Building Adversary-Resistant Deep Neural Networks without Security through Obscurity
Abstract.
Deep neural networks (DNNs) have proven to be quite effective in a vast array of machine learning tasks, with recent examples in cyber security and autonomous vehicles. Despite the superior performance of DNNs in these applications, it has been recently shown that these models are susceptible to a particular type of attack that exploits a fundamental flaw in their design. This attack consists of generating particular synthetic examples referred to as adversarial samples. These samples are constructed by slightly manipulating real data-points in order to “fool” the original DNN model, forcing it to mis-classify previously correctly classified samples with high confidence. Addressing this flaw in the model is essential if DNNs are to be used in critical applications such as those in cyber security.
Previous work has provided various learning algorithms to enhance the robustness of DNN models, and they all fall into the tactic of “security through obscurity”. This means security can be guaranteed only if one can obscure the learning algorithms from adversaries. Once the learning technique is disclosed, DNNs protected by these defense mechanisms are still susceptible to adversarial samples. In this work, we investigate this issue shared across previous research work and propose a generic approach to escalate a DNN’s resistance to adversarial samples. More specifically, our approach integrates a data transformation module with a DNN, making it robust even if we reveal the underlying learning algorithm. To demonstrate the generality of our proposed approach and its potential for handling cyber security applications, we evaluate our method and several other existing solutions on datasets publicly available, such as a large scale malware dataset, MNIST and IMDB datasets. Our results indicate that our approach typically provides superior classification performance and resistance in comparison with state-of-art solutions.
1. Introduction
Beyond highly publicized victories in automatic game-playing as in Go (silver2016mastering, ), there have been many successful applications of deep neural networks (DNN) in image and speech recognition. Recent explorations and applications include those in medical imaging (bar2015deep, ; xu2014deep, ) and self-driving cars (hadsell2009learning, ; farabet2012scene, ). In the domain of cybersecurity, security companies have demonstrated that deep learning could offer a far better way to classify all types of malware (pascanu2015malware, ; dahl2013large, ; yuan2014droid, ).
Despite its potential, deep neural networks (DNN), like all other machine learning approaches, are vulnerable to what is known as adversarial samples (huang2011adversarial, ; barreno2006can, ). This means that they can be easily deceived by non-obvious and potentially dangerous manipulation (42503, ; nguyen2015deep, ). To be more specific, an attacker could use the same training algorithm, back-propagation of errors, and a surrogate dataset to construct an auxiliary model. Since this model could provide the attacker with a capability of exploring a DNN’s blind spots, he can, with minimal effort, craft an adversarial sample – a synthetic example generated by slightly modifying a real example in order to make the deep learning system “believe” the sample subtly perturbed belongs to an incorrect class with high confidence.
According to a recent study (Goodfellow14, ), adversarial samples occur in a subspace relatively broad, which means it is impractical to build a defense that can rule out all adversarial samples. As such, the design principle followed by existing defense mechanisms is not to harden a DNN model naturally resistant to any adversarial samples. Rather, they focus on hiding that subspace, making adversaries difficult in finding impactful adversarial samples. For example, representative defenses – adversarial training (Goodfellow14, ) and defensive distillation (papernot2015distillation, ) both increase the complexity of original DNNs with the goal of making adversarial samples – impactful for original DNNs – no longer effective.
However, in this work, we show that the defenses proposed are far from ideal and even considered a dangerous practice. In particular, we demonstrate existing defense mechanisms all follow the approach of “security through obscurity”, in which security is achieved by keeping defenses obscured from adversaries. Frankly speaking, defenses following this approach indeed mitigate the adversarial sample problem. However, when applied to security critical applications such as malware classification, they become particularly disconcerting.
In the past, there have been a huge amount of debates on security through obscurity, and a general consensus has been reach. That is, obscurity is a perfectly valid security tactic but it cannot be trusted for security. Once design or implementation is uncovered, users totally lost all the security gained by obscurity. To regain the security through obscurity, one has to come up with a completely new design or implementation. As such, Kerckhoffs’ principle (Kerckhoffs1883, ) suggests obscurity can be used as a layer of defense, but it should never be used as the only layer of defense.
Inspired by this, we propose a new mechanism to escalate a DNN’s resistance to adversarial samples. Different from existing defenses, our proposed approach unnecessitates model obscurity. In other words, even though we reveal the model, it will still be more than burdensome for adversaries to craft adversarial samples.
More specifically, we arm a standard DNN with a data transformation module, which projects original data input into a new representation before they are passed through the consecutive DNN. This can be used as a defense for the following two reasons. First, data transformation can potentially stash away the space of adversarial manipulations to a carefully designed hyperspace. This makes attackers difficult in finding adversarial samples impactful for the armed DNN. Second, as we will theoretically prove in Section 4, a data transformation module carefully designed can exponentially increase computation complexity for an attacker to craft impactful adversarial samples. This means that, even though an attacker compromises obscurity and has the full knowledge about the armed DNN model (i.e., the training algorithm, dataset and hyper-parameters), he still cannot launch the attack – detrimental to DNNs enhanced by other adversary-resistant techniques – nor jeopardize model resistance.
The approach proposed in this work is beneficial for the following reasons. First, it escalates a DNN’s resistance to adversarial samples with better security assurance. Second, our approach ensures that a DNN maintains desirable classification performance while requiring only minimal modification to existing architectures. Third, while this work is primarily motivated by the need to safeguard DNN models used in critical security applications, it should be noted that the proposed technique is general and can be adopted to other applications where deep learning is popularly applied, such as image recognition and sentiment analysis. We demonstrate this applicability using publicly-available datasets in Section 5.
In summary, this work makes the following contributions.
-
•
We propose a generic approach to facilitate the development of adversary-resistant DNNs without following the tactic of security through obscurity.
-
•
Using our approach, we develop an adversary-resistant DNN, and theoretically prove its resistance cannot be jeopardized even if the model is fully disclosed.
-
•
We evaluate the classification performance and robustness of our adversary-resistant DNN and compare it with that of existing defense mechanisms. Our result shows that our DNN exhibits similar – sometimes even better – classification performance but with superior model resistance.
The rest of this paper is organized as follows. Section 2 introduces the background of DNNs and adversarial sample problem. Section 3 discusses existing defense mechanisms and defines the problem scope of our research. Section 4 presents our generic approach. In Section 5, we develop and evaluate DNNs in the context of image recognition, sentiment analysis and malware classification. Finally, we conclude this work in Section 6.
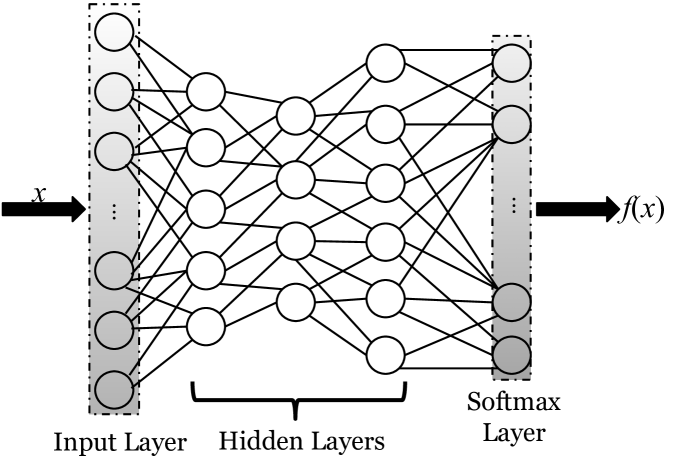
2. Background
A typical DNN architecture consists of multiple successive layers of processing elements, or so-called “neurons”. Each processing layer can be viewed as learning a different, more abstract representation of the original multidimensional input distribution. As a whole, a DNN can be viewed as a highly complex function, that is capable of nonlinearly mapping an original high-dimensional data point to a lower dimensional output. In this section, we briefly introduce the well-established DNN model, followed by the description of the adversarial learning problem.
2.1. Deep Neural Networks
As is graphically depicted in Figure 1, a DNN contains an input layer, multiple hidden layers, and an output layer. The input layer takes in each data sample in the form of a multidimensional vector. Starting from the input, computing the pre-activations of each subsequent layer simply requires, at minimum, a matrix multiplication (where a weight/parameter vector, with length equal to the number of hidden units in the target layer, is assigned to each unit of the layer below) usually followed by summation with a bias vector. This process roughly models the process of a layer of neurons integrating the information received from the layer below (i.e., computing a pre-activation) before applying an elementwise activation function111There are many types of activations to choose from, including the hyperbolic tangent, the logistic sigmoid, or the linear rectified function, etc. (Goodfellow-et-al-2016-Book, ). This integrate-then-fire process is repeated subsequently for each layer until the last layer is reached. The last layer, or output, is generally interpreted as the model’s predictions for some given input data, and is often designed to compute a parameterized likelihood distribution using the softmax function (also known as multi-class regression or minimizing cross entropy). This bottom-up propagation of information is also referred to as feed-forward inference (hinton2007learning, ).
During the learning phase of the model, the DNN’s predictions are evaluated by comparing them with known target labels associated with the training samples (also known as the“ground truth”). Specifically, both predictions and labels are taken as the input to , a selected cost function. The DNN’s parameters are then optimized with respect to this cost function using the method of steepest gradient descent, minimizing prediction errors on the training set.
More formally, given : , where is a data sample and is the corresponding data label, where, if categorical, is typically represented through a 1-of-k encoding, the goal of model learning is to minimize the cost function represented by , where denotes the prediction of training sample and represents the weights and bias associated with the connections between neurons.

2.2. Adversarial Sample Problem
An adversarial sample is a synthetic data sample crafted by introducing slight perturbations to a legitimate input sample (see Figure 2). In multi-class classification tasks, such adversarial samples can cause a DNN to classify themselves into a random class other than the correct one (sometimes not even a reasonable alternative). Recent research (Carlinioakland2017, ) demonstrates that, attackers can uncover such data samples through various approaches (e.g., (42503, ; Goodfellow14, ; papernot2016limitations, ; sabour2015adversarial, ; bastani2016measuring, ; liu2016delving, )) which can all be described as solving either optimization problem
| (1) | ||||
or optimization problem
| (2) | ||||
Here, optimization problem (LABEL:eq:adv1) indicates that an attacker searches for adversarial sample , the prediction of which is as far as its true label, whereas optimization problem (LABEL:eq:adv2) indicates an attacker searches for adversarial sample so that its prediction is as close as target label where is not equal to , the true label of that adversarial sample.
In both optimization problems above, represents the aforementioned cost function and denotes the DNN model trained with the traditional learning method discussed above . is -norm – sometimes also specified as distance – indicating the dissimilarity between adversarial sample and its corresponding legit data sample . With different values of – most popularly selected in adversarial learning research – the optimization problems above can be computed in the following manners.
-
(1)
With , -norm represents the measure of Euclidean distance. The constraint optimization problems above can be specified as unconstrained optimization problems
(3) and
(4) Here, both (3) and (4) can be solved by following either a first-order optimization method (e.g., stochastic gradient descent (Carlinioakland2017, ) and L-BFGS (42503, )) or a second-order method (e.g., Newton-Raphson method).
-
(2)
With , -norm indicates the number of elements in a legit data sample that an attacker needs to manipulate in order to turn it into an adversarial sample. Different from the computation method above, in the setting of where unconstrained optimization problems (3) and (4) are not differentiable, the computation for the optimal solution has to follow an approximation method introduced in (papernot2016limitations, ) or (Carlinioakland2017, ).
-
(3)
With , -norm becomes a measure indicating the maximum change to individual features. As such, the optimal solution for (LABEL:eq:adv1) and (LABEL:eq:adv2) can be approximated by following the fast gradient sign method (Goodfellow14, ), which computes perturbation (or ), multiplies it by distortion scale and then adds the product to legitimate data sample . Note that the way they compute that perturbation can be through back-propagation in conjunction with gradient descent.
As is illustrated in the aforementioned optimization problems, in order to generate impactful adversarial samples, an attacker needs to know either standard DNN model or know of a way to approximate . A recent study (42503, ) has revealed that an attacker could well approximate a standard DNN model using a traditional DNN training algorithm on an auxiliary training dataset. In this paper, we use “cross-model approach” to refer to those adversarial sample crafting methods that rely upon the approximation of a standard DNN model.
3. Existing Defenses and Problem Scope
To counteract the adversarial learning problem described in the section above, recent research invent various training algorithms (Goodfellow14, ; ororbia_ii_unifying_2016, ; 42503, ; gu2014towards, ) to improve the robustness of a DNN model. They indicate, by using new training algorithms they design, one can improve a DNN’s resistance to the adversarial samples crafted through the aforementioned cross-model approach. This is due to the fact that their training algorithms smooth a standard DNN’s decision boundary, making adversarial samples – impactful to standard DNN models – no longer sufficiently effective. In this section, we summarize these defense mechanisms and discuss their limitations. Following our summary and discussion, we also define the problem scope of our research.
3.1. Existing Defense Mechanisms
Recently, research in hardening deep learning mainly focuses on two different tactics – data augmentation and model complexity enhancement. Here, we summarize them in turn and disucss their limitations.
Data augmentation. To resolve the issue of “blind spots” (a more informal name given to adversarial samples), many methods that could be considered as sophisticated forms of data augmentation222Data augmentation refers to artificially expanding the data-set. In the case of images, this can involve deformations and transformations, such as rotation and scaling, of original samples to create new variants. have been proposed (e.g. (Goodfellow14, ; ororbia_ii_unifying_2016, ; gu2014towards, )). In principle, these methods expand their training set by combining known samples with potential blind spots, the process of which has been called adversarial training (Goodfellow14, ). Technically speaking, adversarial training can be formally described as adding a regularization term known as DataGrad to a DNN’s training loss function (ororbia_ii_unifying_2016, ). The regularization penalizes the directions uncovered by adversarial perturbations (introduced in Section 2.2). Therefore, adversarial training can work to improve the robustness of a standard DNN.
Model complexity enhancement. DNN models are already complex, with respect to both the nonlinear function that they try to approximate as well as their layered composition of many parameters. However, the underlying architecture is straightforward when it comes to facilitating the flow of information forwards and backwards, greatly alleviating the effort in generating adversarial samples. Therefore, several ideas (papernot2015distillation, ; gu2014towards, ) have been proposed to enhance the complexity of DNN models, aiming to improve the tolerance of complex DNN models with respect to adversarial samples generated from simple DNN models. For example, (papernot2015distillation, ) developed a defensive distillation mechanism, which trains a DNN from data samples that are “distilled” from another DNN. By using the knowledge transferred from the other DNN, the learned DNN classifiers become less sensitive to adversarial samples. Similarly, (gu2014towards, ) proposed to stack an auto-encoder together with a standard DNN. It shows that this auto-encoding enhancement increases a DNN’s resistance to adversarial samples.
Limitation. While the aforementioned defenses have yielded promising results in terms of increasing model resistance, the scope of the model resistance they provide is relatively limited. Once an attacker obtains the knowledge of the new training algorithms – instead of using a traditional DNN training algorithm to substitute the algorithm which the target DNN is trained with – he can build his own model with the new training algorithm, and then use it as the cross model to facilitate the crafting of adversarial samples. As we will show in Section 5, the adversarial samples crafted through such new cross models sustain their offensiveness to the corresponding DNN models. This indicates that the effectiveness of existing defense mechanisms is highly dependent upon the obscurity of training algorithms.
3.2. Problem Scope
With the existing defenses and their limitation in mind, here we define the problem scope of our research.
Similar to most previous research – if not all – in hardening deep learning, we assume that an attacker crafts adversarial samples by solving the aforementioned optimization problems with derivative calculation (e.g., fast sign gradient descent or Newton-Raphson method). We believe this assumption is realistic for the following reason.
Derivative calculation is the most general approach for solving an optimization problem. In the future, while one might be able to derive new forms of approaches in solving the aforementioned optimization problem, he or she has to ensure the new approaches are computationally efficient. Without the aid from derivative calculation, this can be relatively difficult. Even if one could computationally efficiently resolve the aforementioned optimization problems – for example perhaps through relaxation – without derivative calculation, he still need to prove the adversarial samples derived from such an approach are impactful. Given that relaxation reshapes an optimization problem, the “optimal” solution may not even close to any local optima of that original optimization problem.
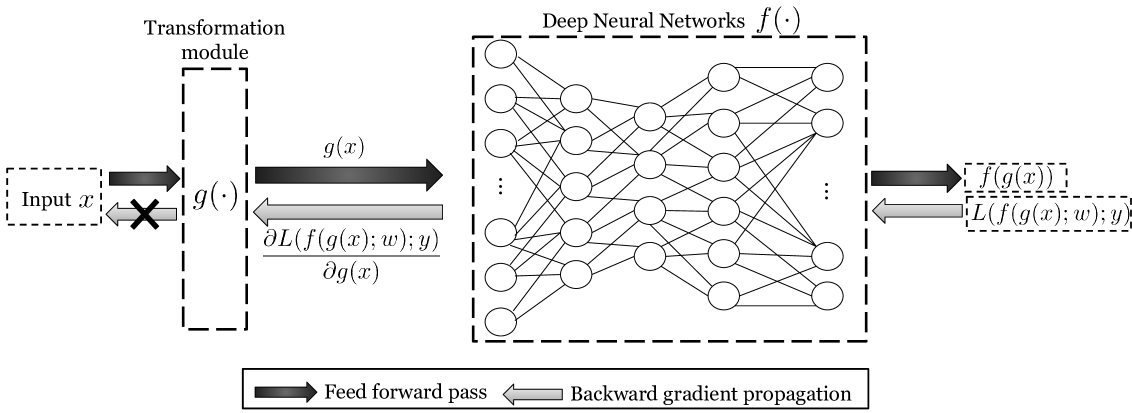
Different from prior research, we also assume that an adversary has not only the access to a DNN’s structure as well as the dataset(s) used to build the DNN but more importantly the algorithm used to train the network. In other words, we assume a target DNN model is no longer obscure to an adversary and rather he has the full knowledge about a DNN model that he attempts to exploit. We believe this assumption is more practical because there is little hope of keeping an adversary-resistant training algorithm completely secret from dedicated attackers. In the long run, any system the security of which relies upon the obscurity of its design can be doomed (Kerckhoffs1883, ).
4. Our Approach
To address the problem above, we propose a new approach to harden DNN models. Technically speaking, it follows the tactic of model complexity enhancement, which improves model resistance by increasing model complexity. Different from the existing techniques mentioned above, our approach however goes beyond the scope of robustness they provide. It ensures that an attacker cannot perform the aforementioned attack to generate adversarial samples impactful to our learning model even if we reveal our training algorithm. In other words, our approach escalate a DNN’s resistance to adversarial samples without the requirement of obscuring training algorithms.
As is discussed in the section above, the adversarial learning problem can be viewed as an optimization problem. To resolve that optimization problem, one needs to conduct analytical computation of gradients with respect to an input data sample and perform backward propagation accordingly. Therefore, we escalate a DNN’s robustness not only by increasing the model complexity but, more importantly, restricting back-propagation.
More specifically, we integrate to a DNN a data transformation module, graphically indicated in Figure 3. As is illustrated in the figure, the data transformation module projects , an input data sample to , a new representation, before passing it through a consecutive DNN. This transformation increases the complexity of a DNN model and augments its resistance to adversarial samples crafted through the aforementioned cross-model scheme. In addition, it blocks the backward flows of gradients. With this block, even if the underlying training algorithm is disclosed, an adversary cannot craft adversarial samples. In the following, we specify the design principle of our data transformation module, followed by its design detail and some necessary discussions.
4.1. Design Principle
To block the backward flow of gradients, the design of data transformation must satisfy three requirements. Most notably, the data transformation must be non-differentiable. As is discussed above, crafting adversarial samples requires the calculation of gradients as well as the back-propagation of those gradients. By making data transformation module non-differentiable, therefore, we can make gradient calculation intractable and thus obstruct the backward flow of gradients. More formally, we can choose non-differentiable function , making the derivative difficult to be calculated, i.e.,
| (5) |
Here, represents the DNN model in tandem with the data transformation module, and denotes the cost function described in Section 2.2. The derivative can be computed using either a first-order optimization method (e.g., gradient descent) or a second-order method (e.g., Newton-Raphson method), in which is equal to 1 and 2, respectively.
While the non-differentiability feature restricts the crafting of adversarial samples, an adversary might still be able to generate adversarial samples. Since end-to-end gradient flow is blocked at the input layer of the successive DNN, back-propagation can only carry error gradients to the output of the transformation module. Given , an adversary could construct an adversarial sample by inverting transformation module and passing the manipulated transformation output through the inversion of the transformation. More formally, the adversary can construct an adversarial sample by computing
| (6) |
In addition to making data transformation non-differentiable, therefore, we must further ensure that the inversion of the data transformation is computationally intractable. In other words, the data transformation needs to have the property of non-invertibility.
Satisfying the two requirements above ensures that our proposed approach can prohibit an attacker from crafting adversarial samples directly from the target DNN model, and one does not need to concern about the disclosure of training algorithms. However, the data transformation proposed may significantly jeopardize the accuracy of a DNN model if not designed carefully. Take the following extreme case for example.
Hash functions like MD5 and SHA1 are one-way functions which have the properties of non-differentiability as well as non-invertibility. By simply using it as the transformation module, we can easily prohibit an attacker from crafting adversarial samples even if he knows of which hash function we choose and how we integrate it with DNNs. However, a hash function significantly changes the distribution of input data samples. Armed with it, a DNN model suffers from significant loss in classification performance. Last but not least, our design therefore must ensure data transformation can preserve the distribution of data representation. This can potentially make a DNN robust without sacrificing classification performance.
4.2. Design Detail
Following the design principle above, we choose Locally Linear Embedding (LLE) (roweis2000nonlinear, ), a non-parametric dimensionality reduction mechanism, serving as the data transformation module. As we will discuss in the following, this representative non-parametric method is non-differentiable. More importantly, it can be theoretically proven that inverting LLE is an NP-hard problem. Last but not least, LLE seeks low-dimensional, neighborhood-preserving map of high-dimensional input samples, and thus is a method that best suited to preserving as much information in the input as possible. In the following, we first describe LLE and then expound upon the fact that, as a non-parametric dimensionality reduction method, LLE is non-differentiable. Furthermore, we theoretically prove LLE is computationally non-invertible.

4.2.1. Locally Linear Embedding
LLE is a non-parametric method designed to reduce input data dimensionality and at the same time preserve local properties of high-dimensional input in a lower-dimensional space. To some extent, this can ensure the distribution of high-dimensional data samples is as close as they are in a lower-dimensional space. Technically speaking, this is achieved by representing each high-dimensional data sample via a linear combination of its nearest neighbors. More formally, this can be expressed as . Here, and () denote the data sample and its neighbor (), respectively. represents the weight, indicating the contribution of to data sample . As is described in (roweis2000nonlinear, ), those weights (a.k.a. reconstruction weights) can be represented as weight matrix and computed by solving the following optimization problem:
| (7) | ||||
In weight matrix , LLE deems if is not considered as a neighbor of , and the total number of neighbors assigned to is a carefully selected hyper-parameter. The neighboring relation between and depends on the value of the distance between and .
Since the reconstruction weights encode the local properties of the high-dimensional data, they can be used to preserve the data distribution at the time of performing dimensionality reduction. More specifically, LLE imposes the corresponding reconstruction weights to each lower-dimensional data sample via a similar linear combination, and then attempts to find , the lower-dimensional representation of by solving the following optimization problem:
| (8) | ||||
where , indicating , consist of of elements.
In order to solve the optimization problem above, the Rayleitz-Ritz theorem (horn1990matrix, ) is typically used. It computes the eigenvectors corresponding to the smallest nonzero eigenvalues of the inner matrix product . For a detailed explication, we refer the readers to (horn1990matrix, ). Here, is an identity matrix, and is the aforementioned reconstruction weight matrix.
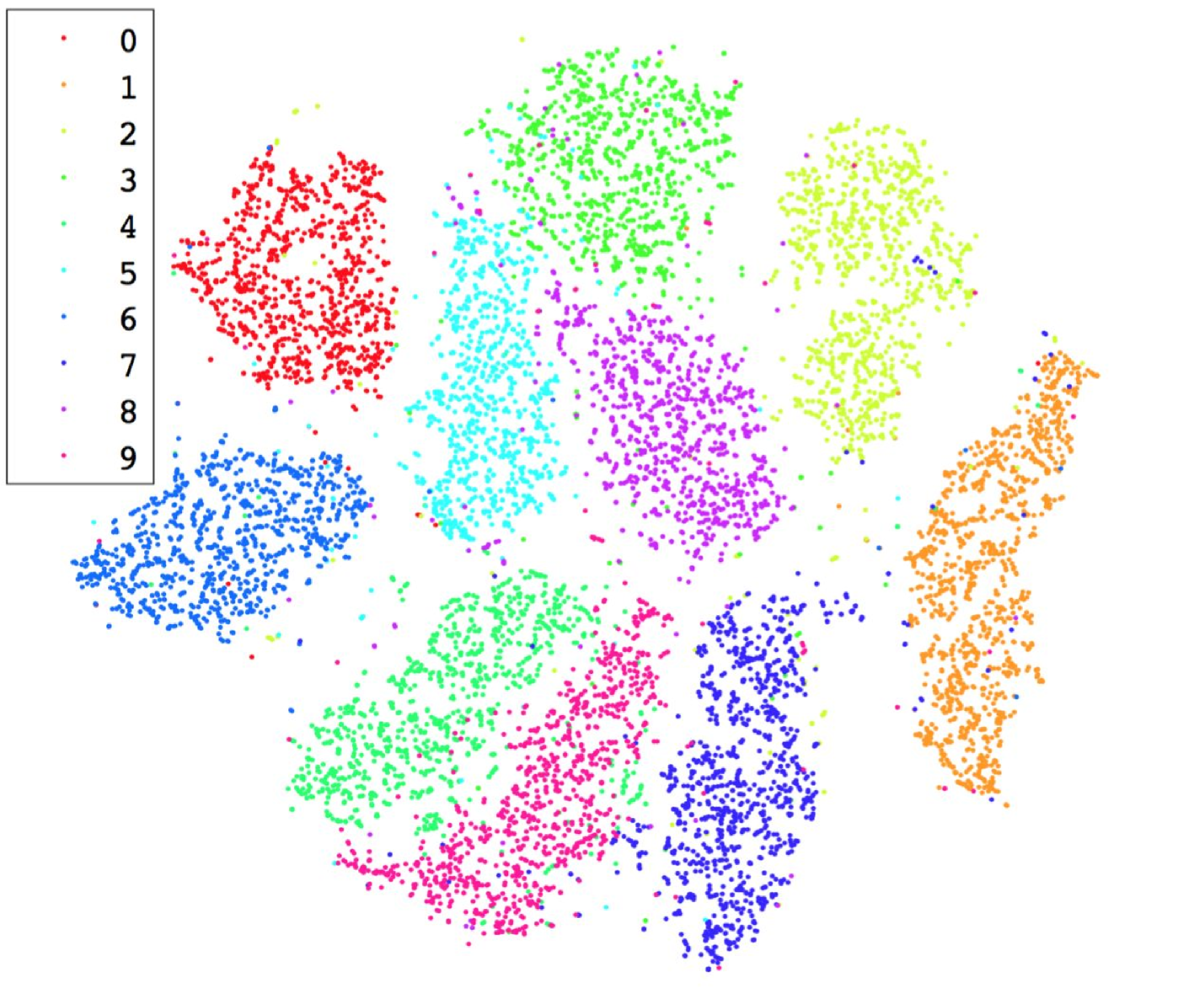
LLE is specifically designed to retain the similarity between pairs of high dimensional samples when they are mapped to lower dimensions (roweis2000nonlinear, ). To illustrate this property, we provide a visualization of the data before and after being processed by LLE in Figure 4. The visualization result demonstrates that using LLE as a data transformation module satisfies the last design principle discussed in Section 4.1 (i.e., preserving the distribution of the original data). More importantly, this property also helps bound the lower dimensional mapping of adversarial samples to a vicinity which is filled by mappings of original test samples that are highly similar to these adversarial samples. As a result, there is a significantly lower chance that an adversarial sample acts as an outliers in the lower dimensional space. In other words, LLE makes a DNN more resistant to adversarial samples. In Section 5, we empirically validate this important property.
4.2.2. Non-differentiability of LLE
Existing dimensionality reduction methods can be categorized as either parametric or non-parametric (Maaten08dimensionality, ). Parametric methods utilize a fixed amount of parameters to specify a direct mapping from high-dimensional data samples to their low-dimensional projections (or vice versa). This direct mapping is characterized by parameters, which are typically optimized to provide the best mapping performance. This is similar to the functionality provided by a standard DNN, which maps high-dimensional data samples to the final decision space through differentiable function . As such, the derivative of parametric methods typically can be computed in an analytically efficient manner. In other words, parametric methods are generally differentiable, and this nature becomes a disadvantage for blocking the backward gradient flow.
On the contrary, non-parametric methods do not suffer from the issue above. For any non-parametric method, , there is no way to express it in a closed form. Therefore, the derivative of can be computed only through a numeric but not an analytical approach. More formally, this means the calculation of needs to be completed through the calculation of limit . Given that a deep neural network takes as input each individual sample, which is discrete in the sample space, it is difficult to define the continuity of with traditional topology and thus the differentiability of cannot be guaranteed. This indicates, as a member of non-parametric methods, LLE perfectly satisfies the first design principle discussed in Section 4.1 (i.e., not capable of performing derivative calculation).
4.2.3. Non-invertibility of LLE
We validate the non-invertibility of LLE by theoretically proving that reconstructing original high-dimensional data from low-dimensional representations transformed by LLE is computationally intractable. More formally, we prove that, given a set of low-dimensional data () produced by LLE, reconstructing their original high-dimensional representations () from is at least an NP-hard problem.
Recall that LLE computes weight matrix and utilizes it to project high-dimensional data samples to a lower-dimensional space. As a result, to restore high-dimensional data from its lower-dimensional representations, one has to recover that matrix by following the calculation similar to that shown in (LABEL:eq:lle_1), except that and are replaced by and .
Once weight matrix is restored, the recovery of original high-dimensional data can be viewed as solving the following optimization problem:
| (9) |
It is not difficult to realize that Equation (9) can be defined in the following quadratic form:
| (10) |
where . Note that if and otherwise. If expressing as the following matrix:
| (11) |
we can easily realize that is a symmetric matrix, which has the property of .
Now, with the analysis above, the validation of non-invertibility amounts to proving that solving (10) is at least an NP-hard problem. In this work, we conduct this proof by introducing several constraints to this equation. Our basic idea is to use these constraints to relax the optimization problem in (10) to a nearby problem which can be easily proved as an NP-hard problem. More specifically, we introduce the following constraints:
| (12) |
and
| (13) |
where denotes a zero vector, and represents the element in vector .
With these constraints introduced to Equation 10, we can relax the optimization problem to a quadratic problem with a non-positive semi-definite constraint, which itself is a class of NP-hard problems (d2003relaxations, ). In the following, we provide more details on why the involvement of the aforementioned constraints transforms the optimization problem in (10) to this class of NP-hard problems.
Let denote a column vector which is the concatenation of for and . Then, we have . Let denote a row vector in which every element is equal to . We further define matrices as follows:
| (14) |
where . is a matrix of ones where every element is equal to .
Given the constraint in (12) that we introduce, it is not difficult to discover . Since the multiplication of a vector and its transpose derives a non-negative value, we have and the constraint in (12) can be expressed as inequation , indicating there exists a positive number, that always holds the inequity. By rewriting the inequation using the notations newly defined above, we can therefore transform the constraint in (12) into the form of .
Given the constraint in (13), we can easily derive inequation , which can be further expressed as indicating there alway exists a constant, that holds the inequity. By rewriting both the constraint itself and this inequation using newly defined notations, we can derive constraints as well as . As such, we can transform Equation (10) and the aforementioned constraints in (12) and (13) into following form:
| (15) | ||||
Here, is negative semi-definite, and thus Equation (LABEL:eq:QCQP) is a quadratic problem with a non-positive semi-definite constraint. According to (Vavasis1991Nonlinear, ; d2003relaxations, ), Equation (LABEL:eq:QCQP) belongs to a class of NP-hard problems, which implies the non-invertability of LLE.
4.3. Discussion
Here, we discuss some related issues and possible attacks against our proposed technique.
Approximation of LLE. While the aforementioned discussion and theoretical proof have already indicated the effectiveness of our proposed approach, intuition suggests that an adversary might still come up with an attack. Specifically, he might approximate LLE using a parametric mapping and then substitute LLE accordingly. Since parametric mappings do not have the property of non-differentiability, the adversary can take advantage of the substitute, pass gradients through and eventually craft adversarial samples. However, as we will show in Section 5, even using the state-of-the-art approximation scheme, an adversary cannot craft impactful adversarial samples.
Other dimensionality reduction methods. As is described above, we choose LLE, a representative non-parametric dimensionality reduction method, to serve as the data transformation module. This is due to the fact that it provides many properties needed for hardening a DNN, such as non-differentiability, non-invertibility and the capability of preserving data distribution.
Going beyond LLE, there are other non-parametric dimensionality reduction methods that offer the same properties, e.g., t-Distributed Stochastic Neighbor Embedding (t-SNE) (maaten2008visualizing, ) and Sammon Mapping (sammon1969nonlinear, ). However, they cannot be utilized in our problem domain for the following reason.
Deep neural networks exhibit superior performance when dealing with data in a relatively high dimensionality. Other non-parametric methods are typically designed more for tasks like visualization (maaten2008visualizing, ) where it is required that the dimensionality of the mappings is two or three. Using them as our data transformation module, they cannot provide high-dimensional data input for the DNN in tandem with the transformation, and may significantly jeopardize classification performance.
| Learning Technology | Black Box | White Box | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MNIST | MALWARE | IMDB | MNIST | MALWARE | IMDB | |||||||
| Standard DNN | 6.86% | 6.40% | 7.50% | 26.19% | 28.10% | 29.56% | 6.86% | 6.40% | 7.50% | 26.19% | 28.10% | 29.56% |
| Distillation | 87.06% | 96.22% | 47.36% | 79.93% | 82.65% | 87.31% | 34.43% | 12.60% | 8.43% | 40.47% | 48.98% | 49.12% |
| Adv. Training | 89.09% | 96.23% | 84.33% | 96.70% | 87.43% | 87.66% | 33.94% | 14.44% | 8.89% | 43.09% | 50.78% | 51.0% |
| LLE-DNN | 95.25% | 96.59% | 86.12% | 95.02% | 87.58% | 87.69% | 97.02% | 97.45% | 87.49% | 94.66% | 87.47% | 87.53% |
| Feature Examples | |||
|---|---|---|---|
| WINDOWS_FILE:Execute:[system]slc.dll | |||
| WINDOWS_FILE:Execute:[system]cryptsp.dll | |||
|
|||
| WINDOWS_FILE:Execute:[system]faultrep.dll | |||
|
|||
|
|||
| WINDOWS_FILE:Execute:[fonts]times.ttf |
| Hyper Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|
| Training Algorithms | Datasets | DNN Structure | Activation | Optimizer | Learning Rate | Dropout | Batch | Epoch |
| MNIST | 784-500-300-100 | Sigmoid | Adam | 0.001 | - | 100 | 70 | |
| Malware | 3738-3000-1000-100-2 | Relu | Adam | 0.001 | 0.25 | 500 | 20 | |
| Standard DNN | IMDB | 600-200-200-100-2 | Tanh | Adam | 0.001 | 0.5 | 100 | 40 |
| MNIST | 784-100-100-100-10 | Tanh | SGD | 0.1 | 0.25 | 100 | 60 | |
| Malware | 3738-3000-1000-100-2 | Relu | Adam | 0.001 | 0.25 | 500 | 20 | |
| Adversarial Training | IMDB | 600-300-100-50-2 | Sigmoid | Adam | 0.001 | 0.2 | 100 | 100 |
| MNIST | 784-200-50-20-10 | Tanh | SGD | 0.1 | 0.25 | 100 | 100 | |
| Malware | 3738-3000-100-20-2 | Relu | SGD | 0.1 | 0.25 | 100 | 20 | |
| Distillation (T=20) | IMDB | 600-100-100-50-2 | Sigmoid | SGD | 0.1 | 0.2 | 100 | 50 |
| MNIST | 200-200-100-10 | Relu | Adam | 0.001 | 0.5 | 100 | 50 | |
| Malware | 1000-500-200-100-2 | Relu | Adam | 0.001 | 0.5 | 100 | 50 | |
| LLE-DNN | IMDB | 500-300-200-100-2 | Tanh | Adam | 0.001 | 0.5 | 100 | 100 |
5. Evaluation
As is described in Section 1, adversarial training (Goodfellow14, ) and defensive distillation (papernot2015distillation, ) are the most representative techniques that have been proposed to defend against adversarial samples. In this work, we use the proposed approach to train our own adversary resistant DNN (LLE-DNN), and then compare it with those enhanced by these two approaches.
5.1. Dataset
We evaluate our adversary-resistant DNN model by performing multiple experiments on several widely used datasets, including a dataset for malware detection (berlin2015malicious, ), the MNIST dataset for image recognition (lecun1998mnist, ) and the IMDB dataset for sentiment analysis (maas2011learning, ).
Malware dataset: It is a collection of window audit logs, each of which ties to either a benign or malicious software sample. The dimensionality of the feature-space for each sample is reduced to 10,000 based on the feature selection metric in (berlin2015malicious, ). Each feature indicates the occurrence of either a single filesystem access or a sequence of access events, thus taking on the value of 0 or 1. Figure 2 illustrates a subset of features of a software sample. Here, 0 indicates that the sequence of events did not occur while 1 indicates the opposite. For each software sample, it has been labeled with either 1 or 0, indicating malicious and benign software, respectively. The dataset is split into 26,078 training examples, with 14,399 benign and 11,679 malicious software samples, and 6,000 testing samples, with benign and malicious software samples evenly divided.
MNIST dataset: It is a large database of handwritten digits that is commonly used for training various image processing systems. It is composed of 70,000 greyscale images (of 2828, or 784, pixels) of handwritten digits, split into a training set of 60,000 samples and a testing set of 10,000 samples.
IMDB dataset: It consists of 25,000 movie reviews, with one half labeled as “positive” and the other “negative”, indicating the sentiment of these reviews. We randomly split the dataset with 70% movie reviews for training and the remaining for testing. Following the procedure introduced in (mikolov2013distributed, ), we encoded the words in each movie review using a dictionary carrying 5,000 words most frequently used. Then, we utilized a word embedding technique (mikolov2013distributed, ) to convert each word into a vector with a dimensionality of 600. For each movie review, we linearly combined the vectors indicating the words appearing in that review, and then treat the embedding as the representation of that movie review.


5.2. Experimental Design
For each application described above, we train 4 DNN models using the traditional deep learning training method, adversarial training (Goodfellow14, ), defensive distillation (papernot2015distillation, ) and our own approach. We specify the hyperparameters of these DNNs in Table 3. We measure their classification accuracy by applying the models to the corresponding testing datasets. By comparing their classification performance, we evaluate the influence that our proposed approach brings to a DNN. More specifically, we examine if LLE-DNN exhibits similar – if not the same or better – classification accuracy.
Since the goal of this work is to improve the robustness of a DNN model, we also evaluate our DNN models’ resistance to adversarial samples. In particular, we derive adversarial samples from the aforementioned testing datasets, test them against our DNN model and compare its model resistance with those of DNNs enhanced by the other two techniques (papernot2015distillation, ; Goodfellow14, ).
As is discussed in Section 2.2, an attacker crafts adversarial samples through auxiliary models. In Table 1, black-box and white-box indicate the auxiliary models trained through different schemes. More specifically, black-box represents the auxiliary model trained through the standard deep learning training scheme, indicating an attacker does not have sufficient knowledge about the underlying training algorithm and he can use only a standard approach to train a cross model and craft adversarial samples. White-box represents the auxiliary model trained exactly through the learning schemes proposed as a defense. This simulates a situation where a defense mechanism is publicly disclosed and an attacker exploits that mechanism to produce a highly similar – if not the same – model to craft adversarial samples. Note that, for both black-box and white-box tactics, we use the same hyperparameters and training dataset to build auxiliary models. More specifically, our auxiliary model training shares the same hyperparameters and training dataset with the standard DNN shown in Table 3.
In addition to the methods described in Section 2.2, the crafting of adversarial samples must ensure a slight perturbation introduced to a data sample does not undermine its semantic. In other words, we must make sure that, while misleading a classifier to output the wrong class with high confidence, the perturbation to an image should be nearly indistinguishable to the human eyes, that to a malicious software sample should not jeopardize software functionality nor break its malevolence, and that to a movie review should not break its semantic meaning. In the following, we describe how we fine-tune adversarial samples to preserve semantic for different applications.
Malware classification. Recall that our malware samples are represented by features, the value of which are binary, indicating the occurrence of an filesystem access or a sequence of access events. When generating adversarial samples, we cannot simply disable filesystem access events in that this might jeopardize the functionality of the software sample and even break down its malevolence. With this in mind, a bit of care must be taken.
In this work, our experiment follows the approach introduced in Section 2.2. To be specific, we craft adversarial software samples by solving optimization problem (LABEL:eq:adv1) with the setting of zero norm (i.e., ). This indicates the manipulation to a sample is restricted to flipping binary feature values. In addition, this implies the strongest attack scenario in that optimization problem (LABEL:eq:adv1) carries less constraints making the adversarial samples chosen for our evaluation more impactful. Going beyond adversarial sample crafting approach discussed in Section 2.2, we also restrict that the value change of a feature can be only from 0 to 1 but not the opposite. This amounts to allowing the addition of new filesystem access events only. This manipulation strategy is reasonable for the reason that malware mutation techniques (e.g., (MohanH12, )) can morph a malware sample by stitching together instructions from benign programs, making the malware perform additional filesystem accesses but not undermining its maliciousness nor its functionality. Since malware manipulation is done with the intent of fooling a malware classifier driven by a DNN, it should be noticed that we do not morph a benign software sample, making it malicious.
Image recognition. Image data samples contain less strict semantic than the malware data samples above. To preserve image semantic – making a perturbation nearly indistinguishable – we follow the approaches introduced in (Carlinioakland2017, ; 42503, ; Goodfellow14, ). More specifically, we selected , and distance to represent the dissimilarity between an image and its corresponding adversarial sample. Especially, we restrict the distance in a relative small range (i.e., ) when crafting adversarial samples.
Sentiment Analysis. To generate adversarial samples for movie reviews, we again followed the approach introduced in Section 2.2. To be specific, we solved optimization problem (LABEL:eq:adv1) and configured -norm with the setting to and . This is due to the fact that each review is encoded in a vector in which each element is a decimal, and and distances represent the best measure for the dissimilarity between a movie review and its corresponding adversarial sample.
As is mentioned above, each vocabulary has been encoded in a vector with a dimensionality of 600, and we embedded a movie review by linearly combining corresponding vectors. When generating an adversarial sample by introducing a slight perturbation to the embedding, we cast the perturbation to only one vector. This ensures that we introduce only one word change to that review with the hope that it preserves the semantic meaning of that review as much as possible. However, one word change does not guarantee the invariance of the semantic meaning. For example, it would be obvious alteration to the semantic meaning if the replacement happens to be the negative word in “… makes it the biggest disappointment I’ve experienced from cinema in years …”. As such, we manually choose the word that incurs minimal semantic change to that movie review. Figure 5 illustrates a movie review sample and its corresponding adversarial sample generated through this approach.
5.3. Experimental Setup and Results
On the datasets described above, we first measure the accuracy of all the aforementioned defense techniques. We then measure their resistance to the adversarial samples crafted through the aforementioned tactics.
| Learning technology | Accuracy | ||
|---|---|---|---|
| MNIST | MALWARE | IMDB | |
| Standard DNN | 98.45% | 92.97% | 87.89% |
| Distillation | 98.46% | 92.45% | 87.36% |
| Adv. training | 98.77% | 91.48% | 87.67% |
| LLE-DNN | 98.19% | 93.56% | 87.79% |
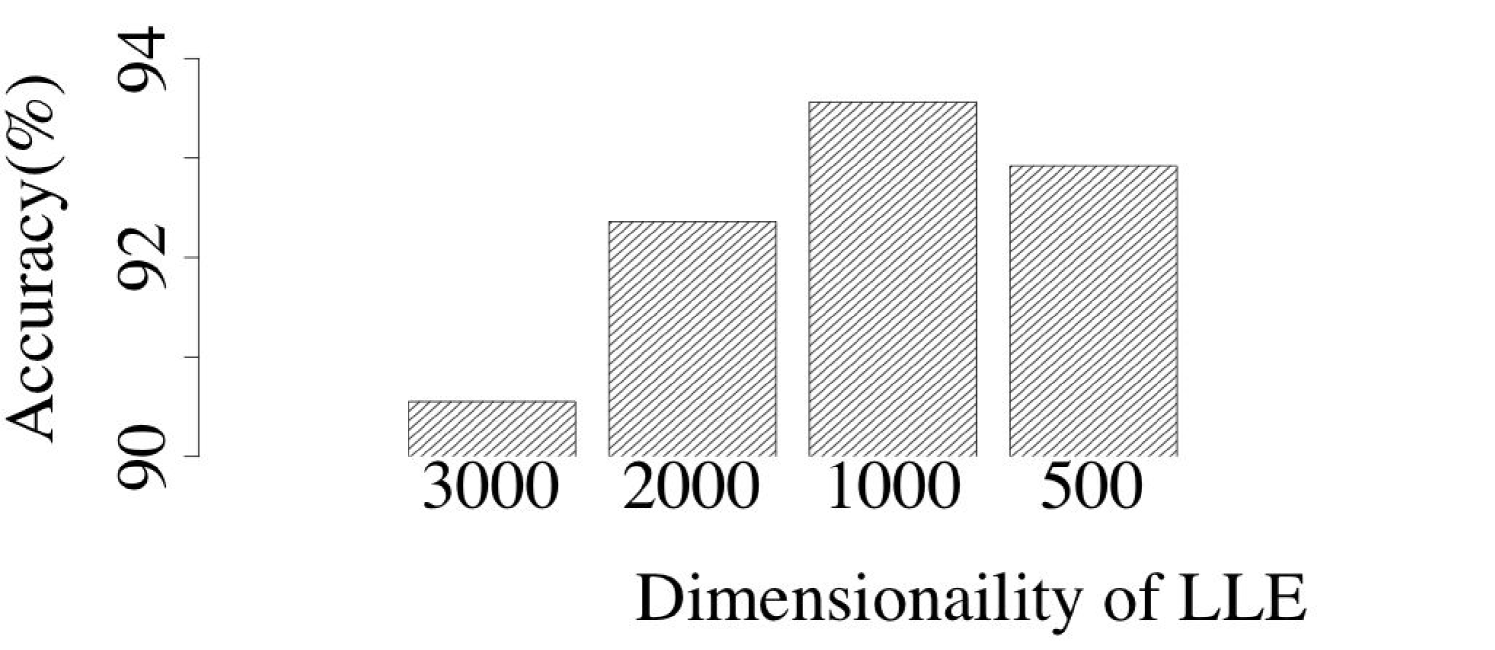
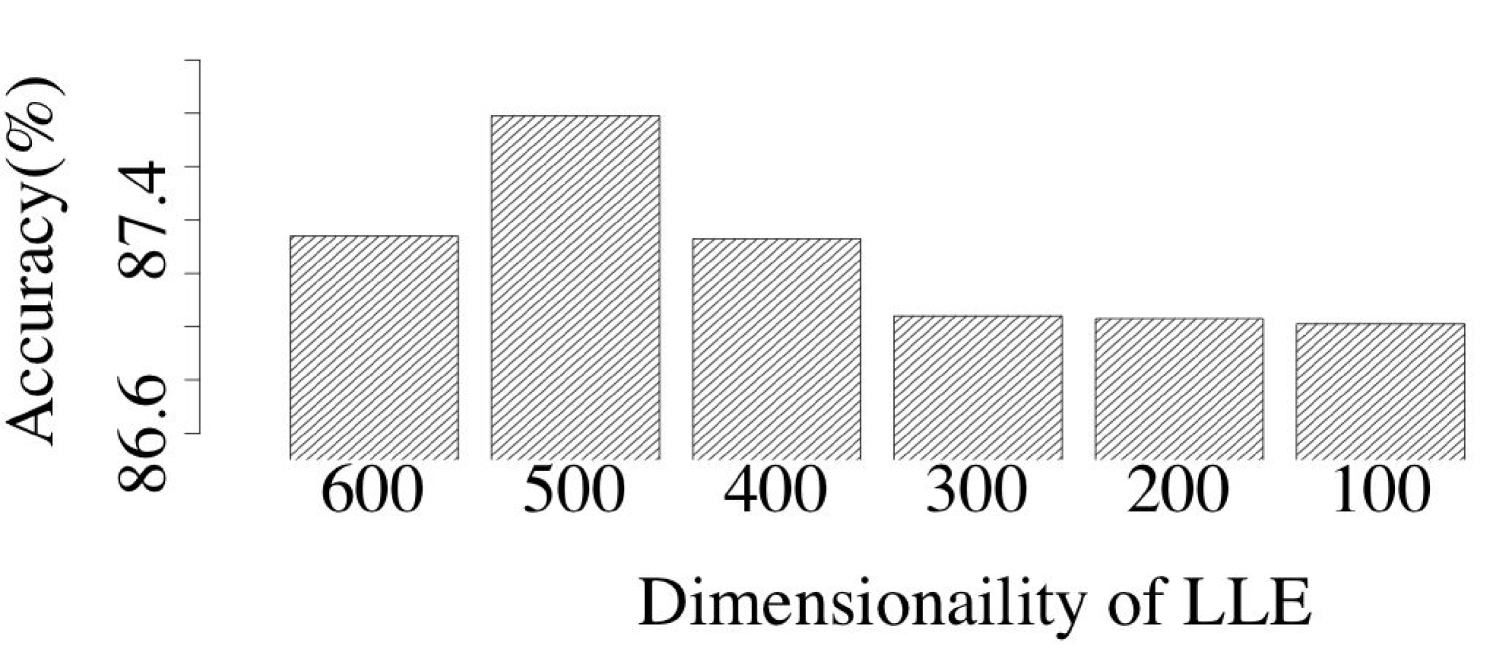
5.3.1. Classification Accuracy
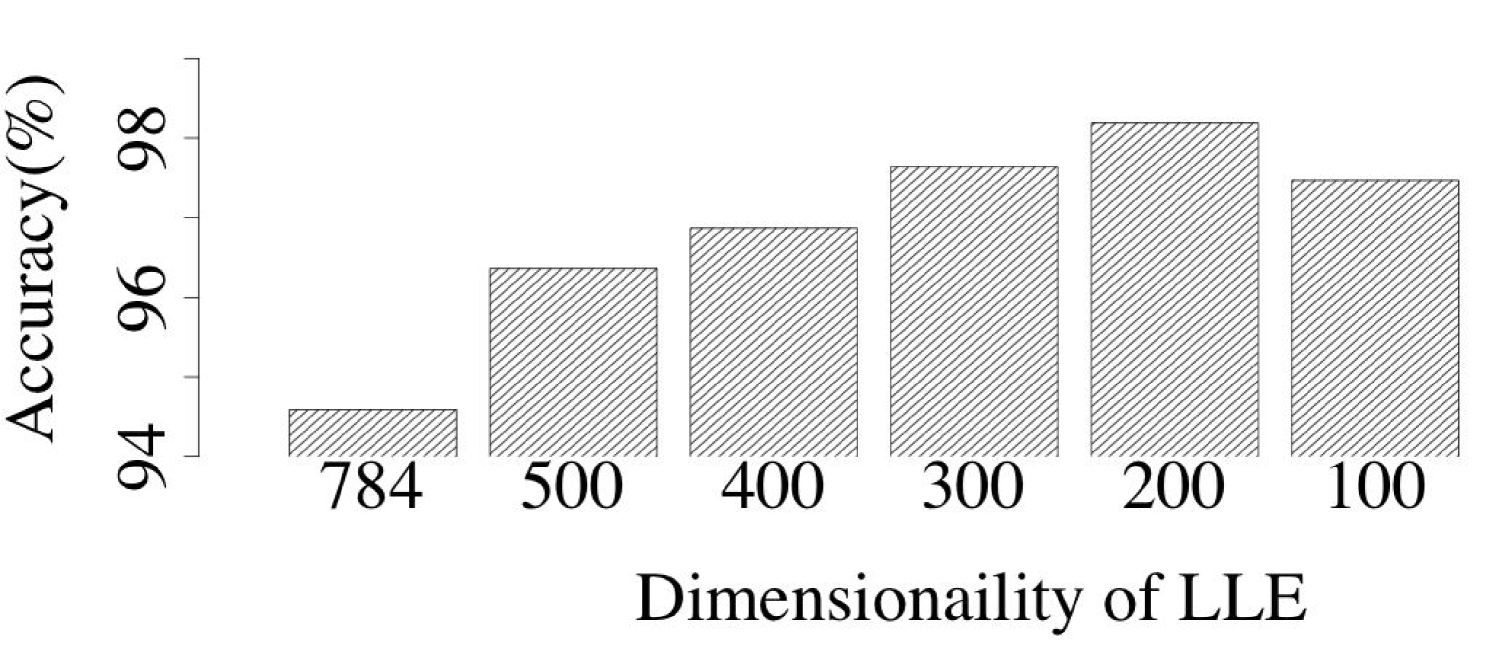
To identify the optimal dimensionality to which LLE needs to map original data samples, we implemented several LLE-DNNs with different settings of dimensionality of LLE mappings. Figure 6 shows the impact of dimensionality mapping upon the classification accuracy obtained by LLE-DNN. Across all three datasets, it is easy to observe that, the classification accuracy first increases when the dimensionality of the LLE mappings rises and then starts to decrease. In our experiment, we choose the highest classification accuracy to represent the performance of our LLE-DNN.
Table 4 presents the classification accuracy results obtained from all investigated DNNs with respect to the testing datasets. Note that, while prior works (e.g, (abs-1003-0358, ; deep-convex-network, )) have already demonstrated they can train a DNN with an error rate less than 1% on the MNIST benchmark, their performance improvement does not result from a DNN but model ensemble or elastic distortions added to training data. To study the influence of our proposed approach upon a standard DNN, therefore, we did not combine models nor augment with artificially distorted versions of the original training samples. The classification accuracy shown in the table has already represented the best performance that a standard DNN can achieve.
Similar to adversarial training and defensive distillation, the LLE-DNN is quite effective in preserving classification accuracy. This implies our proposed approach well preserves data sample distribution. For the malware classification task, it can be observed that LLE-DNN appears to be better at feature learning, achieving the highest classification accuracy among DNNs that we investigated. This is presumably due to the fact that malware data samples are highly sparse carrying a large amount of redundant information, and the data transformation module in LLE-DNN eliminates those redundancy and ameliorates the learning ability of a DNN.
5.3.2. Model Resistance
Table 1 illustrates the DNNs that we investigated as well as their accuracy in classifying adversarial samples. It can be observed that, black-box adversarial samples can cut down the accuracy of the standard DNN to 6.86, 6.40 and 7.50 under the attacks of , and , respectively. In contrast, all of the defense mechanisms investigated demonstrate strong resistance to these black-box adversarial samples. This indicates, without sufficient knowledge on the underlying defense mechanisms, it is difficult for an attacker to craft impactful adversarial samples. In other words, existing defense mechanisms can significantly escalate a DNN’s resistance to adversarial samples if one can obscure the design of the defenses.
Despite the improvement in model robustness, we also observe that our LLE-DNN generally exhibits the best resistance to black-box adversarial samples, whereas the defensive distillation approach typically yields the worst resistance. This is presumably due to the fact that, the dimensionality reduction resided in LLE-DNN transforms adversarial samples into a subspace in which they no longer act as outliers, while defensive distillation smooths only a classification decision boundary which does not significantly reduce the subspace of adversarial samples.
With regard to the white-box setting, we discover both adversarial training and defensive distillation suffer from white-box adversarial samples. Their resistance to white-box adversarial samples is significantly worse than those created under the black-box setting. This observation is consistent with that reported in (Carlinioakland2017, ). The reason behind this is that, both techniques stash away the adversarial sample subspace, but the disclosure of defense mechanisms uncovers the path of finding that subspace.
Different from adversarial training and defensive distillation, our LLE-DNN is naturally resistant to white-box adversarial samples. As is discussed in Section 4, our proposed approach stashes away the adversarial sample subspace and at the same time restricts derivative calculation. Even if our defense mechanism is revealed, therefore, it is still computationally difficult to find adversarial samples.
To perform quantitative comparison with the other two approaches, however, we approximate the data transformation in the LLE-DNN – non-parametric dimensionality reduction component – using a parametric model. To be specific, we choose a DNN to approximate LLE in that a DNN has a large amount of parameters which is typically viewed as the best approximation for non-parametric learning models (hornik1991approximation, ). With the support from this approximation, we treated the LLE-DNN as a white box and generated adversarial samples accordingly. We show its model resistance in Table 1. It can be observed that, our LLE-DNN still demonstrates strong resistance to white-box adversarial samples even if we substituted LLE to its best approximation. This implies that, there might a theoretical lower bound between a non-parametric model and its parametric approximation, which can naturally serve as a defense against white-box adversarial samples.
6. Conclusion
A Deep Neural Network is vulnerable to adversarial samples. Existing defense mechanisms improve a DNN model’s resistance to adversarial samples by using the tactic of security through obscurity. Once the design of the defense is disclosed, therefore, the robustness they provide wane. Motivated by this, this work introduces a new approach to escalate the robustness of a DNN model. In particular, it integrates to a DNN model LLE, a non-parametric dimensionality reduction method. With this approach, we show that one can develop a DNN model resistant to adversarial samples even if he or she reveals its design details (i.e., the underlying training algorithm). By demonstrating the DNNs enhanced by our proposed technique across various applications, we argue the proposed approach introduces nearly no degradation in classification performance. In contrast, for some applications, it even exhibits performance improvement. As part of the future work, we will further explore the performance of this approach in a wider variety of applications across different deep neural architectures.
References
- [1] Y. Bar, I. Diamant, L. Wolf, and H. Greenspan. Deep learning with non-medical training used for chest pathology identification. In SPIE Medical Imaging, pages 94140V–94140V. International Society for Optics and Photonics, 2015.
- [2] M. Barreno, B. Nelson, R. Sears, A. D. Joseph, and J. D. Tygar. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, computer and communications security, pages 16–25. ACM, 2006.
- [3] O. Bastani, Y. Ioannou, L. Lampropoulos, D. Vytiniotis, A. Nori, and A. Criminisi. Measuring neural net robustness with constraints. In Advances In Neural Information Processing Systems, pages 2613–2621, 2016.
- [4] I. G. Y. Bengio and A. Courville. Deep learning. Book in preparation for MIT Press, 2016.
- [5] K. Berlin, D. Slater, and J. Saxe. Malicious behavior detection using windows audit logs. In Proceedings of the 8th ACM Workshop on Artificial Intelligence and Security, pages 35–44. ACM, 2015.
- [6] N. Carlini and D. Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy (S&P). IEEE, 2017.
- [7] D. C. Ciresan, U. Meier, L. M. Gambardella, and J. Schmidhuber. Deep big simple neural nets excel on handwritten digit recognition. CoRR, abs/1003.0358, 2010.
- [8] G. E. Dahl, J. W. Stokes, L. Deng, and D. Yu. Large-scale malware classification using random projections and neural networks. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 3422–3426. IEEE, 2013.
- [9] A. d’Aspremont and S. Boyd. Relaxations and randomized methods for nonconvex qcqps. EE392o Class Notes, Stanford University, 2003.
- [10] L. Deng and D. Yu. Deep convex network: A scalable architecture for speech pattern classification. In Interspeech, 2011.
- [11] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Scene parsing with multiscale feature learning, purity trees, and optimal covers. arXiv preprint arXiv:1202.2160, 2012.
- [12] I. Goodfellow, J. Shlens, and C. Szegedy. Explaining and Harnessing Adversarial Examples. CoRR, 2014.
- [13] S. Gu and L. Rigazio. Towards deep neural network architectures robust to adversarial examples. arXiv:1412.5068 [cs], 2014.
- [14] R. Hadsell, P. Sermanet, J. Ben, A. Erkan, M. Scoffier, K. Kavukcuoglu, U. Muller, and Y. LeCun. Learning long-range vision for autonomous off-road driving. Journal of Field Robotics, 26(2):120–144, 2009.
- [15] G. E. Hinton. Learning multiple layers of representation. Trends in cognitive sciences, 11(10):428–434, 2007.
- [16] R. A. Horn and C. R. Johnson. Matrix analysis. corrected reprint of the 1985 original, 1990.
- [17] K. Hornik. Approximation capabilities of multilayer feedforward networks. Neural networks, 4(2):251–257, 1991.
- [18] L. Huang, A. D. Joseph, B. Nelson, B. I. Rubinstein, and J. Tygar. Adversarial machine learning. In Proceedings of the 4th ACM workshop on Security and artificial intelligence, pages 43–58. ACM, 2011.
- [19] A. Kerckhoffs. La cryptographie militaire. Journal des Sciences Militaires, pages 161–191, 1883.
- [20] Y. LeCun, C. Cortes, and C. J. Burges. The mnist database of handwritten digits, 1998.
- [21] Y. Liu, X. Chen, C. Liu, and D. Song. Delving into transferable adversarial examples and black-box attacks. arXiv preprint arXiv:1611.02770, 2016.
- [22] A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, and C. Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
- [23] L. v. d. Maaten and G. Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008.
- [24] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
- [25] V. Mohan and K. W. Hamlen. Frankenstein: Stitching malware from benign binaries. In WOOT. USENIX Association, 2012.
- [26] A. Nguyen, J. Yosinski, and J. Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 427–436. IEEE, 2015.
- [27] A. G. Ororbia II, C. L. Giles, and D. Kifer. Unifying adversarial training algorithms with flexible deep data gradient regularization. arXiv:1601.07213 [cs], 2016.
- [28] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami. The limitations of deep learning in adversarial settings. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P), pages 372–387. IEEE, 2016.
- [29] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami. Distillation as a defense to adversarial perturbations against deep neural networks. In IEEE Symposium on Security and Privacy (S&P). IEEE, 2016.
- [30] R. Pascanu, J. W. Stokes, H. Sanossian, M. Marinescu, and A. Thomas. Malware classification with recurrent networks. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1916–1920. IEEE, 2015.
- [31] S. T. Roweis and L. K. Saul. Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500):2323–2326, 2000.
- [32] S. Sabour, Y. Cao, F. Faghri, and D. J. Fleet. Adversarial manipulation of deep representations. arXiv preprint arXiv:1511.05122, 2015.
- [33] J. W. Sammon. A nonlinear mapping for data structure analysis. IEEE Transactions on computers, 18(5):401–409, 1969.
- [34] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
- [35] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. In International Conference on Learning Representations, 2014.
- [36] L. van der Maaten, E. O. Postma, and H. J. van den Herik. Dimensionality reduction: A comparative review, 2008.
- [37] S. A. Vavasis. Nonlinear Optimization: Complexity Issues. Oxford University Press, Inc., New York, NY, USA, 1991.
- [38] Y. Xu, T. Mo, Q. Feng, P. Zhong, M. Lai, I. Eric, and C. Chang. Deep learning of feature representation with multiple instance learning for medical image analysis. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1626–1630. IEEE, 2014.
- [39] Z. Yuan, Y. Lu, Z. Wang, and Y. Xue. Droid-sec: Deep learning in android malware detection. In ACM SIGCOMM Computer Communication Review, volume 44, pages 371–372. ACM, 2014.