C11Tester: A Race Detector for C/C++ Atomics
Technical Report
Abstract.
Writing correct concurrent code that uses atomics under the C/C++ memory model is extremely difficult. We present C11Tester, a race detector for the C/C++ memory model that can explore executions in a larger fragment of the C/C++ memory model than previous race detector tools. Relative to previous work, C11Tester’s larger fragment includes behaviors that are exhibited by ARM processors. C11Tester uses a new constraint-based algorithm to implement modification order that is optimized to allow C11Tester to make decisions in terms of application-visible behaviors. We evaluate C11Tester on several benchmark applications, and compare C11Tester’s performance to both tsan11rec, the state of the art tool that controls scheduling for C/C++; and tsan11, the state of the art tool that does not control scheduling.
1. Introduction
The C/C++11 standards added a weak memory model with support for low-level atomics operations (cpp11spec; c11spec) that allows experts to craft efficient concurrent data structures that scale better or provide stronger liveness guarantees than lock-based data structures. The potential benefits of atomics can lure both experts and novice developers to use them. However, writing correct concurrent code using these atomics operations is extremely difficult.
Simply executing concurrent code is not an effective approach to testing. Exposing concurrency bugs often requires executing a specific path that might only occur when the program is heavily loaded during deployment, executed on a specific processor, or compiled with a specific compiler. Some prior work helps record and replay buggy executions (deloren). Debuggers like Symbiosis (symbiosis) and Cortex (cortex) focus on sequential consistency and test programs by modifying thread scheduling of given initial executions. However, both the thread scheduling and relaxed behavior of C/C++ atomics are sources of nondeterminism in a C/C++ programs that use atomics. Thus, it is necessary to develop tools to help test for concurrency bugs. We present the C11Tester tool for testing C/C++ programs that use atomics.
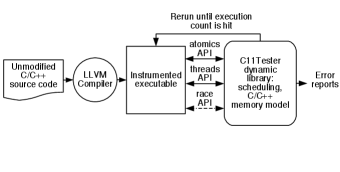
Figure 1 presents an overview of the C11Tester system. C11Tester is implemented as a dynamically linked library together with an LLVM compiler pass, which instruments atomic operations, non-atomic accesses to shared memory locations, and fence operations with function calls into the C11Tester dynamic library. The C++ and pthread library functions are overridden by the C11Tester library—C11Tester implements its own threading library using fibers to precisely control the scheduling of each thread. The C11Tester library implements a race detector and C11Tester reports any races or assertion violations that it discovers.
The C/C++ memory model defines the modification order relation to totally order all atomic stores to a memory location. This relation captures the notion of cache coherence. The modification order is not directly observable by the program execution — it is only observed indirectly through its effects on program visible behaviors such as the values returned by loads. Under the C/C++ memory model, modification order cannot be extended to be a total order over all stores that is consistent with the happens-before relation.
This paper presents a new technique for scaling a constraint-based treatment of the modification order relation to long executions. This technique allows C11Tester to support a larger fragment of the C/C++ memory model than previous race detectors. In particular, this technique can handle the full range of modification orders that are permitted by the C/C++ memory model.
Constraint-based modification order delays decisions about the modification order until the decisions have observable effects on the program’s behavior. For example, when an algorithm decides which store a load will read from, C11Tester adds the corresponding constraints to the modification order. This approach allows testing algorithms to focus on program visible behaviors such as the value a load reads and does not require them to eagerly decide the modification order.
Fibers provide a more efficient means to control thread schedules than kernel threads. However, C/C++ programs commonly make use of thread local storage (TLS) and fibers do not directly support TLS. This paper presents a new technique, thread context borrowing, that allows fiber-based scheduling to support thread local storage without incurring dependencies on TLS implementation details that can vary across different library versions.
1.1. Comparison to Prior Work on Testing C/C++11
Prior work on data race detectors for C/C++11 such as tsan11 (tsan11) and tsan11rec (tsan11rec) require be acyclic and thus miss potentially bug-revealing executions that both are allowed by the C/C++ memory model and can be produced by mainstream hardware including ARM processors. We have found examples of bugs that C11Tester can detect but tsan11 and tsan11rec miss due to the set of edges orders writes in the modification order.
C11Tester’s constraint-based approach to modification order supports a larger fragment of the C/C++ memory model than tsan11 and tsan11rec. C11Tester adds minor constraints to the C/C++ memory model to forbid out-of-thin-air (OOTA) executions for relaxed atomics. Furthermore, these constraints appear to incur minimal overheads on existing ARM processors (oota) while x86 and PowerPC processors already implement these constraints.
1.2. Contributions
This paper makes the following contributions:
-
•
Scalable Concurrency Testing Tool: It presents a tool for the C/C++ memory model that can test full programs.
-
•
Supports a Larger Fragment of the C/C++ Memory Model: It presents a tool that supports a larger fragment of the C/C++ memory model than previous tools.
-
•
Constraint-Based Modification Order: The modification order relation is not directly visible to the application, instead it constrains the behaviors of visible relations such as the reads-from relation. Eagerly selecting the modification order limits the choices of stores that a load can read from and thus limits the information available to algorithms. We develop a scalable constraint-based approach to modeling the modification order relation that allows algorithms to ignore the modification order relation and focus on program visible behaviors.
-
•
Support for Limiting Memory Usage: The size of the C/C++ execution graph and execution trace grows as the program executes and thus limits the length of executions that a testing tool can support. Naively freeing portions of the graph can cause a tool to produce executions that are forbidden by the memory model. We present techniques that can limit the memory usage of C11Tester while ensuring that C11Tester only produces executions that are allowed by the C/C++ memory model.
-
•
Fiber-based Support for Thread Local Storage: Fibers are the most efficient way to control the scheduling of the application under test, but supporting thread local storage with fibers is problematic. We develop a novel approach for borrowing the context of a kernel thread to support thread local storage.
-
•
Evaluation: We evaluate C11Tester on several applications and compare against both tsan11 and tsan11rec. We show that C11Tester can find bugs that tsan11 and tsan11rec miss. We present a performance comparison with both tsan11 and tsan11rec.
2. C/C++ Atomics
In this section, we present general background on the C/C++ memory model and then discuss the fragment of the C/C++ memory model that C11Tester supports. The C and C++ standards were extended in 2011 to include a weak memory model that provides precise guarantees about the behavior of both the compiler and the underlying processor. The standards divide memory locations into two types: normal types, which are accessed using normal memory primitives; and atomic types, which are accessed using atomic memory primitives. The standards forbid data races on normal memory types and allow arbitrary accesses to atomic memory types. Accesses to atomic memory types have an optional memory_order argument that explicitly specifies the ordering constraints. Any operation on an atomic object will have one of six memory orders, each of which falls into one or more of the following categories. Like all other tools for the C/C++ memory model, compilers, and work on formalization to our knowledge, C11Tester does not support the consume memory order and thus we omit consume in our presentation.
- seq-cst::
-
memory_order_seq_cst – strongest memory ordering, there exists a total order of all operations with this memory ordering. Loads that are seq_cst either read from the last store in the seq_cst order or from some store that is not part of seq_cst total order.
- release::
-
memory_order_release, memory_order_acq_rel, and memory_order_seq_cst – when a load-acquire reads from a store-release, it establishes a happens-before relation between the store and the load. Release sequences generalize this notion to allow intervening RMW operations to not break synchronization.
- acquire::
-
memory_order_acquire, memory_order_acq_rel, and memory_order_seq_cst – may form release/acquire synchronization.
- relaxed::
-
memory_order_relaxed – weakest memory ordering. The only constraints for relaxed memory operations are a per-location total order, the modification order, that is equivalent to cache coherence.
The C/C++ memory model expresses program behavior in the form of binary relations or orderings. We briefly summarize the relations:
-
•
Sequenced-Before: The evaluation order within a program establishes an intra-thread sequenced-before (sb) relation—a strict preorder of the atomic operations over the execution of a single thread.
-
•
Reads-From: The reads-from (rf) relation consists of store-load pairs such that takes its value from . In the C/C++ memory model, this relation is non-trivial, as a given load operation may read from one of many potential stores in the execution.
-
•
Synchronizes-With: The synchronizes-with (sw) relation captures the synchronization that occurs when certain atomic operations interact across threads.
-
•
Happens-Before: In the absence of memory operations with the consume memory ordering, the happens-before (hb) relation is the transitive closure of the union of the sequenced-before and the synchronizes-with relations.
-
•
Sequentially Consistent: All operations that declare the memory_order_seq_cst memory order have a total ordering (sc) in the program execution.
-
•
Modification Order: Each atomic object in a program has an associated modification order (mo)—a total order of all stores to that object—which informally represents an ordering in which those stores may be observed by the rest of the program.
2.1. Example
To explore some of the key concepts of the memory-ordering operations provided by the C/C++ memory model, consider the example in Figure 2, assuming that two independent threads execute the methods threadA() and threadB(). This example uses the C++ syntax for atomics; shared, concurrently-accessed variables are given an atomic type, whose loads and stores are marked with an explicit memory_order governing their inter-thread ordering and visibility properties. In the example, the memory operations are specified to have the relaxed memory ordering, which is the weakest ordering in the C/C++ memory model and allows memory operations to different locations to be reordered.
In this example, a few simple interleavings of threadA() and threadB() show that we may see executions in which , , or , but it is somewhat counter-intuitive that we may also see , in which the first load statement sees the second store but the second load statement does not see the first store. While this latter behavior cannot occur under a sequentially-consistent execution of this program, it is, in fact, allowed by the relaxed memory ordering used in the example (and achieved by compiler or processor reorderings).
Now, consider a modification of the same example, where the store and load on variable y (Line LABEL:line:store-relaxed-example and Line LABEL:line:load-relaxed-example) now use memory_order_release and memory_order_acquire, respectively, so that when the load-acquire reads from the store-release, they form a release/acquire synchronization pair. Then in any execution where r1 = 1 and thus the load-acquire statement (Line LABEL:line:load-relaxed-example) reads from the store-release statement (Line LABEL:line:store-relaxed-example), the synchronization between the store-release and the load-acquire forms an ordering between threadB() and threadA()—particularly, that the actions in threadB() after the acquire must observe the effects of the actions in threadA() before the release. In the terminology of the C/C++ memory model, we say that all actions in threadA() sequenced before the release happen before all actions in threadB() sequenced after the acquire.
So when r1 = 1, threadB() must see r2 = 1. In summary, this modified example allows only three of the four previously-described behaviors: , , and .
2.2. C11Tester’s C/C++ Memory Model Fragment
We next describe the fragment of the C/C++ memory model that C11Tester supports. Our memory model has the following changes based on the formalization of Batty et al. (c11popl):
1) Use the C/C++20 release sequence definition: Since the original C/C++11 memory model, the definition of release sequences has been weakened (releasesequences). This change is part of the C/C++20 standard (cpp-draft-n4849). C11Tester uses the newly weakened definition. The new definition of release sequences does not allow memory_order_relaxed stores by the thread that originally performed the memory_order_release store that heads the release sequence to appear in the release sequence.
2) Add is acyclic: Supporting load buffering or out-of-thin-air executions is extremely difficult and the existing approaches introduce high overheads in dynamic tools (prescientmemory; oopsla2013; toplascdschecker). Thus, we prohibit out-of-thin-air executions with a similar assumption made by much work on the C/C++ memory model — we add the constraint that the union of happens-before, sequential consistency, and reads-from relations, i.e., , is acyclic (vafeiadis2013relaxed).111The C/C++11 memory model already requires that is acyclic. This feature of the C/C++ memory model is known to be generally problematic and similar solutions have been proposed to fix the C/C++ memory model (mspc14; N3786; N3710; oota).
3) Strengthen consume atomics to acquire: No compilers support the consume access mode. Instead, all compilers strengthen consume atomics to acquire.
We formalize the above changes in Section LABEL:sec:restricted-model of the Appendix. Our fragment of the C/C++ memory model is larger than that of tsan11 and tsan11rec (tsan11; tsan11rec). The tsan11 and tsan11rec tools add a very strong restriction to the C/C++ memory model that requires that be acyclic.
3. C11Tester Overview
We present our algorithm in this section. In our presentation, we adapt some terminology and symbols from stateless model checking (dpor). We denote the initial state with . We associate every state transition taken by thread with the dynamic operation that affected the transition. We use to denote the set of all threads that are enabled in state (threads can be disabled when waiting on a mutex, condition variable, or when completed). We say that is the next transition in thread at state .
Figure 3 presents pseudocode for C11Tester’s exploration algorithm. C11Tester calls Explore multiple times—each time generates one program execution. Recall from Section 2 that the thread schedule does not uniquely define the behavior of C/C++ atomics. Therefore, we split the exploration into two components: (1) selecting the next thread to execute and (2) selecting the behavior of that thread’s next operation. C11Tester has a pluggable framework for testing algorithms—C11Tester generates a set of legal choices for the next thread and behavior, and then the plugin selects the next thread and behavior. The default plugin implements a random strategy.
Scheduling
Thread scheduling decisions are made at each atomic operation, threading operation, or synchronization operation (such as locking a mutex). Every time a thread finishes a visible operation, the next thread to execute is randomly selected from the set of enabled threads. However, when a thread performs several consecutive stores with memory order release or relaxed, the scheduler executes these stores consecutively without interruption from other threads. Executing these stores consecutively does not limit the set of possible executions and provides C11Tester with more stores to select from when deciding which store a load should read from. This decision also reduces bias in comparison to a purely randomized algorithm.
For example, in Figure 4, under a purely randomized algorithm, the probability that r1 = 1 is much greater than that of r1 = 2, because in order for r1 = 2, the scheduler must schedule threadA() twice before threadB() is scheduled. However, under C11Tester’s strategy, once threadA is scheduled to run, both stores at line LABEL:line:bias-first-store and line LABEL:line:bias-second-store will be performed consecutively. So when the load is encountered, the may-read-from set (defined in the paragraphs below) either only contains the initial store at line LABEL:line:bias-initial-store or contains all three stores. Thus, r1 is equally likely to read 1 or 2.
Transition Behaviors
The source of multiple behaviors for a given schedule arises from the reads-from relation—in C/C++, loads can read from stores besides just the “last” store to an atomic object.
We use the concept of a may-read-from set, which is an overapproximation of the stores that a given atomic load may read from that just considers constraints from the happens-before relation. The may-read-from set for a load is constructed as:
where denotes the set of all stores to the same object from which reads. C11Tester selects a store from the may-read-from set. C11Tester then checks that establishing this rf relation does not violate constraints imposed by the modification order, as described in Section 4. If the given selection is not allowed, C11Tester repeats the selection process. C11Tester delays the modification order check until after a selection is made to optimize for performance.
4. Memory Model Support
In this section, we present how C11Tester efficiently supports key aspects of the C/C++ memory model.
CDSChecker (oopsla2013) initially introduced the technique of using a constraint-based treatment of modification order to remove redundancy from the search space it explores. There are essentially two types of constraints on the modification order: (1) that a store is modification ordered before a store and (2) that a store immediately precedes an RMW in the modification order.
CDSChecker models these constraints using a modification order graph. Two types of edges correspond to these two types of constraints. Edges only exist between two nodes if they both represent memory accesses to the same location. There is a cycle in the modification order graph if and only if the graph corresponds to an unsatisfiable set of constraints. Otherwise, a topological sort of the graph (with the additional constraint that an RMW node immediately follows the store that it reads from) yields a modification order that is consistent with the observed program behavior. CDSChecker used depth first search to check for cycles in the graph. CDSChecker would add edges to the modification order graph to determine whether a given reads-from edge was plausible — if the edge made the set of constraints unsatisfiable, CDSChecker would rollback the changes that the edge made to the graph.
This approach works well for model checking where the graphs are small—the fundamental scalability limits of model checking ensure that the executions always contain a very small number of stores. This approach is infeasible when executions (and thus the modification order graphs) can contain millions of atomic stores, because the graph traversals become extremely expensive.
4.1. Modification Order Graph
We next describe the modification order graph in more detail. We represent modification order (mo) as a set of constraints, built as a constraint graph, namely the modification order graph (mo-graph). A node in the mo-graph represents a single store or RMW in the execution. There are two types of edges in the graph. An mo edge from node to node represents the constraint . A rmw edge from node to node represents the constraint that must immediately precede or formally that: and .
C11Tester must only ensure that there exists some mo that satisfies the set of constraints, or equivalently an acyclic mo-graph. C11Tester dynamically adds edges to mo-graph when new rf and hb relations are formed. We briefly summarize the properties of mo as implications (oopsla2013) in Figure 5. C11Tester maintains a per-thread list of atomic memory accesses to each memory location. Whenever a new atomic load or store is executed, C11Tester uses this list to evaluate the implications in Figure 5 as well as additional implications for fences.
| Read-Read Coherence | ||
|
|
|
|
| Write-Read Coherence | ||
|
|
|
|
| Read-Write Coherence | ||
|
|
|
|
| Write-Write Coherence | ||
|
|
|
|
| Seq-cst / MO Consistency | ||
|
|
|
|
| Seq-cst Write-Read Coherence | ||
|
|
|
|
| RMW / MO Consistency | ||
|
|
|
|
| RMW Atomicity | ||

|
|
|
4.2. Clock Vectors
Due to the high cost of graph traversals for large graphs, graph traversals are not a feasible implementation approach for C11Tester. We next describe how we adapt clock vectors (l-clocks) to efficiently compute reachability in the mo-graph and scale the constraint-based modification order approach to large executions. We associate a clock vector with each node in the mo-graph. It is important to note that our use of clock vectors in the mo-graph is not to track the happens-before relation. Instead we use clock vectors to efficiently compute reachability between nodes in the mo-graph. Thus, our mo-graph clock vectors model a partial order that contains the current set of ordering constraints on the modification order.
Each event 222Events in each thread consist of atomic operations, thread creation and join, mutex lock and unlock, and other synchronization operations. in C11Tester has a unique sequence number . Sequence numbers are a global counter of events across all threads, which is incremented by one at each event. We denote the thread that executed as . Each node in the mo-graph represents an atomic store. The initial mo-graph clock vector associated with the node representing an atomic store , the union operator , and the comparison operator for mo-graph clock vectors are defined as follows:
Note that two mo-graph clock vectors can only be compared if their associated nodes represent atomic stores to the same memory location.
The mo-graph clock vectors are updated when new mo relations are formed. For example, if is a newly formed mo relation, then the node ’s mo-graph clock vector is merged with that of node , i.e., . If is updated by this merge, the change in must be propagated to all nodes reachable from using the union operator.
Figure 7 presents pseudocode for updating the modification order graph. The Merge procedure merges the mo-graph clock vector of the src node into the dst node and returns true if the dst mo-graph clock vector changed. The AddEdge procedure adds a new modification order edge to the graph. It first compares mo-graph clock vectors to check if the edge is redundant and if so drops the edge update. Recall that RMW operations are ordered immediately after the stores that they read from. To implement this, AddEdge checks to see if the from node has a rmw edge, and if so, follows the rmw edge. AddEdge finally adds the relevant edge, and then propagates any changes in the mo-graph clock vectors. The AddRMWEdge procedure has two parameters, where the rmw node reads from the from node. It first adds an rmw edge and then migrates any outgoing edges from the source of the edge to the rmw node. Finally, it calls the AddEdge procedure to add a normal modification order edge and to propagate mo-graph clock vector changes.
Figure 7 presents pseudocode for the helper method AddEdges that adds a set of edges to the mo-graph. The parameter set is a set of atomic stores or RMWs, and is an atomic store or RMW. The GetNode method converts an atomic action to the corresponding node in the mo-graph. If such node does not exist yet, then the method will create a new node in the mo-graph.
4.3. Eliminating Rollback in Mo-graph
Prior work on constraint-based modification order utilized rollback when it was determined that a given reads-from relation was not feasible (oopsla2013; toplascdschecker). C11Tester may also hit such infeasible executions because the may-read-from set defined in Section 3 is an overapproximation of the set of stores that a load can read from. To determine precisely whether a load can read from a store, a naive approach is to add edges to the mo-graph and then utilize rollback if adding these edges introduces cycles in the mo-graph. However, the addition of clock vectors and clock vector propagation makes rollback much more expensive. It is thus critical that C11Tester avoids the need for rollback. We now discuss how C11Tester avoids rollback.
The mo-graph is updated whenever a new atomic store, atomic load, or atomic RMW is encountered. Processing a new atomic store, atomic load, or atomic RMW can potentially add multiple edges to the mo-graph. We next analyze each case to understand how to avoid rollback:
-
•
Atomic Store: Since an atomic load can only read from past stores, a newly created store node in mo-graph has no outgoing edges. By the properties of mo, only incoming edges from other nodes to this new node will be created. Hence, a new store node cannot introduce any cycles.
-
•
Atomic Load: Consider a new atomic load that reads from a store . Forming a new rf relation may only cause edges to be created from other nodes to the node representing the store . We denote this set of ”other nodes” as and compute it using the ReadPriorSet procedure in Figure LABEL:alg:priorset. Lines LABEL:line:rpriorset-s1, LABEL:line:rpriorset-s2, and LABEL:line:rpriorset-s3 in the ReadPriorSet procedure consider statements 5, 4, and 6 in Section 29.3 of the C++11 standard. Line LABEL:line:rpriorset-s4 in the procedure considers write-read and read-read coherences. Therefore, the set returned by the ReadPriorSet procedure captures the set of stores from where new mo relations are to be formed if the rf relation is established.
Before forming the rf relation, C11Tester checks whether any node in is reachable from . If so, then having load read from store will introduce a cycle in the mo-graph, so we discard and try another store. While it is possible for a cycle to contain two or more edges in the set of newly created edges, this also implies that there is a cycle with one edge (since all edges have the same destination).
-
•
Atomic RMWs: An atomic RMW is similar to both a load and store, but with the constraint that it must be immediately modification ordered after the store it reads from. We implement this by moving modification order edges from the store it reads from to the RMW. Thus, the same checks used by the load suffice to check for cycles for atomic RMWs.
Thus, C11Tester first computes a set of edges that reading from a given store would add to the mo-graph. Then for each edge, it checks the mo-graph clock vectors to see if the destination of the edge can reach the source of the edge. If none of the edges would create a cycle, it adds all of the edges to the mo-graph using the AddEdge and AddRMWEdge procedures.
5. Correctness of Mo-graph
To prove the correctness of mo-graphs, we first prove three Lemmas and then prove Theorem 4. Lemma 1 and Lemma 2 characterize some important properties of mo-graph clock vectors. Lemma 3 proves one direction in Theorem 4. Mo-graph clock vectors are simply referred to as clock vectors in the following context.
Lemma 0.
Let be a path in a modification order graph , such that . Then if any new edge is added to using procedures in Figure 7, it holds that
| (5.1) |
for the updated clock vectors. We define if the values of are not actually updated.
Proof.
To simplify notation, we define for all . Let’s first consider the case where no rmw edge is added, i.e., the AddRMWEdge procedure is not called.
By the definition of the union operator, each slot in clock vectors is monotonically increasing when the Merge procedure is called. By the structure of procedure AddEdge’s algorithm, a node is added to if and only if this node’s clock vector is updated by the Merge procedure.
Let’s assume that adding the new edge updates any of . Otherwise, it is trivial. Let be the smallest integer in such that is updated. Then for all , and we have
| (5.2) |
If , then we take . There are two cases.
Case 1: Suppose for some , let be the smallest such integer. Then for all , as nodes will not be added to in the AddEdge procedure, and it holds trivially that
| (5.3) |
By line 14 to line 24 in the AddEdge procedure, we have
| (5.4) |
for all . If happens to be , then take . And we have for all , . Then combining with inequality (5.2), we have
Together with inequality (5.3), we only need to show that to complete the proof.
If , then we are done, because by assumption . If , then and imply that . Based on equation (5.4), we can deduce in a similar way that .
Case 2: Suppose for all . Then by line 14 to line 24 in the AddEdge procedure, all nodes are added to in the AddEdge procedure, and for all . This recursive formula guarantees that for all , . Therefore, combining with inequality (5.2), we have .
Now suppose the newly added edge is a rmw edge. If where and is some node not in path , then the path remains unchanged and AddEdge(,) is called. Then the above proof shows that inequality (5.1) holds. If , then is migrated to by line 3 to line 7 in the AddRMWEdge procedure, and is added.
If is not in path , then path becomes
Since AddEdge(,) is called, the same proof in the case without rmw edges applies. If is in path , then can only be and the path remains unchanged. Otherwise, a cycle is created and this execution is invalid. In any case, the same proof applies. ∎
Let . We define the projection function that extracts the position of as where we assume .
Lemma 0.
Let be a store with sequence number performed by thread in an acyclic modification order graph . Then throughout each execution that terminates.
Proof.
We will prove by contradiction. Let be the sequence of stores performed by thread with sequence numbers , respectively. Suppose that there is a point of time in a terminating execution such that the first store in the sequence with appears. Sequence numbers are strictly increasing and by the Merge procedure, . Let for some .
For to increase to from , must be merged with the clock vector of some node (i.e., some store ) in such that . Such is modification ordered before .
If is performed by thread , then has to be the store , because is unique for all stores in the sequence other than . Then . By the definition of initial values of clock vectors and sequence numbers, happens after and is modification ordered after . However, is also modification ordered before , and we have a cycle in . This is a contradiction.
If is not performed by thread , then . For to be , must be modification ordered after by some store in such that . If is done by thread , then the same argument in the last paragraph leads to a contradiction; otherwise, by repeating the same argument as in this paragraph finitely many times (there are only a finite number of stores in such a terminating execution), we would eventually deduce that is modification ordered after some store by thread . Hence, we would have a cycle in , a contradiction.
∎
Lemma 0.
Let and be two nodes that write to the same location in an acyclic modification order graph . If is reachable from in , then .
Proof.
Suppose that is reachable from in . Let be the shortest path from to in graph . To simplify notation, is abbreviated as in the following. As the AddRMWEdge procedure calls the AddEdge procedure to create an mo edge, we can assume that all the mo edges in are created by directly calling AddEdge.
Base Case 1: Suppose the path has length 1, i.e., immediately precedes . Then when the edge was formed by calling AddEdge(,), was merged with in line 14 of the AddEdge procedure. In other words,
Base Case 2: Suppose the path has length 2, i.e., . There are two cases:
(a) If was formed first, then . When was formed, was merged with and . According to Lemma 1, adding the edge or any edge not in path (if any such edges were formed before was formed) to would not break the inequality . It follows that .
(b) If was formed first, then . Based on Lemma 1, this inequality remains true when was formed. Therefore .
Inductive Step: Suppose that being reachable from implies that for all paths with length or less, for some . We want to prove that the same holds for paths with length . Let be a path from to with length ,
We denote as and as in the following.
Let be the last edge formed in path , where . Then before edge was formed, the inductive hypothesis implies that and , because both and have length or less. Lemma 1 guarantees that
remain true if any edge not in path was added to as well as the moment when was formed. Therefore when the edge was formed, we have , and
∎
Theorem 4.
Let and be two nodes that write to the same location in an acyclic modification order graph for a terminating execution. Then iff is reachable from in .
Proof.
Lemma 3 proves the backward direction, so we only need to prove the forward direction. Suppose that . Let’s first consider the situation where the graph contain no rmw edges.
Case 1: and are two stores performed by the same thread with thread id . Then it is either happens before or happens before . If happens before , then precedes in the modification order because and are performed by the same thread. Hence is reachable from in . We want to show that the other case is impossible.
If happens before and hence precedes in the modification order, then is reachable from . By Lemma 3, being reachable from implies that . Since by assumption, we deduce that . This is impossible according to Lemma 2, because each store has a unique sequence number and , implying that .
Case 2: and are two stores done by different threads. Suppose that is performed by thread . Let and where both and are in the position. By assumption, we have .
Since is not performed by thread , we have . We can apply the same argument similar to the second, third and fourth paragraphs in the proof of Lemma 2 and deduce that is modification ordered after or some store sequenced after . Since modification order is consistent with sequenced-before relation, if follows that is reachable from in graph .
Now, consider the case where rmw edges are present. Adding a rmw edge from a node to a node first transfers to all outgoing mo edges coming from and then adds a normal mo edge from to . So, any updates in are propagated to all nodes that are reachable from . Therefore, the above argument still applies. ∎
6. Operational Model
We present our operational model with respect to the tsan11 (tsan11) core language described by the grammar in Figure 8. A program is a sequence of statements. LocNA and LocA denote disjoint sets of non-atomic and atomic memory locations. A statement can be one of these forms: an if statement, assigning the result of an expression to a non-atomic location, forking a new thread, joining a thread via its thread handle, and atomic statements. The symbol denotes an empty statement. Atomic statements denoted by StmtA include atomic loads, store, RMWs, and fences. An RMW takes a functor, F, to implement RMW operations, such as atomic_fetch_add. We omit loops for simplicity and leave the details of an expression unspecified. We omit lock and unlock operations because they can be implemented with atomic statements.
States:
| Tid | Seq | ||||||
[RELEASE STORE] {mathpar} \inferrule* RF’ = RF [ s := C _t] ( C, RF, F^rel , F^acq ) ⇒^store_rel(s, t) ( C, RF’, F^rel , F^acq )
[RELAXED STORE] {mathpar} \inferrule* RF’ = RF [ s := F^rel _t] ( C, RF, F^rel , F^acq ) ⇒^store_rlx(s, t) ( C, RF’, F^rel , F^acq )
[RELEASE RMW] {mathpar} \inferrule* RF’ = RF [ s := C _t ∪RF _s’] ( C, RF, F^rel , F^acq ) ⇒^rmw_rel(s, t), rf(s’, t’) ( C, RF’, F^rel , F^acq )
[RELAXED RMW] {mathpar} \inferrule* RF’ = RF [ s := F^rel _t ∪RF _s’] ( C, RF, F^rel , F^acq ) ⇒^rmw_rlx(s, t), rf(s’, t’) ( C, RF’, F^rel , F^acq )
[ACQUIRE LOAD] {mathpar} \inferrule* C’ = C [ t := C _t ∪RF _s’ ] ( C, RF, F^rel , F^acq ) ⇒^load_acq(s, t), rf(s’, t’) ( C’, RF, F^rel , F^acq )
[RELAXED LOAD] {mathpar} \inferrule* F^acq ’ = C [ t := F^acq _t ∪RF _s’ ] ( C, RF, F^rel , F^acq ) ⇒^load_rlx(s, t), rf(s’, t’) ( C, RF, F^rel , F^acq ’ )
[RELEASE FENCE] {mathpar} \inferrule* F^rel ’ = F^rel [ t := C _t ] ( C, RF, F^rel , F^acq ) ⇒^fence_rel(t)