Causal Conceptions of Fairness and their Consequences
Abstract
Recent work highlights the role of causality in designing equitable decision-making algorithms. It is not immediately clear, however, how existing causal conceptions of fairness relate to one another, or what the consequences are of using these definitions as design principles. Here, we first assemble and categorize popular causal definitions of algorithmic fairness into two broad families: (1) those that constrain the effects of decisions on counterfactual disparities; and (2) those that constrain the effects of legally protected characteristics, like race and gender, on decisions. We then show, analytically and empirically, that both families of definitions almost always—in a measure theoretic sense—result in strongly Pareto dominated decision policies, meaning there is an alternative, unconstrained policy favored by every stakeholder with preferences drawn from a large, natural class. For example, in the case of college admissions decisions, policies constrained to satisfy causal fairness definitions would be disfavored by every stakeholder with neutral or positive preferences for both academic preparedness and diversity. Indeed, under a prominent definition of causal fairness, we prove the resulting policies require admitting all students with the same probability, regardless of academic qualifications or group membership. Our results highlight formal limitations and potential adverse consequences of common mathematical notions of causal fairness.
1 Introduction
Imagine designing an algorithm to guide decisions for college admissions. To help ensure algorithms such as this are broadly equitable, a plethora of formal fairness criteria have been proposed in the machine learning community (Darlington, 1971; Cleary, 1968; Zafar et al., 2017b; Dwork et al., 2012; Chouldechova, 2017; Hardt et al., 2016; Kleinberg et al., 2017; Woodworth et al., 2017; Zafar et al., 2017a; Corbett-Davies et al., 2017; Chouldechova & Roth, 2020; Berk et al., 2021). For example, under the principle that fair algorithms should have comparable performance across demographic groups (Hardt et al., 2016), one might check that among applicants who were ultimately academically “successful” (e.g., who eventually earned a college degree, either at the institution in question or elsewhere), the algorithm would recommend admission for an equal proportion of candidates across race groups. Alternatively, following the principle that decisions should be agnostic to legally protected attributes like race and gender (cf. Corbett-Davies & Goel, 2018; Dwork et al., 2012), one might mandate that these features not be provided to the algorithm.
Recent scholarship has argued for extending equitable algorithm design by adopting a causal perspective, leading to myriad additional formal criteria for fairness (Coston et al., 2020; Imai & Jiang, 2020; Imai et al., 2020; Wang et al., 2019; Kusner et al., 2017; Nabi & Shpitser, 2018; Wu et al., 2019; Mhasawade & Chunara, 2021; Kilbertus et al., 2017; Zhang & Bareinboim, 2018; Zhang et al., 2017; Chiappa, 2019; Loftus et al., 2018; Galhotra et al., 2022; Carey & Wu, 2022). Less attention, however, has been given to understanding the potential downstream consequences of using these causal definitions of fairness as algorithmic design principles, leaving an important gap to fill if these criteria are to responsibly inform policy choices.
Here we synthesize and critically examine the statistical properties and concomitant consequences of popular causal approaches to fairness. We begin, in Section 2, by proposing a two-part taxonomy for causal conceptions of fairness that mirrors the illustrative, non-causal fairness principles described above. Our first category of definitions encompasses those that consider the effect of decisions on counterfactual disparities. For example, recognizing the causal effect of college admission on later success, one might demand that among applicants who would be academically successful if admitted to a particular college, the algorithm would recommend admission for an equal proportion of candidates across race groups. The second category of definitions encompasses those that seek to limit both the direct and indirect effects of one’s group membership on decisions. For example, because one’s race might impact earlier educational opportunities, and hence test scores, one might require that admissions decisions are robust to the effect of race along such causal paths.
We show, in Section 3, that when the distribution of causal effects is known (or can be estimated), one can efficiently compute utility-maximizing decision policies constrained to satisfy each of the causal fairness criteria we consider. However, for natural families of utility functions—for example, those that prefer both higher degree attainment and more student-body diversity—we prove in Section 4 that causal fairness constraints almost always lead to strongly Pareto dominated decision policies. To establish this result, we use the theory of prevalence (Christensen, 1972; Hunt et al., 1992; Anderson & Zame, 2001; Ott & Yorke, 2005), which extends the notion of full-measure sets to infinite-dimensional vector spaces. In particular, in our running college admissions example, adhering to any of the common conceptions of causal fairness would simultaneously result in a lower number of degrees attained and lower student-body diversity, relative to what one could achieve by explicitly tailoring admissions policies to achieve desired outcomes. In fact, under one prominent definition of causal fairness, we prove that the induced policies require simply admitting all applicants with equal probability, irrespective of one’s academic qualifications or group membership. These results, we hope, elucidate the structure—and limitations—of current causal approaches to equitable decision making.
2 Causal Approaches to Fair Decision Making
We describe two broad classes of causal notions of fairness: (1) those that consider outcomes when decisions are counterfactually altered; and (2) those that consider outcomes when protected attributes are counterfactually altered. We illustrate these definitions in the context of a running example of college admissions decisions.
2.1 Problem Setup
Consider a population of individuals with observed covariates , drawn i.i.d from a set with distribution . Further suppose that describes one or more discrete protected attributes, such as race or gender, which can be derived from (i.e., for some measurable function ). Each individual is subject to a binary decision , determined by a (randomized) rule , where is the probability of receiving a positive decision.111That is, , where is an independent uniform random variable. Given a budget with , we require the decision rule to satisfy , limiting the expected proportion of positive decisions.
In our running example, we imagine a population of applicants to a particular college, where denotes an admissions rule and indicates a binary admissions decision. To simplify our exposition, we assume all admitted students attend the school. In our setting, the covariates consist of an applicant’s test score and race , where, for notational convenience, we consider two race groups. The budget bounds the expected proportion of admitted applicants.
Assuming there is no interference between units (Imbens & Rubin, 2015), we write and to denote potential outcomes of interest under each of the two possible binary decisions, where is the realized outcome. We assume that and are drawn from a (possibly infinite) set , where . In our admissions example, is a binary variable that indicates college graduation (i.e., degree attainment), with and describing, respectively, whether an applicant would attain a college degree if admitted to or if rejected from the school we consider. Note that is not necessarily zero, as a rejected applicant may attend—and graduate from—a different university.
Given this setup, our goal is to construct decision policies that are broadly equitable, formalized in part by the causal notions of fairness described below. We focus on decisions that are made algorithmically, informed by historical data on applicants and subsequent outcomes.
2.2 Limiting the Effect of Decisions on Disparities
A popular class of non-causal fairness definitions requires that error rates (e.g., false positive and false negative rates) are equal across protected groups (Hardt et al., 2016; Corbett-Davies & Goel, 2018). Causal analogues of these definitions have recently been proposed (Coston et al., 2020; Imai & Jiang, 2020; Imai et al., 2020; Mishler et al., 2021), which require various conditional independence conditions to hold between the potential outcomes, protected attributes, and decisions.222In the literature on causal fairness, there is at times ambiguity between “predictions” of and “decisions” . Following past work (e.g., Corbett-Davies et al., 2017; Kusner et al., 2017; Wang et al., 2019), here we focus exclusively on decisions, with predictions implicitly impacting decisions but not explicitly appearing in our definitions.
Below we list three representative examples of this class of fairness definitions: counterfactual predictive parity (Coston et al., 2020), counterfactual equalized odds (Mishler et al., 2021; Coston et al., 2020), and conditional principal fairness (Imai & Jiang, 2020).333Our subsequent analytical results extend in a straightforward manner to structurally similar variants of these definitions (e.g., requiring or , variants of counterfactual predictive parity and counterfactual equalized odds, respectively).
Definition 1.
Counterfactual predictive parity holds when
| (1) |
In our college admissions example, counterfactual predictive parity means that among rejected applicants, the proportion who would have attained a college degree, had they been accepted, is equal across race groups.
Definition 2.
Counterfactual equalized odds holds when
| (2) |
In our running example, counterfactual equalized odds is satisfied when two conditions hold: (1) among applicants who would graduate if admitted (i.e., ), students are admitted at the same rate across race groups; and (2) among applicants who would not graduate if admitted (i.e., ), students are again admitted at the same rate across race groups.
Definition 3.
Conditional principal fairness holds when
| (3) |
where, for a measurable function on , describes a reduced set of the covariates . When is constant (or, equivalently, when we do not condition on ), this condition is called principal fairness.
In our example, conditional principal fairness means that “similar” applicants—where similarity is defined by the potential outcomes and covariates —are admitted at the same rate across race groups.
2.3 Limiting the Effect of Attributes on Decisions
An alternative causal framework for understanding fairness considers the effects of protected attributes on decisions (Wang et al., 2019; Kusner et al., 2017; Nabi & Shpitser, 2018; Wu et al., 2019; Mhasawade & Chunara, 2021; Kilbertus et al., 2017; Zhang & Bareinboim, 2018; Zhang et al., 2017). This approach, which can be understood as codifying the legal notion of disparate treatment (Goel et al., 2017; Zafar et al., 2017a), considers a decision rule to be fair if, at a high level, decisions for individuals are the same in “(a) the actual world and (b) a counterfactual world where the individual belonged to a different demographic group” (Kusner et al., 2017).444Conceptualizing a general causal effect of an immutable characteristic such as race or gender is rife with challenges, the greatest of which is expressed by the mantra, “no causation without manipulation” (Holland, 1986). In particular, analyzing race as a causal treatment requires one to specify what exactly is meant by “changing an individual’s race” from, for example, white to Black (Gaebler et al., 2022; Hu & Kohler-Hausmann, 2020). Such difficulties can sometimes be addressed by considering a change in the perception of race by a decision maker (Greiner & Rubin, 2011)—for instance, by changing the name listed on an employment application (Bertrand & Mullainathan, 2004), or by masking an individual’s appearance (Goldin & Rouse, 2000; Grogger & Ridgeway, 2006; Pierson et al., 2020; Chohlas-Wood et al., 2021b).
In contrast to “fairness through unawareness”—in which race and other protected attributes are barred from being an explicit input to a decision rule (cf. Dwork et al., 2012; Corbett-Davies & Goel, 2018)—the causal versions of this idea consider both the direct and indirect effects of protected attributes on decisions. For example, even if decisions only directly depend on test scores, race may indirectly impact decisions through its effects on educational opportunities, which in turn influence test scores. This idea can be formalized by requiring that decisions remain the same in expectation even if one’s protected characteristics are counterfactually altered, a condition known as counterfactual fairness (Kusner et al., 2017).
Definition 4.
Counterfactual fairness holds when
| (4) |
where denotes the decision when one’s protected attributes are counterfactually altered to be any .
In our running example, this means that for each group of observationally identical applicants (i.e., those with the same values of , meaning identical race and test score), the proportion of students who are actually admitted is the same as the proportion who would be admitted if their race were counterfactually altered.
Counterfactual fairness aims to limit all direct and indirect effects of protected traits on decisions. In a generalization of this criterion—termed path-specific fairness (Chiappa, 2019; Nabi & Shpitser, 2018; Zhang et al., 2017; Wu et al., 2019)—one allows protected traits to influence decisions along certain causal paths but not others. For example, one may wish to allow the direct consideration of race by an admissions committee to implement an affirmative action policy, while also guarding against any indirect influence of race on admissions decisions that may stem from cultural biases in standardized tests (Williams, 1983).
The formal definition of path-specific fairness requires specifying a causal DAG describing relationships between attributes (both observed covariates and latent variables), decisions, and outcomes. In our running example of college admissions, we imagine that each individual’s observed covariates are the result of the process illustrated by the causal DAG in Figure 1. In this graph, an applicant’s race influences the educational opportunities available to them prior to college; and educational opportunities in turn influence an applicant’s level of college preparation, , as well as their score on a standardized admissions test, , such as the SAT. We assume the admissions committee only observes an applicant’s race and test score so that , and makes their decision based on these attributes. Finally, whether or not an admitted student subsequently graduates (from any college), , is a function of both their preparation and whether they were admitted.555In practice, the racial composition of an admitted class may itself influence degree attainment, if, for example, diversity provides a net benefit to students (Page, 2007). Here, for simplicity, we avoid consideration of such peer effects.
To define path-specific fairness, we start by defining, for the decision , path-specific counterfactuals, a general concept in causal DAGs (cf. Pearl, 2001). Suppose is a causal model with nodes , exogenous variables , and structural equations that define the value at each node as a function of its parents and its associated exogenous variable . (See, for example, Pearl (2009a) for further details on causal DAGs.) Let be a topological ordering of the nodes, meaning that (i.e., the parents of each node appear in the ordering before the node itself). Let denote a collection of paths from node to . Now, for two possible values and for the variable , the path-specific counterfactuals for the decision are generated by traversing the list of nodes in topological order, propagating counterfactual values obtained by setting along paths in , and otherwise propagating values obtained by setting . (In Algorithm 1 in the Appendix, we formally define path-specific counterfactuals for an arbitrary node—or collection of nodes—in the DAG.)
To see this idea in action, we work out an illustrative example, computing path-specific counterfactuals for the decision along the single path linking race to the admissions committee’s decision through test score, highlighted in red in Figure 1. In the system of equations below, the first column corresponds to draws for each node in the DAG, where we set to , and then propagate that value as usual. The second column corresponds to draws of path-specific counterfactuals, where we set to , and then propagate the counterfactuals only along the path . In particular, the value for the test score is computed using the value of (since the edge is on the specified path) and the value of (since the edge is not on the path). As a result of this process, we obtain a draw from the distribution of .
Path-specific fairness formalizes the intuition that the influence of a sensitive attribute on a downstream decision may, in some circumstances, be considered legitimate (i.e., it may be acceptable for the attribute to affect decisions along certain paths in the DAG). For instance, an admissions committee may believe that the effect of race on admissions decisions which passes through college preparation is legitimate, whereas the effect of race along the path , which may reflect access to test prep or cultural biases of the tests, rather than actual academic preparedness, is illegitimate. In that case, the admissions committee may seek to ensure that the proportion of applicants they admit from a certain race group remains unchanged if one were to counterfactually alter the race of those individuals along the path .
Definition 5.
Let be a collection of paths, and, for a measurable function on , let describe a reduced set of the covariates . Path-specific fairness, also called -fairness, holds when, for any ,
| (5) |
In the definition above, rather than a particular counterfactual level , the baseline level of the path-specific effect is , i.e., an individual’s actual (non-counterfactually altered) group membership (e.g., their actual race). We have implicitly assumed that the decision variable is a descendant of the covariates . In particular, without loss of generality, we assume is defined by the structural equation , where the exogenous variable , so that . If is the set of all paths from to , then , in which case, for , path-specific fairness is the same as counterfactual fairness.
3 Constructing Causally Fair Policies
The definitions of causal fairness above constrain the set of decision policies one might adopt, but, in general, they do not yield a unique policy. For instance, a policy in which applicants are admitted randomly and independently with probability —where is the specified budget—satisfies counterfactual equalized odds (Def. 2), conditional principal fairness (Def. 3), counterfactual fairness (Def. 4), and path-specific fairness (Def. 5).666A policy satisfying counterfactual predictive parity (Def. 1) is not guaranteed to exist. For example, if —in which case a.s.—and , then Eq. (1) cannot hold. Similar counterexamples can be constructed for .
However, such a randomized policy may be sub-optimal in the eyes of decision-makers aiming to maximize outcomes such as class diversity or degree attainment. Past work has described multiple approaches to selecting a single policy from among those satisfying any given fairness definition, including maximizing concordance of the decision with the outcome variable (Nabi & Shpitser, 2018; Chiappa, 2019) or with an existing policy (Wang et al., 2019) (e.g., in terms of binary accuracy or KL-divergence).
Here, as we are primarily interested in the downstream consequences of various causal fairness definitions, we consider causally fair policies that maximize utility (Liu et al., 2018; Kasy & Abebe, 2021; Corbett-Davies et al., 2017; Cai et al., 2020; Chohlas-Wood et al., 2021a).
Suppose denotes the utility of assigning a positive decision to individuals with observed covariate values , relative to assigning them negative decisions. In our running example, we set
| (6) |
where denotes the likelihood the applicant would graduate if admitted, indicates whether the applicant identifies as belonging to race group (e.g., may denote a group historically underrepresented in higher education), and is an arbitrary constant that balances preferences for both student graduation and racial diversity.
We seek decision policies that maximize expected utility, subject to satisfying a given definition of causal fairness, as well as the budget constraint. Specifically, letting denote the family of all decision policies that satisfy one of the causal fairness definitions listed above, a utility-maximizing policy is given by
| (7) | ||||
Constructing optimal policies poses both statistical and computational challenges. One must, in general, estimate the joint distribution of covariates and potential outcomes—and, even more dauntingly, causal effects along designated paths for path-specific definitions of fairness. In some settings, it may be possible to obtain these estimates from observational analyses of historical data or randomized controlled trials, though both approaches typically involve substantial hurdles in practice.
We prove that if one has this statistical information, it is possible to efficiently compute causally fair utility-maximizing policies by solving either a single linear program or a series of linear programs (Appendix, Theorem B.1). In the case of counterfactual equalized odds, conditional principal fairness, counterfactual fairness, and path-specific fairness, we show that the definitions can be translated to linear constraints. For counterfactual predictive parity, the defining independence condition yields a quadratic constraint, which we show can be expressed as a linear constraint by further conditioning on one of the decision variables, and the optimization problem in turn can be solved through a series of linear programs.
4 The Structure of Causally Fair Policies
Above, for each definition of causal fairness, we sketched how to construct utility-maximizing policies that satisfy the corresponding constraints. Now we explore the structural properties of causally fair policies. We show—both empirically and analytically, under relatively mild distributional assumptions—that policies constrained to be causally fair are disfavored by every individual in a natural class of decision makers with varying preferences for diversity. To formalize these results, we start by introducing some notation and then defining the concept of (strong) Pareto dominance.
4.1 Pareto Dominance and Consistent Utilities
For a real-valued utility function and decision policy , we write to denote the utility of under .
Definition 6.
For a budget , we say a decision policy is feasible if .
Given a collection of utility functions encoding the preferences of different individuals, we say a decision policy is Pareto dominated if there exists a feasible alternative such that none of the decision makers prefers over , and at least one decision maker strictly prefers over , a property formalized in Definition 7.
Definition 7.
Suppose is a collection of utility functions. A decision policy is Pareto dominated if there exists a feasible alternative such that for all , and there exists such that . A policy is strongly Pareto dominated if there exists a feasible alternative such that for all . A policy is Pareto efficient if it is feasible and not Pareto dominated, and the Pareto frontier is the set of Pareto efficient policies.
To develop intuition about the structure of causally fair decision policies, we continue working through our illustrative example of college admissions. We consider a collection of decision makers with utilities of the form in Eq. (6), for . In this example, decision makers differ in their preferences for diversity (as determined by ), but otherwise have similar preferences. We call such a collection of utilities consistent modulo .
Definition 8.
We say that a set of utilities is consistent modulo if, for any :
-
1.
For any , ;
-
2.
For any and such that , if and only if .
For consistent utilities, the Pareto frontier takes a particularly simple form, represented by (a subset of) group-specific threshold policies.
Proposition 1.
Suppose is a set of utilities that is consistent modulo . Then any Pareto efficient decision policy is a multiple threshold policy. That is, for any , there exist group-specific constants such that, a.s.:
| (8) |
The proof of Proposition 1 is in the Appendix.777 In the statement of the proposition, we do not specify what happens at the thresholds themselves, as one can typically ignore the exact manner in which decisions are made at the threshold. Specifically, given a threshold policy , we can construct a standardized threshold policy that is constant within group at the threshold (i.e., when ), and for which: (1) ; and (2) . In our running example, this means we can standardize threshold policies so that applicants at the threshold are admitted with the same group-specific probability.
4.2 An Empirical Example
With these preliminaries in place, we now empirically explore the structure of causally fair decision policies in the context of our stylized example of college admissions, given by the causal DAG in Figure 1. In the hypothetical pool of 100,000 applicants we consider, applicants in the target race group have, on average, fewer educational opportunities than those applicants in group , which leads to lower average academic preparedness, as well as lower average test scores. See Section C in the Appendix for additional details, including the specific structural equations we use.
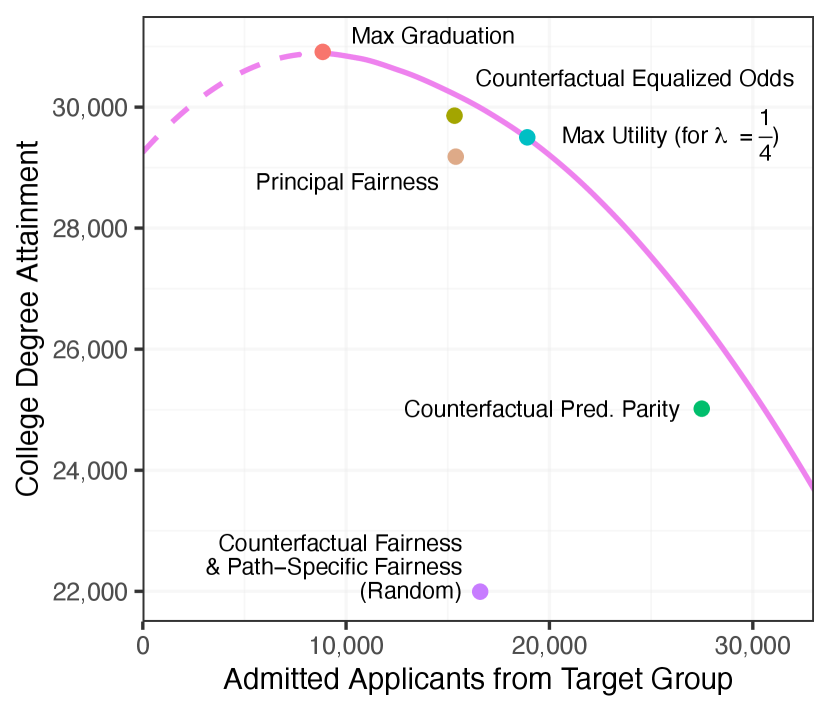
For the utility function in Eq. (6) with , we apply Theorem B.1 to compute utility-maximizing policies for each of the above causal definitions of fairness. We plot the results in Figure 2, where, for each policy, the horizontal axis shows the expected number of admitted applicants from the target race group, and the vertical axis shows the expected number of college graduates. Additionally, for the family of utilities given by Eq. (6) for , we depict the Pareto frontier by the solid purple curve, computed via Proposition 1.888For all the cases we consider, the optimal policies admit the maximum proportion of students allowed under the budget (i.e., ). To compute the Pareto frontier in Figure 2, it is sufficient—by Proposition 1 and Footnote 7—to sweep over (standardized) group-specific threshold policies relative to the utility . For reference, the dashed purple line corresponds to max-utility policies constrained to satisfy the level of diversity indicated on the -axis, though these policies are not on the Pareto frontier, as they result in fewer college graduates and lower diversity than the policy that maximizes graduation alone (indicated by the “max graduation” point in Figure 2).
For each fairness definition, the depicted policies are strongly Pareto dominated, meaning that there is an alternative feasible policy favored by all decision makers with preferences in . In particular, for each definition of causal fairness, there is an alternative feasible policy in which one simultaneously achieves more student-body diversity and more college graduates. In some instances, the efficiency gap is quite stark. Utility-maximizing policies constrained to satisfy either counterfactual fairness or path-specific fairness require one to admit each applicant independently with fixed probability (where is the budget), regardless of academic preparedness or group membership.999For path-specific fairness, we set equal to the single path , and set in this example. These results show that constraining decision-making algorithms to satisfy popular definitions of causal fairness can have unintended consequences, and may even harm the very groups they were ostensibly designed to protect.
4.3 The Statistical Structure of Causally Fair Policies
The patterns illustrated in Figure 2 and discussed above are not idiosyncracies of our particular example, but rather hold quite generally. Indeed, Theorem 1 shows that for almost every joint distribution of , , and such that has a density, any decision policy satisfying counterfactual equalized odds or conditional principal fairness is Pareto dominated. Similarly, for almost every joint distribution of and , we show that policies satisfying path-specific fairness (including counterfactual fairness) are Pareto dominated. (NB: The analogous statement for counterfactual predictive parity is not true, which we address in Proposition 2.)
The notion of almost every distribution that we use here was formalized by Christensen (1972), Hunt et al. (1992), Anderson & Zame (2001), and others (cf. Ott & Yorke, 2005, for a review). Suppose, for a moment, that combinations of covariates and outcomes take values in a finite set of size . Then the space of joint distributions on covariates and outcomes can be represented by the unit -simplex: . Since is a subset of an -dimensional hyperplane in , it inherits the usual Lebesgue measure on . In this finite-dimensional setting, almost every distribution means a subset of distributions that has full Lebesgue measure on the simplex. Given a property that holds for almost every distribution in this sense, that property holds almost surely under any probability distribution on the space of distributions that is described by a density on the simplex. We use a generalization of this basic idea that extends to infinite-dimensional spaces, allowing us to consider distributions with arbitrary support. (See the Appendix for further details.)
To prove this result, we make relatively mild restrictions on the set of distributions and utilities we consider to exclude degenerate cases, as formalized by Definition 9 below.
Definition 9.
Let be a collection of functions from to for some set . We say that a distribution of on is -fine if has a density for all .
In particular, -fineness ensures that the distribution of has a density. In the absence of -fineness, corner cases can arise in which an especially large number of policies may be Pareto efficient, in particular when has large atoms and can be used to predict the potential outcomes and even after conditioning on . See Prop. E.7 for details. Our example of college admissions, where is defined by Eq. (6), is -fine.
Theorem 1.
Suppose is a set of utilities consistent modulo . Further suppose that for all there exist a -fine distribution of and a utility such that , where . Then,
-
•
For almost every -fine distribution of and , any decision policy satisfying counterfactual equalized odds is strongly Pareto dominated.
-
•
If and there exists a -fine distribution of such that for all and , where , then, for almost every -fine joint distribution of , , and , any decision policy satisfying conditional principal fairness is strongly Pareto dominated.
-
•
If and there exists a -fine distribution of such that for all and some distinct , then, for almost every -fine joint distributions of and the counterfactuals , any decision policy satisfying path-specific fairness is strongly Pareto dominated.101010Here, and is the set of for . In other words, the requirement is that the joint distribution of the has a density.
The proof of Theorem 1 is given in the Appendix. At a high-level, the proof proceed in three steps, which we outline below using the example of counterfactual equalized odds. First, we show that for almost every fixed -fine joint distribution of and there is at most one policy satisfying counterfactual equalized odds that is not strongly Pareto dominated. To see why, note that for any specific , since counterfactual equalized odds requires that , setting the threshold for one group determines the thresholds for all the others; the budget constraint then can be used to fix the threshold for the original group. Second, we construct a “slice” around such that for any distribution in the slice, is still the only policy that can potentially lie on the Pareto frontier while satisfying counterfactual equalized odds. We create the slice by strategically perturbing only where , for some . This perturbation moves mass from one side of the thresholds of to the other, consequently breaking the balance requirement for almost every in the slice. This phenomenon is similar to the problem of infra-marginality (Simoiu et al., 2017; Ayres, 2002), which likewise afflicts non-causal notions of fairness (Corbett-Davies et al., 2017; Corbett-Davies & Goel, 2018). Finally, we appeal to the notion of prevalence to stitch the slices together, showing that for almost every distribution, any policy satisfying counterfactual equalized odds is strongly Pareto dominated. Analogous versions of this general argument apply to the cases of conditional principal fairness and path-specific fairness.111111This argument does not depend in an essential way on the definitions being causal. In Corollary E.5, we show an analogous result for the non-counterfactual version of equalized odds.
In some common settings, path-specific fairness with constrains decisions so severely that the only allowable policies are constant (i.e., for all ). For instance, in our running example, path-specific fairness requires admitting all applicants with the same probability, irrespective of academic preparation or group membership. Thus, all applicants are admitted with probability , where is the budget, under the optimal policy constrained to satisfy path-specific fairness.
To build intuition for this result, we sketch the argument for a finite covariate space . Given a policy that satisfies path-specific fairness, select .
By the definition of path-specific fairness, for any ,
| (9) | ||||
That is, the probability of an individual with covariates receiving a positive decision must be the average probability of the individuals with covariates in group receiving a positive decision, weighted by the probability that an individual with covariates in the real world would have covariates counterfactually.
Next, we suppose that there exists an such that for all . In this case, because for all , Eq. (9) shows that in fact for all .
Now, let be arbitrary. Again, by the definition of path-specific fairness, we have that
where we use in the third equality the fact for all , and in the final equality the fact that is supported on .
Theorem 2 formalizes and extends this argument to more general settings, where is not necessarily positive for all . The proof of Theorem 2 is in the Appendix, along with extensions to continuous covariate spaces and a more complete characterization of -fair policies for finite .
Theorem 2.
Suppose is finite and for all . Suppose is a random variable such that:
-
1.
for all ,
-
2.
for all such that and such that .
Then, for any -fair policy , with , there exists a function such that , i.e., is constant across individuals having the same value of .
The first condition of Theorem 2 holds for any reduced set of covariates that is not causally affected by changes in (e.g., is not a descendent of ). The second condition requires that among individuals with covariates , a positive fraction have covariates in a counterfactual world in which they belonged to another group . Because is the same in the real and counterfactual worlds—since is unaffected by , by the first condition—we only consider such that in the second condition.
In our running example, the only non-race covariate is test score, which is downstream of race. Further, among students with a given test score, a positive fraction achieve any other test score in the counterfactual world in which their race is altered. As such, the empty set of reduced covariates—formally encoded by setting to a constant function—satisfies the conditions of Theorem 2. The theorem then implies that under any -fair policy, every applicant is admitted with equal probability.
Even when decisions are not perfectly uniform lotteries, as in our admissions example, Theorem 2 suggests that enforcing -fairness can lead to unexpected outcomes. For instance, suppose we modify our admissions example to additionally include age as a covariate that is causally unconnected to race—as some past work has done. In that case, -fair policies would admit students based on their age alone, irrespective of test score or race. Although in some cases such restrictive policies might be desirable, this strong structural constraint implied by -fairness appears to be a largely unintended consequence of the mathematical formalism.
The conditions of Theorem 2 are relatively mild, but do not hold in every setting. Suppose that in our admissions example it were the case that for some constant —that is, suppose the effect of intervening on race is a constant change to an applicant’s test score. Then the second condition of Theorem 2 would no longer hold for a constant . Indeed, any multiple-threshold policy in which would be -fair. In practice, though, such deterministic counterfactuals would seem to be the exception rather than the rule. For example, it seems reasonable to expect that test scores would depend on race in complex ways that induce considerable heterogeneity.
Lastly, we note that in some variants of path-specific fairness (e.g., Zhang & Bareinboim, 2018; Nabi & Shpitser, 2018), in which case Theorem 2 does not apply. Although, in that case, policies are typically still Pareto dominated in accordance with Theorem 1.
We conclude our analysis by investigating counterfactual predictive parity, the least demanding of the causal notions of fairness we have considered, requiring only that . As such, it is in general possible to have a policy on the Pareto frontier that satisfies this condition. However, in Proposition 2, we show that this cannot happen in some common cases, including our example of college admissions.
In that setting, when the target group has lower average graduation rates—a pattern that often motivates efforts to actively increase diversity—decision policies constrained to satisfy counterfactual predictive parity are Pareto dominated. The proof of the proposition is in the Appendix.
Proposition 2.
Suppose , and consider the family of utility functions of the form
indexed by , where . Suppose the conditional distributions of given are beta distributed, i.e.,
with and .121212Here we parameterize the beta distribution in terms of its mean and sample size . In terms of the common, alternative - parameterization, and . Then any policy satisfying counterfactual predictive parity is strongly Pareto dominated.
5 Discussion
We have worked to collect, synthesize, and investigate several causal conceptions of fairness that recently have appeared in the machine learning literature. These definitions formalize intuitively desirable properties—for example, minimizing the direct and indirect effects of race on decisions. But, as we have shown both analytically and with a synthetic example, they can, perhaps surprisingly, lead to policies with unintended downstream outcomes. In contrast to prior impossibility results (Kleinberg et al., 2017; Chouldechova, 2017), in which different formal notions of fairness are shown to be in conflict with each other, we demonstrate trade-offs between formal notions of fairness and resulting social welfare. For instance, in our running example of college admissions, enforcing various causal fairness definitions can lead to a student body that is both less academically prepared and less diverse than what one could achieve under natural alternative policies, potentially harming the very groups these definitions were ostensibly designed to protect. Our results thus highlight a gap between the goals and potential consequences of popular causal approaches to fairness.
What, then, is the role of causal reasoning in designing equitable algorithms? Under a consequentialist perspective to algorithm design (Chohlas-Wood et al., 2021a; Cai et al., 2020; Liang et al., 2021), one aims to construct policies with the most desirable expected outcomes, a task that inherently demands causal reasoning. Formally, this approach corresponds to solving the unconstrained optimization problem in Eq. (7), where preferences for diversity may be directly encoded in the utility function itself, rather than by constraining the class of policies, mitigating potentially problematic consequences. While conceptually appealing, this consequentialist approach still faces considerable practical challenges, including estimating the expected effects of decisions, and eliciting preferences over outcomes.
Our analysis illustrates some of the limitations of mathematical formalizations of fairness, reinforcing the need to explicitly consider the consequences of actions, particularly when decisions are automated and carried out at scale. Looking forward, we hope our work clarifies the ways in which causal reasoning can aid the equitable design of algorithms.
Acknowledgements
We thank Guillaume Basse, Jennifer Hill, and Ravi Sojitra for helpful conversations. H.N was supported by a Stanford Knight-Hennessy Scholarship and the National Science Foundation Graduate Research Fellowship under Grant No. DGE-1656518. J.G was supported by a Stanford Knight-Hennessy Scholarship. R.S. was supported by the NSF Program on Fairness in AI in Collaboration with Amazon under the award “FAI: End-to-End Fairness for Algorithm-in-the-Loop Decision Making in the Public Sector,” no. IIS-2040898. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation or Amazon. Code to reproduce our results is available at https://github.com/stanford-policylab/causal-fairness.
References
- Anderson & Zame (2001) Anderson, R. M. and Zame, W. R. Genericity with infinitely many parameters. Advances in Theoretical Economics, 1(1):1–62, 2001.
- Ayres (2002) Ayres, I. Outcome tests of racial disparities in police practices. Justice Research and Policy, 4(1-2):131–142, 2002.
- Benji (2020) Benji. The sum of an uncountable number of positive numbers. Mathematics Stack Exchange, 2020. URL https://math.stackexchange.com/q/20661. (version: 2020-05-29).
- Berk et al. (2021) Berk, R., Heidari, H., Jabbari, S., Kearns, M., and Roth, A. Fairness in criminal justice risk assessments: The state of the art. Sociological Methods & Research, 50(1):3–44, 2021.
- Bertrand & Mullainathan (2004) Bertrand, M. and Mullainathan, S. Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination. American Economic Review, 94(4):991–1013, 2004.
- Billingsley (1995) Billingsley, P. Probability and Measure. Wiley Series in Probability and Mathematical Statistics. John Wiley & Sons, Inc., New York, third edition, 1995. ISBN 0-471-00710-2. A Wiley-Interscience Publication.
- Brozius (2019) Brozius, H. Conditional expectation - . Mathematics Stack Exchange, 2019. URL https://math.stackexchange.com/q/3247577. (Version: 2019-06-01).
- Cai et al. (2020) Cai, W., Gaebler, J., Garg, N., and Goel, S. Fair allocation through selective information acquisition. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp. 22–28, 2020.
- Carey & Wu (2022) Carey, A. N. and Wu, X. The causal fairness field guide: Perspectives from social and formal sciences. Frontiers in Big Data, 5, 2022.
- Chiappa (2019) Chiappa, S. Path-specific counterfactual fairness. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 7801–7808, 2019.
- Chohlas-Wood et al. (2021a) Chohlas-Wood, A., Coots, M., Brunskill, E., and Goel, S. Learning to be fair: A consequentialist approach to equitable decision-making. arXiv preprint arXiv:2109.08792, 2021a.
- Chohlas-Wood et al. (2021b) Chohlas-Wood, A., Nudell, J., Yao, K., Lin, Z., Nyarko, J., and Goel, S. Blind justice: Algorithmically masking race in charging decisions. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 35–45, 2021b.
- Chouldechova (2017) Chouldechova, A. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Big data, 5(2):153–163, 2017.
- Chouldechova & Roth (2020) Chouldechova, A. and Roth, A. A snapshot of the frontiers of fairness in machine learning. Communications of the ACM, 63(5):82–89, 2020.
- Christensen (1972) Christensen, J. P. R. On sets of Haar measure zero in Abelian Polish groups. Israel Journal of Mathematics, 13(3-4):255–260, 1972.
- Cleary (1968) Cleary, T. A. Test bias: Prediction of grades of Negro and white students in integrated colleges. Journal of Educational Measurement, 5(2):115–124, 1968.
- Corbett-Davies & Goel (2018) Corbett-Davies, S. and Goel, S. The measure and mismeasure of fairness: A critical review of fair machine learning. arXiv preprint arXiv:1808.00023, 2018.
- Corbett-Davies et al. (2017) Corbett-Davies, S., Pierson, E., Feller, A., Goel, S., and Huq, A. Algorithmic decision making and the cost of fairness. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 797–806, 2017.
- Coston et al. (2020) Coston, A., Mishler, A., Kennedy, E. H., and Chouldechova, A. Counterfactual risk assessments, evaluation, and fairness. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 582–593, 2020.
- Darlington (1971) Darlington, R. B. Another look at “cultural fairness”. Journal of Educational Measurement, 8(2):71–82, 1971.
- Dwork et al. (2012) Dwork, C., Hardt, M., Pitassi, T., Reingold, O., and Zemel, R. Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, pp. 214–226, 2012.
- Gaebler et al. (2022) Gaebler, J., Cai, W., Basse, G., Shroff, R., Goel, S., and Hill, J. A causal framework for observational studies of discrimination. Statistics and Public Policy, 2022.
- Galhotra et al. (2022) Galhotra, S., Shanmugam, K., Sattigeri, P., and Varshney, K. R. Causal feature selection for algorithmic fairness. Proceedings of the 2022 International Conference on Management of Data (SIGMOD), 2022.
- Goel et al. (2017) Goel, S., Perelman, M., Shroff, R., and Sklansky, D. A. Combatting police discrimination in the age of big data. New Criminal Law Review: An International and Interdisciplinary Journal, 20(2):181–232, 2017.
- Goldin & Rouse (2000) Goldin, C. and Rouse, C. Orchestrating impartiality: The impact of “blind” auditions on female musicians. American Economic Review, 90(4):715–741, 2000.
- Greiner & Rubin (2011) Greiner, D. J. and Rubin, D. B. Causal effects of perceived immutable characteristics. Review of Economics and Statistics, 93(3):775–785, 2011.
- Grogger & Ridgeway (2006) Grogger, J. and Ridgeway, G. Testing for racial profiling in traffic stops from behind a veil of darkness. Journal of the American Statistical Association, 101(475):878–887, 2006.
- Hardt et al. (2016) Hardt, M., Price, E., and Srebro, N. Equality of opportunity in supervised learning. Advances in Neural Information Processing Systems, 29:3315–3323, 2016.
- Holland (1986) Holland, P. W. Statistics and causal inference. Journal of the American Statistical Association, 81(396):945–960, 1986.
- Hu & Kohler-Hausmann (2020) Hu, L. and Kohler-Hausmann, I. What’s sex got to do with machine learning? In Proceedings of the 2020 ACM Conference on Fairness, Accountability, and Transparency, 2020.
- Hunt et al. (1992) Hunt, B. R., Sauer, T., and Yorke, J. A. Prevalence: a translation-invariant “almost every” on infinite-dimensional spaces. Bulletin of the American Mathematical Society, 27(2):217–238, 1992.
- Imai & Jiang (2020) Imai, K. and Jiang, Z. Principal fairness for human and algorithmic decision-making. arXiv preprint arXiv:2005.10400, 2020.
- Imai et al. (2020) Imai, K., Jiang, Z., Greiner, J., Halen, R., and Shin, S. Experimental evaluation of algorithm-assisted human decision-making: Application to pretrial public safety assessment. arXiv preprint arXiv:2012.02845, 2020.
- Imbens & Rubin (2015) Imbens, G. W. and Rubin, D. B. Causal Inference in Statistics, Social, and Biomedical Sciences. Cambridge University Press, 2015.
- Kasy & Abebe (2021) Kasy, M. and Abebe, R. Fairness, equality, and power in algorithmic decision-making. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 576–586, 2021.
- Kemeny & Snell (1976) Kemeny, J. G. and Snell, J. L. Finite Markov Chains. Undergraduate Texts in Mathematics. Springer-Verlag, New York-Heidelberg, 1976. Reprinting of the 1960 original.
- Kilbertus et al. (2017) Kilbertus, N., Rojas-Carulla, M., Parascandolo, G., Hardt, M., Janzing, D., and Schölkopf, B. Avoiding discrimination through causal reasoning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 656–666, 2017.
- Kleinberg et al. (2017) Kleinberg, J., Mullainathan, S., and Raghavan, M. Inherent trade-offs in the fair determination of risk scores. In 8th Innovations in Theoretical Computer Science Conference (ITCS). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2017.
- Kusner et al. (2017) Kusner, M., Loftus, J., Russell, C., and Silva, R. Counterfactual fairness. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 4069–4079, 2017.
- Liang et al. (2021) Liang, A., Lu, J., and Mu, X. Algorithmic design: Fairness versus accuracy. arXiv preprint arXiv:2112.09975, 2021.
- Liu et al. (2018) Liu, L. T., Dean, S., Rolf, E., Simchowitz, M., and Hardt, M. Delayed impact of fair machine learning. In International Conference on Machine Learning, pp. 3150–3158. PMLR, 2018.
- Loftus et al. (2018) Loftus, J. R., Russell, C., Kusner, M. J., and Silva, R. Causal reasoning for algorithmic fairness. arXiv preprint arXiv:1805.05859, 2018.
- Mhasawade & Chunara (2021) Mhasawade, V. and Chunara, R. Causal multi-level fairness. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 784–794, 2021.
- Mishler et al. (2021) Mishler, A., Kennedy, E. H., and Chouldechova, A. Fairness in risk assessment instruments: Post-processing to achieve counterfactual equalized odds. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 386–400, 2021.
- Nabi & Shpitser (2018) Nabi, R. and Shpitser, I. Fair inference on outcomes. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Ott & Yorke (2005) Ott, W. and Yorke, J. Prevalence. Bulletin of the American Mathematical Society, 42(3):263–290, 2005.
- Page (2007) Page, S. E. Making the difference: Applying a logic of diversity. Academy of Management Perspectives, 21(4):6–20, 2007.
- Pearl (2001) Pearl, J. Direct and indirect effects. In Proceedings of the Seventeenth Conference on Uncertainty and Artificial Intelligence, 2001, pp. 411–420. Morgan Kaufman, 2001.
- Pearl (2009a) Pearl, J. Causal inference in statistics: An overview. Statistics surveys, 3:96–146, 2009a.
- Pearl (2009b) Pearl, J. Causality. Cambridge University Press, second edition, 2009b.
- Pierson et al. (2020) Pierson, E., Simoiu, C., Overgoor, J., Corbett-Davies, S., Jenson, D., Shoemaker, A., Ramachandran, V., Barghouty, P., Phillips, C., Shroff, R., and Goel, S. A large-scale analysis of racial disparities in police stops across the United States. Nature Human Behaviour, 4(7):736–745, 2020.
- Rao (2005) Rao, M. M. Conditional measures and applications, volume 271 of Pure and Applied Mathematics (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, second edition, 2005.
- Rudin (1987) Rudin, W. Real and Complex Analysis. McGraw-Hill Book Co., New York, third edition, 1987. ISBN 0-07-054234-1.
- Rudin (1991) Rudin, W. Functional Analysis. International Series in Pure and Applied Mathematics. McGraw-Hill, Inc., New York, second edition, 1991. ISBN 0-07-054236-8.
- Silva (2008) Silva, C. E. Invitation to Ergodic Theory, volume 42 of Student Mathematical Library. American Mathematical Society, Providence, RI, 2008.
- Simoiu et al. (2017) Simoiu, C., Corbett-Davies, S., and Goel, S. The problem of infra-marginality in outcome tests for discrimination. The Annals of Applied Statistics, 11(3):1193–1216, 2017.
- Steele (2019) Steele, R. Space of vector measures equipped with the total variation norm is complete. Mathematics Stack Exchange, 2019. URL https://math.stackexchange.com/q/3197508. (Version: 2019-04-22).
- Wang et al. (2019) Wang, Y., Sridhar, D., and Blei, D. M. Equal opportunity and affirmative action via counterfactual predictions. arXiv preprint arXiv:1905.10870, 2019.
- Williams (1983) Williams, T. S. Some issues in the standardized testing of minority students. Journal of Education, pp. 192–208, 1983.
- Woodworth et al. (2017) Woodworth, B., Gunasekar, S., Ohannessian, M. I., and Srebro, N. Learning non-discriminatory predictors. In Conference on Learning Theory, pp. 1920–1953. PMLR, 2017.
- Wu et al. (2019) Wu, Y., Zhang, L., Wu, X., and Tong, H. PC-fairness: A unified framework for measuring causality-based fairness. Advances in Neural Information Processing Systems, 32, 2019.
- Zafar et al. (2017a) Zafar, M. B., Valera, I., Gomez Rodriguez, M., and Gummadi, K. P. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In Proceedings of the 26th International Conference on World Wide Web, pp. 1171–1180, 2017a.
- Zafar et al. (2017b) Zafar, M. B., Valera, I., Rodriguez, M. G., Gummadi, K. P., and Weller, A. From parity to preference-based notions of fairness in classification. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 228–238, 2017b.
- Zhang & Bareinboim (2018) Zhang, J. and Bareinboim, E. Fairness in decision-making—the causal explanation formula. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Zhang et al. (2017) Zhang, L., Wu, Y., and Wu, X. A causal framework for discovering and removing direct and indirect discrimination. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, pp. 3929–3935, 2017.
Appendix A Path-specific Counterfactuals
Constructing policies which satisfy path-specific fairness requires computing path-specific counterfactual values of features. In Algorithm 1, we describe the formal construction of path-specific counterfactuals , for an arbitrary variable (or collection of variables) in the DAG. To generate a sample from the distribution of , we first sample values for the exogenous variables. Then, in the first loop, we traverse the DAG in topological order, setting to and iteratively computing values of the other nodes based on the structural equations in the usual fashion. In the second loop, we set to , and then iteratively compute values for each node. is computed using the structural equation at that node, with value for each of its parents that are connected to it along a path in , and the value for all its other parents. Finally, we set to .
Appendix B Constructing Causally Fair Policies
In order to construct causally fair policies, we prove that the optimization problem in Eq. (7) can be efficiently solved as a single linear program—in the case of counterfactual equalized odds, conditional principal fairness, counterfactual fairness, and path-specific fairness—or as a series of linear programs in the case of counterfactual predictive parity.
Theorem B.1.
Consider the optimization problem given in Eq. (7).
-
1.
If is the class of policies that satisfies counterfactual equalized odds or conditional principal fairness, and the distribution of is known and supported on a finite set of size , then a utility-maximizing policy constrained to lie in can be constructed via a linear program with variables and constraints.
-
2.
If is the class of policies that satisfies path-specific fairness (including counterfactual fairness), and the distribution of is known and supported on a finite set of size , then a utility-maximizing policy constrained to lie in can be constructed via a linear program with variables and constraints.
-
3.
Suppose is the class of policies that satisfies counterfactual predictive parity, that the distribution of is known and supported on a finite set of size , and that the optimization problem in Eq. (7) has a feasible solution. Further suppose is supported on points, and let be the unit -simplex. Then one can construct a set of linear programs , with each having variables and constraints, such that the solution to one of the LPs in is a utility-maximizing policy constrained to lie in .
Proof.
Let ; then, we seek decision variables , , corresponding to the probability of making a positive decision for individuals with covariate value . Therefore, we require that .
Letting denote the mass of at , note that the objective function equals and the budget constraint are both linear in the decision variables.
We now show that each of the causal fairness definitions can be enforced via linear constraints. We do so in three parts as listed in theorem.
Theorem B.1 Part 1
First, we consider counterfactual equalized odds. A decision policy satisfies counterfactual equalized odds when Since is binary, this condition is equivalent to the expression for all and such that . Expanding this expression and replacing by the corresponding decision variable , we obtain that
for each and each of the finitely many values such that . These constraints are linear in the by inspection.
Next, we consider conditional principal fairness. A decision policy satisfies conditional principal fairness when , where denotes a reduced set of the covariates . Again, since is binary, this condition is equivalent to the expression for all , , and satisfying . As above, expanding this expression and replacing by the corresponding decision variable yields linear constraints of the form
for each and each of the finitely many values of such that satisfies . Again, these constraints are linear by inspection.
Theorem B.1 Part 2
Suppose a decision policy satisfies path-specific fairness for a given collection of paths and a (possibly) reduced set of covariates meaning that for every , .
Recall from the definition of path-specific counterfactuals that , where . Since , , it follows that
An analogous calculation yields that . Equating these expressions gives
for each and each of the finitely many such that . Again, each of these constraints is linear by inspection.
Theorem B.1 Part 3
A decision policy satisfies counterfactual predictive parity if or equivalently, for all . We may rewrite this expression to obtain:
where .
Expanding the numerator on the left-hand side of the above equation yields
Similarly, expanding the denominator yields
for each of the finitely many . Therefore, counterfactual predictive parity corresponds to
| (10) | ||||
for each and . Again, these constraints are linear in the by inspection.
Consider the family of linear programs where the linear program has the same objective function and budget constraint as before, together with additional constraints for each as in Eq. (10), where for .
By assumption, there exists a feasible solution to the optimization problem in Eq. (7), so the solution to at least one program in is a utility-maximizing policy that satisfies counterfactual predictive parity. ∎
Appendix C A Stylized Example of College Admissions
In the example we consider in Section 2.1, the exogenous variables in the DAG are independently distributed as follows:
For fixed constants , , , , , , , , , , , , we define the endogenous variables in the DAG by the following structural equations:
where and is the decision policy. In our example, we use constants , , , , , , , , , , , . We also assume a budget .
Appendix D Proof of Proposition 1
We begin by more formally defining (multiple) threshold policies. We assume, without loss of generality, that for all throughout.
Definition D.1.
Let be a utility function. We say that a policy is a threshold policy with respect to if there exists some such that
and is arbitrary if . We say that is a multiple threshold policy with respect to if there exist group-specific constants for such that
and is arbitrary if .
Remark 1.
In general, it is possible for different thresholds to produce threshold policies that are almost surely equal. For instance, if , then the policies are almost surely equal for all . Nevertheless, we speak in general of the threshold associated with the threshold policy unless there is ambiguity.
We first observe that if is consistent modulo , then whether a decision policy is a multiple threshold policy does not depend on our choice of .
Lemma D.1.
Let be a collection of utilities consistent modulo , and suppose is a decision rule. If is a multiple threshold rule with respect to a utility , then is a multiple threshold rule with respect to every . In particular, if can be represented by non-negative thresholds over , it can be represented by non-negative thresholds over any .
Proof.
Suppose is represented by thresholds with respect to . We construct the thresholds explicitly.
Fix and suppose that there exists such that . Then set . Now, if then, by consistency modulo , . Similarly if then . We also note that by consistency modulo , .
If there is no such that , then let
where . Note that since for all by consistency modulo , if , it follows that as well.
We need to show in this case also that if then , and if then . To do so, let be arbitrary, and suppose . Then, by definition, there exists such that and , whence by consistency modulo . On the other hand, if , it follows by the definition of that ; since by hypothesis, it follows that .
Therefore, it follows in both cases that for , if then , and if then . Therefore
i.e., is a multiple threshold policy with respect to . Moreover, as noted above, if for all , then for all . ∎
We now prove the following strengthening of Prop. 1.
Lemma D.2.
Let be a collection of utilities consistent modulo . Let be a feasible decision policy that is not a.s. a multiple threshold policy with non-negative thresholds with respect to , then is strongly Pareto dominated.
Proof.
We prove the claim in two parts. First, we show that any policy that is not a multiple threshold policy is strongly Pareto dominated. Then, we show that any multiple threshold policy that cannot be represented with non-negative thresholds is strongly Pareto dominated.
If is not a multiple threshold policy, then there exists a and such that is not a threshold policy when restricted to with respect to .
We will construct an alternative policy that attains strictly greater utility on and is identical elsewhere. Thus, without loss of generality, we assume there is a single group, i.e., . The proof proceeds heuristically by moving some of the mass below a threshold to above a threshold to create a feasible policy with improved utility.
Let . Define
We show that there exists such that and . For, if not, consider
Note that a.s. If , then by definition a.s., which is a threshold policy, violating our assumption on . If , then for any , we have, by definition that , and so by hypothesis . Therefore a.s., and so, again, is a threshold policy, contrary to hypothesis.
Now, with as above, for notational simplicity, let and and consider the alternative policy
Then it follows by construction that
so is feasible. However,
and so
Therefore
It remains to show that for arbitrary . Let
Note that by construction for any , if and , then . It follows by consistency modulo that , and, moreover, that at least one of the inequalities is strict. Without loss of generality, assume . Then, we have that if and only if . Therefore, it follows that
Since , we see that
where in the inequality we have used the fact that if , , and if , . Therefore
i.e., strongly Pareto dominates .
Now, we prove the second claim, namely, that a multiple threshold policy that cannot be represented with non-negative thresholds is strongly Pareto dominated. For, if is such a policy, then, by Lemma D.1, for any , . It follows immediately that satisfies . By consistency modulo , the definition of does not depend on our choice of , and so for every , i.e., strongly Pareto dominates . ∎
Definition D.2.
We say that a decision policy is budget-exhausting if
Remark 2.
We note that if is consistent modulo , then whether or not a decision policy is budget-exhausting does not depend on the choice of . Further, if —e.g., if the distribution of is -fine—then the decision policy is budget-exhausting if and only if .
Corollary D.1.
Let be a collection of utilities consistent modulo . If is a feasible policy that is not a budget-exhausting multiple threshold policy with non-negative thresholds, then is strongly Pareto dominated.
Proof.
Suppose is not strongly Pareto dominated. By Lemma D.2, it is a multiple threshold policy with non-negative thresholds.
Now, suppose toward a contradiction that is not budget-exhausting. Then, either or .
In the first case, since is feasible, it follows that . It follows that is not almost surely zero. Therefore
and, by consistency modulo , this holds for any . Therefore is strongly Pareto dominated, contrary to hypothesis.
In the second case, consider
Since and
there exists some such that is feasible.
For that , a similar calculation shows immediately that , and, by consistency modulo , for all . Therefore, again, strongly Pareto dominates , contrary to hypothesis. ∎
Lemma D.3.
Given a utility , there exists a mapping from to taking sets of quantiles to thresholds such that:
-
1.
is monotonically non-increasing in each coordinate;
-
2.
For each set of quantiles, there is a multiple threshold policy with thresholds with respect to such that .
Proof.
Simply choose
| (11) |
Then define
Note that , since, by definition, for all . Therefore,
and so . Further, since , we have that .
Finally, let
and it follows immediately that . That is a monotonically non-increasing function of follows immediately from Eq. (11). ∎
Lemma D.4.
Let be a utility. Then a feasible policy is utility maximizing if and only if it is a budget-exhausting threshold policy. Moreover, there exists at least one utility maximizing policy.
Proof.
Let be a constant map, i.e., , where . Then is consistent modulo , and so by Cor. D.1, any Pareto efficient policy is a budget exhausting multiple threshold policy relative to . Since contains a single element, a policy is Pareto efficient if and only if it is utility maximizing. Since is constant, a policy is a multiple threshold policy relative to if and only if it is a threshold policy. Therefore, a policy is utility maximizing if and only if it is a budget exhausting threshold policy. By Lemma D.3, such a policy exists, and so the maximum is attained. ∎
Appendix E Prevalence and the Proof of Theorem 1
The notion of a probabilistically “small” set—such as the event in which an idealized dart hits the exact center of a target—is, in finite-dimensional real vector spaces, typically encoded by the idea of a Lebesgue null set.
Here we prove that the set of distributions such that there exists a policy satisfying either counterfactual equalized odds, conditional principal fairness, or counterfactual fairness that is not strongly Pareto dominated is “small” in an analogous sense. The proof turns on the following intuition. Each of the fairness definitions imposes a number of constraints. By Lemma D.2, any policy that is not strongly Pareto dominated is a multiple threshold policy. By adjusting the group-specific thresholds of such a policy, one can potentially satisfy one constraint per group. If there are more constraints than groups, then one has no additional degrees of freedom that can be used to ensure that the remaining constraints are satisfied. If, by chance, those constraints are satisfied with the same threshold policy, they are not satisfied robustly—even a minor distribution shift, such as increasing the amount of mass above the threshold by any amount on the relevant subpopulation, will break them. Therefore, over a “typical” distribution, at most of the constraints can simultaneously be satisfied by a Pareto efficient policy, meaning that typically no Pareto efficient policy fully satisfies all of the conditions of the fairness definitions.
Formalizing this intuition, however, requires considerable care. In Section E.1, we give a brief introduction to a popular generalization of null sets to infinite-dimensional vector spaces, drawing heavily on a review article by Ott & Yorke (2005). In Section E.2 we provide a roadmap of the proof itself. In Section E.3, we establish the main hypotheses necessary to apply the notion of prevalence to a convex set—in our case, the set of -fine distributions. In Section E.4, we establish a number of technical lemmata used in the proof of Theorem 1, and provide a proof of the theorem itself in Section E.5. In Section E.6, we show why the hypothesis of -fineness is important and how conspiracies between atoms in the distribution of can lead to “robust” counterexamples.
E.1 Shyness and Prevalence
Lebesgue measure on has a number of desirable properties:
-
•
Local finiteness: For any point , there exists an open set containing such that ;
-
•
Strict positivity: For any open set , if , then ;
-
•
Translation invariance: For any and measurable set , .
No measure on an infinite-dimensional, separable Banach space, such as , can satisfy these three properties (Ott & Yorke, 2005). However, while there is no generalization of Lebesgue measure to infinite dimensions, there is a generalization of Lebesgue null sets—called shy sets—to the infinite-dimensional context that preserves many of their desirable properties.
Definition E.3 (Hunt et al. (1992)).
Let be a completely metrizable topological vector space. We say that a Borel set is shy if there exists a Borel measure on such that:
-
1.
There exists compact such that ,
-
2.
For all , .
An arbitrary set is shy if there exists a shy Borel set containing .
We say that a set is prevalent if its complement is shy.
Prevalence generalizes the concept of Lebesgue “full measure” or “co-null” sets (i.e., sets whose complements have null Lebesgue measure) in the following sense:
Proposition E.3 (Hunt et al. (1992)).
Let be a completely metrizable topological vector space. Then:
-
•
Any prevalent set is dense in ;
-
•
If and is prevalent, then is prevalent;
-
•
A countable intersection of prevalent sets is prevalent;
-
•
Every translate of a prevalent set is prevalent;
-
•
If , then is prevalent if and only if .
As is conventional for sets of full measure in finite-dimensional spaces, if some property holds for every , where is prevalent, then we say that the property holds for almost every or that it holds generically in .
Prevalence can also be generalized from vector spaces to convex subsets of vector spaces, although additional care must be taken to ensure that a relative version of Prop. E.3 holds.
Definition E.4 (Anderson & Zame (2001)).
Let be a topological vector space and let be a convex subset completely metrizable in the subspace topology induced by . We say that a universally measurable set is shy in at if for each , and each neighborhood of in , there is a regular Borel measure with compact support such that
and for every .
We say that is shy in or shy relative to if is shy in at for every . An arbitrary set is shy in if there exists a universally measurable shy set containing .
A set is prevalent in if is shy in .
Proposition E.4 (Anderson & Zame (2001)).
If is shy at some point , then is shy at every point in and hence is shy in .
Sets that are shy in enjoy similar properties to sets that are shy in .
Proposition E.5 (Anderson & Zame (2001)).
Let be a topological vector space and let be a convex subset completely metrizable in the subspace topology induced by . Then:
-
•
Any prevalent set in is dense in ;
-
•
If and is prevalent in , then is prevalent in ;
-
•
A countable intersection of sets prevalent in is prevalent in
-
•
If is prevalent in then is prevalent in for all .
-
•
If and is a convex subset with non-empty interior, then is prevalent in if and only if .
Sets that are shy in can often be identified by inspecting their intersections with a finite-dimensional subspace of , a strategy we use to prove Theorem 1.
Definition E.5 (Anderson & Zame (2001)).
A universally measurable set , where is convex and completely metrizable, is said to be -shy in if there exists a -dimensional subspace such that
-
1.
A translate of the set has positive Lebesgue measure in , i.e., for some ;
-
2.
Every translate of the set is a Lebesgue null set in , i.e., for all .
Here denotes -dimensional Lebesgue measure supported on .131313Note that Lebesgue measure on is only defined up to a choice of basis; however, since for any linear automorphism and Lebesgue measure , whether a set has null measure does not depend on the choice of basis. We refer to such a as a -dimensional probe witnessing the -shyness of , and to an element as a perturbation.
The following intuition motivates the use of probes to detect shy sets. By analogy with Fubini’s theorem, one can imagine trying to determine whether a subset of a finite-dimensional vector space is large or small by looking at its cross sections parallel to some subspace . If a set is small in each cross section—i.e., if for all —then itself is small in , i.e., has -measure zero.
Proposition E.6 (Anderson & Zame (2001)).
Every -shy set in is shy in .
E.2 Outline
To aid the reader in following the application of the theory in Section E.1 to the proof of Theorem 1, we provide the following outline of the argument.
In Section E.3 we establish the context to which we apply the notion of relative shyness. In particular, we introduce the vector space consisting of the totally bounded Borel measures on the state space —where is , , or , depending on which notion of fairness is under consideration. We further isolate the subspace of -fine totally bounded Borel measures. Within this space, we are interested in the convex set , the set of -fine joint probability distributions of, respectively, and ; , , ; or and the . Within , we identify , the set of -fine distributions on over which there exists a policy satisfying the relevant fairness definition that is not strongly Pareto dominated. The claim of Theorem 1 is that is shy relative to .
To ensure that relative shyness generalizes Lebesgue null measure in the expected way—i.e., that Prop. E.5 holds—Definition E.4 has three technical requirements: (1) that the ambient vector space be a topological vector space; (2) that the convex set be completely metrizable; and (3) that the shy set be universally measurable. In Lemma E.7, we observe that is a complete topological vector space under the total variation norm, and so is a Banach space. We extend this in Cor. E.2, showing that is also a Banach space. We use this fact in Lemma E.11 to show that is a completely metrizable subset of , as well as convex. Lastly, in Lemma E.13, we show that the set is closed, and therefore universally measurable.
In Section E.4, we develop the machinery needed to construct a probe for the proof of Theorem 1 and prove several lemmata simplifying the eventual proof of the theorem. To build the probe, it is necessary to construct measures with maximal support on the utility scale. This ensures that if any two threshold policies produce different decisions on any , they will produce different decisions on typical perturbations. The construction of the , is carried out in Lemma E.14 and Cor. E.3. Next, we introduce the basic style of argument used to show that a subset of is shy in Lemma E.15 and Lemma E.16, in particular, by showing that the set of that give positive probability to an event is either prevalent or empty. We use then use a technical lemma, Lemma E.17, to show, in effect, that a generic element of has support on the utility scale wherever a given fixed distribution does. In Defn. E.12, we introduce the concept of overlapping and splitting utilities, and show in Lemma E.19 that this property is generic in unless there exists a -stratum that contains no positive-utility observables . Lastly, in Lemma E.20, we provide a mild simplification of the characterization of finitely shy sets that makes the the proof of Theorem 1 more straightforward.
Finally, in Section E.5, we give the proof of Theorem 1. We divide the proof into three parts. In the first part, we restrict our attention to the case of counterfactual equalized odds, and show in detail how to combine the lemmata of the previous section to construct the (at most) -dimensional probe . In the second part we consider two distinct cases. The argument in both cases is conceptually parallel. First, we argue that the balance conditions of counterfactual equalized odds encoded by Eq. (2) must be broken by a typical perturbation in . In particular, we argue that for a given base distribution , there can be at most one budget-exhausting multiple threshold policy that can—although need not necessarily—satisfy counterfactual equalized odds. We show that the form of this policy cannot be altered by an appropriate perturbation in , but that the conditional probability of a positive decision will, in general, be altered in such a way that Eq. (2) can only hold for a -null set of perturbations. In the final section, we lay out modiciations that can be made to the proof given for counterfactual equalized odds in the first two parts that adapt the argument to the cases of conditional principal fairness and path-specific fairness. In particular, we show how to construct the probe in such a way that the additional conditioning on the reduced covariates in Eqs. (3) and (5) does not affect the argument.
E.3 Convexity, Complete Metrizability, and Universal Measurability
In this section, we establish the background requirements of Prop. E.6 for the setting of Theorem 1. In particular, we exhibit the -fine distributions as a convex subset of a topological vector space, the set of totally bounded -fine Borel measures. We show that the -fine probability distributions form a completely metrizable subset in the topology it inherits from the space of totally bounded measures. Lastly, we show that the set of regular distributions under which there exists a Pareto efficient policy satisfying one of the three fairness criteria is closed, and therefore universally measurable.
E.3.1 Background and notation
We begin by establishing some notational conventions. We let denote the underlying state space over which the distributions in Theorem 1 range. Specifically, in the case of counterfactual equalized odds; in the case of conditional principal fairness; and in the case of path-specific fairness. We note that since for some and , may equivalently be considered a subset of for some , with the subspace topology (and Borel sets) inherited from .141414In the case of path-specific fairness, we can equivalently think of as a set of integers indexing the groups.
We recall the definition of totally bounded measures.
Definition E.6.
Let be a -algebra on , and let be a countably additive -measure. Then, we define
| (12) |
where the supremum is taken over all countable partitions , i.e., collections such that and for . We call the total variation of , and the total variation norm of is .
We say that is totally bounded if its total variation norm is finite, i.e., .
Lemma E.5.
If is totally bounded, then is a finite positive measure on , and for all .
See Theorem 6.2 in Rudin (1987) for proof.
We let denote the set of totally bounded Borel measures on . We note that, in the case of path specific fairness, which involves the joint distributions of counterfactuals, is not defined directly. Rather, the joint distribution of the counterfactuals and defines the distribution of through consistency, i.e., what would have happened to someone if their group membership were changed to is what actually happens to them if their group membership is . More formally, for all Borel sets . (See § 3.6.3 in Pearl (2009b).)
For any , we adopt the following notational conventions. If we say that a property holds -a.s., then the subset of on which the property fails has -measure zero. If is a measurable set, then we denote by the restriction of to , i.e., the measure defined by the mapping . We let , and for measurable sets , .151515To state and prove our results in a notationally uniform way, we occasionally write even when ranges over measures that may not be probability measures. The fairness criteria we consider involve conditional independence relations. To make sense of conditional independence relations more generally, for Borel measurable we define to be the Radon-Nikodym derivative of the measure with respect to the measure restricted to the sub–-algebra of Borel sets . (See § 34 in Billingsley (1995).) Similarly, we define to be , where denotes the sub–-algebra of the Borel sets generated by . In cases where the condition can occur with non-zero probability, we can instead make use of the elementary definition of discrete conditional probability.
Lemma E.6.
Let be a Borel function on , and suppose for some constant . Then, we have that -a.s., for any Borel function ,
See Rao (2005) for proof.
With these notational conventions in place, we turn to establishing the background conditions of Prop. E.6.
Lemma E.7.
The set of totally bounded measures on a measure space form a complete topological vector space under the total variation norm, and hence a Banach space.
See, e.g., Steele (2019) for proof. It follows from this that is a Banach space.
Remark 3.
Since is a Banach space, it possesses a topology, and consequently a collection of Borel subsets. These Borel sets are to be distinguished from the Borel subsets of the underlying state space , which the elements of measure. The requirement that the subset of the convex set be universally measurable in Proposition E.6 is in reference to the Borel subsets of ; the requirement that be a Borel measure is in reference to the Borel subsets of .
Recall the definition of absolute continuity.
Definition E.7.
Let and be measures on a measure space . We say that a measure is absolutely continuous with respect to —also written —if, whenever , .
Absolute continuity is a closed property in the topology induced by the total variation norm.
Lemma E.8.
Consider the space of totally bounded measures on a measure space and fix . The set of such that is closed.
Proof.
Let be a convergent sequence of measures absolutely continuous with respect to . Let the limit of the be . We seek to show that . Let be an arbitrary set such that . Then, we have that
since for all . Since was arbitrary, the result follows. ∎
Recall the definition of a pushforward measure.
Definition E.8.
Let be a measurable function. Let be a measure on . We define the pushforward measure on by the map for .
Within , in the case of counterfactual equalized odds and conditional principal fairness, we define the subspace to be the set of totally bounded measures on such that the pushforward measure is absolutely continuous with respect to the Lebesgue measure on for all . By the Radon-Nikodym theorem, these pushforward measures arise from densities, i.e., for any , there exists a unique such that for any measurable subset of , we have
In the case of path-specific fairness, we require the joint distributions of the counterfactual utilities to have a joint density. That is, we define the subspace to be the set of totally bounded measures on such that the pushforward measure is absolutely continuous with respect to Lebesgue measure on for all . Here, we recall that
As before, there exists a corresponding density .
We therefore see that extends in a natural way the notion of a - or -fine distribution, and so, by a slight abuse of notation, refer to as the set of -fine measures on .
Indeed, since , it also follows that, for such that , the conditional distributions of are also absolutely continuous with respect to Lebesgue measure, and so also have densities. For notational convenience, we set to be the function satisfying
so that .
Since absolute continuity is a closed condition, it follows that is a closed subspace of . This leads to the following useful corollary of Lemma E.8.
Corollary E.2.
The collection of -fine measures on is a Banach space.
Proof.
It is straightforward to see that is a subspace of . Since is a closed subset of by Lemma E.8, it is complete, and therefore a Banach space. ∎
We note the following useful fact about elements of .
Lemma E.9.
Consider the mapping from to given by associating a measure with the Radon-Nikodym derivative of the pushforward measure . This mapping is continuous. Likewise, the mapping is continuous for all , and, in the case of path-specific fairness, the mapping of to the Radon-Nikodym derivative of is continuous.
Proof.
We show only the first case. The others follow by virtually identical arguments.
Let be arbitrary. Choose , and suppose that . Then, let
Then and are disjoint, so we have that
where the second equality follows by the definition of pushforward measures and the inequality follows from Lemma E.5. Since was arbitrary, the claim follows. ∎
Finally, we define . We let be the subset of consisting of all -fine probability measures, i.e., measures such that:
-
1.
The measure is -fine;
-
2.
For all Borel sets , ;
-
3.
The measure of the whole space is unity, i.e., .
We conclude the background and notation by observing that threshold policies are defined wholly by their thresholds for distributions in and . Importantly, this observation does not hold when there are atoms on the utility scale—which measures in lack—which can in turn lead to counterexamples to Theorem 1; see Appendix E.6.
Lemma E.10.
Let and be two multiple threshold policies. If and have the same thresholds, then for any , -a.s. Similarly, for , if
for all such that , then -a.s.
Moreover, for in the case of path-specific fairness, if and have the same thresholds, then -a.s. for any . Similarly, for in the case of path-specific fairness, if
then -a.s. as well.
Proof.
First, we show that threshold policies with the same thresholds are equal, then we show that threshold policies that distribute positive decisions across groups in the same way are equal.
Let denote the shared set of thresholds. It follows that if , then . Now,
so . Next, suppose
If the thresholds of the two policies agree for all such that , then we are done by the previous paragraph. Therefore, suppose for some suitable , where represents the threshold for group under the policy . Without loss of generality, suppose . Then, it follows that
Since , , whence
Since this is true for all such that , -a.s.
The proof in the case of path-specific fairness is almost identical. ∎
E.3.2 Convexity, complete metrizability, and universal measurability
The set of regular -fine probability measures is the set to which we wish to apply Prop. E.6. To do so, we must show that is a convex and completely metrizable subset of .
Lemma E.11.
The set of regular probability measures is convex and completely metrizable.
Proof.
The proof proceeds in two pieces. First, we show that the -fine probability distributions are convex, as can be verified by direct calculation. Then, we show that is closed and therefore complete in the original metric of .
We begin by verifying convexity. Let and let be an arbitrary Borel subset of . Then, choose , and note that
and, likewise, that
It remains only to show that is completely metrizable. To prove this, it suffices to show that it is closed, since closed subsets of complete spaces are complete, and is a Banach space by Cor. E.2, and therefore complete.
Suppose is a convergent sequence of probability measures in with limit . Then
and
Therefore is closed, and therefore complete, and hence is a convex, completely metrizable subset of . ∎
Next we prove that the set of regular -fine densities over which there exists a policy satisfying the relevant counterfactual fairness definition that is not strongly Pareto dominated is universally measurable.
Recall the definition of universal measurability.
Definition E.9.
Let be a complete topological space. Then is universally measurable if is measurable by the completion of every finite Borel measure on , i.e., if for every finite Borel measure , there exist Borel sets and such that and .
We note that if a set is Borel, it is by definition universally measurable. Moreover, if a set is open or closed, it is by definition Borel.
To show that is closed, we show that any convergent sequence in has a limit in . The technical complication of the argument stems from the following fact that satisfying the fairness conditions, e.g., Eq. (4), involves conditional expectations, about which very little can be said in the absence of a density, and which are difficult to compare when taken across distinct measures.
To handle these difficulties, we begin with a technical lemma, Lemma E.12, which gives a coarse bound on how different the conditional expectations of the same variable can be with respect to a sub–-algebra over two different distributions, and , before applying the results to the proof of Lemma E.13.
Definition E.10.
Let be a measure on a measure space , and let be -measurable. Consider the equivalence class of -measurable functions .161616Some authors define spaces to consist of such equivalence classes, rather than the definition we use here. We say that any is a version of , and that is a standard version if for some constant and all .
Remark 4.
It is straightforward to see that for , a standard version always exists with .
Remark 5.
Note that in general, the conditional expectation is defined only -a.e. If is not assumed to be absolutely continuous with respect to , it follows that
| (13) |
is not entirely well-defined, in that its value depends on what version of one chooses. For appropriate , however, one can nevertheless bound Eq. (13) for any standard version of .
Lemma E.12.
Let , be totally bounded measures on a measure space . Let . Let be a sub–-algebra of . Let
Then, if is a standard version of , we have that
| (14) |
Proof.
First, we note that both and are -measurable. Therefore, the sets
and
are in . Now, note that
First consider . Then, we have that
where in the final inequality, we have used the fact that, since is a standard version of ,
for all , and the fact that, by the definition of conditional expectation,
for any .
Since is everywhere bounded by , applying Lemma E.5 yields that this final expression is less than or equal to . An identical argument shows that
whence the result follows. ∎
Lemma E.13.
Let denote the set of joint densities on such that there exists a policy satisfying the relevant fairness definition that is not strongly Pareto dominated. Then, is closed, and therefore universally measurable.
Proof.
For notational simplicity, we consider the case of counterfactual equalized odds. The proofs in the other two cases are virtually identical.
Suppose in , where . Then, by Lemma E.9, in . Moreover, by Lemma D.2, there exists a sequence of threshold policies such that both
and
Let be defined by
if , and otherwise.
Since is compact, there exists a convergent subsequence . Let it converge to the collection of quantiles defining, by Lemma D.3, a multiple threshold policy over .
Choose arbitrarily. Then, choose so large that for greater than ,
Then, observe that , and recall that
| (15) |
Therefore, let be a standard version of over . By Eq. (15), is also a standard version of over . Then, by Lemma E.12, we have that
Since was arbitrary, it follows that, -a.e.,
Recall the standard fact that for independent random variables and ,
where is the distribution of .171717For a proof of this fact see, e.g., Brozius (2019). Further recall that , where . It follows that
Hence, by the law of iterated expectations,
Therefore over , i.e., counterfactual equalized odds holds for the decision policy over the distribution . Consequently , and so is closed and therefore universally measurable. ∎
E.4 Shy Sets and Probes
We require a number of additional technical lemmata for the proof of Theorem 1. The probe must be constructed carefully, so that, on the utility scale, an arbitrary element of is absolutely continuous with respect to a typical perturbation. In addition, it is useful to show that a number of properties are generic to simplify certain aspects of the proof of Theorem 1. For instance, Lemma E.16 is used in Theorem 1 to show that a certain conditional expectation is generically well-defined, avoiding the need to separately treat certain corner cases.
Cor. E.3 concerns the construction of the probe used in the proof of Theorem 1. Lemmata E.17 to E.20 use Cor. E.3 to provide additional simplifications to the proof of Theorem 1.
E.4.1 Maximal support
First, to construct the probe used in the proof of Theorem 1, we require elements such that the densities have “maximal” support. To produce such distributions, we use the following measure-theoretic construction.
Definition E.11.
Let be an arbitrary collection of -measurable sets for some positive measure on a measure space . We say that is the measure-theoretic union of if for all and for some countable subcollection .
While measure-theoretic unions themselves are known (cf. Silva (2008), Rudin (1991)), for completeness, we include a proof of their existence, which, to the best of our knowledge, is not found in the literature.
Lemma E.14.
Let be a finite positive measure on a measure space . Then an arbitrary collection of -measurable sets has a measure-theoretic union.
Proof.
For each countable subcollection , consider the “error term”
We claim that the infimum of over all countable subcollections must be zero.
For, toward a contradiction, suppose it were greater than or equal to . Choose any set such that . Such a set must exist, since otherwise . Choose such that . Again, some such set must exist, since otherwise . Continuing in this way, we construct a countable collection .
Therefore, we see that
By construction, every term in the final sum is greater than or equal to , contradicting the fact that .
Therefore, there exist countable collections such that . It follows immediately that for all
for any fixed . Consequently,
and is countable. ∎
The construction of the “maximal” elements used to construct the probe in the proof of Theorem 1 follows as a corollary of Lemma E.14
Corollary E.3.
There are measures such that for every and any ,
Proof.
Consider the collection . By Lemma E.14, there exists a countable collection of measures such that for any ,
where, without loss of generality, we may assume that for all . Such a sequence must exist, since, by the first hypothesis of Theorem 1, for every , there exists such that . Therefore, we can define the probability measure , where
It follows immediately by construction that
and that . ∎
For notational simplicity, we refer to as throughout.
In the case of conditional principal fairness and path-specific fairness, we need a mild refinement of the previous result that accounts for .
Corollary E.4.
There are measures defined for every and any such that for some , . These measures have the property that for any ,
where is the density of the pushforward measure .
Recalling that , the proof is the same as Cor. E.3, and we analogously refer to as . Here, we have assumed without loss of generality—as we continue to assume in the sequel—that for all , there is some such that .
Remark 6.
Because their support is maximal, the hypotheses of Theorem 1, in addition to implying that is well-defined for all , also imply that . In the case of conditional principal fairness, they further imply that for all and . Likewise, in the case of path-specific fairness, they further imply that for and some .
E.4.2 Shy sets and probes
In the following lemmata, we demonstrate that a number of useful properties are generic in . We also demonstrate a short technical lemma, Lemma E.20, which allows us to use these generic properties to simplify the proof of Theorem 1.
We begin with the following lemma, which is useful in verifying that certain subspaces of form probes.
Lemma E.15.
Let be a non-trivial finite dimensional subspace of such that for all . Then, there exists such that .
Proof.
Set
where form a basis of . Then, if , it follows that
Since
it follows that . ∎
Next we show that, given a , a generic element of “sees” events to which assigns non-zero probability. While Lemma E.18 alone in principle suffices for the proof of Theorem 1, we include Lemma E.16 both for conceptual clarity and to introduce at a high level the style of argument used in the subsequent lemmata and in the proof of Theorem 1 to show that a set is shy relative to .
Lemma E.16.
For a Borel set , suppose there exists such that . Then the set of such that is prevalent.
Proof.
First, we note that the set of such that is closed and therefore universally measurable. For, if is a convergent sequence with limit , then
Now, if for all , there is nothing to prove. Therefore, suppose that there exists such that .
Now, for arbitrary , note that if , then
i.e.,
A singleton has null Lebesgue measure, and so the set of such that is -null. Therefore, by Prop. E.6, the set of such that is shy relative to , as desired. ∎
While Lemma E.16 shows that a typical element of “sees” individual events, in the proof of Theorem 1, we require a stronger condition, namely, that a typical element of “sees” certain uncountable collections of events. To demonstrate this more complex property, we require the following technical result, which is closely related to the real analysis folk theorem that any convergent uncountable “sum” can contain only countably many non-zero terms. (See, e.g., Benji (2020).)
Lemma E.17.
Suppose is a totally bounded measure on , and are -measurable real-valued functions, and -a.e. Then the set
has non-zero measure for at most countably many .
Proof.
First, we show that for any countable collection , the sum converges. Then, we show how this implies that for all but countably many .
First, we note that for distinct ,
Now, by hypothesis,
and since , it follows that
as well. Consequently, it follows that if is a countable collection of distinct elements of , then
To see that this implies that for only countably many , let consist of those such that . Then must be finite for all , since otherwise we could form a collection , in which case
contrary to what was just shown. Therefore,
is countable. ∎
We now apply Lemma E.17 to the proof of the following lemma, which states, informally, that, under a generic element of , is supported everywhere it is supported under some particular fixed element of . For instance, Lemma E.17 can be used to show that for a generic element of , the density of is positive -a.e.
Lemma E.18.
Let and suppose is supported on , i.e., . Then the set of such that is prevalent relative to .
Lemma E.18 states, informally, that for generic , is supported everywhere is supported.
Proof.
We begin by showing that the set of such that is Borel, and therefore universally measurable. Then, we construct a probe and use it to show that this collection is finitely shy.
To begin, let denote the set of such that
We note that is open. For, if , then there exists some such that
Let
Now, since , there exists a such that if , then . Choose arbitrarily so that . Then, by Markov’s inequality, we have that
i.e.,
Now, we note that by the triangle inequality, wherever , either or . Therefore
We conclude that , and so is open.
Note that if and only if
By the definition of the support of a function, . Therefore, it follows that
if and only if
Then, it follows immediately that the set of such that is , which is, by construction, Borel, and therefore universally measurable.
Now, since
is a continuous function of , by the intermediate value theorem, there exists such that , where and . Then, we let
Take . Since and , we have by Lemma E.15 that for some .
By the definition of a density, is positive -a.e. Consequently, by the definition of , is non-zero -a.e. Therefore, by Lemma E.17, there exist only countably many such that the density of equals zero on a set of positive -measure. Since countable sets have -measure zero and is arbitrary, the set of such that is prevalent relative to by Prop. E.6. ∎
The following definition and technical lemma are needed to extend Theorem 1 to the cases of conditional principal fairness and path-specific fairness, which involve additional conditioning on . In particular, one corner case we wish to avoid in the proof of Theorem 1 is when the decision policy is non-trivial (i.e., some individuals receive a positive decision and others do not) but from the perspective of each -stratum, the policy is trivial (i.e., everyone in the stratum receives a positive or negative decision). Definition E.12 formalizes this pathology, and Lemma E.19 shows that this issue—under a mild hypothesis—does not arise for a generic element of .
Definition E.12.
We say that overlaps utilities when, for any budget-exhausting multiple threshold policy , if
then there exists such that
If there exists a budget-exhausting multiple threshold policy such that
but for all ,
then we say that splits utilities over .
Informally, having overlapped utilities prevents a budget-exhausting threshold policy from having thresholds that fall on the utility scale exactly between the strata induced by —i.e., a threshold policy that splits utilities. This is almost a generic condition in , as we shown in Lemma E.19.
Lemma E.19.
Let . Suppose that for all there exists such that . Then almost every overlaps utilities.
Proof.
Our goal is to show that the set of measures such that there exists a splitting policy is shy. To simplify the proof, we divide an conquer, showing that the set of measures such that there exists a splitting policy where the thresholds fall below and above is Borel, before constructing a probe that shows that it is shy. Then, we argue that , which shows that is shy.
We begin by considering the linear map given by
For any , the sets
are closed by construction. Therefore, since is continuous,
| (16) |
is closed, and therefore universally measurable.
Note that by our hypothesis and Cor. E.4, for all there exists some such that
We use this to show that is shy. Pick arbitrarily, and consider the measures for defined by
We note that by construction. Therefore, if , then for some by Lemma E.15.
Moreover, we have that for all , i.e.,
Now, since and partitions , it follows that
Since for any subspace , we can assume without loss of generality that .
In that case, there exists such that if , then , and vice versa. Without loss of generality, assume and . It then follows that for arbitrary ,
where is the basis vector corresponding to . From this, it follows immediately by Eq. (E.4.2) that
only if
This is a measure zero subset of , and so it follows that
for all . Therefore, by Prop. E.6, is shy in . Taking the union over , it follows by Prop. E.5 that is shy.
Now, we must show that . By construction, , since the policy is budget-exhausting and separates utilities. To see the reverse inclusion, suppose , i.e., that there exists a budget-exhausting multiple threshold policy that splits utilities over . Then, let
Since is budget-exhausting, it follows immediately that . Therefore, , and so is shy, as desired. ∎
We conclude our discussion of shyness and shy sets with the following general lemma, which simplifies relative prevalence proofs by showing that one can, without loss of generality, restrict one’s attention to the elements of the shy set itself in applying Prop. E.6.
Lemma E.20.
Suppose is a universally measurable subset of a convex, completely metrizable set in a topological vector space . Suppose that for some finite-dimensional subpace , for some . If, in addition, for all ,
| (17) |
then it follows that is shy relative to .
Proof.
Let be arbitrary. Then, either is empty or not.
First, suppose it is empty. Since by definition, it follows immediately that in this case .
Next, suppose the intersection is not empty, and let for some fixed . It follows that
where the first equality follows by definition; the second equality follows by the translation invariance of , and the fact that ; and the final inequality follows from Eq. (17).
Therefore for arbitrary , and so is shy. ∎
E.5 Proof of Theorem 1
Using the lemmata above, we can prove Theorem 1. We briefly summarize what has been established so far:
-
•
Lemma E.7: The set of -fine distributions on is a Banach space;
-
•
Lemma E.11: The subset of -fine probability measures on is a convex, completely metrizable subset of ;
-
•
Lemma E.13: The subset of is a universally measurable subset of , where is the set consisting of -fine probability measures over which there exists a policy satisfying counterfactual equalized odds (resp., conditional principal fairness, or path-specific fairness) that is not strongly Pareto dominated.
Therefore, to apply Prop. E.6, it follows that what remains is to construct a probe and show that for some but for all .
Proof.
We divide the proof into three pieces. First, we illustrate how to construct the probe from a particular collection of distributions . Second, we show that for all . For notational and expository simplicity, we focus in these first two sections on the case of counterfactual equalized odds. Therefore, in the third section, we show how to generalize the argument to conditional principal fairness and path-specific fairness.
Construction of the probe
We will construct our probe to address two different cases. We recall that, by Cor. D.1, any policy that is not strongly Pareto dominated must be a budget-exhausting multiple threshold policy with non-negative thresholds. In the first case, we consider when the candidate budget-exhausting multiple threshold policy is . By perturbing the underlying distribution by , we will be able to break the balance requirements implied by Eq. (2). In the second case, we treat the possibility that the candidate budget-exhausting multiple threshold policy has a non-trivial positive threshold for at least one group. By perturbing the underlying distribution by for an alternative set of perturbations , we will again be able to break the balance requirements.
More specifically, to construct our probe , we want and to have a number of properties. In particular, for all , perturbation by should not affect whether the underlying distribution is a probability distribution, and should not affect how much of the budget is available to budget-exhausting policies. Specifically, for all ,
| (18) |
and
| (19) |
In fact, the amount of budget available to budget-exhausting policies will not change within group, i.e., for all and ,
| (20) |
Additionally, for some distinguished , non-zero perturbations in should move mass between and . That is, they should have the property that if , then
| (21) |
Finally, perturbations in should have the property that for any non-trivial , some mass is moved either above or below . More precisely, for any and any such that
if is such that , then
| (22) |
To carry out the construction, choose distinct . Then, since
is a continuous function of , it follows by the intermediate value theorem that we can partition into three pieces,
so that
Recall that . Let denote projection onto , and be the injection . We define
By construction, concentrates on
while concentrates on
Moreover, if we set
then it is easy to see that Eqs. (18) to (21) will hold. The only non-trivial case is Eq. (22). However, by Cor. E.3, the support of is maximal. That is, for , if
then it follows that . Either or . First, assume ; then, it follows by the construction of that
Similarly, if ,
Therefore Eq. (22) holds.
Shyness
Recall that, by Prop. E.5, a set is shy if and only if, for an arbitrary shy set , is shy. By Lemma E.16, a generic element of satisfies for , and . Likewise, by Lemma E.18, a generic satisfies . Therefore, to simplify our task and recalling Remark 6, we may instead demonstrate the shyness of the set of such that:
-
•
There exists a budget-exhausting multiple threshold policy with non-negative thresholds satisfying counterfactual equalized odds over ;
-
•
For ,
(23) -
•
For all ,
(24)
By a slight abuse of notation, we continue to refer to this set as . We note that, by the construction of , Eq. (23) is not affected by perturbation by , and Eq. (24) is not affected by perturbation by .
In particular, by Lemma E.20, it suffices to show that for .
Therefore, let be arbitrary. Let the budget-exhausting multiple threshold policy satisfying counterfactual equalized odds over it be , so that
with thresholds . We split into two cases based on whether -a.s. or not.
In both cases, we make use of the following two useful observations.
First, note that as , if is not a probability measure, then . Therefore, without loss of generality, we assume throughout that is a probability measure.
Second, suppose is a policy satisfying counterfactual equalized odds over some . Then, if , it follows that for all ,
| (25) |
For, suppose not. Then, without loss of generality, there must be such that
and
But then, by the law of iterated expectation, there must be some such that and so,
contradicting the fact that satisfies counterfactual equalized odds over . Therefore, in what follows, we can assume that Eq. (25) holds.
Our goal is to show that .
Case 1 ().
We argue as follows. First, we show that is the unique budget-exhausting multiple threshold policy with non-negative thresholds over for all . Then, we show that the set of such that satisfies counterfactual equalized odds over is a -null set.
We begin by observing that . For, if that were the case, then Eq. (25) would not hold for .
Next, we note that by Eq. (19), for any ,
and so
If is a feasible multiple threshold policy with non-negative thresholds and -a.s., then, as a consequence,
Therefore, it follows that is the unique budget-exhausting multiple threshold policy over with non-negative thresholds.
Now, note that if counterfactual equalized odds holds with decision policy , then, by Eq. (4) and Lemma E.6, we must have that
for .191919To ensure that both quantities are well-defined, here and throughout the remainder of the proof we use the fact that by Eqs. (20) and (23), .
Now, we will show that a typical element of breaks this balance requirement. Choose such that . Recall that is fixed, and let . Let
Note that it cannot be the case that for all , since, by Eq. (23),
Therefore, by the foregoing discussion, either or and we can choose such that . Since the , are all mutually singular, it follows that counterfactual equalized odds can only hold over if
Now, we observe that by Lemma E.6, that
where
since
Here, the equality follows by the fact that is supported on and the inequality from Eq. (21).
Therefore, if, in the first case, , then counterfactual equalized odds only holds if
since, as noted above, by Eq. (21). In the second case, if , then counterfactual equalized odds can only hold if
Since we chose so that if and by Eq. (23), this is impossible.
In either case, we see that the set of such that there a budget-exhausting threshold policy with positive thresholds satisfying counterfactual equalized odds over has -measure zero. That is
Since was arbitrary, it follows by Fubini’s theorem that .
Case 2 ().
Our proof strategy is similar to the previous case. First, we show that, for a given fixed , there is a unique candidate policy for being a budget-exhausting multiple threshold policy with non-negative thresholds and satisfying counterfactual equalized odds over for any . Then, we show that the set of such that satisfies counterfactual equalized odds has measure zero. Finally, we argue that this in turn implies that the set of such that there exists a Pareto efficient policy satisfying counterfactual equalized odds over has -measure zero.
We seek to show that . To begin, we note that since concentrates on for all , it follows that
for any .
Now, suppose there exists some such that there exists a budget-exhausting multiple threshold policy with non-negative thresholds such that counterfactual equalized odds is satisfied over . (If not, then we are done and , as the measure of the empty set is zero.) Let
Suppose that is an alternative budget-exhausting multiple threshold policy with non-negative thresholds such that counterfactual equalized odds is satisfied. We seek to show that -a.e. for any . Toward a contradiction, suppose that for some ,
Since, by Eq. (23), , it follows that
Therefore, since is budget exhausting, there must be some such that
From this, it follows can be represented by a threshold greater than or equal to that of on , and hence
contradicting the fact that satisfies counterfactual equalized odds.
By the preceding discussion, Lemma E.10, and the fact that is supported on ,
By Eq. (24), it follows that -a.e. for . As a consequence,
for all . Therefore is, indeed, unique, as desired.
Now, we note that since , it follows that . It follows that , since is budget exhausting. Therefore, by Eq. (19), it follows that for any budget-exhausting policy , , and so over .
Therefore, fix and . By Eq. (25), there is some such that
Then, it follows by Eq. (22) that
Fix . Then, for some , set
Since the , are all mutually singular, it follows that counterfactual equalized odds can only hold over if
Now, we observe that by Lemma E.6, that
| (26) | ||||
where
and we note that
Eq. (26) can be rearranged to
This can only hold if
since by Eq. (22), . Since any countable subset of is a -null set,
Since was arbitrary, it follows by Fubini’s theorem that in this case as well. Lastly, since was also arbitrary, applying Fubini’s theorem a final time gives that .
Conditional principal fairness and path-specific fairness
The extension of these results to conditional principal fairness and path-specific fairness is straightforward. All that is required is a minor modification of the probe.
In the case of conditional principal fairness, we set
where is the injection . Our probe is then given by
almost as before.
The proof otherwise proceeds virtually identically, except for two points. First, recalling Remark 6, we use the fact that a generic element of satisfies in place of throughout. Second, we use the fact that overlaps utility in place of Eq. (25). In particular, If does not overlap utilities for a generic , then, by Lemma E.19, there exists such that for all . If this occurs, we can show that no budget-exhausting multiple threshold policy with positive thresholds satisfies conditional principal fairness, exactly as we did to show Eq. (25).
In the case of path-specific fairness, we instead define
where is chosen so that
Let denote the projection from given by
Let denote the projection from the -th component. (That is, given , the distribution of over is given by and the distribution of is given by .) Then, we let be the measure on given by
Finally, let be a permutation of the groups with no fixed points, i.e., so that for all . Then, we define
where is the measure on given by . Then, simply let
Since for all , it follows that , i.e.,
for any and . Therefore Eqs. (18) and (19) hold. Moreover, the satisfy the following strengthening of Eq. (22). Perturbations in have the property that for any non-trivial —not necessarily positive—some of the mass of is moved either above or below . More precisely, for any and any such that
if is such that , then
| (27) |
This stronger property means that we need not separately treat the case where -a.e.
Other than this difference the proof proceeds in the same way, except for two points. First, we again make use of the fact that can be assumed to overlap utilities in place of Eq. (25), as in the case of conditional principal fairness. Second, and take the place of and . In particular, to establish the uniqueness of given and in the second case, instead of conditioning on , we instead condition on , where, following the discussion in Remark 6 and Lemma E.16, this conditioning is well-defined for a generic element of . ∎
We have focused on causal definitions of fairness, but the thrust of our analysis applies to non-causal conceptions of fairness as well. Below we show that policies constrained to satisfy (non-counterfactual) equalized odds (Hardt et al., 2016) are generically strongly Pareto dominated, a result that follows immediately from our proof above.
Definition E.13.
Equalized odds holds for a decision policy when
| (28) |
We note that in Eq. (28) does not depend on our choice of , but rather represents the realized value of , e.g., under some status quo decision making rule.
Corollary E.5.
Suppose is a set of utilities consistent modulo . Further suppose that for all there exist a -fine distribution of and a utility such that , where . Then, for almost every -fine distribution of and on , any decision policy satisfying equalized odds is strongly Pareto dominated.
Proof.
Consider the following maps. Distributions of and , i.e., probability measures on , can be embedded in the space of joint distributions on , , and via pushing forward by the map , where . Likewise, given a fixed decision policy , joint distributions of , , and can be projected onto the space of joint distributions of and by pushing forward by the map . Lastly, we see that the composition of and —regardless of our choice of —is the identity, as shown in the diagram below.
We note also that counterfactual equalized odds holds for exactly when equalized odds holds for . The result follows immediately from this and Theorem 1. ∎
E.6 General Measures on
Theorem 1 is restricted to -fine and -fine distributions on the state space. The reason for this restriction is that when the distribution of induces atoms on the utility scale, threshold policies can possess additional—or even infinite—degrees of freedom when the threshold falls exactly on an atom. In particular circumstances, these degrees of freedom can be used to ensure causal fairness notions, such as counterfactual equalized odds, hold in a locally robust way. In particular, the generalization of Theorem 1 beyond -fine measures to all totally bounded measures on the state space is false, as illustrated by the following proposition.
Proposition E.7.
Consider the set of distributions—not necessarily -fine—on over which there exists a Pareto efficient policy satisfying counterfactual equalized odds. There exist , , , and such that is not relatively shy.
Proof.
We adopt the notational conventions of Section E.3. We note that by Prop. E.5, a set can only be shy if it has empty interior. Therefore, we will construct an example in which an open ball of distributions on in the total variation norm all allow for a Pareto efficient policy satisfying counterfactual equalized odds, i.e., are contained in .
Let , , , and . Let be given by for arbitrary . Likewise, let be given by . Then, if , is vacuously consistent modulo . Consider the joint distribution on where for all , , and ,
where, over , is distributed as a -mixture of and ; that is, and for .
We first observe that there exists a Pareto efficient threshold policy such that counterfactual equalized odds is satisfied with respect to the decision policy . Namely, let
Then, it immediately follows that . Since is a threshold policy and exhausts the budget, it is utility maximizing by Lemma D.4. Moreover, if for some independent of and , then . Since , it follows that
Therefore Eq. (2) is satisfied, i.e., counterfactual equalized odds holds. Now, using , we construct an open ball of distributions over which we can construct similar threshold policies. In particular, suppose is any distribution such that . Then, we claim that there exists a budget-exhausting threshold policy satisfying counterfactual equalized odds over . For, we note that
and so any threshold policy satisfying must have as its threshold.
We will now construct a threshold policy satisfying counterfactual equalized odds over . Consider a threshold policy of the form
For notational simplicity, let
Then, we have that
Therefore, the policy will be budget exhausting if
and it will satisfy counterfactual equalized odds if
| (29) | ||||
since, as above,
Again, for notational simplicity, let
Then, a straightforward algebraic manipulation shows that Eq. (29) is solved by setting to be
and to be
In order for to be a well-defined policy, we need to show that for all and . To that end, note that
Now, we recall that for any event by hypothesis. Therefore,
Using these bounds and the expressions for derived above, we see that
and hence for all and .
Therefore, the policy is well-defined, and, by construction, is budget-exhausting and therefore utility-maximizing by Lemma D.4. It also satisfies counterfactual equalized odds by construction. Since was arbitrary, it follows that the set of distributions on such that there exists a Pareto efficient policy satisfying counterfactual equalized odds contains an open ball, and hence is not shy. ∎
Appendix F Theorem 2 and Related Results
We first prove a variant of Theorem 2 for general, continuous covariates . Then, we extend and generalize Theorem 2 using the theory of finite Markov chains, offering a proof of the theorem different from the sketch included in the main text.
F.1 Extension to Continuous Covariates
Here we follow the proof sketch in the main text for Theorem 2, which assumes a finite covariate-space . In that case, we start with a point with maximum decision probability , and then assume, toward a contradiction, that there exists a point with strictly lower decision probability. The general case is more involved since it is not immediately clear that the maximum value of is achieved with positive probability in . We start with the lemma below before proving the main result.
Lemma F.21.
A decision policy satisfies path-specific fairness with if and only if any ,
Proof.
First, suppose that satisfies path-specific fairness. To show the result, we use the standard fact that for independent random variables and ,
| (30) |
where is the distribution of . (For a proof of this fact see, for example, Brozius, 2019)
Now, we have that
where the first equality follows from the definition of , and the second from Eq. (30), since the exogenous variable is independent of the counterfactual covariates . An analogous argument shows that .
Finally, conditioning on , we have
where the second equality follows from the fact that , the third from the law of iterated expectations, and the fourth from the definition of path-specific fairness.
We are now ready to prove a continuous variant of Theorem 2. The technical hypotheses of the theorem ensure that the conditional probability measures are “sufficiently” mutually non-singular distributions on with respect to the distribution of —for example, the conditions ensure that the conditional distribution of does not have atoms that itself does not have, and vice versa. For notational and conceptual simplicity, we only consider the case of trivial , i.e., where for all .
Proposition F.8.
Suppose that
-
1.
For all and any event satisfying , we have, a.s.,
-
2.
For all and , there exists such that for any event satisfying , we have, a.s.,
Then, for , any -fair policy is constant a.s. (i.e., a.s. for some ).
Proof.
Let , the essential supremum of . To establish the theorem statement, we show that for all . To do that, we begin by showing that there exists some such that .
Assume, toward a contradiction, that for all ,
| (31) |
Because is finite, there must be some such that
| (32) |
for all .
Choose . We show that for values of such that is close to , the distribution of must be concentrated near with high probability to satisfy the definition of path-specific fairness, in Eq. (5). But, under the assumption in Eq. (31), we also show that the concentration occurs with low probability, by the continuity hypothesis in the statement of the theorem, establishing the contradiction.
Specifically, by Markov’s inequality, for any , a.s.,
where the final equality follows from Lemma F.21. Rearranging, it follows that for any , a.s.,
| (33) | ||||
Now let . By the second hypothesis of the theorem, we can choose sufficiently small that if
then, a.s.,
In other words, we can chose such that if
then, a.s.,
By Eq. (31), we can choose so small that
Then, we have that
a.s. Further, by the definition of the essential supremum and , and the fact that , we have that
Therefore, with positive probability, we have that
This contradicts Eq. (33), and so it cannot be the case that , meaning .
Now, we show that . Suppose, toward a contradiction, that
Then, by the first hypothesis, a.s.,
As a consequence,
where we can condition on the set since ; and the second equality above follows from Lemma F.21. This establishes the contradiction, and so .
Finally, we extend this equality to all . Since, , we have, by the second hypothesis of the theorem, that, a.s.,
Since, by definition, , and , we can strengthen this to
F.2 A Markov Chain Perspective
The theory of Markov chains illuminates—and allows us to extend—the proof of Theorem 2. Suppose .202020Because of the technical difficulties associated with characterizing the long-run behavior of arbitrary infinite Markov chains, we restrict our attention in this section to Markov chains with finite state spaces. For any , let where . Then is a stochastic matrix.
To motivate the subsequent discussion, we first note that this perspective conceptually simplifies some of our earlier results. Lemma F.21 can be recast as stating that when , a policy is -fair if and only if —i.e., if and only if is a 1-eigenvector of —for all .
The 1-eigenvectors of Markov chains have a particularly simple structure, which we derive here for completeness.
Lemma F.22.
Let denote the recurrent classes of a finite Markov chain with transition matrix . If is a 1-eigenvector of , then takes a constant value on each , , and
| (34) |
Remark 7.
We note that always exists and is the probability that the Markov chain, beginning at state , is eventually absorbed by the recurrent class .
Proof.
Note that, possibly by reordering the states, we can arrange that the stochastic matrix is in canonical form, i.e., that
where is a sub-stochastic matrix, is non-negative, and
is a block-diagonal matrix with the stochastic matrix corresponding to the transition probabilities on the recurrent set in the -th position along the diagonal.
Now, consider a -eigenvector of . We must have that , i.e., and . Therefore is a 1-eigenvector of . Since is block diagonal, and each diagonal element is a positive stochastic matrix, it follows by the Perron-Frobenius theorem that the 1-eigenvectors of are given by , where is the vector which is 1 at index if and is 0 otherwise.
Now, for , we must find such that .
Note that every finite Markov chain can be canonically associated with an absorbing Markov chain where the set of states of is exactly the union of the transitive states of and the recurrent sets of . (In essence, one tracks which state of the Markov chain is in until it is absorbed by one of the recurrent sets, at which point the entire recurrent set is treated as a single absorbent state.) The transition matrix associated with is given by
where . In particular, it follows that is a 1-eigenvector of if and only if is a 1-eigenvector of , where .
Now, if is a 1-eigenvector of , then it is a 1-eigenvector of for all . Since is sub-stochastic, the series converges to . Since
it follows that
Therefore, if is a 1-eigenvector of , we must have that . By Theorem 3.3.7 in Kemeny & Snell (1976), the entry of is exactly the probability that, conditional on , the Markov chain is eventually absorbed by the recurrent set . This is, in turn, by the Chapman-Kolmogorov equations and the definition of , equal to , and therefore the result follows. ∎
We arrive at the following simple necessary condition on -fair policies.
Corollary F.6.
Suppose is finite, and define the stochastic matrix . If is a -fair policy then it is constant on the recurrent classes of .
Proof.
We note that Theorem 2 follows immediately from this.
Proof of Theorem 2.
Note that decomposes into a block diagonal stochastic matrix, where each block corresponds to a single stratum of and is irreducible. Consequently, each stratum forms a recurrent class, and the result follows. ∎
Appendix G Proof of Proposition 2
To prove the proposition, we must characterize the conditional tail risks of the beta distribution. Note that in the main text, we parameterize beta distributions in terms of their mean and sample size ; here, for mathematical simplicity, we parameterize them in terms of successes, , and failures, , where and .
Lemma G.23.
Suppose for , and that , . Then, for all , .
Proof.
Let . Then,
Since , we may take the partial derivative with respect to by differentiating under the integral sign, which yields that equals
where . Rearranging gives that this is greater than zero when
Since all of the integrands are positive, .
A virtually identical argument shows that . Therefore, the result follows. ∎
We use this lemma to prove a modest generalization of Prop. 2.
Lemma G.24.
Suppose , and consider the family of utility functions of the form
indexed by , where . Suppose the conditional distributions of given are beta distributed, i.e.,
with and . Then any policy satisfying counterfactual predictive parity is strongly Pareto dominated.
Proof.
Suppose there were a Pareto efficient policy satisfying counterfactual predictive parity. Let . Then, by Prop. 1, we may without loss of generality assume that there exist thresholds , and a constant such that a threshold policy witnessing Pareto efficiency is given by
(Note that by our distributional assumption, for all .) Since , we must have that . Since , . Therefore,
where the first equality follows by the law of iterated expectation, the second from the fact that , the third from our distributional assumption and Lemma G.23, and the final again from the law of iterated expectation. However, since counterfactual predictive parity is satisfied, , which is a contradiction. Therefore, no such threshold policy exists. ∎
After accounting for the difference in parameterization, Prop. 2 follows as a corollary.