Bunching and Taxing Multidimensional Skills††thanks: We thank Hector Chade, Paolo Martellini, Chris Moser, Emmanuel Saez, Florian Scheuer, Andrew Shephard, Chris Taber and especially Jean-Charles Rochet for detailed insightful comments.
Abstract
We characterize optimal policy in a multidimensional nonlinear taxation model with bunching. We develop an empirically relevant model with cognitive and manual skills, firm heterogeneity, and labor market sorting. We first derive two conditions for the optimality of taxes that take into account bunching. The first condition a stochastic dominance optimal tax condition shows that at the optimum the schedule of benefits dominates the schedule of distortions in terms of second-order stochastic dominance. The second condition a global optimal tax formula provides a representation that balances the local costs and benefits of optimal taxation while explicitly accounting for global incentive constraints. Second, we use Legendre transformations to represent our problem as a linear program. This linearization allows us to solve the model quantitatively and to precisely characterize bunching. At an optimum, 10 percent of workers is bunched. We introduce two notions of bunching – blunt bunching and targeted bunching. Blunt bunching constitutes 30 percent of all bunching, occurs at the lowest regions of cognitive and manual skills, and lumps the allocations of these workers resulting in a significant distortion. Targeted bunching constitutes 70 percent of all bunching and recognizes the workers’ comparative advantage. The planner separates workers on their dominant skill and bunches them on their weaker skill, thus mitigating distortions along the dominant skill dimension.
1 Introduction
We make significant progress in analyzing multidimensional optimal nonlinear income taxation problems with bunching. This is one of the important open questions in the theory and practice of optimal taxation. Our paper is the first to solve for optimal multidimensional taxation with bunching in an empirically relevant model of wage determination.
The key difficulty of analyzing multidimensional optimal tax problems lies in characterizing regions of bunching. Bunching occurs when workers of different types receive identical allocations. Kleven, Kreiner, and Saez (2009) establish the importance of bunching in a model of couples taxation in which one partner makes only an extensive margin labor supply choice. Little is known about optimal taxation and the nature of bunching in more general settings. At the same time, a large literature in labor economics emphasizes the importance of multidimensional skills and labor market sorting in determining wage dispersion.
We develop an empirically relevant model that incorporates three important elements of wage dispersion. Workers differ in both manual and in cognitive skills, firms differ in productivity, and workers’ output depends on the firms they work for and coworkers they work with. We characterize equilibrium for the positive model in closed form and use this closed-form solution to identify the underlying multidimensional skill distribution.
The characterization of optimal taxes in our model is based on two main theoretical insights. First, we derive two conditions for optimal taxes that take into account bunching. The first condition a stochastic dominance optimal taxation condition shows that at the optimum the benefits and the costs are not necessarily equated for each skill level but rather the entire schedule of benefits dominates the entire schedule of distortions in terms of second-order stochastic dominance. The second condition a global optimal tax formula provides a representation that balances the local costs and benefits of optimal taxation while explicitly accounting for global incentive constraints. These optimal tax conditions generalize the classic unidimensional optimal taxation conditions in Mirrlees (1971), Diamond (1998), and Saez (2001) to a multidimensional optimal taxation problem, accounting for global incentive constraints and bunching. Second, we use Legendre transforms to represent our problem as a linear program. Legendre transforms are a powerful tool from convex analysis that allow to represent a convex function by a family of its tangent lines. This linearization enables us to fully solve the model quantitatively and, in particular, precisely characterize the patterns of bunching.
We find that 10 percent of all workers are bunched at the optimal allocation for our empirically estimated economy. We show that workers are bunched with other workers who are better in one dimension but worse in the other dimension. Moreover, a sizable portion of bunching is nonlocal.
We introduce two notions of bunching: blunt bunching and targeted bunching. Blunt bunching occurs at the lowest regions of cognitive and manual skills. The planner does not distinguish workers’ cognitive skills from their manual skills and lumps their allocations together by an index of their skills. This is a blunt tool for providing incentives as it creates significant distortions leading to high marginal taxes 30 percent of all bunching is blunt. Targeted bunching recognizes the workers’ comparative advantage. The planner separates workers on their dominant skill while bunching them on their weaker skill 70 percent of all bunching is targeted.
We now discuss our model and results in more detail. We consider the optimal policy problem which we formulate as a mechanism design problem (Mirrlees, 1971). The planner chooses consumption allocations, allocations of cognitive and manual tasks, and the assignment of workers to coworkers and firms subject to incentive constraints that workers truthfully report their type. The primary difficulty in analyzing multidimensional optimal taxation problems is in characterizing regions of bunching. Rochet and Choné (1998) shows that bunching is generic in the multidimensional multiproduct monopolist problem that is closely related to the multidimensional optimal taxation problem. An important paper by Kleven, Kreiner, and Saez (2009) solves a multidimensional optimal taxation model under the restriction that one of the allocations is binary and argues for the importance of bunching in their setup. In our model, both the allocations of the manual and cognitive tasks are instead unrestricted. For this general setup, no characterization of optimal tax policy is known.
Our first theoretical result is the derivation of two optimality conditions that take into account the regions of bunching. First, we show that, at the optimum, the utility and revenue benefits from the entire schedule of taxes second-order stochastically dominate the costs of distortions they induce. Without bunching, this tradeoff is made locally and leads the planner to equalize the marginal benefits and costs of taxes as in a unidimensional problem. We show that, when there is bunching, the planner no longer equates the benefits and the costs of the taxes at each worker skill level but instead requires that the entire schedule of the benefits of taxes second-order stochastically dominate the entire schedule of distortions, making this tradeoff nonlocal. Second, we derive an optimal tax formula for the multidimensional taxation problem that holds with equality. We show that the local tradeoffs have to be augmented with an additional term that accounts for global incentive constraints. Specifically, the additional term modifies the social welfare weights through a convexity correction.111When there is no bunching, a classic pointwise optimality condition holds that can be rewritten in terms of a multidimensional ABC taxation formula similar to the unidimensional tax formula in Diamond (1998) and Saez (2001). The absence of bunching is equivalent to the indirect utility function being strongly convex and the first-order approach being valid. Kleven, Kreiner, and Saez (2006, p. 23) derive such a multidimensional ABC formula without bunching. Both formulas are new to the literature on optimal taxation.
Our next main theoretical insight is to transform the planner problem to a linear program. This is a key step that enables computation of the bunching regions. Legendre transformations linearize a convex function by replacing it with the upper envelope of all its tangent lines. The Legendre transform allows us to translate the multidimensional optimal taxation problem into a linear program that can be analyzed quantitatively with high precision. Numerical precision is not merely a technical curiosity but is essential to identify the regions and nature of bunching.
A parallel starting point of our analysis is a characterization of the equilibrium in a positive economy. In our positive economy, workers choose the amount of cognitive and manual tasks to deliver, coworkers to work with, and firms to work for. This problem integrates endogenous labor supply decisions with the assignment of multidimensional workers to teams and to heterogenous firms. Our first result for the positive economy is that workers sort with identical coworkers (self-sorting) and that better teams work on more valuable projects (positive sorting). The resulting assignment is qualitatively identical to the assignment under the optimal policy problem but the exact assignment differs because of differences in labor supply due to incentive constraints.
We use the dual formulation of the equilibrium assignment problem to characterize equilibrium wages. We show that wages are a convex function of an index of the worker’s task inputs rather than a function of each task individually. We further establish an exact mapping between curvature in the wage schedule and the distribution of firm productivity. By choosing a parametric convex function, we can then infer a distribution of firm projects such that this convex function is the equilibrium wage schedule.
Having developed the theory to characterize both positive and optimal allocations, we bring our theory to the data. In order to quantify cognitive and manual skill heterogeneity in the U.S. population, we use earnings information for all workers between 2000 and 2019 in the American Community Survey (ACS). We combine the earnings data from the ACS with data from O*NET on the manual and cognitive task intensity for every occupation (Acemoglu and Autor (2011)).
We use our closed-form characterization for wages in the positive economy to pointwise identify the level of manual and cognitive tasks completed by each worker. We then use the worker’s optimality condition for each task together with these inferred task levels to identify levels of cognitive and manual skill that deliver each worker’s wage and relative task intensity in the cross-sectional data as a model outcome. For the unidimensional taxation problem, an important contribution of Saez (2001) was to infer the underlying productivity distribution using earnings data which then becomes a central input to determine optimal taxes. Our identification generalizes these findings and delivers the distribution of manual and cognitive skills in a model accounting for multiple drivers of earnings (multidimensional skills, coworkers, firms). Our identification resembles Boerma and Karabarbounis (2020, 2021) who use explicit solutions for home production models to identify productivity at home and market productivity using data on consumption, home and market hours.
We next turn to the quantitative characterization of the optimum using the inferred skill distribution. In order to understand our quantitative characterization, we first describe a benchmark without incentive constraints. Due to separability of preferences and technology over tasks, the efforts in a given task depend exclusively on the worker’s skills in this task and, hence, there is no cross-dependence between tasks. Trivially, there is no bunching and there are no distortions.
In sharp contrast to the benchmark, optimal task intensity in our model depends positively on both of the worker’s skills. Workers with high manual skills also deliver high levels of cognitive tasks. This codependence is lower at the top end of the skill distribution. In the limit, workers face zero distortion in their manual task allocation at the top of the manual skill distribution, meaning there is no dependence of their manual task intensity on their cognitive skills as in the benchmark. At the lower end of the skill distribution, the distortion from this positive codependence is high.
A central part of our contribution is to characterize patterns of bunching. We first show that 10.4 percent of all workers is bunched at the optimum. Workers bunch with other workers both near and afar. Moreover, workers exclusively bunch with workers that are better in one skill dimension but worse in another. Workers do not bunch with workers over whom they have an absolute advantage nor with workers who have an absolute advantage over them.
We introduce two types of bunching: blunt bunching and targeted bunching. In the blunt bunching region, the planner requires all workers with the same effective skill index to deliver identical cognitive and manual tasks, and thus bunches workers that vastly differ in their skills. This is a blunt way to provide incentives and comes at a cost of significant output distortions. In the targeted bunching region, the planner recognizes the increasing efficiency costs of distorting higher skill workers. When workers have a higher relative level of, for example, manual skills they are separated along this dimension but are bunched on their relatively low cognitive skill. The planner thus separates according to workers’ comparative advantage and bunches workers by comparative disadvantage. In contrast to the blunt bunching region, targeted bunching occurs with workers who are more similar in skills: not too far away yet still nonlocally. In the region without bunching, the planner distorts allocations as in the unidimensional case.
We summarize the bunching patterns by describing the tax wedges they induce. In particular, we find that the level of tax wedges is high in the bunching regions. The tax wedges are particularly high for low skill workers who are bluntly bunched and are also high along the dimension of comparative disadvantage for the more skilled workers in the targeted bunching region. We further show that the optimum is implementable by a tax function that is only a function of earnings and line of work.
Literature. We now describe related literature. Kleven, Kreiner, and Saez (2009) is the first paper that analyzed optimal multidimensional taxation with bunching. They model a binary labor supply choice for the secondary earner along with continuous labor supply choice for the primary earner. Judd, Ma, Saunders, and Su (2017) consider numerically some cases of optimal taxation with multiple dimensions of heterogeneity (up to five dimensions of heterogeneity with five individual types) and find that some non-local constraints bind. The most ambitious attempt to date to solve a multidimensional policy problem with bunching is Moser and Olea de Souza e Silva (2019) for a model where workers are heterogeneous in two dimensions but only one dimension of heterogeneity enters the planner’s objective. Their key ingredient is paternalistic preferences, which delivers bunching due to disagreement between the planner and workers. In their environment bunching is optimal and, in fact, an essential feature even for the unidimensional problem. The fact that the planner cares only about one dimension of heterogeneity significantly reduces the complexity of deviations patterns. They characterize the model theoretically with the continuous skill distributions and also compute the model with six impatient types in one dimension and a large number of types in the second dimension. In our paper and, more broadly, for multidimensional optimal nonlinear taxation problems the planner cares about heterogeneity in several dimensions and, hence, the deviations and bunching patterns are significantly more complicated and nuanced, especially, when a large number of types within each skill dimension is analyzed. Heathcote and Tsujiyama (2021b) comprehensively analyze computational performance of different algorithms for unidimensional optimal taxation. They show that the number of skill types is not just a technical detail but has an important impact on policy prescriptions. In our settings, the need for fine skill differentiation in both dimensions of heterogeneity is additionally important to recover the nuanced patterns of bunching and deviating, especially in the regions of targeted bunching. More broadly, there is a vast literature on multidimensional mechanisms (e.g., McAfee and McMillan (1988), Armstrong (1996) and Rochet and Choné (1998)) that also emphasizes the complexity, as well as the central role, of bunching for the optimal solutions.
An important strand of papers in Scheuer (2014), Rothschild and Scheuer (2013, 2014, 2016) analyze nonlinear optimal taxation with multidimensional heterogeneity. These papers achieve tractability by transforming the multidimensional problem into a unidimensional screening problem with an endogenous wage distribution. Moreover, Rothschild and Scheuer (2014, 2016) in the multidimensional case and Scheuer and Werning (2017) also emphasize the importance of labor market sorting. Lehmann, Renes, Spiritus, and Zoutman (2021) and Golosov and Krasikov (2022) use a first-order approach to theoretically and numerically study multidimensional optimal taxation when there is no bunching.
A complementary approach is to analyze optimal policy in economies with multidimensional heterogeneity by restricting taxes to parametric families. The most comprehensive recent analysis using this approach is Blundell and Shephard (2012) on optimal taxation of low-income families and Gayle and Shephard (2019) on optimal taxation of couples. Notable papers that use such a parametric approach in a variety of other areas of optimal taxes are, for example, Benabou (2002), Conesa, Kitao, and Krueger (2009), Heathcote, Storesletten, and Violante (2017). Heathcote and Tsujiyama (2021a) synthesize the Mirrleesian approach and the parametric approach to optimal taxation.
Our positive wage determination model relates to a growing literature in labor economics that adopts a task approach to understand the contribution of multidimensional skills to labor market outcomes. Recent prominent examples in this area include Yamaguchi (2012), Sanders and Taber (2012), Lindenlaub (2017), Deming (2017), Guvenen, Kuruscu, Tanaka, and Wiczer (2020), Lise and Postel-Vinay (2020), Roys and Taber (2022) and Lindenlaub and Postel-Vinay (2023). Differently from these papers, we combine multidimensional skill heterogeneity with sorting into worker teams and sorting with heterogeneous firms.
2 Environment
We consider an economy with two-dimensional worker skill heterogeneity and heterogeneous firms. Worker output depends not only on own cognitive and manual efforts but also on the coworker it works with and the firm it works for as emphasized in the modern literature on wage determination.
Workers. The economy is populated by a measure two of workers who differ in two unobservable characteristics. Workers are endowed with a bundle of cognitive and manual skills . The distribution over types is denoted by .
Workers have preferences over consumption and experience disutility from effort in cognitive and manual activities :
| (1) |
where consumption and leisure are positive, utility is increasing and concave in consumption, and decreasing and strictly concave in cognitive and manual efforts. We further assume disutility has the form:
| (2) |
with .
Technology. Cognitive and manual production input for a worker are the product of their skills and their efforts:
| (3) |
for all tasks . The worker’s skill is given by , while their effort is given by .
The economy is populated by a unit mass of heterogeneous firms that produce a single output by organizing two workers into a team to work on a project . Firm production is represented by . We use a bilinear team technology together with a multiplicative firm technology:222The bilinear technology is also used in Lindenlaub (2017), Lise and Postel-Vinay (2020), and Lindenlaub and Postel-Vinay (2023), among others.
| (4) |
Assignment. An assignment pairs workers with coworkers and projects. Formally, an assignment is a probability measure over workers, coworkers, and firms. Given a distribution of worker inputs , a distribution of coworker inputs , and a distribution of firms , the set of feasible assignments is . This is the set of probability measures on the product space such that the marginal distributions of onto the set of workers and coworkers are , and the marginal distribution of onto the set of firms is . The assignment function captures the measure of workers that work together on a project as . Given a feasible assignment total output is .
Resources. Aggregate output and external resources are allocated to workers to consume:
| (5) |
where is aggregate consumption.
3 Planning Problem
In this section, we formulate a planner problem and characterize optimal sorting. The planner problem is to choose an allocation and an assignment to minimize the resource cost of providing welfare :
| (6) |
subject to incentive constraints for all workers , so that workers do not gain by misreporting types to be :
| (7) |
and the promise keeping condition:
| (8) |
which requires that aggregate welfare exceeds promised value .333The planning problem is equivalent to maximizing utilitarian welfare function subject to the resource constraint (6) and the incentive constraints (7). There are no incentive constraints for firms since we assume firm output and inputs and are observed by the planner. Hence, the firm productivity is not private information.
3.1 Assignment
The planning problem contains an assignment problem. The planner pairs worker and coworker inputs with firm projects to maximize output given a distribution of worker inputs and firm projects. We show the planner optimally chooses a self-sorted assignment, meaning that workers are paired with identical coworkers, and also show that the planner pairs better teams with more valuable projects.444This assignment problem falls into a class of multimarginal, multidimensional optimal transportation problems. Multidimensional skill and the dependence of worker output on coworkers are central to recent advances in sorting models that utilize optimal transport theory to characterize equilibrium (Chiappori, McCann, and Nesheim, 2010; Dupuy and Galichon, 2014; Lindenlaub, 2017; Chiappori, McCann, and Pass, 2017; Galichon and Salanié, 2022).
The assignment problem embedded in the planning problem is to choose an assignment to maximize production given the distribution of workers tasks and the project distribution :
| (9) |
We construct an assignment that self-sorts workers and coworkers to obtain a unidimensional distribution for team quality, or effective worker skill, . The assignment combines self-sorting of workers with positive sorting between the effective worker skill and projects .555Self-sorting is defined with respect to distribution of effective task inputs that the workers supply, not necessarily with respect to the underlying worker skills . In the presence of bunching, multiple workers supply the same task levels and hence self-sorting of effective tasks may imply matching different . This assignment solves the assignment problem (9).
Proposition 1.
Optimal Sorting. The planner assignment is characterized by self-sorting of workers and by positive sorting between team quality and project values.
The proof is in Appendix A.1.
We now develop the intuition for Proposition 1. Given a firm project, and since the technology for each task in equation (4) is supermodular, the planner optimally wants to positively sort both cognitive and manual inputs to project . In our economy with multidimensional worker skills, positive sorting within each task is attained by self-sorting. An optimal assignment thus features self-sorting of workers with coworkers within projects . Given that workers are optimally self-sorted, the planner remains to sort self-sorted workers with effective skill to firms . Since the effective production technology is supermodular in team quality and project value , the optimal assignment features positive sorting between teams and project values.666Positive sorting of effective skill with project values follows the classical Beckerian analysis (Becker, 1973).
Given that the assignment features self-sorting, the output per worker produced by a team of two workers supplying task inputs is . Aggregate output is , and the resource cost (6) can be written as:
| (10) |
3.2 Utility Allocations
We next transform the planner problem from choosing consumption and task allocations to choosing consumption utility and labor disutility allocations.
For each task , we define the skill parameter so the skill parameter is inversely related to the underlying skill . The implied distribution function for the skill parameter vector is denoted , and the corresponding assignment is denoted . We use this skill transformation to define a worker’s utility from consumption as a function of their skill vector as . Following this definition, the resource cost of consumption utility is . Since the utility from consumption is strictly increasing and concave in the consumption allocation, the resource cost is strictly increasing and convex in consumption utility. Similarly, we define labor disutility in each task as a function of the transformed skill parameter as . The resource cost of providing disutility is decreasing and strictly convex in labor disutility for .
Given the introduction of the skill parameter and the transformation of the choice variables from allocations to utilities, the planner chooses to minimize the resource cost of providing welfare:
| (11) |
subject to linear incentive constraints:
| (12) |
for all workers , and a linear promise keeping condition:
| (13) |
3.3 Incentive Compatibility
We show that the indirect utility for workers is convex and decreasing in type . The indirect utility is defined as:
| (14) |
which implies that for any incentive compatible allocation almost everywhere. Using the indirect utility function, the incentive constraints (12) are or, equivalently in notation of scalar product :
| (15) |
for the incentive constraint where worker type does not want to report to be of type .
A differentiable function on a convex domain is convex if and only if . This implies that an incentive compatible indirect utility function is necessarily convex. Since the gradient of the indirect utility function is the negative of a worker’s production disutility, and production disutility is positive, the indirect utility function decreases in , or .777The indirect utility function thus increases in skill . In Appendix A.2, we discuss differentiability of the indirect utility function in more detail, and we also establish which incentive compatibility constraints are redundant.
Lemma 1.
Any indirect utility function (14) that is incentive compatible is convex and decreasing in worker type .
We denote the set of utility allocations that satisfy the set of incentive constraints by , which we refer to as feasible allocations.
3.4 Bunching
We refer to bunching as different workers being assigned the same labor allocation , and therefore the same consumption allocation . We label the set of bunching points by .888Alternatively, one could define a worker being bunched when there exists another worker in its neighborhood such that . Our definition of bunching is the closure of this set. While these definitions are economically equivalent, our definition facilitates the presentation of Proposition 4.
Definition.
Worker is bunched, , if and only if in any neighborhood around this worker there exists two other workers and with identical allocations .
We now state the notions of convexity and strong convexity. Assume that the indirect utility is twice continuously differentiable in the neighborhood of a type . An indirect utility function is convex if and only if the Hessian matrix is positive semidefinite. The indirect utility function is strongly convex if is positive semidefinite for some strictly positive , where is the identity matrix.
Lemma 2.
If the indirect utility (14) is strongly convex, then there is no bunching. If the indirect utility is not strongly convex at all points in the neighborhood of type , then worker is bunched.
The proof is in Appendix A.3.
3.5 Taxation
In order to describe optimal distortions, we define tax wedges for each task. The tax wedge captures the difference between a worker’s marginal rate of substitution between task and consumption , , and the marginal rate of transformation, . We define the tax wedge as:
| (16) |
where it follows from the inverse function theorem that . A positive wedge plays a role of an implicit tax on marginal income on task .999Using the definition for the tax wedge, we write .
4 Characterization
We next derive an optimality condition for the multidimensional tax problem that incorporates bunching.
4.1 Implementability Condition
The planner chooses consumption utility and labor disutility to minimize the Lagrangian:
| (17) |
subject to the incentive constraints (12), where denotes the multiplier on the promise keeping constraint (13).101010We suppress the dependence on to streamline notation.
Proposition 2.
Implementability Condition. Let denote a solution to the planner problem, then the implementability condition:
| (18) |
holds for any feasible allocation . At a solution , (18) holds with equality.
The proof is in Appendix A.4. Proposition 2 states that for any feasible allocation , the implementability condition is necessarily satisfied, where the marginal resource costs of providing consumption utility , as well as the marginal resource costs of providing disutility from work , are evaluated at an optimum. Thus, the implementability condition places restrictions on the optimal that need to satisfy (18) for any feasible allocation .
Proposition 2 combines two variational arguments. First, consider a small proportional change in consumption utility and labor disutility. This variation is feasible. Since this scaling is unrestricted, meaning that it can either increase or decrease the utility allocations, it implies that (18) holds with equality at the optimal allocation . Second, consider a convex combination of an optimal allocation and any other feasible allocation with a small weight. The convex combination is equivalent to scaling down the optimal allocation and adding a small positive perturbation. By the previous argument, rescaling does not change the Lagrangian at the optimum allocation. The positive perturbation should not decrease the Lagrangian. Since this perturbation is positive it gives an inequality condition.
Proposition 2 presents an implementability constraint for an incentive constrained economy. The implementability conditions are more common in the Ramsey taxation literature where they represent the distortions to allocations introduced by pre-specified taxes. In our model, we do not impose direct restrictions on the permissible taxes and, instead, an information friction endogenously restricts the set of allocations. Importantly, our implementability condition holds with inequality which, as we show, is essential for characterizing the bunching regions.
4.2 Optimal Tax Condition as Stochastic Dominance
We use Proposition 2 to derive an optimality condition for our multidimensional taxation problem in terms of a stochastic dominance condition.
We first use the indirect utility (14) for a feasible allocation to write the implementability condition (18) as:
| (19) |
for any nonnegative, decreasing and convex indirect utility function . By Proposition 2 it follows that (19) holds with equality for an optimal indirect utility function. Integrating implementability condition (19) by parts we obtain:
| (20) |
for any nonnegative, decreasing and convex indirect utility function , where boundary conditions act on as .
We now define second-order stochastic dominance (Shaked and Shanthikumar, 2007):
Definition.
The measure second-order stochastically dominates the measure , or , if and only if for any nonnegative, decreasing and convex function :
| (21) |
Second-order stochastic dominance states that equation (21) holds for any nonnegative, decreasing, and convex function . These conditions exactly correspond to the indirect utility being feasible (Lemma 1). Applying the definition for second-order stochastic dominance to equation (20) we obtain the following theorem.
Theorem.
Optimal Tax Condition as Stochastic Dominance. Suppose that the optimal allocation , density function, and assignment are all continuously differentiable. Then,
| (22) |
This theorem derives the optimality condition for the multidimensional taxation economy that incorporates bunching. This condition shows that, at the optimum, the measure over marginal tax revenues, , second-order stochastically dominates the measure over marginal tax distortions,
| (23) |
where we use the definition of the labor skill wedge (16) and footnote 9.
Comparing the costs and the benefits of taxes is the key insight of the classic ABC formula and the analysis of Diamond (1998) and Saez (2001). In the classic unidimensional case, these costs and benefits are exactly equated for each of the skill levels. Our theorem shows that for the multidimensional tax case with bunching the logic of the ABC formula applies as the costs and the benefits of the taxes are compared. However, those are not necessarily equated at each skill level. Instead, our optimal tax condition (21) considers the benefits and the costs of the entire schedule of taxes and states that the entire schedule of benefits of taxes should second-order stochastically dominate the entire schedule of distortions showing the non-local nature of the problem with multidimensional skills in the regions with bunching. Our formula applies both to the regions with and without bunching and, in the latter case reduces to equating the costs and the benefits of distortions at each skill level thus making it a local problem for the regions without bunching.111111In Appendix A.5, we develop the connection between our general optimal tax conditions and the classic ABC formula. Our optimal taxation condition as stochastic dominance is also related to the sweeping operator in Rochet and Choné (1998). More specifically, the existence of a version of the sweeping operator can be established by using a variation of the Strassen Theorem (see Shaked and Shanthikumar (2007), Theorem 4.A.5). The optimal taxation formula goes beyond existence of such an operator by further relating the entire schedule of costs to the entire schedule of benefits of optimal taxes.
4.3 Global Optimal Tax Formula
We next provide an optimal tax formula for the multidimensional taxation problem as an equality. This representation also connects to the optimal tax formulas in unidimensional taxation problems which are derived as equality measuring the marginal costs and benefits of taxation (Mirrlees, 1971; Diamond, 1998; Saez, 2001). The main difference with these results is that the optimal tax formula in our multidimensional taxation problem explicitly accounts for global incentive constraints.
Theorem.
Global Optimal Tax Formula. Suppose the optimal allocation , density function, and assignment are all continuously differentiable. Then,
| (24) |
where is a positive semidefinite matrix that enforces the convexity of the indirect utility function, and .
The full proof is in Appendix A.6 and here we provide a sketch of the proof. First, we use the definition of the indirect utility function (14) to reformulate the planner problem as directly choosing an indirect utility function to minimize the resource cost of providing welfare. For the indirect utility function to be globally incentive compatible, the reformulated planning problem is constrained by the condition that the indirect utility function is convex and decreasing in worker type following the characterization in Lemma 1.
Second, the indirect utility function being convex is equivalent to its Hessian being positive semidefinite, for all worker types , which in turn is equivalent to:
| (25) |
for all vectors . These inequalities are an infinite series of constraints parameterized by the vectors for each worker type . For each of these constraints, we introduce a multiplier and include these constraints into the Lagrangian for the planning problem.
Third, we establish (Lemma 8) that one can represent the constraint that the indirect utility function has to be convex as a matrix condition by introducing a positive semidefinite Kuhn-Tucker matrix for each worker . Instead of considering the infinite series of constraints for each worker , a single positive semidefinite matrix induces convexity of the indirect utility function. Upon integration by parts, this restriction appears as a modified social welfare weight . In summary, the main contribution of the convexity constraint to the planning problem is modifying the social welfare weights through a convexity correction. Finally, we derive in Appendix A.6.2 and Appendix A.6.3 how this modified social welfare weight translates into the optimal tax condition (24).
We now discuss in more detail how the optimal tax condition applies in regions without bunching. Specifically, we consider the domain where the indirect utility function is strongly convex and, therefore, there is no bunching.
The main difficulty in analyzing bunching in the multidimensional case is that the possible indirect utility perturbations are required to be convex. The convexity of perturbations thus acts as an additional constraint on the entire tax schedule. Without bunching, the perturbation argument is straightforward to construct and leads to equating of cost and benefits of taxes at each skill level. Intuitively, if the underlying utility function is strongly convex, a small enough additive perturbation preserves convexity. As a result, the optimal tax condition (24) in Theorem Theorem applies with the convexity correction at the types where there is no bunching.
Corollary 3.
Multidimensional Optimal Tax Formula without Bunching. If the indirect utility function is strongly convex for a worker , then:
| (26) |
The proof is in Appendix A.7. In order to provide intuition for Corollary 3, and to connect our expression to the existing literature, we also write this condition in the original worker type coordinates :
| (27) |
which is the same form as derived in Kleven, Kreiner, and Saez (2006, p. 23), Lehmann, Renes, Spiritus, and Zoutman (2021), and Golosov and Krasikov (2022). The left-hand side captures the marginal benefit of increasing taxes, lowering the resource cost by taxing worker at the cost of tightening the promise keeping condition, and where denotes the density function over the types . At an optimum, the marginal benefit of increasing taxes is equated to the marginal distortionary cost of increasing taxes, which is given by the right-hand side. The right-hand side captures the change in labor distortions inversely weighted by the marginal utility of consumption. Distortionary costs of taxation scale with the elasticity of labor supply, which is governed by . When the supply of tasks is elastic (low ), marginal distortionary costs are large. When the supply of tasks is inelastic (high ), marginal distortionary costs are small. All else equal, if the marginal utility from consumption is low, , for high-skill workers, the labor skill distortion decreases with an increase in either cognitive or manual skills. When more workers are affected by a change in the skill distortions, or when the promise keeping constraint is tight, marginal labor distortions change more rapidly.
Finally, we provide a converse to Corollary 3 that allows to determine the regions of bunching.
Proposition 4.
Identifying Bunching. If equation (26) does not hold for a worker type , then this worker is bunched.
Proposition 4 thus provides a test to identify bunching. Whenever equation (26) is violated, the worker is bunched. We prove Proposition 4 in Appendix A.8. By the contrapositive to Corollary 3 it follows that when equation (26) does not hold, the indirect utility function is not strongly convex, meaning that the Hessian matrix is degenerate for worker . We show that the Hessian matrix is also degenerate for all workers within the neighborhood of , which we show is equivalent to worker being bunched.
4.4 Legendre Linearization
In this section, we discuss the main technique that enables the numerical solution of our problem. Specifically, we transform our problem into a linear problem using Legendre transformations for convex functions that translates convex functions into the upper envelopes of their tangent lines. In order to explain the Legendre transform, and show its importance, we use the resource cost of providing consumption utility as an example.
A convex function exceeds all tangent lines. For any consumption utility , and for any point of tangency :
| (28) |
where the equality follows by parameterizing the tangent lines with their slope and by letting for . The function is the Legendre transform for the resource cost of providing consumption utility . Since a convex function exceeds all its tangent lines, and since the function value equals the value of the tangent line at the point of tangency:
| (29) |
The Legendre transformation converts the convex resource cost of providing consumption utility on the left side of (29) into a family of linear constraints on the right. The family of linear constraints is parameterized by the slopes of the tangent lines of the cost function. Since the resource cost increases with consumption utility, the slopes of the tangent lines are positive, or .
The previous steps apply for any convex function, allowing us to use the same argument to transform the resource cost of providing work disutility into a family of linear constraints:
| (30) |
for each skill . An increase in production disutility increases production and therefore lowers resource costs. The resource cost of production disutility is decreasing, implying negative slopes of the tangent lines, or .
To summarize, the transformed planning problem is to minimize the resource cost of providing utilitarian welfare :
| (31) |
subject to incentive constraints (12) for all workers , and the linear promise keeping condition (13).121212In Section A.9, we show this problem is equivalent to maximizing utilitarian welfare subject to the resource constraint, and the incentive constraints. In Section A.10 we establish how to derive the stochastic dominance condition and the general optimal tax formula directly from the transformed problem.
Numerical Approach. The main insight of this analysis is that Legendre transform enables us to translate the planning problem into a linear problem (see Appendix A.11 for more detail). This is the reason why we are able to solve the model for a total of 40 thousand worker types, with 200 types in both the cognitive and the manual dimension, and a total of 1.6 billion incentive constraints. Importantly, a large number of types and numerical precision is not merely a technical and computational curiosity, it is essential to characterize the regions and nature of bunching. In addition, we use two other significant steps to reduce the number of effective incentive constraints.
First, we consider only a small set of incentive constraints by adding incentive constraints between two worker types only if the distance between them is small.131313Oberman (2013) shows that the solution to the problem with only local constraints provides a reasonable initial guess. We then use an iterative procedure to update the set of incentive constraints. On each step, we add all violated incentive constraints to the problem.141414After the final step, the candidate solution satisfies all constraints to the strictly convex optimization problem and hence is the unique solution. In practice, we always obtain the same solution for different initial conditions. With 40 thousand types, this procedure allows to reduce the number of incentive constraints to about 4 million constraints instead of 1.6 billion. Second, an important step that helps us reduce the number of incentive constraints is that we do not need to consider reducible incentive constraints (see Section A.2). This observation additionally reduces the number of constraints by a factor of two. In Appendix A.11 we further prove the accuracy of the approximate planner problem and describe the algorithm that we use to characterize the numerical solution. We finally note that without introducing Legendre transforms the objective is nonlinear. Currently, even the state-of-the-art nonlinear solvers cannot handle the characterization of the solution even for small numbers of types.
5 Positive Economy
We describe and characterize an equilibrium in a positive model of workers with multidimensional skills sorting with heterogeneous firms.
Every firm takes wage schedule as given and chooses two workers to solve:
| (32) |
We define the surplus as output minus payments to the workers and the firm:
| (33) |
Firm output cannot exceed payments to its workers and owner, that is, for any triplet .
Every worker takes the wage schedule as given and chooses their cognitive and manual task inputs to solve:
| (34) |
subject to the budget constraint , where is the wage as a function of cognitive and manual inputs, and the disutility from work is given by (2). The government taxes earnings at a rate to finance public expenditures that are not valued by workers.
The resource constraint is given by:
| (35) |
Total production, , equals output distributed to workers, , to firms , and to public expenditures .
Equilibrium. Given fiscal policy , an equilibrium is a firm value function , a wage schedule , a worker input distribution , a feasible assignment , and an allocation such that firms solve their profit maximization problem (32), workers solve the worker’s problem (34), the government budget constraint is satisfied , and the resource constraint (35) is satisfied.
The equilibrium assignment is the assignment that maximizes aggregate output, that is, solves the primal problem, while the equilibrium wages and firm value function solve the corresponding dual problem. The characterization of the equilibrium assignment, wage schedule, and firm value function through primal and dual problems is discussed for completeness in Appendix A.12.
5.1 Characterizing Equilibrium
We note that solving for the equilibrium assignment in the positive economy follows the same steps as solving for the planner assignment (9) in Section 3.1. It follows from Proposition 1 that the equilibrium features self-sorting between workers and coworkers, and positive sorting between team quality and firm project values.
In order to characterize wages and firm values, we solve the dual transport problem. Since the surplus is negative for any triplet in equilibrium, , and since the aggregate resource constraint (35), the government budget constraint and the household budget constraints hold in equilibrium, the surplus equals zero almost everywhere with respect to the equilibrium assignment, so . Output is distributed to the owner and to the workers. We use this condition to establish further properties of the firm value function and the wage schedule in Section A.14.
In Section A.14, we first note that wages are only a function of effective worker skills , and we define , the firm’s total wage bill, as . By applying standard arguments from optimal transport, wages are convex in effective worker skill . In other words, small differences in effective worker skill translate into increasingly large differences in earnings.151515The hedonic pricing condition delivers superstar effects in our model as well as a number of other assignment models (see, for example, Rosen (1981), Gabaix and Landier (2008), Tervio (2008), Scheuer and Werning (2017), and Boerma, Tsyvinski, and Zimin (2025)). Moreover, the firm value function is the Legendre transform of the wage bill, . As a result, .
In our quantitative analysis, we infer the distribution of project values using earnings data. The key is to show that there exists a firm project such that for any pairing . When the wage bill is continuously differentiable implies . That is, the derivative of the firm’s wage bill equals its project value. Given an increasing and convex wage bill , and effective skills , this condition identifies increasing values for firm productivity .
We apply this logic to the parametric continuously differentiable function where governs the convexity of wages and captures the lowest wage per worker. Using the derived fact that , we can relate the distribution of firm projects to the convexity parameter of the wage bill. If , there is no dispersion in firm productivity. We formalize this in Lemma 3.
Lemma 3.
For some firm distribution there exists an equilibrium with () a self-sorted assignment, and () a wage function:
| (36) |
The proof is in Appendix A.15. The idea is to show there is a firm distribution so that given wage schedule (36), workers and firms both optimize in a self-sorting equilibrium. Given the firm technology (4) and the wage equation (36), firm profits decrease in the difference between their workers’ skills. In order to minimize output losses, firms thus hire pairs of identical workers. Given wage equation (36), the worker problem (34) has a unique solution, so that the distribution of worker inputs is uniquely determined by the worker problem. Finally, we map the firm distribution that induces (36) as an equilibrium wage equation using . We use these steps to pointwise identify the worker skill distribution as we show in Section 6.
6 Quantitative Analysis
In this section we infer the distribution of cognitive and manual talents . The inference of the underlying distributions of skills, a central input for the calculation of the optimal tax formula, generalizes the approach of the unidimensional skills in Saez (2001) to a labor market model with multidimensional skills, coworker and firm effects. We also calibrate the parameter that governs the curvature of disutility with respect to effort.
6.1 Data Sources
We use data from the American Community Survey (ACS). We consider individuals between 25 and 60 years of age. The final sample from the ACS includes almost 16 million individuals between 2000 and 2019. For all our results, we use sample weights provided by the survey. Our measure of labor income is wage and salary income before taxes over the past 12 months.161616This measure includes wages, salaries, commissions, cash bonuses, tips, and other money income received from an employer. We drop individuals with earnings below a threshold to focus on workers who are attached to the labor market. This minimum is one-half of the federal minimum wage times 13 weeks at 40 hours per week (as in Guvenen, Ozkan, and Song (2014)).
The ACS contains occupational information for every worker. We combine a worker with the task intensity for their occupation using O*NET task measures from Acemoglu and Autor (2011). Our cognitive measure is the average of their cognitive measures, and our manual measure is the average of their manual measures. Our resulting scores are approximately normally distributed across occupations.
For identification, we first construct a measure of relative task intensity by occupation. To obtain aggregated task production levels we use a Cobb-Douglas technology to map worker subtasks into final task production similar to Kremer (1993), Acemoglu and Autor (2011) and Deming (2017):
| (37) |
Letting be the -score by subtask , we obtain cognitive and manual task production levels. Since our aggregated cognitive and manual measure are approximately normally distributed, task production levels are approximately lognormal. We now make an identification assumption that the relative task input is equal to the relative task production level, , which is hence also approximately lognormally distributed across occupations.
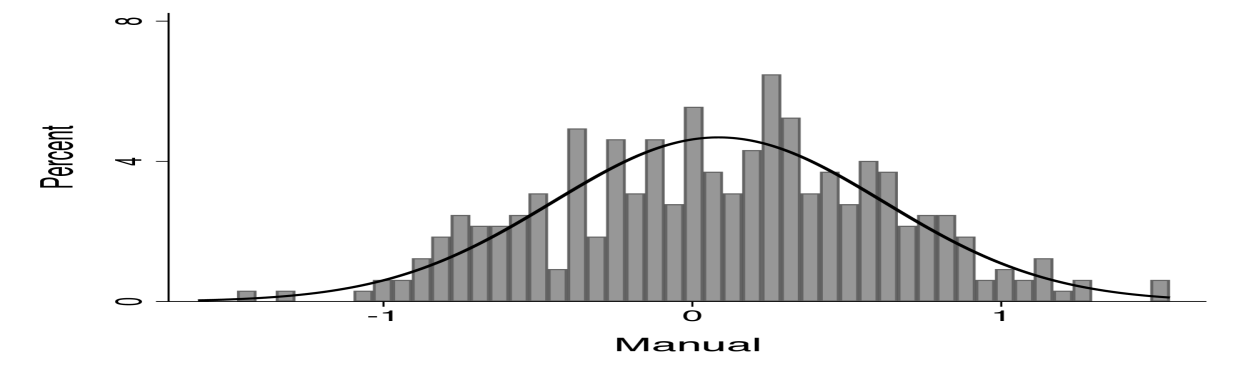
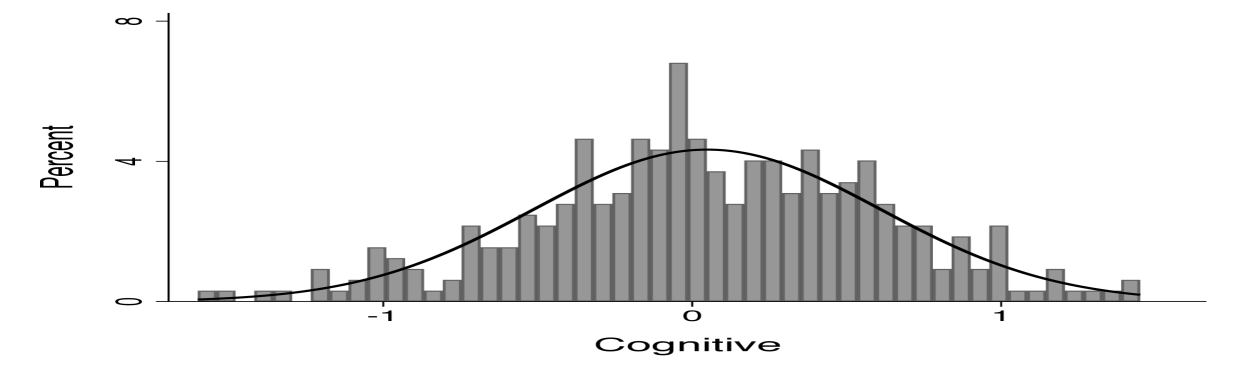
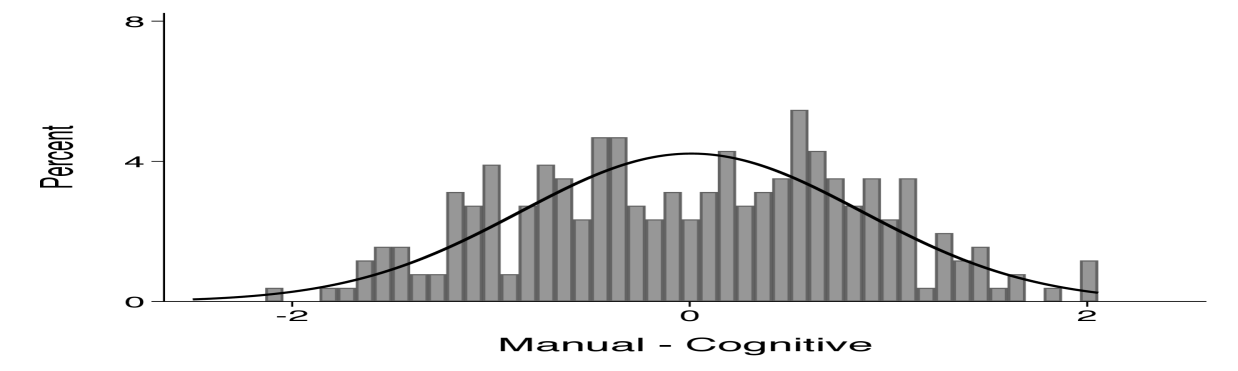
Figure 1 shows the distribution of manual and cognitive task production levels across occupations in logs (left and center panel) together with the relative distribution of manual and cognitive task intensity (right panel). Each distribution is well-approximated by a lognormal distribution.
Figure 1 shows the distribution of manual and cognitive task production levels across occupations in logs together with the relative distribution of manual and cognitive task intensity. The first two panels show that the distribution of manual task production levels and the distribution of cognitive task production levels can be described by a lognormal distribution. The right panel shows that the same holds for the relative manual task intensity.
Figure 2 displays the relation between relative task intensity and average earnings across occupations. Earnings are low for occupations with high manual task intensity, such as gardeners and truck drivers, while earnings are high for occupations with high cognitive task intensity such as software developers and actuaries. Moving from the 25th percentile to the 75th percentile in relative manual task intensity decreases earnings from 62 to 35 thousand dollars.
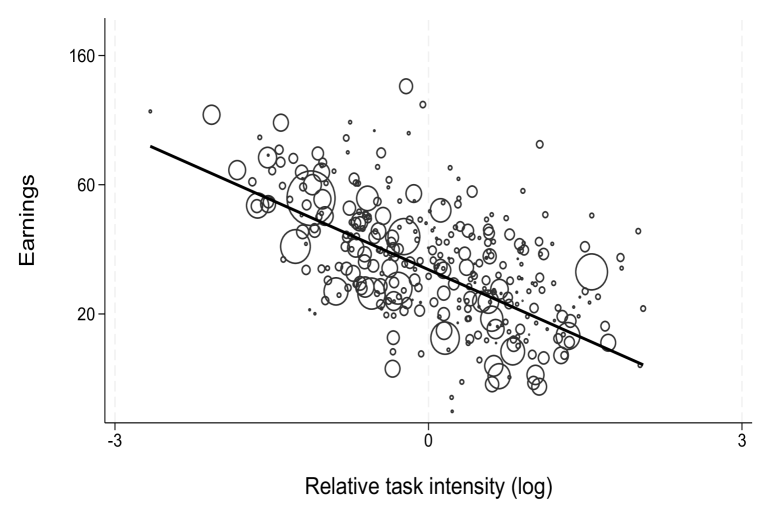
Figure 2 show the relation between average earnings (y-axis, logarithmic scale) and relative task intensity across occupations. Average earnings are decreasing in the relative manual task intensity. The size of each circle corresponds to the occupation’s employment share.
6.2 Calibration
We now calibrate the positive model. We parameterize fiscal policy and preferences, and infer the underlying multidimensional skill distribution.
The government taxes labor earnings to finance expenditures . If pre-tax earnings are , then taxes are given by . After-tax earnings are thus , we set .
Firm heterogeneity governs the convexity of the wage schedule (see Lemma 3). We set the curvature parameter for the wage schedule to align the added variation in log wages due to firm heterogeneity with evidence from the literature on variation in log wages due to firm effects. Using the wage equation (36), the variation in firm projects multiplies the underlying variation across workers by . We set to attribute 17 percent of the added variation in wages to firm effects. Our target of 17 percent is in line with estimates from the literature.171717For example, Abowd, Lengermann, and McKinney (2003) find that firm variation makes up 17 percent of the variance in wages while Song, Price, Guvenen, Bloom, and Von Wachter (2019) instead report that firm variation makes up between 8 percent and 12 percent.
We next discuss the calibration of worker preferences. We use linear preferences with respect to consumption goods, , and estimate the parameter governing the curvature of the disutility function to efforts in each task . We set such that a regression of log market hours on hourly wages, holding constant the marginal value of wealth, yields a coefficient of 0.55. This target value comes from the meta-analysis of estimates of the intensive margin Frisch elasticity from Chetty, Guren, Manoli, and Weber (2012).
To use estimates for the Frisch elasticity for total hours with respect to hourly productivity to calibrate the curvature of the utility function with respect to effort, we derive this expression within our model. Given the specification for the disutility from work (2), the linear utility from consumption, and the worker technology (3), the worker’s problem (34) is:
| (38) |
The optimality condition to the worker’s problem for each task is:
| (39) |
where by wage equation (36) with representing minimum earnings in our data. That is, the marginal consumption utility from supplying extra tasks equals the marginal cost of effort. Taking the ratio of these optimality conditions, this implies that the skill, effort and task intensity ratio are related by:
| (40) |
where the second equality follows from the worker task technology (3). The marginal rate of substitution between activities, , is equal to the ratio of marginal benefits between activities, . Relative efforts are determined by relative skills . Workers spend more effort on tasks in which they are more talented.
Using the first-order conditions for effort, and observing that the share of total efforts on each task is constant by (40), we can express the Frisch elasticity of total hours as:181818See Section A.16.
| (41) |
where is the marginal value of wealth, and is productivity per hour. We set so that the Frisch elasticity is indeed . Finally, we normalize .
Skill Distribution. We now identify the skill distribution pointwise. Using the solution to the worker’s problem, together with data on both total earnings and occupational relative task intensity for each worker, we separately identify two sources of worker productivity that rationalize the data as a model outcome. This identification argument is similar to Boerma and Karabarbounis (2020, 2021) who use explicit solutions for home production models to identify productivity at home and to identify permanent and transitory market productivity using data on consumption, home and market hours.
Using the O*NET task measures, we have information on the relative task intensity for each occupation and, hence, we identify the relative skills by equation (40). In order to determine the level of tasks, we use the wage equation (36):
| (42) |
Given the skill ratio for an individual’s occupation, , and an individual’s earnings , this equation uniquely determines the level of cognitive tasks , and hence the level of manual tasks . By the optimality condition (39), we identify both cognitive skills and manual skills for each worker.
| Relative Task | Wages | Task Intensity | Task Skills | ||||
|---|---|---|---|---|---|---|---|
| 1 | Baseline | 1 | 1 | 1.00 | 1.00 | 0.50 | 0.50 |
| 2 | Task intensity | 3 | 1 | 1.35 | 0.45 | 0.63 | 0.26 |
| 3 | Wages | 1 | 4 | 2.00 | 2.00 | 0.87 | 0.87 |
| 4 | Taxes | 1 | 1 | 1.00 | 1.00 | 0.71 | 0.71 |
| 5 | Firms | 1 | 1 | 0.97 | 0.97 | 0.42 | 0.42 |
Table 1 illustrates the identification of workers’ manual and cognitive skills through five examples. We infer higher levels of manual skills with higher manual task intensity (in Row 2), higher earnings (Row 3), higher taxes (Row 4), and with less dispersion in firms’ project values (Row 5).
Examples. In order to provide insight into the identification of worker skill heterogeneity, we consider a numerical example. We first consider an economy without taxes and without heterogeneity in firm projects, .
Suppose a worker’s occupational relative task intensity is equal to one, , and their earnings equal mean earnings, which we normalize to one. By equation (42), the worker’s cognitive task intensity and the worker’s manual task intensity are equal to . Using the optimality condition for task inputs (39), , implying the worker is equally skilled in both tasks. This worker is presented in the first row of Table 1.
Inferred manual skill increases with manual task intensity. Consider some worker with relative manual task intensity equal to three, , and average earnings. By equation (42), the cognitive task intensity is and hence the worker’s manual task intensity is greater with . Since , it follows that the worker’s inferred manual skill increases with relative manual task intensity, while the worker’s cognitive skills decreases, as shown in the second row of Table 1.
Inferred skill levels increase with earnings. For a worker with a relative task intensity of one, but a high level of earnings, the relative skill intensity is one but the level of each task is greater. Consider a worker earning four times average earnings. By equation (42), we identify the worker’s cognitive task intensity, and therefore the worker’s manual task intensity, to be equal to . Using the worker’s optimality condition for task inputs (39), , implying that the worker is equally skilled in both tasks, and almost 1.75 times as skilled as a worker in the same occupation earning average earnings. This worker is presented in the third row of Table 1.
The presence of taxes does not affect inferred task intensities but does increase the inferred skill levels . Since the identification of the task intensity is based on pretax earnings (42), inferred task intensities do not vary with taxes. For , since the task intensity does not change with taxes, we obtain . When workers are taxed, the marginal benefit from completing tasks is reduced. In order to rationalize the same levels of cognitive and manual task intensity supplied by a worker, it must be less costly for the worker to complete tasks due to increased levels of skills, as shown in the fourth row of Table 1.
Finally, increased dispersion in firm project values decreases wage dispersion that is attributed to dispersion in task intensity. Consider the dispersion in firm projects with . Reorganizing the wage equation (42), , shows that higher values of compress the dispersion in task intensity. Further, by combining the first-order condition (39) with wage equation (42), we obtain . An increase in decreases the effective dispersion in skills. Dispersion in firm projects magnifies underlying differences in task intensity due to the positive sorting between workers and projects. Equivalently, small differences in effective worker skills generate large earnings differences.
| Occupation | Relative | Wages | Manual | Cognitive | Firm | SOC Code |
|---|---|---|---|---|---|---|
| Gardeners | 1.7 | 23 | 0.93 | -2.35 | -1.28 | 373010 |
| Cashiers | 0.7 | 20 | 0.47 | -1.16 | -1.62 | 412010 |
| Police officers | -0.1 | 64 | 0.82 | 0.48 | 0.82 | 333050 |
| Physicians | -0.2 | 184 | 1.77 | 1.32 | 3.11 | 291060 |
| Chief executives | -2.1 | 149 | -2.39 | 1.71 | 2.63 | 111010 |
| Actuaries | -2.7 | 136 | -3.46 | 1.65 | 2.43 | 152010 |
Table 2 shows the identification of worker skills for a number of occupations. Holding constant the relative manual skill intensity, high earnings identify high skill levels as seen by comparing the manual and cognitive skills of police officers and physicians. Holding constant earnings, high manual task intensity identifies high manual skills as seen by comparing the skills of gardeners and cashiers.
Having illustrated the identification with examples, we turn to identification using earnings data. Table 2 illustrates the identification of underlying skills for representative workers in occupations listed in the first column. The second column shows the relative manual task intensity for these occupations from O*NET task measures. The third column shows average earnings of the workers by occupation in the ACS. Table 2 shows a negative relation between manual task intensity and average earnings by occupation, in line with Figure 2.
In order to identify manual and cognitive skills, we use equations (39), (40) and (42). First, we establish that higher earnings identify higher levels of skills, everything else equal. Consider an example of police officers and physicians. Since the relative task intensity for police officers and physicians is comparable, their relative skills are comparable by (40). Average earnings of physicians exceed the average earnings of police officers implying a higher level of both cognitive and manual skills for physicians. Indeed, the fourth and fifth column in Table 2 show that while both physicians and police officers’ cognitive and manual talents exceed the population average, , the skills of physicians exceed the skills of police officers in both dimensions.
Second, we consider two occupations with similar wages to show that high manual task intensity identifies high manual skill all else being equal. While the earnings of gardeners and cashiers are similar, gardening is more demanding in manual skills. By equation (42), the cognitive task requirements of gardeners are lower than the cognitive task requirements for cashiers. By equation (40) it follows that a gardener has more manual skills than a cashier, but less cognitive skills. The fourth and fifth column in Table 2 displays this pattern.
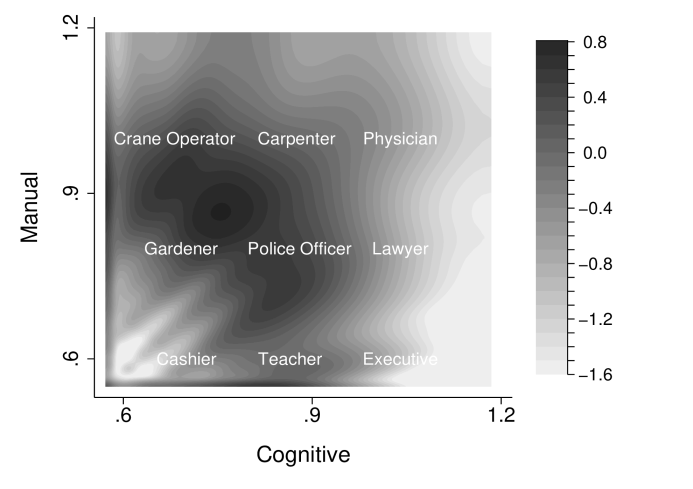
Figure 3 shows the inferred worker skill distribution, with bright colors indicating more mass. The panel shows the smoothed distribution of cognitive and manual skills that exactly rationalizes the data which is obtained using data on relative task intensity by occupation and worker earnings, through equations (39) to (42). The values are normalized such that one reflects a uniform distribution.
We apply the identification argument to all workers in the ACS to identify their skills. By identifying skills at the worker level, we allow for skill heterogeneity within occupations driven by earnings differences within occupation. As in the example, workers with high earnings have higher cognitive and manual skills than a worker with low earnings in the same occupation. Figure 3 shows the resulting distribution of cognitive and manual skills, after 98 percent winsorization and after smoothing the pointwise identified distribution using a kernel density estimation.191919We correct our kernel density estimator at the boundaries of our rectangular type space by reflecting along all boundaries, see, e.g. Karunamuni and Alberts (2005).
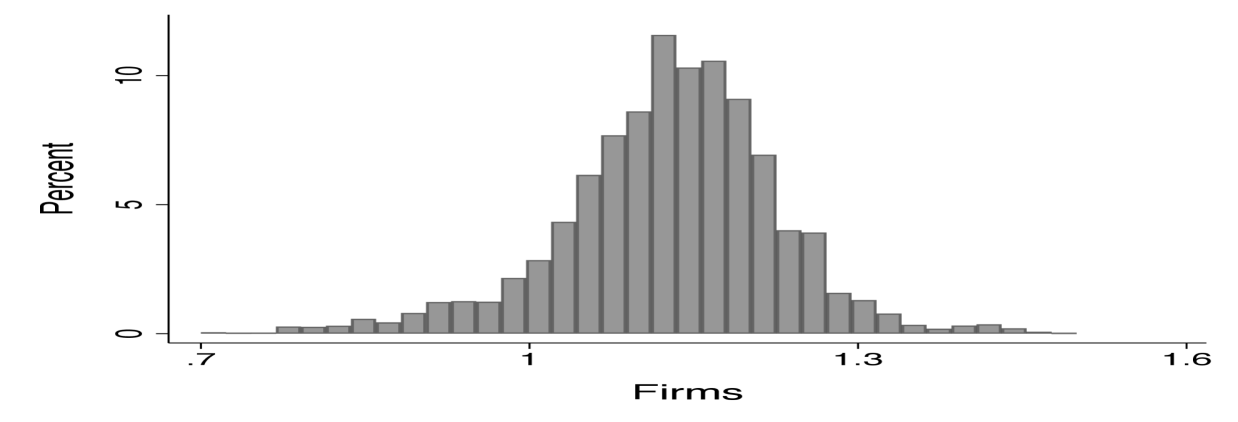
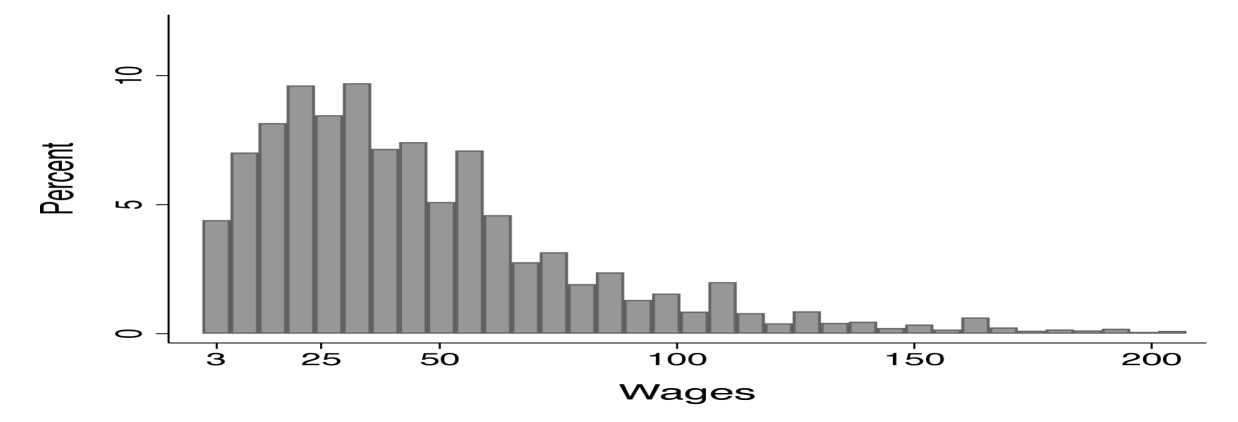
Figure 4 shows the histogram for the inferred firm distribution (left panel) and the model implied distribution of wages (right panel).
For illustrative purposes, we introduce representative occupations in Figure 3. Specifically, we provide nine representative occupations within the type space. For example, cashiers are workers with both low cognitive and low manual skills, chief executives have low manual skills but high cognitive skills, while physicians have both high cognitive and high manual skills.
Finally, Figure 4 shows the inferred firm productivity distribution in the left panel and the implied wage distribution in the right panel. The left hand distribution shows that the distribution of firm projects is relatively concentrated with project values ranging from 30 percent below the mean to 40 percent above the mean (1.1). By construction, the right panel replicates the empirical wage distribution.
7 Quantitative Results
In this section, we present the quantitative results to the planning problem using the empirically relevant model of Section 6.
7.1 Unconstrained Benchmark
In order to build intuition for the solution, we first present a benchmark without incentive constraints and firm heterogeneity. The planning problem then simplifies to minimizing resource costs (10) subject to the promise keeping condition (8). By using the functional form for preferences, the promise keeping condition simplifies to:
| (43) |
At the optimum, cognitive tasks are independent of workers’ routine skills, and the elasticity of cognitive tasks with respect to cognitive skills is . Furthermore, the solution does not feature bunching. In order to see this, note that the following condition has to be satisfied:
| (44) |
for each skill . Due to additive separability of tasks in preferences and technology, the efforts on task depend only on the worker’s skills in this task. Equivalently, there is no cross-dependence between tasks. Since (44) describes a one-to-one relation between the worker’s skills and efforts in each task, there is no bunching at optimum. That is, in a neighborhood of worker , every pair of distinct workers is assigned distinct allocations as .
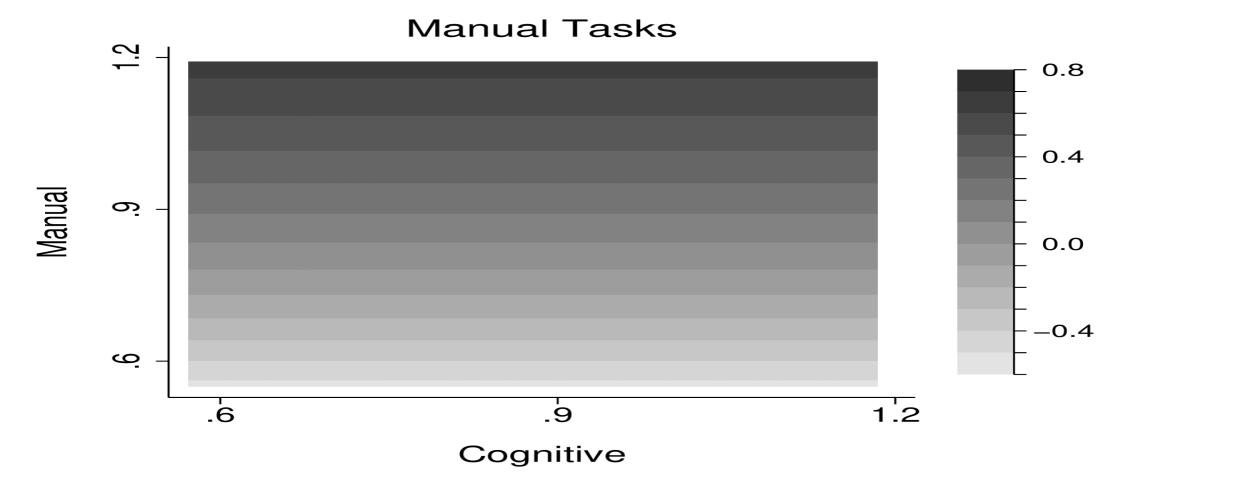
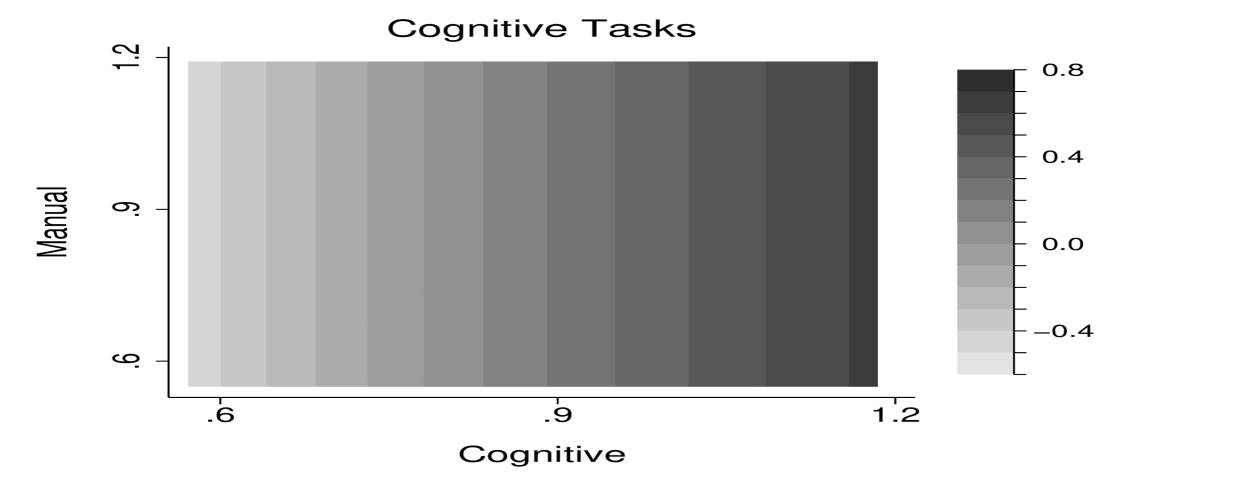
Figure 5 shows the benchmark allocation for task intensity by worker’s cognitive and manual skills. The left panel shows the allocation of manual tasks, the right panel illustrates the allocation of cognitive tasks. The optimal allocation does not feature any cross-dependence between tasks: manual task intensity only varies with manual skill, while cognitive task intensity only varies with cognitive skill.
Given the empirical description of the distribution for cognitive and manual skills in Figure 3, equation (44) gives the optimal allocation of both cognitive and manual tasks. Figure 5 visualizes the benchmark allocation of task intensity by worker’s cognitive and manual skills. The left panel shows the allocation of manual tasks, the right panel shows the allocation of cognitive tasks. Since (44) rules out any cross-dependence between tasks, the optimal allocation is captured by parallel horizontal and vertical lines, respectively. Manual task intensity only varies with manual skill, while cognitive task intensity only varies with cognitive skill.
7.2 Optimal Solution
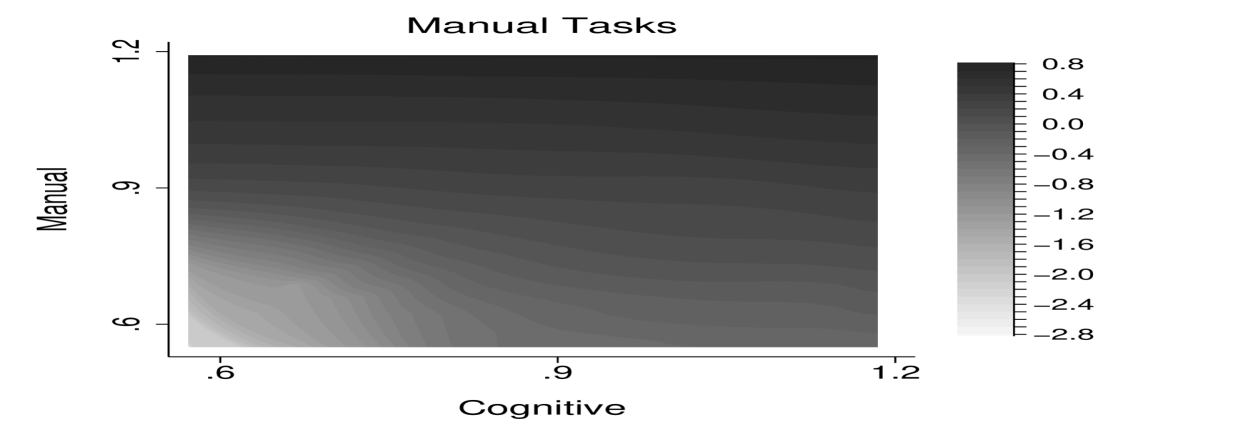
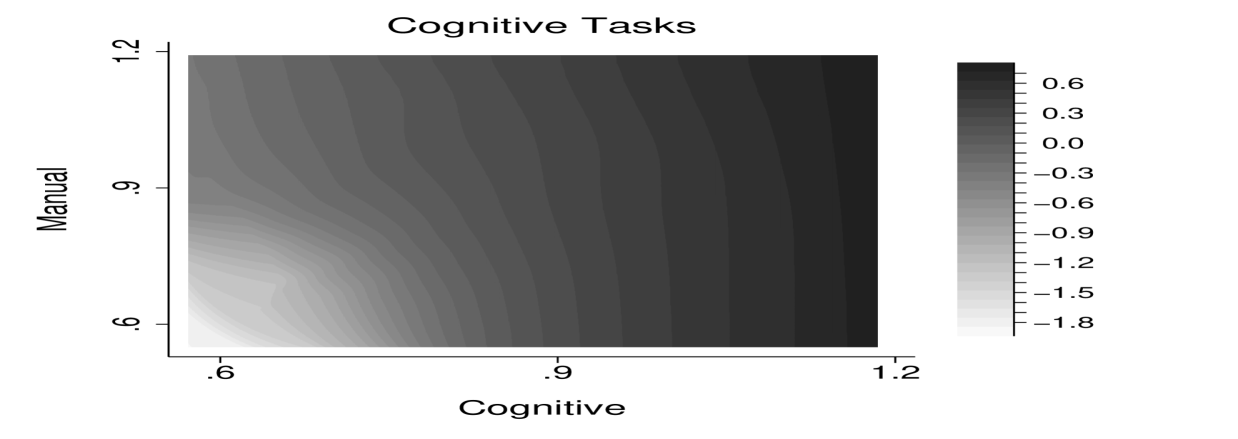
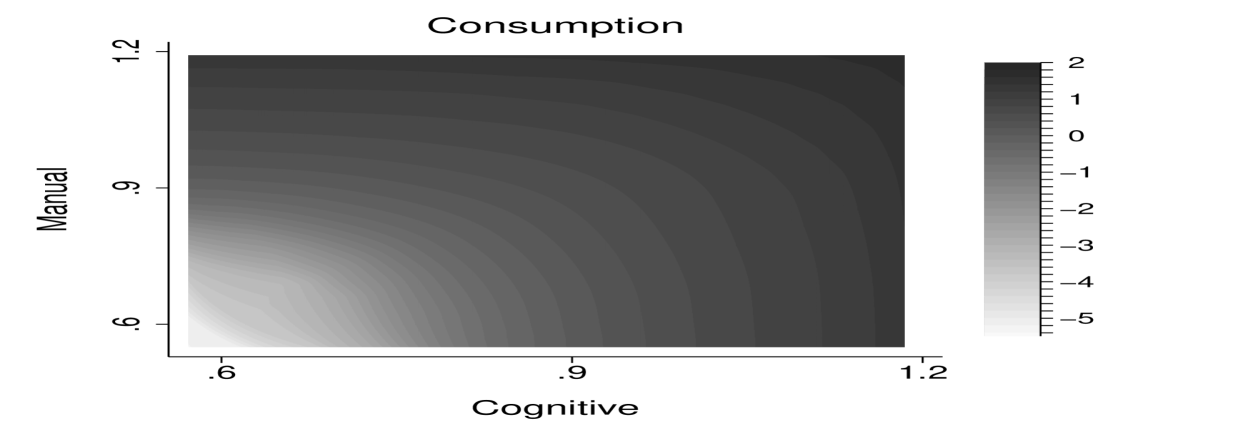
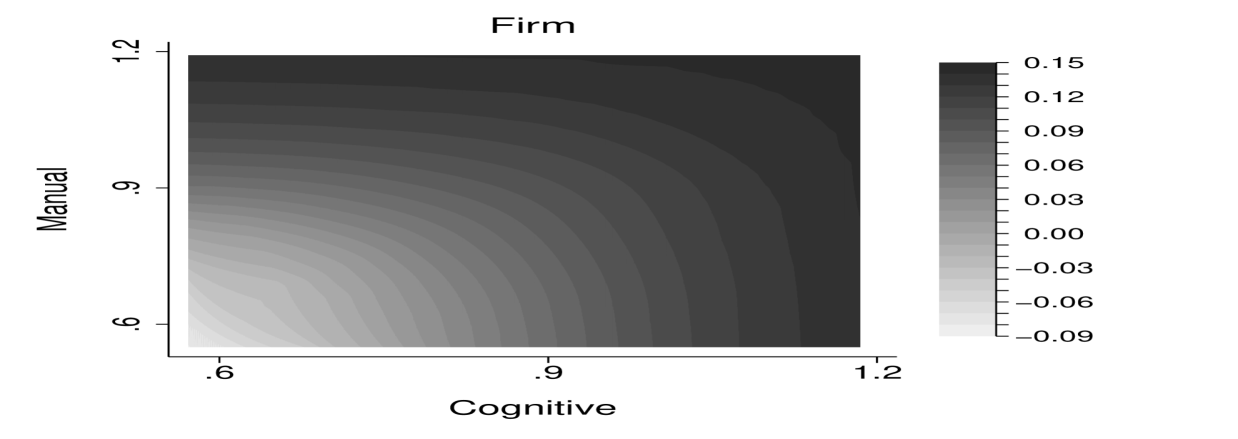
Figure 6 visualizes the solution by worker’s cognitive and manual skills. The top row shows the manual and cognitive task allocation, the bottom row shows the consumption allocation and the assignment of workers to firms. The solution features positive dependence between tasks. For example, optimal cognitive task intensity increases with manual skills.
Figure 6 shows the solution to the planner problem. The top row shows the allocation of manual and cognitive tasks, the bottom row shows the allocation of consumption and the assignment of workers to firms. In contrast to the benchmark, optimal task intensity in one skill depends positively on a worker’s other skills. Consider the manual task allocation in the top left panel. Similar to the benchmark, the manual task intensity increases with a worker’s manual skills holding constant their cognitive skills. In contrast to the benchmark solution, the manual task intensity also increases with workers’ cognitive skills. That is, workers with the same manual ability but with a higher cognitive ability conduct a higher level of manual tasks. Moreover, this codependence between cognitive skills and manual tasks intensifies at low levels of cognitive skill. This can be seen by the contour lines being almost negative 45 degree lines at low levels of manual ability, while being almost flat at high levels of manual ability. The same pattern holds for cognitive tasks.
In this economy, the binding incentive constraints are for high types to mimic to be low types, which is also generally the case with unidimensional skill. In order to prevent the high type from pretending to be the low type, the allocation for the low types is distorted. With multidimensional skills, the allocation for the low types is distorted both by reducing the level of task output similar to the unidimensional case, and by increasing the codependence between tasks. The latter is a new type of distortion that emerges in taxation problems with multidimensional skill.
The bottom left panel shows the solution for consumption. Consumption increases with skills. Consumption of workers with top cognitive skills exceeds consumption of workers with top manual skills due to higher absolute levels of skill. The bottom right panel shows the assignment of workers to firms. Given the cognitive and manual tasks, the planner assigns workers with greatest effective skills to projects of greater value following Proposition 1. A physician thus works on a more valuable project than a cashier as in the positive economy. Since the range of the cognitive skills is higher than the range of the manual skills, the high value projects are assigned towards workers with greater cognitive skills.
Bunching. We now describe the nature of bunching in the optimal solution. Bunching means that different workers are assigned identical labor supply allocations and, therefore, are also assigned identical consumption allocations (see Section 3.4). We use three distinct methods based on the theoretical analysis in Section 3 and Section 4 to comprehensively characterize the bunching patterns that emerge in the quantitative model.
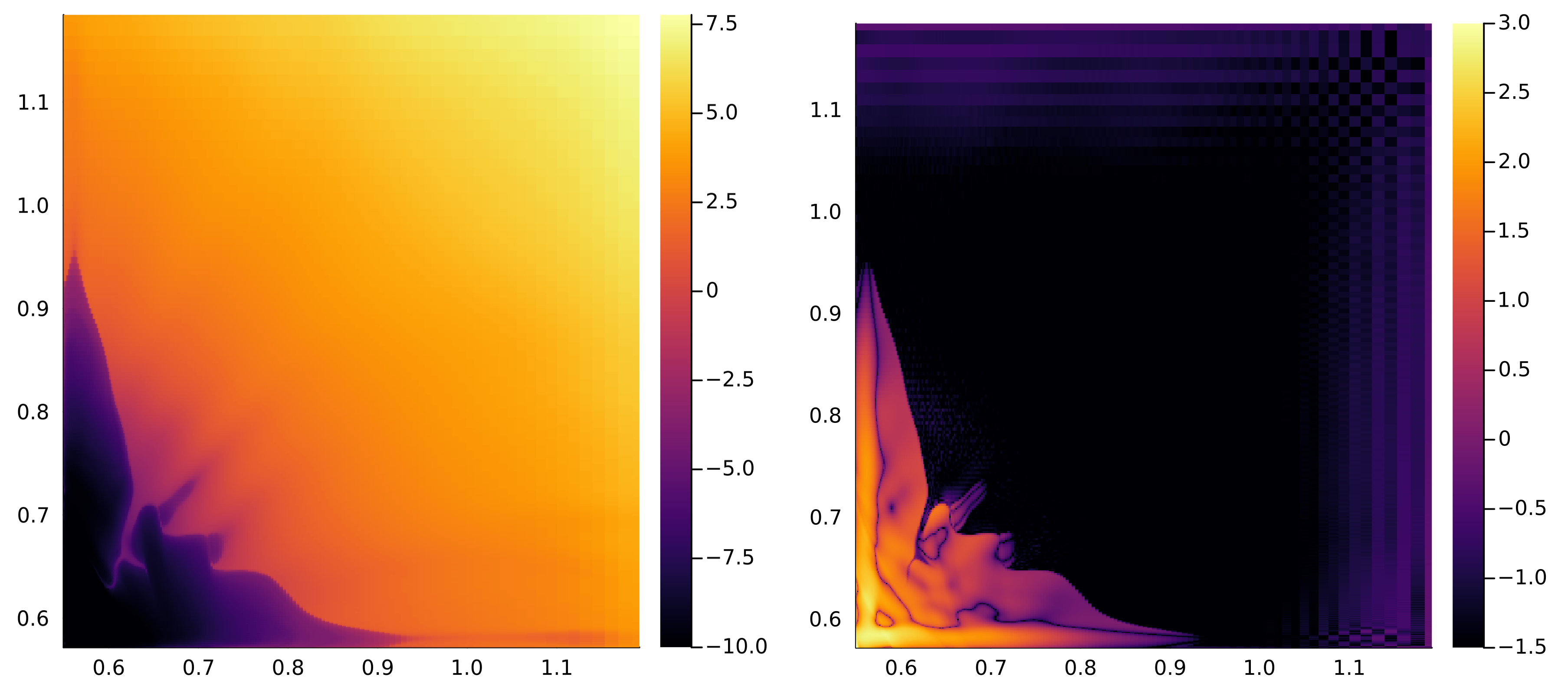
Figure 7 illustrates bunching in the optimal allocation. The left panel identifies bunching by analyzing the determinant of the Hessian matrix of the indirect utility function, and shows the value of the determinant on a log base 10 scale. The right panel identifies bunching using Corollary 3 by analyzing deviations from the multidimensional optimal tax formula on a log base 10 scale. The variable on the horizontal axis is cognitive skill ; the variable on the vertical axis is manual skill . Both panels identify that workers in the bottom left region of the type space are bunched under the optimal allocation.
First, we use our theoretical results in Lemma 2 to identify bunching by analyzing the determinant of the Hessian matrix of the indirect utility function. By Lemma 2, if the indirect utility function is not strongly convex at all points in the neighborhood of type , then worker is bunched. If the Hessian matrix is not invertible, then the indirect utility function is not strongly convex. A matrix is invertible if and only if the determinant is not equal to zero. Therefore, if the determinant of the Hessian matrix equals zero, the matrix is not invertible, so the indirect utility function is not strongly convex and the worker is bunched. Thus bunching is present in regions where the determinant of the Hessian matrix of the indirect utility function is equal to zero. We apply this method in the left panel of Figure 7, which shows the value of the determinant on a log base 10 scale. The left panel shows that workers in the bottom left (dark) region are bunched.
Second, we now use our theoretical results in Corollary 3 to identify bunching. If the multidimensional optimal tax formula without bunching does not hold, then the indirect utility function is not strongly convex for worker . By Lemma 2, this implies that worker type is bunched. Numerically, we analyze deviations from the multidimensional optimal tax formula without bunching to establish bunching. We apply this method in the right panel of Figure 7. The figure shows the deviations from the multidimensional optimal tax formula without bunching on a log base 10 scale. The right panel delivers the same bunching region as the left panel in the bottom left (light) region.
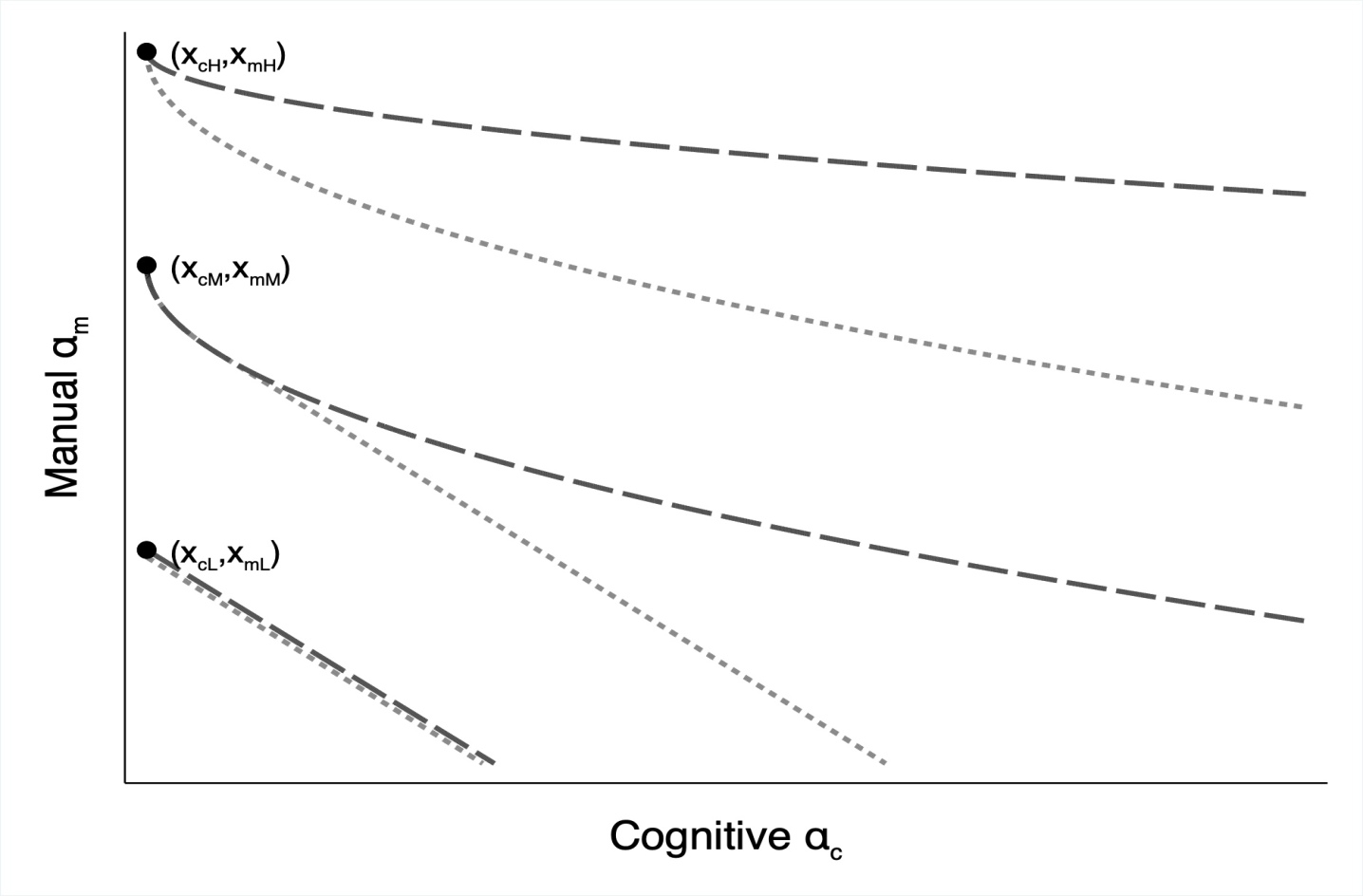
Figure 8 illustrates the procedure to classify bunching using isocurves. The long-dashed lines represent isocurves for different cognitive task levels, while the short-dashed lines represent isocurves for different manual task levels. Worker is bunched with worker if the isocurves for intersect .
The third approach to identify bunching is based directly on the definition of bunching (see Section 3.4). When different worker types bunch, they are assigned identical task levels. Worker is bunched if there are other workers who are assigned the same task levels . Visually, we draw the isocurves corresponding to both and displayed on Figure 8 in the worker space and assess whether the isocurves intersect for any other worker . If there exists a worker such that the isocurves intersect, then workers and are bunched.
Figure 8 gives an example of the procedure to classify optimal bunching using isocurves. The long-dash lines represent isocurves for different cognitive task levels, while the short-dash lines represent isocurves for different manual task levels. The dots indicate three hypothetical allocations. First, consider the isocurves corresponding to the allocation of crane operators in the top left corner. The long-dash isocurve represents workers with other combinations of skills who produce the same cognitive tasks as the crane operator. The short-dash isocurve represents workers with other combinations of skills who produce the same manual tasks as the crane operator. The lines intersect only at one point the skills of the crane operator at the top left corner. That is, no other worker receives the same task allocation that is assigned to the crane operator. Next, consider the isocurves corresponding to the allocation of a gardener in the middle of Figure 8. The long-dash isocurve (workers producing the same cognitive tasks as the gardener) overlaps with the short-dash isocurve (workers producing the same manual tasks as the gardener) for high levels of manual skill and for low levels of cognitive skill . These workers produce the same cognitive and manual tasks as the gardener, indicating that gardeners bunch with workers whose comparative advantage also lies in manual work. We call this type of bunching targeted bunching. Finally, consider the bottom-left allocation corresponding to cashiers. In this case, the long-dash and short-dash isolines for cognitive and manual tasks overlap throughout the type space. All workers with skills on that line produce the same cognitive and manual tasks as the cashier, despite their skill differences. We call this type of bunching blunt bunching, where the planner does not distinguish different worker types when allocating tasks.
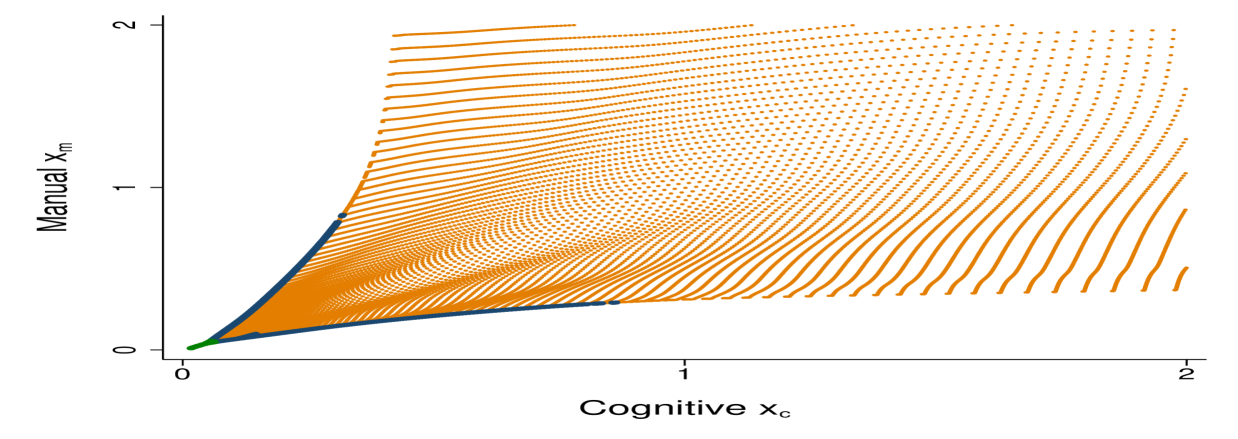
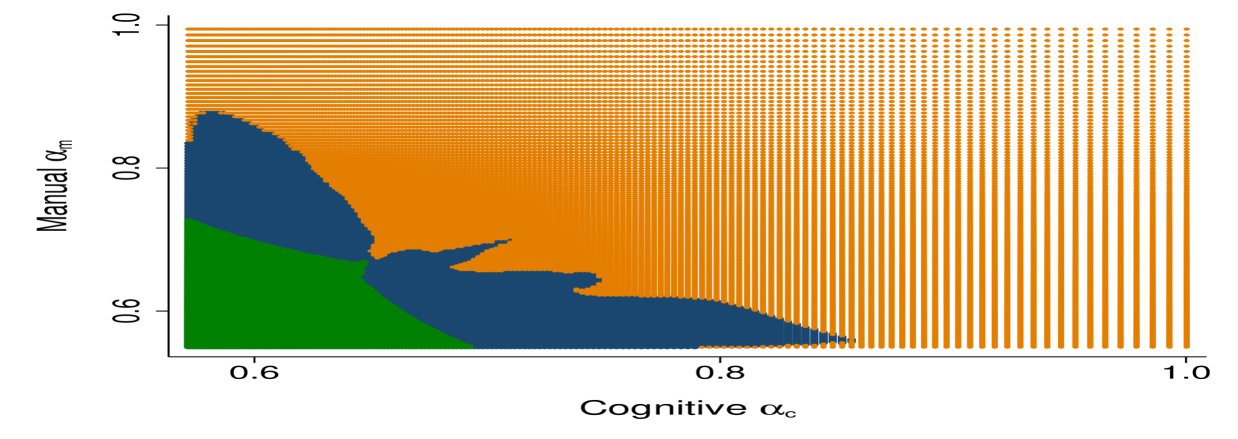
Figure 9 shows bunching at the solution. The left panel demonstrates bunching in the allocation space by displaying combinations of optimal cognitive and manual tasks . An allocation is marked in green or in blue if the allocation is assigned to more than one worker, while the allocation is marked orange if the allocation is assigned to one worker. The right panel displays bunching in the worker type space . In this figure, a worker type is marked in green or in blue if the worker’s task allocation is also assigned to another worker. The green area indicates the blunt bunching region while the blue area indicates the targeted bunching region.
Figure 9 shows bunching at the optimal solution and presents two complementary views of the issue. The left panel displays bunching through the allocation of tasks. We display combinations of cognitive and manual tasks that are optimal. An allocation is marked green or blue if the allocation is assigned to more than one worker, while the allocation is marked orange if the allocation is assigned to one worker. There are two main regions of bunching in this picture. The first region is that of the blunt bunching and is given by the green line segment at the bottom of both cognitive and manual tasks. The second region is that of the targeted bunching and is represented by two blue line segments at the borders of the task trapezoid. That is, targeted bunching happens when the task input is low for only one task. The lower (flat) blue line segment represents low manual tasks, and the upper (vertical) line segment represents low cognitive tasks. Note that on these borders, when the task intensity becomes sufficiently high, the allocations are no longer bunched – that is, the blue line turns orange on the edges of the trapezoid.
Blunt and Targeted Bunching. In order to see which workers are bunched, the right panel shows bunched workers in the type space . In this figure, a worker type is marked in blue or green if the worker’s task allocation is also assigned to another worker.202020We construct the distance between two allocations and by considering the Euclidean distance between the allocations relative to the Euclidean distance between the respective types and . We classify two allocations to be identical if this ratio is below . This panel shows that bunched workers have low cognitive or low manual skills (or both). Worker types are marked blue in the region of targeted bunching, and marked green in the region of blunt bunching. Workers with both low cognitive and manual skills are in the blunt bunching region. Workers with medium manual or medium cognitive skills are in the targeted bunching region when their skill set is asymmetric. Workers with medium cognitive skills bunch when their manual skills are low, and vice versa. In order to quantify the measure of bunched workers in the economy, we now combine the right panel with the worker type distribution of Figure 3. At the optimum, 10.4 percent of the workers is bunched. The blunt bunching region comprises 30 percent of bunched workers. The targeted bunching region comprises 70 percent of bunched workers.
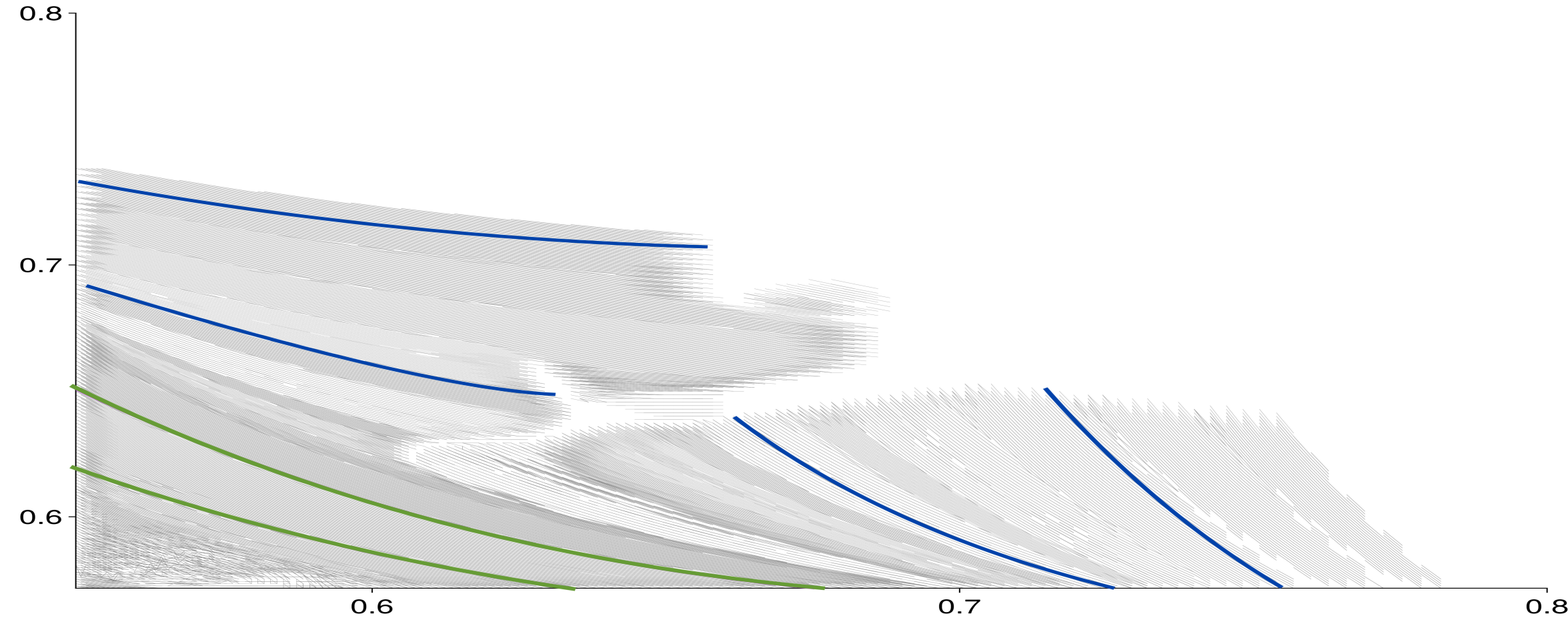
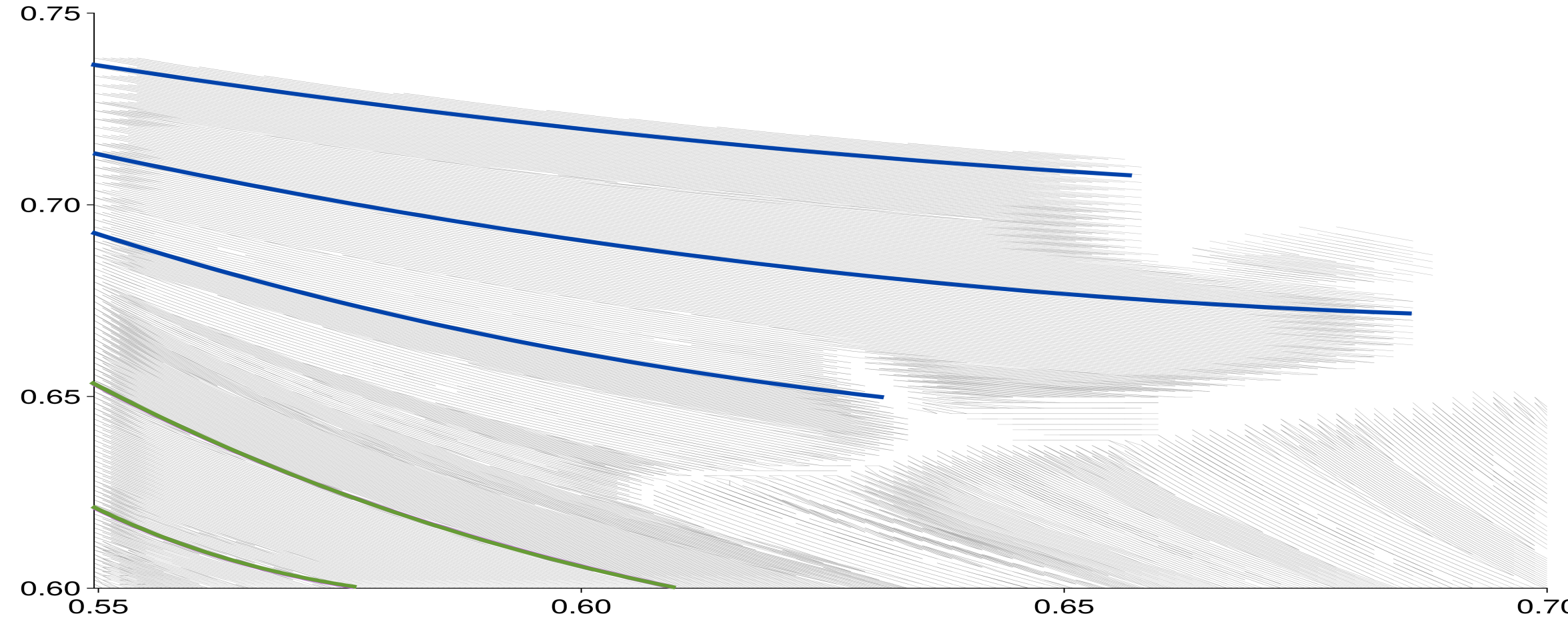
Figure 10 shows with whom workers bunch by connecting workers with a line in the worker type space if their allocations are bunched. Workers exclusively bunch with workers that are better in one skill dimension, but worse in another as represented by downward-sloping lines. Green lines indicate the blunt bunching region, blue lines indicate the targeted bunching region. Under blunt bunching, workers on the vertical boundary bunch with workers on the horizontal boundary, unlike under targeted bunching. The right-hand panel zooms in to distinguish the blunt bunching region from the targeted bunching region.
Workers bunch with other workers both near and far. While Figure 9 shows at what allocations workers are bunched and which workers are bunched, it does not show with whom workers bunch. These bunching relations are shown in Figure 10, which connects two workers with a line in the type space if they are bunched.212121To facilitate the presentation, we display the bunching relations for one quarter of all workers. In addition, we display at most two relations for each worker.
Workers do not bunch with workers over whom they have an absolute advantage or who have an absolute advantage over them. Workers exclusively bunch with workers that are better in one skill dimension but worse in another. In Figure 9 this is evident since all connections are represented by downward-sloping lines. Gardeners with somewhat better cognitive skills, but somewhat lower manual skills are bunched with gardeners with less cognitive skills and higher manual skills. Despite the slight difference in skills, the planner assigns both identical tasks.
Within our bunching regions we distinguish two distinct patterns. In the lower triangle, which we indicate by green lines, the planner bunches together cognitive and manual tasks for all workers, ranging from those with relatively high manual skills to those with relatively high cognitive skills. Workers with the same effective skill index produce the same cognitive and manual tasks. Work is not tailored towards workers’ specific skills but to an overall level of skill. In this blunt region, the planner optimally satisfies the incentive constraints by assigning identical allocations to different workers. Deviations are deterred bluntly at the cost of efficiency.
The planner also bunches workers in the targeted bunching regions, but in a less rudimentary way because the efficiency cost of bunching increases with worker skills. The planner separately bunches together cognitive and manual tasks for workers that are relatively skilled in manual tasks and similarly bunches together the cognitive and manual tasks for workers that are relatively skilled in cognitive tasks. Unlike in the lower triangle, however, workers that are relatively skilled in cognitive labor do not bunch with workers that are skilled in manual labor. In sum, the planner separates on worker’s comparative advantage and bunches on worker’s comparative disadvantage in the targeted bunching region.
In the regions without bunching, the planner distorts allocations to deter deviations by workers to allocations they find desirable similar to the unidimensional case. This is incentive provision through distinct distorted allocations.
Taxation: Wedges and Tax Implementation. We next study the implications for optimal taxes by studying the labor wedge (16) for cognitive and manual tasks. Using linear preferences for consumption, the labor wedge is:
| (45) |
The labor wedge is determined by the optimal assignment through , by the allocation of tasks through , and by worker skills through . Workers at better firms face a higher labor wedge . If the planner reduces task inputs, the labor wedge increases. Keeping allocations constant, the labor wedge increases with worker skills.
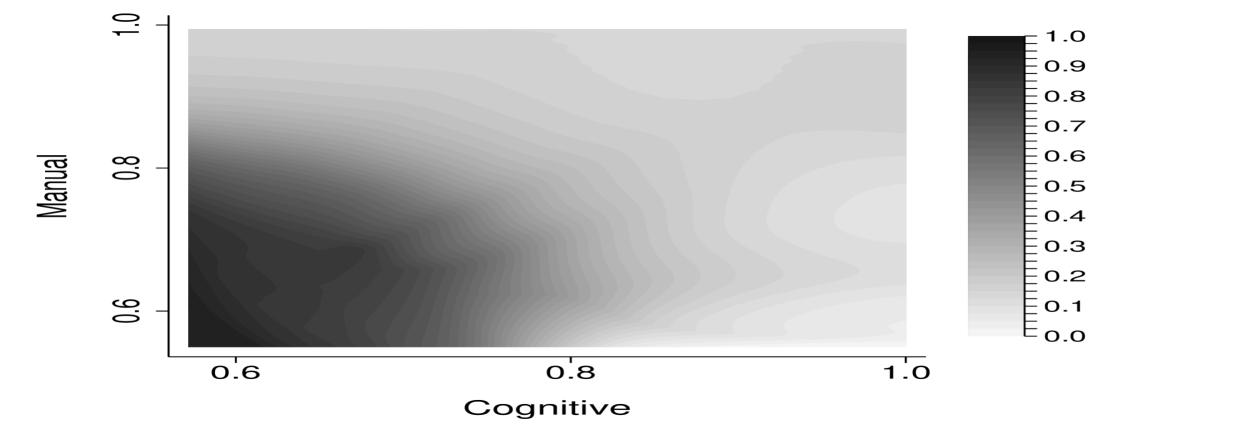
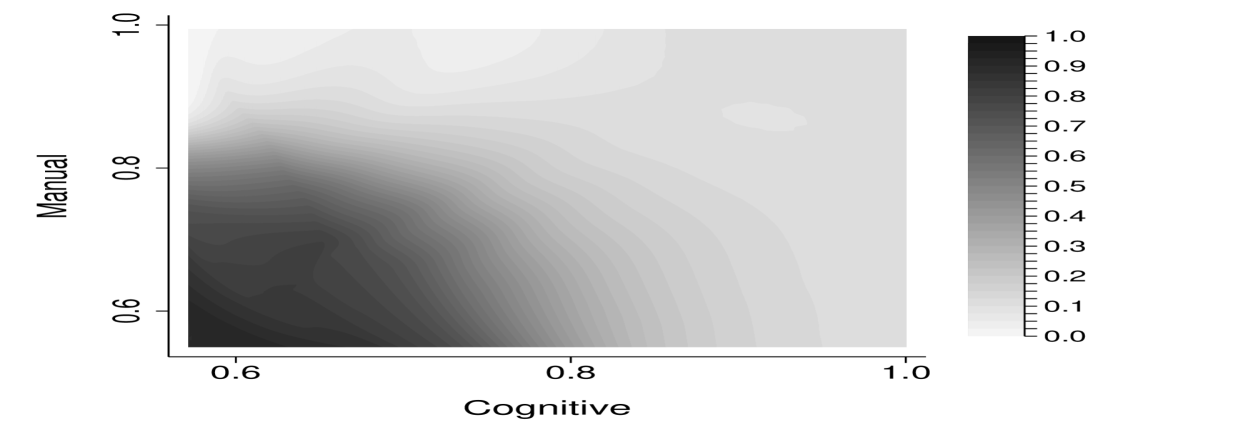
Figure 11 visualizes the tax wedges for the planner solution. The left panel displays the manual tax wedge, the right panel displays the cognitive tax wedge.
The optimal tax wedges are presented in Figure 11. First, the respective wedge is zero for the worker with the highest respective skill in either the cognitive or manual dimension. Consider the graph for the manual tax in the left panel. Workers with the highest manual skill are those represented by the top horizontal boundary of the graph. The manual tax on them is zero. Note that for the workers with the top cognitive skill, who are represented as the right vertical boundary, the manual tax is not zero. The manual tax on the best crane operator (highest manual and low cognitive) and physician (highest manual and high cognitive) is zero while it is positive on the top executive (low manual and highest cognitive).
The cognitive tax is displayed in the right panel of Figure 11. The cognitive tax for workers with the highest cognitive skill is zero. For workers with the top manual skill the cognitive tax is not zero. The cognitive tax on top executives (low manual and highest cognitive) and the best physician (highest manual and high cognitive) are zero while it is positive on the best crane operator (highest manual and low cognitive).
Second, we describe how taxes change with the level of the skill. Figure 12 plots the manual (on the left) and cognitive taxes (on the right) for three groups of workers separated by their skills corresponding to the heatmap in Figure 11. Consider top manual workers. Those are physicians (high cognitive), carpenters (medium cognitive), and crane operators (low cognitive). These workers are located in the top horizontal strip of Figure 11 and represented by the dash-dotted line in the right panel of Figure 12. These workers are not in bunched regions, and the cognitive tax on them is low.
Consider medium manual workers. Those are lawyers (high cognitive), police officers (medium cognitive), and gardeners (low cognitive). These workers are located in the middle horizontal strip of Figure 11 and are represented by the long-dash line in the right panel of Figure 12. The cognitive tax on them is higher. Three forces give this shape from equation (45) the assignment to heterogeneous firms, the task allocation, and the worker skill. The assignment is monotonic: lawyers are assigned to better firms than police officers and gardeners. This force gives a higher labor wedge on lawyers compared to the gardeners. Conversely, the task allocation increases with skills leading to a reduction in labor wedges. Finally, the labor wedge increases in worker skills. The low cognitive skill workers (gardeners) face a higher cognitive labor wedge than the highest cognitive skill workers (lawyers) which is hence driven by the low amounts of cognitive tasks they conduct. The high level of tax distortion on gardeners is also driven by the fact that they are in the targeted bunching region while lawyers and police officers are not bunched.
Consider low manual workers. Those are executives (high cognitive), teachers (medium cognitive), and cashiers (low cognitive). These workers are located in the bottom horizontal strip of Figure 11 and are represented by the dotted line in the right panel of Figure 12. The cognitive tax on them is higher than on medium manual workers. The cognitive tax is generally decreasing in skill with executives facing a lower marginal tax rate than cashiers. The high level of distortions on cashiers and teachers is also driven by the fact that they are bunched. The teachers are in the targeted bunching region – they have comparative advantage in their cognitive skills and are separated along the cognitive dimension but bunched in the manual dimension. The cashiers are in the blunt bunching region. They are bunched in both the manual and the cognitive dimensions and this leads to their allocation being heavily distorted. In the left panel of of Figure 12 we repeat the tax analysis for the manual tax skill wedge, using the left panel of Figure 11.
In Appendix A.17, we show that the planner allocation is implementable through a tax system over task inputs . Since the effective skill index determines worker wages where is strictly increasing (Section 5), there is a one-to-one mapping between the skill index and earnings . Therefore, there is a one-to-one map between and . Since the optimum is implementable by a tax function it is also implementable by a tax function that is only a function of income and line of work .
8 Conclusion
We advance the understanding of optimal tax policy in multidimensional environments with bunching theoretically and quantitatively. Our optimal tax conditions generalize classic unidimensional optimal tax conditions of Mirrlees (1971), Diamond (1998) and Saez (2001) to multidimensional taxation problems and account for global incentive constraints and bunching. For an empirically relevant model, we show that bunching is both substantial and nuanced and, hence, importantly impacts optimal policy design.
References
- (1)
- Abowd, Lengermann, and McKinney (2003) Abowd, J. M., P. Lengermann, and K. L. McKinney (2003): “The Measurement of Human Capital in the U.S. Economy,” U.S. Census Bureau Working Paper.
- Acemoglu and Autor (2011) Acemoglu, D., and D. Autor (2011): “Skills, Tasks and Technologies: Implications for Employment and Earnings,” in Handbook of Labor Economics, vol. 4, pp. 1043–1171.
- Ambrosio and Gigli (2013) Ambrosio, L., and N. Gigli (2013): “A User’s Guide to Optimal Transport,” in Modelling and Optimisation of Flows on Networks, pp. 1–155.
- Armstrong (1996) Armstrong, M. (1996): “Multiproduct Nonlinear Pricing,” Econometrica, 64(1), 51–75.
- Becker (1973) Becker, G. S. (1973): “A Theory of Marriage: Part I,” Journal of Political Economy, 81(4), 813–846.
- Benabou (2002) Benabou, R. (2002): “Tax and Education Policy in a Heterogeneous-Agent Economy: What Levels of Redistribution Maximize Growth and Efficiency?,” Econometrica, 70(2), 481–517.
- Bertsekas and Yu (2011) Bertsekas, D. P., and H. Yu (2011): “A Unifying Polyhedral Approximation Framework for Convex Optimization,” SIAM Journal on Optimization, 21(1), 333–360.
- Blundell and Shephard (2012) Blundell, R., and A. Shephard (2012): “Employment, Hours of Work and the Optimal Taxation of Low-Income Families,” Review of Economic Studies, 79(2), 481–510.
- Boerma and Karabarbounis (2020) Boerma, J., and L. Karabarbounis (2020): “Labor Market Trends and the Changing Value of Time,” Journal of Economic Dynamics and Control, 115.
- Boerma and Karabarbounis (2021) (2021): “Inferring Inequality with Home Production,” Econometrica, 89(5), 2517–2556.
- Boerma, Tsyvinski, and Zimin (2025) Boerma, J., A. Tsyvinski, and A. P. Zimin (2025): “Sorting with Teams,” Journal of Political Economy, 133(2), 421–454.
- Bogachev and Kolesnikov (2012) Bogachev, V. I., and A. V. Kolesnikov (2012): “The Monge-Kantorovich Problem: Achievements, Connections, and Perspectives,” Russian Mathematical Surveys, 67(5), 785–890.
- Chetty, Guren, Manoli, and Weber (2012) Chetty, R., A. Guren, D. Manoli, and A. Weber (2012): “Does Indivisible Labor Explain the Difference Between Micro and Macro Elasticities? A Meta-Analysis of Extensive Margin Elasticities,” NBER Macroeconomics Annual, 27, 1–56.
- Chiappori, McCann, and Nesheim (2010) Chiappori, P.-A., R. J. McCann, and L. P. Nesheim (2010): “Hedonic Price Equilibria, Stable Matching, and Optimal Transport: Equivalence, Topology, and Uniqueness,” Economic Theory, 42(2), 317–354.
- Chiappori, McCann, and Pass (2017) Chiappori, P.-A., R. J. McCann, and B. Pass (2017): “Multi-to One-Dimensional Optimal Transport,” Communications on Pure and Applied Mathematics, 70(12), 2405–2444.
- Conesa, Kitao, and Krueger (2009) Conesa, J. C., S. Kitao, and D. Krueger (2009): “Taxing Capital? Not a Bad Idea After All!,” American Economic Review, 99(1), 25–48.
- Deming (2017) Deming, D. J. (2017): “The Growing Importance of Social Skills in the Labor Market,” Quarterly Journal of Economics, 132(4), 1593–1640.
- Diamond (1998) Diamond, P. A. (1998): “Optimal Income Taxation: An Example with a U-shaped Pattern of Optimal Marginal Tax Rates,” American Economic Review, 88(1), 83–95.
- Dupuy and Galichon (2014) Dupuy, A., and A. Galichon (2014): “Personality Traits and the Marriage Market,” Journal of Political Economy, 122(6), 1271–1319.
- Duran and Grossmann (1986) Duran, M. A., and I. E. Grossmann (1986): “An Outer-Approximation Algorithm for a Class of Mixed-Integer Nonlinear Programs,” Mathematical Programming, 36, 307–339.
- Ekeland and Moreno-Bromberg (2010) Ekeland, I., and S. Moreno-Bromberg (2010): “An Algorithm for Computing Solutions of Variational Problems with Global Convexity Constraints,” Numerische Mathematik, 115(1), 45–69.
- Gabaix and Landier (2008) Gabaix, X., and A. Landier (2008): “Why has CEO Pay Increased so Much?,” Quarterly Journal of Economics, 123(1), 49–100.
- Galichon and Salanié (2022) Galichon, A., and B. Salanié (2022): “Cupid’s Invisible Hand: Social Surplus and Identification in Matching Models,” Review of Economic Studies, 89(5), 2600–2629.
- Gayle and Shephard (2019) Gayle, G.-L., and A. Shephard (2019): “Optimal Taxation, Marriage, Home Production, and Family Labor Supply,” Econometrica, 87(1), 291–326.
- Geoffrion (1970) Geoffrion, A. M. (1970): “Elements of Large Scale Mathematical Programming Part II: Synthesis of Algorithms and Bibliography,” Management Science, 16(11), 676–691.
- Golosov and Krasikov (2022) Golosov, M., and I. Krasikov (2022): “Multidimensional Screening in Public Finance: The Optimal Taxation of Couples,” University of Chicago Working Paper.
- Griessler (2018) Griessler, C. (2018): “C-cyclical Monotonicity as a Sufficient Criterion for Optimality in the Multimarginal Monge-Kantorovich Problem,” Proceedings of the American Mathematical Society, 146(11), 4735–4740.
- Guvenen, Kuruscu, Tanaka, and Wiczer (2020) Guvenen, F., B. Kuruscu, S. Tanaka, and D. Wiczer (2020): “Multidimensional Skill Mismatch,” American Economic Journal: Macroeconomics, 12(1), 210–44.
- Guvenen, Ozkan, and Song (2014) Guvenen, F., S. Ozkan, and J. Song (2014): “The Nature of Countercyclical Income Risk,” Journal of Political Economy, 122(3), 621–660.
- Heathcote, Storesletten, and Violante (2017) Heathcote, J., K. Storesletten, and G. L. Violante (2017): “Optimal Tax Progressivity: An Analytical Framework,” Quarterly Journal of Economics, 132(4), 1693–1754.
- Heathcote and Tsujiyama (2021a) Heathcote, J., and H. Tsujiyama (2021a): “Optimal Income Taxation: Mirrlees meets Ramsey,” Journal of Political Economy, 129(11), 3141–3184.
- Heathcote and Tsujiyama (2021b) (2021b): “Practical Optimal Income Taxation,” FRB of Minneapolis Working Paper.
- Judd, Ma, Saunders, and Su (2017) Judd, K., D. Ma, M. A. Saunders, and C.-L. Su (2017): “Optimal Income Taxation with Multidimensional Taxpayer Types,” Stanford University Working Paper.
- Karunamuni and Alberts (2005) Karunamuni, R. J., and T. Alberts (2005): “A Generalized Reflection Method of Boundary Correction in Kernel Density Estimation,” Canadian Journal of Statistics, 33(4), 497–509.
- Kleven, Kreiner, and Saez (2006) Kleven, H. J., C. T. Kreiner, and E. Saez (2006): “The Optimal Income Taxation of Couples,” NBER Working Paper No. 12685.
- Kleven, Kreiner, and Saez (2009) (2009): “The Optimal Income Taxation of Couples,” Econometrica, 77(2), 537–560.
- Kocherlakota (2010) Kocherlakota, N. R. (2010): The New Dynamic Public Finance. Princeton University Press.
- Kremer (1993) Kremer, M. (1993): “The O-Ring Theory of Economic Development,” Quarterly Journal of Economics, 108(3), 551–575.
- Lehmann, Renes, Spiritus, and Zoutman (2021) Lehmann, E., S. Renes, K. Spiritus, and F. Zoutman (2021): “Optimal Taxation with Multiple Incomes and Types,” CEPR Discussion Paper No. 16571.
- Lindenlaub (2017) Lindenlaub, I. (2017): “Sorting Multidimensional Types: Theory and Application,” Review of Economic Studies, 84(2), 718–789.
- Lindenlaub and Postel-Vinay (2023) Lindenlaub, I., and F. Postel-Vinay (2023): “Multidimensional Sorting under Random Search,” Journal of Political Economy, 131(12), 3497–3539.
- Lions (1998) Lions, P.-L. (1998): “Identification of the Dual Cone of Convex Functions and Applications,” Comptes Rendus de l’Academie des Sciences, 12(326), 1385–1390.
- Lise and Postel-Vinay (2020) Lise, J., and F. Postel-Vinay (2020): “Multidimensional Skills, Sorting, and Human Capital Accumulation,” American Economic Review, 110(8), 2328–76.
- McAfee and McMillan (1988) McAfee, R. P., and J. McMillan (1988): “Multidimensional Incentive Compatibility and Mechanism Design,” Journal of Economic Theory, 46(2), 335–354.
- Mirrlees (1971) Mirrlees, J. A. (1971): “An Exploration in the Theory of Optimum Income Taxation,” Review of Economic Studies, 38(2), 175–208.
- Moser and Olea de Souza e Silva (2019) Moser, C., and P. Olea de Souza e Silva (2019): “Optimal Paternalistic Savings Policies,” Columbia Business School Working Paper.
- Oberman (2013) Oberman, A. M. (2013): “A Numerical Method for Variational Problems with Convexity Constraints,” SIAM Journal on Scientific Computing, 35(1), 378–396.
- Rochet and Choné (1998) Rochet, J.-C., and P. Choné (1998): “Ironing, Sweeping, and Multidimensional Screening,” Econometrica, 66(4), 783–826.
- Rockafellar (1999) Rockafellar, R. T. (1999): Network Flows and Monotropic Optimization, vol. 9. Athena Scientific.
- Rosen (1981) Rosen, S. (1981): “The Economics of Superstars,” American Economic Review, 71(5), 845–858.
- Rothschild and Scheuer (2013) Rothschild, C., and F. Scheuer (2013): “Redistributive Taxation in the Roy Model,” Quarterly Journal of Economics, 128(2), 623–668.
- Rothschild and Scheuer (2014) (2014): “A Theory of Income Taxation under Multidimensional Skill Heterogeneity,” NBER Working Paper No. 19822.
- Rothschild and Scheuer (2016) (2016): “Optimal Taxation with Rent-Seeking,” Review of Economic Studies, 83(3), 1225–1262.
- Roys and Taber (2022) Roys, N., and C. Taber (2022): “Skill Prices, Occupations, and Changes in the Wage Structure for Low Skilled Men,” University of Wisconsin Working Paper.
- Saez (2001) Saez, E. (2001): “Using Elasticities to Derive Optimal Income Tax Rates,” Review of Economic Studies, 68(1), 205–229.
- Sanders and Taber (2012) Sanders, C., and C. Taber (2012): “Life-cycle Wage Growth and Heterogeneous Human Capital,” Annual Review of Economics, 4(1), 399–425.
- Scheuer (2014) Scheuer, F. (2014): “Entrepreneurial Taxation with Endogenous Entry,” American Economic Journal: Economic Policy, 6(2), 126–63.
- Scheuer and Werning (2017) Scheuer, F., and I. Werning (2017): “The Taxation of Superstars,” Quarterly Journal of Economics, 132(1), 211–270.
- Shaked and Shanthikumar (2007) Shaked, M., and J. G. Shanthikumar (2007): Stochastic Orders. Springer Series in Statistics.
- Song, Price, Guvenen, Bloom, and Von Wachter (2019) Song, J., D. J. Price, F. Guvenen, N. Bloom, and T. Von Wachter (2019): “Firming Up Inequality,” Quarterly Journal of Economics, 134(1), 1–50.
- Tervio (2008) Tervio, M. (2008): “The Difference That CEOs Make: An Assignment Model Approach,” American Economic Review, 98(3), 642–68.
- Yamaguchi (2012) Yamaguchi, S. (2012): “Tasks and Heterogeneous Human Capital,” Journal of Labor Economics, 30(1), 1–53.
Bunching and Taxing Multidimensional Skills
Online Appendix
Job Boerma, Aleh Tsyvinski and Alexander Zimin
March 2025
Appendix A Proofs
In this appendix, we formally prove the results in the main text.
A.1 Proposition 1
To understand the optimal assignment, we consider a discrete version of the problem with identical discrete worker distributions , which we denote by , and a discrete firm distribution , which we denote by , for . The discrete problem is to find an assignment to maximize output:
| (A.1) |
where . We next solve this problem in steps.
First, we prove that without loss we can focus on assignments that are symmetric in worker inputs, so that . Suppose a solution is not symmetric, and use that the worker input samples are identical to define another feasible transport plan so that for all workers and projects. When solves the assignment problem, so does because , where the second equality follows as the production technology is symmetric in worker inputs, and the third equality follows by relabeling. This implies that the assignment is also a solution, which is indeed a symmetric solution. In summary, for every optimal assignment there is a symmetric assignment that also solves the assignment problem. Without loss of generality we can therefore focus on assignments that are symmetric in worker inputs.
Second, we prove it is optimal to self-sort workers so that implies that the workers are identical, or . Consider an optimal symmetric assignment and some project , and denote the joint distribution of workers assigned to this project by . We construct the marginal distributions of workers and coworkers assigned to this project as and . Due to the symmetry of the assignment function , the worker and coworker distribution within the firm are identical, . Further, we let denote the optimal reassignment of workers and coworkers within the project:
| (A.2) |
that is, solves the assignment problem within a firm given worker and coworker distribution .
Within firms it is optimal to self-sort workers. Suppose some firm is assigned some worker and coworker distribution , and consider two identical samples from this distribution. The within-firm assignment problem given these identical worker samples for and is to choose an assignment, or equivalently a permutation , to maximize output . Using the rearrangement inequality, aggregate output is bounded by:
| (A.3) |
The final equality follows as the worker and coworker distributions are identical. We conclude that self-sorting within every project attains maximum production. The rearrangement inequality implies optimality of positively sorting the skills of workers within each firm as the production technology for each unidimensional task is supermodular as in Becker (1973). In our environment with multidimensional skills positive sorting within each task is indeed attained by self-sorting, implying that is a diagonal matrix.
To formally establish that the optimal assignment function features self-sorting for each firm, also with continuous marginal distributions , we observe that (A.3) implies that the self-sorting set is -monotone (see, e.g., Bogachev and Kolesnikov (2012) or Ambrosio and Gigli (2013)).
Definition.
The set is -monotone if for all pairings :
| (A.4) |
for any permutation .
The -monotonicity condition directly implies the weaker condition that the matching set is -cyclically monotone, or , where . The self-sorting assignment with support on matching set is optimal as this statement is equivalent to the support of being -cyclically monotone following Theorem 1.2.7 in Bogachev and Kolesnikov (2012) or Theorem 1.13 in Ambrosio and Gigli (2013).
Given optimal self-sorting of workers within each firm, we construct a diagonal assignment by replacing with the optimal self-sorted for every project . Since solves the assignment problem within each firm, . By the construction of , it holds that implies that workers are identical for any . Without loss of generality, an optimal assignment indeed features self-sorting of workers with coworkers within projects . We define effective worker skills, or a team’s quality, by .
Finally, the optimal assignment sorts the best teams with the most valuable firm projects. Since the optimal assignment of workers within firms is self-sorting, the Kantorovich problem (A.1) simplifies to finding assignment to solve:
| (A.5) |
that is, to assign teams to firms. Given that the reduced-form production technology is supermodular, the solution to this problem is a positive sorting between the team quality and the project value . The solution to the original multimarginal Kantorovich problem (A.1) is then constructed using , where is the Kronecker delta function.
While we constructed the solution to the Kantorovich formulation of the assignment problem in the main text, we observe that the optimal assignment to the discrete planning problem is a Monge solution, meaning . This means the optimal assignment is a solution to the discrete planning problem of choosing permutations , to maximize output
| (A.6) |
given the identical worker samples drawn from the distribution and a firm project sample drawn from the distribution for .
Before proceeding, we observe that a transport problem with two identical worker distributions with measure one for each role is equivalent to a transport problem with a single distribution of workers with measure two. Owing to the symmetry of workers’ skills in production (4), these are equivalent. Intuitively, any assignment for a problem with distinct worker distributions can be made symmetric. Consider assignment that solves the discrete assignment problem for distinct worker distributions and . The transpose of the assignment along the worker input dimensions, which we denote by , solves the discrete assignment problem with worker input distributions and . This implies that symmetric assignment solves the discrete assignment problem with worker distributions .
Continuous Distributions. To obtain the solution for continuous distributions of workers and coworkers, we extend our argument for the discrete distributions. We construct an assignment that self-sorts workers and coworkers to obtain a unidimensional distribution for team quality . The assignment combines self-sorting of workers with positive sorting between worker skill index and projects .
This assignment solves the Kantorovich problem (9). To prove this claim, denote the support of the assignment by , the matching set. Consider a collection of points within the matching set, , then for each of those points it holds , and that implies . Since the support is constructed by using a Monge solution for the discrete assignment problem, for all permutations . Equivalently, the matching set is -monotone. By Theorem 1.2 in Griessler (2018), the assignment solves the Kantorovich problem. This concludes the proof to Proposition 1.
A.2 Incentive Constraints
We first discuss the differentiability of the indirect utility function . Feasibility of an allocation is exactly equivalent to the indirect utility function being feasible, which means that is convex, nonnegative, and decreasing, together with the additional constraint , where denotes the subdifferential of at a given point.
Consider the incentive constraint (12):
Using the notation for the indirect utility function (14), that is, , this can be equivalently rewritten as
This inequality for each pair of types is equivalent to the convexity of together with the constraint that , where denotes the subdifferential of at given point. In this case, we know by Alexandrov theorem that , since it is a convex function, is differentiable almost everywhere, and hence almost everywhere.
We next show which incentive compatibility constraints are redundant to the planner problem in the numerical analysis. We establish that every reducible incentive constraint is redundant in the presence of the irreducible constraints, which shrinks the set of incentive constraints that needs to be taken into account by the planner. To show this result, we let be a finite subset and we first define irreducible constraints.
Figure A.1 shows reducible and irreducible incentive constraints for worker . When the irreducible incentive constraints between workers and are satisfied (as indicated by the black solid line between workers and ), and the irreducible incentive constraints between workers and are satisfied (as indicated by the blue solid line between workers and ), then reducible incentive constraints between and are satisfied (as indicated by the orange dashed line). Every reducible incentive constraint is satisfied when the irreducible constraints are. The black solid lines denote all the irreducible incentive constraints for worker .
Definition.
A couple of points is irreducible if there is no point on the interval between and .
Lemma 4.
All reducible incentive constraints are implied by irreducible incentive constraints.
The proof is presented below.
Figure A.1 shows the reducible and the irreducible incentive constraints for worker . When the irreducible incentive constraints between workers and are satisfied (as indicated by the black solid line between workers and ), and the irreducible incentive constraints between workers and are satisfied (as indicated by the blue solid line between workers and ), then reducible incentive constraints between and are satisfied (as indicated by the orange dashed line). Every reducible incentive constraint is satisfied when the irreducible constraints are. The black solid lines denote the irreducible incentive constraints for worker . The incentive constraints between workers and as well as between workers and are also reducible.
We next establish that no other incentive constraints can be eliminated a priori. The set of feasible allocations strictly increases by removing any of the irreducible incentive constraint.
Lemma 5.
Consider any irreducible incentive constraint where worker type does not want to report to be of type . If we eliminate such an incentive constraint, then there exists an allocation that satisfies all other incentive constraints while worker type wants to report . That is, for any irreducible pair there exist functions such that:
for all where and
The proof is presented below.
We denote the set of utility allocations that satisfy the set of irreducible linear incentive constraints by .
Proof to Lemma 4. Let be a ray from a parameter point , and let scalar parameters and such that . We consider points and .
We first show that if incentive constraints between points and as well as and are satisfied, then incentive constraints between and are implied. By (15), we know the incentive constraint that does not want to report implies:
| (A.7) |
Similarly, the incentive constraint that does not want to report implies:
Adding these two constraints, we obtain .
Using the incentive constraint that does not want to report :
| (A.8) |
we show that given these incentive constraints, the constraint between points and is implied. We evaluate
where the first inequality follows from the first and third incentive constraint, while the second inequality follows as . The final equality indeed implies that does not want to report .
Similarly, we use the incentive constraint that does not want to report :
| (A.9) |
in order to prove that does not want to report :
where the final inequality follows by adding (A.8) and (A.9), which implies . This shows we do not need to incorporate incentive constraints between and when we incorporate the incentive constraint between and , and between and .
The final step is that our result so far held for general scalar parameters and be such that . We note that for so that , we can show that the constraints between and are implied by the constraints between and as well as and . Hence, for every point we only need to consider the constraints for the lowest possible values for . These constraints are irreducible.
Proof to Lemma 5. By induction. The induction base is a set of points in with . Let the points within the set be and . We show there exist functions so that:
Construct the function , and and .
Induction step for points. Let denote a vertex of the convex hull of set which is neither nor . Such a point indeed exists, else the convex hull is an interval between and , implying that any other point of the set would be a point between and contradicting is irreducible.
Remove the point from the set . By induction step at , there exist functions for the lattice such that for the same irreducible pair :
for all and and
We need to extend the functions and onto the point . Here, we will use that is a vertex of the convex hull. We construct the value for the functions and at point . At the point , we require:
for all . Reorganizing, the first inequality becomes
where we observe constant is independent of both and . We set . As a result, the second inequality is written as:
To show that the inequality is satisfied, we use the following variation of Farkas’ Lemma. For any convex polytope and for any vertex of this polytope, there exist a hyperplane such that belongs to the hyperplane while all other points of the convex polytope lie strictly on one side of it. Equivalently, there exists a vector such that for all .
Since point is a vertex of the convex hull of there exists so that for every . Define the constant . Then there exists positive value so that:
Further, let , implying that for all . Hence, we set to conclude our claim.
A.3 Lemma 2
We first prove that if the indirect utility function (14) is strongly convex, then there is no bunching. By the inverse function theorem, using that the indirect utility function is twice continuously differentiable, if the Jacobian matrix of the mapping from to is invertible then the labor task allocation is invertible. The Jacobian matrix of the mapping from to is the negative to the Hessian matrix of the indirect utility function using . Since the utility function is strongly convex for worker , its Hessian matrix is invertible, and hence the Jacobian matrix is. Summarizing, if the utility function is strongly convex, then there is no bunching.
Now we prove that if the indirect utility function (14) is not strongly convex, i.e. the Hessian matrix is degenerate for all workers in the neighborhood of , worker is bunched, or . To prove this statement, consider a mapping from worker type to the labor allocation , and let denote the neighborhood of workers around such that Hessian matrix is degenerate for all workers . Since the Jacobian matrix of the mapping is the negative to the Hessian matrix of the indirect utility function, the Jacobian matrix is degenerate for all workers . Equivalently, is a critical set. By Sard’s theorem it follows that the image has Lebesgue measure zero.
To prove that worker is bunched, suppose by contradiction they are not, . Equivalently, the mapping is injective in a neighborhood . By the invariance of domain, the image is a non-empty open set. This implies that the Lebesgue measure is strictly positive for the image, contradicting the implication from Sard’s theorem. Thus, workers are bunched when the optimality condition does not hold.
A.4 Proposition 2
Lemma 6.
Let solve the planner problem. The following condition holds with equality at an optimum:
| (A.10) |
Proof.
Consider an allocation that satisfies the incentive compatibility constraints. Consider multiplying this allocation by a constant factor , to obtain the scaled allocation . The Lagrangian of the scaled allocation exceeds the Lagrangian of the optimal allocation , or . Therefore, we can consider a variation around the optimal allocation , where we scale the allocation by a small factor , so that alternative allocation is feasible. Given such a variation, the implied change in the resource cost is:
| (A.11) |
At an optimum, neither a positive nor a negative small variation decreases the cost of resources, so , which establishes (A.10).∎
Lemma 7.
Let solve the planning problem, then the implementability condition (18) holds for any feasible allocation .
Proof.
If two allocations and satisfy the incentive constraints, so does their convex combination for any . If is a planner solution, it follows that for any and for any feasible allocation , a convex combination of the alternative allocation and the solution increases the Langrangian value relative to its optimum, . By construction of the convex combination, this is equivalent to .
A.5 Global Optimal Tax Formula in One Dimension
In this appendix, we develop the connection of our general optimal tax condition with stochastic dominance to the classic ABC formula. First, we consider equation (20) under unidimensional skill heterogeneity. With a slight abuse of notation, we denote the unidimensional skill by . In this case, equation (20) simplifies to:
| (A.12) |
for any decreasing, nonnegative and convex indirect utility function with .222222Asserting there is no bunching at the top of the unidimensional worker skill distribution, both the boundary conditions are zero under the additional condition that . Moreover, with one dimension of worker heterogeneity, the measure second-order stochastically dominates the measure if and only if , where and denote cumulative distribution functions (see the next paragraph). When the unidimensional measure second-order stochastically dominates the unidimensional measure it thus implies:
| (A.13) |
for every worker , where we use the definition of the labor skill wedge (16), which changes the inequality sign, and also use that . At an optimum, the utility-weighted average benefit of increasing marginal tax rates for all workers below , on the right, exceeds the corresponding costs. The benefit of an increase in a marginal tax rate is an increase in revenues collected from workers below (high ) net of the cost of tightening the promise-keeping constraint, . The cost of increasing the marginal tax for all workers below is captured by the marginal utility-weighted labor wedge. Our optimal tax formula as stochastic dominance (20) extends this logic to multidimensional skills.
Second-Order Stochastic Dominance in One Dimension. Let denote a decreasing, nonnegative and convex function parameterized by that is strictly positive for all and is equal to zero for all . Specifically, we let . Given that is decreasing, nonnegative, and convex, measure second-order stochastically dominating measure implies that for all following (21). Given the specification for this is equivalent to for all , alternatively . Since any unidimensional decreasing, nonnegative and convex indirect utility function with can be considered as a positive combination of , the claim holds.
Relation to Mirrlees (1971), Diamond (1998), and Saez (2001). Second, we discuss in more detail how the optimal tax condition (24) directly relates to the ABC formulas in Diamond (1998) and Saez (2001), and to the optimal tax condition in Mirrlees (1971). To see the relationship, we first take the ABC formula in Saez (2001), which is equation (25) in his paper:
| (A.14) |
Reorganizing this expression, letting , we obtain:
| (A.15) |
which is, in fact, the representation of the optimal tax formula in equation (33) in Mirrlees (1971). Differentiating this expression with respect to type , we obtain:
| (A.16) |
This is the unidimensional analog to our characterization in equation (24), where we observe that the multiplier on the resource constraint in Saez (2001) is the inverse of the multiplier on the promise keeping constraint , which follows directly from the Lagrangian (17).
A.6 Global Optimal Tax Formula
In this appendix, we derive the global optimal taxation formula (24). For ease of presentation, we assume that the convex indirect utility functions are smooth, meaning the second derivative is well-defined and continuous.
First, we reformulate the planner problem using the definition of the indirect utility function (14). Given the indirect utility function , both consumption and effort allocations can be expressed in terms of and its gradient. The planner chooses an indirect utility function to minimize the resource cost of providing welfare:
| (A.17) |
subject to the incentive constraint that requires the indirect utility to be convex and decreasing in worker type (Lemma 1), or , and the promise keeping condition:
| (A.18) |
We introduce multiplier on the promise keeping condition (A.18) in order to formulate the Lagrangian:
In the remainder of this appendix, we refer to the problem of minimizing the Lagrangian shorthand as:
| (A.19) |
where is the contribution of worker type to the Lagrangian and where denotes the type space, a bounded convex subset of .
A.6.1 Convex Indirect Utility
The restriction that the indirect utility function is convex is equivalent to the Hessian matrix of the indirect utility function being positive semidefinite, for all , which in turn is equivalent to:
| (A.20) |
for all . We treat these inequalities as an infinite series of constraints parameterized by both and . For each of these constraints, we introduce a corresponding multiplier . The objective function is augmented to include these multipliers:
| (A.21) |
Next, fix a worker type and consider the multipliers associated with this worker type. Using to denote the inner products of matrices, we write:
| (A.22) |
This equation expresses the quadratic form as an inner product between the Hessian matrix and a matrix defined by the integral , which we denote by .
We next characterize all matrices that can be represented as a convex combination of outer products over the directions :
| (A.23) |
where is a non-negative function.
Lemma 8.
Matrix is a symmetric and positive semidefinite if and only if with respect to some function .
Proof.
We first establish that with respect to some function implies is symmetric and positive semidefinite. Matrix is symmetric as each outer product is a symmetric matrix, and any linear combination or integral of symmetric matrices is symmetric. Second, is positive semidefinite because for any vector , , which shows is positive semidefinite.
Next, we show the converse also holds. We start with a matrix that is symmetric and positive semidefinite and show that it can be written in the form of equation (A.23). Any symmetric matrix can be factorized using its eigenvalue decomposition. If is a positive semidefinite matrix, it can be written as:
where is an orthogonal matrix whose columns are the eigenvectors of . Since the matrix is positive semidefinite, it follows that is a diagonal matrix with nonnegative eigenvalues .
Since each eigenvalue corresponds to an eigenvector , we rewrite as a finite sum of outer products of the eigenvectors:
The sum can be generalized to an integral, with the eigenvectors replaced by the corresponding vectors , and the eigenvalues replaced by the corresponding continuous nonnegative function . In sum, positive semidefinite matrix can be expressed in the form:
where .∎
Instead of considering the continuous family of multipliers , we represent the constraint that the indirect utility function has to be convex as a matrix condition by introducing the Kuhn-Tucker matrix for each . By Lemma 8, the matrix is required to be positive semidefinite, or , for all . The Kuhn-Tucker matrix substitutes the term in the objective function (A.21), where :
| (A.24) |
where is the positive semidefinite matrix that enforces the convexity of the indirect utility function.
We proceed by integrating by parts the term:
| (A.25) |
Through integration by parts, we shift the derivatives from the indirect utility function to the Kuhn-Tucker matrix to obtain:232323Since the boundary terms do not affect the derivation of the optimality condition and the general optimal taxation formula, we suppress them for ease of exposition.
| (A.26) |
where . The resulting objective function for the problem is:
| (A.27) |
We can rewrite this by combining the promise keeping constraint with the convexity correction as:
| (A.28) |
This representation shows that the requirement that the indirect utility function is convex leads to the modified social welfare weight . In other words, the main difference that convexity adds to the planning problem is through modifying the welfare function by the convexity correction. We next show how this result carries over to the optimality conditions.
A.6.2 Optimality Conditions
We derive the optimality conditions by using the objective function (A.27), and by considering a small variation in the indirect utility function. The first variation of the objective gives:
| (A.29) |
where . The left-hand side is the standard optimality condition, . This yields the optimality condition without bunching, , when the convexity constraint does not bind.
The right-hand side gives the additional term involving the second derivatives of the Kuhn-Tucker matrix. This term arises from the integration by parts of the Kuhn-Tucker matrix, and represents the effect of the convexity constraint, which is enforced through the positive semidefinite matrix .
Our derivation shows that the minimizer of our variational problem over convex indirect utility functions satisfies an optimality condition with an additional term arising from the Kuhn-Tucker multipliers associated with the convexity constraint. Our results build on Lions (1998) which analyzes variational problems over convex functions through a duality approach. Lions (1998) shows that the optimality conditions can be understood in terms of the polar cone of convex functions, where elements of the dual space are represented by measures linked to second derivatives. Our result explicitly incorporates Kuhn-Tucker multipliers into the variational problem to enforce the convexity constraint and includes them into the optimality condition. This construction directly shows the effect of convexity by showing how additional measure terms arise in the optimality conditions.
A.6.3 Optimal Tax Formula
We next apply the optimality condition for the general Lagrangian (A.29) to the Lagrangian for the optimality multidimensional taxation problem (A.17). As a result, we write the optimal taxation formula as:
| (A.30) |
Similar to our reformulation of the general optimal tax formula as stochastic dominance (22), we use the definition of the labor skill wedge (16) to rewrite the optimal taxation formula as:
| (A.31) |
which is the optimal taxation formula (24).
A.7 Corollary 3
We start with the region of strong convexity of the indirect utility function and, hence, a region without bunching. To analyze properties of optimal tax distortions, we use a perturbation function. Specifically, we construct a variation of the indirect utility function for a specific worker . Consider a worker in the interior of the type space such that both the assignment function and the distribution of worker types are differentiable in a neighborhood around this worker. Moreover, suppose that the strongly convex utility function is twice continuously differentiable within a neighborhood of the worker .
Consider an arbitrary perturbation of the indirect utility denoted , where is a bump function that is concentrated in a small ball around which lies within the neighborhood around , and is small. The arbitrary perturbation function is convex for small enough values for within the support of the bump function, . Intuitively, if the underlying utility function is strongly convex, a small enough additive perturbation preserves convexity.242424The proof of this statement is presented below. See Convex Perturbation Function.
The perturbation function is convex, positive and non-increasing, and therefore implementable (19). Since the implementability condition (19) is linearly separable and holds with equality for an optimal utility function by Proposition 2, the implementability also has to be satisfied for for all . Since can take either positive or negative values, the implementability condition holds with equality with respect to the bump function :
| (A.32) |
Integrating the left-hand side of this equation by parts and tending the bump function to the Dirac delta function, we obtain the optimality condition equation in Corollary 3.
Convex Perturbation Function. We establish that the perturbation function is convex. We suppose that the indirect utility function is strongly convex for interior worker type and twice continuously differentiable within its neighborhood. Specifically, we suppose that is positive semidefinite for worker for some , where denotes the Hessian matrix and denotes the identity matrix.
Since worker is in the interior of the type space, the indirect utility function is strictly positive and strictly decreasing for worker . By contradiction, suppose the indirect utility function equals zero for worker , . Since the indirect utility function is non-increasing, for small enough , implying that the gradient of the indirect utility function for worker is equal to zero, . By implication, consider that the partial derivative of the indirect utility function with respect to cognitive type equals zero, . Since we consider a partial derivative for a convex function, the partial derivative increases with so that for all , or . It hence follows that , and hence that for which contradicts that is positive semidefinite by the Sylvester criterion. We conclude that the utility function is strictly positive and strictly decreasing for interior worker .
Since the indirect utility function is strongly convex for worker type and twice continuously differentiable within its neighborhood, the utility function is strongly convex in this neighborhood. The restriction that is positive semidefinite in a neighborhood around worker type implies is positive semidefinite in the neighborhood around when the indirect utility function is twice continuously differentiable. Hence, the utility function is indeed strongly convex in this neighborhood.
We consider a perturbation of the indirect utility denoted by , where is a bump function that is concentrated in a small ball around which lies within the neighborhood around , and is small. The arbitrary perturbation function is convex for small enough values for within the support of the bump function, .
While intuitive, we prove that is convex for small enough values for within the support of the bump function in two steps. First, we observe that for some , it holds that is negative semidefinite and that is positive semidefinite. In the former case, negative semidefinite is equivalent to for any . To see this, we first observe . Furthermore, we use that to write . Therefore, there indeed exists such that is negative semidefinite. Through a similar argument is positive semidefinite. Given , it holds that is positive semidefinite for positive , and that is positive semidefinite for negative .
Second, we note that the Hessian matrix for the perturbation function is additively separable, . Since the matrix is positive definite, the matrix is positive definite. Finally, since the sum of positive semidefinite matrices is itself positive semidefinite, it follows that is positive semidefinite for small enough, which confirms that the perturbation function is indeed convex. Following analogous reasoning, the indirect utility function is also decreasing and positive in a neighborhood around worker .
Changing Coordinates. To connect our expression to the existing literature, we transform the optimal tax formula into the original type coordinates . We illustrate this transformation by focusing on the partial derivative with respect to cognitive skill in (26),
| (A.33) |
where is the probability distribution in the transformed worker space . To convert this term into the original worker space, we first recall the change of coordinates , or equivalently , implying that .
We first explicitly formulate the relationship between the distribution function in the original worker type space given by , and the worker distribution function in transformed coordinates given by :
where the distribution function . As a result, we express (A.33) as:
| (A.34) |
Next, by the chain rule we have that , which gives:
The derivation for the manual skill term is symmetric, which allows us to summarize the previous two expressions for both tasks as:
| (A.35) |
Finally, we rewrite the left side of equation (26), using the relation between density functions, as
| (A.36) |
Combining equation (26) in the worker type space , with (A.35) and (A.36), we obtain (27) in the worker space .
A.8 Proposition 4
By Corollary 3 it follows that when the optimality condition does not hold, the Hessian matrix is degenerate for worker . We next show that the Hessian matrix is also degenerate for all workers within the neighborhood of . By contradiction, suppose that in every neighborhood of point we can find a worker such that its Hessian is non-degenerate, or equivalently, has full rank. By Corollary 3, the optimality condition holds for worker . We can thus construct a sequence of points that converges to . Since the optimality equation is continuous in , the sequence converges and that the optimality equation holds for worker , which is a contradiction.
A.9 Planner Duality
We prove duality between our cost minimization problem and a welfare maximization problem. The welfare maximization problem is to choose allocation to maximize utilitarian welfare:
| (A.37) |
subject to the incentive constraints (12) and the linear resource constraint:
| (A.38) |
for some exogenous level of federal resources .
Proposition 5.
Let solve the cost minimization problem associated with maximum welfare level so that the minimum resource cost is less than government resources . Then allocation solves the welfare maximization problem given government resources .
Conversely, if allocation solves the welfare maximization problem for resources and induces welfare , then solves the cost minimization solves the cost minimization problem for .
Proof.
First, we establish that the welfare attained by the cost minimization problem and welfare maximization problem are identical. Consider the solution to the cost minimization problem with maximum welfare level such that the resource cost is below resource level . Allocation satisfies both the incentive constraints and the resource constraints of the welfare maximization problem and is thus a feasible solution to the welfare maximization problem. Welfare in the welfare maximization problem therefore exceeds .
Conversely, take the solution to the welfare maximization and let denote maximum welfare. Consider the allocation that solves the welfare maximization problem. The allocation satisfies both the incentive constraints and the promise keeping constraint to the cost minimization problem. Further, the associated resource cost is below resource level . Hence, , implying that welfare is identical for the two problems, .
Second, we show duality of allocations. Suppose allocation solves the cost minimization problem with maximum welfare level such that the cost is below resources , but the allocation does not solve the welfare maximization problem. Then, there is an alternative allocation that solves the welfare maximization problem, is feasible, and attains strictly greater welfare. This implies that there exists a welfare level so that has a cost below resources , contradicting that is the maximum welfare so that the minimum resource cost is below .
Conversely, suppose allocation solves the welfare maximization problem given resources inducing welfare , but does not solve the cost minimization problem. Then, there exists an alternative allocation that solves the cost minimization problem for a welfare level such that the minimum cost is below resources . Allocation is feasible and attains strictly greater welfare, contradicting that solves the welfare maximization problem.∎
A.10 Transformed Planner Problem
In this appendix, we analyze the planner problem of choosing an allocation to minimize the resource cost of providing welfare as in Section 3.2. Using the Legendre transforms (29) and (30) to linearize the resource costs, the planning problem is equivalent to:
| (A.39) |
subject to the set of linear irreducible incentive constraints (12) and the promise keeping constraint (13).
To develop properties of the solution we formulate a Lagrangian, where is the multiplier on the promise keeping constraint:
| (A.40) |
The Lagrangian is a continuous function that is concave-convex. Since the Legendre transform of a convex function is itself convex, the Lagrangian is concave in the distortions holding constant the allocations , and convex in the allocations when holding constant the distortions. Further, since the set of allocations that satisfies the incentive constraints (12) is convex, we can apply the minimax theorem. We use the minimax relationship, , to establish Lemma 9.
Lemma 9.
For every incentive compatible allocation , stochastic dominance has to be satisfied:
| (A.41) |
The result follows by analyzing . By contradiction, suppose instead that . Consider an increase in the allocation by a constant factor . Since incentive compatible constraints are linear, the alternative allocation is feasible. By increasing the constant factor, , optimization would lead to negative infinity, which is not optimal. At the solution to the planning problem, the stochastic dominance condition (A.41) will hold with equality.
Proposition 6.
Let solve the planning problem, then stochastic dominance condition holds with equality at optimum:
| (A.42) |
Proof.
To establish the result, we use two problems. First, define the maximization problem:
| (A.43) |
where . Let be a solution to this problem. Similarly, we define a minimization problem:
| (A.44) |
where , and let be a minimizer to this problem.
Claim 1.
We show that for the Lagrangian (A.40) evaluated at the optimum it holds that:
| (A.45) |
Proof.
Necessarily it holds that . Since solves the optimization problem, , and thus it follows .
Similarly, note that it necessarily holds that . Since the utility allocation is a solution to the minimization problem, . Combining the previous two statements, we conclude , and hence:
| (A.46) |
By the minimax theorem it follows that (A.45) applies.∎
Optimality Conditions. We obtain optimality conditions analyzing the planner problem using from Claim 1. By reorganizing terms:
| (A.47) |
We observe that only the first four terms depend on the utility allocation, and observe further that these terms are necessarily jointly positive for some utility allocation to be incentive compatible following Lemma 9. Since allocation is incentive compatible and attains the minimum, the optimal utility allocation is chosen such that these terms jointly equal zero, implying:
| (A.42) |
and thus concluding the proof.∎
To obtain further optimality conditions to our problem, we analyze the planner problem using in Claim 1 to write:
| (A.48) |
We observe that only the first four terms depend on the convex conjugates, and that only the final term depends on the multiplier, in terms of the inner maximization problem. Since the promise keeping condition requires , and , it has to hold that . Similarly, it has to hold that and .
A.11 Numerical Approach
Linearization of the Problem. We now discuss the linearization of the problem that is central to numerical tractability. The only nonlinear part of the optimization problem that remains to be linearized is the objective:
| (A.49) |
To illustrate our approach, we focus on the linearization of the convex resource cost function for consumption utility , and we suppose that bounds for the optimal solution are known a priori, or and .
The idea is to approximate the convex cost for consumption utility from below with the tangent lines on the bounded interval. For each worker type , it follows from the definition of the Legendre transform (29) that . We replace this continuous set of tangent slopes in (29) with a finite set of tangent lines. Specifically, we consider a list of slopes with corresponding tangent lines such that the inequality:
| (A.50) |
holds for all in the bounded interval . Analogously, to linearize the resource cost of labor disutility , we consider a list of slopes with corresponding tangent lines such that the inequality:
| (A.51) |
holds for each skill and for all in the interval .
As a key step, we next introduce independent auxiliary variables for each worker satisfying the following set of linear inequalities for all :
| (A.52) |
It follows from the discussion above that for each worker . For the resource cost of disutility from working, we similarly define independent auxiliary variables satisfying the linear inequalities for all :
| (A.53) |
We substitute the auxiliary variables and for and into our nonlinear objective to define the approximate planner problem. The approximate planner problem chooses to solve:
| (A.54) |
subject to the incentive constraints (12), the promise keeping constraint (13), constraints on the auxiliary variables (A.52) and (A.53), and the approximation bounds for consumption utility and task outputs .
Accuracy. We next describe the accuracy of the approximate planner problem and provide the algorithm that we use to characterize its solution. The precision of the solution to the approximate planner’s problem naturally depends on the accuracy of the prior location of the solution. The criterion we evaluate to ensure that the location is accurate is the absence of binding boundary constraints at the optimal solution. In line with this criterion, we define a solution is proper when no boundary constraints binds.
Definition.
The solution to the approximate problem is proper if the solution is strictly interior, that is , if and when .
Proposition 7 shows that one can readily verify that a proper solution approximates well the optimal solution to the initial planner problem.
Proposition 7.
For the approximate problem, introduce the maximal approximation errors:
If the solution to the approximate planner problem is proper, then the overall approximation error is bounded from above by the sum of maximal approximation errors:
where is the minimum value for the original problem.
Proof.
We show that if the solution to the approximation problem is proper, then the overall approximation error is bounded from above by the sum of maximal approximation errors. We next prove that both inequalities are satisfied.
The first inequality is satisfied since the approximate allocation is feasible. Since the approximate planner’s problem produces a feasible solution, we clearly have
| (A.55) |
To prove the second inequality, we use that the definition of the approximation error and the approximation constraints (A.52) implies . Denote by the allocation that attains the minimum resource cost . Since the solution to the approximate problem is proper, there exist a weight such that the convex combination given by and is a proper allocation. To construct an alternative allocation that is feasible under the approximate problem, we can set:
| (A.56) | ||||
| (A.57) |
Since solves the approximate problem, and since is feasible, we know that the cost under the alternative allocation exceeds the cost under the approximate solution. Since the pointwise maximum of convex functions is convex, we have that
| (A.58) | ||||
| (A.59) |
where the final inequalities follows from the definition of the approximation constraints (A.52), and from the observation that approximations are from below. By combining the two previous claims we write that
which implies . Finally, we use the definition of the approximation errors to write:
which concludes the proof.∎
Algorithm. We use an iterative algorithm to solve the approximate planner’s problem for a given precision level.252525See Ekeland and Moreno-Bromberg (2010) for a discussion on numerically solving optimization problems subject to a convexity constraint on the function , and Oberman (2013) for a practical approach of dealing with global incentive constraints. We solve the planner problem for a worker type space with 200 types in both the cognitive and the manual dimension, equivalently, for a total of 40 thousand types. We display the structure of our numerical approach in Algorithm 1.
Having described how to characterize the planner problem given an arbitrary assignment, we next describe how to update the assignment to obtain a jointly optimal assignment and allocation. Given the optimality of positive sorting between workers and firms in Proposition 1, we update our assignment after each step by positively sorting the distribution of project values with the effective worker skill index . By doing so, we reassign projects across workers which yields a new assignment. We then solve the planner’s problem for the new assignment function using Algorithm 1. We proceed until the assignment converges. To the best of our knowledge, there is no proof of unique convergence for this iterative procedure. In practice, however, we find that our algorithm always converges to the same assignment function for distinct initial assignments.
Literature. Our numerical approach relates to outer linearization of a separable convex objective function. This approach is well-established, see for example, Bertsekas and Yu (2011).
Outer linearization of a separable convex objective is part of the outer linearization approach for general problems. For example, Geoffrion (1970) present the idea of approximating a convex function with supporting hyperplanes, which is outer linearization. Duran and Grossmann (1986) applies outer linearization to general convex mixed-integer optimization problems. In our case, the objective is separable in variables, which leads to faster and more efficient algorithms for constructing the supporting hyperplanes. Bertsekas and Yu (2011) also have an objective function that is separable in variables and discuss that this problem has been explored under the framework of extended monotropic programming, which builds on monotropic programming (Rockafellar, 1999). Our approach extends beyond outer linearization of a separable convex objective. Whereas the literature routinely focuses on problems with linear equality constraints, our approach also addresses inequality constraints, making it applicable to a broader class of problems.
A.12 Characterizing Equilibrium using Transport Problems
To characterize an equilibrium, we relate our positive economy to optimal transport problems.
Primal Problem. The primal problem is to choose an assignment to maximize production:
| (A.60) |
The choice of an assignment is restricted by the feasibility constraint, , where denotes the set of probability measures on the product space such that the marginal distributions of onto and are and respectively.
Dual Problem. The dual transport problem is to choose functions and that solve:
| (A.61) |
subject to the constraint that the surplus is weakly negative for any triplet , that is, .
We connect the primal problem and the dual problem to equilibrium in Lemma 10.
Lemma 10.
We use Lemma 10 to characterize the equilibrium.262626We note that a transport problem with two identical worker distributions with unit mass for each role is equivalent to a transport problem with a single worker distribution with mass two (Appendix A.13). We solve the primal problem (A.60) to characterize the equilibrium assignment and the dual problem (A.61) to characterize wages and firm values . To prove Lemma 10, we use Lemma 11.
Lemma 11.
The proof to Lemma 11 only uses of a notion of weak duality.
Weak Duality. Let be a joint probability measure, and be functions such that for all . Then
| (A.62) |
Proof. For any functions so that we have:
where the equality follows as . Since the above inequality holds for any it holds for that minimize the right-hand side.
We use weak duality to establish Lemma 11 by contradiction.
Proof of Lemma 11. Suppose by contradiction that does not solve the planning problem, then
| (A.63) |
where the equality follows by assumption. This contradicts weak duality (A.62).
Suppose by contradiction that the functions , and do not solve the dual problem. Then there exists functions , and such that
| (A.64) |
where the equality follows by the assumption. This inequality contradicts weak duality (A.62).
We now use Lemma 11 to show that equilibrium assignment solves the primal transport problem, and that the wage and firm value function solve the dual transport problem.
In equilibrium, the surplus is negative for any triplet , which implies that . By substituting the household budget constraints , and the government budget constraint , into the aggregate resource constraint (35), we write:
| (A.65) |
By Lemma 11 it thus follows that solves the primal problem and and solve the dual problem.
A.13 Symmetric Equilibrium
We prove that we can restrict our attention to symmetric equilibria without loss of generality.
Lemma 12.
For any equilibrium with wages and assignment function , there exists an equilibrium with wages and a symmetric assignment .
Proof.
Lemma 12 states that for any competitive equilibrium with wages , firm value , and assignment , there is an equilibrium with identical wages , firm value function with a symmetric assignment function , where .
To prove this result, we first define as a pushforward measure of the assignment function . We then show that the symmetric assignment function indeed solves the primal transport problem. Using Lemma 10, this establishes the result.
Definition.
Given spaces and , a measure concentrated on , and a map , the pushforward measure of through , which we denote by , is defined so that:
| (A.66) |
We define as the pushforward measure of through a mapping , or . Our mapping maps from the matching set onto itself interchanging the position of the worker and the coworker, that is, so that . If is a feasible assignment, is a feasible assignment, that is, for we have .
Using the definition of , we construct symmetric assignment function , and observe that the symmetric assignment function is feasible given , that is, . Moreover, we observe that:
| (A.67) |
The left-hand side is unchanged as the production of equilibrium pairings does not change, while the right-hand side is unchanged as the skill distribution is unchanged. By Lemma 11, solves the primal transport problem, and functions and solve the dual transport problem. By Lemma 10, this shows that symmetric assignment is an equilibrium assignment, are equilibrium wages, and are equilibrium firm values.
Finally, we remark that the equilibrium assignment need not be . Specifically, we can replace with any other optimal primal solution. Suppose that there exists another solution to the primal problem , then
| (A.68) |
and hence for almost everywhere.∎
A.14 Wages and Firm Values
To see why only effective skill matters, consider two workers and with identical effective skill . Since the surplus is zero almost everywhere under equilibrium assignment , and using production technology (4), and . By the constraints to the dual problem (A.61), and , where the equalities follow since the workers’ effective skills are identical. Combining these expressions, and , so that . It is useful to define , the firm’s total wage bill, as .
Wages are convex in effective skill , so small differences in effective worker skill translate into increasingly large differences in worker earnings. The dual constraints imply for any . Since the surplus is zero almost everywhere with respect to the equilibrium assignment implying that , the firm’s wage bill is the Legendre transform of the firm value function. Since is the supremum of linear functions in , the wage function is convex.
The firm value function is the Legendre transform of the wage bill. The dual constraints also imply that for any it holds that and therefore . This implies that the firm value function is convex and indeed the Legendre transform of the wage bill . As a result, .
A.15 Lemma 3
We show there exists a firm distribution such that given wage schedule , workers and firms both optimize in a self-sorting equilibrium, where the distribution of worker skills is determined by the worker problems given a talent distribution . We verify this claim by studying the firm and worker problem given the postulated wage schedule (36).
Firm. Taking the wage schedule as given, the firm problem of choosing two workers to employ can be written as:
where the equality follows from substituting in the production technology (4) and wage schedule (36). The solution to this problem is that firm wants to hire two identical workers.
To establish that each firm wants to hire two identical workers, we show that a firm that hires different workers such that can increase its profits by hiring two identical workers . By hiring two identical workers, the firms increases its production and decreases its wage bill. Production increases since the worker production technology is concave, that is, is implied by . To see that the firm decreases its wage bill by hiring two identical workers, observe that implies , which implies that for we have . Since the function is convex , we obtain by applying this inequality to the right-hand side. Equivalently, by hiring two identical workers a firm lowers their wage bill relative to hiring two different workers , . Finally, since firms hire identical workers, the firm’s optimality condition hiring effective worker skill gives . Since the wage schedule is convex, equilibrium sorting is positive.
Worker. The distribution of worker skills is uniquely induced by the worker problems. Given the wage schedule, a worker’s problem is:
| (A.69) |
Using a transformation , the problem is:
| (A.70) |
where .
We prove strict concavity of the objective by examining each of the terms in the objective. The second and third term are linear and thus concave. We remain to verify that the first term, , is strictly concave. First, since the consumption utility is strictly concave:
Since is an increasing and concave function, the first term is strictly concave if is strictly concave. To establish this, we note that the transformed wage equation is a composite function of a concave CES aggregate with an increasing concave function as long as . The worker problem is strictly concave and thus has a unique solution, which implies the distribution of worker skills is uniquely induced by the worker’s problem.
To complete the proof we show there exists a distribution of firm projects such that the wage equation (36) is an equilibrium wage function. Since the wage bill is continuously differentiable, . We can use this expression to uniquely pin down a distribution of firm project values that rationalizes the wage equation. Since the wage bill is convex, the inferred distribution indeed implies positive sorting between effective worker skills and firm project values.272727For the parametric specification, can be characterized as , where is a multiplicative constant independent of . Together with the dual constraint, this closed-form expression for the firm value allows us to characterize project value without relying on the derivative of the firm’s wage bill in the quantitative section.
A.16 Frisch Elasticity
We next show how to derive the expression for the Frisch elasticity of labor supply within our model. Adding the optimality conditions across tasks gives , with constant . Using the constant effort shares implied by (40), and multiplying and dividing by we write , where is constant across workers. To obtain the Frisch elasticity implied by our model, we relate a worker’s total efforts to earnings per hour as to obtain (41):
| (41) |
A.17 Implementation
In this appendix, we describe an implementation of the optimum through an income tax system. This argument follows the analysis in Kocherlakota (2010) for an environment with multidimensional private information. To illustrate this argument, let denote the solution to the planning problem for a finite type space .
We first note that the consumption allocation depends on type only through the allocation of tasks . If while , worker would pretend being type to attain more consumption for identical task inputs and the planner allocation is not incentive compatible. The consumption allocation can thus be written as a function of the task inputs , where the domain of the consumption function is finite and given by .
The consumption function is increasing in both cognitive and manual task disutility as the tax system has to reward workers for providing higher levels of task inputs. Suppose , while . In this case, worker reports , so the planning allocation is not incentive compatible.
While the consumption allocation function has a finite domain, we next extend to all such that and . For all such task inputs, define
| (A.71) |
subject to if the maximizer exists and otherwise. We also set for all outside the domain. We define the tax system over the same values of as:
| (A.72) |
Proposition 8.
Tax system implements the planner allocation.
Proof.
In order to establish the result, we show that workers of skill indeed choose the allocation for worker under the planner allocation.
The problem of worker given the tax system is to choose the level of cognitive and manual task inputs to solve:
| (A.73) |
subject to the constraint . The problem can thus be written as:
| (A.74) |
Choosing cognitive and manual task inputs below their minimum would be suboptimal as the worker pay infinite taxes. We thus restrict the attention to task inputs .
We next show that workers choose a task allocation . By contradiction, suppose that the worker instead chooses an allocation . Hence, the worker attains consumption , which by the definition of the consumption allocation function is given by:
| (A.75) |
subject to . Since , the worker can do better by reducing their work effort choosing that delivers the same consumption level. The worker consumes the same, exerting less effort. As a result, we restrict the choice to without loss of generality.
Worker chooses the optimal bundle of task inputs , which boils down to choosing such that for all
| (A.76) |
By definition of the consumption allocation function over the domain X it follows that this is equivalent to:
| (A.77) |
for all . That worker optimally chooses allocation , implementing the planner allocation, then follows from the incentive constraints.∎