C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Abstract
We present Compound Conditioned ControlNet, C3Net, a novel generative neural architecture taking conditions from multiple modalities and synthesizing multimodal contents simultaneously (e.g., image, text, audio). C3Net adapts the ControlNet [47] architecture to jointly train and make inferences on a production-ready diffusion model and its trainable copies. Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training. Then, it generates multimodal outputs based on the aligned latent space, whose semantic information is combined using a ControlNet-like architecture called Control C3-UNet. Correspondingly, with this system design, our model offers an improved solution for joint-modality generation through learning and explaining multimodal conditions, instead of simply taking linear interpolations on the latent space. Meanwhile, as we align conditions to a unified latent space, C3Net only requires one trainable Control C3-UNet to work on multimodal semantic information. Furthermore, our model employs unimodal pretraining on the condition alignment stage, outperforming the non-pretrained alignment even on relatively scarce training data and thus demonstrating high-quality compound condition generation. We contribute the first high-quality tri-modal validation set to validate quantitatively that C3Net outperforms or is on par with first and contemporary state-of-the-art multimodal generation [44]. Our codes and tri-modal dataset will be released.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c49f999a-d010-4fe3-a841-3a746ca0f2ba/abstruct.png)
1 Introduction
Diffusion models have recently emerged as the new state-of-the-art family of deep generative models, with remarkable performance on multimodal modeling [1, 34, 36, 38, 48]. Correspondingly, we have observed widespread and increasing prevalence of strong cross-modal models that allow generating one single modality from another, including but not limited to text-to-text [2, 31], text-to-image [5, 13, 14, 36, 40] and text-to-audio [15, 26]. However, these existing models cannot simultaneously accept a wider range of input modalities than text or image, nor are they capable of simultaneously generating multiple output modalities in parallel, which leads to limited application in most real-world scenarios where multiple modalities coexist and overlap with one another. The generation capability of each step remains intrinsically constrained even when modality-specific generative models are chained in sequence a multi-step generation setup, which can be laborious, time-consuming and compute-demanding. In this regard, Composable Diffusion (CoDi) [44] is to date the only contemporary work capable of concurrently generating any combinations of modalities, simply by taking linear interpolations on the aligned latent space, which results in the downgraded synthesis qualities. Thus, a better and more flexible joint-modality generative model is necessary.
To achieve better synthesis results while facilitating “any-to-any” generation capabilities, we propose Compound Conditioned ControlNet, or C3Net, whose overall architecture design is adapted from ControlNet [47], which trains and makes inferences on a production-ready diffusion model and its trainable copies. Our model first aligns the conditions obtained from individual modalities to a shared semantic latent space. During the training of alignment encoders, we utilize unimodal pre-training to mitigate the deficiency of high-quality multimodal datasets. The semantic information obtained from individual modalities is further combined through a learnable ControlNet-like architecture called Control C3-UNet. multimodal conditions are then coordinated and merged into the C3-UNet for multimodal synthesis. Consequently, our model can generate multimodal outputs from the aligned latent space.
Thus, 1) C3Net contributes a better solution than straightforward linear interpolations on the latent space, synthesizing more complex and diverse outputs beyond them. Notably, C3Net only requires training one Control C3-UNet to work on multimodal conditions, which substantially reduces complexity for joint-modality training and generation. Furthermore, 2) C3Net employs unimodal pre-training on the condition alignment stage, which facilitates alignment quality even on relatively scarce training data. Overall, C3Net outperforms or is on par with the state-of-the-art multimodal generation counterparts, making it the next strong baseline for generating complex and diverse multimodal outputs.
2 Related Work
2.1 Diffusion Models
Diffusion models (DMs) consist of a class of probabilistic generative models capable of understanding the desired data distribution and synthesizing new samples, through a continuous application of denoising autoencoders in output generation. For the three dominant formulations, Denoising diffusion probabilistic models (DDPMs) [12] utilize two Markov Chains for image generation: a forward chain that injects random noise to the data and transforms the data distribution into an unstructured simple prior, and a reverse chain that denoises and recovers the original data by understanding the learnable transition kernels. Score-based generative models (SGMs) [41, 42] introduce score functions defined as the gradient of log probability density, adding a series of escalating Gaussian noise into the data and jointly calculating the scores for all noisy data distributions. Stochastic Differential Equations (SDEs) [42] can further be leveraged in the injection and denoising processes, allowing for the scenario of unlimited time steps or noise levels in DDPMs and SGMs. Latent diffusion models (LDMs) [36] first train a Variational autoencoder (VAE) [19, 35] to encode inputs into a low-dimensional and efficient latent space, and then apply a diffusion model to further generate latent codes. By abstracting negligible details and reducing modeling dimension, the motivation is to focus on the semantic aspects of the data to achieve higher computational efficiency. The diffusion models have achieved state-of-the-art synthesis quality in image inpainting, image superresolution, and audio generation from text.
2.2 Composable Diffusion
Composable Diffusion (CoDi) [44] is a joint-modality generative model capable of producing a combination of output modalities in parallel based on a combination of input modalities, such as text, audio, image and video. CoDi first trains a latent diffusion model for each modality independently, adds a cross-attention module to each diffuser, and further apply an environment encoder to project the latent variables of different LDMs into a shared latent space. CoDi’s design enables multimodal generation without training on all possible combinations of modalities, reducing the size of training from one of exponential to linear.
2.3 Unimodal Pre-training
Unimodal Models trained on large single-modality datasets can achieve a broader and more diverse coverage of real-world data distribution, without being constrained by the presence of cross-modality data pairs. Specifically, using unimodal models as pre-training can achieve better zero-shot performance compared with the jointly-trained multimodal models, with MAE [9] and T5 [33] outperforming the state-of-the-art CLIP-based model under similar model capacities. Moreover, as an effective unimodal pre-training technique for audio processing tasks, Self-Supervised Audio Spectrogram Transformer (SSAST) [7] enables models to learn the underlying patterns and features of large, unlabeled audio datasets and further improve their performance on the fine-tuning datasets. In the case of C3Net, we first apply unimodal pre-trained encoders for each modality, and then fine-tune the encoders on smaller-scale high-quality datasets based on contrastive learning.
2.4 Multimodal Alignment
Contrastive Language-Image Pre-Training (CLIP) [32, 34] is a neural network that aligns the text and image modalities by pre-training on a large dataset of text-image pairs with a contrastive loss function. Given a sample size of text-image pairs, CLIP learns to map the two modalities into a common embedding space by jointly training a text encoder and image encoder to maximize the cosine similarity of matched pairs and minimize the cosine similarity of () unmatched pairs using a contrastive loss function. Similar with CLIP, Contrastive Language-Audio Pre-Training (CLAP) [4] aligns the text and audio modalities via contrastive learning paradigm between the audio and text embeddings in pair, also following the same loss function. CoDi [44] proposes the “Bridging Alignment” technique to align conditional encoders for multimodal generation. CoDi leverages CLIP as the pretrained text-image paired encoder, and trains audio and video prompt encoders on audio-text and video-text paired datasets using contrastive learning, with text and image encoder weights frozen.
The above alignment techniques can be applied to align the latent space of LDMs with multiple modalities to achieve joint multimodal generation. In comparison, C3Net also utilizes the modality-specific encoders to align the conditions from multi-modalities to the same latent space, while it takes a step further by adding neural architecture similar with ControlNet [47] to facilitate better understanding of multimodal conditions and joint-modality generation.
2.5 ControlNet
ControlNet [47] learns and adds spatial conditioning to control the large pre-trained diffusion models. By freezing the original weights for the pre-trained diffusion model, ControlNet leverages a trainable copy of its deep-and-robust encoding layers to learn the diverse set of conditional controls and avoid overfitting. The original locked model and the trainable copy are then connected with a zero-initialized convolution layer called “zero-convolution”, where the convolution weights are first initialized to zero and progressively learned throughout training.
This architecture provides an effective solution for controlling large diffusion models, while ensuring that no new and harmful noises would be added to the deep features of the diffusion models. In the design of C3Net, we independently apply a ControlNet-like architecture to each input modality, further enabling our model to learn to coordinate multimodal conditions and synthesize more optimized results in the cross-modality generation.
3 Method
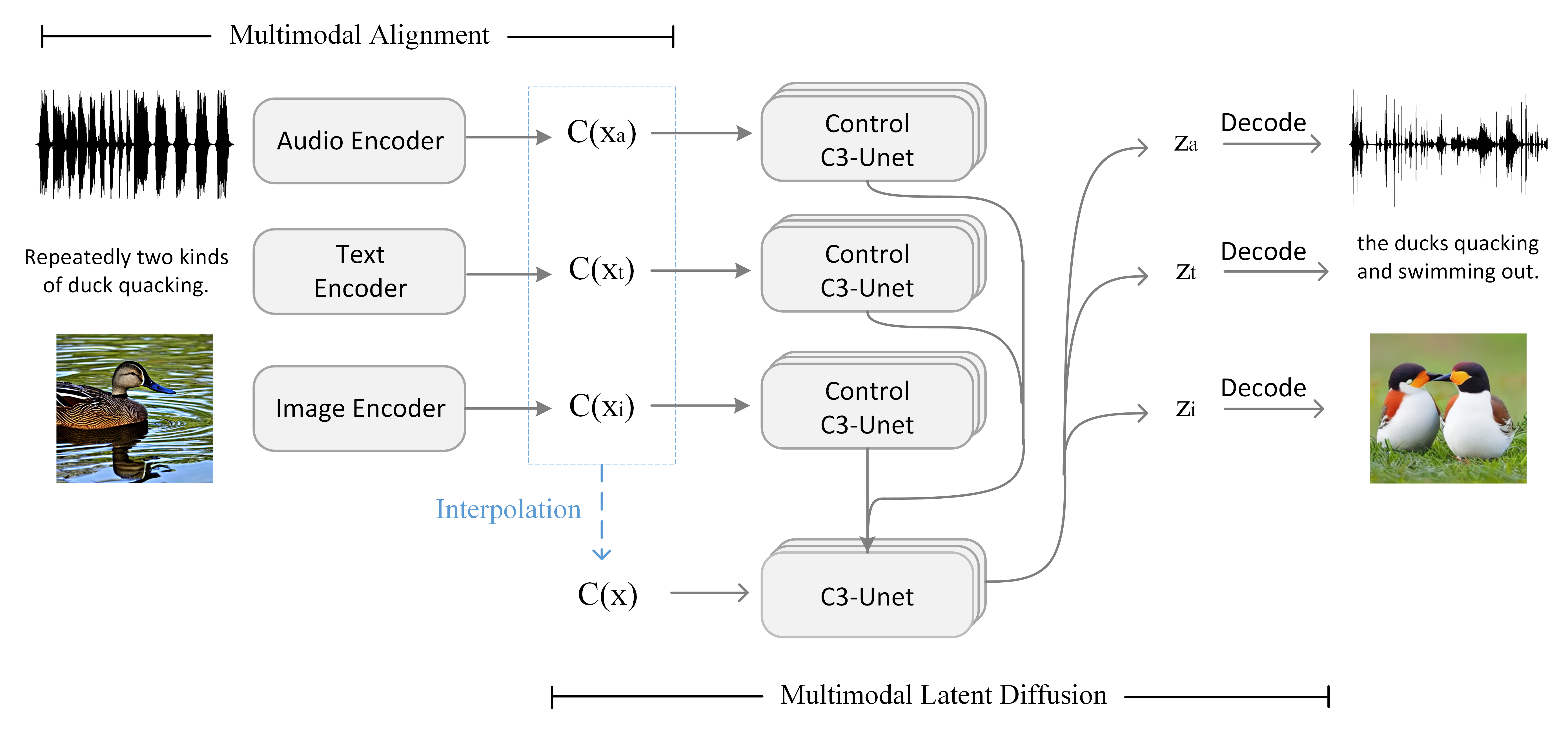
C3Net is a neural network architecture for synthesizing multimodal content conditioned on multimodal inputs. Figure 2 shows C3Net’s overall architecture with content in different modalities (audio, text and image). We first introduce C3Net’s overall structure in Section 3.1, including the alignment encoder , and the latent diffusion model consisting of Control C3-Unet and C3-Unet. Then, we explain the unimodal pre-training for encoders in Section 3.2 where, unlike many existing multimodal approaches, multimodal training data (e.g., audio and image pair-up) is not needed in the pre-training stage. Finally, we explain C3-UNet and Control C3-UNet for compound conditional generation in Section 3.3.
3.1 Compound Conditioned ControlNet
C3Net (Compound Conditioned ControlNet) takes inspiration of the general architecture from [44] to enable multimodal generation conditioned on compound information, such as audio, text and image. C3Net first aligns multimodal conditions to a shared latent space. We consider a compound multimodal condition , , , respectively denoting audio, image, and text conditions, and project them to a shared latent space using an encoder .
We observed that text captioning is ubiquitously adapted in large-scale multimodal datasets as one of the ground truth labels, and that as mentioned in [44], certain dual modalities datasets (e.g., audio and image) are either harshly-aligned or scarce in quantity. To address this issue, choosing a shared latent space in which the text encoder is well-established is advisable. Following the practical implementation of [44], we adopt CLIP [32] latent space as our shared latent space . Thus, an instance of the compound condition alignment stage yields a tuple of latent
| (1) |
denoting the aligned latent from audio, image, and text conditions, respectively.
After acquiring latent conditions, we generate multimodal contents using latent diffusion models with C3-UNet and Control C3-UNet as the backbone. Specifically, we can sample feature maps of any modality from a diffusion model sampling process, which is conditioned on . Note that the synthesis of different modalities utilizes different diffusion models. Then, is decoded on respective decoders to generate the content of its modality.
3.2 Uni-modal Pre-trained Alignment
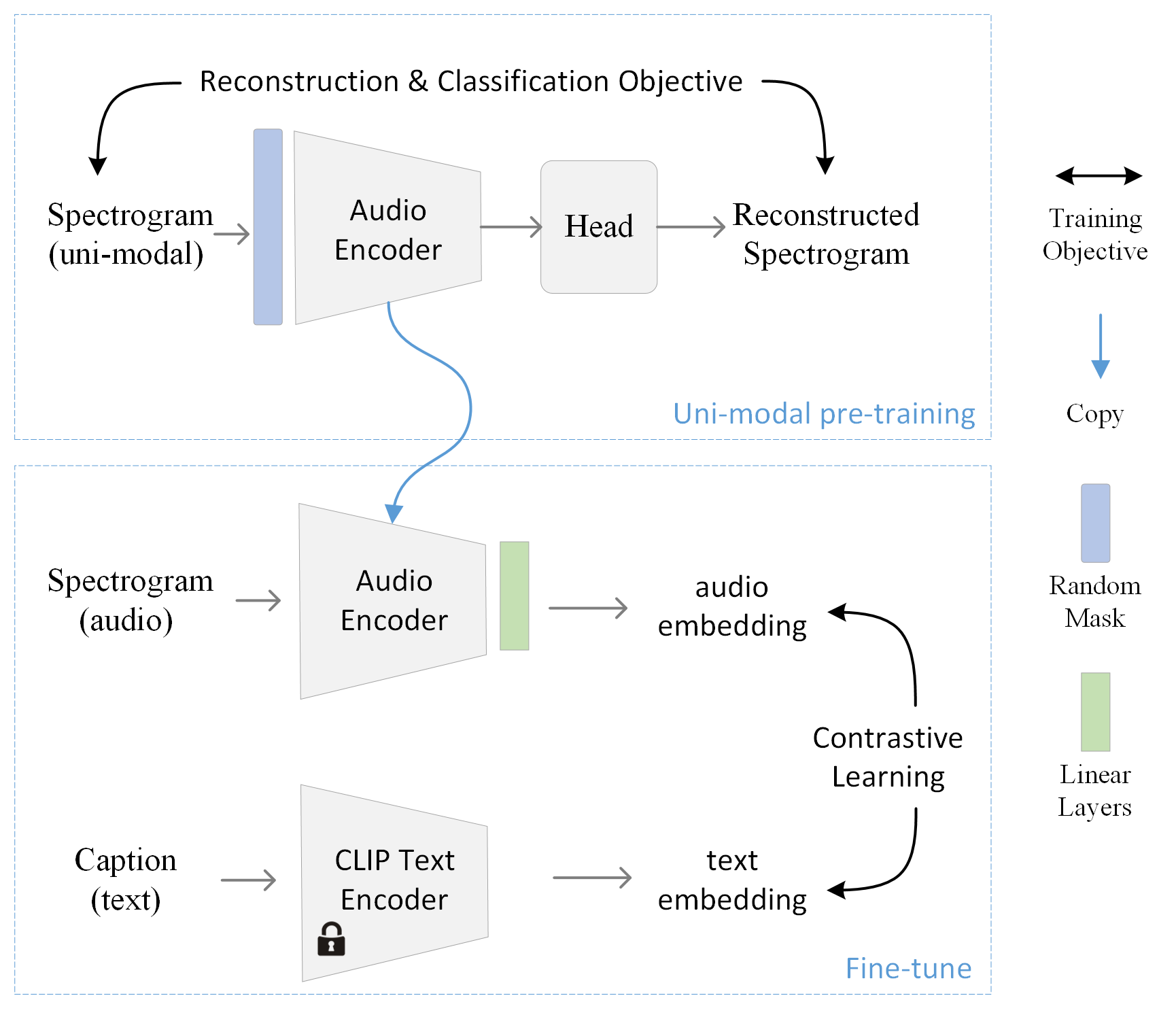
Our encoders are multi-modal encoders aligning conditions in different modalities to the shared space . The encoders are first pre-trained on unimodal datasets and then fine-tuned using contrastive learning proposed in [32]. In contrast, the original settings of [44] is an alignment model trained from scratch on multi-modal datasets.
We propose to pre-train encoders on unimodal data because high-quality paired datasets are scarce for some modalities (e.g., audio and text pair). On the other hand, many high-quality unimodal datasets are readily available. In the following, we use the audio encoder as an example. As shown in Figure 3, we use the pre-trained neural net from [8] which is a masked auto-encoder. The MAE has been trained to extract audio features during the unsupervised training stage, which makes it easier for the following contrastive learning for the audio encoder. We then fine-tune the audio encoder using high-quality datasets, which are available on relatively small scales. During the fine-tuning stage of the audio encoder, we utilize an established frozen text encoder from [32]. In detail, we use contrastive objective to fine-tune the pre-trained audio encoder, so that the audio encoder learns to align audio to latent in as similar as possible to the latent that its ground truth caption is aligned to.
Similar to the findings in [49, 23, 22, 21, 28, 43], our encoder networks can primarily learn the data pattern for respective modalities with unsupervised pre-training. Trained with fewer but high-quality multi-modal data, our unimodal pre-trained encoder is on par with or outperformed encoders trained on only paired data on downstream generation tasks.
3.3 C3-UNet and Control C3-UNet
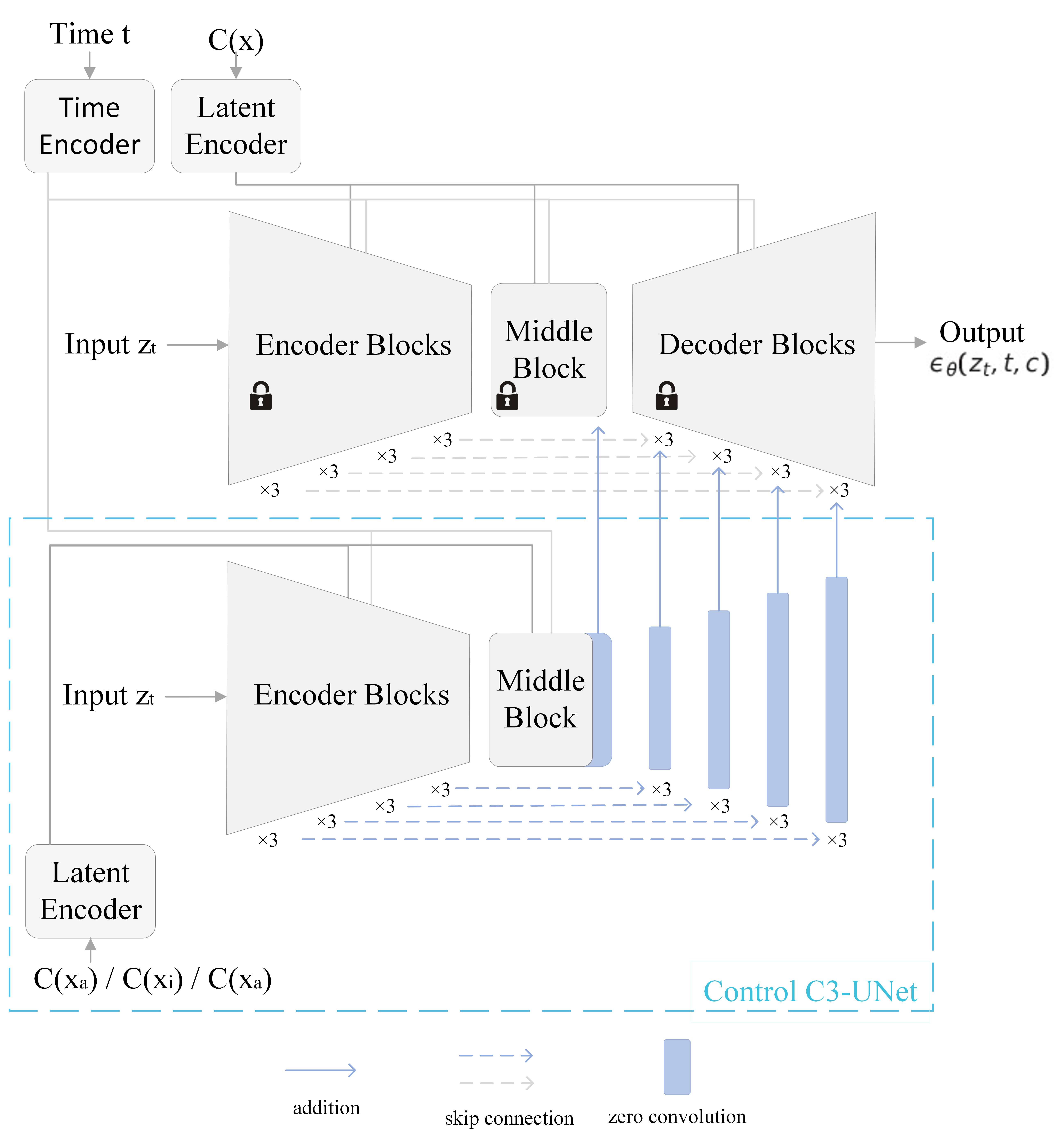
Figure 4 shows the multimodal diffusion model of our C3Net, which consists of the C3-UNet and Control C3-UNet. C3-UNet is a trained UNet employed in a latent diffusion model, which generates feature maps conditioned on instances in . Control C3-UNet, similar to the ControlNet setting in [47], is a trainable copy of the C3-UNet, where denotes the trainable copy of parameters . In the implementation of C3Net, we use the trained UNet of Composable Diffusion [44] as C3-UNet . Figure 4 shows the detailed architecture111 The trained is a U-Net with an encoder, a middle block, and a skip-connected decoder. The encoder and decoder contain 12 blocks, and the full model contains 25 blocks, including the middle block. Of the 25 blocks, there are 4 down-sampling and 4 up-sampling blocks. Refer to Figure 4. In C3-UNet, the “Encoder Blocks” contains 12 encoder blocks in 4 resolutions, while the “×3” indicates the block of the same resolution repeats three times. Condition latent is encoded using the Latent Encoder, and diffusion time steps are encoded with a time encoder using positional encoding. Similar to [47], the Control C3-UNet is a trainable copy of the 12 encoder block and 1 middle block of the C3-UNet. The feature maps are added to the 12 skip-connections and 1 middle block of the C3-UNet after a “zero convolution” layer..
The Control C3-UNet can provide additional information lost during the latent interpolation. Notably, our Control C3Net takes the aligned latent and separately in each modality. The Control C3-UNet is trained to provide extra information in each condition by modifying the feature maps of the C3-UNet. Thanks to the shared latent space , it is sufficient to train one trainable copy of parameters for the Control C3-UNet. This is because conditions from all modalities have been aligned to the shared , and a single set of trained parameters is sufficient for additional control by taking condition latent already aligned in regardless of the original modality.
Our diffusion model follows a similar setting in [44] and [32]. The C3-UNet takes a linear interpolation of the aligned latent as the condition. The Control C3-UNet takes conditions in each modality separately and connects to the C3-UNet at each level of skip-connection after multiplying a constant, which we empirically set to be 0.1, but it varies depending on the generation task. Constant multiplied adjusts the additional control scale the Control C3-UNet provides when using different combinations of compound conditions. However, when only a single condition is provided, the Control C3-UNet can not provide additional information and therefore we set the constant to zero.
During training, we use the text-image dataset to train C3Net’s image and text generation, and the text-audio dataset for audio generation (training and validation datasets will be described in Section 4.1). Specifically, we train Control C3-UNet on each modality separately. Take image generation as an example, for each image-text pair, denoted as and respectively, in the dataset. The ground truth text is aligned to the shared latent space as , and a masked text is generated by randomly selecting 50% of the text prompt to replace with empty strings and it is aligned as . The C3-UNet takes , and Control C3-UNet takes as condition latent, respectively. The ground truth image is used to generate in a typical latent diffusion model [36]. We train the C3-UNet to predict noise in a timestep during the image diffusion. Therefore, the objective function of each modality can be denoted as
| (2) |
where is the ground truth noise, is the network, and is the tuple of .
4 Experiments
4.1 Training Datasets
We collected our training datasets for fine-tuning the alignment encoder as well as the respective Control C3-UNet for image, audio, and text synthesis. Major effort was made to clean up flawed data in some datasets through data prepossessing and relation scores, including CLIP score [10], CLAP [4] similarity score, and the data quality metrics.
For the fine-tuning of audio encoder, we used AudioCap [18], a dataset of sounds with event descriptions for audio captioning. We also added the sound effects from Epidemic Sound as provided in [46]. We selected 1 million ten-second sound clips from AudioSet [6] with optimal quality and CLAP similarity score to their text captions.
For the fine-tuning of image and text Control C3-UNets, we utilized the COCO [25] dataset and part of the LAION-400M [39] dataset, with both consisting of images and corresponding text captions. For the fine-tuning of audio Control C3-UNet, we utilized a combination of AudioCap [18] and AudioSet [6] for training.
4.2 Tri-modality Test Set
In the absence of -modality datasets, where , for multimodal synthesis evaluation, it is crucial to construct a high-quality evaluation set with three modalities (i.e., image, text, and audio) for evaluating C3Net.
Observing that the AudioCap dataset [18] contains high-quality audios and text captions, we curated a tri-modal test set based on AudioCap. Specifically, we first generated the third modality (i.e., image) using Stable Diffusion [37] prompted on the AudioCap text captions. We further selected 2,000 data tuples based on image quality and CLIP score to ensure that the content for each tuple is highly correlated. As a result, a total of 2,000 tri-modal ground-truth tuples, each with highly relevant audio, image and text caption, are available for evaluating C3Net and CoDi [44], which is to date the most representative (and only) work on diffusion-based tri-modality content generation. We show some examples in Figure 5.

4.3 Evaluation Results
Figure 6 shows qualitative comparison on compound condition image synthesis between C3Net and our baseline. We will show quantitative comparison in the following.
4.3.1 Unimodal Pre-training
We evaluate the unimodal pre-training results by comparing the image and text generated by C3Net and CoDi [44]. Evaluation is conducted on the AudioCap [18] test set, with which we generate text captions and images conditioned on the ground truth audio. Table 1 shows the correlation between the generated text and its ground truth captions, assessed by CIDEr-D [45] and SPIDEr [27]. Table 2 tabulates the image synthesis quality assessed by the Inception Score, as well as the correlation between the generated images and ground truth text captions assessed by the CLIP score [10]. Evaluations on audio synthesis are not available in this case, as the model design of CoDi does not support audio generation when taking audio as a condition. Note that in the scenario of taking an audio as the only condition, C3Net and CoDi differ only in the alignment stage, which makes it an ideal ablation study. Under such settings, C3Net applies an audio encoder pre-trained on unimodal data, while CoDi uses an audio encoder without unimodal pre-training.
| Method | CIDEr-D | SPIDEr |
|---|---|---|
| CoDi | 0.0654 | 0.0608 |
| C3Net (Ours) | 0.0704 | 0.0622 |
| Method | Inception Score | CLIP |
|---|---|---|
| CoDi | 1.7730, 0.1450 | 23.192 |
| C3Net (Ours) | 1.7732, 0.1535 | 23.325 |
4.3.2 Multimodal Synthesis
We evaluate the multimodal synthesis capabilities of C3Net on the Tri-modality Test Set introduced in 4.2. To assess the synthesis quality on compound conditions, we generate images, text, and audio conditioned on each respective tuple within the Tri-modality Test Set.
To evaluate image synthesis, we measure the Fréchet inception distance [11] between the synthesized image and its ground truth image as well as the CLIP score [10] between the generated image and its ground truth text caption. Table 3 shows that C3Net generates images that relate closer to both the text and image conditions, demonstrating that our Control C3-UNet architecture offers a more optimized solution for compound condition image synthesis.
| Method | FID | CLIP |
|---|---|---|
| CoDi | 11.39 | 25.17 |
| C3Net (Ours) | 10.97 | 25.29 |
To evaluate text synthesis, we measure the caption correlation metrics between the synthesized text and the ground truth captions. The caption metrics include BLEU-1 [29], ROUGE-L [24], CIDEr-D [45], and SPIDEr [27]. Table 4 shows that C3Net generates text outputs more closely correlated with the ground truth compared to CoDi.
| Method | BLEU-1 | ROUGE-L | CIDEr-D | SPIDEr |
|---|---|---|---|---|
| CoDi | 0.1059 | 0.1019 | 0.0651 | 0.0631 |
| C3Net (Ours) | 0.1104 | 0.1045 | 0.0713 | 0.0665 |
To evaluate audio synthesis, we measure OVL (Overall Impression), REL (Text Relevant) similar with the settings in [20], and FAD [17] to evaluate the audio quality. As shown in Table 5, C3Net outperforms CoDi in terms of OVL and REL. When measuring the correlation between the synthesized audio and the ground truth audio, C3Net yields a slightly weaker FAD score compared to CoDi.
| Method | OVL | REL | FAD |
|---|---|---|---|
| Reference | 81.07 | 79.31 | - |
| CoDi | 62.91 | 59.01 | 11.4 |
| C3Net (Ours) | 63.25 | 59.83 | 11.7 |
4.3.3 Synthesized Audio Classification
To further assess the quality of audio synthesized by C3Net, we compare the classification accuracy of the generated image conditioned on the audio-text pairs in the ESC-50 [30] dataset. In this experiment, we first synthesized audio conditioned on the audio and text pairs. Then, we classified the generated audio using the classification model given in [3]. Table 6 tabulates the results, where a higher accuracy indicates more optimized audio synthesis on compound conditions, which keeps the shared features in multimodal conditions.
| Codi | C3Net (Ours) | |
| Accuracy (%) | 21.05 | 23.25 |
5 Conclusion and Discussion
In this paper, we propose C3Net, a multimodal generative model conditioned on compound content, which applies unsupervised pre-training on unimodal datasets and further leverages a ControlNet-like architecture to coordinate compound conditions. Through extensive experiments, we demonstrate that C3Net is capable of synthesizing high-quality multimodal contents on compound conditions by coordinating them through a learnable process, and addressing the deficiencies of datasets through unimodal pre-training.
While C3Net has shown remarkable progress in joint-modality generation, there exist remaining challenges that need to be addressed in the future. One of the issues is the choice of the shared latent space, such as the CLIP [32] latent, which may not be optimal for all modalities, particularly audio. To address this issue, a contrastive learning process that takes into account multiple modalities may be more effective. Another challenge is that aligning latent conditions using contrastive learning may sacrifice the unique information contained in a modality, as noted in a previous study [16]. One solution to this issue is to use a similar alignment objective as proposed in [16], which aims to construct more meaningful latent modality structures. Addressing these challenges can improve the effectiveness of multimodal generative models, leading to more advanced and sophisticated content synthesis in the future.
References
- Avrahami et al. [2022] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. Sparks of artificial general intelligence: Early experiments with gpt-4, 2023.
- Chen et al. [2022] Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. Beats: Audio pre-training with acoustic tokenizers, 2022.
- Elizalde et al. [2022] Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap: Learning audio concepts from natural language supervision, 2022.
- Esser et al. [2023] Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models, 2023.
- Gemmeke et al. [2017] Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017.
- Gong et al. [2022a] Yuan Gong, Cheng-I Jeff Lai, Yu-An Chung, and James Glass. Ssast: Self-supervised audio spectrogram transformer, 2022a.
- Gong et al. [2022b] Yuan Gong, Cheng-I Jeff Lai, Yu-An Chung, and James Glass. Ssast: Self-supervised audio spectrogram transformer, 2022b.
- He et al. [2021] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021.
- Hessel et al. [2022] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning, 2022.
- Heusel et al. [2018] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020.
- Ho et al. [2022] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, and Tim Salimans. Imagen video: High definition video generation with diffusion models, 2022.
- Hong et al. [2022] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers, 2022.
- Huang et al. [2023] Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models, 2023.
- Jiang et al. [2023] Qian Jiang, Changyou Chen, Han Zhao, Liqun Chen, Qing Ping, Son Dinh Tran, Yi Xu, Belinda Zeng, and Trishul Chilimbi. Understanding and constructing latent modality structures in multi-modal representation learning, 2023.
- Kilgour et al. [2019] Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fréchet audio distance: A metric for evaluating music enhancement algorithms, 2019.
- Kim et al. [2019] Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In NAACL-HLT, 2019.
- Kingma and Welling [2022] Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2022.
- Kreuk et al. [2023] Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. Audiogen: Textually guided audio generation, 2023.
- Li et al. [2021] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, and Steven C. H. Hoi. Align and prompt: Video-and-language pre-training with entity prompts, 2021.
- Li et al. [2023] Pengfei Li, Gang Liu, Jinlong He, Zixu Zhao, and Shenjun Zhong. Masked vision and language pre-training with unimodal and multimodal contrastive losses for medical visual question answering, 2023.
- Liang et al. [2022] Tao Liang, Guosheng Lin, Mingyang Wan, Tianrui Li, Guojun Ma, and Fengmao Lv. Expanding large pre-trained unimodal models with multimodal information injection for image-text multimodal classification. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15471–15480, 2022.
- Lin [2004] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, 2004. Association for Computational Linguistics.
- Lin et al. [2015] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- Liu et al. [2023] Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. Audioldm: Text-to-audio generation with latent diffusion models, 2023.
- Liu et al. [2017] Siqi Liu, Zhenhai Zhu, Ning Ye, Sergio Guadarrama, and Kevin Murphy. Improved image captioning via policy gradient optimization of SPIDEr. In 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017.
- Mañas et al. [2023] Oscar Mañas, Pau Rodriguez, Saba Ahmadi, Aida Nematzadeh, Yash Goyal, and Aishwarya Agrawal. Mapl: Parameter-efficient adaptation of unimodal pre-trained models for vision-language few-shot prompting, 2023.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, 2002. Association for Computational Linguistics.
- [30] Karol J. Piczak. ESC: Dataset for Environmental Sound Classification. In Proceedings of the 23rd Annual ACM Conference on Multimedia, pages 1015–1018. ACM Press.
- Pryzant et al. [2023] Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with ”gradient descent” and beam search, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents, 2022.
- Rezende et al. [2014] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models, 2014.
- Rombach et al. [2022a] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022a.
- Rombach et al. [2022b] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022b.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022.
- Schuhmann et al. [2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs, 2021.
- Singer et al. [2022] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data, 2022.
- Song and Ermon [2020] Yang Song and Stefano Ermon. Improved techniques for training score-based generative models, 2020.
- Song et al. [2021] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021.
- Sun et al. [2023] Yanan Sun, Zihan Zhong, Qi Fan, Chi-Keung Tang, and Yu-Wing Tai. Uniboost: Unsupervised unimodal pre-training for boosting zero-shot vision-language tasks, 2023.
- Tang et al. [2023] Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. Any-to-any generation via composable diffusion, 2023.
- Vedantam et al. [2015] Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation, 2015.
- Wu et al. [2023] Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation, 2023.
- Zhang et al. [2023] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023.
- Zhu et al. [2023] Ye Zhu, Yu Wu, Kyle Olszewski, Jian Ren, Sergey Tulyakov, and Yan Yan. Discrete contrastive diffusion for cross-modal music and image generation, 2023.
- Zou et al. [2023] Heqing Zou, Meng Shen, Chen Chen, Yuchen Hu, Deepu Rajan, and Eng Siong Chng. Unis-mmc: Multimodal classification via unimodality-supervised multimodal contrastive learning, 2023.
Supplementary Material
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c49f999a-d010-4fe3-a841-3a746ca0f2ba/sup.jpeg)
6 Robustness to Contradictory Multimodal Conditions
We further explored how contradictory conditions can influence the generation of C3Net. Through extensive experiments, we found that rather than causing collapse and generating nonsense or dominated by a single condition, C3Net coordinates contradictory inputs innovatively. We elaborate on C3Net’s robustness by an example in Figure 7, where all other conditions indicate a female soprano except one, which describes a male tenor.
The example shows four scenarios, including one control and three experimental scenarios, where two conditions describe a female soprano, while the remaining one relates to a male tensor. C3Net generates images, audio, and text conditioned on these contradictory inputs. The generated images and text all describe a female, the most frequent subject in three conditions. In scenarios (a) and (b), the discrepancy changes the tone of generated audio from a female soprano to a lower frequency humming. In (c), the generated audio and text indicate another singer, coordinating the condition of female soprano and male tenor. In (o), a control, we use consistent conditions to compare the differences in the above experimental scenarios.
We repeated the experiment with the same settings to produce multi-modal generations using the baseline [44]. We found that without the Control C3-UNet structure, the generated contents tend to be intermediates of the contradictory conditions (e.g., scenario (e)) or shifted in meaning (e.g., text generated in scenario (a) and (e)). These defects are likely resulted from using simple interpolation to coordinate multiple conditions.
7 Audio Files
We put in our supplemental zip file all the relevant audio files depicted in each figure in the main paper and this supplementary document, including all condition audios and generated audios.