Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Abstract
Large Language Models (LLMs) demonstrate their versatility in a variety of tasks. However, there are still two inevitable bottlenecks during practical applications: (1) unfaithful hallucination that is not consistent with real-time or specific domains’ facts; (2) weak reasoning of complex tasks over compositional and multiple information. To this end, we need a hybrid Reasoning-Retrieval approach that is capable of breaking down complex tasks, retrieving multimodal demands, and reducing information conflicts. To solve above challenges, we propose a Chain-of-Actinos framework to incorporate various of actions into the LLM’s reasoning chain. In our framework, we design different actions to deal with multimodal data source and propose a systematic prompting method which decomposes a complicated question into a reasoning chain with many subquestions. Experimental results demonstrate that our framework can outperform other methods in public benchmarks. And our case study, a Web3 product, also gets good performance in real-world.
Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
First Author Affiliation / Address line 1 Affiliation / Address line 2 Affiliation / Address line 3 email@domain Second Author Affiliation / Address line 1 Affiliation / Address line 2 Affiliation / Address line 3 email@domain
1 Introduction
Natural Language Processing (NLP) has unprecedented advancements due to the emergence and evolution of LLMs. These advanced LLMs exhibit the extraordinary ability to understand, generate, and interact with human language in a nuanced and contextually relevant manner. Individuals and organizations in various domains are navigating a multitude of complex challenges, ranging from text generation, sentiment analysis, and machine translation to more intricate applications such as automated customer service, content moderation, and even aiding in coding. Although LLMs demonstrate their versatility in a variety of general NLP tasks, there are still two inevitable bottlenecks during practical and real-world applications: (1) unfaithful hallucination that is not consistent with real-time or specific domains’ facts; (2) weak reasoning of complex tasks over compositional and multiple information.
Many studies aim to address the above problems. While Fine-Tuning peng2023instruction is one of the most useful techniques to support specific-domain knowledge which can reduce the hallucination, there remain issues in real-time information-gathering and the complex task reasoning. Chain-of-Thought (CoT) NEURIPS2022_9d560961 and its improved prompting versions wang2022self; saparov2022language try to transfer the complex task into a reasoning chain to get better results. They demonstrate their effectiveness on arithmetic, commonsense, and symbolic reasoning benchmarks. However, these prompting methods could not provide any real-time information beyond the LLM training data. On another front, agents huang2022language try to break reasoning chains by integrating information retrieval (IR) into the reasoning process. React yao2022react and Self-Ask press2022measuring first break the reasoning process into sub-questions and then solve them with customized IR one by one. Unfortunately, these methods do not consider the conflicts between LLM’s and IR’s information, which always makes the correct answer influenced by wrong retrieved information. Search-in-the-Chain xu2023search attempts to deal with information conflicts between the generated answer and the searched content by checking confidence during each round of the chain. Despite this, there is still no support for multimodality. To this end, a hybrid Reasoning-Retrieval approach that is capable of breaking down complex tasks, retrieving multimodal demands and reducing information conflicts is an urgent demand.

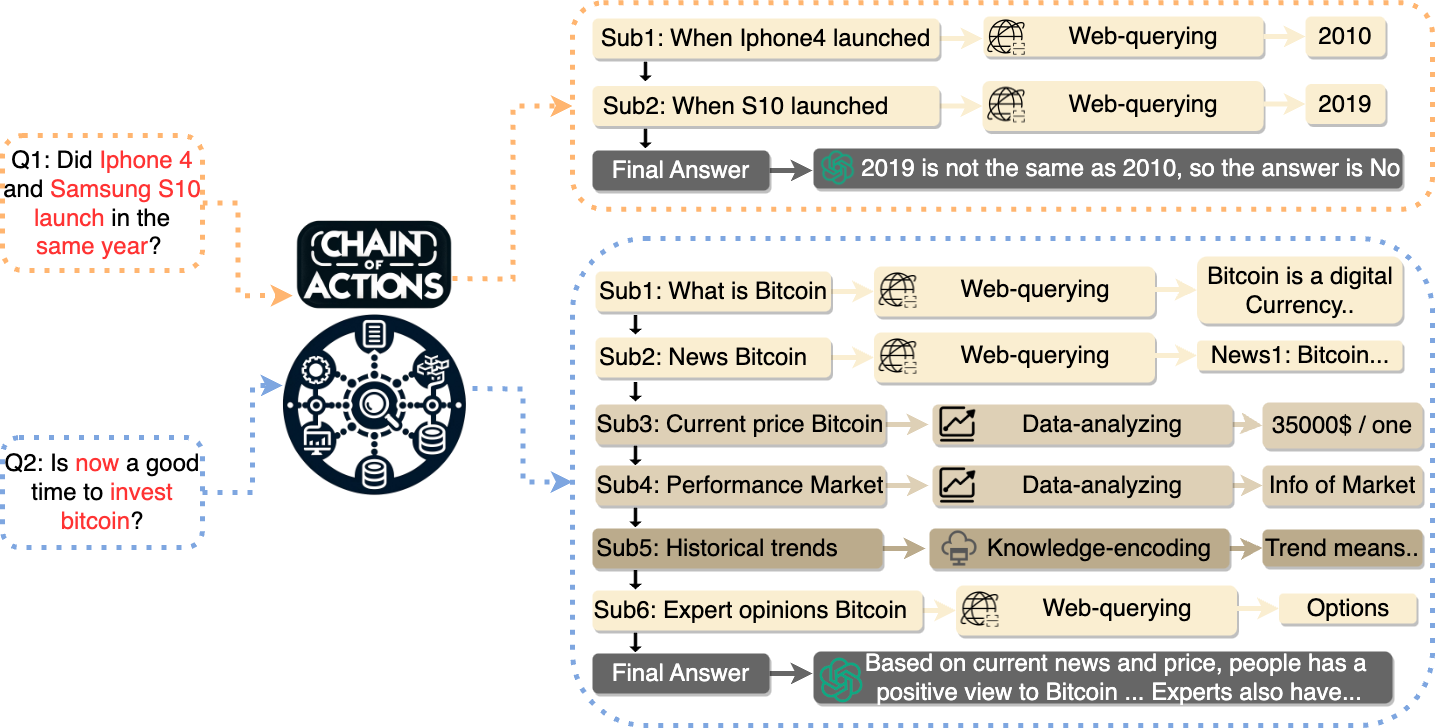
To solve above challenges, we propose the Chain-of-Action framework to incorporate various actions into the LLM’s reasoning chain. In our framework, we design different actions including web-querying, information-analysing and data-analysing to deal with multimodal data. Meanwhile, we also propose a systematic prompting method which can decompose a complicated question into a reasoning chain with many sub-questions. As shown in Fig 1, our framework utilize the in-context learning to inject the question into designed prompt template and then construct a Actions Chain (AC) by the LLM. In AC, each node represents a sub-question, an initial answer generated by LLM, and a missing flag which indicates whether the LLM needs more information. Then, we assign a specific action to verify the initial answer with the retrieved data. If the confidence of LLM’s answer is lower than that of retrieved data, the action request to correct the answer. In addition, if the missing flag is true, the retrieved data will be in the node’s answer. Finally, LLM provides the final answer based on the processed chain.
Furthermore, we deploy our framework to a Web3 Question Answering (QA) product that demonstrates the robust capabilities of the framework in a specialized real-world domain. Within six months, it manages to captivate many users, eliciting an overwhelming amount of positive feedback and increasing user engagement and satisfaction levels.
In summary, Chain-of-Action is the first work that could enable faithful and multimodal Question Answering with conflict checking in a reasoning chain. Our main contributions are as follows:
-
•
We propose the Chain-of-Action framework which decomposes a complicated question into many sub-questions to resolve by leveraging designed Actions.
-
•
We propose different actions which could not only deal with multimodal data source based on subquestions’ demands, but also check the confidence of LLM’s answer and decide whether it needs correct.
-
•
Experimental results demonstrate that our framework can outperform other methods in public benchmarks. In addition, as a case study, our Web3 QA product captivates many users and gets positive feedback to demonstrate the framework’s robust capabilities in the real world.
2 Related Work
In this section, we first talk about the current research about prompting methods including the Chain-of-Though (COT) ’s related works. Then, we summarize the agents injecting different tools, especially information retrieval in LLMs.
Prompting methods.
Prompting is a popular method for improving the performance of LLM. Among the prompting methods, Few-Shot Prompting kaplan2020scaling enables in-context learning to lead LLMs to answer each question. CoT NEURIPS2022_9d560961 and its improved prompting versions wang2022self; saparov2022language try to lead the LLMs to decompose a complex task into a reasoning chain and get better performance. However, they still only support the text information and can not generate with the newest information which is not included in training data.
Agent frameworks.
Many frameworks aim to expand both ability’s and knowledge’s edges of LLMs. ReAct yao2022react allows LLMs to interact with external tools to retrieve additional information. And Self-ask press2022measuring repeatedly prompts the model to ask follow-up questions to construct the thought process through the search engine. However, they do not consider the conflicts between LLM’s answer and retrieved information. While Search-in-the-Chain xu2023search is the first way to do the information verification in reasoning chain, it still cannot support multimodal data processing to solve different domains’ task.
3 Methodology
In this section, we describe the details of our Chain-of-Action. As shown in Fig 1, we first introduce how to generate the global action chain by LLM. Then, we assign different actions dealing with multimodal demands on nodes of the chain for three processes: (1) retrieve the related information; (2) verify the answer of LLM is good enough or in demand of more information from retrieval; (3) check if the initial answer of node’s sub-question is missing so that we should inject the retrieved information into the missing content. Finally, we could get the final answer by the LLM based on the processed actions chain.

3.1 Actions Chain Generation
We use in-context learning to generate actions chain by LLM. As shown in Fig 1 (a), we design a prompt template to transfer a user’s question into many sub-questions, corresponding Missing Flags (MF), and guess answers shown in Fig 1 (b). Then, we assign one of the actions to solve each sub-question.
Prompt design
We design a prompt template as shown in Fig 3 starting with "Construct an action reasoning chain for [questions]…" to make LLM generate an Actions Chain AC not answer our question Q directly.
| (1) |
In above equation, each node of chain represents four elements (Action, Sub, MF, A). are the content of the sub-questions whose assigned actions are . And the are the corresponding guess answers, which may be empty with the Missing Flags (MFs) being true.
If the LLM knows the answer of the sub-question, the answer starts with"[Guess Answer]", otherwise it starts with "[Unsolved Sub]".
3.2 Actions Implementation
We propose three different actions to deal with multimodal demands. And each of them has three working steps: (1) Information Retrieval; (2)Answering Verification; (3) Missing Detection. We first introduce the design of the three actions. Then, we describe the details of the three common steps.
3.2.1 Actions Design
Action 1: Web-querying Engine.
Web-querying Engine utilizes the existed search engines (e.g., Google Search) and follows our query strategy to get the relevant contents from the Internet. In details, it first search for the keywords of the given subquestion to obtain the titles T and snippets Sn of the top M pages. Then, we transfer each pair of title and snippet into a 1536-dimension vector by the embedding model (text-embedding-ada-002 from OpenAI openai2023gpt4). Meanwhile, we also transfer the sub-question and guess answer into . Next, we calculate the similarity between each and to filter the pages whose similarities are lower than 0.8. Then, we extract the contents of high similarity pages and calculate the similarity between them and to rank and get the top-k final pages. Those contents of the k final pages are the final information that we retrieve by this engine.
Action 2: Info-analyzing Engine.
Info-analyzing Engine utilizes the vector database (e.g., ChromaDB) as a data storage to store the domain information and corresponding embedded vectors. For example, we collect web3 domain information from different source (twitter, experts’ blogs, white papers, and trending strategies) to support our QA case study. After data collection, we split each document into many chunks based on the length. Then, we encode each chunk of content into embedded vector and store it in our vector database with its index. When we need to execute this engine to retrieve domain information, we could forward the to compute similarity between input and each chunk to obtain the top-k results.
Action 3: Data-analyzing Engine.
Data-analyzing Engine aims to retrieve the data information from some real-value data sources (e.g., market data of digital currencies). In some special situations, we could directly retrieve the relevant values from our deployed API when some sub-questions demands the up-to-date or historical value data. Furthermore, we can also use LLM to compute more sophistic features by generating python or sql codes to execute. It is flexible and compatible with various situations. In this paper, we only design it to retrieve the market data for Web3 case study.
3.2.2 Actions Workflow
In the action chain, the framework executes the action workflow for each node until it finishes the whole chain as shown in Algorithm 1.
Information Retrieval.
In information retrieval stage, we need to find the most relevant and similar contents from different knowledge/data sources. At first, we choose both sub-question and guess answer of each node as a query section, . Then, with the encoding of LLM’s embedding model (text-embedding-ada-002 from OpenAI), we transfer our query into a 1536-dimension vector . With this embedded vector, we can perform information retrieval and then rank the results by calculating the similarity. Finally, engines return the top-k results :
| (2) |
Answering Verification.
After the information retrieval, we verify the information conflicts between guess answer and retrieved facts . Inspired by the ROUGE lin2004rouge, we propose a multi-reference faith score, MRFS. To get the MRFS, we compute the pairwise faith score between a candidate summary and every reference, then take the maximum of faith scores. is a composite metric computed based on three individual components: Precision (P), Recall (Rcl), and Average Word Length in the Candidate Summary (AWL). The mathematical representation of the score is given by:
| (3) |
Where:
-
•
are weights corresponding to the importance of Precision, Recall, and Average Word Length respectively. Their values can be adjusted based on specific requirements but should sum up to 1 for normalization purposes.
-
•
(Precision) is defined as the fraction of relevant instances among the retrieved instances. It is calculated as:
(4) -
•
(Recall) is defined as the fraction of relevant instances that were retrieved. It is calculated as:
(5) -
•
(Average Word Length in Candidate Summary) represents the mean length of the words present in the summarized content. It is calculated as:
(6)
Adjusting the weights will allow for emphasizing different aspects (Precision, Recall, or Word Length) depending on the specific evaluation criteria or context.
After getting the MRFS through:
| (7) |
we setup a threshold to decide whether the answer is faithful. If MRFS is greater than T, we keep the answer; otherwise we change the answer to reference contents.
Missing Detection.
The last stage of each action is detecting whether the guess answer is complete. When a sub-question needs some special or real-time information, the correspond guess answer could be incomplete with a Missing Flag being "true". If a guess answer’s MF is "true", we inject the retrieved information into the to solve the "[Unsolved Sub]".
3.3 Final answer generation
After all actions’ executions, we propose a prompt template shown in Fig 4 to integrate all corrected answers and corresponding sub-questions of the AC. Then, it can prompt LLM to refer the newest retrieved information and generate the final answer starting with "[Final Content]" through the corrected reasoning chain.

4 Experiments
In this section, we first compare the performance of our framework, Chain-of-Action, with recent state-of-the-art baselines on complex tasks and conduct the analysis. Then, we demonstrate the deployed case study, a Question Answering (QA) application in the Web3 domain, in detail.
4.1 Experiments with Benchmarks
Datasets and Evaluation Metric.
We select four classic QA tasks that include web-based QA (WebQuestions QA (WQA) berant2013), general QA (DATE, General Knowledge, Social IQA (SoQA) and Truth QA srivastava2023beyond), Strategy QA (SQA) geva2021strategyqa, and Fact Checking (FEVER Thorne18Fever).
For the evaluation metric, we use cover-EM rosset2020knowledge to represent whether the generated answer contains the ground truth.
Baselines.
We have two types of baselines, one is reasoning-focus method prompting LLM to solve complex questions (Zero-shot Prompting, Few-shot Prompting, Chain-of-Thought (CoT) NEURIPS2022_9d560961, Self Consistency (SC) wang2022self, Tree of Thought (ToT) yao2023tree, Least-to-Most zhou2022least, and Auto-Chain-of-Thought (Auto-CoT) zhang2023automatic), and the other is Retrieval-Augmented-Generation (RAG) method which not only integrates Information Retrieval but also improves the reasoning capability (Self-Ask press2022measuring, React yao2023react, SearchChain (SeChain) xu2023search, and DSP khattab2022demonstrate).
Implementation.
To be filled. For LLM, we select the gpt-3.5-tubor provided by OpenAI through API.
4.1.1 Experimental Analysis
In the comprehensive evaluation presented in Table 1 of our study, we benchmark the effectiveness of various LLMs across multiple datasets, both in the presence and absence of Information Retrieval mechanisms. These datasets encompass a range of domains. Our framework demonstrates superior performance metrics across all datasets. This is a significant outcome, as it underscores the effectiveness of our model’s architecture and its underlying algorithms, which seem to be well-suited for a variety of question-answering tasks. In particular, the enhancement in performance is consistent regardless of the integration of IR. This suggests that our model has intrinsic robustness and comprehensive understanding that are not overly reliant on external knowledge bases.
Further analysis, as indicated in Table 2, investigates the complexity of the reasoning of these models. Our framework exhibits a higher average number of reasoning steps when decomposing complex questions. This metric is crucial, as it is indicative of the model’s ability to engage in a multi-step inference process, a capability that is essential for solving intricate problems that require more than surface-level understanding. The fact that our framework outperforms others in this measure suggests that it can better understand and navigate the layers of complexity within questions, which is a testament to the sophisticated reasoning algorithms it employs.
Lastly, Table 3 scrutinizes the models in terms of their susceptibility to being misled by external knowledge. This is a nuanced aspect of model evaluation, as it speaks to the model’s ability to discern relevant from irrelevant information, a nontrivial task in the age of information overload. Our framework emerges as the most resistant to misinformation, maintaining high accuracy even when interfacing with external data sources. This reveals not only the advanced data parsing and filtering capabilities of our model, but also its potential in mitigating the risks associated with the proliferation of false information.
In conclusion, the empirical evidence from our assessments presents a compelling case for the superiority of our framework. It excels in understanding and answering complex queries, demonstrates advanced reasoning capabilities, and exhibits resilience against the pitfalls of external misinformation, setting a new benchmark for LLMs in the domain of question-answering and fact-checking tasks.
| Question Answering | Fact Checking | ||||||
| Method | WebQA | DATE | GK | SocialQA | TruthQA | StrategyQA | FEVER |
| Without Information Retrieval | |||||||
| Zero-shot | 43.0 | 43.6 | 91.0 | 73.8 | 65.9 | 66.3 | 50.0 |
| Few-shot | 44.7 | 49.5 | 91.1 | 74.2 | 68.9 | 65.9 | 50.7 |
| CoT | 42.5 | 43.7 | 88.1 | 71.0 | 66.2 | 65.8 | 40.4 |
| SC | 50.0 | 87.5 | … | … | 70.8 | … | |
| ToT | 26.3 | 47.1 | 85.1 | 68.5 | 66.6 | 43.3 | 41.2 |
| Auto-CoT | 52.3 | 85.7 | 19.1 | 42.2 | 65.4 | … | |
| Lest-to-Most | … | … | … | … | 65.8 | … | |
| SeChain w/o IR | … | … | … | 75.6 | … | ||
| CoA w/o actions | 64.7 | 55.3 | 91.4 | 80.2 | 63.3 | 70.6 | 54.2 |
| Interaction with Information Retrieval | |||||||
| Self-Ask | 31.1 | 55.1 | 79.7 | 52.1 | 60.5 | 67.7 | 64.2 |
| React | 38.3 | / | 85.1 | 65.8 | 59.9 | 70.4 | … |
| DSP | 59.4 | 48.8 | 85.1 | 68.2 | 58.4 | 72.4 | 62.2 |
| SearchChain | … | … | … | … | 77.0 | … | |
| CoA | … | … | … | … | … | … | … |
| WQA | SQA | SoQA | |
|---|---|---|---|
| CoT | … | … | … |
| SC | … | … | … |
| ToT | … | … | … |
| Auto-CoT | … | … | … |
| Least-to-Most | … | … | … |
| Self-Ask w/o IR | … | … | … |
| React w/o IR | … | … | … |
| SeChain w/o IR | … | … | … |
| CoA w/o Actions | 3.85 | 4.12 | 4.62 |
| WQA | SQA | SoQA | FEVER | |
|---|---|---|---|---|
| Self-Ask | … | … | … | … |
| React | … | … | … | … |
| DSP | … | … | … | … |
| SeChain | … | … | … | … |
| CoA | … | … | … | … |
4.2 Case Study with Web3 QA application
We also deploy our framework to develop a QA application in the real world Web3 domain. User can ask this QA system up-to-date questions about Web3 domain. Our system will automatically decompose the user’s question into many sub-questions and solve one by one. In the solving sub-questions process, the system will consider injecting knowledge from different sources, such as search engine, existing domain knowledge base, and even market database. Fig 5 is the website interface of our system. Even if we have got a large number of users and good feedback from them, but, we still use expert evaluation to evaluate our case study to demonstrate the performance of our framework in the real world.
Expert Evaluation
We design a expert evaluation to assess the quality of explanations, reasoning trajectories. Our experts rate these explanations on a 1 to 3 scale (with 3 being the best) based on several criteria:
-
•
Coverage: The explanation and reasoning should cover all essential points important for the fact-checking process.
-
•
Non-redundancy: the explanation and reasoning should include only relevant information necessary to understand and fact-check the claim, avoiding any unnecessary or repeated details.
-
•
Readability: The explanation and reasoning should be clear and esasy to read.
-
•
Overall Quality: this is a general assessment of the overall quality of the generated expplanation and reasoning.
| Rt | SA | DSP | CoA | |
|---|---|---|---|---|
| Coverage | … | … | … | … |
| Non-redundancy | … | … | … | … |
| Readability | … | … | … | … |
| Overall | … | … | … | … |
We randomly sample the 100 questions from real users’ question history and use React, Self-Ask and our Chain-of-Action to answer these questions. Table 4 shows that the averaged scores of expert evaluation. We find that ………… In summary, these results demonstrate that our framework can get the best performance in the real world scenario.
5 Summary
The paper introduces the Chain-of-Action framework, an innovative approach designed to enhance Large Language Models’ (LLMs) capabilities in handling complex tasks, particularly in scenarios where real-time or domain-specific information is crucial. This framework addresses two primary challenges: unfaithful hallucination, where the LLM generates information inconsistent with real-world facts, and weak reasoning in complex tasks involving multiple or compositional information.
The Chain-of-Action framework is proposed to enable LLMs to break down complicated tasks into sub-questions, which are then handled through a series of actions. These actions include web-querying, information-analyzing, and data-analyzing, tailored to manage multimodal data sources effectively. The framework employs a systematic prompting method, creating a reasoning chain composed of sub-questions, each linked to an initial answer and a flag indicating the need for additional information. If the confidence in the LLM’s answer is lower than the retrieved data, an action is triggered to correct the answer. The final answer is then derived based on this processed chain, ensuring a higher accuracy and relevance to the real-world data.
A notable application of this framework is in a Web3 Question Answering product, which demonstrated substantial success in user engagement and satisfaction. This case study exemplifies the framework’s potential in specialized, real-world domains.
In summary, the Chain-of-Action framework marks a significant advancement in the field of NLP by enabling LLMs to perform faithful, multimodal question answering with conflict checking. It outperforms existing methods in public benchmarks and has proven effective in practical applications, as evidenced by its success in the Web3 QA product.