Calculation of Epidemic Arrival Time Distributions using Branching processes
Abstract
The rise of the World Airline Network over the past century has lead to sharp changes in our notions of ‘distance’ and ‘closeness’ - both in terms of trade and travel, but also (less desirably) with respect to the spread of disease. When novel pathogens are discovered, countries, cities and hospitals are caught trying to predict how much time they have to prepare. In this paper, by considering the early stages of epidemic spread as a simple branching process, we derive the full probability distribution of arrival times. We are able to re-derive a number of past arrival time results (in suitable limits), and demonstrate the robustness of our approach, both to parameter values far outside the traditionally considered regime, and to errors in the parameter values used. The branching process approach provides some theoretical justification to the ‘effective distance’ introduced by Brockmann & Helbing (2013), however we also observe that when compared to real world data, the predictive power of all methods in this class is significantly lower than has been previously reported.
1 Introduction
It was said by Jules Verne in 1873 that “The world has grown smaller, since a man can now go round it ten times more quickly than a hundred years ago,” that one could travel around the world in eighty days [Verne, 1873]. One can’t help but wonder what Verne would think of the advances in technology that have occurred in the century and a half since, which now allow the circumnavigation of the globe in less than eighty hours. The World Aviation Network (WAN) has, over the past century, shrunk the globe to a fraction of its former size, allowing for vast increases in tourism, immigration, and trade. At the same time, diseases that might once have travelled at the speed of cart, ship or train now cross the world in a number of days or hours. In 2003 Severe Acute Respiratory Syndrome (SARS) was able to spread from China to Vietnam, Hong Kong and Canada within two weeks of being reported to the World Health Organization [WHO, 2003]. Similarly, the 2009 H1N1 flu pandemic first reported in Mexico was able to reach both Europe and Asia within a fortnight [WHO, 2009]. Now, in 2020 we see that coronavirus SARS-CoV-2 has spread quickly across the world [WHO, 2020], reaching all but a handful of countries withing a few short months.
Modelling of disease spread and disease arrival time is critical, both to mitigate the effects of a disease and to determine where best to apply quarantine and screening protocols so as to minimize the spread of infection. In order to model the spread of disease, given the current WAN, a number of highly detailed epidemic simulation models have been created, such as GLEAMviz[Broeck et al., 2011]. Depending on how they are set up, these models can include such factors as vaccination, incubation times, multiple susceptibility classes, non-linear responses, seasonal forcing, quarantine, and the stochastic movement of individual agents, providing a detailed and comprehensive modelling framework. Unfortunately, in many cases, such models quickly become black boxes in and of themselves - objects to be studied and analyzed only via costly simulation - allowing predictions of the future that can be observed, but seldom understood. This difficulty is further exacerbated by the difficulties of determining parameter values, often a delicate task during the initial stages of a disease outbreak when information is scarce.
Depending on the questions being asked, explicit modelling of such intricate details is necessary, however, for other questions, such as the determination of epidemic arrival time (‘AT’), it seems that simpler methods may suffice. For this reason, a number of authors [Brockmann and Helbing, 2013, Iannelli et al., 2017, Gautreau et al., 2007, Chen et al., 2018] have proposed a variety of heuristics and metrics – artificial measures of distance based on flight data from the WAN. The goal of such metrics is to predict relative arrival times for an epidemic starting in a specified location, predicting for example that an epidemic starting in Vancouver will take twice as long to reach Istanbul as it will to reach Rio de Janeiro. Absolute AT will also depend on the parameters of the particular disease in question.
A particularly elegant example of such a metric is Brockmann & Helbing’s [Brockmann and Helbing, 2013] ‘effective distance’, in which they define the direct distance between a pair of locations as
| (1) |
where is the probability that a particular individual who is leaving location is travelling to location . The total effective distance between nodes and is then given as the shortest path between a given pair of nodes:
| (2) |
where here we minimize over all possible paths from to , and denotes the effective distance along each step of this shortest path (and the corresponding probability).
Papers by Gautreau, Ianelli, et al. provide more detailed and mathematically justified metrics, by first calculating the expected time for a growing epidemic to make its first ‘jump’ [Gautreau et al., 2007], and then summing over all possible paths joining a pair of airports (in an appropriate manner) [Iannelli et al., 2017]. More recent work by Chen et al. [Chen et al., 2018] made use of linear spreading theory and the matrix exponential, in order to attain similar accuracy at reduced computational cost.
Underlying each of the above efforts, either implicitly or explicitly, is an assumption of unbound growth; the idea that in the early stages of an epidemic, disease spread is not limited by population size. Such unbound growth can, and often has been, modeled as smooth exponential growth, a continuous approximation of discrete real world populations. An alternative model for unbound growth, one often used when small populations, rare events, and probabilities are of interest, is the branching process [Kimmel and Axelrod, 2015]. The branching process is a classical tool in the study of extinction and evolution[Schaffer, 1970], and has been used to study epidemics[González et al., 2010], surnames and genealogies [Watson and Galton, 1875], and cancers [Goldie and Coldman, 1979, Coldman and Goldie, 1986]. In this paper we apply the branching process framework in order to calculate not only the mean, but also the full distribution of ATs for arbitrary networks.
In section 2 we introduce a basic ‘multi-compartment branching process’ model, and from this model derive a system of ODE’s that precisely determine the probability of epidemic arrival by a given time. In section 3 we determine the mean and variance in the AT, and explore how these results both support and contrast with the results of past papers. Section 4 explores the sensitivity of our predictions to perturbations to system parameters and network structure. In section 5 we use data from real world flight networks, and compare our predictions, along with the predictions of past authors to epidemic arrival times as observed for in the 2003 SARS epidemic, and 2009 H1N1 influenza pandemic. In both cases we observe correlation between predicted and observed results, but also significant noise. We are, unfortunately, unable to reproduce previously published results, and instead observe the observed stochasticity is both larger than previously reported, and larger than might be expected given the underlying model.
Our goal in this paper is to provide a ‘canonical’ approach to calculating arrival times; that is to say, an approach which relies on minimal assumptions and approximations, and can be trusted to provide accurate results across all of parameter space. To the extent that the method works, it can be seen as providing a foundation to past methods and heuristics. To the extent that our predictions disagree with real world data this is suggestive of either flaws in the data, or gaps in the underlying model, gaps that will require not simply better mathematics, but instead better understanding of the system under study.
2 Diffusion on a Network and the Branching Process
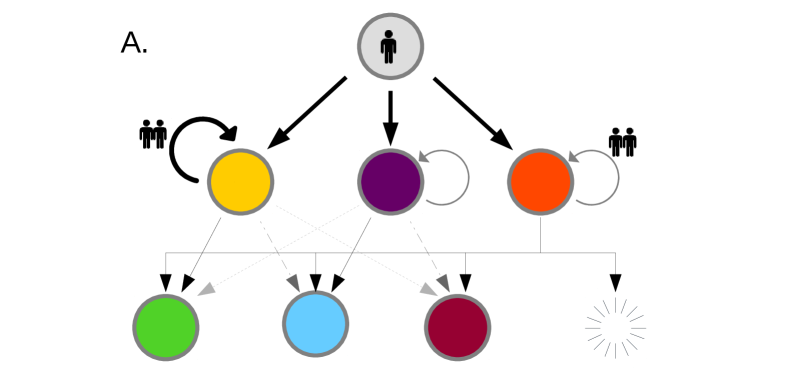
Let us begin by concretely defining the model; we consider a network of connected nodes, each node representing a location. In our case these nodes refer to particular airports in the WAN. Individuals travel from node to node at transport rate . Here gives the relative transport rate along a given route, while is the global flight rate. While and can be folded together as one parameter, maintaining this distinction will prove convenient later. We select to represent the rate at which individuals leave location ; . Each node contains a population of infected individuals, initially set to zero. This population evolves according to a continuous time branching process: in any given small time interval will increase by one with probability and decrease by one with probability . This represents infection and recovery ( and respectively). Parallel with this branching process, infected individuals may travel from one location, , to a neighbouring location, , with probability , resulting in an increment at location and a decrement at location . We thus have what might be described as a “continuous time multitype branching process” [Kimmel and Axelrod, 2015].
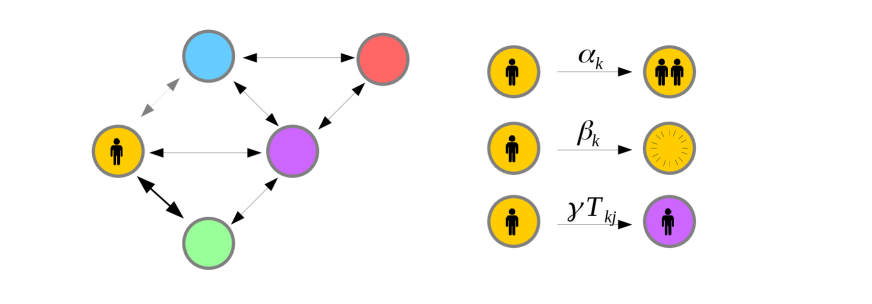
We would like to determine the travel time from to . Stated formally, suppose a novel diseases originates at time , at node . We would like to know the time at which the first infectious individual arrives in location , that is to say the earliest time such that . We denote this epidemic arrival time (AT) as . If no infected individuals ever arrives at we say that . The distribution of will depend on the starting location , the target location , and the network parameters , and . We wish to understand this dependence and do so by considering the survival function .
Consider ‘Patient Zero,’ initially placed in location at time . Now consider the state of the system a short time later, at time . With overwhelming probability, nothing will have happened during this small time window, and the survival times will still be governed by . With probability patient zero will have moved to location , and the survival time distribution will instead be governed by . In the case where , survival is now impossible, hence . Patient zero may also infect someone with probability . In this case, the probability of survival until time is given by the probability that neither traveler arrives at . As both travelers are independent and identical, this probability is given by . Finally, it is possible that the initially infected patient zero may simply recover. This happens with probability . In this case, no infected individual will ever reach , and survival probability is for all time.
The probability of surviving for units of time after is thus a superposition of the possible survival functions for the states the system could transition to. By definition the probability of surviving for units of time after time is also precisely equal to . Stated algebraically we thus have:
| (3) | ||||
| rearranging and taking limits we find, | ||||
| (4) | ||||
| remembering that , we can simplify to | ||||
| (5) | ||||
We refer to arrival times calculated using this method as ‘branching process arrival times’ (BP AT). These equations are equivalent to those given by Goldie & Coldman [Goldie and Coldman, 1979], who model the arrival of treatment resistant cancer cells via rare mutation (although in Goldie’s case, a much smaller collection of ‘types’ of individual are considered).
It is important to note that eq. (5) does not model the internal state of the system. While normal differential equations might be constructed by modelling the internal ‘state’ of the system at time , and using this to model the system at , instead we merely observe that the survival function (whatever it might be), can be written as a superposition of the (as yet unknown) survival functions , and hence derive eq. (3). In so doing, we have lent heavily upon the assumption that system parameters are constant in time; that the behavior and survival curve associated with a single traveller observed at time is identical to the behavior and survival curve of a traveller observed at time . For a discussion of how a similar approach might be taken in the context of time varying parameters, see Appendix A.
2.1 Example Networks
In order to test eq. (5), and get something of an intuitive handle on the behavior of our system, let us consider three example networks of successively increasing complexity. For each network we solve eq. (5) numerically using Matlab’s ode45 [Shampine and Reichelt, 1997] for each target node, and compare to survival times observed in exact agent based simulations, where we track individual infection, migration and recovery events precisely. Where possible simulations are conducted using Gillespie’s exact algorithm [Gillespie, 1977]. In cases where such an approach is computationally infeasible, we make use of -leaping [Gillespie, 2001].
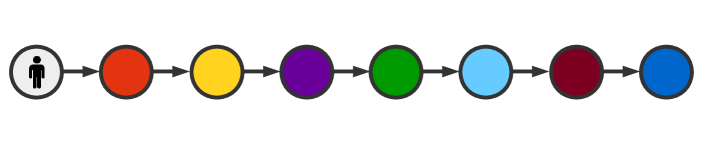
As our first example, consider a simple chain graph, in which infection begins at one end of the chain, and is allowed to propagate from one node to the next (fig. 3). Here we observe that arrival time scales with number of steps taken, as might be expected. Survival curves are sigmoidal, which, as we will later see, is a typical behavior for reasonable parameter values. Mean arrival times as predicted by survival curves and as observed over 5000 Gillespie simulations are found to agree.
We next consider a ‘spinning top’ graph (fig. 3); this graph is constructed in order to illustrate the effects of multiplicity of paths. Here one node of the graph is accessible through only a single possible path, while another node (at equal distance) can be accessed via a great multiplicity of paths, each with a correspondingly reduced probability.
Here we observe that the BP AT gives accurate predictions of arrival time, correctly predicting that the arrival time in the two most distant nodes is equal, regardless of the multiplicity of paths. Counter-intuitively, it is also observed that when (the number of paths) is greater than , the mean arrival time in the outer blue nodes precedes the mean arrival time in the intermediate yellow nodes. This occurs because, while the epidemic must reach some intermediate node before passing to the outer blue node, it is also perfectly possible for a large number of intermediate nodes to be uninfected at this stage, resulting in a higher mean arrival time. In the case this is precisely what occurs, and the ordering of mean arrival times inverts. The qualitative behavior of the system is thus sensitive to transport rate . All of this is correctly described and predicted by the BP AT; heuristic models that account only for a single shortest path (such as eq. (1) ) do not capture this effect (see fig. 3).
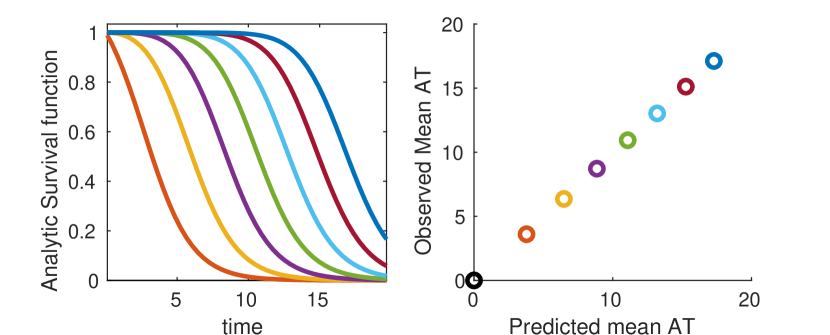
As a third example, in order to illustrate the possible complexity of arrival time distributions, we construct an artificial network with a wide spread of transportation, infection and recovery rates, and compare numerical solutions of equation 5 with survival curves observed over the course of 25000 Gillespie simulations[Gillespie, 1977]. In this case we observe that survival curves exhibit rich, complex behavior. Nonetheless, equation 5 correctly predicts the distribution of arrival times as observed in direct agent based simulation (figure 4) over multiple time scales.
The branching process approach gives similar accuracy over a wide variety of parameter values and network structures. A gallery of such comparisons is provided in Appendix B.
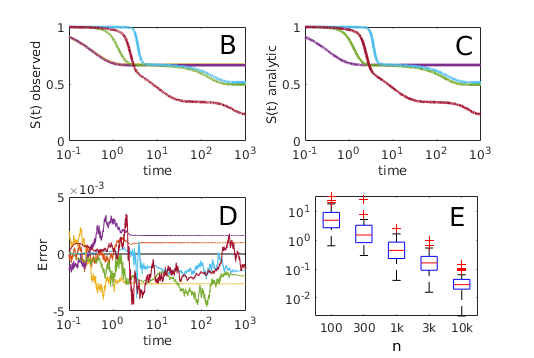
3 Derivation of Mean and Variance in Arrival Time
Equation 5, while accurate, is somewhat cumbersome and does not provide any closed form for values of interest such as expected arrival time and variance in arrival time. If we place no constraints on , and then it is easy to construct survival curves with complex topology such as fig. 4, and it can be shown that any valid survival curve (that is any curve of the form ) can be well approximated, for suitably chosen network and parameter values (see appendix C). While mathematically interesting, such results are of little use to epidemiologists. More useful results can be obtained by placing some mild constraints on parameter values based on real world understanding.
The first assumption that we make is that we are not interested in epidemics that go extinct before spreading; we care only about those epidemics that reach international prevalence. For simplicity in the following discussion, this is achieved by assuming for all . A discussion of non-zero can be found in Appendix D.
The second assumption that we make in what follows is that epidemic dynamics (infection and recovery) take place on on the time scale of days and weeks, while international travel is a rare occurrence, the vast majority of the human population taking international flights at most once or twice per year111With some individuals travelling significantly more often, and many others never flying at all.. Stated algebraically we have ; travel is rarer than infection. This mimics the ‘rare mutation’ assumption made by Goldie & Coldman[Goldie and Coldman, 1979]when studying the the development of treatment resistant cancer cells, and rules out slow epidemics such as HIV.
We further assume that infection rate is equal across all locations: . This greatly simplifies notation, and has limited impact upon our final conclusions.
Taken together, these three assumptions ( are sufficient to avoid the more complex survival curve dynamics, as observed in fig. 4. Instead, we find and the arrival time distribution is well approximated by a logistic function:
| (6) |
Here is the mean arrival time (AT) for an epidemic starting in node and spreading to . Determination of is of some considerable interest. This value is dependent upon the dynamics of the system when ; that is to say the region where the transport is no longer overwhelmed by logistic decay in probability.
3.1 Mean arrival time
Determination of can be seen as equivalent to the question of determining when the exponential term of eq. (6) is equal to . For the sake of convenience, we label this term , and make use of the change of variables . This leads to the differential equation:
| (7) |
Given Eq. 6, the mean arrival time satisfies . Because for , and , we can safely assume in our region of interest, hence allowing the approximation . Because , we can restate eq. (7) as:
| (8) |
At this stage it may be tempting to make the further approximation
| (9) | ||||
| using the matrix exponential we solve to find | ||||
| (10) | ||||
Here we observe that eq. (9) and (10) bear a striking resemblance to the calculation of the expected number of infections at , given an initial epidemic starting at , as studied by Chen et al. [Chen et al., 2018]. Under this interpretation of we are effectively approximating our arrival time as the time at which the expected number of infected individuals in our target node, , reaches one.
In cases where a single path of length dominates the spread of our epidemic from to we can make the further approximation:
| (11) | ||||
| (12) | ||||
| Choosing to ignore a number of small terms, we find | ||||
| (13) | ||||
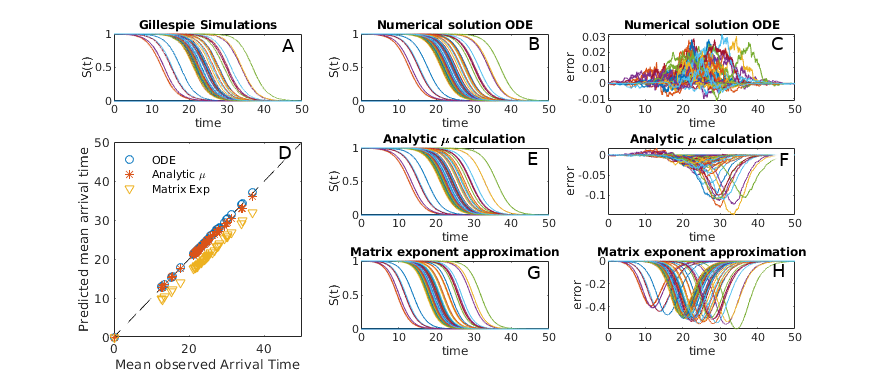
where here are the transport rates along each link of the most probable path epidemic path. We thus reconstruct the results of shortest path methodology similar to Gautreau’s original study [Gautreau et al., 2007] and the work of Brockmann & Helbing [Brockmann and Helbing, 2013]. More detailed discussion of this matrix exponential approach and its relation to previous work is provided in Appendix E. Survival curves as predicted by equation 10 are given in figure 5.
While the approximation is convenient in that it allows us to linearize the equation, more accurate results can be obtained by retaining and following on from equation 8 directly. Applying integrating factors we find,
| (14) | ||||
| Substituting the ansatz for , along with , we find | ||||
| (15) | ||||
| Multiplying through by and integrating provides | ||||
| (16) | ||||
Our approach in this equation is to explicitly solve for while treating all other survival curves as logistic. Because will be non-negligible only when , it is possible to calculate arrival time from smallest up to largest, using knowledge of the previously derived to inform calculation of later . In many cases eq. (16) is dominated by a single term, allowing us to make the approximation for some . Taking logs of both sides we find . Summing over multiple such steps reconstructs a shortest path type metric, similar to eq. (13). Even in cases where shortest path approximations do not apply, Newton’s method can be easily applied to solve , allowing us to determine all for any given .
Eq. 16 can thus be used to accurately approximate and without resorting to computationally expensive numerical ODE solvers; this is particularly helpful in regions of parameter space where high sensitivity near render more direct numerical methods unstable.
A comparison of the various approaches described in this section is given in Fig. 5. Numeric solutions of equation 5 give the best results (when using high accuracy ODE solvers), while predictions based on simple matrix exponentiation (Eq. 10) are the least accurate. All three approaches are highly correlated with mean arrival times as observed in full agent based simulations however. When we are interested in relative rather than absolute arrival time, any of the three approaches will suffice, and matrix exponential based approaches are the fastest (see appendix E for details on efficient computation). When more accuracy, or knowledge of full probability distributions, is required, we recommend using either equation 5 or 16.
3.2 Variance
Another value of practical interest is the variability in arrival time; recognising the difference between days and days allows us to understand how precise we expect arrival predictions to be. When , we can use standard logistic distribution results [Balakrishnan, 2013] to determine , where is the ‘scale parameter’ of the logistic distribution, in our case equal to . In plain language, we find that variance is high for slowly growing epidemics, and low for fast growing epidemics, where the infected population spends shorter periods of time at intermediate levels.
This determination of variance leads naturally to the question of co-variance; if our epidemic arrives three days earlier than expected in Paris, will it also inevitably arrives three days early in Istanbul or São Paulo? Or are the two arrival times relatively independent? This question is of particular importance because, generally speaking, we do not know when an epidemic has started, and hence can only ever compare arrival times in different cities relative to one another.
Unfortunately, by its nature contains minimal information about the state of the system; calculation of such state information using probability generating function techniques [Miller, 2018] would require us to take infinitely many derivatives of with respect to our initial conditions . It would appear that full co-variance and correlation information is thus inaccessible.
One avenue that we can take is to examine the variance in arrival time given a larger starting population - for example , with all individuals starting at location . Such an assumption effectively removes the large levels of variance associated with the epidemics “initial take off” time (the time taken to grow from to ), and leaves only the variation associated with the spreading process throughout our network (and subsequent take off time in the various locations the epidemic emigrates to). Given that we typically do not get to observe the true epidemic start data in practice, such an assumption is likely to better reflect real world data.
The survival time distribution for a starting population of is simply . It can be shown (see appendix F) that for an initial population , the arrival time has variance
| (17) |
In the limit .
Of further note, we also observe that as increases the power of the logistic curve () approaches the Gumbel distribution (figure 6) as observed by Gautreau et al. [Gautreau et al., 2007] in their original study of the epidemic arrival time process. The Gumbel distribution can be loosely thought of as an exponential waiting time with exponentially increasing rate parameter (corresponding to the growing population), and has cumulative distribution function of the form . The continuous population assumption implicit in this result is valid when , but causes noticeable discrepancies for .
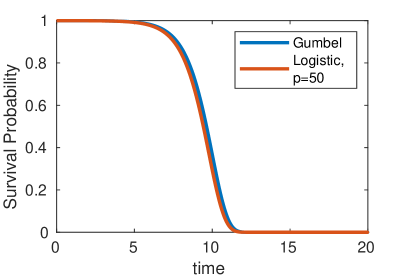
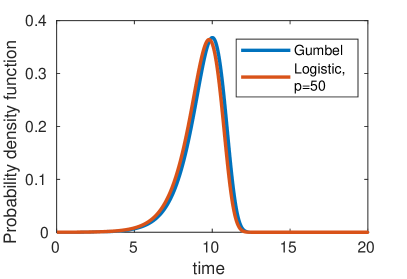
4 Robustness and Limitation
So far we have explored the branching process model in what may be considered close to optimal conditions; we have assumed that , and are exactly known, and that the susceptible population of each node is large enough so as not to limit epidemic growth and spread. Each of the above assumptions may be violated in one context or another, and for this reason it is critical to understand how far each can be stretched. Such understanding sheds light not only on the BP AT itself, but also on past distance metrics, which we have shown to rely on a similar theoretical foundations.
The first, and most likely assumption to be violated in practice is the notion that we know and . While can be determined to some reasonable level of accuracy via commercial flight data, is a number that will vary from illness to illness and may be known only to a limited degree of accuracy, particularly in the early stages of a pandemic. Fortunately the model turns out to be robust against variations in both and – even when varying these parameters by a factor of five compared to the ‘true’ values used in simulations, predicted ATs remain highly correlated with those observed in simulation (see figure 7). When using incorrect the constant of proportionality between and observed ATs is no longer equal to one, suggesting that the BP model robustly estimates , such that the relative time of arrival at any two locations is largely independent of and , but that incorrect estimates of will lead to corresponding inaccuracy in the absolute values of ; if is estimated a factor of two too high, then will be a factor of two too low.
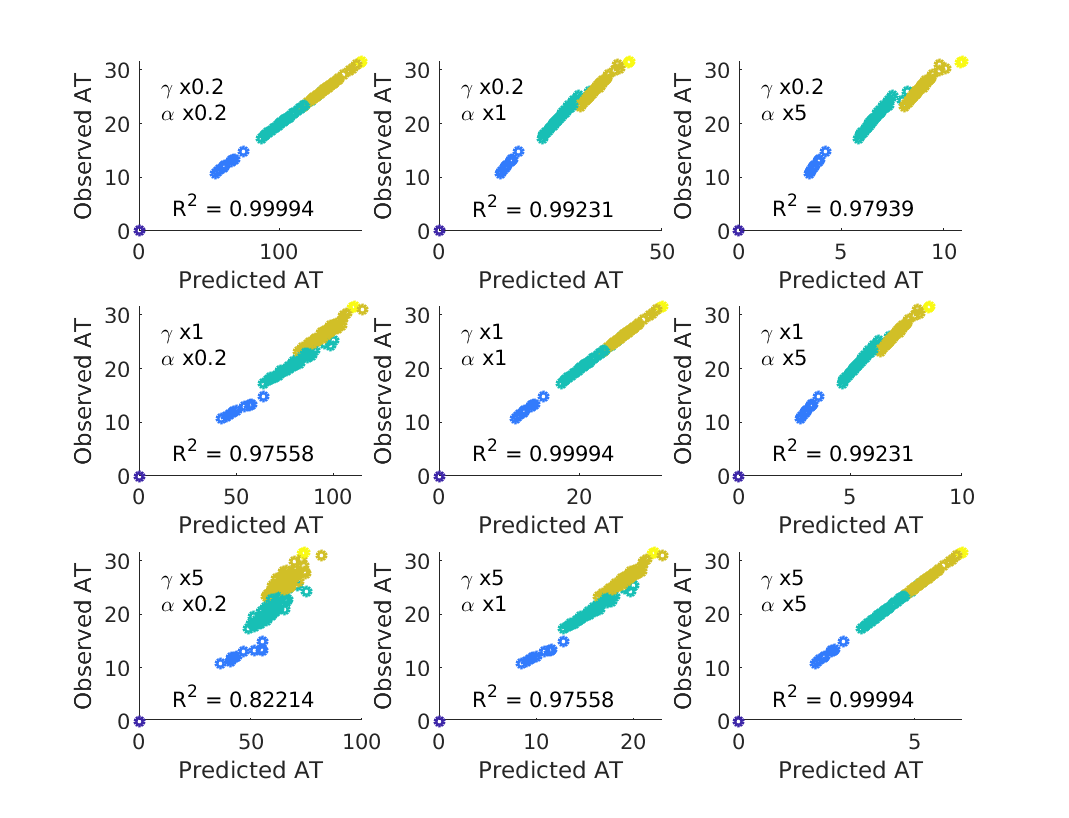
Another systematic source of error is inaccuracies in flight network data. These can be produced due to uncounted or unregistered flights (or alternative forms of transportation), out of date data, or as a direct result of changes to individual flight plans as a result of the epidemic itself. In order to test robustness to noise in available flight data, we compare the results of full Gillespie simulation using flight network , to ATs predicted using the perturbed matrix , where . Here is a constant representing noise level. As can be seen in Fig. 9, the resulting errors are modest.
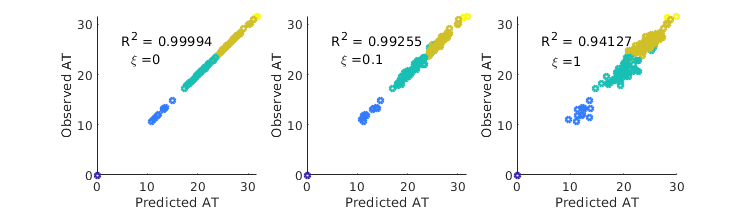
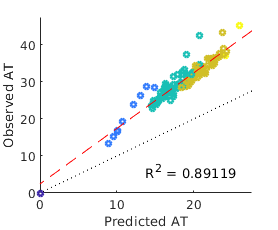
While we have thus far considered arrival times in the context of the global aviation network, effective distance measures have also been considered on a much smaller scale in order to study the spread of antibiotic resistance between wards within a hospital [Friso Coerts, 2018]. In this case, assuming unbound growth becomes problematic, as the susceptible population in each node is rather small; a single ward might contain (for example) beds, a far cry from the tens or hundreds of thousands found when each node represents an entire city. When the local susceptible population is small, the epidemic is frequently no longer in an exponential growth phase by the time it spreads to a neighbouring node; ‘branching random walks’ are no longer independent because it is impossible for person to infect someone who has already been infected by person . Population saturation inevitably leads to less accurate predictions, see figure 9.
In practice, for the SIR type models the parameter window where this concern is relevant is relatively narrow; infections which grow quickly enough to violate our assumptions are liable to burn through the entire local population and drive themselves to extinction before spreading between nodes. For SIS and SI type models, or any infection which is expected to reach a local endemic equilibrium, it is important to determine whether exponential growth is a good approximation before making use of the BP AT, or any distance metric that relies upon the same underlying unbound growth assumption.
5 Real World Data
Finally, while comparison to simulations provides an effective test bed, useful in terms of repeatability and certainty of data, we are, generally speaking more interested in the performance of models as they apply to the real world. Using flight data provided by Dirk Brockmann (private correspondence) we compare observed and predicted AT for both SARS and H1N1 outbreaks (see figure 10). We consider predictions made by both the branching process method described here (Eq. 5) as well as Brockmann & Helbing’s effective distance metric (Eq. 2, [Brockmann and Helbing, 2013]).
Ideally, in order to calculate the BP AT distribution, we would prefer to have access to the full transport matrix , the probability that an individual in location will travel to on any given day. Unfortunately such data is not available, and can not realistically be obtained. Instead, we have access to ; a matrix containing the total number of passengers travelling from to during a given time period. In order to approximate we normalize , hence calculating the probability, , to fly from to , conditioned on the assumption that we board some plane in airport , and multiply by a constant , representing the probability of boarding some flight on a given day. In the real world, we might assume to vary significantly from place to place, based on economic factors, prevalence of tourism, and the size of the population that any given airport is servicing. For the time being we approximate , and rely on the models low sensitivity to to prevent difficulties.
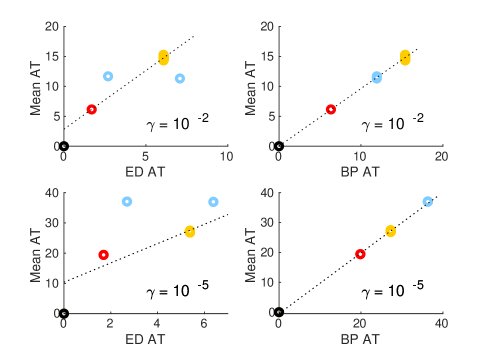
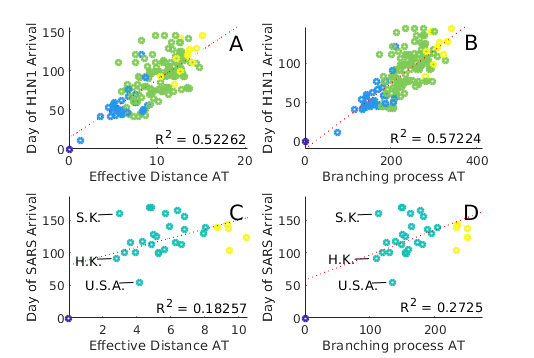
We find that both BP AT and effective distance arrival time (‘ED AT’) methods give qualitatively similar results (see fig. 10), and that these results would appear in many cases plausible: for example, in the case of SARS, we observe that predicted arrival times in both South Korea and Hong Kong are low, while the arrival time in the USA is predicted to be marginally higher. This result is entirely plausible given airline traffic between the respective countries. In practice, predictions for both BP AT and ED AT do not match observed arrival times: SARS is reported to have arrived in the USA days after the first reports in China (11/16/2002), and in South Korea a full after these first reports. For SARS, Arrival times as reported from real world data correlate at best weakly with predictions(note the small in fig. 10 C,D), indicating either inaccuracy in the data or alternatively some complexity in the real world process not accounted for in current models. values are somewhat better when predicting H1N1 ().
We find no method (including ED) is able to reproduce the very high values reported in Brockmann & Helbing’s original paper, and that we are unable to recreate their figures (Figures 2D and 2E in the original paper), instead observing a far broader scatter. It is unclear if the observed discrepancies is due to differences in implementation of the algorithm, differences in the underlying data, or some other cause. While it is possible that inaccuracies in WAN data are to blame for these discrepancies, this explanation seems unlikely; as demonstrated in figure 9, arrival time predictions are generally stable, even to substantial changes in . If we consider the effective distance metric (Eq 2), increasing by , as is needed to correctly predict SARS late arrival time in South Korea, would require a two orders of magnitude smaller than our current value. Such drastic changes appear implausible.
6 Conclusions
Better understanding the spread of epidemics through the WAN allows for both real time forecasting (as has been used during the current COVID-19 pandemic), and also the possibility of network design, making changes to the WAN network so as to slow epidemic spread.
In studying the question of epidemic arrival time, a variety of models have been used, from the the most intricate agent based simulations[Broeck et al., 2011] to the intuitively appealing ‘distance’ based models [Brockmann and Helbing, 2013], and a number of analytic approaches in between [Chen et al., 2018, Iannelli et al., 2017, Gautreau et al., 2008]. While each of these models approaches the question of epidemic arrival time from a different view point, one common thread is the assumption of exponential growth; in the early stages of an epidemic, spread is governed by unbound epidemic growth, and rare transportation events. Population saturation, detailed viral dynamics, and a travellers tendency to return to their port of origin are ignored in all but the most detailed of models.
Given this basic premise, we were able to formulate the problem of epidemic arrival times in term of ‘Branching Processes’ [Kimmel and Axelrod, 2015, Goldie and Coldman, 1979], and calculate the full probability distribution of possible arrival times explicitly. These predictions match perfectly to corresponding simulations. If we further assume that air travel is rare and infection and recovery are common, it is possible to re-derive many of the results of past papers, and in some cases improve upon them. We are also able to give predictions in regions of parameter space where past methods are known to fail, and show that theoretical predictions provide a reasonable match to simulations, even when parameter values are altered significantly.
Unfortunately, when comparing to real world data we observe that the predictive powers of ED metrics may be significantly lower than previously reported [Brockmann and Helbing, 2013]. When compared to real world date, ED and BP like methods predict roughly 50% of variance in the cases of H1N1, and only 20% of variance when compared to SARS-2003, significantly lower than would be predicted given the modest intrinsic variance of our models. While the Branching Process Arrival Time makes very few assumptions and gives exact results given the underlying model assumed, these findings are suggestive of a gap in our knowledge- either in the data available for epidemic arrival times or (more likely) in the model itself. It seems likely that future efforts would be best directed towards determining what real world factors are currently unaccounted for, and which of these are most critical.
7 Acknowledgements and Data Availability
We gratefully acknowledge Dirk Brockmann for stimulating conversation, and for providing historical network and epidemic data. Full code for simulation based figures is available on github [Jamieson-Lane, 2020].
Appendix A Time Varying Parameters and flight networks
Construction of equation 5 relies heavily upon the assumption that the process is memoryless and does not keep track of time.
In order to see the importance of this Markov assumptions, suppose we take equation 5 and replace with some piecewise constant function ; both in our simulation, and in the ODE. As can be seen in figure 11 (top panels), simply replacing with leads a rapid divergence of and our observed survival curve. Under such naive assumptions, our calculated is no longer monotone decreasing, and hence can no longer be considered a survival curve in any sense of the word. This breakdown comes about because even though does not track possible states of the population directly, it must (inevitably) encode these states implicitly. When changes midway through the process, this encoding is rendered invalid, and no longer behaves in a sensible manner. Without the Markov assumption, is no longer a superposition of .
Calculation of survival curves when dealing with time varying parameters is possible however. To do this, we expand the one dimensional to the two dimensional . We define to be the probability that an infected traveller, initially observed at position at time has no decedents arriving at before time . By definition whenever , and . Using similar arguments to equation 3 we find that is a superposition of . Taking limits and converting into a differential equation we find:
| (18) |
Combining equation 18 with the initial conditions given at , it is possible to determine (the survival curve of interest) for any given time by solving a simple ODE in the direction (see figure 11, left panels). This approach accounts for time varying parameters whenever ,, and vary independently from the epidemic course. In the case where parameters are dependent on epidemic spread (for example, border closures in response to observed spread of disease), more complicated methods are needed. Because eq. (18) must be solved independently for each this approach is more computationally costly than the approach taken for Markov systems.
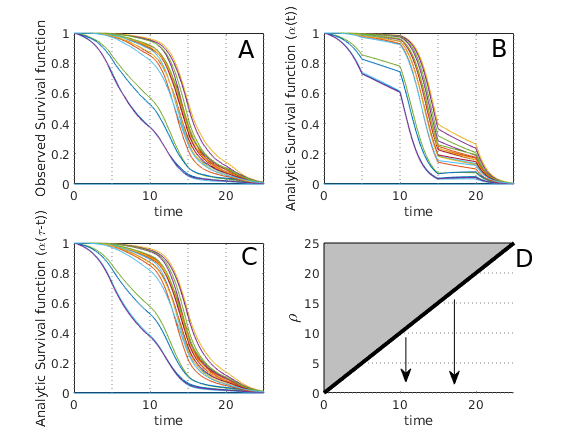
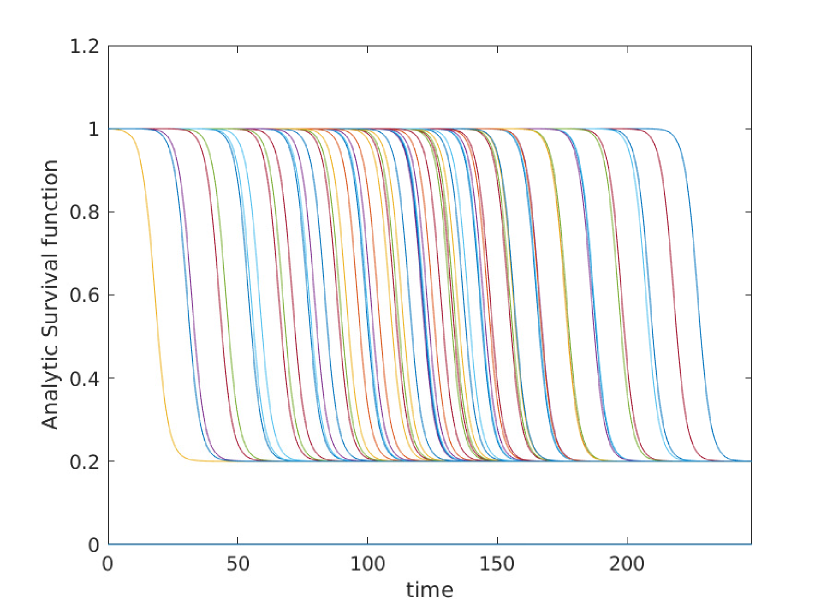
Appendix B Gallery
Here we give a variety of figures, exploring the possible behavior of arrival time distributions in a variety of networks and parameter regimes. In fig. 13 and 13 we examine a variety of scale free networks, varying network size, and parameter values. In fig. 15 we demonstrate the robustness of eq. (5) to unusual parameter values by consider the (unrealistic) case of a fast moving traveller who is non-infectious. We observing tight agreement between analytic predictions and observed survival time in simulations. Finally, in 15 we consider arrival times for travellers on a 30 by 30 mesh.
In all cases where simulation is feasible, we observe strong agreement in arrival probabilities between analytic and simulation based results, for all values sampled.
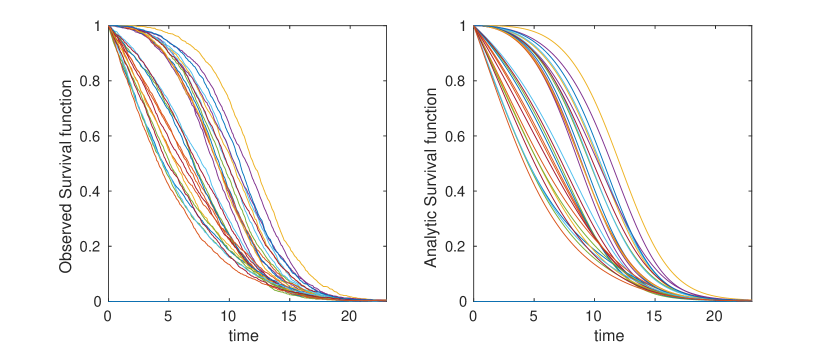
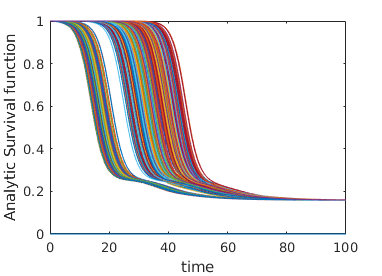
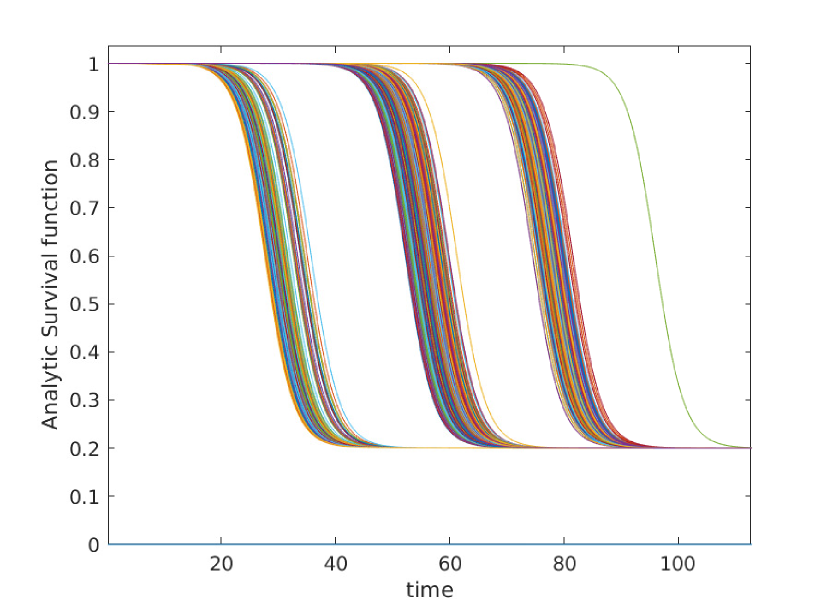
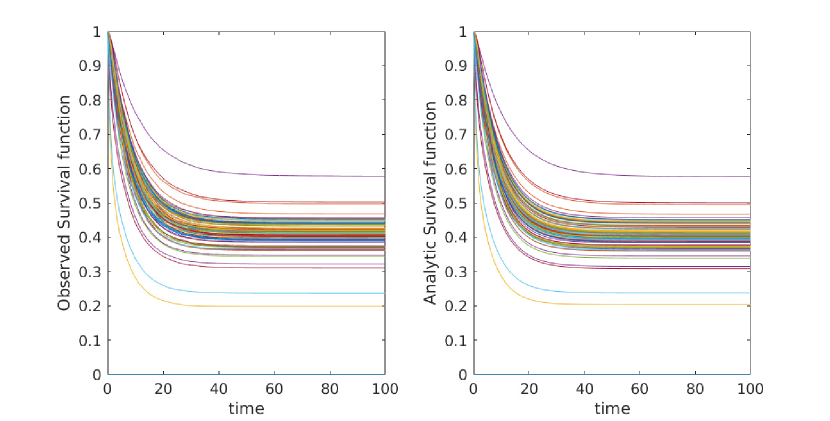
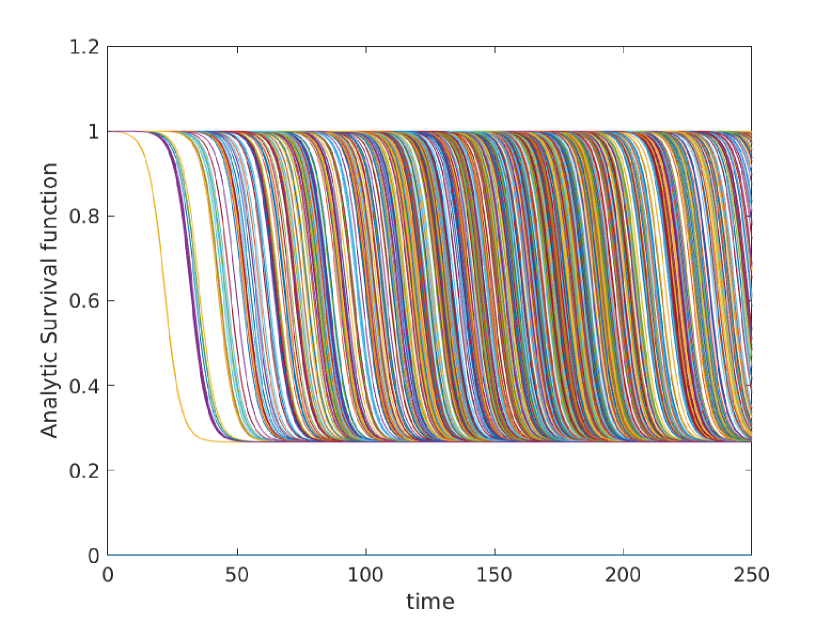
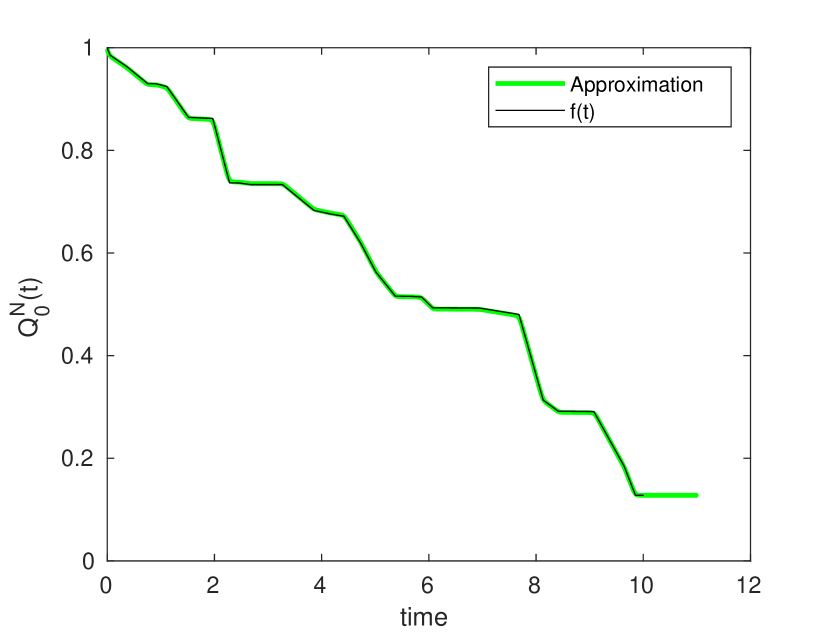
Appendix C Construction of Arbitrary Survival Curves
One of the more concerning results of eq. (5) is the implication that it is possible to construct networks with arbitrary survival curves. In this section we sketch a method for constructing such a network. The purpose of this exercise is to demonstrate that for arbitrary networks, the probability distribution of arrival times may have arbitrary complexity, and hence that any analytically tractable results require further assumptions to be made on and . More detail would be needed in order to make the argument rigorous, the work here is only intended as a proof of concept.
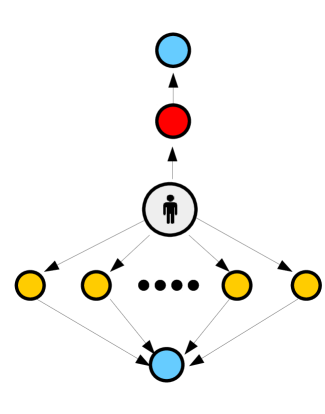
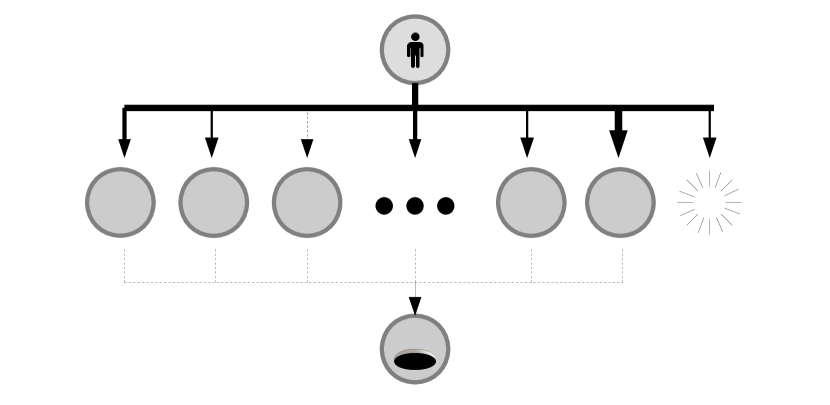
Suppose we are given some function such that . We assume that is well defined for all time. Our goal is to create a network such that approximates as closely as possible. Consider a simple “diamond” network as depicted in figure 16. In this network, node zero has a directed edge connecting it to nodes to , and nodes to have a single outgoing edge, directed towards the ‘final’ node . We assume for all intermediary nodes. We take a travel rate .
For these “intermediate” nodes, the survival time is governed by the equation:
| (19) |
which permits solutions of the form:
| (20) |
Here is selected such that . Because both and are free parameters, it is possible to select them so as to construct a logistic function with arbitrary mean and scale parameters. This allows us to approximate arbitrary step functions.
We now wish to select the transition rates such that . We select such that the initial infection at node zero does not replicate, and instead simply ‘jumps’ to one of our intermediary nodes, or recovers. is governed by the equation:
| (21) |
If we select and very large, then our initial infection will linger in the starting node for only a short time, and
| (22) |
That is to say, is a sum of step functions, and a constant. Transition parameters are selected such that is equal to and . In this way can be approximated using a series of (approximate) step functions. A demonstration of this is given in figure 16. More sophisticated algorithms would presumably be able to approximate using fewer nodes, but for our purposes this simple approach will suffice.
Appendix D Survival curves for non-zero
Throughout the main text, we frequently made use of the simplifying assumption ; an unrealistic assumption in real world context. Suppose we wish to consider non-zero , in the context of global epidemic spread. We assume, as previously, that travel is rare, and also that we interest ourselves only in diseases such that , hence . This leads to the equation
| (23) | ||||
| and hence, | ||||
| (24) | ||||
that is to say, in the limit of small , the arrival time distribution can be approximated using a logistic function. As in the main text is some mean arrival time constant determined by ,, and . In the limit , that is to say, the probability that is precisely the probability of early epidemic extinction in our branching process. Unfortunately, this non-zero probability of ‘infinite’ arrival time leads to ; not an especially informative result. It is thus useful to instead consider the arrival time conditional on :
| (25) | ||||
| (26) |
At this stage we have an ‘ideal’ logistic distribution [Balakrishnan, 2013], with mean value (currently unknown), and scale parameter . Hence, when making predictions concerning real world epidemics that have not gone extinct in their early stages, it is useful to remap our variables such that we imagine and is the net grow rate of our disease (formerly labeled ).
Appendix E Comparison to, and improvement upon past exponential growth methods.
In this appendix we will discuss the Matrix Exponential method, as used by Chen et al. [Chen et al., 2018] (referred to by them as ‘linear spreading theory’). We begin by introducing the method itself, and its connection to the Branching Process approach studied in the main text. We then explain some of the computational details necessary for fast calculation, and the circumstances under which the approximation is and is not accurate.
Let us begin by describing the method itself. Suppose, at time , we have a population of infected individuals – that is to say, there are infected individuals located at node . These individuals travel between nodes at transport rate , and infect others at some rate . This rate is assumed to be constant; we assume that the total population is large enough such that population constraints are not relevant on the timescale we are interested in. Under this unbound growth assumption, the expected number of infectious individuals if governed by the linear equation:
| (27) | ||||
| This equation permits solutions of the form | ||||
| (28) | ||||
Here, we make use of the matrix exponential; that is to say . Here we use the transposed transition matrix, , because here we consider the flow of infected individuals forward through the network, as opposed to the flow of arrival probability backwards through the network (as we do in the main text).
Suppose we start with an initial population of in node . If we wish calculate the deterministic time when the expected population in node reaches , we must solve . Written slightly differently,
| (29) |
where are indicator vectors, equal to at index and respectively, and equal to zero elsewhere.
This equation is equivalent to equation 7 of Chen et al [Chen et al., 2018]. Here we have reached the equation via a direct appeal to unbound population growth, while Chen et al instead describe their formalism as a linearisation of a full SIR model.
Eq. (29) can also be reached via an appeal to branching processes. By making the change of variables as we do in the main text, suitable approximations lead to:
| (30) |
eq. (10) of the main text. The expected arrival time at node is precisely the time when , that is to say
| (31) |
The two methods give the same results (under the influence of suitably powerful approximations).
Before moving on to discuss the accuracy of these results, let us first discuss some computational difficulties. Eq. (29) is transcendental and can thus only be solved approximately, using some suitable numerical scheme. In their paper, Chen et al. approach this difficulty by identifying the minimal number of steps required to get from to , and truncating the polynomial expansion of their matrix exponential after this many steps:
| (32) | ||||
| (33) |
All terms before the term are zero, all terms after are higher powers of and thus assumed to be small. Chen et al solve eq. (33) using the Lambert-W function [Leonhard Euler, 1783, Weisstein, 2020], a nonlinear function originally constructed to solve equations of the form . In cases where we have a single “most probable” path from to , we can make the approximation:
| (34) | ||||
| (35) | ||||
| (36) |
Here are the transition rates along the steps in our shortest path. Such an estimate neglects terms of magnitude , along with contributions from all paths except the shortest. This result mirrors those of both Gautreau et al. [Gautreau et al., 2007], as well as Brockmann et al. [Brockmann and Helbing, 2013] (with the notable difference being that is replaced by when using the effective distance metric).
An alternative method to solve Eq (29) (not used by Chen et al) is the iteration scheme:
| (37) | ||||
| (38) |
Here we make use of the fact that varies faster than ; hence, if we have even a moderately accurate approximation , will be close to the correct value . In contrast varies quickly: demanding to solve eq (38), we quickly approach true solutions of eq. (31).
This iteration scheme requires us to calculate large matrix exponentials repeatedly, an operation which is generically computationally expensive, but can be made significantly less costly by first computing the eigenvector decomposition . Here is a matrix containing the eigenvectors of , while is a diagonal matrix containing the corresponding eigenvalues. This allows us to instead compute the matrix exponential via elementwise exponentials of the diagonal elements:
| (39) |
Matlab code to implement this iteration scheme, approximating transport times to node from all starting points is given by:
%%Set up
[V,D_original] =eig(T);
N=size(T,1);
b=7; %Example start/end points.
delta_b= zeros(N,1);
delta_b(b)=1; %%Set up our initial vectors.
D= gamma * diag(D_original); %D is a vector of length N containing eigenvalues.
RightVect= V\delta_b;
Tk=-ones(N,1);
for(aaa=1:N)
guessT= (-log(gamma))/alpha
deltaT=5;
LeftVect= V(aaa,:);
while(abs(deltaT)>10^-3)
expGammaT= LeftVect*(exp(D*guessT).*RightVect);
deltaT= -log(expGammaT)/alpha
end
Tk(aaa)=guessT;
end
The computational cost of the above code is overwhelmingly dominated by eig(M), and hence the runtime scales like , similar to the Floyd–Warshall algorithm as might be used to identify shortest paths when calculating the effective distance.
It is possible to calculate the time taken to arrive in each location from a fixed starting location by using the transposed transition matrix, , rather than .
Now, in all uses of such methods, it is important to note that the deterministic time when the expected population reaches (as calculated using Chen et al’s method), and the expected time when the stochastically varying population reaches one are not equivalent concepts. This is best illustrated by considering the extreme case , where we observe that for all . Taken at face value this would erroneously imply that the arrival time has an expected value of infinity; in practice this merely illustrates the difficulties of using such an approximation for diseases with low (such as HIV). In general, eq. (10) is observed to be a good approximation when , and performs poorly when .
Appendix F Variance in Arrival Time
Here we provide the algebraic details for calculating variances in arrival time, assuming a starting population greater than 1.
Recall that denotes the arrival time at , assuming an epidemic starts at , and has mean . The survival function of . In what follows, we suppress subscripts and superscripts, considering some generic .
| (40) | ||||
| Assuming the mean | value | |||
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) |
That is to say, if the expected arrival given an initial population of is , then the arrival time assuming individuals is . This makes sense, given that the expected time of transition form to individuals, for a branching rate of is precisely equal to .
Next, we need to determine the expected value of for a starting population of . For a starting population of 1, we have [Balakrishnan, 2013]. For larger populations:
| (45) | ||||
| (46) | ||||
| (47) | ||||
| where is the | ||||
| (48) | ||||
| (49) |
The variance is thus given as:
| (50) | ||||
| (51) | ||||
| (52) |
References
- [Balakrishnan, 2013] Balakrishnan, N. (2013). Handbook of the Logistic Distribution. CRC Press. Google-Books-ID: iaieM_3lcHQC.
- [Brockmann and Helbing, 2013] Brockmann, D. and Helbing, D. (2013). The Hidden Geometry of Complex, Network-Driven Contagion Phenomena. Science, 342(6164):1337–1342.
- [Broeck et al., 2011] Broeck, W. V. d., Gioannini, C., Gonçalves, B., Quaggiotto, M., Colizza, V., and Vespignani, A. (2011). The GLEaMviz computational tool, a publicly available software to explore realistic epidemic spreading scenarios at the global scale. BMC Infectious Diseases, 11(1):37.
- [Chen et al., 2018] Chen, L. M., Holzer, M., and Shapiro, A. (2018). Estimating epidemic arrival times using linear spreading theory. Chaos (Woodbury, N.Y.), 28(1):013105.
- [Coldman and Goldie, 1986] Coldman, A. J. and Goldie, J. H. (1986). A stochastic model for the origin and treatment of tumors containing drug-resistant cells. Bulletin of Mathematical Biology, 48(3):279–292.
- [Friso Coerts, 2018] Friso Coerts (2018). Network analysis as a tool to improve infection prevention & outbreak management. Master’s degree Medical Pharmaceutical Drug Innovation, University of Groningen, Groningen.
- [Gautreau et al., 2007] Gautreau, A., Barrat, A., and Barthelemy, M. (2007). Arrival Time Statistics in Global Disease Spread. Journal of Statistical Mechanics: Theory and Experiment, 2007(09):L09001–L09001. arXiv: 0707.3047.
- [Gautreau et al., 2008] Gautreau, A., Barrat, A., and Barthelemy, M. (2008). Global disease spread: statistics and estimation of arrival times. Journal of Theoretical Biology, 251(3):509–522. arXiv: 0801.1846.
- [Gillespie, 1977] Gillespie, D. T. (1977). Exact stochastic simulation of coupled chemical reactions. The Journal of Physical Chemistry, 81(25):2340–2361.
- [Gillespie, 2001] Gillespie, D. T. (2001). Approximate accelerated stochastic simulation of chemically reacting systems. The Journal of Chemical Physics, 115(4):1716–1733.
- [Goldie and Coldman, 1979] Goldie, J. H. and Coldman, A. J. (1979). A mathematic model for relating the drug sensitivity of tumors to their spontaneous mutation rate. Cancer Treatment Reports, 63(11-12):1727–1733.
- [González et al., 2010] González, M. V., Puerto, I. M., Martínez, R., Molina, M., Mota, M., and Ramos, A., editors (2010). Workshop on Branching Processes and Their Applications. Lecture Notes in Statistics - Proceedings. Springer-Verlag, Berlin Heidelberg.
- [Iannelli et al., 2017] Iannelli, F., Koher, A., Brockmann, D., Hoevel, P., and Sokolov, I. M. (2017). Effective Distances for Epidemics Spreading on Complex Networks. Physical Review E, 95(1):012313. arXiv: 1608.06201.
- [Jamieson-Lane, 2020] Jamieson-Lane, A. (2020). alastair-JL/EpidemicSpread. original-date: 2020-06-22T23:17:54Z.
- [Kimmel and Axelrod, 2015] Kimmel, M. and Axelrod, D. (2015). Branching Processes in Biology. Interdisciplinary Applied Mathematics. Springer-Verlag, New York, 2 edition.
- [Leonhard Euler, 1783] Leonhard Euler (1783). ”De serie Lambertina Plurimisque eius insignibus proprietatibus. Acta Acad. Scient. Petropol., 2:29–51.
- [Mathew George, 2020] Mathew George (2020). B-A Scale-Free Network Generation and Visualization.
- [Miller, 2018] Miller, J. C. (2018). A primer on the use of probability generating functions in infectious disease modeling. Infectious Disease Modelling, 3:192–248.
- [Schaffer, 1970] Schaffer, H. E. (1970). Survival of Mutant Genes as a Branching Process. In Kojima, K.-i., editor, Mathematical Topics in Population Genetics, Biomathematics, pages 317–336. Springer, Berlin, Heidelberg.
- [Shampine and Reichelt, 1997] Shampine, L. F. and Reichelt, M. W. (1997). The MATLAB ODE Suite. SIAM Journal on Scientific Computing, 18(1):1–22.
- [Verne, 1873] Verne, J. (1873). Around the World in Eighty Days. Porter & Coates. Google-Books-ID: sd06RZq4mN4C.
- [Watson and Galton, 1875] Watson, H. W. and Galton, F. (1875). On the Probability of the Extinction of Families. The Journal of the Anthropological Institute of Great Britain and Ireland, 4:138–144. Publisher: [Royal Anthropological Institute of Great Britain and Ireland, Wiley].
- [Weisstein, 2020] Weisstein, E. W. (2020). Lambert W-Function. Library Catalog: mathworld.wolfram.com Publisher: Wolfram Research, Inc.
- [WHO, 2003] WHO (2003). WHO | Situation Updates - SARS.
- [WHO, 2009] WHO (2009). WHO | Situation updates - Avian influenza.
- [WHO, 2020] WHO (2020). Novel Coronavirus (2019-nCoV) situation reports.