{vivek.a.khetan, roshni.r.ramnani , shubhashis.sengupta, andrew.e.fano,}@accenture.com
mayuresh@ucsb.edu
Causal-BERT : Language models for causality detection between events expressed in text
Abstract
Causality understanding between events is a critical natural language processing task that is helpful in many areas, including health care, business risk management, and finance. On close examination, one can find a huge amount of textual content both in the form of formal documents or in content arising from social media like Twitter, dedicated to communicating and exploring various types of causality in the real world. Recognizing these ”Cause-Effect” relationships between natural language events continues to remain a challenge simply because it is often expressed implicitly. Implicit causality is hard to detect through most of the techniques employed in literature and can also, at times be perceived as ambiguous or vague. Also, although well-known datasets do exist for this problem, the examples in them are limited in the range and complexity of the causal relationships they depict especially when related to implicit relationships. Most of the contemporary methods are either based on lexico-semantic pattern matching or are feature-driven supervised methods. Therefore, as expected these methods are more geared towards handling explicit causal relationships leading to limited coverage for implicit relationships, and are hard to generalize. In this paper, we investigate the language model’s capabilities for causal association among events expressed in natural language text using sentence context combined with event information, and by leveraging masked event context with in-domain and out-of-domain data distribution. Our proposed methods achieve the state-of-art performance in three different data distributions and can be leveraged for extraction of a causal diagram and/or building a chain of events from unstructured text.
keywords:
Causal Relations, Cause-Effect, Causality Extraction, Language Models, Causality in natural language text1 Introduction
Recent advances in machine learning have enabled progress on a range of tasks. Causal and common sense reasoning, however, has not benefited proportionately. Causal reasoning efforts can be grouped into the task of causal discovery [25] and the task of causality understanding for events described in natural language text [15]. Causality detection in natural language is often simplified/described as detection of ”Cause-Effect” relation between two events, where an event is expressed as a nominal, phrase, or short span of text in the same or different sentences [22].
Understanding causal association between everyday events is very important for common sense language understanding (e.g., ”John was late; Bob got angry.”) as well as causal discovery. For our purposes, however, we will focus on commercial industry applications (e.g., “The phone was dropped in a lake; hence the warranty is void.”). Understanding the potential ”Cause-Effect” relationship between events can form the basis of several tasks such as binary causal question-answering ([15] and [28]), a plausible understating of the relationship between everyday activities ([12] and [22]), adverse effects of drugs, and decision-support tasks [16].
Most of the current methods for causality understanding write linguistic pattern-matching rules or use careful feature engineering to train a supervised machine learning algorithm [9]. They often lack coverage and are hard to scale for an unseen sequence of events. Identifying the relationship often depends on the whole sentence structure, along with its semantic features. Additionally, it is challenging to decompose every event and the rest of the expression completely in their lexical representation [27]. Furthermore, due to the limited availability of comprehensive annotated datasets for ”Cause-Effect,” only a few deep learning-based approaches have been proposed [3].
This work focuses on understanding the causality between events expressed in natural language text. The intent is simply to identify possible causal relationships between marked events implied by a given sequence of text. It is not to determine the validity of those relationships nor to provide a highly nuanced representation of those relationships. The events can be a nominal, a phrase, or a span of text in the given event statement. We built network-architectures on top of language models that leverage overall sentence context, event’ context ,and events’ masked context for causality detection between expressed events. Pre-training on out of domain data-distribution helped our model gain performance, showing that language models can learn implicit structural representation in natural language text that is in line with the findings of Jawahar, Goldberg and Gururangan [[20], [11] and [14]]. We curated the datasets from Semeval 2010 task 8 [17], Semeval 2007 task 4 [1]111We use terms Semeval 2010 and Semeval 2007 for Semeval 2010 Task 8 and Semeval 2007 Task 4 respectively, ADE [13] corpus. All the sentences in the three mentioned datasets were annotated with the provided event description and were given ”Cause-Effect” or ”Other” labels for each pair of event interactions.
Our contributions can be summarised as follows:
-
•
We curated three different datasets from publicly available tasks for causality detection in natural language text
-
•
We showed that language models can be trained to learn causal interaction between events expressed in natural language text
-
•
We showed that that pre-training of language models using out-of-domain text expression improves the performance in low resource causality detection
2 Event-structure and causality in natural language text
Interaction between events expressed in natural language text is not just dependent on how implicit or explicit the events are mentioned in the expression, but also on the sentence’s arguments and the lexical representation of those arguments [27]. Predicting causal interaction between events is a complex task because it depends on interactions between the particular linguistic expression of information, semantic context established in the text, knowledge of the causal relationships for the domain in question, and the communicative goals of the text’s author (e.g., recognition of a well known causal relationship or conveying a possibly new causal relationship)
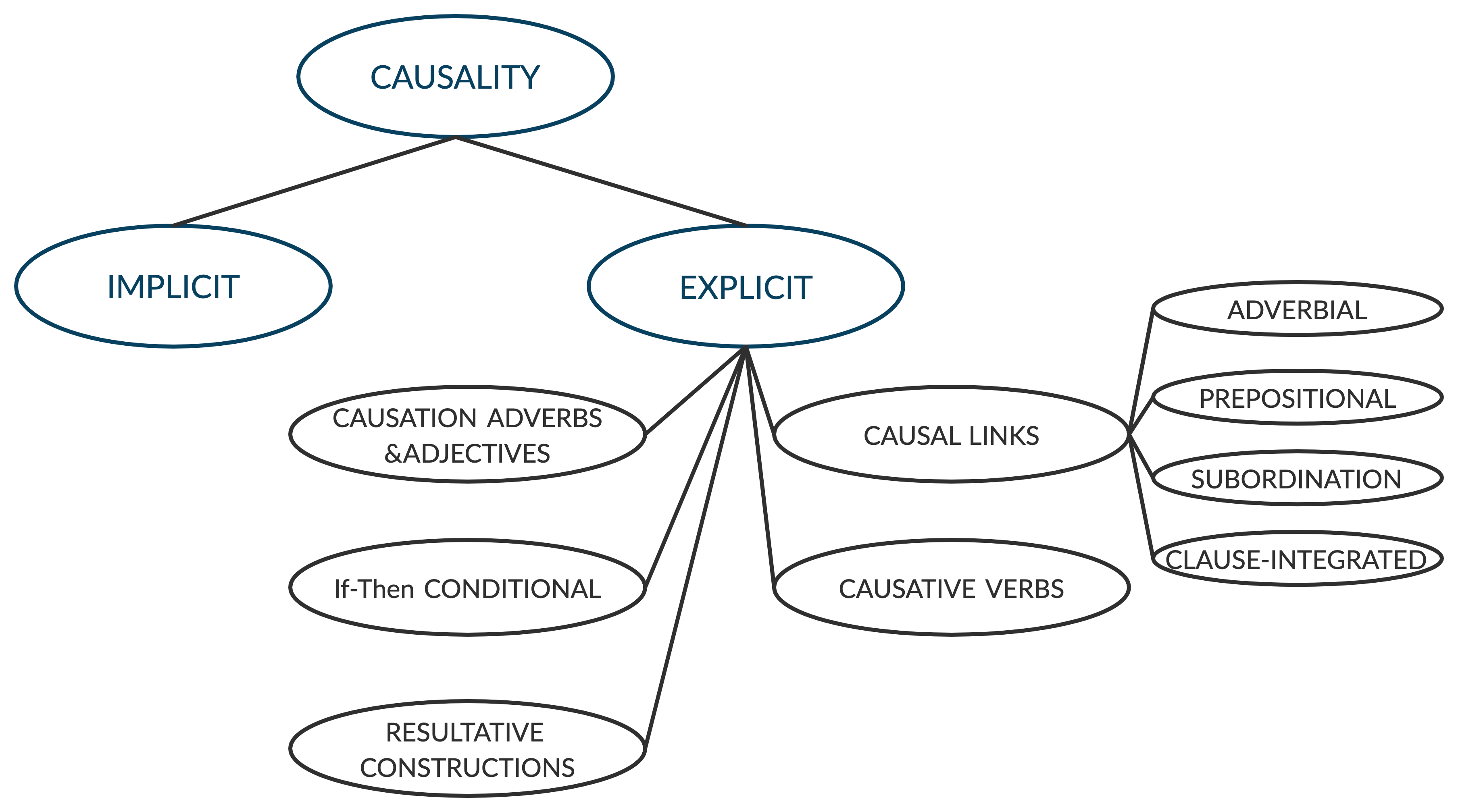
Causality in the text is expressed in arbitrarily complex ways; even when events are in a single sentence, it might be mentioned in a sparse, ambiguous, or implicit manner. Even explicit causal expressions have rich variation across their syntax, and it is challenging to extract complete lexical features and understand causality based on any single grammatical model. Figure 1 shows a few popular classes of explicit causality as discussed by Khoo et al.[21]. For example, in the sentence ”smoking causes cancer,” it is easy to understand the causal relationship between smoking and cancer. Nevertheless, it gets complicated when the interaction between events is implicit. In the sentence, ”I think the greater danger is from the unelected justices than from the elected Congress and the elected president.” Identifying the ”Cause-Effect” interaction between ”greatest danger” and ”unelected justices” from the given text is not a trivial task. The task gets complicated when the ”Cause-Effect” is not explicitly mentioned between events of interest. Furthermore, as the length of the sentence increases or there is more than one pair of casual events in a given sentence, it becomes difficult for any statistical model to capture the sentence’s context unambiguously. Causality in the text can be expressed simply by using the prepositions of the form ”A causes B” or ”A is caused by B.” This form of expression is intuitive and can often be subjective to the field and also to the researcher’s views. Instead of predicting ”A causes B,” in this work, we predict ”could A cause B” from a given textual expression, where causal interaction between events can be explicit or implicit with a wide variety of writing styles.
3 Dataset
We used three different datasets to train and evaluate our models; Semeval 2007 and Semeval 2010 is curated using pattern-based web search while ADE is curated from biomedical text. Semeval 2007, Semeval 2010, and ADE datasets are publicly available and have annotated events and ”Cause-Effect” interaction between them. Unlike Dunietz et al. and Mirza et al. [6], [24], who incorporated the association between temporal and other relations with causality and Prasad et al [26], who focuses on inter-sentence causality; in this task, we only focused on causality between events in the same sentence.
Table 1 provides statistical details about datasets and Table 2 provides a sample example from each of the curated dataset. Further details on data curation and preparation are below:
- SemEval2007: SemEval 2007 [10] is an evaluation task designed to provide a framework for comparing different approaches to classifying semantic relations between nominals in a sentence. The task provides a dataset for seven different semantic relations, including ”Cause-Effect”. For this work, we use part of the SemEval 2007 dataset with the ”Cause-Effect” relationship. For a given sentence, if the interaction between marked events is causal, we label it as ”Cause-Effect” else the sentence is labeled as ”Other.”
- SemEval2010: Similar to the above dataset, we use SemEval 2010 [17] dataset with causal interaction between events labeled as ”Cause-Effect”, and all the other types of interactions between events in rest of the sentences are labeled as ”Other”.
- ADE: The adverse drug effect [13] dataset is a collection of biomedical text annotated with drugs and their adverse effects. The first corpus of this dataset, with drugs causing adverse effects, has drugs as well as effects annotated. In the second corpus, where drugs are not causing any side-effect, the drug and its effect name are not manually annotated. We curated a list of unique drugs and affect names using the first corpus data and use this set to annotate the drugs and effect names in the second corpus. While we take sentences with two or more drugs/effect mention in them; for simplicity, we do not replicate the sentence in our final corpus. We marked the first two mention of drug/effect mention we find in the sentence.
| Train Dataset | Test Datast | ||||||||
| Dataset |
|
#Total | #Cause-Effect | #Other | #Total | #Cause-Effect | #Other | ||
| Semeval 2010 | (85, 60) | 8000 | 1003 | 6997 | 2717 | 134 | 2389 | ||
| Semeval 2007 | (82,62) | 980 | 80 | 900 | 549 | 46 | 503 | ||
| ADE | (135, 93) | 8947 | 5379 | 3568 | 2276 | 1341 | 935 | ||
| Curated Corpus | |||
|---|---|---|---|
| Dataset | Example Sentence | Sentence with event marker | Sentence with masked event marker |
| Semeval 2007 | Most of the taste of strong onions comes from the smell. | Most of the e1 taste /e1 of strong onions comes from the e2 smell/e2. | Most of the e1 blank /e1 of strong onions comes from the e2 blank /e2. |
| Semeval 2010 | As in the popular movie ”Deep Impact”, the action of the Perseid meteor shower is caused by a comet, in this case periodic comet Swift-Tuttle. | As in the popular movie ”Deep Impact”, the action of the Perseid e1 meteor shower /e1 is caused by a e2 comet /e2, in this case periodic comet Swift-Tuttle. | As in the popular movie ”Deep Impact”, the action of the Perseid e1 blank /e1 is caused by a e2 blank /e2, in this case periodic comet Swift-Tuttle. |
| ADE | Quinine induced coagulopathy –a near fatal experience. | e2 Quinine /e2 induced e1 coagulopathy /e1–a near fatal experience. | e2 blank /e2 induced e1 blank /e1–a near fatal experience. |
| Optimizer | Learning rate | Epsilon | Dropout rate | Train batch | Max sequence length |
|---|---|---|---|---|---|
| Adam | 1e-05 | 1e-08 | 0.4 | 16 | 384 |
4 Problem definition and Proposed Methodology
Our causality understanding approach can be simplified as a binary classification of ”Cause-Effect”/”Other” relationship between events expressed in natural language text. The detailed methodology, problem definition and network architecture are described below:
4.1 Methodology
Our methodology involves:
-
•
Fine-tuning Bert based feed forward network for “Cause-Effect”/“Other” relationship label between events expressed in natural language text
-
•
Combining both the event’s context and BERT’s sentence context to predict “Cause-Effect”/“Other” relationship label between events. This methodology is built on the method suggested by Wu et al.[31] and works on the intuition that the interaction between two events is result of the information in the sentence as well as in the events
-
•
Combining both the event’s masked context with BERT’s sentence context to predict “Cause-Effect”/“Other” relationship label between events. This methodology is built on the model suggested by Soares et al.[29] and works on the intuition that training with event’s masked context can help language model learn task specific implicit sentence structure([20] and [14]).
4.2 Problem definition
The overall problem can be defined as follow: for a given sentence and the two marked events , the goal is to predict the possible casual interaction between the events. Mathematically, a given sentence can be seen as a sequence of tokens , and possible interaction can be either Cause-Effect or Other. Event1 and Event2 are a continuous span of text in the given statement.
For a given sequence of token
| (1) |
| (2) |
| (3) |
| (4) |
0ij-1; jk; kl-1; ln, where n is sequence length.
For a given sentence x with two marked Event1 and Event2, we used a pre-trained BERT model to obtain the event expression encoding hr = Rd in the contextualized latent space. This latent space representation varies based on the model used for experimentation. Finally, the model is trained to maximize the probability (P(interactionhr)) of causal interaction between event for a given context vector (hr = Rd). During Inference, the trained model predicts the possible interaction based on marked events and sentence expression.
4.3 Models
BERT [4] is a pre-trained language model based on a widely used Transformer architecture proposed by Vaswani et al.[30]. BERT provides deep bidirectional representations from the unlabeled text by jointly conditioning on the left and right contexts. BERT based pre-trained models has shown to be very effective at many tasks, including question-answering, relation extraction, and NLI. We built the following three network architectures on top of the pre-trained BERT222BERT diagrams - adapted from the image by Jimmy Lin model to investigate and evaluate our proposed methodologies:
-
•
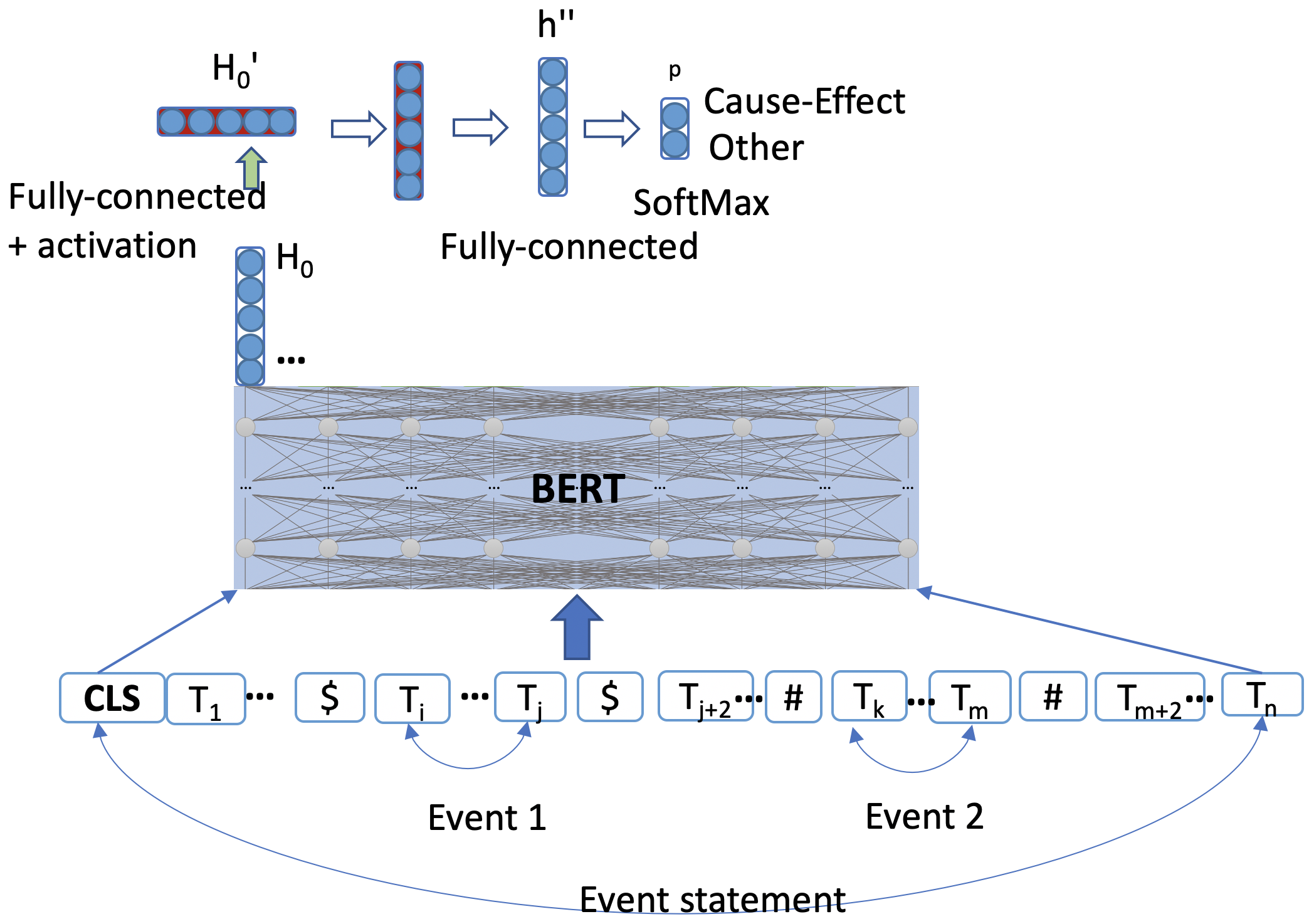
C-BERT: This network architecture is a feed-forward network build on top of BERT [4]. This network can be trained for binary classification of the “Cause-Effect”/“Other” relationship between two events in a given input sentence. In this network architecture, we feed the input sentence as a sequence of tokens to the BERT model and take the overall sentence context vector from the BERT model’s output, feed it to a non-linear activation layer followed by two fully connected layers. We have applied dropout before each fully connected layer with a probability of 0.4. The likelihood of interaction being Cause-Effect using a soft-max layer is shown in fig: 3. We used back-propagation with adam-optimizer on binary loss function to learn the optimal solution with training batch size as 16. Mathematical formulation for C-BERT model is:
(5) (6) (7) where, ; , is the output token of bi-directional context (i.e. [CLS]) of BERT, and L = 2 (Cause-Effect, Other)
-
•
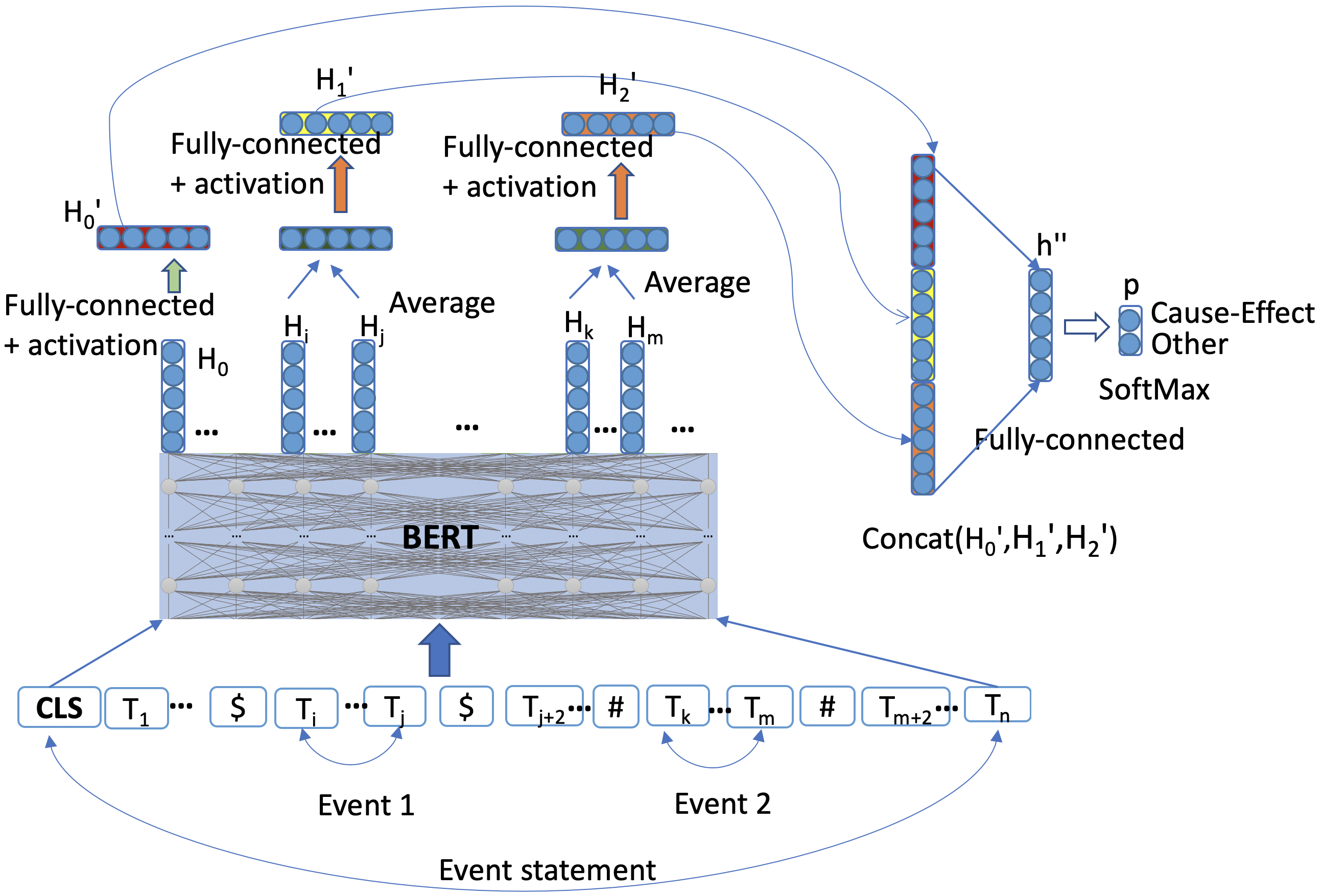
Event aware C-BERT:
This network architecture learns event informed representation of the given sentence expression and can predict causality between identified/marked events. As shown in the fig: 3, events can be more than a single token, resulting in many vectors when the input sentence is fed into a pre-trained BERT model. We averaged them to get the final context of each event expression and passed the sentence context as well as both the event’s context to a non-linear activation layer followed by a fully connected layer. The sentence context is concatenated with both the events’ averaged context and is feed to another fully connected layer followed by a softmax layer. This network architecture also has a dropout before each fully connected layer with a probability of 0.4. Finally, the model is trained using back-propagation with adam-optimizer on a binary loss function to predict the “Cause-Effect”/”Other” relationship between events. Mathematical formulation for Event Aware C-BERT model is :
(8) (9) (10) (11) (12) where, , , ; and L = 2 (Cause-Effect, Other).
-
•
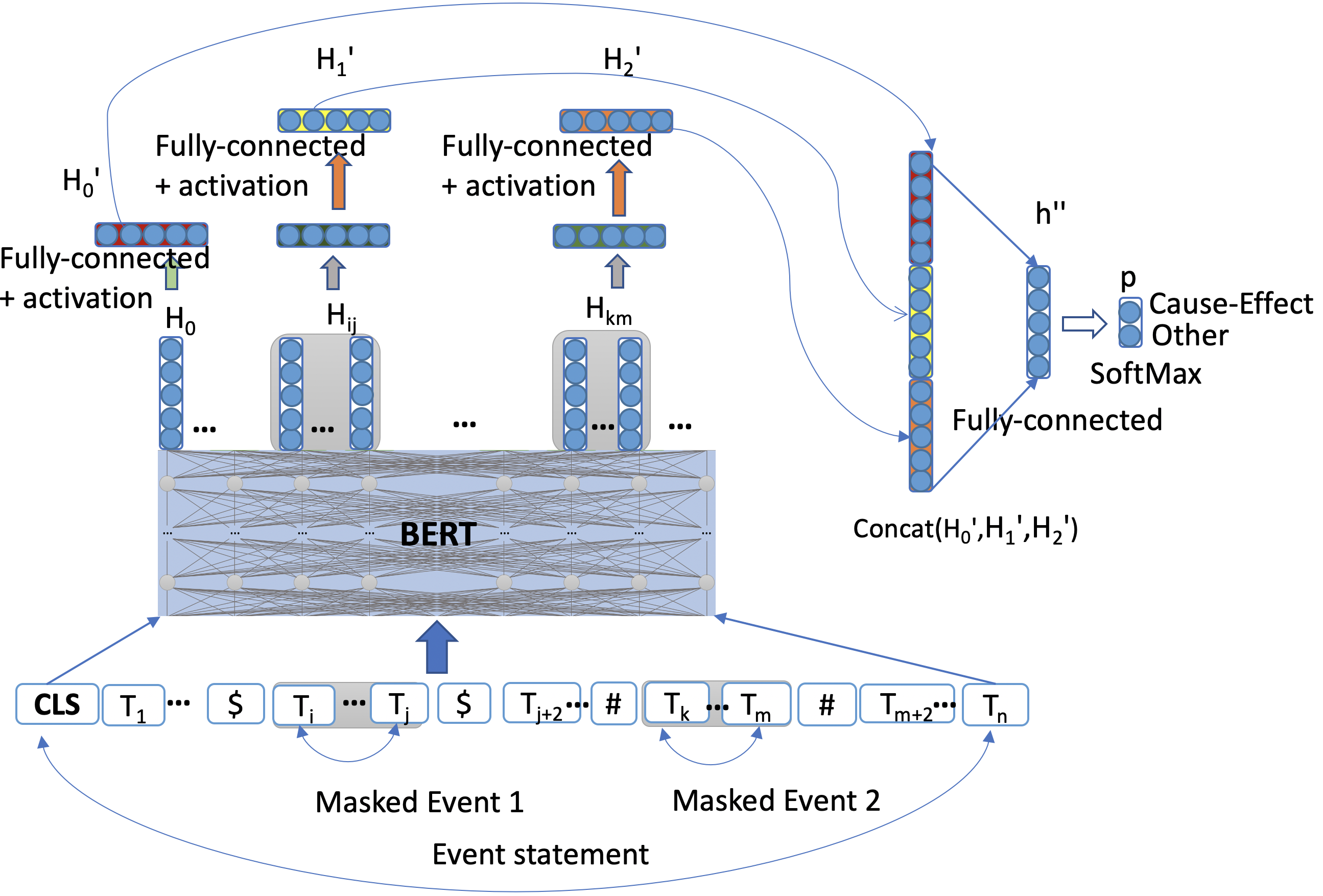
Masked Event C-BERT:
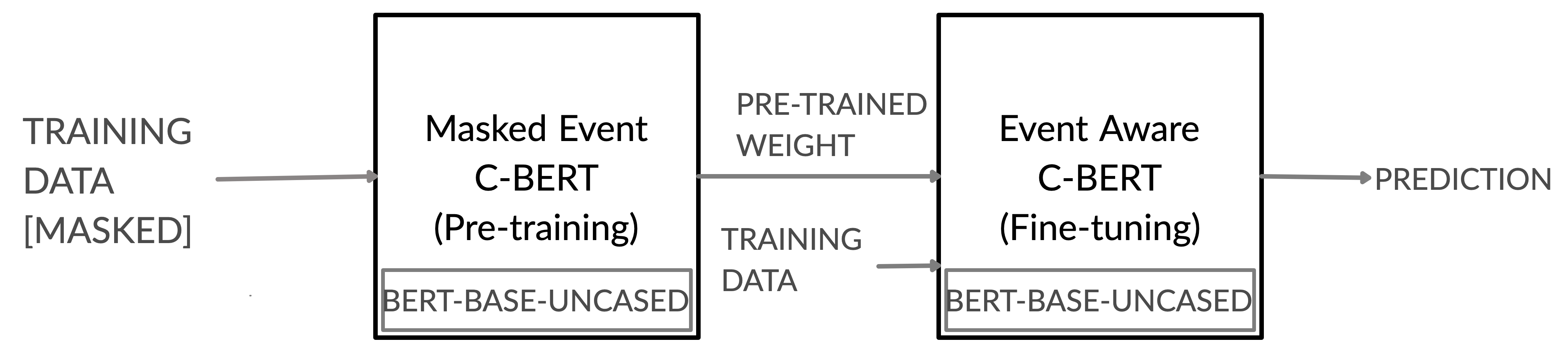
This network architecture shown in fig: 5 is very similar to the event aware C-BERT network architecture (fig: 3), where the whole span of event text is replaced with a ”BLANK” token. As each event is just a single blank token, unlike Event aware C-BERT we don’t need to take an average to get the final context of any event. Each model trained by this approach is then fine-tuned using actual event information using the Event Aware C-BERT model described above. Mathematical formulation for Masked Event C-BERT is:
(13) (14) (15) (16) (17) where, , , ; and L = 2 (Cause-Effect, Other).
5 Experiments and results
To evaluate the language model’s capabilities in learning the “Cause-Effect” relationship between events, we trained three different BERT [4] based network architecture’s on each one of the dataset’s. We also experimented with the effectiveness of pretraining a Masked Event C-Bert model on the out of domain data distribution and fine-tuning using the Event Aware C-BERT model for handling low resource situations. For each of the dataset distribution, we created two different corpora. The first corpus is created by adding a positional indicator before, and after both the event in the sentence, and then to prepare the second corpus, we replaced the event text span with a BLANK token.
5.1 Experiments:
Using models described in Section Models, we performed four sets of experiments for each of the dataset. The experiments are discussed in more details below:
-
•
End to end training of C-BERT model using target data distribution: In these set of experiments, for each of the data distribution, we trained a model based on C-BERT’s network architecture. For each experiment, the input is a sequence of tokens, and the output is the ”Cause-Effect”/”Other” relationship between them. This is our base model and reported performance gain on the previously reported results by Girju et al. and Dasgupta et al.[[9], [3]].
-
•
End to end training of Event Aware C-BERT model using target data distribution: In these set of experiments, for each of the data distribution, we trained a model based on Event Aware C-BERT’s network architecture. In each of these training, the network combines the BERT’s bidirectional context of the sentence with both the event’s encoding. These experiments improved our base model’s performance for all three data distribution.
-
•
Pre-training of Masked Event C-BERT and fine-tuning of Event aware C-BERT both using same in-domain data distribution: In these set of experiments, for each of the data distribution, we pre-trained a model based on Masked Event C-BERT’s network architecture and fine-tuned the weights using Event Aware C-BERT’s network architecture. Here, by pre-training on masked event corpus, we leverage the language model’s ability to learn implicit task-specific sentence argument representation as discussed by Jawahar et al. and Gururangan et al.[[20],[14]]. When trained (pre-training + fine-tuning) the models using only in-domain data distribution and obtained either similar or improved performance gain on all four data distribution.
-
•
Pre-training of Masked Event C-BERT using a different data distribution than our target data distribution and fine-tuning of Event Aware C-BERT using target data distribution: Task of “Cause-Effect” prediction between events does not have a large scale dataset and is as challenging as all other low resource language tasks. Moreover, it is also challenging to transfer trained models from one data distribution to another (even in the same domain) or from one domain to another. Based on the findings of Jawahar et al.[20], in these experiments, we tried to learn implicit task-specific sentence argument representation by pre-training on distribution different from our target data distribution. For each of the available data distribution, we pre-trained two models using the other two out of domain distribution, respectively. This set of experiments resulted in additional performance gain for most of the experiments and is shown in table 5. Fig: 5 gives an intuitive overview of the proposed training methodology.
5.2 Learning setup: experiment settings
We used AWS p3.2xlarge instance for all the experiments. It has 8 vCPU and 61 GiB Memory and NVIDIA Tesla V100 GPUs with 16 GiB Memory. To test the performance gain with the change in network architecture, we used the same hyper-parameter for all the experiments.
5.3 Results and analysis
In this work, we experimented with network architecture built on top of BERT to investigate language models’ capability in causality understanding between events expressed in natural language text.
Table 4 compares the performance of our models built using three different network architecture trained on in/out of domain data distribution with previously reported F1 performance measures.
Our base C-BERT model itself outperformed the previously reported performance measure [3, 10, 19] on the corpus created using the SemEval 2010, SemEval 2007, and ADE dataset. Further experimentation using event aware C-BERT and training methodology described in fig 5 (Masked Event C-BERT for pre-training and Event Aware C-BERT for fine-tuning on the same dataset) reported additional performance gain, respectively.
Table 5 shows the result of another set of experiments where we evaluate the performance of the models when pre-training and fine-tuning is performed using in-domain data distribution in comparison to the models when pre-training uses out of domain data distribution. For each of the target data distribution, we pre-trained three models using the other out of domain data distribution. In general, pre-training on a different dataset than our target data distribution reported either similar or improved performance.
Further analysis of the results shows that Semeval 2007 benefited most from our experimental settings. Semeval 2007 is the smallest of the three corpora. It gained more performance than others when models were pre-trained on out of domain data-distribution. Therefore, one can intuitively understand that pre-training helps the model learn implicit task-specific sentence’s lexical representation in line with the findings of Jawahar et al. and Gururangan et al. [20, 14].
| Semeval 2007 | Semeval 2010 | ADE | |||
| C-BERT | 93.78 | 97.68 | 97.10 | ||
| Event Aware C-ERT | 94.94 | 98.35 | 97.85 | ||
|
95.31 | 97.85 | 97.85 | ||
| Dasgupta et al.(2019) | - | 75.39 | - | ||
| Girju et al.(2007) | 82.00 | - | - | ||
| Huynh et al.(2016) | - | - | 87.00 |
| Dataset for fine-tuning of event aware C-BERT model | ||||||
|---|---|---|---|---|---|---|
|
Semeval 2007 | Semeval 2010 | ADE | |||
| Semeval 2007 | 95.31 | 98.42 | 97.27 | |||
| Semeval 2010 | 97.14 | 98.39 | 97.47 | |||
| ADE | 96.42 | 98.49 | 97.85 | |||
6 Related work
One direction of efforts in causality detection between events expressed in natural language text can be summarised as the use of lexico-syntactic patterns and contextual cue matching around the events. Early proposed methods in this direction lacked coverage and were domain-dependent [7]. Khoo et al.[21] proposed a syntactic graph pattern matching method for explicitly mentioned ”Cause-Effect” relationships between events and reduced a lot of domain knowledge requirements. An interesting semi-automatic linguistic pattern-based approach came from Girju et al.[9]. They automatically extract causal relationships based on explicit inter-sentence lexico-syntactic pattern of the form verb and then disambiguate the extracted causal relationship based on semantic constraints on nouns and verbs. Later Girju et al. [8] also showed the usefulness of the causation module for QA tasks, especially when the questions are ambiguous and implicit. In contrast to the above work, we are trying to learn causality without doing extensive feature engineering.
Another direction of efforts can be summarised as data-driven approaches. Early proposed methods in this direction use Point-wise Mutual Information (PMI) [2]. Mihalcea et al.[23] proposed a PMI based semantic similarity method that measures semantic similarity based on the co-occurrence of frequent pairs of words in the given sentence. But, this method results in noisy predictions depending upon the variation in the frequency of the words. The Cause-Effect association (CAE) method proposed by Do et al.[5] improves their similarity measure by penalizing phrases that occur frequently. However, this method ignored the semantics of text spans surrounding the causal events. Hu et al.[18] proposed a Causal Potential (CP) based method to access causal relation between everyday events (film-scripts, blogs) considering the relative ordering of the event.
An interesting data-driven approach using support vector machines(SVMs) was suggested by Beamer et al.[1]. They used a knowledge-driven approach to extract lexical, syntactic, and semantic features for automatic identification of semantic relations in SemEval 2007 Task 04 [10]. Another interesting data-driven approach was suggested by Dasgupta et al.[3]. They leveraged a bi-directional LSTM model for general-purpose causality detection. However, it lacks the generality of language models and will not give expected results when a sequence of unseen natural language expression is fed. Dasgupta et al.[3] also proposed the use of a lexical feature-based k-means clustering to cluster Cause-Effect events. However, Sharp et al.[28] had used the method suggested by Goldberg et al.[11] to replace the standard linear context with the causal dependency context, resulting in a more task-specific and context dedicated embedding for Cause-Effect event detection. These proposed data-driven approaches either don’t use the linguistic context of the event expression or lacks the complete bi-directional understanding of the text expression. Our proposed approach uses BERT’s bidirectional context to learn causal interaction between events.
More recently,Hassanzadeh et al.[15] used BERT based language model to identify and rank sentences similar to binary casual questions (”If A could cause B.”). They used ranked documents to add explainability to their methods’ final prediction and also to get over the restriction on what type of phrases they can use or the need to map the causal phrases to some knowledge base. Hassanzadeh et al. [16] also showed causal embedding and language modeling-based approaches could be useful in extracting causal knowledge from a large scale unstructured text. We also used BERT based language models for our causality understanding task but unlike Hassanzadeh et al., in this work, we predicted implicit and explicit causal relationship between previously identified events in natural language text.
7 Conclusion
In this work, we studied the problem of causal relationship detection between events expressed in natural language text where both the events are expressed as nominal or phrase or a short span of text in the same sentence. We showed that the network architectures built on top of the contextualized language model can learn causal relations in the text using sentence context, event information, and masked event context. Our proposed methodology significantly outperforms the reported performance measure on curated datasets, and it can be useful in automatic causal graph extraction as well as identifying a causal chain of events in event expressions. This can further help recognize counterfactuals by connecting antecedent and consequent with causal relations.
For a complete causal understanding of events expressed in natural language text, we need the ability to recognize sentences with causal events, identify those events, causal relations between the events, and understand the influences between those events. There can be several future directions from here. One interesting direction would be the automatic identification of events as well as sub-events in a given text expression. And then, identifying richer and fine-grained causal relationships (e.g., caused, contributed, likelihood, and encouraged, influenced) between them even when the events are described in the same or different sentences.
References
- [1] Brandon Beamer, Suma Bhat, Brant Chee, Andrew Fister, Alla Rozovskaya, and Roxana Girju. Uiuc: A knowledge-rich approach to identifying semantic relations between nominals. Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), pages 386–389, 2007.
- [2] Kenneth Ward Church and Patrick Hanks. Word Association Norms, Mutual Information, and Lexicography. Comput. Linguist., 16(1):22–29, 1990.
- [3] Tirthankar Dasgupta, Rupsa Saha, Lipika Dey, and Abir Naskar. Automatic Extraction of Causal Relations from Text using Linguistically Informed Deep Neural Networks. Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, pages 306–316, 2019.
- [4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT (1), 2019.
- [5] Quang Xuan Do, Yee Seng Chan, and Dan Roth. Minimally supervised event causality identification. EMNLP 2011 - Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, pages 294–303, 2011.
- [6] Jesse Dunietz, Lori Levin, and Jaime G Carbonell. The because corpus 2.0: Annotating causality and overlapping relations. In Proceedings of the 11th Linguistic Annotation Workshop, pages 95–104, 2017.
- [7] Daniela Gaxcia. Coatis, an nlp system to locate expressions of actions connected by causality links. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 1319(Section 2):347–352, 1997.
- [8] Roxana Girju. Automatic detection of causal relations for question answering. Proceedings of the ACL 2003 workshop on Multilingual summarization and question answering, pages 76–83, 2003.
- [9] Roxana Girju and Dan Moldovan. Text mining for causal relations. Proceedings of the FLAIRS Conference, page 360–364, 2002.
- [10] Roxana Girju, Preslav Nakov, Vivi Nastase, Stan Szpakowicz, Peter Turney, and Deniz Yuret. Semeval-2007 task 04: Classification of semantic relations between nominals. Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), pages 13–18, 2007.
- [11] Yoav Goldberg. Assessing bert’s syntactic abilities. arXiv preprint arXiv:1901.05287, 2019.
- [12] Andrew S. Gordon, Cosmin Adrian Bejan, and Kenji Sagae. Commonsense causal reasoning using millions of personal stories. Proceedings of the National Conference on Artificial Intelligence, 2:1180–1185, 2011.
- [13] Harsha Gurulingappa, Abdul Mateen Rajput, Angus Roberts, Juliane Fluck, Martin Hofmann-Apitius, and Luca Toldo. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. Journal of Biomedical Informatics, 45(5):885–892, 2012.
- [14] Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964, 2020.
- [15] Oktie Hassanzadeh, Debarun Bhattacharjya, Mark Feblowitz, Kavitha Srinivas, Michael Perrone, Shirin Sohrabi, and Michael Katz. Answering binary causal questions through large-scale text mining: An evaluation using cause-effect pairs from human experts. IJCAI International Joint Conference on Artificial Intelligence, 2019-Augus:5003–5009, 2019.
- [16] Oktie Hassanzadeh, Debarun Bhattacharjya, Mark Feblowitz, Kavitha Srinivas, Michael Perrone, Shirin Sohrabi, and Michael Katz. Causal knowledge extraction through large-scale text mining. AAAI, pages 13610–13611, 2020.
- [17] Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid O. Séaghdha, Sebastian Padó, Marco Pennacchiotti, Lorenza Romano, and Stan Szpakowicz. SemEval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. ACL 2010 - SemEval 2010 - 5th International Workshop on Semantic Evaluation, Proceedings, pages 33–38, 2010.
- [18] Zhichao Hu, Elahe Rahimtoroghi, and Marilyn A Walker. Inference of fine-grained event causality from blogs and films. In arXiv preprint arXiv:1708.09453, 2017.
- [19] Trung Huynh, Yulan He, A. Willis, and S. Rüger. Adverse drug reaction classification with deep neural networks. In COLING, 2016.
- [20] Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. What does BERT learn about the structure of language? ACL 2019 - 57th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, pages 3651–3657, 2020.
- [21] Christopher S. G. Khoo, Syin Chan, and Yun Niu. Extracting causal knowledge from a medical database using graphical patterns. Proceedings of the 38th annual meeting of the association for computational linguistics, pages 336–343, 2000.
- [22] Zhiyi Luo, Yuchen Sha, Kenny Q Zhu, Seung-won Hwang, and Zhongyuan Wang. Commonsense causal reasoning between short texts. KR, pages 421–431, 2016.
- [23] Rada Mihalcea, Courtney Corley, and Carlo Strapparava. Corpus-based and knowledge-based measures of text semantic similarity. Proceedings of the National Conference on Artificial Intelligence, 1:775–780, 2006.
- [24] Paramita Mirza, Rachele Sprugnoli, Sara Tonelli, and Manuela Speranza. Annotating causality in the TempEval-3 corpus. In Proceedings of the EACL 2014 Workshop on Computational Approaches to Causality in Language (CAtoCL), pages 10–19, Gothenburg, Sweden, April 2014. Association for Computational Linguistics.
- [25] Judea Pearl. Causal inference in statistics: An overview. Statistics Surveys, 3:96–146, 2009.
- [26] Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Miltsakaki, Livio Robaldo, Aravind K Joshi, and Bonnie L Webber. The penn discourse treebank 2.0. In LREC. Citeseer, 2008.
- [27] James Pustejovsky. The syntax of event structure. cognition, 41(1-3):47–81, 1991.
- [28] Rebecca Sharp, Mihai Surdeanu, Peter Jansen, Peter Clark, and Michael Hammond. Creating causal embeddings for question answering with minimal supervision. EMNLP 2016 - Conference on Empirical Methods in Natural Language Processing, Proceedings, pages 138–148, 2016.
- [29] Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. Matching the blanks: Distributional similarity for relation learning. ACL 2019 - 57th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, pages 2895–2905, 2020.
- [30] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem(Nips):5999–6009, 2017.
- [31] Shanchan Wu and Yifan He. Enriching pre-trained language model with entity information for relation classification. International Conference on Information and Knowledge Management, Proceedings, pages 2361–2364, 2019.
Appendix A Appendix
In this section, we elaborate on data curation with examples and showed few example where our models worked as well as where it missed totally.
Table 6 shows examples where our model could detect causality in sentences where it was not apparent as well as where our model got confused. Table 6 shows two examples of causal sentences where event interactions were correctly classified as Cause-Effect (True Positive) and as Other (True Negative) and where event interactions were incorrectly classified as Cause-Effect (False Positive) as Other (False Negatives).
| True positives | This as well as kinetic data support the hypothesis of <e1 >inhibition <e1>through <e2 >altered membrane properties </e2 >. |
|---|---|
| <e1>Dehydration </e1>from <e2>fluid loss </e2>generally is the only major problem the virus can cause, most often in the elderly. | |
| False Positives | If your main <e1>aim </e1>is for <e2>growth </e2>in the value of the property then obviously you need to look at where you think the next ”value-spurt” is going to be. |
| <e1>Brushing </e1>after <e2>meals </e2>should become part of your daily schedule. | |
| True Negatives | My <e1>sore throat </e1>from <e2>yesterday </e2>has turned into a full-blown cold overnight. |
| The <e1>evacuation </e1>after the Chernobyl <e2>accident </e2>was poorly planned and chaotic. | |
| False Negatives | Most of the <e1>taste </e1>of strong onions comes from the <e2>smell </e2>. |
| Subjects will be secured at all times with a safety harness to prevent <e1>injury </e1>from <e2>falling </e2>. |
Table 7 shows the example sentence as well as marked events in them. In Semeval 2007 and Semeval 2010 datasets, original data contained additional information about the direction of causality. But due to the small size of the dataset our experiments do not focused on the directional aspects of causal interaction between events. In Semeval 2007 and Semeval 2010 dataset, we only had one pair of events in each sentence, whereas, in ADE, we had more than one pair of events in each sentence.
While curating the data for our experiments, for each sentence, for each pair of interactions, we curated a new data point. In the Semeval 2007 and Semeval 2010 ratio of unique lines to total lines is 1, whereas, in the ADE dataset it is 0.9780.975 (test/train). It is clear that ADI has some repeating sentence expressions with different pairs of marked events.
| Dataset | Sentences | Event Pairs |
|---|---|---|
| Semeval 2007 | He had chest pains and headaches from mold in the bedrooms. | (headaches, mold) |
| Semeval 2010 | The treaty establishes a double majority rule for Council decisions. | (treaty, rule) |
| ADE | A 79-year-old man with ischemic heart disease, chronic atrial fibrillation, chronic renal failure, hypothyroidism, and gout arthritis was hospitalized because of fatigue, myalgia, and leg weakness, shortly after starting treatment with colchicine. | (fatigue, colchicine) (myalgia,colchicine) (leg weakness, colchicine) |