∎
22email: mnorton@nps.edu 33institutetext: V. Khokhlov 44institutetext: 44email: vkhokhlov.embals2016@london.edu 55institutetext: S. Uryasev 66institutetext: University of Florida, Department of Industrial and Systems Engineering, Risk Management and Financial Engineering Laboratory
66email: uryasev@ufl.edu
Calculating CVaR and bPOE for Common Probability Distributions With Application to Portfolio Optimization and Density Estimation
Abstract
Conditional Value-at-Risk (CVaR) and Value-at-Risk (VaR), also called the superquantile and quantile, are frequently used to characterize the tails of probability distribution’s and are popular measures of risk in applications where the distribution represents the magnitude of a potential loss. Buffered Probability of Exceedance (bPOE) is a recently introduced characterization of the tail which is the inverse of CVaR, much like the CDF is the inverse of the quantile. These quantities can prove very useful as the basis for a variety of risk-averse parametric engineering approaches. Their use, however, is often made difficult by the lack of well-known closed-form equations for calculating these quantities for commonly used probability distribution’s. In this paper, we derive formulas for the superquantile and bPOE for a variety of common univariate probability distribution’s. Besides providing a useful collection within a single reference, we use these formulas to incorporate the superquantile and bPOE into parametric procedures. In particular, we consider two: portfolio optimization and density estimation. First, when portfolio returns are assumed to follow particular distribution families, we show that finding the optimal portfolio via minimization of bPOE has advantages over superquantile minimization. We show that, given a fixed threshold, a single portfolio is the minimal bPOE portfolio for an entire class of distribution’s simultaneously. Second, we apply our formulas to parametric density estimation and propose the method of superquantile’s (MOS), a simple variation of the method of moment’s (MM) where moment’s are replaced by superquantile’s at different confidence levels. With the freedom to select various combinations of confidence levels, MOS allows the user to focus the fitting procedure on different portions of the distribution, such as the tail when fitting heavy-tailed asymmetric data.
Keywords:
Conditional Value-at-Risk Buffered Probability of Exceedance Superquantile Density Estimation Portfolio Optimization1 Introduction
When faced with randomness and uncertainty, some of the most popular techniques for dealing with such randomness are parametric in nature. Given a real valued random variable , analysis can be greatly simplified if one assumes that belongs to a specific parametric family of distribution’s. For example, the Method of Moment’s (MM) is one of the simplest and most widely used methods for parametric density estimation. These techniques, however, often require that certain characteristics of the distribution family be representable by a simple, ideally closed-form, expression. For example, traditional MM uses closed-form expression’s for the moments of the parametric distribution family. Similarly, the Matching of Quantile’s (MOQ) procedure (see e.g., Sgouropoulos et al. (2015); Karian and Dudewicz (1999)) uses expression’s for the quantile function. In portfolio optimization, the availability of simple expression’s for the mean and variance of portfolio returns yields a tractable Markowitz portfolio optimization problem.111See Section 4 for specifics. For a variety of problem’s, application of a parametric method relies upon the availability of a closed-form expression for a specific characteristic of the parametric family of interest.
Luckily, for a variety of distribution’s, closed-from expression’s are available for commonly utilized characteristic’s. These include characteristic’s such as the moment’s, the quantile, and the CDF. Over the past two decades, however, new fundamental characteristic’s like the superquantile have emerged from the field of quantitative risk management with important applications across engineering fields like financial, civil, and environmental engineering. (see e.g., Rockafellar and Royset (2010); Rockafellar and Uryasev (2000); Davis and Uryasev (2016)). Furthermore, closed-form expressions for these characteristics, for a large variety of common parametric distribution families, have not been widely disseminated. While emerging from specific engineering applications, some of these characteristics are very general and can be viewed as fundamental aspects of a random variable just like the mean or quantile. Thus, utilization of these characteristics within parametric methods is a natural consideration. To facilitate their use, however, we must develop closed-form expressions.222When closed-form expressions are not available, we look to provide simple calculation methods that might still be utilized within parametric methods.
We focus on developing these expressions for the superquantile and Buffered Probability of Exceedance (bPOE) for a variety of distribution families. Developments in financial risk theory over the last two decades have heavily emphasized measurement of tail risk. After Artzner et al. (1999) introduced the concept of a coherent risk measure, Rockafellar and Uryasev (2000) introduced the superquantile, also called Conditional Value at Risk (CVaR) in the financial literature. This began to be considered a preferable characterization of tail risk compared to the quantile, or Value-at-Risk (VaR). While some closed-form expression are available to use the superquantile within parametric procedures, see e.g., Rockafellar and Uryasev (2000); Landsman and Valdez (2003); Andreev et al. (2005), the variety of distribution’s discussed within each of these sources is limited.
We illustrate that for a variety of common distribution’s, straightforward techniques such as integration of the quantile function obtain a closed-form expression for the superquantile that is easy to use within subsequent parametric methods. We attempt to include a variety, providing superquantile formulas for the Exponential, Pareto/Generalized Pareto (GPD), Laplace, Normal, LogNormal, Logistic, LogLogistic, Generalized Student-t, Weibull, and Generalized Extreme Value (GEV) distribution’s. These provide examples varying from the exponentially tailed (Exponential, Pareto/GPD, Laplace), to the symmetric (Normal, Laplace, Logistic, Student-t), to the asymmetric heavier tailed (Weibull, LogLogistic, GEV) distribution’s. While some of these formulas may exist elsewhere, we hope that this paper serves as a good resource for practitioners in search of superquantile formulas.
While the superquantile has risen in popularity over the past decade, a related characteristic called Buffered Probability of Exceedance (bPOE) has recently been introduced, first by Rockafellar and Royset (2010) in the context of Buffered Failure Probability and then generalized by Mafusalov and Uryasev (2018). This concept has grown in popularity within the risk management community with application in finance, logistics, analysis of natural disasters, statistics, stochastic programming, and machine learning (Shang et al. (2018); Uryasev (2014); Davis and Uryasev (2016); Mafusalov et al. (2018); Norton et al. (2017); Norton and Uryasev (2016). Specifically, bPOE is the inverse of the superquantile in the same way that the CDF is the inverse of the quantile. However, much like the superquantile when compared against the quantile, bPOE has many mathematically advantageous properties over the traditionally used Probability of Exceedance (POE). Direct optimization often reduces to convex or linear programming, it can be calculated via a one dimensional convex optimization problem, and it provides a risk-averse probabilistic assessment of the risk of experiencing outcomes larger than some fixed upper threshold. Thus, the second aim of this paper is to provide closed-form expressions for bPOE and, when unable to do so, show that calculation of bPOE is still simple, reducing to a one-dimensional convex optimization problem or a one-dimensional root finding problem. For the parametric portfolio application, in particular, we will see that when closed-form bPOE is unavailable and the superquantile is available, finding the optimal bPOE portfolio is no more difficult, computationally, than finding the optimal superquantile (CVaR) portfolio.
Motivating us to derive closed-form expressions (or simple calculation formulas) for the superquantile and bPOE for common distribution’s is the inclusion of these risk averse, tail measurements within parametric methods. In particular, we explore the use of the superquantile and bPOE within parametric portfolio optimization and density estimation. First, we consider parametric portfolio optimization, where returns are assumed to follow a specific distribution and, using these assumptions, a tractable portfolio optimization problem is formulated and solved. We begin by narrowing our choices of distribution to only those that both fit the pattern of portfolio returns and generate tractable portfolio optimization problems. Then, we consider two companion problems, solving for portfolio’s that minimize the superquantile (CVaR) of the distribution of potential losses (i.e. the average of the worst-case scenarios) and portfolio’s that minimize bPOE of the loss distribution (i.e. the buffered probability that losses will exceed a fixed upper threshold ). In comparing these problems, we discover that bPOE optimization can often be highly preferable to superquantile (CVaR) optimization in the parametric context. Specifically, for fixed , the portfolio that minimizes the superquantile depends upon the distributional assumption (i.e., even if is fixed, changing the assumed parametric distribution for returns will change the contents of the optimal portfolio). However, for fixed threshold , the portfolio that minimizes bPOE does not depend upon the distributional assumption (at least for the specific class of distribution’s we consider, which includes the Logistic, Laplace, Normal, Student-t, and GEV). In other words, no matter which of these distribution’s we choose, we will always achieve the same optimal portfolio for fixed value of threshold . Thus, bPOE-based portfolio optimization can provide additional consistency with respect to parameter choices, eliminating one source of additional variability for the decision maker.
Finally, we consider parametric density estimation, proposing a variant of MM where moments are replaced by superquantile’s. This can also be seen as a natural variation of the MOQ procedure where quantiles are replaced by superquantile’s. Made possible by the closed-form superquantile expressions, we show that this framework allows one to flexibly perform density estimation, allowing the user to focus the fitting procedure on specific portions of the distribution. For example, we illustrate by fitting a Weibull with additional emphasis put onto estimating the right tail. Compared against traditional MM and maximum likelihood (ML), we see that we get a better fit for such asymmetric, heavy tailed situations.
1.1 Organization of Paper
We first provide a brief introduction to superquantile’s and bPOE in Section 1.2. In Section 2, we give formulas for both the superquantile and bPOE for the Exponential, Pareto, Generalized Pareto, and Laplace distribution’s. Along the way, we highlight some simple relationships between POE, bPOE, the quantile, and the superquantile. In Section 3, we treat distribution’s for which a closed-form superquantile formula exists, but where we are unable to derive a simple closed-form bPOE formula. In order of appearance, we consider the Normal, LogNormal, Logistic, Generalized Student-t, Weibull, LogLogistic, and Generalized Extreme Value Distribution. However, we point out for these cases that because a formula for the superquantile is known, bPOE can be solved for via a simple root finding problem. We also illustrate for some cases that the one-dimensional convex optimization formula for bPOE can also be used in these cases. In Section 4, we illustrate the use of these formulas in portfolio optimization and parametric distribution approximation.
1.2 Background and Notation
When working with optimization of tail probabilities, one frequently works with constraints or objectives involving probability of exceedance (POE), , or its associated quantile , where is a probability level. The quantile is a popular measure of tail risk in financial engineering, but when included in optimization problems via constraints or objectives, is quite difficult to treat with continuous (linear or non-linear) optimization techniques.
A significant advancement was made in Rockafellar and Uryasev (2000, 2002) in the development of a replacement called the superquantile or CVaR. The superquantile is a measure of uncertainty similar to the quantile, but with superior mathematical properties. Formally, the superquantile (CVaR) for a continuously distributed is defined as,
Similar to , the superquantile can be used to assess the tail of the distribution. The superquantile, though, is far easier to handle in optimization contexts. It also has the important property that it considers the magnitude of events within the tail. Therefore, in situations where a distribution may have a heavy tail, the superquantile accounts for magnitudes of low-probability large-loss tail events while the quantile does not account for this information.
The notion of buffered probability was originally introduced by Rockafellar and Royset (2010) in the context of the design and optimization of structures as the Buffered Probability of Failure (bPOF). Working to extend this concept, bPOE was developed as the inverse of the superquantile by Mafusalov and Uryasev (2018) in the same way that POE is the inverse of the quantile. Specifically, for continuously distributed , bPOE at threshold is defined in the following way, where denotes the essential supremum of random variable and threshold .
In words, bPOE calculates one minus the probability level at which the superquantile, the tail expectation, equals the threshold . Roughly speaking, bPOE calculates the proportion of worst-case outcomes which average to . Figure 1 presents an illustration of bPOE for a Lognormal distributed random variable . We note that there exist two slightly different variants of bPOE, called Upper and Lower bPOE which are identical for continuous random variables. For this paper, we utilize only continuous random variables. For the interested reader, details regarding the difference between Upper and Lower bPOE can be found in Mafusalov and Uryasev (2018).
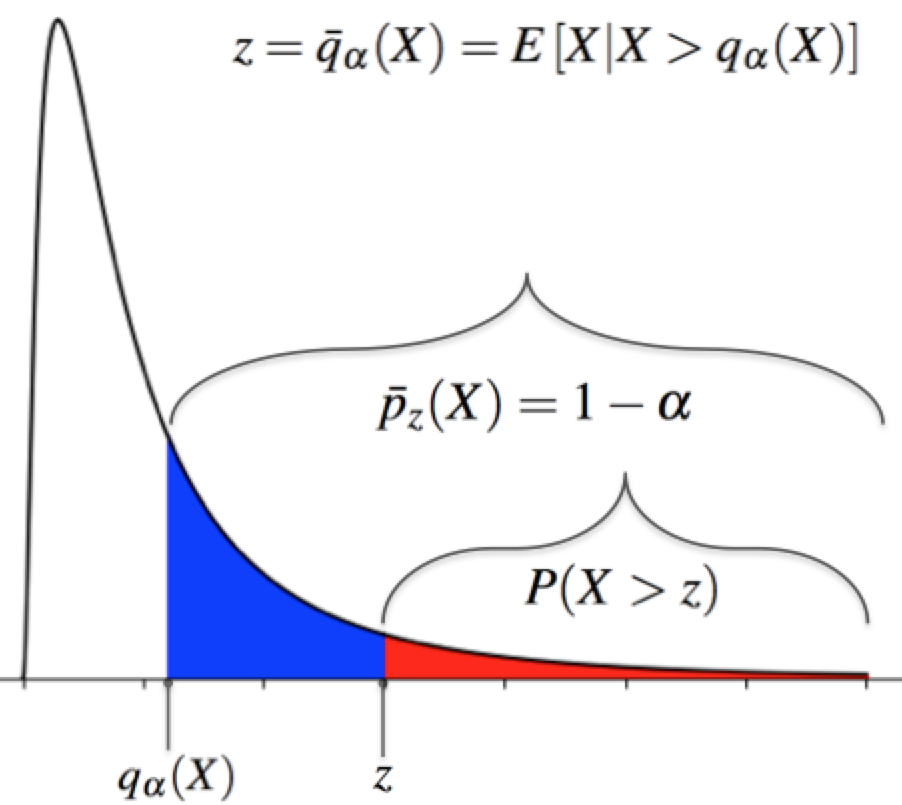
Similar to the superquantile, bPOE is a more robust measure of tail risk, as it considers not only the probability that events/losses will exceed the threshold , but also the magnitude of these potential events. Also, much like the superquantile, bPOE can be represented as the unique minimum of a one-dimensional convex optimization problem with the formulas given by Norton and Uryasev (2016); Mafusalov and Uryasev (2018) as follows, where .
Note that these formulas are valid for general real valued random variables, not only continuously distributed random variables. It is also useful to note that the argmin of both the bPOE and superquantile optimization formulas gives the quantile. For the bPOE calculation formula, we have that the argmin is where and for the other representation. For the superquantile calculation formula, we have that the argmin is where was the desired probability level for calculating the superquantile.
The bPOE concept is also closely related to the concept of a superdistribution function , introduced by Rockafellar and Royset (2014). For the CDF, we have that POE equals and we have the inverse CDF given by The superdistribution function is motivated by the inverse relation Thus, bPOE equals . The superdistribution function of a random variable can also be understood as the CDF of an auxiliary random variable where is a uniformly distributed random variable. In this case, where the subscript indicates that it is the distribution function associated with a particular random variable.
2 Distributions With Closed Form Superquantile and bPOE
In this section, we derive closed-form expressions for both the superquantile and bPOE for the Exponential, Pareto, Generalized Pareto, and Laplace distribution’s. For these distribution’s, we see that they exhibit a reproducing type of property, where the formula for POE is identical to bPOE up to a constant. The Laplace distribution presents an interesting case in which only the right tail exhibits this reproducing property. Along the way, for completeness, we also highlight relationships between the expressions for bPOE, POE, the superquantile, and the quantile.
2.1 Exponential
For this section, we have exponential random variable . Recall that the Exponential parameter has range with , and that the Exponential CDF, PDF, and quantile are given by,
Proposition 1
Let . Then,
Proof
First, note that for exponential RV’s with rate parameter . We then have,
Since , we have,
We can then see that,
∎
Next, we relate bPOE and POE as well as the superquantile and quantile.
Corollary 1
Let , with mean . Then, and .
Proof
We know that , being exponential, has CDF given by . From Proposition 1, we know that
Then, since , it follows that . The equality for CVaR follows easily from Proposition 1 since . ∎
2.2 Pareto
Assume . Recall that Pareto parameters have range with and , and that the Pareto CDF, PDF, and quantile are given by,
Proposition 2
Assume with . Then, for and ,
Note that if , then implying that and for all and .
Proof
First, note that the conditional distribution of a pareto, conditioned on the event that the random value is larger than some , is simply another pareto with parameters . This implies that if otherwise the expectation is . Also, . Since,
we will have that,
This gives us bPOE formula,
Since , the maximization objective is concave over the range which contains the range , so we just need to take the gradient of function and set it to zero to find the optimal as follows:
Plugging this value of into the objective of our bPOE formula yields,
CVaR is then equal to the value of which solves the equation or,
which has solution,
∎
Corollary 2
Relating bPOE and POE, as well as the quantile and superquantile, we can say that,
Proof
Follows from Proposition 1 and the known formulas for POE and the quantile. ∎
2.3 Generalized Pareto Distribution (GPD)
Assume . Recall that GPD parameters have range with if and if , and that the GPD CDF and PDF are given by,
for when and when . Furthermore, the quantiles are given by,
Proposition 3
Assume with . Then,
Proof
For these results, we rely on the fact that if , then , meaning that the excess distribution of a GPD random variable is also GPD. Now, note also that if , then . This gives us,
which further implies that,
Plugging in the values of the quantile functions yields the final formulas. Using the formulas we just found for , it is an elementary exercise to solve for which equals such that solves the equation . ∎
2.4 Laplace
Assume . Recall that Laplace parameters have range , with and , and that the Laplace CDF, PDF, and quantile function are given by,
Proposition 4
If , then
where and is the Lambert- function.333Also called the product logarithm or omega function.
Proof
To get the superquantile, we begin with the integral representation:
To evaluate the integral, we utilize simple substitution as well as the identity . After simplifying, we see that with the integral evaluates to,
Similarly, we find that with the integral evaluates to,
For bPOE, first assume that threshold . Using our formula for CVaR, we see that . Thus, implies that implying that,
Assume contrarily that . Since , we have that which implies that,
Letting , we must now find which solves the equation . We do so, via the following:
where the final step follows from the definition of the Lambert- function which is given by the relation . Thus, . ∎
3 Distributions With Closed Form Superquantile
In this section, we derive closed-form expressions for the superquantile of the Normal, LogNormal, Logistic, Student-t, Weibull, LogLogistic, and GEV distribution’s. The Normal, Logistic, and Student-t provide us with examples of symmetric distribution’s with varying tail heaviness. The LogNormal, Weibull, LogLogistic, and GEV provide us with examples of asymmetric distribution’s that have heavy right tails. In particular, we will utilize the Weibull formula for density estimation in Section 5.
For these distribution’s, we are not able to reduce calculation of bPOE to closed-form. However, we highlight for the case of the Normal and Logistic that bPOE can be calculated by solving a one-dimensional convex optimization problem or one-dimensional root finding problem. In general, we note that for continuous , bPOE at equals where solves . Thus, if the superquantile is known in closed-form, this reduces to a simple one-dimensional root finding problem in .
3.1 Normal
Let be a standard normal random variable. Recall that
where is the commonly known error function with denoting its inverse.
We show that the superquantile can be calculated by utilizing the quantile function and PDF, which is a well known result (see e.g., Rockafellar and Uryasev (2000)). We also show that bPOE can be calculated in two ways: by solving a simple root finding problem involving only the PDF and CDF or by solving a convex optimization problem with gradients calculated via the commonly used error function. Some results are presented only for the Standard Normal , but can easily be applied to the non-standard case with appropriate shifting and scaling.
Proposition 5
If , then
Proof
It is well known that if , then the conditional expectation is given by the inverse Mills Ratio, . It follows then that . ∎
Proposition 6
If , then
Furthermore, if , then equals the quantile of at probability level .
Proof
Note that for a standard normal random variable, the tail expectation beyond any threshold is given by the inverse Mills Ratio,
Note also that for any threshold and any random variable we have,
Using the mills ratio gives us,
Plugging this result into the minimization formula for bPOE yields the final formula. ∎
Proposition 7
Let with given. If is the solution to the equation
then . Additionally, we will have that and at probability level .
Proof
This follows from the fact that and the optimization formula of bPOE given in the previous proposition for normally distributed variables. ∎
The following proposition provides the gradient calculation for solving the bPOE minimization problem.
Proposition 8
For , we have that the bPOE minimization formula has the following integral representation,
Furthermore, the function is convex w.r.t. over the range . Additionally, has gradient given by,
where denotes the complementary error function.
Proof
To derive the integral representation, simply plug in the formula for , then utilize the definition of the PDF and CDF. The gradient calculation is a standard calculus exercise. ∎
3.2 LogNormal
Assume . Recall that LogNormal parameters have range , , with and and that the LogNormal CDF, PDF, and quantile function are given by,
Proposition 9
If , then
Proof
We simply evaluate the integral of the quantile function as follows.
∎
3.3 Logistic
Assume . Recall that Logistic parameters have range , , with and and that the Logistic CDF, PDF, and quantile function are given by,
Here, we derive a closed-form expression for the superquantile for the logistic distribution and derive a simple root finding problem for calculating bPOE. We also find that these quantities have a correspondence with the binary entropy function.
Proposition 10
If , then
where is the binary entropy function . Furthermore, for any , if solves the equation,
then . Additionally, if is the solution to the transformed system,
Note that both functions and are one-dimensional, convex, and monotonic over the range , and thus unique solutions exist and can easily be found via root finding methods.
Proof
To obtain the superquantile, we have
Utilizing simple substitution as well as the identity , we get
To get bPOE, we simply follow the bPOE definition, needing to find which solves . The transformed system arises from combining logarithms within the superquantile formula and applying exponential transformations. ∎
We can also utilize the minimization formula to calculate bPOE. Calculating bPOE in this way has the added benefit of simultaneously calculating the quantile .
Proposition 11
If , then
which is a convex optimization problem over the range . Furthermore, the minimum occurs at such that,
Proof
This follows from the fact that . Evaluating this integral for yields, which can then be plugged into the minimization formula for bPOE. The second part of the proposition follows from the fact that the gradient of the objective function w.r.t. is given by,
Setting this gradient to zero and simplifying yields the stated optimality condition. ∎
3.4 Student
Assume -t. Recall that Student parameters have range , , with and , and that the Student CDF and PDF are given by,
where , is the regularized incomplete Beta function, and is the Gamma function. Note that a general closed-form expression for is not known but is a readily available function within common software packages like EXCEL.
Proposition 12
If -t, then
where is the inverse of the standardized Student CDF and is standardized Student PDF.
Proof
Since there is no closed-form expression for the quantile, we utilize the representation of the superquantile given by . To evaluate this integral, we first take the derivative of the PDF, giving
Rearranging yields,
We can then integrate both sides,
Integrating by parts, gives us the following form of the middle term,
Then, finally, after substituting this new expression for the middle term and simplifying, we get
Taking the definite integral yields,
It is easy to see that the second limit goes to one and, after applying L’Hopital where necessary, that the first limit goes to zero. This leaves
where the final step comes from writing the non-standardized quantile and PDF in their standardized form. Then, finally, dividing by yields the formula,
∎
3.5 Weibull
Assume . Recall that Weibull parameters have range , with and , and that the Weibull CDF, PDF, and quantile function are given by,
where is the gamma function.
Proposition 13
If , then
where is the upper incomplete gamma function.
Proof
To calculate the superquantile, we utilize the integral representation, which is
To put this integral into the form of the upper incomplete gamma function, make the change of variable . This gives and with new lower limit of integration and upper limit of integration . Applying to the integral, yields
∎
3.6 Log-Logistic
Assume . Recall that Log-Logistic parameters have range , with when and
when , and that the Log-Logistic CDF, PDF, and quantile function are given by,
where is the cosecant function.
Proposition 14
If , then
where is the incomplete beta function.
Proof
To calculate the superquantile, we utilize the integral representation as follows:
Now, note first that for , we have . Next, for the incomplete beta function, letting and , we can see that
Using these two facts, we have,
∎
3.7 Generalized Extreme Value Distribution
Assume follows a Generalized Extreme Value (GEV) Distribution, which we denote as . Recall that GEV parameters have range , , with and
where and is the Euler-Mascheroni constant.
Additionally, recall that the GEV has CDF, PDF, and quantile function given by,
.
Proposition 15
If , then
where is the lower incomplete gamma function, is the logarithmic integral function, and is the Euler-Mascheroni constant.
Proof
Assume we have . Then, we have
Assume now that . Then, we have that,
∎
4 Portfolio Optimization
A common parametric approach to portfolio optimization is to assume that portfolio returns follow some specified distribution. In this context, particularly when taking a risk averse approach, closed-form representations of the superquantile and bPOE for the specified distribution allow one to formulate a tractable portfolio optimization problem. In this section, we show that our derived formulas for the superquantile and bPOE reveal important properties about portfolio optimization problems formulated with particular distributional assumptions placed upon portfolio returns.
Portfolio optimization with the superquantile is common, so we begin by simply pointing out which of the closed-form superquantile formulas yield tractable portfolio optimization problems. Portfolio optimization with bPOE, however, is not common and we show that it can be advantageous compared to the superquantile approach. In particular, superquantile optimization requires that one sets the probability level . One can then observe that for fixed , the optimal superquantile portfolio may change based upon the distribution utilized to model returns. We show that if portfolio returns are assumed to follow a Laplace, Logistic, Normal, or Student- distribution, the minimal bPOE portfolio’s for fixed threshold are the same regardless of the distribution chosen, meaning that there exists a single portfolio that is -bPOE optimal for multiple choices of distribution.
Note that in this section we will be dealing with asset returns , as it is typical for financial problems, and the loss is the opposite of return: , and .
The portfolio optimization problem consists of finding a vector of asset weights for a set of assets with unknown random returns that solves the following optimization problem,
| (1) | ||||||
where is some function to be maximized,444Or minimized if we consider the negative. functions and enforce inequality and equality constraints respectively, and vectors enforce upper and lower bounds on the individual asset weights. A simple example is the standard Markowitz optimization problem where we maximize the expected utility, which is a weighted combination of the expected return and its variance via a positive trade-off parameter :
| (2) | ||||||
An important aspect of the random portfolio return which can be seen within the Markowitz problem and will be used later on in this section is the fact that the expectation and variance are given by and respectively, where is the vector of expected returns for the assets and is the covariance matrix for the assets. This allows us to represent the expected value and variance of the portfolio return in terms of , and consequently to formulate an optimization problem with decision vector .
4.1 Superquantile and bPOE Optimization with Qualified Distributions
As we are dealing with asset returns, and not losses, we need to define the superquantile using that notation. The superquantile is the expected loss above the quantile (conditional expected value of losses in the right tail), so in terms of returns it would be the conditional expected value of returns in the left tail, which can be described by the left superquantile:
We can use the closed-form superquantile formulas derived in the previous sections for the right superquantile to calculate the left superquantile , as
so
Since , bPOE is defined as
4.1.1 Qualified Distributions for Portfolio Optimization
The superquantile or bPOE portfolio optimization problem has its objective function or one of the constraints defined in terms of or . To formulate such a problem using a given distribution, we begin by defining a set of qualified distribution’s which we will consider. These qualified distribution’s satisfy the following set of conditions, which allow us to verify that they make sense in terms of portfolio theory and admit superquantile/bPOE expression in a way that can represented in terms of decision variable :
Definition 1 (Qualified Distribution)
A qualified distribution satisfies the following conditions:
(C1) , where is a function depending only upon and possibly a set of fixed parameters that do not depend on , is the vector of the expected asset returns, and is the covariance matrix for asset returns.
(C2) The statistical parameters of the distribution must be consistent with the descriptive statistics of real-life asset returns.
(C3) The shape of the PDF for the given distribution must conform to the shape of the empirical PDF of typical real-life asset returns.
Why should we enforce these preconditions? Condition (C1) guarantees that the superquantile can be expressed in terms of . This is necessary to express the superquantile optimization problem. For example, if we assume that , we need to be able to express and in terms of . Since and , we have
which satisfies (C1). Other examples that satisfy this condition are Laplace, Normal, Exponential, Student, Pareto, GPD, and GEV. Note that for Student, we assume that parameter is fixed and the same for all assets, i.e. , and for GPD/GEV distribution’s .
Condition (C2) and (C3) are simple sanity checks on our model assumptions. For example, for exponential distribution , however for the real-life asset returns the sample mean is not generally equal to the sample standard deviation. So, Exponential and Pareto distribution’s make no sense in portfolio optimization problems even if they satisfy (C1). As for (C3), a distribution is not practical if there is obvious discrepancy between the shape of its PDF and the shape of the empirical PDF observed using real-life asset returns. The latter is generally bell-shaped or, more likely, inverse-V shaped, and is never shaped like the PDF of an Exponential, Pareto/GPD, or Weibull for .
This leaves us with a set of four elliptical distribution’s which satisfy all three conditions: Logistic, Laplace, Normal, and Student, as well as the nonelliptical GEV distribution. For the latter, with the left superquantile can be expressed as
where is the upper incomplete Gamma function, .
4.1.2 Superquantile and bPOE Optimization
An alternative to the Markowitz problem is to find the portfolio with minimal superquantile (3) or bPOE (4).
| (3) | ||||||
| (4) | ||||||
For qualified distribution’s, however, these problems can be greatly simplified. First, we see that (3) reduces to (5):
| (5) | ||||||
Khokhlov (2016) shows that the optimal solution to (5) is the same as the optimal solution to a Markowitz optimization problem (2) with . Thus, the superquantile optimal portfolio is also mean-variance optimal in the Markowitz sense.
Now, for bPOE we see that the picture is actually much simpler. Specifically, we have the following proposition.
Proposition 16
| (6) | ||||||
Proof
First, note that by definition of the superquantile, we know that must be an increasing function w.r.t. . Second, as and for qualified distribution’s, the problem (4) can be rewritten as:
| (7) | ||||||
which can then be written as:
| (8) | ||||||
Finally, since is an increasing function w.r.t. and does not dependent upon , we see that we can formulate the maximization as (6) without changing the argmin. ∎
This proposition has the important implication for portfolio theory that the optimal bPOE portfolio for the qualified distribution does not depend on the distribution itself. The same portfolio will have the lowest bPOE for any of those distribution’s. The fact that bPOE optimization is, in some sense, independent from distributional assumptions makes it preferable to superquantile optimization.
4.1.3 Numerical Demonstration
In this example, we consider a global equity portfolio that consists of 6 market portfolios - U.S., Japan, U.K., Germany, France, and Switzerland, represented by the corresponding MSCI indices - MXUS, MXJP, MXGB, MXDE, MXFR, MXCH. Parameters of returns for portfolio components are provided in Table 1 (source: Capital IQ sample of monthly returns from April 1987 to April 1996, annualized).
| Asset | Expected | Standard | Correlations | |||||
|---|---|---|---|---|---|---|---|---|
| ticker | return | deviation | MXUS | MXJP | MXGB | MXDE | MXFR | MXCH |
| MXUS | 10.25% | 13.79% | 1 | 0.190041 | 0.639133 | 0.481857 | 0.499406 | 0.605384 |
| MXJP | 6.90% | 26.05% | 0.190041 | 1 | 0.450337 | 0.251601 | 0.378753 | 0.373964 |
| MXGB | 8.81% | 19.16% | 0.639133 | 0.450337 | 1 | 0.579918 | 0.584215 | 0.654687 |
| MXDE | 9.15% | 20.31% | 0.481857 | 0.251601 | 0.579918 | 1 | 0.753072 | 0.628426 |
| MXFR | 8.83% | 20.40% | 0.499406 | 0.378753 | 0.584215 | 0.753072 | 1 | 0.580626 |
| MXCH | 13.85% | 17.45% | 0.605384 | 0.373964 | 0.654687 | 0.628426 | 0.580626 | 1 |
This problem was solved using a non-linear programming algorithm and the results are provided in Table 2. The respective values of are also provided, which allows deriving the same portfolios using the standard MVO solver that uses a quadratic programming algorithm.
| Asset | min risk | CVaR 99% optimal portfolios | CVaR 95% optimal portfolios | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ticker | portfolio | normal | t (df=3) | Laplace | logistic | normal | t (df=3) | Laplace | logistic |
| MXUS | 70.99% | 65.80% | 67.59% | 67.03% | 66.53% | 64.23% | 64.78% | 65.05% | 64.64% |
| MXJP | 13.98% | 9.61% | 11.11% | 10.64% | 10.21% | 8.28% | 8.74% | 8.97% | 8.62% |
| MXGB | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| MXDE | 9.24% | 2.87% | 5.07% | 4.37% | 3.76% | 0.95% | 1.61% | 1.94% | 1.44% |
| MXFR | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| MXCH | 5.79% | 21.72% | 16.22% | 17.96% | 19.50% | 26.54% | 24.87% | 24.04% | 25.30% |
| Return | 9.89% | 10.68% | 10.40% | 10.49% | 10.57% | 10.91% | 10.83% | 10.79% | 10.85% |
| St.dev. | 12.86% | 13.01% | 12.93% | 12.95% | 12.97% | 13.11% | 13.08% | 13.06% | 13.09% |
| 20.48 | 31.28 | 26.82 | 23.80 | 15.73 | 17.11 | 17.88 | 16.73 | ||
Table 2 shows that superquantile optimal portfolios are not the same as the global minimum variance portfolio (min. risk portfolio), but are quite close to it. Distributional assumptions play their role in the optimal portfolios composition, with the Student-t distribution rendering the most conservative allocation for CVaR 99%. However, the differences between optimal portfolios for CVaR 95% are insignificant.
We can note from (5) that if portfolio return is constrained from below, unless this constraint is very close to the return of the global minimum variance portfolio, it results in the superquantile optimization being essentially the same as the variance minimization. If the risk is constrained from above, that superquantile optimization is the same as return maximization.
Using the same set of assets, we also solved the bPOE optimization problem (4) with thresholds and (i.e. losses exceeding 16% and 25% of the initial portfolio respectively), , and . Table 3 shows the results: the minimal bPOE achieved, the optimal portfolio composition and parameters, and CVaR for the optimal portfolios for all distribution’s.
| Assumed distribution | normal | t (df=3) | Laplace | logistic | normal | t (df=3) | Laplace | logistic |
|---|---|---|---|---|---|---|---|---|
| bPOE threshold, | 16% | 25% | ||||||
| bPOE value, | 5.13% | 6.21% | 7.46% | 6.36% | 0.80% | 2.93% | 2.81% | 1.86% |
| Asset tiker | bPOE-optimal portfolio composition | |||||||
| MXUS | 64.20% | 64.19% | 64.20% | 64.20% | 65.95% | 65.95% | 65.95% | 65.95% |
| MXJP | 8.26% | 8.27% | 8.25% | 8.25% | 9.73% | 9.73% | 9.73% | 9.73% |
| MXGB | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| MXDE | 0.90% | 0.91% | 0.90% | 0.90% | 3.05% | 3.05% | 3.06% | 3.05% |
| MXFR | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| MXCH | 26.64% | 26.63% | 26.64% | 26.65% | 21.27% | 21.27% | 21.27% | 21.27% |
| Return | 10.92% | 10.92% | 10.92% | 10.92% | 10.65% | 10.65% | 10.65% | 10.65% |
| St.dev. | 13.12% | 13.12% | 13.12% | 13.12% | 13.00% | 13.00% | 13.00% | 13.00% |
| Test distribution | CVaR for the test distribution’s | |||||||
| normal | 16.00% | 14.93% | 13.87% | 14.79% | 25.00% | 18.95% | 19.16% | 21.16% |
| t (df=3) | 18.14% | 16.00% | 14.05% | 15.74% | 46.31% | 25.00% | 25.56% | 31.46% |
| Laplace | 19.48% | 17.70% | 16.00% | 17.48% | 36.62% | 24.61% | 25.00% | 28.79% |
| logistic | 17.61% | 16.18% | 14.81% | 16.00% | 31.14% | 21.71% | 22.01% | 25.00% |
All the optimal solutions were generated by the non-linear programming algorithm for different distribution’s, but the results support the conclusion that the optimal portfolio composition does not depend on the distribution (small discrepancies are due to the optimization algorithm accuracy).
5 Parametric Density Estimation with Superquantile’s
One of the motivation’s for providing closed-form superquantile formulas is so that they can be used within common parametric estimation frameworks. The Exponential, Parteo/GPD, Laplace, Normal, LogNormal, Logistic, Student-t, Weibull, LogLogistic, and GEV represent a wide range of distribution’s that can now be utilized within these parametric procedures, but with superquantile’s incorporated into the fitting criteria. We illustrate this idea by proposing a simple variation of the Method of Moments (MM), which we call the Method of Superquantile’s (MOS), where superquantile’s at varying levels of take the place of moments. Our numerical example utilizes a heavy tailed Weibull to illustrate MOS, since it is particularly well-suited for asymmetric heavy-tailed data. However, any of the listed distribution’s could be used as well.
5.1 Method of Superquantile’s
The MM is a well known tool for estimating the parameters of a distribution when moments are available in parametric form and desired moments are either assumed to be known or are measured from empirical observations. It looks for the distribution , parameterized by , with moments equal to some known moments or, if moments are unknown, empirical moments. With moments used, the problem reduces to solving a set of equations w.r.t. the set of parameters of the distribution family.
This method, though, can be generalized where moments are replaced by other distributional characteristics, such as the superquantile and quantile. We utilize superquantile’s in this context. This method provides flexibility through the choices of different , allowing the user to focus the fitting procedure on particular portions of the distribution. This flexibility is advantageous compared to other methods such as MM or maximum likelihood (ML), since these fitting methods treat each portion of the distribution equally. When fitting the tail is important, for example, and there are many samples around the mean with few samples in the tail, it can be desirable to focus the fitting procedure on carefully fitting the tail samples. As will be shown, one can focus MOS by choice of . One will see that this procedure is similar to fitting with Probability Weighted Moments (PWM)555also sometimes called L-moments., but where MOS is much more straightforward with superquantiles far easier to interpret than PWM’s.
We formulate the following problem, where denotes either a known superquantile or an empirical estimate from a sample of and denotes parameterized formulas for the superquantile when has density function with the set of parameters :
Method of Superquantiles: Fix and choose a parametric distribution family with parameters . Solve for such that,
which is a system of equations in unknowns.
This problem, however, may not have a solution. For example, if and the parametric family only has a single parameter (i.e. ). In this case, one can solve the following surrogate Least Squares minimization problem:
LS Method of Superquantiles (LS-MOS): Fix and choose a parametric distribution family with parameters . Choose weights and solve for,
This procedure finds the distribution which has superquantile’s that are close to the empirical superquantile’s. The freedom to select as well as provides the user with much flexibility as to which portion of the distribution should match more exactly the empirical superquantile’s.
5.1.1 Example Customization: Conservative Tail Fitting
When sample size is small and the tail of the distribution at hand is long, it is likely that the tail will be difficult to characterize from empirical data since few observations will be observed in the tail (with high probability). The proposed method of superquantile’s can easily, however, be made more conservative based upon empirical data in an intuitive way. For example, one could have the following condition where is a pre-specified constant such that :
Or, for the least squares variant, one can fit the problem,
Notice that these conditions are effectively making the assumption that the empirical superquantile has underestimated the true tail expectation, which is often the case with heavy tailed distribution’s.
5.1.2 Example: Weibull Distribution Fitting
We illustrate the basic method on fitting a Weibull distribution, with , from a small sample of 50 observations. We took two independent samples, denoted , of size 50 from a Weibull with . We then estimated the Weibull parameters using MM, ML, and the LS-MOS. The MM was solved using the first two moments. The LS-MOS was solved twice. It was first solved with , a choice which was made to mimic the behavior of MM and ML, where the fit emphasizes most of the observed data. To put more emphasis on the tail observations, it was also solved with . We denote these solutions as LS1, LS2 respectively. The ML solution is available in closed-form and we solved MM, LS1, and LS2 using Scipy’s optimization library.666Specifically, we used the leastsq function which implements MINPACK’s lmdif routine. This routine requires function values and calculates the Jacobian by a forward-difference approximation.
Looking at Figure 2 for and Figure 3 for , we see that the LS1 fit is, indeed, much like the MM a ML fit for both data sets. However, we see that the LS2 fit is the best in both cases. The ML, MM, and LS1 methods have put too much emphasis on the observations around the mode. The LS2 fit, however, has put appropriate emphasis on the less frequent observations in the tail.
It is also important to notice how the differences in and have affected the fit from each method. Looking at the differences between and , we can see that the samples differ in the observed density in the lower portion of the range. This is directly reflected in the fits given by MM, ML, and LS1. Compared to their fits on , they are more heavily favoring the left side of the distribution. The LS2 fit, however, is robust to these differences between data sets and, by focusing on the tail, has remained mostly unchanged from the fit on . This is the intended effect from the selection of larger values for in LS2.
We duplicated this procedure on a heavier tailed Weibull. We took 50 samples of a Weibull with true parameters and fit MM, ML, LS1, and LS2 using the empirical data. Figure 4 and Figure 5 highlight different aspects of the resulting fits. We see that LS2 clearly provides the best fit, with Figure 5 in particular showing that MM, ML, and LS1 underestimate the tail densities. MM, ML, and LS1 put more emphasis on fitting the observations around the mode. As intended, however, LS2 focuses more on fitting the right tail observations and arrives at a better fit.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2b8a91cc-3c70-40e7-9745-cc884f8d7025/pic1.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2b8a91cc-3c70-40e7-9745-cc884f8d7025/pic2.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2b8a91cc-3c70-40e7-9745-cc884f8d7025/pic3.png)
5.1.3 Constrained Likelihood and Entropy Maximization
While we focused primarily on a variant of the method of moments, the formulas provided for superquantile’s and bPOE can be used in other parametric procedures. For example, one could consider a constrained variant of the maximum likelihood or maximum entropy method, where superquantile constraints are introduced. Letting denote the entropy of the random variable with density function , and denote an observation, constrained entropy maximization and maximum likelihood can be set up as follows:
where .
While we leave full exploration of this framework for future work, this simple formulation illustrates another potential use for the provided superquantile and bPOE formulas within traditional parametric frameworks.
6 Conclusion
In this paper, we first derived closed-form formulas for the superquantile and bPOE, then utilized them within parametric portfolio optimization and density estimation problems. We were able to derive superquantile formulas for a variety of distribution’s, including ones with exponeitial tails (Exponential, Pareto/GPD, Laplace), symmetric distribution’s (Normal, Laplace, Logistic, Student-t), and asymmetric distribution’s with heavy tails (LogNormal, Weibull, LogLogistic, GEV). With bPOE formulas, while we had less success deriving truly closed-form solutions, we saw that it can still be calculated by solving a one-dimensional convex optimization problem or one-dimensional root finding problem.
We then utilized these formulas to develop two parametric procedures, one in portfolio optimization and one in density estimation. We first found that formulas for Normal, Laplace, Student-t, Logistic, and GEV are all distribution’s which yield tractable superquantile and bPOE portfolio optimization problems. Furthermore, we found that bPOE-optimal portfolios are more robust to changing distributional assumptions compared to superquantile-optimal portfolios. Specifically, bPOE optimal portfolios are optimal, simultaneously, for an entire class of distributions. Finally, we presented a variation on the method of moments where moments are replaced by superquantile’s. This parametric procedure is made possible by our closed-form formula’s and we illustrate its use in the case of heavy tailed assymetric data, where additional emphasis on fitting the tail via superquantile conditions can be highly desirable. We find that this method makes it easy to direct the focus of the fitting procedure on tail samples.
References
- Andreev et al. (2005) Andreev A, Kanto A, Malo P (2005) On closed-form calculation of cvar. Helsinki School of Economics Working Paper W-389
- Artzner et al. (1999) Artzner P, Delbaen F, Eber JM, Heath D (1999) Coherent measures of risk. Mathematical Finance 9:203–228
- Davis and Uryasev (2016) Davis JR, Uryasev S (2016) Analysis of tropical storm damage using buffered probability of exceedance. Natural Hazards 83(1):465–483
- Karian and Dudewicz (1999) Karian ZA, Dudewicz EJ (1999) Fitting the generalized lambda distribution to data: a method based on percentiles. Communications in Statistics-Simulation and Computation 28(3):793–819
- Khokhlov (2016) Khokhlov V (2016) Portfolio value-at-risk optimization. Wschodnioeuropejskie Czasopismo Naukowe 13(2):107–113
- Landsman and Valdez (2003) Landsman ZM, Valdez EA (2003) Tail conditional expectation for elliptical distributions. North American Actuarial Journal 7(4):55–71
- Mafusalov and Uryasev (2018) Mafusalov A, Uryasev S (2018) Buffered probability of exceedance: Mathematical properties and optimization. SIAM Journal on Optimization 28(2):1077–1103
- Mafusalov et al. (2018) Mafusalov A, Shapiro A, Uryasev S (2018) Estimation and asymptotics for buffered probability of exceedance. European Journal of Operational Research 270(3):826–836
- Norton and Uryasev (2016) Norton M, Uryasev S (2016) Maximization of auc and buffered auc in binary classification. Mathematical Programming pp 1–38
- Norton et al. (2017) Norton M, Mafusalov A, Uryasev S (2017) Soft margin support vector classification as buffered probability minimization. The Journal of Machine Learning Research 18(1):2285–2327
- Rockafellar and Royset (2010) Rockafellar R, Royset J (2010) On buffered failure probability in design and optimization of structures. Reliability Engineering & System Safety, Vol 95, 499-510
- Rockafellar and Uryasev (2000) Rockafellar R, Uryasev S (2000) Optimization of conditional value-at-risk. The Journal of Risk, Vol 2, No 3, 2000, 21-41
- Rockafellar and Royset (2014) Rockafellar RT, Royset JO (2014) Random variables, monotone relations, and convex analysis. Mathematical Programming 148(1-2):297–331
- Rockafellar and Uryasev (2002) Rockafellar RT, Uryasev S (2002) Conditional value-at-risk for general loss distributions. Journal of banking & finance 26(7):1443–1471
- Sgouropoulos et al. (2015) Sgouropoulos N, Yao Q, Yastremiz C (2015) Matching a distribution by matching quantiles estimation. Journal of the American Statistical Association 110(510):742–759
- Shang et al. (2018) Shang D, Kuzmenko V, Uryasev S (2018) Cash flow matching with risks controlled by buffered probability of exceedance and conditional value-at-risk. Annals of Operations Research 260(1-2):501–514
- Uryasev (2014) Uryasev S (2014) Buffered probability of exceedance and buffered service level: Definitions and properties. Department of Industrial and Systems Engineering, University of Florida, Research Report 3