Change-point Detection for Sparse and Dense Functional Data in General Dimensions
2Department of ACMS, University of Notre Dame
3Mendoza College of Business, University of Notre Dame
4Department of Statistics, University of Warwick
)
Abstract
We study the problem of change-point detection and localisation for functional data sequentially observed on a general -dimensional space, where we allow the functional curves to be either sparsely or densely sampled. Data of this form naturally arise in a wide range of applications such as biology, neuroscience, climatology and finance. To achieve such a task, we propose a kernel-based algorithm named functional seeded binary segmentation (FSBS). FSBS is computationally efficient, can handle discretely observed functional data, and is theoretically sound for heavy-tailed and temporally-dependent observations. Moreover, FSBS works for a general -dimensional domain, which is the first in the literature of change-point estimation for functional data. We show the consistency of FSBS for multiple change-point estimation and further provide a sharp localisation error rate, which reveals an interesting phase transition phenomenon depending on the number of functional curves observed and the sampling frequency for each curve. Extensive numerical experiments illustrate the effectiveness of FSBS and its advantage over existing methods in the literature under various settings. A real data application is further conducted, where FSBS localises change-points of sea surface temperature patterns in the south Pacific attributed to El Niño.
1 Introduction
Recent technological advancement has boosted the emergence of functional data in various application areas, including neuroscience (e.g. Dai et al., 2019; Petersen et al., 2019), finance (e.g. Fan et al., 2014), transportation (e.g. Chiou et al., 2014), climatology (e.g. Bonner et al., 2014; Fraiman et al., 2014) and others. We refer the readers to Wang et al. (2016) - a comprehensive review, for recent development of statistical research in functional data analysis.
In this paper, we study the problem of change-point detection and localisation for functional data, where the data are observed sequentially as a time series and the mean functions are piecewise stationary, with abrupt changes occurring at unknown time points. To be specific, denote as a general -dimensional space that is homeomorphic to , where is considered as arbitrary but fixed. We assume that the observations are generated based on
| (1) |
In this model, denotes the discrete grids where the (noisy) functional data are observed, denotes the deterministic mean functions, denotes the functional noise and denotes the measurement error. We refer to 1 below for detailed technical conditions on the model.
To model the unstationarity of sequentially observed functional data which commonly exists in real world applications, we assume that there exist change-points, namely , satisfying that , if and only if . Our primary interest is to accurately estimate .
Due to the importance of modelling unstationary functional data in various scientific fields, this problem has received extensive attention in the statistical change-point literature, see e.g. Aue et al. (2009), Berkes et al. (2009), Hörmann and Kokoszka (2010), Zhang et al. (2011), Aue et al. (2018) and Dette et al. (2020). Despite the popularity, we identify a few limitations in the existing works. Firstly, both the methodological validity and theoretical guarantees of all these papers require fully observed functional data without measurement error, which may not be realistic in practice. Secondly, most existing works focus on the single change-point setting and to our best knowledge, there is no consistency result of multiple change-point estimation for functional data. Lastly but most importantly, existing algorithms only consider functional data with support on and thus are not applicable to functional data with multi-dimensional domain, a type of data frequently encountered in neuroscience and climatology.
In view of the aforementioned three limitations, in this paper, we make several theoretical and methodological contributions, summarized below.
In terms of methodology, our proposed kernel-based change-point detection algorithm, functional seeded binary segmentation (FSBS), is computationally efficient, can handle discretely observed functional data contaminated with measurement error, and allows for temporally-dependent and heavy-tailed data. FSBS, in particular, works for a general -dimensional domain with arbitrary but fixed . This level of generality is the first time seen in the literature.
In terms of theory, we show that under standard regularity conditions, FSBS is consistent in detecting and localising multiple change-points. We also provide a sharp localisation error rate, which reveals an interesting phase transition phenomenon depending on the number of functional curves observed and the sampling frequency for each curve . To the best of our knowledge, the theoretical results we provide in this paper are the sharpest in the existing literature.
A striking case we handle in this paper is that each curve is only sampled at one point, i.e. . To the best of our knowledge, all the existing functional data change-point analysis papers assume full curves are observed. We not only allow for discrete observation, but carefully study this most extreme sparse case and provide consistent localisation of the change-points.
We conduct extensive numerical experiments on simulated and real data. The result further supports our theoretical findings, showcases the advantages of FSBS over existing methods and illustrates the practicality of FSBS.
A byproduct of our theoretical analysis is new theoretical results on kernel estimation for functional data under temporal dependence and heavy-tailedness. This set of new results per se are novel, enlarging the toolboxes of functional data analysis.
Notation and definition. For any function and for , define and for , define . Define . For any vector , define , and the associated partial differential operator . For , denote to be the largest integer smaller than . For any function that is -times continuously differentiable at point , denote by its Taylor polynomial of degree at , which is defined as For a constant , let be the set of functions such that is -times differentiable for all and satisfy , for all . Here is the Euclidean distance between . In non-parametric statistical literature, are often referred to as the class of Hölder smooth functions. We refer the interested readers to Rigollet and Vert (2009) for more detailed discussion on Hölder smooth functions.
For two positive sequences and , we write or if with some constant that does not depend on , and or if and .
2 Functional seeded binary segmentation
2.1 Problem formulation
Detailed model assumptions imposed on model (1) are collected in 1. For notational simplicity, without loss of generality, we set the general -dimensional domain to be , as the results apply to any that is homeomorphic to .
Assumption 1.
The data are generated based on model (1).
a. (Discrete grids) The grids are independently sampled from a common density function . In addition, there exist constants and such that and that with an absolute constant .
b. (Mean functions) For and , we have . The minimal spacing between two consecutive change-points satisfies that .
c. (Functional noise) Let be i.i.d. random elements taking values in a measurable space and be a measurable function . The functional noise takes the form
There exists an absolute constant , such that for some absolute constant . Define a coupled process
We have for some absolute constant .
d. (Measurement error) Let be i.i.d. random elements taking values in a measurable space and be a measurable function . The measurement error takes the form
There exists an absolute constant , such that for some absolute constant . Define a coupled process
We have for some absolute constant .
1a allows the functional data to be observed on discrete grids and moreover, we allow for different grids at different time points. The sampling distribution is required to be lower bounded on the support , which is a standard assumption widely used in the nonparametric literature (e.g. Tsybakov, 2009). Here, different functional curves are assumed to have the same number of grid points . We remark that this is made for presentation simplicity only. It can indeed be further relaxed and the main results below will then depend on both the minimum and maximum numbers of grid points.
Note that 1a does not impose any restriction between the sampling frequency and the number of functional curves , and indeed our method can handle both the dense case where and the sparse case where can be upper bounded by a constant. Besides the random sampling scheme studied here, another commonly studied scenario is the fixed design, where it usually assumes that the sampling locations are common to all functional curves across time. We remark that while we focus on the random design here, our proposed algorithm can be directly applied to the fixed design case without any modification. Furthermore, its theoretical justification under the fixed design case can be established similarly with minor modifications, which is omitted.
The observed functional data have mean functions , which are assumed to be Hölder continuous in 1b. Note that the Hölder parameters in 1a and b are both denoted by . We remark that different smoothness are allowed and we use the same here for notational simplicity. This sequence of mean functions is our primary interest and is assumed to possess a piecewise constant pattern, with the minimal spacing being of the same order as . This assumption essentially requires that the number of change-points is upper bounded. It can also be further relaxed and we will have more elaborated discussions on this matter in Section 5.
Our model allows for two sources of noise - functional noise and measurement error, which are detailed in 1c and d, respectively. Both the functional noise and the measurement error are allowed to possess temporal dependence and heavy-tailedness. For temporal dependence, we adopt the physical dependence framework by Wu (2005), which covers a wide range of time series models, such as ARMA and vector AR models. It further covers popular functional time series models such as functional AR and MA models (Hörmann and Kokoszka, 2010). We also remark that 1c and d impose a short range dependence, which is characterized by the absolute upper bounds and . Further relaxation is possible by allowing the upper bounds and to vary with the sample size .
The heavy-tail behavior is encoded in the parameter . In 1c and d, we adopt the same quantity for presentational simplicity and remark that different heavy-tailedness levels are allowed. An extreme example is that when , the noise is essentially sub-Gaussian. Importantly, 1d does not impose any restriction on the cross-sectional dependence among measurement errors observed on the same time , which can be even perfectly correlated.
2.2 Kernel-based change-point detection
To estimate the change-point in the mean functions , we propose a kernel-based cumulative sum (CUSUM) statistic, which is simple, intuitive and computationally efficient. The key idea is to recover the unobserved from the observations based on kernel estimation.
Given a kernel function and a bandwidth parameter , we define for Given the random grids and a bandwidth parameter , we define the density estimator of the sampling distribution as
Given and a bandwidth parameter , for any time , we define the kernel-based estimation for as
| (2) |
Based on the kernel estimation , for any integer pair , we define the CUSUM statistic as
| (3) |
The CUSUM statistic defined in (3) is the cornerstone of our algorithm and is based on two kernel estimators and . At a high level, the CUSUM statistic estimates the difference in mean between the functional data in the time intervals and . In the functional data analysis literature, other popular approaches for mean function estimation are reproducing kernel Hilbert space based methods and local polynomial regression. However, to our best knowledge, existing works based on the two approaches typically require that the functional data are temporally independent and it is not obvious how to extend their theoretical guarantees to the temporal dependence case. We therefore choose the kernel estimation method owing to its flexibility in terms of both methodology and theory and we derive new theoretical results on kernel estimation for functional data under temporal dependence and heavy-tailedness.
For multiple change-point estimation, a key ingredient is to isolate each single change-point with well-designed intervals in . To achieve this, we combine the CUSUM statistic in (3) with a modified version of the seeded binary segmentation (SBS) proposed in Kovács et al. (2020). SBS is based on a collection of deterministic intervals defined in Definition 1.
Definition 1 (Seeded intervals).
Let , with some sufficiently large absolute constant . For , let be the collection of intervals of length that are evenly shifted by , i.e.
The overall collection of seeded intervals is denoted as .
The essential idea of the seeded intervals defined in Definition 1 is to provide a multi-scale system of searching regions for multiple change-points. SBS is computationally efficient with a computational cost of the order (Kovács et al., 2020).
Based on the CUSUM statistic and seeded intervals, Algorithm 1 summarises the proposed functional seeded binary segmentation algorithm (FSBS) for multiple change-point estimation in sequentially observed functional data. There are three main tuning parameters involved in Algorithm 1, the kernel bandwidth in the estimation of the sampling distribution, the kernel bandwidth in the estimation of the mean function and the threshold parameter for declaring change-points. Their theoretical and numerical guidance will be presented in Sections 3.1 and 4, respectively.
Algorithm 1 is conducted in an iterative way, starting with the whole time course, using the multi-scale seeded intervals to search for the point according to the largest CUSUM value. A change-point is declared if the corresponding maximum CUSUM value exceeds a pre-specified threshold and the whole sequence is then split into two with the procedure being carried on in the sub-intervals.
Algorithm 1 utilizes a collection of random grid points to detect changes in the functional data. For a change of mean functions at the time point with , we show in the appendix that, as long as grid points are sampled, with high probability, there is at least one point such that Thus, this procedure allows FSBS to detect changes in the mean functions without evaluating functions on a dense lattice grid and thus improves computational efficiency.
3 Main Results
3.1 Assumptions and theory
We begin by imposing assumptions on the kernel function used in FSBS.
Assumption 2 (Kernel function).
Let be compactly supported and satisfy the following conditions.
a. The kernel function is adaptive to the Hölder class , i.e. for any , it holds that where is a constant that only depends on .
b. The class of functions is separable in and is a uniformly bounded VC-class. This means that there exist constants such that for every probability measure on and every , it holds that , where denotes the -covering number of the metric space .
2 is a standard assumption in the nonparametric literature, see Giné and Guillou (1999, 2001), Kim et al. (2019), Wang et al. (2019) among many others. These assumptions hold for most commonly used kernels, including uniform, polynomial and Gaussian kernels.
Recall the minimal spacing defined in 1b. We further define the jump size at the th change-point as and define as the minimal jump size. 3 below details how strong the signal needs to be in terms of and , given the grid size , the number of functional curves , smoothness parameter , dimensionality and moment condition .
Assumption 3 (Signal-to-noise ratio, SNR).
There exists an arbitrarily-slow diverging sequence such that
We are now ready to present the main theorem, showing the consistency of FSBS.
Theorem 1.
Under Assumptions 1, 2 and 3, let be the estimated change-points by FSBS detailed in Algorithm 1 with data , bandwidth parameters , and threshold parameter , for some absolute constants . It holds that
where is an absolute constant.
In view of 3 and Theorem 1, we see that with properly chosen tuning parameters and with probability tending to one as the sample size grows, the output of FSBS estimates the correct number of change-points and
where the last inequality follows from 3. The above inequality shows that there exists a one-to-one mapping from to , assigning by the smallest distance.
3.2 Discussions on functional seeded binary segmentation (FSBS)
From sparse to dense regimes. In our setup, each curve is only observed at discrete points and we allow the full range of choices of , representing from sparse to dense scenarios, all accompanied with consistency results. In the most sparse case , 3 reads as a logarithmic factor, under which the localisation error is upper bounded by , up to a logarithmic factor. To the best of our knowledge, this challenging case has not been dealt in the existing change-point detection literature for functional data. In the most dense case, we can heuristically let and for simplicity let representing the sub-Gaussian noise case. 3 reads as and the localisation error is upper bounded by . Both the SNR ratio and localisation error are the optimal rate in the univariate mean change-point localisation problem (Wang et al., 2020), implying the optimality of FSBS in the dense situation.
Tuning parameters. There are three tuning parameters involved. In the CUSUM statistic (3), we specify that the density estimator of the sampling distribution is a kernel estimator with bandwidth . Due to the independence of the observation grids, such a choice of the bandwidth follows from the classical nonparametric literature (e.g. Tsybakov, 2009) and is minimax-rate optimal in terms of the estimation error. For completeness, we include the study of ’s theoretical properties in Appendix B. In practice, there exist different default methods for the selection of , see for example the function Hpi from the R package ks (Chacón and Duong (2018)).
The other bandwidth tuning parameter is also required to be . Despite that we allow for physical dependence in both functional noise and measurement error, we show that the same order of bandwidth (as ) is required under 1. This is an interesting finding, if not surprising. This particular choice of is due to the fact that the physical dependence put forward by Wu (2005) is a short range dependence condition and does not change the rate of the sample size.
The threshold tuning parameter is set to be a high-probability upper bound on the CUSUM statistics when there is no change-point and is in fact of the form
This also reflects the requirement on the SNR detailed in 3, that .
Phase transition. Recall that the number of curves is and the number of observations on each curve is . The asymptotic regime we discuss is to let diverge, while allowing all other parameters, including , to be functions of . In Theorem 1, we allow a full range of cases in terms of the relationship between and . As a concrete example, when the smooth parameter , the jump size and in the one-dimensional case , with high probability (ignoring logarithmic factors for simplicity),
This relationship between and was previously demonstrated in the mean function estimation literature (e.g. Cai and Yuan, 2011; Zhang and Wang, 2016), where the observations are discretely sampled from independently and identically distributed functional data. It is shown that the minimax estimation error rate also possesses the same phase transition between and , i.e. with the transition boundary , which agrees with our finding under the change-point setting.
Physical dependence and heavy-tailedness In 1c and d, we allow for physical dependence type temporal dependence and heavy-tailed additive noise. As we have discussed, since the physical dependence is in fact a short range dependence, all the rates involved are the same as those in the independence cases, up to logarithmic factors. Having said this, the technical details required in dealing with this short range dependence are fundamentally different from those in the independence cases. From the result, it might be more interesting to discuss the effect of the heavy-tail behaviours, which are characterised by the parameter . It can be seen from the rates in 3 and Theorem 1 that the effect of disappears and it behaves the same as if the noise is sub-Gaussian when .
4 Numerical Experiments
4.1 Simulated data analysis
We compare the proposed FSBS with state-of-the-art methods for change-point detection in functional data across a wide range of simulation settings. The implementations for our approaches can be found at https://github.com/cmadridp/FSBS. We compare with three competitors: BGHK in Berkes et al. (2009), HK in Hörmann and Kokoszka (2010) and SN in Zhang et al. (2011). All three methods estimate change-points via examining mean change in the leading functional principal components of the observed functional data. BGHK is designed for temporally independent data while HK and SN can handle temporal dependence via the estimation of long-run variance and the use of self-normalization principle, respectively. All three methods require fully observed functional data. In practice, they convert discrete data to functional observations by using B-splines with 20 basis functions.
For the implementation of FSBS, we adopt the Gaussian kernel. Following the standard practice in kernel density estimation, the bandwidth is selected by the function Hpi in the R package ks (Chacón and Duong (2018)). The tuning parameter and the bandwidth are chosen by cross-validation, with evenly-indexed data being the training set and oddly-indexed data being the validation set. For each pair of candidate , we obtain change-point estimators on the training set and compute the validation loss The pair is then chosen to be the one corresponding to the lowest validation loss.
We consider five different scenarios for the observations . For all scenarios 1-5, we set Given the dimensionality , denote a generic grid point as . Scenarios 1 to 4 are generated based on model (1). The basic setting is as follows.
Scenario 1 (S1) Let , the unevenly-spaced change-points be and the three distinct mean functions be , and .
Scenario 2 (S2) Let , the unevenly-spaced change-points be and the three distinct mean functions be , and .
Scenario 3 (S3) Let , the unevenly-spaced change-points be and the three distinct mean functions be , and .
Scenario 4 (S4) Let , the unevenly-spaced change-points be and the three distinct mean functions be , and .
For S1-S4, the functional noise is generated as , where are basis functions and are i.i.d. standard normal random variables. The measurement error is generated as , where are i.i.d. . We observe the noisy functional data at grid points independently sampled from .
Scenario 5 is adopted from Zhang et al. (2011) for densely-sampled functional data without measurement error.
Scenario 5 (S5) Let , the evenly-spaced change-points be and the three distinct mean functions be 0, and .
The grid points are evenly-spaced points in for all . The functional noise is generated as , where are independent standard Brownian motions and is a bivariate Gaussian kernel.
S1-S5 represent a wide range of simulation settings including the extreme sparse case S1, sparse case S2, the two-dimensional domain case S4, and the densely sampled cases S3 and S5. Note that S1 and S4 can only be handled by FSBS as for S1 it is impossible to estimate a function via B-spline based on one point and for S4, the domain is of dimension 2.
Evaluation result: For a given set of true change-points , we evaluate the accuracy of the estimator by the difference and the Hausdorff distance , defined by . For , we use the convention that and .
For each scenario, we repeat the experiments 100 times and Figure 1 summarizes the performance of FSBS, BGHK, HK and SN. Tabulated results can be found in Appendix A. As can be seen, FSBS consistently outperforms the competing methods by a wide margin and demonstrates robust behaviour across the board for both sparsely and densely sampled functional data.
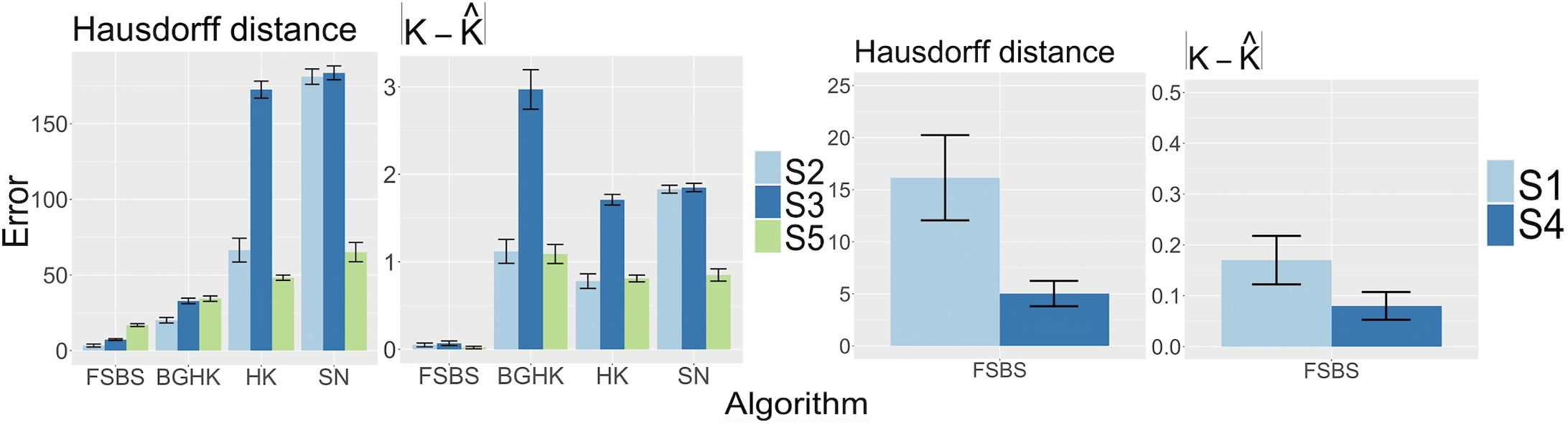
4.2 Real data application
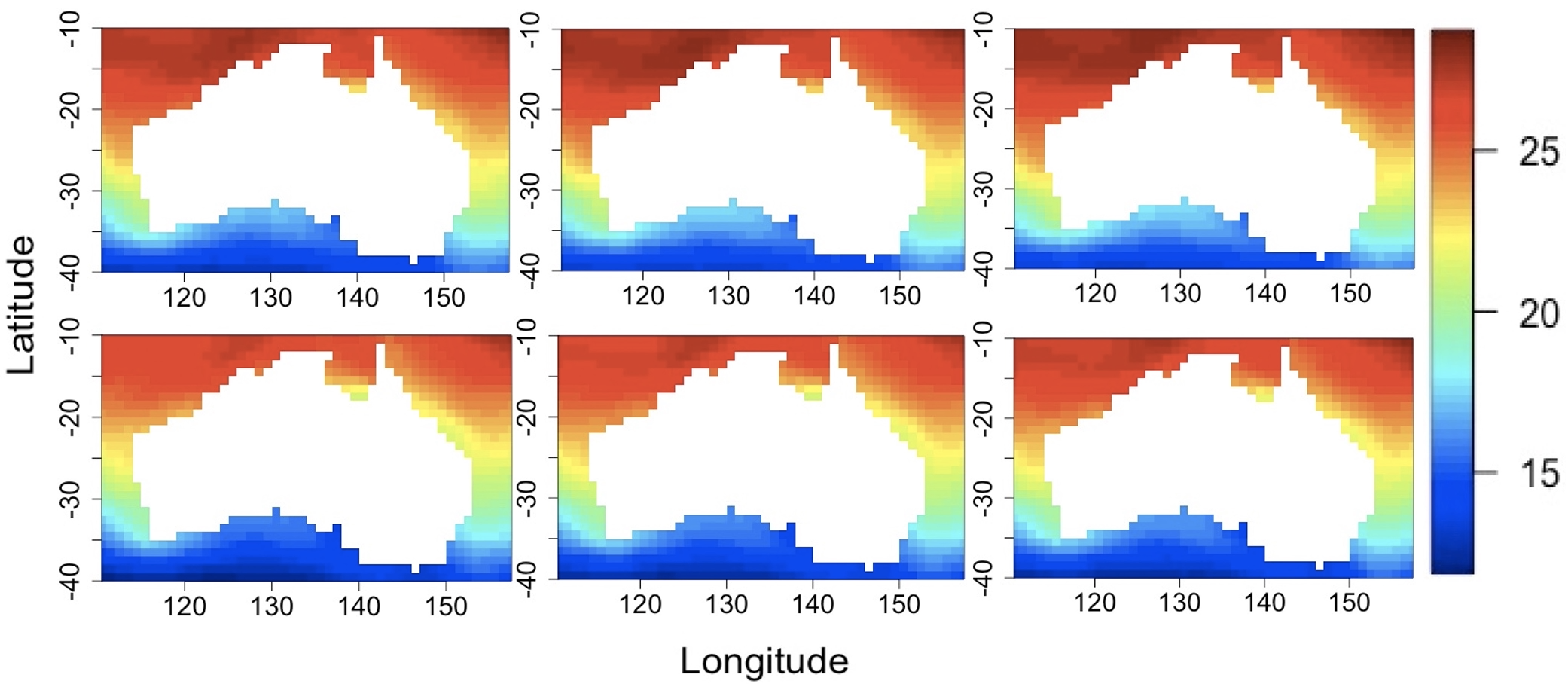
We consider the COBE-SSTE dataset (Physical Sciences Laboratory, 2020), which consists of monthly average sea surface temperature (SST) from 1940 to 2019, on a degree latitude by degree longitude grid covering Australia. The specific coordinates are latitude S-S and longitude E-E.
We apply FSBS to detect potential change-points in the two-dimensional SST. The implementation of FSBS is the same as the one described in Section 4.1. To avoid seasonality, we apply FSBS to the SST for the month of June from 1940 to 2019. We further conduct the same analysis separately for the month of July for robustness check.
For both the June and July data, two change-points are identified by FSBS, Year 1981 and 1996, suggesting the robustness of the finding. The two change-points might be associated with years when both the Indian Ocean Dipole and Oceanic Niño Index had extreme events (Ashok et al., 2003). The El Niño/Southern Oscillation has been recognized as an important manifestation of the tropical ocean-atmosphere-land coupled system. It is an irregular periodic variation in winds and sea surface temperatures over the tropical eastern Pacific Ocean. Much of the variability in the climate of Australia is connected with this phenomenon (Australian Government, 2014).
To visualize the estimated change, Figure 2 depicts the average SST before the first change-point Year 1981, between the two change-points, and after the second change-point Year 1996. The two rows correspond to the June and July data, respectively. As we can see, the top left corners exhibit different patterns in the three periods, suggesting the existence of change-points.
5 Conclusion
In this paper, we study change-point detection for sparse and dense functional data in general dimensions. We show that our algorithm FSBS can consistently estimate the change-points even in the extreme sparse setting with . Our theoretical analysis reveals an interesting phase transition between and , which has not been discovered in the existing literature for functional change-point detection. The consistency of FSBS relies on the assumption that the minimal spacing . To relax this assumption, we may consider increasing in Definition 1 to enlarge the coverage of the seeded intervals in FSBS and apply the narrowest over threshold selection method (Theorem 3 in Kovács et al., 2020). With minor modifications of the current theoretical analysis, the consistency of FSBS can be established for the case of . Since such a relaxation does not add much more methodological insights to our paper, we omit this additional technical discussion for conciseness.
References
- Ashok et al. (2003) Karumuri Ashok, Zhaoyong Guan, and Toshio Yamagat. A look at the relationship between the enso and the indian ocean dipole. Journal of the Meteorological Society of Japan. Ser. II, 81(1):41–56, 2003. doi: 10.2151/jmsj.81.41.
- Aue et al. (2009) Alexander Aue, Robertas Gabrys, Lajos Horváth, and Piotr Kokoszka. Estimation of a change-point in the mean function of functional data. Journal of Multivariate Analysis, 100(10):2254–2269, 2009.
- Aue et al. (2018) Alexander Aue, Gregory Rice, and Ozan Sönmez. Detecting and dating structural breaks in functional data without dimension reduction. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 80(3):509–529, 2018.
- Australian Government (2014) Australian Government. What is El Niño and how does it impact Australia? http://www.bom.gov.au/climate/updates/articles/a008-el-nino-and-australia.shtml, June 2014.
- Berkes et al. (2009) István Berkes, Robertas Gabrys, Lajos Horváth, and Piotr Kokoszka. Detecting changes in the mean of functional observations. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 71(5):927–946, 2009.
- Bonner et al. (2014) Simon J Bonner, Nathaniel K Newlands, and Nancy E Heckman. Modeling regional impacts of climate teleconnections using functional data analysis. Environmental and Ecological Statistics, 21(1):1–26, 2014.
- Cai and Yuan (2011) T Tony Cai and Ming Yuan. Optimal estimation of the mean function based on discretely sampled functional data: Phase transition. The Annals of Statistics, 39(5):2330–2355, 2011.
- Chacón and Duong (2018) José E Chacón and Tarn Duong. Multivariate kernel smoothing and its applications. Chapman and Hall/CRC, 2018.
- Chiou et al. (2014) Jeng-Min Chiou, Yi-Chen Zhang, Wan-Hui Chen, and Chiung-Wen Chang. A functional data approach to missing value imputation and outlier detection for traffic flow data. Transportmetrica B: Transport Dynamics, 2(2):106–129, 2014.
- Dai et al. (2019) Xiongtao Dai, Hans-Georg Müller, Jane-Ling Wang, and Sean CL Deoni. Age-dynamic networks and functional correlation for early white matter myelination. Brain Structure and Function, 224(2):535–551, 2019.
- Dette et al. (2020) Holger Dette, Kevin Kokot, and Stanislav Volgushev. Testing relevant hypotheses in functional time series via self-normalization. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(3):629–660, 2020.
- Fan et al. (2014) Yingying Fan, Natasha Foutz, Gareth M James, and Wolfgang Jank. Functional response additive model estimation with online virtual stock markets. The Annals of Applied Statistics, 8(4):2435–2460, 2014.
- Fraiman et al. (2014) Ricardo Fraiman, Ana Justel, Regina Liu, and Pamela Llop. Detecting trends in time series of functional data: A study of antarctic climate change. Canadian Journal of Statistics, 42(4):597–609, 2014.
- Giné and Guillou (1999) Evarist Giné and Armelle Guillou. Laws of the iterated logarithm for censored data. The Annals of Probability, 27(4):2042–2067, 1999.
- Giné and Guillou (2001) Evarist Giné and Armelle Guillou. On consistency of kernel density estimators for randomly censored data: rates holding uniformly over adaptive intervals. Annales de l’IHP Probabilités et statistiques, 37(4):503–522, 2001.
- Giné and Guillou (2002) Evarist Giné and Armelle Guillou. Rates of strong uniform consistency for multivariate kernel density estimators. Annales de l’Institut Henri Poincare (B) Probability and Statistics, 38(6):907–921, 2002. ISSN 0246-0203. doi: https://doi.org/10.1016/S0246-0203(02)01128-7.
- Hörmann and Kokoszka (2010) Siegfried Hörmann and Piotr Kokoszka. Weakly dependent functional data. The Annals of Statistics, 38(3):1845–1884, 2010.
- Jiang (2017) Heinrich Jiang. Uniform convergence rates for kernel density estimation. In International Conference on Machine Learning, pages 1694–1703. PMLR, 2017.
- Kim et al. (2019) Jisu Kim, Jaehyeok Shin, Alessandro Rinaldo, and Larry Wasserman. Uniform convergence rate of the kernel density estimator adaptive to intrinsic volume dimension. In International Conference on Machine Learning, pages 3398–3407. PMLR, 2019.
- Kirch (2006) Claudia Kirch. Resampling methods for the change analysis of dependent data. PhD thesis, Universität zu Köln, 2006.
- Kovács et al. (2020) Solt Kovács, Housen Li, Peter Bühlmann, and Axel Munk. Seeded binary segmentation: A general methodology for fast and optimal change point detection. arXiv preprint arXiv:2002.06633, 2020.
- Liu et al. (2013) Weidong Liu, Han Xiao, and Wei Biao Wu. Probability and moment inequalities under dependence. Statistica Sinica, pages 1257–1272, 2013.
- Petersen et al. (2019) Alexander Petersen, Sean Deoni, and Hans-Georg Müller. Fréchet estimation of time-varying covariance matrices from sparse data, with application to the regional co-evolution of myelination in the developing brain. The Annals of Applied Statistics, 13(1):393–419, 2019.
- Physical Sciences Laboratory (2020) Physical Sciences Laboratory. COBE SST2 and Sea-Ice. https://psl.noaa.gov/data/gridded/data.cobe2.html, April 2020.
- Rigollet and Vert (2009) Philippe Rigollet and Régis Vert. Optimal rates for plug-in estimators of density level sets. Bernoulli, 15(4):1154–1178, 2009.
- Rinaldo and Wasserman (2010) Alessandro Rinaldo and Larry Wasserman. Generalized density clustering. The Annals of Statistics, 38(5):2678–2722, 2010.
- Sriperumbudur and Steinwart (2012) Bharath Sriperumbudur and Ingo Steinwart. Consistency and rates for clustering with dbscan. In Artificial Intelligence and Statistics, pages 1090–1098. PMLR, 2012.
- Tsybakov (2009) Alexandre B Tsybakov. Introduction to Nonparametric Estimation. Springer series in statistics. Springer, Dordrecht, 2009. doi: 10.1007/b13794.
- Vershynin (2018) Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- Wang et al. (2019) Daren Wang, Xinyang Lu, and Alessandro Rinaldo. Dbscan: Optimal rates for density-based cluster estimation. Journal of Machine Learning Research, 2019.
- Wang et al. (2020) Daren Wang, Yi Yu, and Alessandro Rinaldo. Univariate mean change point detection: Penalization, cusum and optimality. Electronic Journal of Statistics, 14(1):1917–1961, 2020.
- Wang et al. (2016) Jane-Ling Wang, Jeng-Min Chiou, and Hans-Georg Müller. Functional data analysis. Annual Review of Statistics and Its Application, 3:257–295, 2016.
- Wu (2005) Wei Biao Wu. Nonlinear system theory: Another look at dependence. Proceedings of the National Academy of Sciences, 102(40):14150–14154, 2005.
- Zhang et al. (2011) Xianyang Zhang, Xiaofeng Shao, Katharine Hayhoe, and Donald J Wuebbles. Testing the structural stability of temporally dependent functional observations and application to climate projections. Electronic Journal of Statistics, 5:1765–1796, 2011.
- Zhang and Wang (2016) Xiaoke Zhang and Jane-Ling Wang. From sparse to dense functional data and beyond. The Annals of Statistics, 44(5):2281–2321, 2016.
Appendices
Appendix A Detailed simulation results
We present the tables containing the results of the simulation study in Section 4.1 of the main text.
| Model | |||||
|---|---|---|---|---|---|
| FSBS | 0.05 | 0.86 | 0.09 |
Changes occur at the times and .
| Model | |||||
|---|---|---|---|---|---|
| FSBS | 0.05 | 0.95 | 0 | ||
| BGHK | |||||
| HK | |||||
| SN |
Changes occur at the times and .
| Model | |||||
|---|---|---|---|---|---|
| FSBS | 0 | 0.93 | 0.07 | ||
| BGHK | |||||
| HK | |||||
| SN |
Changes occur at the times and .
| Model | |||||
|---|---|---|---|---|---|
| FSBS | 0 | 0.92 | 0.08 |
Changes occur at the times and .
| Model | |||||
|---|---|---|---|---|---|
| FSBS | 0.02 | 0.98 | 0 | ||
| BGHK | |||||
| HK | |||||
| SN |
Changes occur at the times and .
Appendix B Proof of Theorem 1
In this section, we present the proofs of theorem Theorem 1. To this end, we will invoke the following well-known bounds for kernel density estimation.
Lemma 1.
Let be random grid points independently sampled from a common density function . Under Assumption 2-b, the density estimator of the sampling distribution ,
satisfies,
| (4) |
with probability at least . Moreover, under Assumption 2-a, the bias term satisfies
| (5) |
Therefore,
| (6) |
with probability at least .
The verification of these bounds can be found in many places in the literature. For equation (4) see for example Giné and Guillou (2002), Rinaldo and Wasserman (2010), Sriperumbudur and Steinwart (2012) and Jiang (2017). For equation (5), Tsybakov (2009) is a common reference.
Proof of Theorem 1.
For any , let
For any and , we consider
From Algorithm 1, we have that
We observe that, and for we have that
Therefore, Proposition 1 and Corollary 1 imply that with
| (7) |
for some diverging sequence , it holds that
and
Then, using that from above
Now, we notice that,
In addition, there are number of change-points. In consequence, it follows that
| (8) | |||
| (9) | |||
| (10) |
The rest of the argument is made by assuming the events in equations (8), (9) and (10) hold.
Denote
where . Since is the desired localisation rate, by induction, it suffices to consider any generic interval that satisfies the following three conditions:
Here indicates that there is no change-point contained in .
Denote
Observe that since
for all
and that
,
it holds that .
Therefore, it has to be the case that for any true change-point ,
either
or
. This means that
indicates that
is a detected change-point in the previous induction step, even if .
We refer to
as an undetected change-point if
.
To complete the induction step, it suffices to show that FSBS
(i) will not detect any new change
point in if
all the change-points in that interval have been previously detected, and
(ii) will find a point in such that if there exists at least one undetected change-point in .
In order to accomplish this, we need the following series of steps.
Step 1. We first observe that if is any change-point in the functional time series, by Lemma 8,
there exists a seeded interval containing exactly one change-point such that
where,
Even more, we notice that if is any undetected change-point in . Then it must hold that
Since and for any positive numbers and , we have that . Moreover, , so that it holds that
and in consequence . Similarly . Therefore
Step 2. Consider the collection of intervals in Step 1. In this step, it is shown that for each , it holds that
| (11) |
for some sufficient small constant .
Let .
By Step 1,
contains exactly one change-point . Since for every
, is a one dimensional population time series and there is only one change-point in ,
it holds that
which implies, for
Similarly, for
Therefore,
| (12) |
By Lemma 7, with probability at least , there exists such that
Since , and for any positive numbers and we have that
| (13) |
so that . Then, from (12), (13) and the fact that and ,
| (14) |
Therefore, it holds that
where the first inequality follows from the fact that , the second inequality follows from the good event in (8), and the last inequality follows from (14).
Next, we observe that , , and .
In consequence, since is a positive constant, by the upper bound of on Equation 7, for sufficiently large , it holds that
Therefore,
Therefore Equation 11 holds with
Step 3.
In this step, it is shown that FSBS can
consistently detect or reject the existence of undetected
change-points within .
Suppose is any undetected change-point. Then by the second half of Step 1, . Therefore
where the second inequality follows from Equation 11, and the last inequality follows from the fact that, for any positive numbers and implies
.
Suppose there does not exist any undetected change-point in . Then for any , one of the following situations must hold,
-
(a)
There is no change-point within ;
-
(b)
there exists only one change-point within and ;
-
(c)
there exist two change-points within and
The calculations of (c) are provided as the other two cases are similar and simpler. Note that for any , it holds that
and similarly
By Lemma 10 and the assumption that contains only two change-points, it holds that for all ,
Thus
| (15) |
Therefore in the good event in Equation 8, for any and any , it holds that
where the first inequality follows from Equation 8, and the last inequality follows from Equation 15. Then,
We observe that . Moreover,
and given that,
we get,
Following the same line of arguments, we have that
Thus, by the choice of , it holds that with sufficiently large constant ,
| (16) |
As a result, FSBS will correctly
reject if contains no undetected change-points.
Step 4.
Assume that there exists an undetected change-point such that
Let and be defined as in FSBS with
To complete the induction, it suffices to show that, there exists a change-point such that
and .
Consider the uni-variate time series
Since the collection of the change-points of the time series is a subset of that of , we may apply Lemma 9 to by setting
on the interval
.
Therefore, it suffices to justify that all the assumptions of
Lemma 9 hold.
In the following, is used in Lemma 9.
Then Equation 36 and Equation 37 are directly consequence of
Equation 8, Equation 9, Equation 10.
We observe that, for any
for all . By Step 1 with , it holds that
Therefore for all ,
where the last inequality follows from Equation 11. Therefore Equation 38 holds in Lemma 9. Finally, Equation 39 is a direct consequence of the choices that
Thus, all the conditions in Lemma 9 are met. So that, there exists a change-point of , satisfying
| (17) |
and
for sufficiently large constant , where we have followed the same line of arguments than for the conclusion of (16).
Observe that
i) The change-points
of belong to ; and
ii) Equation 17 and imply that
As discussed in the argument before Step 1, this implies that must be an undetected change-point of . ∎
Appendix C Deviation bounds related to kernels
In this section, we deal with all the large probability events occurred in the proof of Theorem 1. Recall that , and
By assumption 2, we have , where is an absolute constant. Moreover, assumption 1b implies for any
Proof.
The proofs of Proposition 1 and Proposition 1 are the same. So only the proof of Proposition 1 is presented. We define the events and . Using Lemma 1, especifically by equation (6), we have that . Then, we observe that in event , for
which implies . Therefore, .
Now, for any , observe that, by definition of and triangle inequality
| (20) | ||||
In the following, we will show that , and that
-
1.
,
-
2.
,
-
3.
,
-
4.
,
-
5.
,
in order to conclude that,
Step 1. The analysis for is done. We observe that,
Step 1.1 The analysis for is done. We note that the random variables are independent distributed with mean and
Since , by Bernstein inequality Vershynin (2018), we have that
Since if , with probability at most , it holds that
Therefore, using that we conclude
with probability at most
Step 1.2 The analysis for and is done.
We observe that
| (21) | ||||
| (22) |
Then, we observe that
where the second inequality follows from assumption 2. Therefore, using event , we can bound (21) by with probability at least Meanwhile, for (22) we have that,
Corollary 1.
Suppose that and that . Then for
Proof.
By definition of and , we have that
Then, we observe that,
Therefore,
Finally, letting we get that
where the last inequality follows from Proposition 1. ∎
C.1 Additional Technical Results
The following lemmas provide lower bounds for
They are a direct consequence of the temporal dependence and heavy-tailedness of the data considered in 1.
Lemma 2.
Let be such that and
Let be such that .
a.
Suppose that for any it holds that
| (24) |
Then for any ,
b. Suppose that for some ,
| (25) |
Then for any ,
Proof.
The proof of part b is similar and simpler than that of part a. For conciseness, only the proof of a is presented.
By Lemma 4 and Equation 24, for all , it holds that
As a result there exists a constant such that
We observe that
| (26) | ||||
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
which implies, there is a constant such that
where
By theorem B.2 of Kirch (2006),
where the last inequality follows from the fact that and that Since
it holds that, Moreover,
It follows that,
By Markov’s inequality, for any and the assumption that
Since , this directly implies that
∎
Lemma 3.
Suppose 1 c holds and . Then there exists absolute constants so that
| (32) |
If in addition , then there exists absolute constants such that
| (33) |
Proof.
The proof of the Equation 33 is simpler and simpler than Equation 32. So only the proof of Equation 32 is presented. Note that since and are independent, and that are independent identically distributed,
Step 1. Note that, by the Newton’s binomial
Step 2. For a fixed such that and that , consider
Without loss of generality, assume that are non-zero. Then it holds that
where the third equality follows by using the change of variable the first inequality by assumption 2.
Step 3.
Let be fixed. Note that . Consider set
To bound the cardinality of the set , first note that since , there are
number of ways to choose the index of non-zero entries of .
Suppose are the chosen index such that
Then the constrains and are equivalent to that of diving balls into groups (without distinguishing each ball).
As a result there are
number of ways to choose the once the index are chosen.
Step 4.
Combining the previous three steps, it follows that for some constants only depending on ,
where the second inequality is satisfied by step 3 and that , while the third inequality is achieved by using that Moreover, given that the fourth inequality is obtained. The last inequality holds because if , then and if , then . ∎
Lemma 4.
Suppose 1 c holds. Let be such that and Let be such that . Then, it holds that
Proof.
We have that and by the use of Lemma 3. Then, making use of Theorem 1 of Liu et al. (2013), we obtain that
where . Moreover, we observe that since for any , it follows
Next, by the first part of Lemma 3,
even more, we have that , implies that
From 1 c,
By the second part of Lemma 3, it holds that
This immediately implies the desired result. ∎
Lemma 5.
Suppose 1 holds. Then there exists absolute constants such that
| (34) |
If in addition for all , then there exists absolute constants such that
| (35) |
Proof.
The proof is similar to that of Lemma 3. The proof of the Equation 35 is simpler and simpler than Equation 34. So only the proof of Equation 34 is presented. Note that since and are independent, and that are independent identically distributed,
Step 1. Note that, by the Newton’s binomial
Step 2. For a fixed such that and that , consider
Without loss of generality, assume that are non-zero. Then it holds that
where the third equality follows by using the change of variable the first inequality by assumption 2.
Step 3.
Let be fixed. Note that . Consider set
To bound the cardinality of the set , first note that since , there are
number of ways to choose the index of non-zero entries of .
Suppose are the chosen index such that
Then the constrains and are equivalent to that of diving balls into groups (without distinguishing each ball).
As a result there are
number of ways to choose the once the index are chosen.
Step 4.
Combining the previous three steps, it follows that for some constants only depending on ,
where the second inequality is satisfied by step 3 and that , while the third inequality is achieved by using that Moreover, given that the fourth inequality is obtained. The last inequality holds because if , then and if , then . ∎
Lemma 6.
Suppose 1 d holds. Let be such that and Let be such that . Then, it holds that
Proof.
We have that and by the use of Lemma 5. Then, making use of Theorem 1 of Liu et al. (2013), we obtain that
where . Moreover, we observe that since for any , it follows
Next, by the first part of Lemma 3,
Since we have that , the above inequality further implies that
From 1 d, the above inequality further implies that
By the second part of Lemma 3, it holds that
This immediately implies the desired result. ∎
Appendix D Additional Technical Results
Lemma 7.
Suppose that such that for some . Suppose in addition that is a collection of grid points randomly sampled from a density such that . If for some parameter , then
where is a constant only depending on .
Proof.
Let . Since , . Since , we have that
for some absolute constant . Let be such that
Then for all ,
Therefore
Since
the desired result follows. ∎
Lemma 8.
Let be defined as in Definition 1 and suppose 1 e holds. Denote
Then for each change-point there exists a seeded interval such that
a.
contains exactly one change-point ;
b.
; and
c.
;
Proof.
These are the desired properties of seeded intervals by construction. The proof is the same as theorem 3 of Kovács et al. (2020) and is provided here for completeness.
Since , by construction of seeded intervals, one can find a seeded interval
such that
,
and
.
So contains only one change-point .
In addition,
and similarly , so b holds. Finally, since , it holds that and so
∎
D.1 Univariate CUSUM
We introduce some notation for one-dimensional change-point detection and the corresponding CUSUM statistics. Let be two univariate sequences. We will make the following assumptions.
Assumption 4 (Univariate mean change-points).
Let , where and , and
Assume
We also have the corresponding CUSUM statistics over any generic interval defined as
Throughout this section, all of our results are proven by
regarding and as two deterministic sequences.
We will frequently assume that is a good approximation
of in ways that we will specify through appropriate assumptions.
Consider the following events
Lemma 9.
Suppose 4 holds. Let be an subinterval of and contain at least one change-point with for some constant . Let . Let
For some , and , suppose that the following events hold
| (36) | |||
| (37) |
and that
| (38) |
If there exists a sufficiently small such that
| (39) |
then there exists a change-point such that
where is some sufficiently small constant independent of .
Proof.
The proof is the same as that for Lemma 22 in Wang et al. (2020). ∎
Lemma 10.
If contain two and only two change-points and , then
Proof.
This is Lemma 15 in Wang et al. (2020). ∎
Appendix E Common Stationary Processes
Basic time series models which are widely used in practice, can be incorporated by 1b and c. Functional autoregressive model (FAR) and functional moving average model (FMA) are presented in examples 1 below. The vector autoregressive (VAR) model and vector moving average (VMA) model can be defined in similar and simpler fashions.
Example 1 (FMA and FAR).
Let be the set of bounded linear operators from to , where . For we define the norm operator
Suppose with and .
a) For FMA model,
let be a sequence of independent and identically distributed random functions with mean zero.
Then the FMA time series of order is given by the equation
| (40) |
For any , by (40) we have that
and As a result
Therefore 1b is satisfied by FMA models.
b) We can define a FAR time series as
| (41) |
It admits the expansion,
Then for any we have that Thus,
1b incorporates FAR time series.
Example 2 (MA and AR).
Suppose and are constants with Let , be a sequence of independent and identically distributed random variables with mean zero. The moving average (MA) time series of order , is given by the equation
| (42) |
For any , we have that
and Then, Therefore 1b is satisfied by FMA. Functional autoregressive time series, AR, is defined as
| (43) |
It admits the expansion,
Then, for any Thus,
1b incorporates AR time series.