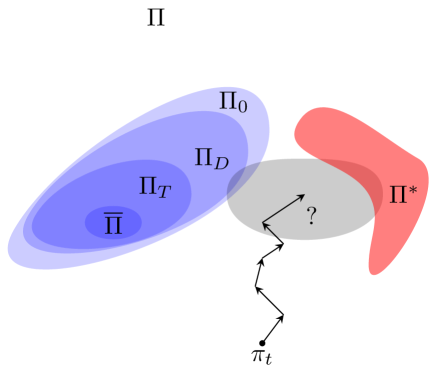
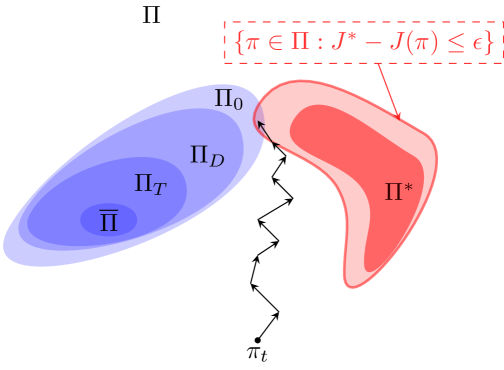
1.1 Preliminaries
Notation
We use calligraphic letters for collections of sets and as the space of probability measures over . For two probability distributions defined on the same algebra , is the total variation distance. For two elements of a vector space we use as the inner product. We use as a column-vector of size that has all entries equal to 1. We say that an MDP is ergodic if for any policy the resulting Markov Chain (MC) is ergodic. We say that is a row-stochastic matrix if and each row of sums 1. We assume all learning rates in this work (…) satisfy the conditions and .
Lexicographic Reinforcement Learning
Consider a parameterised policy with , and two objective functions and . PB-LRL uses a multi-timescale optimisation scheme to optimise faster for higher-priority objectives, iteratively updating the constraints induced by these priorities and encoding them via Lagrangian relaxation techniques (Bertsekas, 1997). Let . Then, PB-LRL can be used to find parameters This is done through the update:
| (1) |
where , is a Langrange multiplier, are learning rates, and is an estimate of . Typically, we set , though we can use other tolerances too, e.g., . For more details see Skalse et al. (2022b).
2 Observationally Robust Reinforcement Learning
Robustness-inducing methods in model-free RL must address the following dilemma: How do we deal with uncertainty without an explicit mechanism to estimate such uncertainty during policy execution? Consider an example of an MDP where, at policy roll-out phase, there is a non-zero probability of measuring a “wrong” state. In such a scenario, measuring the wrong state can lead to executing unboundedly bad actions. This problem is represented by the following version of a noise-induced partially observable Markov Decision Process (Spaan, 2012).
Definition 2.1.
An observationally-disturbed MDP (DOMDP) is (a POMDP) defined by the tuple where is a finite set of states, is a set of actions, is a probability measure of the transitions between states and is a reward function. The map is a stochastic kernel induced by some unknown noise signal, such that is the probability of measuring while the true state is , and acts only on the state observations. At last is a reward discount.
A (memoryless) policy for the agent is a stochastic kernel . For simplicity, we overload notation on , denoting by as the probability of taking action at state . In a DOMDP222Definition 2.1 is a generalised form of the State-Adversarial MDP used by Zhang et al. (2020): the adversarial case is a particular form of DOMDP where assigns probability 1 to one adversarial state. agents can measure the full state, but the measurement will be disturbed by some unknown random signal in the policy deployment. The difficulty of acting in such DOMDP is that agents will have to act based on disturbed states . We then need to construct policies that will be as robust as possible against such noise without the existance of a model to estimate, filter or reject disturbances. The value function of a policy (critic), , is given by . The action-value function of (-function) is given by We then define the objective function as with being a distribution of initial states, and we use and as the optimal policy, and is the set of -optimal policies. If a policy is parameterised by we write and .
Assumption 1
For any DOMDP and policy , the resulting MC is irreducible and aperiodic.
We now formalise a notion of observational robustness. Firstly, due to the presence of the stochastic kernel , the policy we are applying is altered as we are applying a collection of actions in a possibly wrong state. Then, where is the disturbed policy, which averages the current policy given the error induced by the presence of the stochastic kernel. Notice that is an averaging operator yielding the alteration of the policy due to noise. We define the robustness regret333The robustness regret satisfies for all kernels , and it allows us to directly compare the robustness regret with the utility regret of the policy.:
Definition 2.2 (Policy Robustness).
A policy is -robust against a stochastic kernel if . If is -robust it is maximally robust. The sets of -robust policies are , with being the maximally robust policies.
One can motivate the characterisation and models above from a control perspective, where policies use as input discretised state measurements with possible sensor measurement errors. Formally ensuring robustness properties when learning RL policies will, in general, force the resulting policies to deviate from optimality in the undisturbed MDP. We propose then the following problem.
Problem 2.3.
Consider a DOMDP model as per Definition 2.1 and let be a non-negative tolerance level. Our goal is to find amongst all -optimal policies those that minimize the robustness level :
Note that this is formulated as general as possible with respect to the robustness of the policies: We would like to find a policy that, trading off in terms of cumulative rewards, observes the same discounted rewards when disturbed by .
3 Characterisation of Robust Policies
An important question to be addressed before trying to synthesise robust policies is what these robust policies look like, and how they are related to DOMDP properties. A policy is said to be constant if for all , and the collection of all constant policies is denoted by . A policy is called a fixed point of if for all . The collection of all fixed points is . Observe furthermore that only depends on the kernel and the set444There is a (natural) bijection between the set of constant policies and the space . The set of fixed points of the operator also has an algebraic characterisation in terms of the null space of the operator . We are not exploiting the later characterisation in this paper. . Let us assume we have a policy iteration algorithm that employs an action-value function and policy . The advantage function for is defined as . We can similarly define the noise disadvantage of policy as:
| (2) |
which measures the difference of applying at state an action according to the policy with that of playing an action according to and then continuing playing an action according to . Our intuition says that if it happens to be the case that for all states in the DOMDP, then such a policy is maximally robust. And this is indeed the case, as shown in the next proposition.
Proposition 3.1.
Consider a DOMDP as in Definition 2.1 and the robustness notion as in Definition 2.2. If a policy is such that for all , then is maximally robust, i.e., let then we have that .
Proof 3.2.
We want to show that . Taking one has a policy that produces an disadvantage of zero when noise kernel is applied. Then,
| (3) |
Now define the value of the disturbed policy as We will now show that for all . Observe, from \eqrefeq:qtilde using , we have :
| (4) |
Now, taking the sup norm at both sides of \eqrefeq:recursive we get
| (5) |
Since the norm on the right hand side of \eqrefeq:recursive2 is over and , it follows that . Finally, , and .
So far we have shown that both the set of fixed points and the set of policies for which the disadvantage function is equal to zero are contained in the set of maximally robust policies. We now show how the defined robust policy sets can be linked in a single result through the following policy inclusions.
Theorem 3.3 (Policy Inclusions).
For a DOMDP with noise kernel , consider the sets and . Then, the following inclusion relation holds: Additionally, the sets are convex for all MDPs and kernels , but may not be.
Proof 3.4.
If a policy is a fixed point of the operator , then . Therefore, . Now, the space of stochastic kernels is equivalent to the space of row-stochastic matrices, therefore one can write as the th entry of the matrix . Then, the representation of a constant policy as an matrix can be written as , where where is any probability distribution over the action space. Observe that, applying the operator to a constant policy yields . By the Perron-Frobenius Theorem (Horn and Johnson, 2012), since is row-stochastic it has at least one eigenvalue , and this admits a (strictly positive) eigenvector . Therefore, Combining this result with Proposition 3.1, we simply need to show that . Take to be a fixed point of . Then , and from the definition in \eqrefeq:valdis:
Therefore, , which completes the sequence of inclusions. Convexity of follows from considering the convex hulls of two constant or fixed point policies.
Let us reflect on the inclusion relations of Theorem 3.3. The inclusions are in general not strict, and in fact the geometry of the sets (as well as whether some of the relations are in fact equalities) is highly dependent on the reward function, and in particular on the complexity (from an information-theoretic perspective) of the reward function. As an intuition, less complex reward functions (more uniform) will make the inclusions above expand to the entire policy set, and more complex reward functions will make the relations collapse to equalities.
Corollary 3.5.
For any ergodic DOMDP there exist reward functions and such that the resulting DOMDP satisfies A) (any policy is max. robust) if , and B) (only fixed point policies are maximally robust) if .
Proof 3.6 (Corollary 3.5).
For statement A) let for some constant . Then, , which does not depend on the policy . For any noise kernel and policy , . For statement B assume . Then, and such that . Let if and , 0 otherwise. Then, and since the MDP is ergodic is visited infinitely often and , which contradicts the assumption. Therefore, .
We can now summarise the insights from Theorem 3.3 and Corollary 3.5 in the following conclusions: (1) The set is maximally robust, convex and independent of the DOMDP, (2) The set is maximally robust, convex, includes , and its properties only depend on , (3) The set includes and is maximally robust, but its properties depend on the DOMDP.
4 Robustness through Lexicographic Objectives
To be able to apply LRL results to our robustness problem we need to first cast robustness as a valid objective to be maximised, and then show that a stochastic gradient descent approach would indeed find a global maximum of the objective, therefore yielding a maximally robust policy. 555The advantage of using LRL is that we can formally bound the trade-off between robustness and optimality through , determinining how far we allow our resulting policy to be from an optimal policy in favour of it being more robust.
Proposed approach
Following the framework presented in previous sections, we propose the following approach to obtain lexicographic robustness. In the introduction, we emphasised that the motivation for this work comes partially from the fact that we may not know in reality, or have a way to estimate it. However, the theoretical results until now depend on . Our proposed solution to this lies in the results of Theorem 3.3. We can use a design generator to perturb the policy during training such that has the smallest possible fixed point set (i.e. the constant policy set, satisfies ), and any algorithm that drives the policy towards the set of fixed points of will also drive the policy towards fixed points of : from Theorem 3.3, .
4.1 Lexicographically Robust Policy Gradient
Consider then the objective to be minimised:
| (6) |
Notice that optimising \eqrefeq:ProxyOptimisationPolicies projects the current policy onto the set of fixed points of the operator , and due to Assumption 1, which requires for all , the optimal solution is equal to zero if and only if there exists a value of the parameter for which the corresponding is a fixed point of . We present now the proposed LRPG meta-algorithm to achieve lexicographic robustness for any policy gradient algorithm at choice. From Skalse et al. (2022b), the convergence of PB-LRL algorithms is guaranteed as long as the original policy gradient algorithm for each single objective converges.
Assumption 2
The policy is updated through an algorithm (e.g. A2C, PPO…) such that converges a.s. to a (local or global) optimum .
Theorem 4.1.
Consider a DOMDP as in Definition 2.1 and let be a parameterised policy. Take a design kernel . Consider the following modified gradient for objective and sampled point :
| (7) |
Given an , if Assumptions 1 and 2 hold, then the following iteration (LRPG):
| (8) |
converges a.s. to parameters that satisfy such that where if is globally optimal and a compact local neighbourhood of otherwise.
Proof 4.2.
To apply LRL results, we need to show that both gradient descent schemes converge (separately) to local or global maxima. Let us first show that converges a.s. to parameters satisfying . We prove this making use of fixed point iterations with non-expansive operators (specifically, Theorem 4, section 10.3 in Borkar (2008)). First, observe that for a tabular representation, , and is a vector of zeros, with value for the position . We can then write the SGD in terms of the policy for each state , considering . Let . Then:
We now need to verify that the necessary conditions for applying Theorem 4, section 10.3 in Borkar (2008) hold. First, making use of the property for any row-stochastic matrix , for any two policies :
Therefore, the operator is non-expansive with respect to the sup-norm. For the final condition:
Therefore, the difference is a martingale difference for all . One can then apply Theorem 4, sec. 10.3 (Borkar, 2008) to conclude that almost surely. Finally from Assumption 1, for any policy all states are visited infinitely often, therefore and satisfies , and .
Now, from Assumption 2, the iteration converges a.s. to a (local or global) optimum . Then, both objectives are invex Ben-Israel and Mond (1986b) (either locally or globally), and any linear combination of them will also be invex (again, locally or globally). Finally, we can directly apply the results from Skalse et al. (2022b), and
converges a.s. to parameters that satisfy such that , where if is globally optimal and a compact local neighbourhood of otherwise.
Remark 4.3.
Observe that \eqrefeq:approxgrad is not the true gradient of \eqrefeq:ProxyOptimisationPolicies, and if there exists a (local) minimum of in . However, from Theorem 4.1 we know that the (pseudo) gradient descent scheme converges to a global minimum in the tabular case, therefore (Borkar, 2008), and gradient-like descent schemes will converge to (local or) global minimisers, which motivates the choice of this gradient approximation.
We reflect again on Figure 1. The main idea behind LRPG is that by formally expanding the set of acceptable policies with respect to , we may find robust policies more effectively while guaranteeing a minimum performance in terms of expected rewards. This addresses directly the premise behind Problem 2.3. In LRPG the first objective is still to minimise the distance up to some tolerance. Then, from the policies that satisfy this constraint, we want to steer the learning algorithm towards a maximally robust policy, and we can do so without knowing .
5 Considerations on Noise Generators
A natural question emerging is how to choose , and how the choice influences the resulting policy robustness towards any other true . In general, for any arbitrary policy utility landscape in a given MDP, there is no way of bounding the distance of the resulting policies for two different noise kernels . However, the optimality of the policy remains bounded: Through LRPG guarantees we know that, for both cases, the utility of the resulting policy will be at most far from the optimal.
Corollary 5.1.
Take to be any arbitrary noise kernel, and to satisfy . Let be a policy resulting from a LRPG algorithm. Assume that for some . Then, it holds for any that .
Proof 5.2.
The proof follows by the inclusion results in Theorem 3.3. If , then for any other . Then, the distance from to the set is at most the distance to .
That is, when using LRPG to obtain a robust policy , the resulting policy is at most far from the set of fixed points (and therefore a maximally robust policy) with respect to the true . This is the key argument behind our choices for : A priori, the most sensible choice is a kernel that has no other fixed point than the set of constant policies. This fixed point condition is satisfied in the discrete state case for any that induces an irreducible Markov Chain, and in continuous state for any that satisfies a reachability condition (i.e. for any , there exists a finite time for which the probability of reaching any ball of radius through a sequence is measurable). This holds for (additive) uniform or Gaussian disturbances.
6 Experiments
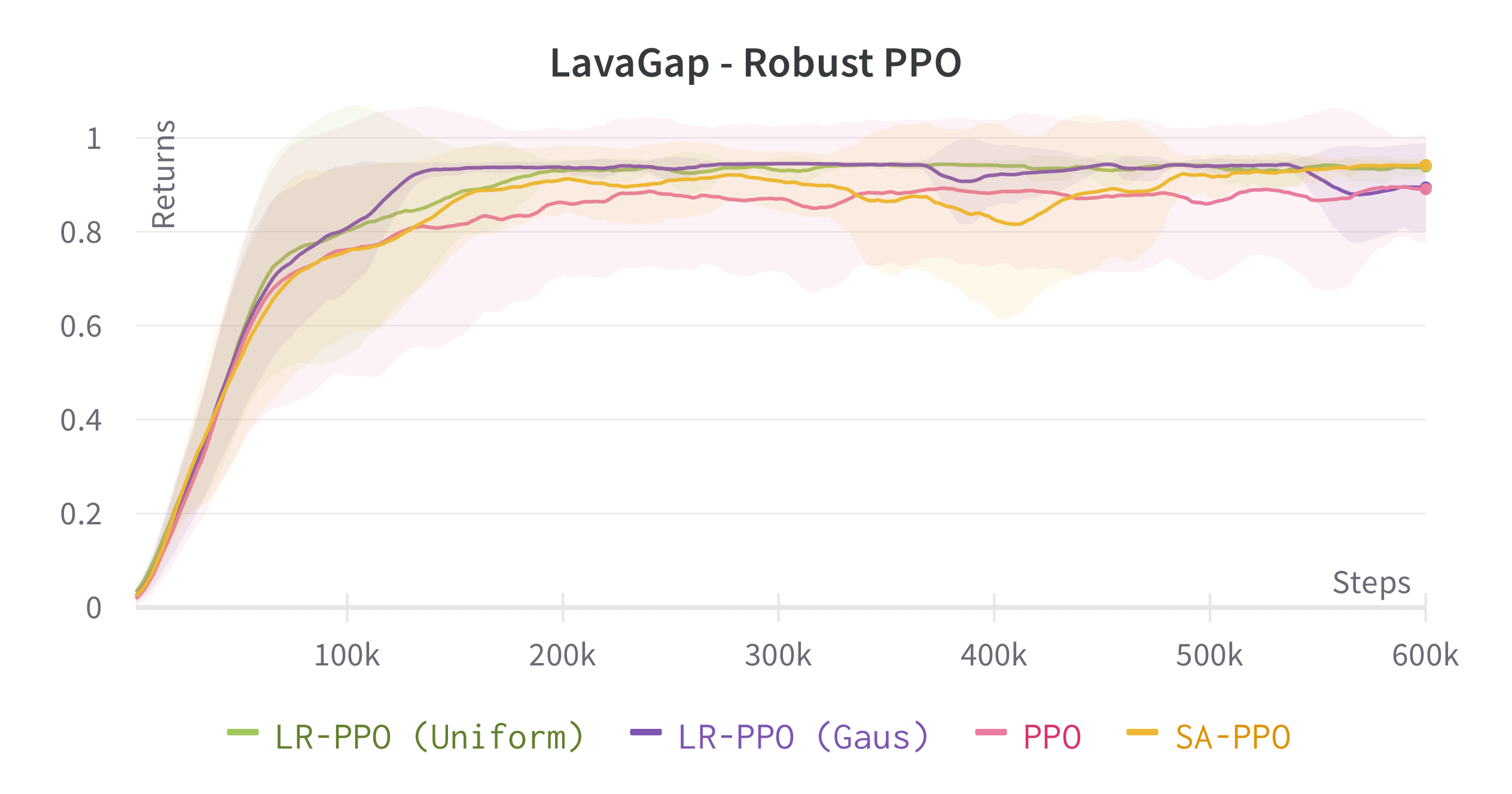
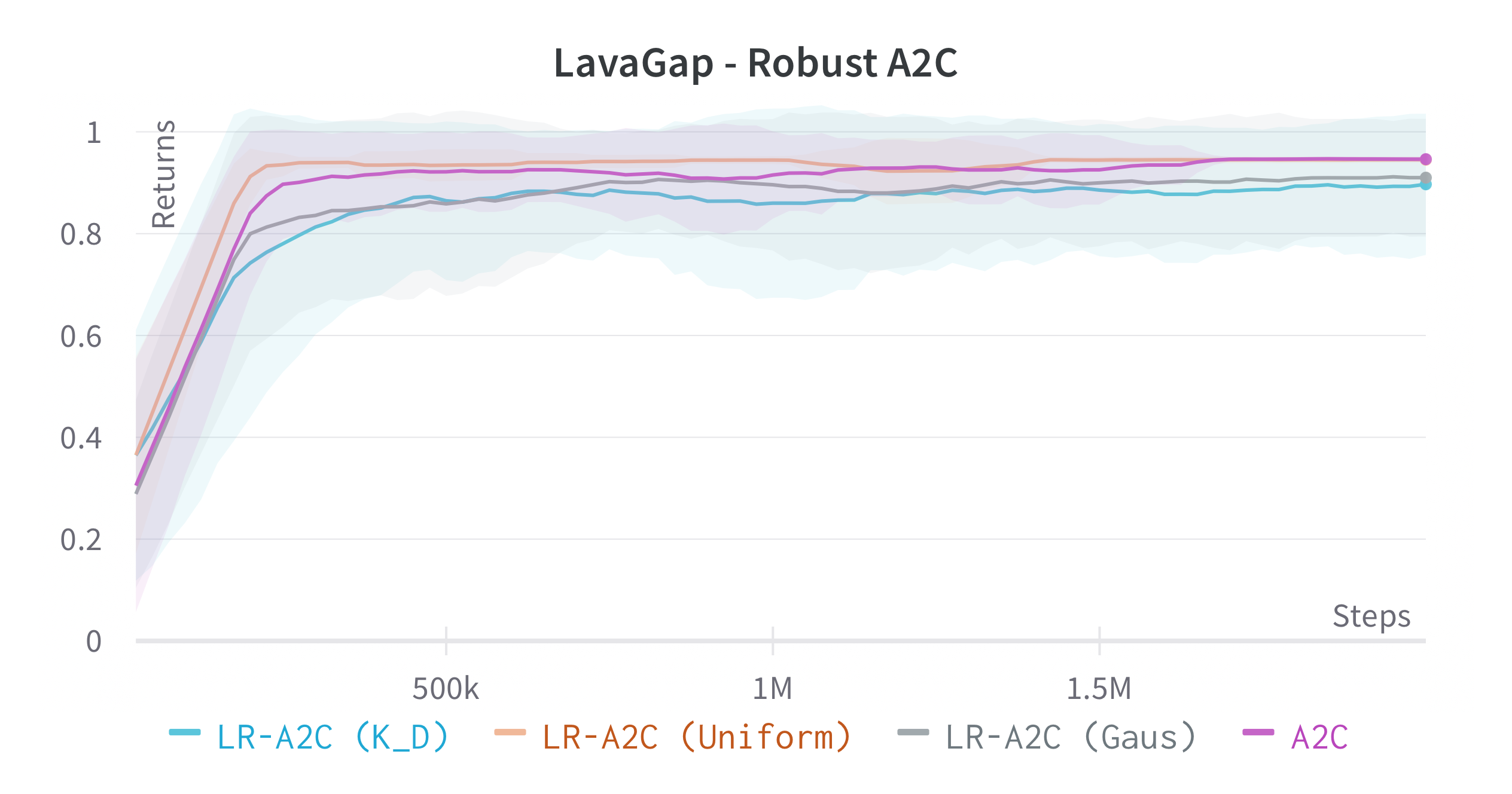
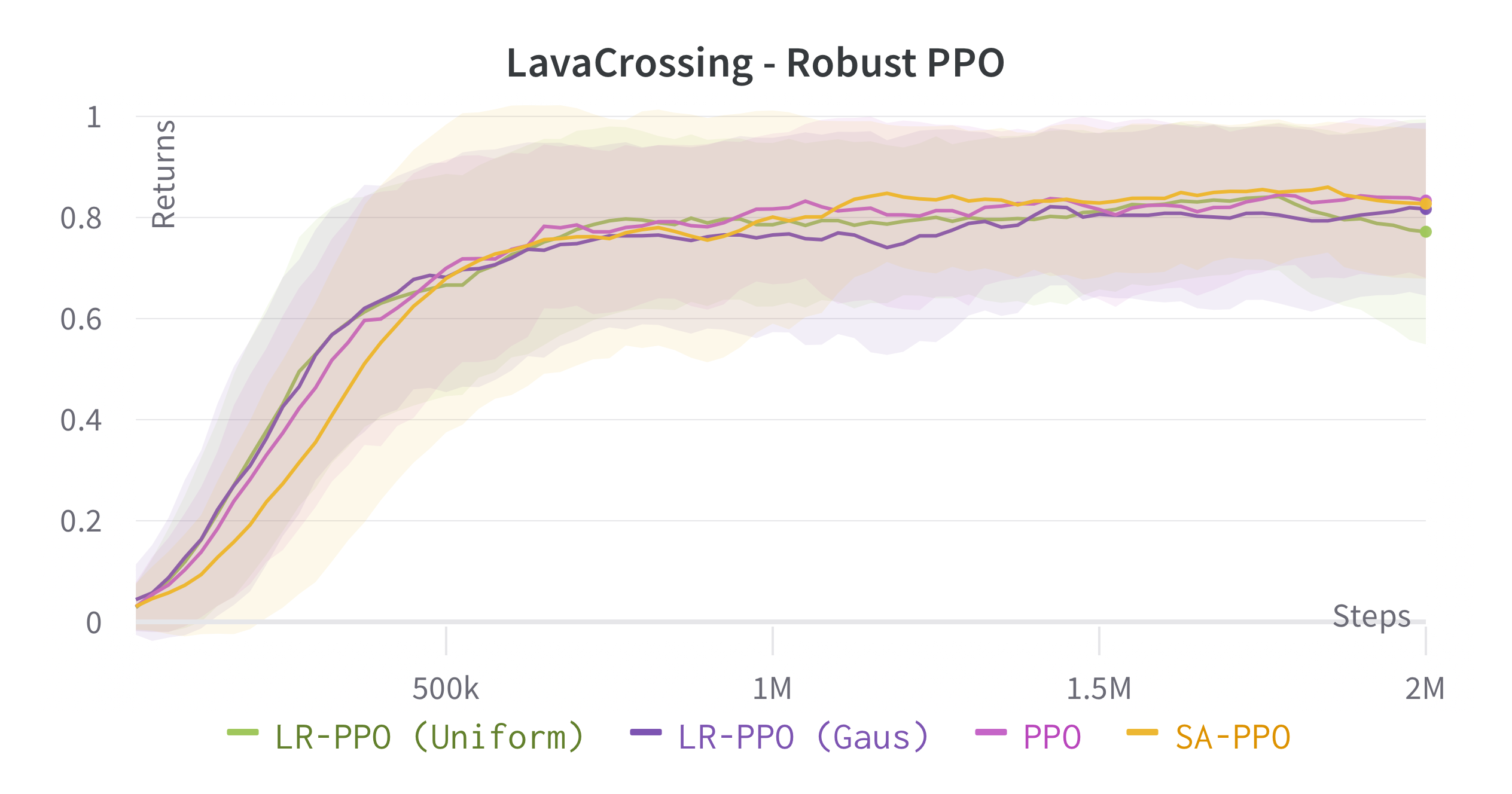
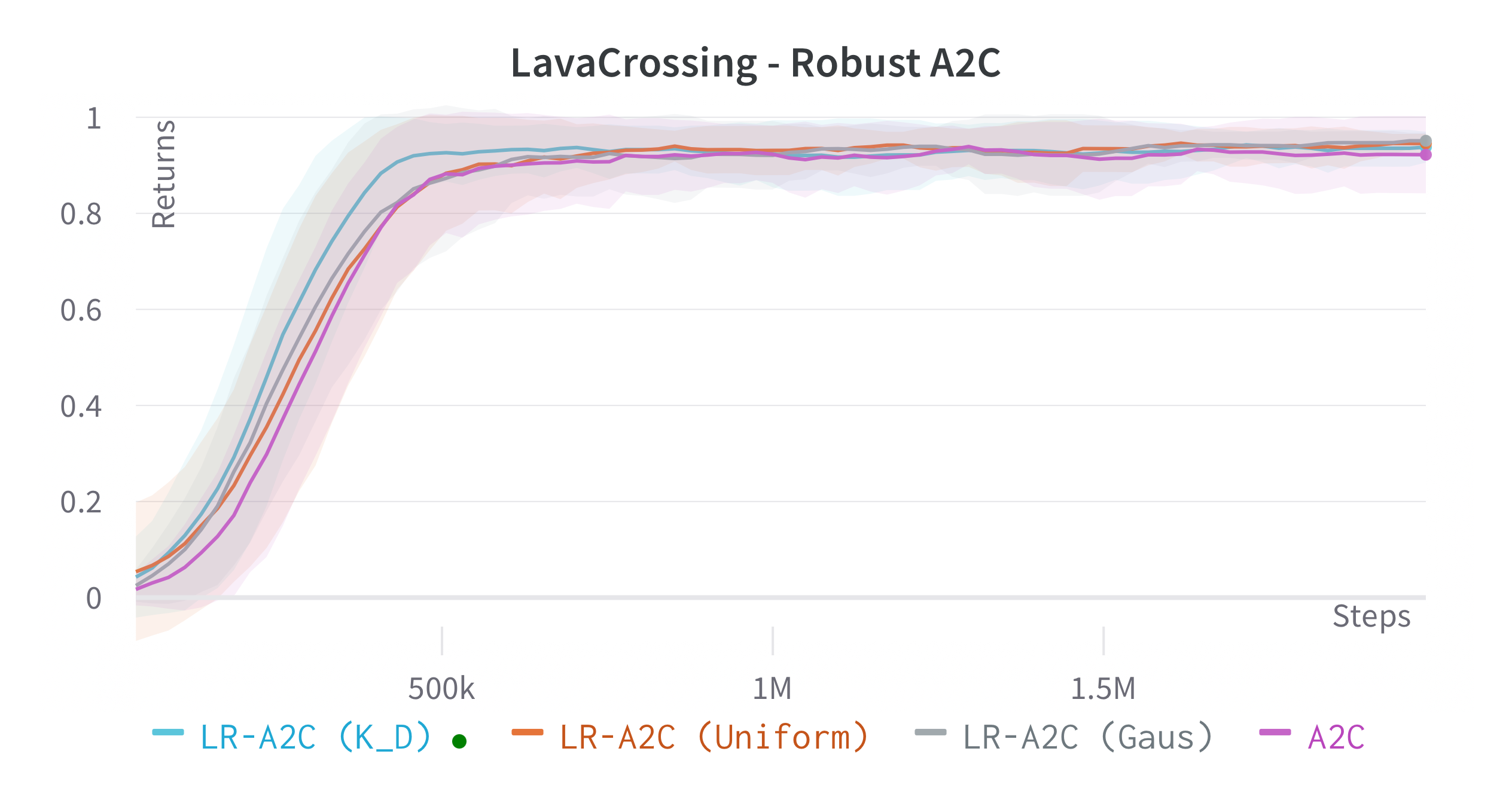
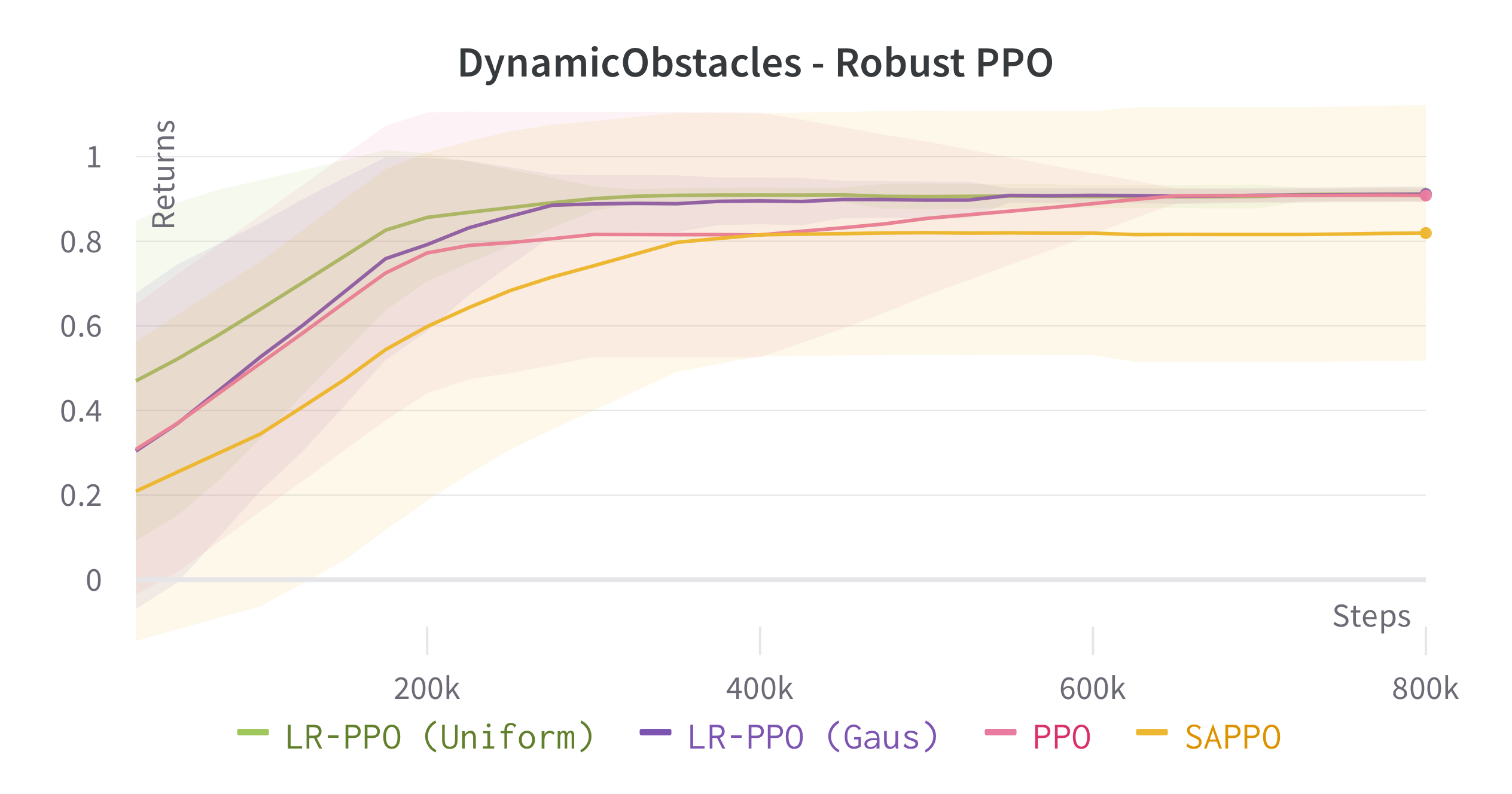
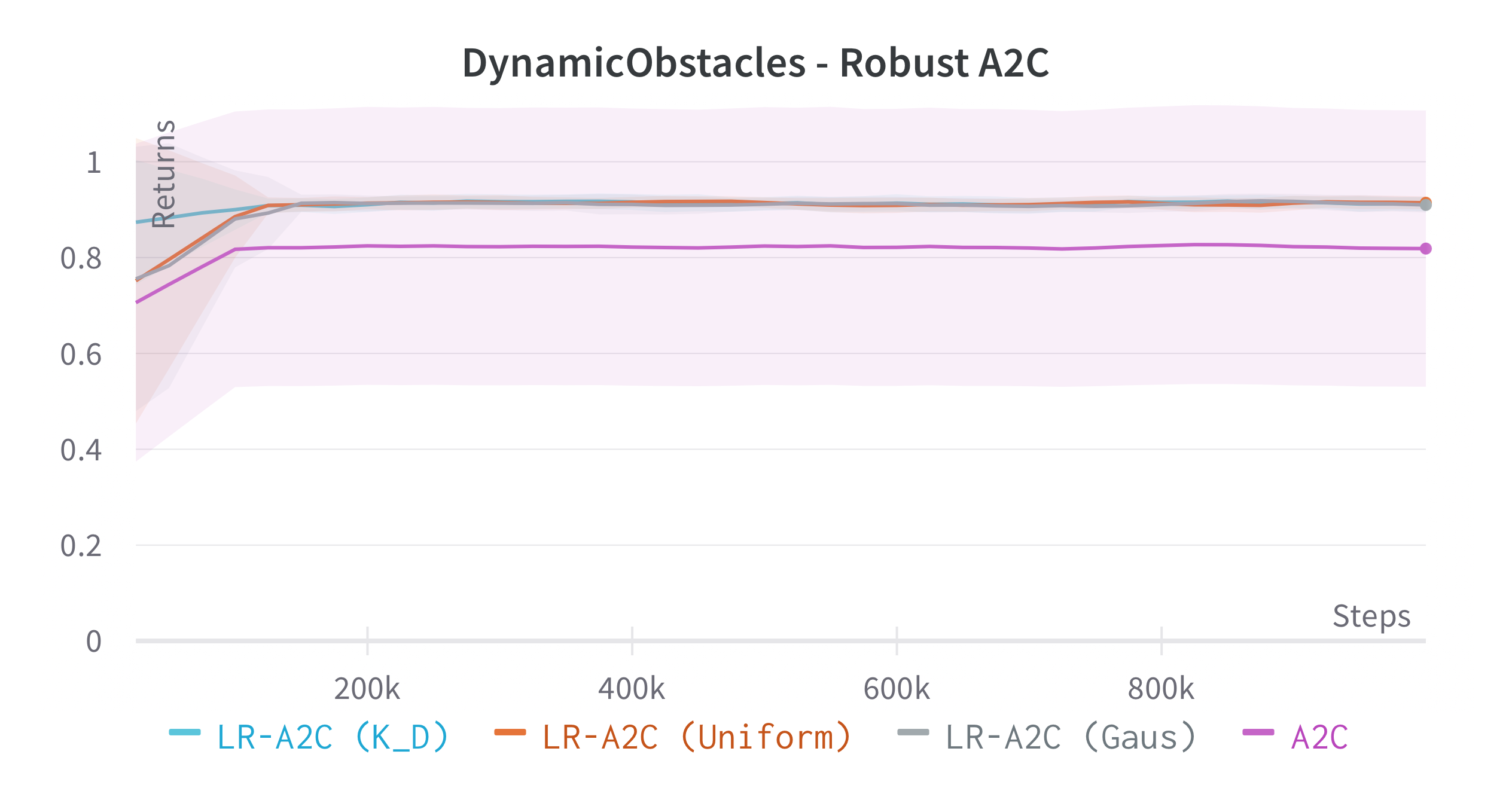
We verify the theoretical results of LRPG in a series of experiments on discrete state/action safety-related environments (Chevalier-Boisvert et al., 2018) (for extended experiments in continuous control tasks, hyperparameters etc. see \hrefhttps://arxiv.org/abs/2209.15320extended version). We use A2C (Sutton and Barto, 2018) (LR-A2C) and PPO (Schulman et al., 2017) (LR-PPO) for our implementations of LRPG. In all cases, the lexicographic tolerance was set to to deviate as little as possible from the primary objective. We compare against the baseline algorithms and against SA-PPO (Zhang et al., 2020) which is among the most effective (adversarial) robust RL approaches in literature. We trained 10 independent agents for each algorithm, and reported scores of the median agent (as in Zhang et al. (2020)) for 50 roll-outs. To simulate we disturb as for (1) a uniform bounded noise signal () and (2) and a Gaussian noise () such that . We test the resulting policies against a noiseless environment (), a kernel , a kernel and against two different state-adversarial noise configurations () as proposed by Zhang et al. (2021) to evaluate how effective LRPG is at rejecting adversarial disturbances.
Robustness Results
We use objectives as defined in \eqrefeq:ProxyOptimisationPolicies. Additionally, we aim to test the hypothesis: If we have an estimator for the critic we can obtain robustness without inducing regularity in the policy using , yielding a larger policy subspace to steer towards, and hopefully achieving policies closer to optimal. For this, we consider the objective by modifying A2C to retain a Q critic. We investigate the impact of LRPG PPO and A2C for discrete action-space problems on Gymnasium (Brockman et al., 2016). Minigrid-LavaGap (fully observable), Minigrid-LavaCrossing (partially observable) are safe exploration tasks where the agent needs to navigate an environment with cliff-like regions. Minigrid-DynamicObstacles (stochastic, partially observable) is a dynamic obstacle-avoidance environment. See Table 1.
| PPO on MiniGrid Environments | A2C on MiniGrid Environments | |||||||
|---|---|---|---|---|---|---|---|---|
| Noise | PPO | LR | LR | SA-PPO | A2C | LR | LR | LR |
| LavaGap | ||||||||
| 0.950.003 | 0.950.075 | 0.950.101 | 0.940.068 | 0.940.004 | 0.940.005 | 0.940.003 | 0.940.006 | |
| 0.800.041 | 0.950.078 | 0.930.124 | 0.880.064 | 0.830.061 | 0.930.019 | 0.890.032 | 0.910.088 | |
| 0.920.015 | 0.950.052 | 0.950.094 | 0.930.050 | 0.890.029 | 0.940.008 | 0.930.011 | 0.930.021 | |
| 0.010.051 | 0.710.251 | 0.210.357 | 0.870.116 | 0.270.119 | 0.790.069 | 0.680.127 | 0.560.249 | |
| LavaCrossing | ||||||||
| 0.950.023 | 0.930.050 | 0.930.018 | 0.880.091 | 0.910.024 | 0.910.063 | 0.900.017 | 0.920.034 | |
| 0.500.110 | 0.920.053 | 0.890.029 | 0.640.109 | 0.660.071 | 0.780.111 | 0.720.073 | 0.760.098 | |
| 0.840.061 | 0.920.050 | 0.920.021 | 0.850.094 | 0.780.054 | 0.830.105 | 0.860.029 | 0.870.063 | |
| 0.00.004 | 0.500.171 | 0.380.020 | 0.820.072 | 0.060.056 | 0.040.030 | 0.010.008 | 0.090.060 | |
| DynamicObstacles | ||||||||
| 0.910.002 | 0.910.008 | 0.910.007 | 0.910.131 | 0.910.011 | 0.880.020 | 0.890.009 | 0.910.013 | |
| 0.230.201 | 0.770.102 | 0.610.119 | 0.450.188 | 0.270.104 | 0.430.108 | 0.450.162 | 0.560.270 | |
| 0.500.117 | 0.750.075 | 0.700.072 | 0.680.490 | 0.450.086 | 0.530.109 | 0.520.161 | 0.670.203 | |
| -0.490.312 | 0.510.234 | 0.330.202 | 0.550.170 | -0.540.209 | -0.210.192 | -0.530.261 | -0.510.260 | |
7 Discussion
Experiments
We applied LRPG on PPO and A2C (and SAC algorithms), for a set of discrete and continuous control environments. These environments are particularly sensitive to robustness problems; the rewards are sparse, and applying a sub-optimal action at any step of the trajectory often leads to terminal states with zero (or negative) reward. LRPG successfully induces lower robustness regrets in the tested scenarios, and the use of as an objective (even though we did not prove the convergence of a gradient based method with such objective) yields a better compromise between robustness and rewards. When compared to recent observational robustness methods, LRPG obtains similar robustness results while preserving the original guarantees of the chosen algorithm.
Shortcomings and Contributions
The motivation for LRPG comes from situations where, when deploying a model-free controller in a dynamical system, we do not have a way of estimating the noise generation and we are required to retain convergence guarantees of the algorithms used. Although LRPG is a useful approach for learning policies in control problems where the noise sources are unknown, questions emerge on whether there are more effective methods of incorporating robustness into RL policies when guarantees are not needed. Specifically, since a completely model-free approach does not allow for simple alternative solutions such as filtering or disturbance rejection, there are reasons to believe it could be outperformed by model-based (or model learning) approaches. However, we argue that in completely model-free settings, LRPG provides a rational strategy to robustify RL agents.
References
- Abdullah et al. (2019) Mohammed Amin Abdullah, Hang Ren, Haitham Bou Ammar, Vladimir Milenkovic, Rui Luo, Mingtian Zhang, and Jun Wang. Wasserstein robust reinforcement learning. arXiv preprint arXiv:1907.13196, 2019.
- Agarwal et al. (2021) Alekh Agarwal, Sham M Kakade, Jason D Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift. J. Mach. Learn. Res., 22(98):1–76, 2021.
- Behzadan and Munir (2017) Vahid Behzadan and Arslan Munir. Vulnerability of deep reinforcement learning to policy induction attacks. In International Conference on Machine Learning and Data Mining in Pattern Recognition, pages 262–275. Springer, 2017.
- Ben-Israel and Mond (1986a) A. Ben-Israel and B. Mond. What is invexity? The Journal of the Australian Mathematical Society. Series B. Applied Mathematics, 28(1):1–9, 1986a.
- Ben-Israel and Mond (1986b) Adi Ben-Israel and Bertram Mond. What is invexity? The ANZIAM Journal, 28(1):1–9, 1986b.
- Bertsekas (1999) Dimitri Bertsekas. Nonlinear Programming. Athena Scientific, 1999.
- Bertsekas (1997) Dimitri P Bertsekas. Nonlinear programming. Journal of the Operational Research Society, 48(3):334–334, 1997.
- Bhandari and Russo (2019) Jalaj Bhandari and Daniel Russo. Global optimality guarantees for policy gradient methods. arXiv preprint arXiv:1906.01786, 2019.
- Borkar (2008) Vivek S. Borkar. Stochastic Approximation. Hindustan Book Agency, 2008.
- Borkar and Soumyanatha (1997) V.S. Borkar and K. Soumyanatha. An analog scheme for fixed point computation. i. theory. IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications, 44(4):351–355, 1997. 10.1109/81.563625.
- Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Chevalier-Boisvert et al. (2018) Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. Minimalistic gridworld environment for openai gym. https://github.com/maximecb/gym-minigrid, 2018.
- Fu et al. (2018) Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adverserial inverse reinforcement learning. In International Conference on Learning Representations, 2018.
- Gleave et al. (2020) Adam Gleave, Michael Dennis, Cody Wild, Neel Kant, Sergey Levine, and Stuart Russell. Adversarial policies: Attacking deep reinforcement learning. In International Conference on Learning Representations, 2020.
- Hanson (1981) Morgan A Hanson. On sufficiency of the kuhn-tucker conditions. Journal of Mathematical Analysis and Applications, 80(2):545–550, 1981.
- Heger (1994) Matthias Heger. Consideration of risk in reinforcement learning. In Machine Learning Proceedings 1994, pages 105–111. Elsevier, 1994.
- Horn and Johnson (2012) Roger A Horn and Charles R Johnson. Matrix analysis. Cambridge university press, 2012.
- Huang et al. (2017) Sandy Huang, Nicolas Papernot, Ian Goodfellow, Yan Duan, and Pieter Abbeel. Adversarial attacks on neural network policies. arXiv preprint arXiv:1702.02284, 2017.
- Isermann (1982) H Isermann. Linear lexicographic optimization. Operations-Research-Spektrum, 4(4):223–228, 1982.
- Klima et al. (2019) Richard Klima, Daan Bloembergen, Michael Kaisers, and Karl Tuyls. Robust temporal difference learning for critical domains. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, page 350–358, Richland, SC, 2019. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9781450363099.
- Korkmaz (2023) Ezgi Korkmaz. Adversarial robust deep reinforcement learning requires redefining robustness. arXiv preprint arXiv:2301.07487, 2023.
- Kos and Song (2017) Jernej Kos and Dawn Song. Delving into adversarial attacks on deep policies. arXiv preprint arXiv:1705.06452, 2017.
- Liang et al. (2022) Yongyuan Liang, Yanchao Sun, Ruijie Zheng, and Furong Huang. Efficient adversarial training without attacking: Worst-case-aware robust reinforcement learning. Advances in Neural Information Processing Systems, 35:22547–22561, 2022.
- Lin et al. (2017) Yen-Chen Lin, Zhang-Wei Hong, Yuan-Hong Liao, Meng-Li Shih, Ming-Yu Liu, and Min Sun. Tactics of adversarial attack on deep reinforcement learning agents. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, pages 3756–3762, 2017.
- Mandlekar et al. (2017) Ajay Mandlekar, Yuke Zhu, Animesh Garg, Li Fei-Fei, and Silvio Savarese. Adversarially robust policy learning: Active construction of physically-plausible perturbations. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3932–3939. IEEE, 2017.
- Moos et al. (2022) Janosch Moos, Kay Hansel, Hany Abdulsamad, Svenja Stark, Debora Clever, and Jan Peters. Robust reinforcement learning: A review of foundations and recent advances. Machine Learning and Knowledge Extraction, 4(1):276–315, 2022.
- Ng et al. (1999) Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transformations: Theory and application to reward shaping. In Proc. of the Sixteenth International Conference on Machine Learning, 1999, 1999.
- Pan et al. (2019) Xinlei Pan, Daniel Seita, Yang Gao, and John Canny. Risk averse robust adversarial reinforcement learning. In 2019 International Conference on Robotics and Automation (ICRA), pages 8522–8528. IEEE, 2019.
- Paternain et al. (2019) Santiago Paternain, Luiz F. O. Chamon, Miguel Calvo-Fullana, and Alejandro Ribeiro. Constrained reinforcement learning has zero duality gap. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pages 7553–7563, 2019.
- Pattanaik et al. (2018) Anay Pattanaik, Zhenyi Tang, Shuijing Liu, Gautham Bommannan, and Girish Chowdhary. Robust deep reinforcement learning with adversarial attacks. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’18, page 2040–2042, Richland, SC, 2018. International Foundation for Autonomous Agents and Multiagent Systems.
- Pirotta et al. (2013) Matteo Pirotta, Marcello Restelli, Alessio Pecorino, and Daniele Calandriello. Safe policy iteration. In International Conference on Machine Learning, pages 307–315. PMLR, 2013.
- Raffin et al. (2021) Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22(268):1–8, 2021. URL http://jmlr.org/papers/v22/20-1364.html.
- Rentmeesters et al. (1996) Mark J Rentmeesters, Wei K Tsai, and Kwei-Jay Lin. A theory of lexicographic multi-criteria optimization. In Proceedings of ICECCS’96: 2nd IEEE International Conference on Engineering of Complex Computer Systems (held jointly with 6th CSESAW and 4th IEEE RTAW), pages 76–79. IEEE, 1996.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Skalse et al. (2022a) Joar Skalse, Matthew Farrugia-Roberts, Stuart Russell, Alessandro Abate, and Adam Gleave. Invariance in policy optimisation and partial identifiability in reward learning. arXiv preprint arXiv:2203.07475, 2022a.
- Skalse et al. (2022b) Joar Skalse, Lewis Hammond, Charlie Griffin, and Alessandro Abate. Lexicographic multi-objective reinforcement learning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, pages 3430–3436, jul 2022b. 10.24963/ijcai.2022/476.
- Slater (1950) Morton Slater. Lagrange multipliers revisited. Cowles Commission Discussion Paper No. 403, 1950.
- Spaan (2012) Matthijs TJ Spaan. Partially observable markov decision processes. In Reinforcement Learning, pages 387–414. Springer, 2012.
- Spaan and Vlassis (2004) Matthijs TJ Spaan and N Vlassis. A point-based pomdp algorithm for robot planning. In IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, volume 3, pages 2399–2404. IEEE, 2004.
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Tan et al. (2020) Kai Liang Tan, Yasaman Esfandiari, Xian Yeow Lee, Soumik Sarkar, et al. Robustifying reinforcement learning agents via action space adversarial training. In 2020 American control conference (ACC), pages 3959–3964. IEEE, 2020.
- Tessler et al. (2019) Chen Tessler, Yonathan Efroni, and Shie Mannor. Action robust reinforcement learning and applications in continuous control. In International Conference on Machine Learning, pages 6215–6224. PMLR, 2019.
- van der Pol et al. (2020) Elise van der Pol, Thomas Kipf, Frans A. Oliehoek, and Max Welling. Plannable approximations to mdp homomorphisms: Equivariance under actions. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’20, page 1431–1439, Richland, SC, 2020. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9781450375184.
- Van Parys et al. (2015) Bart PG Van Parys, Daniel Kuhn, Paul J Goulart, and Manfred Morari. Distributionally robust control of constrained stochastic systems. IEEE Transactions on Automatic Control, 61(2):430–442, 2015.
- Wiesemann et al. (2014) Wolfram Wiesemann, Daniel Kuhn, and Melvyn Sim. Distributionally robust convex optimization. Operations Research, 62(6):1358–1376, 2014.
- Xu and Mannor (2006) Huan Xu and Shie Mannor. The robustness-performance tradeoff in markov decision processes. Advances in Neural Information Processing Systems, 19, 2006.
- Zhang et al. (2020) Huan Zhang, Hongge Chen, Chaowei Xiao, Bo Li, Mingyan Liu, Duane Boning, and Cho-Jui Hsieh. Robust deep reinforcement learning against adversarial perturbations on state observations. Advances in Neural Information Processing Systems, 33:21024–21037, 2020.
- Zhang et al. (2021) Huan Zhang, Hongge Chen, Duane Boning, and Cho-Jui Hsieh. Robust reinforcement learning on state observations with learned optimal adversary. In International Conference on Learning Representation (ICLR), 2021.
- Zhang (2018) Shangtong Zhang. Modularized implementation of deep rl algorithms in pytorch. https://github.com/ShangtongZhang/DeepRL, 2018.
Appendix A Examples and Further Considerations
We provide here two examples to show how we can obtain limit scenarios (any policy is maximally robust) or (Example 1), and how for some MDPs the third inclusion in Theorem 3.3 is strict (Example 2).
Example 1
Consider the simple MDP in Figure 2. First, consider the reward function . This produces a “dummy” MDP where all policies have the same reward sum. Then, , , and therefore we have .
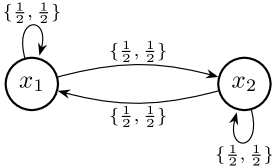
Now, consider the reward function elsewhere. Take a non-constant policy , i.e., . In the example DOMDP (assuming the initial state is drawn uniformly from ) one can show that at any time in the trajectory, there is a stationary probability . Let us abuse notation and write and . For the given reward structure we have , and therefore:
| (9) |
Since the transitions of the MDP are independent of the actions, following the same principle as in \eqrefeq:costex: For any noise map , for the two-state policy it holds that . Therefore and:
which implies that .
Example 2
Consider the same MDP in Figure 2 with reward function and a reward of zero for all other transitions. Take a policy , . The policy yields a reward of in state and a reward of in state . Again we assume the initial state is drawn uniformly from . Then, observe:
Define now noise map and . Observe this noise map yields a policy with non-zero disadvantage, and similarly , therefore . However, the policy is maximally robust:
| (10) |
Therefore, .
Appendix B Theoretical Results
B.1 Auxiliary Results
Theorem B.1 (Stochastic Approximation with Non-Expansive Operator).
Let be a random sequence with defined by the iteration:
where:
-
1.
The step sizes satisfy standard learning rate assumptions.
-
2.
is a non-expansive map. That is, for any , .
-
3.
is a martingale difference sequence with respect to the increasing family of fields .
Then, the sequence almost surely where is a fixed point such that .
Proof B.2.
See Borkar and Soumyanatha (1997).
Theorem B.3 (PB-LRL Convergence with 2 objectives.(Skalse et al., 2022b)).
Let be a multi-objective MDP with objectives , . Assume a policy is twice differentiable in parameters , and if using a critic assume it is continuously differentiable on parameters . Choose a tolerance , and suppose that if PB-LRL is run for steps, there exists some limit point when is held fixed. If for both objectives there exists a gradient descent scheme such that then combining the objectives as in \eqrefeq:LRLupdates yields .
Proof B.4 (Proof Sketch).
We refer the interested reader to Skalse et al. (2022b) for a full proof, and here attempt to provide the intuition behind the result in the form of a proof sketch.
Let us begin by briefly recalling the general problem statement: we wish to take a multi-objective MDP with objectives, and obtain a lexicographically optimal policy (one that optimises the first objective, and then subject to this optimises the second objective, and so on). More precisely, for a policy parameterised by , we say that is (globally) lexicographically -optimal if , where is the set of all policies in , , and .666The proof in Skalse et al. (2022b) also considers local lexicographic optima, though for the sake of simplicity, we do not do so here.
The basic idea behind policy-based lexicographic reinforcement learning (PB-LRL) is to use a multi-timescale approach to first optimise using , then at a slower timescale optimise using while adding the condition that the loss with respect to remains bounded by its current value, and so on. This sequence of constrained optimisations problems can be solved using a Lagrangian relaxation (Bertsekas, 1999), either in series or – via a judicious choice of learning rates – simultaneously, by exploiting a separation in timescales (Borkar, 2008). In the simultaneous case, the parameters of the critic (if using an actor-critic algorithm, if not this part of the argument may be safely ignored) for each objective are updated on the fastest timescale, then the parameters , and finally (i.e., most slowly) the Lagrange multipliers for each of the remaining constraints.
The proof proceeds via induction on the number of objectives, using a standard stochastic approximation argument (Borkar, 2008). In particular, due to the learning rates chosen, we may consider those more slowly updated parameters fixed for the purposes of analysing the convergence of the more quickly updated parameters. In the base case where , we have (by assumption) that . This is simply the standard (non-lexicographic) RL setting. Before continuing to the inductive step, Skalse et al. (2022b) observe that because gradient descent on converges to globally optimal stationary point when then must be globally invex (where the opposite implication is also true) (Ben-Israel and Mond, 1986a).777A differentiable function is (globally) invex if and only if there exists a function such that for all (Hanson, 1981).
The reason this observation is useful is that because each of the objectives shares the same functional form, they are all invex, and furthermore, invexity is conserved under linear combinations and the addition of scalars, meaning that the Lagrangian formed in the relaxation of each constrained optimisation problem is also invex. As a result, if we assume that as our inductive hypothesis, then the stationary point of the Lagrangian for optimising objective is a global optimum, given the constraints that it does not worsen performance on . Via Slater’s condition (Slater, 1950) and standard saddle-point arguments (Bertsekas, 1999; Paternain et al., 2019), we therefore have that , completing the inductive step, and thus the overall inductive argument.
This concludes the proof that . We refer the reader to Skalse et al. (2022b) for a discussion of the error , but intuitively it corresponds to a combination of the representational power of , the critic parameters (if used), and the duality gap due to the Lagrangian relaxation (Paternain et al., 2019). In cases where the representational power of the various parameters is sufficiently high, then it can be shown that .
B.2 On Adversarial Disturbances and other Noise Kernels
A problem that remains open after this work is what constitutes an appropriate choice of , and what can we expect by restricting a particular class of . We first discuss adversarial examples, and then general considerations on versus .
Adversarial Noise
As mentioned in the introduction, much of the previous work focuses on adversarial disturbances. We did not directly address this in the results of this work since our motivation lies in the scenarios where the disturbance is not adversarial and is unknown. However, following the results of Section 3, we are able to reason about adversarial disturbances. Consider an adversarial map to be
with being a set of admissible disturbance states for , and is a distance measure between distributions (e.g. 2-norm).
Proposition B.5.
Constant policies are a fixed point of , and are the only fixed points if for all pairs there exists a sequence such that .
Proof B.6.
First, it is straight-forward that if . To show they are the only fixed points, assume that there is a non-constant policy that is a fixed point of . Then, there exists such that . However, by assumption, we can construct a sequence that connects and and every state in the sequence is in the admissible set of the previous one. Assume without loss of generality that this sequence is . Then, if is a fixed point, , and . However, , so either or , therefore cannot be a fixed point of .
The main difference between an adversarial operator and the random noise considered throughout this work is that is not a linear operator, and additionally, it is time varying (since the policy is being modified at every time step of the PG algorithm). Therefore, including it as a LRPG objective would invalidate the assumptions required for LRPG to retain formal guarantees of the original PG algorithm used, and it is not guaranteed that the resulting policy gradient algorithm would converge.
Appendix C Experiment Methodology
We use in the experiments well-tested implementations of A2C, PPO and SAC from Stable Baselines 3 (Raffin et al., 2021) to include the computation of the lexicographic parameters in \eqrefeq:LRLupdates. All experiments were run on an Ubuntu 18.04 system, with a 16 core CPU and a graphic card Nvidia GeForce 3060.
LRPG Parameters.
The LRL parameters are initialised in all cases as and . The LRL tolerance is set to to ensure we never deviate too much from the original objective, since the environments have very sparse rewards. We use a first order approximation to compute the LRL weights from the original LMORL implementation.
C.1 Discrete Control
The discrete control environments used can be seen in Figure 3.
Since all the environments use a pixel representation of the observation, we use a shared representation for the value function and policy, where the first component is a convolutional network, implemented as in Zhang (2018). The hyper-parameters of the neural representations are presented in Table 2.
| Layer | Output | Func. |
|---|---|---|
| Conv1 | 16 | ReLu |
| Conv2 | 32 | ReLu |
| Conv3 | 64 | ReLu |
The actor and critic layers, for both algorithms, are a fully connected layer with features as input and the corresponding output. We used in all cases an Adam optimiser. We optimised the parameters for each (vanilla) algorithm through a quick parameter search, and apply the same parameters for the Lexicographically Robust versions.
| LavaGap | LavaCrossing | DynObs | |
| Parallel Envs | 16 | 16 | 16 |
| Steps | |||
| 0.99 | 0.99 | 0.98 | |
| 0.00176 | 0.00176 | 0.00181 | |
| (Adam) | |||
| Grad. Clip | 0.9 | 0.9 | 0.5 |
| Gae | 0.95 | 0.95 | 0.95 |
| Rollout | 64 | 64 | 64 |
| E. Coeff | 0.01 | 0.014 | 0.011 |
| V. Coeff | 0.05 | 0.05 | 0.88 |
| LavaGap | LavaCrossing | DynObs | |
| Parallel Envs | 8 | 8 | 8 |
| Steps | |||
| 0.95 | 0.99 | 0.97 | |
| 0.001 | 0.001 | 0.001 | |
| (Adam) | |||
| Grad. Clip | 1 | 1 | 0.1 |
| Ratio Clip | 0.2 | 0.2 | 0.2 |
| Gae | 0.95 | 0.95 | 0.95 |
| Rollout | 256 | 512 | 256 |
| Epochs | 10 | 10 | 10 |
| E. Coeff | 0 | 0.1 | 0.01 |
For the implementation of the LRPG versions of the algorithms, in all cases we allow the algorithm to iterate for of the total steps before starting to compute the robustness objectives. In other words, we use until , and from this point we resume the lexicographic robustness computation as described in Algorithm 1. This is due to the structure of the environments simulated. The rewards (and in particular the positive rewards) are very sparse in the environments considered. Therefore, when computing the policy gradient steps, the loss for the primary objective is practically zero until the environment is successfully solved at least once. If we implement the combined lexicographic loss from the first time step, many times the algorithm would converge to a (constant) policy without exploring for enough steps, leading to convergence towards a maximally robust policy that does not solve the environment.
Noise Kernels. We consider two types of noise; a normal distributed noise and a uniform distributed noise . For the environments LavaGap and DynamicObstacles, the kernel produces a disturbed state where , and for LavaCrossing . The normal distributed noise is in all cases . The maximum norm of the noise is quite large, but this is due to the structure of the observations in these environments. The pixel values are encoded as integers , where each integer represents a different feature in the environment (empty space, doors, lava, obstacle, goal…). Therefore, any noise would most likely not be enough to confuse the agent. On the other hand, too large noise signals are unrealistic and produce pathological environments. All the policies are then tested against two “true” noise kernels, and . The main reason for this is to test both the scenarios where we assume a wrong noise kernel, and the case where we are training the agents with the correct kernel.
Comparison with SA-PPO. One of the baselines included is the State-Adversarial PPO algorithm proposed in Zhang et al. (2020). The implementation includes an extra parameter that multiplies the regularisation objective, . Since we were not able to find indications on the best parameter for discrete action environments, we implemented and picked the best result for each entry in Table 1. Larger values seemed to de-stabilise the learning in some cases. The rest of the parameters are kept as in the vanilla PPO implementation.
C.1.1 Extended Results: Adversarial Disturbances
Even though we do not use an adversarial attacker or disturbance in our reasoning through this work, we implemented a policy-based state-adversarial noise disturbance to test the benchmark algorithms against, and evaluate how well each of the methods reacts to such adversarial disturbances.
Adversarial Disturbance
We implement a bounded policy-based adversarial attack, where at each state we maximise for the KL divergence between the disturbed and undisturbed state, such that the adversarial operator is:
The optimisation problem is solved at every point by using a Stochastic Gradient Langevin Dynamics (SGLD) optimiser. The results are presented in Table 5.
| PPO on MiniGrid Environments | A2C on MiniGrid Environments | |||||||
|---|---|---|---|---|---|---|---|---|
| Noise | Vanilla | LR | LR | SA-PPO | Vanilla | LR | LR | LR |
| LavaGap | ||||||||
| 0.950.003 | 0.950.075 | 0.950.101 | 0.940.068 | 0.940.004 | 0.940.005 | 0.940.003 | 0.940.006 | |
| 0.800.041 | 0.950.078 | 0.930.124 | 0.880.064 | 0.830.061 | 0.930.019 | 0.890.032 | 0.910.088 | |
| 0.920.015 | 0.950.052 | 0.950.094 | 0.930.050 | 0.890.029 | 0.940.008 | 0.930.011 | 0.930.021 | |
| 0.560.194 | 0.930.101 | 0.910.076 | 0.900.123 | 0.920.034 | 0.940.003 | 0.940.007 | 0.930.015 | |
| 0.200.243 | 0.900.124 | 0.680.190 | 0.900.135 | 0.750.123 | 0.940.006 | 0.920.038 | 0.880.084 | |
| 0.010.051 | 0.710.251 | 0.210.357 | 0.870.116 | 0.270.119 | 0.790.069 | 0.680.127 | 0.560.249 | |
| LavaCrossing | ||||||||
| 0.950.023 | 0.930.050 | 0.930.018 | 0.880.091 | 0.910.024 | 0.910.063 | 0.900.017 | 0.920.034 | |
| 0.500.110 | 0.920.053 | 0.890.029 | 0.640.109 | 0.660.071 | 0.780.111 | 0.720.073 | 0.760.098 | |
| 0.840.061 | 0.920.050 | 0.920.021 | 0.850.094 | 0.780.054 | 0.830.105 | 0.860.029 | 0.870.063 | |
| 0.290.098 | 0.910.081 | 0.910.054 | 0.870.045 | 0.560.039 | 0.510.089 | 0.430.041 | 0.680.126 | |
| 0.030.022 | 0.830.122 | 0.860.132 | 0.870.059 | 0.270.158 | 0.250.118 | 0.170.067 | 0.430.060 | |
| 0.00.004 | 0.500.171 | 0.380.020 | 0.820.072 | 0.060.056 | 0.040.030 | 0.010.008 | 0.090.060 | |
| DynamicObstacles | ||||||||
| 0.910.002 | 0.910.008 | 0.910.007 | 0.910.131 | 0.910.011 | 0.880.020 | 0.890.009 | 0.910.013 | |
| 0.230.201 | 0.770.102 | 0.610.119 | 0.450.188 | 0.270.104 | 0.430.108 | 0.450.162 | 0.560.270 | |
| 0.500.117 | 0.750.075 | 0.700.072 | 0.680.490 | 0.450.086 | 0.530.109 | 0.520.161 | 0.670.203 | |
| 0.740.230 | 0.890.118 | 0.850.061 | 0.900.142 | 0.460.214 | 0.550.197 | 0.510.371 | 0.620.249 | |
| 0.260.269 | 0.790.157 | 0.680.144 | 0.840.150 | 0.190.284 | 0.350.197 | 0.230.370 | 0.100.379 | |
| -0.490.312 | 0.510.234 | 0.330.202 | 0.550.170 | -0.540.209 | -0.210.192 | -0.530.261 | -0.510.260 | |
This type of adversarial attack with SGLD optimiser was proposed in Zhang et al. (2020). As one can see, the adversarial disturbance is quite successful at severely lowering the obtained rewards in all scenarios. Additionally, as expected SA-PPO was the most effective at minimizing the disturbance effect (as it is trained with adversarial disturbances), although LRPG produces reasonably robust policies against this type of disturbances as well. At last, A2C appears to be much more sensitive to adversarial disturbances than PPO, indicating that the policies produced by PPO are by default more robust than A2C.
C.2 Continuous Control
The continuous control environments simulated are MountainCar, LunarLander and BipedalWalker. The policies used are in all cases MLP policies with ReLU gates and a feature extractor plus a fully connected layer to output the values and actions unless stated otherwise. The hyperparameters can be found in tables 7 and 8. The implementation is based on Stable Baselines 3 (Raffin et al., 2021) tuned algorithms.
| PPO on Continuous Environments | SAC on Continuous Environments | ||||||
|---|---|---|---|---|---|---|---|
| Noise | Vanilla | LR | LR | SA-PPO | Vanilla | LR | LR |
| MountainCar | |||||||
| 94.770.26 | 93.170.89 | 94.661.61 | 88.693.93 | 93.520.05 | 94.430.19 | 93.840.05 | |
| 88.671.41 | 91.461.22 | 94.911.35 | 88.413.99 | 1.8965.31 | 71.8113.04 | 76.907.11 | |
| 92.221.11 | 92.401.28 | 94.761.42 | 89.323.79 | -27.8273.10 | 72.938.57 | 69.4113.03 | |
| LunarLander | |||||||
| 267.9938.04 | 269.7622.93 | 243.0837.03 | 220.1898.78 | 268.9651.52 | 275.1714.04 | 282.2415.95 | |
| 156.0922.87 | 280.9120.34 | 182.8049.26 | 164.53 45.48 | 128.1817.73 | 187.6476.30 | 153.8133.16 | |
| 158.0246.57 | 276.7616.20 | 212.6237.56 | 221.8473.61 | 140.9220.61 | 187.8225.27 | 158.1828.60 | |
| BipedalWalker | |||||||
| 265.3982.36 | 261.3983.19 | 276.6644.85 | 251.60103.08 | 236.39 157.03 | 302.5670.79 | 313.5652.17 | |
| 174.15170.30 | 253.5672.66 | 220.28118.61 | 264.6961.63 | 203.93 167.83 | 241.45124.54 | 241.60139.93 | |
| 135.16182.30 | 243.2789.86 | 265.3780.60 | 255.2190.61 | 84.10 198.12 | 198.20151.64 | 229.75166.87 | |
Noise Kernels. We consider again two types of noise; a normal distributed noise and a uniform distributed noise . In all cases, algorithms are implemented with a state observation normalizer. That is, assimptotically all states will be observed to be in the set . For this reason, the uniform noise is bounded at lower values than for the discrete control environments. For BipedalWalker and for Lunarlander and MountainCar . Larger values were shown to destabilize learning.
| MountainCarContinuous | LunarLanderContinuous | BipedalWalker-v3 | |
| Parallel Envs | 1 | 16 | 32 |
| Steps | |||
| 0.9999 | 0.999 | 0.999 | |
| Grad. Clip | 5 | 0.5 | 0.5 |
| Ratio Clip | 0.2 | 0.2 | 0.18 |
| Gae | 0.9 | 0.98 | 0.95 |
| Epochs | 10 | 4 | 10 |
| E. Coeff | 0.00429 | 0.01 | 0 |
| MountainCarContinuous | LunarLanderContinuous | BipedalWalker-v3 | |
| Steps | |||
| 0.9999 | 0.99 | 0.98 | |
| 0.01 | 0.01 | 0.01 | |
| Train Freq. | 32 | 1 | 64 |
| Grad. Steps | 32 | 1 | 64 |
| MLP Arch | (64,64) | (400,300) | (400,300) |
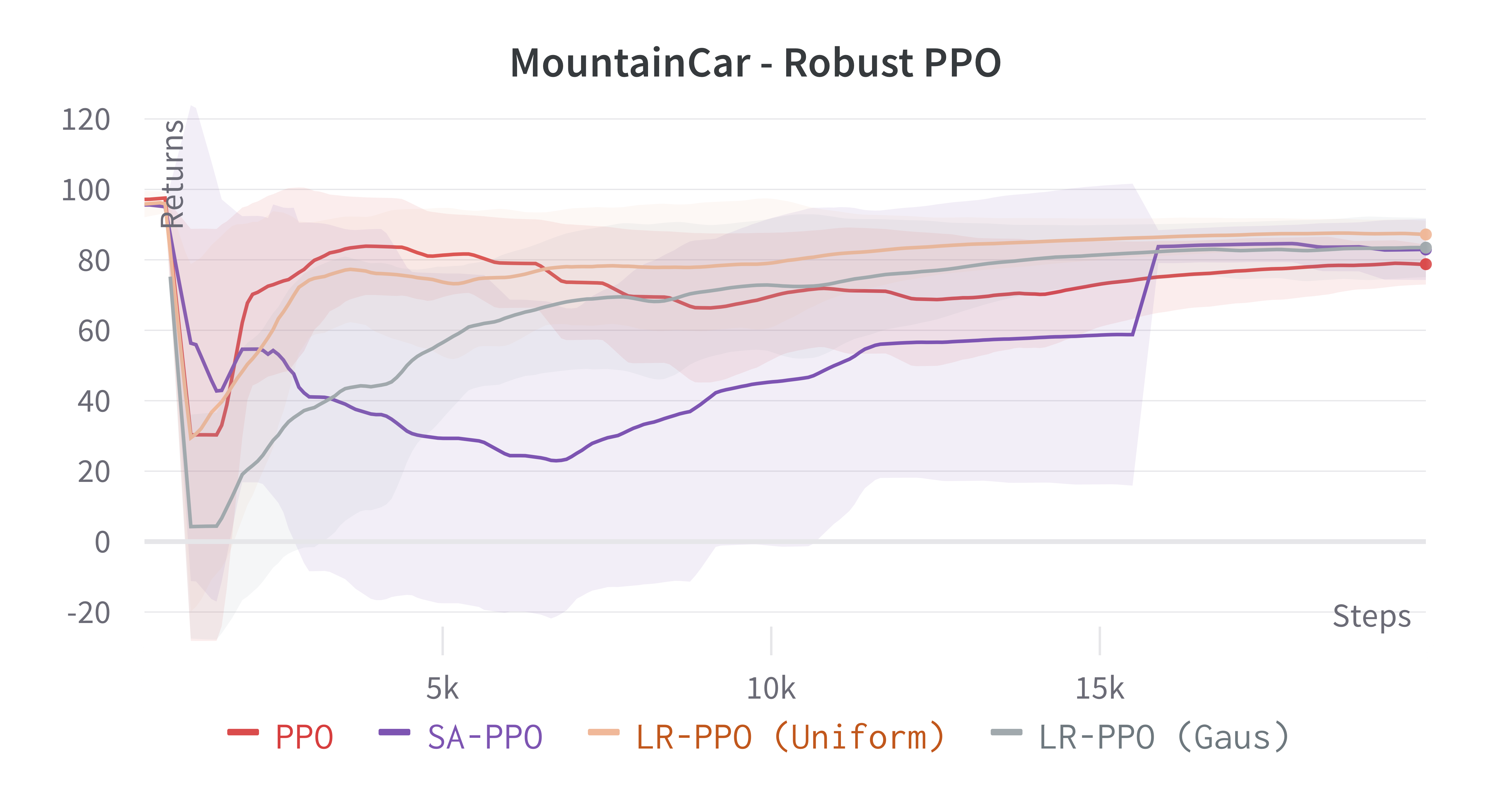
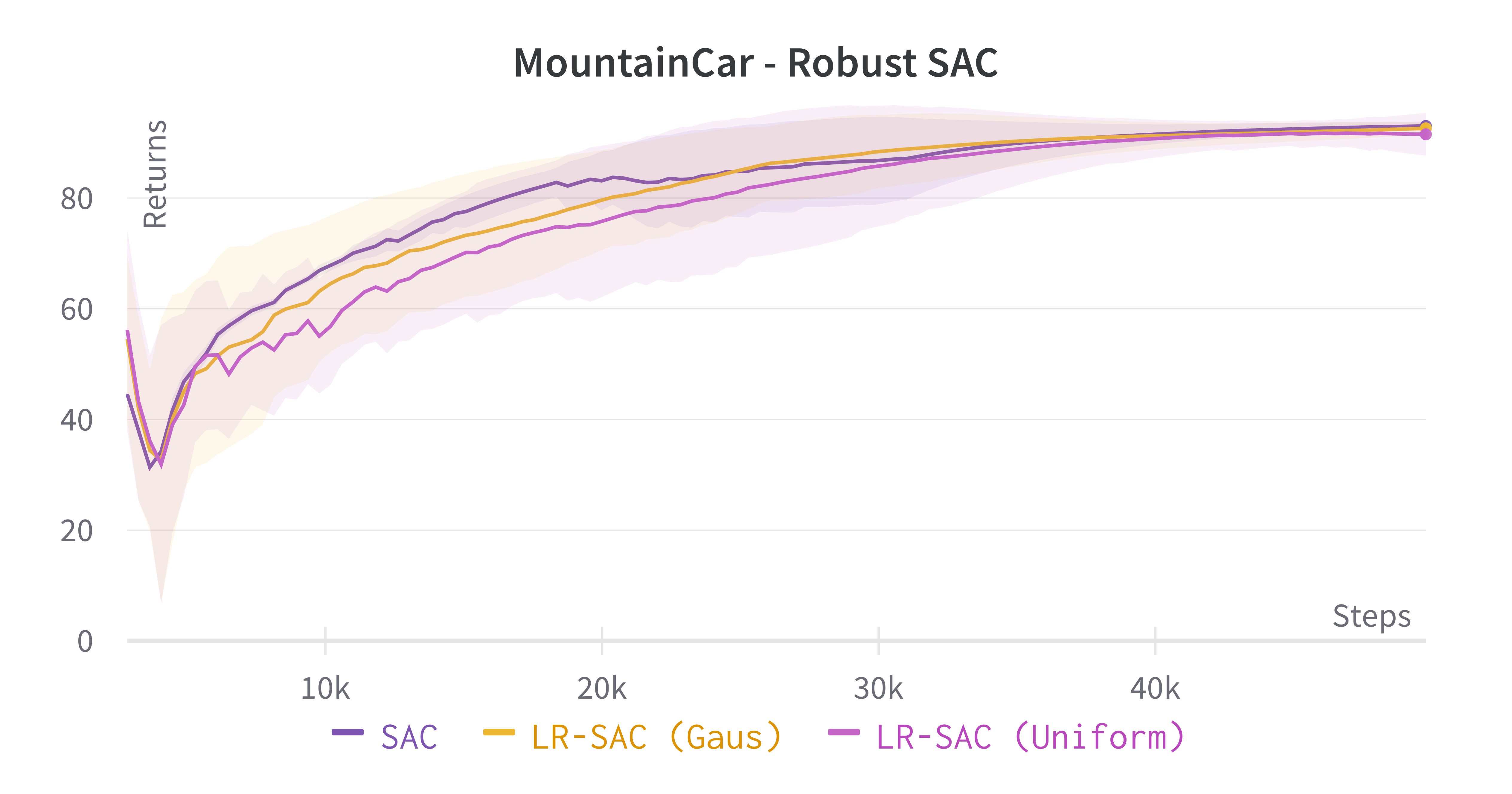
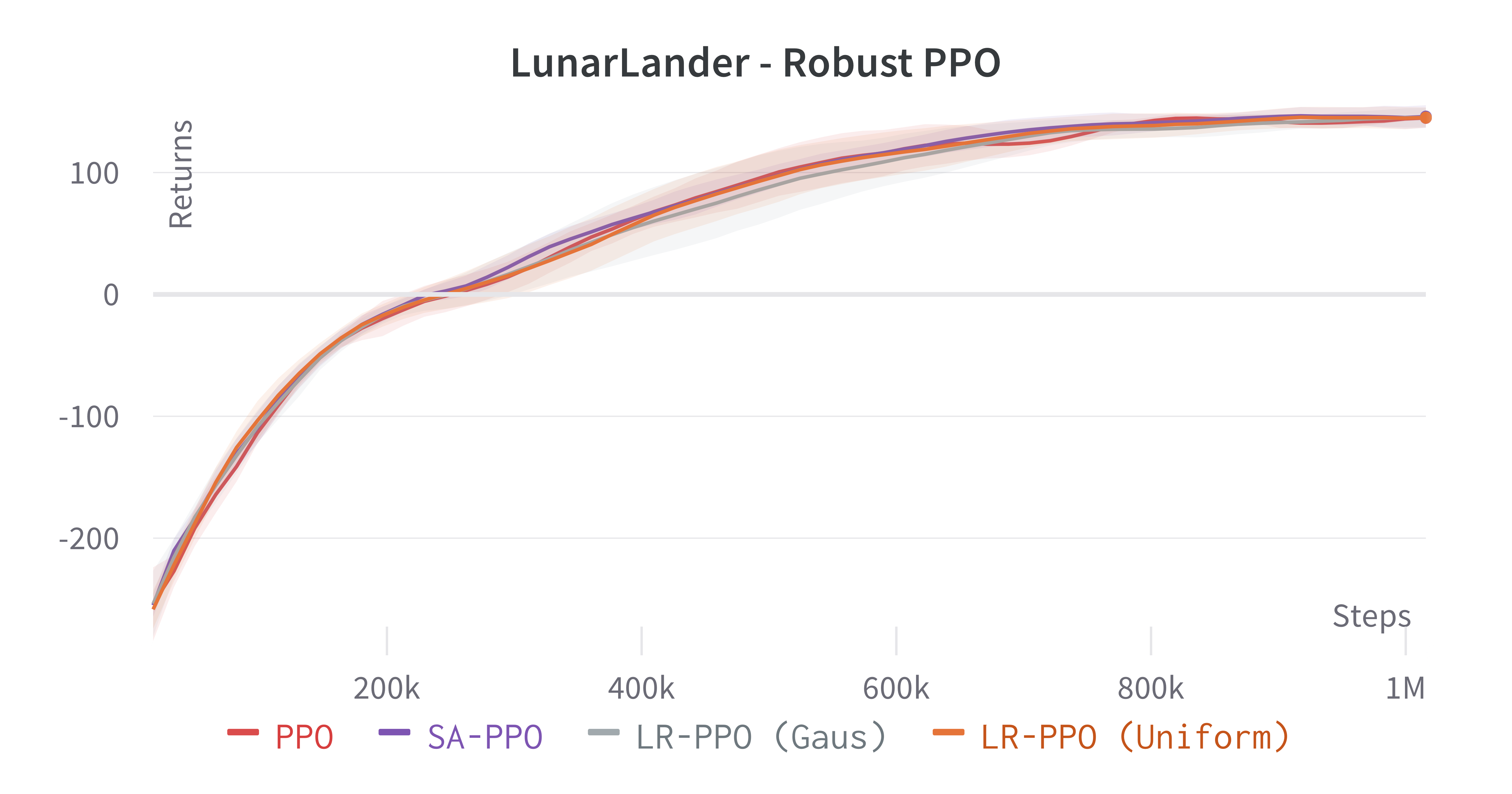
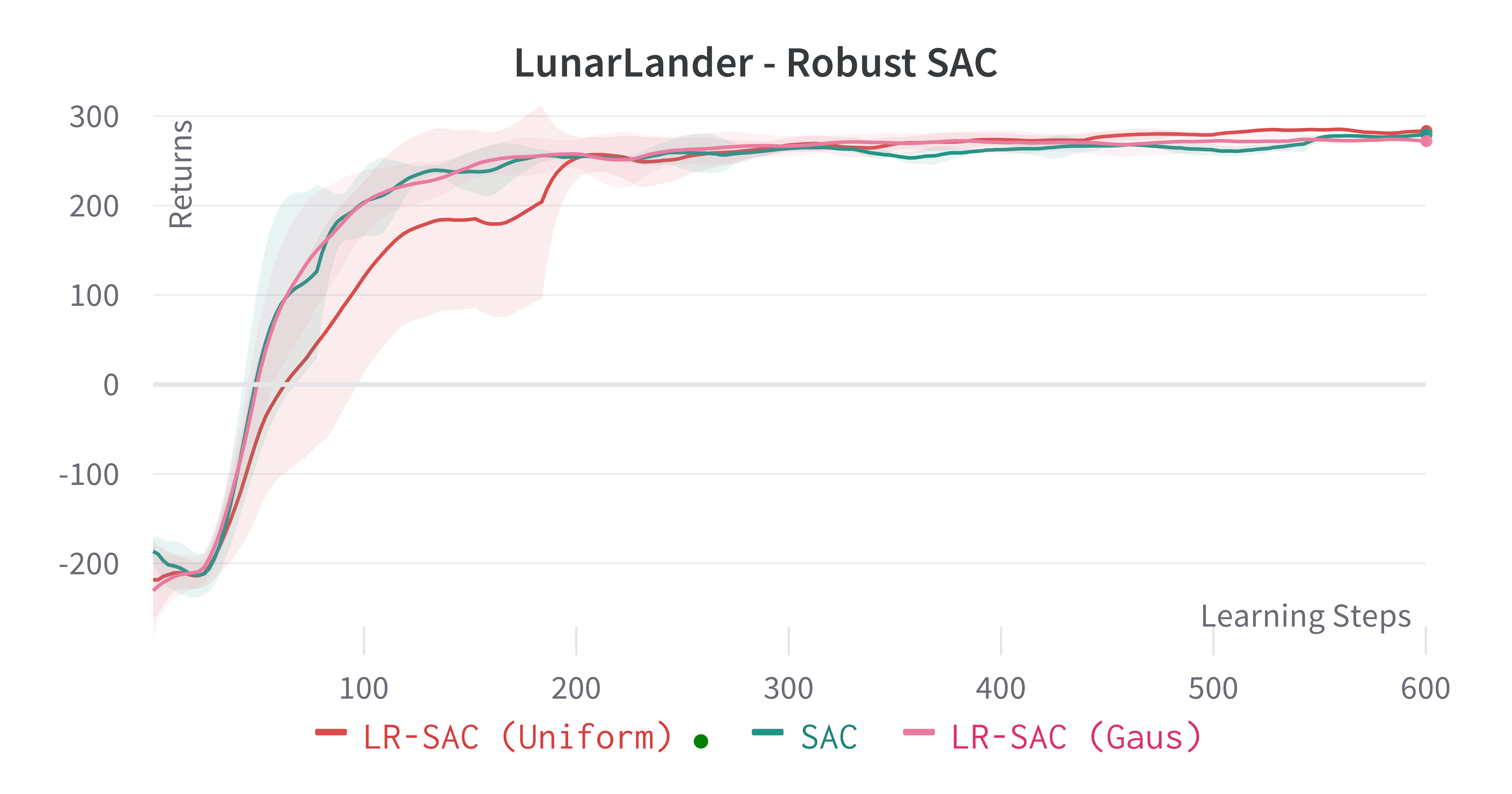
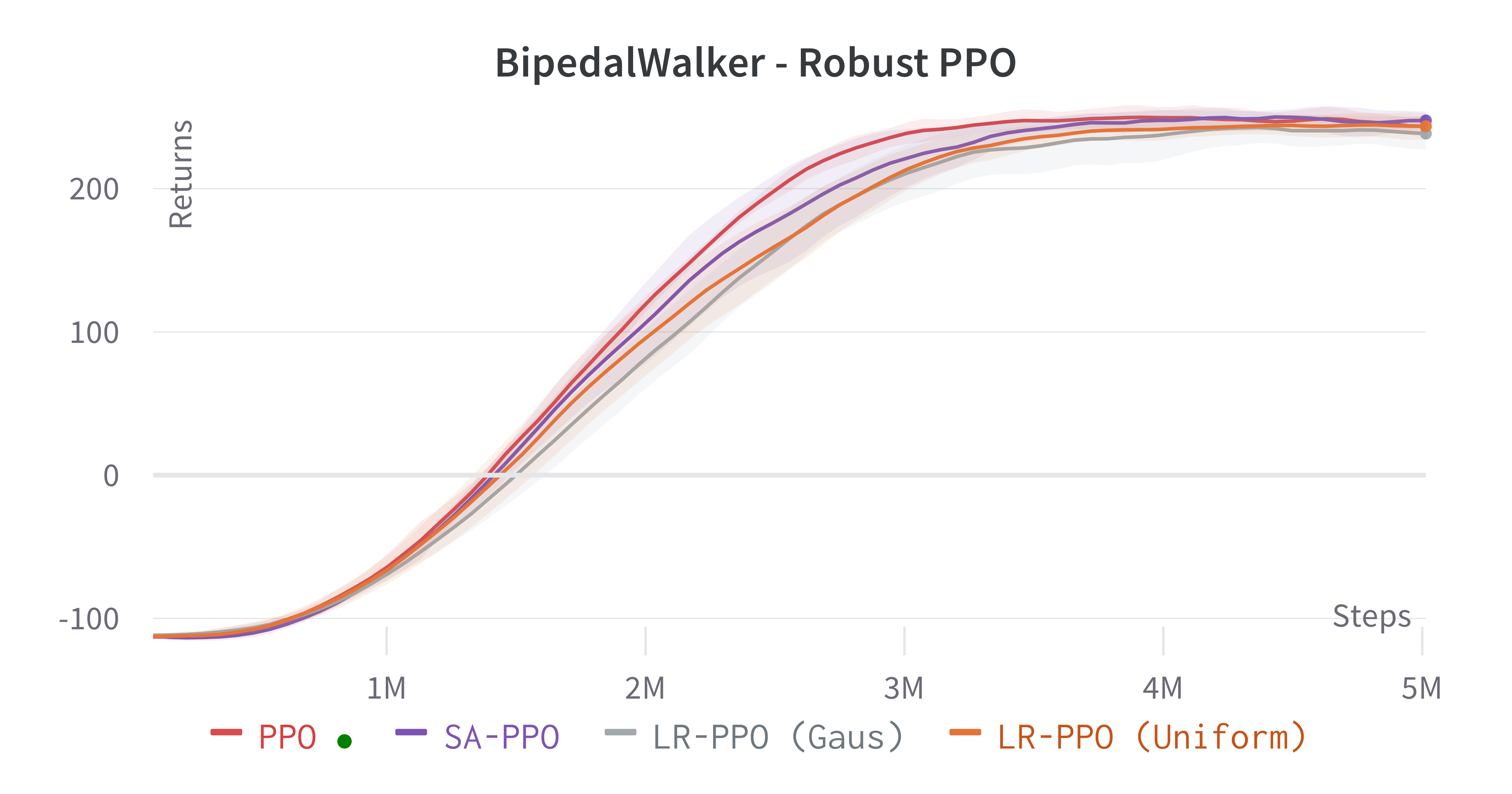
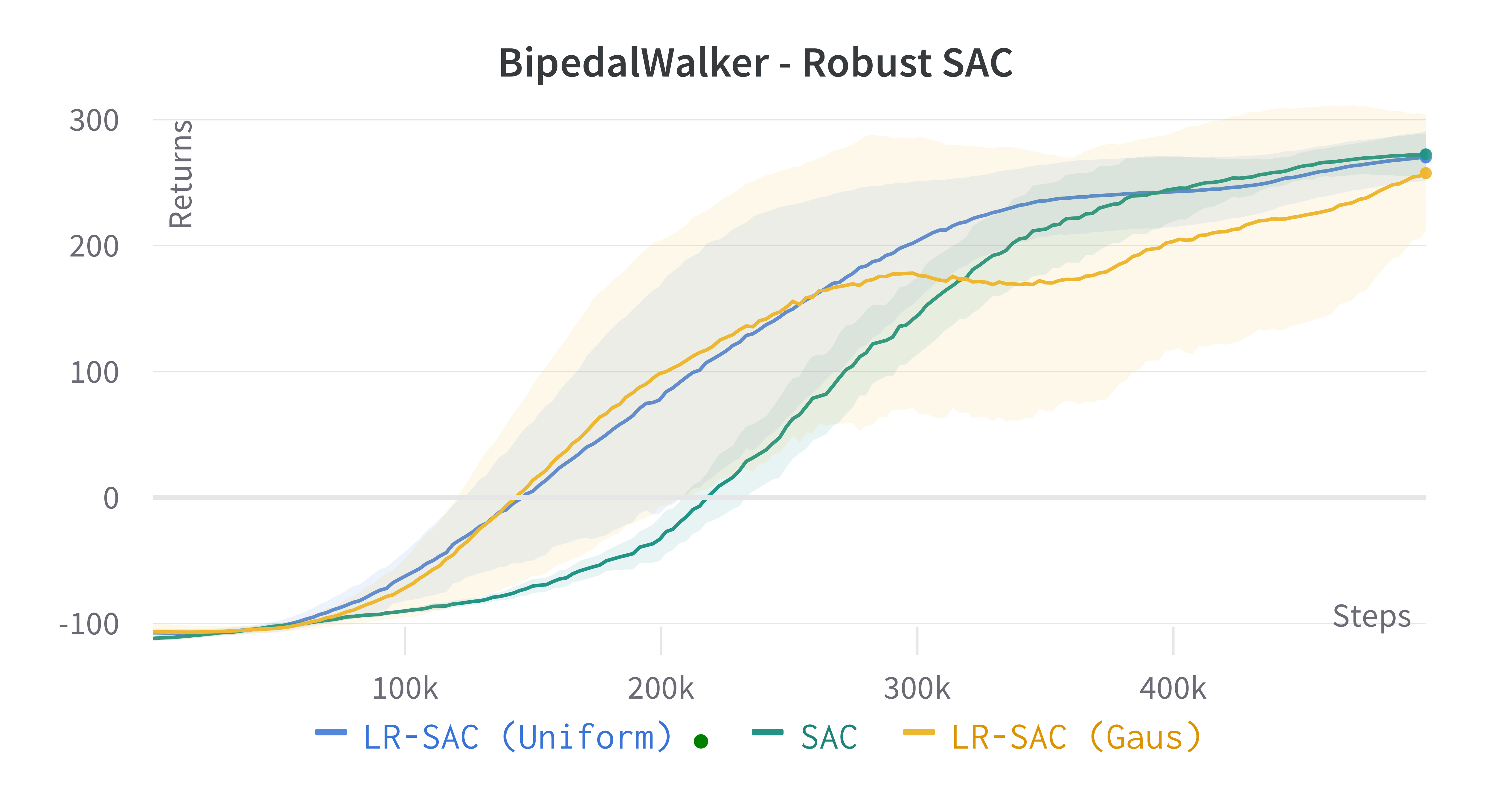
Learning processes
In general, learning was not severlely affected by the LRPG scheme. However, it was shown to induce a larger variance in the trajectories observed, as seen in LunarLander with LR-SAC and BipedalWalker with LR-SAC.