Causal Feature Learning in the Social Sciences
Abstract
Variable selection poses a significant challenge in causal modeling, particularly within the social sciences, where constructs often rely on inter-related factors such as age, socioeconomic status, gender, and race. Indeed, it has been argued that such attributes must be modeled as macro-level abstractions of lower-level manipulable features, in order to preserve the modularity assumption essential to causal inference (Mossé et al. (2025)). This paper accordingly extends the theoretical framework of Causal Feature Learning (CFL). Empirically, we apply the CFL algorithm to diverse social science datasets, evaluating how CFL-derived macrostates compare with traditional microstates in downstream modeling tasks.
1 Introduction
When an individual is discriminated against, their worse treatment is partly explained by the fact that they possess a protected attribute, such as race or gender (Thomsen (2018)). Where explanation is understood causally, we arrive at a causal fairness constraint, which restricts causal pathways between individuals’ protected attributes and their treatment Loi et al. (2023). Causal algorithmic fairness criteria provide different ways of making this constraint precise (Kilbertus et al. (2017); Kusner et al. (2017); Barocas et al. (2023)). For example, counterfactual fairness compares the distribution of a predictor , given an individual’s features and their protected attribute (e.g. a race or gender), to the counterfactual distribution of the predictor, where that individual’s protected attribute takes a different attribute (Kusner et al. (2017)):111For comparison between metric fairness criteria (Dwork et al. (2012)) and causal criteria, see ((Plečko and Bareinboim, 2024, pp.90-97)). For comparison between so-called “statistical” criteria and causal criteria, see Glymour and Herington (2019); Beigang (2023).
| (1) |
Of course, estimating the quantities that feature in causal criteria, e.g. (1), requires substantive assumptions, but this is a general feature of causal inference, and theorists have developed methods for handling uncertainty about the underlying causal structure (Russell et al. (2017)). A more basic problem for causal notions of fairness is to clarify the sense in which an individual’s race, gender, or other protected attribute can cause their worse treatment.
An initial challenge contended that protected attributes cannot cause outcomes, because they are not manipulable (cf. Holland (1986), p. 946; Greiner and Rubin (2011), pp. 1-2; Glymour and Glymour (2014); Sen and Wasow (2016), p. 504). However, the impossibility of intervening on protected attributes is not necessarily a problem (Pearl (2018)). After all, it is impossible to intervene on people’s smoking habits, but we can estimate the effects of smoking ((Weinberger, 2022, p. 1268)). A more recent challenge contends that protected attributes like race cannot be modeled as causes of worse treatment, because the constitutive relations between these attributes and individuals’ other features violate the modularity assumption essential to causal inference, which requires the ability to isolate causal effects (Kohler-Hausmann (2018); Hu and Kohler-Hausmann (2020); Hu (2022, 2024)).
In reply, theorists have suggested that modularity can be preserved, if the constitutive relations between race and other attributes are modeled using the framework of causal abstraction (Mossé et al. (2025)), i.e. protected attributes like race are modeled as macrostates, which correspond systematically to the states of micro-variables that constitute them. While this answers the modularity worry in theory, the approach is empirically untested. Heterogeneity among micro-variables is a general obstacle to the construction of macrostates Spirtes and Scheines (2004), and theorists have given principled reasons for thinking that this problem may arise for macrostates corresponding to protected attributes (Tolbert (2024a, b)). In sum, it is an open empirical question whether one can construct protected attributes like age, race, and gender as macrostates, in a way that preserves the causal profile of the corresponding micro-variables.
Variable selection poses a significant challenge in causal modeling, particularly within the social sciences, which rely heavily on causal inference ((Imbens, 2024, p. 650)), and which often study complex, inter-related factors such as age, socioeconomic status, gender, and race. At the same time, the practical impossibility of experimentation often requires that researchers working in the social sciences rely on merely observational data ((Gangl, 2010, pp. 25-29)), which in general greatly under-determines the underlying causal structure, as formalized in the so-called “causal hierarchy theorems” (Ibeling and Icard (2021); Bareinboim et al. (2022)).222We follow much of the algorithmic fairness literature in using Structural Causal Models. See Ibeling and Icard (2024) for a partial equivalence between this framework and potential outcomes. See Pearl (2010) for a defense of Structural Causal Models in sociology. Some have proposed that social scientists conjecture causal structure using qualitative data, for example by relying on ethnographies that describe how existing social practices produce outcomes of interest ((Steel, 2004, pp. 67-70)).
Other fields, including healthcare, genetics, and climatology, have turned to Causal Feature Learning (CFL) (Chalupka et al. (2014, 2016a, 2016b, 2017)), which addresses the variable selection challenge by identifying features that sustain causal relationships under various manipulations. CFL operates by partitioning the data into clusters of macrostates that encapsulate the essential causal dynamics among microstates. This allows the data to determine how variables are constructed, uncovering latent structures that predefined categories may overlook. Formally, CFL seeks to identify a partition of the microstates into macrostates such that for each macrostate, the causal effect on the outcome is preserved. That is, given a set of microstate causes and microstate effects , CFL aims to find a partition such that for any two microstates , if under , then for any macrostate :
| (2) |
This equivalence ensures that the macrostates derived from maintain the causal relationships necessary for accurate causal inference. However, CFL assumes that all variables are discrete, and is not directly applicable to many social scientific data sets. It is an open question how this theoretical framework can be extended to the continuous setting.
This paper provides answers to these theoretical and empirical questions. On the theory side, we show that a simple binning technique immediately extends the Causal Coarsening Theorem (CCT) of Chalupka et al. (2017) to the continuous setting:
Theorem 1 (Extended CCT, informal).
A partition of continuous variables based purely on observational data can be refined into the partition defined by (2); the subset of distributions for which this fails has Lebesgue measure zero.
Because equation 2 is a strict requirement, the partition guaranteed by the CCT may be trivial when each micro-state has a distinctive effect. Further, a natural question is whether non-trivial partitions exit, for which equation 2 holds only approximately. We show that this is indeed the case:
Theorem 2 (Regularity, informal).
There always exist partition on micro-states and for which the equation 2 holds approximately.
After making theoretical extensions to the framework of CFL, we apply the extended CFL algorithm to diverse social science datasets, evaluating how CFL-derived macrostates compare with traditional microstates in downstream modeling tasks.333See https://github.com/Rorn001/causal-learning.git for replication code and data We show that CFL reliably reduces dimensionality while detecting heterogeneity in the effects of macrostates.
2 Preliminaries and Notation
We follow standard notation and terminology from the causal inference literature. Let represent the set of microstates, with denoting the individual covariates or features of interest in a dataset. These microstates represent the most granular elements in the data, such as age, education, income, or other social indicators in the context of social sciences. Let represent the set of outcomes, with denoting the observed effects or responses (e.g., voting behavior, income after a treatment, etc.).
Additionally, we assume the presence of treatment variables, where the intervention sets the microstate to a specific value through a treatment or policy intervention. Our primary goal is to develop methodologies that construct macrostates from the microstates. A macrostate is a coarser, aggregated version of the microstates, grouped in such a way that the underlying causal structure is preserved. Formally, a macrostate is a partition of the set of microstates into clusters, where each cluster summarizes multiple microstates while maintaining their causal effect on the outcome variable .
In this paper, we extend the Causal Feature Learning (CFL) framework to automatically construct these macrostates, particularly when dealing with both discrete and continuous microstates. The goal is to find partitions of into macrostates that preserve the causal relationships necessary for accurate causal inference, specifically ensuring that for any two microstates and in the same partition, their causal effect on microstate effect remains equivalent under manipulation:
This ensures that the derived macrostates are both informative and causally consistent with the microstates they summarize.
3 Causal Feature Learning
This section provides an overview of the CFL framework, and shows Theorem 1.
3.1 Preliminaries and Assumptions
Definition 3.1 (Microstates).
Let denote the set of microstate causes and the set of microstate effects. The variable denotes a confounder influencing both and .
Assumption 1 (Discrete Macrostates).
All macrostates are discretized into a finite number of states, denoted by . This ensures a finite state space, facilitating the application of clustering methods for data partitioning.
Assumption 2 (Smoothness).
The conditional distribution may exhibit discontinuities at the boundaries of observational states. However, a continuous density function exists such that , where is piecewise continuous.
Definition 3.2 (Partitions).
The observational partition with respect to is induced by the equivalence relation:
The fundamental causal partition with respect to is induced by the equivalence relation:
The confounding partition with respect to is induced by the equivalence relation:
Definition 3.3 (Macrostate Manipulation).
The operation on a macrostate is defined by manipulating the underlying microstate to a value such that . Formally, is expressed as for .
3.2 Causal Coarsening Theorem (CCT)
Chalupka et al. (2017) prove that the causal partition will (almost always) be a coarsening of the observational partition, which justifies applying clustering algorithm to observed data to uncover the underlying causal structure.
Theorem 3 (Causal Coarsening Theorem).
Consider the set of joint distributions that induce a fixed causal partition and a fixed confounding partition . The subset of distributions where is not a coarsening of has Lebesgue measure zero.
Remark 3.1.
Analogous to partitioning , Chalupka et al. (2017) define the observational partition and causal partition of . They used the same teniniques stated above to prove the following statement: The subset of distributions where is not a coarsening of has Lebesgue measure zero.
Instead of considering point mass of the conditional distribution , we consider the probability of falling into certain interval while conditioning on . More formally, we discretize into bins of the form , where . Such discretization induces the observational partition and causal partition for continuous variables.
Definition 3.4 (Partitions with Binning).
For continuous macrostates, the observational partition is induced by the equivalence relation:
Analogously, the causal partition with binning is induced by the equivalence relation:
The binning process involves partitioning continuous variables into discrete intervals, allowing CFL to apply in scenarios where variables are not naturally categorical. The choice of the number of bins and the binning thresholds can be guided by statistical methods such as equal-width binning, equal-frequency binning, or more sophisticated techniques like entropy-based binning to optimize the preservation of causal relationships. With the binning technique, the Causal Coarsening Theorem extends to continuous variables straightaway:
Theorem 4 (Extended Causal Coarsening Theorem).
Consider the set of joint distributions that induce a fixed causal partition and a fixed confounding partition . Under the binning technique defined in Definition 3.4, the subset of distributions where is not a coarsening of has Lebesgue measure zero.
The full proof is relegated to Appendix A. Here we include a sketch:
Proof Sketch.
Define the following probabilities:
Fixing directly fixes , and fixing directly fixes , effectively fixing .
The conditions can be expressed as equations based on , which turn out to impose polynomial constraints on the joint distribution . These constraints are non-trivial, as demonstrated by constructing specific examples where they do not hold. Therefore, the subset of violating the theorem’s conditions is of Lebesgue measure zero. Consequently, the subset of joint distributions that violate the theorem is also of measure zero. ∎
Remark 3.2.
Analogously, we could define the observational partition and causal partition of with the binning technique. The same argument applies to the and , ensuring that the subset of distributions where is not a coarsening of also has Lebesgue measure zero.
3.3 Approximate Partitions
The causal coarsening theorem says that the causal partition refines the observational one. But it provides no guarantee regarding the size of the partition. At the extreme, if each state has a distinctive effect , the partition will be trivial: no two states will belong to the same equivalence class. A natural question, then, is whether one can find a partition which ensures that states have effects which are individually close to the average within their cell:
The objective is to maximize the minimum value of for which the above holds for all pairs (Beckers et al. (2019)). This may be relaxed to hold on average over all pairs (Rischel and Weichwald (2021)),444For a very general statement of the objective, see (Geiger et al., 2024, p. 18). but here we consider a different relaxation: we can require that the average effects across any -fraction of the variables in a cell be -close to the average effects across the cell as a whole. In other words, where , and similarly for , we require that for disjoint with ,
As we now show, the existence of such partitions over (and ), and their relationship to the “randomness” of the effects of on , follow from a result of Csaba and Pluhár (2014), who show (roughly) that a weighted graph can be partitioned into similarly sized cells, which have relatively stable average weights into each other. We first introduce the relevant notion of a partition:
Definition 3.5 (Weighted graphs).
A weighted graph is a set of vertices and a set of undirected edges , along with a weight function assigning a weight to each edge .
Definition 3.6 (-regularity).
Let be disjoint subsets of . The pair is -regular if for every with ,
Definition 3.7 (-regular partitions).
A weighted graph has an -regular partition if its vertex set can be participated clusters , such that
-
•
The clusters are equal in size (plus or minus one), and .
-
•
All but at most of the pairs are -regular.
The upper bound on the number of clusters needed to provide a partition of this kind depends on how “random” the graph is, in the following sense:
Definition 3.8 (Quasi-randomness).
A weighted graph with vertex set is -quasi-random if for any disjoint such that ,
where denote the sum of the weights of all edges with one endpoint in and the other in .
In other words, is quasi-random when subsets of sizes at least (relative to ) have an average edge density which is equal to that of the overall graph, up to a multiplicative factor. Csaba and Pluhár (2014) show (p. 5):
Lemma 3.1 (Weighted Regularity Lemma).
Let and such that and let . If is a weighted -quasi-random graph on vertices with sufficiently large depending on , then admits a weighted -regular partition into sets such that for some constant .
The desired result follows immediately:
Theorem 5.
For micro-causes and effects , let for denote the equivalence classes of and under partitions and . There exist partitions and which are -regular, in the sense that for all with ,
Indeed, let be a bipartite graph, with vertices corresponding to microstates . Define . Then apply Lemma 3.1 to obtain the desired partition. Note that Theorem 5 is in fact equivalent to Lemma 3.1, restricted to bipartite graphs. For any such graph, we may scale down edge weights by a constant (the maximum edge weight), view the resulting weights as probabilities , apply Theorem 5, and then obtain an -regular partition, for .
Lemma 3.1 generalizes Szemerédi’s Regularity Lemma (Szemerédi (1975)), and a significant literature explores the algorithmic side of this lemma, e.g. Fox et al. (2017). Nonetheless, it what follows, we deploy a straightforward generalization of the CFL algorithm, which we find reliably reduces dimensionality while detecting heterogeneous effects of macro-states.
4 Social Science Applications
This section presents empirical results from applying the CFL algorithm to two prominent social science datasets: the National Supported Work (NSW) dataset and the Voting dataset. We demonstrate how CFL-derived macrostates enhance causal inference, uncover the heterogeneity in causal effects, and reduce the dimensionality of the causal analysis. In Appendix B, using the redlining dataset with census data, We also show that CFL can be incorporated with the canonical causal inference technique, such as propensity score matching, to combat issues due to the nature of the observational dataset. Appendix C presents the results from binning implementation on the NSW dataset.
Algorithmic Preliminaries: The CFL algorithm constitutes a conditional density estimation by a neural network and a partition of the dataset by clustering observations based on the estimated conditional probability. Common clustering techniques are KMeans and DBSCAN (Density-Based Spatial Clustering of Applications with Noise), the first of which allows controlling for the number of clusters as a hyperparameter, while the second of which tunes the number of clusters as a model parameter (CFL (2022)). We use KMeans for our clustering tasks in this paper allowing for more flexible visualization and a better understanding of the algorithm, though the aim of the CFL algorithm is to identify the optimal number of macrostate without supervision.
4.1 The NSW Dataset
The National Supported Work (NSW) dataset is a cornerstone in evaluating the effectiveness of job training programs. Originally utilized to assess the impact of a randomized labor training program on participants’ future earnings in LaLonde (1986), this dataset provides a robust framework for testing the validity of the CFL algorithm in social science data. By deriving macrostates from socioeconomic indicators, we aim to construct variables that better capture the causal pathways influencing earnings outcomes.
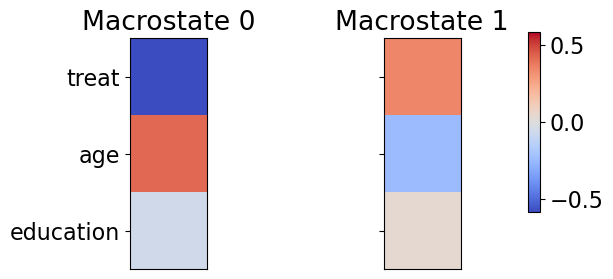
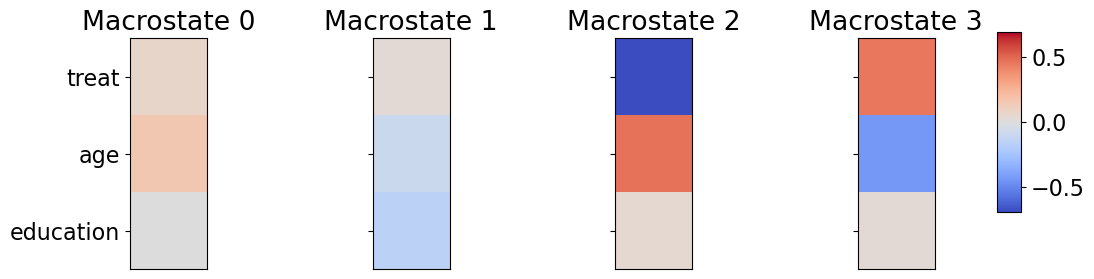
Clustering Analysis: Figure 1c compares global (sample) averages and local (within-macrostate) averages of covariates across clusters constructed by the CFL algorithm. The variable ‘treat’ is a treatment indicator. Varaible ‘age’ and ‘education’ are integers representing participants’ age and years of education, respectively. The outcome variable measures the change in income between pre- and post-treatment periods.
With two clusters, CFL partitions the sample into one macrostate predominantly composed of younger, treated individuals and another macrostate composed of older, untreated individuals. The local averages of education remain close to the global average, whereas the local averages of treatment and age differ significantly from global ones, suggesting that they drive the clustering process.
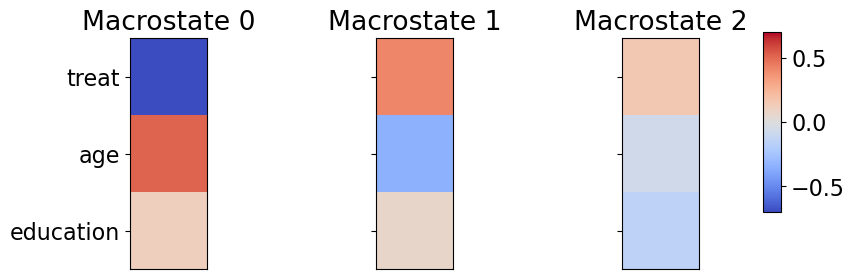
As the number of clusters increases, CFL refines the partitioning, introducing greater granularity. While education initially plays a limited role in defining macrostate, it becomes more influential in the three- and four-cluster cases. A cluster primarily composed of untreated individuals remains stable across different specifications, whereas other groups are further divided into subgroups with distinct characteristics.
4.2 Causal Feature Learning Detects Heterogeneous Causal Effects
Heterogeneity in causal effects is a prevalent phenomenon in social sciences, where the impact of an intervention varies across different subpopulations. The CFL algorithm facilitates the identification of such heterogeneity by uncovering macrostates that segment the population based on underlying causal mechanisms.
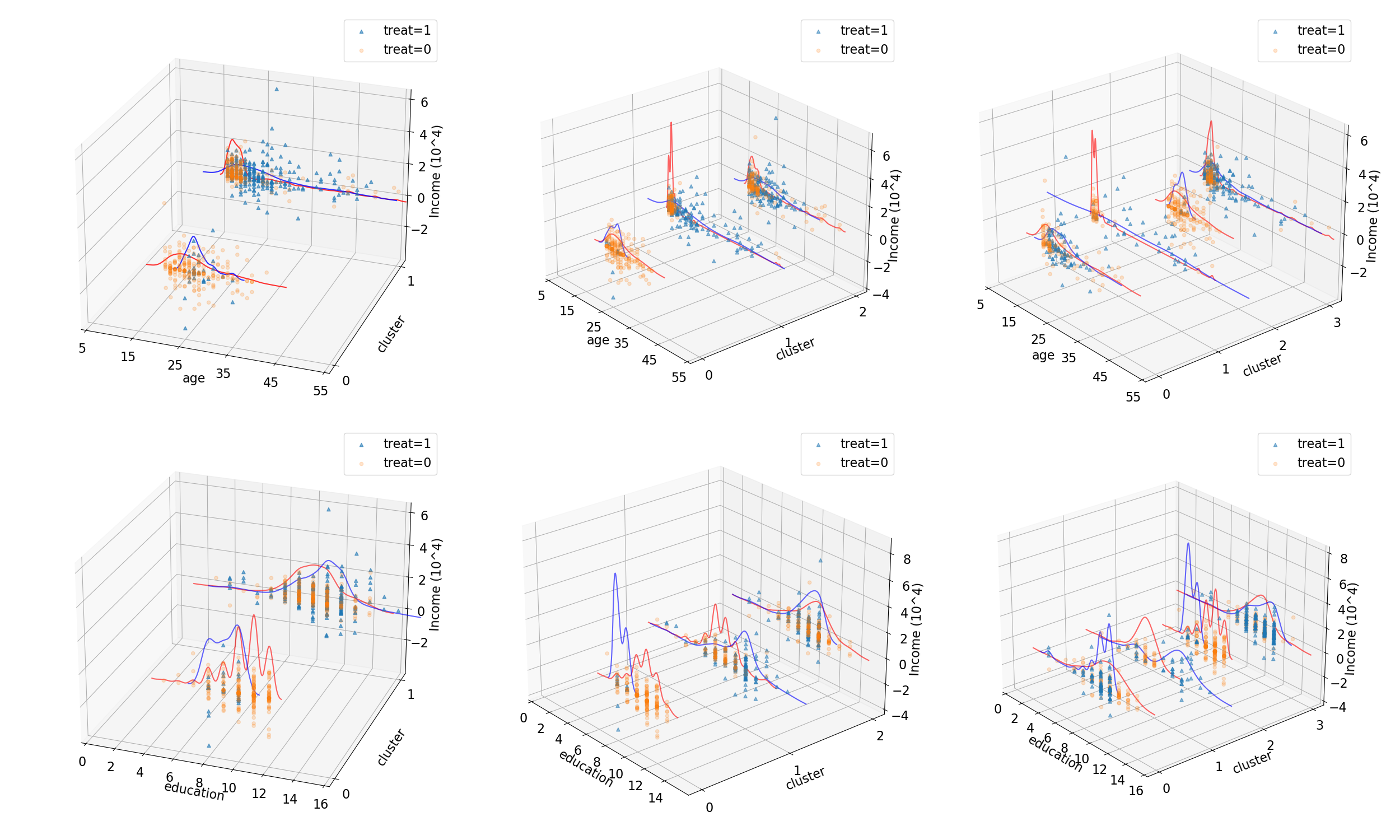
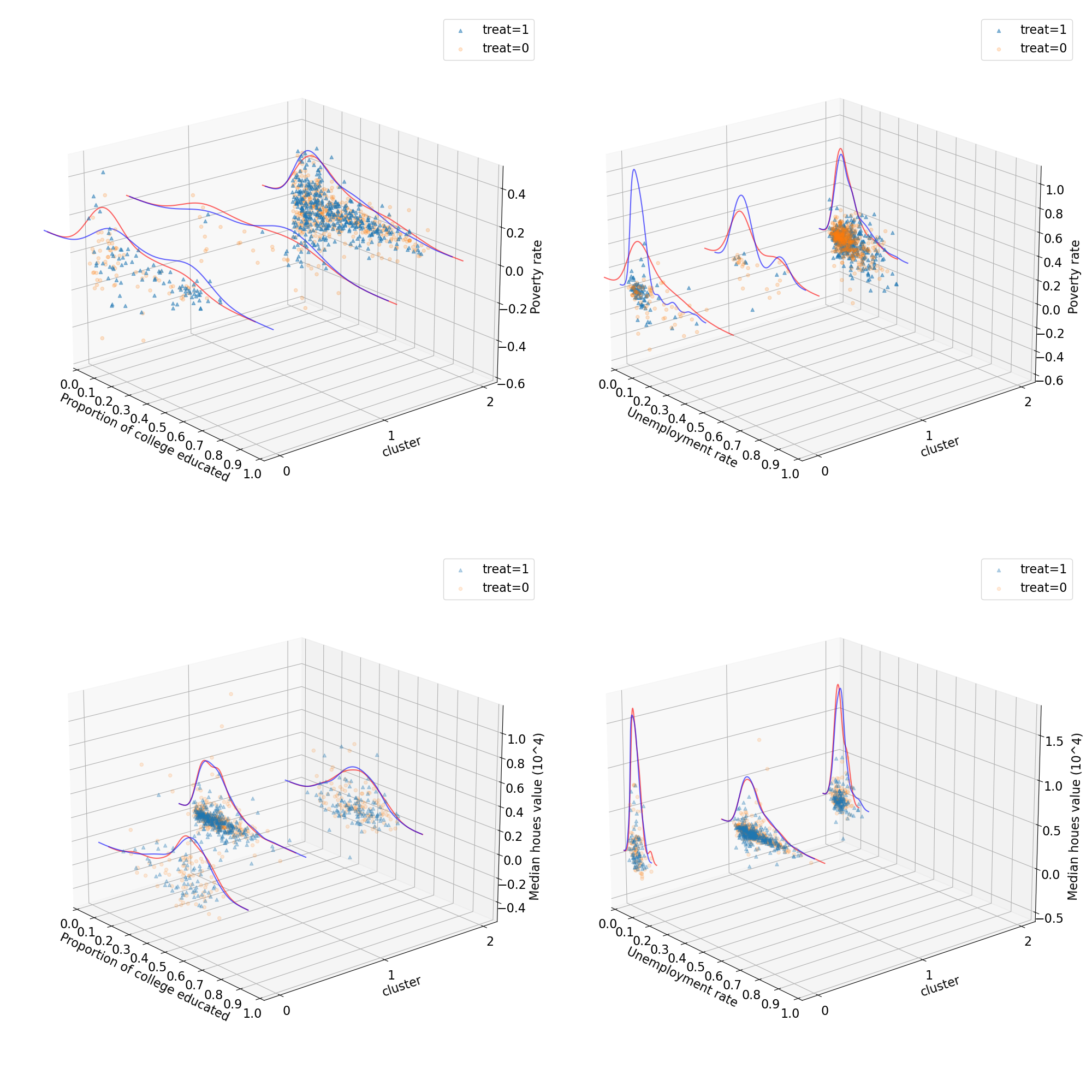
Cluster Distribution Across Ages: Figure 2 illustrates the distribution of treated and untreated units across age and education-based clusters. The CFL algorithm partitions the NSW participants into distinct subgroups based on these covariates and treatment status. Notably, younger participants (under 20 years old) predominantly cluster within the treated group, suggesting that CFL identifies them as having a comparable likelihood of achieving similar earnings outcomes, regardless of treatment status. A bifurcation around age 20 suggests a threshold beyond which treatment effects become more pronounced. For younger participants, the similarity in outcome probabilities between treated and untreated groups implies that external factors, such as baseline earning ability, may overshadow the treatment effect. This finding highlights the presence of heterogeneous treatment effects, with age acting as a moderating factor. Conversely, older participants exhibit a more balanced distribution between treated and untreated groups, suggesting that the treatment effect is sufficiently strong for CFL to distinguish between them.
We can test the validity of the heterogeneity detected by CFL, from a more canonical perspective, by considering the following regression:
The interaction term coefficient, , captures the heterogeneity in treatment effects on earnings changes between individuals below and above the sample’s average age. Table A1 shows that is large and statistically significant, indicating that younger individuals exhibit a weaker response to treatment, while older individuals experience significantly greater earnings gains post-treatment. These findings align with CFL clustering results shown above.
Implications of Asymmetric Clustering: The persistence of this asymmetric distribution, even as the number of clusters increases in Figure 2, reinforces the notion that the detected heterogeneity is not an artifact of inadequate clustering granularity. Instead, it reflects genuine variations in treatment effects across different age groups. The younger cohort may inherently possess characteristics that mitigate the treatment’s impact leading to similar outcome distributions irrespective of treatment status.
Heterogeneity vs. Bias Considerations: The asymmetric clustering in the NSW example raises important considerations regarding heterogeneity and potential biases. If the treatment assignment is not well randomized, it becomes challenging to discern whether the observed differences in treatment effects across subgroups indicate true heterogeneity or merely reflect biased sampling. For example, if younger people with inherently higher baseline earning ability, which could be unobservable, are more likely to remain untreated, the similar outcome distributions in Figure 2 between treated and untreated young individuals could stem from this confounding relationship rather than the treatment’s heterogeneous effectiveness.
4.2.1 Rationale behind heterogeneity detection by CFL
Lemma 4.1 (Heterogeneity on Average).
Assume randomized treatment, and let Y be an outcome of interest, be a treatment dummy variable, and be a random vector for covariates. Further assume that the expectations of two variables are unequal as long as the distributions are unequal. If there exists some such that and , or if there exists some such that and , this implies the heterogeneity of treatment effect.
Proof.
Heterogeneity arises when
for some . If
this can imply the previous inequality, but the converse may not necessarily be true. Thus, if CFL can detect some such that the above inequality holds, CFL will manifest heterogeneity. There are two cases where this will hold:
1. For some , , which means they are clustered into one macrostate, so that
but for some , is not in the same equivalence class as , so
meaning that treatment has no effect on some subpopulation but has an effect on others.
2. For some , , so
but is not in the same equivalence class as , so
meaning that is not constant across all values of .
∎
The assumption that unequal distribution implies unequal expectation may not always be true in the above lemma, so in this case, the CFL algorithm may not be valid to manifest heterogeneity on average. However, though heterogeneity on average is a common way to define the heterogeneous treatment effect, it is a summary statistic of the distribution, and the treatment can still be heterogeneous on the distribution level, if not on the expected level. Therefore, we can propose that it is sufficient for a treatment to be heterogeneous if it is heterogeneous on the distribution level according to the next lemma.
Lemma 4.2 (Heterogeneity on Distribution).
Assume randomized treatment, and let Y be an outcome of interest, be a treatment dummy variable, and be a random vector for covariates. Heterogeneous treatment effect exists if .
These arguments are similar and can account for the heterogeneity detected by CFL in the NSW dataset, where a portion of untreated young individuals are clustered into the same macrostate as the treated young individuals.
Remark 4.1.
Randomized treatment is a necessary condition for the validity of CFL in detecting heterogeneity.
Note that if the treatment is not randomly assigned, under the potential outcome framework, we can write a formal decomposition to show the existence of selection bias that will contaminate the detection of heterogeneity by CFL:
Plus and minus the unobserved term:
Rearrange:
Therefore, there could be no heterogeneity e.g. if , but different degrees of selection biases across values of covariate will still result in the above inequality that manifests heterogeneity empirically through CFL. In other words, randomized treatment is a necessary condition for the validity of CFL in detecting heterogeneity.
4.3 The Voting Dataset
The Voting dataset, derived from the study by Gerber et al. (2009), examines the “persuasion effect” of offering a free subscription to the Washington Post (more liberal) or Washington Times (more conservative) on post-treatment political preference. In this randomized controlled trial, individuals were assigned to receive either Washington Times (), Washington Post (), or control (). The outcome variable we focused on is the broad policy index constructed by the authors to estimate the political attitude after the treatment, with higher index values indicating a more conservative stance. This dataset also includes a rich set of covariates encompassing demographic information, baseline political preferences, and historical voter turnout. Jun and Lee (2023) utilized this dataset to explore persuasion effects, and we extend their analysis by applying the CFL algorithm to derive macrostates that may better capture the causal influence of the treatment on voting behavior.
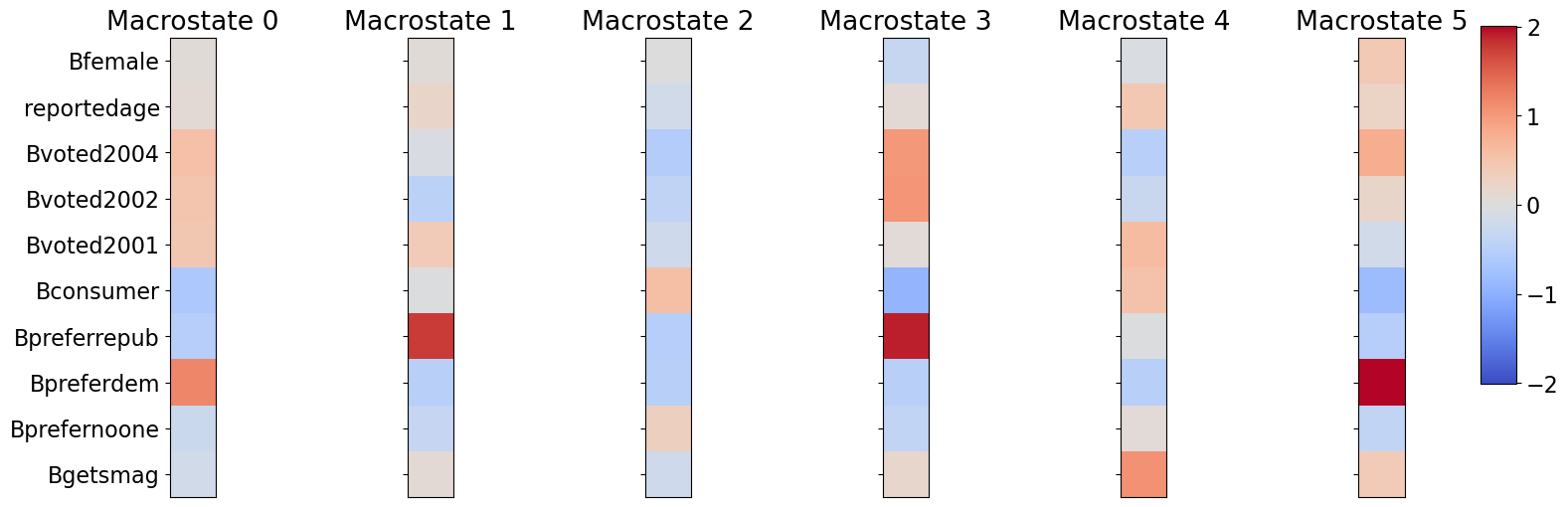
Clustering Analysis and Downstream Implementation: As depicted in Figure A1, the CFL algorithm identifies distinct clusters among the Voting dataset participants based on the same covariates in the analysis of Gerber et al. (2009), including gender (Bfemale), age (reportedage), voting history (Bvoted2001/02/04), the source of sampling (Bconsumer), baseline political preference (Bpreferrepub/dem), and baseline exposure to similar types of papers (Bgetsmag). By excluding the treatment dummy, Figure A1 presents a coarsened covariate space constructed by above variables.
Table A2 summarizes the treatment effects of receiving Washington Post and Times, using the same regression specification in the original paper except that all covariates are replaced by cluster indicators. While the original paper concluded that, though not significant, receiving either type of paper lead to more support liberal attitude (both effects are negative), results in Table A2 show that receiving the more liberal paper lead to more liberal post-treatment political attitude, and receiving the more conservative paper lead to more conservative political attitude. Despite this difference, which signifies different parts of the variations in data that the constructed macrostates and the original microstates respectively account for, they are still very similar in relative magnitude and significance level of coefficients, especially in the case of receiving the more liberal paper.
4.3.1 CFL as Dimensionality Reduction Technique:
Lemma 4.3.
Let be the random vector for all relevant covariates such that the unconfoundedness assumption holds, then the observational coarsening, , of the covariate space of by CFL also satisfy
Proof.
With the unconfoundedness assumption, the independence of the potential outcomes, , and the treatment conditional on all confounders , which is a vector of all relevant covariates, ensures the recovery of the average treatment effect. We can formally write the unconfoundedness assumption as:
Recall that CFL conducts observational partition of the covariate space by the following equivalence relation: for any :
Suppose is the sequence of all possible values in , and is a subsequence that includes all the representatives of equivalent classes. Define a new random vector such that This random vector is a coarsening of the original covariate space, and all the equivalence classes are mutually exclusive and jointly exhaustively. In other words, if , then and for . Within each equivalence class , the conditional distribution of given is constant. This implies is independent of given :
By the law of total probability for conditional probability in continuous case:
Since , we have . Since , we have . Additionally, since does not depend on , it can be factored out of the integral. Substituting all these into the integral:
The integral equals 1 by the definition of probability distributions. Therefore, this shows that is independent of given :
∎
Therefore, the coarsening of the covariate space does not affect the conditional independence between the outcome and treatment, which then ensures that selection bias disappears:
In other words, the treatment is still as if randomized after controlling for all the macrostates created by the CFL algorithm.
Remark 4.2.
Under the unconfoundedness assumption, the observational partition reduces the dimensionality of the covariate space while preserving the causal structure in the data.
Let there are continuous covariates in , which would have a dimension of . By assumption of CFL, we have finite macrostate, or equivalence classes in the original covariate space, so the coarsened covariate space, , will have a dimension of where is finite as each random variable in the random vector is binary.
5 Conclusion
Our work extends the theoretical foundation of CFL for macrostate construction. To handle continuous variables, we developed a principled binning strategy and introduced extended definitions of the observational and causal partitions. Our central theoretical contribution, the Extended Causal Coarsening Theorem, demonstrates that under mild conditions the causal partition is almost surely a coarsening of the observational partition—even when outcomes are discretized into a finite number of bins. Our empirical analyses of social science datasets show that CFL-derived macrostates effectively reduce dimensionality, uncover heterogeneous treatment effects, and preserve essential causal structures.
Acknowledgments
We gratefully acknowledge the insightful feedback provided by our colleagues, particularly Frederick Eberhardt and Milan Mossé, whose suggestions significantly enhanced this work.
References
- Bareinboim et al. (2022) Elias Bareinboim, Juan D Correa, Duligur Ibeling, and Thomas Icard. On pearl’s hierarchy and the foundations of causal inference. In Probabilistic and causal inference: the works of judea pearl, pages 507–556. Association for Computing Machinery, 2022.
- Barocas et al. (2023) Solon Barocas, Moritz Hardt, and Arvind Narayanan. Fairness and Machine Learning: Limitations and Opportunities. MIT Press, 2023.
- Beckers et al. (2019) Sander Beckers, Frederick Eberhardt, and Joseph Y. Halpern. Approximate Causal Abstraction, June 2019. URL http://arxiv.org/abs/1906.11583.
- Beigang (2023) Fabian Beigang. Reconciling algorithmic fairness criteria. Philosophy & Public Affairs, 2023.
- CFL (2022) CFL. Causal feature learning, 2022. URL https://github.com/eberharf/cfl.
- Chalupka et al. (2014) Krzysztof Chalupka, Pietro Perona, and Frederick Eberhardt. Visual causal feature learning. arXiv preprint arXiv:1412.2309, 2014.
- Chalupka et al. (2016a) Krzysztof Chalupka, Tobias Bischoff, Pietro Perona, and Frederick Eberhardt. Unsupervised discovery of el nino using causal feature learning on microlevel climate data. arXiv preprint arXiv:1605.09370, 2016a.
- Chalupka et al. (2016b) Krzysztof Chalupka, Frederick Eberhardt, and Pietro Perona. Multi-level cause-effect systems. In Artificial intelligence and statistics, pages 361–369. PMLR, 2016b.
- Chalupka et al. (2017) Krzysztof Chalupka, Frederick Eberhardt, and Pietro Perona. Causal feature learning: an overview. Behaviormetrika, 44:137–164, 2017.
- Csaba and Pluhár (2014) Béla Csaba and András Pluhár. A weighted regularity lemma with applications. International Journal of Combinatorics, 2014(1):602657, 2014.
- Dwork et al. (2012) Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference, pages 214–226, 2012.
- Fox et al. (2017) Jacob Fox, László Miklós Lovász, and Yufei Zhao. On regularity lemmas and their algorithmic applications. Combinatorics, Probability and Computing, 26(4):481–505, 2017. doi: 10.1017/S0963548317000049.
- Gangl (2010) Markus Gangl. Causal inference in sociological research. Annual review of sociology, 36(1):21–47, 2010.
- Geiger et al. (2024) Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, and Thomas Icard. Causal abstraction: A theoretical foundation for mechanistic interpretability. Journal of Machine Learning Research, 2024. URL https://arxiv.org/abs/2301.04709. Forthcoming.
- Gerber et al. (2009) Alan S Gerber, Dean Karlan, and Daniel Bergan. Does the media matter? a field experiment measuring the effect of newspapers on voting behavior and political opinions. American Economic Journal: Applied Economics, 1(2):35–52, 2009.
- Glymour and Herington (2019) Bruce Glymour and Jonathan Herington. Measuring the biases that matter: The ethical and casual foundations for measures of fairness in algorithms. In Proceedings of the conference on fairness, accountability, and transparency, pages 269–278, 2019.
- Glymour and Glymour (2014) Clark Glymour and Madelyn R. Glymour. Commentary: Race and sex are causes. Epidemiology, 25(4):488–490, 2014. URL http://www.jstor.org/stable/24759150.
- Greiner and Rubin (2011) D. James Greiner and Donald B. Rubin. Causal effects of perceived immutable characteristics. Review of Economics and Statistics, 93(3):775–85, 2011.
- Holland (1986) Paul W Holland. Statistics and causal inference. Journal of the American statistical Association, 81(396):945–960, 1986.
- Hu and Kohler-Hausmann (2020) Licheng Hu and Issa Kohler-Hausmann. What’s sex got to do with machine learning? In Proceedings of the 2020 ACM Conference on Fairness, Accountability, and Transparency, 2020.
- Hu (2022) Lily Hu. Causation in the Social World. PhD thesis, Harvard University Graduate School of Arts and Sciences, 2022.
- Hu (2024) Lily Hu. What is “race” in algorithmic discrimination on the basis of race? Journal of Moral Philosophy, pages 1–26, 2024.
- Ibeling and Icard (2021) Duligur Ibeling and Thomas Icard. A topological perspective on causal inference. Advances in Neural Information Processing Systems, 34:5608–5619, 2021.
- Ibeling and Icard (2024) Duligur Ibeling and Thomas Icard. Comparing causal frameworks: Potential outcomes, structural models, graphs, and abstractions. Advances in Neural Information Processing Systems, 36, 2024.
- Imbens (2024) Guido W Imbens. Causal inference in the social sciences. Annual Review of Statistics and Its Application, 11, 2024.
- Jun and Lee (2023) Sung Jae Jun and Sokbae Lee. Identifying the effect of persuasion. Journal of Political Economy, 131(8):2032–2058, 2023.
- Kilbertus et al. (2017) Niki Kilbertus, Mateo Rojas Carulla, Giambattista Parascandolo, Moritz Hardt, Dominik Janzing, and Bernhard Schölkopf. Avoiding discrimination through causal reasoning. Advances in Neural Information Processing Systems (NIPS), 30, 2017.
- Kohler-Hausmann (2018) Issa Kohler-Hausmann. Eddie murphy and the dangers of counterfactual causal thinking about detecting racial discrimination. Northwestern University Law Review, 113(5):1163–1228, 2018.
- Kusner et al. (2017) M. Kusner, C. Russell, J. Loftus, and R. Silva. Counterfactual fairness. In Advances in Neural Information Processing Systems (NIPS), 2017.
- LaLonde (1986) Robert J. LaLonde. Evaluating the econometric evaluations of training programs with experimental data. The American Economic Review, 76(4):604–620, 1986. ISSN 00028282. URL http://www.jstor.org/stable/1806062.
- Loi et al. (2023) Michele Loi, Francesco Nappo, and Eleonora Viganò. How i would have been differently treated. discrimination through the lens of counterfactual fairness. Res Publica, 29(2):185–211, 2023.
- Mossé et al. (2025) Milan Mossé, Kara Schechtman, Frederick Eberhardt, and Thomas Icard. Modeling discrimination with causal abstraction, 2025. URL https://arxiv.org/abs/2501.08429.
- Pearl (2010) Judea Pearl. The foundations of causal inference. Sociological Methodology, 40(1):75–149, 2010. doi: https://doi.org/10.1111/j.1467-9531.2010.01228.x. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-9531.2010.01228.x.
- Pearl (2018) Judea Pearl. Does obesity shorten life? or is it the soda? on non-manipulable causes. Journal of Causal Inference, 6(2):20182001, 2018.
- Plečko and Bareinboim (2024) Drago Plečko and Elias Bareinboim. Causal fairness analysis. Foundations and Trends in Machine Learning, 17(3):304–589, 2024.
- Rischel and Weichwald (2021) Eigil F. Rischel and Sebastian Weichwald. Compositional abstraction error and a category of causal models. In Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence, pages 1013–1023. PMLR, December 2021. URL https://proceedings.mlr.press/v161/rischel21a.html. ISSN: 2640-3498.
- Russell et al. (2017) Chris Russell, Matt J Kusner, Joshua Loftus, and Ricardo Silva. When worlds collide: integrating different counterfactual assumptions in fairness. Advances in neural information processing systems, 30, 2017.
- Sen and Wasow (2016) Maya Sen and Omar Wasow. Race as a bundle of sticks: Designs that estimate effects of seemingly immutable characteristics. Annual Review of Political Science, 19:499–522, 2016.
- Spirtes and Scheines (2004) Peter Spirtes and Richard Scheines. Causal inference of ambiguous manipulations. Philosophy of Science, 71(5):833–845, 2004.
- Steel (2004) Daniel Steel. Social mechanisms and causal inference. Philosophy of the social sciences, 34(1):55–78, 2004.
- Szemerédi (1975) E. Szemerédi. On sets of integers containing no elements in arithmetic progression. Acta Arith., 27:299–345, 1975.
- Thomsen (2018) Frej Klem Thomsen. Direct discrimination. In Kasper Lippert-Rasmussen, editor, Routledge Handbook of Discrimination, pages 19–29. Routledge, 2018.
- Tolbert (2024a) Alexander Williams Tolbert. Causal agnosticism about race: Variable selection problems in causal inference. Philosophy of Science, pages 1–11, 2024a.
- Tolbert (2024b) Alexander Williams Tolbert. Restricted racial realism: Heterogeneous effects and the instability of race. Philosophy of the Social Sciences, page 00483931241299884, 2024b.
- Weinberger (2022) Naftali Weinberger. Signal manipulation and the causal analysis of racial discrimination. Ergo, 2022.
Appendix A Proof of Theorem 4
To establish the Extended Causal Coarsening Theorem (CCT), we demonstrate that the set of joint distributions violating the coarsening conditions has Lebesgue measure zero. This ensures that, almost surely, the causal partition is a coarsening of the observational partition . The proof is similar to the proof of Theorem 3.
We begin by defining the following probabilities:
These definitions allow us to express the joint distribution as:
By fixing , we determine the distribution of given , thereby fixing the confounding partition . Similarly, fixing specifies the causal relationship between and given , effectively fixing the causal partition .
Next, consider the observational partition , which groups together treatment variables and if and only if they induce the same distribution over . Formally, under if :
Expanding using the law of total probability:
Therefore, the equivalence condition imposes:
Rearranging terms leads to the polynomial constraints:
These constraints define a system of polynomial equations in the parameters , , and .
The set of joint distributions that violate the condition being a coarsening of corresponds to the solutions of these polynomial equations. In the space of all possible joint distributions, these equations define an algebraic variety of lower dimension.
We then verify that the polynomial constraints are non-trivial, i.e., not all satiafies these constraints. We first consider for all . If such do not satisfy the constraints, then the constraints are non-trivial. If the constraints are satisfied in this case, there exists such that is positive. And there also exists such that is negative. Without loss of generality, we assume that . Then we set for all and set and . This is an example that violates the constraints.
Since the polynomial constraints are non-trivial, this variety has Lebesgue measure zero. Consequently, the subset of distributions that do not satisfy the coarsening condition is of measure zero. Thus, with probability one (in the sense of Lebesgue measure), the causal partition is a coarsening of the observational partition .
Appendix B Appendix: The Redlining Dataset
The Historic Redlining Indicator (HRI) is a measure of the mortgage investment risk of neighborhoods across the nation based on the residential security grades provided by The Home Owners’ Loan Corporation (HOLC). A higher HRI score means greater redlining of the census tract. Using the 2010 and 2020 HRI datasets, we merged them with the US census dataset to investigate the impact of redlining on multiple socioeconomic outcomes.
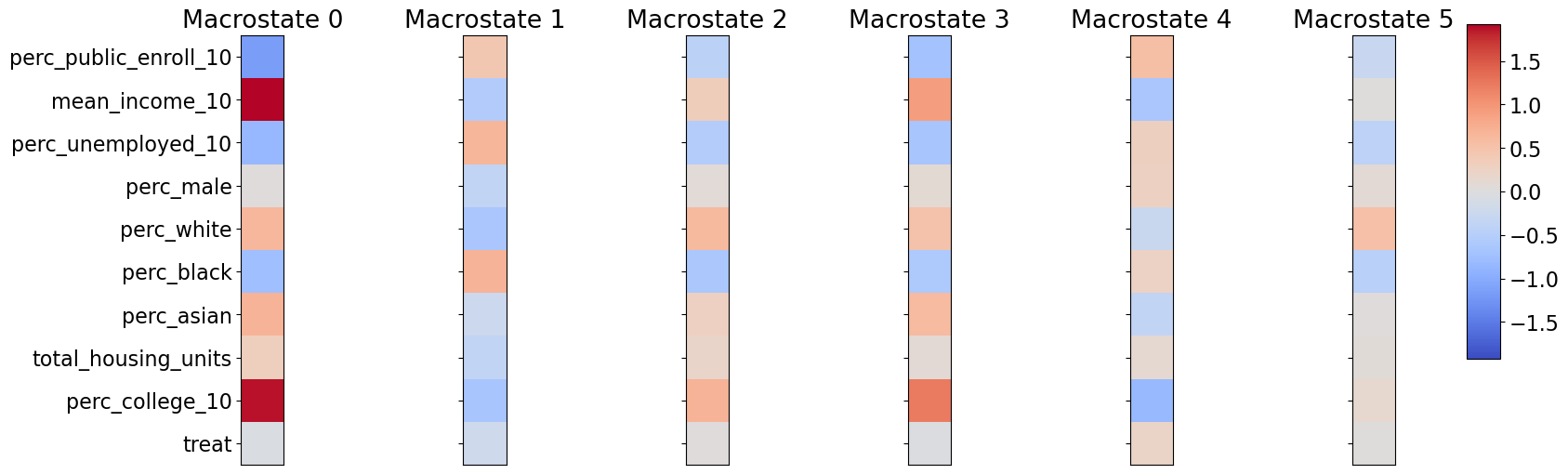
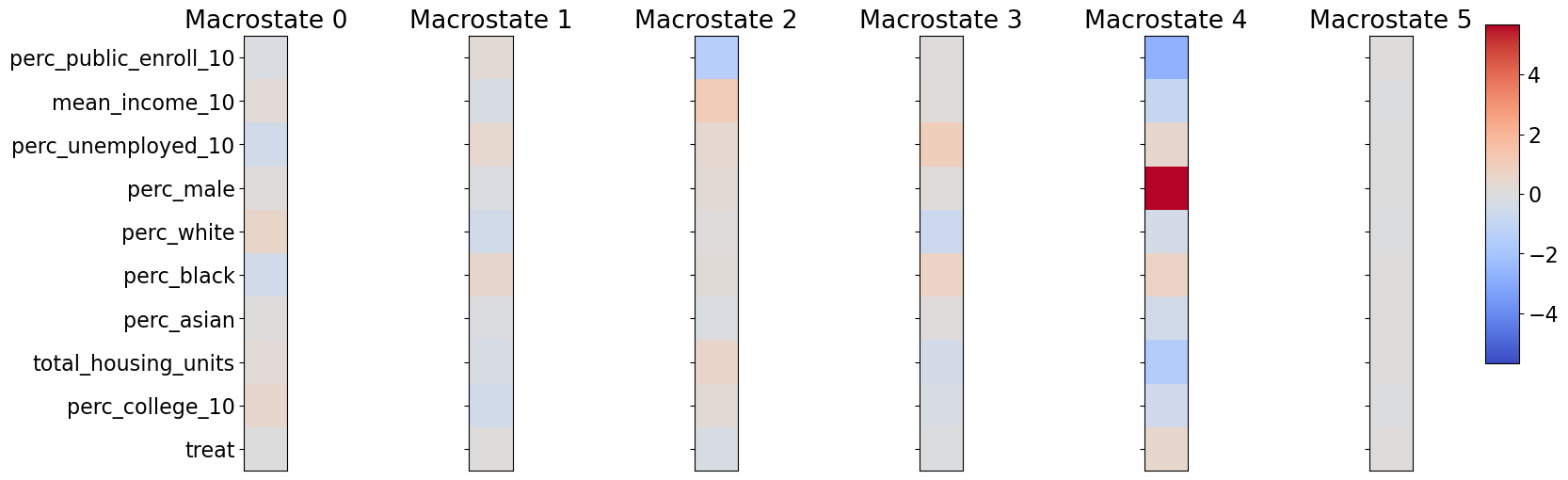
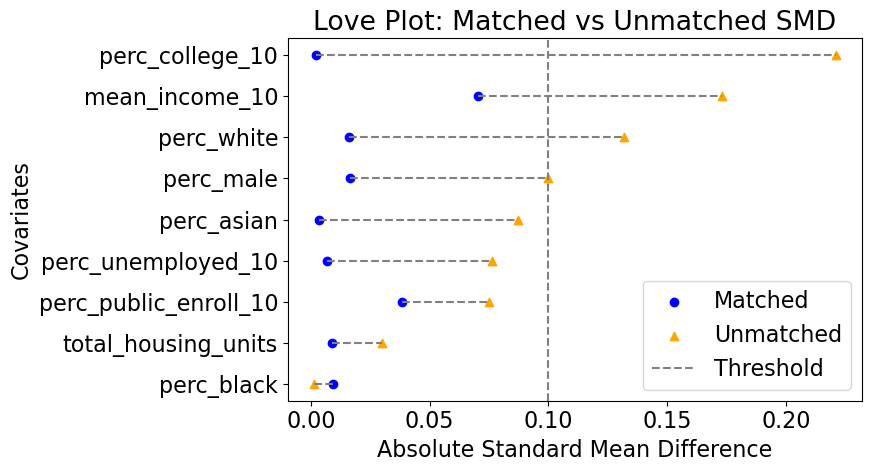
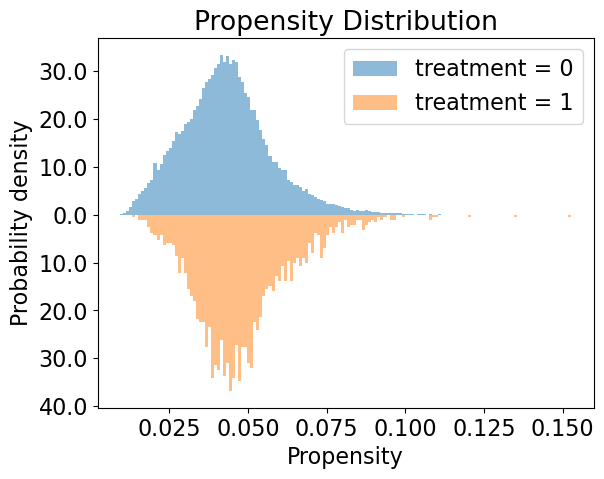
Clustering on Balanced Pseudo-Population after PSM: Though randomized treatment is necessary for analysis using CFL, we can balance the data and create a pseudo-population using the propensity score matching. We define the treated group as those census tracts with an increase in the intensity of redlining, the HRI score, from 2010 to 2020, and untreated if the HRI score remains the same or decreases. Out of 11348 census tracts (an intersection of 2010 and 2020 census tracts), 487 are treated. Currently, we choose two outcomes, changes in the proportion below the poverty line and changes in the median house value (in 2020 dollars), and 9 baseline covariates in 2010, including pubic school enrollment rate, average income, unemployment rate, the proportion of male, proportion of 3 racial groups (black, Asian, white), total housing units, and proportion of bachelor degrees, for the analysis. We used PSM with the nearest neighbor matching without replacement to create a pseudo-population such that each treated unit has a matched untreated unit (964 units). Figure A4 and A4 present the balance of covariates and distribution of the propensity to treatment after propensity score matching. The estimated ATE and bootstrapped SE for two outcomes are 0.0028 [0.0128] (poverty rate) and -22599 [14928] (median house value). In other words, assume selection on observables, increase in redlining of a census tract increase the proportion of families below the poverty line, and lower the house value in the area, though both are insignificant.
After implementing CFL on the pseudo-population, there are two major observations. From Figure A5, we can see that, since the treatment is insignificant in both cases, CFL does not separate clusters primarily based on the treatment. However, CFL preserves the balance of treatment within each cluster. Though the distribution of the treated units and untreated units within each cluster is still similar to each other, the level of certain covariates is different between clusters, e.g. some are more skewed/sparse than others, indicating that different compositions of covariates across clusters are still related to the level of the outcome as shown in figure A2b.
Appendix C Appendix: Implementation of Binning Technique
Here, we implement quantile binning, which is also known as equal frequency binning, in the example of the NSW dataset. We first apply an arbitrary number of bins, for example, 10 bins, by assigning a value to all observations in the same bin. We repeat the same CFL algorithm with the only change being the discretization of the outcome variable. Note that the variable is only discretized for the training of the CFL algorithm and construction of the macrostates; the original values of the variable should be retained for the rest of the analyzes.
When the number of clusters is two, we almost replicate the distribution as in Figure 2, indicating that the amount of information on the causal relationship between the treatment, covariate, and outcome is not significantly compromised when we have a small number of clusters. When we increase the number of clusters to four, the results are less replicable as the CFL algorithm does not categorize a group of all untreated observations as in Figure 2. While we increase the number of clusters, during which the CFL algorithm creates more subgroups that capture more nuanced interaction between variables, a smaller number of bins eliminates some essential information entailed in a larger number of clusters.
To verify this, we increase the number of bins and observe which bins we can obtain a distribution close enough to the one without the binning. If such a number of bins exist, it suggests that the same causal information relationship could be preserved while we discretize the variable and do not violate the assumption of discrete macrostate. As Table A3 shows, when we increase the number of bins, there are some cases where the CFL algorithm captures the group with only untreated units (value 0 in the table). As the algorithm includes randomness when constructing macrostates, the likelihood of successful construction of this particular macrostate increases as the number of bins increases.
Appendix D Appendix: Tables and Figures
| Variable | Coef. | Std. Err. | t | P |
|---|---|---|---|---|
| Intercept | 2790.36 | 476.31 | 5.85 | 0.00 |
| treat | -409.66 | 742.27 | -0.55 | 0.58 |
| -1670.13 | 721.93 | -2.31 | 0.02 | |
| 2889.34 | 1125.78 | 2.56 | 0.01 |
| # Cluster | Post Effect | Times Effect |
|---|---|---|
| 3 | -0.0733 | 0.0112 |
| (0.0475) | (0.0469) | |
| [0.1230] | [0.8118] | |
| 4 | -0.0742 | 0.0007 |
| (0.0472) | (0.0465) | |
| [0.1164] | [0.9880] | |
| 6 | -0.0684 | -0.0022 |
| (0.0470) | (0.0465) | |
| [0.1458] | [0.9618] | |
| 8 | -0.0684 | 0.0090 |
| (0.0473) | (0.0467) | |
| [0.1488] | [0.8478] | |
| 12 | -0.0646 | 0.0018 |
| (0.0474) | (0.0468) | |
| [0.1727] | [0.9688] |
P-values are presented in square brackets and standard errors are presented in parentheses.
| # Bins | Min % of Treated |
|---|---|
| 10 | 0.321 |
| 27 | 0.129 |
| 45 | 0.336 |
| 62 | 0.230 |
| 88 | 0.292 |
| 131 | 0.198 |
| 174 | 0.320 |
| 218 | 0.000 |
| 262 | 0.311 |
| 305 | 0.102 |
| 348 | 0.207 |
| 392 | 0.327 |
| 435 | 0.000 |