C-SENN: Contrastive Self-Explaining
Neural Network
Abstract
In this study, we use a self-explaining neural network (SENN), which learns unsupervised concepts, to acquire concepts that are easy for people to understand automatically. In concept learning, the hidden layer retains verbalizable features relevant to the output, which is crucial when adapting to real-world environments where explanations are required. However, it is known that the interpretability of concepts output by SENN is reduced in general settings, such as autonomous driving scenarios. Thus, this study combines contrastive learning with concept learning to improve the readability of concepts and the accuracy of tasks. We call this model Contrastive Self-Explaining Neural Network (C-SENN).
1 Introduction
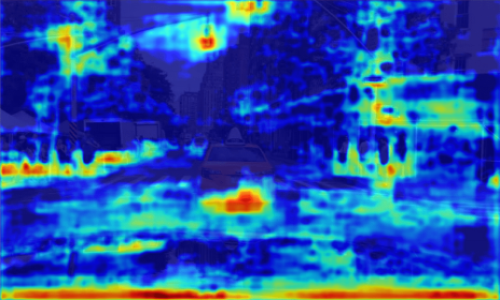
(A)

(B)
When people are given an input signal, they use concepts in their brains to understand its meaning. Concepts are abstract and verbalizable information arrangements [2], and the construction of models, which incorporate them, is essential for model utilization in a real environment where explainability and interpretability are required. To make deep learning models more accessible to the world outside the laboratory, we build a model in which individual neurons correspond to individual concepts on a one-to-one basis.
To develop models that incorporate concepts, this study focuses on the self-explaining neural network (SENN) [3, 1], which is a generalized linear model that acquires unsupervised concepts. Alvarez-Melis and Jaakkola [3] confirmed the SENN’s ability to acquire concepts for the final output [3]. However, their validation work was performed only on relatively simple image datasets, such as MNIST [4] and CIFAR-10 [5]; thus, no validation was performed on datasets that capture more complex and near-real-world environments, such as Berkeley DeepDrive (BDD) [6]. Sawada and Nakamura [1] tackled this problem by using the discriminator and shared intermediate network (They called modified SENN (M-SENN)). However, the interpretability of the concepts output by M-SENN is still low in such environments, as shown in Fig. 1 (A) (see Sec. 4 for details).
In this study, we adopt contrastive learning [7] to acquire concepts that are highly interpretable, even for images captured in complex environments. Contrastive learning is a self-supervised learning method that has been actively studied in recent years [7, 8, 9, 10]. We utilize supervised contrastive learning (SCL) [8] and the Barlow Twins (BT) [9]. SCL utilizes target labels for the final output, whereas BT ensures the independence of each feature (neuron) acquired via self-supervised learning. By incorporating these methods, we successfully acquire different concepts related to the final output without duplication. Furthermore, by augmenting contrastive learning data with the results of the Faster RCNN [11], which we use as a feature extractor, we generate concepts from verbalizable object regions. We refer to our proposed method as the Contrastive SENN(C-SENN, See Fig. 2). We apply C-SENN to the BDD-OIA dataset [12], finding that it improves the interpretability of the generated concepts (see Fig. 1 (B)). We also successfully achieved a higher accuracy than other methods, including conventional SENN.
2 Conventional Methods
2.1 Self-Explaining Neural Network (SENN)
SENN generates concepts in the layer just prior to the output layer. In its generalized form, it is expressed as the linear model, , as follows [3]:
| (1) |
where is the input image, is the model that outputs weights for each concept, and represents the model (encoder) that outputs concepts. Additionally, and , where denotes the number of concepts set in advance and denotes the number of category of final output. SENN expresses and as neural networks optimized by the training dataset, ( is the -dimensional vector representing the final output label) and minimizes the following loss function.
| (2) |
where represents the classification loss (e.g., binary-cross entropy), and represents the reconstruction error. is the reconstructed image using the decoder , and and are the hyperparameters. is the regularization term representing the stability of by the gradient.
| (3) |
where is the derivative of , and is the Jacobian of the concept with respect to . This regularization term makes robust to small changes in concepts [3].
2.2 Modified Self-Explaining Neural Network (M-SENN)
As desribed in Sec. 2.1, original SENN is the encoder-decoder model that requires a large number of parameters [13]. In addition, SENN must compute the Jacobian with respect to each input . Therefore, SENN cannot apply datasets larger than MNIST and CIFAR-10 [14]. Sawada and Nakamura [1] tackled this problem by using the discriminator and shared intermediate network as follows.
| (4) |
where , , and represents an image different from . () is the intermediate network. We use the output of backbone with FPN of Faster RCNN [11]. represents the squared error [1].
| (5) |
where , , and represent the discriminator. Since the number of parameters of is much smaller than the decoder’s one, [1] used this discriminator loss instead of the reconstruction error . Additionally, represents a constraint term that constrains the variation of as follows:
| (6) |
where is the derivative of with respect to the intermediate feature, is the Jacobian of , and the relationship between and , and and are as follows:
| (7) | |||||
| (8) |
By using these techniques, [1] achieved to train models for the BDD-OIA [12] and CUB-200-2011 [15].
3 Contrastive Self-Explaining Neural Network (C-SENN)
As noted in Section 1, the interpretability of concepts generated by M-SENN is low in complex environments. One of the reasons is that it is challenging for the true/false discriminator to generate concepts while maintaining the similarity in the input space. In this study, we focus on contrastive learning to better maintain the similarity in the input space.
Contrastive learning is a kind of self-supervised learning that has been actively studied in recent years [7, 16]. Many contrastive learning methods combine multiple data augmentation techniques and learn to place transformations from the same image closer together in the feature space and those from different images farther apart. Then, the top layer (projection head) is removed, and the rest is used as a feature extractor. In contrast, as in [17], we minimize the contrastive loss simultaneously with other losses.
This study utilizes supervised contrastive learning (SCL) [8] and the Barlow Twins (BT) [9] for generating concepts.
| (9) |
| (10) |
where is the SCL loss function and is the BT loss function. Furthermore,
| (11) |
where is the hyperparameter, is the set of concepts of all data except the -th data, and . is the set of concepts in the data having the same label as the -th target label, and is the total number of such concepts. represents the -th concept of , which is a result of data augmentation of . We utilize the detection results of Faster RCNN [11] for data augmentation. Note that the intermediate extractor is part of this Faster RCNN pretrained by the COCO [18] and fine-tuned with BDD100k [6]. We detect bounding boxes with Faster RCNN, and replace the regions other than the bounding box ( is a constant) with white noise. Then, we treat the resulting image as (Fig. 3). As a result, the model learns to acquire concepts from the periphery of the object region. Notably, is included in .
By combining Equations (9) and (10) with Equation (4), the final loss function of C-SENN is as follows:
| (12) |
where and represent hyperparameters that control the loss function’s value. Notably, (the distance measure loss) is not used here. The purpose of is to preserve distance relations in the input image and concept space [1]. However, the same result is obtained using the SCL loss clearly from Equation (9). Thus, because we consider to be substitutable by , we do not use to reduce redundancy. In this study, the resultant SENN is termed “C-SENN”.
Figure 2 shows a schematic diagram of C-SENN. As shown, for computational efficiency, only the Faster RCNN masking described above is used for data augmentation. Similarly, the original image is used as input without masking during inferencing.

(A)

(B)
4 Experimental Results
This section describes our evaluation of C-SENN using the BDD-OIA [12] for autonomous driving, consisting of 16,802 training mages, 2,270 evaluation images, and 4,572 test images. Each image is assigned target labels (“forward ()”, “stop ()”, “right turn ()”, and “left turn ()”), representing possible driving actions (namely, ). Notably, BDD-OIA has 21 concept labels (e.g., “green light” or “‘good visibility”) for each image, but these are not used for C-SENN and M-SENN training (original SENN could not run).
In this article, we set , , , , and to equal the number of BDD-OIA concepts. The network structure and other hyperparameters are the same as those in [1], and all experiments were performed using one NVIDIA Tesla v100 GPU with 32-GB memory.

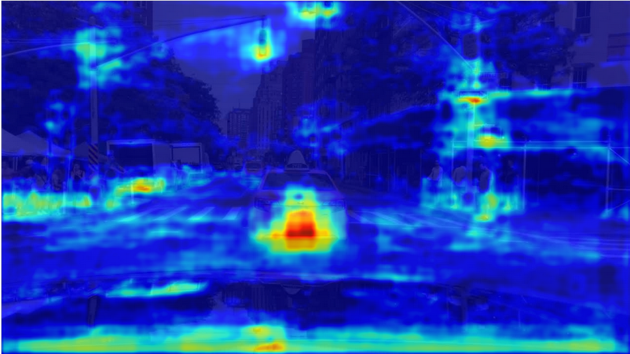
SENN


SC-SENN


C-SENN
Figure 4 shows examples of concept saliency maps obtained by each method. These maps were generated by the grad-CAM [19]. Notably, the SC-SENN model replaced the of the SENN with and did not use the BT loss function. With , each concept was focused on a more local region in the image. For example, the SC-SENN image on the right side of Fig. 4 focuses on traffic signals and signs. The addition of improved the focus to even finer regions. For example, the C-SENN image on the left side of Fig. 4 focuses on the right side of each object, whereas the image on the right focuses on the foot of each. The former is a useful concept for the “right turn” action, whereas the latter is a useful concept for “forward” and “stop” actions. The results of the C-SENN saliency map for other images are shown in the appendix.
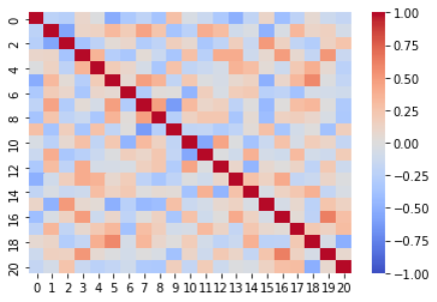
(A)
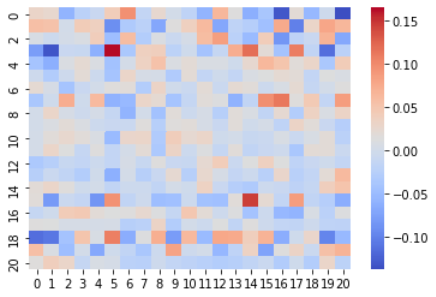
(B)
Figure B (A) shows the correlation matrix between concepts acquired by C-SENN, and Fig. B (B) shows the correlation matrix of C-SENN concepts and concept labels in the BDD-OIA dataset. Fig. B (A) shows that the correlation between concepts was small; thus, multiple concepts can be acquired by C-SENN without duplication. This is the effect of SCL. In contrast, Fig. B (B) shows that the concepts acquired by C-SENN had little correlation with the concept labels. Thus, the C-SENN makes predictions based on concepts that differ from those deemed necessary by human annotators. For example, concepts corresponding to the foot and right sides of each object, as shown in the C-SENN image in Fig. 4, do not exist in the teacher concepts. This suggests that it is possible to discover new insights by checking the concepts generated by C-SENN. Additional analyses are shown in the appendix.




Next, Fig. 6 shows examples of the regions in each image where each concept was focused. In the bottom part of the figure, the X-axis represents image ID, and the Y-axis represents the object detected by Faster RCNN. The higher the average gradCAM score in each object region, the brighter the display. This confirms that C-SENN generates concepts that span multiple object regions. Concerning interpretability, it is desirable that concepts be generated from a smaller number of objects. This is a topic for future research.
| Model | F | S | R | L | |
|---|---|---|---|---|---|
| Vanilla | 0.54 | 0.666 | 0.11 | 0.151 | 0.367 |
| CBM [14] | 0.795 | 0.732 | 0.431 | 0.483 | 0.610 |
| M-SENN [1] | 0.705 | 0.727 | 0.339 | 0.385 | 0.539 |
| C-SENN | 0.772 | 0.744 | 0.486 | 0.469 | 0.618 |
Finally, we show the driving behavior recognition results using each method. Table 1 shows result. Note that vanilla is the model that does not explicitly generate concepts between input and output, and the concept bottleneck model (CBM) [14] is the model that trains by utilizing concept labels assigned in the BDD-OIA dataset. The evaluation indices used were the F1-score for each driving behavior and , which is the average F1-score for each action [12]. Comparing the results to vanilla confirms that recognition accuracy improved by generating concepts between input and output. Additionally, the results show that C-SENN was more accurate than M-SENN. C-SENN also showed higher values than CBM in many indices. This suggests that C-SENN can generate more appropriate recognition concepts than human-annotator preassigned concept labels. Although CBM offers the potential to improve accuracy by refining the concept labels related to driving behaviors in advance, it makes the annotation costs enormous.
5 Conclusion
In this study, we proposed C-SENN, which combines the M-SENN with two types of contrastive learning, BT and SCL. We conducted experiments on the BDD-OIA dataset, confirming that C-SENN acquired concepts that were more highly interpretable than those of other methods, and it recognizes driving actions with high accuracy. In the future, we plan to conduct a detailed analysis of what constitutes a highly interpretable concept through functional evaluations. However, collaboration with various researchers, such as psychologists, will be essential to know the ideal form of the concepts we are acquiring. This is not low-hanging fruit, but it is necessary to work on over the long term.
References
- [1] Yoshihide Sawada and Keigo Nakamura. Concept bottleneck model with additional unsupervised concepts. IEEE Access, 10:41758–41765, 2022.
- [2] Wikipedia. https://en.wikipedia.org/wiki/Concept.
- [3] David Alvarez Melis and Tommi Jaakkola. Towards robust interpretability with self-explaining neural networks. Advances in Neural Information Processing Systems, 31:7775–7784, 2018.
- [4] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. In Proceedings of the IEEE, number 11 in 86, pages 2278–2324, 1998.
- [5] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. master’s thesis, university of tronto, 2009.
- [6] Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2636–2645, 2020.
- [7] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- [8] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. arXiv preprint arXiv:2004.11362, 2020.
- [9] Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. arXiv preprint arXiv:2103.03230, 2021.
- [10] Feng Wang and Huaping Liu. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2495–2504, 2021.
- [11] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. Faster R-CNN: towards real-time object detection with region proposal networks. CoRR, abs/1506.01497, 2015.
- [12] Yiran Xu, Xiaoyin Yang, Lihang Gong, Hsuan-Chu Lin, Tz-Ying Wu, Yunsheng Li, and Nuno Vasconcelos. Explainable object-induced action decision for autonomous vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9523–9532, 2020.
- [13] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In International Conference on Learning Representations, 2019.
- [14] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International Conference on Machine Learning, pages 5338–5348. PMLR, 2020.
- [15] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011.
- [16] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15750–15758, 2021.
- [17] Li Fu, Xiaoxiao Li, Runyu Wang, Zhengchen Zhang, Youzheng Wu, Xiaodong He, and Bowen Zhou. Scala: Supervised contrastive learning for end-to-end automatic speech recognition. arXiv preprint arXiv:2110.04187, 2021.
- [18] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. CoRR, abs/1405.0312, 2014.
- [19] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017.
- [20] Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning. arXiv preprint arXiv:2105.04906, 2021.
Appendix
A Saliency Maps for Other Images
Figure A shows the C-SENN saliency maps for other images. Bottom right-most images are input, and other images are saliency maps obtained by the grad-CAM. As shown in these figures, some neurons focus on small areas, while others focus on the whole image with few obstacles and good visibility. When driving good visibility environments, humans also focus on the entire field of view. Therefore, we consider that neurons concentrating over the whole image corresponds to this human action.






B Additional Analysis
Here, we show some results when changing conditions.
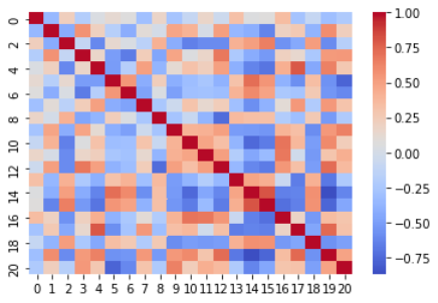
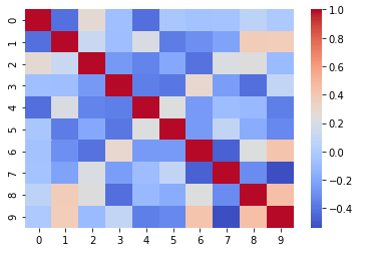
Figure B (A) and (B) show the correlation matrix using Barlow Twins [9] (same as Fig. 6(A)) and Variance-Invariance-Covariance Regularization (VICReg) [20], respectively. VICReg is also a method that ensures the independence of each concept, as in BT. Comparing these matrices, BT has smaller values of the non-diagonal components than VICReg. Therefore, we used the BT for C-SENN.
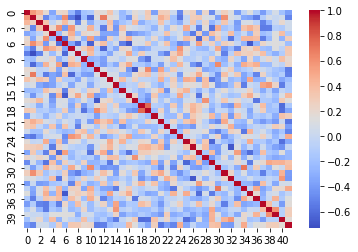
Figure B (C) and (D) show the correlation matrix when changing the number of concepts . These figures show that C-SENN has smaller values of the non-diagonal components irrelevant to . Figure C shows the saliency maps of and . When increasing , C-SENN focuses on small areas and vice-vasa. Namely, generated concepts change by changing . Automatic acquisition of the appropriate number of concepts, taking interpretability and recognition rate into account, is an issue for future work.
(A)
(B)
(C)
(D)

